
Method Article
眼窩コンピュータ断層撮影 による 深層学習に基づく医用画像セグメンテーションの応用
要約
眼窩コンピュータ断層撮影(CT)画像のための物体セグメンテーションプロトコルが導入されました。教師あり学習のために、超解像を用いた軌道構造のグラウンドトゥルースラベリング手法、CT画像からの関心体積抽出法、軌道CT画像に対する2次元シーケンシャルU-Netを用いたマルチラベルセグメンテーションのモデル化手法について解説する。
要約
近年、深層学習に基づくセグメンテーションモデルが眼科分野で広く応用されています。本研究では、U-Netに基づく眼窩コンピュータ断層撮影(CT)セグメンテーションモデルを構築する完全なプロセスを提示する。教師あり学習には、労働集約的で時間のかかるプロセスが必要です。軌道CT画像上のグラウンドトゥルースを効率的にマスクするための超解像ラベリング手法を紹介します。また、データセットの前処理の一環として、対象のボリュームがトリミングされます。次に、軌道構造の関心のあるボリュームを抽出した後、U-Netを使用して軌道CTの主要な構造をセグメント化するためのモデルを構築し、入力として使用されるシーケンシャル2Dスライスと、スライス間の相関を保存するための2つの双方向畳み込み長期短期メモリを使用します。この研究は主に眼球、視神経、および外眼筋のセグメンテーションに焦点を当てています。セグメンテーションの評価により、深層学習法を用いた眼窩CT画像へのセグメンテーションの応用の可能性が明らかになりました。
概要
眼窩は、眼球、神経、外眼筋、支持組織、視覚や眼球運動のための血管などの重要な構造を含む約30.1cm3の小さく複雑な空間です1。眼窩腫瘍は眼窩上の異常な組織成長であり、それらのいくつかは患者の視力または眼球運動を脅かし、致命的な機能障害につながる可能性があります。患者の視覚機能を維持するために、臨床医は腫瘍の特性に基づいて治療法を決定する必要があり、外科的生検は一般的に避けられません。このコンパクトで混雑したエリアは、臨床医が正常な構造を損なうことなく生検を行うことをしばしば困難にします。眼窩の状態を判断するための深層学習に基づく病理の画像解析は、生検2中の眼窩組織への不必要または回避可能な損傷を回避するのに役立つ可能性があります。眼窩腫瘍の画像解析の1つの方法は、腫瘍の検出とセグメンテーションです。しかし、眼窩腫瘍を含むCT画像の大量データの収集は、発生率が低いため制限されています3。計算腫瘍診断4のための他の効率的な方法は、腫瘍を軌道の正常な構造と比較することを含む。正常な構造の眼窩CT画像の数は、腫瘍のそれよりも比較的多い。したがって、通常の軌道構造のセグメンテーションは、この目標を達成するための最初のステップです。
本研究では、深層学習に基づく軌道構造セグメンテーションの全過程を、データ収集、前処理、その後のモデリングを含めて提示する。この研究は、現在の方法を使用してマスクされたデータセットを効率的に生成することに関心のある臨床医、および眼窩CT画像の前処理とモデリングに関する情報を必要とする眼科医のためのリソースとなることを目的としています。本稿では、医用画像セグメンテーションのためのU-Netの代表的な深層学習ソリューションに基づくシーケンシャル2Dセグメンテーションモデルである、軌道構造セグメンテーションとシーケンシャルU-Netの新しい手法を紹介します。プロトコルは、(1)軌道構造セグメンテーションのグラウンドトゥルースのためのマスキングツールの使用方法、(2)軌道画像の前処理に必要なステップ、(3)セグメンテーションモデルを訓練し、セグメンテーション性能を評価する方法など、軌道セグメンテーションの詳細な手順を記述します。
教師あり学習のために、5年以上にわたって理事会認定を受けた4人の経験豊富な眼科医が、眼球、視神経、外眼筋のマスクに手動で注釈を付けました。すべての眼科医は、CTスキャンで効率的なマスキングのために超解像を使用するマスキングソフトウェアプログラム(MediLabel、材料表を参照)を使用しました。マスキングソフトウェアには、次の半自動機能があります:(1)SmartPencilは、画像強度5の同様の値を持つスーパーピクセルマップクラスターを生成します。(2)SmartFillは、進行中の前景と背景のエネルギー関数を計算することによってセグメンテーションマスクを生成します6,7;(3)セグメンテーションマスクの境界線をきれいにし、元の画像と一貫性を持たせるオートコレクト。半自動フィーチャーの画像例を図 1 に示します。手動マスキングの詳細な手順は、プロトコルセクション(ステップ1)に記載されています。
次のステップは、眼窩CTスキャンの前処理です。軌道の関心体積(VOI)を得るために、眼球、筋肉、および神経が通常の状態で位置する軌道の領域が特定され、これらの領域がトリミングされます。データセットの解像度は高く、面内ボクセル解像度とスライスの厚さは <1 mm であるため、補間プロセスはスキップされます。代わりに、ウィンドウ クリッピングは 48 HU クリッピング レベルと 400 HU ウィンドウで実行されます。トリミングおよびウィンドウクリッピングの後、セグメンテーションモデル入力8に対して軌道VOIの3つのシリアルスライスが生成される。プロトコルセクション(ステップ2)には、前処理ステップの詳細が記載されています。
U-Net9は、医用画像に広く使用されているセグメンテーションモデルです。U-Netアーキテクチャは、医用画像の特徴を抽出するエンコーダと、識別的な特徴を意味的に提示するデコーダで構成されています。CTスキャンにU-Netを採用する場合、畳み込み層は3Dフィルタ10,11からなる。3Dフィルタの計算には大きなメモリ容量が必要なため、これは課題です。3D U-Netのメモリ要件を減らすために、U-Netでシーケンシャルな2Dスライスのセットが使用されるSEQ-UNET8が提案されました。3D CTスキャンの2D画像スライス間の時空間相関の喪失を防ぐために、基本的なU-Netでは2つの双方向畳み込み長期短期記憶(C-LSTM)12が採用されています。最初の双方向C-LSTMは、エンコーダの最後にスライス間の相関関係を抽出します。第2の双方向C−LSTMは、デコーダの出力の後に、スライスシーケンスの次元におけるセマンティックセグメンテーション情報を単一の画像セグメンテーションに変換する。SEQ-UNET のアーキテクチャを図 2 に示します。実装コードは github.com/SleepyChild1005/OrbitSeg で入手でき、コードの使用方法はプロトコルのセクション(ステップ3)で詳しく説明されています。
プロトコル
本作業は、カトリック医療センターの治験審査委員会(IRB)の承認を得て実施され、健康情報のプライバシー、機密性、およびセキュリティが保護されました。眼窩CTデータは、韓国カトリック大学医学部(CMC;ソウル聖母病院、汝矣島聖母病院、大田聖母病院、聖ビンセント病院)。眼窩CTスキャンは2016年1月から2020年12月までに取得されました。データセットには、20歳から60歳までの韓国の男性と女性からの46の眼窩CTスキャンが含まれていました。ランタイム環境 (RTE) は、 補足表 1 に要約されています。
1.眼窩CTスキャンで眼球、視神経、外眼筋をマスキングします
- マスキングソフトウェアプログラムを実行します。
注:マスキングソフトウェアプログラム(MediLabel、 材料表を参照)は、セグメンテーション用の医用画像ラベリングソフトウェアプログラムであり、数回のクリックで高速です。 - ファイルを開く アイコンをクリックし 、ターゲットCTファイルを選択して、軌道CTをロードします。次に、CTスキャンが画面に表示されます。
- スーパーピクセルを使用して眼球、視神経、外眼筋をマスクします。
- MediLabel のスマートペンシル ウィザードをクリックして、 スマートペンシル を実行します (ビデオ 1)。
- 必要に応じて、スーパーピクセルマップの解像度を制御します(100、500、1,000、2,000スーパーピクセルなど)。
- 類似した画像強度値のピクセルがクラスター化されているスーパーピクセルマップ上の眼球、視神経、および外眼筋のスーパーピクセルのクラスターをクリックします。
- MediLabel の自動修正機能を使用してマスクを調整します。
- スライス上のスーパーピクセルの一部をマスクした後、 SmartFill ウィザードをクリックします(ビデオ2)。
- オートコレクトアイコンをクリックし、修正されたマスクラベルが計算されていることを確認します(ビデオ3)。
- マスキングの調整が完了するまで、ステップ1.3とステップ1.4を繰り返します。
- マスクされた画像を保存します。
2.前処理:VOIのウィンドウクリッピングとトリミング
- preprocessing_multilabel.pyを使用して VOI を抽出します (ファイルは GitHub からダウンロードできます)。
- preprocessing_multilabel.pyを実行します。
- トリミングされてVOIフォルダに保存されているスキャンとマスクを確認します。
- builder_multilabel.pyを使用して SEQ-UNET への入力用に VOI を 3 つの順次 CT スライスのセットに変換します (ファイルは GitHub からダウンロードできます)。
- sequence_builder_multilabel.pyを実行します。
- 変換中にスライスとマスクのサイズが 64 x 64 ピクセルに変更されていることを確認します。
- 変換中に、48 HU クリッピング レベルと 400 HU ウィンドウでクリッピングを実行します。
- 保存した変換CTスキャン(niiファイル)とマスク(niiファイル)を、スキャンフォルダとマスクフォルダの下にあるマスクフォルダにそれぞれ確認してください。
3. 軌道分割モデルの4つの交差検証
- 以下の手順に従ってモデルを構築します。
- main.py を実行します。
- main.py を実行するときは、4つの交差検証のフォールド番号を「-fold num x」(xは0、1、2、または3)で指定します。
- main.py を実行する場合は、トレーニングの反復回数であるエポックをオプションとして使用します (たとえば、"-epoch x" (x はエポック番号)。デフォルトの数は 500 です。
- main.py を実行する場合は、バッチサイズ(1回のトレーニングセッション内のトレーニングサンプルの数)を設定します。デフォルトの数は 32 です。
- main.py では、CTスキャンとマスクをロードし、LIDC-IDRIデータセット(がん画像アーカイブからダウンロード可能)を使用して、事前にトレーニングされたパラメーターでSEQ-UXETを初期化します。
- main.py、トレーニング後にモデルのテストを実行します。評価メトリック、サイコロスコア、ボリュームの類似性を計算し、メトリックフォルダーに保存します。
- セグメント化されたフォルダーで結果を確認します。
結果
定量的評価には、CT画像セグメンテーションタスクで使用された2つの評価指標が採用されました。これらは、サイコロスコア(DICE)とボリューム類似度(VS)を含む2つの類似性メトリックでした13。
サイコロ (%) = 2 × TP/(2 × TP + FP + FN)
対 (%) = 1 − |FN − FP|/(2 × TP + FP + FN)
ここで、TP、FP、およびFNは、セグメンテーション結果とセグメンテーションマスクが指定されている場合、それぞれ真陽性、偽陽性、および偽陰性の値を示します。
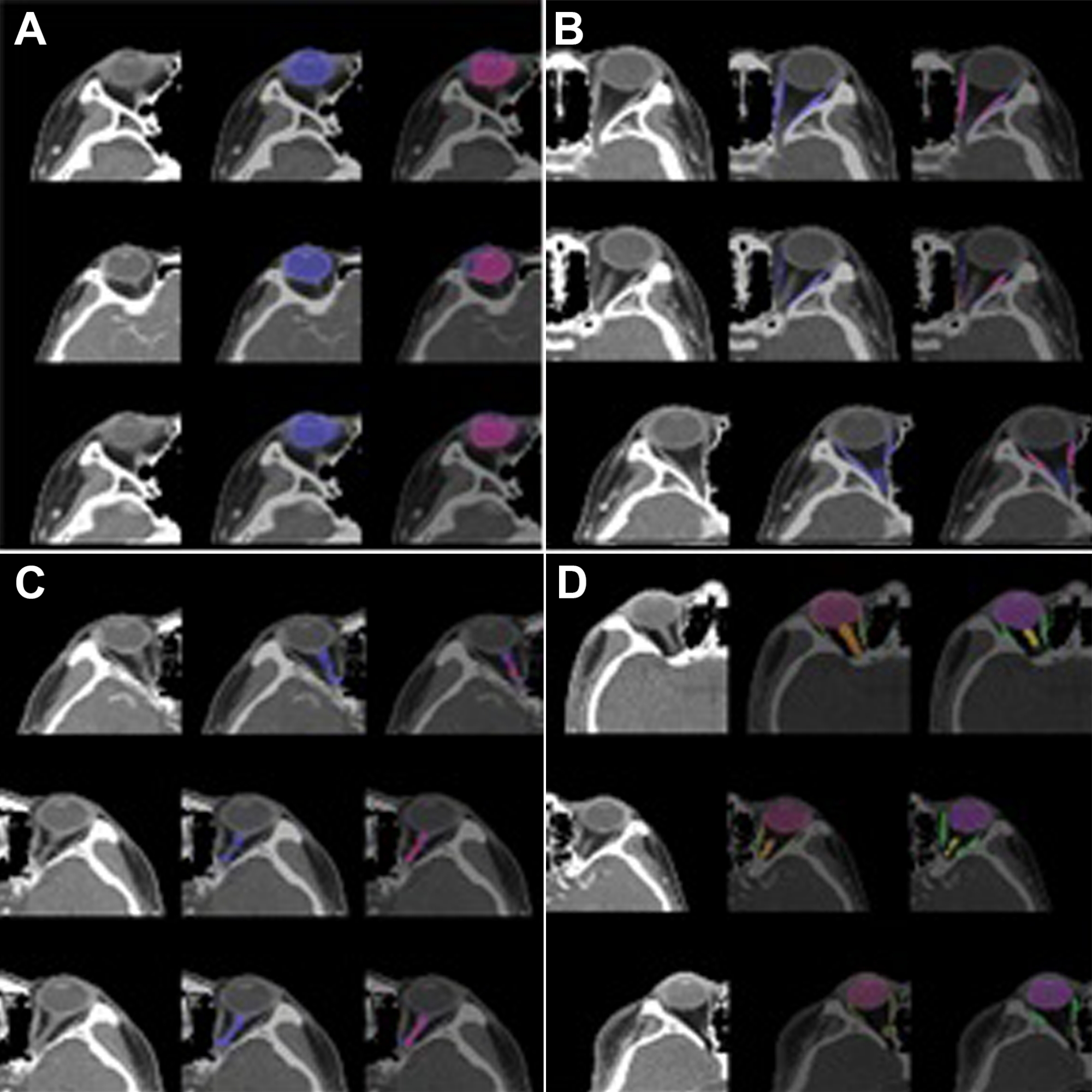
軌道構造セグメンテーションのためのSEQ-UXEの性能は、4つの交差検証によって評価されました。結果を表1に示す。SEQ-UNTを用いた眼球セグメンテーションは、0.86のサイコロスコアと0.83のVSを達成しました。外眼筋と視神経のセグメンテーションは、低いサイコロスコア(それぞれ0.54と0.34)を達成しました。眼球セグメンテーションのサイコロスコアは、VOIの大部分を占め、CTスキャン間の不均一性がほとんどないため、80%を超えました。外眼筋と視神経のサイコロスコアは、CTボリュームに現れる頻度が低く、CTスライスの数が比較的少なかったため、比較的低かった。しかし、外眼筋と視神経の視覚的類似性スコア(それぞれ0.65と0.80)は、サイコロスコアよりも高かった。この結果は、セグメンテーションの特異度が低かったことを示している。全体として、すべての軌道下部構造のセグメンテーションに対するSEQ-UXEのサイコロスコアと視覚的類似性はそれぞれ0.79と0.82でした。軌道構造分割の視覚的結果の例を図3に示す。図3A-Cでは、青は予測されたセグメンテーション結果で、赤はグラウンドトゥルースマスクです。図3Dでは、赤、緑、オレンジがそれぞれ眼球、視神経、神経のセグメンテーションです。

図1:半自動マスキング機能。 眼窩CTスキャンで眼球、外眼筋、視神経をマスキングし、(A)スマートペンシル、(B)スマートフィル、および(C)オートコレクトを使用します。眼球のマスクは、スライスのスーパーピクセルを計算するSmartPencilによってラベル付けされ、マスクはスーパーピクセルをクリックして作成されます。眼球スーパーピクセルのいくつかをクリックした後、眼球マスク全体をSmartFillで計算できます。視神経をマスキングする場合、マスキングの改良はオートコレクトによって行われます。青色標識眼球を(A)及び(B)に示す。 この図の拡大版を表示するには、ここをクリックしてください。
{kind=link}

図2:シーケンスU-Netアーキテクチャ。 入力および出力としてのシーケンシャル2Dスライス。2つの双方向C-LSTMは、U-Netアーキテクチャに基づいてエンコードおよびデコードブロックの最後に適用されます。 この図の拡大版を表示するには、ここをクリックしてください。
{kind=link}

図3:軌道構造のセグメンテーション結果。 (A)眼球(標識1)、(B)視筋(標識2)、(C)視神経(標識3)、および(D)マルチラベル(標識1、2、および3)。左の画像は軌道のVOI、中央の画像は予測されたセグメンテーション、右の画像はグラウンドトゥルースです。(A)、(B)、および(C)では、青は予測されたセグメンテーション結果であり、赤はグラウンドトゥルースマスクです。(D)では、赤、緑、オレンジがそれぞれ眼球、外眼筋、視神経の分節です。予測されたセグメンテーションは、眼球の場合は高いパフォーマンス(DICE:0.86対0.82)を示しましたが、外眼筋(DICE:0.54対0.65)および視神経(DICE:0.34対0.8)の場合は低いパフォーマンスを示しました。 この図の拡大版を表示するには、ここをクリックしてください。
{kind=link}
| マルチラベル | ラベル 1 (眼球) | ラベル2(外眼筋) | ラベル3(視神経) | |||||
| ダイス | 対 | ダイス | 対 | ダイス | 対 | ダイス | 対 | |
| シークUNET | 0.79 | 0.82 | 0.86 | 0.83 | 0.54 | 0.65 | 0.34 | 0.8 |
表1:サイコロスコアと視覚的類似性のセグメンテーション結果。 スライス数が比較的多い眼球はDICE0.8でよく分節されたが、スライス数や線状が少ない外眼筋と視神経は部分的に分節され、それぞれ 0.54と0.34のDICE値であった。
ビデオ1:マスキングソフトウェアプログラムのSmartPencilウィザード。 眼球マスキングのために複数のピクセルに注釈を付けるデモンストレーション。マスキングタスクは、クラスター化されたスーパーピクセルをワンクリックで有効にします。 このビデオをダウンロードするには、ここをクリックしてください。
ビデオ2:マスキングソフトウェアプログラムのスマートフィルウィザード。 眼球マスキングのために複数のピクセルに注釈を付けるデモンストレーション。注釈領域でいくつかのピクセルを選択すると、この機能は選択したピクセルと同様の強度を持つ完全なセグメンテーションマスクを生成します。 このビデオをダウンロードするには、ここをクリックしてください。
ビデオ3:マスキングソフトウェアプログラムのオートコレクト。 事前学習済みの畳み込みニューラルネットワークアルゴリズムを使用したマスクされたピクセルの自動補正のデモンストレーション。 このビデオをダウンロードするには、ここをクリックしてください。
補足表1:マスキング、前処理、およびセグメンテーションモデリングの実行時環境(RTE)。この表をダウンロードするには、ここをクリックしてください。
ディスカッション
ディープラーニングベースの医用画像分析は、病気の検出に広く使用されています。眼科領域では、糖尿病性網膜症、緑内障、加齢黄斑変性症、および未熟児網膜症において、検出およびセグメンテーションモデルが使用されています。しかし、眼科以外の希少疾患は、ディープラーニング分析のための大規模なオープンパブリックデータセットへのアクセスが制限されているため、研究されていません。パブリックデータセットが利用できない状況でこの方法を適用する場合、労働集約的で時間のかかる作業であるマスキングステップは避けられません。ただし、提案されたマスキングステップ(プロトコルセクション、ステップ1)は、短時間で高精度のマスキングを生成するのに役立ちます。スーパーピクセルとニューラルネットワークベースの塗りつぶしを使用して、低レベルの画像プロパティが類似しているピクセルをクラスター化し、臨床医は特定のピクセルを指摘する代わりにピクセルのグループをクリックしてマスクにラベルを付けることができます。また、自動補正機能は、マスクプロセスを改善するのに役立ちます。この方法の効率と有効性は、医学研究においてより多くのマスク画像を生成するのに役立ちます。
前処理における多くの可能性の中で、VOIの抽出とウィンドウクリッピングは効果的な方法です。ここでは、VOIの抽出とウィンドウクリッピングがプロトコルのステップ2で紹介されています。臨床医がデータセットを準備する場合、ほとんどのセグメンテーションケースは医用画像全体の小さな特定の領域に焦点を当てているため、特定のデータセットからVOIを抽出することがプロセスの最も重要なステップです。VOIに関しては、眼球、視神経、外眼筋の領域は位置に基づいてトリミングされますが、VOIを抽出するためのより効果的な方法は、セグメンテーションパフォーマンスを改善する可能性があります14。
セグメンテーションのために、SEQ-UNETが研究に採用されています。3D医用画像は大容量であるため、ディープニューラルネットワークモデルには大きなメモリ容量が必要です。SEQ-UNETでは、3D情報の特徴を失うことなく必要なメモリサイズを削減するために、セグメンテーションモデルを少数のスライスで実装します。
モデルは46個のVOIでトレーニングされましたが、これはモデルトレーニングでは多くありません。トレーニングデータセットの数が少ないため、視神経と外眼筋のセグメンテーションのパフォーマンスは制限されています。転移学習15 およびドメイン適応8 は、セグメンテーション性能を改善するための解決策を提供することができる。
ここで紹介するセグメンテーションプロセス全体は、軌道CTセグメンテーションに限定されません。効率的なラベリング方法は、アプリケーションドメインが研究分野に固有の場合の新しい医用画像データセットを作成するのに役立ちます。前処理とセグメンテーションモデリングに関するGitHubのPythonコードは、トリミング領域、ウィンドウクリッピングレベル、およびシーケンシャルスライスの数、U-Netアーキテクチャなどのモデルのハイパーパラメーターを変更することで、他のドメインに適用できます。
開示事項
著者は利益相反を宣言しません。
謝辞
この研究は、韓国国立研究財団(NRF)、韓国科学情報通信部(MSIT)の助成金(番号:2020R1C1C1010079)の支援を受けました。CMC-ORBITデータセットについては、カトリック医療センターの中央治験審査委員会(IRB)が承認を与えました(XC19REGI0076)。この研究は、2022年の弘益大学研究基金によってサポートされました。
資料
| Name | Company | Catalog Number | Comments |
| GitHub link | github.com/SleepyChild1005/OrbitSeg | ||
| MediLabel | INGRADIENT (Seoul, Korea) | a medical image labeling software promgram for segmentation with fewer click and higher speed | |
| SEQ-UNET | downloadable from GitHub | ||
| SmartFil | wizard in MediLabel | ||
| SmartPencil | wizard in MediLabel |
参考文献
- Li, Z., et al. Deep learning-based CT radiomics for feature representation and analysis of aging characteristics of Asian bony orbit. Journal of Craniofacial Surgery. 33 (1), 312-318 (2022).
- Hamwood, J., et al. A deep learning method for automatic segmentation of the bony orbit in MRI and CT images. Scientific Reports. 11, 1-12 (2021).
- Kim, K. S., et al. Schwannoma of the orbit. Archives of Craniofacial Surgery. 16 (2), 67-72 (2015).
- Baur, C., et al. Autoencoders for unsupervised anomaly segmentation in brain MR images: A comparative study. Medical Image Analysis. 69, 101952(2021).
- Trémeau, A., Colantoni, P. Regions adjacency graph applied to color image segmentation. IEEE Transactions on Image Processing. 9 (4), 735-744 (2000).
- Boykov, Y. Y., Jolly, M. -P. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. Proceedings of Eighth IEEE International Conference on Computer Vision. International Conference on Computer Vision. 1, 105-122 (2001).
- Rother, C., Kolmogorov, V., Blake, A. "GrabCut" interactive foreground extraction using iterated graph cuts. ACM Transactions on Graphics. 23 (3), 309-314 (2004).
- Suh, S., et al. Supervised segmentation with domain adaptation for small sampled orbital CT images. Journal of Computational Design and Engineering. 9 (2), 783-792 (2022).
- Ronneberger, O., Fischer, P., Brox, T. U-net: Convolutional networks for biomedical image segmentation. International Conference on Medical Image Computing and Computer-Assisted Intervention.Medical Image Computing and Computer-Assisted Intervention - MICCAI. , 234-241 (2015).
- Qamar, S., et al. A variant form of 3D-UNet for infant brain segmentation. Future Generation Computer Systems. 108, 613-623 (2020).
- Nguyen, H., et al. Ocular structures segmentation from multi-sequences MRI using 3D UNet with fully connected CRFS. Computational Pathology and Ophthalmic Medical Image Analysis. , Springer. Cham, Switzerland. 167-175 (2018).
- Liu, Q., et al. Bidirectional-convolutional LSTM based spectral-spatial feature learning for hyperspectral image classification. Remote Sensing. 9 (12), 1330(2017).
- Yeghiazaryan, V., Voiculescu, I. D. Family of boundary overlap metrics for the evaluation of medical image segmentation. Journal of Medical Imaging. 5 (1), 015006(2018).
- Zhang, G., et al. Comparable performance of deep learning-based to manual-based tumor segmentation in KRAS/NRAS/BRAF mutation prediction with MR-based radiomics in rectal cancer. Frontiers in Oncology. 11, 696706(2021).
- Christopher, M., et al. Performance of deep learning architectures and transfer learning for detecting glaucomatous optic neuropathy in fundus photographs. Scientific Reports. 8, 16685(2018).
転載および許可
このJoVE論文のテキスト又は図を再利用するための許可を申請します
許可を申請さらに記事を探す
This article has been published
Video Coming Soon
Copyright © 2023 MyJoVE Corporation. All rights reserved