
Method Article
在XChem设施的Diamond Light Source实现高效的片段筛选
* 这些作者具有相同的贡献
摘要
本文描述了基于晶体的片段筛选的完整XChem过程,从申请访问到数据传播的所有后续步骤。
摘要
在基于片段的药物发现中,数百种或数千种小于 ~300 Da 的化合物与目标蛋白进行测试,以识别可以开发成有效候选药物的化学实体。由于化合物体积小,相互作用较弱,因此筛选方法必须具有高度的灵敏度;此外,结构信息对于将这些命中物细化为铅状化合物往往至关重要。因此,蛋白质晶体学一直是一种黄金标准技术,但从历史上看,它太具有挑战性,无法作为主要筛选的广泛应用。
2014 年展示了最初的 XChem 实验,然后与学术界和工业合作者进行了试验,以验证该过程。从那时起,大量的研究工作和大量的光束时间简化了样品制备,开发了一个具有快速随访可能性的片段库,自动化并改进了 I04-1 光束线的无人值守数据收集能力,并实施了用于数据管理、分析和命中识别的新工具。
XChem 现在是一个用于大规模晶体碎片筛选的设施,支持整个晶体到沉积过程,可供全球学术界和工业界用户使用。自 2016 年以来,同行评审的学术用户计划一直在积极开发,以适应尽可能广泛的科学范围的项目,包括经过充分验证的项目和探索性项目。学术访问是通过每半年征集同行评审提案来分配的,专有工作由 Diamond 的工业联络小组安排。该工作流程已常规应用于来自不同治疗领域的一百多个靶点,并有效识别弱结合剂(1%-30%命中率),既可作为化合物设计的高质量起点,又可提供有关结合位点的广泛结构信息。在 COVID-19 大流行期间持续筛选 SARS-CoV-2 靶点,包括主要蛋白酶的 3 周周转,证明了该过程的弹性。
引言
基于片段的药物发现 (FBDD) 是一种广泛使用的先导化合物发现策略,自 25 年前出现以来,它已交付了四种用于临床的药物,并且已有 40 多种分子已进入临床试验 1,2,3。碎片是分子量通常为 300 Da 或更低的小化学实体。它们因其化学复杂性低而被选中,这为开发具有优异物理化学性质的高配体高效抑制剂提供了良好的起点。它们的大小意味着它们比较大的药物或铅样化合物库更彻底地采样蛋白质的结合景观,因此也揭示了热点和假定的变构位点。结合结构信息,片段提供了蛋白质和配体之间潜在分子相互作用的详细图谱。然而,可靠地检测和验证这些往往与靶蛋白结合较弱的实体需要一系列强大而灵敏的生物物理筛选方法,例如表面等离子体共振 (SPR)、核磁共振 (NMR) 或等温滴定量热法 (ITC)4,5。
X射线晶体学是FBDD工具包的重要组成部分:它足够灵敏,可以识别弱粘合剂,并直接产生有关分子水平相互作用的结构信息。它是其他生物物理学筛选的补充,通常对于将片段命中进展为先导化合物至关重要;它需要高质量的晶体系统,这意味着结晶具有高度的可重复性,并且晶体的理想衍射分辨率优于 2.8 Å。
从历史上看,无论是在学术界还是在工业界,使用晶体学作为主要的碎片筛选6,7,8都是非常困难的。相比之下,同步加速器在机器人技术、自动化9、10、11 和探测器技术12、13 方面实现了数量级的改进,并且结合同样加速的计算能力和数据处理算法14,15、16,完整的衍射数据集可以在几秒钟内测量,并且大量衍射数据集完全无人值守,正如 LillyCAT7 所开创的那样以及后来的 MASSIF17,18(欧洲同步辐射设施 (ESRF))。这促使同步加速器开发了高度简化的平台,使基于晶体的片段筛选作为主要屏幕可供广泛的用户社区使用(XChem at Diamond;EMBL/ESRF19 的 CrystalDirect;柏林亥姆霍兹中心(Helmholtz-Zentrum)的BESSY20;MaxIV21 的 FragMax)。
本文记录了构成 XChem 平台的协议,用于通过 X 射线晶体学进行片段筛选,从样品制备到 3D 建模命中的最终结构结果。该管道(图1)需要开发新的晶体鉴定方法22、浸泡23和收获24,以及数据管理软件25和鉴定碎片26的算法方法,该方法现已在社区中广泛使用。晶体收集技术现在由供应商出售(见材料表),这些工具的开放可用性使其他同步加速器能够调整它们以建立等效的平台21。正在进行的项目涉及数据分析、模型完成和通过 Fragalysis 平台进行数据传播27.样品制备实验室毗邻光束线 I04-1,简化了将数百个冷冻样品转移到光束线的物流,I04-1 上的专用光束时间允许快速 X 射线反馈来指导活动。
XChem 是 Diamond 用户计划不可或缺的一部分,每年两次(4 月初和 10 月初)。在与学术界和工业界的药物发现专家协商后,对同行评审过程进行了改进。除了强有力的科学案例外,提案过程28 还要求申请人不仅要自我评估晶体系统的准备情况,还要评估他们在生化和正交生物物理方法方面的专业知识以及通过后续化学推进筛选命中的能力。访问模式也不断发展,以适应多学科用户社区:
第1层(单个项目 )适用于处于探索阶段的项目,并不需要制定命中验证工具(生物物理学或生化工具)和后续策略。如果被接受,该项目将获得减少的光束时间偏移次数,足以进行概念验证。
第 2 层(单个项目) 适用于经过充分验证的项目,需要制定下游工具和后续策略。如果被接受,该项目将获得足够的光束时间用于完整的片段筛选活动。单个项目(第 1 级或第 2 级)将在分配期(4 月至 9 月或 10 月至 3 月)的 6 个月内完成。
区块分配组 (BAG) 适用于组和项目联盟,其中 BAG 中有一个强大的目标选择和优先级排序流程,以及明确的后续管道。BAG必须至少有一名经过XChem培训的专家(超级用户),他们与钻石员工协调他们的活动,并培训BAG成员。分配的波束时间偏移数量由 BAG 中科学性强的项目数量定义,并根据 BAG 的报告在每个分配周期内重新评估。访问有效期为 2 年。
XChem 实验分为三个阶段,每个阶段都有一个决策点:溶剂耐受性测试、预筛选和主筛选(图 2)。溶剂耐受性测试有助于确定浸泡参数、晶体系统可以耐受的溶剂(DMSO、乙二醇或其他冷冻保护剂,如果需要)的量以及耐受时间。溶剂浓度通常在至少两个时间点的5%-30%之间。收集衍射数据并与晶体体系的基底衍射进行比较;这将确定下一阶段的浸泡参数。对于预筛选,使用溶剂测试中确定的条件浸泡 100-150 种化合物,其目的是确认晶体在这些条件下可以耐受化合物。如果需要,随后将冷冻保护剂添加到已经含有碎片的液滴中。成功的标准是80%或更多的晶体存活得足够好,以产生良好且质量一致的衍射数据;如果失败,通常通过改变浸泡时间或溶剂浓度来修改浸泡条件。在成功的预筛选之后,可以使用最终参数设置为实验选择的其余化合物。
DSI准备库(见 材料表)经过专门设计,允许使用准备化学29 进行快速后续进展,并一直是该设施的主力库。用户可在DMSO中以500 mM的浓度获得它。学术用户还可以访问合作者提供的其他库(总共超过2,000种化合物),DMSO中浓度为100-500 mM(完整列表可在网站28上找到)。大部分产品也以乙二醇形式提供,用于不耐受DMSO的晶体系统。用户也可以自带文库,前提是它们位于与声学液体处理系统兼容的板中(参见 材料表)。
对于实验的所有三个步骤(溶剂表征、预筛选或全屏),以下样品制备程序是相同的(图 3):通过使用 TeXRank22 对结晶液滴进行成像和靶向来选择化合物分配位置;使用声学液体分配系统将溶剂和化合物分配到液滴中23;使用晶体移位器24高效收集晶体;并将样品信息上传到光束线数据库 (ISPyB)。目前实验设计和执行的接口是基于Excel的应用程序(SoakDB),它为平台的不同设备生成必要的输入文件,并将所有结果跟踪和记录在SQLite数据库中。在整个过程的各个阶段使用条形码扫描仪来帮助跟踪样品,并将这些数据添加到数据库中。
衍射数据在无人值守模式下使用光束线 I04-1 上的专用光束时间收集。有两种定心模式可供选择,即光学和基于 X 射线的17。对于针状和棒状晶体,建议使用 X 射线对中,而较厚的晶体通常支持光学模式,该模式速度更快,因此允许在分配的光束时间内收集更多样品。根据晶体的分辨率(在进入平台之前建立),数据收集可以是 60 秒或 15 秒的总曝光。溶剂测试阶段的数据收集通常会告知哪种组合最适合光束线 I04-1 的性能。
大量的数据分析通过XChemExplorer(XCE)25进行管理,XChemExplorer(XCE)25也可用于使用PanDDA26启动命中识别步骤。XCE是一种数据管理和工作流程工具,支持蛋白质-配体结构的大规模分析(图4);它从钻石光源(DIALS16、Xia214、AutoPROC30 和 STARANISO31)收集的数据中读取任何自动处理结果,并根据数据质量和与参考模型的相似性自动选择其中一个结果。重要的是,该模型必须代表用于XChem筛选的晶体系统,并且必须包括所有水或其他溶剂分子,以及仅用溶剂浸泡的晶体中可见的所有辅因子、配体和替代构象。此参考模型的质量将直接影响模型构建和优化阶段所需的工作量。PanDDA用于分析所有数据并识别结合位点。它将结构与参考结构对齐,计算统计映射,识别事件,并计算事件映射26,32。在PanDDA范式中,建立完整的晶体学模型既没有必要,也不可取;必须建模的只是片段结合的蛋白质视图(结合态模型),因此重点只需要根据事件图32构建配体和周围的残基/溶剂分子。
研究方案
1. 项目建议书提交
- 提案内容:由于 XChem 计划超额认购,提案中全面完整的信息对于通过同行评审至关重要。
- 说明理由!提出目标的重要性,并将其置于更广泛的背景下。
- 阐明片段筛选活动后的策略:验证命中的正交方法以及如何推进它们。如果需要,安排合作。
- 由于实验室和数据分析部分紧张,强烈建议提前指派一位经验丰富的晶体学家。
- 稳健的晶体系统是消除技术变化的关键,用户应解决这些要点。
- 确保结晶条件在适合在储液槽体积为 30 μL(或更小)且液滴大小在 200-500 nL 之间的平台上使用的板中产生具有相似衍射质量晶体的可重现液滴。理想情况下,板中超过 50% 的液滴将具有至少 35 μm 大小33 的晶体。
- 确保晶体的衍射质量一致(2.6 Å 或更好)。
- 检查晶体系统是否适合片段筛选,包括晶体堆积和已知位点的可及性。先前在这些位点结合的分子的证据通常令人放心。
- 说明理由!提出目标的重要性,并将其置于更广泛的背景下。
2. 参观准备
- 转移现场结晶的结晶方案。
- 提供 2 x 50 mL 储液槽溶液,即用型。
- 提供结晶所需浓度的蛋白质溶液,以 30-50 μL 的等分试样随时使用。
- 提供 10 mL 蛋白质缓冲溶液。
- 提供种子储备液(即使结晶方案中不需要)。
注:晶种有利于结晶重现性并加快成核时间33. - 填写 XChem 网站上提供的结晶信息表28.
- 在 XChem 网站上提供的运输表格中提供存储信息web网站 28.
- 安装 NoMachine 并将远程桌面设置为 Diamond (https://www.diamond.ac.uk/Users/Experiment-at-Diamond/IT-User-Guide/Not-at-DLS/Nomachine.html)。
- 与晶体学专家或XChem支持人员协商,生成并转移良好的参考模型。
3.片段筛选实验
- 定义复合分配位置。
- 对结晶板进行成像。
- 在晶体板成像仪中对实验所需的所有晶体板(见材料 表)进行成像(见 材料表)。使用成像仪软件,在正确的目录中为板类型生成以下格式的板名称 :提案Number_Plate编号。
- 打印条形码(右键单击板名称并从菜单中选择),将它们与行字母放在板的另一侧,将板放入加载端口,条形码背对用户。
- 使用成像仪控制软件,扫描加载端口,右键单击印版,然后选择 成像印版。
- 成像完成后,从成像仪中取出板。
- 选择晶体和化合物位置
注:结晶液滴的图像在 Luigi 管道中使用 TexRank 的基于 textons 的算法 Ranker 进行处理,以根据晶体22 的可能存在对液滴进行排名。这大约需要 10 分钟,然后图像将在 TexRank 中可用。- 从 PC 打开 TeXRank ,然后从右下角的列表中选择水晶托盘,或者在左上角的框中输入条形码。
- 选择正确的成像仪格式和单孔视图。在液滴图像中移动,当有适合在实验中使用的晶体时,右键单击远离晶体但在液滴内部 - 目的是瞄准液滴中添加溶剂/化合物的位置,因此不想直接击中晶体23。
- 继续浏览整个板,完成后选择 Echo 1 Target 按钮;保存在相关访问下的 Crystal Targets 目录中。请勿更改文件名。
- 对任何其他板重复上述步骤。
- 对结晶板进行成像。
- 复合点胶
- 生成复合分配文件
- 在 SoakDB 中,在库/溶剂表中输入库选择或溶剂信息。
- 在目标晶体列表中输入液滴体积和负载。
- 生成所需的批次。
- 输入浸泡参数。单击" 计算 ",然后单击" 导出待处理 "按钮。对于溶剂,将各种浓度添加到表中。这将生成用于声学分配器的文件。
- 如果使用冷冻保护剂,请输入浓度并以相同的方式创建文件。
- 使用声学点胶机点胶溶液(参见 材料表)
- 取源板(化合物或溶剂/冷冻保护剂),并在离心机中以1,000× g旋转板2分钟。
- 如果分配溶剂或冷冻保护剂,则将 30 μL 移液到 384PP 板上的相关孔中;盖上微封膜,然后如上离心。
- 打开软件;选择 "新建 ",然后选择正确的源孔板(384PP、384LDV 或 1536LDV)和液体类别(DMSO、CP、BP 或 GP)。确保选择正确的板类型作为目标板。然后选中 "自定义 "框并继续。
- 选择 "导入 ",然后选择相关的批处理文件。根据软件提示完成导入步骤。
- 使用板图检查要分配的溶液和目标位置。
- 运行协议,按照出现的提示进行操作。来自源板的溶液将分配到选定的晶体滴中。
- 将培养板存放在培养箱中所需的时间。
注:这些参数在溶剂表征步骤中确定,温度为4°C或20°C,具体取决于晶体生长温度,时间通常在1小时至3小时之间。
- 生成复合分配文件
- 使用半自动晶体采集装置采集晶体(见 材料清单).
注意:如果需要冷冻保护,请在收获样品之前重复步骤3.2.2,将冷冻保护剂溶液添加到晶体滴上。- 收获前的准备工作
- 准备在 SoakDB 中收获所需的文件。当询问时,确认浸泡已完成,批次已完成。
- 在正确的建议编号下扫描出实验所需的冰球数量。
- 为晶体选择适当尺寸的环(35 μm、75 μm 或 150 μm)的托盘。重要的是,选择尽可能与晶体尺寸相匹配的环尺寸,以使光束线上的自动对中更加准确,通过减少背景来提高数据质量,并消除对冷冻保护剂的需求。
- 打开相关软件并打开工作流选项卡。
- 将冰球扫描到软件中,然后滚动回列表顶部,突出显示第一个冰球。
- 将冰球放入泡沫杜瓦瓶中,并用液氮冷却。
- 选择 Import File From SoakDB 并选择要收获的批次;检查批次是否分配给左侧持有人。此时将显示一个工作列表。
- 取水晶板,取下封口,放入左手支架;将车牌移动到停车位置。
- 收获晶体
- 舒适并按下 "开始工作流程 "按钮(屏幕为触摸屏)移动到第一个选定的孔位置。
- 如果晶体存活下来,将晶体安装在环中并插入液氮中,将其置于列表中第一个冰球的位置 1。
- 从界面中选择晶体的适当描述(正常、熔化、破裂、果冻或有色)。
- 如果液滴是化合物浸泡,请记录化合物状态的描述(透明、结晶、沉淀、分配不良或相分离)。
- 如果晶体已成功安装,请选择" 已安装 ",否则选择 "失败"。
- 板将移动到下一个选定的孔。连续填充所有冰球位置(如果晶体失效,不要留下间隙)。继续到工作流程结束。
- 在工作流程结束时,加载任何其他批次并继续按顺序填充冰球。无需为新批次启动新冰球。
- 收割结果的条形码跟踪
- 收获完所有晶体后,将冰球带到条形码扫描仪上,一次放置一个以扫描冰球并固定条形码。
- 完成后,盖上冰球的盖子并存放在液氮储存杜瓦瓶中。
- 将输出文件加载到 SoakDB 接口中。
- 将样品信息记录到 ISPyB34、35、36 中
- 将示例数据上传到 ISPyB
- 在 SoakDB 中,更新光束线,访问 ISPyB 的更新,然后单击导出以创建要上传到 ISPyB 的文件。
- 打开腻子。登录并浏览到以下目录:dls/labxchem/data/year/lbXXXX-1/processing/lab36/ispyb。
- 运行脚本 csv2ispyb (csv2ispyb lbXXXX-1-date.csv)
注意:示例现在已加载到 ISPyB 中。
- 记录冰球位置和数据收集策略。
- 记录冰球的细节和位置
注意:记录冰球的细节和位置非常重要,以便可以定位它们并将其加载到光束线上。- 在 SoakDB 中,打开标记为 Pucks 的第二个选项卡。
- 在顶部的框中填写详细信息。具体来说,冰球的位置(储存杜瓦瓶和手杖)、数据收集参数,包括预期的分辨率和提案编号。
- 单击 "保存 "按钮,所有冰球的列表将出现在表格中。复制最近填充的冰球。
- 打开 XChem 队列电子表格(桌面上的快捷方式)并粘贴信息。填写任何其他相关信息。
- 记录冰球的细节和位置
- 将示例数据上传到 ISPyB
- 收获前的准备工作
4. 数据收集
注意:数据以无人值守模式收集,并由 XChem/beamline 团队管理。
- 收集错误中心的样本。
注意:当某些样本的数据收集出现问题时,这些是必需的,很可能是由于引脚未正确居中引起的。- 查看 ISPyB 中的样品更换器视图,选择 Rank by AP 以自动处理的分辨率对样品进行分级,颜色渐变从绿色到红色。
- 单击样品以检查是否有任何红色或黄色样品。
注意:这将调出数据收集。 - 检查晶体快照,查看晶体是否居中。
- 记下所有未居中的样本,并发送给当地联系人,他们将收集丢失的样本。
5. 数据分析
- 通过 XChemExplorer (XCE)25 检索和分析 Diamond 的自动处理结果。
- 在终端中,转到子文件夹 Processing:cd /dls/labxchem/data/year/visit/processing 或 XChem BAG:cd /dls/labxchem/data/year/visit/processing/project/processing/。
- 使用别名 xce 打开 XChemExplorer。
- 选择" 从数据源更新表 "按钮。
- 在"概述"选项卡下,有实验数据的摘要。使用"数据源"菜单中的"选择要显示的列"选项添加其他类别。
- 在 "设置 "选项卡下,选择数据收集目录 (/dls/i04-1/data/year/visit/)。
- 打开"数据集"选项卡,从"选择目标"下拉菜单中选择目标,从"数据集"下拉菜单中选择"自动处理中的 Get New Results",然后单击"运行"。
注意:XCE 现在将解析数据收集访问以获取自动处理结果。首次运行时,这可能需要一些时间,具体取决于正在分析的数据集/目录的数量。 - 通过检查分辨率、空间组和 Rmerge 来检查数据的一致性和质量。排除分辨率低于 2.8 Å 的数据。
注意:默认情况下,数据集选择基于根据 I/sigI、完整性和唯一反射数计算得出的分数,但可以选择其他处理结果以供使用25。 - 要为单个数据集选择不同的处理结果,如果愿意,请单击"样本 ID"并选择所需的程序/运行。要更改所有数据集的处理管道,请从"首选项"菜单中选择"编辑首选项",然后更改"数据集选择机制"。
- 如果需要,通过 ISPyB37 重新处理数据。
- 如果样本的处理数据不可接受,则标记为 "无法 从进一步分析中排除"。
- 完成后,单击" 从数据源更新 表"以将数据添加到后续表中。
- 使用 DIMPLE38 计算初始映射。
- 打开 "映射 "选项卡,从下拉菜单中选择参考模型,然后选择所需的数据集,然后在 选定的 MTZ 文件上运行 DIMPLE。
- XCE 在 Diamond 的集群上同时运行多个 DIMPLE 作业。在" 凹坑状态 "列下查找这些作业的状态,然后使用 "从数据源更新表 "按钮或使用 Linux 中的 qstat 命令进行刷新。
- 完成后,检查 Dimple Rcryst、Dimple Rfree 和 Space Group 值是否可接受。如有必要(高自由值/错误的空间群/晶胞体积差异大),如前所述更改自动处理结果,并重复为这些数据集生成地图。
- 使用 Grade39、AceDRG40 或 phenix.eLBOW41 生成配体约束。
- 选择所需的程序(首选项、编辑首选项、约束生成程序),然后在"地图"选项卡下选择数据集,然后从"地图和约束"下拉列表中运行"创建所选化合物的 CIF/PDB/PNG 文件"。
- 使用"从数据源更新表"按钮刷新在"复合状态"列下找到的这些作业的状态。
- 构建基态模型(预运行)
注意:术语基态模型表示蛋白质的无配体形式的结构,如在 100 个数据集中观察到的那样(此数字是任意选择的)。由于基态模型被用作构建配体结合态的参考,因此在分析整个片段筛选活动之前,建立准确的基态模型(包括所有溶剂和水分子)至关重要。在此步骤中,使用 PanDDA 标记为缺乏有趣事件(因此可能不含配体)的 100 个第一最高分辨率数据集来生成基态均值图,同时选择自由 R 最低的数据集进行细化。基态均值图不是晶体学图,但是,仅将此图用于构建基态模型非常重要。- 打开 PanDDAs 选项卡,并在必要时更新数据源中的表。
- 定义 输出目录 (/dls/labxchem/data/year/visit/processing/analysis/panddas)。
- 选择" 基态模型的预 运行",然后单击" 运行"。
注意:具有高 Rfree 和意外空间组的数据集应自动从分析中排除。 - 要手动排除具有高 Rfree 和意外空间组的数据集,请选择 完全忽略。
- 在终端窗口中使用 qstat 检查预运行作业的状态。
- 完成后,选择" 构建基态模型 ",然后单击" 运行"。
注意:这将使用 PanDDA 均值图和参考模型/2Fo-Fc/Fo-Fc 图从最高质量的数据集中打开 Coot,以便使用 Coot 进行重新建模和细化。最重要的是,仅使用 PanDDA 均值图进行建模。
- 使用 PanDDA26 识别命中
- PanDDA分析
注意:如果有很多数据集,晶胞很大,并且不对称单元中有多个蛋白质拷贝,则可能需要一些时间才能在集群上运行。- 重复前面描述的 分析 DLS 自动处理结果 和 初始地图计算步骤。对于映射计算,使用基态模型作为参考: 刷新参考文件列表>设置新参考 ,并根据需要为新数据生成 配体约束 (步骤 6.1-6.3)。
- 在 PanDDAs 选项卡下,确保输出目录设置为之前,然后从 Hit Identification 下拉菜单中运行 pandda.analyse。
- 使用 qstat 命令在 Linux 终端中检查作业的状态。
- PanDDA 检查 - 检查/构建绑定 事件
- 在 XCE 的 PanDDAs 选项卡下,从 Hit Identification 下拉菜单中运行 pandda.inspect,以使用 PanDDA 控制面板打开 Coot42。
注意:pandda.inspect 控制面板提供 PanDDA 统计信息的摘要,并允许用户浏览绑定事件/站点。还会生成结果的摘要 HTML 文件,并且可以在检查期间通过选择 "更新 HTML"进行更新。 - 要对配体进行建模,请单击"将 配体与模型合并 "和"保存模型",然后再导航到另一个事件,以避免丢失对绑定态 模型 的任何更改。
注意:只有已更新和保存的模型才会导出,以便在以后阶段进行优化。 - 使用 "事件注释 "字段对绑定事件进行批注,使用" 记录站点信息 "对绑定站点进行批注。
- 平均负载和 2mFo-DFc 映射(来自 DIMPLE),用于与事件映射和模型进行比较。
- 根据事件图对所有可行的配体进行建模、合并和保存后,关闭 pandda.inspect。
- 在 XCE 的 PanDDAs 选项卡下,从 Hit Identification 下拉菜单中运行 pandda.inspect,以使用 PanDDA 控制面板打开 Coot42。
- PanDDA 导出和优化
注意:在 PanDDA 检查之后,模型将导出回项目目录,并启动初始一轮优化。目前,在 XCE 的 PANDDAs 选项卡下有两个可用的管道可以执行此操作。- 导出 NEW/ALL/SELECTED PANDDA 模型会生成绑定和未绑定模型的集合以进行细化,并为 Refmac43 生成占用限制参数。
注意:集成模型将用于细化,但只有绑定态模型将在 Coot 中更新并存放在 PDB 中。此管道最适合用于具有低占用率片段和蛋白质模型发生重大变化的数据集。 - 使用 BUSTER 细化 NEW/ALL 束缚态模型 仅使用 Buster44 细化束缚态。
注意:这最适合用于高占用率配体/数据集,对蛋白质模型的更改最小。
- 导出 NEW/ALL/SELECTED PANDDA 模型会生成绑定和未绑定模型的集合以进行细化,并为 Refmac43 生成占用限制参数。
- PanDDA分析
- 优化命中(现在,所有选择进行优化的数据集都将在"优化"选项卡中可见)。从"细化"下拉菜单中选择"打开 COOT - BUSTER 细化"或"打开 COOT - REFMAC 细化",以使用 XCE 细化控制面板打开 Coot。
- 从 "选择 样本"下拉列表中选择要优化的样本的状态(通常为 3 - 优化),然后单击 "开始"。
注意:XCE 控制面板提供该类别的数据集数量的摘要,并允许在数据集之间导航,同时提供优化统计信息的摘要。 - 在 XCE 控制面板中注释配体置信度:0 - 不存在配体 - 片段未结合; 1 - 低置信度 - 片段可能已绑定,但不是特别令人信服; 2 - 配体正确,密度弱 - 用户确信片段已结合,但占用率低/图谱存在一些问题; 3 - 清晰的密度,意想不到的配体图谱清楚地表明配体结合与提供的化学结构无关; 4 - 高置信度 - 配体是明确结合的。
- 在此阶段对模型进行任何必要的更改,并使用"优化"按钮启动进一步 优化 。
- 使用 "显示 MolProbity 待办事项列表" 按钮访问在所有精简周期上运行的 MolProbity45 分析。
- 如果需要,通过选择"细化参数"按钮来添加 细化参数 ,例如,各向异性温度因子、孪生数据或占用细化。
注意:XCE 中的 "细化 "选项卡下也提供了数据处理统计信息,如果使用 Buster 管道执行细化,则提供包括 MOGUL 分析46 在内的 Buster 报告。 - 在数据集的" 优化 "选项卡下的"XCE"主窗口或" Coot XCE "控制面板中更改数据集的状态。如果对配体周围的模型准确且适合共享以进行进一步分析感到满意,请将状态更改为 CompChem Ready。当优化完成且模型准备好上传到 PDB 时,将状态更改为 "沉积就绪"。
- 从 "选择 样本"下拉列表中选择要优化的样本的状态(通常为 3 - 优化),然后单击 "开始"。
6. 存储数据
注意:来自片段屏幕的所有数据集和用于生成 PanDDA 事件映射的基态模型都可以使用组沉积沉积在 PDB 中。
- 通过从 Hit Identification 菜单运行 Event Map ->SF,将所有 PanDDA 事件映射转换为 MTZ 格式。
- 通过选择 "沉积">"编辑信息"来提供其他元数据,例如作者和方法。填写所有必填项目,然后单击"保存 到数据库 ",然后保存此信息以沉积基态模型。在模型状态更改为 "沉积就绪"后执行此操作。
- 在"沉积"选项卡中,选择"准备 mmcif"按钮,为所有"沉积就绪"数据集生成结构因子 mmcif 文件。完成此操作后,终端窗口中将出现以下消息:已完成为 wwPDB 沉积准备 mmcif 文件。
- 选择" 复制 mmcif "按钮,将所有这些文件复制到访问的 Group Deposition Directory 中的单个压缩 tar 存档中。
- 转到 https://deposit-group-1.rcsb.rutgers.edu/groupdeposit;使用用户名:GroupTester 和密码:!2016RCSBPDB 登录。创建一个会话并从组沉积目录上传配体绑定.tar.bz2文件。
- 成功提交配体结合结构后,将发送一封包含PDB代码的电子邮件。从"沉积"菜单中选择"使用 PDB 代码更新数据库";将此电子邮件中的信息复制并粘贴到弹出窗口中,然后单击"更新数据库"以添加 PDB ID。
- 要存放 PanDDA 使用的基态模型,请在 XCE 中选择相关的 PanDDA 目录,然后从 Hit Identification 菜单中运行 apo->mmcif。
注意:XCE将任意选择具有低Rfree的高分辨率结构作为沉积束的模型,然后将所有结构因子mmcif文件编译为一个文件。 - 在"沉积"选项卡中,选择"基态模型组沉积"部分下方的"添加到数据库"按钮。
- 输入基态模型的元数据(再次通过选择 沉积 > 编辑信息),加载上一个文件并 保存到数据库。
- 通过运行"基态模型的组沉积"部分中的"准备 mmcif"来准备基态 mmcif 文件,完成后,通过选择同一部分中的"复制 mmcif"按钮将 mmcif 复制到组沉积目录。
- 和以前一样,去 https://deposit-group-1.rcsb.rutgers.edu/groupdeposit;使用用户名:GroupTester 和密码:!2016RCSBPDB 登录。创建一个会话并从组沉积目录上传 ground_state_structures.tar.bz2 文件。
结果
用于通过 X 射线晶体学进行片段筛选的 XChem 流程已得到广泛简化,使其能够被科学界采用(图 5)。这个过程已经在 150 多个筛选活动上得到了验证,命中率在 1% 到 30% 之间变化47,48,49,50,51,52 和许多回头客。不合适的晶体系统(分辨率低、结晶或衍射质量不一致)或不能耐受DMSO或乙二醇,在工艺早期就被淘汰,从而节省时间、精力和资源。成功的活性细胞提供了靶蛋白上潜在相互作用位点的三维图谱;典型的结果是 SARS-CoV-2 主要蛋白酶的 XChem 筛选(图 6)。通常,片段命中存在于:(a)已知的感兴趣位点,例如酶活性位点和亚口袋48;(b)假定的变构位点,例如蛋白质-蛋白质相互作用53;(c)晶体封装界面,通常被认为是假阳性(图6)。这种结构数据通常为将片段命中合并、连接或生长为铅样小分子提供了基础 1,3。

图 1:XChem 管道。 该平台从项目提案到样品制备、数据收集和命中识别,以示意性方式表示。 请点击这里查看此图的较大版本.
{kind=link}

图2:筛选策略。 工作流指示每个里程碑的目的、实验的要求和决策点。 请点击这里查看此图的较大版本.
{kind=link}

图 3:样品制备工作流程。 样品制备的关键步骤由每个步骤的信息记录在SQLite数据库中表示。 请点击这里查看此图的较大版本.
{kind=link}

图4:使用XCE进行数据分析。 数据分析中的关键步骤由带有相关软件包的工作流程图表示。 请点击这里查看此图的较大版本.
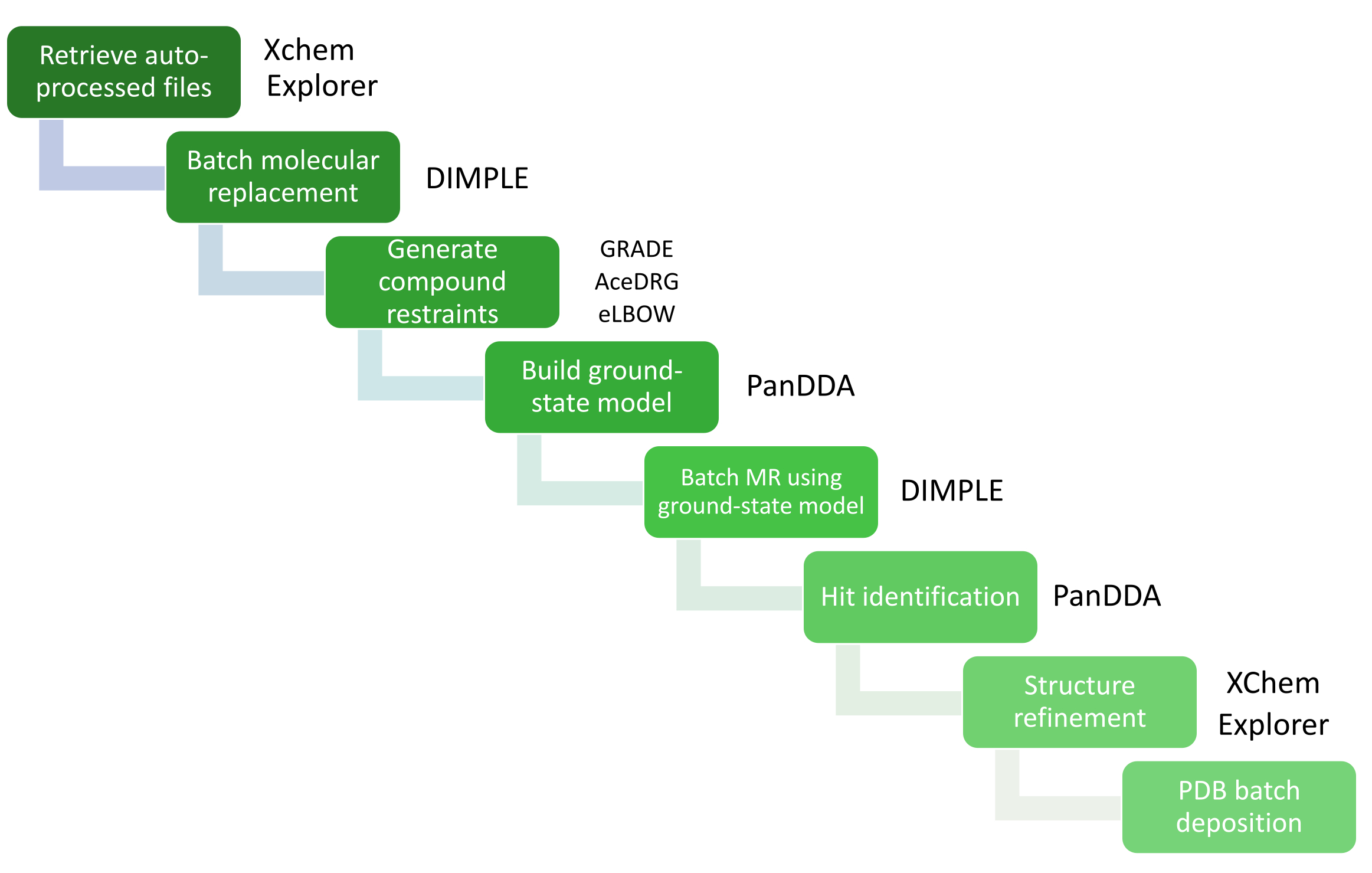{kind=link}

图 5:XChem 用户计划的演变:该图表显示了 2015 年至 2019 年用户计划的采用和整合,以及 2019 年 BAG 的创建以及该平台在 2020 年 COVID-19 大流行期间的弹性。请点击这里查看此图的较大版本.
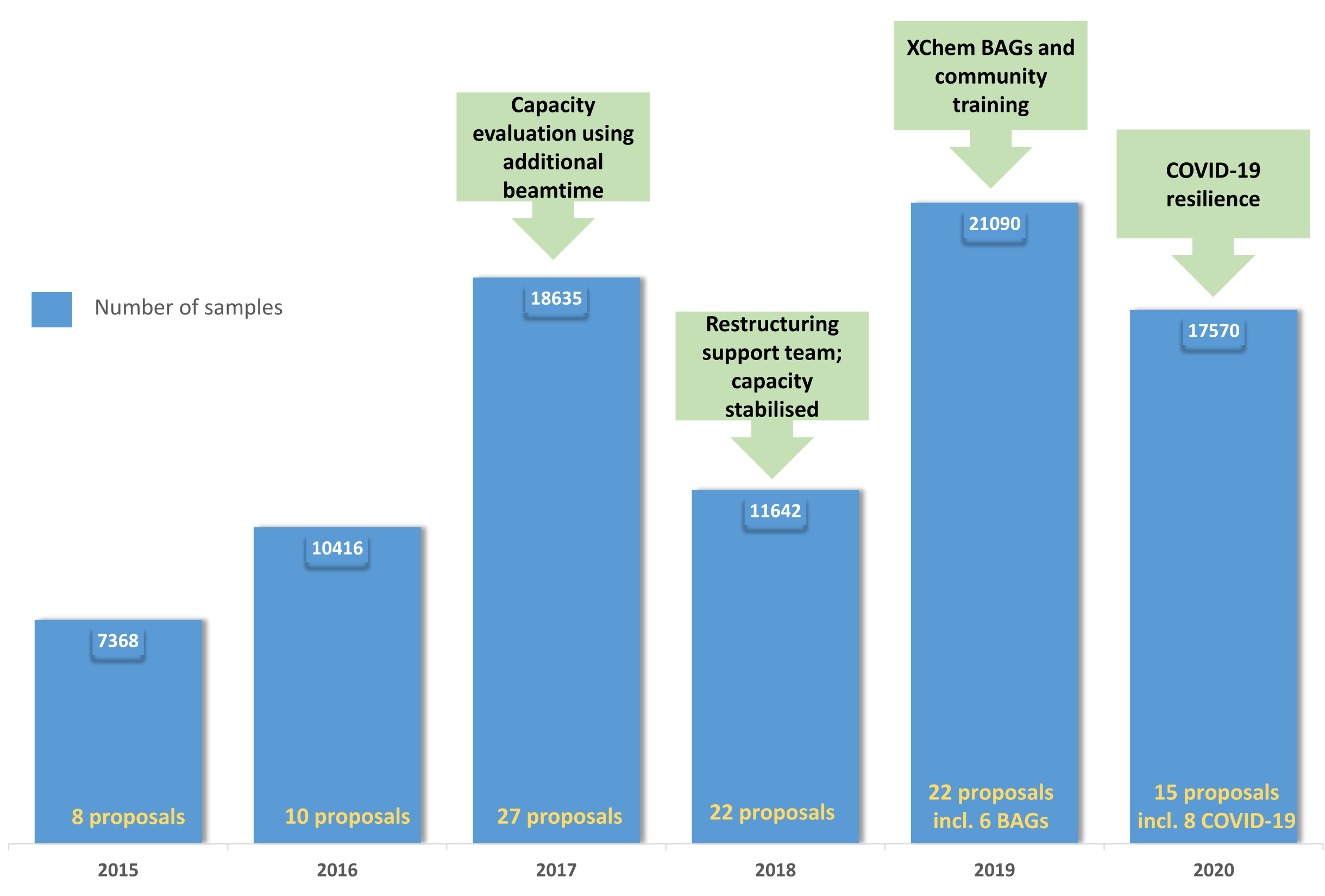{kind=link}

图 6:XChem 片段筛选的代表性结果。 SARS-CoV2 主要蛋白酶 (Mpro) 二聚体在表面表示,活性位点命中以黄色表示,推定变构命中以洋红色显示,表面/晶体堆积伪影以绿色显示。该图是使用组沉积G_1002156中的 Chimera 和 Mpro PDB 条目制作的。 请点击这里查看此图的较大版本.
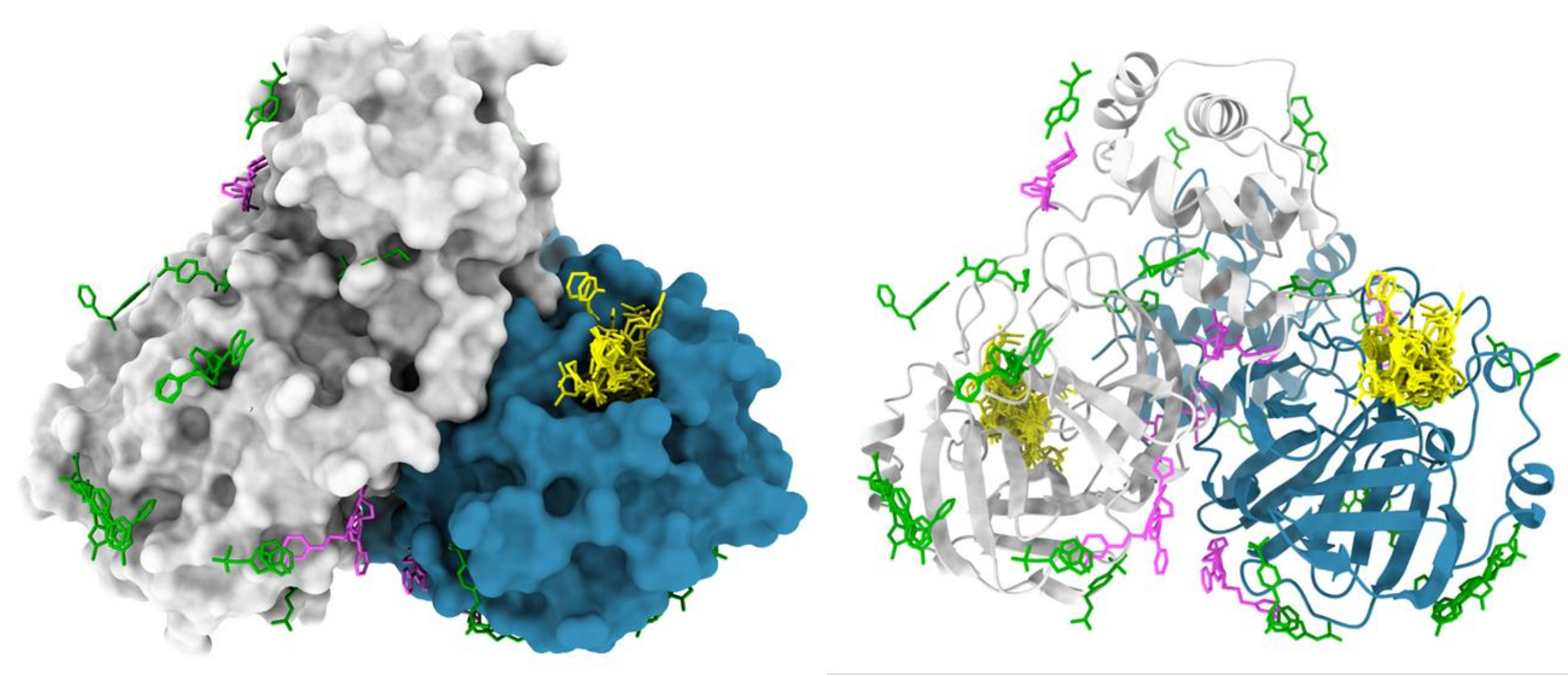{kind=link}
讨论
本文中概述的过程已经过用户社区的广泛测试,此处描述的协议的适应性是处理平台上通常遇到的各种项目的关键。但是,晶体系统的一些先决条件是必要的。
对于使用 X 射线晶体学进行的任何碎片筛选活动,可重复且稳健的晶体系统至关重要。由于标准XChem方案涉及将片段直接添加到晶体液滴中,因此优化应侧重于含有高质量晶体的液滴数量,而不是晶体总数。如果液滴包含多个晶体,那么它们实际上是多余的,尽管可以缓解收获过程。此外,将结晶方案从家庭研究所转移到现场设施可能具有挑战性。这通常最好使用晶体接种来实现,以促进可重复的成核54,因此,一个好的做法是让用户提供种子储备液以及他们的蛋白质和结晶溶液。
为确保良好的化合物溶解度和支持性,高浸泡浓度旨在驱动弱片段的结合,片段库在有机溶剂中提供,特别是DMSO和乙二醇。提供两种不同的溶剂为用户提供了一种晶体的替代品,这些晶体完全不耐受DMSO,或者它阻塞了目标位点中片段的结合。用户可以在水性缓冲液中提供替代文库:只要化合物完全溶解并在与液体分配机器人兼容的板中格式化,它们就可以很好地分配。
对于无法找到既能溶解库又能被晶体系统耐受的合适有机溶剂的项目,另一种方法是使用 BESSY55 中规定的干燥化合物。
在社区中,有一个长期存在的问题,即能够将化合物浸泡到在含有高盐浓度的结晶条件下生长的晶体中。实际上,在收获阶段观察到更多的化合物沉淀和盐晶体的快速形成,通过在收获区域周围施加潮湿的环境来减少这种情况。通常,在晶体系统中从高盐结晶条件下进行筛选活动,其命中率与低盐条件相当。
XChem 工艺的初始阶段(溶剂耐受性测试和预筛选)是相对小规模和快速的实验,但允许对项目做出明确的通过/不通过决定。最痛苦的是,如果两种溶剂都不能被接受,或者预筛选导致命中率非常低,则需要找到替代晶体系统。相反,如果成功,结果将直接告知用于筛选实验的浸泡条件,以及数据收集的最佳策略。由于数据质量,尤其是分辨率,将影响用于命中识别和分析的电子密度质量,因此目的是以尽可能高的化合物浓度浸泡,而不会对衍射质量产生有害影响(大多数数据集(~80%)衍射到2.8 Å或更高的分辨率)。
XChemExplorer简化了数据分析过程,它依靠PanDDA软件来检测弱粘合剂,并允许用户快速可视化和查看筛查活动的结果。XChemExplorer 从 Diamond 提供的软件包(DIALS16、autoPROC 30、STARANISO31 和 Xia214)导入数据处理结果,分辨率限制由每个软件包的标准方法确定(即CC1/2 = 0.3)。默认情况下,数据集选择基于根据 I/sigI、完整性和一些唯一反射计算得出的分数,但可以选择特定的处理结果用于全局或单个样本25。PanDDA 还根据包括分辨率、游离 R 以及参考数据和目标数据之间的晶胞体积差异(默认值分别为 3.5 Å、0.4 和 12%)等标准将数据排除在分析之外,因此衍射不良、偏心错误或索引错误的晶体不会影响分析。
PanDDA 算法利用片段分析期间收集的大量数据集来检测标准晶体图中不可见的部分占有配体。最初,PanDDA 使用在溶剂耐受性测试和预筛选步骤中收集的数据来准备平均密度图,然后用于创建基态模型。由于该模型将用于所有后续分析步骤,因此在用于片段筛选的条件下准确表示未配体的蛋白质至关重要。然后,PanDDA使用统计分析来识别结合的配体,为晶体的结合状态生成事件图。通过从部分占用数据集中减去晶体的未结合部分来生成事件映射,并显示配体在完全占用时被结合时将观察到的情况。如果不查阅事件图,即使是在传统 2mFo-DF c 图中看起来清晰的片段也可能建模错误32。虽然 PanDDA 是一种强大的方法,用于识别与平均图谱不同的数据集(通常表示片段结合),并且在细化过程中提供了 RSCC、RSZD、B 因子比和 RMSD 等指标以造福用户,但用户最终负责决定观察到的密度是否准确描述了预期的配体和最合适的构象。
经过数据分析和改进后,所有用户都可以使用XChemExplorer同时将多个结构存入蛋白质数据库(PDB)中。对于每个片段筛选,进行两次组沉积。第一个沉积包含所有片段绑定模型,MMCIF 文件中包含用于计算 PanDDA 事件映射的系数。第二次沉积提供了随附的基态模型,以及实验所有数据集的测量结构因子:这些数据可用于重现PanDDA分析,并用于开发未来的算法。至于命中的结构,当片段占用率较低时,如果模型是配体结合和混杂基态结构的复合体,则细化表现更好32;然而,这种做法是只存入束缚态分数,因为完整的复合模型通常很复杂且难以解释。因此,PDB重新计算的一些质量指标(特别是R/Rfree)有时会略有提高。也可以使用 Zenodo56 等平台提供所有原始数据,尽管 XChem 管道目前不支持此功能。
总体而言,自 2016 年运行以来,使用该程序可以在超过 95% 的靶标中鉴定片段配体。XChem 支持的许多项目的经验被提炼成晶体制备的最佳实践33,同时发展了一个片段库,实现了帮助片段进展的成熟概念29,也有助于建立公开库组成的实践。该平台已经证明了维护良好的基础设施和记录在案的流程的重要性,详见此处,并可以评估其他片段库57,58,比较库 48,并为协作 EUOpenscreen-DRIVE 库的设计提供信息59,60。
披露声明
作者没有要披露的利益冲突。
致谢
这项工作代表了金刚石光源和结构基因组联盟之间的巨大共同努力。作者要感谢 Diamond 的各种支持小组和 MX 小组对 i04-1 光束线自动化的贡献,以及提供简化的数据收集和自动处理管道,这些管道通常在所有 MX 光束线上运行。他们还要感谢SGC PX集团作为第一批测试设置的用户所表现出的韧性,并感谢Evotec成为第一个认真的工业用户。这项工作得到了由欧盟委员会地平线2020计划资助的iNEXT-Discovery(Grant 871037)的支持。
材料
| Name | Company | Catalog Number | Comments |
| DSI-poised library | Enamine | DSI-896 | fragment library |
| Echo 550 and 650 series | Beckman-Coulter | acoustic dispensing system | |
| Echo microplates | Beckman-Coulter | 001-12380; 001-8768; 001-6025 | 1536-well and 384-well microplates |
| Shifter | Oxford Lab Technology | harvesting device | |
| Microplate centrifuge with a swing-out rotor | Sigma | model 11121 | microplate centrifuge |
| 3-drops crystallisation plates | Swissci | 3W96T-UVP | Crystallisation plates |
| Formulatrix plate imager and Rockmaker software | Formulatrix | Crystallisation plates imaging device |
参考文献
- Erlanson, D. A., Fesik, S. W., Hubbard, R. E., Jahnke, W., Jhoti, H. Twenty years on: The impact of fragments on drug discovery. Nature Reviews Drug Discovery. 15 (9), 605-619 (2016).
- Jacquemard, C., Kellenberger, E. A bright future for fragment-based drug discovery: what does it hold. Expert Opinion on Drug Discovery. 14 (5), 413-416 (2019).
- Jahnke, W., et al. Fragment-to-lead medicinal chemistry publications in 2019. Journal of Medicinal Chemistry. 63 (24), 15494-15507 (2019).
- Li, Q. Application of fragment-based drug discovery to versatile targets. Frontiers in Molecular Biosciences. 7, 180 (2020).
- Kirsch, P., Hartman, A. M., Hirsch, A. K. H., Empting, M. Concepts and core principles of fragment-based drug design. Molecules. 24 (23), 4309 (2019).
- Patel, D., Bauman, J. D., Arnold, E. Advantages of crystallographic fragment screening: functional and mechanistic insights from a powerful platform for efficient drug discovery. Progress in Biophysics and Molecular Biology. 116 (2-3), 92-100 (2014).
- Wasserman, S., et al. Automated synchrotron crystallography for drug discovery: the LRL-CAT beamline at the APS. Acta Crystallographica Section A Foundations of Crystallography. 67 (1), 46-47 (2011).
- Hartshorn, M. J. Fragment-based lead discovery using X-ray crystallography. Journal of Medicinal Chemistry. 48 (2), 403-413 (2005).
- Arzt, S., et al. Automation of macromolecular crystallography beamlines. Progress in Biophysics and Molecular Biology. 89 (2), 124-152 (2005).
- Beteva, A. High-throughput sample handling and data collection at synchrotrons: Embedding the ESRF into the high-throughput gene-to-structure pipeline. Acta Crystallographica Section D, Biological Crystallography. 62, 1162-1169 (2006).
- Papp, G., et al. FlexED8: The first member of a fast and flexible sample-changer family for macromolecular crystallography. Acta Crystallographica. Section D, Structural Biology. 73, 841-851 (2017).
- Casanas, A., et al. EIGER detector: Application in macromolecular crystallography. Acta Crystallographica Section D, Structural Biology. 72, 1036-1048 (2016).
- Henrich, B., et al. PILATUS: A single photon counting pixel detector for X-ray applications. Nuclear Instruments and Methods in Physics Research, Section A: Accelerators, Spectrometers, Detectors and Associated Equipment. 607 (1), 247-249 (2009).
- Winter, G., Lobley, C. M. C., Prince, S. M. Decision making in xia2. Acta Crystallographica Section D, Biological Crystallography. 69, 1260-1273 (2013).
- Winter, G., McAuley, K. E. Automated data collection for macromolecular crystallography. Methods. 55 (1), 81-93 (2011).
- Winter, G., et al. DIALS: Implementation and evaluation of a new integration package. Acta Crystallographica Section D, Structural Biology. 74, 85-97 (2018).
- Bowler, M. W. MASSIF-1: A beamline dedicated to the fully automatic characterization and data collection from crystals of biological macromolecules. Journal of Synchrotron Radiation. 22 (6), 1540-1547 (2015).
- Von Stetten, D., et al. ID30A-3 (MASSIF-3) - A beamline for macromolecular crystallography at the ESRF with a small intense beam. Journal of Synchrotron Radiation. 27, 844-851 (2020).
- Cipriani, F., et al. CrystalDirect: a new method for automated crystal harvesting based on laser-induced photoablation of thin films. Acta Crystallographica. Section D, Biological Crystallography. 68, 1393-1399 (2012).
- . Helmholtz Zentrum Berlin Available from: https://www.helmholtzberlin.de/forschung/oe/np/gmx/fragment-screening/index_en.html (2021)
- Lima, G. M. A., et al. FragMAX: the fragment-screening platform at the MAX IV Laboratory. Acta crystallographica. Section D, Structural biology. 76 (8), 771-777 (2020).
- Ng, J. T., Dekker, C., Kroemer, M., Osborne, M., Von Delft, F. Using textons to rank crystallization droplets by the likely presence of crystals. Acta Crystallographica. Section D, Biological Crystallography. 70, 2702-2718 (2014).
- Collins, P. M., et al. Gentle, fast and effective crystal soaking by acoustic dispensing. Acta Crystallographica. Section D, Structural Biology. 73, 246-255 (2017).
- Wright, N. D., et al. The low-cost Shifter microscope stage transforms the speed and robustness of protein crystal harvesting. Acta Crystallographica. Section D, Structural Biology. 77, 62-74 (2021).
- Krojer, T., et al. The XChemExplorer graphical workflow tool for routine or large-scale protein-ligand structure determination. Acta Crystallographica. Section D, Structural Biology. 73, 267-278 (2017).
- Pearce, N. M., et al. A multi-crystal method for extracting obscured crystallographic states from conventionally uninterpretable electron density. Nature Communications. 8, 15123 (2017).
- . Fragalysis Available from: https://fragalysis.diamond.ac.uk (2021)
- . Diamond Light Source Ltd Available from: https://www.diamond.ac.uk/Instruments/Mx/Fragment-Screening.html (2021)
- Cox, O. B., et al. A poised fragment library enables rapid synthetic expansion yielding the first reported inhibitors of PHIP(2), an atypical bromodomain. Chemical Science. 7 (3), 2322-2330 (2016).
- Vonrhein, C., et al. Data processing and analysis with the autoPROC toolbox. Acta Crystallographica. Section D, Biological Crystallography. 67, 293-302 (2011).
- Vonrhein, C., et al. Advances in automated data analysis and processing within autoPROC , combined with improved characterisation, mitigation and visualisation of the anisotropy of diffraction limits using STARANISO. Acta Crystallographica Section A: Foundations and Advances. 74 (1), 360 (2018).
- Pearce, N. M., Krojer, T., Von Delft, F. Proper modelling of ligand binding requires an ensemble of bound and unbound states. Acta Crystallographica. Section D, Structural Biology. 73, 265-266 (2017).
- Collins, P. M., et al. Achieving a good crystal system for crystallographic x-ray fragment screening. Methods in Enzymology. 610, 251-264 (2018).
- Delageniere, S., et al. ISPyB: an information management system for synchrotron macromolecular crystallography. Bioinformatics. 27 (22), 3186-3192 (2011).
- Fisher, S. J., Levik, K. E., Williams, M. A., Ashton, A. W., McAuley, K. E. SynchWeb: a modern interface for ISPyB. Journal of Applied Crystallography. 48, 927-932 (2015).
- Ginn, H. M., et al. SynchLink: an iOS app for ISPyB. Journal of Applied Crystallography. 47, 1781-1783 (2014).
- . Diamond Light Source Ltd Available from: https://www.diamond.ac.uk/Instruments/Mx/Common/Common-Manual/Data-Analysis/Reprocessing-in-ISPyB.html (2021)
- Wojdyr, M., Keegan, R., Winter, G., Ashton, A. DIMPLE - a pipeline for the rapid generation of difference maps from protein crystals with putatively bound ligands. Acta Crystallographica. Section A, Foundations of Crystallography. 69, 299 (2013).
- Long, F., et al. AceDRG: A stereochemical description generator for ligands. Acta Crystallographica. Section D, Structural Biology. 73, 112-122 (2017).
- Moriarty, N. W., Grosse-Kunstleve, R. W., Adams, P. D. Electronic ligand builder and optimization workbench (eLBOW): A tool for ligand coordinate and restraint generation. Acta Crystallographica. Section D, Biological Crystallography. 65, 1074-1080 (2009).
- Emsley, P., Lohkamp, B., Scott, W. G., Cowtan, K. Features and development of Coot. Acta Crystallographica. Section D, Biological Crystallography. 66, 486-501 (2010).
- Murshudov, G. N., Vagin, A. A., Dodson, E. J. Refinement of macromolecular structures by the maximum-likelihood method. Acta Crystallographica. Section D, Biological Crystallography. 53, 240-255 (1997).
- Bricogne, G., et al. Buster version 2.10.3. Global Phasing Ltd. , (2017).
- Chen, V. B., et al. MolProbity: All-atom structure validation for macromolecular crystallography. Acta Crystallographica. Section D, Biological Crystallography. 66, 12-21 (2010).
- Bruno, I. J., et al. Retrieval of crystallographically-derived molecular geometry information. Journal of Chemical Information and Computer Sciences. 44 (6), 2133-2144 (2004).
- Delbart, F., et al. An allosteric binding site of the α7 nicotinic acetylcholine receptor revealed in a humanized acetylcholine-binding protein. TheJournal of Biological Chemistry. 293, 2534-2545 (2018).
- Douangamath, A., et al. Crystallographic and electrophilic fragment screening of the SARS-CoV-2 main protease. Nature Communications. 11 (1), 5047 (2020).
- Guo, J., et al. In crystallo-screening for discovery of human norovirus 3C-like protease inhibitors. Journal of Structural Biology: X. 4, 100031 (2020).
- Keedy, D. A., et al. An expanded allosteric network in PTP1B by multitemperature crystallography, fragment screening, and covalent tethering. eLife. 7, 36307 (2018).
- McIntyre, P. J., et al. Characterization of three druggable hot-spots in the aurora-a/tpx2 interaction using biochemical, biophysical, and fragment-based approaches. ACS Chemical Biology. 12 (11), 2906-2914 (2017).
- Thomas, S. E., et al. Structure-guided fragmentbased drug discovery at the synchrotron: Screening binding sites and correlations with hotspot mapping. Philosophical Transactions. Series A, Mathematical, Physical and Engineering Sciences. 377 (2147), 20180422 (2019).
- Nichols, C., et al. Mining the PDB for tractable cases where x-ray crystallography combined with fragment screens can be used to systematically design protein-protein inhibitors: Two test cases illustrated by IL1β-IL1R and p38α-TAB1 complexes. Journal of Medicinal Chemistry. 63 (14), 7559-7568 (2020).
- D'Arcy, A., Bergfors, T., Cowan-Jacob, S. W., Marsh, M. Microseed matrix screening for optimization in protein crystallization: What have we learned. Acta Crystallographica. Section F, Structural Biology Communications. 70, 1117-1126 (2014).
- Wollenhaupt, J., et al. F2X-Universal and F2X-Entry: Structurally diverse compound libraries for crystallographic fragment screening. Structure. 28 (6), 694-706 (2020).
- . Zenodo Available from: https://zenodo.org (2021)
- Foley, D. J., et al. Synthesis and demonstration of the biological relevance of sp(3) -rich scaffolds distantly related to natural product frameworks. Chemistry. 23 (60), 15227-15232 (2017).
- Kidd, S. L., et al. Demonstration of the utility of DOS-derived fragment libraries for rapid hit derivatisation in a multidirectional fashion. Chemical Science. 11 (39), 10792-10801 (2020).
- . EU-openscreen ERIC Available from: https://www.eu-openscreen.eu/ (2021)
- Schuller, M., et al. Fragment binding to the Nsp3 macrodomain of SARS-CoV-2 identified through crystallographic screening and computational docking. bioRxiv. 393405, (2020).
转载和许可
请求许可使用此 JoVE 文章的文本或图形
请求许可探索更多文章
This article has been published
Video Coming Soon
版权所属 © 2025 MyJoVE 公司版权所有,本公司不涉及任何医疗业务和医疗服务。