
Summary
Abstract
Protocol
Discussion
Acknowledgements
Materials
References
Biology
जीनोम चौड़ा चिप का उपयोग isoform विशेष जीन लक्ष्य पहचानें विश्लेषण
यहाँ हम जीनोम चौड़ा प्रोटीन isoforms है कि एक histone बाध्यकारी डोमेन में अलग स्थान विश्लेषण के लिए एक chromatin immunoprecipitation प्रक्रिया (चिप) प्रस्तुत कर रहे हैं. हम यह चिप Seq विश्लेषण के लिए आवेदन कर रहे हैं KDM5A/JARID1A/RBP2 histone demethylase के लक्ष्यों की पहचान.
Recruitment of transcriptional and epigenetic factors to their targets is a key step in their regulation. Prominently featured in recruitment are the protein domains that bind to specific histone modifications. One such domain is the plant homeodomain (PHD), found in several chromatin-binding proteins. The epigenetic factor RBP2 has multiple PHD domains, however, they have different functions (Figure 4). In particular, the C-terminal PHD domain, found in a RBP2 oncogenic fusion in human leukemia, binds to trimethylated lysine 4 in histone H3 (H3K4me3)1. The transcript corresponding to the RBP2 isoform containing the C-terminal PHD accumulates during differentiation of promonocytic, lymphoma-derived, U937 cells into monocytes2. Consistent with both sets of data, genome-wide analysis showed that in differentiated U937 cells, the RBP2 protein gets localized to genomic regions highly enriched for H3K4me33. Localization of RBP2 to its targets correlates with a decrease in H3K4me3 due to RBP2 histone demethylase activity and a decrease in transcriptional activity. In contrast, two other PHDs of RBP2 are unable to bind H3K4me3. Notably, the C-terminal domain PHD of RBP2 is absent in the smaller RBP2 isoform4. It is conceivable that the small isoform of RBP2, which lacks interaction with H3K4me3, differs from the larger isoform in genomic location. The difference in genomic location of RBP2 isoforms may account for the observed diversity in RBP2 function. Specifically, RBP2 is a critical player in cellular differentiation mediated by the retinoblastoma protein (pRB). Consistent with these data, previous genome-wide analysis, without distinction between isoforms, identified two distinct groups of RBP2 target genes: 1) genes bound by RBP2 in a manner that is independent of differentiation; 2) genes bound by RBP2 in a differentiation-dependent manner.
To identify differences in localization between the isoforms we performed genome-wide location analysis by ChIP-Seq. Using antibodies that detect both RBP2 isoforms we have located all RBP2 targets. Additionally we have antibodies that only bind large, and not small RBP2 isoform (Figure 4). After identifying the large isoform targets, one can then subtract them from all RBP2 targets to reveal the targets of small isoform. These data show the contribution of chromatin-interacting domain in protein recruitment to its binding sites in the genome.
प्रोटोकॉल मूल रूप से बी रेन, 2001 से रूपांतरित किया गया. यह Odom एट अल द्वारा प्रोटोकॉल के एक मामूली संशोधन का प्रतिनिधित्व करता है. 5 कि में पाया जा सकता http://jura.wi.mit.edu/cgi-bin/young_public/navframe.cgi?s=22&f=appendices_downloads
1. पूर्व ब्लॉक और एंटीबॉडी के चुंबकीय मोतियों के लिए बाध्य (अगले कदम से पहले रात के लिए प्रदर्शन करना चाहिए)
- ताजा / BSA पीबीएस समाधान (10 एमएल में 50 मिलीग्राम BSA पीबीएस यह समाधान एक सप्ताह के लिए पिछले जाएगा). 1 की एमएल में Dynabeads प्रोटीन जी के 100 μL (आईपी प्रति एकाधिक आईपी के लिए गठबंधन) धो
- मोती एक चुंबकीय स्टैंड का उपयोग कर लीजिए और धोने प्रक्रिया दो बार दोहराएँ.
- अगला, पीबीएस / BSA समाधान में मोती घोल (आईपी) के प्रति के 250 μl एंटीबॉडी के 10 μg जोड़ने और 4 पर एक rotating मंच पर रातोंरात सेते डिग्री सेल्सियस
- पूरा होने पर, मोती पीबीएस / BSA समाधान के 1 मिलीलीटर में तीन बार धो लो और फिर समाधान / पीबीएस BSA (आईपी) के प्रति 10 μl में resuspend.
2. पार से जोड़ने सेल
- इस प्रक्रिया को शुरू करने के लिए, प्रत्येक immunoprecipitation के लिए लगभग 10 8 कोशिकाओं, या आईपी बढ़ता है. यहाँ, फैलाना histiocytic लिंफोमा U937 कोशिकाओं का इस्तेमाल किया और 96 घंटे के लिए टीपीए के साथ monocytic भेदभाव के लिए प्रेरित कर रहे हैं.
- सेल के विकास के बाद, formaldehyde समाधान सीधे 1% की एक अंतिम एकाग्रता के लिए मीडिया को जोड़ने. फिर, बोतल संक्षिप्त ज़ुल्फ़ और उन्हें 10 मिनट के लिए कमरे के तापमान पर बैठने के लिए अनुमति देते हैं. फिर, मीडिया aspirate और ठंडा पीबीएस के 15 एमएल के साथ कोशिकाओं कुल्ला. इस धोने एक बार दोहराएँ.
- अगला, प्रत्येक के लिए lysis बफर 1 के 6 एमएल (50 मिमी HEPES - KOH, 7.5 पीएच, 140 मिमी NaCl, 1 मिमी EDTA, 10% ग्लिसरॉल, 0.5% एनपी 40, 0.25% ट्राइटन X-100, protease inhibitors युक्त) जोड़ने बर्फ पर बोतल की. फिर, 20 मिनट के लिए 4 पर बोतल रॉक डिग्री सेल्सियस
- अंत में, एक सेल खुरचनी का उपयोग कोशिकाओं फसल और उन्हें 15 एमएल शंक्वाकार ट्यूबों के लिए स्थानांतरण. इस बिंदु पर कोशिकाओं -80 डिग्री सेल्सियस पर संग्रहीत किया जा सकता है
3. सेल Sonication
- यदि कोशिकाओं जमे हुए थे, उन्हें बाहर पिघलना. एक बार thawed, कोशिकाओं नीचे 4 में 10 मिनट के लिए 3000 rpm पर स्पिन ° सी और सतह पर तैरनेवाला त्यागने. फिर, lysis बफर 2 (10 मिमी Tris - एचसीएल, 8.0 पीएच, 200 मिमी NaCl, 1mm EDTA, 0.5 मिमी EGTA, protease inhibitors युक्त) के 6 एमएल में कोशिकाओं resuspend. ट्यूबों धीरे 10 मिनट के लिए कमरे के तापमान पर रॉक.
- Centrifugation दोहराएँ और lysis बफर 3 (10 मिमी Tris - एचसीएल, 8.0 पीएच, 100 मिमी NaCl, 1 मिमी EDTA, 0.5 मिमी EGTA, 0.1% सोडियम deoxycholate, 0.5% एन lauroylsarcosine, protease inhibitors युक्त) 2.5 एमएल में कोशिकाओं resuspend .
- अगले sonication के लिए यह एक Branson 450 Sonifier microtip 50 और 60% आयाम के बीच करने के लिए सेट के साथ बर्फीले पानी की एक बीकर में रखकर निलंबन तैयार.
- समाधान के लिए एक 30 दूसरा लगातार और 1 मिनट के लिए बर्फ पर फट शांत Sonicate. इन दालों में 10 से 15 बार दोहराएँ. फिर, ट्यूब की सामग्री विंदुक ऊपर और नीचे और उन्हें एक नया ट्यूब को हस्तांतरण. नाड़ी और शांत समाधान एक अतिरिक्त 5 बार जारी रखें.
- Sonication के बाद, 10% जोड़ ट्राइटन X-100 / 1 समाधान की मात्रा के 10. 1.5 एमएल अपकेंद्रित्र ट्यूबों lysates स्थानांतरण, और मलबे microcentrifuge में बाहर स्पिन. फिर एक नया ट्यूब सेल lysate हस्तांतरण.
4. Chromatin immunoprecipitation
- पहले chromatin immunoprecipitation, या चिप के लिए, इनपुट नमूने के रूप में सेल lysate के 50 μL बचाने के लिए. फिर, Dynabeads एंटीबॉडी कि पहले से तैयार किया गया है ऊपर वर्णित के रूप में पूर्व बाध्य के साथ मंजूरी दे दी सेल lysate गठबंधन. मिश्रण रॉक, 50 μL इनपुट नमूना के अलावा में 4 डिग्री सेल्सियस रातोंरात.
- धो बफर के 1 एमएल (50 मिमी HEPES KOH, पीएच 7.6, 0.5 एम LiCl, 1mm EDTA, 0.7% सोडियम deoxycholate, 1% एनपी 40) के साथ मोती धो लें. फिर, एक चुंबकीय स्टैंड का उपयोग करने के लिए मोती को इकट्ठा करने और सतह पर तैरनेवाला हटायें. इस धोने 6 से 8 बार दोहराएँ.
- के साथ एक अंतिम धोने प्रदर्शन 1 एमएल ते से अधिक-50 मिमी NaCl (10 मिमी Tris - एचसीएल, 8.0 पीएच, 50 मिमी NaCl, 1 मिमी EDTA). 2 मिनट के लिए 3,000 rpm पर एक microcentrifuge में 4 बजे मोती स्पिन डिग्री सेल्सियस Centrifugation के बाद, किसी भी अवशिष्ट ते बफर aspirate.
- फिर, नमूने के Elution बफर के 100 μL (50 मिमी Tris - एचसीएल, 8.0 पीएच, 10 मिमी EDTA, 1% एसडीएस) जोड़ें. तुरंत बाद, 65 नमूने सेते ° सी के 10 से 15 मिनट के लिए. एक 1.5 एमएल ट्यूब रैक हर 2 मिनट के निलंबन में मोती रखने के खिलाफ ट्यूबों स्क्रैच.
- Centrifugation और चुंबकीय स्टैंड का उपयोग मोती ले लीजिए, और एक पीसीआर ट्यूब स्थानांतरण सतह पर तैरनेवाला. फिर, पहले से बचाया इनपुट नमूना पुनः प्राप्त करने और Elution बफर के 3 खंडों को जोड़ने.
- अंत में, थर्मल cycler में आईपी और इनपुट के नमूने रातोंरात 65 में ° सी जगह- पार सम्पर्कों रिवर्स.
- अगले दिन, नमूने के ते बफर के एक मात्रा में जोड़ें. फिर, 0.2 μg / μL के अंतिम एकाग्रता RNase एक जोड़ने. 1 से 2 घंटे के लिए थर्मल cycler में 37 नमूने सेते डिग्री सेल्सियस
- ऊष्मायन के बाद, 0.2 μg / μL के अंतिम एकाग्रता proteinase कश्मीर में जोड़ें. फिर, 2 घंटे के लिए 55 ° सी में थर्मल cycler में नमूने सेते हैं.
- अगले, एक बार नमूने निकालने के phenol के एक मात्रा के साथ. क्लोरोफॉर्म: isoamyl शराब नमूने phenol के एक मात्रा के साथ एक दूसरे समय निकालें. Isoamyl शराब: अंत में, नमूने क्लोरोफॉर्म की एक मात्रा के साथ एक बार और निकालने.
- फिर, प्रत्येक नमूने में ग्लाइकोजन के 30 μg जोड़ें. इसके अलावा, नमूने के लिए इथेनॉल के 0.2 Molar और दो संस्करणों की एक अंतिम एकाग्रता NaCl जोड़ने. उन्हें 30 मिनट के लिए -80 पर सेते डिग्री सेल्सियस ऊष्मायन के बाद, नमूने स्पिन और सतह पर तैरनेवाला छानना. 75% इथेनॉल 500 μL के साथ छर्रों धो लें. फिर, छर्रों सूखी और उन्हें पानी के 40 μL में फिर से निलंबित.
- डीएनए टुकड़े sonication प्रक्रिया द्वारा उत्पादित के आकार की जाँच करने के लिए, एक 1.8% agarose जेल में शुद्ध इनपुट नमूना के 5 μg लोड और जेल चलाने. sonication प्रक्रिया 150-350 आधार जोड़े की रेंज में टुकड़े का उत्पादन करना चाहिए. हालांकि, अगर टुकड़े इस श्रेणी में गिरावट नहीं है, sonication प्रक्रिया फटने और आयाम की संख्या अलग से समायोजित किया जाना चाहिए.
- मजबूती और चिप के विशिष्टता की जांच करने के लिए, आईपी नमूनों की 1 μl और इनपुट नमूने के एक कमजोर पड़ने श्रृंखला के साथ विशिष्ट जीन पीसीआर प्रदर्शन द्वारा नियंत्रण बाइंडिंग क्षेत्रों में संवर्धन. दो से तीन "बाध्य" क्षेत्रों और एक अनबाउंड नियंत्रण क्षेत्र के क्रम में आईपी और इनपुट के नमूने की गुणवत्ता का परीक्षण करने के लिए चयनित किया जा की जरूरत है.
5. जीनोमिक डीएनए के प्रवर्धन
- आईपी नमूना या नमूना इनपुट के 200 एनजी के 34 μl के साथ शुरू, अंत मरम्मत, 'ए' पूंछ अलावा और डीएनए जीनोमिक डीएनए नमूना तैयारी किट का उपयोग कर टुकड़े के लिए adapters के ligation प्रदर्शन http://www.illumina.com/systems/ genome_analyzer.ilmn (Illumina, इंक, सैन डिएगो, CA).
- डीएनए एक MinElute पीसीआर शोधन किट का उपयोग कर शुद्ध और फिर यह बफर EB (10 मिमी Tris सीएल, पीएच 8.5) में elute किया गया है कि 50 डिग्री सेल्सियस पूर्व गरम उदाहरण के लिए, आईपी और इनपुट डीएनए नमूने की अंतिम elution के लिए 23 μL और 46 μL क्रमशः का उपयोग करें,.
- पीसीआर प्रतिक्रिया एडेप्टर के साथ डीएनए के 23 μL का उपयोग, और किट से 25 μL Phusion डीएनए पोलीमरेज़, 20 Sol_PCR_1 सुक्ष्ममापी की 1 μL, और 1 20 Sol_PCR_2 सुक्ष्ममापी की μL बनाओ. भागो पीसीआर प्रतिक्रिया के रूप में इस प्रकार:, 2) 10 सेकंड में 98 डिग्री सेल्सियस, 3) 65 डिग्री सेल्सियस पर 30 सेकंड, 98 पर 1) 30 सेकंड डिग्री सेल्सियस 72 पर 4) 30 सेकंड डिग्री सेल्सियस; दोहरा 2-4 18 कदम कदम और फिर 72 पर 5 मिनट बार डिग्री सेल्सियस, अंत में 4 बजे पकड़े डिग्री सेल्सियस
- पीसीआर प्रवर्धन के बाद, QIAGEN MinElute पीसीआर शोधन किट के साथ डीएनए शुद्ध. पूर्व गर्म 15 बफर EB के 50 μL डिग्री सेल्सियस और डीएनए elute. नमूना 01:04 0.5 μL पतला और Nanodrop पढ़ने प्रदर्शन.
6. प्रवर्धित उत्पादों की जेल शुद्धि
- प्रवर्धित उत्पादों को शुद्ध करने के लिए, एक 1.8% 50 एमएल के agarose जेल HPLC - ग्रेड पानी का उपयोग तैयार. जोड़ें TAE और ethidium ब्रोमाइड बाद agarose पिघल गया है. फिर, जेल डालना. इनपुट और आईपी के नमूने लोड हो रहा है बफर के 4 μL जोड़ने के बाद जेल लोड. फिर 45 मिनट के लिए 120 वोल्ट पर जेल चला रहे हैं.
- जेल विश्लेषण के बाद यह चला गया है. जेल रेंज बेस जोड़े के बीच 150 और 350 का उत्पादन कर रहे हैं कि टुकड़ों में प्रकट करना चाहिए. वे 50 और 250 की लंबाई और एक adapter में बेस जोड़े के बीच जीनोमिक डीएनए टुकड़े का प्रतिनिधित्व करते हैं.
- एक स्केलपेल के साथ 150 350 आधार जोड़ी रेंज में सामग्री युक्त जेल की आबकारी क्षेत्र. बैंड एडाप्टर के अनुकूलक excising से बचने के लिए ध्यान रखना है, जो के बारे में 120 आधार जोड़े पर चलाता है. निर्माता के निर्देशों के अनुसार एक QIAquick जेल निकालना किट का उपयोग डीएनए पुनर्प्राप्त. विशेष रूप से, QIAquick जेल निकालना किट से 400 मिलीग्राम या उससे कम की एक जेल टुकड़ा के लिए एक स्तंभ का उपयोग करें. निष्कर्षण प्रक्रिया शुरू करने के लिए, जेल की एक मात्रा के लिए बफर Qg के 3 खंडों को जोड़ने. Isopropanol के एक मात्रा में जोड़ें और स्तंभ पर मिश्रण लोड. स्तंभ धोने Qg 0.5 मिलीलीटर का उपयोग करें, मानक किट के मैनुअल में वर्णित प्रक्रिया द्वारा पीछा किया. एच 2 हे का उपयोग करें पूर्व गर्म 50 से डिग्री सेल्सियस करने के लिए डीएनए elute. 37 पर 5 मिनट के लिए एच 2 हे 30 μl के साथ स्तंभ सेते ° सी यह कताई नीचे से पहले.
- सूखी गर्मी के बिना एक Speedvac में ठीक 11 μL नीचे नमूना. नमूने के 1 μL निकालें और डीएनए एक Nanodrop स्पेक्ट्रोफोटोमीटर का उपयोग कर एकाग्रता को मापने.
- अंत में, समृद्ध जीन Illumina जीनोम के रूप में वर्णित AnalyzerIIe का उपयोग उत्पादों की पहचान http://genesdev.cshlp.org/content/suppl/ 2008/12/15/22.24.3403.DC1/GuentherSuppMat.pdf 6.
7. प्रतिनिधि परिणाम
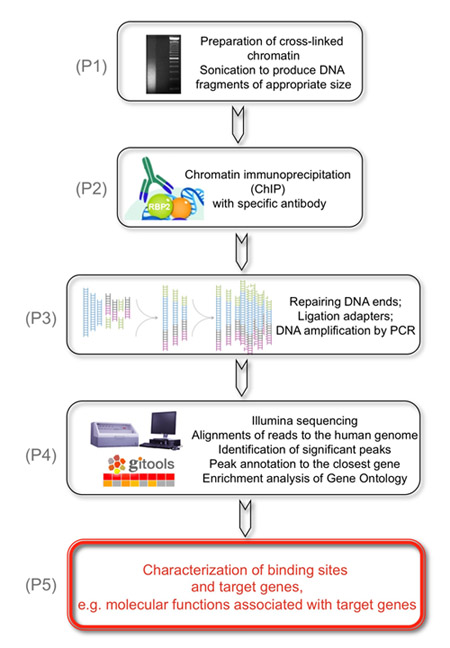
चित्रा 1. निम्न प्रयोग के समग्र लक्ष्य KDM5A/JARID1A/RBP2 histone demethylase के जीनोमिक लक्ष्यों की पहचान है.
(P1) इस पार से जुड़े chromatin है कि उपयुक्त आकार के डीएनए टुकड़े का उत्पादन करने के लिए sonicated है की तैयारी के द्वारा हासिल की है. (P2) एक दूसरे कदम के रूप में, RBP2 बाध्य डीएनए टुकड़े RBP2 एंटीबॉडी के साथ immunoprecipitated हैं. (P3) अगला, डीएनए टुकड़े बरामद सिरों पर मरम्मत कर रहे हैं और एडेप्टर जीनोमिक डीएनए के सिरों पर ligated कर रहे हैं विश्लेषण के लिए Illumina क्लस्टर स्टेशन में प्रवाह कोशिकाओं पर जीनोमिक डीएनए के पुस्तकालयों को तैयार है. डीएनए पुस्तकालयों चक्रों की कम संख्या का उपयोग करते हुए पीसीआर से परिलक्षित कर रहे हैं. (P4) अंत में, Illumina अनुक्रम कम पढ़ता विशिष्ट मानव जीनोम के लिए गठबंधन है, महत्वपूर्ण चोटियों की पहचान कर रहे हैं और क्रम में RBP2 समृद्ध क्षेत्रों की पहचान करने के लिए निकटतम जीन एनोटेट. (P5) परिणाम प्राप्त कर रहे हैं कि आणविक RBP2 जीनोम चौड़ा RBP2 समृद्ध क्षेत्रों की पहचान पर आधारित लक्ष्य जीन के साथ जुड़े कार्यों बताते हैं.
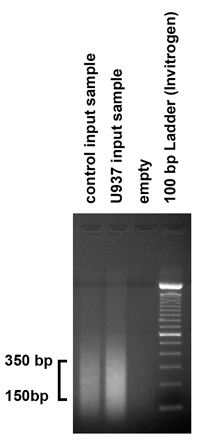
चित्रा 2. Chromatin sonication के परिणामों की जाँच के लिए डीएनए sonication प्रक्रिया द्वारा उत्पादित टुकड़े का आकार की जाँच करें, शुद्ध इनपुट नमूने के 5 μg (1 / 10) 1.8% agarose जेल पर लोड किया गया था. जैसी उम्मीद थी, हमारे sonication प्रक्रिया 150-350 बीपी की रेंज में टुकड़े का उत्पादन किया. हालांकि, अगर टुकड़े इस श्रेणी में गिरावट नहीं है, sonication प्रक्रिया तदनुसार समायोजित किया जाना चाहिए फटने की संख्या और आयाम अलग से.
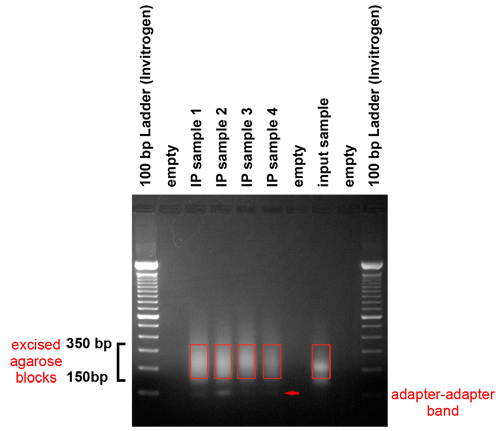
चित्रा 3. प्रवर्धित उत्पादों की जेल शुद्धि. पीसीआर उत्पादों की एक जेल पर चलाए जा रहे हैं करने के लिए एडाप्टर को हटाने और एक क्लस्टर पीढ़ी मंच के लिए टेम्पलेट्स का आकार श्रेणी का चयन करें. इस जेल से पता चलता है कि रेंज में 150 और 350 आधार जोड़े के बीच टुकड़े का उत्पादन किया गया. वे 50 और 250 की लंबाई और एक adapter में बेस जोड़े के बीच जीनोमिक डीएनए टुकड़े का प्रतिनिधित्व करते हैं. हम उत्पाद एक स्केलपेल के साथ जेल के चयनित क्षेत्र. केयर बैंड अनुकूलक अनुकूलक, जो बारे में 120 आधार जोड़े रन पर से बचने के लिया जाना चाहिए.
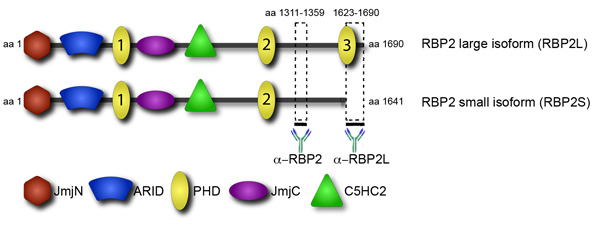
चित्रा 4. Isoform विशिष्ट एंटीबॉडी RBP2 के बड़े और छोटे isoforms के बीच भेद RBP2 प्रोटीन संरचना की अनुमति देता है डोमेन दृश्य में प्रस्तुत किया है. : RBP2 कई डोमेन उत्प्रेरक histone demethylation JmjC डोमेन और संबद्ध JmjN डोमेन, एक शुष्क अनुक्रम विशिष्ट डीएनए बाध्यकारी C5HC2 जस्ता उंगली है कि संभवतः डीएनए या अन्य प्रोटीन, और एकाधिक डोमेन पीएचडी के साथ बातचीत कर सकते में सक्षम डोमेन शामिल हैं. दो विरोधी RBP2 एंटीबॉडी कि RBP2 isoforms के बीच भेद अनुमति देते हैं RBP2 मोटी लाइनों द्वारा संकेत टुकड़े के खिलाफ प्राप्त किए गए.
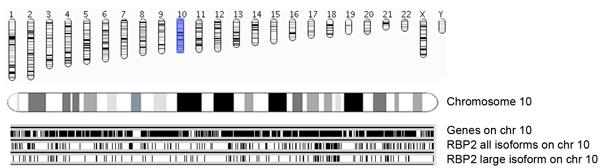
चित्रा 5a. गुणसूत्र और Ensembl जीन के साथ साथ RBP2 बाध्यकारी क्षेत्रों के अवलोकन की पहचान समृद्ध RBP2 के जीनोमिक निर्देशांक (सभी isoforms और बड़े isoform) बाध्यकारी क्षेत्रों गुणसूत्र बुद्धिमान प्रस्तुत कर रहे हैं . Ensembl जीन की Occupances (54 संस्करण, hg18) (इस चित्र में 10 गुणसूत्र) गुणसूत्रों में काली सलाखों (शीर्ष पैनल) के रूप में प्रस्तुत कर रहे हैं. प्रत्येक RBP2 बाध्यकारी क्षेत्र एक खड़ी रेखा है, जहां मध्यम पैनल सभी RBP2 isoforms 10 गुणसूत्र पर बाध्यकारी क्षेत्रों से पता चलता है के रूप में प्रतिनिधित्व किया है, और वह नीचे के पैनल RBP2 बड़े isoform बाध्यकारी क्षेत्रों से पता चलता है. मध्यम और नीचे पैनलों अतिव्यापी का सिंहावलोकन और 10 गुणसूत्र पर RBP2 isoforms की विशिष्ट अधिभोग दे.
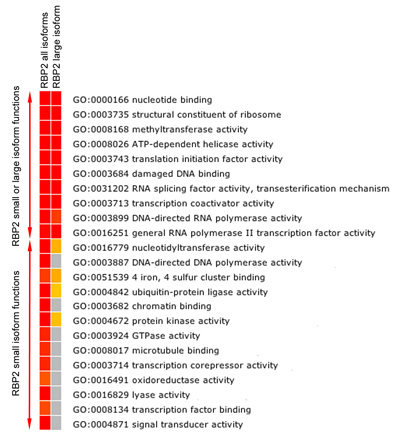
चित्रा 5 ब. RBP2 लक्ष्य जीन की कार्यात्मक संवर्धन विश्लेषण हीटमैप दिखा एफडीआर काफी सही (पी मान ≤ 0.05) समृद्ध RBP2 (सब और बड़े isoforms) से बंधे (RBP2 बाध्यकारी क्षेत्र के लिए जीन निकटतम) जीन के बीच आणविक समारोह श्रेणियों जाओ . लाल की ओर रंग उच्च आंकड़ा महत्व का संकेत मिलता है, पीला कम आंकड़ा महत्व का संकेत है, और ग्रे कोई आंकड़ा महत्व को इंगित करता है. संवर्धन विश्लेषण RBP2 लक्ष्य जीन की अतिव्यापी और isoform विशिष्ट आणविक कार्यों से पता चलता है.
RBP2 isoforms के बीच कार्यात्मक मतभेद नहीं निर्धारित किया गया है. हम एक व्यापक दृष्टिकोण का इस्तेमाल किया है जीनोमिक RBP2 isoforms द्वारा बाध्य क्षेत्रों की पहचान और परिभाषित कार्यात्मक श्रेणियों कि इन क्षेत्रों का प्रतिनिधित्व करते हैं. इस चिप Seq प्राप्त अनुक्रम के जैव सूचना विज्ञान विश्लेषण पढ़ता द्वारा पीछा विश्लेषण के द्वारा पूरा किया गया था.
RBP2 histone पूंछ पर methylated लाइसिन अवशेषों को संशोधित. हमने पाया है कि RBP2 बड़े isoform methylated histone lysine और RBP2 छोटे मानव जीनोम (चित्रा 5A) में विभिन्न क्षेत्रों के लिए इस मॉड्यूल बाँध कमी isoform के लिए मान्यता मॉड्यूल से युक्त है. महत्वपूर्ण बात, isoform विशिष्ट क्षेत्रों और अतिव्यापी क्षेत्रों अलग आणविक कार्यों (चित्रा 5B) के साथ जीन के हैं. उदाहरण के लिए, "chromatin बाध्यकारी" और "प्रतिलेखन कारक बाध्यकारी" कार्यों, RBP2 छोटे isoform के जीन लक्ष्य को जिम्मेदार माना जा सकता है लेकिन RBP2 बड़े नहीं isoform (चित्रा 5B). वास्तविक जीन की तुलना करके उत्पन्न सेट सभी isoforms और RBP2 बड़े isoform (नहीं दिखाया डेटा है) के लिए, हम भी परिभाषित कर सकते हैं अगर बड़े isoform विशेष रूप से कुछ जीनों के लिए भर्ती है.
इस काम के लिए 115,347-RSG-08-271 01-जीएमसी ACS से, और CA138631 द्वारा NIH से अनुदान द्वारा समर्थित किया गया.
Oligonucleotide दृश्यों 2006 Illumina, इंक सभी अधिकार सुरक्षित.
- Sol_PCR_1
अनुक्रम 5'-AAT GAT ACG GCG एसीसी एसीसी भूमिकाः एटीसी टीएसी अधिनियम सीटीटी टीसीसी CTA सीएसी GAC GCT सीटीटी CCG एटीसी T-3 ' - Sol_PCR_2
अनुक्रम 5'-CAA GAA GAC GGC एटीए CGA GCT सीटीटी CCG एटीसी GCA T-3 '
- Wang, G. G. Haematopoietic malignancies caused by dysregulation of a chromatin-binding PHD finger. Nature. 459 (7248), (2009).
- Benevolenskaya, E. V. Binding of pRB to the PHD protein RBP2 promotes cellular differentiation. Mol Cell. 18 (6), 623-623 (2005).
- Lopez-Bigas, N. Genome-wide analysis of the H3K4 histone demethylase RBP2 reveals a transcriptional program controlling differentiation. Mol Cell. 31 (4), 520-520 (2008).
- Benevolenskaya, E. V. Histone H3K4 demethylases are essential in development and differentiation. Biochem Cell Biol. 85 (4), 435-435 (2007).
- Odom, D. T. Control of pancreas and liver gene expression by HNF transcription factors. Science. 303 (5662), 1378-1378 (2004).
- Guenther, M. G. Aberrant chromatin at genes encoding stem cell regulators in human mixed-lineage leukemia. Genes Dev. 22 (24), 3403-3403 (2008).
ABOUT JoVE
Copyright © 2024 MyJoVE Corporation. All rights reserved