
Se requiere una suscripción a JoVE para ver este contenido. Inicie sesión o comience su prueba gratuita.
Method Article
Uso de la descomposición de Cholesky para explorar las diferencias individuales en las relaciones longitudinales entre las habilidades de lectura
En este artículo
Resumen
Este artículo demuestra el uso del método estándar de oro en la genética conductual, el método de descomposición Cholesky, para estimar influencias genéticas y ambientales únicas y superpuestas en diferentes variables para responder a investigaciones motivadas longitudinalmente Preguntas.
Resumen
El método de descomposición Cholesky es el estándar de oro utilizado en el campo de la genética conductual. El método es popular porque es fácil de programar y resolver. Usando este método, los investigadores pueden explorar las diferencias individuales en las relaciones longitudinales de diferentes variables a través de múltiples puntos de tiempo. El método permite a los investigadores descomponer la varianza en (1) efectos genéticos, compartidos y no compartidos únicos que surgen en momentos específicos, así como (2) efectos ambientales superpuestos, compartidos y no compartidos que se punto de tiempo a otro. Sin embargo, el método no identifica los mecanismos u orígenes subyacentes a estos efectos. El informe actual se centra en la aplicación del método de descomposición Cholesky en el campo de la psicología educativa. Específicamente, analiza las diferencias individuales en las relaciones longitudinales entre el conocimiento de la carta de jardín de infantes, la conciencia fonológica de jardín de infantes, las habilidades de lectura a nivel de palabra de primer grado y la comprensión de lectura de séptimo grado.
Introducción
Convertirse en un lector experto con la capacidad de leer y comprender texto con fluidez es importante para los resultados escolares de los niños. Para prevenir el desarrollo de problemas de lectura, es vital entender hasta qué punto las diferentes habilidades de lectura predicen la comprensión de la lectura. Las investigaciones existentes han demostrado que las habilidades de lectura previa y a nivel de palabras en la escuela primaria predicen longitudinalmente la comprensión de la lectura en la escuela media1,2. Las diferencias individuales en estas predicciones apuntan principalmente a factores genéticos subyacentes (y en cierta medida, ambientales) desde el jardín de infantes hasta el grado cuatro3,4. Sin embargo, es necesario explorar si estos mismos factores genéticos y ambientales siguen influyendo en estas predicciones hasta los grados de la escuela media.
Un método para comprender mejor las diferencias individuales subyacentes a las asociaciones entre las habilidades de lectura de primaria y secundaria es el uso de la metodología genética conductual, específicamente el método de descomposición Cholesky. El método de descomposición Cholesky se considera uno de los análisis estándar de oro en genética conductual. Este método es fácil de programar y resolver y permite la descomposición de la varianza y la covarianza en (A) la genética, (C) influencias ambientales compartidas y (E) no compartidas, generalmente en una muestra de gemelos. Un ejemplo de una descomposición de Cholesky univariado (una variable) se indica en la Figura 1. El factor A latente se refiere a los efectos genéticos, que son influencias genéticas heredadas de los padres. El factor C latente se refiere a los efectos ambientales compartidos, que son aspectos del medio ambiente que sirven para hacer que los gemelos sean más similares, como los entornos domésticos y escolares. Por último, el factor E latente se refiere a los efectos ambientales no compartidos, que son influencias ambientales que son únicas para cada gemelo y contribuyen a las diferencias entre los gemelos, como la propia experiencia de cada uno. El factor E también captura el error de medición.

Figura 1: Descomposición en (A) genética, (C) influencias ambientales compartidas y (E) influencias ambientales no compartidas. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}
Los factores A, C y E de la Figura 1 estiman hasta qué punto los genes y los entornos influyen en una variable (lectura). Aún así, para investigar las diferencias individuales subyacentes a las asociaciones longitudinales entre más de una habilidad de lectura de la escuela primaria a la secundaria, es necesario un análisis longitudinal. Para responder a preguntas de investigación motivadas longitudinalmente, un método de descomposición Cholesky multivariante se utiliza aquí5. Conceptualmente, el método de descomposición multivariante Cholesky es similar a la regresión múltiple jerárquica, de modo que la contribución independiente de los factores genéticos y ambientales se evalúa después de que se hayan tomado en cuenta las contribuciones de factores anteriores Cuenta.
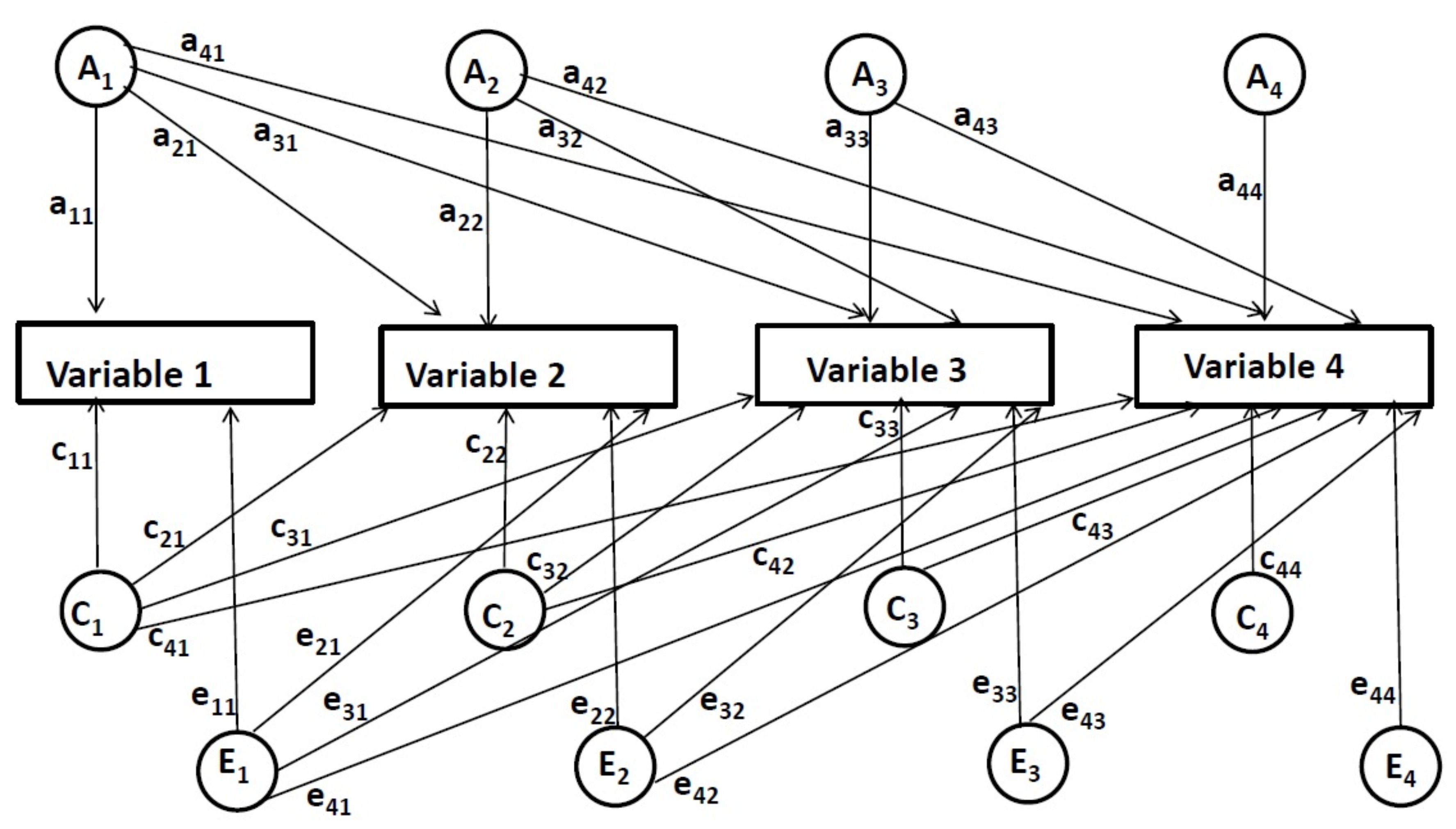
Por ejemplo, en una descomposición multivariante de Cholesky con datos longitudinales en cuatro puntos de tiempo (véase la figura 2), el primer conjunto de factores [genéticos (A1), entorno compartido (C1) y medio ambiente no compartido (E1)] contribuye a la varianza de todas las variables, representadas como trayectosa 11,a 21, a31, a41, c11, c21, ..., e11, etc., de A1, C1, E1 factores a cada variable . El segundo conjunto de factores (A2, C2, E2) contribuye a la varianza de la segunda y las variables subsiguientes después de controlar para el primer punto de tiempo. El segundo conjunto de factores se representa como trayectos22,un 32, un42,c22,c32, ..., e22,etc. A continuación, se estiman las influencias del tercer conjunto de factores (A3, C3, E3) para la tercera y cuarta variables después de controlar los dos puntos de tiempo anteriores. Se representan como trayectosa 33,a 43, c33, c43, e33, e43. Por último, las influencias del cuarto conjunto de factores (A4, C4, E4) se miden para el punto de tiempo final después de controlar todos los puntos de tiempo anteriores. Se representan como trayectos44,c44,e44.

Figura 2: Modelo de descomposición Cholesky multivariante para cuatro puntos de tiempo. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}
En esta aplicación longitudinal del método de descomposición multivariante Cholesky, las influencias genéticas y ambientales en cada momento se estiman después de que se hayan controlado los efectos de los puntos de tiempo anteriores. Como tal, este método permite determinar en qué medida las influencias genéticas y ambientales únicas se encuentran en línea en cada momento determinado, independientemente de las influencias de los puntos de tiempo anteriores (estos efectos se estiman por los trayectos11, a 22,a 33,a 44, c11, c22, ..., e11, e22, etc.). Además, el método también permite examinar el grado en que se comparten las mismas influencias genéticas y medioambientales (superpuestas) entre los puntos de tiempo. En otras palabras, se puede determinar en qué medida las influencias genéticas y ambientales se arrastran de un punto a otro (es decir, estos efectos se estiman por los trayectos21,un31,un41,un32,un42,un 43, c21, c31, ..., e21, etc.). Cabe señalar que los caminosa 11, c11, y e11 representan todas las posibles influencias genéticas y ambientales hasta e incluyendo el primer punto de tiempo, que puede ser único o superpuesto con puntos de tiempo anteriores. Sin embargo, no se estiman los puntos de tiempo anteriores al primer punto de tiempo; por lo tanto, no se puede determinar con precisión si representan influencias únicas o superpuestas. A efectos de simplificación, se incluyen como influencias únicas en el informe actual.
El orden de las variables medidas introducidas en una descomposición de Cholesky es arbitrario. Sin embargo, el orden suele estar impulsado por una perspectiva teórica. Este es también el caso en el estudio actual, en el que el orden se basó en el desarrollo de habilidades de lectura, de modo que las habilidades de lectura en la escuela primaria son predictivas de la comprensión lectora en la escuela media.
Hay varios informes en la literatura que investigan los factores genéticos y ambientales subyacentes a las asociaciones longitudinales de habilidades de lectura utilizando el método de descomposición Cholesky. Estos estudios previos se centraron principalmente en investigar las relaciones entre las habilidades de lectura entre los escolares de primaria6,7. Sólo hay un estudio publicado que examina las diferencias individuales asociadas con la lectura de los grados elementales a los grados de la escuela media utilizando el método de descomposición multivariante Cholesky8. Este protocolo detalla el método multivariado de descomposición Cholesky de ese informe específico para explorar las diferencias individuales en las relaciones longitudinales entre el conocimiento de la carta de jardín de infantes, la conciencia fonológica de jardín de infantes, el nivel de palabras de primer grado habilidades de lectura, y comprensión de lectura de séptimo grado.
Los resultados del estudio se centran en el uso del método multivariante de descomposición Cholesky para distinguir entre dos tipos de influencias genéticas y ambientales. En primer lugar, se muestra cómo estimar las influencias genéticas y ambientales que se derivan (se superponen) de la lectura primaria a la escuela media (por ejemplo, estimar los caminos43,c43y e43, que son influencias genéticas y ambientales habilidades de lectura a nivel de palabra según el primer grado que afectan la comprensión de la lectura en séptimo grado). En segundo lugar, se demuestra cómo estimar las influencias genéticas y ambientales únicas que se encuentran en línea en cada grado en particular (por ejemplo, estimar los caminosun 33,c33y e33, que son influencias genéticas y ambientales únicas en habilidades de lectura a nivel de la palabra que surgen en primer grado).
Protocolo
Los pasos a continuación describen el proceso de estimación de las diferencias individuales subyacentes a las asociaciones longitudinales entre las habilidades de lectura primaria y media en (A) en (A) factores ambientales compartidos y (E) no compartidos utilizando un programa de modelado estadístico, procesador de textos y software con una interfaz gráfica de usuario (GUI). Este estudio ha sido aprobado por la Junta de Revisión Institucional de la Universidad Estatal de Florida.
1. Preparación de datos para el programa de modelado estadístico
- Prepare los datos en un formato que pueda ser leído por el programa de modelado estadístico de su elección. Los programas de modelado estadístico más populares incluyen Mx, OpenMx en la plataforma R y MPlus9. Mx puede leer archivos de datos en formatos de datos .vl o .dat, OpenMx en cualquier formato de datos y Mplus en formato de datos .dat. El ejemplo que se muestra aquí se ejecuta en el programa MPlus9.
NOTA: Un archivo de datos de muestra en formato .dat para seis participantes elegidos al azar está disponible en archivos suplementarios. Las variables utilizadas en un archivo de datos de ejemplo reflejan las variables utilizadas en el archivo de codificación de entrada.
2. Leer datos en el programa de modelado estadístico, ejecutar el script y estimar los efectos
- Abra el programa de modelado estadístico.
- Busque el archivo de datos relevante que se leerá en el programa de modelado estadístico escribiendo "El archivo es [insertar la ubicación del archivo de datos en su ordenador]".
- Haga clic en el icono RUN en la cinta del programa de modelado estadístico para obtener estimaciones de influencias genéticas, ambientales compartidas y ambientales no compartidas del método de descomposición multivariante Cholesky. El script de entrada anotado para el modelo de descomposición Multivariante Cholesky para cuatro puntos de tiempo, así como su salida utilizando MPlus se puede encontrar en archivos de codificación suplementarios.
- Una vez que el programa de modelado estadístico genere estimaciones de influencias genéticas, ambientales compartidas y ambientales no compartidas, localice las estimaciones en el archivo de salida bajo stx11 para el trayectoa 11, stx21 para el trayectoa 21, ..., sty11 para el trayecto c11, sty21 para el trayecto c21, ..., stz11 para el trayecto e11, stz21 para el trayecto e21, etc.
3. Creación de una tabla con estimaciones generadas
- Abra el procesador de palabras.
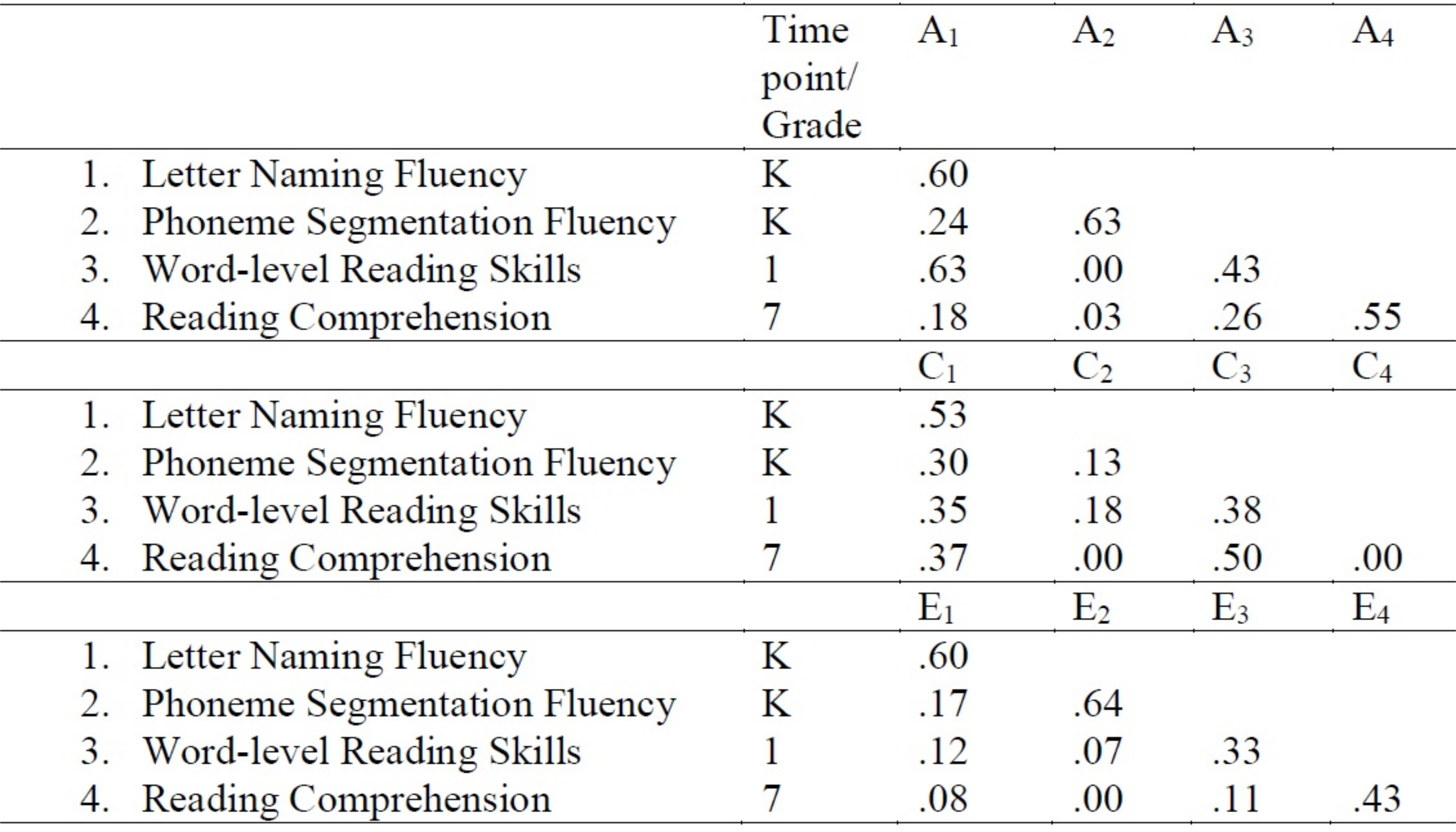
- Copie las estimaciones generadas en una tabla de un procesador de textos. La tabla se puede crear en un formato como se indica en la Figura 3. Por ejemplo, en este caso, las estimaciones para las rutas de accesoa 11, un21, un31y un41 tienen valores de 0.60, 0.24, 0.63 y 0.18, respectivamente.

Figura 3: Descomposición multivariante Cholesky modelando estimaciones de trayectoria estandarizadas de influencias genéticas y ambientales. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}
4. Trazar influencias genéticas, ambientales compartidas y ambientales no compartidas
- Abra el software con una GUI.
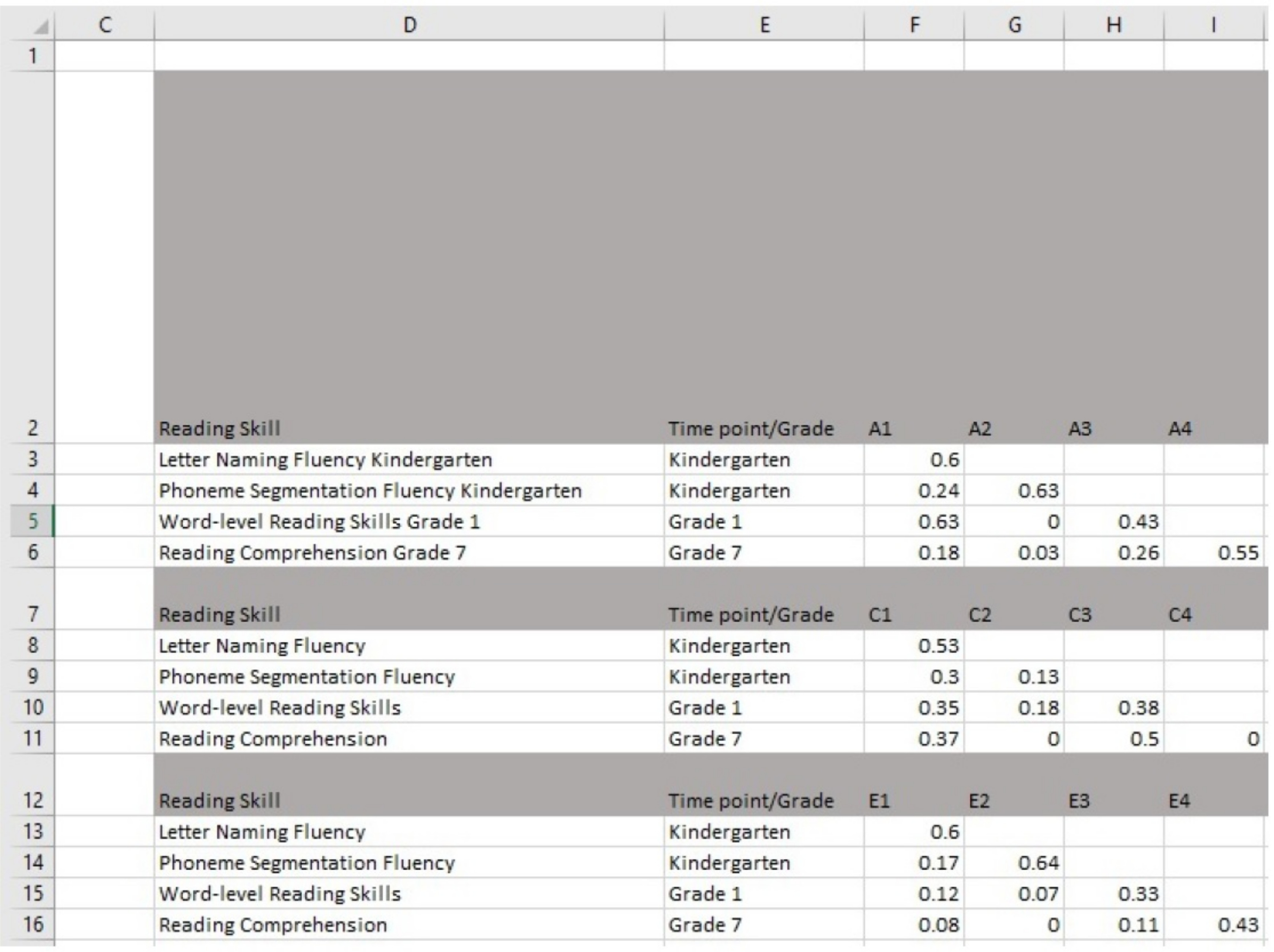
- Ingrese las estimaciones de la tabla creada en las células F3-F16, G4-G16, H5-H16, y I6-I16. Una captura de pantalla del software con una GUI se muestra en la Figura 4.

Figura 4: Introducción de estimaciones en el software con una GUI. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}
- Calcule la varianza de las influencias genéticas, ambientales compartidas y ambientales no compartidas cuadrando las estimaciones en las células F3-F16, G4-G16, H5-H16 e I6-I16. Escriba los valores al cuadrado en las celdas J3-J16, K4-K16, L5-L16 y M6-M16.
- Calcule la varianza porcentual multiplicando los valores en las celdas J3-J16, K4-K16, L5-L16 y M6-M16 por 100. Escriba los valores porcentuales en las celdas N3-N16, O4-O16, P5-P16 y Q6-Q16. Los pasos 4.3 y 4.4 se describen en la Figura 5.

Figura 5: Ilustración de los pasos 4.3 y 4.4. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}
- Calcular hasta qué punto las influencias genéticas se retrasan (se superponen) de la escuela primaria a la escuela media.
- En la celda R3, escriba "0".
- En la celda R4, escriba "-N4". Esta es la medida en que las influencias genéticas desde el primer punto de tiempo se retrasan hasta el segundo punto de tiempo. En este caso, indica las influencias genéticas de la fluidez de nomenclatura de letras en el jardín de infantes que se lleva a cabo a la fluidez de segmentación de foneas en el jardín de infantes.
- En la celda R5, escriba "A N5+O5". Este es el grado en que las influencias genéticas de los dos primeros puntos de tiempo se retrasan al tercer punto de tiempo. En este caso, indica las influencias genéticas de la fluidez de nomenclatura de letras en la fluidez de segmentación de kindergarten y foneme en el jardín de infantes que se lleva a cabo a las habilidades de lectura a nivel de palabra en el grado 1.
- En la celda R6, escriba "A N6+O6+P6". Esta es la medida en que las influencias genéticas de los tres primeros puntos de tiempo se retrasan al cuarto punto de tiempo. En este caso, indica las influencias genéticas de la fluidez de nomenclatura de letras en el jardín de infantes, la fluidez de segmentación del fonemo en el jardín de infantes y las habilidades de lectura a nivel de palabra en el grado 1, lo que se lleva a la comprensión de la lectura en el grado 7.
- Calcular hasta qué punto las influencias ambientales compartidas y no compartidas del medio ambiente se retrasan (se superponen) de la escuela primaria a la escuela media, como en el paso 4.5.
- Calcular en qué medida los factores genéticos, ambientales compartidos y ambientales no compartidos únicos se incluyen en línea en cada momento determinado (es decir, grado).
- Copie los porcentajes de las celdas N3, O4, P5 y Q6 en las celdas S3, S4, S5 y S6, respectivamente, para obtener hasta qué punto los factores genéticos únicos se intervienen en cada grado.
- Copie los porcentajes de las celdas N8, O9, P10 y Q11 en las celdas U3, U4, U5 y U6, respectivamente, para obtener la medida en que los factores ambientales compartidos únicos se enlínean en cada grado.
- Copie los porcentajes de las celdas N13, O14, P15 y Q16 en las celdas W3, W4, W5 y W6, respectivamente, para obtener la medida en que los factores ambientales únicos no compartidos se enlínean en cada grado.
- Para asegurarse de que todos los cálculos son correctos, los valores de las celdas R3-W3, R4-W4, R5-W5 y R6-W6 deben sumar cada uno 100. Los pasos 4.5–4.7 se describen en la Figura 6.

Figura 6: Ilustración de los pasos 4.5-4.8. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}
- Trazar la superposición genética, así como las influencias genéticas únicas haciendo clic y arrastrando el ratón sobre las celdas R2–R6 y S2–S6 para resaltar los datos.
- Haga clic en el menú Insertar.
- Haga clic en Gráficos > Columna apilada.
- Repita los pasos 4.9–4.11 para la superposición ambiental y no compartida del medio ambiente, así como las influencias únicas. Elija las celdas T2–T6 y U2–U6 para trazar las influencias ambientales compartidas y elija las celdas V2–V6 y W2–W6 para las influencias ambientales no compartidas.
Resultados
Las estimaciones estandarizadas de las influencias genéticas, ambientales compartidas y ambientales no compartidas del modelo de descomposición multivariante Cholesky se describen en la Figura 7. En general, los resultados revelaron que las diferencias individuales en la prelectura del jardín de infantes y las habilidades de lectura a nivel de palabra de primer grado representaron una gran proporción de la varianza de la genética (40%) así como el medio ambiente com...
Discusión
El objetivo de este estudio fue demostrar cómo el método bien establecido dentro de la genética conductual, el método multivariado de descomposición Cholesky, puede ser utilizado eficazmente para entender las relaciones entre variables en contexto temporal. Específicamente, este método permite estimar hasta qué punto surgen influencias genéticas y ambientales únicas durante determinados momentos (por ejemplo, grado escolar), así como demostrar la superposición de influencias genéticas y ambientales en muchos...
Divulgaciones
Los autores no tienen nada que revelar.
Agradecimientos
Esta investigación fue apoyada en parte por una subvención del Instituto Nacional de Salud Infantil y Desarrollo Humano (P50 HD052120). Las opiniones expresadas en el presente documento son las de los autores y no han sido revisadas ni aprobadas por los organismos otorgantes.
Materiales
| Name | Company | Catalog Number | Comments |
| Microsoft Office Excel | Microsoft | ||
| Microsoft Office Powerpoint | Microsoft | ||
| Microsoft Office Visio | Microsoft | ||
| Microsoft Office Word | Microsoft | ||
| Mplus Statistical Program | Mplus |
Referencias
- Muter, V., Hulme, C., Snowling, M. J., Stevenson, J. Phonemes, rimes, vocabulary and grammatical skills as foundations of early reading development: Evidence from a longitudinal study. Developmental Psychology. 40 (5), 665-681 (2004).
- Schatschneider, C., Fletscher, J. M., Francis, D. J., Carlson, C. D., Foorman, B. R. Kindergarten prediction of reading skills: A longitudinal comparative analysis. Journal of Educational Psychology. 96 (2), 265-282 (2004).
- Byrne, B., et al. Longitudinal twin study of early literacy development: Preschool and kindergarten phases. Scientific Studies of Reading. 9 (3), 219-235 (2005).
- Christopher, M. E., et al. Genetic and environmental etiologies of the longitudinal relations between prereading skills and. Child Development. 86 (2), 342-361 (2015).
- Neale, M. C., Cardon, L. R. . Methodology for Genetic Studies of Twins and Families. , (1992).
- Byrne, B., et al. Genetic and environmental influences on early literacy. Journal of Research in Reading. 29 (1), 33-49 (2006).
- Byrne, B., et al. Genetic and environmental influences on aspects of literacy and language in early childhood: Continuity and change from preschool to grade 2. Journal of Neurolinguistics. 22 (3), 219-236 (2009).
- Erbeli, F., Hart, S. A., Taylor, J. Longitudinal associations among reading related skills and reading comprehension: A twin study. Child Development. 89 (6), e480-e493 (2018).
- Muthén, L. K., Muthén, B. O. . Mplus. The comprehensive modeling program for applied researchers: User’s guide. , (2012).
- Hart, S. A., et al. Exploring how nature and nurture affect the development of reading: An analysis of the Florida Twin Project on Reading. Developmental Psychology. 49 (10), 1971-1981 (2013).
- Taylor, J., Roehrig, A. D., Hensler, B. S., Connor, C. M., Schatschneider, C. Teacher quality moderates the genetic effects on early reading. Science. 328 (5977), 512-514 (2010).
Reimpresiones y Permisos
Solicitar permiso para reutilizar el texto o las figuras de este JoVE artículos
Solicitar permisoExplorar más artículos
This article has been published
Video Coming Soon
ACERCA DE JoVE
Copyright © 2025 MyJoVE Corporation. Todos los derechos reservados