
Summary
Abstract
Protocol
Discussion
Acknowledgements
Materials
References
Biology
采用芯片识别亚型特定的靶基因的全基因组分析
在这里,我们提出的全基因组的不同在一个组蛋白结合结构域的蛋白异构体的位置分析染色质免疫沉淀(ChIP)的过程。我们把它应用到芯片的SEQ分析,以确定KDM5A/JARID1A/RBP2组蛋白去甲基化酶的目标。
招聘转录和表观遗传因素对他们的目标是在调控的关键一步。突出在招聘绑定到特定的组蛋白修饰的蛋白结构域。这样一个领域是植物同源结构域(PHD),发现在几个染色质结合蛋白。后生因素RBP2多PHD域,然而,他们具有不同的功能(图4)。特别是,C -末端PHD域,发现在RBP2在人类白血病的致癌融合,结合,以三甲基赖氨酸4组蛋白H3(H3K4me3)1 。相应的谈话内容RBP2亚型,含有C -末端PHD promonocytic,淋巴瘤衍生成单核细胞 2,U937细胞分化过程中积累。这两组数据相一致,全基因组分析显示,在已分化的U937细胞,RBP2蛋白质获取本地化H3K4me3 3高度浓缩的基因组区域。 RBP2组蛋白去甲基化酶活性和转录活性的下降,由于减少在H3K4me3相关的RBP2其目标定位。相比之下,两个其他博士RBP2无法绑定H3K4me3。值得注意的是,RBP2的C端结构域博士是在较小的RBP2亚型4缺席。可以想象的是,RBP2小异构体,缺乏互动,与H3K4me3较大的异构体在基因组的位置不同。 RBP2亚型基因组的位置差异或许可以解释观察到的多样性RBP2功能。具体来说,RBP2是在视网膜母细胞瘤蛋白(PRB)介导的细胞分化的关键球员。与这些数据亚型之间没有区别,以前的全基因组分析,相一致,确定RBP2靶基因的两个不同的群体:1)由RBP2约束的方式,是独立的分化的基因; 2)绑定到RBP2基因分化依赖性。
为了确定本地化的异构体之间的差异,我们进行了全基因组的位置分析芯片序号。利用抗体检测RBP2我们已经找到所有RBP2目标亚型。此外,我们还只有绑定大,不小的RBP2异构体(图4)的抗体。大型异构体的目标确定后,再减去从所有RBP2目标揭示小异构体的目标。这些数据显示,其结合位点的基因组中的染色质相互作用的蛋白质招聘域的贡献。
从B,2001年任该协议最初是适应。它代表了奥多姆等协议的轻微修改。5,可在发现 http://jura.wi.mit.edu/cgi-bin/young_public/navframe.cgi?s=22&f=appendices_downloads
1。前块和结合抗体的磁珠(应执行下一步前的晚上)
- 100μL磁珠G蛋白(每个IP,结合多个IP)洗1毫升新鲜的BSA / PBS液(50毫克,于10 mL BSA的PBS该解决方案将最后一个星期)。
- 收集珠使用磁性的立场和重复洗涤过程两次。
- 接下来,添加10微克的抗体,以250μLPBS / BSA溶液中珠浆(每个IP)和一个旋转的平台上过夜孵育4 ° C。
- 工程完成后,洗珠三次在1毫升的PBS / BSA溶液,然后在10μL的PBS / BSA溶液(每个IP)悬浮。
2。细胞的交联
- 要开始此过程中,增长约10 8每个免疫细胞,或IP。在这里,弥漫性组织细胞淋巴瘤U937细胞的使用和96小时与TPA单核细胞分化诱导。
- 随着细胞的生长,直接添加甲醛溶液媒体的终浓度为1%。然后,摇动烧瓶简要,并允许他们在室温下坐了10分钟。然后,吸媒体和15毫升冰冷的PBS漂洗细胞。重复洗一次。
- 接下来,添加6裂解液1毫升(50毫米的HEPES - KOH,pH值7.5,氯化钠140毫米,1毫米EDTA,10%的甘油,0.5%NP - 40,0.25%的Triton X - 100含蛋白酶抑制剂)每个冰块的保温瓶。然后,岩石烧瓶20分钟,在4 ° C。
- 最后,收获细胞,使用细胞刮刀,他们转移到15 mL锥形管。此时细胞可以储存在-80 ° C
3。细胞超声
- 如果细胞被冻结,解冻出来。一旦解冻,在10分钟3000转旋转的细胞在4 ° C和上清液。然后,重悬的细胞裂解液2(10毫米的Tris - HCl,pH值8.0,氯化钠200毫米,1毫米EDTA,EGTA 0.5毫米,含蛋白酶抑制剂)在6毫升。岩石在室温下的管,轻轻为10分钟。
- 重复离心重悬在2.5毫升细胞裂解液(10毫米的Tris - HCl,pH值8.0,氯化钠100毫米,1毫米EDTA,EGTA 0.5毫米,0.1%去氧胆酸钠,0.5%的N - lauroylsarcosine,含蛋白酶抑制剂)细胞。
- 下一步,准备对超声悬挂,放置在一个冰冷的水的烧杯中,设置为50和60%的幅度之间的一个布兰森450 Sonifier微尖。
- 超声不断爆裂,30秒1分钟冰酷的解决方案。这些脉冲重复10至15倍。然后,吸液管的管的内容和和它们转移到一个新的管。继续脉冲和冷却解决方案的一个额外的5倍。
- 超声波处理后,添加10%Triton X一100溶液体积的1 / 10。的裂解物转移到1.5 mL离心管中,并在离心旋转的碎片。然后转移到一个新的管细胞裂解液。
4。染色质免疫沉淀
- 染色质免疫沉淀,或芯片之前,节省50μL细胞裂解液作为输入样本。然后,结合磁珠抗体,此前已准备如上所述预先绑定清除的细胞裂解液。岩石的混合物,在50μL输入采样此外,在4 ° C过夜。
- 洗洗涤缓冲液1毫升(50毫米的HEPES - KOH,pH值7.6,0.5 M的氯化锂,为1mM EDTA的,0.7%去氧胆酸钠,1%NP - 40)珠。然后,使用一个磁性的立场收集珠,去除上清。重复此洗6至8倍。
- 执行最终洗1毫升TE - 加50 mM氯化钠(10毫米的Tris - HCl,pH值8.0,50毫米氯化钠,1毫米EDTA)。在2分钟3000转离心旋转珠在4 ° C。离心后,吸出任何残留的TE缓冲液。
- 然后,添加100μL洗脱缓冲液(50毫米的Tris - HCl,pH值8.0,10 mM的EDTA,1%SDS)的样品。后立即孵化样品在65 ° C为10至15分钟。刮擦管1.5 ml的试管架,每2分钟保持在暂停的珠子。
- 收集珠子,用离心法和磁立场,将上清转移至一个PCR管。然后,检索以前保存的输入采样和洗脱缓冲液中添加3卷。
- 最后,放入热循环仪的IP地址和输入样本一夜之间在65 ° C至反向的相互联系。
- 次日,加1体积的TE缓冲液的样品。然后,添加一个终浓度为0.2μg/μLRNase A至。孵育样品在1至2小时的热循环仪,在37 ° C。
- 孵育后,加入蛋白酶K至终浓度为0.2μg/μL。然后,在55 ° C孵育样品2个小时,在热循环。
- 下一步,一次提取的样品之一体积的苯酚。提取的样品,第二次与一体积的苯酚:氯仿:异戊醇。最后,再次提取样品之一体积的氯仿:异戊醇。
- 然后,将每个样品30微克的糖原。此外,添加氯化钠的终浓度为0.2摩尔乙醇样品和两个卷。孵育30分钟,在-80 ° C。孵化后,旋转样品,倒出上清液。 500μL75%乙醇洗涤颗粒。然后,干燥颗粒,再暂停40μL水。
- 要检查由超声过程中产生的DNA片段的大小,负载在1.8%琼脂糖凝胶5微克纯化输入采样和运行凝胶。超声程序应产生范围在150-350个碱基对的片段。但是,如果碎片不属于这个范围,超声过程应该由不同的阵阵数量和幅度调整。
- 要检查芯片的鲁棒性和特殊性,结合区域控制的执行与1μL的IP样本和一个输入样本的稀释系列基因特异性PCR富集。为了测试IP和输入样本的质量,需要选择两到三个“束缚”的地区和未绑定的控制区域。
5。基因组DNA的扩增
- 与34μL的IP样品或200输入采样吴开始,执行结束修复“,一个”尾巴除了结扎适配器的DNA片段,利用基因组DNA样品制备试剂盒http://www.illumina.com/systems/ genome_analyzer.ilmn (Illumina公司,加利福尼亚州圣迭戈)。
- 净化使用MinElute PCR纯化试剂盒的DNA,然后洗脱缓冲液EB(10毫米三氯,pH值8.5)在已预热至50 ° C例如,使用的IP,并输入DNA样本的最终洗脱23μL和46μL,分别为。
- 请使用适配器23μL的DNA的PCR反应,和25μLPhusion DNA聚合酶套件,1μL,20微米Sol_PCR_1,和1μL20μMSol_PCR_2。运行在98 PCR反应如下:1)° C,2)10秒98℃; 3)在65℃30秒; 4)30秒30秒72 ° C,重复步骤2-4 18步次,然后在72℃5分钟,最后保持在4 ° C。
- PCR扩增后,与QIAGEN公司MinElute的PCR纯化试剂盒纯化的DNA。预温15μL缓冲的EB至50 ° C和洗脱的DNA。稀释0.5μL的样品1:4和执行Nanodrop阅读。
6。扩增产物的凝胶净化
- 为了净化的扩增产物,准备为50毫升的1.8%琼脂糖凝胶,用HPLC级水。琼脂糖融化后,加入TAE和溴化乙锭。然后,倒入凝胶。加载后加入4μL上样缓冲输入和IP样本凝胶。然后,运行在120伏45分钟的凝胶。
- 分析它运行后的凝胶。凝胶在150和350之间的碱基对生产的范围内,碎片揭示。他们代表之间的50和250个碱基对的长度和一个适配器,基因组DNA片段。
- 海关的区域包含在150 350基础一双用手术刀范围材料的凝胶。小心避免切除适配器适配器的乐队,它运行在约120个碱基对。恢复每制造商的说明使用QIAquick凝胶提取试剂盒的DNA。具体来说,使用一列从QIAquick凝胶提取试剂盒为400毫克或更少的凝胶片。要开始提取过程中,添加3卷1体积的凝胶QG缓冲区。加入1体积的异丙醇和负载列的混合物。用0.5毫升QG洗列,其次是试剂盒说明书中描述的标准程序。使用H 2 O预热至50 ° C,以洗脱DNA。 5分钟的H 2 O与30μL列在37℃前纺下来。
- 干下来,正是11μL无热Speedvac样品。取出1μL的样品和使用Nanodrop分光光度计测量DNA的浓度。
- 最后,确定使用Illumina公司的基因组AnalyzerIIe 描述 http://genesdev.cshlp.org/content/suppl丰富的基因产物/ 2008/12/15/22.24.3403.DC1/GuentherSuppMat.pdf 6。
7。代表性的成果
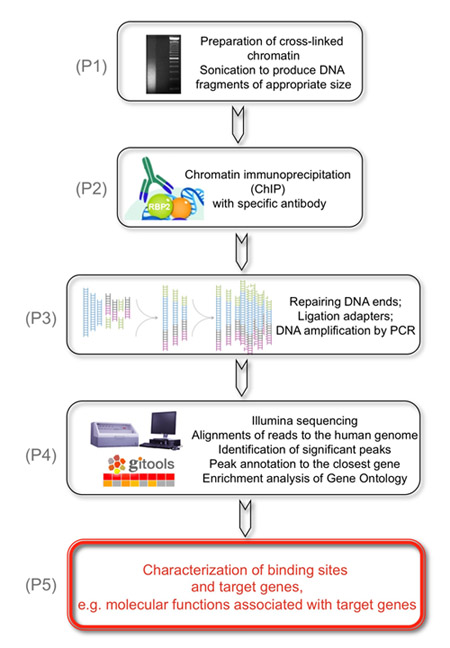
图1。以下实验的总体目标是,确定KDM5A/JARID1A/RBP2组蛋白去甲基化酶基因目标。
(P1)这是通过交联的染色质,是超声产生适当大小的DNA片段的准备。 (P2),作为第二步,RBP2结合的DNA片段与RBP2抗体免疫沉淀。 (P3),接下来,回收DNA片段在两端修复和适配器上的基因组DNA的两端结扎Illumina的群集站流量细胞基因组DNA库,以备分析。使用周期低PCR扩增的DNA库。 (P4),最后,Illumina的测序短读取唯一的人类基因组对齐,重要的山峰是识别和注释到最接近的基因,以确定RBP2丰富的地区。 (P5)的结果,得到显示基于RBP2丰富地区的全基因组识别与RBP2目标基因相关的分子功能。
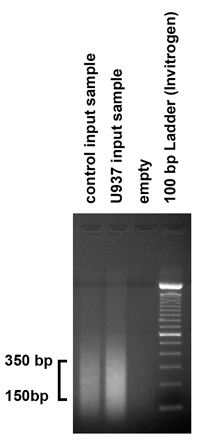
图2。染色超声检查的结果,检查由超声过程中产生的DNA片段的大小,纯化输入样本的5微克(1 / 10)装上1.8%的琼脂糖凝胶。正如预期的那样,我们的超声过程范围在150-350 bp的片段。然而,如果碎片不属于这个范围,超声程序应作相应调整,由不同的阵阵数量和幅度。
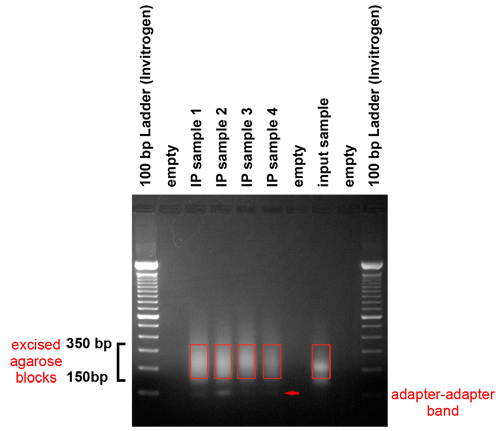
图3。凝胶纯化扩增产物。PCR产物凝胶上运行,删除的适配器,并选择一个集群代平台的模板的大小范围。这种凝胶显示范围在150至350个碱基对的片段进行生产。他们代表之间的50和250个碱基对的长度和一个适配器,基因组DNA片段。我们消费的凝胶用手术刀选定的区域。应注意避免适配器,适配器带,运行约120个碱基对。
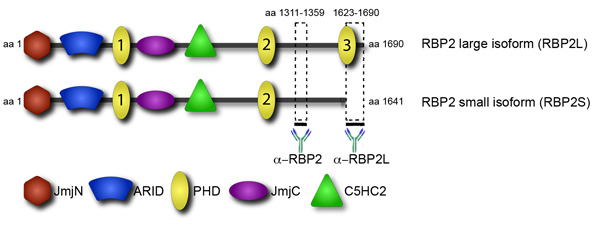
图4。亚型特异性抗体允许RBP2大型和小型亚型之间的区别 。RBP2蛋白质结构域视图。 RBP2包含多个域:催化的组蛋白去甲基化JmjC域和相关JmjN域,干旱域序列特异的DNA结合,C5HC2锌指潜在可能与DNA或其他蛋白质,多PHD域交互。两个反RBP2的抗体,使RBP2异构体之间的区分,是根据对粗线表示的RBP2片段。
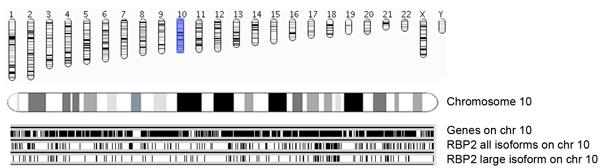
图5a。概述RBP2与染色体和Ensembl基因的结合区域,确定丰富RBP2基因组坐标(所有异构体和大型异构体)结合区域是染色体明智。 Occupances Ensembl基因在染色体(54版; hg18)(图片10号染色体)黑网吧(顶部面板)。每RBP2结合区域表示为一条垂直线,中间的面板显示所有RBP2亚型10号染色体上的结合区域,底部面板显示RBP2大型异构体结合区域。中部和底部面板让重叠的概述和10号染色体上的RBP2亚型的特定入住。
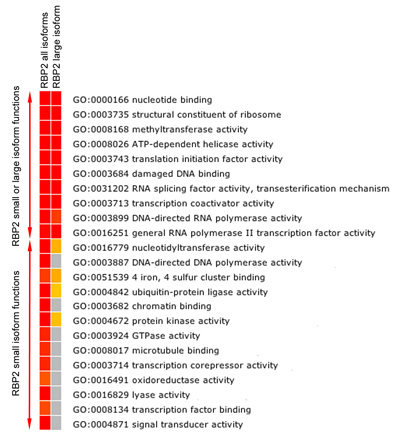
图5b。 RBP2靶基因功能富集分析,热图显示罗斯福纠正显着(P值≤0.05)丰富当中去约束RBP2(所有大型异构体)(最接近的基因RBP2结合区域)的基因的分子功能分类。偏红的颜色表示高统计学意义,黄色表示低统计学意义,灰色表示无统计学意义。富集分析显示重叠和异构体的具体RBP2靶基因的分子功能。
RBP2异构体之间功能上的差异尚未确定。我们已经使用了一个全面的方式来确定约束RBP2亚型的基因组区域和定义,这些地区所代表的功能类别。这是通过获得序列的生物信息学分析读取芯片SEQ分析。
RBP2修改的组蛋白尾巴的甲基化赖氨酸残基。我们发现,RBP2大型异构体中含有甲基化的组蛋白赖氨酸和RBP2小,缺乏这种模块绑定到不同地区的人类基因组中(图5A)的亚型识别模块。更重要的是,异构体的特定区域和重叠的区域,属于基因具有不同的分子功能(图5B)。例如,“染色约束力”和“转录因子结合”功能,可以归因于RBP2小亚型的基因目标,但不是RBP2大型异构体(图5B)。通过比较实际的基因组产生的所有异构体和RBP2大型异构体(数据未显示),我们也可以定义,如果大量的异构体是专门招募某些基因。
这项工作是支持115347 - RSG - 08 - 271 - 01 - GMC从ACS,并通过CA138631授予由美国国立卫生研究院。
2006 Illumina公司的寡核苷酸序列保留所有权利。
- Sol_PCR_1
序列5' - GAT ACG的GCG ACC ACC GAG ATC交咨会的ACT铁通台泥税务师CAC GAC GCT CTT CCG ATC学能测验的T - 3' - Sol_PCR_2
序列5' - CAA GCA GAA GGC GAC中的ATA CGA GCT CTT CCG ATC的T - 3“
- Wang, G. G. Haematopoietic malignancies caused by dysregulation of a chromatin-binding PHD finger. Nature. 459 (7248), (2009).
- Benevolenskaya, E. V. Binding of pRB to the PHD protein RBP2 promotes cellular differentiation. Mol Cell. 18 (6), 623-623 (2005).
- Lopez-Bigas, N. Genome-wide analysis of the H3K4 histone demethylase RBP2 reveals a transcriptional program controlling differentiation. Mol Cell. 31 (4), 520-520 (2008).
- Benevolenskaya, E. V. Histone H3K4 demethylases are essential in development and differentiation. Biochem Cell Biol. 85 (4), 435-435 (2007).
- Odom, D. T. Control of pancreas and liver gene expression by HNF transcription factors. Science. 303 (5662), 1378-1378 (2004).
- Guenther, M. G. Aberrant chromatin at genes encoding stem cell regulators in human mixed-lineage leukemia. Genes Dev. 22 (24), 3403-3403 (2008).
ABOUT JoVE
Copyright © 2024 MyJoVE Corporation. All rights reserved