
Method Article
Conception et analyse pour la simplification du système de détection des chutes
Dans cet article
Résumé
Nous présentons une méthodologie basée sur des capteurs multimodaux pour configurer un système simple, confortable et rapide de détection des chutes et de reconnaissance d’activité humaine. L’objectif est de construire un système de détection précise des chutes qui peut être facilement mis en œuvre et adopté.
Résumé
Cet article présente une méthodologie basée sur des capteurs multimodaux pour configurer un système simple, confortable et rapide de détection des chutes et de reconnaissance d’activité humaine qui peut être facilement mis en œuvre et adopté. La méthodologie est basée sur la configuration de types spécifiques de capteurs, de méthodes et de procédures d’apprentissage automatique. Le protocole est divisé en quatre phases : (1) création de base de données (2) analyse des données (3) simplification du système et (4) évaluation. À l’aide de cette méthodologie, nous avons créé une base de données multimodale pour la détection des chutes et la reconnaissance des activités humaines, à savoir la détection UP-Fall. Il comprend des échantillons de données de 17 sujets qui effectuent 5 types de chutes et 6 activités simples différentes, au cours de 3 essais. Toutes les informations ont été recueillies à l’aide de 5 capteurs portables (accéléromètre tri-axe, gyroscope et intensité lumineuse), 1 casque d’électroencéphalographe, 6 capteurs infrarouges comme capteurs ambiants, et 2 caméras dans les points de vue latéraux et avant. La nouvelle méthodologie proposée ajoute quelques étapes importantes pour effectuer une analyse approfondie des problèmes de conception suivants afin de simplifier un système de détection des chutes : a) sélectionnez quels capteurs ou combinaison de capteurs doivent être utilisés dans un simple système de détection des chutes, b) déterminer le meilleur placement des sources d’information, et c) sélectionner la méthode de classification d’apprentissage automatique la plus appropriée pour la détection et la reconnaissance des activités humaines. Même si certaines approches multimodales rapportées dans la littérature ne se concentrent que sur une ou deux des questions mentionnées ci-dessus, notre méthodologie permet de résoudre simultanément ces trois problèmes de conception liés à une chute humaine et le système de détection et de reconnaissance d’activité.
Introduction
Depuis le phénomène mondial du vieillissement de la population1, la prévalence de l’automne a augmenté et est en fait considéré comme un problème de santé majeur2. Lorsqu’une chute se produit, les gens ont besoin d’une attention immédiate afin de réduire les conséquences négatives. Les systèmes de détection des chutes peuvent réduire le temps pendant lequel une personne reçoit des soins médicaux en envoyant une alerte lorsqu’une chute se produit.
Il existe diverses catégorisations des systèmes de détection des chutes3. Les premiers travaux4 classent les systèmes de détection des chutes par leur méthode de détection, les méthodes d’analyse et les méthodes d’apprentissage automatique. Plus récemment, d’autres auteurs3,5,6 ont considéré les capteurs d’acquisition de données comme la principale caractéristique de classification des détecteurs de chute. Igual et coll.3 divisent les systèmes de détection des chutes en systèmes contextuelles, qui comprennent des approches basées sur la vision et les capteurs ambiants, et des systèmes d’appareils portables. Mubashir et coll.5 classent les détecteurs de chute en trois groupes basés sur les dispositifs utilisés pour l’acquisition de données : appareils portables, capteurs d’ambiance et dispositifs basés sur la vision. Perry et coll.6 envisagent des méthodes de mesure de l’accélération, des méthodes de mesure de l’accélération combinées à d’autres méthodes et des méthodes de non-mesure de l’accélération. À partir de ces enquêtes, nous pouvons déterminer que les capteurs et les méthodes sont les principaux éléments pour classer la stratégie générale de recherche.
Chacun des capteurs a des faiblesses et des forces discutées dans Xu et al.7. Les approches basées sur la vision utilisent principalement des caméras normales, des caméras de capteurs de profondeur et/ou des systèmes de capture de mouvement. Les caméras Web normales sont peu coûteuses et faciles à utiliser, mais elles sont sensibles aux conditions environnementales (variation de la lumière, occlusion, etc.), ne peuvent être utilisées que dans un espace réduit et avoir des problèmes de confidentialité. Les caméras de profondeur, telles que le Kinect, fournissent lemouvement 3D complet et sont moins affectées par des conditions d’éclairage que les caméras normales. Cependant, les approches basées sur le Kinect ne sont pas aussi robustes et fiables. Les systèmes de capture de mouvement sont plus coûteux et difficiles à utiliser.
Les approches basées sur les appareils accéléromètres et les téléphones intelligents/montres avec accéléromètres intégrés sont très couramment utilisées pour la détection des chutes. Le principal inconvénient de ces appareils est qu’ils doivent être portés pendant de longues périodes. L’inconfort, l’immobilité, le placement du corps et l’orientation sont des problèmes de conception à résoudre dans ces approches. Bien que les smartphones et les montres intelligentes soient des appareils moins envahissants que les capteurs, les personnes âgées oublient souvent ou ne portent pas toujours ces appareils. Néanmoins, l’avantage de ces capteurs et dispositifs est qu’ils peuvent être utilisés dans de nombreuses pièces et / ou à l’extérieur.
Certains systèmes utilisent des capteurs placés autour de l’environnement pour reconnaître les chutes/activités, de sorte que les gens n’ont pas à porter les capteurs. Cependant, ces capteurs sont également limités aux endroits où ils sont déployés8 et sont parfois difficiles à installer. Récemment, les systèmes de détection des chutes multimodales comprennent différentes combinaisons de capteurs de vision, portables et ambiants afin d’obtenir plus de précision et de robustesse. Ils peuvent également surmonter certaines des limites du capteur unique.
La méthodologie utilisée pour la détection des chutes est étroitement liée à la chaîne de reconnaissance d’activité humaine (ARC) présentée par Bulling et coll.9, qui se compose d’étapes pour l’acquisition de données, le prétraitement et la segmentation des signaux, l’extraction et la sélection des fonctionnalités, la formation et la classification. Les problèmes de conception doivent être résolus pour chacune de ces étapes. Différentes méthodes sont utilisées à chaque étape.
Nous présentons une méthodologie basée sur des capteurs multimodaux pour configurer un système simple, confortable et rapide de détection/reconnaissance d’activité humaine. L’objectif est de construire un système de détection précise des chutes qui peut être facilement mis en œuvre et adopté. La nouvelle méthodologie proposée est basée sur l’ARC, mais elle ajoute quelques phases importantes pour effectuer une analyse approfondie des questions suivantes afin de simplifier le système : a) sélectionner quels capteurs ou combinaison de capteurs doivent être utilisés dans un simple système de détection des chutes; b) déterminer le meilleur placement des sources d’information; c) sélectionnez la méthode de classification d’apprentissage automatique la plus appropriée pour la détection des chutes et la reconnaissance de l’activité humaine afin de créer un système simple.
Il ya quelques travaux connexes dans la littérature qui traitent d’un ou deux des problèmes de conception mentionnés ci-dessus, mais à notre connaissance, il n’y a pas de travail qui se concentre sur une méthodologie pour surmonter tous ces problèmes.
Les œuvres connexes utilisent des approches multimodales pour la détection des chutes et la reconnaissance de l’activité humaine10,11,12 afin d’acquérir de la robustesse et d’augmenter la précision. Kwolek et coll.10 ont proposé la conception et la mise en œuvre d’un système de détection des chutes basé sur des données accélérométriques et des cartes de profondeur. Ils ont conçu une méthodologie intéressante dans laquelle un accéléromètre à trois axes est mis en œuvre pour détecter une chute potentielle ainsi que le mouvement de la personne. Si la mesure d’accélération dépasse un seuil, l’algorithme extrait une personne différenciant la carte de profondeur de la carte de référence de profondeur mise à jour en ligne. Une analyse des combinaisons de profondeur et d’accéléromètre a été faite à l’aide d’un classificateur de machine vectorielle de soutien.
Ofli et coll.11 ont présenté une base de données multimodale d’action humaine (MHAD) afin de fournir un banc d’essai pour de nouveaux systèmes de reconnaissance d’activité humaine. Le jeu de données est important puisque les actions ont été recueillies simultanément à l’aide de 1 système de capture de mouvement optique, 4 caméras multi-vue, 1 système Kinect, 4 microphones et 6 accéléromètres sans fil. Les auteurs ont présenté des résultats pour chaque modalité : le Kinect, le mocap, l’accéléromètre et l’audio.
Dovgan et coll.12 ont proposé un prototype pour détecter le comportement anormal, y compris les chutes, chez les personnes âgées. Ils ont conçu des tests pour trois systèmes de capteurs afin de trouver l’équipement le plus approprié pour la détection de l’automne et du comportement inhabituel. La première expérience consiste en des données provenant d’un système de capteurs intelligents avec 12 étiquettes attachées aux hanches, genoux, chevilles, poignets, coudes et épaules. Ils ont également créé un jeu de données de test à l’aide d’un système de capteur Ubisense avec quatre étiquettes attachées à la taille, la poitrine et les deux chevilles, et un accéléromètre Xsens. Dans une troisième expérience, quatre sujets n’utilisent le système Ubisense que lorsqu’ils effectuent 4 types de chutes, 4 problèmes de santé comme comportement anormal et une activité différente de la vie quotidienne (ADL).
D’autres travaux dans la littérature13,14,15 traitent du problème de trouver le meilleur emplacement de capteurs ou de dispositifs pour la détection des chutes en comparant les performances de diverses combinaisons de capteurs avec plusieurs classificateurs. Santoyo et coll.13 ont présenté une évaluation systématique évaluant l’importance de l’emplacement de 5 capteurs pour la détection des chutes. Ils ont comparé les performances de ces combinaisons de capteurs à l’aide de voisins k-nearest (KNN), de machines vectorielles de soutien (SVM), de bayes naïfs (NB) et de classificateurs d’arbres de décision (DT). Ils concluent que l’emplacement du capteur sur le sujet a une influence importante sur la performance du détecteur de chute indépendamment du classificateur utilisé.
Une comparaison des placements de capteurs portables sur le corps pour la détection des chutes a été présentée par 'zdemir14. Afin de déterminer le placement du capteur, l’auteur a analysé 31 combinaisons de capteurs des positions suivantes : tête, taille, poitrine, poignet droit, cheville droite et cuisse droite. Quatorze volontaires ont effectué 20 chutes simulées et 16 ADL. Il a constaté que la meilleure performance a été obtenue quand un seul capteur est positionné sur la taille de ces expériences de combinaison exhaustive. Une autre comparaison a été présentée par Ntanasis15 à l’aide de l’ensemble de données d’Izdemir. Les auteurs ont comparé les positions individuelles sur la tête, la poitrine, la taille, le poignet, la cheville et la cuisse à l’aide des classificateurs suivants : J48, KNN, RF, comité aléatoire (RC) et SVM.
Des points de repère de la performance de différentes méthodes de calcul pour la détection des chutes peuvent également être trouvés dans la littérature16,17,18. Bagala et coll.16 ont présenté une comparaison systématique pour comparer les performances de treize méthodes de détection des chutes testées sur des chutes réelles. Ils ne considéraient que les algorithmes basés sur des mesures d’accéléromètre placées sur la taille ou le tronc. Bourke et coll.17 ont évalué les performances de cinq algorithmes analytiques pour la détection des chutes à l’aide d’un ensemble de données de ADL et de chutes basées sur des lectures d’accéléromètres. Kerdegari18 a également fait une comparaison des performances des différents modèles de classification pour un ensemble de données d’accélération enregistrées. Les algorithmes utilisés pour la détection des chutes étaient zeroR, oneR, NB, DT, multicouche perceptron et SVM.
Une méthodologie de détection des chutes a été proposée par Alazrai et coll.18 utilisant le descripteur géométrique de pose de mouvement pour construire une représentation accumulée à base d’histogramme de l’activité humaine. Ils ont évalué le cadre à l’aide d’un jeu de données recueilli avec des capteurs Kinect.
En résumé, nous avons trouvé des travaux liés à la détection des chutes multimodales10,11,12 qui comparent les performances de différentes combinaisons de modalités. Certains auteurs abordent le problème de trouver le meilleur placement de capteurs13,14,15, ou des combinaisons de capteurs13 avec plusieurs classificateurs13,15,16 avec plusieurs capteurs de la même modalité et des accéléromètres. Aucun travail n’a été trouvé dans la littérature qui traitent le placement, les combinaisons multimodales et le point de repère de classificateur en même temps.
Protocole
Toutes les méthodes décrites ici ont été approuvées par le Comité de recherche de l’École d’ingénierie de l’Universidad Panamericana.
REMARQUE : Cette méthodologie est basée sur la configuration des types spécifiques de capteurs, de méthodes et de procédures d’apprentissage automatique afin de configurer un système simple, rapide et multimodal de détection des chutes et de reconnaissance des activités humaines. Pour cette raison, le protocole suivant est divisé en phases : (1) création de base de données (2) analyse des données (3) simplification du système et (4) évaluation.
1. Création de base de données
- Configurez le système d’acquisition de données. Cela permettra de recueillir toutes les données auprès de sujets et de stocker l’information dans une base de données de récupération.
- Sélectionnez les types de capteurs portables, de capteurs ambiants et d’appareils basés sur la vision requis comme sources d’information. Attribuer une pièce d’identité pour chaque source d’information, le nombre de canaux par source, les spécifications techniques et le taux d’échantillonnage de chacun d’eux.
- Connectez toutes les sources d’information (c.-à-d. portables et capteurs ambiants, et appareils basés sur la vision) à un ordinateur central ou à un système informatique distribué :
- Vérifiez que les appareils câblés sont connectés correctement à un ordinateur client. Vérifiez que les appareils sans fil sont entièrement chargés. Considérez que la batterie basse pourrait avoir un impact sur les connexions sans fil ou les valeurs du capteur. De plus, les connexions intermittentes ou perdues augmenteront la perte de données.
- Configurez chacun des appareils pour récupérer les données.
- Configurez le système d’acquisition de données pour stocker des données sur le cloud. En raison de la grande quantité de données à stocker, l’informatique en nuage est prise en compte dans ce protocole.
- Validez que le système d’acquisition de données répond à la synchronisation des données et à la cohérence des données20 propriétés. Cela maintient l’intégrité du stockage de données à partir de toutes les sources d’information. Il pourrait nécessiter de nouvelles approches dans la synchronisation des données. Par exemple, voir Pesafort-Asturiano et al.20.
- Commencez à collecter certaines données avec les sources d’information et stockez les données dans un système préféré. Inclure des timestamps dans toutes les données.
- Interrogez la base de données et déterminez si toutes les sources d’information sont recueillies aux mêmes taux d’échantillonnage. Si vous êtes fait correctement, rendez-vous à l’étape 1.1.6. Dans le cas contraire, effectuez un échantillonnage à la hausse ou un échantillonnage à la baisse à l’aide de critères rapportés dans l’arrêt Pesafort-Asturiano, et autres20.
- Mettre en place l’environnement (ou laboratoire) en tenant compte des conditions requises et des restrictions imposées par l’objectif du système. Définissez les conditions d’atténuation des forces d’impact dans les chutes simulées, comme le suggèrent les systèmes de plancher conformes à Lachance et coll.23 afin d’assurer la sécurité des participants.
- Utilisez un matelas ou tout autre système de plancher conforme et placez-le au centre de l’environnement (ou laboratoire).
- Gardez tous les objets loin du matelas pour donner au moins un mètre d’espace sûr tout autour. Au besoin, préparez de l’équipement de protection individuelle pour les participants (p. ex., gants, casquette, lunettes, soutien du genou, etc.).
REMARQUE : Le protocole peut être mis en pause ici.
- Déterminez les activités humaines et les chutes que le système détectera après la configuration. Il est important d’avoir à l’esprit le but du système de détection des chutes et de reconnaissance des activités humaines, ainsi que la population cible.
- Définissez l’objectif du système de détection des chutes et de reconnaissance des activités humaines. Écrivez-le dans une feuille de planification. Pour cette étude de cas, l’objectif est de classer les types de chutes humaines et les activités effectuées dans une base quotidienne intérieure des personnes âgées.
- Définir la population cible de l’expérience conformément à l’objectif du système. Écrivez-le dans la feuille de planification. Dans l’étude, considérez les personnes âgées comme la population cible.
- Déterminer le type d’activités quotidiennes. Inclure certaines activités non-automne qui ressemblent à des chutes afin d’améliorer la détection réelle des chutes. Attribuez une pièce d’identité pour chacun d’eux et décrivez-les aussi détaillé que possible. Définissez la période d’exécution de chaque activité. Notez toutes ces informations dans la feuille de planification.
- Déterminez le type de chutes humaines. Attribuez une pièce d’identité pour chacun d’eux et décrivez-les aussi détaillé que possible. Définissez la période de temps pour que chaque automne soit exécuté. Considérez si les chutes seront auto-générées par les sujets ou générées par d’autres (p. ex., pousser le sujet). Notez toutes ces informations dans la feuille de planification.
- Dans la feuille de planification, notez les séquences d’activités et de chutes qu’un sujet effectuera. Spécifier la période de temps, le nombre d’essais par activité/chute, la description pour effectuer l’activité/chute, et l’activité/les D.I.
REMARQUE : Le protocole peut être mis en pause ici.
- Sélectionnez les sujets pertinents à l’étude qui exécuteront les séquences d’activités et de chutes. Les chutes sont des événements rares à attraper dans la vie réelle et se produisent généralement pour les personnes âgées. Néanmoins, pour des raisons de sécurité, n’incluez pas les personnes âgées et les personnes ayant une déficience dans la simulation d’automne sous les conseils médicaux. Stunts ont été utilisés pour éviter les blessures22.
- Déterminez le sexe, la tranche d’âge, le poids et la taille des sujets. Définir les conditions de dépréciation requises. En outre, définir le nombre minimum de sujets requis pour l’expérience.
- Sélectionnez aléatoirement l’ensemble des sujets requis, suivant les conditions indiquées dans l’étape précédente. Utilisez un appel pour les bénévoles pour les recruter. Remplissez toutes les directives éthiques applicables de l’institution et du pays, ainsi que toute réglementation internationale lors de l’expérimentation avec les humains.
REMARQUE : Le protocole peut être mis en pause ici.
- Récupérez et stockez les données des sujets. Ces informations seront utiles pour une analyse expérimentale plus approfondie. Remplissez les étapes suivantes sous la supervision d’un expert clinique ou d’un chercheur responsable.
- Commencez à collecter des données avec le système d’acquisition de données configuré dans l’étape 1.1.
- Demandez à chacun des sujets d’effectuer les séquences d’activités et de chutes déclarées dans l’étape 1.2. Économisez clairement les délais de départ et de fin de chaque activité/chute. Vérifiez que les données de toutes les sources d’information sont enregistrées sur le cloud.
- Si les activités n’étaient pas bien faites ou s’il y avait des problèmes avec les appareils (p. ex., connexion perdue, batterie basse, connexion intermittente), jetez les échantillons et répétez l’étape 1.4.1 jusqu’à ce qu’aucun problème d’appareil ne soit détecté. Répéter l’étape 1.4.2 pour chaque essai, par sujet, déclaré dans la séquence de l’étape 1.2.
REMARQUE : Le protocole peut être mis en pause ici.
- Pré-traiter toutes les données acquises. Appliquer l’échantillonnage et l’échantillonnage à la baisse pour chacune des sources d’information. Voir les détails sur les données de pré-traitement pour la détection des chutes et la reconnaissance de l’activité humaine dans Martinez-Villaseor et al.21.
REMARQUE : Le protocole peut être mis en pause ici.
2. Analyse des données
- Sélectionnez le mode de traitement des données. Sélectionnez les données brutes si les données stockées dans la base de données seront utilisées purement et simplement (c.-à-d., en utilisant l’apprentissage profond pour l’extraction automatique des fonctionnalités) et iront à l’étape 2.2. Sélectionnez les données de fonctionnalité si l’extraction des fonctionnalités sera utilisée pour une analyse plus approfondie et passez à l’étape 2.3.
- Pour Raw Data, aucune étape supplémentaire n’est nécessaire alors allez à l’étape 2.5.
- Pour feature Data, extraire les fonctionnalités des données brutes.
- Segmentez les données brutes dans les fenêtres temporelles. Déterminez et fixez la durée de la fenêtre (p. ex., des cadres d’une seconde). De plus, déterminez si ces fenêtres de temps se chevaucheront ou non. Une bonne pratique consiste à choisir 50 % qui se chevauchent.
- Extraire les fonctionnalités de chaque segment de données. Déterminer l’ensemble des caractéristiques temporelles et fréquentes à extraire des segments. Voir Martinez-Villaseor et al.21 pour l’extraction commune de dispositif.
- Enregistrer l’ensemble de données d’extraction de fonctionnalités sur le cloud, dans une base de données indépendante.
- Si différentes fenêtres temporelles sont sélectionnées, répétez les étapes 2.3.1 à 2.3.3, et enregistrez chaque ensemble de données de fonctionnalité dans des bases de données indépendantes.
REMARQUE : Le protocole peut être mis en pause ici.
- Sélectionnez les fonctionnalités les plus importantes extraites et réduisez l’ensemble de données des fonctionnalités. Appliquer certaines méthodes de sélection des fonctionnalités couramment utilisées (p. ex., sélection nonivaire, analyse des composants principaux, élimination des fonctionnalités récursives, importance des caractéristiques, matrice de corrélation, etc.).
- Sélectionnez une méthode de sélection des fonctionnalités. Ici, nous avons utilisé l’importance des fonctionnalités.
- Utilisez chaque fonctionnalité pour former un modèle donné (nous avons utilisé RF) et mesurer la précision (voir l’équation 1).
- Classez les caractéristiques en triant par ordre de précision.
- Sélectionnez les fonctionnalités les plus importantes. Ici, nous avons utilisé les dix premières fonctionnalités les mieux classées.
REMARQUE : Le protocole peut être mis en pause ici.
- Sélectionnez une méthode de classification de l’apprentissage automatique et formez un modèle. Il existe des méthodes d’apprentissage automatique bien connues16,17,18,21, tels que : machines vectorielles de soutien (SVM), forêt aléatoire (RF), perceptron multicouche (MLP) et voisins k-nearest (KNN), parmi beaucoup d’autres.
- En option, si une approche d’apprentissage profond est choisie, considérezalors 21: réseaux neuronaux convolutionnels (CNN), réseaux neuronaux à longue mémoire (LSTM), entre autres.
- Sélectionnez un ensemble de méthodes d’apprentissage automatique. Ici, nous avons utilisé les méthodes suivantes: SVM, RF, MLP et KNN.
- Fixer les paramètres de chacune des méthodes d’apprentissage automatique, comme suggéré dans la littérature21.
- Créez un ensemble de données de fonctionnalités combinées (ou ensemble de données brutes) à l’aide des ensembles de données de fonctionnalités indépendants (ou ensembles de données brutes), pour combiner des types de sources d’information. Par exemple, si une combinaison d’un capteur portable et d’une caméra est nécessaire, puis combiner les ensembles de données de fonctionnalités de chacune de ces sources.
- Divisez l’ensemble de données de fonctionnalité (ou ensemble de données brutes) dans les ensembles de formation et de test. Un bon choix est de diviser au hasard 70% pour la formation et 30% pour les tests.
- Exécutez une validation croiséek-fold 21 à l’aide de l’ensemble de données de fonctionnalité (ou ensemble de données brutes), pour chaque méthode d’apprentissage automatique. Utilisez une mesure commune de l’évaluation, comme la précision (voir l’équation 1) pour sélectionner le meilleur modèle formé par méthode. Les expériences de sortie3 sont également recommandées.
- Ouvrez l’ensemble de données de fonctionnalité de formation (ou ensemble de données brutes) dans le logiciel de langage de programmation préféré. Python est recommandé. Pour cette étape, utilisez la bibliothèque de pandas pour lire un fichier CSV comme suit :
training_set pandas.csv(md)lt;filename.csv.gt;). - Divisez l’ensemble de données de fonctionnalité (ou ensemble de données brutes) en paires d’entrées-sorties. Par exemple, utilisez Python pour déclarer les valeurs x (entrées) et les valeurs y (sorties) :
training_set_X training_set.drop ('tag', axe'1), training_set_Y 'training_set.tag'
où l’étiquette représente la colonne de l’ensemble de données de fonctionnalité qui inclut les valeurs cibles. - Sélectionnez une méthode d’apprentissage automatique et définissez les paramètres. Par exemple, utilisez SVM in Python avec le sklearn de bibliothèque comme la commande suivante :
classificateur et sklearn. SVC (noyau et 'poly')
dans lequel la fonction de noyau est sélectionnée comme polynomiale. - Entraînez le modèle d’apprentissage automatique. Par exemple, utilisez le classificateur ci-dessus dans Python pour former le modèle SVM :
classifier.fit (training_set_X,training_set_Y). - Calculez les valeurs d’estimation du modèle à l’aide de l’ensemble de données des fonctionnalités de test (ou de l’ensemble de données brutes). Par exemple, utilisez la fonction d’estimation dans Python comme suit : estimations et classificateur.predict (testing_set_X) où testing_set_X représente les valeurs x de l’ensemble d’essais.
- Répéter les étapes 2.5.6.1 à 2.5.6.5, le nombre de fois k spécifié dans la validation croisée k-fold (ou le nombre de fois requis pour l’approche LOSO).
- Répétez les étapes 2.5.6.1 à 2.5.6.6 pour chaque modèle d’apprentissage automatique sélectionné.
REMARQUE : Le protocole peut être mis en pause ici.
- Ouvrez l’ensemble de données de fonctionnalité de formation (ou ensemble de données brutes) dans le logiciel de langage de programmation préféré. Python est recommandé. Pour cette étape, utilisez la bibliothèque de pandas pour lire un fichier CSV comme suit :
- Comparez les méthodes d’apprentissage automatique en testant les modèles sélectionnés avec l’ensemble de données de test. D’autres mesures de l’évaluation peuvent être utilisées : précision (Équation 1), précision(Equation 2), sensibilité(Equation 3), spécificité(Equation 4) ou F1-score (Equation 5), où TP sont les vrais positifs, TN sont les vrais négatifs, FP sont les faux positifs et FN sont les faux négatifs.





- Utilisez d’autres mesures de performance bénéfiques telles que la matrice de confusion9 pour évaluer la tâche de classification des modèles d’apprentissage automatique, ou une précision-rappel indépendant de décision9 (PR) ou récepteur fonctionnant caractéristique9 (ROC) courbes. Dans cette méthodologie, le rappel et la sensibilité sont considérés comme équivalents.
- Utilisez les caractéristiques qualitatives des modèles d’apprentissage automatique pour comparer entre eux, telles que : la facilité d’interprétation de l’apprentissage automatique; performance en temps réel; ressources limitées de temps, de mémoire et de traitement informatique; et la facilité de déploiement de l’apprentissage automatique dans des dispositifs de bord ou des systèmes embarqués.
- Sélectionnez le meilleur modèle d’apprentissage automatique à l’aide de l’information de: Les mesures de qualité (Equations 1-5), les mesures de performance et les caractéristiques qualitatives de la faisabilité de l’apprentissage automatique des étapes 2.5.6, 2.5.7 et 2.5.8.
REMARQUE : Le protocole peut être mis en pause ici.
3. Simplification du système
- Sélectionnez les emplacements appropriés des sources d’information. Parfois, il est nécessaire de déterminer le meilleur emplacement des sources d’information (p. ex., l’emplacement d’un capteur portable est le meilleur).
- Déterminer le sous-ensemble de sources d’information qui seront analysées. Par exemple, s’il y a cinq capteurs portables dans le corps et qu’un seul doit être sélectionné comme le meilleur capteur placé, chacun de ces capteurs fera partie du sous-ensemble.
- Pour chaque source d’information dans ce sous-ensemble, créez un ensemble de données distinct et stockez-le séparément. Gardez à l’esprit que cet ensemble de données pourrait être soit l’ensemble de données de fonctionnalités précédentes ou l’ensemble de données brutes.
REMARQUE : Le protocole peut être mis en pause ici.
- Sélectionnez une méthode de classification de l’apprentissage automatique et formez un modèle pour une seule source de placement d’information. Étapes complètes de 2.5.1 à 2.5.6 en utilisant chacun des ensembles de données créés dans l’étape 3.1.2. Détecter la source de placement d’information la plus appropriée par classement. Pour cette étude de cas, nous utilisons les méthodes suivantes : SVM, RF, MLP et KNN.
Remarque : Le protocole peut être mis en pause ici. - Sélectionnez les emplacements appropriés dans une approche multimodale si une combinaison de deux sources d’information ou plus est nécessaire pour le système (p. ex., combinaison d’un capteur portable et d’une caméra). Dans cette étude de cas, utilisez le capteur à la taille et la caméra 1 (vue latérale) comme modalités.
- Sélectionnez la meilleure source d’information de chaque modalité du système et créez un ensemble de données de fonctionnalités combinées (ou ensemble de données brutes) à l’aide des ensembles de données indépendants de ces sources d’information.
- Sélectionnez une méthode de classification de l’apprentissage automatique et formez un modèle pour ces sources d’information combinées. Étapes complètes 2.5.1 à 2.5.6 à l’aide de l’ensemble de données de fonctionnalités combinées (ou ensemble de données brutes). Dans cette étude, utilisez les méthodes suivantes : SVM, RF, MLP et KNN.
REMARQUE : Le protocole peut être mis en pause ici.
4. Évaluation
- Préparer un nouvel ensemble de données avec les utilisateurs dans des conditions plus réalistes. N’utilisez que les sources d’information sélectionnées dans l’étape précédente. Préférable, mettre en œuvre le système dans le groupe cible (p. ex., les personnes âgées). Recueillir des données en plus longues périodes de temps.
- Optionnellement, si le groupe cible n’est utilisé que, créez un protocole de groupe de sélection comprenant les conditions d’exclusion (p. ex., toute déficience physique ou psychologique) et arrêtez la prévention des critères (p. ex., détectez toute blessure physique pendant les essais; souffre de nausées, de vertiges et/ou de vomissements; évanouissement). Tenez également compte des préoccupations éthiques et des questions de confidentialité des données.
- Évaluer le rendement du système de détection des chutes et de reconnaissance des activités humaines mis au point jusqu’à présent. Utilisez Equations 1-5 pour déterminer la précision et la puissance prédictive du système, ou toute autre mesure de performance.
- Discutez des résultats sur les résultats expérimentaux.
Résultats
Création d’une base de données
Nous avons créé un ensemble de données multimodaux pour la détection des chutes et la reconnaissance des activités humaines, à savoir UP-Fall Detection21. Les données ont été recueillies sur une période de quatre semaines à l’École d’ingénierie de l’Universidad Panamericana (Mexico, Mexique). Le scénario d’essai a été sélectionné compte tenu des exigences suivantes : a) un espace dans lequel les sujets pouvaient effectuer confortablement et en toute sécurité des chutes et des activités, et (b) un environnement intérieur avec une lumière naturelle et artificielle qui convient bien aux réglages multimodaux des capteurs.
Il existe des échantillons de données de 17 sujets qui ont effectué 5 types de chutes et 6 activités simples différentes, au cours de 3 essais. Toutes les informations ont été recueillies à l’aide d’un système interne d’acquisition de données avec 5 capteurs portables (accéléromètre tri-axe, gyroscope et intensité lumineuse), 1 casque électroencéphalographe, 6 capteurs infrarouges comme capteurs ambiants, et 2 caméras aux points de vue latéraux et avant. La figure 1 montre la disposition du placement du capteur dans l’environnement et sur le corps. Le taux d’échantillonnage de l’ensemble des données est de 18 Hz. La base de données contient deux ensembles de données : l’ensemble de données brutes consolidés (812 Go) et un ensemble de données de fonctionnalités (171 Go). Toutes les bases de données stockées dans le cloud pour un accès public : https://sites.google.com/up.edu.mx/har-up/. Plus de détails sur l’acquisition de données, le pré-traitement, la consolidation et le stockage de cette base de données ainsi que des détails sur la synchronisation et la cohérence des données peuvent être trouvés dans Martinez-Villaseor et al.21.
Pour cette base de données, tous les sujets étaient de jeunes volontaires en bonne santé (9 mâles et 8 femelles) sans aucune déficience, allant de 18 à 24 ans, avec une hauteur moyenne de 1,66 m et un poids moyen de 66,8 kg. Pendant la collecte de données, le chercheur technique responsable supervisait que toutes les activités étaient effectuées par les sujets correctement. Les sujets ont effectué cinq types de chutes, chacune pendant 10 secondes, comme tombant : vers l’avant à l’aide des mains (1), vers l’avant à l’aide des genoux (2), à l’envers (3), assis dans une chaise vide (4) et vers le côté (5). Ils ont également effectué six activités quotidiennes pour 60 s chacun, sauf pour sauter (30 s): marche (6), debout (7), ramasser un objet (8), assis (9), sauter (10) et la pose (11). Bien que les chutes simulées ne puissent pas reproduire tous les types de chutes réelles, il est important au moins d’inclure des types représentatifs de chutes permettant la création de meilleurs modèles de détection des chutes. Il est également pertinent d’utiliser des ADL et, en particulier, des activités qui peuvent généralement se tromper avec des chutes telles que la cueillette d’un objet. Les types de chutes et de DDL ont été sélectionnés après un examen des systèmes de détection des chutesconnexes 21. À titre d’exemple, la figure 2 montre une séquence d’images d’un essai lorsqu’un sujet tombe sur le côté.
Nous avons extrait 12 temporels (moyenne, déviation standard, amplitude maximale, amplitude minimale, racine moyenne carrée, médiane, nombre zéro croisement, inclinaison, kurtose, premier quartile, troisième quartile et autocorrelation) et 6 fréquents (moyen, médiane, entropie, énergie, fréquence principale et centroïde spectral) caractéristiques21 de chaque canal des capteurs portables et ambiants comprenant 756 caractéristiques dans les caractéristiques totales. Nous avons également calculé 400 caractéristiques visuelles21 pour chaque appareil photo sur le mouvement relatif des pixels entre deux images adjacentes dans les vidéos.
Analyse des données entre les approches unimodale et multimodal
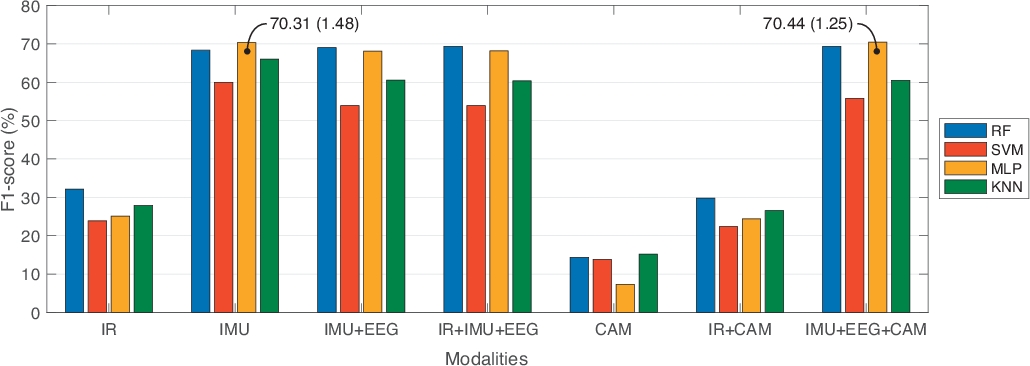
À partir de la base de données UP-Fall Detection, nous avons analysé les données à des fins de comparaison entre les approches nonimodales et multimodales. En ce sens, nous avons comparé sept combinaisons différentes de sources d’information : les capteurs infrarouges seulement (IR); capteurs portables seulement (IMU); capteurs portables et casque (IMU-EEG); capteurs et casque infrarouges et portables (IR-IMU-EEG); caméras seulement (CAM); capteurs infrarouges et caméras (IR-CAM); et des capteurs portables, un casque et des caméras (IMU-EEG-CAM). En outre, nous avons comparé trois tailles de fenêtre de temps différentes avec 50% se chevauchant: une seconde, deux secondes et trois secondes. À chaque segment, nous avons sélectionné les fonctionnalités les plus utiles en appliquant la sélection et le classement des fonctionnalités. Grâce à cette stratégie, nous n’avons utilisé que 10 fonctionnalités par modalité, sauf dans la modalité IR en utilisant 40 fonctionnalités. De plus, la comparaison a été faite sur quatre classificateurs d’apprentissage automatique bien connus : RF, SVM, MLP et KNN. Nous avons utilisé 10 fois la multi-validation, avec des ensembles de données de train à 70% et 30% de test, pour former les modèles d’apprentissage automatique. Le tableau 1 montre les résultats de ce point de repère, en rapportant les meilleures performances obtenues pour chaque modalité selon le modèle d’apprentissage automatique et la meilleure configuration de longueur de fenêtre. Les mesures d’évaluation indiquent l’exactitude, la précision, la sensibilité, la spécificité et le score F1. La figure 3 montre ces résultats dans une représentation graphique, en termes de F1-score.
À partir du tableau 1, les approches multimodales (capteurs et casques infrarouges et portables, IR-IMU-EEG; et capteurs portables et casque et caméras, IMU-EEG-CAM) ont obtenu les meilleures valeurs de F1,50 , par rapport aux approches unimodal (infrarouge seulement, IR; et caméras seulement, CAM). Nous avons également remarqué que les capteurs portables seulement (IMU) ont obtenu des performances similaires à une approche multimodale. Dans ce cas, nous avons opté pour une approche multimodale parce que différentes sources d’information peuvent gérer les limites des autres. Par exemple, l’immobilité des caméras peut être manipulée par des capteurs portables, et ne pas utiliser tous les capteurs portables peut être complété par des caméras ou des capteurs ambiants.
En ce qui concerne la référence des modèles axés sur les données, les expériences du tableau 1 ont montré que la RF présente les meilleurs résultats dans presque toutes les expériences; bien que le MLP et le SVM n’aient pas été très cohérents en matière de performance (p. ex., l’écart standard dans ces techniques montre plus de variabilité que dans les RF). Au sujet de la taille des fenêtres, celles-ci ne représentaient aucune amélioration significative parmi eux. Il est important de noter que ces expériences ont été faites pour la classification de l’automne et de l’activité humaine.
Placement de capteur et meilleure combinaison multimodale
D’autre part, nous avons cherché à déterminer la meilleure combinaison de dispositifs multimodaux pour la détection des chutes. Pour cette analyse, nous avons limité les sources d’information aux cinq capteurs portables et aux deux caméras. Ces appareils sont les plus confortables pour l’approche. En outre, nous avons considéré deux classes : l’automne (tout type d’automne) ou la non-chute (toute autre activité). Tous les modèles d’apprentissage automatique, et la taille des fenêtres restent les mêmes que dans l’analyse précédente.
Pour chaque capteur portable, nous avons construit un modèle de classificateur indépendant pour chaque longueur de fenêtre. Nous avons formé le modèle à l’aide de 10 fois de validation croisée avec 70% de formation et 30% de jeux de données de test. Le tableau 2 résume les résultats du classement des capteurs portables par classificateur de performance, basé sur le score F1. Ces résultats ont été triés dans l’ordre décroissant. Comme on le voit dans le tableau 2, la meilleure performance est obtenue lors de l’utilisation d’un seul capteur à la taille, le cou ou la poche droite serrée (région ombragée). En outre, les capteurs portables de cheville et de poignet gauche ont exécuté le pire. Le tableau 3 montre la préférence de longueur de fenêtre par capteur portable afin d’obtenir les meilleures performances dans chaque classificateur. D’après les résultats, la taille, le cou et les capteurs serrés de poche droite avec classificateur RF et la taille de fenêtre de 3 s avec 50% de chevauchement sont les capteurs portables les plus appropriés pour la détection des chutes.
Nous avons effectué une analyse similaire pour chaque caméra du système. Nous avons construit un modèle de classificateur indépendant pour chaque taille de fenêtre. Pour la formation, nous avons fait 10 fois la validation croisée avec 70% de formation et 30% de jeux de données de test. Le tableau 4 montre le classement du meilleur point de vue de la caméra par classificateur, basé sur le score F1. Comme on l’a observé, la vue latérale (caméra 1) a effectué la meilleure détection des chutes. En outre, RF a surpassé par rapport aux autres classificateurs. En outre, le tableau 5 montre la préférence de longueur de fenêtre par point de vue de caméra. D’après les résultats, nous avons constaté que le meilleur emplacement d’une caméra est en point de vue latéral en utilisant RF dans la taille de la fenêtre 3 et 50% se chevauchant.
Enfin, nous avons choisi deux placements possibles de capteurs portables (c.-à-d. taille et poche droite serrée) pour être combinés avec la caméra du point de vue latéral. Après la même procédure de formation, nous avons obtenu les résultats du tableau 6. Comme indiqué, le classificateur modèle RF a obtenu la meilleure performance en précision et F1-score dans les deux multimodalités. En outre, la combinaison entre la taille et la caméra 1 classé dans la première position obtenant 98,72% en précision et 95,77% en F1-score.

Figure 1 : Disposition des capteurs portables (gauche) et ambiants (à droite) dans la base de données de détection UP-Fall. Les capteurs portables sont placés dans le front, le poignet gauche, le cou, la taille, la poche droite du pantalon et la cheville gauche. Les capteurs ambiants sont six capteurs infrarouges appariés pour détecter la présence de sujets et de deux caméras. Les caméras sont situées à la vue latérale et à la vue avant, à la fois en ce qui concerne la chute humaine. S’il vous plaît cliquez ici pour voir une version plus grande de ce chiffre.
{kind=link}

Figure 2 : Exemple d’enregistrement vidéo extrait de la base de données up-Fall Detection. En haut, il y a une séquence d’images d’un sujet tombant sur le côté. En bas, il y a une séquence d’images représentant les caractéristiques de vision extraites. Ces caractéristiques sont le mouvement relatif des pixels entre deux images adjacentes. Les pixels blancs représentent un mouvement plus rapide, tandis que les pixels noirs représentent un mouvement plus lent (ou près de zéro). Cette séquence est triée de gauche à droite, chronologiquement. S’il vous plaît cliquez ici pour voir une version plus grande de ce chiffre.
{kind=link}

Figure 3 : Résultats comparatifs indiquant le meilleur score F1 de chaque modalité par rapport au modèle d’apprentissage automatique et à la meilleure longueur de fenêtre. Les barres représentent les valeurs moyennes du score F1. Le texte dans les points de données représente une déviation moyenne et standard dans la parenthèse. S’il vous plaît cliquez ici pour voir une version plus grande de ce chiffre.
{kind=link}
| Modalité | Modèle | Précision (%) | Précision (%) | Sensibilité (%) | Spécificité (%) | F1-score (%) |
| Ir | RF (3 sec) | 67,38 à 0,65 | 36,45 à 2,46 | 31,26 à 0,89 | 96,63 à 0,07 | 32.16 à 0,99 |
| SVM (3 sec) | 65,16 à 0,90 | 26,77 à 0,58 | 25.16 à 0,29 | 96,31 à 0,09 | 23,89 à 0,41 | |
| MLP (3 sec) | 65,69 à 0,89 | 28.19 3.56 | 26,40 à 0,71 | 96,41 à 0,08 | 25.13 à 1.09 | |
| kNN (3 sec) | 61,79 à 1,47 | 30,04 à 1,44 | 27,55 à 0,97 | 96,05 à 0,16 | 27,89 à 1,13 | |
| Imu | RF (1 sec) | 95,76 à 0,18 | 70,78 à 1,53 | 66,91 à 1,28 | 99,59 à 0,02 | 68,35 à 1,25 |
| SVM (1 sec) | 93,32 à 0,23 | 66.16 à 3.33 | 58,82 à 1,53 | 99,32 à 0,02 | 60,00 à 1,34 | |
| MLP (1 sec) | 95,48 à 0,25 | 73,04 à 1,89 | 69,39 à 1,47 | 99,56 à 0,02 | 70,31 à 1,48 | |
| kNN (1 sec) | 94,90 à 0,18 | 69,05 à 1,63 | 64,28 à 1,57 | 99,50 à 0,02 | 66,03 à 1,52 | |
| IMU-EEG | RF (1 sec) | 95,92 à 0,29 | 74,14 à 1,29 | 66,29 à 1,66 | 99,59 à 0,03 | 69,03 à 1,48 |
| SVM (1 sec) | 90,77 à 0,36 | 62,51 à 3,34 | 52,46 à 1,19 | 99,03 à 0,03 | 53,91 à 1,16 | |
| MLP (1 sec) | 93,33 à 0,55 | 74,10 à 1,61 | 65,32 à 1,15 | 99,32 à 0,05 | 68,13 à 1,16 | |
| kNN (1 sec) | 92,12 à 0,31 | 66,86 à 1,32 | 58,30 à 1,20 | 98,89 à 0,05 | 60,56 à 1,02 | |
| IR-IMU-EEG | RF (2 sec) | 95,12 à 0,36 | 74,63 à 1,65 | 66,71 à 1,98 | 99,51 à 0,03 | 69,38 à 1,72 |
| SVM (1 sec) | 90,59 à 0,27 | 64,75 à 3,89 | 52,63 à 1,42 | 99,01 à 0,02 | 53,94 à 1,47 | |
| MLP (1 sec) | 93,26 à 0,69 | 73,51 à 1,59 | 66,05 à 1,11 | 99,31 à 0,07 | 68,19 à 1,02 | |
| kNN (1 sec) | 92,24 à 0,25 | 67,33 à 1,94 | 58.11 1,61 | 99,21 à 0,02 | 60,36 à 1,71 | |
| Cam | RF (3 sec) | 32,33 à 0,90 | 14,45 à 1,07 | 14,48 à 0,82 | 92,91 à 0,09 | 14,38 à 0,89 |
| SVM (2 sec) | 34,40 à 0,67 | 13,81 à 0,22 | 14,30 à 0,31 | 92,97 à 0,06 | 13,83 à 0,27 | |
| MLP (3 sec) | 27,08 à 2,03 | 8,59 à 1,69 | 10,59 à 0,38 | 92,21 à 0,09 | 7,31 à 0,82 | |
| kNN (3 sec) | 34.03 1.11 | 15,32 à 0,73 | 15,54 à 0,57 | 93,09 à 0,11 | 15,19 à 0,52 | |
| IR-CAM | RF (3 sec) | 65,00 à 0,65 | 33,93 à 2,81 | 29,02 à 0,89 | 96,34 à 0,07 | 29,81 à 1,16 |
| SVM (3 sec) | 64,07 à 0,79 | 24,10 à 0,98 | 24.18 à 0,17 | 96,17 à 0,07 | 22,38 à 0,23 | |
| MLP (3 sec) | 65,05 à 0,66 | 28,25 à 3,20 | 25,40 à 0,51 | 96,29 à 0,06 | 24,39 à 0,88 | |
| kNN (3 sec) | 60,75 à 1,29 | 29,91 à 3,95 | 26.25 à 0,90 | 95,95 à 0,11 | 26,54 à 1,42 | |
| IMU-EEG-CAM | RF (1 sec) | 95,09 à 0,23 | 75,52 à 2,31 | 66,23 à 1,11 | 99,50 à 0,02 | 69,36 à 1,35 |
| SVM (1 sec) | 91,16 à 0,25 | 66,79 à 2,79 | 53,82 à 0,70 | 99,07 à 0,02 | 55,82 à 0,77 | |
| MLP (1 sec) | 94,32 à 0,31 | 76,78 à 1,59 | 67,29 à 1,41 | 99,42 à 0,03 | 70,44 à 1,25 | |
| kNN (1 sec) | 92,06 à 0,24 | 68,82 à 1,61 | 58,49 à 1,14 | 99,19 à 0,02 | 60,51 à 0,85 |
Tableau 1 : Résultats comparatifs indiquant la meilleure performance de chaque modalité par rapport au modèle d’apprentissage automatique et à la meilleure longueur de fenêtre (entre parenthèses). Toutes les valeurs de performance représentent la moyenne et l’écart standard.
| # | Type IMU | |||
| Rf | Svm | Mlp | KNN (KNN) | |
| 1 | (98.36) Taille | (83.30) Poche droite | (57.67) Poche droite | (73.19) Poche droite |
| 2 | (95.77) Cou | (83.22) Taille | (44.93) Cou | (68.73) Taille |
| 3 | (95.35) Poche droite | (83.11) Cou | (39.54) Taille | (65.06) Cou |
| 4 | (95.06) Cheville | (82.96) Cheville | (39.06) Poignet gauche | (58.26) Cheville |
| 5 | (94.66) Poignet gauche | (82.82) Poignet gauche | (37.56) Cheville | (51.63) Poignet gauche |
Tableau 2 : Classement du meilleur capteur portable par classificateur, trié par le score F1 (entre parenthèses). Les régions d’ombre représentent les trois meilleurs classificateurs pour la détection des chutes.
| Type IMU | Longueur de fenêtre | |||
| Rf | Svm | Mlp | KNN (KNN) | |
| Cheville gauche | 2-sec | 3-sec | 1-sec | 3-sec |
| Taille | 3-sec | 1-sec | 1-sec | 2-sec |
| Cou | 3-sec | 3-sec | 2-sec | 2-sec |
| Poche droite | 3-sec | 3-sec | 2-sec | 2-sec |
| Poignet gauche | 2-sec | 2-sec | 2-sec | 2-sec |
Tableau 3 : Durée préférée des capteurs portables par classificateur.
| # | Vue de caméra | |||
| Rf | Svm | Mlp | KNN (KNN) | |
| 1 | (62.27) Vue latérale | (24.25) Vue latérale | (13.78) Vue d’avant | (41.52) Vue latérale |
| 2 | (55.71) Vue d’avant | (0.20) Vue avant | (5.51) Vue latérale | (28.13) Vue d’avant |
Tableau 4 : Classement du meilleur point de vue de la caméra par classificateur, trié par le F1-score (entre parenthèses). Les régions d’ombre représentent le meilleur classificateur pour la détection des chutes.
| Caméra | Longueur de fenêtre | |||
| Rf | Svm | Mlp | KNN (KNN) | |
| Vue latérale | 3-sec | 3-sec | 2-sec | 3-sec |
| Vue avant | 2-sec | 2-sec | 3-sec | 2-sec |
Tableau 5 : Durée de la fenêtre préférée dans les points de vue de la caméra par classificateur.
| Multimodal | Classificateur | Précision (%) | Précision (%) | Sensibilité (%) | F1-score (%) |
| Taille + Vue latérale | Rf | 98,72 à 0,35 | 94,01 1,51 | 97,63 à 1,56 | 95,77 à 1,15 |
| Svm | 95,59 à 0,40 | 100 | 70,26 à 2,71 | 82,51 à 1,85 | |
| Mlp | 77,67 à 11,04 | 33,73 à 11,69 | 37.11 26.74 | 29,81 à 12,81 | |
| KNN (KNN) | 91,71 à 0,61 | 77,90 à 3,33 | 61,64 à 3,68 | 68,73 à 2,58 | |
| Poche droite + Vue latérale | Rf | 98,41 à 0,49 | 93,64 à 1,46 | 95,79 à 2,65 | 94,69 à 1,67 |
| Svm | 95,79 à 0,58 | 100 | 71,58 à 3,91 | 83,38 à 2,64 | |
| Mlp | 84,92 à 2,98 | 55,70 à 11,36 | 48,29 à 25,11 | 45.21 14.19 | |
| KNN (KNN) | 91,71 à 0,58 | 73,63 à 3,19 | 68,95 à 2,73 | 71,13 à 1,69 |
Tableau 6 : Résultats comparatifs du capteur portable combiné et du point de vue de la caméra à l’aide de la longueur de la fenêtre de 3 secondes. Toutes les valeurs représentent l’écart moyen et standard.
Discussion
Il est courant de rencontrer des défis dus à la synchronisation, à l’organisation et aux problèmes d’incohérence des données20 lorsqu’un jeu de données est créé.
Synchronisation
Dans l’acquisition de données, des problèmes de synchronisation surviennent étant donné que plusieurs capteurs fonctionnent généralement à des taux d’échantillonnage différents. Les capteurs à fréquences plus élevées recueillent plus de données que celles dont les fréquences sont inférieures. Ainsi, les données provenant de différentes sources ne seront pas appariées correctement. Même si les capteurs fonctionnent aux mêmes taux d’échantillonnage, il est possible que les données ne soient pas alignées. À cet égard, les recommandations suivantes pourraient aider à gérer ces problèmes de synchronisation20: (i) enregistrer l’échéanation, le sujet, l’activité et l’essai dans chaque échantillon de données obtenu à partir des capteurs; (ii) la source d’information la plus cohérente et la moins fréquente doit être utilisée comme signal de référence pour la synchronisation; et (iii) utiliser des procédures automatiques ou semi-automatiques pour synchroniser les enregistrements vidéo que l’inspection manuelle ne serait pas pratique.
Prétaitment des données
Le prétraitage des données doit également être effectué, et les décisions critiques influencent ce processus : a) déterminer les méthodes de stockage des données et de représentation des données de sources multiples et hétérogènes b) décider des moyens de stocker des données dans l’hôte local ou sur le cloud (c) sélectionner l’organisation des données, y compris les noms de fichiers et les dossiers (d) gérer les valeurs manquantes des données ainsi que les redondances trouvées dans les capteurs , entre autres. En outre, pour le cloud des données, la mise en mémoire tampon locale est recommandée lorsque cela est possible pour atténuer la perte de données au moment du téléchargement.
Incohérence des données
L’incohérence des données est courante entre les essais qui trouvent des variations dans la taille des échantillons de données. Ces problèmes sont liés à l’acquisition de données dans des capteurs portables. De brèves interruptions de l’acquisition de données et de collision de données à partir de plusieurs capteurs entraînent des incohérences dans les données. Dans ces cas, les algorithmes de détection d’incohérence sont importants pour gérer les défaillances en ligne dans les capteurs. Il est important de souligner que les appareils sans fil doivent être surveillés fréquemment tout au long de l’expérience. Une batterie faible peut avoir un impact sur la connectivité et entraîner une perte de données.
Éthique
Le consentement à participer et l’approbation éthique sont obligatoires dans tous les types d’expérimentations où les gens sont impliqués.
En ce qui concerne les limites de cette méthodologie, il est important de noter qu’elle est conçue pour des approches qui tiennent compte des différentes modalités de collecte de données. Les systèmes peuvent inclure des capteurs portables, ambiants et/ou de vision. Il est suggéré d’examiner la consommation d’énergie des appareils et la durée de vie des batteries dans les capteurs sans fil, en raison de problèmes tels que la perte de la collecte de données, la diminution de la connectivité et la consommation d’énergie dans l’ensemble du système. En outre, cette méthodologie est destinée aux systèmes qui utilisent des méthodes d’apprentissage automatique. Une analyse de la sélection de ces modèles d’apprentissage automatique doit être effectuée à l’avance. Certains de ces modèles pourraient être précis, mais très long et d’énergie. Il faut tenir compte d’un compromis entre une estimation précise et une disponibilité limitée des ressources pour l’informatique dans les modèles d’apprentissage automatique. Il est également important de noter que, dans la collecte de données du système, les activités ont été menées dans le même ordre; aussi, les essais ont été exécutés dans la même séquence. Pour des raisons de sécurité, un matelas de protection a été utilisé pour que les sujets tombent dessus. En outre, les chutes ont été auto-initiées. Il s’agit d’une différence importante entre les chutes simulées et réelles, qui se produisent généralement vers les matériaux durs. En ce sens, ce jeu de données enregistré tombe avec une réaction intuitive essayant de ne pas tomber. En outre, il existe certaines différences entre les chutes réelles chez les personnes âgées ou handicapées et la simulation tombe; et ceux-ci doivent être pris en compte lors de la conception d’un nouveau système de détection des chutes. Cette étude a été axée sur les jeunes sans aucune déficience, mais il est remarquable de dire que la sélection des sujets devrait être alignée sur l’objectif du système et la population cible qui l’utilisera.
D’après les travaux connexes décrits au-dessusde 10,11,12,13,14,15,16,17,18, nous pouvons observer qu’il ya des auteurs qui utilisent des approches multimodales se concentrant sur l’obtention de détecteurs de chute robustes ou se concentrer sur le placement ou la performance de la classificateur. Par conséquent, ils ne traitent qu’un ou deux des problèmes de conception pour la détection des chutes. Notre méthodologie permet de résoudre simultanément trois des principaux problèmes de conception d’un système de détection des chutes.
Pour les travaux futurs, nous suggérons la conception et la mise en œuvre d’un système de détection des chutes multimodales simple basé sur les résultats obtenus suivant cette méthodologie. Pour l’adoption dans le monde réel, l’apprentissage des transferts, la classification hiérarchique et les approches d’apprentissage profond devraient être utilisés pour développer des systèmes plus robustes. Notre mise en œuvre n’a pas tenu compte des mesures qualitatives des modèles d’apprentissage automatique, mais il faut tenir compte des ressources informatiques en temps réel et limitées pour le développement de systèmes de détection/reconnaissance de la chute humaine et des activités. Enfin, afin d’améliorer notre jeu de données, des activités de trébuchement ou de chute presque et un suivi en temps réel des bénévoles au cours de leur vie quotidienne peuvent être envisagés.
Déclarations de divulgation
Les auteurs n’ont rien à divulguer.
Remerciements
Cette recherche a été financée par Universidad Panamericana grâce à la subvention "Fomento a la Investigacion UP 2018", selon le code du projet UP-CI-2018-ING-MX-04.
matériels
| Name | Company | Catalog Number | Comments |
| Inertial measurement wearable sensor | Mbientlab | MTH-MetaTracker | Tri-axial accelerometer, tri-axial gyroscope and light intensity wearable sensor. |
| Electroencephalograph brain sensor helmet MindWave | NeuroSky | 80027-007 | Raw brainwave signal with one forehand sensor. |
| LifeCam Cinema video camera | Microsoft | H5D-00002 | 2D RGB camera with USB cable interface. |
| Infrared sensor | Alean | ABT-60 | Proximity sensor with normally closed relay. |
| Bluetooth dongle | Mbientlab | BLE | Dongle for Bluetooth connection between the wearable sensors and a computer. |
| Raspberry Pi | Raspberry | Version 3 Model B | Microcontroller for infrared sensor acquisition and computer interface. |
| Personal computer | Dell | Intel Xeon E5-2630 v4 @2.20 GHz, RAM 32GB |
Références
- United Nations. World Population Prospects: The 2017 Revision, Key Findings and Advance Tables. United Nations. Department of Economic and Social Affairs, Population Division. , (2017).
- World Health Organization. Ageing, and Life Course Unit. WHO Global Report on Falls Prevention in Older Age. , (2008).
- Igual, R., Medrano, C., Plaza, I. Challenges, Issues and Trends in Fall Detection Systems. Biomedical Engineering Online. 12 (1), 66 (2013).
- Noury, N., et al. Fall Detection-Principles and Methods. 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 1663-1666 (2007).
- Mubashir, M., Shao, L., Seed, L. A Survey on Fall Detection: Principles and Approaches. Neurocomputing. 100, 144-152 (2002).
- Perry, J. T., et al. Survey and Evaluation of Real-Time Fall Detection Approaches. Proceedings of the 6th International Symposium High-Capacity Optical Networks and Enabling Technologies. , 158-164 (2009).
- Xu, T., Zhou, Y., Zhu, J. New Advances and Challenges of Fall Detection Systems: A Survey. Applied Sciences. 8 (3), 418 (2018).
- Rougier, C., Meunier, J., St-Arnaud, A., Rousseau, J. Robust Video Surveillance for Fall Detection Based on Human Shape Deformation. IEEE Transactions on Circuit Systems for Video Technologies. 21, 611-622 (2011).
- Bulling, A., Blanke, U., Schiele, B. A Tutorial on Human Activity Recognition Using Body-Worn Inertial Sensors. ACM Computing Surveys. 46 (3), 33 (2014).
- Kwolek, B., Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Computational Methods and Programs in Biomedicine. 117, 489-501 (2014).
- Ofli, F., Chaudhry, R., Kurillo, G., Vidal, R., Bajcsy, R. Berkeley MHAD: A Comprehensive Multimodal Human Action Database. Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision. , 53-60 (2013).
- Dovgan, E., et al. Intelligent Elderly-Care Prototype for Fall and Disease Detection. Slovenian Medical Journal. 80, 824-831 (2011).
- Santoyo-Ramón, J., Casilari, E., Cano-García, J. Analysis of a Smartphone-Based Architecture With Multiple Mobility Sensors for Fall Detection With Supervised Learning. Sensors. 18 (4), 1155 (2018).
- Özdemir, A. An Analysis on Sensor Locations of the Human Body for Wearable Fall Detection Devices: Principles and Practice. Sensors. 16 (8), 1161 (2016).
- Ntanasis, P., Pippa, E., Özdemir, A. T., Barshan, B., Megalooikonomou, V. Investigation of Sensor Placement for Accurate Fall Detection. International Conference on Wireless Mobile Communication and Healthcare. , 225-232 (2016).
- Bagala, F., et al. Evaluation of Accelerometer-Based Fall Detection Algorithms on Real-World Falls. PLoS One. 7, 37062 (2012).
- Bourke, A. K., et al. Assessment of Waist-Worn Tri-Axial Accelerometer Based Fall-detection Algorithms Using Continuous Unsupervised Activities. Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 2782-2785 (2010).
- Kerdegari, H., Samsudin, K., Ramli, A. R., Mokaram, S. Evaluation of Fall Detection Classification Approaches. 4th International Conference on Intelligent and Advanced Systems. , 131-136 (2012).
- Alazrai, R., Mowafi, Y., Hamad, E. A Fall Prediction Methodology for Elderly Based on a Depth Camera. 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 4990-4993 (2015).
- Peñafort-Asturiano, C. J., Santiago, N., Núñez-Martínez, J. P., Ponce, H., Martínez-Villaseñor, L. Challenges in Data Acquisition Systems: Lessons Learned from Fall Detection to Nanosensors. 2018 Nanotechnology for Instrumentation and Measurement. , 1-8 (2018).
- Martínez-Villaseñor, L., et al. UP-Fall Detection Dataset: A Multimodal Approach. Sensors. 19 (9), 1988 (2019).
- Rantz, M., et al. Falls, Technology, and Stunt Actors: New approaches to Fall Detection and Fall Risk Assessment. Journal of Nursing Care Quality. 23 (3), 195-201 (2008).
- Lachance, C., Jurkowski, M., Dymarz, A., Mackey, D. Compliant Flooring to Prevent Fall-Related Injuries: A Scoping Review Protocol. BMJ Open. 6 (8), 011757 (2016).
Réimpressions et Autorisations
Demande d’autorisation pour utiliser le texte ou les figures de cet article JoVE
Demande d’autorisationThis article has been published
Video Coming Soon
À PROPOS DE JoVE
Copyright © 2025 MyJoVE Corporation. Tous droits réservés.