
Two-Dimensional Graphs
Some chemistry experiments take the form of directly changing one property of the system that you are studying otherwise known as the independent variable, like temperature, and measuring the effects on another property, otherwise known as the dependent variable, like volume. Once the data have been collected, the interaction between the two parameters must be quantified — or converted into a form that can be evaluated — and compared to other relationships.
Two-dimensional graphs can be used to derive certain types of mathematical relationships between two properties or to establish that no such relationship exists between them. The analysis will ultimately determine how the dependent variable changes in response to the independent variable. In the example of adjusting the temperature of a liquid or gas and monitoring changes in its volume, the temperature is the independent variable, and the volume is the dependent variable.
To make a two-dimensional graph, each data point must have a value known as the coordinate for both the dependent and independent variables. The independent variable is plotted on the x-axis, and the dependent variable is plotted on the y-axis. These plots are easily made in spreadsheet software, which can also be used to analyze the plotted data.
Curve Fitting
Once a data set has been plotted on a two-dimensional graph, curve fitting can be used to generate an equation, or function, for the dependent variable in terms of the independent variable. Functions represent a mathematical model that best models the data from which it is derived. Curve fitting is the technique of finding a function that produces a line that is a good match for the pattern of data points. Spreadsheet software has various curve-fitting tools, which is referred to as ‘best-fit’. This is usually a linear least-squares regression analysis, though most software also offers nonlinear least-squares regression.
The precision of the best-fit linear equation can be checked by plugging in the x values for the data points and comparing the ‘theoretical’ results of the equation to the actual y values of the data points. Spreadsheet software will typically calculate the coefficient of determination (R2) value for the function, which shows how well the function matches the data points. The closer the R2 value is to 1, the better the fit for a linear regression. Other functions have more specialized methods to determine how well the fit of the function is to the data.
Determining the uncertainty of dependent values calculated from the best-fit function would require complicated “error propagation” techniques. However, it is possible to calculate uncertainty within the equation in the form of the standard deviation for both the slope and y-intercept of a best-fit function. This is usually performed with a different tool than the one used to generate a two-dimensional plot.
Standard Deviation
The standard deviation describes the amount of variation present in a set of values. The population standard deviation (σ) is used when there is data from each member of a finite population, such as the mass of each marble in a bag of marbles. The sample standard deviation (s) is used for all other cases and is the default standard deviation calculation in spreadsheet software.1 You can assume that ‘standard deviation’ refers to the sample standard deviation.
Random measurement error is assumed to follow a roughly ‘normal’ distribution, where about 68% of a set of values lie within a range of one standard deviation on either side of the mean, 95% of the values lie within two standard deviations on either side of the mean, and 99.7% of the values lie within three standard deviations on either side of the mean. Thus, the standard deviation is a useful way to describe error and uncertainty.
The equation for the sample standard deviation is:
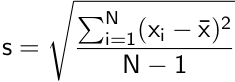
In this equation, N is the number of values; 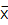 is the average (or mean) of the values; and xi represents each individual value. Thus, to calculate the standard deviation by hand, calculate the mean of the set of values, subtract the mean from each value, square each difference, add the squared differences, divide the total sum by one less than the number of values, and take the square root of the quotient. The closer s is to zero, the less variation there is between the values. If the values are entered into spreadsheet software, the standard deviation can be calculated from within the software.
is the average (or mean) of the values; and xi represents each individual value. Thus, to calculate the standard deviation by hand, calculate the mean of the set of values, subtract the mean from each value, square each difference, add the squared differences, divide the total sum by one less than the number of values, and take the square root of the quotient. The closer s is to zero, the less variation there is between the values. If the values are entered into spreadsheet software, the standard deviation can be calculated from within the software.
The number of significant figures in a standard deviation depends on what values it is for. When reporting the standard deviation for a group of data points taken under the same conditions, the appropriate number of significant figures in the mean value must first be determined. The standard deviation is then rounded to the same number of decimal places as the mean. For a set of volumes with four significant figures, a mean of 15.361 mL, and a standard deviation of 0.2313, the mean and standard deviation would be reported as 15.36 mL ± 0.23 mL.
When reporting the standard deviation of the mean and y-intercept for a best-fit function determined by least-squares analysis, which is the usual method for spreadsheet software, the first decimal place of the standard deviation is the last significant figure of the mean or y-intercept. Thus, the standard deviation should be rounded to one significant decimal place, and the slope or y-intercept should be rounded to the corresponding decimal place. For example, if the slope is 0.1691 L·K-1 and it has a standard deviation of 0.00512, the slope should be reported as 0.169 L·K-1 ± 0.005 L·K-1.
If the standard deviation of the slope or y-intercept is so much smaller than its corresponding value that following this rule would give more significant figures to the slope or y-intercept than the original measurement data would allow, then instead determine the significant figures of the slope or y-intercept from the x and y values and round the standard deviation to one significant figure. Thus, for a slope of 0.1691 L·K-1, a standard deviation of 0.0000512, and x and y values with four significant figures, the slope should be reported as 0.1691 L·K-1 ± 0.00005 L·K-1. In this case, it’s fine for the calculated value and its standard deviation to have a different number of decimal places. Keep in mind that the least-squares method uses both the x and y values to calculate the slope and y-intercept.
When reporting standard deviation as an uncertainty range, be sure to note specifically that the uncertainty represents one standard deviation. This tells the reader that there is about a 68% chance that the true value of a measurement falls within that range of the mean, assuming a normal distribution. It may often be more suitable to report uncertainty as two standard deviations from the mean, as that increases the probability to about 95%. To do this, simply multiply the standard deviation by two before rounding it to the appropriate number of significant figures.
References
- Harris, D.C. (2015). Quantitative Chemical Analysis. New York, NY: W.H. Freeman and Company.
ABOUT JoVE
Copyright © 2024 MyJoVE Corporation. All rights reserved