
Method Article
基于深度学习的医学图像分割在轨道计算机断层扫描 中的 应用
摘要
介绍了轨道计算机断层扫描(CT)图像的目标分割协议。解释了使用超分辨率标记轨道结构地面真相的方法,从CT图像中提取感兴趣的体积,以及使用2D顺序U-Net对轨道CT图像进行多标签分割建模的方法。
摘要
近年来,基于深度学习的分割模型在眼科领域得到了广泛的应用。本研究介绍了基于U-Net构建轨道计算机断层扫描(CT)分割模型的完整过程。对于监督学习,需要一个劳动密集型和耗时的过程。介绍了利用超分辨率标记以有效掩盖轨道CT图像的地面真相的方法。此外,作为数据集预处理的一部分,将裁剪感兴趣的卷。然后,在提取轨道结构的感兴趣体积后,利用U-Net构建用于分割轨道CT关键结构的模型,使用顺序2D切片作为输入,并有两个双向卷积长期短存储器以保持切片间的相关性。这项研究主要集中在眼球、视神经和眼外肌的分割上。对分割的评估揭示了使用深度学习方法将分割应用于轨道CT图像的潜在应用。
引言
眼眶是一个约30.1 cm3 的小而复杂的空间,包含重要的结构,如眼球、神经、眼外肌、支撑组织以及用于视觉和眼球运动的血管1。眼眶肿瘤是眼眶内组织异常生长,其中一些威胁到患者的视力或眼球运动,可能导致致命的功能障碍。为了保护患者的视觉功能,临床医生必须根据肿瘤特征决定治疗方式,手术活检通常是不可避免的。这种紧凑而拥挤的区域通常使临床医生在不破坏正常结构的情况下进行活检具有挑战性。基于深度学习的病理学图像分析用于确定眼眶状况,有助于避免活检期间对眼眶组织造成不必要或可避免的损伤2。眼眶肿瘤图像分析的一种方法是肿瘤检测和分割。然而,由于发病率低,包含眼眶肿瘤的CT图像的大量数据收集受到限制3。计算肿瘤诊断的 另一种有效方法4涉及将肿瘤与眼眶的正常结构进行比较。正常结构中的眼眶CT图像数量相对大于肿瘤。因此,分割正常轨道结构是实现这一目标的第一步。
本研究介绍了基于深度学习的轨道结构分割的整个过程,包括数据收集、预处理和后续建模。该研究旨在为有兴趣使用当前方法有效生成掩蔽数据集的临床医生以及需要有关轨道CT图像预处理和建模信息的眼科医生提供资源。本文提出了一种基于U-Net代表性深度学习解决方案的顺序二维分割模型,用于医学图像分割,提出了一种轨道结构分割和顺序U-Net的新方法。该协议描述了轨道分割的详细过程,包括(1)如何使用掩蔽工具进行轨道结构分割的地面真相,(2)轨道图像预处理所需的步骤,以及(3)如何训练分割模型并评估分割性能。
对于监督学习,四位经验丰富的眼科医生已经获得了董事会认证超过 5 年,他们手动注释了眼球、视神经和眼外肌的面罩。所有眼科医生都使用掩蔽软件程序(MediLabel,见 材料表),该程序使用超分辨率在CT扫描上高效掩蔽。遮罩软件具有以下半自动功能:(1)SmartPencil,生成图像强度为5的超像素图簇;(2)SmartFill,通过计算正在进行的前景和背景6,7的能量函数来生成分割掩码;(3)自动校正,使分割蒙版的边框干净并与原始图像一致。半自动功能的示例图像如图 1 所示。协议部分(步骤 1)中提供了手动屏蔽的详细步骤。
下一步是轨道CT扫描的预处理。为了获得感兴趣的眼眶体积(VOI),确定了眼球,肌肉和神经在正常情况下所在的眼眶区域,并裁剪了这些区域。数据集具有高分辨率,面内体素分辨率和切片厚度为 <1 mm,因此跳过插值过程。相反,窗口剪辑是在 48 HU 剪辑级别和 400 HU 窗口进行的。裁剪和窗口裁剪后,为分割模型输入8生成轨道VOI的三个连续切片。协议部分(步骤 2)提供了有关预处理步骤的详细信息。
U-Net9 是一种广泛使用的医学图像分割模型。U-Net架构包括一个编码器和一个解码器,前者提取医学图像的特征,后者以语义方式呈现判别特征。当使用U-Net进行CT扫描时,卷积层由3D过滤器10,11组成。这是一个挑战,因为3D滤镜的计算需要很大的内存容量。为了减少3D U-Net的内存需求,提出了SEQ-UNET8,其中在U-Net中使用了一组顺序的2D切片。为了防止3D CT扫描的2D图像切片之间失去时空相关性,在基本U-Net中使用了两个双向卷积长期短记忆(C-LSTM)12 。第一个双向C-LSTM提取编码器末端的切片间相关性。第二个双向C-LSTM在解码器输出后,将切片序列维度中的语义分割信息转换为单个图像分割。SEQ-UNET 的架构如图 2 所示。实现代码可在 github.com/SleepyChild1005/OrbitSeg 中找到,协议部分(步骤 3)中详细介绍了代码的用法。
研究方案
目前的工作是在天主教医疗中心机构审查委员会(IRB)的批准下进行的,健康信息的隐私,机密性和安全性受到保护。轨道CT数据是从韩国天主教大学医学院附属医院(CMC;首尔圣母医院、汝矣岛圣母医院、大田圣母医院、圣文森特医院)。2016年1月至2020年12月进行眼眶CT扫描。该数据集包含来自韩国男性和女性的46次轨道CT扫描,年龄从20岁到60岁不等。运行时环境 (RTE) 总结在 补充表 1 中。
1. 在眼眶 CT 扫描上掩盖眼球、视神经和眼外肌
- 运行屏蔽软件程序。
注意:掩蔽软件程序(MediLabel,见 材料表)是一种用于分割的医学图像标记软件程序,只需点击几下即可实现高速。 - 通过单击 打开的文件 图标并选择目标 CT 文件来加载轨道 CT。然后,CT扫描显示在屏幕上。
- 使用超级像素掩盖眼球、视神经和眼外肌。
- 通过单击MediLabel中的SmartPencil向导来运行 SmartPencil (视频1)。
- 如有必要,控制超级像素贴图的分辨率(例如,100、500、1,000 和 2,000 超级像素)。
- 单击超级像素图上的眼球、视神经和眼外肌的超级像素聚类,其中聚集了相似图像强度值的像素。
- 使用MediLabel中的自动更正功能优化面膜。
- 在屏蔽切片上的一些超级像素后单击智能 填充 向导(视频 2)。
- 单击 "自动更正 "图标,并确保已计算校正的掩码标签(视频 3)。
- 重复步骤 1.3 和步骤 1.4,直到遮罩的细化完成。
- 保存被遮罩的图像。
2. 预处理:窗口剪切和裁剪 VOI
- 使用preprocessing_multilabel.py提取 VOI(该文件可从 GitHub 下载)。
- 运行preprocessing_multilabel.py。
- 检查扫描和掩码,它们被裁剪并保存在VOIs文件夹中。
- 将 VOI 转换为一组三个连续的 CT 切片,以便输入到 SEQ-UNET builder_multilabel.py(该文件可从 GitHub 下载)。
- 运行sequence_builder_multilabel.py。
- 确保切片和蒙版在转换过程中调整为 64 x 64 像素。
- 在转换过程中,使用 48 HU 裁剪级别和 400 HU 窗口执行剪切。
- 分别检查扫描文件夹中保存的转换CT扫描(nii文件)和掩码(nii文件)和预处理文件夹下的掩码文件夹。
3. 轨道分割模型的四个交叉验证
- 按照以下步骤构建模型。
- 运行 main.py。
- 运行 main.py 时,通过"-fold num x"给出四个交叉验证的折叠编号,其中 x 为 0、1、2 或 3。
- 运行 main.py 时,请使用 epoch(即训练迭代次数)作为选项,例如"-epoch x",其中 x 是 epoch 编号。默认数字为 500。
- 运行 main.py 时,设置批大小,即单个训练会话中的训练样本数。默认数字为 32。
- 在 main.py 中,加载CT扫描和掩模,并使用LIDC-IDRI数据集(可从癌症成像档案下载)使用预训练参数初始化SEQ-UNET。
- 在 main.py 中,在训练后执行模型测试。计算评估指标、骰子分数和数量相似性,并将它们保存在指标文件夹中。
- 检查分段文件夹中的结果。
结果
对于定量评估,采用两个评估指标,用于CT图像分割任务。这是两个相似性指标,包括骰子得分(DICE)和交易量相似性(VS)13:
骰子 (%) = 2 × TP/(2 × TP + FP + FN)
VS (%) = 1 − |FN − FP|/(2 × TP + FP + FN)
其中 TP、FP 和 FN 分别表示给出分割结果和分割掩码时的真阳性、假阳性和假阴性值。
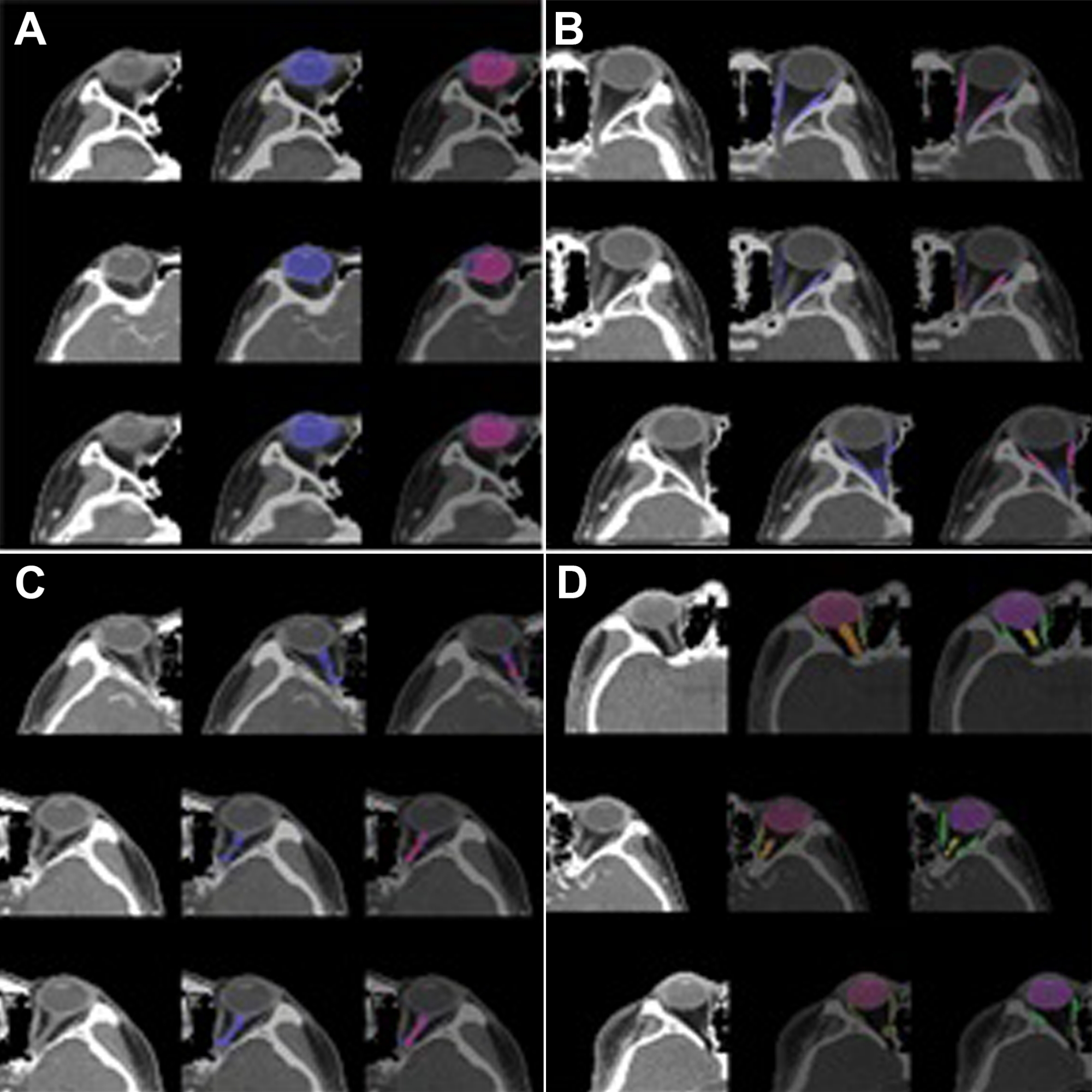
SEQ-UNET在轨道结构分割方面的性能通过四次交叉验证进行了评估。结果如表1所示。使用SEQ-UNET的眼球分割得分为0.86,VS为0.83。眼外肌和视神经的分割得分较低(分别为0.54和0.34)。眼球分割的骰子得分超过80%,因为它具有大部分VOI,CT扫描之间的异质性很小。眼外肌和视神经的骰子评分相对较低,因为它们很少出现在CT体积中,并且在相对较少的CT切片中发现。然而,眼外肌和视神经的视觉相似性得分(分别为0.65和0.80)高于他们的骰子得分。该结果表明分割的特异性较低。总体而言,SEQ-UNET对所有轨道子结构进行分割的骰子得分和视觉相似度分别为0.79和0.82。轨道结构分割的视觉结果示例如图3所示。在图 3A-C 中,蓝色是预测的分割结果,红色是真实面罩。在图 3D 中,红色、绿色和橙色分别是眼球、视肌和神经分割。

图 1:半自动遮罩功能。 使用 (A) 智能铅笔、(B) 智能填充和 (C) 自动校正在眼眶 CT 扫描上屏蔽眼球、眼外肌和视神经。眼球的蒙版由SmartPencil标记,SmartPencil计算切片的超级像素,并通过单击超级像素来制作蒙版。点击一些眼球超级像素后,整个眼球遮罩可以通过SmartFill计算出来。在屏蔽视神经的情况下,掩蔽细化是通过自动校正进行的。蓝色标记的眼球显示在(A)和(B)中。 请点击此处查看此图的大图。
{kind=link}

图 2:SEQ U-Net 架构。 连续的2D切片作为输入和输出;基于U-Net架构,将两个双向C-LSTM应用于编解码块的末端。 请点击此处查看此图的大图。
{kind=link}

图3:轨道结构的分割结果。 (A)眼球(标签1),(B)视肌(标签2),(C)视神经(标签3)和(D)多标签(标签1,2和3)。左图是轨道的VOI,中心图是预测的分割,右图是地面实况。在 (A)、(B) 和 (C) 中,蓝色是预测的分割结果,红色是地面真实掩码。在 (D) 中,红色、绿色和橙色分别是眼球、眼外肌和视神经分割。预测的分割在眼球的情况下显示出高性能(DICE:0.86 vs. 0.82),但在眼外肌(DICE:0.54 vs. 0.65)和视神经(DICE:0.34 vs. 0.8)的情况下表现不佳。 请点击此处查看此图的大图。
{kind=link}
| 多标签 | 标签 1(眼球) | 标签2(眼外肌) | 标签 3(视神经) | |||||
| 骰子 | 与 | 骰子 | 与 | 骰子 | 与 | 骰子 | 与 | |
| SEQ-UNET | 0.79 | 0.82 | 0.86 | 0.83 | 0.54 | 0.65 | 0.34 | 0.8 |
表 1:骰子分数和视觉相似性的分割结果。 切片数量较多的眼球被很好地分割,DICE为0.8,但切片数量和线形较少的眼外肌和视神经被部分分割,DICE值分别为 0.54和0.34。
视频 1:遮罩软件程序中的智能铅笔向导。 注释多个像素以进行眼球遮罩的演示。只需单击聚类超级像素即可启用遮罩任务。 请点击此处下载此视频。
视频 2:遮罩软件程序中的智能填充向导。 注释多个像素以进行眼球遮罩的演示。在注释区域中选择一些像素后,此功能会生成与所选像素强度相似的完整分割蒙版。 请点击此处下载此视频。
视频 3:遮罩软件程序中的自动更正。 使用预先训练的卷积神经网络算法自动校正遮罩像素的演示。 请点击此处下载此视频。
补充表 1:屏蔽、预处理和分段建模的运行时环境 (RTE)。请按此下载此表格。
讨论
基于深度学习的医学图像分析广泛应用于疾病检测。在眼科领域,检测和分割模型用于糖尿病视网膜病变、青光眼、年龄相关性黄斑变性和早产儿视网膜病变。然而,除了眼科之外,其他罕见疾病尚未得到研究,因为对用于深度学习分析的大型开放公共数据集的访问有限。在没有公共数据集可用的情况下应用此方法时,屏蔽步骤是不可避免的,这是一项劳动密集型且耗时的任务。然而,建议的掩蔽步骤(协议部分,步骤1)有助于在短时间内生成高精度的掩蔽。使用超级像素和基于神经网络的填充(对低级图像属性相似的像素进行聚类),临床医生可以通过单击像素组而不是指出特定像素来标记遮罩。此外,自动校正功能有助于优化掩模过程。这种方法的效率和有效性将有助于在医学研究中生成更多的蒙版图像。
在预处理的众多可能性中,提取VOI和窗口剪切是有效的方法。在这里,提取VOI和窗口剪辑在协议的步骤2中介绍。当临床医生准备数据集时,从给定数据集中提取VOI是该过程中最重要的一步,因为大多数分割病例都集中在整个医学图像中的小区域和特定区域。关于 VOI,眼球、视神经和眼外肌的区域根据位置进行裁剪,但提取 VOI 的更有效方法有可能提高分割性能14。
对于细分,SEQ-UNET用于研究。3D医学图像体积大,因此深度神经网络模型需要大内存容量。在SEQ-UNET中,分段模型是用少量切片实现的,以减少所需的内存大小,而不会丢失3D信息的特征。
该模型使用 46 个 VOI 进行训练,这对于模型训练来说并不是一个很大的数字。由于训练数据集数量少,视神经和眼外肌分割的性能受到限制。迁移学习15 和域自适应8 可以为提高分割性能提供解决方案。
这里介绍的整个分割过程不仅限于眼眶CT分割。高效的标记方法有助于在应用领域对研究领域唯一时创建新的医学图像数据集。GitHub 关于预处理和分割建模的 python 代码可以通过修改裁剪区域、窗口裁剪级别和模型超参数(例如顺序切片的数量、U-Net 架构等)应用于其他领域。
披露声明
作者声明不存在利益冲突。
致谢
这项工作得到了韩国国家研究基金会(NRF)的支持,该基金会由韩国科学和信息通信技术部(MSIT)资助(编号:2020R1C1C1010079)。对于CMC-ORBIT数据集,天主教医学中心的中央机构审查委员会(IRB)提供了批准(XC19REGI0076)。这项工作得到了2022年弘益大学研究基金的支持。
材料
| Name | Company | Catalog Number | Comments |
| GitHub link | github.com/SleepyChild1005/OrbitSeg | ||
| MediLabel | INGRADIENT (Seoul, Korea) | a medical image labeling software promgram for segmentation with fewer click and higher speed | |
| SEQ-UNET | downloadable from GitHub | ||
| SmartFil | wizard in MediLabel | ||
| SmartPencil | wizard in MediLabel |
参考文献
- Li, Z., et al. Deep learning-based CT radiomics for feature representation and analysis of aging characteristics of Asian bony orbit. Journal of Craniofacial Surgery. 33 (1), 312-318 (2022).
- Hamwood, J., et al. A deep learning method for automatic segmentation of the bony orbit in MRI and CT images. Scientific Reports. 11, 1-12 (2021).
- Kim, K. S., et al. Schwannoma of the orbit. Archives of Craniofacial Surgery. 16 (2), 67-72 (2015).
- Baur, C., et al. Autoencoders for unsupervised anomaly segmentation in brain MR images: A comparative study. Medical Image Analysis. 69, 101952(2021).
- Trémeau, A., Colantoni, P. Regions adjacency graph applied to color image segmentation. IEEE Transactions on Image Processing. 9 (4), 735-744 (2000).
- Boykov, Y. Y., Jolly, M. -P. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. Proceedings of Eighth IEEE International Conference on Computer Vision. International Conference on Computer Vision. 1, 105-122 (2001).
- Rother, C., Kolmogorov, V., Blake, A. "GrabCut" interactive foreground extraction using iterated graph cuts. ACM Transactions on Graphics. 23 (3), 309-314 (2004).
- Suh, S., et al. Supervised segmentation with domain adaptation for small sampled orbital CT images. Journal of Computational Design and Engineering. 9 (2), 783-792 (2022).
- Ronneberger, O., Fischer, P., Brox, T. U-net: Convolutional networks for biomedical image segmentation. International Conference on Medical Image Computing and Computer-Assisted Intervention.Medical Image Computing and Computer-Assisted Intervention - MICCAI. , 234-241 (2015).
- Qamar, S., et al. A variant form of 3D-UNet for infant brain segmentation. Future Generation Computer Systems. 108, 613-623 (2020).
- Nguyen, H., et al. Ocular structures segmentation from multi-sequences MRI using 3D UNet with fully connected CRFS. Computational Pathology and Ophthalmic Medical Image Analysis. , Springer. Cham, Switzerland. 167-175 (2018).
- Liu, Q., et al. Bidirectional-convolutional LSTM based spectral-spatial feature learning for hyperspectral image classification. Remote Sensing. 9 (12), 1330(2017).
- Yeghiazaryan, V., Voiculescu, I. D. Family of boundary overlap metrics for the evaluation of medical image segmentation. Journal of Medical Imaging. 5 (1), 015006(2018).
- Zhang, G., et al. Comparable performance of deep learning-based to manual-based tumor segmentation in KRAS/NRAS/BRAF mutation prediction with MR-based radiomics in rectal cancer. Frontiers in Oncology. 11, 696706(2021).
- Christopher, M., et al. Performance of deep learning architectures and transfer learning for detecting glaucomatous optic neuropathy in fundus photographs. Scientific Reports. 8, 16685(2018).
转载和许可
请求许可使用此 JoVE 文章的文本或图形
请求许可探索更多文章
This article has been published
Video Coming Soon
版权所属 © 2025 MyJoVE 公司版权所有,本公司不涉及任何医疗业务和医疗服务。