
このコンテンツを視聴するには、JoVE 購読が必要です。 サインイン又は無料トライアルを申し込む。
Method Article
コレスキー分解を用いて読書技能間の縦方向関係の個人差を探る
要約
本論文では、行動遺伝学におけるゴールドスタンダード法、コレスキー分解法を用いて、異なる変数に対する遺伝的および環境的影響の一意性を推定し、縦方向に動機付けられた研究に答えることを示す。質問。
要約
コレスキー分解法は、行動遺伝学の分野で使用されるゴールドスタンダードです。プログラムや解き方が簡単なので人気があります。この方法を使用して、研究者は、複数の時点にわたって異なる変数の縦方向の関係の個々の違いを探索することができます。この方法により、研究者は、(1)特定の時点で発生する固有の遺伝的、共有、非共有の環境影響、および(2)1から引き継ぐ遺伝的、共有および非共有環境効果の重複に分散を分解することができます。時間は別のポイントにします。ただし、このメソッドは、これらの効果の根底にあるメカニズムまたは起源を特定しません。今回の報告書は、教育心理学の分野におけるコレスキー分解法の応用に焦点を当てている。具体的には、幼稚園の手紙知識、幼稚園の言語意識、1年生の単語レベルの読解力、7年生の読解との間の縦方向の関係の個人差について議論する。
概要
テキストを流暢に読み、理解する能力を持つ熟練した読者になることは、子供たちの学校の成果にとって重要です。読解問題の発症を防ぐためには、読解力の違いがどの程度予測されるのかを理解することが重要です。既存の研究は、小学校の読み取り前と単語レベルの読解力が縦方向に中学校1、2の読解を予測することを示しています。これらの予測の個人差は、主に幼稚園からグレード43、4までの基礎的な遺伝的要因(そしてある程度は環境)要因を指しています。しかし、これらの同じ遺伝的要因と環境要因が、中学校の学年までこれらの予測に影響を与え続けるかどうかを探る必要があります。
小中学校の読解力の根底にある個人差をより深く理解する方法の1つは、行動遺伝的方法論、特にコレスキー分解法を用いすることである。コレスキー分解法は、行動遺伝学におけるゴールドスタンダード分析の一つと考えられています。この方法は、プログラムと解決が容易であり、(A)遺伝的、(C)共有環境、および(E)非共有環境影響、通常は双子のサンプルに対する分散および共分散の分解を可能にする。コレスキー分解の一例を図1に示す。A潜伏因子は、親から受け継がれた遺伝的影響である遺伝的影響を指します。C潜伏因子は、家庭や学校の環境など、双子をより類似させる環境の側面である共有環境効果を指します。最後に、E潜伏因子は、各双子に固有の環境影響であり、それぞれの経験などの双子間の違いに寄与する非共有環境影響を指します。E 係数は測定誤差も取り込む。

図1:(A)遺伝的、(C)共有環境、および(E)非共有環境影響への分解。この図のより大きなバージョンを表示するには、ここをクリックしてください。
{kind=link}
図1のA、C、およびE因子は、遺伝子と環境が1つの(読み取り)変数に影響を与える程度を推定します。それでも、小学校から中学校までの複数の読解力の間の縦方向の関連性の根底にある個人差を調べるためには、縦方向の分析が必要である。縦方向に動機付けられた研究の質問に答えるために、多変量コレスキー分解法がここで使用される5.概念的には、多変量コレスキー分解法は階層的な多重回帰に類似しており、以前の因子の寄与が取り込まれた後に遺伝的および環境的要因の独立した寄与が評価されるアカウント。
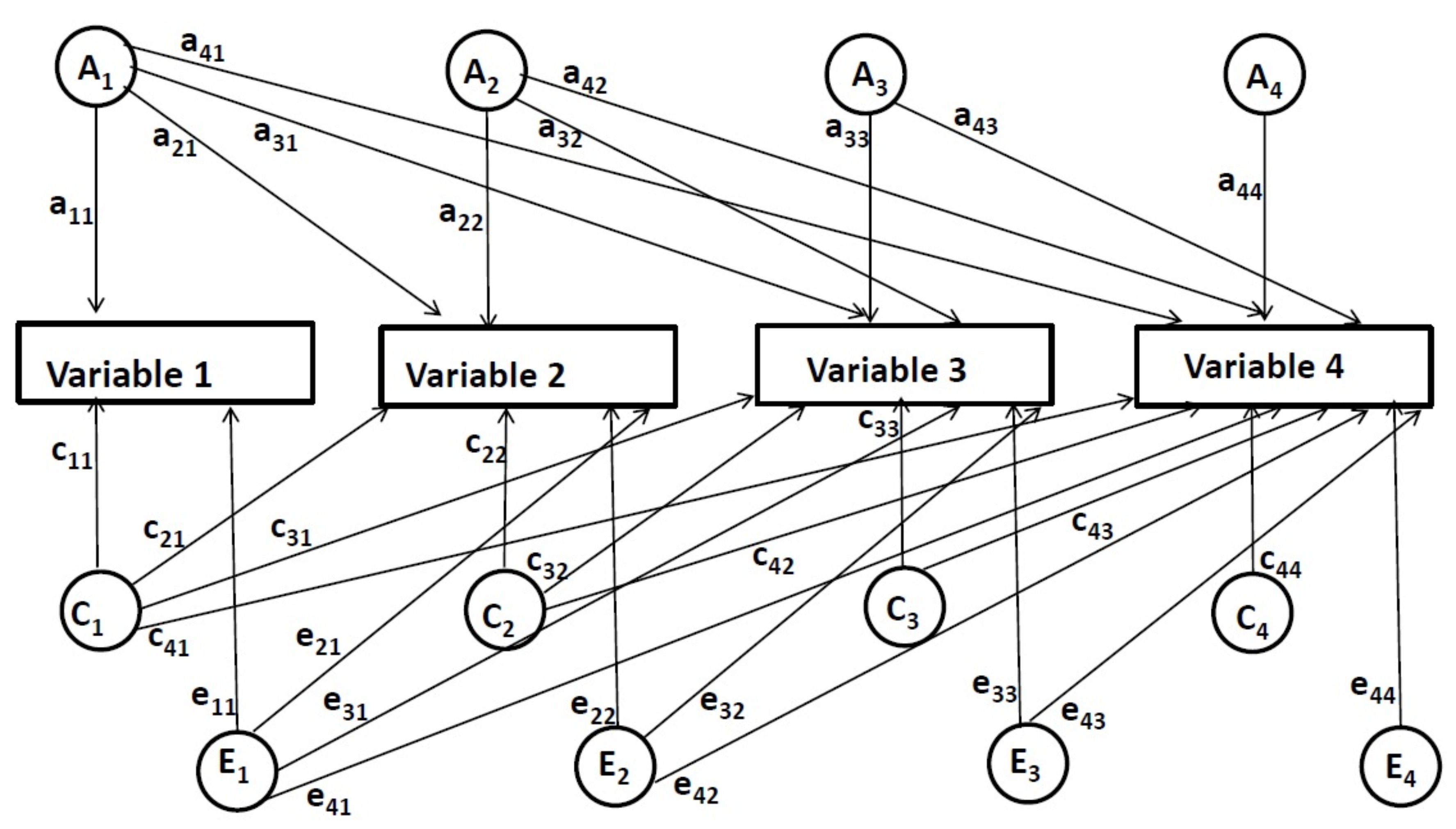
例えば、4つの時点で縦方向のデータを用いた多変量コレスキー分解(図2参照)、最初の因子セット[遺伝的(A1)]、共有環境(C1)、および非共有環境(E1))パスとして表されるすべての変数の分散に寄与し、パスとして表される11、21、31、41、 c11、 c21、 e11など、 A1、 C1、 E1の各変数に対する因子.2 番目の因子セット(A2、C2、E2)は、最初の時間点を制御した後の2番目の変数とその後の変数の分散に寄与します。因子の2番目のセットは、パスa22、a32、42、c22、c32、...、e22などとして表されます。次に、3 番目の因子セット(A3、C3、E3)の影響は、前の2つの時点を制御した後の3番目と4番目の変数について推定される。これらはパスとして表されます33, a43, c33 , c43, e33, e43.最後に、4 番目の因子セット(A4、C4、E4)の影響は、すべての前の時点を制御した後の最終時点で測定されます。これらはパスとして表されます44,c44, e44.

図2:4つの時間点のための多変量コレスキー分解モデル。この図のより大きなバージョンを表示するには、ここをクリックしてください。
{kind=link}
多変量コレスキー分解法のこの縦方向の適用では、各時点における遺伝的および環境的影響は、前の時点の効果が制御された後に推定される。したがって、この方法は、以前の時点からの影響とは無関係に、特定の時点で特定の時点で固有の遺伝的および環境的影響がどの程度オンラインに来るかの決定を可能にします(これらの効果は、パス11によって推定されます。22, a33, a44, c11 , c22, ..., e11, e22など)さらに、この方法は、同じ(重なり合う)遺伝的および環境的影響が時間ポイント間で共有される程度の検討も可能にする。言い換えれば、遺伝的および環境的影響が1つの時点から別の時間ポイントにどの程度引き継がれるかを決定することができる(すなわち、これらの効果は、パスによって推定される21、31、41、32、42、43,c21, c31, ..., e21など)パス11、c11、およびe11は、最初の時点まで、および前の時点と一意であるか、または重複することができる最初の時点までのすべての可能な遺伝的および環境的影響を表す。ただし、最初の時点より前の時点は推定されません。したがって、それらが一意であるか重複する影響を表すかを正確に判断することはできません。簡略化のために、これらは現在のレポートに一意の影響として含まれます。
コレスキー分解に入力された測定変数の順序は任意です。ただし、順序は通常、理論的な視点によって駆動されます。これは、小学校の読解力が中学校の読解力を予測するような、読解力の発達に基づく今回の研究でも当てはまる。
コレスキー分解法を利用した読解力の縦方向の関連の根底にある遺伝的および環境的要因を調査する文献には、いくつかの報告がある。これらの先行研究は、主に小学生6,7の読解力との関係を調査することに焦点を当てた。多変量コレスキー分解方法8を使用して、小学校から中学校の学年への読書に関連する個人差を調べる唯一の公開された研究があります。このプロトコルは、幼稚園の手紙の知識、幼稚園のフォンロジカルな認識、1年生の単語レベルとの間の縦方向の関係の個々の違いを探求するために、その特定のレポートから多変量コレスキー分解方法を詳述します読解力と7年生の読解力。
今回の研究結果は、多変量コレスキー分解法を用いて、2種類の遺伝的影響と環境影響を区別することに焦点を当てている。まず、小学校から中学校の読み取り(例えば、遺伝的および環境的影響である43、c43、およびe43のパスを推定する)に持ち越す遺伝的および環境的影響を推定する方法を示す。7年生の読解力に影響を与える1年生の単語レベルの読解力)。第二に、各グレードでオンラインで来るユニークな遺伝的および環境的影響を推定する方法を示す(例えば、パスを推定する33、c33、およびe33、これは固有の遺伝的および環境的影響である)1年生で生じる単語レベルの読解力)。
プロトコル
以下のステップは、小中学校の読解力の根底にある個人差を(A)遺伝的、(C)共有環境、および(E)非共有環境因子に推定するプロセスを説明する。グラフィカルユーザーインターフェイス(GUI)を備えた統計モデリングプログラム、ワードプロセッサ、およびソフトウェア。この研究は、フロリダ州立大学の機関レビュー委員会によって承認されています.
1. 統計モデリングプログラムのデータの準備
- 選択した統計モデリング プログラムで読み取ることができる形式でデータを準備します。人気の統計モデリングプログラムには、Mx、プラットフォームRのOpenMx、MPlus9が含まれます。Mx は、.vl または .dat データ形式、任意のデータ形式の OpenMx、および .dat データ形式の Mplus でデータ ファイルを読み取ることができます。ここで示す例は、プログラム MPlus9で実行されます。
注: ランダムに選択された 6 人の参加者の .dat 形式のサンプル データ ファイルは、補足ファイルで使用できます。サンプル データ ファイルで使用される変数は、入力コーディング ファイルで使用される変数を反映します。
2. 統計モデリングプログラムへのデータの読み込み、スクリプトの実行、および効果の推定
- 統計モデリング プログラムを開きます。
- 統計モデリング プログラムに読み込む関連データ ファイルを検索するには、「ファイルは [コンピュータ上のデータ ファイルの挿入場所] と入力します。
- 統計モデリング プログラムのリボンにあるアイコンRUNをクリックすると、多変量コレスキー分解法から遺伝的、共有環境、および非共有環境影響の推定値が得られます。MPlusを使用した4つの時間ポイントの多変量コレスキー分解モデルのアヌ釈付き入力スクリプトは、補足的なコーディングファイルで見つけることができます。
- 統計モデリング プログラムが遺伝的、共有環境、および非共有環境影響の推定値を生成したら、パス a11 、パスa 21のstx11の出力ファイル内の推定値を検索します。...、パス c11の sty11、パス c 21 の sty21、パス e 11 の stz11、パス e 21 の stz21など。
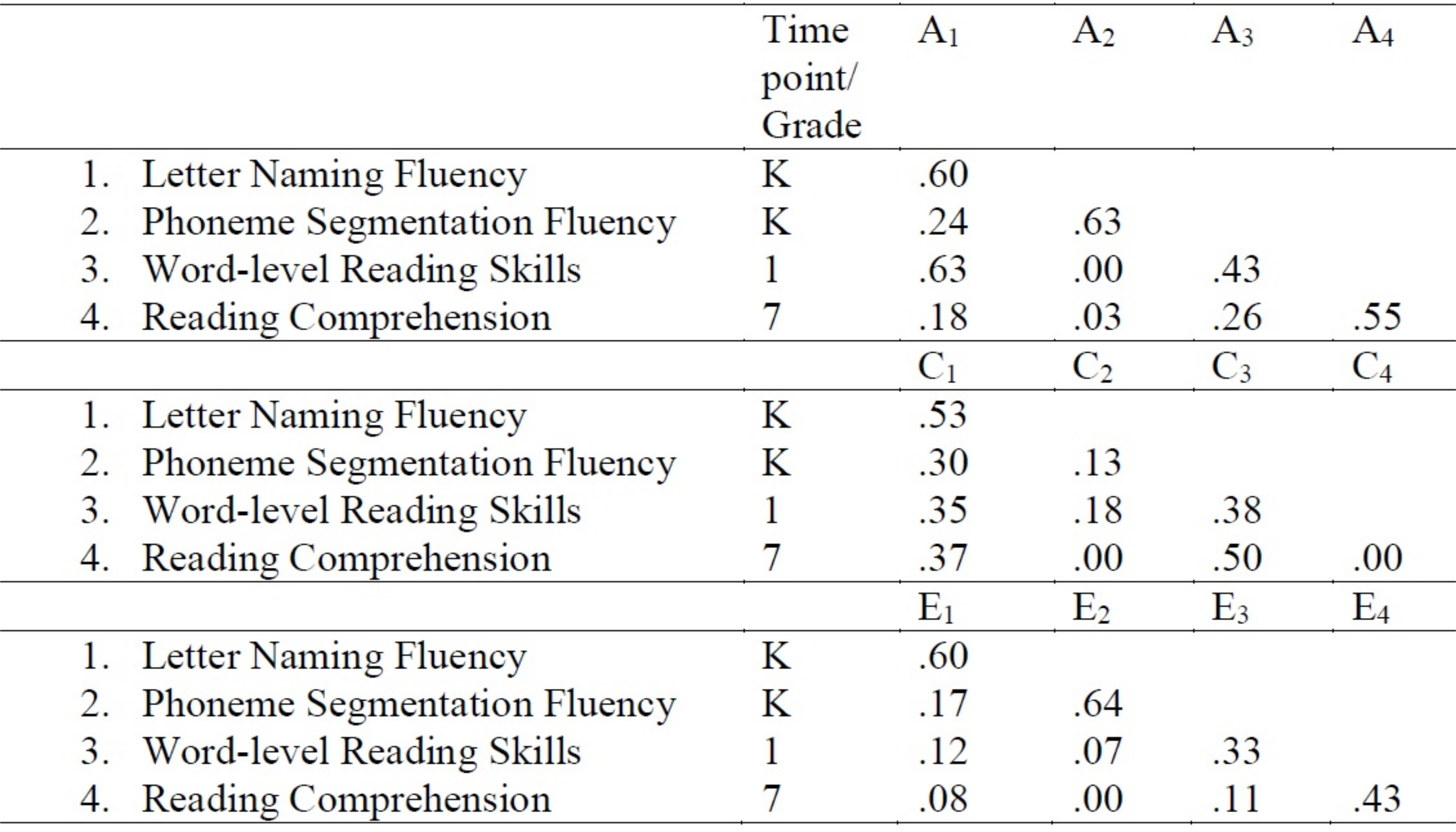
3. 生成された見積もりを含むテーブルの作成
- ワード プロセッサを開きます。
- 生成された推定値をワード プロセッサのテーブルにコピーします。表は、図 3に示すように形式で作成できます。たとえば、この場合、パスの推定値は11、21、31、および41はそれぞれ 0.60、0.24、0.63、および 0.18 の値を持ちます。

図3:多変量コレスキー分解モデリング標準化された経路の遺伝的および環境的影響の推定値。この図のより大きなバージョンを表示するには、ここをクリックしてください。
{kind=link}
4. 遺伝的、共有環境、非共有環境の影響をプロットする
- GUI でソフトウェアを開きます。
- 作成されたテーブルの見積もりをセル F3-F16、G4-G16、H5-H16、および I6-I16 に入力します。GUI を使用したソフトウェアのスクリーンショットを図 4 に示します。

図 4: GUI を使用してソフトウェアに見積もりを入力します。この図のより大きなバージョンを表示するには、ここをクリックしてください。
{kind=link}
- 細胞F3-F16、G4-G16、H5-H16、およびI6-I16の推定値をスクワリングすることにより、遺伝的、共有環境、および非共有環境影響の分散を計算します。セル J3-J16、K4-K16、L5-L16、および M6-M16 に二乗値を入力します。
- セル J3-J16、K4-K16、L5-L16、および M6-M16 の値を 100 で乗算して、分散率を計算します。セル N3-N16、O4-O16、P5-P16、および Q6-Q16 のパーセンテージ値を入力します。手順 4.3 および 4.4 を図 5 に示します。

図 5: 手順 4.3 および 4.4 の図を示します。この図のより大きなバージョンを表示するには、ここをクリックしてください。
{kind=link}
- 遺伝的影響が小学校から中学校に持ち越す(重複する)程度を計算します。
- セル R3 に「0」と入力します。
- セル R4 に「=N4」と入力します。これは、最初の時点から2番目の時点まで遺伝的影響がどの程度引き継がれたかです。この場合、幼稚園における文字命名流暢さから幼稚園の文言セグメンテーション流暢さへの遺伝的影響を示す。
- セル R5 に「= N5+O5」と入力します。これは、最初の2つの時点からの遺伝的影響が3番目の時点に引き継がす度合いです。この場合、幼稚園における文字命名流暢さと幼稚園の文言セグメンテーション流暢さから、1年生の単語レベルの読解能力に引き継がれたことによる遺伝的影響を示す。
- セル R6 に「= N6+O6+P6」と入力します。これは、最初の3つの時点からの遺伝的影響が4番目の時点に引き継がれ等の程度です。この場合、幼稚園における文字命名流暢さ、幼稚園における文言セグメンテーション流暢さ、および1年生の単語レベルの読解力から7年生の読解に引き継がれたことによる遺伝的影響を示す。
- ステップ 4.5 のように、共有環境と非共有環境の影響が小学校から中学校に持ち越す (重複する) 程度を計算します。
- 特定の時点(等級)で、固有の遺伝的、共有環境、および非共有環境因子がどの程度オンラインになるかを計算します。
- 細胞N3、O4、P5、およびQ6のパーセンテージをそれぞれ細胞S3、S4、S5、S6にコピーし、各グレードで独自の遺伝的因子がオンラインに入る程度を得る。
- セル N8、O9、P10、および Q11 のパーセンテージをそれぞれセル U3、U4、U5、および U6 にコピーして、各グレードで独自の共有環境因子がオンラインにする範囲を取得します。
- セル N13、O14、P15、および Q16 のパーセンテージをそれぞれセル W3、W4、W5、および W6 にコピーして、各グレードで独自の非共有環境因子がオンラインにする範囲を取得します。
- すべての計算が正しいことを確認するために、セル R3-W3、R4-W4、R5-W5、および R6-W6 の値は、それぞれ最大 100 を加算する必要があります。手順 4.5 ~ 4.7 を図 6 に示します。

図 6: 手順 4.5 ~ 4.8 の図を示します。この図のより大きなバージョンを表示するには、ここをクリックしてください。
{kind=link}
- 細胞R2-R6とS2-S6の上にマウスをクリックしてドラッグして、データを強調表示することにより、遺伝的重複だけでなく、遺伝的ユニークな影響をプロットします。
- [挿入]メニューをクリックします。
- グラフ>積み上げ縦棒をクリックします。
- 共有環境と非共有環境の重複と固有の影響については、手順 4.9 ~ 4.11 を繰り返します。セル T2-T6 と U2-U6 を選択して共有環境影響をプロットし、共有されていない環境影響のセル V2-V6 と W2-W6 を選択します。
結果
多変量コレスキー分解モデルからの遺伝的、共有環境、および非共有環境影響の標準化された推定値を図7に示す。一般的に、幼稚園の読書前と1年生の単語レベルの読み取りスキルの個人差が遺伝的差異の大部分を占めていることが明らかになった(40%)だけでなく、共有環境 (39%)7年生の読解力に影響を与える。さらに、結果は、各学年の個々の読書スキル...
ディスカッション
本研究の目的は、行動遺伝学における確立された方法、多変量コレスキー分解法が、時間的文脈における変数間の関係を理解するために効果的に使用できることを実証することであった。具体的には、この方法は、特定の時点(例えば、学校の学年)の間に固有の遺伝的および環境的影響が生じる程度の推定を可能にするだけでなく、多くの間で遺伝的および環境的影響の重複を実証すること?...
開示事項
著者は何も開示する必要はありません。
謝辞
この研究は、国立小児保健人間開発研究所(P50 HD052120)の助成金によって一部支援されました。ここに表明された見解は著者のものであり、認可機関によってレビューも承認もされていません。
資料
| Name | Company | Catalog Number | Comments |
| Microsoft Office Excel | Microsoft | ||
| Microsoft Office Powerpoint | Microsoft | ||
| Microsoft Office Visio | Microsoft | ||
| Microsoft Office Word | Microsoft | ||
| Mplus Statistical Program | Mplus |
参考文献
- Muter, V., Hulme, C., Snowling, M. J., Stevenson, J. Phonemes, rimes, vocabulary and grammatical skills as foundations of early reading development: Evidence from a longitudinal study. Developmental Psychology. 40 (5), 665-681 (2004).
- Schatschneider, C., Fletscher, J. M., Francis, D. J., Carlson, C. D., Foorman, B. R. Kindergarten prediction of reading skills: A longitudinal comparative analysis. Journal of Educational Psychology. 96 (2), 265-282 (2004).
- Byrne, B., et al. Longitudinal twin study of early literacy development: Preschool and kindergarten phases. Scientific Studies of Reading. 9 (3), 219-235 (2005).
- Christopher, M. E., et al. Genetic and environmental etiologies of the longitudinal relations between prereading skills and. Child Development. 86 (2), 342-361 (2015).
- Neale, M. C., Cardon, L. R. . Methodology for Genetic Studies of Twins and Families. , (1992).
- Byrne, B., et al. Genetic and environmental influences on early literacy. Journal of Research in Reading. 29 (1), 33-49 (2006).
- Byrne, B., et al. Genetic and environmental influences on aspects of literacy and language in early childhood: Continuity and change from preschool to grade 2. Journal of Neurolinguistics. 22 (3), 219-236 (2009).
- Erbeli, F., Hart, S. A., Taylor, J. Longitudinal associations among reading related skills and reading comprehension: A twin study. Child Development. 89 (6), e480-e493 (2018).
- Muthén, L. K., Muthén, B. O. . Mplus. The comprehensive modeling program for applied researchers: User’s guide. , (2012).
- Hart, S. A., et al. Exploring how nature and nurture affect the development of reading: An analysis of the Florida Twin Project on Reading. Developmental Psychology. 49 (10), 1971-1981 (2013).
- Taylor, J., Roehrig, A. D., Hensler, B. S., Connor, C. M., Schatschneider, C. Teacher quality moderates the genetic effects on early reading. Science. 328 (5977), 512-514 (2010).
転載および許可
このJoVE論文のテキスト又は図を再利用するための許可を申請します
許可を申請さらに記事を探す
This article has been published
Video Coming Soon
Copyright © 2023 MyJoVE Corporation. All rights reserved