Systematic Hearing Performance Evaluation Process for Adolescents with Cochlear Implantation at Early Ages
In This Article
Summary
This paper describes a battery of tests used to clinically assess the hearing performance of adolescent, Mandarin-speaking, experienced cochlear implant users upgraded to a new fine structure coding strategy. The battery of tests include speech in quiet conditions, speech in noisy conditions, lexical tone, and music perception.
Abstract
Cochlear implant (CI) provision is the most effective clinical treatment to restore hearing performance in individuals with profound sensorineural hearing loss (SNHL). It has been successful in providing improved speech perception outcomes, especially in quiet environments. However, speech perception performance within complex environments, lexical tone recognition, and music perception have been shown to only improve with newer fine structure coding strategies or related techniques. Therefore, the methods used to assess hearing performance in noisy environments, lexical tone recognition, and music perception are of vital importance. These assessments must reflect the postoperative outcomes and also provide guidance for the programming, rehabilitation, and application of new coding strategies. In this study, hearing performance in simple and complex situations was evaluated before and after upgrading to a fine structure strategy. The participants were a cohort of Mandarin-speaking adolescents, who were experienced CI users. The comprehensive clinical workflow involved assessments of speech in quiet conditions, speech in noisy conditions, lexical tone recognition, and music perception. This battery of tests is explained in detail, from the coding strategy to the test methods, including the test process, environment, device, material, and order. The details that require special attention are discussed, such as the position of the participants, the angle of the loudspeaker, the intensity of the sound, the noise type, the practice test, and the way of answering questions. Each test step, method, and material for speech, lexical tone, and music perception is presented in detail. Finally, the clinical results are discussed.
Introduction
Technological improvements in cochlear implants (CIs) have given users increasingly greater benefits, particularly in speech understanding in quiet and noisy environments, but also through tinnitus reduction and increased quality of life1,2,3,4. It is common and necessary to evaluate how technological upgrades potentially alter postoperative outcomes. Therefore, establishing a strict battery of tests is of benefit, as it can better enable the direct comparison of results of different types of hearing implant users from different clinics. This can enable the pooling of data and provide more robust results that can better inform patients and health care providers in the decision-making process. The sound coding strategy of a CI audio processor is one of the core technologies that affects a CI user's hearing performance5,6,7. Coding strategies have progressed from the previous envelope-based continuous interleaved sampling (CIS) strategy to the newer FS4, a temporal fine structure strategy8,9,10,11,12.
Sound coding strategies are responsible for processing sound signals into electrical pulses that are sent to the implant's electrode channels. In CIS, all electrode contacts on the array are stimulated with envelope-modulated strains of pulses at a constant rate (i.e., there is no temporal coding). In fine structure coding, the apical region (low frequencies) is stimulated at a variable rate so as to mimic the phase-locking of the inner hair cells in normal (acoustic) hearing, and thereby mimic the perception of normal hearing as closely as possible. Channels in the basal and middle regions are stimulated at a constant rate, as in CIS8,9,10,11,12,13.
In this study, a strict battery of tests was used to evaluate performance with the FS4 coding strategy. Tonal languages, such as Mandarin and Cantonese, use pitch cues to provide lexical meaning14. Apart from the frequently used speech tests, the battery of tests can carefully consider the pitch cues used in most tonal languages. Mandarin contains four lexical tones, characterized by variations in the fundamental frequency (F0 or pitch) in speech. Therefore, it is of key importance when evaluating Mandarinspeaking CI users to be able to identify these variations in frequency and speech15,16,17,18,19.
Throughout the years, there has been a considerable lack of tests which evaluate music perception in young Mandarinspeaking CI users. However, fine structure coding strategies must help tonal-speaking CI users discriminate pitch contours and lexical tones20. So far, only two studies have investigated coding strategies on speech and tone perception in adult CI users who are Mandarin speakers21,22. To the best of our knowledge, no investigation has assessed the hearing performance of adolescent Mandarin-speaking CI users when upgraded to the FS4 coding strategy. Therefore, the current study aimed to establish a battery of tests to evaluate the performance of adolescent Mandarin-speaking CI users, following an upgrade from an audio processor using the CIS+ coding strategy to one using the FS4 coding strategy.
Protocol
This study was approved by the Medical Ethics Committee of Shandong Provincial ENT Hospital (approval No. XYK20211201). Informed consent was obtained from all study participants.
1. Instrumentation
- Use a standard sound booth (≤30 dB [A]), including a calibrated audiometer, a computer, and two loudspeakers. 'A' means the human hearing response to sound through a weighted filtering. The unit of measurement is dB SPL (sound pressure level). Perform all tests using the loudspeaker.
- Use mapping software to fit the participants. Assess the speech performance of monosyllable recognition in quiet conditions, spondee (disyllable) speech recognition in quiet conditions, sentence recognition in quiet conditions, and sentence recognition in noisy conditions. For this experiment, 20 monosyllables (i.e., cai, chu, fei, fen, feng, ge, mi, pi, qi, qiao, qing, sha, shen, shi, tao, tui, xiang, xie, xuan, and zhe), combined with four lexical tones spoken by a male native Mandarin Chinese speaker were selected.
- Assess tone recognition using tone test software. For this experiment, four tones in each monosyllable that retained the natural variation in durations were selected. Normalize the tokens to the same root mean square level to eliminate natural variation in amplitude.
- Choose one correct answer from four tones in the Mandarin lexical tone task. For this experiment, 25 monosyllabic words were spoken with the four Mandarin lexical tones, 80 tone tokens were created for each test, and words were written in simplified Chinese.
- Assess music pitch perception using music software. For the protocol here, use a test battery consisting of six objective subtests assessing several areas of music perception. The battery contains approximately 2,800 sound files.
- For the pitch-ranking procedure, use different instruments in the range of 27-4,186 Hz. The pitch ranking test used a two-interval, two-alternative, forced-choice adaptive procedure to determine the threshold for discriminating variation of pitch.
- For this experiment, set the target tone to the sine note of F4 (349 Hz) and start 32 quartertones above the target tone. Set the interval size of the two tones between one and 26 quartertones. The quartertone interval was produced from the nearest semitone.
2. Participant preparation
NOTE: A total of 10 participants (seven males, three females) volunteered for this study, two of whom volunteered to film the protocol. The participants were unilateral CI users with a mean age of 10.4 ± 1.2 years (range: 9-14 years), who were implanted at a mean age of 2.8 ± 1.2 years (range: 1-4 years) and had at least 5 years of experience using the CIS+ coding strategy (Table 1). All the participants were fluent in Mandarin and were willing to comply with all planned study procedures.
- To be included, ensure the potential participants have at least 5 years of experience using the CIS+ coding strategy with a TEMPO+ audio processor, speak Mandarin, and are willing to comply with the planned study procedures.
- Use the exclusion criteria as unwillingness or inability to cooperate with the test procedures.
- Screen the participants in accordance with the inclusion/exclusion criteria mentioned above. Obtain verbal and written informed consent from all participants.
- Position the participants 1 m from the loudspeaker, at a 45° angle to the CI side in the sound booth when testing.
- Remove any hearing aids, if present, from the contralateral ear and make sure the masking (earplug and earmuffs) is effective for participants with residual hearing.
- Inform the participants that practice test sessions will be conducted until they understand the task. When the task is understood, formal testing can begin. Inform the participants that they can take breaks when needed.
3. Experimental protocol
- Complete a battery of tests at each of the following four intervals: (i) pre-upgrade (the old processor and coding strategy), (ii) immediately post-upgrade (i.e., same day as the upgrade to the new processor and coding strategy), (iii) 6 weeks post-upgrade, and (iv) 3 months post-upgrade.
- Immediately at the post-upgrade interval, test each participant with both coding strategies. Randomize the order in which they are tested, either CIS first or FS4. Blind the participants to which coding strategy they are being tested with.
- Perform mapping, as described below.
NOTE: Mapping refers to programming the stimulation levels of each of the 12 channels on the array. In the present study, this was done according to the responses of each CI user and resulted in each participant receiving a customized fitting map.- Take the participants and guardians to the mapping room (sound booth). Seat the participants in the mapping room.
- Click the mapping software and enter the password. Take off the speech processor and connect it to the MAX box via the programming cable.
- Select the participant's name on the software and choose the impedance option. Test the electrode impedance and make sure the electrode impedance is normal (2.2-12 kOhm; typical value). Abnormal electrode impedance is automatically shown with open circuits or short circuits.
- Ensure that the coding strategy is FS4 and a standard pulse rate of 1,224 pps/channel is used. Set single electrode stimulation to three sweeps and let the participants distinguish the loudness of each electrode by pointing to the appropriate image on a loud/comfort pictorial scale. Use up and down methods for testing and take the same results that are repeated twice as the final electrical stimulation result. Make sure the participants understand and can accomplish this task.
- Set the maximum comfortable level (MCL) of all the electrodes using the method mentioned above (step 3.3.4). The MCL is considered the highest (i.e., loudest) level that is not uncomfortable. In the present study, participants indicate this on a loud/comfort pictorial scale.
- To test the real-life application of the MCL levels, activate the map by pressing the Live button. This allows the participants to hear ambient noises. Return the participants to the fitting mode. Based on their subjective feedback from listening in live mode, adjust the MCLs if needed.
- Set other parameters with the default settings: the stimulation rate is 1,288 pps; the channel-specific sampling sequences (CSSSs) channel is four; the pulse is biphasic pulse; the phase gap (IPG) is 2.1 µs; the input and output signals are logarithmic compression with the default MCL value set to 500; the compression ratio is 3:1; the sensitivity is 75%; the threshold (THR), which is the maximum sound level that the participant cannot hear, is generally 10% of the MCL. Verify the THR for each channel by retesting, as in the MCL; the frequency range is 70-8,500 Hz.
- Perform speech tests, as described below.
- Test speech perception in the following order: spondee (disyllable) speech recognition in quiet conditions, monosyllable recognition in quiet conditions, sentence recognition in quiet conditions, and sentence recognition in noisy conditions.
- Seat the participants 1 m beside the computer from the loudspeaker at a 45° angle to the CI side in another sound booth.
- Ensure the processors are switched on and the program is correct. Click the speech software and carefully interpret the answer methods. Tell the participants to clearly repeat the content they have heard. Be careful to ensure that the practice test procedure is correct.
- Open the audiometry and select the hearing test options. Set the sound loudness to 30 dB HL (hearing level) above the average pure-tone threshold of 500, 1,000, 2,000, and 4,000 Hz through the audiometry.
- Present the practice lists at the time of the formal tests23. For each test, ask the participants to repeat the words/sentences they heard. Keep the order of contents random for each test and play the words/sentences once.
- Set a +10 dB signal to noise ratio (SNR) for the sentence recognition in noisy conditions test and use four-talker babble as the noise signal.
- Perform the tone test, as described below.
- Click the tone software and set the SPL to 65 dB in the same sound booth. Carefully interpret the answer methods.
- Confirm that the participants are familiar with all of the vocabulary tested. Present the practice lists at the same time as the formal test21.
- Direct the participants to say what they have heard once. Choose the tone in which the participants repeat the content and keep the order of contents random for each test.
- Perform the music test, as described below.
- Click the music software and choose the pitch selection in the same booth. Present the practice lists at the same time as the formal test24.
- Instruct the participant to listen to the two stimuli presented sequentially with 1 s of silence in between. Ask them to determine which of the two intervals has a falling or rising pitch contour.
- Input the answers of the participant and repeat. Keep the order of contents random for both practice and normal tests. Choose the answers the participants selected.
4. Data analysis
- For speech and tone tests, record the percentage of correct answers provided and compare for each test. For the musical pitch test, record the quartertones and compare.
- Depending on the data distribution, apply repeated measures (RM) ANOVA with time as a factor, or the Friedman test to examine a change over time. Use pairwise comparisons to compare the performance after upgrading compared to pre-upgrading, with either paired samples t-testing or the Wilcoxon signed-rank test.
- Use the Kolmogorov-Smirnov test together with the Shapiro-Wilk test to check the data distribution. If both tests confirm that the data were normally distributed, then apply parametric statistical methods. Otherwise, apply non-parametric statistical methods. Set the statistical significance at p ≤ 0.05.
- Because of multiple comparisons (three pairwise comparisons: pre-upgrade vs. immediately post-upgrade, pre-upgrade vs. 6 weeks post-upgrade, and pre-upgrade vs. 3 months post-upgrade), use the Bonferroni correction method when interpreting the obtained p values. Hence, use p ≤ 0.017 instead of p ≤ 0.05 as significant.
Representative Results
The speech test results indicate speech recognition ability both in quiet and in noisy conditions. The tone test results indicate the lexical tone discrimination for Mandarin lexical tones. The pitch results indicate musical discrimination ability. For speech and tone test results, all results are presented as percentages. A higher percentage score indicates a better test result. For speech tests, the results for words and sentences are presented separately. This enables the results to be analyzed and compared separately. The result for the pitch test is displayed as a visualized resolution threshold. Lower limens indicate better results. These data are easy to analyze and compare.
Spondee recognition in quiet conditions
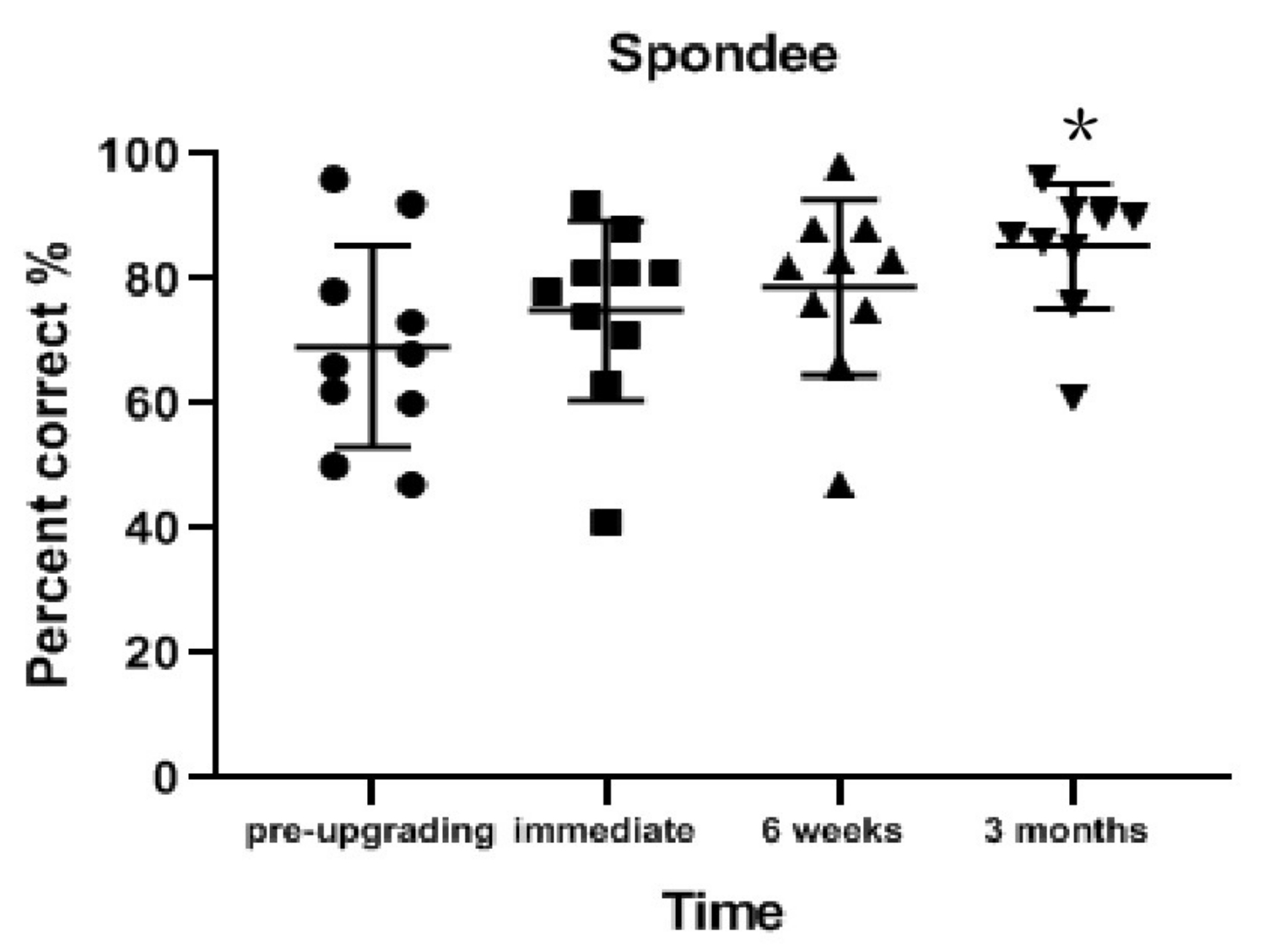
Spondee recognition in quiet conditions significantly improved from pre-upgrade to 3 months post-upgrade (on average 16.1% better; z = 2.497; p = 0.013). The improvement was not significant from pre-upgrade to 6 weeks post-upgrade (on average 9.4% better; z = 1.735; p = 0.083) or from pre-upgrade to immediately post-upgrade (on average 5.8% better; z = 1.429; p = 0.153; Table 2 and Figure 1).
Monosyllable recognitionin quiet conditions
Monosyllable recognition in quiet conditions significantly improved from pre-upgrade to immediately post-upgrade (on average 8.2% better; z = 2.494; p = 0.013), from pre-upgrade to 6 weeks post-upgrade (on average 11.8% better; z = 2.570; p = 0.010), and from pre-upgrade to 3 months post-upgrade (on average 22.5% better; z = 2.810; p = 0.005; Table 2 and Figure 2).
Sentence recognition in quietconditions
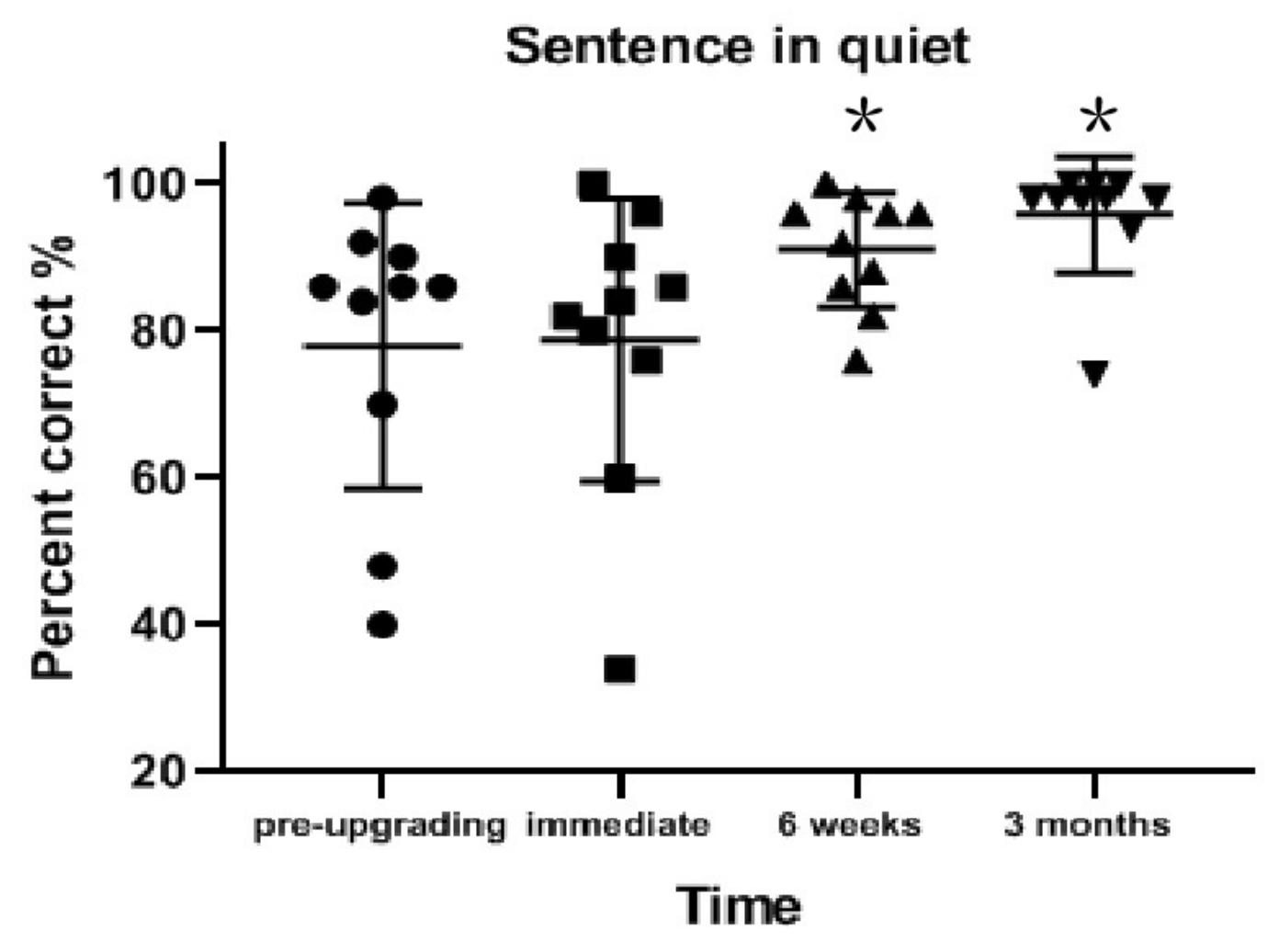
Sentence recognition rate in quiet conditions significantly improved from pre-upgrade to 3 months post-upgrade (on average 17.8% better; z = 2.670; p = 0.008). No significant improvement was observed from pre-upgrade to 6 weeks post-upgrade (on average 13.0% better; z = 2.314; p = 0.021) or from pre-upgrade to immediate post-upgrade (on average 0.8% better; z = 0.255; p = 0.798; Table 2 and Figure 3).
Sentence recognition in noisy conditions
The pairwise comparisons from pre-upgrade to each of the post-upgrade sessions confirmed the non-significant differences in sentence recognition in noisy conditions (Wilcoxon signed-rank test: z = 1.355; p = 0.176 to z = 0.674; p = 0.500). However, sentence recognition in noisy conditions did increase on average 26% from pre-upgrade to 3 months post-upgrade (Table 2).
Tone recognition
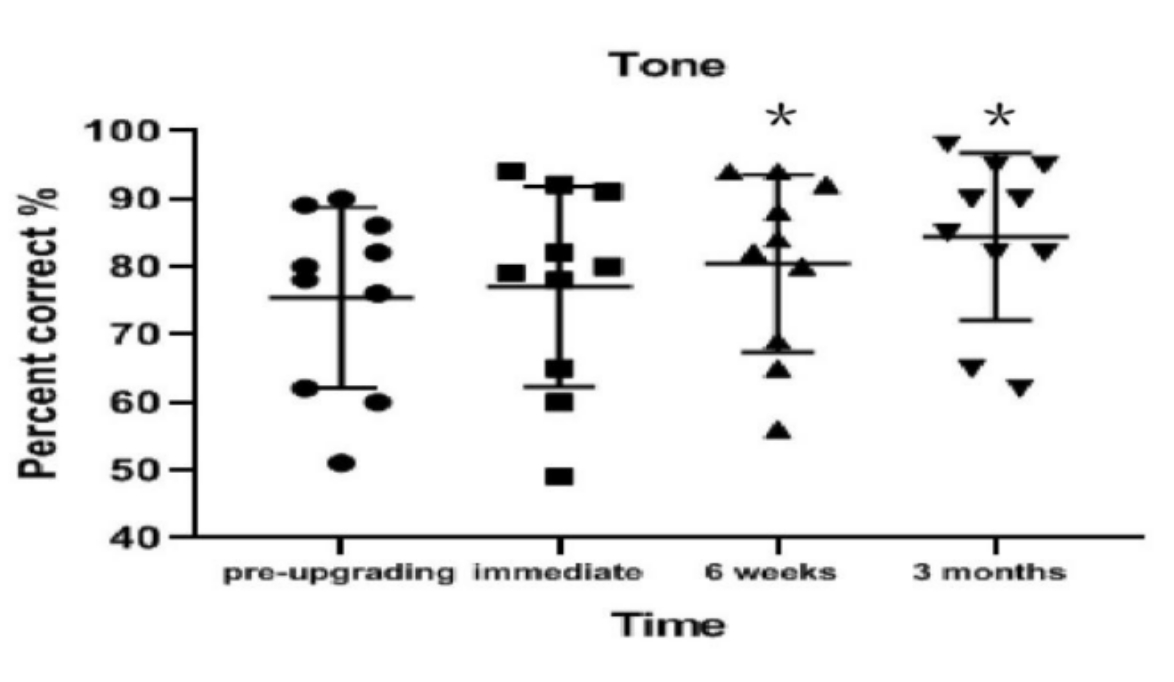
Tone recognition significantly improved from pre-upgrade to 6 weeks post-upgrade (on average 5.0% better; t = 11.180; p < 0.001) and from pre-upgrade to 3 months post-upgrade (on average 9% better; t = 4.803; p = 0.001). No significant improvement was found from pre-upgrade to immediately post-upgrade (on average 1.6% better; t = 1.652; p = 0.133; Table 2 and Figure 4).
Musical pitch perception
Musical pitch perception significantly improved from pre-upgrade to 4 months post-upgrade (on average, 12.7 limen better; z = 2.371; p = 0.018). A non-significant improvement was observed from pre-upgrade to 6 weeks post-upgrade (on average 5.5 limen better; z = 0.840; p = 0.401), and a non-significant deterioration was observed from pre-upgrade to immediately post-upgrade (on average 7.2 limen worse; z = 0.491; p = 0.623; Table 2).
| ID | Gender | Ear implanted | Age at time of surgery (years) | Age at time of evaluation (years) | Implant type |
| S01 | M | R | 2.0 | 14.2 | COMBI 40+ |
| S02 | F | L | 1.5 | 10.3 | COMBI 40+ |
| S03 | M | L | 4.4 | 12.2 | COMBI 40+ |
| S04 | F | R | 1.6 | 9.4 | COMBI 40+ |
| S05 | M | R | 3.8 | 10.6 | COMBI 40+ |
| S06 | M | R | 4.2 | 11.1 | COMBI 40+ |
| S07 | F | R | 4.2 | 11.7 | COMBI 40+ |
| S08 | M | R | 2.3 | 9.8 | COMBI 40+ |
| S09 | M | R | 4.3 | 9.4 | COMBI 40+ |
| S10 | M | R | 3.7 | 9.3 | COMBI 40+ |
Table 1: Demographic data of all participants. Abbreviations: M = male; F = female; R = right; L = left.
| Tests | Pre-upgrade | Immediately post | 6-weeks post | 3-months post |
| Monosyllables (quiet; %) | 59.6 (±14.3) | 67.8 (±17.6) | 71.4 (±13.3) | 82.1 (±12.2) |
| Spondees (quiet; %) | 69.2 (±16.1) | 75.0 (±14.5) | 78.6 (±14.1) | 85.3 (±10.0) |
| Sentence (quiet; %) | 78.0 (±19.4) | 78.8 (±19.2) | 91.0 (±7.8) | 95.8 (±7.9) |
| Sentence (noise; %) | 59.8 (±33.78) | 70.2 (±13.5) | 80.0 (±12.9) | 85.8 (±10.7) |
| Tone recognition (%) | 75.4 (±13.3) | 77.0 (±14.8) | 80.4 (±13.1) | 84.4 (±12.3) |
| Musical pitch (quartertone) | 16.5 (±11.5) | 23.7 (±20.4) | 11.0 (±13.2) | 3.8 (±3.4) |
Table 2: Hearing performance on each test at each interval. All data are presented as mean values (± standard deviation). There are significant differences in spondee, monosyllable, and sentence recognition in quiet conditions in favor of the FS4 coding strategy (p ≤ 0.017). However, no significant differences can be found in the sentence recognitions in noisy conditions test (p > 0.05).

Figure 1: Spondee recognition results for each interval. Spondee recognition in quiet conditions significantly improved from pre-upgrade to 3 months post-upgrade (p = 0.013). Data are presented as mean values (± standard deviation). *p < 0.05. Circles, squares, and triangles indicate individual participant's results. Please click here to view a larger version of this figure.
{kind=link}

Figure 2: Monosyllable recognition results for each interval. Monosyllable recognition in quiet conditions significantly improved from pre-upgrade to immediately post-upgrade (p = 0.013), from pre-upgrade to 6 weeks post-upgrade (p = 0.010), and from pre-upgrade to 3 months post-upgrade (p = 0.005). Data are presented as mean values (± standard deviation). *p < 0.05. Circles, squares, and triangles indicate individual participant's results. Please click here to view a larger version of this figure.
{kind=link}

Figure 3: Sentence recognition in quiet conditions results for each interval. Sentence recognition rate in quiet conditions significantly improved from pre-upgrade to 3 months post-upgrade (p = 0.008). Data are presented as mean values (± standard deviation). *p < 0.05. Circles, squares, and triangles indicate individual participant's results. Please click here to view a larger version of this figure.
{kind=link}

Figure 4: Tone recognition results for each interval. Tone recognition significantly improved from pre-upgrade to 6 weeks post-upgrade (p < 0.001) and from pre-upgrade to 3 months post-upgrade (p = 0.001). Data are presented as mean values (± standard deviation). *p < 0.05. Circles, squares, and triangles indicate individual participant's results. Please click here to view a larger version of this figure.
{kind=link}
Discussion
In the present study, the hearing performance of adolescent Mandarin-speaking CI users were systematically evaluated. The results showed significant improvements in speech recognition in quiet conditions, tone recognition, and musical pitch recognition after upgrading from the CIS+ to the FS4 coding strategy. This approach can help establish guidance for exploring clinical evaluation tools to evaluate the comprehensive effects with the new fine structure coding strategy in young Mandarin-speaking CI users.
Within the current study, the primary outcome measure was speech performance, especially speech performance in noisy conditions. Due to the difficulty of the test materials for young participants, the tests were presented in the order of easiest to hardest: spondee speech recognition in quiet conditions, monosyllable recognition in quiet conditions, sentence recognition in quiet conditions, and sentence recognition in noisy conditions. Throughout the sentence recognition in noisy conditions test, participants were asked to focus on the speech rather than the babble noise. All participants performed adequately on the sentence recognition in noisy conditions. Recognition of monosyllables in quiet conditions significantly improved at each of the three sessions compared to pre-upgrade. Similarly, the spondee and the sentence recognition in quiet conditions significantly improved between pre-upgrade and 3 months post-upgrade. These results are consistent with the previous findings in adult Mandarin-speaking CI users21,22. Although the results in the present study were not statistically significant for the sentence recognition in noisy conditions test, mean scores did increase from 59.8% at pre-upgrade to 85.8% after 3 months of use. This was in accordance with the previous report21. This test procedure and the results shown here verify the effective use of a newer speech processor for adolescent Mandarin-speaking CI users and demonstrated the usefulness of the proposed testing method.
After the speech performance tests, the tone test was conducted. In contrast to speech recognition in noisy conditions, the tone test appeared to be more interesting than speech tests for participants, with shorter test times. All participants understood the testing method after one practice session and performed well. As previously stated, recognition of tone is a crucial aspect of hearing and communication for Mandarin speakers. Normal hearing children can discriminate lexical tones in a domain-general fashion as early as 12 months17; however, this is certainly not the case in children with pre-lingual bilateral deafness. Previous studies have shown that pediatric CI users with pre-lingual deafness have marked deficits in tone recognition compared to their normal-hearing counterparts14,17. Studies on adult Mandarin-speaking CI users have shown that tone perception significantly improves over time with the FS4 coding strategy22. Similarly, the present study demonstrated that tone recognition significantly improves after both 6weeks and 3 months of using FS4.
The music software was chosen because it takes less time and thus helps keep the overall test time short. As indicated earlier, pitch perception, especially musical pitch perception, alongside tone recognition, is important for CI users. However, this is the most difficult and tedious portion of the battery of tests. Due to the difficult nature of the testing, four participants needed more than one practice session, six needed one practice round, three needed two practice rounds, and one needed multiple rounds. Due to the practice sessions, all the participants had a clear understanding of the test protocols and were able to perform the tests. The results showed significant improvements in pitch perception after 3 months of using FS4. These results were in accordance with previous literature in adult Mandarin-speaking CI users9. This validates the importance of fine structure information for music recognition in pediatric, Mandarin-speaking CI users, and the suitability of this method for evaluating young, non-Mandarin-speaking CI users of any language.
In the present study, assessing the utility of upgrading to the new coding strategy in the short term can be fully validated and tested by this battery of tests. Mandarin-speaking CI users demonstrated significantly better scores in all tests except the sentence recognition in noisy conditions test. In addition to the test methods being applicable to participants, all the tests were convenient and intuitive for the evaluation of the effect. Other than the results of musical pitch perception, all results are presented as percentages. The higher the percentage score, the better the result. For musical pitch, the lower the result, the better the effect. Researchers should ensure that all the test software have strict pre-experimental and formal test tables and the content is not repeated.
Therefore, the present study, for the first time, explored a battery of tests that could be used for clinically evaluating hearing performance in young Mandarin-speaking CI users after upgrading to the FS4 coding strategy. The approach presents valid test material, appropriate preparation, a strict test sequence, and a rigorous test procedure. However, the current study was not without limitations. Firstly, the sample size makes it difficult to extrapolate these findings to larger populations. Future studies must benefit from having a greater number of participants. Secondly, future studies must test timings, to determine how long completing each part of the test battery takes, thus being more useful for younger populations, especially those with a limited attention span. An easier methodology that shortens the overall testing time can be of clinical benefit.
Overall, the present study demonstrates that fine structure information plays a crucial role in the discrimination of speech in quiet conditions, pitch contours, and lexical tone recognition amongst adolescent Mandarin-speaking unilateral CI users. This battery of tests provides guidance for both CI users and candidates and doctors to choose different technologies, as well as to steer their clinical rehabilitation.
Acknowledgements
This work was supported by the National Natural Science Foundation of China under grants (number 81670932, 81600803, 82071053). Michael Todd (MED-EL) edited a version of this manuscript.
Materials
| Name | Company | Catalog Number | Comments |
| INVENTIS PIANO audiometer | Russia | This audiometer is mainly used for the behavioural audiometry in this study. | |
| HOPE software | Chinese PLA General Hospital | This software is used for testing the speech performance including adequate test lists for testing the monosyllable recognition in quiet, spondee (disyllable) speech recognition in quiet, sentence recognition in quiet, and sentence recognition in noise | |
| JAMO Loudspeaker | China | these loudspeakerw are used for all the tests in the sound booth. | |
| Lenovo computers | China | They are used for mapping and manipulating all the test softwares. | |
| MAESTRO mapping device | MED-EL | These devices include the MAX box and programming cable used for connecting the processor to the mapping software. | |
| MAESTRO software | MED-EL | This software is used for mapping | |
| Mandarin Tone Identification in Noise Test (MTINT) | Beijing Tongren Hospital | This software is used to measure tone recognition. A 4-alternative forced-choice (4AFC) Mandarin lexical tone task is used. The test material consists of 25 monosyllabic words spoken with the four Mandarin lexical tones to create 100 different words for each talker. | |
| Musical Sounds in Cochlear Implants (MuSIC) | MED-EL | The MuSIC test battery consists of six objective subtests assessing several areas of music perception. This software is chosen as it takes less time and thus helps keep the overall test time rather short. The battery contains approximately 2800 sound files recorded at the Royal Scottish Academy of Music and Drama by prefessional musicians playing natural instruments. |
References
- Wilson, B. S., Dorman, M. F. Cochlear implants: a remarkable past and a brilliant future. Hearing Research. 242 (1-2), 3-21 (2008).
- Carlyon, R. P., Goehring, T. Cochlear implant research and development in the Twenty-first Century: a critical update. Journal of the Association for Research in Otolaryngology. 22 (5), 481-508 (2021).
- Assouly, K. K. S., et al. Changes in tinnitus prevalence and distress after cochlear implantation. Trends in Hearing. 26, 23312165221128431 (2022).
- Lassaletta, L., et al. Using generic and disease-specific measures to assess quality of life before and after 12 months of hearing implant use: a prospective, longitudinal, multicenter, observational clinical study. International Journal Environmental Research and Public Health. 19 (5), 2503 (2022).
- Seligman, P., McDermott, H. Architecture of the Spectra 22 speech processor. The Annals of Otology, Rhinology & Laryngology. 166, 139-141 (1995).
- van Hoesel, R. J. M., Tyler, R. S. Speech perception, localization, and lateralization with bilateral cochlear implants. The Journal of the Acoustical Society of America. 113 (3), 1617-1630 (2003).
- Hochmair, I., et al. MED-EL cochlear implants: State of the art and a glimpse into the future. Trends in Amplification. 10 (4), 201-219 (2006).
- Helms, J., et al. Comparison of the TEMPO+ ear-level speech processor and the CIS PRO+ body-worn processor in adult MED-EL cochlear implant users. ORL; Journal for Oto-Rhino-Laryngology and its Related Specialties. 63 (1), 31-40 (2001).
- Arnoldner, C., et al. Speech and music perception with the new fine structure speech coding strategy: preliminary results. Acta Oto-Laryngologica. 127 (12), 1298-1303 (2007).
- Lorens, A., Zgoda, M., Polak, M., Skarzynski, H. FS4 for partial deafness treatment. Cochlear Implants International. 15, 78-80 (2014).
- Riss, D., et al. Effects of stimulation rate with the FS4 and HDCIS coding strategies in cochlear implant recipients. Otology & Neurotology. 37 (7), 882-888 (2016).
- Riss, D., et al. Effects of fine structure and extended low frequencies in pediatric cochlear implant recipients. International Journal of Pediatric Otorhinolaryngology. 75 (4), 573-578 (2011).
- Riss, D., et al. Envelope versus fine structure speech coding strategy: a crossover study. Otology & Neurotology. 32 (7), 1094-1101 (2011).
- Chen, A., Stevens, C. J., Kager, R. Pitch perception in the first year of life, a comparison of lexical tones and musical pitch. Frontiers in Psychology. 8, 297 (2017).
- Holt, C. M., Lee, K. Y. S., Dowell, R. C., Vogel, A. P. Perception of Cantonese lexical tones by pediatric cochlear implant users. Journal of Speech, Language, and Hearing Research. 61 (1), 174-185 (2018).
- Gu, X., et al. A follow-up study on music and lexical tone perception in adult Mandarin-speaking cochlear implant users. Otology & Neurotology. 38 (10), 421-428 (2017).
- Mao, Y., Xu, L. Lexical tone recognition in noise in normal-hearing children and prelingually deafened children with cochlear implants. International Journal of Audiology. 56, 23-30 (2017).
- Tan, J., Dowell, R., Vogel, A. Mandarin lexical tone acquisition in cochlear implant users with prelingual deafness: A review. American Journal of Audiology. 25 (3), 246-256 (2016).
- Tang, P., Yuen, I., Rattanasone, N. X., Gao, L., Demuth, K. The acquisition of Mandarin tonal processes by children with cochlear implants. Journal of Speech, Language, and Hearing Research. 62 (5), 1309-1325 (2019).
- Vandali, A. E., Dawson, P. W., Arora, K. Results using the OPAL strategy in Mandarin speaking cochlear implant recipients. International Journal of Audiology. 56, 74-85 (2016).
- Chen, X. Q., et al. Cochlear implants with fine structure processing improve speech and tone perception in Mandarin-speaking adults. Acta Oto-Laryngologica. 133 (7), 733-738 (2013).
- Qi, B., Liu, Z. Y., Gu, X., Lin, B. Speech recognition outcomes in Mandarin-speaking cochlear implant users with fine structure processing. Acta Oto-Laryngologica. 137 (3), 286-292 (2017).
- Xi, X., et al. Development of a corpus of Mandarin sentences in babble with homogeneity optimized via psychometric evaluation. International Journal of Audiology. 51 (5), 399-404 (2012).
- Brockmeier, S. J., et al. The MuSIC perception test: a novel battery for testing music perception of cochlear implant users. Cochlear Implants International. 12 (1), 10-20 (2011).
This article has been published
Video Coming Soon
ABOUT JoVE
Copyright © 2024 MyJoVE Corporation. All rights reserved