
Method Article
エラー修正 DNA ・ RNA シーケンスを用いた珍しいイベント検出
要約
次世代シーケンス (NGS)、プラットフォーム (~0.5–2.0%) の高い誤り率によって制限されるゲノム解析の強力なツールです。NGS のエラーレートを未然に防ぐし、バリアント アレル分 0.0001 のようにまれに突然変異を検出するエラー修正のシーケンスの我々 の方法をについて説明します。
要約
従来の次世代シーケンシング技術 (NGS) は、10 年以上の巨大なゲノム解析を許可しています。具体的には、NGS は悪性腫瘍にクローン変異のスペクトルを分析するために使用されています。従来サンガー、NGS 闘争その高い誤り率 ~0.5–2.0% によるまれなクローンと subclonal 突然変異を識別するよりもはるかに効率的です。したがってがある突然変異の検出限界を持つ標準的な NGS > 0.02 バリアント アレル分数 (エン)。患者のまれな突然変異の臨床的意義、知られている病気は、明白でなく残ることがなく白血病の治療を受けた患者が大幅に向上成果残存病変が < フローサイトメトリーによる 0.0001。NGS のこの artefactual 背景を軽減するために多くの方法が開発されています。ここでエラー修正 DNA および RNA シーケンス (ECS)、エラー訂正のため 16 bp ランダム インデックスと多重化のための 8 bp 患者固有のインデックスの個々 の分子のタグ付けを含むため手法について述べる。本手法は検出し、バリアント アレル分数 (VAFs) 2 桁の NGS の検出限界よりも低く、0.0001 エンのようにまれにクローン変異を追跡できます。
概要
我々 として年齢、変異原性物質と細胞分裂結果、ゲノム、これで身体異常の蓄積で中確率のエラーへの暴露の基となる悪性転化の根本的な病因神経疾患、小児障害と正常な老化1,2。病気運転可能性と体細胞突然変異は、早期発見とリスク管理3,4、5の重要な診断と予後バイオ マーカーです。生理学的な clonogenesis が理解するために臨床通知し、意思決定、定量の正確さおよびこれらの突然変異の特性を研究する重要です。次世代シーケンス (NGS) は、異種の DNA サンプルにクローン変異の研究に現在使用されてただし、NGS は突然変異を識別する制限 > 0.02 バリアント アレル分数 (エン)-0.5-2.0 の固有の誤り率のためシーケンス プラットフォーム6,7,8%。その結果、診断と予後追跡低いエンで重要な体の亜種では得られない標準 NGS。
近年、様々 なメソッドは、NGS8,9,10,11のエラー率を回避するために開発されています。これらのメソッドは、シーケンス処理の後のエラー訂正を可能分子タギングを利用します。各分子やゲノム断片配列ライブラリでは付くと、ランダムなユニークな分子識別子 (UMI) その分子に固有です。行政は、無作為化ヌクレオチド (8-16 N) の文字列の順列を構築されています。2 番目サンプル固有のバーコードも、ワークフロー実行同じ NGS シーケンスに複数のサンプルを多重伝送が可能に統合されます。Pcr は分子タグ ライブラリで実行され、シーケンス処理用ライブラリを送信するその後。ライブラリの準備中、エラーでがゲノム フラグメントを pcr とシーケンス8中にランダムに導入されることが期待されます。ランダムなシーケンス エラーを削除するには、生配列読み取りが UMI に従ってグループ化されます。シーケンスからの人工物は真のバリアントが忠実に増幅し、同じ海を共有すべての読み取りでシーケンスに対し導入の確率論的性質同じゲノムの位置に同じ海ですべての読み取りに存在することは行われません。成果物が削除されます bioinformatically です。ここでは、3 つのメソッドのエラー修正のシーケンス (ECS) 研究所単一のヌクレオチドの亜種 (SNVs) と小さな挿入削除 (オクターリピート) を識別するために DNA および RNA 遺伝子発現下の定量化を容易にするための最適化について述べる、NGS のエラーのしきい値。
最初の方法では、研究者によって設計された遺伝子特異的プライマーを用いた珍しい体イベントを探す方法について説明します。ライブラリの準備の前に研究者は興味のかけらをターゲットにプライマーを設計する必要があります。Web アプリ Primer3 を使いました (http://bioinfo.ut.ee/primer3-0.4.0/)。200-250 bp の産物は、これらは、行政が組み込まれて一度ポリメラーゼの連鎖反応 (PCR) に最適、ペアエンド リード 150 bp ペアエンド リードでの重複を生成します。使用する最適なプライマー設計条件: 最小プライマー サイズ = 19;最適なプライマー サイズ = 25;最大プライマー サイズ = 30;最小 Tm = 64 ° C;最適な Tm = 70 ° C;最大 Tm = 74 ° C;Tm 差の最大値 = 5 ° C;GC の最小の内容 = 45;最大 GC コンテンツ = 80。返される数 = 20;最大 3' 端安定性 = 100。
方法 2 のクローン SNVs と小さなオクターリピート 0.0001 エン amplicons の数百を含む市販遺伝子パネルを使用してのようにまれにイルミナ化学と ECS DNA のプロトコルを組み合わせる手法について述べる.TruSight 骨髄性シーケンス パネル (イルミナ) を実験に使用し、小児の骨髄性疾患のための興味の遺伝子を含むように拡張されたパネルを設計しました。これらのパネルがこれらのパネルに独自のアダプターの戦略を追加しましたので、エラー訂正を促進するようなユニークな分子識別子 (Umi) を提供していません。ECS が動作するはずです同様に他のさまざまな病気と関連付けられる遺伝子の豊かに設計のパネルのいずれかで。次の DNA の隔離および組織または目的の標本から後続の定量化、それは少なくとも 500 に勧め株 DNA 試料当りの ng。我々 は日常的に 250 を使用して単一配列ライブラリを作る ng の下流をできるだけ多くユニークなゲノム フラグメントとしてキャプチャするために DNA の重複とエン計算を読み取ります。残りの 250 とオプションの複製シーケンス ライブラリを作ることができる DNA の ng。標本あたり 2 つのライブラリのレプリケートを常に確認、真陽性として両方の複製で独立して検出されたイベントのみを考えます。4,13を呼び出すバリエーションの精度を高めるためのゲノム位置特異的二項エラー モデルを実施します。
最後に、ECS を市販の QIAseq ターゲット RNA パネル (Qiagen) を使用して転写定量化のための RNA シーケンスに結合手法について述べる。重複除外に必要な行政とエラー訂正は、キットに盛り込まれているし、研究者は、ライブラリの製造元の推奨事項に従います。Bioinformatically、研究者は、ECS-DNA のプロトコル セクションで詳細に説明するために概説パイプラインを従うことができます。
プロトコル
1. ターゲット dna シーケンスのエラー修正
- 興味のゲノム断片の PCR の拡大。
- (材料表項目 1) amplicons を増幅するのに高忠実度 DNA ポリメラーゼを使用します。サーマルサイクラーに以下の条件で PCR 反応を増幅する: 30 98 ° c; s10 の 18-40 のサイクル 98 ° c、30 秒 66 ° c、s と 30 s 72 ° c;72 ° C で 2 分4 ° C で保持します。
- 常磁性ビーズ (材料表項目 2) PCR の製品を浄化します。1: 1.8 インチ比でビーズに PCR 反応を追加 (PCR の反作用ボリューム: ボリュームをビーズ) 製造元のプロトコルに従って。DdH2o. の 20 μ L の溶出します。
- (材料表項目 3) DNA の最終濃度を決定する DNA の濃度を定量化します。
- 2% アガロース ゲル (材料表アイテム 4)、産物のサイズを確認するための DNA の因数を実行します。
注: 代わりに、研究者は、増幅されたゲノム断片のサイズだけでなく、製品の濃度を決定する PCR の製品のバイオアナライザー分析を実行を選択できます。
- アダプター熱処理シーケンス
- I7 アダプター (材料表項目 5) を取得します。以降の手順のためのものです、それらを使用します。
- 次の oligo シーケンス (材料表の項目 6) と商業的 16N i5 アダプターを購入: AATGATACGGCGACCACCGAGATCTACAC(N1:25252525)(N1)(N1)(N1)(N1)(N1)(N1)(N1)(N1)(N1)(N1)(N1)(N1)(N1)(N1) (N1) ACACTCTTTCCCTACACGACGCTCTTCCGATCT
メモ: 16N i5 アダプター交換標準 i5 アダプター、ECS を容易にするために 16 のランダムな塩基配列の文字列でアダプターです。 - 16N i5 アダプター実用的なソリューションを作る: 100 μ M 16N i5 アダプター在庫 40 μ、10 μ L TE バッファーの 500 μ M の塩化ナトリウム溶液 10 μ L。
- 個別 PCR 井戸に 1.2.3 のステップで、i5 作業溶液の分注 7.5 μ。
- 対応する井戸にサンプル固有 i7 アダプターの 5 μ L を追加します。
- 95 ° C、5 分インキュベートし、すべての 30 の 1 ° C でクールなサーマルサイクラーに 4 ° C に s。
- 4 ° C で保持します。
- 最後修理 & ライブラリの dA テーリング
注: でアダプターがアニール処理と並行して、1 つに対して実行できます最後の修理や dA テーリング手順 1.1 から PCR 産物。これらの手順が完了した後、修理終了と PCR 産物の dA 尾にステップ 1.2 から焼鈍のアダプターの ligation が実行されます。次のアダプターの ligation ECS ライブラリーの構築は完了です。- せいぜい 1 μ g の DNA を開始始まる (最小 ~ 200 ng)
- Amplicons (材料表項目 7) で終了-修理および dA 尾を実行します。
- 終了準備酵素ミックス 3.0 μ と終わり修理バッファーの 6.5 μ L を追加します。
- ミックス 65 ° C で 30 分間、20 の ° C で 30 分間インキュベートし、4 ° C で保持
- 焼なましアダプター (材料表項目 8) で結紮を実行します。
- ステップ 2、鈍/TA リガーゼ マスター ミックスの 15 μ L、結紮エンハンサーの 1 μ L から焼鈍アダプターの 2.5 μ L を追加します。
- 37 ° C で 15 分間、20 の ° C で 15 分間のミックスを孵化させなさい
- 磁気ビーズ (材料表項目 2) ライブラリのクリーンアップ: 修正 1: 0.75 の比率でビーズに PCR 反応を追加 (PCR の反作用ボリューム: 磁気ビーズ容積)。
- 1.2.7 のステップからの PCR の製品の 83.5 μ L に磁気ビーズ ソリューションの 62.6 μ L をピペットします。
- 1.5 mL 低バインド チューブに混合物を転送します。
- 10 回以上でピペッティングを上下で徹底的にミックスします。
- 5 分間室温で放置に混合物を残します。
- マグネット ホルダーにチューブを置きます。室温でまたは清まで 2 分間インキュベートは明らか。
- 上清を除去します。
- 70% エタノール 200 μ L でビーズを洗浄します。
- 30 s. 削除エタノール間インキュベートします。
- エタノールの洗浄ステップをもう一度繰り返します。
- ビーズを風乾します。
- DdH2o. の 20 μ L の溶出します。
注: 磁気ビーズ比 PCR の反作用のこの変更は、200 より小さい DNA のフラグメントが削除されます優先的に bp。
- 液滴による定量化デジタル PCR
注: 正確な突然変異定量化シーケンサーに読み込まれた各ライブラリの分子の数の厳守が必要です。これを達成するため、個々 のライブラリ単位体積あたりの分子数を定量化は実行 QX200 液滴デジタル PCR (ddPCR) プラットフォームを使用して-量的な PCR は、代替オプションです。DdPCR 分析、次の読み出しはライブラリごと μ L あたりの分子の数を指定します。- PCR ストリップ管の 10 倍段階希釈して ECS ライブラリ縮尺を希釈します。
- 1.5 mL チューブに ddPCR の次のマスター ミックスを準備: 10 μ L の PCR ミックス (材料表項目 9)、プライマー P5、P7 プライマー、ステップ 1.4.1 から ECS クリーンアップ製品の 5 μ L の 0.2 μ L の 0.2 μ L、と 4.5 μ ddH2o.。
- それぞれにマスター ミックスの 20 μ L 分注のサンプルも 8 の倍数があることを確かめます。
- 分注 70 μ L 各油井に液滴生成油 (材料表、項目 10)。ゴム製のガスケットとカセットをカバーします。
- 液滴の液滴形成配列装置 (材料表、項目 11) を使用してください。
- マルチ チャンネル ピペットを使用して、確保する PCR プレートに DNA をせん断を避けるために 5 秒のスパンでゆっくりと行われるサンプル分注ステップ 1.4.4 で生成された液滴をロードします。
- 次の条件を使用して熱 cycler で 40 サイクルの液滴に信号を増幅する: 95 ° C、5 分30 の 40 のサイクル 95 ° C、63 ° C で 1 分で s4 ° C、90 ° C で 5 分間で 5 分4 ° C で押し
- DdPCR テンプレート液滴リーダー マシン (材料表、項目 11) を準備します。絶対定量および使用するためのパラメーター指定ください、 QX200 ddPCR エバー グリーン スーパーミックス。
- DdPCR 分析が完了すると、すべてのサンプルの間で同じの不和を生じるしきい値を設定するを確認してください。
- QX200 液滴リーダー、因数後続の手順に必要な分子数を導入する適切なボリュームから濃度読み出しを使用しています。
- シーケンス処理用ライブラリの PCR の拡大
- 1.4.9 のステップから分子の所望の数の次のマスター ミックスの準備: Q5 マスター ミックス (材料表項目 1) P5 プライマーの 2.5 μ L を 25 μ l 添加 (10 μ M)、P7 プライマーの 2.5 μ L (10 μ M)、dna の ddH2o. の 20 X μ L X µL
- 次の条件を使用してサーマルサイクラーのステップ 1.5.1 からライブラリを増幅する: 30 98 ° c; s10 の 20 サイクル 98 ° c、30 秒 63 ° c、30 s 72 ° c; s72 ° C で 2 分4 ° C で押し
-
磁気ビーズ (材料表、項目 2) ライブラリのクリーンアップ: 磁気に PCR の反作用は 1: 0.75 比変更されるのビーズを追加 (PCR の反作用ボリューム: 磁気ビーズ ボリューム)。
- 磁気ビーズ ソリューションの 37.5 μ L のピペット ステップ 1.5.2 から 50 μ L の PCR の製品に。
- 1.5 mL 低バインド チューブに混合物を転送します。
- 10 回以上でピペッティングを上下で徹底的にミックスします。
- 5 分間室温で放置に混合物を残します。
- マグネット ホルダーにチューブを置きます。室温でまたは清まで 2 分間インキュベートは明らか。
- 上清を除去します。
- 70% エタノール 200 μ L でビーズを洗浄します。
- 30 s. 削除エタノール間インキュベートします。
- エタノールの洗浄ステップをもう一度繰り返します。
- ビーズを風乾します。
- DdH2o. の 20 μ L の溶出します。
- 産物のサイズを確認するため 2% の agarose のゲルの DNA の因数を実行します。
- (材料表項目 3) 別々 の ECS ライブラリの濃度を決定する DNA の濃度を定量化します。
- 等モル量でライブラリをプールします。
注: たとえば、研究者をプールできます 400 万開始まで 4 億読み取りを出力シーケンス プラットフォームを使用して配列の分子のモルのグループ4の 8 つのライブラリ。保守的、分子あたりのエラー訂正のための 10 の raw 読み取りの平均を使用することをお勧めします。これは 3 億 6000 万ヒットを取るだろう (400 万分子 * 8 ライブラリ * 10 読み取りエラー訂正のため)。ライブラリあたり 400 万ユニークな分子増幅 (遺伝子パネルから 400 万/568 amplicons) あたり 7042 x の報道を読む理論的な平均のコンセンサスを得るために研究者が期待できます。 - (材料表項目 3) プールの ECS ライブラリの濃度を決定する DNA の濃度を定量化します。
- 約 4 でプールされた ECS ライブラリを提出 nM。
- イルミナ シーケンス プラットフォーム (MiSeq、HiSeq または NextSeq) 次のシーケンス設定を提供する: 2 x 144 ペアエンドを読み取り、8 サイクル インデックス 1 と 16 サイクル インデックス 2。
2. 遺伝子 DNA のシーケンスをエラー修正パネル
- 遺伝子パネルから oligos の交配
注: この手順で Umi (材料表、項目 17) を組み込むイルミナ TruSight または TruSeq の修正されたプロトコルを使用してシーケンス ライブラリの構築が一つ。- ゲノム フラグメント製造元のプロトコルを次に oligos を交配させます。DNA (または開始材料の任意の希望の金額) の使用 250 ng。
- 非連結 oligos 次の製造元のプロトコルを削除します。
- 拡張子結紮を行う次の製造元のプロトコル。
注: 以下製造元のプロトコルへの変更を開始します。
- PCR によって i5 および i7 のアダプターの組み込み
- 適切なボリューム サイズのチューブに以下の試薬を分注して PCR マスター ミックスを準備: Q5 マスター ミックス (材料表項目 1)、6 μ 10 μ M 16N i5 アダプター (で詳細な方法 1、ステップ 1.2.2) i7 アダプター (使用異なる i7 の 6 μ L の 37.5 μ L多重の個別サンプルのアダプター)、およびステップ 2.1.3 のビーズを使った拡張結紮ソリューションの 22 μ L。
メモ: Q5 マスター ミックスは、イルミナによって提供されるポリメラーゼのマスター ミックスを置き換えられます。Q5 ポリメラーゼは、高い再現性と導入エラーを減らすゲノム断片を増幅させます。 - 次のパラメーターを使用してサーマルサイクラー PCR プログラムを実行: 30 s 98 ° C で、10 の 4-6 サイクル 98 ° c、30 秒 66 ° c、30 s 72 ° c; s72 ° C および 4 ° C で、保留で 2 分
注: サイクルの数はパネルの大きさに依存します。500-600 組 oligos のパネルに PCR の 6 サイクルが必要ですが私たちの経験から 4 サイクルの PCR で遺伝子パネル遺伝子特定 oligos の約 1,500 の別のペアを持っている場合は十分です。 -
(材料表、項目 2) 磁気ビーズの PCR の反作用のクリーンアップ: 修正された 1 PCR の反作用の磁性ビーズに PCR 反応を追加: 0.75 磁気ビーズ比。
- 2.2.2 のステップからの PCR の製品の 75 μ L に磁気ビーズ ソリューションの 56.25 μ L をピペットします。
- 1.5 mL 低バインド チューブに混合物を転送します。
- 10 回以上でピペッティングを上下で徹底的にミックスします。
- 5 分間室温で放置に混合物を残します。
- マグネット ホルダーにチューブを置きます。室温でまたは清まで 2 分間インキュベートは明らか。
- 上清を除去します。
- 70% エタノール 200 μ L でビーズを洗浄します。
- 30 s. 削除エタノール間インキュベートします。
- エタノールの洗浄ステップをもう一度繰り返します。
- ビーズを風乾します。
- DdH2o. の 20 μ L の溶出します。
- 適切なボリューム サイズのチューブに以下の試薬を分注して PCR マスター ミックスを準備: Q5 マスター ミックス (材料表項目 1)、6 μ 10 μ M 16N i5 アダプター (で詳細な方法 1、ステップ 1.2.2) i7 アダプター (使用異なる i7 の 6 μ L の 37.5 μ L多重の個別サンプルのアダプター)、およびステップ 2.1.3 のビーズを使った拡張結紮ソリューションの 22 μ L。
- QX200 ddPCR プラットフォームを使用してライブラリを定量化します。
- 方法 1 で手順 1.4。
注: 400 万分子サンプル ライブラリ4代表的な結果 (図 2) にあたり 7,042 固有インデックス化された分子 (400 万 568 遺伝子特定 oligos で割った値) の理論的な平均値を得るために正規化されました。
- 方法 1 で手順 1.4。
- 増幅し、シーケンス処理用ライブラリを正規化します。
- 必要な合計 50 μ L 最終的な PCR のための次のマスター ミックスを用いた分子数を増幅する: Q5 マスター ミックス、P5 のプライマーの 2 μ L の 25 μ L (1 μ M)、P7 プライマーの 2 μ L (1 μ M) と 21 μ L の DNA 分子の。
- 次のパラメーターを使用してサーマルサイクラー PCR プログラムを実行: 30 98 ° c; s10 の 16 サイクル 98 ° c、30 秒 66 ° c、30 s 72 ° c; s72 ° C で 2 分4 ° C で押し
- (材料表項目 2) 磁気ビーズを用いたシーケンス ライブラリのクリーンアップ: 修正された 1 PCR の反作用の磁性ビーズに PCR 反応を追加: 0.75 磁気ビーズ比。
- 2.4.2 のステップから 50 μ L の PCR の製品に磁気ビーズ ソリューションの 37.5 μ L をピペットします。
- 1.5 mL 低バインド チューブに混合物を転送します。
- 10 回以上でピペッティングを上下で徹底的にミックスします。
- 5 分間室温で放置に混合物を残します。
- マグネット ホルダーにチューブを置きます。室温でまたは清まで 2 分間インキュベートは明らか。
- 上清を除去します。
- 70% エタノール 200 μ L でビーズを洗浄します。
- 30 s. 削除エタノール間インキュベートします。
- エタノールの洗浄ステップをもう一度繰り返します。
- ビーズを風乾します。
- DdH2o. の 20 μ L の溶出します。
- 溶離された DNA の因数を実行 (〜 3 μ L) 2% の agarose ゲル、産物のサイズを確認します。
- (材料表項目 3) 別々 の ECS ライブラリの濃度を決定する DNA の濃度を定量化します。
- 等モル量でライブラリをプールします。方法 1 の手順 1.5.6 を参照してください。プーリングの詳細についても議論。
- 約 4 でプールされた ECS ライブラリを提出 nM。
- イルミナ シーケンス プラットフォーム (MiSeq、HiSeq または NextSeq) 次のシーケンス設定を提供する: 2 x 144 ペアエンドを読み取り、8 サイクル インデックス 1 と 16 サイクル インデックス 2。
- ECS バイオ情報処理・解析
- シーケンサーからサンプルにデマルチプレックスした読み取りを取得したり、カスタム スクリプトで i7 アダプター シーケンス bioinformatically を使用してさまざまなサンプルに塩基配列読み取りの逆多重化を行います。
- 遺伝子パネルからオリゴのシーケンスを削除する各デマルチプレクスされた読み取りの最初 30 ヌクレオチドを切り落とします。
- 読み取りの家族を形成する互いに同じ行政を共有読み取りを合わせます。
メモ: 読み取り家族を抽出する MAGERI13など海対応ソフトウェアは、研究者が使用できます。法の特異性を高めるため、この実験で海シーケンス内のハミング距離は許可されません。 - 重複およびエラー訂正次のパラメーターを使用して実行します。
- 使用 ≥5 読む同じペアの家族。読み取りの 3 つのペアの最小値をお勧めします。
- 同じ読み取りファミリのすべての読み取りの間であらゆる位置にある塩基配列を比較し、コンセンサス塩基を生成する 90% 以上がある場合特定の塩基配列を読み取るの一致。塩基位置の 90% の契約より小さい N がある場合を呼び出します。
- 持っているコンセンサス読み取りを破棄 > (名) と呼ばれているコンセンサス塩基数の合計の 10%
- Hg19 または hg38 のいずれかの人間の参照ゲノム Bowtie2、BWA など研究者の最寄りの aligner(s) を使用してローカルにすべての保有コンセンサス読み取りを合わせます。
- プロセス パラメーターを使用して Mpileup の読み取りを揃えます-BQ0-d エンに関係なく適切な玉突き事故出力を確保するカバレッジしきい値を削除する 10,000,000,000,000。
- 1000 未満 x 合意報道を読むと位置を除外します。
メモ: 研究者は任意各ヌクレオチドの位置の最小範囲を決定、勧め下流解析のための報道を読む、少なくとも 500 x コンセンサスを持っています。 - 二項分布を使用して、次のパラメーターでステップ 2.5.7 から保有データの単一のヌクレオチドの亜種 (SNPs) を呼び出します。二項分布の統計は、ゲノムの位置固有のエラー モデルに基づいているが。その特定の位置のためのすべてのサンプルのエラー率を加算した後、それぞれのゲノム位置は独立してモデル化します。次の例。
所定ゲノムの位置、 pにヌクレオチド プロファイルの確率
∑ バリアント RF2 σ 合計 RFs
= 26/255505
= 0.000101759
24 バリアント 35911 合計 RFs、 Pから RFs の二項確率 (X ≥ x) サンプル K
1-binomial(24, 35911, 0.000101759) を =
= 2.26485E-13
注: 照会各ゲノムの位置にある 3 つの可能な変異 (すなわち、A > T、A > C、A > G) とそれぞれの背景の成果物として表現されます。ボンフェローニ補正後背景と異なっている体細胞のイベントが保持されます。表 1に示す例では、実行したテストの数が 11、それ故、ボンフェローニ修正p-≤0.00454545 の値 (0.05/11) 重要な統計としてイベントを呼び出すために必要だった。 - 体細胞イベントが同じ標本; から両方のレプリケートに存在する必要があります。そうしないと、誤検知として考えてください。

表 1: この例位置特異的二項誤差モデルを構築する方法を示します。
3 エラー訂正 RNA の塩基配列決定
-
DNA レベルでの突然変異の評価に加えて RNA レベルで稀または低豊富なトラン スクリプトを検出する様々 なターゲット RNA シーケンス パネルと ECS を統合します。市販の Qiagen RNA シーケンス パネルと ECS を組み合わせて、ハウスキーピング遺伝子に対する正規化を必要とせず 10 冊ほど成績の遺伝子発現の定量を行った。エラー訂正のために必要な行政は、パネルに統合されています。
- 総 RNA の抽出 (材料表、アイテム 20) を実行します。
- 製造元のプロトコル (材料表、項目 19) によると ECS RNA ライブラリの準備を行います。
- ステップ 2.5.1–2.5.6 によるとバイオインフォマティクス パイプラインを実行します。前のセクションで説明されているメソッド 2。2.5.6 のステップの後は、遺伝子ごとの一直線に並べられたコンセンサス読み取りの数は遺伝子の長さの正規化を必要とせず遺伝子の発現レベルを表します。
結果
Targeted Error-Corrected は、DNA の配列に突然変異患者商業の genomic DNA の DNA を希釈原理検証実験の証拠を行った。患者は、GATA1 突然変異 (chrX:48650264、C > G) 0.19 の元エンと。図 1に ECS が単一のヌクレオチドのバリアントのため 1: 10,000 レベルを定量的であることを示します。

図 1: GATA1 SNV が ECS が 1: 10,000 レベルを定量的であることを示す希釈系列。この図の拡大版を表示するのにはここをクリックしてください。
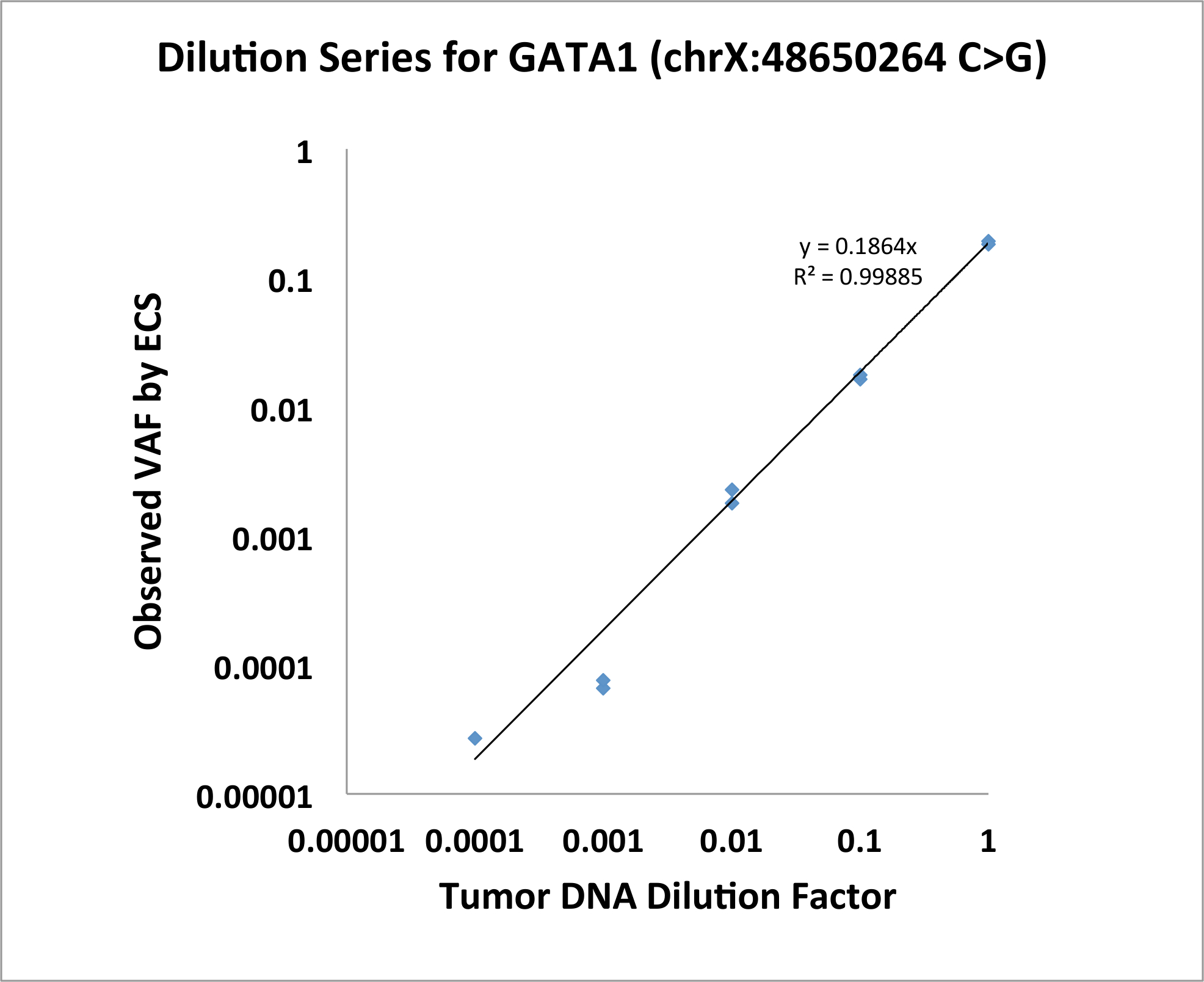{kind=link}
また、ECS DNA は確実に高齢健常者4成人急性骨髄性白血病 (AML) における反復的遺伝子のまれなクローン変異を検出.バンク約離れて 〜 10 年ナースの健康における 20 健常者からバフィー コートのサンプルを入手しました。我々 はこれらのサンプルに ECS DNA パネル プロトコルを適用されます。この実験は、我々 イルミナ TruSight 骨髄性シーケンス パネル 568 amplicons (詳細 https://www.illumina.com/products/by-type/clinical-research-products/trusight-myeloid.html の遺伝子リスト) で構成される適応し、シーケンス20 人から 80 ライブラリ (異なる時点での 2 コレクションは、時間ごとに個別あたり 2 複製ポイント) 4770 万ペアエンド読み取りの平均と 340 万エラー修正の平均を生成するイルミナ NextSeq プラットフォームを使用してライブラリ4ごとコンセンサス配列。ライブラリあたり平均ヌクレオチド報道約 6,000 (3.4 百万 568 で割った値) x だった。各サンプルでは、同じサンプルからはシーケンスのライブラリを使用して位置固有のエラー プロファイルを構築しました。我々 は、少なくとも 1 つのコレクションの時間ポイントの両方のレプリケートに存在していた 109 のクローン体細胞の突然変異を見つけた。これらの突然変異があるエン 0.0003-0.1451 に至る。既知の宇宙の表現と 21 の突然変異を選択し、ddPCR を使用して 1 つまたは 2 つのコレクションの時間ポイントのすべての 21 の変異を検証 (n = 34、図 2、若いら20164から適応)。

図 2: ECS によって識別される突然変異が高い一致 VAFs と ddPCR を介して確認した。(n = 34、若いら20164から変更)。この図の拡大版を表示するのにはここをクリックしてください。
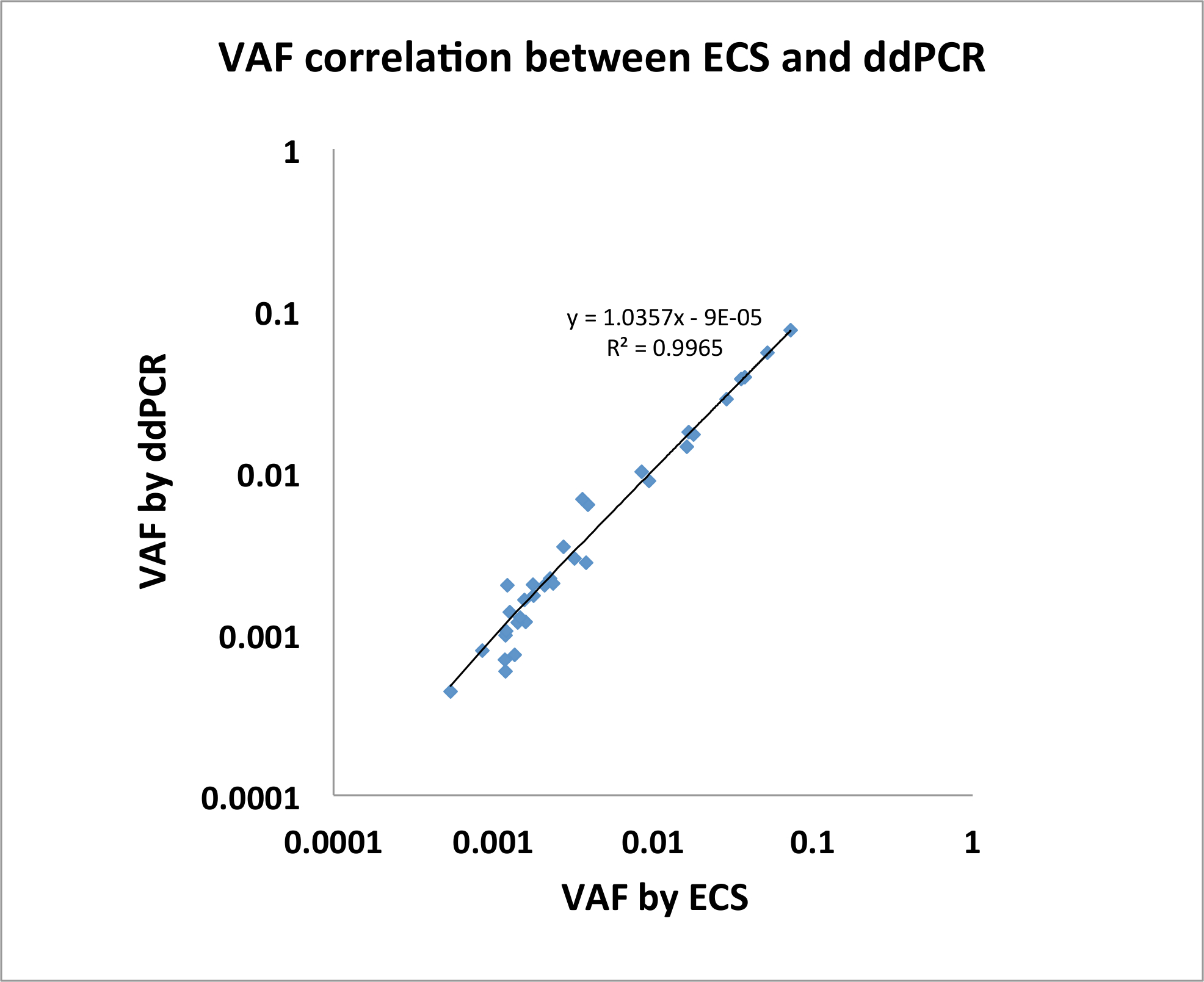{kind=link}
(QIAseq 人間癌トランスクリプトーム パネルから適応)、種々 の癌と関連付けられる知られていた 416 の遺伝子で構成される QIAseq 化学を用いた遺伝子パネルをカスタマイズしました ECS RNA のプロトコルを使用して表現のエラー訂正レベルに関してある特定の遺伝子 (遺伝子リスト補足資料1) の最も一般に表されたエクソンを増幅します。我々 はライブラリあたり 830 万読み取りの平均を与えたペアエンド形式でイルミナ MiSeq プラットフォームを使用してライブラリを塩基配列し、41 万 7000 エラー修正コンセンサス シーケンスの平均値を取り込むことができた。低豊富な転写産物の発現レベルを示した (< 1,000 トラン スクリプト数 50 ng のトータル RNA の) 複製間再現性の高い、(データ ポイント n = 300、図 3)。DdPCR (表現の度合いの六つの選択した遺伝子) を使用した検証は、遺伝子の発現レベルが正しく正規化を必要とせず ECS プロトコルによって捕獲されていたことを示した。

図 3: 同じサンプルの複製の間 ECS RNA によって上部には、トラン スクリプトの相関をカウント (n = 300).下、ECS で識別されるカウントは ddPCR によって立証されたトラン スクリプト (n = 6)。この図の拡大版を表示するのにはここをクリックしてください。
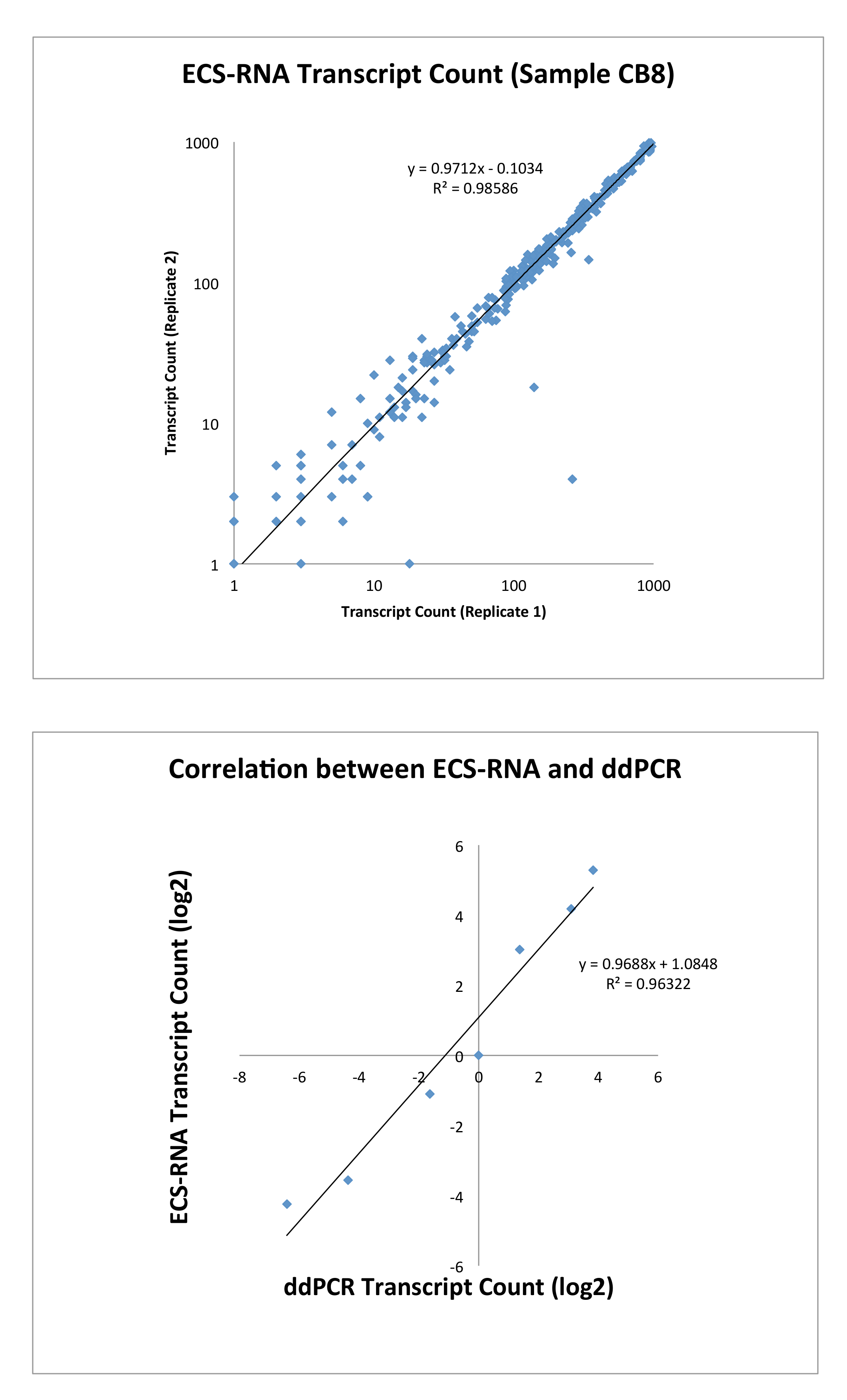{kind=link}
ディスカッション
ここでは、さまざまな病気で低 VAFs と突然変異を研究する簡単に実装することができますシーケンスのエラー修正プロトコルのスイートを紹介します。最も重要な彼らは raw 読み取りのエラー訂正を有効にすると各分子シーケンスの前に行政の混入であります。ここで説明する方法は、市販遺伝子パネルおよび自己設計されていた遺伝子特定 oligos の両方にカスタマイズされた行政を組み込む研究者を許可します。
NGS の標準プロトコル シーケンス エラー率 2% 以下エンと遺伝子変異の検出を排除する、これは稀な変形の検出は重要な研究の NGS のアプリケーションを制限します。標準の NGS 誤り率を回避、ECS これら生の変異体の高感度検出できます。例えば、これらの突然変異は最初 (したがって、低エン) 起こるとき病原性の変異の検出は病気14,15の早期介入を通知することが不可欠。白血病研究、最小残差の検出の病 (治療後残存白血病細胞) がリスク層別化を通知し、バイナリ流れフローサイトメトリー評価できない方法で治療の選択肢が通知される可能性があります。さらに、ECS は循環腫瘍核酸を検出し、プライマリの特性は、特定の突然変異のバリアントの負担と同様に有無を評価することによって固形腫瘍患者における転移能を評価する適切です腫瘍16。
表 1に示されているように、バリアントを呼び出す位置固有のエラーの二項分布に基づくモデルを使用しての力はエラー モデルの構築に使用されるシーケンスの深さと同様に、シーケンスされたライブラリの数に大きく依存します。エラー モデルのロバスト性のサンプルと詳細シーケンス数の増加とともに増加します。各サンプルのエラー プロファイルを構築するサンプルあたり 3000 x のエラー修正リード カバレッジの平均で少なくとも 10 シーケンスされたサンプルを使用することをお勧めします。位置特定方法と同じです、MAGERI がすべての六つの異なる置換タイプの集計エラー率を使用しての代わり (A > C/T > G、A > G/T > C、A > T/T >、C > A/G > T、C > G > C、C > T/G > A)13, 我々 はすべての位置で独立して各置換モデルします。例えば、C のエラー発生率 > 所定ゲノムの位置に T は別の位置から異なる。我々 のアプローチも考慮シーケンス バッチ効果シーケンス実行の 1 つにみられる塩基置換率は別の実行から異なる場合があります。したがって異なるシーケンスの実行からのサンプルはモデルの構築にプールされる場合は特にすべての置換型のそれぞれの位置をモデル化することが重要です。
ECS 実験を設計するときの重要な考慮事項は、所望の検出のしきい値です。NGS 研究の美しさは遺伝子/ターゲットの興味、(配列の深さによって決定)、検出しきい値および照会個体数の面で、簡単に縮小できます。たとえば、研究者が 0.0001 の検出閾値を持つ 2 つの産物のまれな突然変異を見つけるに興味があるなら、MiSeq V2 化学まで 1500 万読み取りを出力を使用して実行、単一シーケンスで最大限に 75 検体をプールできる (2 amplicons * 10,000分子 * 10 読み取りエラー補正 * 75 検体 = 1500 万配列読み取り)。研究者は分子シーケンスまたは検出しきい値を調整するために実行する単一シーケンスでプールされたサンプルの数に入るの数を変更できます。私たちの研究で検出しきい値を持つ 0.0001 エン (1:10, 000) の突然変異を見つけることを目指しましたイルミナ遺伝子パネルを使用します。我々 は日常的に 250 を使用して十分な分子が前述の検出閾値を達成するためにキャプチャされるように DNA の開始の ng。研究者は、DNA の低量の開始する選ぶことができます (50 ng をお勧めします) 目的の検出限界がある場合 > 0.001 エン。
行政は、i5 のインデックスに追加されます、シーケンス設定はそれに応じて改正されるあります。たとえば、16 の N 行政を使いました、シーケンス設定された 2 x 144 対最後の読み取り、インデックス 1 の 8 サイクル、インデックス 2 の通常 8 サイクルではなくインデックス 2 の 16 のサイクル。インデックス 2 サイクルの増加は、読み取りに割り当てられた合計回数の減少によって補償されています。研究者は 12 n Umi10,17を使用することを選ぶ、設定はインデックス 2 の 12 のサイクルを変更する必要があります。
この海ベースのシーケンスのメソッドは、シーケンス エラーの修正に最適です。すべて増幅方式のための問題である PCR 表示をあつかう上で最適ではないままです。ポスト シーケンスと ddPCR を使用してポスト バイオインフォマティクス検証のラウンドを行い、我々 はほとんど PCR 表示による任意の偽陽性を検出します。それにもかかわらず、研究者が低増幅エラー高忠実度ポリメラーゼを用いた実験を行うことをお勧めします。
開示事項
著者が明らかに何もありません。
謝辞
我々 は腫瘍グループ AAML1531 子どもと看護師の保健研究患者サンプルの形で彼らの貢献のために参加者に感謝します。この仕事、国立衛生研究所 (UM1 CA186107、RO1 CA49449 RO1 CA149445)、子供の発見研究所のワシントン大学とセントルイス子供病院 (MC-II-2015-461) とイーライ セス ・ マシューズ白血病財団によって資金を供給されました。
資料
| Name | Company | Catalog Number | Comments |
| Q5 High Fidelity Hot Start Master Mix | New England BioLabs | M0492S | |
| Agencourt AMPure XP | Beckman Coulter | A63880 | |
| Qubit dsDNA HS Assay Kit | Thermo Fisher Scientific | Q32854 | |
| SYBR Safe DNA Gel Stain | Thermo Fisher Scientific | S33102 | |
| Truseq Custom Amplicon Index Kit | Illumina | FC-130-1003 | |
| UMI i5 adapter sequences | Integrated DNA Technologies | - | |
| NEBNext Ultra End Repair/dA-Tailing Module | New England BioLabs | E7442S | |
| NEBNext Ultra II Ligation Module | New England BioLabs | E7595S | |
| QX200 ddPCR EvaGreen Supermix | Bio-Rad | 1864034 | |
| QX200 Droplet Generation Oil for EvaGreen | Bio-Rad | 1864005 | |
| QX200 Droplet Digital PCR System | Bio-Rad | 1864001 | |
| ddPCR 96-Well Plates | Bio-Rad | 12001925 | |
| DG8 Cartridges for QX200/QX100 Droplet Generator | Bio-Rad | 1864008 | |
| DG8 Gaskets for QX200/QX100 Droplet Generator | Bio-Rad | 1863009 | |
| Bioanalyzer | Agilent Genomics | G2939BA | |
| TapeStation | Agilent Genomics | G2991AA | |
| TruSight Myeloid Sequencing Panel | Illumina | FC-130-1010 | |
| Bowtie 2 | Johns Hopkins University | - | |
| Customized QIAseq Targeted RNA Panel | Qiagen | - | |
| Rneasy Plus Mini Kit (50) | Qiagen | 74134 |
参考文献
- Hoang, M. L., et al. Genome-wide quantification of rare somatic mutations in normal tissues using massively parallel sequencing. Proceedings of the National Academy of Sciences USA. 113, 9846-9851 (2016).
- O'Roak, B. J., et al. Sporadic autism exomes reveal a highly interconnected protein network of de novo mutations. Nature. 485, 246-250 (2012).
- Young, A. L., et al. Quantifying ultra-rare pre-leukemic clones via targeted error-corrected sequencing. Leukemia. 29 (7), 1608-1611 (2015).
- Young, A. L., Challen, G. A., Birmann, B. M., Druley, T. E. Clonal hematopoiesis harbouring AML-associated mutations is ubiquitous in healthy adults. NatureCommunications. 7, 12484(2016).
- Patel, J. P., et al. Prognostic relevance of integrated genetic profiling in acute myeloid leukemia. New England Journal of Medicine. 366, 1079-1089 (2012).
- Shendure, J., Ji, H. Next-generation DNA sequencing. Nature Biotechnology. 26 (10), 1135-1145 (2008).
- Kohlmann, A., et al. Monitoring of residual disease by next-generation deep-sequencing of RUNX1 mutations can identify acute myeloid leukemia patients with resistant disease. Leukemia. 28, 129-137 (2014).
- Luthra, R., et al. Next-generation sequencing-based multigene mutational screening for acute myeloid leukemia using MiSeq: applicability for diagnostics and disease monitoring. Haematologica. 99, 465-473 (2014).
- Kinde, I., Wu, J., Papadopoulos, N., Kinzler, K. W., Vogelstein, B. Detection and quantification of rare mutations with massively parallel sequencing. Proceedings of the National Academy of Sciences USA. 108 (23), 9530-9535 (2011).
- Schmitt, M., et al. Detection of ultra-rare mutations by next-generation sequencing. Proceedings of the National Academy of Sciences USA. 109 (36), 14508-14513 (2012).
- Vander Heiden, J. A., et al. pRESTO: a toolkit for processing high-throughput sequencing raw reads of lymphocyte receptor repertoires. Bioinformatics. 30 (13), 1930-1932 (2014).
- Newman, A. M., et al. Integrated digital error suppression for improved detection of circulating tumor DNA. NatureBiotechnology. 34, 547-555 (2016).
- Shugay, M., et al. MAGERI: Computational pipeline for molecular-barcoded targeted resequencing. PLOSComputationalBiology. 13 (5), e1005480(2017).
- Wong, T. N., et al. Role of TP53 mutations in the origin and evolution of therapy-related acute myeloid leukaemia. Nature. 518, 552-555 (2014).
- Krimmel, J. D., et al. Ultra-deep sequencing detects ovarian cancer cells in peritoneal fluid and reveals somatic TP53 mutations in noncancerous tissues. Proceedings of the National Academy of Sciences USA. 113 (21), 6005-6010 (2016).
- Phallen, J., et al. Direct detection of early-stage cancers using circulating tumor DNA. ScienceTranslationalMedicine. 9, eaan2415(2017).
- Egorov, E. S., et al. Quantitative profiling of immune repertoires for minor lymphocyte counts using unique molecular identifiers. The Journal of Immunology. 194 (12), 6155-6163 (2015).
転載および許可
このJoVE論文のテキスト又は図を再利用するための許可を申請します
許可を申請さらに記事を探す
This article has been published
Video Coming Soon
Copyright © 2023 MyJoVE Corporation. All rights reserved