
Method Article
Diseño y análisis para la simplificación del sistema de detección de caídas
En este artículo
Resumen
Presentamos una metodología basada en sensores multimodales para configurar un sistema de detección de caídas y reconocimiento de actividad humana simple, cómodo y rápido. El objetivo es construir un sistema para la detección precisa de caídas que se pueda implementar y adoptar fácilmente.
Resumen
Este documento presenta una metodología basada en sensores multimodales para configurar un sistema de detección de caídas y detección de caídas simple, cómodo y rápido que se pueda implementar y adoptar fácilmente. La metodología se basa en la configuración de tipos específicos de sensores, métodos y procedimientos de aprendizaje automático. El protocolo se divide en cuatro fases: (1) creación de bases de datos (2) análisis de datos (3) simplificación del sistema y (4) evaluación. Con esta metodología, creamos una base de datos multimodal para la detección de caídas y el reconocimiento de actividad humana, a saber, la detección de caídas UP. Comprende muestras de datos de 17 sujetos que realizan 5 tipos de caídas y 6 actividades simples diferentes, durante 3 ensayos. Toda la información se recopiló utilizando 5 sensores portátiles (acelerómetro de trieje, giroscopio e intensidad de la luz), 1 casco de electroencefalógrafo, 6 sensores infrarrojos como sensores ambientales y 2 cámaras en puntos de vista laterales y frontales. La metodología novedosa propuesta añade algunas etapas importantes para realizar un análisis profundo de los siguientes problemas de diseño con el fin de simplificar un sistema de detección de caídas: a) seleccionar qué sensores o combinación de sensores se utilizarán en un sistema simple de detección de caídas, b) determinar la mejor ubicación de las fuentes de información, y c) seleccionar el método de clasificación de aprendizaje automático más adecuado para la detección y reconocimiento de caídas y actividades humanas. A pesar de que algunos enfoques multimodales reportados en la literatura sólo se centran en uno o dos de los temas antes mencionados, nuestra metodología permite resolver simultáneamente estos tres problemas de diseño relacionados con un sistema de detección y reconocimiento de caída sin vida humana.
Introducción
Dado que el fenómeno mundial del envejecimiento de la población1, la prevalencia de caídas ha aumentado y en realidad se considera un problema de salud importante2. Cuando se produce una caída, las personas requieren atención inmediata para reducir las consecuencias negativas. Los sistemas de detección de caídas pueden reducir la cantidad de tiempo en el que una persona recibe atención médica enviando una alerta cuando se produce una caída.
Existen varias categorizaciones de los sistemas de detección de caídas3. Early works4 clasifica los sistemas de detección de caídas por su método de detección, métodos más o menos analíticos y métodos de aprendizaje automático. Más recientemente, otros autores3,5,6 han considerado los sensores de adquisición de datos como la característica principal para clasificar los detectores de caídas. 3 divide los sistemas de detección de caídas en sistemas conscientes del contexto, que incluyen enfoques basados en la visión y los sensores ambientales, y sistemas de dispositivos portátiles. 5 clasifica los detectores de caídas en tres grupos basados en los dispositivos utilizados para la adquisición de datos: dispositivos portátiles, sensores de ambiente y dispositivos basados en la visión. 6 considera los métodos para medir la aceleración, los métodos para medir la aceleración combinados con otros métodos y los métodos que no miden la aceleración. A partir de estas encuestas, podemos determinar que los sensores y métodos son los principales elementos para clasificar la estrategia general de investigación.
Cada uno de los sensores tiene debilidades y fortalezas discutidas en Xu et al.7. Los enfoques basados en la visión utilizan principalmente cámaras normales, cámaras de sensores de profundidad y/o sistemas de captura de movimiento. Las cámaras web normales son de bajo costo y fáciles de usar, pero son sensibles a las condiciones ambientales (variación de la luz, oclusión, etc.), solo se pueden utilizar en un espacio reducido y tienen problemas de privacidad. Las cámaras de profundidad, como la Kinect, proporcionan movimiento 3D de cuerpo completo7 y se ven menos afectadas por las condiciones de iluminación que las cámaras normales. Sin embargo, los enfoques basados en Kinect no son tan robustos y confiables. Los sistemas de captura de movimiento son más caros y difíciles de usar.
Los enfoques basados en dispositivos de acelerómetro y teléfonos inteligentes/ relojes con acelerómetros incorporados se utilizan muy comúnmente para la detección de caídas. El principal inconveniente de estos dispositivos es que tienen que ser usados durante largos períodos. La incomodidad, la obtrusividad, la colocación del cuerpo y la orientación son problemas de diseño a resolver en estos enfoques. Aunque los teléfonos inteligentes y los relojes inteligentes son dispositivos menos molestos que los sensores, las personas mayores a menudo olvidan o no siempre usan estos dispositivos. Sin embargo, la ventaja de estos sensores y dispositivos es que se pueden utilizar en muchas habitaciones y/ o al aire libre.
Algunos sistemas utilizan sensores colocados alrededor del entorno para reconocer caídas/actividades, por lo que las personas no tienen que usar los sensores. Sin embargo, estos sensores también se limitan a los lugares donde se despliegan8 y a veces son difíciles de instalar. Recientemente, los sistemas de detección de caídas multimodales incluyen diferentes combinaciones de sensores de visión, portátiles y ambientales con el fin de obtener más precisión y robustez. También pueden superar algunas de las limitaciones del sensor único.
La metodología utilizada para la detección de caídas está estrechamente relacionada con la cadena de reconocimiento de actividad humana (ARC) presentada por Bulling et al.9, que consiste en etapas para la adquisición de datos, preprocesamiento y segmentación de señales, extracción y selección de características, entrenamiento y clasificación. Los problemas de diseño deben resolverse para cada una de estas etapas. Se utilizan diferentes métodos en cada etapa.
Presentamos una metodología basada en sensores multimodales para configurar un sistema de detección/reconocimiento de caídahumana simple, cómodo y rápido. El objetivo es construir un sistema para la detección precisa de caídas que se pueda implementar y adoptar fácilmente. La metodología novedosa propuesta se basa en arc, pero añade algunas fases importantes para realizar un análisis profundo de los siguientes problemas con el fin de simplificar el sistema: a seleccionar qué sensores o combinación de sensores se utilizarán en un sistema simple de detección de caídas; (b) determinar la mejor ubicación de las fuentes de información; y c) seleccionar el método de clasificación de aprendizaje automático más adecuado para la detección de caídas y el reconocimiento de la actividad humana para crear un sistema simple.
Hay algunas obras relacionadas en la literatura que abordan uno o dos de los temas de diseño antes mencionados, pero hasta nuestro conocimiento, no hay trabajo que se centre en una metodología para superar todos estos problemas.
Las obras relacionadas utilizan enfoques multimodales para la detección de caídas y el reconocimiento de la actividad humana10,11,12 con el fin de ganar robustez y aumentar la precisión. 10 propusieron el diseño y la implementación de un sistema de detección de caídas basado en datos acelerométricos y mapas de profundidad. Diseñaron una metodología interesante en la que se implementa un acelerómetro de tres ejes para detectar una posible caída, así como el movimiento de la persona. Si la medida de aceleración supera un umbral, el algoritmo extrae una persona que difiere el mapa de profundidad del mapa de referencia de profundidad actualizado en línea. Se realizó un análisis de las combinaciones de profundidad y acelerómetro utilizando un clasificador de máquina vectorial de soporte.
11 presentaron11 una base de datos multimodal de acción humana (MHAD) con el fin de proporcionar un banco de pruebas para nuevos sistemas de reconocimiento de la actividad humana. El conjunto de datos es importante ya que las acciones se reunieron simultáneamente utilizando 1 sistema de captura de movimiento óptico, 4 cámaras multivista, 1 sistema Kinect, 4 micrófonos y 6 acelerómetros inalámbricos. Los autores presentaron resultados para cada modalidad: Kinect, el mocap, el acelerómetro y el audio.
12 propusieron un prototipo para detectar comportamientos anómalos, incluidas las caídas, en los ancianos. Diseñaron pruebas para tres sistemas de sensores con el fin de encontrar el equipo más adecuado para la detección de caídas y comportamientoinusual. El primer experimento consiste en datos de un sistema de sensor inteligente con 12 etiquetas unidas a las caderas, rodillas, tobillos, muñecas, codos y hombros. También crearon un conjunto de datos de prueba utilizando un sistema de sensor Ubisense con cuatro etiquetas unidas a la cintura, el pecho y ambos tobillos, y un acelerómetro Xsens. En un tercer experimento, cuatro sujetos sólo utilizan el sistema Ubisense mientras realizan 4 tipos de caídas, 4 problemas de salud como comportamiento anómalo y diferente actividad de la vida diaria (ADL).
Otras obras en la literatura13,14,15 abordan el problema de encontrar la mejor colocación de sensores o dispositivos para la detección de caídas comparando el rendimiento de varias combinaciones de sensores con varios clasificadores. 13 presentaron una evaluación sistemática que evalúa la importancia de la ubicación de 5 sensores para la detección de caídas. Compararon el rendimiento de estas combinaciones de sensores utilizando vecinos k-más cercanos (KNN), máquinas vectoriales de soporte (SVM), bayes ingenuos (NB) y clasificadores de árbol de decisión (DT). Concluyen que la ubicación del sensor en el sujeto tiene una influencia importante en el rendimiento del detector de caídas independientemente del clasificador utilizado.
Una comparación de las colocaciones de sensores portátiles en el cuerpo para la detección de caídas fue presentada por el zdemir14. Para determinar la colocación del sensor, el autor analizó 31 combinaciones de sensores de las siguientes posiciones: cabeza, cintura, pecho, muñeca derecha, tobillo derecho y muslo derecho. Catorce voluntarios realizaron 20 caídas simuladas y 16 ADL. Descubrió que el mejor rendimiento se obtuvo cuando un solo sensor se coloca en la cintura de estos experimentos de combinación exhaustiva. Otra comparación fue presentada por Ntanasis15 utilizando el conjunto de datos de Izdemir. Los autores compararon posiciones individuales en la cabeza, el pecho, la cintura, la muñeca, el tobillo y el muslo utilizando los siguientes clasificadores: J48, KNN, RF, comité aleatorio (RC) y SVM.
Los puntos de referencia del rendimiento de los diferentes métodos computacionales para la detección de caídas también se pueden encontrar en la literatura16,17,18. 16 presentaron una comparación sistemática para comparar el rendimiento de trece métodos de detección de caídas probados en caídas reales. Sólo consideraron algoritmos basados en mediciones de acelerómetro colocados en la cintura o el tronco. 17 evaluaron el rendimiento de cinco algoritmos analíticos para la detección de caídas utilizando un conjunto de datos de ADU y caídas basadas en lecturas de acelerómetro. Kerdegari18 también hizo una comparación del rendimiento de los diferentes modelos de clasificación para un conjunto de datos de aceleración registrados. Los algoritmos utilizados para la detección de caídas fueron zeroR, oneR, NB, DT, perceptron multicapa y SVM.
Alazrai et al.18 propuso una metodología para la detección de caídas utilizando un descriptor geométrico de pose de movimiento para construir una representación acumulada basada en histograma de la actividad humana. Evaluaron el marco de trabajo mediante un conjunto de datos recopilado con sensores Kinect.
En resumen, encontramos trabajos relacionados con la detección de caídasmultimodales 10,11,12 que comparan el rendimiento de diferentes combinaciones de modalidades. Algunos autores abordan el problema de encontrar la mejor colocación de sensores13,14,15,o combinaciones de sensores13 con varios clasificadores13,15,16 con múltiples sensores de la misma modalidad y acelerómetros. No se encontró ningún trabajo en la literatura que aborda la colocación, las combinaciones multimodales y el punto de referencia del clasificador al mismo tiempo.
Protocolo
Todos los métodos descritos aquí han sido aprobados por el Comité de Investigación de la Escuela de Ingeniería de la Universidad Panamericana.
NOTA: Esta metodología se basa en la configuración de los tipos específicos de sensores, métodos y procedimientos de aprendizaje automático con el fin de configurar un sistema de detección de caídas simple, rápido y multimodal y reconocimiento de actividad humana. Debido a esto, el siguiente protocolo se divide en fases: (1) creación de bases de datos (2) análisis de datos (3) simplificación del sistema y (4) evaluación.
1. Creación de bases de datos
- Configure el sistema de adquisición de datos. Esto recopilará todos los datos de los sujetos y almacenará la información en una base de datos de recuperación.
- Seleccione los tipos de sensores portátiles, sensores ambientales y dispositivos basados en la visión necesarios como fuentes de información. Asigne un ID para cada fuente de información, el número de canales por fuente, las especificaciones técnicas y la frecuencia de muestreo de cada uno de ellos.
- Conecte todas las fuentes de información (es decir, dispositivos portátiles y sensores ambientales, y dispositivos basados en la visión) a un ordenador central o a un sistema informático distribuido:
- Compruebe que los dispositivos con cable están conectados correctamente a un equipo cliente. Compruebe que los dispositivos inalámbricos estén completamente cargados. Tenga en cuenta que la batería baja podría afectar a las conexiones inalámbricas o a los valores del sensor. Además, las conexiones intermitentes o perdidas aumentarán la pérdida de datos.
- Configure cada uno de los dispositivos para recuperar datos.
- Configure el sistema de adquisición de datos para almacenar datos en la nube. Debido a la gran cantidad de datos que se almacenarán, la computación en la nube se considera en este protocolo.
- Valide que el sistema de adquisición de datos cumple la sincronización de datos y la coherencia de datos20 propiedades. Esto mantiene la integridad del almacenamiento de datos de todas las fuentes de información. Puede requerir nuevos enfoques en la sincronización de datos. Por ejemplo, véase Peñafort-Asturiano et al.20.
- Comience a recopilar algunos datos con las fuentes de información y almacene los datos en un sistema preferido. Incluya marcas de tiempo en todos los datos.
- Consulte la base de datos y determine si todos los orígenes de información se recopilan a las mismas velocidades de muestreo. Si se hace correctamente, vaya al paso 1.1.6. De lo contrario, realice muestreos o muestreos descendentes utilizando los criterios indicados en Peñafort-Asturiano, et al.20.
- Establecer el entorno (o laboratorio) teniendo en cuenta las condiciones requeridas y las restricciones impuestas por el objetivo del sistema. Establezca las condiciones para la atenuación de la fuerza de impacto en las caídas simuladas como sistemas de pisos conformes sugeridos en Lachance, et al.23 para garantizar la seguridad de los participantes.
- Utilice un colchón o cualquier otro sistema de pisos compatible y colóquelo en el centro del medio ambiente (o laboratorio).
- Mantenga todos los objetos alejados del colchón para dar al menos un metro de espacio seguro alrededor. Si es necesario, prepare equipo de protección personal para los participantes (por ejemplo, guantes, gorra, gafas, soporte de rodilla, etc.).
NOTA: El protocolo se puede pausar aquí.
- Determinar las actividades humanas y caídas que el sistema detectará después de la configuración. Es importante tener en cuenta el propósito del sistema de detección de caídas y reconocimiento de la actividad humana, así como la población objetivo.
- Definir el objetivo del sistema de detección de caídas y reconocimiento de actividad humana. Escríbalo en una hoja de planificación. Para este caso de estudio, el objetivo es clasificar los tipos de caídas humanas y las actividades realizadas en interiores todos los días de las personas mayores.
- Definir la población objetivo del experimento de acuerdo con el objetivo del sistema. Escríbalo en la hoja de planificación. En el estudio, considere a las personas mayores como la población objetivo.
- Determinar el tipo de actividades diarias. Incluya algunas actividades que no sean de otoño que parezcan caídas para mejorar la detección de caídas reales. Asigne un ID para todos ellos y descríbalos lo más detallados posible. Establezca el período de tiempo para cada actividad que se va a ejecutar. Anote toda esta información en la hoja de planificación.
- Determinar el tipo de caídas humanas. Asigne un ID para todos ellos y descríbalos lo más detallados posible. Establezca el período de tiempo para cada caída que se va a ejecutar . Considere si las caídas serán autogeneradas por los sujetos o generadas por otros (por ejemplo, empujando al sujeto). Anote toda esta información en la hoja de planificación.
- En la hoja de planificación, anote las secuencias de actividades y las caídas que realizará un sujeto. Especifique el período de tiempo, el número de ensayos por actividad/caída, la descripción para realizar la actividad/caída y los identificadores de actividad/caída.
NOTA: El protocolo se puede pausar aquí.
- Seleccione los temas relevantes para el estudio que ejecutarán las secuencias de actividades y caídas. Las caídas son eventos raros para atrapar en la vida real y por lo general ocurren a las personas mayores. Sin embargo, por razones de seguridad, no incluya a personas mayores y con discapacidad en la simulación de caídas bajo consejo médico. Los stunts se han utilizado para evitar lesiones22.
- Determinar el sexo, rango de edad, peso y altura de los sujetos. Definir las condiciones de deterioro requeridas. Además, defina el número mínimo de sujetos necesarios para el experimento.
- Seleccione aleatoriamente el conjunto de sujetos requeridos, siguiendo las condiciones indicadas en el paso anterior. Use una llamada para que los voluntarios los recluten. Cumplir con todas las pautas éticas aplicables de la institución y el país, así como cualquier regulación internacional al experimentar con los seres humanos.
NOTA: El protocolo se puede pausar aquí.
- Recuperar y almacenar datos de sujetos. Esta información será útil para un análisis experimental posterior. Complete los siguientes pasos bajo la supervisión de un experto clínico o un investigador responsable.
- Comience a recopilar datos con el sistema de adquisición de datos configurado en el paso 1.1.
- Pida a cada uno de los sujetos que realicen las secuencias de actividades y las caídas declaradas en el paso 1.2. Guarde claramente las marcas de tiempo del inicio y el final de cada actividad/caída. Compruebe que los datos de todas las fuentes de información se guardan en la nube.
- Si las actividades no se realizaron correctamente o hubo problemas con los dispositivos (por ejemplo, pérdida de conexión, batería baja, conexión intermitente), deseche las muestras y repita el paso 1.4.1 hasta que no se encuentren problemas con el dispositivo. Repita el paso 1.4.2 para cada prueba, por sujeto, declarada en la secuencia del paso 1.2.
NOTA: El protocolo se puede pausar aquí.
- Preprocesar todos los datos adquiridos. Aplique muestreo y muestreo descendente para cada una de las fuentes de información. Consulte los detalles sobre el preprocesamiento de datos para la detección de caídas y el reconocimiento de la actividad humana en Martínez-Villaseñor et al.21.
NOTA: El protocolo se puede pausar aquí.
2. Análisis de datos
- Seleccione el modo de tratamiento de datos. Seleccione Datos sin procesar si los datos almacenados en la base de datos se utilizarán directamente (es decir, utilizando el aprendizaje profundo para la extracción automática de características) y vaya al paso 2.2. Seleccione Datos de entidad si la extracción de entidades se utilizará para un análisis posterior y vaya al paso 2.3.
- Para los datos sin procesar,no se requieren pasos adicionales, así que vaya al paso 2.5.
- En Datos de entidad, extraiga entidades de los datos sin procesar.
- Segmente los datos sin procesar en las ventanas de tiempo. Determine y corrija la longitud de la ventana de tiempo (por ejemplo, fotogramas de un segundo tamaño). Además, determine si estas ventanas de tiempo se superpondrán o no. Una buena práctica es elegir 50% de superposición.
- Extraiga entidades de cada segmento de datos. Determine el conjunto de entidades temporales y frecuentes que se extraerán de los segmentos. 21 para la extracción de características comunes.
- Guarde el conjunto de datos de extracción de entidades en la nube, en una base de datos independiente.
- Si se seleccionan diferentes ventanas de tiempo, repita los pasos 2.3.1 a 2.3.3 y guarde cada conjunto de datos de entidades en bases de datos independientes.
NOTA: El protocolo se puede pausar aquí.
- Seleccione las entidades más importantes extraídas y reduzca el conjunto de datos de entidades. Aplique algunos métodos de selección de características de uso común (porejemplo, selección univariada, análisis de componentes principales, eliminación recursiva de entidades, importancia de entidades, matriz de correlación, etc.).
- Seleccione un método de selección de entidades. Aquí, usamos la importancia de las características.
- Utilice cada característica para entrenar un modelo determinado (utilizamos RF) y medir la precisión (consulte la ecuación 1).
- Clasifica las entidades por clasificación en orden de precisión.
- Seleccione las características más importantes. Aquí, usamos las diez características mejor clasificadas.
NOTA: El protocolo se puede pausar aquí.
- Seleccione un método de clasificación de aprendizaje automático y entrene un modelo. Existen métodos de aprendizaje automático conocidos16,17,18,21, tales como: máquinas vectoriales de soporte (SVM), bosque aleatorio (RF), perceptron multicapa (MLP) y vecinos más cercanos k (KNN), entre muchos otros.
- Opcionalmente, si se selecciona un enfoque de aprendizaje profundo, entonces considere21: redes neuronales convolucionales (CNN), redes neuronales de memoria a largo plazo a corto plazo (LSTM), entre otras.
- Seleccione un conjunto de métodos de aprendizaje automático. Aquí, utilizamos los siguientes métodos: SVM, RF, MLP y KNN.
- Corrija los parámetros de cada uno de los métodos de aprendizaje automático, como se sugiere en la literatura21.
- Cree un conjunto de datos de entidades combinado (o conjunto de datos sin procesar) utilizando los conjuntos de datos de entidades independientes (o conjuntos de datos sin procesar) para combinar tipos de orígenes de información. Por ejemplo, si se requiere una combinación de un sensor portátil y una cámara, combine los conjuntos de datos de entidades de cada una de estas fuentes.
- Divida el conjunto de datos de entidades (o conjunto de datos sin procesar) en conjuntos de entrenamiento y pruebas. Una buena opción es dividir aleatoriamente 70% para el entrenamiento y 30% para las pruebas.
- Ejecute una validación cruzadak-fold 21 mediante el conjunto de datos de características (o conjunto de datos sin procesar) para cada método de aprendizaje automático. Utilice una métrica común de evaluación, como la precisión (consulte la ecuación 1) para seleccionar el mejor modelo entrenado por método. También se recomiendan los experimentos de salida de un sujeto (LOSO)3.
- Abra el conjunto de datos de entidades de entrenamiento (o conjunto de datos sin procesar) en el software de lenguaje de programación preferido. Se recomienda Python. Para este paso, utilice la biblioteca pandas para leer un archivo CSV de la siguiente manera:
training_set de correos de correo de correo de correo de pandas.csv(). - Divida el conjunto de datos de entidades (o conjunto de datos sin procesar) en pares de entradas-salidas. Por ejemplo, utilice Python para declarar los valores x (entradas) y los valores y (salidas):
training_set_X de training_set.drop('tag',axis-1), training_set_Y á training_set.tag
donde tag representa la columna del conjunto de datos de entidades que incluye los valores de destino. - Seleccione un método de aprendizaje automático y establezca los parámetros. Por ejemplo, utilice SVM en Python con la biblioteca sklearn como el siguiente comando:
clasificador : sklearn. SVC(kernel á 'poly')
en el que la función del núcleo se selecciona como polinomio. - Entrene el modelo de aprendizaje automático. Por ejemplo, utilice el clasificador anterior en Python para entrenar el modelo SVM:
classifier.fit(training_set_X,training_set_Y). - Calcular los valores de estimaciones del modelo mediante el conjunto de datos de entidades de prueba (o el conjunto de datos sin procesar). Por ejemplo, utilice la función estimate en Python de la siguiente manera: estimates á classifier.predict(testing_set_X) donde testing_set_X representa los valores x del conjunto de pruebas.
- Repita los pasos 2.5.6.1 a 2.5.6.5, el número de veces k especificado en la validación cruzada k-fold (o el número de veces necesario para el enfoque DE LOSO).
- Repita los pasos 2.5.6.1 a 2.5.6.6 para cada modelo de aprendizaje automático seleccionado.
NOTA: El protocolo se puede pausar aquí.
- Abra el conjunto de datos de entidades de entrenamiento (o conjunto de datos sin procesar) en el software de lenguaje de programación preferido. Se recomienda Python. Para este paso, utilice la biblioteca pandas para leer un archivo CSV de la siguiente manera:
- Compare los métodos de aprendizaje automático probando los modelos seleccionados con el conjunto de datos de prueba. Se pueden utilizar otras métricas de evaluación: precisión (Ecuación 1), precisión (Ecuación 2), sensibilidad (Ecuación 3), especificidad (Ecuación 4) o Puntuación F1 (Ecuación 5), donde TP son los verdaderos positivos, TN son los verdaderos negativos, FP son los falsos positivos y FN son los falsos negativos.





- Utilice otras métricas de rendimiento beneficiosas, como la matriz de confusión9 para evaluar la tarea de clasificación de los modelos de aprendizaje automático, o una curva de recuperación de precisión9 (PR) independiente de la toma de decisiones o la característica de funcionamiento del receptor9 (ROC). En esta metodología, la recuperación y la sensibilidad se consideran equivalentes.
- Utilice características cualitativas de los modelos de aprendizaje automático para comparar entre ellos, tales como: facilidad de interpretación del aprendizaje automático; rendimiento en tiempo real; recursos limitados de tiempo, memoria y computación de procesamiento; y la facilidad de implementación de aprendizaje automático en dispositivos perimetrales o sistemas integrados.
- Seleccione el mejor modelo de aprendizaje automático utilizando la información de: Las métricas de calidad(Ecuaciones 1–5), las métricas de rendimiento y las características cualitativas de la viabilidad del aprendizaje automático de los pasos 2.5.6, 2.5.7 y 2.5.8.
NOTA: El protocolo se puede pausar aquí.
3. Simplificación del sistema
- Seleccione las ubicaciones adecuadas de las fuentes de información. A veces, es necesario determinar la mejor ubicación de las fuentes de información (por ejemplo, qué ubicación de un sensor portátil es mejor).
- Determine el subconjunto de fuentes de información que se analizarán. Por ejemplo, si hay cinco sensores portátiles en el cuerpo y solo uno tiene que ser seleccionado como el mejor sensor colocado, cada uno de estos sensores formará parte del subconjunto.
- Para cada fuente de información de este subconjunto, cree un conjunto de datos independiente y guárdelo por separado. Tenga en cuenta que este conjunto de datos podría ser el conjunto de datos de entidades anterior o el conjunto de datos sin procesar.
NOTA: El protocolo se puede pausar aquí.
- Seleccione un método de clasificación de aprendizaje automático y entrene un modelo para una fuente de ubicación de información. Complete los pasos de 2.5.1 a 2.5.6 usando cada uno de los conjuntos de datos creados en el paso 3.1.2. Detectar la fuente más adecuada de ubicación de información por clasificación. Para este caso práctico, utilizamos los siguientes métodos: SVM, RF, MLP y KNN.
Nota: El protocolo se puede pausar aquí. - Seleccione las ubicaciones adecuadas en un enfoque multimodal si se requiere una combinación de dos o más fuentes de información para el sistema (por ejemplo, combinación de un sensor portátil y una cámara). En este caso práctico, utilice el sensor de cintura y la cámara 1 (vista lateral) como modalidades.
- Seleccione la mejor fuente de información de cada modalidad en el sistema y cree un conjunto de datos de entidades combinado (o conjunto de datos sin procesar) utilizando los conjuntos de datos independientes de estas fuentes de información.
- Seleccione un método de clasificación de aprendizaje automático y entrene un modelo para estas fuentes combinadas de información. Complete los pasos 2.5.1 a 2.5.6 utilizando el conjunto de datos de entidades combinado (o conjunto de datos sin procesar). En este estudio, utilice los siguientes métodos: SVM, RF, MLP y KNN.
NOTA: El protocolo se puede pausar aquí.
4. Evaluación
- Prepare un nuevo conjunto de datos con los usuarios en condiciones más realistas. Utilice solo las fuentes de información seleccionadas en el paso anterior. Preferiblemente, implemente el sistema en el grupo objetivo (por ejemplo, personas mayores). Recopile datos en períodos de tiempo más largos.
- Opcionalmente, si el grupo objetivo se utiliza únicamente, cree un protocolo de grupo de selección que incluya los términos de exclusión (por ejemplo, cualquier deterioro físico o psicológico) y detenga la prevención de criterios (por ejemplo, detecte cualquier lesión física durante los ensayos; sufran náuseas, mareos y/o vómitos; desmayos). Considere también las preocupaciones éticas y los problemas de privacidad de datos.
- Evaluar el rendimiento del sistema de detección de caídas y reconocimiento de actividad humana desarrollado hasta ahora. Utilice las ecuaciones 1–5 para determinar la precisión y la potencia predictiva del sistema, o cualquier otra métrica de rendimiento.
- Discuta acerca de los hallazgos sobre los resultados experimentales.
Resultados
Creación de una base de datos
Hemos creado un conjunto de datos multimodal para la detección de caídas y el reconocimiento de actividad humana, a saber, UP-Fall Detection21. Los datos se recopilaron durante un período de cuatro semanas en la Escuela de Ingeniería de la Universidad Panamericana (Ciudad de México, México). El escenario de prueba fue seleccionado teniendo en cuenta los siguientes requisitos: a) un espacio en el que los sujetos pudieran realizar de forma cómoda y segura caídas y actividades, y b) un entorno interior con luz natural y artificial que sea adecuado para la configuración de sensores multimodales.
Hay muestras de datos de 17 sujetos que realizaron 5 tipos de caídas y 6 actividades simples diferentes, durante 3 ensayos. Toda la información se recopiló utilizando un sistema interno de adquisición de datos con 5 sensores portátiles (acelerómetro de trieje, giroscopio e intensidad de luz), 1 casco de electroencefalógrafo, 6 sensores infrarrojos como sensores ambientales y 2 cámaras en los puntos de vista laterales y frontales. La Figura 1 muestra el diseño de la colocación del sensor en el entorno y en el cuerpo. La frecuencia de muestreo de todo el dataset es de 18 Hz. La base de datos contiene dos conjuntos de datos: el conjunto de datos sin procesar consolidado (812 GB) y un conjunto de datos de entidades (171 GB). Todas las bases de datos almacenadas en la nube para el acceso público: https://sites.google.com/up.edu.mx/har-up/. Puede encontrar más detalles sobre la adquisición de datos, el preprocesamiento, la consolidación y el almacenamiento de esta base de datos, así como detalles sobre la sincronización y la coherencia de los datos en Martínez-Villaseñor et al.21.
Para esta base de datos, todos los sujetos eran jóvenes voluntarios sanos (9 hombres y 8 mujeres) sin ningún tipo de deterioro, que van desde 18 a 24 años de edad, con una altura media de 1,66 m y un peso medio de 66,8 kg. Durante la recopilación de datos, el investigador técnico responsable supervisaba que todas las actividades eran realizadas por los sujetos correctamente. Los sujetos realizaron cinco tipos de caídas, cada una durante 10 segundos, como caída: hacia adelante usando las manos (1), hacia adelante usando las rodillas (2), hacia atrás (3), sentados en una silla vacía (4) y hacia los lados (5). También llevaron a cabo seis actividades diarias para 60 s cada una, excepto para saltar (30 s): caminar (6), pararse (7), recoger un objeto (8), sentarse (9), saltar (10) y poner (11). Aunque las caídas simuladas no pueden reproducir todo tipo de caídas de la vida real, es importante al menos incluir tipos representativos de caídas que permitan la creación de mejores modelos de detección de caídas. También es relevante utilizar AX y, en particular, actividades que normalmente se pueden confundir con caídas como recoger un objeto. Los tipos de caídas y ADU se seleccionaron después de una revisión de los sistemas de detección de caídas relacionados21. Por ejemplo, la Figura 2 muestra una secuencia de imágenes de un ensayo cuando un sujeto cae de lado.
Extrajimos 12 características temporales (media, desviación estándar, amplitud máxima, amplitud mínima, cuadrado medio de la raíz, mediana, número de cruce cero, asimetría, kurtosis, primer cuartil, tercer cuartil y autocorrelación) y 6 características frecuentes (media, mediana, entropía, energía, frecuencia principal y centroide)21 de cada canal de los sensores portátiles y ambientales que comprenden 756 características en total. También calculamos 400 características visuales21 para cada cámara sobre el movimiento relativo de píxeles entre dos imágenes adyacentes en los videos.
Análisis de datos entre enfoques unimodales y multimodales
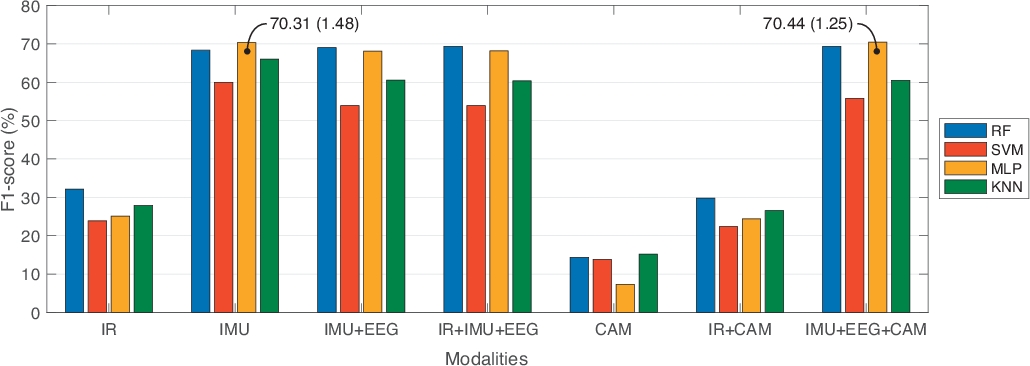
Desde la base de datos UP-Fall Detection, analizamos los datos con fines de comparación entre enfoques unimodales y multimodales. En ese sentido, comparamos siete combinaciones diferentes de fuentes de información: sólo sensores infrarrojos (IR); sólo sensores portátiles (IMU); sensores portátiles y casco (IMU+EEG); sensores infrarrojos y portátiles y casco (IR+IMU+EEG); sólo cámaras (CAM); sensores infrarrojos y cámaras (IR+CAM); y sensores portátiles, casco y cámaras (IMU+EEG+CAM). Además, comparamos tres tamaños de ventana de tiempo diferentes con un 50% de superposición: un segundo, dos segundos y tres segundos. En cada segmento, seleccionamos las características más útiles aplicando la selección y clasificación de entidades. Usando esta estrategia, empleamos sólo 10 características por modalidad, excepto en la modalidad IR usando 40 características. Además, la comparación se realizó en cuatro clasificadores de aprendizaje automático conocidos: RF, SVM, MLP y KNN. Empleamos 10 veces la validación cruzada, con conjuntos de datos de 70% de tren y 30% de prueba, para entrenar los modelos de aprendizaje automático. La Tabla 1 muestra los resultados de este punto de referencia, reportando el mejor rendimiento obtenido para cada modalidad dependiendo del modelo de aprendizaje automático y la mejor configuración de longitud de ventana. Las métricas de evaluación informan de precisión, precisión, sensibilidad, especificidad y puntuación F1. La Figura 3 muestra estos resultados en una representación gráfica, en términos de puntuación F1.
A partir de la Tabla 1,los enfoques multimodales (sensores y cascos infrarrojos y ponibles, IR+IMU+EEG; y sensores portátiles y cascos y cámaras, IMU+EEG+CAM) obtuvieron los mejores valores de puntuación F1, en comparación con los enfoques unimodales (solo infrarrojos, IR; y solo cámaras, CAM). También notamos que los sensores portátiles solamente (IMU) obtuvieron un rendimiento similar al de un enfoque multimodal. En este caso, optamos por un enfoque multimodal porque diferentes fuentes de información pueden manejar las limitaciones de otros. Por ejemplo, la obtrusividad en las cámaras se puede manejar mediante sensores portátiles, y no usar todos los sensores portátiles se puede complementar con cámaras o sensores ambientales.
En términos del punto de referencia de los modelos basados en datos, los experimentos del Cuadro 1 mostraron que RF presenta los mejores resultados en casi todo el experimento; mientras que mlP y SVM no eran muy consistentes en el rendimiento (por ejemplo, la desviación estándar en estas técnicas muestra más variabilidad que en RF). Acerca de los tamaños de las ventanas, estos no representaban ninguna mejora significativa entre ellos. Es importante notar que estos experimentos se hicieron para la clasificación de caídas y actividades humanas.
Colocación del sensor y mejor combinación multimodal
Por otro lado, nuestro objetivo era determinar la mejor combinación de dispositivos multimodales para la detección de caídas. Para este análisis, limitamos las fuentes de información a los cinco sensores portátiles y las dos cámaras. Estos dispositivos son los más cómodos para el enfoque. Además, consideramos dos clases: caída (cualquier tipo de caída) o no caída (cualquier otra actividad). Todos los modelos de aprendizaje automático y los tamaños de ventana siguen siendo los mismos que en el análisis anterior.
Para cada sensor portátil, construimos un modelo clasificador independiente para cada longitud de ventana. Entrenamos el modelo usando validación cruzada de 10 veces con un 70% de entrenamiento y un 30% de conjuntos de datos de prueba. En la Tabla 2 se resumen los resultados de la clasificación de los sensores portátiles por clasificador de rendimiento, en función de la puntuación F1. Estos resultados se ordenaron en orden descendente. Como se ve en la Tabla 2,el mejor rendimiento se obtiene cuando se utiliza un solo sensor en la cintura, cuello o bolsillo derecho apretado (región enlazada). Además, los sensores portátiles de tobillo y muñeca izquierda tuvieron un desempeño peor. La Tabla 3 muestra la preferencia de longitud de ventana por sensor portátil para obtener el mejor rendimiento en cada clasificador. A partir de los resultados, la cintura, el cuello y los sensores de bolsillo derecho apretados con clasificador de RF y tamaño de ventana de 3 s con 50% de superposición son los sensores portátiles más adecuados para la detección de caídas.
Realizamos un análisis similar para cada cámara del sistema. Construimos un modelo clasificador independiente para cada tamaño de ventana. Para el entrenamiento, realizamos 10 veces la validación cruzada con un 70% de entrenamiento y un 30% de conjuntos de datos de prueba. La Tabla 4 muestra la clasificación del mejor punto de vista de cámara por clasificador, basado en la puntuación F1. Como se observó, la vista lateral (cámara 1) realizó la mejor detección de caídas. Además, RF superó en comparación con los otros clasificadores. Además, la Tabla 5 muestra la preferencia de longitud de ventana por punto de vista de cámara. A partir de los resultados, encontramos que la mejor ubicación de una cámara está en el punto de vista lateral usando RF en tamaño de ventana de 3 s y 50% superpuesto.
Por último, elegimos dos posibles ubicaciones de sensores ponibles (es decir, cintura y bolsillo derecho apretado) para combinar con la cámara del punto de vista lateral. Después del mismo procedimiento de formación, obtuvimos los resultados de la Tabla 6. Como se muestra, el clasificador de modelo RF obtuvo el mejor rendimiento en precisión y puntuación F1 en ambas multimodalidades. Además, la combinación entre la cintura y la cámara 1 se clasificó en la primera posición obteniendo 98,72% en precisión y 95,77% en Puntuación F1.

Figura 1: Diseño de los sensores portátiles (izquierda) y ambiente (derecha) en la base de datos UP-Fall Detection. Los sensores portátiles se colocan en la frente, la muñeca izquierda, el cuello, la cintura, el bolsillo derecho de los pantalones y el tobillo izquierdo. Los sensores ambientales son seis sensores infrarrojos emparejados para detectar la presencia de sujetos y dos cámaras. Las cámaras se encuentran en la vista lateral y en la vista frontal, tanto con respecto a la caída humana. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 2: Ejemplo de una grabación de vídeo extraída de la base de datos UP-Fall Detection. En la parte superior, hay una secuencia de imágenes de un sujeto cayendo hacia un lado. En la parte inferior, hay una secuencia de imágenes que representan las características de visión extraídas. Estas entidades son el movimiento relativo de píxeles entre dos imágenes adyacentes. Los píxeles blancos representan un movimiento más rápido, mientras que los píxeles negros representan un movimiento más lento (o casi cero). Esta secuencia se ordena de izquierda a derecha, cronológicamente. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 3: Resultados comparativos que informan de la mejor puntuación F1 de cada modalidad con respecto al modelo de aprendizaje automático y la mejor longitud de ventana. Las barras representan los valores medios de la puntuación F1. El texto en los puntos de datos representa la media y la desviación estándar entre paréntesis. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}
| Modalidad | Modelo | Precisión (%) | Precisión (%) | Sensibilidad (%) | Especificidad (%) | Puntuación F1 (%) |
| IR | RF (3 seg) | 67,38 á 0,65 | 36,45 x 2,46 | 31,26 á 0,89 | 96,63 a 0,07 | 32,16 a 0,99 |
| SVM (3 seg) | 65,16 á 0,90 | 26,77 a 0,58 | 25,16 á 0,29 | 96,31 a 0,09 | 23,89 a 0,41 | |
| MLP (3 seg) | 65,69 a 0,89 | 28,19 a 3,56 | 26,40 á 0,71 | 96,41 a 0,08 | 25,13 a 1,09 | |
| kNN (3 seg) | 61,79 a 1,47 | 30,04 a 1,44 | 27,55 á 0,97 | 96,05 a 0,16 | 27,89 a 1,13 | |
| Imu | RF (1 seg) | 95,76 á 0,18 | 70,78 a 1,53 | 66,91 a 1,28 | 99,59 á 0,02 | 68,35 a 1,25 |
| SVM (1 seg) | 93,32 a 0,23 | 66,16 a 3,33 | 58,82 a 1,53 | 99,32 a 0,02 | 60,00 a 1,34 | |
| MLP (1 seg) | 95,48 á 0,25 | 73,04 a 1,89 | 69,39 á 1,47 | 99,56 á 0,02 | 70,31 a 1,48 | |
| kNN (1 seg) | 94,90 á 0,18 | 69,05 a 1,63 | 64,28 á 1,57 | 99,50 á 0,02 | 66,03 a 1,52 | |
| IMU+EEG | RF (1 seg) | 95,92 a 0,29 | 74,14 a 1,29 | 66,29 á 1,66 | 99,59 á 0,03 | 69,03 a 1,48 |
| SVM (1 seg) | 90,77 a 0,36 | 62,51 a 3,34 | 52,46 á 1,19 | 99,03 a 0,03 | 53,91 a 1,16 | |
| MLP (1 seg) | 93,33 á 0,55 | 74,10 a 1,61 | 65,32 a 1,15 | 99,32 á 0,05 | 68,13 a 1,16 | |
| kNN (1 seg) | 92,12 a 0,31 | 66,86 a 1,32 | 58,30 a 1,20 | 98,89 a 0,05 | 60,56 á 1,02 | |
| IR+IMU+EEG | RF (2 seg) | 95,12 a 0,36 | 74,63 a 1,65 | 66,71 a 1,98 | 99,51 a 0,03 | 69,38 á 1,72 |
| SVM (1 seg) | 90,59 a 0,27 | 64,75 a 3,89 | 52,63 a 1,42 | 99,01 a 0,02 | 53,94 a 1,47 | |
| MLP (1 seg) | 93,26 á 0,69 | 73,51 a 1,59 | 66,05 a 1,11 | 99,31 a 0,07 | 68,19 a 1,02 | |
| kNN (1 seg) | 92,24 á 0,25 | 67,33 a 1,94 | 58,11 a 1,61 | 99,21 a 0,02 | 60,36 á 1,71 | |
| Cam | RF (3 seg) | 32,33 a 0,90 | 14,45 á 1,07 | 14,48 á 0,82 | 92,91 a 0,09 | 14,38 á 0,89 |
| SVM (2 seg) | 34,40 á 0,67 | 13,81 a 0,22 | 14,30 á 0,31 | 92,97 a 0,06 | 13,83 a 0,27 | |
| MLP (3 seg) | 27,08 a 2,03 | 8,59 x 1,69 | 10,59 a 0,38 | 92,21 á 0,09 | 7,31 a 0,82 | |
| kNN (3 seg) | 34,03 a 1,11 | 15,32 a 0,73 | 15,54 á 0,57 | 93,09 a 0,11 | 15,19 a 0,52 | |
| IR+CAM | RF (3 seg) | 65,00 a 0,65 | 33,93 a 2,81 | 29,02 a 0,89 | 96,34 á 0,07 | 29,81 a 1,16 |
| SVM (3 seg) | 64,07 a 0,79 | 24,10 a 0,98 | 24,18 á 0,17 | 96,17 a 0,07 | 22,38 a 0,23 | |
| MLP (3 seg) | 65,05 a 0,66 | 28,25 a 3,20 | 25,40 á 0,51 | 96,29 a 0,06 | 24,39 a 0,88 | |
| kNN (3 seg) | 60,75 á 1,29 | 29,91 a 3,95 | 26,25 á 0,90 | 95,95 á 0,11 | 26,54 a 1,42 | |
| IMU+EEG+CAM | RF (1 seg) | 95,09 a 0,23 | 75,52 a 2,31 | 66,23 a 1,11 | 99,50 á 0,02 | 69,36 á 1,35 |
| SVM (1 seg) | 91,16 a 0,25 | 66,79 x 2,79 | 53,82 a 0,70 | 99,07 a 0,02 | 55,82 á 0,77 | |
| MLP (1 seg) | 94,32 a 0,31 | 76,78 a 1,59 | 67,29 á 1,41 | 99,42 á 0,03 | 70,44 á 1,25 | |
| kNN (1 seg) | 92,06 a 0,24 | 68,82 a 1,61 | 58,49 a 1,14 | 99,19 a 0,02 | 60,51 a 0,85 |
Tabla 1: Resultados comparativos que informan del mejor rendimiento de cada modalidad con respecto al modelo de aprendizaje automático y a la mejor longitud de ventana (entre paréntesis). Todos los valores de rendimiento representan la media y la desviación estándar.
| # | Tipo IMU | |||
| Rf | Svm | Mlp | Knn | |
| 1 | (98.36) Cintura | (83.30) Bolsillo derecho | (57.67) Bolsillo derecho | (73.19) Bolsillo derecho |
| 2 | (95.77) Cuello | (83.22) Cintura | (44.93) Cuello | (68.73) Cintura |
| 3 | (95.35) Bolsillo derecho | (83.11) Cuello | (39.54) Cintura | (65.06) Cuello |
| 4 | (95.06) Tobillo | (82.96) Tobillo | (39.06) Muñeca izquierda | (58.26) Tobillo |
| 5 | (94.66) Muñeca izquierda | (82.82) Muñeca izquierda | (37.56) Tobillo | (51.63) Muñeca izquierda |
Tabla 2: Clasificación del mejor sensor portátil por clasificador, ordenado por la puntuación F1 (entre paréntesis). Las regiones en la sombra representan los tres clasificadores principales para la detección de caídas.
| Tipo IMU | Longitud de la ventana | |||
| Rf | Svm | Mlp | Knn | |
| Tobillo izquierdo | 2 segundos | 3 segundos | 1-seg | 3 segundos |
| Cintura | 3 segundos | 1-seg | 1-seg | 2 segundos |
| Cuello | 3 segundos | 3 segundos | 2 segundos | 2 segundos |
| Bolsillo derecho | 3 segundos | 3 segundos | 2 segundos | 2 segundos |
| Muñeca izquierda | 2 segundos | 2 segundos | 2 segundos | 2 segundos |
Tabla 3: Longitud de la ventana de tiempo preferida en los sensores portátiles por clasificador.
| # | Vista de cámara | |||
| Rf | Svm | Mlp | Knn | |
| 1 | (62.27) Vista lateral | (24.25) Vista lateral | (13.78) Vista frontal | (41.52) Vista lateral |
| 2 | (55.71) Vista frontal | (0.20) Vista frontal | (5.51) Vista lateral | (28.13) Vista frontal |
Tabla 4: Clasificación del mejor punto de vista de cámara por clasificador, ordenado por la puntuación F1 (entre paréntesis). Las regiones en la sombra representan el clasificador superior para la detección de caídas.
| Cámara | Longitud de la ventana | |||
| Rf | Svm | Mlp | Knn | |
| Vista lateral | 3 segundos | 3 segundos | 2 segundos | 3 segundos |
| Vista frontal | 2 segundos | 2 segundos | 3 segundos | 2 segundos |
Tabla 5: Longitud de la ventana de tiempo preferida en los puntos de vista de la cámara por clasificador.
| Multimodal | Clasificador | Precisión (%) | Precisión (%) | Sensibilidad (%) | Puntuación F1 (%) |
| Cintura + Vista lateral | Rf | 98,72 á 0,35 | 94,01 a 1,51 | 97,63 á 1,56 | 95,77 á 1,15 |
| Svm | 95,59 a 0,40 | 100 | 70,26 x 2,71 | 82,51 a 1,85 | |
| Mlp | 77,67 a 11,04 | 33,73 a 11,69 | 37,11 a 26,74 | 29,81 a 12,81 | |
| Knn | 91,71 a 0,61 | 77,90 á 3,33 | 61,64 a 3,68 | 68,73 a 2,58 | |
| Bolsillo derecho + Vista lateral | Rf | 98,41 a 0,49 | 93,64 a 1,46 | 95,79 x 2,65 | 94,69 a 1,67 |
| Svm | 95,79 a 0,58 | 100 | 71,58 a 3,91 | 83,38 a 2,64 | |
| Mlp | 84,92 a 2,98 | 55,70 a 11,36 | 48,29 a 25,11 | 45,21 a 14,19 | |
| Knn | 91,71 a 0,58 | 73,63 a 3,19 | 68,95 x 2,73 | 71,13 a 1,69 |
Tabla 6: Resultados comparativos del sensor portátil combinado y el punto de vista de la cámara utilizando una longitud de ventana de 3 segundos. Todos los valores representan la media y la desviación estándar.
Discusión
Es común encontrar desafíos debido a problemas de sincronización, organización e incoherencia de datos20 cuando se crea un conjunto de datos.
Sincronización
En la adquisición de datos, surgen problemas de sincronización dado que varios sensores suelen funcionar a diferentes velocidades de muestreo. Los sensores con frecuencias más altas recopilan más datos que aquellos con frecuencias más bajas. Por lo tanto, los datos de diferentes fuentes no se emparejarán correctamente. Incluso si los sensores funcionan a las mismas velocidades de muestreo, es posible que los datos no se alineen. En este sentido, las siguientes recomendaciones podrían ayudar a manejar estos problemas de sincronización20:(i) registrar la marca de tiempo, el asunto, la actividad y la prueba en cada muestra de datos obtenida de los sensores; (ii) la fuente de información más coherente y menos frecuente debe utilizarse como señal de referencia para la sincronización; y (iii) utilizar procedimientos automáticos o semiautomáticos para sincronizar grabaciones de vídeo que la inspección manual sería poco práctica.
Preprocesamiento de datos
También se debe realizar el preprocesamiento de datos, y las decisiones críticas influyen en este proceso: (a) determinar los métodos para el almacenamiento de datos y la representación de datos de fuentes múltiples y heterogéneas (b) decidir las formas de almacenar datos en el host local o en la nube (c) seleccionar la organización de los datos, incluidos los nombres de archivo y carpetas (d) que manejan los valores faltantes de los datos, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores, así como las redundancias que se encuentran en los sensores , entre otros. Además, para la nube de datos, se recomienda el almacenamiento en búfer local cuando sea posible para mitigar la pérdida de datos en el momento de la carga.
Incoherencia de datos
La incoherencia de datos es común entre los ensayos que encuentran variaciones en los tamaños de las muestras de datos. Estos problemas están relacionados con la adquisición de datos en sensores portátiles. Las breves interrupciones de la adquisición de datos y la colisión de datos de múltiples sensores conducen a incoherencias de datos. En estos casos, los algoritmos de detección de incoherencias son importantes para manejar fallas en línea en sensores. Es importante destacar que los dispositivos inalámbricos deben supervisarse con frecuencia durante todo el experimento. La batería baja puede afectar a la conectividad y provocar la pérdida de datos.
Ética
El consentimiento para participar y la aprobación ética son obligatorios en todos los tipos de experimentación en los que las personas están involucradas.
En cuanto a las limitaciones de esta metodología, es importante tener en cuenta que está diseñada para enfoques que tienen en cuenta diferentes modalidades para la recopilación de datos. Los sistemas pueden incluir sensores portátiles, ambientales y/o de visión. Se sugiere considerar el consumo de energía de los dispositivos y la vida útil de las baterías en sensores inalámbricos, debido a problemas como la pérdida de datos, la disminución de la conectividad y el consumo de energía en todo el sistema. Además, esta metodología está destinada a sistemas que utilizan métodos de aprendizaje automático. Se debe realizar un análisis de la selección de estos modelos de aprendizaje automático de antemano. Algunos de estos modelos podrían ser precisos, pero consume mucho tiempo y energía. Debe tenerse en cuenta un equilibrio entre la estimación precisa y la disponibilidad limitada de recursos para la informática en modelos de aprendizaje automático. También es importante observar que, en la recopilación de datos del sistema, las actividades se llevaron a cabo en el mismo orden; también, los ensayos se realizaron en la misma secuencia. Por razones de seguridad, se utilizó un colchón de protección para que los sujetos cayeran. Además, las cataratas fueron auto-iniciadas. Esta es una diferencia importante entre caídas simuladas y reales, que generalmente ocurren hacia materiales duros. En ese sentido, este conjunto de datos registrado cae con una reacción intuitiva tratando de no caer. Además, hay algunas diferencias entre las caídas reales en personas mayores o deterioradas y las caídas de simulación; y estos deben tenerse en cuenta al diseñar un nuevo sistema de detección de caídas. Este estudio se centró en los jóvenes sin ningún tipo de impedimento, pero es notable decir que la selección de temas debe estar alineado con el objetivo del sistema y la población objetivo que lo utilizará.
A partir de las obras relacionadas descritas anteriormente10,11,12,13,14,15,16,17,18, podemos observar que hay autores que utilizan enfoques multimodales centrándose en la obtención de detectores de caídas robustos o centrarse en la colocación o el rendimiento del clasificador. Por lo tanto, solo abordan uno o dos de los problemas de diseño para la detección de caídas. Nuestra metodología permite resolver simultáneamente tres de los principales problemas de diseño de un sistema de detección de caídas.
Para el trabajo futuro, sugerimos diseñar e implementar un sistema simple de detección de caídas multimodal basado en los hallazgos obtenidos siguiendo esta metodología. Para la adopción en el mundo real, el aprendizaje de transferencia, la clasificación jerárquica y los enfoques de aprendizaje profundo deben utilizarse para desarrollar sistemas más robustos. Nuestra implementación no tuvo en cuenta las métricas cualitativas de los modelos de aprendizaje automático, pero los recursos informáticos limitados y en tiempo real deben tenerse en cuenta para un mayor desarrollo de los sistemas de detección/reconocimiento de actividades y caídas humanas. Por último, con el fin de mejorar nuestro conjunto de datos, se pueden considerar las actividades de tropiezo o casi caída y el monitoreo en tiempo real de los voluntarios durante su vida diaria.
Divulgaciones
Los autores no tienen nada que revelar.
Agradecimientos
Esta investigación ha sido financiada por la Universidad Panamericana a través de la beca "Fomento a la Investigación UP 2018", bajo el código de proyecto UP-CI-2018-ING-MX-04.
Materiales
| Name | Company | Catalog Number | Comments |
| Inertial measurement wearable sensor | Mbientlab | MTH-MetaTracker | Tri-axial accelerometer, tri-axial gyroscope and light intensity wearable sensor. |
| Electroencephalograph brain sensor helmet MindWave | NeuroSky | 80027-007 | Raw brainwave signal with one forehand sensor. |
| LifeCam Cinema video camera | Microsoft | H5D-00002 | 2D RGB camera with USB cable interface. |
| Infrared sensor | Alean | ABT-60 | Proximity sensor with normally closed relay. |
| Bluetooth dongle | Mbientlab | BLE | Dongle for Bluetooth connection between the wearable sensors and a computer. |
| Raspberry Pi | Raspberry | Version 3 Model B | Microcontroller for infrared sensor acquisition and computer interface. |
| Personal computer | Dell | Intel Xeon E5-2630 v4 @2.20 GHz, RAM 32GB |
Referencias
- United Nations. World Population Prospects: The 2017 Revision, Key Findings and Advance Tables. United Nations. Department of Economic and Social Affairs, Population Division. , (2017).
- World Health Organization. Ageing, and Life Course Unit. WHO Global Report on Falls Prevention in Older Age. , (2008).
- Igual, R., Medrano, C., Plaza, I. Challenges, Issues and Trends in Fall Detection Systems. Biomedical Engineering Online. 12 (1), 66 (2013).
- Noury, N., et al. Fall Detection-Principles and Methods. 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 1663-1666 (2007).
- Mubashir, M., Shao, L., Seed, L. A Survey on Fall Detection: Principles and Approaches. Neurocomputing. 100, 144-152 (2002).
- Perry, J. T., et al. Survey and Evaluation of Real-Time Fall Detection Approaches. Proceedings of the 6th International Symposium High-Capacity Optical Networks and Enabling Technologies. , 158-164 (2009).
- Xu, T., Zhou, Y., Zhu, J. New Advances and Challenges of Fall Detection Systems: A Survey. Applied Sciences. 8 (3), 418 (2018).
- Rougier, C., Meunier, J., St-Arnaud, A., Rousseau, J. Robust Video Surveillance for Fall Detection Based on Human Shape Deformation. IEEE Transactions on Circuit Systems for Video Technologies. 21, 611-622 (2011).
- Bulling, A., Blanke, U., Schiele, B. A Tutorial on Human Activity Recognition Using Body-Worn Inertial Sensors. ACM Computing Surveys. 46 (3), 33 (2014).
- Kwolek, B., Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Computational Methods and Programs in Biomedicine. 117, 489-501 (2014).
- Ofli, F., Chaudhry, R., Kurillo, G., Vidal, R., Bajcsy, R. Berkeley MHAD: A Comprehensive Multimodal Human Action Database. Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision. , 53-60 (2013).
- Dovgan, E., et al. Intelligent Elderly-Care Prototype for Fall and Disease Detection. Slovenian Medical Journal. 80, 824-831 (2011).
- Santoyo-Ramón, J., Casilari, E., Cano-García, J. Analysis of a Smartphone-Based Architecture With Multiple Mobility Sensors for Fall Detection With Supervised Learning. Sensors. 18 (4), 1155 (2018).
- Özdemir, A. An Analysis on Sensor Locations of the Human Body for Wearable Fall Detection Devices: Principles and Practice. Sensors. 16 (8), 1161 (2016).
- Ntanasis, P., Pippa, E., Özdemir, A. T., Barshan, B., Megalooikonomou, V. Investigation of Sensor Placement for Accurate Fall Detection. International Conference on Wireless Mobile Communication and Healthcare. , 225-232 (2016).
- Bagala, F., et al. Evaluation of Accelerometer-Based Fall Detection Algorithms on Real-World Falls. PLoS One. 7, 37062 (2012).
- Bourke, A. K., et al. Assessment of Waist-Worn Tri-Axial Accelerometer Based Fall-detection Algorithms Using Continuous Unsupervised Activities. Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 2782-2785 (2010).
- Kerdegari, H., Samsudin, K., Ramli, A. R., Mokaram, S. Evaluation of Fall Detection Classification Approaches. 4th International Conference on Intelligent and Advanced Systems. , 131-136 (2012).
- Alazrai, R., Mowafi, Y., Hamad, E. A Fall Prediction Methodology for Elderly Based on a Depth Camera. 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 4990-4993 (2015).
- Peñafort-Asturiano, C. J., Santiago, N., Núñez-Martínez, J. P., Ponce, H., Martínez-Villaseñor, L. Challenges in Data Acquisition Systems: Lessons Learned from Fall Detection to Nanosensors. 2018 Nanotechnology for Instrumentation and Measurement. , 1-8 (2018).
- Martínez-Villaseñor, L., et al. UP-Fall Detection Dataset: A Multimodal Approach. Sensors. 19 (9), 1988 (2019).
- Rantz, M., et al. Falls, Technology, and Stunt Actors: New approaches to Fall Detection and Fall Risk Assessment. Journal of Nursing Care Quality. 23 (3), 195-201 (2008).
- Lachance, C., Jurkowski, M., Dymarz, A., Mackey, D. Compliant Flooring to Prevent Fall-Related Injuries: A Scoping Review Protocol. BMJ Open. 6 (8), 011757 (2016).
Reimpresiones y Permisos
Solicitar permiso para reutilizar el texto o las figuras de este JoVE artículos
Solicitar permisoThis article has been published
Video Coming Soon
ACERCA DE JoVE
Copyright © 2025 MyJoVE Corporation. Todos los derechos reservados