
Method Article
Горнодобывающей промышленности фраза облачной и анализа определяемых пользователем фразы Категория ассоциации в биомедицинских публикаций
* Эти авторы внесли равный вклад
В этой статье
Резюме
Мы представляем протокол и связанного программного кода, а также образцы метаданных для поддержки облачной автоматической идентификации фразы Категория ассоциации, представляющие уникальные концепции в домене выбранного знания пользователя в биомедицинских литературе. Фраза Категория Ассоциация количественно этот протокол может облегчить в глубине анализа в домене выбранного знаний.
Аннотация
Быстрое накопление биомедицинских текстовых данных намного превышает человеческого потенциала ручного курирование и анализ, требующий Роман инструменты интеллектуального анализа текста для извлечения биологических идеи из большого количества научных докладов. Контекстно зависимые семантической онлайн аналитическая обработка (CaseOLAP) трубопровода, разработанная в 2016 году, успешно количественно определяемых пользователем фразы Категория отношения путем анализа текстовых данных. CaseOLAP имеет много биомедицинских приложений.
Мы разработали протокол для облачной среды, поддержке конец в конец фразы добыча и анализ платформы. Наш протокол включает в себя данные предварительной обработки (например, загрузки, извлечения и анализа текстовых документов), индексация и поиск с Elasticsearch, создание функциональной структуры под названием текст-куб и количественного определения фразы Категория отношения Использование основной алгоритм CaseOLAP.
Наши данные препроцессирование генерирует ключ значение сопоставления для всех документов. Предварительно обработанные данные индексируются осуществлять поиск документов, включая сущности, который далее облегчает создание текста-куб и CaseOLAP Оценка вычисления. Полученные оценки сырья CaseOLAP интерпретируются с помощью ряда комплексных анализов, включая сокращение размерности, кластеризация, височной и географических анализов. Кроме того CaseOLAP оценки используются для создания графической базы данных, которая позволяет семантическое сопоставление документов.
CaseOLAP определяет фразу Категория отношения в точной (определяет отношения), последовательные (высокую воспроизводимость) и эффективным образом (процессы 100 000 слов/сек). После этого протокола пользователи могут получить доступ к среде облачных вычислений для поддержки их собственных конфигураций и приложений CaseOLAP. Эта платформа предлагает расширение доступности и уполномочивает биомедицинского сообщества с горнодобывающей промышленности фраза инструменты для приложений широко биомедицинских исследований.
Введение
Ручная оценка миллионов текстовых файлов для изучения фразу Категория ассоциации (например., возрастной группы Ассоциации белка) сравнима с методом автоматизированной вычислительной эффективностью. Мы хотим познакомить облачной платформы контекстно зависимые семантической онлайн аналитическая обработка (CaseOLAP) как метод горнодобывающей промышленности фраза для автоматического вычисления фразу Категория ассоциации в контексте биомедицинского.
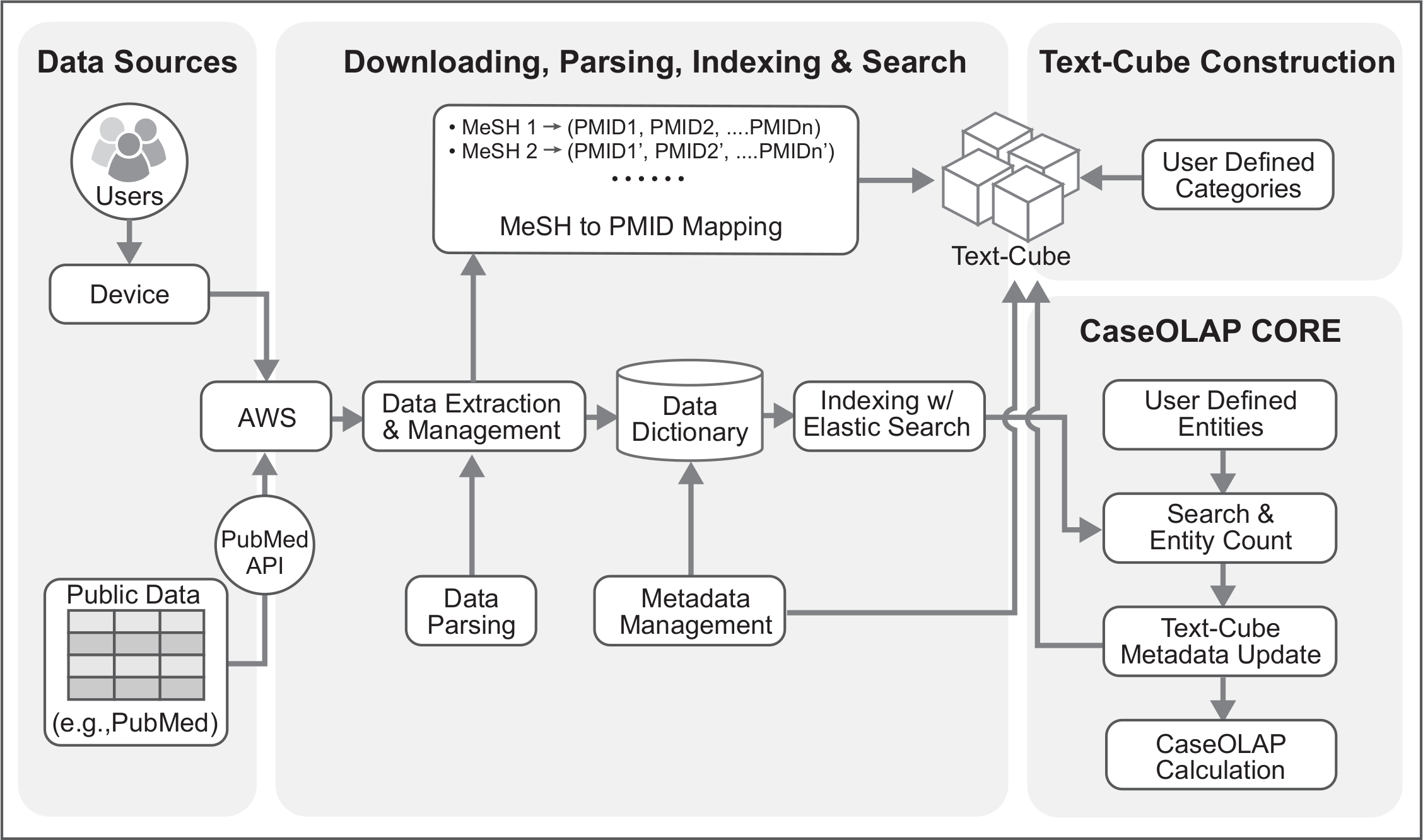
CaseOLAP платформа, которая впервые была определена в 20161, является весьма эффективным по сравнению с традиционными методами управления данными и вычислений из-за своей функциональной документооборота, называется текст-куб2,3, 4, который распределяет документы при сохранении основополагающих иерархии и микрорайонов. Она применялась в5 биомедицинских исследований для изучения сущности Категория ассоциации. CaseOLAP платформа состоит из шести основных этапов, включая загрузки и извлечения данных, разбор, индексации, создания текста-куб, количество сущностей, и CaseOLAP Оценка расчет; которая является основным направлением протокола (рис. 1, рис. 2, Таблица 1).
Для реализации алгоритма CaseOLAP, пользователь устанавливает категории интересов (например, болезнь, признаки и симптомы, возрастных групп, диагностика) и подразделений, представляющих интерес (например, белки, наркотики). Одним из примеров категории, включенные в этой статье является возрастных групп, которые имеет «Детей», «ребенок», «подростков», и «взрослый» подкатегории как клетки текста-куб и белков (синонимы) полных и сокращенных названий как сущности. Медицинские предметные рубрики (MeSH) реализованы для получения публикаций, соответствующих определенной категории (Таблица 2). Дескрипторы сетки организованы в иерархическую древовидную структуру разрешить поиск публикаций на различных уровнях специфичности (образец, показанный на рисунке 3). CaseOLAP платформа использует функции индексирования и поиска данных для курирование документов, связанных с сущностью, которые еще более облегчить документ сущности количество карт и CaseOLAP Оценка вычисления.
Подробная информация о расчетах Оценка CaseOLAP доступен в предыдущих публикаций1,5. Эта оценка вычисляется с помощью конкретных ранжирование критериев, на основе базовой структуры документа текст-куб. Окончательная оценка является продуктом целостности, популярностии самобытности. Целостность описывает, является ли представитель сущность семантической целое, которое коллективно относится к значимой концепции. Целостность пользовательская фраза берется быть 1.0, потому что он стоит как стандартная фраза в литературе. Особенностей представляет относительную значимость фразы в одно подмножество документов по сравнению с остальной частью других клеток. Он сначала вычисляет значение сущности для конкретной ячейки, сравнивая вхождения имени белка в наборе данных и обеспечивает нормализованный показатель своеобразность . Популярность представляет тот факт, что фраза с показатель популярности более часто появляется в одно подмножество документов. Имена редких белка в клетке ранжируются низкий, в то время как увеличение их частоты упоминания имеет сокращается прибыль за счет осуществления логарифмической функции частоты. Количественное измерение эти три понятия зависит от (1) срок частоты сущности над клетки и клетки и (2) количество документов этой сущности (документ частоты) внутри клетки и клетки.
Мы изучили два представителя сценариев с использованием набора данных PubMed и наш алгоритм. Мы заинтересованы в как митохондриальных протеинов связаны с двух уникальных категориях дескрипторов MeSH; «Возрастных групп» и «питания и метаболических заболеваний». В частности мы получить 15,728,250 публикаций из 20 лет публикаций, собранные PubMed (1998-2018 годы), среди них, 8,123,458 уникальных рефератов имели полный дескрипторов MeSH. Соответственно, 1842 человека митохондриальных белок имена (включая аббревиатуры и синонимы), полученные от UniProt (uniprot.org), а также от MitoCarta2.0 (http://mitominer.mrc-mbu.cam.ac.uk/release-4.0/begin.do >), систематически рассмотрены. Их ассоциации с этими 8,899,019 изданий и организаций были изучены с помощью нашего протокола; Мы построен текст-куб и рассчитаны соответствующие оценки CaseOLAP.
протокол
Примечание: Мы разработали этот протокол, основанный на языке программирования Python. Для запуска этой программы, имеют Анаконда Python и Git предварительно установлена на устройстве. Команды в этом протоколе не предусмотрено основаны на Unix-среду. Этот протокол обеспечивает детали загрузки данных из базы данных PubMed (MEDLINE), анализ данных и создание облачных вычислений платформы для горнодобывающей промышленности фраза и количественной оценки определяемых пользователем сущностей Категория ассоциации.
1. получение кода и python среды установки
- Скачать или клонировать репозиторий кода из Github (https://github.com/CaseOLAP/caseolap) или, набрав «git clone https://github.com/CaseOLAP/caseolap.git» в окне терминала.
- Перейдите в каталог «caseolap». Это корневой каталог проекта. В этом каталоге будет заполняться в каталог «данные» с несколькими наборами данных как вы прогресса через эти шаги в протоколе. «Входной» каталог предназначен для предоставленных пользователем данных. Каталог «журнал» имеет файлов журнала для устранения неполадок. Каталог «результат» является, где будут храниться окончательные результаты.
- Использование окна терминала, перейдите в каталог, где вы склонировали наш репозиторий на GitHub. Создать CaseOLAP условия, используя файл «environment.yml», набрав 'Конда env создать environment.yaml -f ' в терминале. Затем активируйте окружающей среды, набрав «источник активировать caseolap» в терминале.
2. Загрузка документов
- Убедитесь, что FTP-адрес в «ftp_configuration.json» в папке config является таким же, как адрес ссылки ежегодного базового или ежедневные обновления файлов, найденных в ссылке (https://www.nlm.nih.gov/databases/download/pubmed_medline.html) .
- Для загрузки исходных только или обновления файлов, задать только «true» в файле «download_config.json» в «config» директория. По умолчанию он загружает и извлекает файлы как базовых, так и обновления. Пример извлечения данных XML можно просмотреть на (https://github.com/CaseOLAP/caseolap-pipelines/blob/master/data/extracted-data-sample.xml)
- Тип «python run_download.py» в окне терминала скачать рефераты из базы данных Pubmed. Это создаст директорию с именем «ftp.ncbi.nlm.nih.gov» в текущем каталоге. Этот процесс проверяет целостность загруженных данных и извлекает его в целевой каталог.
- Перейдите в каталог «журнал» читать сообщения журнала в «download_log.txt», в случае, если происходит сбой процесса загрузки. Если процесс завершен успешно, сообщения отладки процесса загрузки будет распечатать в этот файл журнала.
- Когда загрузка будет завершена, перемещаться по «ftp.ncbi.nlm.nih.gov», чтобы убедиться, что есть «updatefiles» или «basefiles» или обоих каталогов на основе загрузки конфигурации в «download_config.json». Файл статистики становятся доступными в «filestat.txt» в папке «данные».
3. разбор документов
- Убедитесь, что загружены и извлеченных данных доступен в каталоге «ftp.ncbi.nlm.nih.gov» из шага 2. Это каталог входных данных, в этом шаге.
- Чтобы изменить схему синтаксического анализа данных, выберите параметры в файле «parsing_config.json» в «config» каталог, установив их значение «true». По умолчанию, он анализирует PMID, авторы, аннотация, сетка, местоположение, журнал, Дата публикации.
- Тип «python run_parsing.py» в терминале для разбора документов из файлов, загруженных (или удалять). Этот шаг анализирует все скачанные файлы XML и создает словарь python для каждого документа с ключами (например., сетка PMID, авторы, аннотация, из файла на основе синтаксического анализа схемы установки на шаге 3.2).
- После завершения анализа данных, убедитесь, что анализируемые данные сохраняются в файле под названием «pubmed.json» в каталоге данных. Образец разбора данных доступен в Рисунок 3.
- Перейдите в каталог «журнал» читать сообщения журнала в «parsing_log.txt», в случае сбоя процесса анализа. Если процесс завершен успешно, сообщения отладки будут распечатаны в файле журнала.
4. сетка PMID сопоставления
- Убедитесь, что анализируемые данные («pubmed.json») доступен в папке «данных».
- Тип «python run_mesh2pmid.py» в терминале, чтобы выполнить сопоставление PMID сетки. Это создает таблицу сопоставления, где каждый из сетки собирает связанного PMIDs. Один PMID может подпадать под несколько терминов MeSH.
- По завершении сопоставления убедитесь, что есть «mesh2pmid.json» в каталоге данных. В таблице 2, рисунки 4 и 5доступен образец 20 лучших сопоставления статистики.
- Перейдите в каталог «журнал» читать сообщения журнала в «mesh2pmid_mapping_log.txt», в случае, если этот процесс не выполняется. Если процесс завершен успешно, сообщения отладки сопоставления будут распечатаны в этот файл журнала.
5. документ индексация
- Скачайте приложение Elasticsearch из https://www.elastic.co. В настоящее время загрузка доступна на (https://www.elastic.co/downloads/elasticsearch). Для загрузки программного обеспечения в удаленном облако, введите «wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-x.x.x.tar.gz» в терминале. Убедитесь, что «x.x.x» в команде выше заменяется номером правильной версии.
- Убедитесь, что файл загруженный «elasticsearch-x.x.x.tar.gz» появляется в корневом каталоге, а затем извлечь файлы, набрав 'смолы xvzf elasticsearch-x.x.x.tar.gz' в окне терминала.
- Открыть новый терминал и перейдите в каталог bin ElasticSearch, набрав «cd Elasticsearch/bin» в терминале из корневого каталога.
- Запустите сервер Elasticsearch, набрав '. / Elasticsearch' в окне терминала. Убедитесь, что сервер запущен без сообщений об ошибках. В случае ошибки на начиная Elasticsearch сервера следуйте инструкциям в (https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html).
- Измените содержимое в «index_init_config.json» в каталоге «config», чтобы установить индекс посвящения. По умолчанию он будет выделить все элементы настоящего.
- Тип «python run_index_init.py» в терминале, чтобы инициировать индекса-базы данных на сервере Elasticsearch. Это Инициализирует индекс с набором критериев, известных как индекс информацию (например, имя индекса, имя типа, количество осколков, количество реплик). Вы увидите сообщение, отметить, что успешно создан индекс.
- Выберите элементы в «index_populate_config.json» в «config» каталог, установив их значение «true». По умолчанию он будет выделить все элементы настоящего.
- Убедитесь, что анализируемые данные («pubmed.json») присутствует в папке «данные».
- Тип «python run_index_populate.py» в терминале, чтобы заполнить индекс путем создания массовых данных с двумя компонентами. Первый компонент — это словарь с метаданными на имя индекса, имя типа и основной идентификатор (например, «PMID»). A второй компонент — это словарь данных, содержащей всю информацию о теги (например, «название», «абстрактные», «Сеть»).
- Перейдите в каталог «журнал» читать сообщения журнала в «indexing_log.txt», в случае, если этот процесс не выполняется. Если процесс завершен успешно, сообщения отладки индексирования будут распечатаны в файле журнала.
6. текст куб создание
- Скачайте последнюю MeSH дерево на (https://www.nlm.nih.gov/mesh/filelist.html). Текущая версия кода используется сетка 2018 дерево как «meshtree2018.bin» в папке ввода.
- Определите категории интересов (например, болезнь имена, возрастные группы, пола). Категория может включать один или несколько дескрипторов MeSH (https://meshb-prev.nlm.nih.gov/treeView). Соберите идентификаторы сетки для категории. Сохраните имена категорий в файле «textcube_config.json» в каталоге config каталога (см. образец категории «Возрастной группы» в загруженный версия файла «textcube_config.json»).
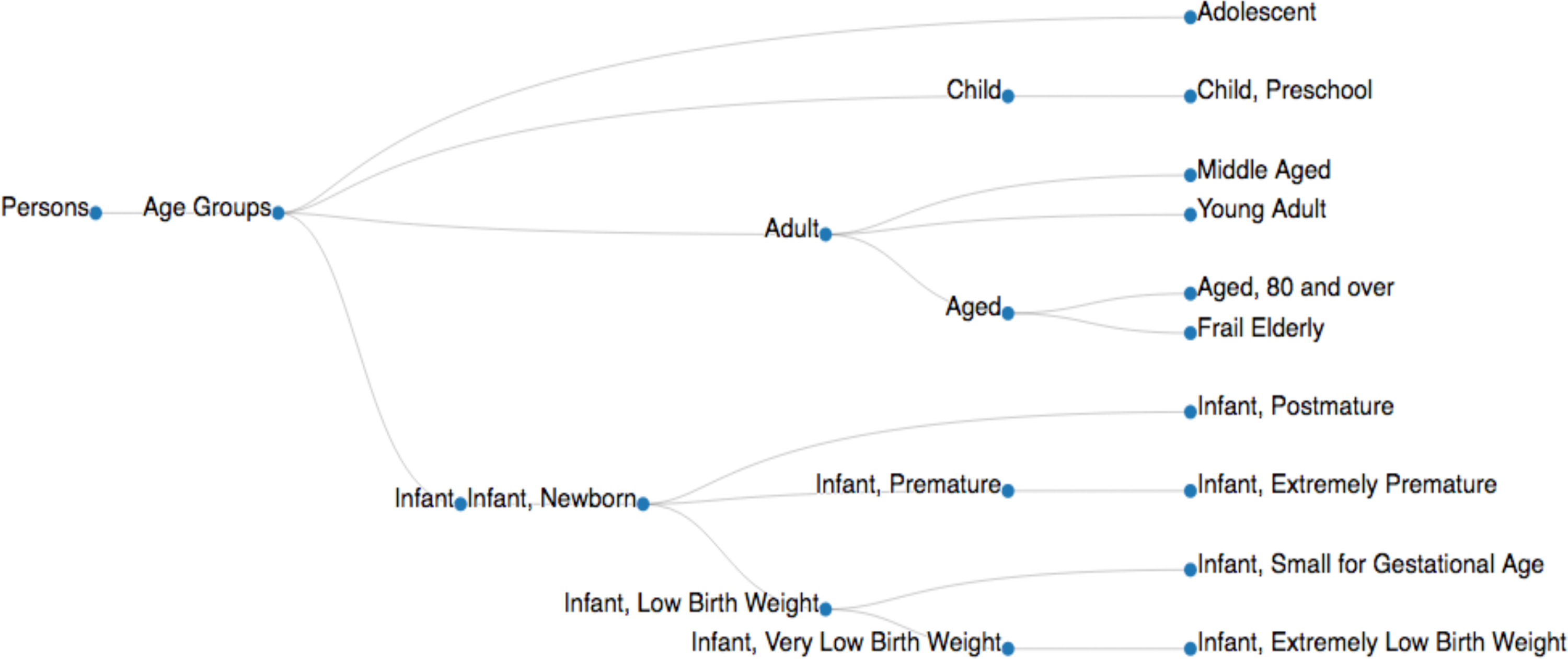
- Положите собранные категории идентификаторов сетки в строки, разделенные пробелом. Сохраните файл категории как «categories.txt» в «ввода» директории (см. образец «Возрастной группе» Сетка идентификаторов в загруженный версия файла «categories.txt»). Этот алгоритм автоматически выбирает все дочерние дескрипторы сетки. Пример из корневых узлов и потомки представлены в Рисунок 4.
- Убедитесь, что «mesh2pmid.json» находится в директории «данные». Если дерево сетка была обновлена с другим именем (например, «meashtree2019.bin») в «ввода» каталог, убедитесь, что это должным образом представлены в пути ввода данных в файле «run_textube.py».
- Тип «python run_textcube.py» в терминале для создания структуры данных документа под названием текст-куб. Это создает коллекцию документов (PMIDs) для каждой категории. Один документ (PMID) может подпадают под несколько категорий, (см. таблица 3A, 3B таблицы, Рисунок 6A и рис. 7A).
- После завершения шага создания текста-куб, убедитесь, что следующие файлы данных сохраняются в папке «данных»: (1) в ячейку таблицы PMID как «textcube_cell2pmid.json», (2 PMID в ячейку таблицы сопоставления как «textcube_pmid2cell.json», (3 Коллекция всех потомков термины сетки для ячейки как «meshterms_per_cat.json» (4) текст-куб данных статистики как «textcube_stat.txt».
- Перейдите в каталог «журнал» читать сообщения журнала в «textcube_log.txt», в случае, если этот процесс не выполняется. Если процесс завершен успешно, сообщения отладки создание текста-куб будет распечатать в файле журнала.
7. сущность фото
- Создание определяемых пользователем сущностей (например, имена белка, гены, химических веществ). Положить в виде одной строки, разделенные одной сущности и ее аббревиатуры «|». Сохраните файл сущности как «entities.txt» в папке «входной». Выборки из организаций можно найти в Таблица 4.
- Убедитесь, что запущен сервер Elasticsearch. В противном случае перейдите к шагу 5.2 и 5.3, чтобы перезапустить сервер Elasticsearch. Ожидается, что иметь индексированную базу данных под названием «pubmed» в вашем сервере Elasticsearch, который был создан в шаге 5.
- Убедитесь, что «textcube_pmid2cell.json» находится в директории «данные».
- Тип «python run_entitycount.py» в терминале для выполнения операции количество сущностей. Это ищет документы из индексированной базы данных и подсчитывает сущности в каждом документе, а также собирает PMIDs, в которых были найдены сущностей.
- После завершения количество сущностей, убедитесь, что окончательные результаты сохраняются как «entitycount.txt» и «entityfound_pmid2cell.json» в папке «данные».
- Перейдите в каталог «журнал» читать сообщения журнала в «entitycount_log.txt», в случае, если этот процесс не выполняется. Если процесс завершен успешно, сообщения отладки количество сущностей будут распечатаны в файле журнала.
8. метаданные обновления
- Убедитесь, что все входные данные («entitycount.txt», «textcube_pmid2cell.json», «entityfound_pmid2cell.txt») находятся в директории «данные». Это входные данные для обновления метаданных.
- Тип «python run_metadata_update.py» в терминале, чтобы обновить метаданные. Это готовит коллекцию метаданных (например, имя ячейки, связанной сетки, PMIDs) представляющие каждый текстовый документ в ячейке. Образец текста-куб метаданных представлена в таблице 3A и Таблица 3В.
- После завершения обновления метаданных, убедитесь, что «metadata_pmid2pcount.json» и «metadata_cell2pmid.json» файлы сохраняются в каталоге «данные».
- Перейдите в каталог «журнал» читать сообщения журнала в «metadata_update_log.txt», в случае, если этот процесс не выполняется. Если процесс завершен успешно, сообщения отладки обновления метаданных будут распечатаны в файле журнала.
9. CaseOLAP расчет и оценка
- Убедитесь, что файлы «metadata_pmid2pcount.json» и «metadata_cell2pmid.json» присутствуют в каталоге «данные». Это входные данные для вычисления оценка.
- Тип «python run_caseolap_score.py» в терминале для выполнения вычисления Оценка CaseOLAP. Это вычисляет Оценка CaseOLAP сущностей, основанных на пользовательских категорий. CaseOLAP Оценка является продуктом целостности, популярностии самобытности.
- После завершения вычисления оценка, убедитесь, что это сохраняет результаты в нескольких файлах (например, популярность как «pop.csv», самобытность как «dist.csv», CaseOLAP Оценка как «caseolap.csv»), в папке «результат». Резюме CaseOLAP Оценка вычисления также представлены в таблице 5.
- Перейдите в каталог «журнал» читать сообщения журнала в «caseolap_score_log.txt», в случае, если этот процесс не выполняется. Если процесс завершен успешно, сообщения отладки вычисления Оценка CaseOLAP будут распечатаны в файле журнала.
Результаты
Для получения результатов, мы реализовали CaseOLAP алгоритм в два субъекта заголовки/дескрипторы: «Возрастные группы» и «Питания и метаболических заболеваний» как варианты использования.
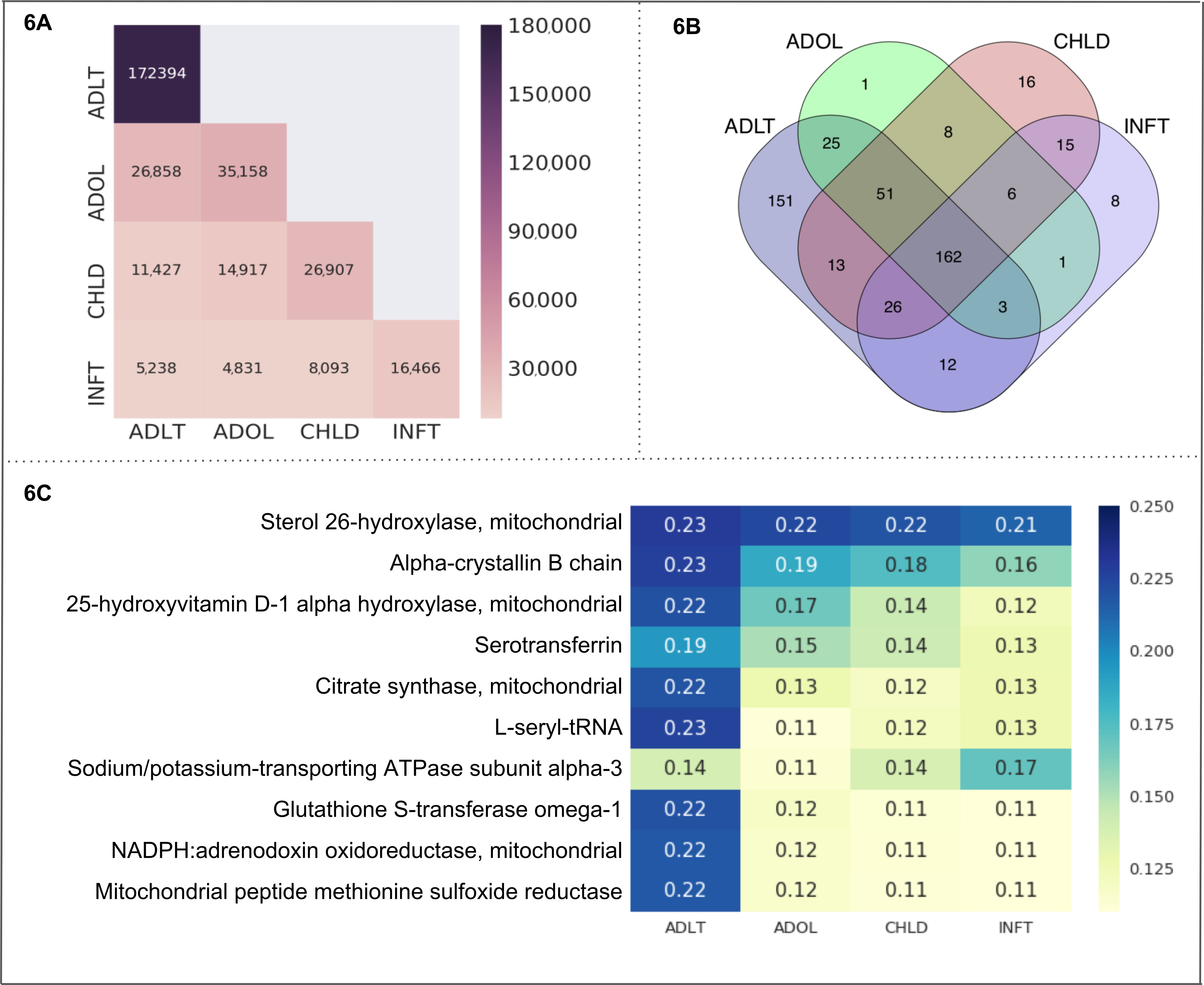
Возрастных групп. Мы выбрали все 4 подкатегории «Возрастных групп» (младенцев, детей, подростков и взрослых) как клетки в текст-куб. Полученные метаданные и статистические данные приводятся в таблице 3A. Сравнение числа документов среди клеток текста-Куба отображается в рисунке 6A. Взрослого содержит 172,394 документов, который является наибольшим числом для всех ячеек. Подкатегории взрослых и подростков имеют наибольшее количество общих документов (26,858 документы). В частности эти документы включали сущность нашего интереса только (то есть, митохондриальных протеинов). Венна в рисунке 6B представляет количество сущностей (т.е., митохондриальных протеинов) найдены в пределах каждой ячейки и в течение нескольких совпадений среди клеток. Количество белков, совместно в рамках всех возрастных групп подкатегорий — 162. Взрослый подкатегории изображает наибольшее количество уникальных белков (151) следуют ребенка (16), товары для детей (8) и подростков (1). Мы рассчитали белка возрастной группы ассоциации как оценка CaseOLAP. Топ 10 белков (на основе их средняя оценка CaseOLAP) связанные с младенцев, детей, подростков и взрослых подкатегории, стерол 26-гидроксилазы, альфа кристаллин B цепи, 25-гидроксивитамина альфа D-1-гидроксилазы, Serotransferrin, цитрат синтаза, L-seryl тРНК, натрия/калия транспортировки АТФазы Субблок альфа-3, глутатион-S-трансферазы омега-1, Оксидоредуктазы NADPH: adrenodoxin и митохондриальной пептид метионина сульфоксида редуктаза (показано на рисунке 6 c). Взрослый подкатегории отображаются 10 heatmap ячейки с большей интенсивностью, по сравнению с heatmap клетки подростков, детской и младенческой подкатегории, указав, что топ 10 митохондриальных протеинов exhibit сильных ассоциаций для взрослых подкатегории. Митохондриальных белок стерол 26-гидроксилазы имеет высокий ассоциаций всех подкатегорий возраст которых подтверждается heatmap клеток с более высокой интенсивности по сравнению с heatmap клетки 9 других митохондриальных протеинов. Статистическое распределение абсолютная разница в счете между двумя группами показывает следующий диапазон для разность с 99% доверительный интервал: (1) означает разницу между «ADLT» и «INFT» лежит в диапазоне (0,029 0,042), среднее (2 Разница давлений между «ADLT» и «CHLD» лежит в диапазоне (0,021 до 0,030), (3) означает разницу между «ADLT» и «ADOL» лежит в диапазоне (0,020 0,029), (4) означает разницу между «ADOL» и «INFT» лежит в диапазоне (0,015-0,022), (5) средняя разность «ADOL» и «CHLD» лежит в диапазоне (0,007-0,010), (6) средняя разность между «CHLD» и «INFT» лежит в диапазоне (0,011 до 0,016).
Питания и метаболических заболеваний. Мы выбрали 2 подкатегории «Питания и метаболических заболеваний» (то есть, метаболические заболевания и расстройства питания) для создания 2 клетки в текст-куб. Полученные метаданные и статистические данные приводятся в таблице 3B. Сравнение числа документов среди клеток текста-Куба отображается Рисунок 7а. Метаболические болезни подкатегории содержит 54,762 документы следуют 19,181 документов в расстройства питания. Подкатегории метаболических болезней и нарушений питания у 7,101 Общие документы. В частности эти документы включали сущность нашего интереса только (то есть, митохондриальных протеинов). Венна в Рисунок 7B представляет количество сущностей найден внутри каждой клетки и в течение нескольких дублирования между ячейками. Мы рассчитали белка-«Пищевая и метаболических заболеваний» ассоциации как CaseOLAP баллов. Топ 10 белков (на основе их средняя оценка CaseOLAP) связанные с этим вариантом использования являются стерины 26-гидроксилазы, альфа кристаллин B цепи, L-seryl ТРНК синтетазы цитрат, ТРНК синтетазы pseudouridine A, 25-гидроксивитамина альфа D-1-гидроксилазы, Глутатион-S-трансферазы омега-1, NADPH: adrenodoxin Оксидоредуктазы, митохондриальных пептид метионина сульфоксида редуктазы, ингибитора активатора плазминогена 1 (показано на рисунке 7 c). Более половины (54%) из всех белков являются общими для подкатегорий метаболических болезней и нарушений питания (397 белки). Интересно, что почти половина (43%) всех связанных белков в подкатегории метаболические заболевания являются уникальные (300 белки), тогда как расстройства питания выставлять только несколько уникальных белков (35). Альфа кристаллин B цепи отображает сильных ассоциаций подкатегории метаболических заболеваний. Стерол 26-гидроксилазы, митохондриальных отображает сильных ассоциаций в подкатегории расстройства питания, указав, что этот митохондриальных белок является весьма актуальным в исследования, описывающие расстройства питания. Статистическое распределение абсолютная разница в счете между двумя группами «MBD» и «NTD» показывает диапазон (0,046 0,061) для средняя разность как 99% доверительного интервала.

Рисунок 1. Динамическое представление рабочего процесса CaseOLAP. Эта цифра 5 основных шагов в процессе CaseOLAP. В шаге 1 рабочий процесс начинается с загрузки и извлечения текстовых документов (например, от PubMed). В шаге 2 создание словаря данных для каждого документа, а также сетку для сопоставления PMID анализируются извлеченные данные. В шаге 3 индексирование данных проводится для облегчения поиска быстрый и эффективный орган. В шаге 4 предоставляемый пользователем категории информации (например,., корень сетки для каждой ячейки) осуществляется для построения текста-куб. В шаге 5 операция фото сущности реализуется над данных индекса для подсчета очков CaseOLAP. Эти шаги повторяются в последовательной манере для обновления системы с последней информации, имеющейся в публичной базе данных (например, PubMed). Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 2. Техническая архитектура CaseOLAP рабочего процесса. Эта цифра представляет собой технические детали CaseOLAP рабочего процесса. Данные из хранилища PubMed получаются из PubMed FTP-сервера. Пользователь подключается к серверу облака (например, подключения AWS) через их устройства и создает скачать трубопровода, который загружает и извлекает данные в локальное хранилище в облаке. Извлеченные данные структурированы, проверены и привели в надлежащий формат с разбора конвейер данных. Одновременно сетки в таблице сопоставления PMID создается во время выполнения синтаксического анализа, который используется для текста-куб строительства. Анализируемые данные хранятся в виде JSON как словарь ключ значение формат метаданных документа (например, год издания PMID, сетка,). Индексация дальше улучшает данные путем реализации Elasticsearch для обработки больших объемов данных. Далее текст-куб создается с определяемые пользователем категории путем реализации сетки PMID сопоставления. После завершения формирования текста-куб и индексирование шаги, проводится количество сущностей. Данные сущностей реализуются для метаданных текста-Куба. Наконец CaseOLAP оценка рассчитывается на основе базовой структуры текста-куб. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 3. Образец анализируемого документа. На этом рисунке представлен образец разбора данных. Анализируемые данные организованы как пара ключ значение, которая совместима с индексации и документ метаданных создание. На этом рисунке PMID (например, «25896987») выступает в качестве ключа и коллекции связанных сведений (например, название, журнал, даты, аннотация, сетка, вещества, Департамент и местоположение публикации), как значение. Очень первое применение такого документа метаданных является строительство сетки PMID сопоставления (рис. 5 и Таблица 2), которая осуществляется позже для создания текста-Куба и вычисления CaseOLAP Оценка с пользователем сущности и категории. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 4. Пример дерева MeSH. 'Возрастных групп сетки дерево адаптировано из дерева структуры данных в базе данных NIH (MeSH дерево 2018, < https://meshb.nlm.nih.gov/treeView>). Дескрипторы сетки осуществляется с их идентификаторы (например, лица [M01], возрастные группы [M01.060], подростков [M01.060.057], взрослого [M01.060.116], ребенок [M01.060.406], ребенок [M01.060.703]) для сбора документов, касающихся конкретных дескрипторов MeSH ( узлов Таблица 3а). Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

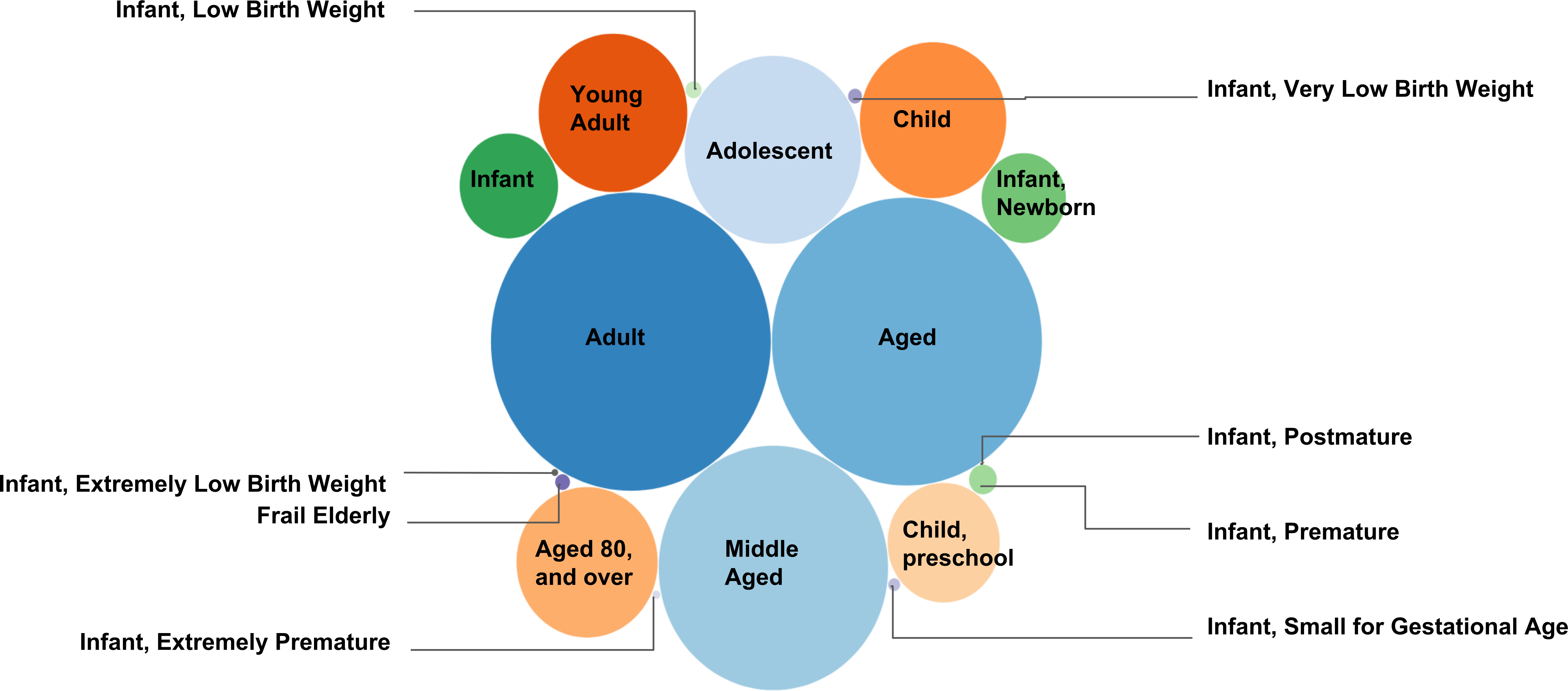
Рисунок 5. Сетка для картирования PMID в возрастных группах. Эта цифра представляет количество текстовых документов (каждый связано с PMID), собранные под дескрипторов MeSH «Возрастных групп» как пузырь сюжет. Сетки для сопоставления PMID генерируется предоставлять точное число документов, собранных под дескрипторов MeSH. Общее количество 3,062,143 уникальных документов были собраны под 18 дочерних дескрипторов MeSH (см. таблицу 2). Чем выше количество PMIDs подбирать под дескриптор конкретного сетки, тем больше радиус пузырь, представляющий дескриптор сетки. К примеру, наибольшее количество документов были собраны под дескриптор сетки «Взрослый» (1,786,371 документы), тогда как наименьшее количество текстовых документов были собраны под дескриптор сетки «Младенец, Postmature» (62 документов).
Дополнительный пример сетки для сопоставления PMID предоставляется для «Питания и метаболических заболеваний» (https://caseolap.github.io/mesh2pmid-mapping/bubble/meta.html). Общее количество 422,039 уникальных документов были собраны под 361 потомком дескрипторов MeSH в «Питания и метаболических заболеваний». Наибольшее количество документов были собраны под дескриптор сетки «Ожирение» (77,881 документы) следуют «сахарный диабет типа 2» (61,901 документы), тогда как «гликогена хранения заболевания, типа VIII» выставлены наименьшее количество документов (1 документ ). Связанная таблица также доступны онлайн на (https://github.com/CaseOLAP/mesh2pmid-mapping/blob/master/data/diseaseall.csv). Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 6. «Возрастных групп» как вариант использования. Эта цифра представляет результаты от варианта использования платформы CaseOLAP. В этом случае имена белков и их аббревиатуры (см. пример в таблице 4) реализованы в виде сущностей и «Возрастные группы», включая клетки: Товары для детей (INFT), ребенка (CHLD), подростков (ADOL) и взрослых (ADLT), реализованы в виде подкатегорий (см. Таблица 3а). (A) Количество документов в «Возрастных групп»: Это тепло карта показывает количество документов, распределенных по клетки «Возрасте групп» (Дополнительные сведения о см. Создание текста-куб 4 протокола и таблица 3A). Большее количество документов представлен с темнее интенсивностью heatmap клеток (см. шкалы). Один документ может быть включена в более чем одной ячейке. Тепловая карта представляет количество документов в ячейке вдоль диагонали позицию (например, ADLT содержит 172,394 документы которая наибольшее число для всех ячеек). Недиагональными позиция представляет количество документов, подпадающих под две клетки (например, ADLT и ADOL у 26,858 Общие документы). (B) . Количество сущностей в «Возрастных групп»: Венна представляет количество белков, обнаруженных в четырех ячейках, представляющих «Возрастных групп» (INFT, CHLD, ADOL и ADLT). Количество белков, совместно в рамках всех ячеек — 162. В возрастной группе ADLT изображает наибольшее количество уникальных белков (151) следуют CHLD (16), INFT (8) и ADOL (1). (C) CaseOLAP Оценка презентация «Возрастных групп»: Топ 10 белков с наивысшими баллами средняя CaseOLAP в каждой группе представлены в тепловую карту. Более высокий балл CaseOLAP представлен с темнее интенсивностью heatmap клеток (см. шкалы). В левом столбце отображаются имена белка и клетки (CHLD, ADOL, ADLT и INFT) отображаются вдоль оси x. Некоторые белки показывают сильную связь для определенной возрастной группы (например, стерол 26-гидроксилазы, альфа кристаллин цепи B и L-seryl-tRNA имеют сильные ассоциации с ADLT, тогда как натрия/калия транспортировки АТФазы Субблок альфа-3 имеет сильную связь с INFT). Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 7. «Питания и метаболических заболеваний» как вариант использования: эта цифра представляет результаты из другого случая использования платформы CaseOLAP. В этом случае имена белков и их аббревиатуры (см. пример в таблице 4) реализованы в виде сущностей и питания и метаболических заболеваний «» включая две ячейки: метаболические болезни (MBD) и трофические нарушения (НТД) реализованы как подкатегорий (см. таблицу 3Б). (A). количество документов в «Питания и метаболических заболеваний»: этой heatmap изображает количество текстовых документов в клетках «Питания и метаболических заболеваний» (Дополнительные сведения о создании текста-куб см протокол 4 и Таблица 3В ). Большее количество документов представлен с темнее интенсивностью heatmap клеток (см. Шкала). Один документ может быть включена в более чем одной ячейке. Тепловая карта представляет общее количество документов в ячейке вдоль диагонали позицию (например, MBD содержит 54,762 документы что является наибольшим числом через две клетки). Недиагональными позиция представляет количество документов, разделяют две ячейки (например, MBD и NTD у 7,101 Общие документы). (B). количество сущностей в «Питания и метаболических заболеваний»: Венна представляет количество белков, обнаруженных в двух клетках, представляющие «Питания и метаболических заболеваний» (MBD и NTD). Количество белков, совместно в двух ячейках-397. MBD клеток изображает 300 уникальных белков, и клетки NTD изображает 35 уникальных белков. (C). CaseOLAP Оценка презентации в «Питания и метаболических заболеваний»: в тепловой карте представлены топ 10 белков с наивысшими баллами средняя CaseOLAP в «Питания и метаболических заболеваний». Более высокая оценка CaseOLAP представлен с темнее интенсивностью heatmap клеток (см. Шкала). В левом столбце отображаются имена белка и клетки (MBD и NTD) отображаются вдоль оси x. Некоторые белки показывают сильную связь в категорию конкретных заболеваний (например, альфа кристаллин B цепь имеет высокий ассоциации с метаболические болезни и стерол 26-гидроксилазы имеет высокий ассоциации с расстройства питания). Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}
| Время (в процентах от общего времени) | Шаги в платформе CaseOLAP | Алгоритм и структура данных платформы CaseOLAP | Сложность алгоритма и структуры данных | Подробная информация о шаги |
| 40% | Загрузка и Синтаксический анализ | Итерации и дерево синтаксического анализа алгоритмов | Итерации с вложенного цикла и постоянной умножения: O(n^2), O (log n). Где Sit'n ' является количество итераций. | Загрузка конвейера выполняет итерацию каждой процедуры несколько файлов. Разбор одного документа каждой процедуры пробегает древовидная структура необработанных XML-данных. |
| 30% | Индексирование, Поиск и создание Куба текста | Итерации, алгоритмы поиска по Elasticsearch (сортировка, индекса Lucene, приоритет очереди, конечные автоматы, сложа хаки, запросы regex бит) | Сложности, связанные с Elasticsearch (https://www.elastic.co/) | Документы индексируются путем реализации процесса итерацию над словаря данных. Создание текста-куб реализует документ мета данных и информации, предоставленных пользователем категории. |
| 30% | Подсчет сущностей и CaseOLAP расчет | Итерации в целостности, популярности, своеобразность расчет | O(1), O(n^2), несколько сложностей, связанных с caseOLAP Оценка вычисления, основанные на типах итерации. | Сущность операции перечислены документы и сделать операции над списком. Количество данных сущности используется для вычисления CaseOLAP балла. |
Таблицы 1. Алгоритмы и сложность. В этой таблице представлена информация о времени (в процентах от общего времени) о процедурах (например, Закачка, разбор), структура данных и сведений о реализованных алгоритмов в платформе CaseOLAP. CaseOLAP реализует профессиональные индексации и поиска приложение под названием Elasticsearch. Дополнительная информация о сложностях, связанных с Elasticsearch и внутренние алгоритмы можно найти на (https://www.elastic.co).
| Дескрипторы сетки | Количество собранных PMIDs |
| Взрослый | 1,786,371 |
| Возрасте от среднего | 1,661,882 |
| В возрасте | 1,198,778 |
| Подростков | 706,429 |
| Молодых взрослых | 486,259 |
| Ребенок | 480,218 |
| Возрасте, 80 лет и старше | 453,348 |
| Ребенок, детей дошкольного | 285,183 |
| Младенец | 218,242 |
| Ребенок, новорожденный | 160,702 |
| Ребенок, недоношенный | 17,701 |
| Вес при рождении младенческой, низкий | 5,707 |
| Немощных престарелых | 4,811 |
| Вес при рождении младенческой, очень низкая | 4,458 |
| Младенец, Малый для гестационного возраста | 3168 |
| Младенец, чрезвычайно недоношенных | 1,171 |
| Младенческой, чрезвычайно низкой массой тела при рождении | 1003 |
| Младенец, Postmature | 62 |
В таблице 2. Сетка для PMID сопоставления статистики. Эта таблица представляет все потомки дескрипторов MeSH от «Возрастных групп» и их количество собранных PMIDs (текстовые документы). Визуализация эти статистические данные представлены на рисунке 5.
| A | Товары для детей (INFT) | Ребенок (CHLD) | Подростков (ADOL) | Взрослый (ADLT) |
| Идентификатор корня сетки | M01.060.703 | M01.060.406 | M01.060.057 | M01.060.116 |
| Количество потомков дескрипторов MeSH | 9 | 2 | 1 | 6 |
| Количество выбранных PMIDs | 16,466 | 26,907 | 35,158 | 172,394 |
| Количество организаций | 233 | 297 | 257 | 443 |
| B | Метаболические заболевания (MBD) | Расстройства питания (НТД) | ||
| Идентификатор корня сетки | C18.452 | C18.654 | ||
| Количество потомков сетки дескрипторы | 308 | 53 | ||
| Количество PMIDs | 54,762 | 19,181 | ||
| Количество организаций | 697 | 432 |
В таблице 3. Текст куб метаданные. Просмотр метаданных куба текст представлен. Таблицы, предоставляют информацию о категориях и MeSH дескриптор корни и потомков, которые осуществляются для сбора документов в каждой ячейке. Таблица также содержит статистические данные о собранных документов и организаций. (A) «Возрастных групп»: это табличного отображения «Возрастных групп», включая младенцев (INFT), ребенок (CHLD), подростков (ADOL) и взрослых (ADLT) и их сетки корневого идентификаторы, Количество потомков сетки дескрипторы, количество отдельных PMIDs и количество найденных сущностей. (B) «Питания и метаболических заболеваний»: это табличного отображения «Питания и метаболических заболеваний» включая метаболические болезни (MBD) и трофические нарушения (НТД) с их сетки корневого идентификаторы, Количество потомков сетки дескрипторов, количество выбранный PMIDs и количество найденных сущностей.
| Белка названия и синонимы | Аббревиатуры |
| N-acetylglutamate NO-синтетазы, митохондриальных, аминокислоты Ацетилтрансфераза, N-acetylglutamate синтетазы длинной формы; N-acetylglutamate синтетазы короткая форма; N-acetylglutamate синтетазы сохраняется домена форма] | (EC 2.3.1.1) |
| Белка/нуклеиновых кислот deglycase DJ-1 (deglycase Маяра) (онкогена DJ1) (Паркинсона болезнь белка 7) (паркинсонизм связанные deglycase) (белок DJ-1) | (EC 3.1.2.-) (EC 3.5.1.-) (ЕС 3.5.1.124) (DJ-1) |
| Пируват carboxylase, митохондриальных (пировиноградная carboxylase) | (EC 6.4.1.1) (ПХД) |
| Bcl-2-привязки компонента 3 (p53 регулирует вверх модулятор апоптоза) | (JFY-1) |
| Взаимодействующих BH3 домен смерти агонист [взаимодействующих BH3 домен смерти агонист p15 (p15 BID); Взаимодействующих BH3 домен смерти агонист p13; Взаимодействующих BH3 домен смерти агонист p11] | (p22 BID) (СТАВОК) (p13 BID) (p11 BID) |
| ATP синтазы Субблок альфа, митохондриальных (ATP синтазы F1 Субблок альфа) | |
| Цитохрома P450 11B2, митохондриальных (альдостерона синтетазы) (фермент синтеза альдостерона) (CYPXIB2) (цитохрома P-450Aldo) (цитохрома P-450_C_18) (стероидных 18-гидроксилазы) | (АЛЬДОС) (ЕС 1.14.15.4) (ЕС 1.14.15.5) |
| 60 кДа теплового шока белка, митохондриальных (60 kDa chaperonin) (Chaperonin 60) (CPN60) (тепловой шок белков 60) (митохондриальной матрица белка P1) (P60 протеина лимфоцита) | (HSP-60) (Hsp60) (HuCHA60) (ЕС 3.6.4.9) |
| Каспаза-4 (гомолога 2 льда и КНИ-3) (протеазы TX) [расщепляется в: Caspase-4 Субблок 1; Субблок caspase-4 2] | (КАСП-4) (ЕС 3.4.22.57) (ИЧ-2) (ICE(rel)-II) (Mih1) |
Таблица 4 . Пример сущности таблицы. Эта таблица представляет образец сущностей реализована в наших двух случаях: «Возрастные группы» и «Питания и метаболических заболеваний» (Рисунок 6 и рис. 7, таблица 3A,B). Организации включают в себя имена белка, синонимы и сокращения. Каждая сущность (с его синонимы и сокращения) является выбранным по одному и передается через операции поиска сущности над индексированных данных (см. Протокол 3 и 5). Поиск производит список документов, которые еще более облегчить операции количество сущностей.
| Количества | Определяемые пользователем | Расчет | Уравнение количества | Значение количества |
| Целостность | Да | Нет | Целостности пользователей определены сущности, считается 1.0. | Представляет смысл фразы. Числовое значение — 1.0, когда это уже установленные фразы. |
| Популярность | Нет | Да | Популярность уравнение на рисунке 1 (рабочего процесса и алгоритм) из ссылки 5, раздел «Материалы и методы». | На основе термина частоты слов в ячейке. Нормированный по частоте общий срок ячейки. Увеличение частоты термина имеет уменьшение результат. |
| Своеобразие | Нет | Да | Своеобразность уравнение на рисунке 1 (рабочего процесса и алгоритм) из ссылки 5, раздел «Материалы и методы». | На основе термина частоты и частоты документа внутри клетки и через соседние клетки. Нормированный, общий срок частоты и частоты документа. Количественно это вероятность того, что фраза уникальна в определенной ячейке. |
| CaseOLAP Оценка | Нет | Да | CaseOLAP Оценка уравнения на рисунке 1 (рабочего процесса и алгоритм) из ссылки 5, раздел «Материалы и методы». | На основе целостности, популярности и самобытности. Численное значение всегда попадает в пределах 0 до 1. Количественно CaseOLAP Оценка представляет собой объединение фразу категории |
В таблице 5. Уравнения CaseOLAP: CaseOLAP алгоритм был разработан Fangbo-Тао и Джиавей Han et al. в 2016 году1. Вкратце, эта таблица представляет расчет Оценка CaseOLAP, состоящий из трех компонентов: целостность, популярности и самобытности, и их связанные математические значения. В наших вариантов использования, оценка целостности для белков является 1.0 (максимальная оценка) потому, что они стоят как имена установленных сущностей. CaseOLAP баллы в нашем случаи использования можно увидеть в рисунке 6 c и рис. 7 c.
Обсуждение
Мы продемонстрировали, что алгоритм CaseOLAP можно создать фразы на основе количественных ассоциации в категорию на основе знаний через большие объемы текстовых данных для извлечения значимые идеи. После нашего протокола можно построить CaseOLAP рамки для создания желаемого текста-куб и количественного определения сущности категории ассоциаций путем вычисления Оценка CaseOLAP. Полученные оценки сырья CaseOLAP могут быть приняты для комплексных анализов, включая сокращение размерности, кластеризации, анализа временных и географических, а также создание графической базы данных, которая позволяет семантическое сопоставление документов.
Применение алгоритма. Примеры определяемых пользователем сущностей, помимо белков, может быть список имена гена, наркотики, конкретные признаки и симптомы, включая их сокращения и синонимы. Кроме того есть много вариантов для выбора категории для облегчения конкретные определяемые пользователем биомедицинских анализов (например, Анатомия [A], дисциплина и оккупации [H], явлений и процессов [G]). В наших двух случаев использования, всех научных публикаций и их текстовые данные извлекаются из базы данных MEDLINE, используя PubMed в качестве поисковой системы, как управляется Национальной медицинской библиотекой. Однако CaseOLAP платформа может применяться к другим базам данных интерес, содержащих биомедицинских документы текстовых данных как FDA неблагоприятных событий отчетности системы (FAERS). Это открытые базы данных, содержащей информацию о медицинских побочных эффектов и лечение ошибка доклады, представляемые FDA. В отличие от MEDLINE и FAERS базы данных в больницах, содержащие электронных медицинских записей из больных не открыты для публики и ограничены медицинское страхование портативности и акт об ответственности, известный как HIPAA.
CaseOLAP алгоритм успешно применяется для различных типов данных (например, статьи новостей)1. Реализация этого алгоритма в биомедицинских документов был достигнут в 20185. Требования для применения алгоритма CaseOLAP является, что каждый из документов должны быть назначены с ключевых слов, связанных с понятиями (например, дескрипторов MeSH в биомедицинских публикациях, ключевые слова в новостных статей). Если ключевые слова не найдены, можно применять Autophrase6,7 для сбора Топ представитель фраз и построить список сущностей перед реализацией нашего протокола. Наш протокол не предусматривает шаг для выполнения Autophrase.
Сравнение с другими алгоритмами. Концепция с использованием куба данных8,9,10 и текст-куб2,,34 развивается с 2005 года с новых достижений более применимым для интеллектуального анализа данных. Концепция оперативной аналитической обработки (OLAP)11,12,13,14,15 интеллектуального анализа данных и бизнес-аналитики восходит к 1993 году. OLAP, в общем, собирает информацию из нескольких систем и сохраняет его в многомерный формат. Существуют различные типы систем OLAP, реализованы в интеллектуальном анализе данных. К примеру обработки транзакций/аналитический (1) гибрид (ПЗВП)16,17,18,(2) многомерного OLAP (MOLAP)19-куб на основе и (3) реляционного OLAP (ROLAP)20.
В частности, алгоритм CaseOLAP была по сравнению с многочисленными существующих алгоритмов, в частности, с их слова сегментации усовершенствований, включая TF-ИДФ + Seg, MCX + Seg, MCX и SegPhrase. Кроме того, RepPhrase (RP, также известный как SegPhrase +) была по сравнению с собственной абляции вариации, включая (1) RP без целостности мера включена (RP No INT), (2) RP без популярности мера включена (RP нет POP) и (3) RP без Своеобразность мера включена (RP нет DIS). В исследовании Fangbo Tao et al.1показаны результаты тестов.
Есть еще проблемы интеллектуального анализа данных, который можно добавить дополнительные функциональные возможности сохранения и извлечения данных из базы данных. Контекстно зависимые семантической аналитическая обработка (CaseOLAP) систематически реализует Elasticsearch для построения индексации базы данных миллионов документов (протокол 5). Текст-куб — это структура документа, построен над индексированных данных, предоставленных пользователем категорий (Протокол 6). Это повышает функциональность документов внутри и через ячейку текста-Куба и позволит нам рассчитать срок частоты образований над документ и документ частоты над определенной ячейке (протокол 8). Окончательная оценка CaseOLAP использует эти вычисления частоты для вывода итоговый счет (Протокол 9). В 2018 году мы внедрили этот алгоритм для изучения белков ECM и шести заболеваний сердца для анализа белка болезнь ассоциаций. Подробности этого исследования можно найти в исследовании, лием, д.а. et al.5. Указывает, что CaseOLAP могут широко использоваться в биомедицинских сообщество изучает различные заболевания и механизмов.
Ограничения алгоритма. Горнодобывающей промышленности фраза сама методика управлять и извлекать важные концепции от текстовых данных. Открывая сущности Категория Ассоциация как математические количество (вектор), этот метод не может выяснить, полярность (например, положительный или отрицательный наклон) ассоциации. Одно может построить количественных сводных данных, используя структуру документа текст-Cude с назначенным подразделениями и категории, но качественной концепции с микроскопическим гранулярности не может быть достигнуто. Некоторые концепции из прошлого до сих теперь постоянно эволюционируют. Уплотнения для конкретной сущности категории ассоциации включает в себя все случаи всей литературе. Это может отсутствие временного распространения инноваций. В будущем мы планируем решить эти ограничения.
Будущих приложений. Около 90% накопленных данных в мире находится в неструктурированных текстовых данных. Найти представителя фразу и отношение к сущности, внедренный в текст является очень важной задачей для внедрения новых технологий (например, машинное обучение, извлечения информации, искусственного интеллекта). Чтобы сделать текст данные машины для чтения, данные должны быть организованы в базе данных, над которой может осуществляться следующий слой инструментов. В будущем этот алгоритм может быть решающим шагом в создании более функциональным для поиска информации и количественной оценки ассоциаций сущности Категория интеллектуального анализа данных.
Раскрытие информации
Авторы не имеют ничего сообщать.
Благодарности
Эта работа частично поддержали национальные сердца, легких и крови института: R35 HL135772 (для P. Ping); Национальный институт Генеральной медицинских наук: U54 GM114833 (для P. Ping, K. Уотсон и W. Wang); U54 GM114838 (с J. Han); подарок от Элен и Ларри Хоаг фонда и Dr. S. Сетти; и T.C. Laubisch облечение в Калифорнийском университете (для P. Ping).
Материалы
| Name | Company | Catalog Number | Comments |
Ссылки
- Tao, F., Zhuang, H., et al. Phrase-Based Summarization in Text Cubes. IEEE Data Engineering Bulletin. , 74-84 (2016).
- Ding, B., Zhao, B., Lin, C. X., Han, J., Zhai, C. TopCells: Keyword-based search of top-k aggregated documents in text cube. IEEE 26th International Conference on Data Engineering (ICDE). , 381-384 (2010).
- Ding, B., et al. Efficient Keyword-Based Search for Top-K Cells in Text Cube. IEEE Transactions on Knowledge and Data Engineering. 23 (12), 1795-1810 (2011).
- Liu, X., et al. A Text Cube Approach to Human, Social and Cultural Behavior in the Twitter Stream.Social Computing, Behavioral-Cultural Modeling and Prediction. Lecture Notes in Computer Science. 7812, (2013).
- Liem, D. A., et al. Phrase Mining of Textual Data to analyze extracellular matrix protein patterns across cardiovascular disease. American Journal of Physiology-Heart and Circulatory. , (2018).
- Shang, J., et al. Automated Phrase Mining from Massive Text Corpora. IEEE Transactions on Knowledge and Data Engineering. 30 (10), 1825-1837 (2018).
- Liu, J., Shang, J., Wang, C., Ren, X., Han, J. Mining Quality Phrases from Massive Text Corpora. Proceedings ACM-Sigmod International Conference on Management of Data. , 1729-1744 (2015).
- Lee, S., Kim, N., Kim, J. A Multi-dimensional Analysis and Data Cube for Unstructured Text and Social Media. IEEE Fourth International Conference on Big Data and Cloud Computing. , 761-764 (2014).
- Lin, C. X., Ding, B., Han, J., Zhu, F., Zhao, B. Text Cube: Computing IR Measures for Multidimensional Text Database Analysis. IEEE Data Mining. , 905-910 (2008).
- Hsu, W. J., Lu, Y., Lee, Z. Q. Accelerating Topic Exploration of Multi-Dimensional Documents Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE International. , 1520-1527 (2017).
- Chaudhuri, S., Dayal, U. An overview of data warehousing and OLAP technology. SIGMOD Record. 26 (1), 65-74 (1997).
- Ravat, F., Teste, O., Tournier, R. Olap aggregation function for textual data warehouse. ICEIS - 9th International Conference on Enterprise Information Systems, Proceedings. , 151-156 (2007).
- Ho, C. T., Agrawal, R., Megiddo, N., Srikant, R. Range Queries in OLAP Data Cubes. SIGMOD Conference. , (1997).
- Saxena, V., Pratap, A. Olap Cube Representation for Object- Oriented Database. International Journal of Software Engineering & Applications. 3 (2), (2012).
- Maniatis, A. S., Vassiliadis, P., Skiadopoulos, S., Vassiliou, Y. Advanced visualization for OLAP. DOLAP. , (2003).
- Bog, A. . Benchmarking Transaction and Analytical Processing Systems: The Creation of a Mixed Workload Benchmark and its Application. , 7-13 (2013).
- Özcan, F., Tian, Y., Tözün, P. Hybrid Transactional/Analytical Processing: A Survey. In Proceedings of the ACM International Conference on Management of Data (SIGMOD). , 1771-1775 (2017).
- Hasan, K. M. A., Tsuji, T., Higuchi, K. An Efficient Implementation for MOLAP Basic Data Structure and Its Evaluation. International Conference on Database Systems for Advanced Applications. , 288-299 (2007).
- Nantajeewarawat, E. Advances in Databases: Concepts, Systems and Applications. DASFAA 2007. Lecture Notes in Computer Science. 4443, (2007).
- Shimada, T., Tsuji, T., Higuchi, K. A storage scheme for multidimensional data alleviating dimension dependency. Third International Conference on Digital Information Management. , 662-668 (2007).
Перепечатки и разрешения
Запросить разрешение на использование текста или рисунков этого JoVE статьи
Запросить разрешениеСмотреть дополнительные статьи
This article has been published
Video Coming Soon
Авторские права © 2025 MyJoVE Corporation. Все права защищены