
Method Article
落下検知システムの単純化のための設計と解析
要約
マルチモーダルセンサをベースにした手法を提示し、シンプルで快適で高速な落下検知と人間の活動認識システムを構成します。目標は、簡単に実装し、採用することができる正確な落下検出のためのシステムを構築することです。
要約
本論文では、マルチモーダルセンサをベースにした手法を用いて、簡単に実装し、採用できる、シンプルで快適で高速な落下検出と人間の活動認識システムを構成する方法論を紹介する。この方法論は、特定のタイプのセンサー、機械学習方法、および手順の構成に基づいています。このプロトコルは、(1)データベース作成(2)データ分析(3)システムの簡素化と(4)評価の4つのフェーズに分けられる。この方法論を用いて、落下検出と人間の活動認識のためのマルチモーダルデータベース、すなわちUP-Fall Detectionを作成しました。これは、3回の試験中に5種類の転倒と6つの異なる単純な活動を行う17の被験者からのデータサンプルで構成されています。すべての情報は、5つのウェアラブルセンサー(3軸加速度計、ジャイロスコープ、光強度)、1つの脳波ヘルメット、6つの赤外線センサーを周囲センサー、および横と正面の視点で2台のカメラを使用して収集されました。提案された新しい方法論は、落下検出システムを簡素化するために、次の設計上の問題の深い分析を行うためにいくつかの重要な段階を追加します:a)単純な落下検出システムで使用するセンサーまたはセンサーの組み合わせを選択し、b)情報源の最適な配置を決定し、c)落下および人間の活動検出および認識に最も適した機械学習分類方法を選択する。文献で報告されている一部のマルチモーダルアプローチは、上記の問題の1つまたは2つに焦点を当てていますが、我々の方法論は、人間の転倒と活動検出および認識システムに関連するこれら3つの設計上の問題を同時に解決することを可能にする。
概要
人口高齢化の世界現象は1、転倒率が増加しており、実際には大きな健康問題と考えられています2。転倒が起こると、人々は否定的な結果を減らすために直ちに注意を払う必要があります。落下検知システムは、転倒が発生したときにアラートを送信する医師の診察を受ける時間を短縮することができます。
落下検出システム3にはさまざまな分類があります。初期の作品4は、検出方法、分析方法、機械学習方法によって落下検出システムを分類します。最近では、他の著者33、5、65,6は、落下検出器を分類するための主な特徴としてデータ取得センサーを考慮しています。Igualら3は、落下検出システムを、ビジョンおよびアンビエントセンサーベースのアプローチ、ウェアラブルデバイスシステムを含むコンテキスト対応システムに分割します。Mubashirら5は、データ収集に使用されるデバイス(ウェアラブルデバイス、アンビエンスセンサー、ビジョンベースのデバイス)に基づいて、落下検出器を3つのグループに分類します。Perry et al.6では、加速度測定方法、他の方法と組み合わせた加速度測定方法、および加速度を測定しない方法を検討する。これらの調査から、センサとメソッドが一般的な研究戦略を分類する主要な要素であると判断できます。
各センサーには、Xuら 7 で説明されている弱点と強みがあります。ビジョンベースのアプローチでは、主に通常のカメラ、深度センサーカメラ、モーションキャプチャシステムを使用します。通常のウェブカメラは低コストで使いやすいですが、環境条件(光変動、遮蔽など)に敏感であり、スペースの削減でしか使用できないので、プライバシーの問題があります。Kinect などの深度カメラは、フルボディの 3D モーション7を提供し、通常のカメラよりも照明条件の影響を受けにくい。しかし、Kinect に基づくアプローチは、堅牢で信頼性が高くはありません。モーション キャプチャ システムは、コストが高く、使用が困難です。
加速度計を内蔵した加速度計やスマートフォン/時計に基づくアプローチは、落下検知に非常に一般的に使用されます。これらのデバイスの主な欠点は、長期間着用しなければならないということです。不快感、目立たさ、身体の配置、向きは、これらのアプローチで解決すべき設計上の問題です。スマートフォンやスマートウォッチはセンサーの目立たないデバイスですが、高齢者はしばしば忘れているか、常にこれらのデバイスを着用するとは限りません。それにもかかわらず、これらのセンサーおよび装置の利点は多くの部屋および/または屋外で使用することができることである。
システムによっては、環境周辺に設置されたセンサーを使用して転倒/活動を認識するため、センサーを装着する必要がないものがあります。ただし、これらのセンサーは、8を展開する場所に限定され、インストールが困難な場合もあります。近年、マルチモーダル落下検出システムには、より正確で堅牢性を高めるために、ビジョン、ウェアラブル、および周囲のセンサの異なる組み合わせが含まれています。また、シングルセンサーの制限の一部を克服することもできます。
落下検出に使用される方法論は、データ取得、信号前処理およびセグメンテーション、特徴抽出および選択、トレーニングおよび分類の段階からなるBulling et al.9によって提示されたヒト活動認識チェーン(ARC)と密接に関連している。これらの各段階で、設計上の問題を解決する必要があります。各ステージでは、さまざまな方法が使用されます。
マルチモーダルセンサをベースにした手法を提示し、シンプルで快適で高速な人の転倒と人間の活動検出/認識システムを構成します。目標は、簡単に実装し、採用することができる正確な落下検出のためのシステムを構築することです。提案された新しい方法論はARCに基づいていますが、システムを簡素化するために次の問題の詳細な分析を実行するための重要なフェーズが追加されます: (a)単純な落下検出システムで使用するセンサーまたはセンサーの組み合わせを選択します。(b) 情報源の最適な配置を決定する。(c)落下検出と人間の活動認識のための最も適した機械学習分類方法を選択して、単純なシステムを作成します。
上記のデザイン問題の1つまたは2つに対応した文献に関連する作品がいくつかありますが、私たちの知る限りでは、これらの問題をすべて克服するための方法論に焦点を当てた作品はありません。
関連作品は、堅牢性を高め、精度を高めるために、落下検出と人間活動認識10、11、1211,12のためのマルチモーダルアプローチを使用しています。10Kwolekら10は、加速度データと深度マップに基づく落下検出システムの設計と実装を提案した。彼らは、潜在的な落下と人の動きを検出するために3軸加速度計を実装する興味深い方法論を設計しました。加速度メジャーがしきい値を超えると、アルゴリズムはオンライン更新された深度参照マップから深度マップを差分化する人物を抽出します。深さと加速度計の組み合わせの分析は、サポートベクターマシン分類器を使用して行われました。
Ofli et al.11は、新しいヒト活動認識システムの試験床を提供するために、マルチモーダルヒューマンアクションデータベース(MHAD)を発表した。このデータセットは、1つの光学モーションキャプチャシステム、4つのマルチビューカメラ、1つのKinectシステム、4つのマイク、6つのワイヤレス加速度計を使用して同時に収集されるため、重要です。著者らは、Kinect、モキャップ、加速度計、オーディオの各モダリティの結果を発表した。
Dovgan et al.12は、高齢者における転倒を含む異常な挙動を検出するためのプロトタイプを提案した。彼らは、落下および異常な行動検出のための最も適切な機器を見つけるために、3つのセンサーシステムのテストを設計しました。最初の実験は、腰、膝、足首、手首、肘、肩に12個のタグが取り付けられたスマートセンサーシステムのデータで構成されています。また、腰、胸部、足首の両方に4つのタグを取り付けた1つのUbisenseセンサーシステムと、1つのXsens加速度計を使用してテストデータセットを作成しました。第3の実験では、4つの被験者がUbisenseシステムのみを使用し、4種類の転倒、4つの健康問題を異常な行動として、そして日常生活の異なる活動(ADL)を行う。
文献13、14、15,15の他の作品は13、センサーの様々な組み合わせと複数の分類器を比較して、落下検出のためのセンサーまたはデバイスの最良の配置を見つけるという問題に取り組んでいます。三世ら13は、落下検出のための5つのセンサーの位置の重要性を評価する体系的な評価を提示した。K-近傍(KNN)、サポートベクターマシン(SVM)、ナイーブベイズ(NB)、デシジョンツリー(DT)分類子を使用して、これらのセンサーの組み合わせの性能を比較しました。彼らは、被検体上のセンサーの位置は、使用される分類器とは無関係に落下検出器の性能に重要な影響を及ぼすと結論付ける。
落下検出のための身体のウェアラブルセンサー配置の比較は、Özdemir14によって提示されました。センサーの配置を決定するために、著者は、次の位置の31のセンサーの組み合わせを分析しました:頭、腰、胸、右手首、右足首と右太もも。14人のボランティアが20の模擬滝と16のADLを行いました。彼は、これらの徹底的な組み合わせ実験から単一のセンサーがウエストに配置されたときに最高の性能が得られたことを発見しました。もう一つの比較は、オズデミールのデータセットを使用してNtanasis15によって提示されました。著者らは、J48、KNN、RF、ランダム委員会(RC)およびSVMを使用して、頭部、胸部、腰、手首、足首および太ももの単一の位置を比較した。
落下検出のための異なる計算方法の性能のベンチマークは、文献16、17、1817,18にも見られる。16Bagalaら16は、実際の転倒で試験した13個の落下検出方法の性能を評価する系統的比較を提示した。彼らは、腰やトランクに置かれた加速度計の測定値に基づいてアルゴリズムのみを考慮しました。Bourkeら17は、ADLのデータセットを用いて落下検出のための5つの分析アルゴリズムの性能を評価し、加速度計の測定値に基づいて落下した。ケルデガリ18はまた、記録された加速度データのセットに対する異なる分類モデルの性能の比較を行った。落下検出に使用されるアルゴリズムは、ゼロR、1R、NB、DT、多層パーセプトロン、SVMであった。
落下検出の方法論は、人間の活動の累積ヒストグラムベースの表現を構築するために運動ポーズ幾何学的記述子を使用してAlazraiららによって提案された。彼らはKinectセンサーで収集されたデータセットを使用してフレームワークを評価しました。
要約すると、モダリティの異なる組み合わせのパフォーマンスを比較するマルチモーダル落下検出関連の作品10,10、11、1212を発見しました。11一部の著者は、センサー13、14、15、,14,15または複数の分類子を持つセンサ13の組み合わせの最良の配置を見つけるという問題に取り組んでいます13,,15,,16同じモダリティと加速度計の複数のセンサーを持つ.配置、マルチモーダルの組み合わせ、分類器ベンチマークに同時に対処する文献には作品は見つかりませんでした。
プロトコル
ここで説明するすべての方法は、パナメリカーナ大学工学部の研究委員会によって承認されています。
注: この方法論は、シンプルで高速でマルチモーダルな落下検出と人間の活動認識システムを構成するために、特定のタイプのセンサー、機械学習方法および手順の構成に基づいています。このため、(1)データベース作成(2)データ分析(3)システムの単純化と(4)評価のフェーズで、次のプロトコルが分かれています。
1. データベースの作成
- データ収集システムを設定します。これにより、すべてのデータがサブジェクトから収集され、取得データベースに格納されます。
- 情報源として必要なウェアラブルセンサー、アンビエントセンサー、ビジョンベースのデバイスの種類を選択します。各情報源、ソースあたりのチャンネル数、技術仕様、サンプリングレートごとにIDを割り当てます。
- すべての情報源(ウェアラブル、アンビエントセンサー、ビジョンベースのデバイス)を中央コンピュータまたは分散コンピュータシステムに接続します。
- 有線ベースのデバイスが 1 台のクライアント コンピュータに正しく接続されていることを確認します。ワイヤレス ベースのデバイスが完全に充電されていることを確認します。バッテリの低下がワイヤレス接続やセンサー値に影響する可能性があることを考慮してください。また、接続が断続的に失われた場合は、データの損失が増加します。
- データを取得する各デバイスを設定します。
- クラウド上にデータを格納するためのデータ取得システムを設定します。大量のデータが格納されるため、クラウド コンピューティングがこのプロトコルで考慮されます。
- データ取得システムがデータ同期とデータの整合性20のプロパティを満たしていることを検証します。これにより、すべての情報源からデータストレージの整合性を維持できます。データ同期では、新しいアプローチが必要になる場合があります。例えば、ペニャフォルト・アストリアノら20を参照してください。
- 情報ソースを使用してデータの収集を開始し、優先システムにデータを格納します。すべてのデータにタイムスタンプを含めます。
- データベースに対してクエリを実行し、すべての情報源が同じサンプルレートで収集されているかどうかを確認します。適切に実行したら、ステップ 1.1.6 に進みます。それ以外の場合は、ペニャフォルト・アストゥリアーノで報告された基準を使用してアップサンプリングまたはダウンサンプリングを実行します。
- 必要な条件とシステムの目標によって課される制限を考慮して、環境(または実験室)を設定します。シミュレーションでの衝撃力減衰の条件をLachance、23等で提案された準拠フローリングシステムとして設定し、参加者23の安全を確保する。
- マットレスやその他の準拠フローリングシステムを使用し、環境(または実験室)の中心に配置します。
- すべてのオブジェクトをマットレスから離して、少なくとも1メートルの安全なスペースを与えてください。必要に応じて、参加者(手袋、キャップ、ゴーグル、膝のサポートなど)のための個人的な保護具を準備します。
注: プロトコルはここで一時停止することができます。
- 構成後にシステムが検出するヒューマンアクティビティとフォールを決定します。転倒検出と人間活動認識システムの目的、ならびに標的集団を念頭に置いておく事が重要である。
- 落下検出と人間活動認識システムの目標を定義します。計画シートに書き留めこのケーススタディでは、高齢者の日常的に行われる人間の転倒の種類と活動を分類することが目標です。
- システムの目標に従って、実験の目標集団を定義します。計画シートに書き留め研究では、高齢者をターゲット人口と考えています。
- 毎日の活動の種類を決定します。実際の落下検出を改善するために、落下のように見えるいくつかの非落下活動を含めます。すべての ID を割り当て、できるだけ詳細に記述します。実行する各アクティビティの期間を設定します。計画シートにこの情報をすべて書き留めます。
- 人間の転倒の種類を決定します。すべての ID を割り当て、できるだけ詳細に記述します。各秋の実行期間を設定します。滝が被験者によって自己生成されるか、他の人によって生成される(例えば、被験者を押す)かどうかを検討してください。計画シートにこの情報をすべて書き留めます。
- 計画シートで、被験者が実行する活動と転倒の順序を書き留めます。期間、アクティビティ/フォールあたりの試行回数、アクティビティ/フォールを実行する説明、およびアクティビティ/フォール ID を指定します。
注: プロトコルはここで一時停止することができます。
- 活動と転倒のシーケンスを実行するスタディに関連する対象を選択します。滝は、現実の生活の中でキャッチするまれなイベントであり、通常、老人に発生します。それにもかかわらず、安全上の理由から、高齢者や障害のある人々を医学的アドバイスの下で秋のシミュレーションに含めないでください。スタントは怪我を避けるために使用されています22.
- 被験者の性別、年齢範囲、体重、身長を決定します。必要な減損条件を定義します。また、実験に必要な被験者の最小数も定義します。
- 前の手順で示した条件に従って、必要なサブジェクトのセットをランダムに選択します。ボランティアの募集を呼びかける。人間と実験する際の国際規制だけでなく、機関や国から適用されるすべての倫理指針を遵守します。
注: プロトコルはここで一時停止することができます。
- サブジェクトからデータを取得して格納します。この情報は、さらなる実験分析に役立ちます。臨床専門家または責任ある研究者の監督下で、次の手順を実行します。
- ステップ 1.1 で構成されたデータ収集システムでデータ収集を開始します。
- 各被験者に,ステップ1.2で宣言された活動と転倒のシーケンスを実行するよう依頼する。各アクティビティ/フォールの開始と終了のタイムスタンプを明確に保存します。すべての情報源からのデータがクラウドに保存されていることを確認します。
- アクティビティが適切に実行されなかった場合、またはデバイスに問題があった場合(例:接続が失われた、バッテリが少ない、断続的な接続)、サンプルを破棄し、デバイスの問題が見つからないまでステップ 1.4.1 を繰り返します。ステップ 1.4.2 の順序で宣言された各試験ごとに、各試行についてステップ 1.4.2 を繰り返します。
注: プロトコルはここで一時停止することができます。
- 取得したすべてのデータを事前処理します。情報のソースごとにアップサンプリングとダウンサンプリングを適用します。マルティネス・ヴィッラセニョールら21の落下検出と人間活動認識の前処理データの詳細を参照してください。
注: プロトコルはここで一時停止することができます。
2. データ分析
- データ処理のモードを選択します。データベースに保存されているデータを完全に使用する場合 (つまり、自動機能抽出にディープラーニングを使用する場合)、[Raw Data]を選択し、ステップ 2.2 に進みます。フィーチャー抽出を使用してさらに解析する場合は、[フィーチャ データ] を選択し、ステップ 2.3 に進みます。
- Raw データの場合は、追加の手順は必要ないので、ステップ 2.5 に進みます。
- [フィーチャ データ] で、生データからフィーチャを抽出します。
- タイム ウィンドウで生データをセグメント化します。時間枠の長さを決定し、固定します(例えば、1秒のサイズのフレーム)。また、これらのタイム ウィンドウが重なっているかどうかを確認します。50%の重なりを選択することをお勧めします。
- データの各セグメントからフィーチャを抽出します。セグメントから抽出する一時的および頻繁な特徴のセットを決定します。共通の特徴抽出については、マルティネス・ヴィッラセニョールら21を参照してください。
- 独立したデータベースに、クラウド上の機能抽出データ セットを保存します。
- 異なる時間枠が選択される場合は、ステップ 2.3.1 から 2.3.3 を繰り返し、各フィーチャ データセットを独立したデータベースに保存します。
注: プロトコルはここで一時停止することができます。
- 抽出される最も重要なフィーチャーを選択し、フィーチャー・データ・セットを削減します。一般的に使用される機能選択方法(例えば、一変量選択、主成分分析、再帰的特徴除去、特徴の重要性、相関行列など)を適用します。
- 機能の選択方法を選択します。ここでは、機能の重要性を使用しました。
- 各フィーチャーを使用して、特定のモデルをトレーニングし (RF を採用)、精度を測定します (式 1を参照)。
- 精度の順に並べ替えてフィーチャをランク付けします。
- 最も重要な機能を選択します。ここでは、最高ランクの最初の10の機能を使用しました。
注: プロトコルはここで一時停止することができます。
- 機械学習の分類方法を選択し、モデルをトレーニングします。よく知られた機械学習方法があります16,17,18,21など:サポートベクターマシン(SVM)、ランダムフォレスト(RF)、多層パーセプトロン(MLP)およびk-最も近い隣人(KNN)など、
- 必要に応じて、ディープラーニングのアプローチを選択した場合は、21: 畳み込みニューラルネットワーク (CNN) 、長期短期記憶ニューラルネットワーク (LSTM) などを考慮します。
- 機械学習メソッドのセットを選択します。ここでは、SVM、RF、MLP、KNNの方法を使用しました。
- 文献21で提案されているように、各機械学習メソッドのパラメータを修正します。
- 独立したフィーチャ データセット (または生データ セット) を使用して結合フィーチャ データセット (または生データ セット) を作成し、情報ソースの種類を結合します。たとえば、1 つのウェアラブル センサーと 1 台のカメラの組み合わせが必要な場合は、これらの各ソースのフィーチャ データ セットを組み合わせます。
- トレーニング セットとテスト セットでフィーチャ データ セット (または生データ セット) を分割します。トレーニングの場合は 70% 、テスト用に 30% をランダムに分割することをお勧めします。
- 各機械学習方法に対して、機能データセット(または生データセット)を使用してK-foldクロス検証21を実行する。精度などの評価の共通メトリックを使用して(式1を参照)、方法ごとにトレーニングされた最良のモデルを選択します。脱退対象外(LOSO)実験3も推奨される。
- 優先プログラミング言語ソフトウェアでトレーニング機能データ セット (または生データ セット) を開きます。Python が推奨されます。この手順では、次のように、パンダライブラリを使用してCSVファイルを読み取ります。
training_set = パンダ.csv(<ファイル名.csv>)。 - 入力出力のペアでフィーチャ データ セット (または生データ セット) を分割します。たとえば、Python を使用して、x 値 (入力) と y 値 (出力) を宣言します。
training_set_X = training_set.drop('タグ',軸=1),training_set_Y = training_set.tag
タグは、ターゲット値を含むフィーチャ データ セットの列を表します。 - 1 つの機械学習方法を選択し、パラメーターを設定します。たとえば、次のコマンドのように、Python で SVM をライブラリ sklearn と共に使用します。
分類子 = sklearn.SVC(カーネル = 'ポリ')
カーネル関数が多項式として選択される。 - 機械学習モデルをトレーニングします。たとえば、上記の分類子を Python で使用して SVM モデルをトレーニングします。
分類子.fit(training_set_X,training_set_Y)。 - テストフィーチャー・データ・セット (または生データ・セット) を使用して、モデルの見積もり値を計算します。たとえば、Python で、推定値 = classifier.predict(testing_set_X)を使用testing_set_X、テストセットの x 値を表します。
- k 折り曲げクロス検証で指定された k 回数 (または LOSO アプローチに必要な回数) のステップ 2.5.6.1 ~ 2.5.6.5 を繰り返します。
- 選択した機械学習モデルごとに、ステップ 2.5.6.1 から 2.5.6.6 を繰り返します。
注: プロトコルはここで一時停止することができます。
- 優先プログラミング言語ソフトウェアでトレーニング機能データ セット (または生データ セット) を開きます。Python が推奨されます。この手順では、次のように、パンダライブラリを使用してCSVファイルを読み取ります。
- 選択したモデルをテスト データ セットでテストして、機械学習方法を比較します。その他の評価指標として使用できるのは、精度(式1)、精度(式2)、感度(式3)、特異性(式4)またはF1スコア(式5)、TPが真陽性、TNが真の陰性、FPが偽陽性、FNが偽陰性である。 TP





- 混乱行列9などの他の有益なパフォーマンス メトリックを使用して、機械学習モデルの分類タスクを評価したり、決定に依存しない精度リコール9 (PR) またはレシーバー動作特性9 (ROC) 曲線を評価したりします。この方法論では、リコールと感度は同等と見なされます。
- 機械学習モデルの定性的な機能を使用して、機械学習の解釈の容易さなど、それらの間で比較します。リアルタイムのパフォーマンス。時間、メモリ、処理コンピューティングの限られたリソース。エッジ デバイスまたは組み込みシステムでの機械学習の展開が容易になります。
- 品質指標 (方程式 1 ~5)、パフォーマンスメトリック、およびステップ 2.5.6、2.5.7、2.5.8 の機械学習実現可能性の質的特徴を使用して、最適な機械学習モデルを選択します。
注: プロトコルはここで一時停止することができます。
3. システムの簡素化
- 情報源の適切な配置を選択します。場合によっては、情報源の最適な配置(ウェアラブルセンサーの位置が優れているなど)を決定する必要があります。
- 分析する情報源のサブセットを決定します。たとえば、本体に 5 つのウェアラブル センサーがあり、1 つだけを最適なセンサーとして選択する必要がある場合、これらの各センサーはサブセットの一部になります。
- このサブセットの情報ソースごとに、別々のデータ・セットを作成し、個別に保管します。このデータ セットは、前の機能データセットまたは生データ セットのいずれかである可能性があります。
注: プロトコルはここで一時停止することができます。
- 機械学習の分類方法を選択し、1 つの情報源の配置に対するモデルをトレーニングします。ステップ 3.1.2 で作成した各データ・セットを使用して、2.5.1 から 2.5.6 までのステップを完了します。ランキングによって、最適な情報源を検出します。このケーススタディでは、SVM、RF、MLP、KNNの方法を使用します。
注: プロトコルはここで一時停止できます。 - システムに 2 つ以上の情報源 (たとえば、1 つのウェアラブル センサーと 1 つのカメラの組み合わせ) が必要な場合は、マルチモーダル アプローチで適切な配置を選択します。このケーススタディでは、腰装着センサーとカメラ1(横ビュー)をモダリティとして使用します。
- システム内の各モダリティの最適な情報源を選択し、これらの情報源の独立したデータ・セットを使用して、結合フィーチャー・データ・セット (または生データ・セット) を作成します。
- 機械学習の分類方法を選択し、これらの組み合わせの情報源のモデルをトレーニングします。結合フィーチャー・データ・セット (または生データ・セット) を使用して、ステップ 2.5.1 から 2.5.6 を実行します。本研究では、SVM、RF、MLP、KNNの方法を使用します。
注: プロトコルはここで一時停止することができます。
4. 評価
- より現実的な条件でユーザーと新しいデータセットを準備します。前の手順で選択した情報のソースのみを使用します。好ましくは、対象群(例えば高齢者)でシステムを実施する。より長い期間でデータを収集します。
- 必要に応じて、対象グループのみを使用する場合は、除外条件(身体的または心理的障害など)および停止基準予防(例えば、試験中に身体的傷害を検出し、吐き気、めまいおよび/または嘔吐、失神)を含む選択グループプロトコルを作成します。倫理的な懸念やデータのプライバシーに関する問題も考慮してください。
- これまでに開発された転倒検出とヒト活動認識システムの性能を評価する。方程式 1 ~ 5 を使用して、システムの精度と予測力、またはその他のパフォーマンス メトリックを決定します。
- 実験結果について考察する。
結果
データベースの作成
落下検出と人間の活動認識、すなわちUP-落下検出21のためのマルチモーダルデータセットを作成しました。データは、パナメリカーナ大学(メキシコ・メキシコシティ)の工学部で4週間にわたって収集されました。テストシナリオは、(a)被験者が快適かつ安全に転倒や活動を行うことができる空間と、(b)マルチモーダルセンサーの設定に適した自然光と人工光を備えた屋内環境の要件を考慮して選択されました。
3回の試行中に5種類の転倒と6つの異なる単純な活動を行った17の被験者からのデータサンプルがあります。すべての情報は、5つのウェアラブルセンサー(3軸加速度計、ジャイロスコープ、光強度)、1つの脳波ヘルメット、アンビエントセンサーとして6つの赤外線センサー、および横方向および前面の視点で2台のカメラを備えた社内データ取得システムを使用して収集されました。図1は、環境と本体におけるセンサ配置のレイアウトを示しています。データセット全体のサンプリング レートは 18 Hz です。このデータベースには、統合生データ・セット (812 GB) とフィーチャー・データ・セット (171 GB) の 2 つのデータ・セットが含まれています。パブリック アクセス用にクラウドに格納されているすべてのデータベース: https://sites.google.com/up.edu.mx/har-up/。データの取得、前処理、統合、およびこのデータベースの格納の詳細、および同期とデータの一貫性に関する詳細は、マルティネス・ヴィッラセニョールら21を参照してください。
このデータベースでは、すべての被験者が健康な若いボランティア(男性9人と女性8人)で、18歳から24歳まで、平均身長は1.66m、体重は66.8kgでした。データ収集の間、技術的責任ある研究者は、すべての活動が被験者によって正しく行われたことを監督していました。被験者は5種類の転倒を行い、それぞれが10秒間、手を使って前方(1)、前方に膝を使用して(2)、後方(3)、空の椅子(4)および横向き(5)に座った。彼らはまた、ジャンプ(30 s)を除いてそれぞれ60 sのための6つの毎日の活動を行いました:ウォーキング(6)、立っている(7)、オブジェクトを拾う(8)、座っている(9)、ジャンプ(10)と敷設(11)。シミュレートされた落下は、すべてのタイプの実際の落下を再現することはできませんが、少なくとも、より良い落下検出モデルの作成を可能にするフォールの代表的なタイプを含める必要があります。ADL を使用すること、特に、オブジェクトのピックアップなどの転倒と通常は間違えが起きるアクティビティも関連しています。フォール検出システム21の検討後に、フォールとADLの種類を選択した。例として、図 2は、被験者が横に倒れたときの 1 回の試行の一連の画像を示しています。
我々は、12時間(平均、標準偏差、最大振幅、最小振幅、二乗平均平方根、中央値、ゼロ交差数、歪度、尖度、第1四分位数、第3四分位数および自己相関)および6つの頻繁な(平均、中央値、エントロピー、エネルギー、主周波数およびスペクトル重心)特徴を、合計756の特徴の各チャネルから抽出した。また、ビデオ内の2つの隣接する画像間のピクセルの相対的な動きについて、カメラごとに400の視覚機能21を計算しました。
ユニモーダルアプローチとマルチモーダルアプローチ間のデータ解析
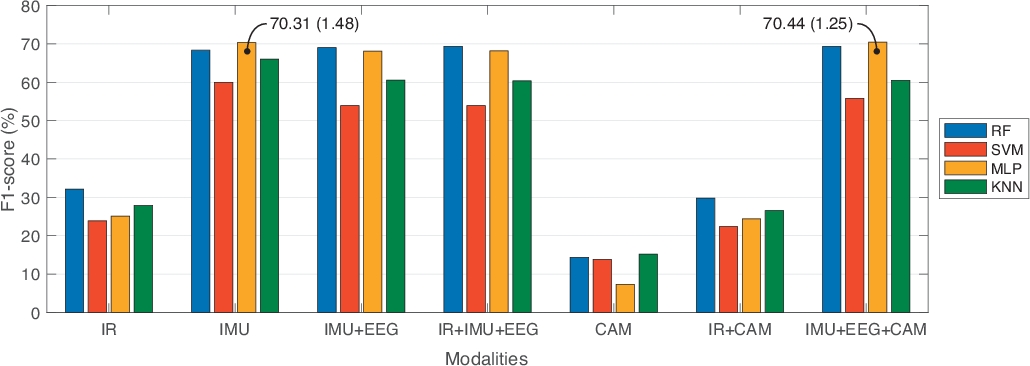
UP-落下検出データベースから、単相型アプローチとマルチモーダルアプローチの比較目的でデータを分析した。その意味で、我々は7つの異なる情報源の組み合わせを比較しました:赤外線センサーのみ(IR)。ウェアラブルセンサーのみ(IMU);ウェアラブルセンサーとヘルメット(IMU + EEG);赤外線およびウェアラブルセンサーとヘルメット (IR +IMU +EEG);カメラのみ(CAM);赤外線センサーとカメラ (IR +CAM);およびウェアラブルセンサー、ヘルメット、カメラ(IMU +EEG+CAM)。さらに、3つの異なる時間枠のサイズを比較し、50%のオーバーラップ(1秒、2秒、3秒)を比較しました。各セグメントで、機能の選択とランキングを適用する最も有用な機能を選択しました。この戦略を使用して、40の機能を使用するIRモダリティを除き、モダリティごとに10の特徴のみを採用しました。さらに、比較は、RF、SVM、MLPおよびKNNの4つの有名な機械学習分類子で行われた。機械学習モデルをトレーニングするために、70%の列車と30%のテストのデータセットを備えた10倍のクロス検証を採用しました。表 1は、このベンチマークの結果を示し、機械学習モデルと最適なウィンドウ長構成に応じて、各モダリティで得られた最適なパフォーマンスを報告しています。評価メトリックは、精度、精度、感度、特異性、F1スコアを報告します。図 3は、F1 スコアの点で、これらの結果をグラフィカルに表示したものです。
表1から、マルチモーダルアプローチ(赤外線およびウェアラブルセンサーとヘルメット、IR+IMU+EEG;ウェアラブルセンサーとヘルメットとカメラ、IMU +EEG +CAM)は、ユニモーダルアプローチ(赤外線のみ、IR、カメラのみ、CAM)と比較して、最高のF1スコア値を得ました。また、ウェアラブルセンサー(IMU)のみでは、マルチモーダルアプローチと同様の性能を得ている点にも気付いた。この場合、異なる情報源が他の情報源からの制限を処理できるため、マルチモーダルアプローチを選択しました。例えば、カメラの目立ちはウェアラブルセンサーで処理でき、すべてのウェアラブルセンサーを使用しない場合は、カメラや周囲センサーで補完することができます。
データ駆動モデルのベンチマークに関しては、表1の実験では、RFがほぼすべての実験で最良の結果を示しています。MLPとSVMはパフォーマンスにあまり一貫性がありませんでしたが(例えば、これらの技術の標準偏差はRFよりも変動性を示しています)。ウィンドウサイズについては、これらはそれらの中で有意な改善を表すものではなかった。これらの実験は、転倒と人間の活動分類のために行われたことに注意することが重要です。
センサーの配置と最適なマルチモーダルの組み合わせ
一方、落下検知のためのマルチモーダルデバイスの最適な組み合わせを決定することを目指しました。この分析では、5つのウェアラブルセンサーと2台のカメラに情報源を制限しました。これらのデバイスは、アプローチのための最も快適なものです。さらに、秋(任意のタイプの秋)または無落下(他の活動)の2つのクラスを検討しました。すべての機械学習モデルとウィンドウ サイズは、前回の分析と同じままです。
各ウェアラブルセンサーに対して、各ウィンドウ長に対して独立した分類器モデルを構築しました。70%のトレーニングと30%のテストデータセットで、10倍のクロス検証を使用してモデルをトレーニングしました。表 2は、F1 スコアに基づいて、パフォーマンス分類器ごとのウェアラブル センサーのランキングの結果をまとめます。これらの結果は降順で並べ替えられました。表2に示すように、腰、首、またはタイトな右ポケット(影付き領域)で単一のセンサーを使用する場合に最適な性能が得られます。さらに、足首と左手首のウェアラブルセンサーは最悪のパフォーマンスを示しました。表 3 は、各分類器で最高のパフォーマンスを得るために、ウェアラブル センサーごとのウィンドウ長の設定を示しています。結果から、腰、首、およびRF分類器と50%のオーバーラップを持つ3 sの窓サイズを備えたタイトな右ポケットセンサーは、落下検出に最も適したウェアラブルセンサーです。
システム内の各カメラについて同様の分析を行いました。各ウィンドウ サイズに対して独立した分類子モデルを構築しました。トレーニングでは、70%のトレーニングと30%のテストデータセットで10倍のクロス検証を行いました。表4は、F1スコアに基づいて、分類器あたりの最適なカメラ視点のランキングを示しています。観察されるように、横ビュー(カメラ1)は最良の落下検出を行った。さらに、RFは他の分類子と比較して上回った。また、表5はカメラ視点ごとの窓長の設定を示す。その結果、カメラの最適な位置は、3 sウィンドウサイズと50%の重なり合いのRFを使用して横方向の視点にあることがわかりました。
最後に、横方向のカメラと組み合わせるウェアラブルセンサー(ウエストとタイトな右ポケット)の2つの配置を選択しました。同じトレーニング手順の後、表6から結果を得た。図に示すように、RF モデル分類器は、両方のマルチモダリティで精度と F1 スコアで最高のパフォーマンスを得ました。また、ウエストとカメラ1の組み合わせは、精度が98.72%、F1スコアで95.77%を得た最初の位置にランク付けされました。

図1:UP-Fall検出データベース内のウェアラブル(左)センサーとアンビエント(右)センサーのレイアウト装着可能なセンサーは額、左手首、首、腰、ズボンの右ポケット、左足首に置かれます。周囲のセンサーは、被写体と2台のカメラの存在を検出するための6つのペアの赤外線センサーです。カメラは、人間の転倒に関して、横のビューと正面図に配置されています。この図の大きなバージョンを表示するには、ここをクリックしてください。
{kind=link}

図2:UP-Fall検出データベースから抽出されたビデオ録画の例。上部には、横に落下する被写体の画像のシーケンスがあります。下部には、抽出されたビジョン機能を表す一連の画像があります。これらの機能は、2 つの隣接する画像間のピクセルの相対モーションです。白色のピクセルは高速なモーションを表し、黒のピクセルはモーションの速度が遅い (またはゼロに近い) を表します。このシーケンスは、左から右へ、時系列で並べ替えられます。この図の大きなバージョンを表示するには、ここをクリックしてください。
{kind=link}

図3:機械学習モデルと最適なウィンドウ長に関して、各モダリティの最良のF1スコアを報告する比較結果。バーは、F1 スコアの平均値を表します。データポイント内のテキストは、平均と標準偏差を括弧で囲んで表します。この図の大きなバージョンを表示するには、ここをクリックしてください。
{kind=link}
| モダリティ | モデル | 精度 (%) | 精度 (%) | 感度 (%) | 特異性 (%) | F1スコア (%) |
| Ir | RF (3 秒) | 67.38 ± 0.65 | 36.45 ± 2.46 | 31.26 ± 0.89 | 96.63 ± 0.07 | 32.16 ± 0.99 |
| SVM (3 秒) | 65.16 ± 0.90 | 26.77 ± 0.58 | 25.16 ± 0.29 | 96.31 ± 0.09 | 23.89 ± 0.41 | |
| MLP (3 秒) | 65.69 ± 0.89 | 28.19 ± 3.56 | 26.40 ± 0.71 | 96.41 ± 0.08 | 25.13 ± 1.09 | |
| kNN (3 秒) | 61.79 ± 1.47 | 30.04 ± 1.44 | 27.55 ± 0.97 | 96.05 ± 0.16 | 27.89 ± 1.13 | |
| Imu | RF (1秒) | 95.76 ± 0.18 | 70.78 ± 1.53 | 66.91 ± 1.28 | 99.59 ± 0.02 | 68.35 ± 1.25 |
| SVM (1 秒) | 93.32 ± 0.23 | 66.16 ± 3.33 | 58.82 ± 1.53 | 99.32 ± 0.02 | 60.00 ± 1.34 | |
| MLP (1 秒) | 95.48 ± 0.25 | 73.04 ± 1.89 | 69.39 ± 1.47 | 99.56 ± 0.02 | 70.31 ± 1.48 | |
| kNN (1 秒) | 94.90 ± 0.18 | 69.05 ± 1.63 | 64.28 ± 1.57 | 99.50 ± 0.02 | 66.03 ± 1.52 | |
| IMU +EEG | RF (1秒) | 95.92 ± 0.29 | 74.14 ± 1.29 | 66.29 ± 1.66 | 99.59 ± 0.03 | 69.03 ± 1.48 |
| SVM (1 秒) | 90.77 ± 0.36 | 62.51 ± 3.34 | 52.46 ± 1.19 | 99.03 ± 0.03 | 53.91 ± 1.16 | |
| MLP (1 秒) | 93.33 ± 0.55 | 74.10 ± 1.61 | 65.32 ± 1.15 | 99.32 ± 0.05 | 68.13 ± 1.16 | |
| kNN (1 秒) | 92.12 ± 0.31 | 66.86 ± 1.32 | 58.30 ± 1.20 | 98.89 ± 0.05 | 60.56 ± 1.02 | |
| IR +IMU + EEG | RF (2 秒) | 95.12 ± 0.36 | 74.63 ± 1.65 | 66.71 ± 1.98 | 99.51 ± 0.03 | 69.38 ± 1.72 |
| SVM (1 秒) | 90.59 ± 0.27 | 64.75 ± 3.89 | 52.63 ± 1.42 | 99.01 ± 0.02 | 53.94 ± 1.47 | |
| MLP (1 秒) | 93.26 ± 0.69 | 73.51 ± 1.59 | 66.05 ± 1.11 | 99.31 ± 0.07 | 68.19 ± 1.02 | |
| kNN (1 秒) | 92.24 ± 0.25 | 67.33 ± 1.94 | 58.11 ± 1.61 | 99.21 ± 0.02 | 60.36 ± 1.71 | |
| カム | RF (3 秒) | 32.33 ± 0.90 | 14.45 ± 1.07 | 14.48 ± 0.82 | 92.91 ± 0.09 | 14.38 ± 0.89 |
| SVM (2 秒) | 34.40 ± 0.67 | 13.81 ± 0.22 | 14.30 ± 0.31 | 92.97 ± 0.06 | 13.83 ± 0.27 | |
| MLP (3 秒) | 27.08 ± 2.03 | 8.59 ± 1.69 | 10.59 ± 0.38 | 92.21 ± 0.09 | 7.31 ± 0.82 | |
| kNN (3 秒) | 34.03 ± 1.11 | 15.32 ± 0.73 | 15.54 ± 0.57 | 93.09 ± 0.11 | 15.19 ± 0.52 | |
| IR +カム | RF (3 秒) | 65.00 ± 0.65 | 33.93 ± 2.81 | 29.02 ± 0.89 | 96.34 ± 0.07 | 29.81 ± 1.16 |
| SVM (3 秒) | 64.07 ± 0.79 | 24.10 ± 0.98 | 24.18 ± 0.17 | 96.17 ± 0.07 | 22.38 ± 0.23 | |
| MLP (3 秒) | 65.05 ± 0.66 | 28.25 ± 3.20 | 25.40 ± 0.51 | 96.29 ± 0.06 | 24.39 ± 0.88 | |
| kNN (3 秒) | 60.75 ± 1.29 | 29.91 ± 3.95 | 26.25 ± 0.90 | 95.95 ± 0.11 | 26.54 ± 1.42 | |
| IMU +EEG+CAM | RF (1秒) | 95.09 ± 0.23 | 75.52 ± 2.31 | 66.23 ± 1.11 | 99.50 ± 0.02 | 69.36 ± 1.35 |
| SVM (1 秒) | 91.16 ± 0.25 | 66.79 ± 2.79 | 53.82 ± 0.70 | 99.07 ± 0.02 | 55.82 ± 0.77 | |
| MLP (1 秒) | 94.32 ± 0.31 | 76.78 ± 1.59 | 67.29 ± 1.41 | 99.42 ± 0.03 | 70.44 ± 1.25 | |
| kNN (1 秒) | 92.06 ± 0.24 | 68.82 ± 1.61 | 58.49 ± 1.14 | 99.19 ± 0.02 | 60.51 ± 0.85 |
表1:機械学習モデルに関する各モダリティの最高のパフォーマンスと最適なウィンドウ長(括弧内)を報告する比較結果。パフォーマンスのすべての値は、平均と標準偏差を表します。
| # | IMUタイプ | |||
| Rf | Svm | Mlp | Knn | |
| 1 | (98.36) ウエスト | (83.30) 右ポケット | (57.67) 右ポケット | (73.19) 右ポケット |
| 2 | (95.77)ネック | (83.22) ウエスト | (44.93) ネック | (68.73) ウエスト |
| 3 | (95.35) 右ポケット | (83.11) ネック | (39.54) ウエスト | (65.06) ネック |
| 4 | (95.06) 足首 | (82.96) 足首 | (39.06) 左手首 | (58.26) 足首 |
| 5 | (94.66) 左手首 | (82.82) 左手首 | (37.56) 足首 | (51.63) 左手首 |
表2:F1スコア(括弧内)でソートされた分類器あたりの最高のウェアラブルセンサーのランキング。シャドウ内の領域は、落下検出の上位 3 つの分類子を表します。
| IMUタイプ | ウィンドウの長さ | |||
| Rf | Svm | Mlp | Knn | |
| 左足首 | 2秒 | 3秒 | 1秒 | 3秒 |
| 腰 | 3秒 | 1秒 | 1秒 | 2秒 |
| 首 | 3秒 | 3秒 | 2秒 | 2秒 |
| 右ポケット | 3秒 | 3秒 | 2秒 | 2秒 |
| 左手首 | 2秒 | 2秒 | 2秒 | 2秒 |
表3:分類器ごとのウェアラブルセンサーにおける優先時間枠の長さ。
| # | カメラビュー | |||
| Rf | Svm | Mlp | Knn | |
| 1 | (62.27) 横ビュー | (24.25) 横ビュー | (13.78) フロントビュー | (41.52) 横ビュー |
| 2 | (55.71) フロントビュー | (0.20) フロントビュー | (5.51) 横ビュー | (28.13) フロントビュー |
表4:分類器ごとの最適なカメラ視点のランキング(括弧内)をF1スコアでソート。シャドウ内の領域は、落下検出の最上位の分類子を表します。
| カメラ | ウィンドウの長さ | |||
| Rf | Svm | Mlp | Knn | |
| 横ビュー | 3秒 | 3秒 | 2秒 | 3秒 |
| フロントビュー | 2秒 | 2秒 | 3秒 | 2秒 |
表 5: 分類器ごとのカメラ ビューポイントでの優先時間枠の長さ。
| マルチ モーダル | 分類 | 精度 (%) | 精度 (%) | 感度 (%) | F1スコア (%) |
| 腰 + 横ビュー | Rf | 98.72 ± 0.35 | 94.01 ± 1.51 | 97.63 ± 1.56 | 95.77 ± 1.15 |
| Svm | 95.59 ± 0.40 | 100 | 70.26 ± 2.71 | 82.51 ± 1.85 | |
| Mlp | 77.67 ± 11.04 | 33.73 ± 11.69 | 37.11 ± 26.74 | 29.81 ± 12.81 | |
| Knn | 91.71 ± 0.61 | 77.90 ± 3.33 | 61.64 ± 3.68 | 68.73 ± 2.58 | |
| 右ポケット + 横ビュー | Rf | 98.41 ± 0.49 | 93.64 ± 1.46 | 95.79 ± 2.65 | 94.69 ± 1.67 |
| Svm | 95.79 ± 0.58 | 100 | 71.58 ± 3.91 | 83.38 ± 2.64 | |
| Mlp | 84.92 ± 2.98 | 55.70 ± 11.36 | 48.29 ± 25.11 | 45.21 ± 14.19 | |
| Knn | 91.71 ± 0.58 | 73.63 ± 3.19 | 68.95 ± 2.73 | 71.13 ± 1.69 |
表6:3秒窓長を用いたウェアラブルセンサとカメラ視点の比較結果すべての値は、平均と標準偏差を表します。
ディスカッション
データセットの作成時に同期、組織、データの不整合の問題20が発生するのは一般的です。
同期
データの取得では、複数のセンサーが一般的に異なるサンプリングレートで動作することを考えると、同期の問題が発生します。周波数の高いセンサーは、周波数の低いセンサーよりも多くのデータを収集します。したがって、異なるソースからのデータは正しくペアにされません。センサーが同じサンプリングレートで動作する場合でも、データが整列されない可能性があります。この点に関して、以下の推奨事項は、これらの同期問題20:(i) レジスタタイムスタンプ、件名、アクティビティ、およびセンサーから取得した各データサンプルの試行を処理するのに役立つ可能性があります。(ii) 最も一貫性があり、頻度の低い情報源は、同期の基準信号として使用する必要があります。(iii) 自動または半自動の手順を使用して、手動検査が実用的でなくてはなることをビデオ録画と同期させます。
データの前処理
データの事前処理も行う必要があり、重要な決定がこのプロセスに影響を与えます:(a)データストレージの方法と複数および異機種のソースのデータ表現(b)ローカルホストまたはクラウド上のデータを保存する方法を決定する(c)ファイル名とフォルダ(d)データの欠損値とセンサーで見つかった冗長性を含むデータの組織を選択する、とりわけ。また、データ クラウドでは、アップロード時のデータ損失を軽減するために可能な場合はローカル バッファリングをお勧めします。
データの不一致
データの不一致は、データ サンプル サイズのばらつきを検出する試行の間で一般的です。これらの問題は、ウェアラブルセンサーのデータ収集に関連しています。複数のセンサーからのデータ取得とデータ衝突の一時的な中断は、データの不整合につながります。このような場合、センサーのオンライン障害を処理するには、不整合検出アルゴリズムが重要です。実験を通してワイヤレス ベースのデバイスを頻繁に監視する必要があることを強調することが重要です。バッテリが少なくなると、接続に影響を与え、データが失われる可能性があります。
倫理 的
参加の同意と倫理的承認は、人々が関与するすべてのタイプの実験に必須です。
この方法論の制限事項については、データ収集に対して異なるモダリティを考慮するアプローチを考慮するように設計されていることに注意することが重要です。システムには、ウェアラブル、アンビエントセンサー、および/またはビジョンセンサーを含めることができます。データ収集の損失、システム全体の接続性の低下、電力消費などの問題により、デバイスの消費電力とワイヤレスベースのセンサーのバッテリ寿命を考慮することをお勧めします。さらに、この方法論は機械学習方式を使用するシステムを対象としています。これらの機械学習モデルの選択の分析は、事前に行う必要があります。これらのモデルの中には正確であるものの、時間とエネルギーが非常に高いものもあります。機械学習モデルにおけるコンピューティングの正確な見積もりと限られたリソースの利用可能性との間のトレードオフを考慮する必要があります。また、システムのデータ収集において、活動が同じ順序で行われたことを観察することも重要です。また、試験は同じ順序で行われた。安全上の理由から、被験者が転倒するために保護マットレスが使用されました。さらに、滝は自己開始されました。これは、一般的に硬い材料に対して発生する、シミュレートされた落下と実際の落下の間の重要な違いです。その意味で、記録されたこのデータセットは、落下しないようにしようとする直感的な反応で落ちる。さらに、高齢者や障害のある人々の実際の転倒とシミュレーションの落ち込みとの間には、いくつかの違いがあります。そして、新しい落下検知システムを設計する際に、これらを考慮する必要があります。この研究は、障害のない若者に焦点を当てたが、被験者の選択は、システムとそれを使用するターゲット人口の目標に合わせるべきであると言うことは顕著である。
,10,11,12,13,14,15,16,17,18,1811,12,13に記載の関連作品から、堅牢な落下検出器の取得に焦点を当てたマルチモーダルアプローチを用いたり14,15,16,17、分類器の配置や性能に焦点を当てた著者がいるのを観察することができます。1018したがって、落下検出の設計上の問題は 1 つか 2 つしか取り扱えないためです。当社の方法論により、落下検知システムの主な設計上の3つの問題を同時に解決することができます。
今後の研究では、この方法論に基づいて得られた知見に基づいて、単純なマルチモーダル落下検出システムを設計し、実装することをお勧めします。実際の採用では、より堅牢なシステムを開発するために、転送学習、階層分類、およびディープラーニングのアプローチを使用する必要があります。我々の実装では、機械学習モデルの定性的指標は考慮されていませんでしたが、人間の転倒と活動検出/認識システムのさらなる開発のために、リアルタイムで限られたコンピューティングリソースを考慮する必要があります。最後に、データセットを改善するために、日常生活の中でのトリップやほとんど落ち込む活動とボランティアのリアルタイム監視を検討することができます。
開示事項
著者らは開示するものは何もない。
謝辞
この研究は、プロジェクトコードUP-CI-2018-ING-MX-04の下で、助成金「フォメント・ア・ラ・インベスティガシオンUP 2018」を通じてパンアメリカーナ大学から資金提供されています。
資料
| Name | Company | Catalog Number | Comments |
| Inertial measurement wearable sensor | Mbientlab | MTH-MetaTracker | Tri-axial accelerometer, tri-axial gyroscope and light intensity wearable sensor. |
| Electroencephalograph brain sensor helmet MindWave | NeuroSky | 80027-007 | Raw brainwave signal with one forehand sensor. |
| LifeCam Cinema video camera | Microsoft | H5D-00002 | 2D RGB camera with USB cable interface. |
| Infrared sensor | Alean | ABT-60 | Proximity sensor with normally closed relay. |
| Bluetooth dongle | Mbientlab | BLE | Dongle for Bluetooth connection between the wearable sensors and a computer. |
| Raspberry Pi | Raspberry | Version 3 Model B | Microcontroller for infrared sensor acquisition and computer interface. |
| Personal computer | Dell | Intel Xeon E5-2630 v4 @2.20 GHz, RAM 32GB |
参考文献
- United Nations. World Population Prospects: The 2017 Revision, Key Findings and Advance Tables. United Nations. Department of Economic and Social Affairs, Population Division. , (2017).
- World Health Organization. Ageing, and Life Course Unit. WHO Global Report on Falls Prevention in Older Age. , (2008).
- Igual, R., Medrano, C., Plaza, I. Challenges, Issues and Trends in Fall Detection Systems. Biomedical Engineering Online. 12 (1), 66 (2013).
- Noury, N., et al. Fall Detection-Principles and Methods. 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 1663-1666 (2007).
- Mubashir, M., Shao, L., Seed, L. A Survey on Fall Detection: Principles and Approaches. Neurocomputing. 100, 144-152 (2002).
- Perry, J. T., et al. Survey and Evaluation of Real-Time Fall Detection Approaches. Proceedings of the 6th International Symposium High-Capacity Optical Networks and Enabling Technologies. , 158-164 (2009).
- Xu, T., Zhou, Y., Zhu, J. New Advances and Challenges of Fall Detection Systems: A Survey. Applied Sciences. 8 (3), 418 (2018).
- Rougier, C., Meunier, J., St-Arnaud, A., Rousseau, J. Robust Video Surveillance for Fall Detection Based on Human Shape Deformation. IEEE Transactions on Circuit Systems for Video Technologies. 21, 611-622 (2011).
- Bulling, A., Blanke, U., Schiele, B. A Tutorial on Human Activity Recognition Using Body-Worn Inertial Sensors. ACM Computing Surveys. 46 (3), 33 (2014).
- Kwolek, B., Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Computational Methods and Programs in Biomedicine. 117, 489-501 (2014).
- Ofli, F., Chaudhry, R., Kurillo, G., Vidal, R., Bajcsy, R. Berkeley MHAD: A Comprehensive Multimodal Human Action Database. Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision. , 53-60 (2013).
- Dovgan, E., et al. Intelligent Elderly-Care Prototype for Fall and Disease Detection. Slovenian Medical Journal. 80, 824-831 (2011).
- Santoyo-Ramón, J., Casilari, E., Cano-García, J. Analysis of a Smartphone-Based Architecture With Multiple Mobility Sensors for Fall Detection With Supervised Learning. Sensors. 18 (4), 1155 (2018).
- Özdemir, A. An Analysis on Sensor Locations of the Human Body for Wearable Fall Detection Devices: Principles and Practice. Sensors. 16 (8), 1161 (2016).
- Ntanasis, P., Pippa, E., Özdemir, A. T., Barshan, B., Megalooikonomou, V. Investigation of Sensor Placement for Accurate Fall Detection. International Conference on Wireless Mobile Communication and Healthcare. , 225-232 (2016).
- Bagala, F., et al. Evaluation of Accelerometer-Based Fall Detection Algorithms on Real-World Falls. PLoS One. 7, 37062 (2012).
- Bourke, A. K., et al. Assessment of Waist-Worn Tri-Axial Accelerometer Based Fall-detection Algorithms Using Continuous Unsupervised Activities. Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 2782-2785 (2010).
- Kerdegari, H., Samsudin, K., Ramli, A. R., Mokaram, S. Evaluation of Fall Detection Classification Approaches. 4th International Conference on Intelligent and Advanced Systems. , 131-136 (2012).
- Alazrai, R., Mowafi, Y., Hamad, E. A Fall Prediction Methodology for Elderly Based on a Depth Camera. 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 4990-4993 (2015).
- Peñafort-Asturiano, C. J., Santiago, N., Núñez-Martínez, J. P., Ponce, H., Martínez-Villaseñor, L. Challenges in Data Acquisition Systems: Lessons Learned from Fall Detection to Nanosensors. 2018 Nanotechnology for Instrumentation and Measurement. , 1-8 (2018).
- Martínez-Villaseñor, L., et al. UP-Fall Detection Dataset: A Multimodal Approach. Sensors. 19 (9), 1988 (2019).
- Rantz, M., et al. Falls, Technology, and Stunt Actors: New approaches to Fall Detection and Fall Risk Assessment. Journal of Nursing Care Quality. 23 (3), 195-201 (2008).
- Lachance, C., Jurkowski, M., Dymarz, A., Mackey, D. Compliant Flooring to Prevent Fall-Related Injuries: A Scoping Review Protocol. BMJ Open. 6 (8), 011757 (2016).
転載および許可
このJoVE論文のテキスト又は図を再利用するための許可を申請します
許可を申請さらに記事を探す
This article has been published
Video Coming Soon
Copyright © 2023 MyJoVE Corporation. All rights reserved