
Method Article
Design e Análise para Simplificação do Sistema de Detecção de Queda
Neste Artigo
Resumo
Apresentamos uma metodologia baseada em sensores multimodais para configurar um sistema simples, confortável e rápido de detecção de quedas e reconhecimento de atividades humanas. O objetivo é construir um sistema para detecção precisa de quedas que possa ser facilmente implementado e adotado.
Resumo
Este artigo apresenta uma metodologia baseada em sensores multimodais para configurar um sistema simples, confortável e rápido de detecção de quedas e reconhecimento de atividade humana que pode ser facilmente implementado e adotado. A metodologia baseia-se na configuração de tipos específicos de sensores, métodos e procedimentos de aprendizagem de máquina. O protocolo é dividido em quatro fases: (1) criação de banco de dados (2) análise de dados (3) simplificação do sistema e (4) avaliação. Utilizando essa metodologia, criamos um banco de dados multimodal para detecção de quedas e reconhecimento de atividades humanas, ou seja, DEtecção up-fall. Compreende amostras de dados de 17 sujeitos que realizam 5 tipos de quedas e 6 atividades simples diferentes, durante 3 ensaios. Todas as informações foram coletadas utilizando-se 5 sensores vestíveis (acelerômetro de três eixos, giroscópio e intensidade de luz), 1 capacete eletroencefalograma, 6 sensores infravermelhos como sensores ambientais e 2 câmeras nos mirantes lateral e frontal. A nova metodologia proposta adiciona algumas etapas importantes para realizar uma análise profunda dos seguintes problemas de design, a fim de simplificar um sistema de detecção de queda: a) selecionar quais sensores ou combinação de sensores devem ser usados em um sistema simples de detecção de quedas, b) determinar a melhor colocação das fontes de informação, e c) selecionar o método de classificação de aprendizagem de máquina mais adequado para detecção e reconhecimento de atividade humana. Embora algumas abordagens multimodais relatadas na literatura se concentrem apenas em uma ou duas das questões acima mencionadas, nossa metodologia permite resolver simultaneamente esses três problemas de design relacionados a um sistema humano de detecção e reconhecimento de atividades.
Introdução
Desde o fenômeno mundial do envelhecimento populacional1, a prevalência de queda aumentou e é, na verdade, considerada um grande problema de saúde2. Quando ocorre uma queda, as pessoas requerem atenção imediata para reduzir as consequências negativas. Sistemas de detecção de quedas podem reduzir a quantidade de tempo em que uma pessoa recebe atenção médica enviando um alerta quando ocorre uma queda.
Existem várias categorizações de sistemas de detecção de quedas3. Os primeiros trabalhos4 classificam os sistemas de detecção de quedas por seu método de detecção, métodos aproximadamente analíticos e métodos de aprendizagem de máquina. Mais recentemente, outros autores3,5,6 consideraram os sensores de aquisição de dados como a principal característica para classificar os detectores de queda. Igual et al.3 divide sistemas de detecção de quedas em sistemas de reconhecimento de contexto, que incluem abordagens baseadas em visão e sensores ambientais e sistemas de dispositivos vestíveis. Mubashir et al.5 classificam os detectores de queda em três grupos com base nos dispositivos usados para aquisição de dados: dispositivos vestíveis, sensores de ambiente e dispositivos baseados em visão. Perry et al.6 considera métodos para medir aceleração, métodos para medir aceleração combinados com outros métodos e métodos que não medem aceleração. A partir desses inquéritos, podemos determinar que sensores e métodos são os principais elementos para classificar a estratégia geral de pesquisa.
Cada um dos sensores tem fraquezas e pontos fortes discutidos em Xu et al.7. Abordagens baseadas em visão usam principalmente câmeras normais, câmeras de sensores de profundidade e/ou sistemas de captura de movimento. As câmeras web normais são de baixo custo e fáceis de usar, mas são sensíveis às condições ambientais (variação de luz, oclusão, etc.), só podem ser usadas em um espaço reduzido, e têm problemas de privacidade. Câmeras de profundidade, como o Kinect, fornecem movimento 3D de corpo inteiro7 e são menos afetadas pelas condições de iluminação do que as câmeras normais. No entanto, abordagens baseadas no Kinect não são tão robustas e confiáveis. Os sistemas de captura de movimento são mais caros e difíceis de usar.
Abordagens baseadas em dispositivos acelerômetros e telefones/relógios inteligentes com acelerômetros embutidos são muito comumente usadas para detecção de quedas. A principal desvantagem desses dispositivos é que eles têm que ser usados por longos períodos. Desconforto, intrusividade, colocação corporal e orientação são questões de design a serem resolvidas nessas abordagens. Embora smartphones e relógios inteligentes sejam dispositivos menos intrusivos que os sensores, as pessoas mais velhas muitas vezes esquecem ou nem sempre usam esses dispositivos. No entanto, a vantagem desses sensores e dispositivos é que eles podem ser usados em muitos cômodos e/ou ao ar livre.
Alguns sistemas usam sensores colocados ao redor do ambiente para reconhecer quedas/atividades, para que as pessoas não precisem usar os sensores. No entanto, esses sensores também são limitados aos locais onde são implantados8 e às vezes são difíceis de instalar. Recentemente, os sistemas multimodais de detecção de quedas incluem diferentes combinações de visão, sensores vestíveis e ambientais, a fim de ganhar mais precisão e robustez. Eles também podem superar algumas das limitações de sensor único.
A metodologia utilizada para detecção de quedas está intimamente relacionada com a cadeia de reconhecimento de atividade humana (ARC) apresentada por Bulling et al.9, que consiste em etapas para aquisição de dados, pré-processamento e segmentação de sinais, extração e seleção de recursos, treinamento e classificação. Os problemas de projeto devem ser resolvidos para cada uma dessas etapas. Métodos diferentes são usados em cada etapa.
Apresentamos uma metodologia baseada em sensores multimodais para configurar um sistema de detecção/reconhecimento de atividadehumana simples, confortável e rápido. O objetivo é construir um sistema para detecção precisa de quedas que possa ser facilmente implementado e adotado. A nova metodologia proposta é baseada em ARC, mas adiciona algumas fases importantes para realizar uma análise profunda das seguintes questões, a fim de simplificar o sistema: (a) selecionar quais sensores ou combinação de sensores devem ser usados em um sistema simples de detecção de quedas; b Determinar a melhor colocação das fontes de informação; e (c) selecionar o método de classificação de aprendizagem de máquina mais adequado para detecção de quedas e reconhecimento de atividade humana para criar um sistema simples.
Existem alguns trabalhos relacionados na literatura que abordam uma ou duas das questões de design acima mencionadas, mas, pelo que sabemos, não há trabalho que foque em uma metodologia para superar todos esses problemas.
Trabalhos relacionados utilizam abordagens multimodais para detecção de quedas e reconhecimento de atividade humana10,11,12 a fim de ganhar robustez e aumentar a precisão. Kwolek et al.10 propuseram o projeto e a implementação de um sistema de detecção de quedas baseado em dados aelerométricos e mapas de profundidade. Eles projetaram uma metodologia interessante na qual um acelerômetro de três eixos é implementado para detectar uma possível queda, bem como o movimento da pessoa. Se a medida de aceleração exceder um limiar, o algoritmo extrai uma pessoa diferenciando o mapa de profundidade do mapa de referência de profundidade atualizado on-line. Uma análise das combinações de profundidade e acelerômetro foi feita usando um classificador de máquina vetorial de suporte.
Ofli et al.11 apresentaram um Banco de Dados de Ação Humana Multimodal (MHAD) a fim de fornecer um teste para novos sistemas de reconhecimento de atividades humanas. O conjunto de dados é importante, pois as ações foram coletadas simultaneamente usando 1 sistema óptico de captura de movimento, 4 câmeras multi-view, 1 sistema Kinect, 4 microfones e 6 acelerômetros sem fio. Os autores apresentaram resultados para cada modalidade: o Kinect, o mocap, o acelerômetro e o áudio.
Dovgan et al.12 propuseram um protótipo para detectar comportamentos anômalos, incluindo quedas, em idosos. Eles projetaram testes para três sistemas de sensores, a fim de encontrar o equipamento mais apropriado para queda e detecção de comportamento incomum. O primeiro experimento consiste em dados de um sistema de sensores inteligentes com 12 etiquetas presas aos quadris, joelhos, tornozelos, pulsos, cotovelos e ombros. Eles também criaram um conjunto de dados de teste usando um sistema de sensores Ubisense com quatro tags presas à cintura, peito e ambos os tornozelos, e um acelerômetro Xsens. Em um terceiro experimento, quatro indivíduos só utilizam o sistema Ubisense enquanto realizam 4 tipos de quedas, 4 problemas de saúde como comportamento anômalo e atividade diferente da vida diária (ADL).
Outros trabalhos na literatura13,,14,15 abordam o problema de encontrar a melhor colocação de sensores ou dispositivos para detecção de queda comparando o desempenho de várias combinações de sensores com vários classificadores. Santoyo et al.13 apresentaram uma avaliação sistemática avaliando a importância da localização de 5 sensores para detecção de quedas. Eles compararam o desempenho dessas combinações de sensores usando os vizinhos k-mais próximos (KNN), as máquinas vetoriais de suporte (SVM), as classificadas ingênuas Bayes (NB) e a árvore de decisão (DT). Eles concluem que a localização do sensor sobre o objeto tem uma influência importante no desempenho do detector de queda independente do classificador utilizado.
Uma comparação das colocações de sensores vestíveis no corpo para detecção de queda foi apresentada por Özdemir14. Para determinar a colocação do sensor, o autor analisou 31 combinações de sensores das seguintes posições: cabeça, cintura, tórax, pulso direito, tornozelo direito e coxa direita. Quatorze voluntários realizaram 20 quedas simuladas e 16 ADL. Ele descobriu que o melhor desempenho foi obtido quando um único sensor está posicionado na cintura a partir desses exaustivos experimentos de combinação. Outra comparação foi apresentada por Ntanasis15 usando o conjunto de dados de Özdemir. Os autores compararam posições individuais na cabeça, tórax, cintura, pulso, tornozelo e coxa utilizando os seguintes classificadores: J48, KNN, RF, random committee (RC) e SVM.
Os benchmarks do desempenho de diferentes métodos computacionais para detecção de quedas também podem ser encontrados na literatura16,17,18. Bagala et al.16 apresentaram uma comparação sistemática para comparar o desempenho de treze métodos de detecção de quedas testados em quedas reais. Eles só consideraram algoritmos baseados em medidas de acelerômetro colocadas na cintura ou tronco. Bourke et al.17 avaliaram o desempenho de cinco algoritmos analíticos para detecção de quedas usando um conjunto de dados de ADLs e quedas com base em leituras de acelerômetro. Kerdegari18 fez também uma comparação do desempenho de diferentes modelos de classificação para um conjunto de dados de aceleração registrados. Os algoritmos utilizados para detecção de queda foram zeroR, oneR, NB, DT, multicamada perceptron e SVM.
Uma metodologia de detecção de quedas foi proposta por Alazrai et al.18 usando descritor geométrico de pose de movimento para construir uma representação acumulada baseada em histograma da atividade humana. Eles avaliaram a estrutura usando um conjunto de dados coletado com sensores Kinect.
Em resumo, encontramos trabalhos relacionados à detecção de quedas multimodais10,11,12 que comparam o desempenho de diferentes combinações de modalidades. Alguns autores abordam o problema de encontrar a melhor colocação de sensores13,,14,,15, ou combinações de sensores13 com vários classificadores13,,15,16 com múltiplos sensores da mesma modalidade e acelerômetros. Nenhum trabalho foi encontrado na literatura que abordasse colocação, combinações multimodais e referência de classificação ao mesmo tempo.
Protocolo
Todos os métodos descritos aqui foram aprovados pelo Comitê de Pesquisa da Faculdade de Engenharia da Universidad Panamericana.
NOTA: Esta metodologia baseia-se na configuração dos tipos específicos de sensores, métodos e procedimentos de aprendizagem de máquina, a fim de configurar um sistema simples, rápido e multimodal de detecção de quedas e reconhecimento de atividade humana. Devido a isso, o seguinte protocolo é dividido em fases: (1) criação de banco de dados (2) análise de dados (3) simplificação do sistema e (4) avaliação.
1. Criação de banco de dados
- Configure o sistema de aquisição de dados. Isso coletará todos os dados dos sujeitos e armazenará as informações em um banco de dados de recuperação.
- Selecione os tipos de sensores vestíveis, sensores ambientais e dispositivos baseados em visão necessários como fontes de informação. Atribuir um ID para cada fonte de informação, o número de canais por fonte, as especificações técnicas e a taxa de amostragem de cada um deles.
- Conecte todas as fontes de informação (ou seja, wearables e sensores ambientais e dispositivos baseados em visão) a um computador central ou a um sistema de computador distribuído:
- Verifique se os dispositivos baseados em fio estão conectados corretamente a um computador cliente. Verifique se os dispositivos baseados em sem fio estão totalmente carregados. Considere que a bateria fraca pode impactar conexões sem fio ou valores de sensores. Além disso, conexões intermitentes ou perdidas aumentarão a perda de dados.
- Configure cada um dos dispositivos para recuperar dados.
- Configure o sistema de aquisição de dados para armazenar dados na nuvem. Devido à grande quantidade de dados a serem armazenados, a computação em nuvem é considerada neste protocolo.
- Valide que o sistema de aquisição de dados cumpre a sincronização de dados e a consistência dos dados20 propriedades. Isso mantém a integridade do armazenamento de dados de todas as fontes de informação. Pode exigir novas abordagens na sincronização de dados. Por exemplo, ver Peñafort-Asturiano et al.20.
- Comece a coletar alguns dados com as fontes de informação e armazene dados em um sistema preferido. Inclua carimbos de tempo em todos os dados.
- Consulte o banco de dados e determine se todas as fontes de informação são coletadas nas mesmas taxas de amostra. Se for feito corretamente, vá para o Passo 1.1.6. Caso contrário, realize a amostragem para cima ou para baixo utilizando critérios relatados em Peñafort-Asturiano, et al.20.
- Configurar o meio ambiente (ou laboratório) considerando as condições exigidas e as restrições impostas pelo objetivo do sistema. Definir condições para atenuação da força de impacto nas quedas simuladas como sistemas de piso compatíveis sugeridos em Lachance, et al.23 para garantir a segurança dos participantes.
- Use um colchão ou qualquer outro sistema de piso compatível e coloque-o no centro do ambiente (ou laboratório).
- Mantenha todos os objetos longe do colchão para dar pelo menos um metro de espaço seguro ao redor. Se necessário, prepare equipamentos de proteção individual para os participantes (por exemplo, luvas, boné, óculos, apoio ao joelho, etc.).
NOTA: O protocolo pode ser pausado aqui.
- Determine as atividades humanas e as quedas que o sistema detectará após a configuração. É importante ter em mente o propósito do sistema de detecção de quedas e de reconhecimento da atividade humana, bem como da população-alvo.
- Defina o objetivo do sistema de detecção de queda e de reconhecimento de atividade humana. Anote em uma folha de planejamento. Para este estudo de caso, o objetivo é classificar os tipos de quedas humanas e atividades realizadas diariamente em ambientes fechados de idosos.
- Defina a população-alvo do experimento de acordo com o objetivo do sistema. Anote na folha de planejamento. No estudo, considere os idosos como a população-alvo.
- Determine o tipo de atividades diárias. Inclua algumas atividades não-fall que parecem quedas, a fim de melhorar a detecção real de quedas. Atribua uma id para todos eles e descreva-os o mais detalhado possível. Defina o período de tempo para cada atividade a ser executada. Anote todas essas informações na folha de planejamento.
- Determine o tipo de quedas humanas. Atribua uma id para todos eles e descreva-os o mais detalhado possível. Defina o período de tempo para cada queda a ser executada . Considere se as quedas serão autogeradas pelos sujeitos ou geradas por outros (por exemplo, empurrando o assunto). Anote todas essas informações na folha de planejamento.
- Na ficha de planejamento, anote as sequências de atividades e quedas que um sujeito irá realizar. Especifique o período de tempo, o número de ensaios por atividade/queda, a descrição para realizar a atividade/queda e os IDs de atividade/queda.
NOTA: O protocolo pode ser pausado aqui.
- Selecione os sujeitos relevantes para o estudo que executará as sequências de atividades e quedas. Quedas são eventos raros para serem pegos na vida real e geralmente ocorrem com pessoas idosas. No entanto, por razões de segurança, não incluem idosos e deficientes na simulação de outono sob orientação médica. Acrobacias têm sido usadas para evitar lesões22.
- Determinar o sexo, faixa etária, peso e altura dos sujeitos. Defina as condições de comprometimento necessárias. Além disso, defina o número mínimo de sujeitos necessários para o experimento.
- Selecione aleatoriamente o conjunto de assuntos necessários, seguindo as condições indicadas na etapa anterior. Use uma chamada para voluntários para recrutá-los. Cumprir todas as diretrizes éticas aplicáveis da instituição e do país, bem como qualquer regulação internacional ao experimentar com humanos.
NOTA: O protocolo pode ser pausado aqui.
- Recuperar e armazenar dados dos sujeitos. Essas informações serão úteis para análises experimentais posteriores. Complete as seguintes etapas sob supervisão de um especialista clínico ou um pesquisador responsável.
- Comece a coletar dados com o sistema de aquisição de dados configurado na Etapa 1.1.
- Peça a cada um dos sujeitos para realizar as sequências de atividades e quedas declaradas na Etapa 1.2. Guarde claramente os carimbos de tempo do início e do fim de cada atividade/queda. Verifique se os dados de todas as fontes de informação são salvos na nuvem.
- Se as atividades não foram devidamente feitas ou houve problemas com dispositivos (por exemplo, conexão perdida, bateria fraca, conexão intermitente), descarte as amostras e repita a Etapa 1.4.1 até que não sejam encontrados problemas no dispositivo. Repita a Etapa 1.4.2 para cada ensaio, por sujeito, declarada na seqüência da Etapa 1.2.
NOTA: O protocolo pode ser pausado aqui.
- Pré-processo todos os dados adquiridos. Aplicar amostragem para cima e para baixo para cada uma das fontes de informação. Veja detalhes sobre os dados de pré-processamento para detecção de quedas e reconhecimento da atividade humana em Martínez-Villaseñor et al.21.
NOTA: O protocolo pode ser pausado aqui.
2. Análise de Dados
- Selecione o modo de tratamento de dados. Selecione Dados Brutos se os dados armazenados no banco de dados forem usados de imediato (ou seja, usando deep learning para extração automática de recursos) e vá para a Etapa 2.2. Selecione Dados de recurso se a extração do recurso for usada para análise suplementar e vá para a Etapa 2.3.
- Para Dados Brutos,não são necessárias etapas extras, então vá para a Etapa 2.5.
- Para dados de recursos,extraia recursos dos dados brutos.
- Segmentar dados brutos em janelas de tempo. Determine e corrija o comprimento da janela de tempo (por exemplo, quadros de tamanho de um segundo). Além disso, determine se essas janelas de tempo serão sobrepostas ou não. Uma boa prática é escolher 50% de sobreposição.
- Extrair recursos de cada segmento de dados. Determine o conjunto de características temporais e freqüentes a serem extraídas dos segmentos. Consulte Martínez-Villaseñor et al.21 para extração de características comuns.
- Salve os dados de extração de recursos definidos na nuvem, em um banco de dados independente.
- Se diferentes janelas de tempo forem selecionadas, repita as etapas 2.3.1 a 2.3.3 e salve cada conjunto de dados de recursos em bancos de dados independentes.
NOTA: O protocolo pode ser pausado aqui.
- Selecione os recursos mais importantes extraídos e reduza o conjunto de dados do recurso. Aplique alguns métodos de seleção de recursos comumente utilizados (porexemplo, seleção univariada, análise de componentes principais, eliminação de recursos recursivos, importância de características, matriz de correlação, etc.).
- Selecione um método de seleção de recursos. Aqui, usamos a importância dos recursos.
- Use cada recurso para treinar um determinado modelo (empregamos RF) e medir a precisão (ver Equação 1).
- Classifique os recursos classificando-os por ordem de precisão.
- Selecione os recursos mais importantes. Aqui, usamos os dez melhores classificados.
NOTA: O protocolo pode ser pausado aqui.
- Selecione um método de classificação de aprendizado de máquina e treine um modelo. Existem métodos bem conhecidos de aprendizado de máquina16,17,18,21, tais como: máquinas vetoriais de suporte (SVM), floresta aleatória (RF), perceptron multicamada (MLP) e k-vizinhos mais próximos (KNN), entre muitos outros.
- Opcionalmente, se uma abordagem de aprendizagem profunda for selecionada, considere21: redes neurais convolucionais (CNN), redes neurais de memória de longo prazo (LSTM), entre outras.
- Selecione um conjunto de métodos de aprendizado de máquina. Aqui, usamos os seguintes métodos: SVM, RF, MLP e KNN.
- Corrigir os parâmetros de cada um dos métodos de aprendizagem de máquina, conforme sugerido na literatura21.
- Crie um conjunto de dados de recursos combinados (ou conjunto de dados brutos) usando os conjuntos de dados de recursos independentes (ou conjuntos de dados brutos), para combinar tipos de fontes de informação. Por exemplo, se for necessária uma combinação de um sensor vestível e uma câmera, então combine os conjuntos de dados de recursos de cada uma dessas fontes.
- Divida o conjunto de dados do recurso (ou conjunto de dados brutos) em conjuntos de treinamento e testes. Uma boa escolha é dividir aleatoriamente 70% para treinamento e 30% para testes.
- Execute uma validação cruzada k-fold21 usando o conjunto de dados de recursos (ou conjunto de dados brutos), para cada método de aprendizado de máquina. Use uma métrica comum de avaliação, como precisão (ver Equação 1) para selecionar o melhor modelo treinado por método. Os experimentos de leave-one subject-out (LOSO)3 também são recomendados.
- Abra o conjunto de dados do recurso de treinamento (ou conjunto de dados brutos) no software de linguagem de programação preferido. Python é recomendado. Para esta etapa, use a biblioteca pandas para ler um arquivo CSV da seguinte forma:
training_set = pandas.csv(). - Divida o conjunto de dados do recurso (ou conjunto de dados brutos) em pares de entradas-saídas. Por exemplo, use Python para declarar os valores x (entradas) e os valores y (saídas):
training_set_X = training_set.drop ('tag',axis=1), training_set_Y = training_set.tag
onde a tag representa a coluna do conjunto de dados de recurso que inclui os valores-alvo. - Selecione um método de aprendizado de máquina e defina os parâmetros. Por exemplo, use SVM em Python com o sklearn da biblioteca como o seguinte comando:
classificador = sklearn. SVC (kernel = 'poly')
em que a função do kernel é selecionada como polinômio. - Treine o modelo de aprendizagem de máquina. Por exemplo, use o classificador acima em Python para treinar o modelo SVM:
classificador.fit(training_set_X,training_set_Y). - Calcule os valores estimados do modelo usando o conjunto de dados do recurso de teste (ou o conjunto de dados brutos). Por exemplo, use a função de estimativa em Python da seguinte forma: estimativas = classifier.predict(testing_set_X) onde testing_set_X representa os valores x do conjunto de testes.
- Repita as etapas 2.5.6.1 a 2.5.6.5, o número de vezes k especificado na validação cruzada de dobra sél (ou o número de vezes necessário para a abordagem loso).
- Repita as etapas 2.5.6.1 a 2.5.6.6 para cada modelo de aprendizado de máquina selecionado.
NOTA: O protocolo pode ser pausado aqui.
- Abra o conjunto de dados do recurso de treinamento (ou conjunto de dados brutos) no software de linguagem de programação preferido. Python é recomendado. Para esta etapa, use a biblioteca pandas para ler um arquivo CSV da seguinte forma:
- Compare os métodos de aprendizado de máquina testando os modelos selecionados com o conjunto de dados de teste. Outras métricas de avaliação podem ser utilizadas: precisão(Equação 1),precisão(Equação 2),sensibilidade(Equação 3),especificidade(Equação 4)ou F1-score(Equação 5),onde TP são os verdadeiros positivos, TN são os verdadeiros negativos, FP são os falsos positivos e FN são os falsos negativos.





- Use outras métricas de desempenho benéficas, como a matriz de confusão9 para avaliar a tarefa de classificação dos modelos de aprendizagem de máquina, ou uma curva de precisão de recuperação de precisão9 (RP) ou de ajuste de receptor9 (ROC). Nesta metodologia, recordação e sensibilidade são consideradas equivalentes.
- Use características qualitativas dos modelos de aprendizagem de máquina para comparar entre eles, tais como: facilidade de interpretação de aprendizagem de máquina; desempenho em tempo real; recursos limitados de tempo, memória e processamento de computação; e facilidade de implantação de aprendizado de máquina em dispositivos de borda ou sistemas embarcados.
- Selecione o melhor modelo de aprendizagem de máquina usando as informações de: As métricas de qualidade(Equações 1-5), as métricas de desempenho e as características qualitativas da viabilidade de aprendizagem de máquina das Etapas 2.5.6, 2.5.7 e 2.5.8.
NOTA: O protocolo pode ser pausado aqui.
3. Simplificação do sistema
- Selecione as colocações adequadas das fontes de informação. Às vezes, é necessário determinar a melhor colocação de fontes de informação (por exemplo, qual a localização de um sensor vestível é melhor).
- Determine o subconjunto de fontes de informação que serão analisadas. Por exemplo, se houver cinco sensores vestíveis no corpo e apenas um tiver que ser selecionado como o melhor sensor colocado, cada um desses sensores fará parte do subconjunto.
- Para cada fonte de informação neste subconjunto, crie um conjunto de dados separado e armazene-os separadamente. Tenha em mente que esse conjunto de dados pode ser o conjunto de dados do recurso anterior ou o conjunto de dados brutos.
NOTA: O protocolo pode ser pausado aqui.
- Selecione um método de classificação de aprendizado de máquina e treine um modelo para uma fonte de colocação de informações. Passos completos de 2.5.1 a 2.5.6 usando cada um dos conjuntos de dados criados na Etapa 3.1.2. Detecte a fonte mais adequada de colocação de informações por classificação. Para este estudo de caso, utilizamos os seguintes métodos: SVM, RF, MLP e KNN.
Nota: O protocolo pode ser pausado aqui. - Selecione as colocações adequadas em uma abordagem multimodal se uma combinação de duas ou mais fontes de informação for necessária para o sistema (por exemplo, combinação de um sensor vestível e uma câmera). Neste estudo de caso, use o sensor cintura-wearable e a câmera 1 (visão lateral) como modalidades.
- Selecione a melhor fonte de informação de cada modalidade no sistema e crie um conjunto de dados de recursos combinados (ou conjunto de dados brutos) usando os conjuntos de dados independentes dessas fontes de informação.
- Selecione um método de classificação de aprendizado de máquina e treine um modelo para essas fontes combinadas de informações. Concluir as etapas 2.5.1 a 2.5.6 usando o conjunto de dados de recursos combinados (ou conjunto de dados brutos). Neste estudo, utilize os seguintes métodos: SVM, RF, MLP e KNN.
NOTA: O protocolo pode ser pausado aqui.
4. Avaliação
- Prepare um novo conjunto de dados com usuários em condições mais realistas. Use apenas as fontes de informação selecionadas na etapa anterior. Preferível, implementar o sistema no grupo-alvo (por exemplo, idosos). Coletar dados em períodos mais longos de tempo.
- Opcionalmente, se o grupo-alvo for usado apenas, crie um protocolo de grupo de seleção incluindo os termos de exclusão (por exemplo, qualquer comprometimento físico ou psicológico) e pare a prevenção de critérios (por exemplo, detecte qualquer lesão física durante os ensaios; sofrendo náuseas, tonturas e/ou vômitos; desmaios). Considere também preocupações éticas e questões de privacidade de dados.
- Avalie o desempenho do sistema de detecção de queda e de reconhecimento de atividade humana desenvolvido até agora. Use equações 1-5 para determinar a precisão e o poder preditivo do sistema, ou quaisquer outras métricas de desempenho.
- Discutir sobre os resultados experimentais.
Resultados
Criação de um banco de dados
Criamos um conjunto de dados multimodal para detecção de quedas e reconhecimento de atividade humana, ou seja, UP-Fall Detection21. Os dados foram coletados durante um período de quatro semanas na Escola de Engenharia da Universidad Panamericana (Cidade do México, México). O cenário de teste foi selecionado considerando os seguintes requisitos: (a) um espaço no qual os sujeitos poderiam realizar de forma confortável e segura quedas e atividades, e (b) um ambiente interno com luz natural e artificial que seja adequado para configurações de sensores multimodais.
Há amostras de dados de 17 sujeitos que realizaram 5 tipos de quedas e 6 atividades simples diferentes, durante 3 ensaios. Todas as informações foram coletadas usando um sistema interno de aquisição de dados com 5 sensores vestíveis (acelerômetro de três eixos, giroscópio e intensidade de luz), 1 capacete eletroencefalograma, 6 sensores infravermelhos como sensores ambientais e 2 câmeras nos mirantes laterais e frontais. A Figura 1 mostra o layout da colocação do sensor no ambiente e no corpo. A taxa de amostragem de todo o conjunto de dados é de 18 Hz. O banco de dados contém dois conjuntos de dados: o conjunto de dados brutos consolidado (812 GB) e um conjunto de dados de recursos (171 GB). Todos os armazenamentos de bancos de dados armazenados na nuvem para acesso público: https://sites.google.com/up.edu.mx/har-up/. Mais detalhes sobre aquisição de dados, pré-processamento, consolidação e armazenamento deste banco de dados, bem como detalhes sobre sincronização e consistência dos dados podem ser encontrados em Martínez-Villaseñor et al.21.
Para este banco de dados, todos os indivíduos foram voluntários jovens saudáveis (9 homens e 8 mulheres) sem qualquer deficiência, variando entre 18 e 24 anos, com altura média de 1,66 m e peso médio de 66,8 kg. Durante a coleta de dados, o pesquisador responsável técnico estava supervisionando que todas as atividades eram realizadas pelos sujeitos corretamente. Os sujeitos realizaram cinco tipos de quedas, cada uma por 10 segundos, como queda: para frente usando as mãos (1), para a frente usando joelhos (2), para trás (3), sentado em uma cadeira vazia (4) e para o lado (5). Também realizaram seis atividades diárias para 60 s cada, exceto para pular (30 s): caminhar (6), ficar em pé (7), pegar um objeto (8), sentar (9), saltar (10) e colocar (11). Embora as quedas simuladas não possam reproduzir todos os tipos de quedas da vida real, é importante pelo menos incluir tipos representativos de quedas permitindo a criação de melhores modelos de detecção de quedas. Também é relevante usar ADLs e, em particular, atividades que geralmente podem ser confundidas com quedas, como pegar um objeto. Os tipos de queda e ADLs foram selecionados após uma revisão dos sistemas de detecção de quedas relacionados21. Como exemplo, a Figura 2 mostra uma seqüência de imagens de um teste quando um sujeito cai de lado.
Extraímos 12 temporais (média, desvio padrão, amplitude máxima, amplitude mínima, quadrado médio radicular, mediano, número de cruzamento zero, distorção, kurtose, primeiro quartil, terceiro quartil e autocorrelação) e 6 freqüência (média, mediana, entropia, energia, frequência principal e centroide espectral) apresenta21 de cada canal do ambiente vestível e sensores compostos por 756 características no total. Também calculamos 400 recursos visuais21 para cada câmera sobre o movimento relativo de pixels entre duas imagens adjacentes nos vídeos.
Análise de Dados entre Abordagens Unimodais e Multimodais
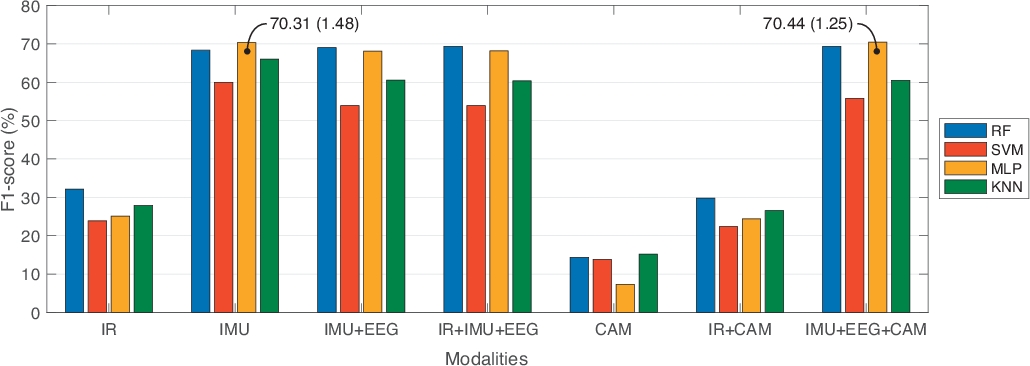
A partir do banco de dados UP-Fall Detection, foram analisados os dados para fins de comparação entre abordagens unimodais e multimodais. Nesse sentido, comparamos sete combinações diferentes de fontes de informação: apenas sensores infravermelhos (IR); apenas sensores vestíveis (IMU); sensores vestíveis e capacete (IMU+EEG); sensores infravermelhos e vestíveis e capacete (IR+IMU+EEG); apenas câmeras (CAM); sensores e câmeras infravermelhas (IR+CAM); e sensores vestíveis, capacete e câmeras (IMU+EEG+CAM). Além disso, comparamos três tamanhos de janela de tempo diferentes com 50% de sobreposição: um segundo, dois segundos e três segundos. Em cada segmento, selecionamos os recursos mais úteis para aplicar a seleção e classificação de recursos. Utilizando essa estratégia, empregamos apenas 10 recursos por modalidade, exceto na modalidade IR utilizando 40 recursos. Além disso, a comparação foi feita em quatro classificadores de aprendizagem de máquina bem conhecidos: RF, SVM, MLP e KNN. Empregamos 10 vezes a validação cruzada, com conjuntos de dados de 70% de trem e 30% de teste, para treinar os modelos de aprendizagem de máquina. A Tabela 1 mostra os resultados deste benchmark, relatando o melhor desempenho obtido para cada modalidade, dependendo do modelo de aprendizado de máquina e da melhor configuração de comprimento da janela. As métricas de avaliação relatam precisão, precisão, sensibilidade, especificidade e pontuação de F1. A Figura 3 mostra esses resultados em uma representação gráfica, em termos de pontuação de F1.
Da Tabela 1, abordagens multimodais (sensores infravermelhos e vestíveis e capacete, IR+IMU+EEG; e sensores vestíveis e capacete e câmeras, IMU+EEG+CAM) obtiveram os melhores valores de pontuação de F1, em comparação com abordagens unimodais (apenas infravermelho, IR; e apenas câmeras, CAM). Também notamos que apenas os sensores vestíveis (IMU) obtiveram desempenho semelhante ao de uma abordagem multimodal. Neste caso, optamos por uma abordagem multimodal, pois diferentes fontes de informação podem lidar com as limitações dos outros. Por exemplo, a obtrusividade nas câmeras pode ser manuseada por sensores vestíveis, e não usar todos os sensores vestíveis pode ser complementado com câmeras ou sensores ambientais.
Em termos de referência dos modelos baseados em dados, os experimentos na Tabela 1 mostraram que a RF apresenta os melhores resultados em quase todos os experimentos; enquanto MLP e SVM não foram muito consistentes em desempenho (por exemplo, o desvio padrão nessas técnicas mostra maior variabilidade do que na RF). Quanto aos tamanhos das janelas, estes não representaram nenhuma melhora significativa entre eles. É importante notar que esses experimentos foram feitos para classificação de outono e atividade humana.
Colocação do sensor e melhor combinação multimodal
Por outro lado, buscamos determinar a melhor combinação de dispositivos multimodais para detecção de quedas. Para esta análise, restringimos as fontes de informação aos cinco sensores vestíveis e às duas câmeras. Estes dispositivos são os mais confortáveis para a abordagem. Além disso, foram consideradas duas classes: queda (qualquer tipo de queda) ou não-queda (qualquer outra atividade). Todos os modelos de aprendizado de máquina e tamanhos de janelas permanecem os mesmos da análise anterior.
Para cada sensor vestível, construímos um modelo de classificador independente para cada comprimento da janela. Treinamos o modelo usando validação cruzada de 10 vezes com 70% de treinamento e 30% de conjuntos de dados de teste. A Tabela 2 resume os resultados para o ranking dos sensores vestíveis por classificador de desempenho, com base na pontuação da F1. Estes resultados foram classificados em ordem decrescente. Como visto na Tabela 2,o melhor desempenho é obtido ao utilizar um único sensor na cintura, pescoço ou bolso direito apertado (região sombreada). Além disso, os sensores vestíveis do tornozelo e do pulso esquerdo tiveram o pior desempenho. A Tabela 3 mostra a preferência de comprimento da janela por sensor vestível, a fim de obter o melhor desempenho em cada classificador. A partir dos resultados, sensores de cintura, pescoço e bolso direito apertado com classificador RF e tamanho de janela 3 s com 50% de sobreposição são os sensores vestíveis mais adequados para detecção de queda.
Fizemos uma análise semelhante para cada câmera no sistema. Construímos um modelo de classificação independente para cada tamanho de janela. Para o treinamento, fizemos 10 vezes a validação cruzada com 70% de treinamento e 30% de conjuntos de dados de teste. A Tabela 4 mostra o ranking do melhor mirante de câmera por classificador, com base na pontuação da F1. Como observado, a visão lateral (câmera 1) realizou a melhor detecção de queda. Além disso, o RF superou em comparação com os outros classificadores. Além disso, a Tabela 5 mostra a preferência de comprimento da janela por mirante da câmera. A partir dos resultados, descobrimos que a melhor localização de uma câmera é em ponto de vista lateral usando RF em tamanho de janela de 3 s e 50% sobreposição.
Por fim, escolhemos duas colocações possíveis de sensores vestíveis (ou seja, cintura e bolso direito apertado) para serem combinadas com a câmera do ponto de vista lateral. Após o mesmo procedimento de treinamento, obtivemos os resultados da Tabela 6. Como mostrado, o classificador modelo RF obteve o melhor desempenho em precisão e pontuação de F1 em ambas as multimodalidades. Além disso, a combinação entre cintura e câmera 1 ficou na primeira posição obtendo 98,72% de precisão e 95,77% na pontuação da F1.

Figura 1: Layout dos sensores vestível (esquerdo) e ambiente (direita) no banco de dados UP-Fall Detection. Os sensores vestíveis são colocados na testa, no pulso esquerdo, no pescoço, na cintura, no bolso direito da calça e no tornozelo esquerdo. Os sensores ambientais são seis sensores infravermelhos emparelhados para detectar a presença de sujeitos e duas câmeras. As câmeras estão localizadas na vista lateral e na vista frontal, ambas com relação à queda humana. Clique aqui para ver uma versão maior desta figura.
{kind=link}

Figura 2: Exemplo de uma gravação de vídeo extraída do banco de dados UP-Fall Detection. No topo, há uma seqüência de imagens de um sujeito caindo de lado. Na parte inferior, há uma seqüência de imagens representando as características de visão extraídas. Essas características são o movimento relativo de pixels entre duas imagens adjacentes. Pixels brancos representam movimento mais rápido, enquanto pixels pretos representam movimento mais lento (ou quase zero). Esta seqüência é classificada da esquerda para a direita, cronologicamente. Clique aqui para ver uma versão maior desta figura.
{kind=link}

Figura 3: Resultados comparativos relatando a melhor pontuação de F1 de cada modalidade em relação ao modelo de aprendizado de máquina e o melhor comprimento da janela. As barras representam os valores médios da pontuação da F1. Texto em pontos de dados representa média e desvio padrão entre parênteses. Clique aqui para ver uma versão maior desta figura.
{kind=link}
| Modalidade | Modelo | Precisão (%) | Precisão (%) | Sensibilidade (%) | Especificidade (%) | Pontuação de F1 (%) |
| IR | RF (3 segundos) | 67,38 ± 0,65 | 36,45 ± 2,46 | 31,26 ± 0,89 | 96,63 ± 0,07 | 32,16 ± 0,99 |
| SVM (3 seg) | 65,16 ± 0,90 | 26,77 ± 0,58 | 25,16 ± 0,29 | 96,31 ± 0,09 | 23,89 ± 0,41 | |
| MLP (3 seg) | 65,69 ± 0,89 | 28,19 ± 3,56 | 26,40 ± 0,71 | 96,41 ± 0,08 | 25,13 ± 1,09 | |
| kNN (3 segundos) | 61,79 ± 1,47 | 30,04 ± 1,44 | 27,55 ± 0,97 | 96,05 ± 0,16 | 27,89 ± 1,13 | |
| IMU | RF (1 seg) | 95,76 ± 0,18 | 70,78 ± 1,53 | 66,91 ± 1,28 | 99,59 ± 0,02 | 68,35 ± 1,25 |
| SVM (1 seg) | 93,32 ± 0,23 | 66,16 ± 3,33 | 58,82 ± 1,53 | 99,32 ± 0,02 | 60,00 ± 1,34 | |
| MLP (1 seg) | 95,48 ± 0,25 | 73,04 ± 1,89 | 69,39 ± 1,47 | 99,56 ± 0,02 | 70,31 ± 1,48 | |
| kNN (1 seg) | 94,90 ± 0,18 | 69,05 ± 1,63 | 64,28 ± 1,57 | 99,50 ± 0,02 | 66,03 ± 1,52 | |
| IMU+EEG | RF (1 seg) | 95,92 ± 0,29 | 74,14 ± 1,29 | 66,29 ± 1,66 | 99,59 ± 0,03 | 69,03 ± 1,48 |
| SVM (1 seg) | 90,77 ± 0,36 | 62,51 ± 3,34 | 52,46 ± 1,19 | 99,03 ± 0,03 | 53,91 ± 1,16 | |
| MLP (1 seg) | 93,33 ± 0,55 | 74,10 ± 1,61 | 65,32 ± 1,15 | 99,32 ± 0,05 | 68,13 ± 1,16 | |
| kNN (1 seg) | 92,12 ± 0,31 | 66,86 ± 1,32 | 58,30 ± 1,20 | 98,89 ± 0,05 | 60,56 ± 1,02 | |
| IR+IMU+EEG | RF (2 seg) | 95,12 ± 0,36 | 74,63 ± 1,65 | 66,71 ± 1,98 | 99,51 ± 0,03 | 69,38 ± 1,72 |
| SVM (1 seg) | 90,59 ± 0,27 | 64,75 ± 3,89 | 52,63 ± 1,42 | 99,01 ± 0,02 | 53,94 ± 1,47 | |
| MLP (1 seg) | 93,26 ± 0,69 | 73,51 ± 1,59 | 66,05 ± 1,11 | 99,31 ± 0,07 | 68,19 ± 1,02 | |
| kNN (1 seg) | 92,24 ± 0,25 | 67,33 ± 1,94 | 58,11 ± 1,61 | 99,21 ± 0,02 | 60,36 ± 1,71 | |
| Cam | RF (3 segundos) | 32,33 ± 0,90 | 14,45 ± 1,07 | 14,48 ± 0,82 | 92,91 ± 0,09 | 14,38 ± 0,89 |
| SVM (2 seg) | 34,40 ± 0,67 | 13,81 ± 0,22 | 14,30 ± 0,31 | 92,97 ± 0,06 | 13,83 ± 0,27 | |
| MLP (3 seg) | 27,08 ± 2,03 | 8,59 ± 1,69 | 10,59 ± 0,38 | 92,21 ± 0,09 | 7,31 ± 0,82 | |
| kNN (3 segundos) | 34,03 ± 1,11 | 15,32 ± 0,73 | 15,54 ± 0,57 | 93,09 ± 0,11 | 15,19 ± 0,52 | |
| IR+CAM | RF (3 segundos) | 65,00 ± 0,65 | 33,93 ± 2,81 | 29,02 ± 0,89 | 96,34 ± 0,07 | 29,81 ± 1,16 |
| SVM (3 seg) | 64,07 ± 0,79 | 24,10 ± 0,98 | 24,18 ± 0,17 | 96,17 ± 0,07 | 22,38 ± 0,23 | |
| MLP (3 seg) | 65,05 ± 0,66 | 28,25 ± 3,20 | 25,40 ± 0,51 | 96,29 ± 0,06 | 24,39 ± 0,88 | |
| kNN (3 segundos) | 60,75 ± 1,29 | 29,91 ± 3,95 | 26,25 ± 0,90 | 95,95 ± 0,11 | 26,54 ± 1,42 | |
| IMU+EEG+CAM | RF (1 seg) | 95,09 ± 0,23 | 75,52 ± 2,31 | 66,23 ± 1,11 | 99,50 ± 0,02 | 69,36 ± 1,35 |
| SVM (1 seg) | 91,16 ± 0,25 | 66,79 ± 2,79 | 53,82 ± 0,70 | 99,07 ± 0,02 | 55,82 ± 0,77 | |
| MLP (1 seg) | 94,32 ± 0,31 | 76,78 ± 1,59 | 67,29 ± 1,41 | 99,42 ± 0,03 | 70,44 ± 1,25 | |
| kNN (1 seg) | 92,06 ± 0,24 | 68,82 ± 1,61 | 58,49 ± 1,14 | 99,19 ± 0,02 | 60,51 ± 0,85 |
Tabela 1: Resultados comparativos relatando o melhor desempenho de cada modalidade em relação ao modelo de aprendizagem de máquina e o melhor comprimento da janela (entre parênteses). Todos os valores em desempenho representam a média e o desvio padrão.
| # | Tipo IMU | |||
| Rf | Svm | Mlp | KNN | |
| 1 | (98,36) Cintura | (83.30) Bolso Direito | (57.67) Bolso Direito | (73.19) Bolso Direito |
| 2 | (95,77) Pescoço | (83.22) Cintura | (44.93) Pescoço | (68,73) Cintura |
| 3 | (95.35) Bolso Direito | (83.11) Pescoço | (39.54) Cintura | (65.06) Pescoço |
| 4 | (95.06) Tornozelo | (82,96) Tornozelo | (39.06) Pulso esquerdo | (58.26) Tornozelo |
| 5 | (94.66) Pulso esquerdo | (82.82) Pulso esquerdo | (37.56) Tornozelo | (51.63) Pulso esquerdo |
Tabela 2: Ranking do melhor sensor vestível por classificador, classificado pela pontuação da F1 (entre parênteses). As regiões na sombra representam os três melhores classificadores para detecção de quedas.
| Tipo IMU | Comprimento da janela | |||
| Rf | Svm | Mlp | KNN | |
| Tornozelo Esquerdo | 2-s | 3 seg | 1-seg | 3 seg |
| Cintura | 3 seg | 1-seg | 1-seg | 2-s |
| Pescoço | 3 seg | 3 seg | 2-s | 2-s |
| Bolso direito | 3 seg | 3 seg | 2-s | 2-s |
| Pulso Esquerdo | 2-s | 2-s | 2-s | 2-s |
Tabela 3: Comprimento da janela de tempo preferido nos sensores vestíveis por classificador.
| # | Visualização da câmera | |||
| Rf | Svm | Mlp | KNN | |
| 1 | (62.27) Visão Lateral | (24.25) Visão Lateral | (13.78) Vista frontal | (41.52) Visão Lateral |
| 2 | (55.71) Vista frontal | (0.20) Vista Frontal | (5.51) Visão Lateral | (28.13) Vista frontal |
Tabela 4: Ranking do melhor mirante de câmera por classificador, classificado pela pontuação da F1 (entre parênteses). As regiões na sombra representam o melhor classificador para detecção de quedas.
| Câmera | Comprimento da janela | |||
| Rf | Svm | Mlp | KNN | |
| Vista lateral | 3 seg | 3 seg | 2-s | 3 seg |
| Vista frontal | 2-s | 2-s | 3 seg | 2-s |
Tabela 5: Comprimento da janela de tempo preferido nos mirantes da câmera por classificador.
| Multimodal | Classificador | Precisão (%) | Precisão (%) | Sensibilidade (%) | Pontuação de F1 (%) |
| Cintura + Vista lateral | Rf | 98,72 ± 0,35 | 94,01 ± 1,51 | 97,63 ± 1,56 | 95,77 ± 1,15 |
| Svm | 95,59 ± 0,40 | 100 | 70,26 ± 2,71 | 82,51 ± 1,85 | |
| Mlp | 77,67 ± 11,04 | 33,73 ± 11,69 | 37,11 ± 26,74 | 29,81 ± 12,81 | |
| KNN | 91,71 ± 0,61 | 77,90 ± 3,33 | 61,64 ± 3,68 | 68,73 ± 2,58 | |
| Bolso direito + Vista lateral | Rf | 98,41 ± 0,49 | 93,64 ± 1,46 | 95,79 ± 2,65 | 94,69 ± 1,67 |
| Svm | 95,79 ± 0,58 | 100 | 71,58 ± 3,91 | 83,38 ± 2,64 | |
| Mlp | 84,92 ± 2,98 | 55,70 ± 11,36 | 48,29 ± 25,11 | 45,21 ± 14,19 | |
| KNN | 91,71 ± 0,58 | 73,63 ± 3,19 | 68,95 ± 2,73 | 71,13 ± 1,69 |
Tabela 6: Resultados comparativos do sensor vestível combinado e do mirante da câmera usando o comprimento da janela de 3 segundos. Todos os valores representam a média e o desvio padrão.
Discussão
É comum encontrar desafios devido a problemas de sincronização, organização e inconsistência de dados20 quando um conjunto de dados é criado.
Sincronização
Na aquisição de dados, surgem problemas de sincronização, dado que múltiplos sensores geralmente funcionam em diferentes taxas de amostragem. Sensores com frequências mais altas coletam mais dados do que aqueles com frequências mais baixas. Assim, dados de diferentes fontes não serão emparelhados corretamente. Mesmo que os sensores funcionem com as mesmas taxas de amostragem, é possível que os dados não estejam alinhados. Nesse sentido, as seguintes recomendações podem ajudar a lidar com esses problemas de sincronização20: (i) registrar carimbo de data, sujeito, atividade e teste em cada amostra de dados obtidos a partir dos sensores; (ii) a fonte de informação mais consistente e menos freqüente deve ser usada como sinal de referência para sincronização; e (iii) utilizar procedimentos automáticos ou semiautomáticos para sincronizar gravações de vídeo que a inspeção manual seria impraticável.
Pré-processamento de dados
O pré-processamento de dados também deve ser feito, e decisões críticas influenciam esse processo: (a) determinar os métodos de armazenamento de dados e representação de dados de múltiplas e heterogêneas (b) decidir as maneiras de armazenar dados no host local ou na nuvem (c) selecionar a organização dos dados, incluindo os nomes de arquivos e pastas (d) lidar com valores ausentes de dados, bem como redundâncias encontradas nos sensores, bem como redundâncias encontradas nos sensores encontrados nos sensores , entre outros. Além disso, para a nuvem de dados, o bufferlocal é recomendado quando possível para mitigar a perda de dados no momento do upload.
Inconsistência de dados
A inconsistência dos dados é comum entre os ensaios que encontraram variações nos tamanhos da amostra de dados. Essas questões estão relacionadas à aquisição de dados em sensores vestíveis. Breves interrupções na aquisição de dados e colisão de dados de múltiplos sensores levam a inconsistências de dados. Nesses casos, algoritmos de detecção de inconsistência são importantes para lidar com falhas on-line nos sensores. É importante destacar que os dispositivos baseados em sem fio devem ser monitorados com freqüência durante todo o experimento. Bateria fraca pode afetar a conectividade e resultar em perda de dados.
Ética
O consentimento para participar e a aprovação ética são obrigatórios em todos os tipos de experimentação onde as pessoas estão envolvidas.
Quanto às limitações dessa metodologia, é importante notar que ela é projetada para abordagens que consideram diferentes modalidades de coleta de dados. Os sistemas podem incluir sensores vestíveis, ambientais e/ou de visão. Sugere-se considerar o consumo de energia dos dispositivos e a vida útil das baterias em sensores baseados em sem fio, devido a problemas como perda de coleta de dados, diminuição da conectividade e consumo de energia em todo o sistema. Além disso, essa metodologia destina-se a sistemas que utilizam métodos de aprendizagem de máquina. Uma análise da seleção desses modelos de aprendizagem de máquina deve ser feita com antecedência. Alguns desses modelos podem ser precisos, mas altamente detempo e consumo de energia. Uma troca entre estimativa precisa e disponibilidade limitada de recursos para computação em modelos de aprendizado de máquina deve ser levada em consideração. Também é importante observar que, na coleta de dados do sistema, as atividades foram realizadas na mesma ordem; também, os ensaios foram realizados na mesma sequência. Por razões de segurança, um colchão de proteção foi usado para que os sujeitos caíssem. Além disso, as quedas foram auto-iniciadas. Esta é uma diferença importante entre quedas simuladas e reais, que geralmente ocorrem em direção a materiais duros. Nesse sentido, esse conjunto de dados registrado cai com uma reação intuitiva tentando não cair. Além disso, existem algumas diferenças entre quedas reais em idosos ou deficientes e a simulação cai; e estes devem ser levados em conta ao projetar um novo sistema de detecção de quedas. Este estudo foi focado em jovens sem prejuízos, mas é notável dizer que a seleção dos sujeitos deve estar alinhada ao objetivo do sistema e da população-alvo que irá usá-lo.
A partir dos trabalhos relacionados descritos acimade 10,11,12,,13,,14,15,16,17,18, podemos observar que existem autores que utilizam abordagens multimodais com foco na obtenção de detectores de queda robustos ou focam na colocação ou desempenho do classificador. Assim, eles só abordam um ou dois dos problemas de design para detecção de quedas. Nossa metodologia permite resolver simultaneamente três dos principais problemas de projeto de um sistema de detecção de quedas.
Para trabalhos futuros, sugerimos a concepção e implementação de um sistema simples de detecção de quedas multimodais com base nos achados obtidos seguindo essa metodologia. Para a adoção do mundo real, o aprendizado de transferência, a classificação hierárquica e abordagens de aprendizagem profunda devem ser usados para o desenvolvimento de sistemas mais robustos. Nossa implementação não considerou métricas qualitativas dos modelos de aprendizagem de máquina, mas os recursos de computação em tempo real e limitados devem ser levados em conta para o desenvolvimento adicional de sistemas de detecção/reconhecimento de quedas humanas e de atividades. Por fim, para melhorar nosso conjunto de dados, atividades de tropeços ou quase queda e monitoramento em tempo real de voluntários durante seu dia a dia podem ser considerados.
Divulgações
Os autores não têm nada para revelar.
Agradecimentos
Esta pesquisa foi financiada pela Universidad Panamericana através da bolsa "Fomento a la Investigación UP 2018", sob o código do projeto UP-CI-2018-ING-MX-04.
Materiais
| Name | Company | Catalog Number | Comments |
| Inertial measurement wearable sensor | Mbientlab | MTH-MetaTracker | Tri-axial accelerometer, tri-axial gyroscope and light intensity wearable sensor. |
| Electroencephalograph brain sensor helmet MindWave | NeuroSky | 80027-007 | Raw brainwave signal with one forehand sensor. |
| LifeCam Cinema video camera | Microsoft | H5D-00002 | 2D RGB camera with USB cable interface. |
| Infrared sensor | Alean | ABT-60 | Proximity sensor with normally closed relay. |
| Bluetooth dongle | Mbientlab | BLE | Dongle for Bluetooth connection between the wearable sensors and a computer. |
| Raspberry Pi | Raspberry | Version 3 Model B | Microcontroller for infrared sensor acquisition and computer interface. |
| Personal computer | Dell | Intel Xeon E5-2630 v4 @2.20 GHz, RAM 32GB |
Referências
- United Nations. World Population Prospects: The 2017 Revision, Key Findings and Advance Tables. United Nations. Department of Economic and Social Affairs, Population Division. , (2017).
- World Health Organization. Ageing, and Life Course Unit. WHO Global Report on Falls Prevention in Older Age. , (2008).
- Igual, R., Medrano, C., Plaza, I. Challenges, Issues and Trends in Fall Detection Systems. Biomedical Engineering Online. 12 (1), 66 (2013).
- Noury, N., et al. Fall Detection-Principles and Methods. 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 1663-1666 (2007).
- Mubashir, M., Shao, L., Seed, L. A Survey on Fall Detection: Principles and Approaches. Neurocomputing. 100, 144-152 (2002).
- Perry, J. T., et al. Survey and Evaluation of Real-Time Fall Detection Approaches. Proceedings of the 6th International Symposium High-Capacity Optical Networks and Enabling Technologies. , 158-164 (2009).
- Xu, T., Zhou, Y., Zhu, J. New Advances and Challenges of Fall Detection Systems: A Survey. Applied Sciences. 8 (3), 418 (2018).
- Rougier, C., Meunier, J., St-Arnaud, A., Rousseau, J. Robust Video Surveillance for Fall Detection Based on Human Shape Deformation. IEEE Transactions on Circuit Systems for Video Technologies. 21, 611-622 (2011).
- Bulling, A., Blanke, U., Schiele, B. A Tutorial on Human Activity Recognition Using Body-Worn Inertial Sensors. ACM Computing Surveys. 46 (3), 33 (2014).
- Kwolek, B., Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Computational Methods and Programs in Biomedicine. 117, 489-501 (2014).
- Ofli, F., Chaudhry, R., Kurillo, G., Vidal, R., Bajcsy, R. Berkeley MHAD: A Comprehensive Multimodal Human Action Database. Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision. , 53-60 (2013).
- Dovgan, E., et al. Intelligent Elderly-Care Prototype for Fall and Disease Detection. Slovenian Medical Journal. 80, 824-831 (2011).
- Santoyo-Ramón, J., Casilari, E., Cano-García, J. Analysis of a Smartphone-Based Architecture With Multiple Mobility Sensors for Fall Detection With Supervised Learning. Sensors. 18 (4), 1155 (2018).
- Özdemir, A. An Analysis on Sensor Locations of the Human Body for Wearable Fall Detection Devices: Principles and Practice. Sensors. 16 (8), 1161 (2016).
- Ntanasis, P., Pippa, E., Özdemir, A. T., Barshan, B., Megalooikonomou, V. Investigation of Sensor Placement for Accurate Fall Detection. International Conference on Wireless Mobile Communication and Healthcare. , 225-232 (2016).
- Bagala, F., et al. Evaluation of Accelerometer-Based Fall Detection Algorithms on Real-World Falls. PLoS One. 7, 37062 (2012).
- Bourke, A. K., et al. Assessment of Waist-Worn Tri-Axial Accelerometer Based Fall-detection Algorithms Using Continuous Unsupervised Activities. Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 2782-2785 (2010).
- Kerdegari, H., Samsudin, K., Ramli, A. R., Mokaram, S. Evaluation of Fall Detection Classification Approaches. 4th International Conference on Intelligent and Advanced Systems. , 131-136 (2012).
- Alazrai, R., Mowafi, Y., Hamad, E. A Fall Prediction Methodology for Elderly Based on a Depth Camera. 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 4990-4993 (2015).
- Peñafort-Asturiano, C. J., Santiago, N., Núñez-Martínez, J. P., Ponce, H., Martínez-Villaseñor, L. Challenges in Data Acquisition Systems: Lessons Learned from Fall Detection to Nanosensors. 2018 Nanotechnology for Instrumentation and Measurement. , 1-8 (2018).
- Martínez-Villaseñor, L., et al. UP-Fall Detection Dataset: A Multimodal Approach. Sensors. 19 (9), 1988 (2019).
- Rantz, M., et al. Falls, Technology, and Stunt Actors: New approaches to Fall Detection and Fall Risk Assessment. Journal of Nursing Care Quality. 23 (3), 195-201 (2008).
- Lachance, C., Jurkowski, M., Dymarz, A., Mackey, D. Compliant Flooring to Prevent Fall-Related Injuries: A Scoping Review Protocol. BMJ Open. 6 (8), 011757 (2016).
Reimpressões e Permissões
Solicitar permissão para reutilizar o texto ou figuras deste artigo JoVE
Solicitar PermissãoThis article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. Todos os direitos reservados