
Method Article
Cloud-basierte Phrase Mining und Analyse von Benutzer-definierten Satz-Kategorie Assoziation in biomedizinischen Veröffentlichungen
* Diese Autoren haben gleichermaßen beigetragen
In diesem Artikel
Zusammenfassung
Wir präsentieren Ihnen ein Protokoll und zugehörigen Programmcode sowie Metadaten Proben, eine Cloud-basierte automatische Identifikation von Phrasen-Kategorie Verband, einzigartige Konzepte in ausgewählten Knowledge Benutzerdomäne in der biomedizinischen Literatur zu unterstützen. Die Satz-Kategorie Assoziation quantifiziert durch dieses Protokoll kann eingehende Analyse im Bereich ausgewählten Knowledge erleichtern.
Zusammenfassung
Die schnelle Anhäufung von biomedizinischen Textdaten hat die menschliche Fähigkeit der manuellen Kuration und Analyse, erfordern neuartige Text-Mining-Tools um biologische Erkenntnisse aus große Mengen an wissenschaftliche Berichte zu extrahieren weit übertroffen. Die kontextsensitive semantische Online Analytical Processing (CaseOLAP)-Pipeline, entwickelt im Jahr 2016, quantifiziert erfolgreich benutzerdefinierten Satz-Kategorie-Beziehungen durch die Analyse von Textdaten. CaseOLAP hat viele biomedizinische Anwendungen.
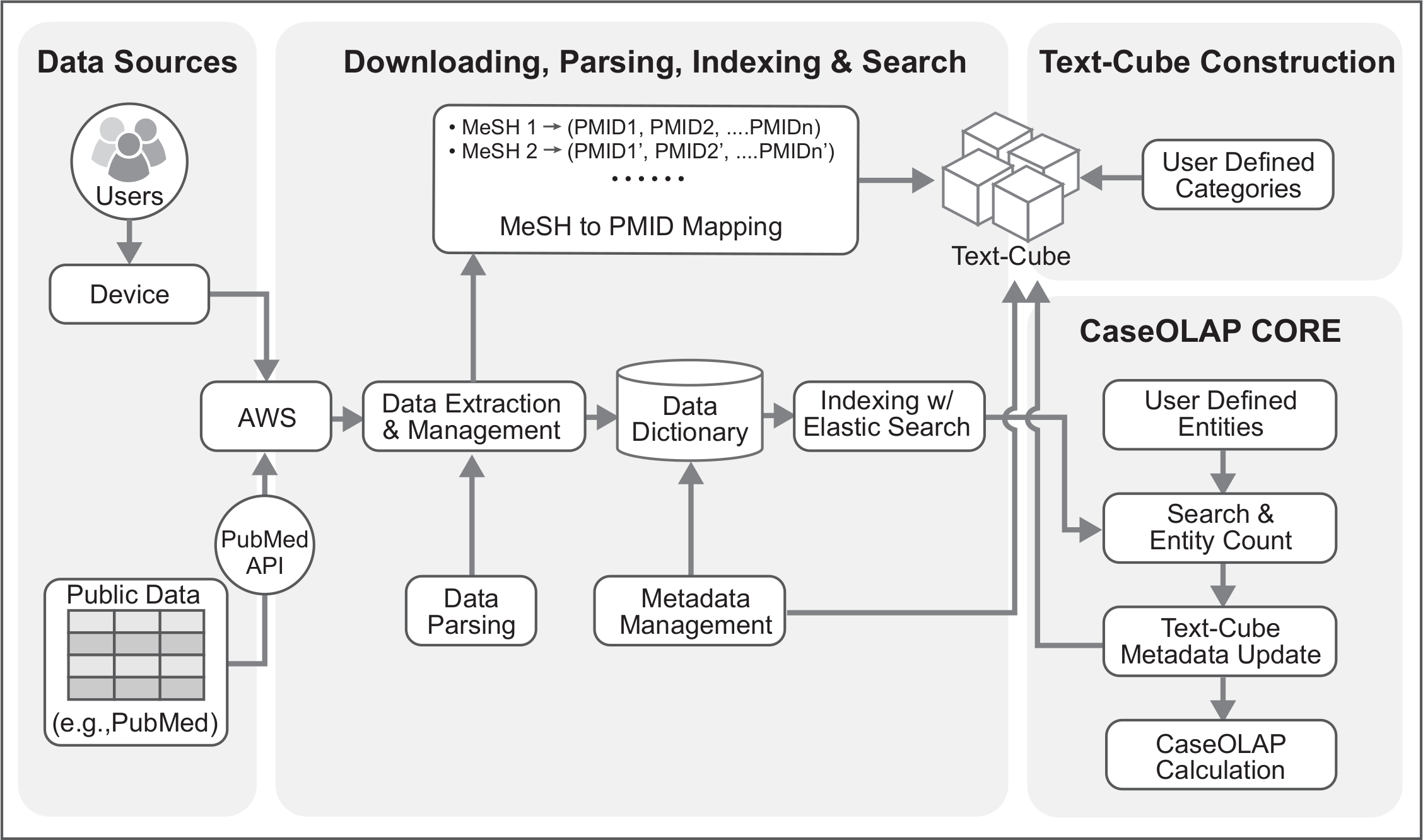
Wir haben ein Protokoll für eine Cloud-basierte Umgebung Unterstützung der End-to-End Satz-Bergbau und Analyse-Plattform entwickelt. Unser Protokoll beinhaltet Daten Vorverarbeitung (z. B. Download, Extraktion und Analyse Textdokumente), Indizierung und Suche mit Elasticsearch, Erstellung einer funktionalen Dokumentenstruktur namens Text-Cube und Quantifizierung der Satz-Kategorie-Beziehungen Verwendung des Kern-CaseOLAP-Algorithmus.
Unsere Daten-Vorverarbeitung erzeugt Schlüssel-Wert-Zuordnungen für alle Dokumente beteiligt. Die vorverarbeiteten Daten ist indiziert zur Durchführung einer Suche von Dokumenten, einschließlich Einrichtungen, der weitere Text-Cube-Erstellung und CaseOLAP Partitur Berechnung erleichtert. Die erhaltenen rohen CaseOLAP Scores werden mit einer Reihe von integrativen Analysen, einschließlich der Reduzierung der Dimensionalität, clustering, zeitliche, und geografische interpretiert. Darüber hinaus werden die CaseOLAP Noten verwendet, um eine grafische Datenbank erstellen die semantische Zuordnung der Dokumente ermöglicht.
CaseOLAP Satz-Kategorie Beziehungen definiert in einer genauen (identifiziert Beziehungen), konsistent (hoch reproduzierbare), und effizient (Prozesse 100.000 Wörter/sec). Nach diesem Protokoll können Benutzer eine Cloud-computing Umgebung zur Unterstützung ihre eigenen Konfigurationen und Anwendungen des CaseOLAP zugreifen. Diese Plattform bietet verbesserte Zugänglichkeit und befähigt die biomedizinische Gemeinschaft mit Satz-Mining-Tools für Anwendungen in der weit verbreiteten biomedizinische Forschung.
Einleitung
Manuelle Auswertung von Millionen von Text-Dateien für das Studium der Satz-Kategorie Assoziation (z. B.., Altersgruppe Protein Verband) ist unvergleichbar mit der Effizienz von eine automatisierte, computergestützte Methode zur Verfügung gestellt. Wir wollen die Cloud-basierte kontextsensitive semantische Online Analytical Processing (CaseOLAP)-Plattform als ein Satz-Mining-Methode für die automatische Berechnung der Satz-Kategorie Assoziation im biomedizinischen Bereich einzuführen.
Die CaseOLAP-Plattform, die erstmals im Jahr 20161definiert wurde, ist sehr effizient im Vergleich zu den traditionellen Methoden der Datenverwaltung und Berechnung aufgrund seiner funktionalen Dokumentenmanagement als Text-Cube2,3, 4, der die Dokumente verteilt und gleichzeitig die zugrunde liegende Hierarchie und Nachbarschaften. Es wurde in der biomedizinischen Forschung5 Entität-Kategorie Assoziation zu studieren angewendet. Die CaseOLAP-Plattform besteht aus sechs Hauptschritte einschließlich Download und die Extraktion von Daten, Analyse, Indizierung, Text-Cube-Erstellung, Entität Graf und CaseOLAP Partitur Berechnung; Das ist der Schwerpunkt des Protokolls (Abbildung 1, Abbildung 2, Tabelle 1).
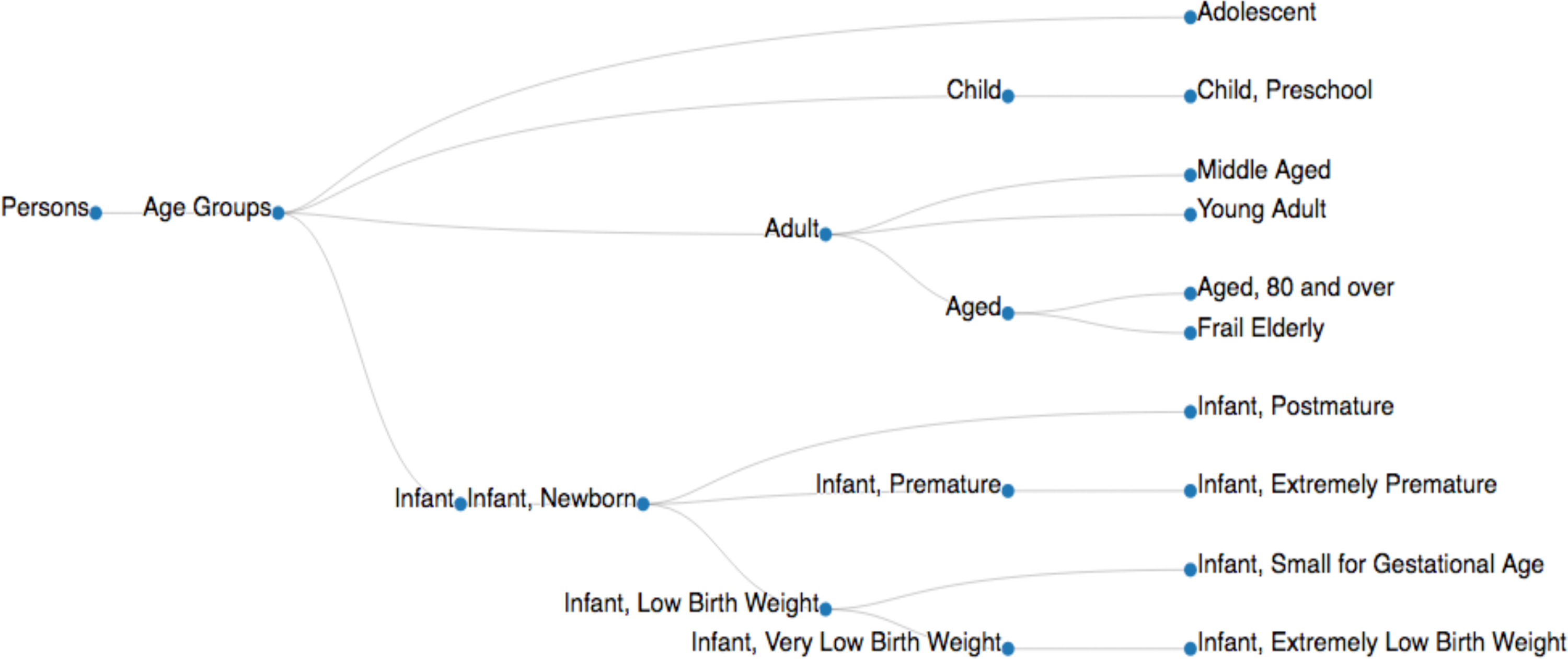
Um den CaseOLAP-Algorithmus zu implementieren, stellt der Benutzer Kategorien von Interesse (z. B. Krankheit, Anzeichen und Symptome, Altersgruppen, Diagnose) und Unternehmen von Interesse (z.B. Proteine, Drogen). Ein Beispiel für eine Kategorie, die in diesem Artikel enthalten ist die "Altersklassen", die "Baby", "Kind", "Jugendliche", und "Erwachsenen" Unterkategorien wie Zellen des Text-Cube und Protein Namen (Synonyme) und Abkürzungen als Entitäten. Medical Subject Headings (MeSH) sind implementiert, um Publikationen entsprechend den definierten Kategorien (Tabelle 2) abrufen. MeSH-Deskriptoren werden in einer hierarchischen Baumstruktur organisiert, um Suche nach Publikationen zu unterschiedlichen Ebenen der Spezifität (ein Beispiel in Abbildung 3dargestellt) zu ermöglichen. Die CaseOLAP-Plattform nutzt die Datenfunktionalität Indizierung und Suche für Kuration der Dokumente, die einer Entität zugeordnet die Dokument Entität Graf Mapping und CaseOLAP Partitur Berechnung weiter zu erleichtern.
Die Details der CaseOLAP-Score-Berechnung gibt es in früheren Veröffentlichungen1,5. Dieses Ergebnis wird anhand von bestimmten Kriterien basierend auf zugrunde liegende Dokumentstruktur Text-Cube berechnet. Das Endergebnis ist das Produkt von Integrität, Popularitätund Unverwechselbarkeit. Integrität beschreibt, ob eine repräsentative Einheit ist eine semantische Einheit, die gemeinsam auf ein sinnvolles Konzept verweist. Die Integrität der benutzerdefinierten Satz stammt 1.0 sein, weil es als eine standard Phrase in der Literatur steht. Besonderheit stellt die relative Bedeutung eines Ausdrucks in einer Teilmenge der Dokumente, die verglichen mit dem Rest der anderen Zellen. Es berechnet die Relevanz eines Unternehmens auf eine bestimmte Zelle durch den Vergleich der Vorkommen des Namens Protein in den Ziel-Datensatz und bietet eine standardisierte Bewertung der Unterscheidungskraft . Popularität stellt erscheint die Tatsache, die mit einer höheren Punktzahl Popularität phrase immer häufiger in eine Teilmenge der Dokumente. Seltene Protein Namen in einer Zelle sind niedrig, eingestuft, während eine Zunahme der Häufigkeit ihrer Erwähnung eine abnehmende Rendite aufgrund der Umsetzung der logarithmischen Funktion der Frequenz hat. Quantitativ messen diese drei Konzepte hängt von (1) Begriff der Entität in einer Zelle und in den Zellen und (2) die Anzahl der Dokumente, die mit dieser Entität (Dokument Frequenz) innerhalb der Zelle und über die Zellen.
Wir haben zwei repräsentative Szenarien mithilfe einer PubMed-Dataset und unser Algorithmus untersucht. Wir sind interessiert an wie mitochondrialen Proteinen zwei eindeutige Kategorien von MeSH Deskriptoren; zugeordnet sind "Altersklassen" und "Ernährungs- und metabolische Krankheiten". Insbesondere wir abgerufen 15,728,250 Publikationen aus 20 Jahren Publikationen gesammelt von PubMed (1998 bis 2018), unter ihnen, 8.123.458 einzigartige Abstracts hatten volle MeSH-Deskriptoren. Dementsprechend 1.842 menschlichen mitochondrialen Proteins Namen (einschließlich Abkürzungen und Synonyme), erworben von UniProt (uniprot.org) sowie MitoCarta2.0 (http://mitominer.mrc-mbu.cam.ac.uk/release-4.0/begin.do >), werden systematisch untersucht. Ihre Verbände mit diesen 8.899.019 Publikationen und Organisationen waren mit unser Protokoll untersucht; wir einen Text-Würfel gebaut und die jeweiligen CaseOLAP Scores berechnet.
Protokoll
Hinweis: Wir haben dieses Protokoll basiert auf der Programmiersprache Python entwickelt. Zum Ausführen dieses Programms haben Anaconda Python und Git auf dem Gerät vorinstalliert. Die Befehle in diesem Protokoll basieren auf Unix-Umgebung. Dieses Protokoll sieht das Detail der herunterladen von Daten aus PubMed (MEDLINE) Datenbank, die Daten analysieren und Einrichten einer Cloud computing-Plattform für die Phrase Bergbau und Quantifizierung der benutzerdefinierten Entität-Kategorie Assoziation.
1. immer Code und Python-Umgebung einrichten
- Herunterladen Sie oder Klonen Sie das Code-Repository von Github (https://github.com/CaseOLAP/caseolap) oder durch die Eingabe "Git clone https://github.com/CaseOLAP/caseolap.git" in das terminal-Fenster.
- Navigieren Sie zu dem Verzeichnis "Caseolap". Dies ist das Root-Verzeichnis des Projekts. In diesem Verzeichnis wird "Datenverzeichnis" mit mehreren Datensätzen wie Sie Fortschritte durch diese Schritte im Protokoll aufgefüllt werden. Das 'input' Verzeichnis ist für Benutzer bereitgestellten Daten. Die 'Log'-Verzeichnis hat Log-Dateien für die Problembehandlung. Das 'Ergebnis'-Verzeichnis ist der Speicherort der Endergebnisse.
- Gehen Sie das terminal-Fenster verwenden, zum Verzeichnis wo Sie unser GitHub Repository geklont. Erstellen Sie die CaseOLAP-Umgebung mithilfe der Datei "environment.yml" durch Eingabe von 'Conda Env erstellen -f environment.yaml' im Terminal. Aktivieren Sie dann die Umwelt indem Sie im Terminal eingeben "Quelle zu aktivieren Caseolap".
2. herunterladen von Dokumenten
- Stellen Sie sicher, dass die FTP-Adresse in "ftp_configuration.json" im Config-Verzeichnis das gleiche wie die jährliche Baseline oder täglichen Update-Dateien Linkadresse ist, gefunden in den Link (https://www.nlm.nih.gov/databases/download/pubmed_medline.html) .
- Um nur Basis- oder Update herunterladen Dateien nur, "auf true gesetzt," in der Datei "download_config.json" im Verzeichnis "Config". In der Standardeinstellung es downloads und Grundlinie und Update-Dateien extrahiert. Ein Beispiel für extrahierte XML-Daten kann eingesehen werden (https://github.com/CaseOLAP/caseolap-pipelines/blob/master/data/extracted-data-sample.xml)
- Geben Sie "Python run_download.py" im Terminalfenster Abstracts aus der Pubmed-Datenbank herunterladen. Dadurch wird ein Verzeichnis namens "ftp.ncbi.nlm.nih.gov" im aktuellen Verzeichnis erstellt. Dieser Prozess überprüft die Integrität der heruntergeladenen Daten und extrahiert sie in das Zielverzeichnis.
- Gehen Sie zum Logverzeichnis "", die Log-Meldungen in "download_log.txt" zu lesen, für den Fall, dass der Download-Vorgang schlägt fehl. Wenn der Vorgang erfolgreich abgeschlossen ist, werden die Debuggen Meldungen des Download-Prozesses in dieser Log-Datei ausgedruckt werden.
- Wenn der Download abgeschlossen ist, navigieren Sie durch "ftp.ncbi.nlm.nih.gov", um sicherzustellen, dass es "Updatefiles" oder "Basefiles" oder beide Verzeichnisse basierend auf Konfiguration in "download_config.json Download". Die Datei-Statistiken werden bei "filestat.txt" im Verzeichnis "Data" verfügbar.
3. Dokumente Parsen
- Achten Sie darauf, dass bei "ftp.ncbi.nlm.nih.gov" Verzeichnis aus Schritt 2 heruntergeladene und extrahierte Daten vorliegen. Dieses Verzeichnis ist das input-Daten-Verzeichnis in diesem Schritt.
- Um die Daten-Analyse-Schema zu ändern, wählen Sie Parameter in "parsing_config.json" Datei im Verzeichnis "Config" durch ihren Wert auf "True" setzen. Standardmäßig, es analysiert die PMID, Autoren, abstrakt, MeSH, Lage, Journal, Veröffentlichungsdatum.
- Geben Sie "Python run_parsing.py" in der Klemme, die Dokumente von heruntergeladenen (oder extrahierten Dateien) zu analysieren. Dieser Schritt analysiert alle heruntergeladene XML-Dateien und erstellt ein Python-Wörterbuch für jedes Dokument mit Schlüssel (z. B.., PMID, Autoren, abstrakt, MeSH der Datei anhand der Analyse Schema-Setup Schritt 3.2).
- Sobald Daten Analyse abgeschlossen ist, ist darauf zu achten, dass die analysierte Daten in die Datei namens "pubmed.json" im Datenverzeichnis gespeichert werden. Eine Probe der analysierten Daten gibt es bei Abbildung 3.
- Gehen Sie zum Logverzeichnis "", die Log-Meldungen in "parsing_log.txt" zu lesen, für den Fall, dass der Analyseprozess schlägt fehl. Wenn der Vorgang erfolgreich abgeschlossen ist, werden die Debuggen-Meldungen in der Protokolldatei ausgedruckt werden.
(4) mesh PMID Zuordnung
- Stellen Sie sicher, dass die analysierte Daten ("pubmed.json") im Verzeichnis "Data" zur Verfügung steht.
- Geben Sie "Python run_mesh2pmid.py" im Terminal MeSH PMID Zuordnung durchführen. Dadurch entsteht eine Mapping-Tabelle, wo jeder des Netzes verbunden PMIDs sammelt. Ein einzelnes PMID kann unter mehreren MeSH-Terms fallen.
- Sobald die Zuordnung abgeschlossen ist, ist darauf zu achten, dass es "mesh2pmid.json" im Datenverzeichnis ist. Ein Beispiel für die Top-20-Mapping-Statistik ist in Tabelle 2, 4 und 5erhältlich.
- Gehen Sie zum Logverzeichnis "", die Log-Meldungen in "mesh2pmid_mapping_log.txt" zu lesen, für den Fall, dass dieser Vorgang fehlschlägt. Wenn der Vorgang erfolgreich abgeschlossen ist, werden die Debuggen Meldungen des Mappings in dieser Log-Datei ausgedruckt werden.
5. Dokument indizieren
- Die Elasticsearch Anwendung von https://www.elastic.coherunterladen. Derzeit steht der Download (https://www.elastic.co/downloads/elasticsearch). Zum download der Software in der abgelegenen Cloud geben Sie ein "Wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-x.x.x.tar.gz" im Terminal. Stellen Sie sicher, dass "x.x.x" im obigen Befehl durch korrekte Versionsnummer ersetzt wird.
- Stellen Sie sicher, dass heruntergeladene "Elasticsearch-x.x.x.tar.gz" Datei im Root-Verzeichnis erscheint dann extrahieren Sie die Dateien durch Eingabe "tar-Xvzf Elasticsearch-X.x.x.tar.gz' im terminal-Fenster.
- Öffnen Sie ein neues Terminal und gehen auf die ElasticSearch-bin-Verzeichnis durch die Eingabe von 'cd Elasticsearch/bin' im Terminal aus dem Stammverzeichnis.
- Starten Sie den Elasticsearch-Server durch Eingabe von ". / Elasticsearch" in das terminal-Fenster. Stellen Sie sicher, dass der Server ohne Fehlermeldungen gestartet wird. Im Falle eines Fehlers auf Elasticsearch Server starten befolgen Sie die Anweisungen (https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html).
- Ändern Sie den Inhalt in die "index_init_config.json" im "Config" Verzeichnis Index Einleitung festlegen. Standardmäßig wählt es alle Elemente vorhanden.
- Geben Sie "Python run_index_init.py" im Terminal, eine Index-Datenbank in den Elasticsearch-Server zu initiieren. Das initialisiert den Index mit einer Reihe von Kriterien, die als Index-Informationen (z.B. Index-Name, Typname, Anzahl der Scherben, Anzahl der Replikate) bekannt. Sie werden sehen, dass die Nachricht zu erwähnen, Index erfolgreich erstellt wurde.
- Wählen Sie die Elemente in der "index_populate_config.json" im Verzeichnis "Config" durch ihren Wert auf "True" setzen. Standardmäßig wählt es alle Elemente vorhanden.
- Stellen Sie sicher, dass analysierte Daten ("pubmed.json") im Verzeichnis "Data" vorliegt.
- Geben Sie "Python run_index_populate.py" im Terminal, um den Index auffüllen, indem Sie Massendaten mit zwei Komponenten. Eine erste Komponente ist ein Wörterbuch mit Metadateninformationen über die Index-Name, Typname und Bulk-Id (z. B. "PMID"). A zweite Komponente ist ein Data-Dictionary enthält alle Informationen über die Tags (z. B. "Titel", "abstrakt", "MeSH").
- Gehen Sie zum Logverzeichnis "", die Log-Meldungen in "indexing_log.txt" zu lesen, für den Fall, dass dieser Vorgang fehlschlägt. Wenn der Vorgang erfolgreich abgeschlossen ist, werden die Debuggen Meldungen der Indizierung in der Log-Datei ausgedruckt werden.
6. Text-Cube-Erstellung
- Laden Sie die neueste MeSH-Baum (https://www.nlm.nih.gov/mesh/filelist.html) abrufbar. Die aktuelle Version des Codes ist als "meshtree2018.bin" im Eingabeverzeichnis MeSH Baum 2018 verwenden.
- Definieren Sie die Kategorien von Interesse (z. B. Krankheit Namen, Altersgruppen, Geschlecht). Eine Kategorie kann eine oder mehrere MeSH Deskriptoren (https://meshb-prev.nlm.nih.gov/treeView) enthalten. MeSH-IDs für eine Kategorie zu sammeln. Speichern Sie die Namen der Kategorien in der Datei "textcube_config.json" im Config-Verzeichnis (siehe Beispiel der Kategorie "Altersgruppe" in die Download-Version der Datei "textcube_config.json").
- Setzen Sie die erfassten Kategorien von MeSH-IDs in einer Linie, die durch ein Leerzeichen getrennt. Speichern Sie die Kategorie Datei als 'categories.txt' im 'input'-Verzeichnis (siehe Beispiel der "Altersgruppe" MeSH-IDs in die Download-Version der Datei "categories.txt"). Dieser Algorithmus wählt automatisch alle untergeordnete MeSH-Deskriptoren. Ein Beispiel der Wurzelknoten und Nachkommen werden präsentiert Abbildung 4.
- Stellen Sie sicher, dass "mesh2pmid.json" im Verzeichnis "Data" ist. Wenn die MeSH-Struktur mit einem anderen Namen (z. B. "meashtree2019.bin") in das Verzeichnis 'input' aktualisiert wurde, stellen Sie sicher, dass diese ordnungsgemäß in die input-Daten-Pfad in der Datei "run_textube.py" vertreten ist.
- Geben Sie "Python run_textcube.py" im Terminal, um ein Dokument Datenstruktur namens Text-Cube zu erstellen. Dadurch entsteht eine Sammlung von Dokumenten (PMIDs) für jede Kategorie. Ein einzelnes Dokument (PMID) kann unter mehrere Kategorien fallen (siehe Tabelle 3A, 3 b Tabelle, Abbildung 6A und Abbildung 7A).
- Sobald Text-Cube Schöpfung Schritt abgeschlossen ist, stellen Sie sicher, dass die folgenden Dateien im Verzeichnis "Data" gespeichert werden: (1) eine Zelle PMID Tabelle als "textcube_cell2pmid.json", (2) ein PMID zu Zelle-Mapping-Tabelle als "textcube_pmid2cell.json", (3) Auflistung von allen untergeordneten MeSH-Terms für eine Zelle als "meshterms_per_cat.json" (4) Text-Cube Datenstatistiken als "textcube_stat.txt".
- Gehen Sie zum Logverzeichnis "", die Log-Meldungen in "textcube_log.txt" zu lesen, für den Fall, dass dieser Vorgang fehlschlägt. Wenn der Vorgang erfolgreich abgeschlossen ist, werden die Debuggen Nachrichten von der Text-Cube-Erstellung in der Log-Datei ausgedruckt werden.
7. Einheit Graf
- Erstellen Sie benutzerdefinierte Entitäten (z. B. Protein Namen, Gene, Chemikalien). Legen Sie eine Einheit und ihre Abkürzungen in einer einzigen Zeile getrennt durch "|". Speichern Sie die Entität als 'entities.txt' im 'input'-Verzeichnis. Eine Stichprobe von Personen finden Sie Tabelle 4.
- Stellen Sie sicher, dass Elasticsearch-Server ausgeführt wird. Fahren Sie andernfalls mit Schritt 5.2 und 5.3 den Elasticsearch-Server neu starten. Es wird voraussichtlich eine indizierte Datenbank mit dem Namen "Pubmed" in Ihrem Elasticsearch-Server, die in Schritt 5 gegründet haben.
- Stellen Sie sicher, dass "textcube_pmid2cell.json" im Verzeichnis "Data" ist.
- Geben Sie "Python run_entitycount.py" im Terminal Entität Zählung durchführen. Dies sucht die Dokumente aus der indizierte Datenbank zählt das Unternehmen in jedem Dokument sowie und sammelt die PMIDs, in dem Objekte gefunden wurden.
- Sobald die Anzahl der Einheit abgeschlossen ist, stellen sicher, dass die endgültigen Ergebnisse als "entitycount.txt" gespeichert sind und "Entityfound_pmid2cell.json" im Verzeichnis "Data".
- Gehen Sie zum Logverzeichnis "", die Log-Meldungen in "entitycount_log.txt" zu lesen, für den Fall, dass dieser Vorgang fehlschlägt. Wenn der Vorgang erfolgreich abgeschlossen ist, werden die Debuggen Nachrichten von der Entität Graf in der Log-Datei ausgedruckt werden.
(8) Metadaten aktualisieren
- Stellen Sie sicher, dass alle eingegebenen Daten ('entitycount.txt', 'textcube_pmid2cell.json', 'entityfound_pmid2cell.txt') im Verzeichnis "Data" sind. Dies sind die Eingabedaten für Metadaten aktualisieren.
- Geben Sie "Python run_metadata_update.py" im Terminal, um die Metadaten zu aktualisieren. Dies bereitet eine Sammlung von Metadaten (z. B. Zellnamen, zugehörigen MeSH, PMIDs), jedes Textdokument in der Zelle darstellt. Eine Probe des Text-Cube Metadaten werden in Tabelle 3A und Tabelle 3 b.
- Sobald das Metadaten-Update abgeschlossen ist, stellen Sie sicher, dass "metadata_pmid2pcount.json" und "metadata_cell2pmid.json" Dateien in Verzeichnis "Data" gespeichert werden.
- Gehen Sie zum Logverzeichnis "", die Log-Meldungen in "metadata_update_log.txt" zu lesen, für den Fall, dass dieser Vorgang fehlschlägt. Wenn der Vorgang erfolgreich abgeschlossen ist, werden die Debuggen Meldungen des Metadaten-Updates in der Log-Datei ausgedruckt werden.
9. CaseOLAP-Score-Berechnung
- Stellen Sie sicher, dass "metadata_pmid2pcount.json" und "metadata_cell2pmid.json" Dateien im Verzeichnis "Data" vorhanden sind. Dies sind die Eingabedaten für die Berechnung der Punktzahl.
- Geben Sie "Python run_caseolap_score.py" im Terminal CaseOLAP Score Berechnung durchzuführen. Diese berechnet die CaseOLAP Punkte der Entitäten basierend auf benutzerdefinierten Kategorien. Das CaseOLAP Ergebnis ist das Produkt von Integrität, Popularitätund Unverwechselbarkeit.
- Sobald die Score-Berechnung abgeschlossen ist, stellen Sie sicher, dass dies die Ergebnisse in mehreren Dateien (z. B. Beliebtheit als 'pop.csv', Unterscheidungskraft als 'dist.csv', CaseOLAP Score als "caseolap.csv"), im "Ergebnis" Verzeichnis speichert. Die CaseOLAP-Score-Berechnung ist auch in Tabelle 5zusammengefasst.
- Gehen Sie zum Logverzeichnis "", die Log-Meldungen in "caseolap_score_log.txt" zu lesen, für den Fall, dass dieser Vorgang fehlschlägt. Wenn der Vorgang erfolgreich abgeschlossen ist, werden die Debuggen Nachrichten von der CaseOLAP-Score-Berechnung in der Log-Datei ausgedruckt werden.
Ergebnisse
Probenergebnisse zu erzielen, haben wir zwei Thema Überschriften/Deskriptoren den CaseOLAP-Algorithmus umgesetzt: "Altersklassen" und "Ernährung und Stoffwechselerkrankungen" als Anwendungsfälle.
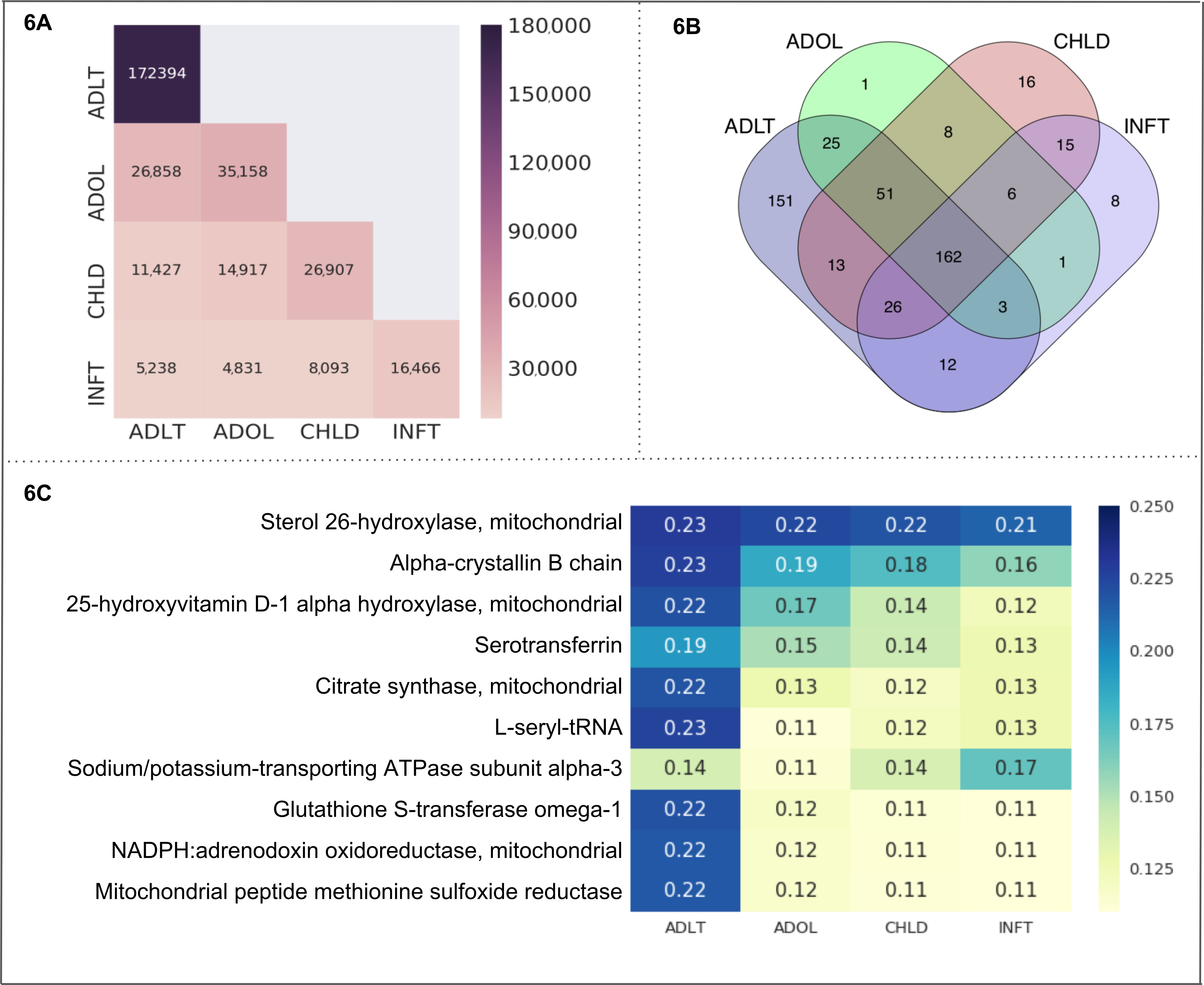
Altersgruppen. Wir haben alle 4 Unterkategorien "Altersklassen" (Säuglings-, Kinder-, Jugendlichen und Erwachsenen) als Zellen in einem Text-Cube. Die erhaltenen Metadaten und Statistiken entnehmen Sie bitte Tabelle 3A. Der Vergleich der Anzahl der Dokumente unter den Text-Cube-Zellen wird in Abbildung 6Aangezeigt. Erwachsenen enthält Dokumente, die 172.394 das ist die höchste Zahl über alle Zellen. Die Erwachsenen und Jugendlichen Unterkategorien haben die höchste Anzahl der freigegebenen Dokumente (26.858 Dokumente). Diese Dokumente enthalten vor allem die Entität unseres Interesses nur (z. B. mitochondrialen Proteine). Das Venn-Diagramm in Abbildung 6 b entspricht der Anzahl der Einrichtungen (z. B. mitochondrialen Proteine) gefunden in jede Zelle und in mehrere Überschneidungen zwischen den Zellen. Die Zahl der Proteine, die in allen Altersgruppen Unterkategorien geteilt ist 162. Der Unterkategorie "Erwachsenen" zeigt die höchste Zahl der einzigartigen Proteine (151) gefolgt von Kind (16), Kleinkind (8) und Jugendlichen (1). Der Protein-Age Group Association als CaseOLAP Partitur berechnet. Die Top-10-Proteine (basierend auf deren Durchschnittsnote CaseOLAP) Säuglings-, Kinder-, Jugendlichen und Erwachsenen Unterkategorien zugeordnet sind Sterol 26-Hydroxylase, Alpha-kristallin B-Kette, 25-Hydroxy-Vitamin-d-1-Alpha-Hydroxylase, Serotransferrin, Citrat-Synthase, L-Seryl-tRNA, Natrium/Kalium-Transport-ATPase Untereinheit Alpha-3, Glutathione-S-Transferase Omega-1 NADPH: Adrenodoxin Oxidoreductase und mitochondriale Peptid Methionin Sulfoxid Reduktase (siehe Abbildung 6). Die Erwachsenen Unterkategorie zeigt 10 Heatmap Zellen mit einer höheren Intensität im Vergleich zu der Heatmap Zellen der Jugendlicher, Kind und Säugling Unterkategorie, darauf hinweist, dass die oberen 10 mitochondrialen Proteine die stärksten Verbände der Unterkategorie "Erwachsenen" ausstellen. Die mitochondriale Protein Sterol 26-Hydroxylase hat hohe Verbände in allen Alter Unterkategorien Heatmap Zellen mit höherer Intensität im Vergleich zu der Heatmap Zellen der anderen 9 mitochondrialen Proteine zeigt. Die statistische Verteilung der in der Partitur die absolute Differenz zwischen beiden Gruppen zeigt das folgende Angebot für mittlere Differenz mit einem Konfidenzintervall von 99 %: (1) die mittlere Differenz zwischen 'ADLT' und 'INFT' liegt im Bereich (0.029 zu 0,042), (2) der Mittelwert Unterschied zwischen 'ADLT' und "CHLD" liegt im Bereich (0,021 bis 0,030) (3) die mittlere Differenz zwischen "ADLT" und 'ADOL' liegt in dem Bereich (0,020-0.029), (4) der mittleren Differenz zwischen 'ADOL' und 'INFT' liegt im Bereich (0,015 bis 0,022), (5) die mittlere Differenz zwischen 'ADOL' und "CHLD" liegt im Bereich (0,007-0.010), (6) die mittlere Differenz zwischen 'CHLD' und 'INFT' liegt im Bereich von (0,011 bis 0,016).
Ernährungs- und metabolische Krankheiten. Wir haben 2 Unterkategorien von "Ernährung und Stoffwechselerkrankungen" (d. h. Stoffwechselerkrankung und Ernährungsstörungen) 2 Zellen in einem Text-Cube zu erstellen. Die erhaltenen Metadaten und Statistiken sind in Tabelle 3 bgezeigt. Der Vergleich der Anzahl der Dokumente unter den Text-Cube-Zellen wird in Abbildung 7Aangezeigt. Die Unterkategorie Stoffwechselerkrankung enthält 54.762 Dokumente, gefolgt von 19.181 Dokumente in Ernährungsstörungen. Die Unterkategorien Stoffwechselerkrankung und Ernährungsstörungen haben 7.101 freigegebene Dokumente. Diese Dokumente enthalten vor allem die Entität unseres Interesses nur (z. B. mitochondrialen Proteine). Das Venn-Diagramm in Abbildung 7 b steht für die Anzahl der Elemente in jeder Zelle und in mehrere Überschneidungen zwischen den Zellen. Wir berechnen die Protein-"Ernährungs- und Stoffwechselkrankheiten" Verband als CaseOLAP Partitur. Die Top-10-Proteine (basierend auf deren Durchschnittsnote CaseOLAP) dieser Use Case zugeordnet sind Sterol 26-Hydroxylase, Alpha-kristallin B-Kette, L-Seryl-tRNA, Citrat-Synthase, tRNA Pseudouridine Synthase A 25-Hydroxy-Vitamin-d-1-Alpha-Hydroxylase, Glutathione-S-Transferase Omega-1, NADPH: Adrenodoxin Oxidoreductase, mitochondriale Peptid Methionin Sulfoxid Reduktase, Plasminogen-Aktivator-Inhibitor 1 (siehe Abbildung 7). Mehr als die Hälfte (54 %) alle Proteine sind zwischen den Unterkategorien Stoffwechselerkrankungen und Ernährungsstörungen (397 Proteine) geteilt. Interessant ist, fast die Hälfte (43 %) alle damit verbundenen Proteine in der Unterkategorie "Stoffwechselkrankheit" sind einzigartig (300 Proteine), während Ernährungsstörungen nur wenige eindeutige Proteine (35) aufweisen. Alpha-kristallin-B-Kette zeigt die stärkste Vereinigung der Unterkategorie Stoffwechselerkrankungen. Sterol 26-Hydroxylase, mitochondriale zeigt der stärkste Verein in der Unterkategorie "Ernährungsstörungen", darauf hinweist, dass dieser mitochondrialen Proteins in Studien beschreiben Ernährungsstörungen von hoher Relevanz ist. Die statistische Verteilung der in der Partitur die absolute Differenz zwischen beiden Gruppen "MBD" und "NTD" zeigt die Bandbreite (0.046, 0.061) für die mittlere Differenz als ein Konfidenzniveau von 99 %.

Abbildung 1: Dynamische Ansicht des CaseOLAP Workflows. Diese Zahl steht für die 5 wichtigsten Schritte in der CaseOLAP-Workflow. In Schritt 1 beginnt der Workflow durch das Herunterladen und Extrahieren von Textdokumenten (z. B. von PubMed). In Schritt 2 sind extrahierte Daten analysiert, um eine Data-Dictionary für jedes Dokument sowie ein Netz PMID Zuordnung zu erstellen. In Schritt 3 ist Indizierung der Daten durchgeführt, um schnelle und effiziente Einheit Suche zu erleichtern. Umsetzung der Benutzer bereitgestellte Kategorieinformationen (z.B.., Wurzel MeSH für jede Zelle) erfolgt in Schritt 4 um einen Text-Würfel konstruieren. In Schritt 5 wird die Entität Graf Betrieb über Indexdaten zu CaseOLAP Ergebnisse berechnen implementiert. Diese Schritte werden wiederholt, iterativ, das System mit den aktuellen Informationsstand in einer öffentlichen Datenbank (z. B. PubMed) zu aktualisieren. Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}

Abbildung 2: Technische Architektur des CaseOLAP Workflows. Diese Abbildung zeigt die technischen Details des CaseOLAP Workflows. Von der PubMed-FTP-Server sind Daten aus der PubMed-Repository. Der Benutzer verbindet sich mit dem Cloud-Server (z. B. AWS-Konnektivität) über ihr Gerät und schafft eine Download-Pipeline, die heruntergeladen und extrahiert die Daten zu einem lokalen Repository in der Cloud. Extrahierte Daten werden strukturiert, überprüft und ins richtige Format mit einer Daten-Analyse-Pipeline. Gleichzeitig entsteht ein Netz, PMID Mapping-Tabelle während der Analyse Schritt, der für Text-Cube Bau verwendet wird. Analysierte Daten werden als ein JSON wie Schlüssel-Wert-Wörterbuch-Format mit Dokument-Metadaten (z. B. PMID, MeSH, Erscheinungsjahr) gespeichert. Die Indizierung Schritt weiter verbessert die Daten durch die Implementierung von Elasticsearch um Massendaten zu behandeln. Als nächstes wird die Text-Cube mit frei definierbaren Kategorien erstellt, durch die Implementierung von MeSH PMID Zuordnung. Wenn der Text-Cube Bildung und Indizierung Schritte abgeschlossen sind, wird eine Entität Zählung durchgeführt. Graf Entitätsdaten werden auf die Text-Cube-Metadaten implementiert. Zu guter Letzt die CaseOLAP Partitur auf die zugrunde liegende Text-Cube-Struktur errechnet. Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}

Abbildung 3. Ein Beispiel eines analysierten Dokuments. Eine Probe der analysierten Daten wird in dieser Abbildung dargestellt. Die analysierten Daten sind als ein Schlüssel-Wert-Paar angeordnet, die kompatibel mit Indexierung und Dokument-Metadaten-Kreation ist. In dieser Abbildung ein PMID (z. B. "25896987") dient als Schlüssel und Sammlung von Informationen (z. B. Titel, Journal, Erscheinungsdatum, abstrakt, MeSH, Stoffe, Abteilung und Position) werden als Wert. Die erste Anwendung der solche Dokumentmetadaten ist der Bau des Netzes, PMID Zuordnung (Abbildung 5 und Tabelle 2), die später zu den Text-Cube erstellen und berechnen Sie die CaseOLAP Partitur mit Benutzer bereitgestellten Einrichtungen umgesetzt wird und Kategorien. Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}

Abbildung 4. Ein Beispiel für ein MeSH-Baum. Die 'Alter Gruppen MeSH Baum ist aus der Baumstruktur in der NIH-Datenbank vorhandenen Daten angepasst (MeSH-Baum 2018, < Https://meshb.nlm.nih.gov/treeView>). Netz-Deskriptoren werden mit ihren Knoten IDs (z. B. Personen [M01], Altersgruppen [M01.060], Jugendlichen [M01.060.057], Erwachsenen [M01.060.116], Kind [M01.060.406], Kleinkind [M01.060.703]), eine spezifische MeSH-Deskriptor ( Unterlagen zu sammeln implementiert. Tabelle 3A). Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}

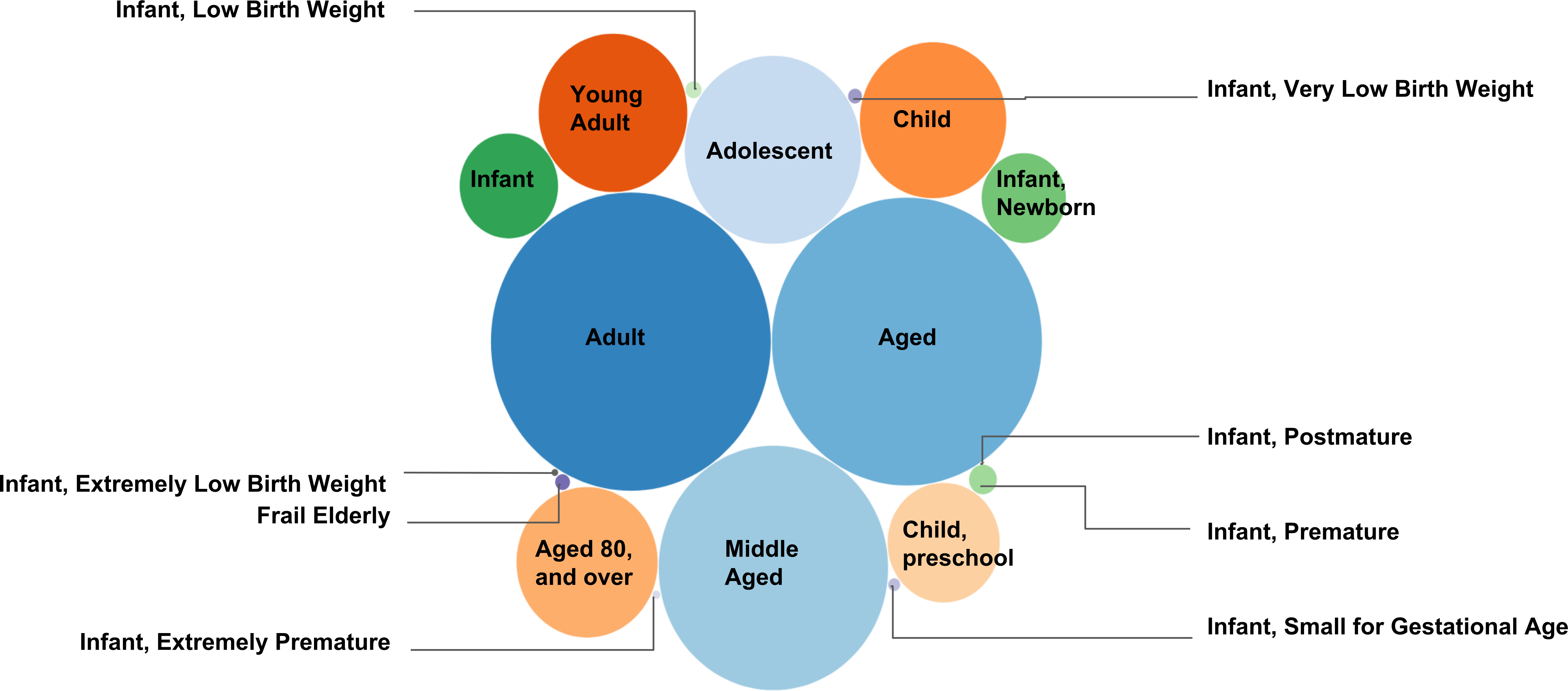
Abbildung 5. MeSH PMID Zuordnung in Altersgruppen. Diese Zahl stellt die Anzahl von Textdokumenten (jeweils im Zusammenhang mit einem PMID) unter die MeSH-Deskriptoren in "Altersklassen" als ein Blasendiagramm gesammelt. Das Netz PMID Zuordnung wird erzeugt, um die genaue Anzahl der Dokumente gesammelt unter den MeSH-Deskriptoren zu bieten. Eine Gesamtanzahl von 3.062.143 einzigartige Dokumente wurden gesammelt unter den 18 Nachkommen MeSH-Deskriptoren (siehe Tabelle 2). Je höher gewählte die Anzahl der PMIDs unter einen bestimmten MeSH-Deskriptor, desto größer den Radius der Blase repräsentieren den MeSH-Deskriptor. Zum Beispiel die höchste Anzahl der Dokumente wurden gesammelt unter den MeSH-Deskriptor "Erwachsenen" (1.786.371 Dokumente), während die kleinstmögliche Anzahl von Text-Dokumenten unter den MeSH-Deskriptor "Kleinkind, Postmature" gesammelt wurden (62-Dokumente).
Ein weiteres Beispiel des Netzes PMID Zuordnung erhält für "Ernährung und Stoffwechselerkrankungen" (https://caseolap.github.io/mesh2pmid-mapping/bubble/meta.html). Eine Gesamtanzahl von 422.039 einzigartige Dokumente wurden unter den 361 Nachkommen MeSH-Deskriptoren in "Ernährung und Stoffwechselerkrankungen" gesammelt. Die höchste Anzahl der Dokumente wurden gesammelt unter den MeSH-Deskriptor "Adipositas" (77.881 Dokumente) gefolgt von "Diabetes Mellitus Typ 2" (61.901 Dokumente), während "Glykogen-Speicherkrankheit Typ VIII" die geringste Anzahl von Dokumenten (1 Dokument ausgestellt ). Eine verknüpfte Tabelle ist es auch online unter (https://github.com/CaseOLAP/mesh2pmid-mapping/blob/master/data/diseaseall.csv). Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}

Abbildung 6. "Altersklassen" als ein Use-Case. Diese Zahl stellt die Ergebnisse aus einem Use Case der CaseOLAP Plattform. In diesem Fall werden Protein-Namen und ihre Abkürzungen (siehe Beispiel in Tabelle 4) als Entitäten und "Altersklassen", einschließlich der Zellen umgesetzt: Säugling (INFT), Kind (CHLD), Jugendlichen (ADOL) und Erwachsene (ADLT), werden als Unterkategorien (siehe implementiert Tabelle 3A). (A) Anzahl der Dokumente in "Altersklassen": Diese Heatmap zeigt die Anzahl der Dokumente, die auf die Zellen "Im Alter von Gruppen" verteilt (für Details zu den Text-Cube erstellen siehe Protokoll Nr. 4 und Tabelle 3A). Eine höhere Anzahl von Dokumenten ist mit einer dunkleren Intensität der Heatmap vorgestellt (siehe Waage). Ein einzelnes Dokument kann in mehrere Zellen enthalten. Die Heatmap zeigt die Anzahl der Dokumente innerhalb einer Zelle entlang der Diagonale (z. B. ADLT enthält 172.394 Dokumente ist die höchste Zahl über alle Zellen). Die nondiagonal Position steht für die Anzahl von Dokumenten fallen unter zwei Zellen (z. B. ADLT und ADOL haben 26.858 freigegebene Dokumente). (B) . Entität Graf in "Altersklassen": das Venn-Diagramm stellt die Anzahl der Proteine in den vier Zellen "Altersklassen" (INFT, CHLD ADOL und ADLT) vertreten. Die Zahl der Proteine, die in allen Zellen geteilt ist 162. Die Altersgruppe ADLT zeigt die höchste Zahl der einzigartigen Proteine (151) gefolgt von CHLD (16), INFT (8) und ADOL (1). (C) CaseOLAP Partitur Präsentation in "Altersklassen": Die Top 10 Proteine mit den höchsten durchschnittlichen CaseOLAP Punktzahlen in den einzelnen Gruppen werden in einer Heatmap dargestellt. Eine höhere CaseOLAP Punktzahl wird mit einem dunkleren Intensität der Heatmap vorgestellt (siehe Waage). Die Protein-Namen werden in der linken Spalte angezeigt, und die Zellen (INFT, CHLD, ADOL ADLT) entlang der x-Achse angezeigt. Einige Proteine zeigen eine starke Assoziation zu einer bestimmten Altersgruppe (z. B. Sterol 26-Hydroxylase, Alpha-kristallin-B-Kette und L-Seryl-tRNA starke Verbände mit ADLT, haben während Natrium/Kalium-Transport-ATPase Untereinheit Alpha-3 verfügt über eine starke Assoziation mit INFT). Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}

Abbildung 7. "Ernährungs- und Stoffwechselkrankheiten" als einem Use Case: diese Zahl stellt die Ergebnisse aus einem anderen Anwendungsfall der CaseOLAP Plattform. In diesem Fall werden Protein-Namen und ihre Abkürzungen (siehe Beispiel in Tabelle 4) als Entitäten und "Ernährungs-und metabolische Krankheit" unter anderem die beiden Zellen umgesetzt: Stoffwechselerkrankung (MBD) und Ernährungsstörungen (NTD) sind als implementiert Unterkategorien (siehe Tabelle 3 b). (A). Anzahl der Dokumente in "Ernährung und Stoffwechselerkrankungen": dieser Heatmap zeigt die Anzahl der Text-Dokumente in den Zellen der "Ernährung und Stoffwechselerkrankungen" (für Details auf die Text-Cube-Erstellung Protokoll Nr. 4 und Tabelle 3 b Siehe ). Eine höhere Anzahl von Dokumenten ist mit einer dunkleren Intensität der Heatmap vorgestellt (siehe Skalierung). Ein einzelnes Dokument kann in mehrere Zellen enthalten. Die Heatmap zeigt die Gesamtzahl der Dokumente innerhalb einer Zelle entlang der Diagonale (z. B. MBD enthält 54.762 Dokumente ist die höchste Zahl über die zwei Zellen). Die nondiagonal Position steht für die Anzahl der Dokumente, die von den beiden Zellen (z. B. MBD und NTD haben 7.101 freigegebene Dokumente) geteilt. (B). Entität Graf in "Ernährung und Stoffwechselerkrankungen": das Venn-Diagramm stellt die Anzahl der Proteine in den beiden Zellen "Ernährungs-und Stoffwechselkrankheiten" (MBD und NTD) vertreten. Die Zahl der Proteine, die in zwei Zellen geteilt ist 397. Die MBD-Zelle zeigt 300 einzigartige Proteine und die NTD-Zelle zeigt 35 einzigartige Proteine. (C). CaseOLAP Partitur Präsentation in "Ernährung und Stoffwechselerkrankungen": die Top-10-Proteine mit den höchsten durchschnittlichen CaseOLAP Punktzahlen in "Ernährung und Stoffwechselerkrankungen" werden in einer Heatmap präsentiert. Eine höhere CaseOLAP Punktzahl wird mit einem dunkleren Intensität der Heatmap vorgestellt (siehe Skalierung). Die Protein-Namen werden in der linken Spalte angezeigt und Zellen (MBD und NTD) werden entlang der x-Achse angezeigt. Einige Proteine zeigen eine starke Assoziation zu einer bestimmten Krankheit-Kategorie (z. B. Alpha-kristallin-B-Kette hat eine hohe Assoziation mit Stoffwechselerkrankung und Sterol 26-Hydroxylase hat eine hohe Assoziation mit Ernährungsstörungen). Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}
| Zeitaufwand (in Prozent der Gesamtzeit) | Schritte in der CaseOLAP-Plattform | Algorithmus und Datenstruktur der CaseOLAP Plattform | Komplexität des Algorithmus und Datenstruktur | Details zu den Schritten |
| 40 % | Herunterladen und Parsen | Iteration und Baum Analyse Algorithmen | Iteration mit nested Loops und ständige Vermehrung: O(n^2), O (Log n). Wo ' n ' ist Anzahl der Iterationen. | Die Download-Pipeline durchläuft jedes Verfahren über mehrere Dateien. Jede Prozedur überfährt eines einzelnen Dokuments Parsen der Baumstruktur des XML-Rohdaten. |
| 30 % | Indizierung, suchen und Text-Cube-Erstellung | Iteration, Such-Algorithmen von Elasticsearch (Sortierung, Lucene Index, Prioritätswarteschlangen, endliche Zustandsautomaten, Bit twiddling Hacks, Regex Abfragen) | Komplexität im Zusammenhang mit Elasticsearch (https://www.elastic.co/) | Dokumente werden durch die Umsetzung der Iterationsprozess über das Data Dictionary indiziert. Die Text-Cube-Erstellung implementiert Dokument-Metadaten und Benutzer bereitgestellten Informationen. |
| 30 % | Unternehmen zählen und CaseOLAP-Berechnung | Iteration in Integrität, Popularität, Unterscheidungskraft Berechnung | O(1), O(n^2), mehrere Komplexität im Zusammenhang mit CaseOLAP Score-Berechnung basiert auf einer Iteration Arten. | Entität Graf Betrieb führt die Dokumente auf und bilden eine Anzahl Betrieb über die Liste. Die Entität Zähldaten werden verwendet, um CaseOLAP-Score berechnen. |
Tabelle 1. Algorithmen und Komplexität. Diese Tabelle enthält Informationen über die Zeit (in Prozent der Gesamtzeit) über die Verfahren (z. B. Download, Parsen), Datenstruktur und Details über die implementierten Algorithmen in der CaseOLAP-Plattform. CaseOLAP setzt die professionelle Indizierung und Suche Anwendung namens Elasticsearch. Weitere Informationen zur Komplexität im Zusammenhang mit Elasticsearch und internen Algorithmen finden Sie im (https://www.elastic.co).
| MeSH-Deskriptoren | Anzahl der PMIDs gesammelt |
| Erwachsene | 1.786.371 |
| Im mittleren Alter | 1.661.882 |
| Im Alter von | 1.198.778 |
| Jugendlicher | 706.429 |
| Junger Erwachsener | 486.259 |
| Kind | 480.218 |
| Im Alter von, 80 und älter | 453.348 |
| Kind, Vorschule | 285.183 |
| Kleinkind | 218.242 |
| Säugling, Neugeborenes | 160.702 |
| Kleinkind, vorzeitige | 17.701 |
| Säugling, niedriges Geburtsgewicht | 5.707 |
| Gebrechlichen älteren Menschen | 4.811 |
| Säugling, sehr niedrigen Geburtsgewicht | 4.458 |
| Kleinkind, klein für Gestational Alter | 3.168 |
| Kleinkind, extrem vorzeitige | 1.171 |
| Säugling, extrem niedrigen Geburtsgewicht | 1.003 |
| Kleinkind, übertragenen | 62 |
Tabelle 2: MeSH PMID Zuordnung Statistik. Die nachstehende Tabelle gibt alle Nachfolgerelemente MeSH-Deskriptoren "Altersklassen" und die Anzahl Ihrer gesammelten PMIDs (Textdokumente). Die Visualisierung dieser Statistiken ist in Abbildung 5dargestellt.
| A | Kleinkind (INFT) | Kind (CHLD) | Jugendlicher (ADOL) | Erwachsener (ADLT) |
| Netz-Root-ID | M01.060.703 | M01.060.406 | M01.060.057 | M01.060.116 |
| Anzahl der Nachkomme MeSH-Deskriptoren | 9 | 2 | 1 | 6 |
| Anzahl der PMIDs ausgewählt | 16.466 | 26.907 | 35.158 | 172.394 |
| Anzahl der Objekte gefunden | 233 | 297 | 257 | 443 |
| B | Stoffwechselerkrankungen (MBD) | Ernährungsstörungen (NTD) | ||
| Netz-Root-ID | C18.452 | C18.654 | ||
| Anzahl der Nachkomme MeSH Deskriptoren | 308 | 53 | ||
| Anzahl der gesammelten PMIDs | 54.762 | 19.181 | ||
| Anzahl der Objekte gefunden | 697 | 432 |
Tabelle 3. Text-Cube Metadaten. Eine tabellarische Ansicht des Text-Cube Metadaten wird vorgestellt. Die Tabellen informieren über die Kategorien und MeSH-Deskriptor Wurzeln und Nachkommen, die umgesetzt werden, um die Dokumente in jeder Zelle zu sammeln. Die Tabelle enthält auch die Statistiken der gesammelten Dokumente und Einrichtungen. (A) "Altersklassen": Dies ist eine tabellarische Darstellung der "Altersklassen" einschließlich Kleinkind (INFT), Kind (CHLD), Jugendlichen (ADOL) und Erwachsene (ADLT) und ihre MeSH Wurzel IDs, Anzahl der Nachkomme MeSH Deskriptoren, Anzahl der ausgewählten PMIDs und Anzahl der gefunden Personen. (B) "Ernährung und Stoffwechselerkrankungen": Dies ist eine tabellarische Darstellung der "Ernährungs-und Stoffwechselkrankheiten" einschließlich Stoffwechselerkrankung (MBD) und Ernährungsstörungen (NTD) mit ihren MeSH Wurzel IDs, Nummer der Nachkomme MeSH-Deskriptoren ausgewählte PMIDs und die Anzahl der gefundenen Objekte.
| Protein-Namen und Synonyme | Abkürzungen |
| N-Acetylglutamate Synthase, mitochondriale, Aminosäure Acetyltransferase, N-Acetylglutamate Synthase Langform; N-Acetylglutamate Synthase Kurzform; N-Acetylglutamate Synthase konserviert Domainformular] | (EG 2.3.1.1) |
| Protein/Nuclein-Säure Deglycase DJ-1 (Maillard Deglycase) (Onkogen DJ1) (Parkinson Krankheit Protein 7) (Parkinson-assoziierten Deglycase) (Protein DJ-1) | (EG 3.1.2.-) (EG 3.5.1.-) (EG 3.5.1.124) (DJ-1) |
| Pyruvat-Carboxylase, mitochondriale (Brenztraubensäure Carboxylase) | (EG 6.4.1.1) (PCB) |
| BCL-2-verbindlicher Bestandteil 3 (p53 bis geregelt Modulator der Apoptose) | (JFY-1) |
| BH3-Interaktion Domäne Tod Agonist [BH3-Interaktion Domäne Tod Agonist p15 (p15 BID); BH3-Interaktion Domäne Tod Agonist p13; BH3-Interaktion Domäne Tod Agonist p11] | (p22 BID) (BID) (p13 BID) (p11 BID) |
| ATP-Synthase Untereinheit Alpha, mitochondriale (ATP-Synthase F1-Untereinheit Alpha) | |
| Cytochrom P450 11B2, mitochondriale (Aldosteron-Synthase) (Aldosteron-Synthese-Enzym) (CYPXIB2) (Cytochrom P-450Aldo) (Cytochrom P-450_C_18) (Steroid 18-Hydroxylase) | (ALDOS) (EG 1.14.15.4) (EG 1.14.15.5) |
| 60 kDa Hitze Schock-Protein, mitochondriale (60 kDa chaperonin) (Chaperonin 60) (CPN60) (Heat Shock Protein 60) (mitochondriale Matrix Protein P1) (P60 Lymphozyten Protein) | (HSP-60) (Hsp60) (HuCHA60) (EG 3.6.4.9) |
| Caspase-4 (Eis und Ced-3 Homolog 2) (Protease TX) [gespalten in: Caspase-4 Untereinheit 1; Caspase-4 Untereinheit 2] | (CASP-4) (EG 3.4.22.57) (ICH-2) (ICE(rel)-II) (Mih1) |
Tabelle 4. Probieren Sie Entität Tabelle. Die nachstehende Tabelle gibt das Beispiel von Entitäten, die in unseren zwei Anwendungsfälle umgesetzt: "Altersklassen" und "Ernährung und Stoffwechselerkrankungen" (Abbildung 6 und Abbildung 7, Tabelle 3A,B). Die Entitäten enthalten Protein Namen, Synonyme und Abkürzungen. Jede Entität (mit seiner Synonyme und Abkürzungen) ist ausgewählten eins nach dem anderen und wird durch die Entität Suchvorgang über indizierte Daten (siehe Protokoll 3 und 5) bestanden. Die Suche wird eine Liste von Dokumenten, die die Entität Graf Betrieb weiter zu erleichtern.
| Mengen | Benutzer definiert | Berechnet | Gleichung der Menge | Bedeutung der Menge |
| Integrität | Ja | Nein | Integrität der Benutzer definierten Entitäten als 1,0 sein. | Stellt einen sinnvollen Satz. Numerischer Wert ist 1.0, wenn es bereits ein etablierter Begriff. |
| Popularität | Nein | Ja | Popularität Gleichung in Abbildung 1 (Workflow und Algorithmus) aus Referenz 5, Abschnitt "Materialien und Methoden". | Anhand der Begriff Frequenz der Phrase innerhalb einer Zelle. Durch Gesamtlaufzeit Häufigkeit der Zelle normiert. Zunahme der Begriff Frequenz hat Ergebnis rückläufig. |
| Unterscheidungskraft | Nein | Ja | Unterscheidungskraft Gleichung in Abbildung 1 (Workflow und Algorithmus) aus Referenz 5, Abschnitt "Materialien und Methoden". | Anhand der Begriff Frequenz und Dokument-Frequenz innerhalb einer Zelle und über die benachbarten Zellen. Durch Gesamtlaufzeit Frequenz und Dokument Frequenz normiert. Quantitativ, ist die Wahrscheinlichkeit, dass ein Satz in einer bestimmten Zelle eindeutig ist. |
| CaseOLAP Ergebnis | Nein | Ja | CaseOLAP Partitur Gleichung in Abbildung 1 (Workflow und Algorithmus) aus Referenz 5, Abschnitt "Materialien und Methoden". | Basierend auf Integrität, Popularität und Unverwechselbarkeit. Numerischer Wert fällt immer innerhalb von 0 bis 1. Quantitativ vertritt die CaseOLAP Partitur den Satz-Kategorie Verein |
Tabelle 5. CaseOLAP Gleichungen: The CaseOLAP-Algorithmus wurde von Fangbo Tao und Jiawei Han Et Al. in 20161entwickelt. Kurz, die nachstehende Tabelle gibt die CaseOLAP-Score-Berechnung bestehend aus drei Komponenten: Integrität, Popularität, und Unverwechselbarkeit und deren zugehörige mathematische Bedeutung. In unseren Anwendungsfällen, die Integrität Punktzahl für Proteine ist 1,0 (Höchstpunktzahl) weil sie als etablierte Entity-Namen stehen. Die CaseOLAP Punkte in unseren Anwendungsfällen ist in Abbildung 6 und Abbildung 7ersichtlich.
Diskussion
Wir haben gezeigt, dass der CaseOLAP-Algorithmus eine Satz basiert quantitative Zuordnung zu einer wissensbasierten Kategorie über große Mengen von Textdaten für die Extraktion von aussagekräftige Erkenntnisse erstellen kann. Im Anschluss an unser Protokoll kann man bauen, CaseOLAP Rahmen um einen gewünschten Text-Cube erstellen und Entität-Berufsverbände durch CaseOLAP Score Berechnung zu quantifizieren. Die erhaltenen rohen CaseOLAP Noten können auf integrative Analysen einschließlich der Reduzierung der Dimensionalität, clustering, zeitliche und räumliche Analyse sowie die Erstellung einer grafischen Datenbank ermöglicht semantische Zuordnung der Dokumente weitergeleitet.
Anwendbarkeit des Algorithmus. Beispiele für benutzerdefinierte Entitäten als Proteine, könnte eine Liste von gen Namen, Drogen, bestimmte Anzeichen und Symptome, einschließlich ihrer Abkürzungen und Synonyme. Darüber hinaus gibt es viele Möglichkeiten für Kategorieauswahl um bestimmte benutzerdefinierte biomedizinische Analysen (z. B. Anatomie [A], Disziplin und Beruf [H], Phänomene und Prozesse [G]) zu erleichtern. In unseren beiden Anwendungsfällen, alle wissenschaftlichen Publikationen und ihrer textuellen Daten werden abgerufen, aus der MEDLINE-Datenbank PubMed als Suchmaschine verwenden, beide von der National Library of Medicine verwaltet. Allerdings kann die CaseOLAP-Plattform auf andere Datenbanken von Interesse, biomedizinische Dokumente mit textuellen Daten wie die FDA nachteilige Event Reporting System (FAERS) angewendet werden. Dies ist eine offene Datenbank mit Informationen über medizinische Zwischenfälle und Fehlerberichte Medikamente FDA eingereicht. Im Gegensatz zu MEDLINE und FAERS Datenbanken in Krankenhäusern mit elektronischen Krankenakten von Patienten sind nicht für die Öffentlichkeit zugänglich und werden von der Health Insurance Portability and Accountability Act bekannt als HIPAA eingeschränkt.
CaseOLAP-Algorithmus wurde erfolgreich auf die verschiedenen Arten von Daten (z. B. Zeitungsartikel)1. angewendet Die Implementierung dieses Algorithmus in biomedizinischen Dokumenten 20185verzeichnen. Die Voraussetzungen für die Anwendbarkeit des CaseOLAP-Algorithmus ist, dass jedes Dokument mit Schlüsselwörtern, verbunden mit den Konzepten (z. B. MeSH Deskriptoren in biomedizinischen Veröffentlichungen, Schlüsselwörter in News-Artikel) zugewiesen werden soll. Wenn Schlüsselwörter nicht gefunden werden, können eine Autophrase6,7 Top repräsentative Sätze zu sammeln und bauen Entity List vor der Implementierung unserer Protokoll anwenden. Unser Protokoll bietet nicht den Schritt, um Autophrase durchzuführen.
Vergleich mit anderen Algorithmen. Das Konzept des Verwendens einer Daten-Cube8,9,10 und eine Text-Cube2,3,4 hat sich seit 2005 mit neuen Zuführungen, Data-Mining mehr anwendbar zu machen weiter entwickelt. Das Konzept von Online Analytical Processing (OLAP)11,12,13,14,15 in Data-Mining und Business Intelligence geht zurück bis 1993. OLAP, sammelt die Informationen aus verschiedenen Systemen im allgemeinen und speichert es in einem multi-dimensionalen Format. Es gibt verschiedene Arten von OLAP-Systemen implementiert im Datamining. Zum Beispiel (1) Hybrid Transaktion/Analytical Processing (HTAP)16,17, (2) multidimensionale OLAP (MOLAP)18,19-Cube basiert, und (3) relationale OLAP (ROLAP)20.
Insbesondere der CaseOLAP-Algorithmus wurde im Vergleich mit zahlreichen vorhandenen Algorithmen, insbesondere mit ihren Satz Segmentierung Verbesserungen, darunter TF-IDF + Seg, MCX + Seg, MCX und SegPhrase. Darüber hinaus RepPhrase (RP, auch bekannt als SegPhrase +) wurde im Vergleich mit ihren eigenen Ablation Variationen, einschließlich RP (1) ohne die Integrität Maßnahme aufgenommen (RP No INT), (2) RP ohne die Popularität Maßnahme aufgenommen (RP No POP) und (3) RP ohne die Unterscheidungskraft Maßnahme aufgenommen (RP No DIS). Die Benchmark-Ergebnisse sind in der Studie von Fangbo Tao Et Al.1gezeigt.
Data Mining, die zusätzlichen Funktionalität hinzufügen können, speichern und Abrufen von Daten aus der Datenbank gibt es noch Herausforderungen. Kontextsensitive semantische Analytical Processing (CaseOLAP) implementiert systematisch die Elasticsearch um eine Indexdatenbank von Millionen von Dokumenten (Protokoll Nr. 5) zu bauen. Text-Cube ist ein Dokument über die indizierten Daten mit Benutzer bereitgestellten Kategorien (Protokoll Nr. 6) gebaut. Dies verbessert die Funktionalität zu den Dokumenten innerhalb und über der Zelle des Text-Cubes und ermöglichen es uns, Begriff Frequenz der Entitäten über ein Dokument und Dokument-Frequenz über eine bestimmte Zelle (Protokoll 8) zu berechnen. Das Endergebnis der CaseOLAP nutzt diese Frequenz Berechnungen zur Ausgabe von einem Endstand (Protokoll 9). Im Jahr 2018 implementierten wir dieser Algorithmus um ECM Proteine und sechs Herzkrankheiten, Protein-Krankheit Verbände analysieren zu studieren. Die Details dieser Studie finden Sie in der Studie von Liem, D.A. Et Al.5. darauf hinweist, dass CaseOLAP weit in die biomedizinische Gemeinschaft eine Vielzahl von Krankheiten und Mechanismen zu erforschen verwendet werden könnte.
Einschränkungen des Algorithmus. Satz-Bergbau selbst ist eine Technik zu verwalten und wichtige Konzepte von textuellen Daten abzurufen. Während die Entdeckung Entität-Kategorie Assoziation als eine mathematische Größe (Vektor), ist diese Technik nicht in der Lage, herauszufinden, die Polarität (z. B. positive oder negative Neigung) des Vereins. Man kann die quantitative Zusammenfassung der Daten unter Verwendung der Text-Glaswürfel Dokumentstruktur mit zugewiesenen Einheiten und Kategorien bauen, aber eine qualitative Konzept mit mikroskopischen Granularitäten nicht erreicht werden kann. Einige Konzepte werden kontinuierlich weiterentwickelt, seit dem letzten bis jetzt. Die Zusammenfassung für eine bestimmte Entität-Kategorie Association präsentiert umfasst alle Fälle in der Literatur. Dies kann die zeitliche Verbreitung der Innovation fehlt. In Zukunft planen wir, diese Einschränkungen zu beheben.
Zukünftige Anwendungen. Etwa 90 % der gesammelten Daten in der Welt ist in den unstrukturierten Textdaten. Suche nach einem repräsentativen Ausdruck und die Beziehung zu den Entitäten in den Text eingebettet ist eine sehr wichtige Aufgabe für die Umsetzung neuer Technologien (z.B. maschinelles lernen, Information Extraction, künstliche Intelligenz). Um die Textdaten Maschine lesbar zu machen, müssen die Daten in der Datenbank organisiert werden, die nächste Schicht von Werkzeugen umgesetzt werden könnten. Dieser Algorithmus kann in Zukunft ein entscheidender Schritt bei der Herstellung von Data-Mining funktioneller für den Abruf von Informationen und die Quantifizierung der Entität-Berufsverbände sein.
Offenlegungen
Die Autoren haben nichts preisgeben.
Danksagungen
Diese Arbeit wurde teilweise durch National Heart, Lung and Blood Institute unterstützt: R35 HL135772 (auf s. Ping); National Institute of General Medical Sciences: U54 GM114833 (zu P. Ping, K. Watson und W. Wang); U54 GM114838 (in J. Han); ein Geschenk von den Hellen & Larry Hoag Foundation und Dr. S. Setty; und der t.c. Laubisch-Stiftung an der UCLA (auf s. Ping).
Materialien
| Name | Company | Catalog Number | Comments |
Referenzen
- Tao, F., Zhuang, H., et al. Phrase-Based Summarization in Text Cubes. IEEE Data Engineering Bulletin. , 74-84 (2016).
- Ding, B., Zhao, B., Lin, C. X., Han, J., Zhai, C. TopCells: Keyword-based search of top-k aggregated documents in text cube. IEEE 26th International Conference on Data Engineering (ICDE). , 381-384 (2010).
- Ding, B., et al. Efficient Keyword-Based Search for Top-K Cells in Text Cube. IEEE Transactions on Knowledge and Data Engineering. 23 (12), 1795-1810 (2011).
- Liu, X., et al. A Text Cube Approach to Human, Social and Cultural Behavior in the Twitter Stream.Social Computing, Behavioral-Cultural Modeling and Prediction. Lecture Notes in Computer Science. 7812, (2013).
- Liem, D. A., et al. Phrase Mining of Textual Data to analyze extracellular matrix protein patterns across cardiovascular disease. American Journal of Physiology-Heart and Circulatory. , (2018).
- Shang, J., et al. Automated Phrase Mining from Massive Text Corpora. IEEE Transactions on Knowledge and Data Engineering. 30 (10), 1825-1837 (2018).
- Liu, J., Shang, J., Wang, C., Ren, X., Han, J. Mining Quality Phrases from Massive Text Corpora. Proceedings ACM-Sigmod International Conference on Management of Data. , 1729-1744 (2015).
- Lee, S., Kim, N., Kim, J. A Multi-dimensional Analysis and Data Cube for Unstructured Text and Social Media. IEEE Fourth International Conference on Big Data and Cloud Computing. , 761-764 (2014).
- Lin, C. X., Ding, B., Han, J., Zhu, F., Zhao, B. Text Cube: Computing IR Measures for Multidimensional Text Database Analysis. IEEE Data Mining. , 905-910 (2008).
- Hsu, W. J., Lu, Y., Lee, Z. Q. Accelerating Topic Exploration of Multi-Dimensional Documents Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE International. , 1520-1527 (2017).
- Chaudhuri, S., Dayal, U. An overview of data warehousing and OLAP technology. SIGMOD Record. 26 (1), 65-74 (1997).
- Ravat, F., Teste, O., Tournier, R. Olap aggregation function for textual data warehouse. ICEIS - 9th International Conference on Enterprise Information Systems, Proceedings. , 151-156 (2007).
- Ho, C. T., Agrawal, R., Megiddo, N., Srikant, R. Range Queries in OLAP Data Cubes. SIGMOD Conference. , (1997).
- Saxena, V., Pratap, A. Olap Cube Representation for Object- Oriented Database. International Journal of Software Engineering & Applications. 3 (2), (2012).
- Maniatis, A. S., Vassiliadis, P., Skiadopoulos, S., Vassiliou, Y. Advanced visualization for OLAP. DOLAP. , (2003).
- Bog, A. . Benchmarking Transaction and Analytical Processing Systems: The Creation of a Mixed Workload Benchmark and its Application. , 7-13 (2013).
- Özcan, F., Tian, Y., Tözün, P. Hybrid Transactional/Analytical Processing: A Survey. In Proceedings of the ACM International Conference on Management of Data (SIGMOD). , 1771-1775 (2017).
- Hasan, K. M. A., Tsuji, T., Higuchi, K. An Efficient Implementation for MOLAP Basic Data Structure and Its Evaluation. International Conference on Database Systems for Advanced Applications. , 288-299 (2007).
- Nantajeewarawat, E. Advances in Databases: Concepts, Systems and Applications. DASFAA 2007. Lecture Notes in Computer Science. 4443, (2007).
- Shimada, T., Tsuji, T., Higuchi, K. A storage scheme for multidimensional data alleviating dimension dependency. Third International Conference on Digital Information Management. , 662-668 (2007).
Nachdrucke und Genehmigungen
Genehmigung beantragen, um den Text oder die Abbildungen dieses JoVE-Artikels zu verwenden
Genehmigung beantragenThis article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. Alle Rechte vorbehalten