
Method Article
Design und Analyse zur Vereinfachung des Fallerkennungssystems
In diesem Artikel
Zusammenfassung
Wir präsentieren eine Methodik, die auf multimodalen Sensoren basiert, um ein einfaches, komfortables und schnelles Fallerkennungs- und Menschlicheaktivitätserkennungssystem zu konfigurieren. Das Ziel ist es, ein System für eine genaue Fallerkennung zu bauen, das einfach implementiert und übernommen werden kann.
Zusammenfassung
Dieses Papier stellt eine Methodik vor, die auf multimodalen Sensoren basiert, um ein einfaches, komfortables und schnelles Fallerkennungs- und System zur Erkennung menschlicher Aktivitäten zu konfigurieren, das einfach implementiert und übernommen werden kann. Die Methodik basiert auf der Konfiguration spezifischer Sensortypen, Machine-Learning-Methoden und -Verfahren. Das Protokoll gliedert sich in vier Phasen: (1) Datenbankerstellung (2) Datenanalyse (3), Systemvereinfachung und (4) Evaluierung. Mit dieser Methode haben wir eine multimodale Datenbank zur Sturzerkennung und Erkennung menschlicher Aktivitäten erstellt, nämlich UP-Fall Detection. Es umfasst Datenproben von 17 Probanden, die 5 Arten von Stürzen und 6 verschiedene einfache Aktivitäten durchführen, während 3 Studien. Alle Informationen wurden mit 5 tragbaren Sensoren (Tri-Achsen-Beschleunigungsmesser, Gyroskop und Lichtintensität), 1 Elektroenzephalographhelm, 6 Infrarotsensoren als Umgebungssensoren und 2 Kameras in seitlichen und vorderen Blickwinkeln gesammelt. Die vorgeschlagene neuartige Methodik fügt einige wichtige Schritte hinzu, um eine gründliche Analyse der folgenden Konstruktionsprobleme durchzuführen, um ein Fallerkennungssystem zu vereinfachen: a) auswählen, welche Sensoren oder Sensoren in einem einfachen Fallerkennungssystem verwendet werden sollen, b) die beste Platzierung der Informationsquellen bestimmen und c) die am besten geeignete Klassifizierungsmethode für maschinelles Lernen für die Erkennung und Erkennung von Aktivitäten beim Fall und beim Menschen auswählen. Obwohl sich einige multimodale Ansätze, die in der Literatur berichtet werden, nur auf ein oder zwei der oben genannten Themen konzentrieren, ermöglicht unsere Methodik die gleichzeitige Lösung dieser drei Konstruktionsprobleme im Zusammenhang mit einem menschlichen Fall- und Aktivitätserkennungs- und -erkennungssystem.
Einleitung
Seit dem Weltphänomen der Bevölkerungsalterung1hat die Fallprävalenz zugenommen und gilt eigentlich als großes Gesundheitsproblem2. Wenn ein Sturz eintritt, menschenbrauchen die Menschen sofortige Aufmerksamkeit, um negative Folgen zu reduzieren. Fallerkennungssysteme können die Zeit reduzieren, in der eine Person bei einem Sturz medizinisch versorgt wird.
Es gibt verschiedene Kategorisierungen von Fallerkennungssystemen3. Frühe Arbeiten4 klassifizieren Fallerkennungssysteme nach ihrer Methode der Detektion, grob analytischemethoden und maschinellen Lernmethoden. In jüngerer Zeit haben andere Autoren3,5,6 Datenerfassungssensoren als Hauptmerkmal zur Klassifizierung von Falldetektoren betrachtet. Igual et al.3 unterteilt Fallerkennungssysteme in kontextbewusste Systeme, die Visions- und Umgebungssensor-basierte Ansätze sowie tragbare Gerätesysteme umfassen. Mubashir et al.5 klassifiziert Falldetektoren in drei Gruppen basierend auf den Geräten, die für die Datenerfassung verwendet werden: tragbare Geräte, Ambientesensoren und visionsbasierte Geräte. Perry et al.6 betrachtet Methoden zur Messung der Beschleunigung, Methoden zur Messung der Beschleunigung in Kombination mit anderen Methoden und Methoden, die die Beschleunigung nicht messen. Anhand dieser Erhebungen können wir feststellen, dass Sensoren und Methoden die Hauptelemente für die Klassifizierung der allgemeinen Forschungsstrategie sind.
Jeder der Sensoren hat Schwächen und Stärken, die in Xu et al.7diskutiert werden. Vision-basierte Ansätze verwenden hauptsächlich normale Kameras, Tiefensensorkameras und/oder Motion-Capture-Systeme. Normale Webkameras sind kostengünstig und einfach zu bedienen, aber sie sind empfindlich gegenüber Umgebungsbedingungen (Lichtvariation, Okklusion usw.), können nur auf reduziertem Raum verwendet werden und haben Datenschutzprobleme. Tiefenkameras, wie z. B. die Kinect, bieten Eine Ganzkörper-3D-Bewegung7 und sind weniger von den Lichtverhältnissen betroffen als normale Kameras. Ansätze, die auf dem Kinect basieren, sind jedoch nicht so robust und zuverlässig. Motion Capture-Systeme sind teurer und schwieriger zu bedienen.
Ansätze, die auf Beschleunigungsmessern und Smartphones/Uhren mit eingebauten Beschleunigungsmessern basieren, werden sehr häufig für die Sturzerkennung verwendet. Der Hauptnachteil dieser Geräte ist, dass sie für längere Zeit getragen werden müssen. Beschwerden, Aufdringlichkeit, Körperplatzierung und Orientierung sind Gestaltungsfragen, die in diesen Ansätzen gelöst werden müssen. Obwohl Smartphones und Smartwatches weniger aufdringliche Geräte sind, die Sensoren, ältere Menschen vergessen oder tragen diese Geräte oft nicht immer. Dennoch ist der Vorteil dieser Sensoren und Geräte, dass sie in vielen Räumen und/oder im Freien eingesetzt werden können.
Einige Systeme verwenden Sensoren, die in der Umgebung platziert sind, um Stürze/Aktivitäten zu erkennen, sodass die Menschen die Sensoren nicht tragen müssen. Diese Sensoren sind jedoch auch auf die Orte beschränkt, an denen sie eingesetzt werden8 und sind manchmal schwierig zu installieren. In jüngster Zeit umfassen multimodale Fallerkennungssysteme verschiedene Kombinationen von Vision-, Wearable- und Umgebungssensoren, um mehr Präzision und Robustheit zu erreichen. Sie können auch einige der einzelnen Sensoreinschränkungen überwinden.
Die für die Sturzerkennung verwendete Methode steht in engem Zusammenhang mit der von Bulling et al.9vorgestellten Wertschöpfungskette (Human Activity Recognition Chain), die aus Stufen für die Datenerfassung, Signalvorverarbeitung und -segmentierung, Merkmalsextraktion und -auswahl, Schulung und Klassifizierung besteht. Designprobleme müssen für jede dieser Phasen gelöst werden. In jeder Phase werden unterschiedliche Methoden verwendet.
Wir präsentieren eine Methodik, die auf multimodalen Sensoren basiert, um ein einfaches, komfortables und schnelles System zur Erkennung/Erkennung menschlicher Aktivitäten für menschliche Aktivitäten zu konfigurieren. Das Ziel ist es, ein System für eine genaue Fallerkennung zu bauen, das einfach implementiert und übernommen werden kann. Die vorgeschlagene neuartige Methodik basiert auf ARC, fügt jedoch einige wichtige Phasen hinzu, um eine gründliche Analyse der folgenden Probleme durchzuführen, um das System zu vereinfachen: a) auswählen, welche Sensoren oder Sensoren in einem einfachen Fallerkennungssystem verwendet werden sollen; b) die beste Platzierung der Informationsquellen zu bestimmen; und (c) wählen Sie die am besten geeignete Klassifizierungsmethode für maschinelles Lernen für die Sturzerkennung und die Erkennung menschlicher Aktivitäten aus, um ein einfaches System zu erstellen.
Es gibt einige verwandte Arbeiten in der Literatur, die ein oder zwei der oben genannten Design-Themen behandeln, aber nach unserem Wissen gibt es keine Arbeit, die sich auf eine Methodik konzentriert, um all diese Probleme zu überwinden.
Verwandte Arbeiten verwenden multimodale Ansätze zur Fallerkennung und erkennung menschlicher Aktivitäten10,11,12, um Robustheit zu gewinnen und die Präzision zu erhöhen. Kwolek et al.10 schlugen die Konzeption und Implementierung eines Fallerkennungssystems auf der Grundlage von beschleunigungsmetrischen Daten und Tiefenkarten vor. Sie entwickelten eine interessante Methodik, in der ein dreiachsiger Beschleunigungsmesser implementiert wird, um einen möglichen Sturz sowie die Bewegung der Person zu erkennen. Wenn die Beschleunigungsmessung einen Schwellenwert überschreitet, extrahiert der Algorithmus eine Person, die die Tiefenkarte von der aktualisierten Online-Tiefenreferenzkarte unterscheidet. Eine Analyse der Tiefen- und Beschleunigungskombinationen wurde mit einem Unterstützungsvektor-Maschinenklassifier durchgeführt.
Ofli et al.11 präsentierten eine Multimodal Human Action Database (MHAD), um ein Testfeld für neue Systeme zur Erkennung menschlicher Aktivitäten bereitzustellen. Das Dataset ist wichtig, da die Aktionen gleichzeitig mit 1 optischem Bewegungserfassungssystem, 4 Multi-View-Kameras, 1 Kinect-System, 4 Mikrofonen und 6 drahtlosen Beschleunigungsmessern gesammelt wurden. Die Autoren präsentierten Ergebnisse für jede Modalität: die Kinect, die Mocap, den Beschleunigungsmesser und das Audio.
Dovgan et al.12 schlugen einen Prototypen zur Erkennung von anomalem Verhalten, einschließlich Stürzen, bei älteren Menschen vor. Sie entwickelten Tests für drei Sensorsysteme, um die am besten geeignete Ausrüstung für Diekfall- und ungewöhnliche Verhaltenserkennung zu finden. Das erste Experiment besteht aus Daten eines intelligenten Sensorsystems mit 12 Tags, die an Hüften, Knien, Knöcheln, Handgelenken, Ellbogen und Schultern befestigt sind. Sie erstellten auch einen Test-Datensatz mit einem Ubisense-Sensorsystem mit vier Tags, die an der Taille, der Brust und beiden Knöcheln befestigt sind, und einem Xsens-Beschleunigungsmesser. In einem dritten Experiment verwenden vier Probanden das Ubisense-System nur, während sie 4 Arten von Stürzen, 4 Gesundheitsprobleme als anomales Verhalten und unterschiedliche Aktivität des täglichen Lebens (ADL) durchführen.
Andere Arbeiten in der Literatur13,14,15 befassen sich mit dem Problem, die beste Platzierung von Sensoren oder Geräten für die Fallerkennung zu finden, wodurch die Leistung verschiedener Kombinationen von Sensoren mit mehreren Klassifikatoren verglichen wird. Santoyo et al.13 präsentierten eine systematische Bewertung, in der die Bedeutung der Lage von 5 Sensoren für die Fallerkennung bewertet wurde. Sie verglichen die Leistung dieser Sensorkombinationen mit k-nearest neighbors (KNN), Support Vector Machines (SVM), naive Bayes (NB) und Entscheidungsbaumklassifikatoren (DT). Sie kommen zu dem Schluss, dass die Position des Sensors auf dem Gegenstand einen wichtigen Einfluss auf die Falldetektorleistung unabhängig vom verwendeten Klassifikationsmittel hat.
Einen Vergleich der tragbaren Sensorplatzierungen am Körper zur Sturzerkennung präsentierte Özdemir14. Um die Sensorplatzierung zu bestimmen, analysierte der Autor 31 Sensorkombinationen der folgenden Positionen: Kopf, Taille, Brust, rechtes Handgelenk, rechter Knöchel und rechter Oberschenkel. 14 Freiwillige führten 20 simulierte Stürze und 16 ADL durch. Er fand heraus, dass die beste Leistung erzielt wurde, wenn ein einzelner Sensor auf der Taille aus diesen erschöpfenden Kombinationsexperimenten positioniert ist. Ein weiterer Vergleich wurde von Ntanasis15 anhand von Özdemirs Datensatz präsentiert. Die Autoren verglichen einzelne Positionen an Kopf, Brust, Taille, Handgelenk, Knöchel und Oberschenkel mit den folgenden Klassifikatoren: J48, KNN, RF, Random Committee (RC) und SVM.
Benchmarks der Leistung verschiedener Rechenmethoden zur Sturzerkennung finden sich auch in der Literatur16,17,18. Bagala et al.16 präsentierten einen systematischen Vergleich mit der Leistung von dreizehn Fallnachweismethoden, die bei realen Stürzen getestet wurden. Sie berücksichtigten nur Algorithmen, die auf Beschleunigungsmessermessungen basierten, die an der Taille oder am Rumpf platziert wurden. Bourke et al.17 bewerteten die Leistung von fünf analytischen Algorithmen zur Sturzerkennung anhand eines Datensatzes von ADLs und Stürzen basierend auf Beschleunigungsmesserwerten. Kerdegari18 machte auch einen Vergleich der Leistung verschiedener Klassifizierungsmodelle für eine Reihe von aufgezeichneten Beschleunigungsdaten. Die Algorithmen für die Sturzerkennung waren zeroR, oneR, NB, DT, Multilayer Perceptron und SVM.
Alazrai et al.18 schlugen eine Methode zur Sturzerkennung vor, die einen geometrischen Bewegungs-Pose-Deskriptor verwendete, um eine akkumulierte histogrammbasierte Darstellung menschlicher Aktivität zu konstruieren. Sie werteten das Framework anhand eines Datensatzes aus, der mit Kinect-Sensoren gesammelt wurde.
Zusammenfassend haben wir multimodale Fallerkennungsarbeitengefunden 10,11,12, die die Leistung verschiedener Kombinationen von Modalitäten vergleichen. Einige Autoren befassen sich mit dem Problem der Suche nach der besten Platzierung von Sensoren13,14,15, oder Kombinationen von Sensoren13 mit mehreren Klassifikatoren13,15,16 mit mehreren Sensoren der gleichen Modalität und Beschleunigungsmesser. In der Literatur wurde kein Werk gefunden, das sich gleichzeitig mit Platzierung, multimodalen Kombinationen und Klassifikaten-Benchmarks befasst.
Protokoll
Alle hier beschriebenen Methoden wurden vom Forschungsausschuss der School of Engineering der Universidad Panamericana genehmigt.
HINWEIS: Diese Methode basiert auf der Konfiguration der spezifischen Arten von Sensoren, Machine-Learning-Methoden und -Verfahren, um ein einfaches, schnelles und multimodales Fallerkennungs- und System zur Erkennung menschlicher Aktivitäten zu konfigurieren. Aus diesem Grund ist das folgende Protokoll in Phasen unterteilt: (1) Datenbankerstellung (2) Datenanalyse (3) Systemvereinfachung und (4) Auswertung.
1. Datenbankerstellung
- Richten Sie das Datenerfassungssystem ein. Dadurch werden alle Daten von den Betroffenen erfasst und die Informationen in einer Abrufdatenbank gespeichert.
- Wählen Sie die Arten von tragbaren Sensoren, Umgebungssensoren und visionsbasierten Geräten aus, die als Informationsquellen benötigt werden. Weisen Sie jeder Informationsquelle, der Anzahl der Kanäle pro Quelle, den technischen Spezifikationen und der Abtastrate der einzelnen Kanäle eine ID zu.
- Schließen Sie alle Informationsquellen (z. B. Wearables und Umgebungssensoren sowie visionsbasierte Geräte) an einen zentralen Computer oder ein verteiltes Computersystem an:
- Stellen Sie sicher, dass kabelgebundene Geräte ordnungsgemäß mit einem Clientcomputer verbunden sind. Stellen Sie sicher, dass drahtlose Geräte vollständig aufgeladen sind. Beachten Sie, dass sich ein niedriger Akku auswirken kann, der sich auf drahtlose Verbindungen oder Sensorwerte auswirkt. Darüber hinaus erhöhen intermittierende oder verlorene Verbindungen den Datenverlust.
- Richten Sie jedes Gerät ein, um Daten abzurufen.
- Richten Sie das Datenerfassungssystem zum Speichern von Daten in der Cloud ein. Aufgrund der großen Datenmenge, die gespeichert werden soll, wird Cloud Computing in diesem Protokoll berücksichtigt.
- Überprüfen Sie, ob das Datenerfassungssystem die Datensynchronisierungs- und Datenkonsistenz20 Eigenschaften erfüllt. Dadurch wird die Integrität der Datenspeicherung aus allen Informationsquellen gewahrt. Möglicherweise sind neue Ansätze bei der Datensynchronisierung erforderlich. Siehe z. B. Peafort-Asturiano et al.20.
- Beginnen Sie mit dem Sammeln einiger Daten mit den Informationsquellen und speichern Sie Daten in einem bevorzugten System. Fügen Sie Zeitstempel in alle Daten ein.
- Abfragen Sie die Datenbank, und ermitteln Sie, ob alle Informationsquellen mit den gleichen Abtastraten gesammelt werden. Wenn Sie richtig fertig sind, fahren Sie mit Schritt 1.1.6 fort. Andernfalls führen Sie Up-Sampling oder Down-Sampling mit Kriterien durch, die in Peafort-Asturiano, et al.20berichtet wurden.
- Richten Sie die Umgebung (oder das Labor) unter Berücksichtigung der erforderlichen Bedingungen und der durch das Systemziel auferlegten Einschränkungen ein. Stellen Sie Bedingungen für die Stoßkraftdämpfung in den simulierten Wasserfällen als konforme Bodensysteme in Lachance, et al.23, um die Sicherheit der Teilnehmer zu gewährleisten.
- Verwenden Sie eine Matratze oder ein anderes konformes Bodensystem und stellen Sie sie in die Mitte der Umgebung (oder des Labors).
- Halten Sie alle Objekte von der Matratze fern, um mindestens einen Meter sicheren Platz rundherum zu geben. Bereiten Sie bei Bedarf persönliche Schutzausrüstung für die Teilnehmer vor (z. B. Handschuhe, Mütze, Schutzbrille, Kniestütze usw.).
HINWEIS: Das Protokoll kann hier angehalten werden.
- Bestimmen Sie die menschlichen Aktivitäten und Stürze, die das System nach der Konfiguration erkennt. Es ist wichtig, den Zweck des Systems zur Erkennung von Stürzen und der Erkennung menschlicher Aktivitäten sowie die Zielpopulation im Auge zu behalten.
- Definieren Sie das Ziel des Fallerkennungs- und Aktivitätserkennungssystems. Notieren Sie es in einem Planungsblatt. Für diese Fallstudie besteht das Ziel darin, die Arten von menschlichen Stürzen und Aktivitäten zu klassifizieren, die täglich in innenräumeen Einrichtungen von älteren Menschen durchgeführt werden.
- Definieren Sie die Zielpopulation des Experiments entsprechend dem Ziel des Systems. Notieren Sie es im Planungsblatt. Berücksichtigen Sie in der Studie ältere Menschen als Zielbevölkerung.
- Bestimmen Sie die Art der täglichen Aktivitäten. Schließen Sie einige Nicht-Fall-Aktivitäten ein, die wie Stürze aussehen, um die echte Fallerkennung zu verbessern. Weisen Sie allen eine ID zu und beschreiben Sie sie so detailliert wie möglich. Legen Sie den Zeitraum für jede auszuführende Aktivität fest. Schreiben Sie alle diese Informationen in das Planungsblatt.
- Bestimmen Sie die Art der menschlichen Stürze. Weisen Sie allen eine ID zu und beschreiben Sie sie so detailliert wie möglich. Legen Sie den Zeitraum für jeden Fall fest, der ausgeführt werden soll. Überlegen Sie, ob die Stürze von den Probanden selbst generiert oder von anderen generiert werden (z. B. schieben des Subjekts). Schreiben Sie alle diese Informationen in das Planungsblatt.
- Notieren Sie im Planungsblatt die Sequenzen von Aktivitäten und Stürzen, die ein Betreff ausführen wird. Geben Sie den Zeitraum, die Anzahl der Versuche pro Aktivität/Fall, die Beschreibung zum Ausführen der Aktivität/Fall und die Aktivität/Fall-IDs an.
HINWEIS: Das Protokoll kann hier angehalten werden.
- Wählen Sie die relevanten Themen der Studie aus, die die Sequenzen von Aktivitäten und Stürzen ausführen. Stürze sind seltene Ereignisse im wirklichen Leben zu fangen und in der Regel für alte Menschen auftreten. Aus Sicherheitsgründen schließen ältere und behinderte Menschen jedoch in der Herbstsimulation unter ärztlicher Beratung nicht ein. Stunts wurden verwendet, um Verletzungen zu vermeiden22.
- Bestimmen Sie das Geschlecht, den Altersbereich, das Gewicht und die Körpergröße der Probanden. Definieren Sie alle erforderlichen Beeinträchtigungsbedingungen. Legen Sie außerdem die Mindestanzahl der Probanden fest, die für das Experiment erforderlich sind.
- Wählen Sie nach dem zufallszusichtun den Satz der erforderlichen Themen aus, und folgen Sie den im vorherigen Schritt angegebenen Bedingungen. Nutzen Sie einen Aufruf für Freiwillige, um sie zu rekrutieren. Erfüllen Sie alle ethischen Richtlinien, die von der Institution und dem Land gelten, sowie jede internationale Regulierung, wenn Sie mit Menschen experimentieren.
HINWEIS: Das Protokoll kann hier angehalten werden.
- Abrufen und Speichern von Daten von Personen. Diese Informationen werden für weitere experimentelle Analysen nützlich sein. Führen Sie die folgenden Schritte unter Aufsicht eines klinischen Sachverständigen oder eines verantwortlichen Forschers aus.
- Beginnen Sie mit dem Sammeln von Daten mit dem in Schritt 1.1 konfigurierten Datenerfassungssystem.
- Bitten Sie jeden der Probanden, die Sequenzen von Aktivitäten und Fällen auszuführen, die in Schritt 1.2 deklariert sind. Sparen Sie eindeutig die Zeitstempel des Anfangs und des Endes jeder Aktivität/Fall. Stellen Sie sicher, dass Daten aus allen Informationsquellen in der Cloud gespeichert werden.
- Wenn die Aktivitäten nicht ordnungsgemäß ausgeführt wurden oder Probleme mit Geräten (z. B. Verbindungsverlust, batteriearme, intermittierende Verbindung) auftraten, verwerfen Sie die Proben und wiederholen Sie Schritt 1.4.1, bis keine Geräteprobleme gefunden wurden. Wiederholen Sie Schritt 1.4.2 für jede Versuchszeit pro Versuch, die in der Reihenfolge von Schritt 1.2 deklariert wurde.
HINWEIS: Das Protokoll kann hier angehalten werden.
- Verarbeiten Sie alle erfassten Daten vorab. Wenden Sie Up-Sampling und Down-Sampling für jede der Informationsquellen an. Siehe Details zu Vorverarbeitungsdaten zur Sturzerkennung und zur Erkennung menschlicher Aktivitäten in Dermarténez-Villase-or et al.21.
HINWEIS: Das Protokoll kann hier angehalten werden.
2. Datenanalyse
- Wählen Sie die Art der Datenverarbeitung aus. Wählen Sie Rohdaten aus, wenn die in der Datenbank gespeicherten Daten direkt verwendet werden (d. h. Deep Learning für die automatische Feature-Extraktion verwenden) und gehen Sie zu Schritt 2.2. Wählen Sie Feature-Daten aus, wenn die Feature-Extraktion für die weitere Analyse verwendet wird, und fahren Sie mit Schritt 2.3 fort.
- Für Rohdatensind keine zusätzlichen Schritte erforderlich, also gehen Sie zu Schritt 2.5.
- Extrahieren Sie für Feature-DatenFeatures-Features aus den Rohdaten.
- Segmentieren Sie Rohdaten in Zeitfenstern. Bestimmen und fixieren Sie die Länge des Zeitfensters (z. B. Rahmen mit einer Sekunde Größe). Bestimmen Sie außerdem, ob sich diese Zeitfenster überlappen oder nicht. Eine gute Methode besteht darin, 50 % überlappend zu wählen.
- Extrahieren Sie Features aus jedem Datensegment. Bestimmen Sie den Satz von zeitlichen und häufigen Features, die aus den Segmenten extrahiert werden sollen. Siehe Martinez-Villase'or et al.21 für common feature extraction.
- Speichern Sie den Feature-Extraktionsdatensatz in der Cloud in einer unabhängigen Datenbank.
- Wenn unterschiedliche Zeitfenster ausgewählt werden, wiederholen Sie die Schritte 2.3.1 bis 2.3.3, und speichern Sie jeden Feature-Datensatz in unabhängigen Datenbanken.
HINWEIS: Das Protokoll kann hier angehalten werden.
- Wählen Sie die wichtigsten extrahierten Features aus, und reduzieren Sie den Feature-Datensatz. Wenden Sie einige häufig verwendete Feature-Selektionsmethoden an(z. B., univariate Auswahl, Hauptkomponentenanalyse, rekursive Feature-Eliminierung, Feature-Bedeutung, Korrelationsmatrix usw.).
- Wählen Sie eine Feature-Auswahlmethode aus. Hier haben wir Feature-Bedeutung verwendet.
- Verwenden Sie jedes Feature, um ein bestimmtes Modell zu trainieren (wir verwendeten RF) und messen Sie die Genauigkeit (siehe Gleichung 1).
- Ordnen Sie die Features nach Sortierung nach der Genauigkeit.
- Wählen Sie die wichtigsten Funktionen aus. Hier haben wir die bestplatzierten ersten zehn Features verwendet.
HINWEIS: Das Protokoll kann hier angehalten werden.
- Wählen Sie eine Klassifizierungsmethode für maschinelles Lernen aus, und trainieren Sie ein Modell. Es gibt bekannte machine Learning-Methoden16,17,18,21, wie z. B.: Unterstützung sVECTOR Maschinen (SVM), Random Forest (RF), Multilayer Perceptron (MLP) und k-nearest neighbors (KNN), unter vielen anderen.
- Optional, wenn ein Deep-Learning-Ansatz ausgewählt wird, dann betrachten21: convolutional neuronale Netzwerke (CNN), lange Kurzzeitgedächtnis neuronale Netzwerke (LSTM), unter anderem.
- Wählen Sie eine Reihe von Machine Learning-Methoden aus. Hier haben wir die folgenden Methoden verwendet: SVM, RF, MLP und KNN.
- Fixieren Sie die Parameter der einzelnen Machine Learning-Methoden, wie in Literatur21vorgeschlagen.
- Erstellen Sie einen kombinierten Feature-Datensatz (oder Rohdatensatz) mithilfe der unabhängigen Feature-Datensätze (oder Rohdatensätze), um Informationsquellentypen zu kombinieren. Wenn beispielsweise eine Kombination aus einem tragbaren Sensor und einer Kamera erforderlich ist, kombinieren Sie die Feature-Datensätze aus jeder dieser Quellen.
- Teilen Sie den Feature-Datensatz (oder Rohdatensatz) in Schulungs- und Testsätzen auf. Eine gute Wahl ist es, 70% für das Training und 30% für Tests nach dem Zufallsprinzip zu teilen.
- Führen Sie für jede Machine Learning-Methode eine k-fache Kreuzvalidierung21 mit dem Feature-Datensatz (oder Rohdatensatz) aus. Verwenden Sie eine gemeinsame Bewertungsmetrik, z. B. Genauigkeit (siehe Gleichung 1), um das am besten trainierte Modell pro Methode auszuwählen. Leave-One Subject-out (LOSO) Experimente3 werden ebenfalls empfohlen.
- Öffnen Sie den Trainingsfunktionsdatensatz (oder Rohdatensatz) in der bevorzugten Programmiersprachensoftware. Python wird empfohlen. Verwenden Sie für diesen Schritt die Pandas-Bibliothek, um eine CSV-Datei wie folgt zu lesen:
training_set = pandas.csv(). - Teilen Sie den Feature-Datensatz (oder Rohdatensatz) in Paare von Ein-Input-Outputs auf. Verwenden Sie beispielsweise Python, um die x-Werte (Eingänge) und die y-Werte (Ausgänge) zu deklarieren:
training_set_X = training_set.drop('tag',axis=1), training_set_Y = training_set.tag
wobei das Tag die Spalte des Feature-Datensatzes darstellt, der die Zielwerte enthält. - Wählen Sie eine Machine Learning-Methode aus, und legen Sie die Parameter fest. Verwenden Sie z. B. SVM in Python mit der Bibliothek sklearn wie folgt:
Klassifier = sklearn. SVC(kernel = 'poly')
in dem die Kernelfunktion als Polynom ausgewählt ist. - Trainieren Sie das Machine Learning-Modell. Verwenden Sie beispielsweise den obigen Klassifier in Python, um das SVM-Modell zu trainieren:
classifier.fit(training_set_X,training_set_Y). - Berechnen Sie die Schätzwerte des Modells mithilfe des Test-Feature-Datensatzes (oder des Rohdatensatzes). Verwenden Sie beispielsweise die Vorkalkulationsfunktion in Python wie folgt: estimates = classifier.predict(testing_set_X), wobei testing_set_X die x-Werte des Testsatzes darstellt.
- Wiederholen Sie die Schritte 2.5.6.1 bis 2.5.6.5, die Anzahl der in der k-falten Kreuzvalidierung angegebenen Zeiten (oder die Anzahl der für den LOSO-Ansatz erforderlichen Zeiten).
- Wiederholen Sie die Schritte 2.5.6.1 bis 2.5.6.6 für jedes ausgewählte Machine Learning-Modell.
HINWEIS: Das Protokoll kann hier angehalten werden.
- Öffnen Sie den Trainingsfunktionsdatensatz (oder Rohdatensatz) in der bevorzugten Programmiersprachensoftware. Python wird empfohlen. Verwenden Sie für diesen Schritt die Pandas-Bibliothek, um eine CSV-Datei wie folgt zu lesen:
- Vergleichen Sie die Machine Learning-Methoden, indem Sie die ausgewählten Modelle mit dem Testdatensatz testen. Andere Metriken der Auswertung können verwendet werden: Genauigkeit (Gleichung 1), Genauigkeit (Gleichung 2), Empfindlichkeit ( Gleichung3), Spezifität (Gleichung 4) oder F1-Score ( Gleichung5), wobei TP die wahren Positiven sind, TN die wahren Negative sind, FP sind die falschen Positivwerte und FN sind die falschen Negative.





- Verwenden Sie andere vorteilhafte Leistungsmetriken, wie z. B. die Verwechslungsmatrix9, um die Klassifizierungsaufgabe der Machine Learning-Modelle oder eine entscheidungsunabhängige Präzisions-Rückruf-9(PR) oder Empfänger-Betriebskennlinie9 (ROC) zu bewerten.9 In dieser Methodik werden Rückruf und Empfindlichkeit als gleichwertig angesehen.
- Verwenden Sie qualitative Funktionen der Machine Learning-Modelle, um zwischen ihnen zu vergleichen, wie z. B.: einfache Interpretation des maschinellen Lernens; Echtzeit-Performance; begrenzte Ressourcen für Zeit, Speicher und Verarbeitungs-Computing; und einfache Bereitstellung von Machine Learning in Edge-Geräten oder eingebetteten Systemen.
- Wählen Sie das beste Machine Learning-Modell aus den Informationen aus: Die Qualitätsmetriken (Gleichungen 1–5), die Leistungsmetriken und die qualitativen Merkmale der Machine Learning-Machbarkeit der Schritte 2.5.6, 2.5.7 und 2.5.8.
HINWEIS: Das Protokoll kann hier angehalten werden.
3. Systemvereinfachung
- Wählen Sie die geeigneten Platzierungen von Informationsquellen aus. Manchmal ist es notwendig, die beste Platzierung von Informationsquellen zu bestimmen (z. B. welche Position eines tragbaren Sensors besser ist).
- Bestimmen Sie die Teilmenge der Informationsquellen, die analysiert werden sollen. Wenn sich beispielsweise fünf tragbare Sensoren im Körper befinden und nur einer als bester Sensor ausgewählt werden muss, ist jeder dieser Sensoren Teil der Teilmenge.
- Erstellen Sie für jede Informationsquelle in dieser Teilmenge einen separaten Datensatz, und speichern Sie ihn separat. Beachten Sie, dass es sich bei diesem Datensatz entweder um den vorherigen Feature-Datensatz oder den Rohdatensatz handelt.
HINWEIS: Das Protokoll kann hier angehalten werden.
- Wählen Sie eine Klassifizierungsmethode für maschinelles Lernen aus, und trainieren Sie ein Modell für eine Informationsquelle. Führen Sie die Schritte von 2.5.1 bis 2.5.6 mit jedem der in Schritt 3.1.2 erstellten Datensätze aus. Erkennen Sie die am besten geeignete Informationsquelle durch Ranking. Für diese Fallstudie verwenden wir die folgenden Methoden: SVM, RF, MLP und KNN.
Hinweis: Das Protokoll kann hier angehalten werden. - Wählen Sie die geeigneten Platzierungen in einem multimodalen Ansatz aus, wenn eine Kombination aus zwei oder mehr Informationsquellen für das System erforderlich ist (z. B. Kombination aus einem tragbaren Sensor und einer Kamera). Verwenden Sie in dieser Fallstudie den hüfttragbaren Sensor und die Kamera 1 (Seitenansicht) als Modalitäten.
- Wählen Sie die beste Informationsquelle für jede Modalität im System aus, und erstellen Sie einen kombinierten Feature-Datensatz (oder Rohdatensatz) mit den unabhängigen Datensätzen dieser Informationsquellen.
- Wählen Sie eine Klassifizierungsmethode für maschinelles Lernen aus, und trainieren Sie ein Modell für diese kombinierten Informationsquellen. Führen Sie die Schritte 2.5.1 bis 2.5.6 mit dem kombinierten Feature-Datensatz (oder Rohdatensatz) aus. Verwenden Sie in dieser Studie die folgenden Methoden: SVM, RF, MLP und KNN.
HINWEIS: Das Protokoll kann hier angehalten werden.
4. Bewertung
- Bereiten Sie einen neuen Datensatz mit Benutzern unter realistischeren Bedingungen vor. Verwenden Sie nur die im vorherigen Schritt ausgewählten Informationsquellen. Vorzugsweise ist es, das System in der Zielgruppe (z.B. ältere Menschen) umzusetzen. Sammeln Sie Daten in längeren Zeiträumen.
- Optional, wenn die Zielgruppe nur verwendet wird, erstellen Sie ein Auswahlgruppenprotokoll mit den Ausschlussbedingungen (z. B. körperliche oder psychische Beeinträchtigungen) und stoppen Sie die Prävention von Kriterien (z. B. Erkennung von körperlichen Verletzungen während der Studien; Übelkeit, Schwindel und/oder Erbrechen; Ohnmacht). Berücksichtigen Sie auch ethische Bedenken und Datenschutzfragen.
- Bewerten Sie die Leistung des bisher entwickelten Fallerkennungs- und Humanaktivitätserkennungssystems. Verwenden Sie Gleichungen 1–5, um die Genauigkeit und Vorhersageleistung des Systems oder anderer Leistungsmetriken zu bestimmen.
- Diskutieren Sie über die Ergebnisse der experimentellen Ergebnisse.
Ergebnisse
Erstellung einer Datenbank
Wir haben einen multimodalen Datensatz für die Sturzerkennung und die Erkennung menschlicher Aktivitäten erstellt, nämlich UP-Fall Detection21. Die Daten wurden über einen Zeitraum von vier Wochen an der School of Engineering der Universidad Panamericana (Mexiko-Stadt, Mexiko) gesammelt. Das Testszenario wurde unter Berücksichtigung der folgenden Anforderungen ausgewählt: a) ein Raum, in dem die Probanden Stürze und Aktivitäten bequem und sicher durchführen können, und (b) eine Innenumgebung mit natürlichem und künstlichem Licht, die sich gut für multimodale Sensoren eignet.
Es gibt Datenproben von 17 Probanden, die 5 Arten von Stürzen und 6 verschiedene einfache Aktivitäten durchgeführt haben, während 3 Studien. Alle Informationen wurden mit einem internen Datenerfassungssystem mit 5 tragbaren Sensoren (Tri-Achsen-Beschleunigungsmesser, Gyroskop und Lichtintensität), 1 Elektroenzephalographenhelm, 6 Infrarotsensoren als Umgebungssensoren und 2 Kameras an seitlichen und vorderen Aussichtspunkten gesammelt. Abbildung 1 zeigt das Layout der Sensorplatzierung in der Umgebung und auf dem Körper. Die Abtastrate des gesamten Datensatzes beträgt 18 Hz. Die Datenbank enthält zwei Datensätze: den konsolidierten Rohdatensatz (812 GB) und einen Feature-Datensatz (171 GB). Alle Datenbanken, die in der Cloud für den öffentlichen Zugriff gespeichert sind: https://sites.google.com/up.edu.mx/har-up/. Weitere Details zur Datenerfassung, Vorverarbeitung, Konsolidierung und Speicherung dieser Datenbank sowie Details zur Synchronisation und Datenkonsistenz finden Sie in der Unterkunft Martinez-Villase'or et al.21.
Für diese Datenbank waren alle Probanden gesunde junge Freiwillige (9 Männer und 8 Frauen) ohne Beeinträchtigung, im Alter von 18 bis 24 Jahren, mit einer mittleren Körpergröße von 1,66 m und einem Mittleren Gewicht von 66,8 kg. Während der Datenerhebung überwachte der technisch verantwortliche Forscher, ob alle Aktivitäten von den Probanden korrekt durchgeführt wurden. Die Probanden führten fünf Arten von Stürzen durch, jede für 10 Sekunden, als fallend: vorwärts mit Denkhänden (1), vorwärts mit Knien (2), rückwärts (3), sitzend in einem leeren Stuhl (4) und seitlich (5). Sie führten auch sechs tägliche Aktivitäten für 60 s mit Ausnahme des Springens (30 s): Gehen (6), Stehen (7), Aufheben eines Gegenstandes (8), Sitzen (9), Springen (10) und Legen (11). Obwohl simulierte Stürze nicht alle Arten von realen Stürzen reproduzieren können, ist es wichtig, zumindest repräsentative Fallarten einzubeziehen, die die Erstellung besserer Fallerkennungsmodelle ermöglichen. Es ist auch relevant, ADLs und insbesondere Aktivitäten zu verwenden, die in der Regel mit Stürzen verwechselt werden können, wie z. B. das Aufnehmen eines Objekts. Die Arten von Fall- und ADLs wurden nach einer Überprüfung der zugehörigen Fallerkennungssysteme21ausgewählt. Beispiel: Abbildung 2 zeigt eine Abfolge von Bildern einer Studie, wenn ein Motiv seitlich fällt.
Wir extrahierten 12 zeitliche (Mittelwert, Standardabweichung, maximale Amplitude, minimale Amplitude, Wurzelmittelquadrat, Median, Null-Kreuzungszahl, Schiefe, Kurtose, erstes Quartil, drittes Quartil und Autokorrelation) und 6 häufige (Mittelwert, Median, Entropie, Energie, Hauptfrequenz und Spektralzentroid) verfügt über21 aus jedem Kanal des tragbaren und Umgebungssensoren mit insgesamt 756 Features. Wir berechneten auch 400 visuelle Features21 für jede Kamera über die relative Bewegung von Pixeln zwischen zwei benachbarten Bildern in den Videos.
Datenanalyse zwischen unimodalen und multimodalen Ansätzen
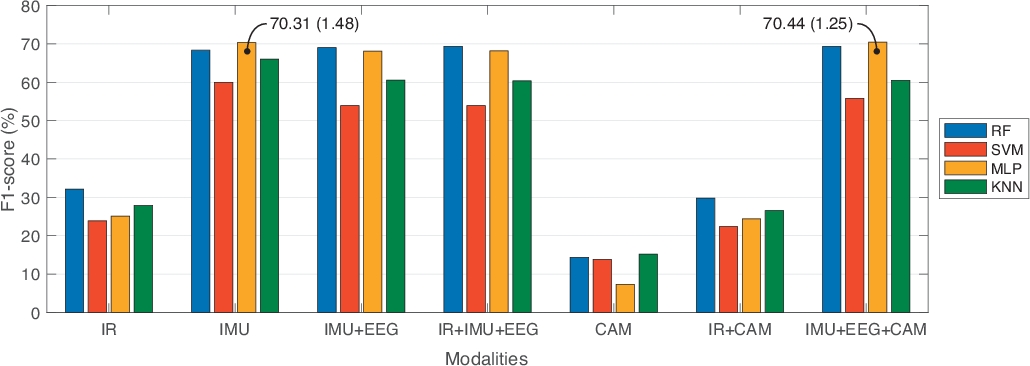
Aus der UP-Fall Detection-Datenbank analysierten wir die Daten zu Vergleichszwecken zwischen unimodalen und multimodalen Ansätzen. In diesem Sinne haben wir sieben verschiedene Kombinationen von Informationsquellen verglichen: nur Infrarotsensoren (IR); Nur tragbare Sensoren (IMU); tragbare Sensoren und Helm (IMU+EEG); Infrarot- und tragbare Sensoren und Helm (IR+IMU+EEG); Kameras (NUR CAM); Infrarotsensoren und Kameras (IR+CAM); und tragbare Sensoren, Helm und Kameras (IMU+EEG+CAM). Darüber hinaus haben wir drei verschiedene Zeitfenstergrößen mit 50% Überlappung verglichen: eine Sekunde, zwei Sekunden und drei Sekunden. In jedem Segment haben wir die nützlichsten Features ausgewählt, die die Feature-Auswahl und -Rangfolge anwenden. Mit dieser Strategie haben wir nur 10 Features pro Modalität verwendet, außer in der IR-Modalität mit 40 Funktionen. Darüber hinaus wurde der Vergleich über vier bekannte Machine Learning-Klassifikatoren durchgeführt: RF, SVM, MLP und KNN. Wir verwendeten 10-fache Kreuzvalidierung mit Datensätzen von 70% Zug und 30% Test, um die Machine Learning-Modelle zu trainieren. Tabelle 1 zeigt die Ergebnisse dieses Benchmarks und meldet die beste Leistung, die je nach Machine Learning-Modell und der besten Fensterlängenkonfiguration für jede Modalität erzielt wurde. Die Auswertungsmetriken berichten über Genauigkeit, Genauigkeit, Empfindlichkeit, Spezifität und F1-Score. Abbildung 3 zeigt diese Ergebnisse in einer grafischen Darstellung in Bezug auf F1-Score.
Aus Tabelle 1, multimodale Ansätze (Infrarot- und tragbare Sensoren und Helm, IR+IMU +EEG; und tragbare Sensoren und Helm und Kameras, IMU + EEG +CAM) erhielt die besten F1-Score-Werte, im Vergleich zu unimodalen Ansätzen (nur Infrarot, IR; und Kameras nur, CAM). Wir haben auch festgestellt, dass nur tragbare Sensoren (IMU) eine ähnliche Leistung erreicht haben wie ein multimodaler Ansatz. In diesem Fall haben wir uns für einen multimodalen Ansatz entschieden, da verschiedene Informationsquellen die Einschränkungen von anderen handhaben können. Beispielsweise kann die Aufdringlichkeit von Kameras mit tragbaren Sensoren gehandhabt werden, und nicht alle tragbaren Sensoren können durch Kameras oder Umgebungssensoren ergänzt werden.
In Bezug auf den Benchmark der datengesteuerten Modelle zeigten die Experimente in Tabelle 1, dass RF in fast allen Experimenten die besten Ergebnisse liefert; während MLP und SVM in der Leistung nicht sehr konsistent waren (z. B. zeigt die Standardabweichung in diesen Techniken eine größere Variabilität als bei RF). Über die Fenstergrößen, diese keine wesentliche Verbesserung unter ihnen darstellen. Es ist wichtig zu beachten, dass diese Experimente für die Klassifizierung der menschlichen Aktivitäten durchgeführt wurden.
Sensorplatzierung und beste multimodale Kombination
Auf der anderen Seite wollten wir die beste Kombination von multimodalen Geräten für die Sturzerkennung ermitteln. Für diese Analyse beschränkten wir die Informationsquellen auf die fünf tragbaren Sensoren und die beiden Kameras. Diese Geräte sind die bequemsten für den Ansatz. Darüber hinaus haben wir zwei Klassen in Betracht gezogen: Fall (jede Art von Sturz) oder No-Fall (jede andere Aktivität). Alle Machine Learning-Modelle und Fenstergrößen bleiben die gleichen wie in der vorherigen Analyse.
Für jeden tragbaren Sensor haben wir für jede Fensterlänge ein unabhängiges Klassifikatsmodell erstellt. Wir haben das Modell mit 10-facher Kreuzvalidierung mit 70% Training und 30% Testing-Datensätzen trainiert. Tabelle 2 fasst die Ergebnisse für die Rangfolge der tragbaren Sensoren pro Leistungsklassifikum auf basis des F1-Scores zusammen. Diese Ergebnisse wurden in absteigender Reihenfolge sortiert. Wie in Tabelle 2zu sehen, wird die beste Leistung erzielt, wenn ein einzelner Sensor an der Taille, im Nacken oder in der engen rechten Tasche (Schattenbereich) verwendet wird. Darüber hinaus schnitten tragbare Sensoren für Knöchel und linkes Handgelenk am schlechtesten ab. Tabelle 3 zeigt die Fensterlängenpräferenz pro tragbarem Sensor, um die beste Leistung in jedem Klassifikatzusteller zu erzielen. Aus den Ergebnissen sind Taille, Hals und enge rechte Taschensensoren mit RF-Klassifikater und 3 s Fenstergröße mit 50% Überlappung die am besten geeigneten tragbaren Sensoren für die Sturzerkennung.
Wir haben eine ähnliche Analyse für jede Kamera im System durchgeführt. Wir haben für jede Fenstergröße ein unabhängiges Klassifiermodell erstellt. Für die Schulung haben wir eine 10-fache Kreuzvalidierung mit 70% Schulungen und 30% Testdatensätzen durchgeführt. Tabelle 4 zeigt die Rangfolge des besten Kamera-Ansichtspunktes pro Klassifier, basierend auf dem F1-Score. Wie beobachtet, führte die seitliche Ansicht (Kamera 1) die beste Fallerkennung durch. Darüber hinaus übertraf RF im Vergleich zu den anderen Klassifikatoren. Außerdem zeigt Tabelle 5 die Fensterlängeneinstellung pro Kameraansicht an. Aus den Ergebnissen, fanden wir, dass die beste Position einer Kamera ist in seitlichen Standpunkt mit RF in 3 s Fenstergröße und 50% Überlappung.
Schließlich haben wir zwei mögliche Platzierungen von tragbaren Sensoren (d. h. Taille und enge rechte Tasche) gewählt, die mit der Kamera des seitlichen Standpunkts kombiniert werden sollen. Nach dem gleichen Training haben wir die Ergebnisse aus Tabelle 6erhalten. Wie gezeigt, erhielt der RF-Modellklassifier die beste Leistung in Genauigkeit und F1-Score in beiden Multimodalitäten. Auch die Kombination zwischen Taille und Kamera 1 rangierte an der ersten Position und erhielt 98,72% in der Genauigkeit und 95,77% in F1-Score.

Abbildung 1: Layout der tragbaren (links) und Umgebungssensoren (rechts) in der UP-Fall Detection-Datenbank. Die tragbaren Sensoren sind in der Stirn, dem linken Handgelenk, dem Hals, der Taille, der rechten Tasche der Hose und dem linken Knöchel platziert. Die Umgebungssensoren sind sechs gekoppelte Infrarotsensoren, um das Vorhandensein von Probanden und zwei Kameras zu erkennen. Kameras befinden sich an der Seitlichen Ansicht und an der Frontansicht, sowohl in Bezug auf den menschlichen Sturz. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}

Abbildung 2: Beispiel für eine Videoaufzeichnung, die aus der UP-Fall Detection-Datenbank extrahiert wurde. Oben befindet sich eine Abfolge von Bildern eines Themas, das nach einander fällt. Am unteren Rand befindet sich eine Abfolge von Bildern, die die extrahierten Sehelemente darstellen. Diese Features sind die relative Bewegung von Pixeln zwischen zwei benachbarten Bildern. Weiße Pixel stellen eine schnellere Bewegung dar, während schwarze Pixel eine langsamere (oder nahe Null) Bewegung darstellen. Diese Reihenfolge ist chronologisch von links nach rechts sortiert. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}

Abbildung 3: Vergleichsergebnisse, die den besten F1-Score jeder Modalität in Bezug auf das Machine Learning-Modell und die beste Fensterlänge melden. Balken stellen die Mittelwerte von F1-Score dar. Text in Datenpunkten stellen Mittelwert und Standardabweichung in Klammern dar. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}
| Modalität | Modell | Genauigkeit (%) | Präzision (%) | Empfindlichkeit (%) | Spezifität (%) | F1-Wert (%) |
| Ir | HF (3 Sek.) | 67,38 bei 0,65 | 36,45 € 2,46 | 31,26 € 0,89 | 96,63 € 0,07 | 32,16 € 0,99 |
| SVM (3 Sek.) | 65,16 € 0,90 | 26,77 € 0,58 | 25,16 € 0,29 | 96,31 € 0,09 | 23,89 € 0,41 | |
| MLP (3 Sek.) | 65,69 € 0,89 | 28,19 € 3,56 | 26,40 € 0,71 | 96,41 € 0,08 | 25,13 € 1,09 | |
| kNN (3 Sek.) | 61,79 € 1,47 | 30,04 € 1,44 | 27,55 € 0,97 | 96,05 € 0,16 | 27,89 € 1,13 | |
| Imu | HF (1 Sek.) | 95,76 € 0,18 | 70,78 € 1,53 | 66,91 € 1,28 | 99,59 € 0,02 | 68,35 € 1,25 |
| SVM (1 Sek.) | 93,32 € 0,23 | 66,16 € 3,33 | 58,82 € 1,53 | 99,32 € 0,02 | 60,00 € 1,34 | |
| MLP (1 Sek.) | 95,48 € 0,25 | 73,04 € 1,89 | 69,39 € 1,47 | 99,56 € 0,02 | 70,31 € 1,48 | |
| kNN (1 Sek.) | 94,90 € 0,18 | 69,05 € 1,63 | 64,28 € 1,57 | 99,50 € 0,02 | 66,03 € 1,52 | |
| IMU+EEG | HF (1 Sek.) | 95,92 € 0,29 | 74,14 € 1,29 | 66,29 € 1,66 | 99,59 € 0,03 | 69,03 € 1,48 |
| SVM (1 Sek.) | 90,77 € 0,36 | 62,51 € 3,34 | 52,46 € 1,19 | 99,03 € 0,03 | 53,91 € 1,16 | |
| MLP (1 Sek.) | 93,33 € 0,55 | 74,10 € 1,61 | 65,32 € 1,15 | 99,32 € 0,05 | 68,13 € 1,16 | |
| kNN (1 Sek.) | 92,12 € 0,31 | 66,86 € 1,32 | 58,30 € 1,20 | 98,89 € 0,05 | 60,56 € 1,02 | |
| IR+IMU+EEG | HF (2 Sek.) | 95,12 € 0,36 | 74,63 € 1,65 | 66,71 € 1,98 | 99,51 € 0,03 | 69,38 € 1,72 |
| SVM (1 Sek.) | 90,59 € 0,27 | 64,75 € 3,89 | 52,63 € 1,42 | 99,01 € 0,02 | 53,94 € 1,47 | |
| MLP (1 Sek.) | 93,26 € 0,69 | 73,51 € 1,59 | 66,05 € 1,11 | 99,31 € 0,07 | 68,19 € 1,02 | |
| kNN (1 Sek.) | 92,24 € 0,25 | 67,33 € 1,94 | 58,11 € 1,61 | 99,21 € 0,02 | 60,36 € 1,71 | |
| Cam | HF (3 Sek.) | 32,33 € 0,90 | 14,45 € 1,07 | 14,48 bei 0,82 | 92,91 € 0,09 | 14,38 € 0,89 |
| SVM (2 Sek.) | 34,40 € 0,67 | 13,81 € 0,22 | 14,30 x 0,31 | 92,97 € 0,06 | 13,83 € 0,27 | |
| MLP (3 Sek.) | 27,08 € 2,03 | 8,59 x 1,69 | 10,59 € 0,38 | 92,21 € 0,09 | 7,31 x 0,82 | |
| kNN (3 Sek.) | 34,03 € 1,11 | 15,32 € 0,73 | 15,54 € 0,57 | 93,09 € 0,11 | 15,19 € 0,52 | |
| IR+CAM | HF (3 Sek.) | 65,00 € 0,65 | 33,93 € 2,81 | 29,02 € 0,89 | 96,34 € 0,07 | 29,81 € 1,16 |
| SVM (3 Sek.) | 64,07 € 0,79 | 24,10 € 0,98 | 24,18 € 0,17 | 96,17 € 0,07 | 22,38 € 0,23 | |
| MLP (3 Sek.) | 65,05 € 0,66 | 28,25 € 3,20 | 25,40 € 0,51 | 96,29 € 0,06 | 24,39 € 0,88 | |
| kNN (3 Sek.) | 60,75 € 1,29 | 29,91 € 3,95 | 26,25 € 0,90 | 95,95 € 0,11 | 26,54 € 1,42 | |
| IMU+EEG+CAM | HF (1 Sek.) | 95,09 € 0,23 | 75,52 € 2,31 | 66,23 € 1,11 | 99,50 € 0,02 | 69,36 € 1,35 |
| SVM (1 Sek.) | 91,16 € 0,25 | 66,79 € 2,79 | 53,82 € 0,70 | 99,07 € 0,02 | 55,82 € 0,77 | |
| MLP (1 Sek.) | 94,32 € 0,31 | 76,78 € 1,59 | 67,29 € 1,41 | 99,42 € 0,03 | 70,44 € 1,25 | |
| kNN (1 Sek.) | 92,06 € 0,24 | 68,82 € 1,61 | 58,49 € 1,14 | 99,19 € 0,02 | 60,51 € 0,85 |
Tabelle 1: Vergleichsergebnisse, die die beste Leistung jeder Modalität in Bezug auf das Machine Learning-Modell und die beste Fensterlänge (in Klammern) melden. Alle Werte in der Leistung stellen den Mittelwert und die Standardabweichung dar.
| # | IMU-Typ | |||
| Rf | Svm | Mlp | Knn | |
| 1 | (98.36) Taille | (83.30) Rechte Tasche | (57.67) Rechte Tasche | (73.19) Rechte Tasche |
| 2 | (95.77) Hals | (83.22) Taille | (44.93) Hals | (68.73) Taille |
| 3 | (95.35) Rechte Tasche | (83.11) Hals | (39.54) Taille | (65.06) Hals |
| 4 | (95.06) Knöchel | (82.96) Knöchel | (39.06) Linkes Handgelenk | (58.26) Knöchel |
| 5 | (94.66) Linkes Handgelenk | (82.82) Linkes Handgelenk | (37.56) Knöchel | (51.63) Linkes Handgelenk |
Tabelle 2: Rangfolge des besten tragbaren Sensors pro Klassifikater, sortiert nach dem F1-Score (in Klammern). Die Bereiche im Schatten stellen die drei wichtigsten Klassifikatoren für die Sturzerkennung dar.
| IMU-Typ | Fensterlänge | |||
| Rf | Svm | Mlp | Knn | |
| Linker Knöchel | 2 Sek. | 3 Sek. | 1 Sek. | 3 Sek. |
| Taille | 3 Sek. | 1 Sek. | 1 Sek. | 2 Sek. |
| Hals | 3 Sek. | 3 Sek. | 2 Sek. | 2 Sek. |
| Rechte Tasche | 3 Sek. | 3 Sek. | 2 Sek. | 2 Sek. |
| Linkes Handgelenk | 2 Sek. | 2 Sek. | 2 Sek. | 2 Sek. |
Tabelle 3: Bevorzugte Zeitfensterlänge in den tragbaren Sensoren pro Klassifikater.
| # | Kameraansicht | |||
| Rf | Svm | Mlp | Knn | |
| 1 | (62.27) Seitenansicht | (24.25) Seitenansicht | (13.78) Frontansicht | (41.52) Seitenansicht |
| 2 | (55.71) Frontansicht | (0.20) Frontansicht | (5.51) Seitenansicht | (28.13) Frontansicht |
Tabelle 4: Rangfolge des besten Kamera-Ansichtspunktes pro Klassifier, sortiert nach dem F1-Score (in Klammern). Die Bereiche im Schatten stellen den obersten Klassifier für die Sturzerkennung dar.
| Kamera | Fensterlänge | |||
| Rf | Svm | Mlp | Knn | |
| Seitenansicht | 3 Sek. | 3 Sek. | 2 Sek. | 3 Sek. |
| Frontansicht | 2 Sek. | 2 Sek. | 3 Sek. | 2 Sek. |
Tabelle 5: Bevorzugte Zeitfensterlänge in den Kamera-Ansichtspunkten pro Klassifier.
| Multimodale | Klassifizierung | Genauigkeit (%) | Präzision (%) | Empfindlichkeit (%) | F1-Wert (%) |
| Taille + Seitenansicht | Rf | 98,72 € 0,35 | 94,01 € 1,51 | 97,63 € 1,56 | 95,77 € 1,15 |
| Svm | 95,59 € 0,40 | 100 | 70,26 € 2,71 | 82,51 € 1,85 | |
| Mlp | 77,67 € 11,04 | 33,73 € 11,69 | 37,11 € 26,74 | 29,81 € 12,81 | |
| Knn | 91,71 € 0,61 | 77,90 € 3,33 | 61,64 € 3,68 | 68,73 € 2,58 | |
| Rechte Tasche + Seitenansicht | Rf | 98,41 € 0,49 | 93,64 € 1,46 | 95,79 € 2,65 | 94,69 € 1,67 |
| Svm | 95,79 € 0,58 | 100 | 71,58 € 3,91 | 83,38 € 2,64 | |
| Mlp | 84,92 € 2,98 | 55,70 bei 11,36 | 48,29 € 25,11 | 45,21 € 14,19 | |
| Knn | 91,71 € 0,58 | 73,63 € 3,19 | 68,95 € 2,73 | 71,13 € 1,69 |
Tabelle 6: Vergleichsergebnisse des kombinierten tragbaren Sensors und Kamera-Ansichtsbilds mit 3-Sekunden-Fensterlänge. Alle Werte stellen den Mittelwert und die Standardabweichung dar.
Diskussion
Es ist üblich, dass beim Erstellen eines Datasets Probleme aufgrund von Synchronisierungs-, Organisations- und Dateninkonsistenzproblemen20 auftreten.
Synchronisierung
Bei der Datenerfassung treten Synchronisierungsprobleme auf, da mehrere Sensoren häufig mit unterschiedlichen Abtastraten arbeiten. Sensoren mit höheren Frequenzen erfassen mehr Daten als Sensoren mit niedrigeren Frequenzen. Daher werden Daten aus verschiedenen Quellen nicht korrekt gekoppelt. Selbst wenn Sensoren mit den gleichen Abtastraten laufen, ist es möglich, dass die Daten nicht ausgerichtet werden. In diesem Zusammenhang könnten die folgenden Empfehlungen helfen, diese Synchronisierungsprobleme zu behandeln20:(i) Erfassung von Zeitstempel, Betreff, Aktivität und Versuch in jeder Datenstichprobe, die von den Sensoren erhalten wird; ii) die konsistenteste und weniger häufige Informationsquelle als Referenzsignal für die Synchronisierung verwendet werden muss; und (iii) automatische oder halbautomatische Verfahren verwenden, um Videoaufzeichnungen zu synchronisieren, die eine manuelle Inspektion unpraktisch wären.
Datenvorverarbeitung
Die Datenvorverarbeitung muss ebenfalls erfolgen, und kritische Entscheidungen beeinflussen diesen Prozess: (a) bestimmen Die Methoden für die Datenspeicherung und Datendarstellung mehrerer und heterogener Quellen (b) entscheiden, wie Daten auf dem lokalen Host oder in der Cloud gespeichert werden können (c) wählen Sie die Organisation der Daten, einschließlich der Dateinamen und Ordner (d) und behandeln sie fehlende Datenwerte sowie Redundanzen in den Sensoren , unter anderem. Darüber hinaus wird für die Datenwolke nach Möglichkeit eine lokale Pufferung empfohlen, um datenverlust zum Hochladezeitpunkt zu verringern.
Dateninkonsistenz
Dateninkonsistenzen sind häufig zwischen Versuchen, bei der Abweichungen in der Datenstichprobengröße festgestellt werden. Diese Probleme stehen im Zusammenhang mit der Datenerfassung in tragbaren Sensoren. Kurze Unterbrechungen der Datenerfassung und Datenkollision durch mehrere Sensoren führen zu Dateninkonsistenzen. In diesen Fällen sind Algorithmen zur Inkonsistenzerkennung wichtig, um Onlinefehler in Sensoren zu behandeln. Es ist wichtig zu betonen, dass drahtlose Geräte während des gesamten Experiments häufig überwacht werden sollten. Eine niedrige Batterie kann die Konnektivität beeinträchtigen und zu Datenverlusten führen.
Ethisch
Die Zustimmung zur Teilnahme und die ethische Genehmigung sind bei jeder Art von Experimenten, an denen Menschen beteiligt sind, obligatorisch.
Hinsichtlich der Grenzen dieser Methodik ist es wichtig zu beachten, dass sie für Ansätze konzipiert ist, die unterschiedliche Modalitäten für die Datenerhebung berücksichtigen. Die Systeme können tragbare, Umgebungs- und/oder Visionssensoren enthalten. Es wird vorgeschlagen, den Stromverbrauch von Geräten und die Lebensdauer von Batterien in drahtlosen Sensoren zu berücksichtigen, aufgrund von Problemen wie Verlust der Datenerfassung, abnehmender Konnektivität und Stromverbrauch im gesamten System. Darüber hinaus ist diese Methode für Systeme gedacht, die maschinelle Lernmethoden verwenden. Eine Analyse der Auswahl dieser Machine Learning-Modelle sollte im Voraus durchgeführt werden. Einige dieser Modelle könnten genau sein, aber sehr zeit- und energieaufwendig. Ein Kompromiss zwischen genauer Schätzung und begrenzter Ressourcenverfügbarkeit für die Datenverarbeitung in Machine Learning-Modellen muss berücksichtigt werden. Es ist auch wichtig zu beachten, dass bei der Datenerhebung des Systems die Tätigkeiten in der gleichen Reihenfolge durchgeführt wurden; auch wurden Versuche in der gleichen Reihenfolge durchgeführt. Aus Sicherheitsgründen wurde eine Schutzmatratze verwendet, auf die die Probanden fallen können. Darüber hinaus wurden die Stürze selbst initiiert. Dies ist ein wichtiger Unterschied zwischen simulierten und realen Stürzen, die in der Regel in Richtung harter Materialien auftreten. In diesem Sinne fällt dieser aufgezeichnete Datensatz mit einer intuitiven Reaktion, die versucht, nicht zu fallen. Darüber hinaus gibt es einige Unterschiede zwischen realen Rückgängen bei älteren oder behinderten Menschen und den Simulationsrückgängen; und diese müssen bei der Entwicklung eines neuen Fallerkennungssystems berücksichtigt werden. Diese Studie konzentrierte sich auf junge Menschen ohne Beeinträchtigungen, aber es ist bemerkenswert zu sagen, dass die Auswahl der Probanden an das Ziel des Systems und die Zielgruppe, die es verwenden wird, ausgerichtet werden sollte.
Aus den oben beschriebenen Verwandten10,11,12,13,14,15,16,17,18, können wir beobachten, dass es Autoren gibt, die multimodale Ansätze verwenden, die sich auf die Erlangung robuster Falldetektoren konzentrieren oder sich auf die Platzierung oder Leistung des Klassifiierers konzentrieren. Daher behandeln sie nur ein oder zwei der Designprobleme für die Sturzerkennung. Unsere Methodik ermöglicht die gleichzeitige Lösung von drei der wichtigsten Konstruktionsprobleme eines Fallerkennungssystems.
Für zukünftige Arbeiten schlagen wir die Entwicklung und Implementierung eines einfachen multimodalen Fallerkennungssystems auf der Grundlage der ergebnisse, die nach dieser Methodik erzielt wurden, vor. Für die reale Akzeptanz sollten Transfer-Learning, hierarchische Klassifizierungunden und Deep Learning-Ansätze für die Entwicklung robusterer Systeme verwendet werden. Bei unserer Implementierung wurden keine qualitativen Metriken der Machine Learning-Modelle berücksichtigt, aber Echtzeit- und begrenzte Rechenressourcen müssen bei der Weiterentwicklung von Systemen zur Erkennung/Erkennung von Aktivitäten berücksichtigt werden. Schließlich können zur Verbesserung unseres Datensatzes, Stolpern oder fast sinkende Aktivitäten und Echtzeitüberwachung von Freiwilligen während ihres täglichen Lebens in Betracht gezogen werden.
Offenlegungen
Die Autoren haben nichts zu verraten.
Danksagungen
Diese Forschung wurde von der Universidad Panamericana durch das Stipendium "Fomento a la Investigacion UP 2018" unter dem Projektcode UP-CI-2018-ING-MX-04 finanziert.
Materialien
| Name | Company | Catalog Number | Comments |
| Inertial measurement wearable sensor | Mbientlab | MTH-MetaTracker | Tri-axial accelerometer, tri-axial gyroscope and light intensity wearable sensor. |
| Electroencephalograph brain sensor helmet MindWave | NeuroSky | 80027-007 | Raw brainwave signal with one forehand sensor. |
| LifeCam Cinema video camera | Microsoft | H5D-00002 | 2D RGB camera with USB cable interface. |
| Infrared sensor | Alean | ABT-60 | Proximity sensor with normally closed relay. |
| Bluetooth dongle | Mbientlab | BLE | Dongle for Bluetooth connection between the wearable sensors and a computer. |
| Raspberry Pi | Raspberry | Version 3 Model B | Microcontroller for infrared sensor acquisition and computer interface. |
| Personal computer | Dell | Intel Xeon E5-2630 v4 @2.20 GHz, RAM 32GB |
Referenzen
- United Nations. World Population Prospects: The 2017 Revision, Key Findings and Advance Tables. United Nations. Department of Economic and Social Affairs, Population Division. , (2017).
- World Health Organization. Ageing, and Life Course Unit. WHO Global Report on Falls Prevention in Older Age. , (2008).
- Igual, R., Medrano, C., Plaza, I. Challenges, Issues and Trends in Fall Detection Systems. Biomedical Engineering Online. 12 (1), 66 (2013).
- Noury, N., et al. Fall Detection-Principles and Methods. 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 1663-1666 (2007).
- Mubashir, M., Shao, L., Seed, L. A Survey on Fall Detection: Principles and Approaches. Neurocomputing. 100, 144-152 (2002).
- Perry, J. T., et al. Survey and Evaluation of Real-Time Fall Detection Approaches. Proceedings of the 6th International Symposium High-Capacity Optical Networks and Enabling Technologies. , 158-164 (2009).
- Xu, T., Zhou, Y., Zhu, J. New Advances and Challenges of Fall Detection Systems: A Survey. Applied Sciences. 8 (3), 418 (2018).
- Rougier, C., Meunier, J., St-Arnaud, A., Rousseau, J. Robust Video Surveillance for Fall Detection Based on Human Shape Deformation. IEEE Transactions on Circuit Systems for Video Technologies. 21, 611-622 (2011).
- Bulling, A., Blanke, U., Schiele, B. A Tutorial on Human Activity Recognition Using Body-Worn Inertial Sensors. ACM Computing Surveys. 46 (3), 33 (2014).
- Kwolek, B., Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Computational Methods and Programs in Biomedicine. 117, 489-501 (2014).
- Ofli, F., Chaudhry, R., Kurillo, G., Vidal, R., Bajcsy, R. Berkeley MHAD: A Comprehensive Multimodal Human Action Database. Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision. , 53-60 (2013).
- Dovgan, E., et al. Intelligent Elderly-Care Prototype for Fall and Disease Detection. Slovenian Medical Journal. 80, 824-831 (2011).
- Santoyo-Ramón, J., Casilari, E., Cano-García, J. Analysis of a Smartphone-Based Architecture With Multiple Mobility Sensors for Fall Detection With Supervised Learning. Sensors. 18 (4), 1155 (2018).
- Özdemir, A. An Analysis on Sensor Locations of the Human Body for Wearable Fall Detection Devices: Principles and Practice. Sensors. 16 (8), 1161 (2016).
- Ntanasis, P., Pippa, E., Özdemir, A. T., Barshan, B., Megalooikonomou, V. Investigation of Sensor Placement for Accurate Fall Detection. International Conference on Wireless Mobile Communication and Healthcare. , 225-232 (2016).
- Bagala, F., et al. Evaluation of Accelerometer-Based Fall Detection Algorithms on Real-World Falls. PLoS One. 7, 37062 (2012).
- Bourke, A. K., et al. Assessment of Waist-Worn Tri-Axial Accelerometer Based Fall-detection Algorithms Using Continuous Unsupervised Activities. Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 2782-2785 (2010).
- Kerdegari, H., Samsudin, K., Ramli, A. R., Mokaram, S. Evaluation of Fall Detection Classification Approaches. 4th International Conference on Intelligent and Advanced Systems. , 131-136 (2012).
- Alazrai, R., Mowafi, Y., Hamad, E. A Fall Prediction Methodology for Elderly Based on a Depth Camera. 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 4990-4993 (2015).
- Peñafort-Asturiano, C. J., Santiago, N., Núñez-Martínez, J. P., Ponce, H., Martínez-Villaseñor, L. Challenges in Data Acquisition Systems: Lessons Learned from Fall Detection to Nanosensors. 2018 Nanotechnology for Instrumentation and Measurement. , 1-8 (2018).
- Martínez-Villaseñor, L., et al. UP-Fall Detection Dataset: A Multimodal Approach. Sensors. 19 (9), 1988 (2019).
- Rantz, M., et al. Falls, Technology, and Stunt Actors: New approaches to Fall Detection and Fall Risk Assessment. Journal of Nursing Care Quality. 23 (3), 195-201 (2008).
- Lachance, C., Jurkowski, M., Dymarz, A., Mackey, D. Compliant Flooring to Prevent Fall-Related Injuries: A Scoping Review Protocol. BMJ Open. 6 (8), 011757 (2016).
Nachdrucke und Genehmigungen
Genehmigung beantragen, um den Text oder die Abbildungen dieses JoVE-Artikels zu verwenden
Genehmigung beantragenThis article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. Alle Rechte vorbehalten