Method Article
Un T-laberinto automatizado basado en aparato y protocolo para el análisis de decisiones basado en el retraso y el esfuerzo en roedores en movimiento gratis
En este artículo
Resumen
Este artículo presenta un aparato automatizado de T-laberinto que hemos inventado, y un protocolo basado en este aparato para el análisis basado en el retraso de la toma de decisiones y decisiones basadas en el esfuerzo en roedores de movimiento libres.
Resumen
Muchos pacientes neurológicos y psiquiátricos demuestran dificultades o déficits en la toma de decisiones. Modelos de roedores son útiles para producir una comprensión más profunda de las causas neurobiológicas subyacentes a los problemas de toma de decisiones. Una tarea de T-laberinto base de costo-beneficio se utiliza para medir la toma de decisiones en la que roedores elegir entre un brazo de la recompensa alta (HRA) y un brazo baja recompensa (del Señor LRA). Hay dos paradigmas de la tarea de toma de decisiones de T-laberinto, en el que el costo es de un intervalo de tiempo y el otro en el que es esfuerzo físico. Ambos paradigmas requieren de un manejo intensivo y tedioso de animales de experimentación, varias puertas, recompensa de la pelotilla y brazo de grabaciones de elección. En el presente trabajo, hemos inventado un aparato basado en el tradicional T-laberinto con automatización completa para entrega de pellets, gestión de puerta y grabaciones de elección. Esta configuración automática puede utilizarse para la evaluación de ambas decisiones basado en el retraso y el esfuerzo en roedores. Con el protocolo descrito aquí, nuestro laboratorio investigado los fenotipos de toma de decisiones de múltiples ratones modificados genéticamente. Los datos representativos, nos demostró que los ratones con habernular medial seccionado mostraron aversión de retardo y esfuerzo y tendían a elegir la recompensa inmediata y sin esfuerzo. Este protocolo ayuda a disminuir la variabilidad causada por la intervención del experimentador y a mejorar la eficiencia del experimento. Además, sonda de silicona crónica o microelectrodo grabación, proyección de imagen de fibra óptica o manipulación de la actividad de los nervios se aplica fácilmente durante la tarea de toma de decisiones utilizando la configuración que se describe aquí.
Introducción
Los seres humanos y otros animales evaluación el costo (incluyendo retardo, esfuerzo y riesgo) para obtener una recompensa y luego hacen su decisión de elegir un determinado curso de acción. Déficit de toma de decisiones aparece en numerosas enfermedades neuropsiquiátricas, incluyendo esquizofrenia (SZ), trastorno por déficit de atención con hiperactividad (TDAH), trastorno obsesivo-compulsivo (TOC), enfermedad de Parkinson (EP) y adicciones1. Estudios en seres humanos y monos revelaron cerebro clave varias regiones están implicadas en la decisión que hace2,3,4. Aunque primates participan en ingredientes de decisión más complicadas, roedores se han divulgado para ser capaces de tomar decisiones de adaptación para sobrevivir en un entorno donde las contingencias de recompensa cambian con frecuencia. Además, los mecanismos de circuitos neuronales y mecanismos moleculares subyacentes la toma de decisiones se pueden bien investigar en modelos de ratón debido a la disponibilidad de herramientas de chemogenetic, herramientas optogenetic y ratones modificados genéticamente. Hay múltiples tareas utilizadas en la evaluación de comportamientos de toma de decisiones de roedores, incluyendo la tarea de cambio de set atencional, la tarea de T-laberinto effortful o en retraso, la tarea de apuestas Iowa, la revocación de discriminación visual aprendizaje tarea5, etcetera. T-laberinto análoga relación costo-beneficio protocolos fueron desarrollados originalmente por el grupo de Pierre6 y se han utilizado para examinar los efectos de dos tipos de costos de decisión (retraso y esfuerzo) en libre movimiento roedores7,8, 9,10. La ventaja de esta tarea es que animales no tienen que ser entrenados para pulsar palancas o cavar en un bol. En cambio, los animales hacen una elección entre una recompensa alta alto costo opción en uno de los brazos (HRA) o una recompensa baja opción de bajo costo en el otro brazo (LRA). Por lo tanto, esta tarea es mucho más fácil de realizar.
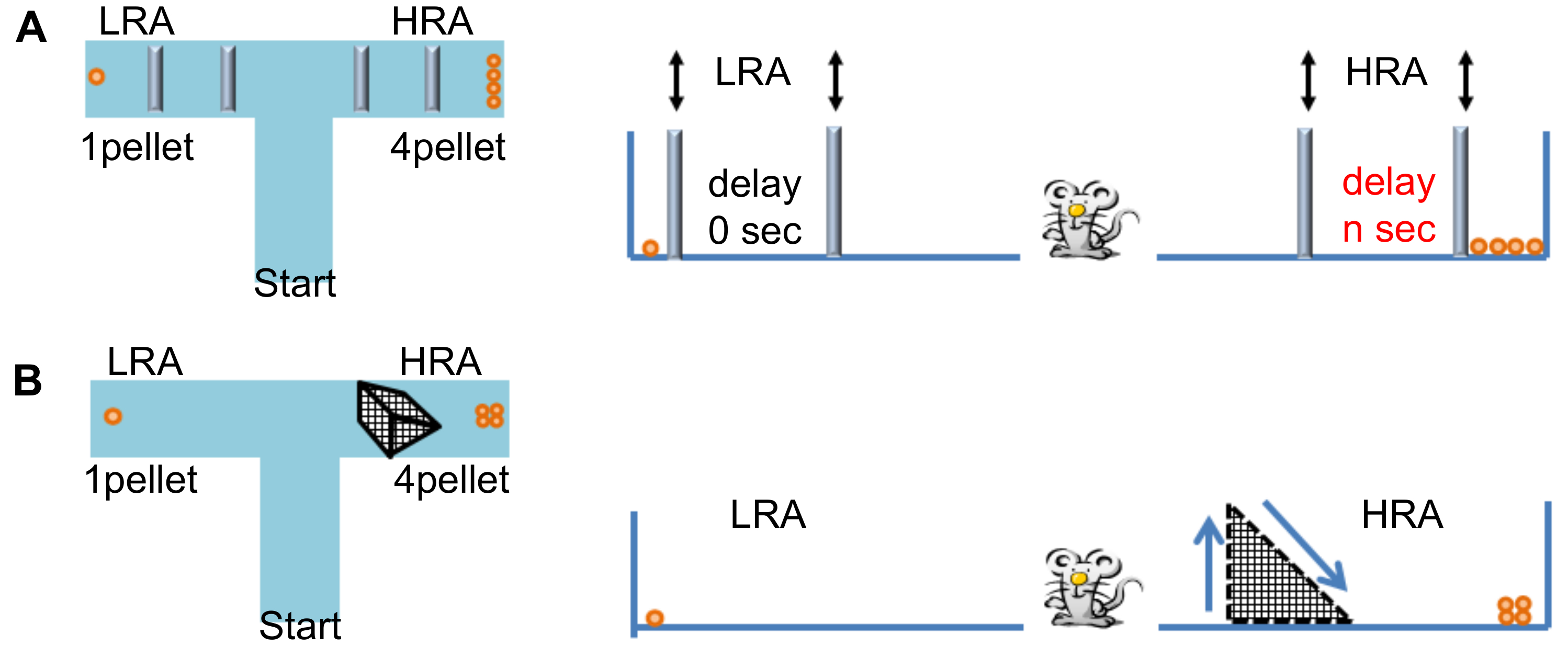
En el paradigma de retraso, una puerta de salida se introduce una vez el animal de experimento entra en uno de los brazos de la meta, para que el animal se mantiene en el brazo de la meta. Si el animal elige la LRA, la puerta del meta en el ERS se retrae inmediatamente y se entrega una cantidad pequeña de alimento. Si el animal elige la HRA, la puerta del meta en el HRA se retrae después de la demora necesaria y una gran cantidad de alimentos pellets se entrega (figura 1A). En el paradigma basado en el esfuerzo, la HRA es obstruida por una barrera y animales deben subir sobre él para obtener una gran cantidad de gránulos (figura 1B). En términos generales, el paradigma de retraso es muy útil para probar la impulsividad de modelos animales y una base de esfuerzo puede ayudar a averiguar animales apáticos2,4,11,12, 13. Hitherto los investigadores han estado realizando este ensayo manualmente contando el tiempo de retardo, insertar y retirar puertas, maniobrar la barrera del esfuerzo, contando el número de pellets, pellets de colocar en su posición, colocando y devolver animales y el registro de opciones de animales para cada ensayo. Estos costos de mano de obra y el tiempo representan un severo cuello de botella experimental para investigadores, dificultando el uso generalizado de este ensayo conductual. En el trabajo actual, hemos desarrollado una configuración de T-laberinto base para evaluar decisiones basado en el esfuerzo o el retraso de los roedores, con automatización total, estandarización y capacidad de alto rendimiento.
Aparato de
En colaboración con un fabricante comercial (véase Tabla de materiales), hemos desarrollado una modificación automática aparato de T-laberinto que utiliza control de instrumentos basados en software (figura 2). En particular, presentamos una "puerta trasera" y "nuevo camino" en comparación con el tradicional T-laberinto (figura 2), para que los animales podrían ir detrás al comienzo se señalan y comenzar un nuevo juicio. El T-laberinto es gris mate de color, y cuando la condición de experimento y el software están establecidas correctamente, pueden detectar ambos ratones blanco y negro. Está compuesto por tres brazos: brazo de un inicio y meta dos brazos, cada 410 mm de largo con paredes en forma de V de 155 mm de altura, una base de 30 mm de ancho y una parte superior abierta del 155 mm de ancho. El corredor en forma de V puede prevenir con eficacia ratones saltando. Además, el corredor en forma de V hace más fácil de aplicar en vivo grabando con cables. Un cuadro de comienzo se une a la extremidad del brazo de inicio. Una caja de gol se adjunta al final de cada brazo de la meta. Un dispensador de comida automático se instala en cada caja de meta para entregar a un número predefinido de pellets de alimento dulce. El consumo de pellets es detectado por un sensor infrarrojo y se registra automáticamente por una computadora. Cada caja de gol está conectado a la caja de inicio por un pasillo recto. Animales autónomamente pueden volver al cuadro de inicio vía el corredor una vez que terminen un juicio. Hay puertas correderas de 155 mm de altura en la entrada y salida de las cajas de salida y meta. Además, una puerta corredera se encuentra en la entrada de cada brazo del objetivo para evitar que animales mueva hacia atrás después de hacer una elección (figura 2A). Todas las puertas correderas son controladas por un ordenador y puede automáticamente abrir y cerrar. Una alta sensibilidad 1/2" carga acoplado (CCD) monocle cámara dispositivo está situado encima del aparato para rastrear el comportamiento de los animales. La distancia focal de la lente es de 2.8-12 mm. La posición de la cámara es alrededor de 1,9 m de alto. Puesto que la altura del laberinto es 0.5 m del piso, la distancia entre la cámara y el laberinto es alrededor de 1,4 m (figura 2B). Los datos de seguimiento de la cámara CCD se utilizan para control de vivir T-laberinto, abriendo y cerrando las puertas específicas cuando los animales entran en ciertas regiones de interés (ROIs). Las barreras que se utiliza para el paradigma basado en el esfuerzo en la forma de un triángulo rectángulo tridimensional (figura 2), que cabe perfectamente en las paredes en forma de V y son alrededor de 155 mm de altura. Animales deben escalar la cara vertical pero son capaces de descender una pendiente de 45°. El aparato se enciende a 100 lux durante el experimento. Azúcar pellets utilizados en el experimento (véase Tabla de materiales), y gel de sílice (véase Tabla de materiales) se utiliza para mantener el pellet seco.
Protocolo
Todos los protocolos experimentales fueron aprobados por los comités de uso del RIKEN Brain Science Institute y de cuidado Animal.
1. animal preparación
- Elegir el sexo, edad, genotipo y tratamientos farmacológicos de ratones experimentales (o ratas) dependiendo el propósito experimental.
Nota: Aquí hemos demostrado el rendimiento de cuatro ratones C57B/6 machos de 2 meses de edad. - Casa de los ratones en una habitación mantenida en condiciones estándar (h oscuro ciclo de 12 h luz/12, luces entre 8:00 y 20:00, 22 ± 1 ° C).
Nota: Si el objetivo es comparar la diferencia entre los dos genotipos, grupo 4 ratones por jaula e incluir 2 ratones de cada genotipo. - Manejar los ratones para 2 min/día durante 5 días para familiarizarse con el contacto humano. Alimentarlos con raciones medidos para que su peso corporal se mantenga más o menos cerca de 80 – 85% del peso de alimentación libre durante todo el experimento. Proporcionar agua ad libitum.
- Habituarse a ratones a la sala experimental mediante la transferencia de todos los ratones del ratón vivienda habitación a la sala experimental de 30 minutos antes del experimento cada día.
- Iniciar experimentos al mismo tiempo cada día para evitar los efectos de los ritmos circadianos en el rendimiento animal.
2. animal habituación al laberinto
- Inicio habituación para el laberinto simultáneamente con ratón manejo (2 min/día). Mantenga todas las puertas abiertas en esta etapa. Para un total de 5 días realice la habituación.
- El día 1, Esparza los gránulos de alimento a lo largo del laberinto.
- En los días 2 y 3, esparcir los pellets por los brazos del dos objetivo.
- Los días 4 y 5, poner las pastillas solamente en las casillas de dos meta.
- Todos los días, después de colocar los balines, coloque el ratón en el cuadro de inicio de la T-Laberinto en grupos de cuatro y permitir que los ratones explorar el laberinto durante 10 minutos.
Nota: Habituar a los ratones en grupos de cuatro les ayudará a aprender unos de otros y la velocidad de formación.
3. animal discriminación de HRA de LRA
Nota: Este protocolo incluye pruebas de toma de decisiones basada en el retraso tanto en esfuerzo. Sin embargo, dependiendo de la finalidad, los investigadores pueden probar sólo uno de ellos, o ambos. Software de control (Tabla de materiales) se utiliza para controlar automáticamente la configuración de T-laberinto para los siguientes pasos. Si se probará decisiones basadas en el esfuerzo, introducir barreras a HRA y LRA en la fase de entrada forzada del brazo. Entonces los animales serán capacitados para la discriminación y barrera al mismo tiempo que sube. Los ratones hambrientos activamente suben las barreras y después de esta fase, todos ellos pueden trepar hábilmente. Por lo tanto, no es necesario partir de una barrera inferior con este protocolo.
-
Fase de entrada forzada del brazo
- Abra la ventana de registro de parámetros del software de control y configurar los parámetros como sigue (figura 3).
- Elija la opción de"fase". Establece el número de"prueba" en 10, para que cada animal pasará por 10 ensayos por día durante 5 días continuos.
Nota: Se puede elegir un número de ensayos diferentes en sus propios experimentos. - Ajuste la "duración" a 900 s para que la formación de un ratón por día no exceda 900 s. ajuste "por defecto inicio de retraso" a 3 s, para que la puerta de salida se abrirá 3 s después de que el animal es detectado en la zona de salida.
- Establece el número de"pellets" para la HRA y el LRA para que 4 pastillas se dispensan automáticamente en el HRA y 1 pellet se distribuye en la LRA.
Nota: En nuestros experimentos, hemos encontrado que 1:4 es la mejor relación cuando se utilizan bolitas de azúcar de 10 mg. Si utilizamos bolitas de 6 a 10, los ratones no pueden terminar comiendo todos ellos y habrá suceso de omisión. - Establecer el "retraso" a 0 s, por lo que no habrá delay para HRA y LRA durante esta fase.
- Elija la opción de"fase". Establece el número de"prueba" en 10, para que cada animal pasará por 10 ensayos por día durante 5 días continuos.
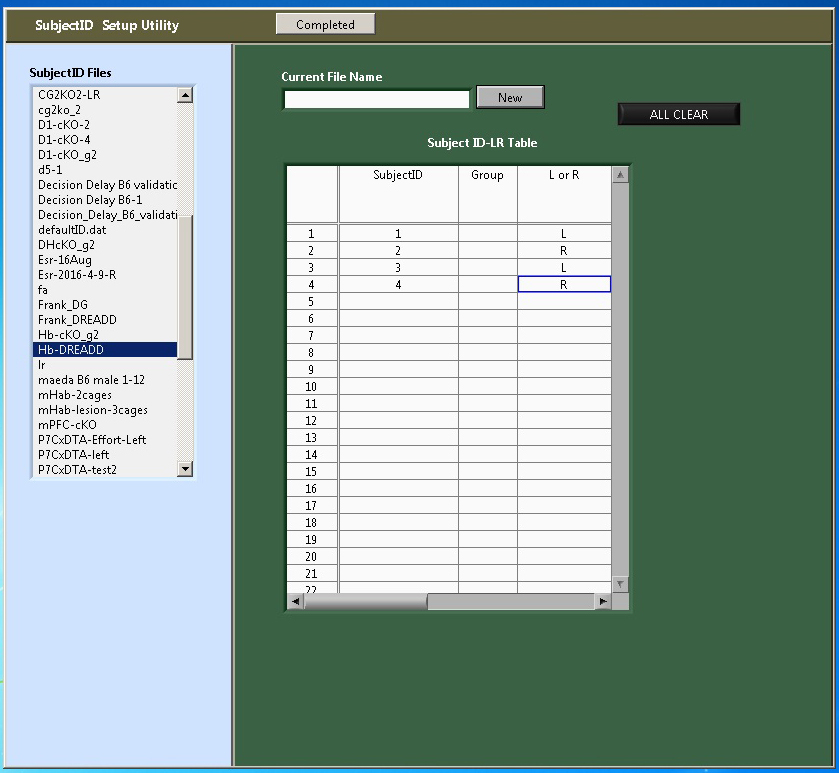
- Abra la ventana de "Registro de identificación" de software de control. Registro de identificación de cada ratón individual para software de acuerdo con la ubicación de la HRA, ya sea izquierda o derecha. (Figura 4).
Nota: La ubicación debe ser contrapesada con respecto a los grupos de genotipos. 50% de cada grupo de genotipo, la HRA está siempre a la izquierda y el LRA está siempre a la derecha. Para el otro 50%, la HRA está siempre a la derecha y el LRA está siempre a la izquierda. - Abra la ventana de la aplicación del software, seleccione "Decisiones" de la lista desplegable de "Tarea". ID de objeto de entrada y seleccione "Fase 2" de la lista desplegable de "Fase". Seleccione número de días en la lista desplegable de "Día". Pulsa el botón "OK" para ingresar a la ventana de interfaz del experimento.
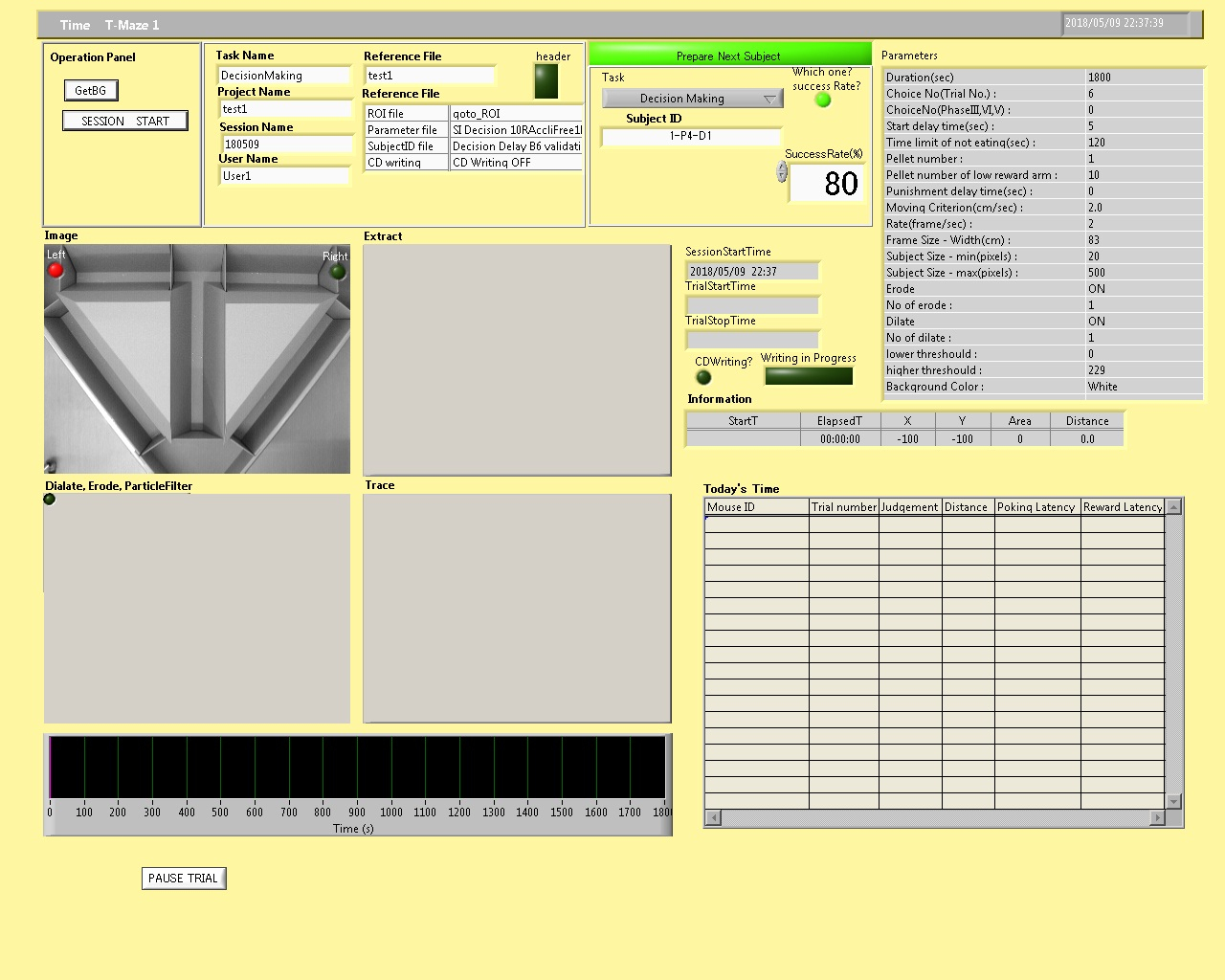
- En la ventana de interfaz de experimento, pulse "GetBG" para registrar la información del laberinto para que el animal será rastreado con precisión sin importar el fondo del medio ambiente. Presione el botón de "Inicio de sesión" (figura 5).
- Coloque el ratón en la casilla de inicio e iniciar la formación pulsando el botón "start" del mando.
- Tenga en cuenta que la puerta de salida, una puerta de salida (izquierda o derecha) se abrirá automáticamente después de 3 s; una vez que el ratón entra en la zona de cruce, la puerta de salida se cerrará automáticamente.
- Observar que cuando el mouse entra en la zona de demora (ya sea lado derecho o izquierdo), la puerta de salida se cerrará automáticamente y automáticamente se abrirá la puerta de la meta.
- Observar que una vez que el ratón lleva el diábolo, la puerta trasera y antes de la salida la puerta se abrirán automáticamente. Una vez que el ratón entra en la zona de la espalda, la puerta se cerrará automáticamente.
- Observar que una vez que el ratón entra en la caja de inicio, la puerta antes de la salida se cerrará automáticamente y comenzará un nuevo juicio.
Nota: Dentro de los 10 ensayos de cada día durante esta fase de formación, el software automáticamente asegurará que cada ratón visita la HRA para 5 ensayos y el LRA 5 ensayos.
- Limpie el laberinto completamente cada día.
- Abra la ventana de registro de parámetros del software de control y configurar los parámetros como sigue (figura 3).
-
Fase de entrada de brazo libre
- Registrar parámetros y ID de objeto de la misma manera como hecho en la fase de entrada forzada (paso 3.1.1 y 3.1.2). Elija la opción de fase "". Establece el número de"prueba" en 20, para que cada animal pasará por 20 ensayos, por día por 7 días continuos.
- En la ventana de la aplicación, seleccione "Fase 3" de la lista desplegable de "Fase". Establecer otros parámetros según paso 3.1.3.
- En la ventana de interfaz de experimento, establecer el valor de "Tasa de éxito" como 80% para que la capacitación continuará automáticamente hasta que el ratón selecciona la HRA en el 80% de los ensayos, o cuando el ratón termina 20 ensayos por día (como está registrado en la configuración de parámetros). Se aplican otras operaciones según paso 3.1.4.
- Permitir que el ratón para elegir libremente uno de los brazos, HRA o LRA.
- Tenga en cuenta que la puerta de salida, dos puertas de salida se abrirán automáticamente después de 3 s; una vez que el ratón entra en la zona de cruce, la puerta de salida se cerrará automáticamente.
- Observar que una vez que el ratón elige uno de los brazos y entra en la zona de demora (ya sea lado derecho o izquierdo), la puerta de salida se cerrará automáticamente y automáticamente se abrirá la puerta de la meta.
- Observar que una vez que el ratón lleva el diábolo, la puerta trasera y antes de la salida la puerta se abrirán automáticamente. Una vez que el ratón entra en la zona de la espalda, la puerta se cerrará automáticamente.
- Observar que una vez que el ratón entra en la caja de inicio, la puerta antes de la salida se cerrará automáticamente y comenzará un nuevo juicio.
4. prueba retardo basado en la toma de decisiones
- Registrar parámetros y ID de objeto de la misma manera como hecho en la fase de entrada del brazo libre (paso 3.2.1). Establecer el "retraso" al 5, 10,15 s el día 1, día 2 y día 3 respectivamente, así que habrá retraso s 5 para HRA el día 1, 10 retardo s para HRA en retraso de s días 2 y 15 para HRA en día 3.
- En la ventana de la aplicación, seleccione "Fase 4" de la lista desplegable de "Fase". Establecer otros parámetros de la misma manera como en 3.2.2.
- En la ventana de la interfaz del experimento, se aplican todas las operaciones según el paso 3.2.3.
-
Permitir que el ratón para elegir libremente uno de los brazos, HRA o LRA.
- Tenga en cuenta que la puerta de salida, dos puertas de salida se abrirán automáticamente después de 3 s; una vez que el ratón entra en la zona de cruce, la puerta de salida se cerrará automáticamente.
- Observar que una vez que el ratón elige uno de los brazos y entra en la zona de demora (ya sea lado derecho o izquierdo), la puerta de salida se cerrará automáticamente.
Nota: Si el ratón elige LRA, la puerta del meta se abrirá automáticamente inmediatamente. Sin embargo, si el ratón elige HRA, la puerta del meta se abrirá automáticamente después de 5 s, 10 s y 15 s en los días 1, 2, 3 respectivamente. - Observar que una vez que el ratón lleva el diábolo, la puerta trasera y antes de la salida la puerta se abrirán automáticamente. Una vez que el ratón entra en la zona de la espalda, la puerta se cerrará automáticamente.
- Observar que una vez que el ratón entra en la caja de inicio, la puerta antes de la salida se cerrará automáticamente y comenzará un nuevo juicio.
Nota: Aquí, capacitamos a los ratones durante 5 – 7 días con cada condición de retardo. Sin embargo, basándonos en nuestra experiencia en la prueba de múltiples líneas de ratones transgénicos o mutados, 1 día (20 ensayos) es absolutamente suficiente para ver la diferencia entre los ratones de diferentes genotipos y no significa prolongar el tiempo de formación (véase la figura 6 como un ejemplo). Por lo tanto, actualmente sólo se aplican 1 día por cada hora de retraso y funciona bien. No habrá ningún problema si los investigadores quieren alargar los días de entrenamiento según su propio propósito.
- Opcional: Realice la prueba con la HRA invertida. Para comprobar si la elección del ratón es el resultado de una preferencia de orientación, cambiar la posición izquierda / derecha de la HRA y el LRA (que se puede lograr automáticamente por el software) y permitir que los ratones a elegir libremente un brazo como en 4.4.
- Opcional: Realice una prueba de control de retardo. Para comprobar cualquier déficit observado es el resultado de la alteración de memoria espacial o la sensibilidad de la recompensa, más que el resultado de cambios en la toma de decisiones, introducir un retardo s 15 ERS como la HRA y permitir que los ratones a elegir libremente un brazo como en 4.4.
5. prueba esfuerzo basada en la toma de decisiones
- Introducir la barrera a la HRA como se muestra en el diagrama (figura 1).
- Configurar todos los parámetros y aplicar todas las operaciones según el paso 3.2: los animales de prueba de 3 días continuos y sin fase de entrada de brazo.
- Permitir que los ratones a elegir libremente un brazo, HRA o LRA.
Nota: Aquí, capacitamos a los ratones durante 14 días. Sin embargo, basándonos en nuestra experiencia en la prueba de múltiples líneas de ratones transgénicos o mutados, 3 días son absolutamente suficientes para ver la diferencia entre los ratones de diferentes genotipos y no hay ningún significado para extender el tiempo de entrenamiento (véase la figura 6 como ejemplo ). Por lo tanto actualmente aplicamos sólo 3 días para la prueba de esfuerzo y funciona bien. No habrá ningún problema si los investigadores quieren alargar los días de entrenamiento según su propio propósito. - Opcional: Realice la prueba con la HRA invertida. Para comprobar si la elección del ratón es el resultado de una preferencia de orientación, cambiar la posición izquierda / derecha de la HRA y el LRA (que se puede lograr automáticamente por el software) y permitir que los ratones a elegir libremente un brazo como en el paso 5.3.
- Opcional: Realizar prueba de esfuerzo de control. Para comprobar cualquier déficit observado es el resultado de la alteración de memoria espacial o la sensibilidad de la recompensa, más que el resultado de cambios en la toma de decisiones, presentar una barrera al ERS, así como la HRA y permitir que los ratones a elegir libremente un brazo como en el paso 5.3.
6. Análisis de datos
-
Obtener datos y resultados directamente desde el software de control.
- Tenga en cuenta que el software automáticamente registrar fecha experimental, empezar y terminar a tiempo, duración, número de juicio, la situación de la HRA, el número de pellets en la HRA y el LRA, la posición (X, Y) y el movimiento traza, etc., de cada ratón en la carpeta "Data" .
- Compruebe que el software tiene automáticamente analizar lo siguiente y registrar en la carpeta de "Resultado" en cada animal ID: duración, número del ensayo, HRA opción número, LRA opción número, porcentaje de elección HRA, porcentaje de elección LRA, distancia de movimiento total, y total de tiempo de cruce.
- Realizar análisis estadístico de los datos de todos los experimentos por un ANOVA mixto (parcelas divididas ANOVA), con jornada como factor de sujeto y grupo factor (genotipo grupo o grupos con diferentes condiciones experimentales) como factor entre sujetos.
- Analizar el efecto principal del factor de grupo si no hay ninguna interacción entre jornada con el factor grupo. Aplique post hoc de comparaciones pares si hay una interacción significativa entre la jornada con el factor grupo.
Resultados
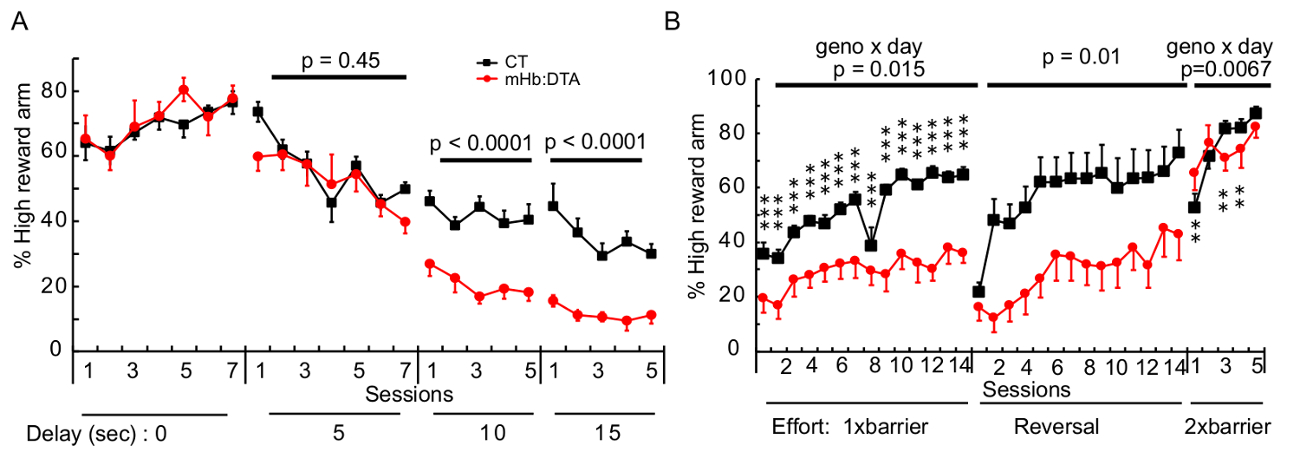
Un ejemplo de la demora y esfuerzo - base tarea toma de decisiones por intermedio habernular ablación ratones (ratones mHb:DTA)14 con sus tipo salvaje littermate control ratones (CT) se muestra en la figura 6. Dos mHb:DTA de ratones y ratones de dos CT fueron alojados conjuntamente en una jaula después del destete.
En el demora-examen basado en toma de decisiones (figura 6A), no hubo ninguna interacción significativa entre el genotipo y la sesión en cualquier fase, la fase de formación de discriminación (cuando el tiempo de retardo de HRA era 0) y pruebas de toma de decisiones basado en la demora fase (cuando el tiempo de retardo de HRA era 5 s, 10 s y 15 s, respectivamente). El principal efecto del genotipo no fue significativo cuando el tiempo era 5 s. Sin embargo, cuando el tiempo de retardo fue alargado a 10 s y 15 s, mHb:DTA ratones demostraron una reducción significativa en el porcentaje de visitas HRA en comparación con ratones de CT. Estos resultados revelaron que la ablación de mHb disminuido la preferencia de los ratones esperando una recompensa mayor y en su lugar aparece una tendencia a seleccionar una pequeña recompensa inmediata, cuando los tiempos de espera 10 segundos o incluso más. Los datos sugieren que eso mHb puede ser una estructura cerebral importante en el control de la impulsividad o la evaluación de costo/beneficio de tiempo, representar animales más propensos a tolerar el acceso retrasado para obtener una recompensa grande.
En el esfuerzo de prueba basada en toma de decisiones (Figura 6B), el porcentaje de HRA visitas fueron disminuidas perceptiblemente en ratones mHb:DTA cuando una barrera se colocó en la HRA, independientemente de la localización izquierda de la HRA (fase de barrera 1 x y la fase de inversión ). Esto significa que el fenotipo de los ratones de mHb:DTA no era debido a un déficit en la memoria y la preferencia espacial. En la prueba de control de esfuerzo, se colocaron barreras en ambos brazos del objetivo (2 × barreras fase) y LRA y HRA se asociaron con alto esfuerzo. Por lo tanto, el costo de esfuerzo fue el mismo para los animales seleccionando la recompensa baja o la alta recompensa. Los ratones de mHb:DTA visitaron más con frecuencia que el ERS la HRA, alcanzó un comparable HRA visita y número en la última sesión (sesión 5). Este resultado sugiere que la sensibilidad de recompensa y memoria espacial en ratones mHb:DTA estaba intacta. Los datos que aclaran mHb puede jugar un papel importante en la evaluación de costo/beneficio de esfuerzo, permitiendo a los animales poner en más trabajo para obtener recompensas mayores.

Figura 1: diagrama esquemático del tradicional aparato T-laberinto para test de toma de decisiones (A) aparato de la prueba de toma de decisiones basado en la demora. Animales fueron colocados en el brazo de arranque y elegir entre dos brazos de la meta, HRA y LRA. Cuando los animales eligieron la HRA, tenían que esperar (según el tiempo de retardo en segundos) para obtener una recompensa más grande. Los investigadores deben manejar manualmente animales, pellets y puertas para cada ensayo. (B) aparatos de prueba de toma de decisiones basada en el esfuerzo. Animales fueron colocados en el brazo de arranque y elegir entre dos brazos de la meta, HRA y LRA. Cuando los animales eligieron la HRA, tuvieron que subir una barrera triangular para obtener una recompensa más grande. Los investigadores deben manejar manualmente animales, pellets, puertas y barreras para cada ensayo. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 2: automatizado de configuración T-laberinto para test de toma de decisiones (A) vista superior de la configuración automatizada. (B) vista lateral de la configuración automatizada. Barrera (C) el triángulo de ángulo recto 3D utilizado para la prueba de toma de decisiones basada en el esfuerzo, de izquierda a derecha, es la vista lateral, la vista lateral opuesto y la vista lateral de hipotenusa, respectivamente. Fotos técnicas originales editados con permiso de los fabricantes comerciales. GBL: caja de gol (izquierda), GBR: caja de gol (derecha), GDL: puerta objetivo (izquierda), RDA: puerta del meta (derecha), DAL: retrasar la zona (izquierda), DAR: retrasar la zona (derecha), JDL: puerta de salida (izquierda), JDR: (derecha), de la puerta de la ensambladura BDL: puerta trasera (izquierda), BDR: puerta trasera (derecha), CCD: cargo juntada cámara del dispositivo). Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 3: ventana de parámetros del registro. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 4: ventana de registro de la identificación del tema. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 5: la ventana de la interfaz experimento. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 6: decisiones basadas en la demora y esfuerzo en ratones mHb:DTA. (A) demora decisión prueba en ratones mHb:DTA (ratones eran 12 – 14 meses-edad, n = 8/genotipo). El porcentaje de elección HRA era comparable entre los genotipos cuando el tiempo de retardo era s 0 y 5, pero disminuyó significativamente en los ratones de mHb:DTA cuando el tiempo de retardo 10 s y 15 s. Cuando el tiempo era 5 s, interacción genotipo × día: F(1,14) = 0.594, p = 0.236; el efecto del genotipo: F(1,14) = 0,61, p = 0,45; Cuando el tiempo de retardo era 10 interacción s: genotipo × día: F(1,14) = 37.5, p = 0.346; el efecto del genotipo: F(1,14) = 32.4, p < 0.0001; Cuando el tiempo de retardo fue s: 15 F(1,14) = 38.7, p = 0.243; el efecto del genotipo: F(1,14) = 31.6 y p ≤0.0001. (B) esfuerzo toma prueba en ratones mHb:DTA (ratones fueron 12-14 meses-edad, n = 9/genotipo). En 1 x fase barrera, hubo una interacción significativa entre el genotipo y el período de sesiones (interacción genotipo × día: F(1,16) = 2.11, p = 0.015), y la comparación pares post hoc revelaron que HRA el % de ratones mHb:DTA disminuido significativamente en todos los sesiones. Durante la fase de inversión, no hubo ninguna interacción significativa entre el genotipo y el período de sesiones (interacción genotipo × día: F(1,16) = 1.61, p = 0,08). ratones mHb:DTA visitaron HRA significativamente menos que los ratones CT (efecto principal genotipo: F(1,16) = 8.18, p = 0,01). Fase 2 × barreras, hubo una interacción significativa entre genotipos y sesiones y una diferencia significativa en la sesión 3 y sesión 4 (2 x fase barreras: interacción genotipo × día: F(1,16) = 3.9, p = 0.0067). Los ratones de mHb:DTA alcanzados una HRA visitan número comparable a la de los ratones de la CT en la sesión final, sesión 5. Los datos representan la media ± SEM. ** p < 0.01; p < 0.001. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 7: Diagrama de flujo de toma de decisiones de prueba (basado en demora o esfuerzo).
Discusión
Toma de decisiones es un proceso cognitivo altamente conservado durante la evolución15. Los seres humanos y animales pueden evaluar el costo de opciones de acción que compiten en relación con la potencial recompensa y luego hacer su elección. Pacientes que sufren de un número de enfermedades neurológicas y trastornos psicológicos demuestran déficit en diferentes formas de toma de decisiones16. Por lo tanto es importante investigar los mecanismos neurobiológicos y fisiopatológicos subyacente a la toma de decisiones. En los últimos años, retraso y esfuerzo basado en toma de decisiones está atrayendo más y más investigación de interés. Además, los roedores, especialmente ratas se han utilizado para el estudio de estas dos formas de toma de decisiones17.
Muchos estudios condujeron a descubrimientos interesantes utilizando una tarea conductual que implica un aparato de T-laberinto con una HRA y en un LRA2,6,7,8,9,10, 18 , 19 , 20 , 21 , 22. en la tarea, HRA asocia grandes recompensas o un tiempo demora o esfuerzo esfuerzo. En el LRA, los animales pueden adquirir una pequeña recompensa inmediatamente sin retraso de tiempo y esfuerzo físico. El enfoque tradicional se basa en la intervención manual del experimentador humano. En cada ensayo, el experimentador necesita contar las pelotillas y colocarlos en las bandejas de comida de HRA y LRA, coloque las puertas de la meta en HRA y LRA y luego coloque el animal en el extremo del brazo de inicio. Cuando el animal entra en cualquiera de los brazos, una puerta de salida necesita ser colocado para restringir el animal en el brazo de la meta. Dependiendo del Protocolo, el experimentador debe contar el tiempo y abrir la puerta del meta después de un retraso determinado. Después de que el animal entra en el área de portería y obtiene el pellet(s), el experimentador debe volver a la jaula y grabar la opción de brazo del animal y el comportamiento. Entonces el experimentador debe preparar las puertas T-laberinto y pellets para el próximo ensayo. El conjunto de entrenamiento y pruebas de procesos consumen mucho tiempo y trabajo. Además, una falta de estandarización a través de diferentes laboratorios es otro motivo de preocupación.
En este trabajo, presentamos un protocolo basado en un aparato de T-laberinto automatizado modificado con un sistema de seguimiento de video (figura 7) para resolver los problemas de los protocolos tradicionales. Mediante la introducción de una "puerta trasera" y "corredor posterior" a la T-laberinto tradicional, obtuvimos el laberinto con forma de "triángulo isósceles bisecado". Las ventajas de esta configuración son (1) automatización completa de la conducta de entrenamiento y pruebas. Esto elimina el impacto de la subjetividad del experimentador y minimiza el tiempo de los humano y los compromisos de trabajo. Tenemos cuatro configuraciones en el laboratorio, para que cuatro ratones podrían ser entrenados o probados simultáneamente por un experimentador, que es imposible de lograr utilizando protocolos tradicionales. (2) hay flexibilidad de software como el software de control permite a los experimentadores libremente configurar varios parámetros, incluyendo el número de pellets, tiempo de retardo, abertura de la puerta y cierre, números de prueba, duración y modo de rastreo. Por lo tanto, este sistema puede cumplir a diferentes tipos de necesidades experimentales. (3) hay compatibilidad amplia como todas las puertas correderas en el T-laberinto están diseñadas para almacenarse en la base del laberinto cuando están abiertos. Por lo tanto, la configuración puede integrarse fácilmente con diversos sistemas fisiológicos, incluyendo la manipulación optogenetic óptico, vivo electrofisiología grabación y microdiálisis. Además, para excluir la posibilidad de que los ratones eligieron la HRA debido a una preferencia de posición, se recomienda aplicar una prueba de control para el análisis basado en la demora - tanto esfuerzo. Por igualar los costos en los brazos del dos objetivo, animales tienen la oportunidad de experimentar ambos resultados de recompensa con el mismo costo. La elección puede hacerse simplemente sobre la base de la recompensa diferencial, eliminando así la necesidad de integrar los costos y beneficios antes de decidir. Esto también comprueba si cualquier cambio en las opciones de los animales es el resultado de una incapacidad para escalar el precio o recompensa, o déficit de la memoria en lugar de una alteración en la forma en que evalúan sus decisiones.
En nuestro laboratorio hemos analizado alrededor de 10 cepas de ratones con esta configuración. Un ejemplo se muestra en los datos representativos, mHb:DTA ratones demostraron un fenotipo resistente en delay - tanto esfuerzo-base de toma de decisiones. Es decir, valor de recompensa fuertemente con descuento por tiempo y esfuerzo en ratones mHb:DTA. El resultado reveló el importante papel de mHb en control de la impulsividad. Además, hemos aplicado grabaciones de sonda de silicona en ratones móviles gratis durante el proceso de toma de decisiones (datos no publicados). Todos los experimentos proporcionan criterios de validación para la capacidad de la configuración automatizada. Así, el protocolo estandarizado para el T-laberinto base de toma de decisiones con el equipo automatizado es conveniente para la detección de efectos genéticos, efectos farmacológicos y circuito neural en retraso y esfuerzo descuento de roedores. En Resumen, la configuración tiene muchas ventajas para servir como un sistema ideal para los ensayos de toma de decisiones basado en el retraso y el esfuerzo.
Divulgaciones
Los autores no tienen nada que revelar.
Agradecimientos
Nos gustaría agradecer a Dr. Matthew F S Rushworth (Departamento de Psicología Experimental, Universidad de Oxford) y Dr. Sakagami Masamichi (centro de investigación de Ciencias de cerebro, Universidad de Tamagawa) por sus valiosos consejos en la iniciación del proyecto y en los detalles de los protocolos. Agradecemos Dr. Lily Yu comentarios críticos y editando el manuscrito. Este proyecto fue apoyado por el proyecto de investigación RIKEN incentivo (100226201701100443) para Q.Z, el proyecto de Ciencias del cerebro, centro de iniciativas de nuevas ciencias, institutos nacionales de Ciencias naturales (BS291003) para Q.Z, el (proyecto envejecimiento RIKEN 10026-201701100263-340120) a Q.Z y el JSP Kakenhi subvenciones para jóvenes científicos (B) (17841749) a Q.Z.
Las contribuciones de los autores: Q.Z concebido y puesto en marcha el proyecto Q.Z, Y.K y H.G realizaron los experimentos y análisis de datos, H.G coordinado el trabajo entre el laboratorio y o ' Hara & Co., Ltd., Q.Z y Y.K escribieron el manuscrito, S.I supervisó el proyecto.
Materiales
| Name | Company | Catalog Number | Comments |
| automated t-maze for decion making testing | O’HARA & Co.,ltd | no catalog number, customorized | Address requested by the reviewer: 4-28-16 Ekoda, Nakano-ku, Tokyo 165-0022 TEL: 81-3-3389-2451 FAX:81-3-3389-2453 |
| slica gel | Nacalai Tesque | 1709155 | |
| AIN-76A Rodent Tablet 10mg | Test Diet | 1811213(5TUL) | Manufactured for Japan,SLC |
| Time TM1 software | O’HARA & Co.,ltd | no catalog number | |
| SPSS statistics V21.0 | IBM |
Referencias
- Frank, M. J., Scheres, A., Sherman, S. J. Understanding decision-making deficits in neurological conditions: insights from models of natural action selection. Philosophical Transactions of the Royal Society B: Biological Sciences. 362 (1485), 1641-1654 (2007).
- Prevost, C., Pessiglione, M., Metereau, E., Clery-Melin, M. L., Dreher, J. C. Separate valuation subsystems for delay and effort decision costs. J Neurosci. 30 (42), 14080-14090 (2010).
- Kennerley, S. W., Walton, M. E. Decision Making and Reward in Frontal Cortex: Complementary Evidence From Neurophysiological and Neuropsychological Studies. Behavioral Neuroscience. 125 (3), 297-317 (2011).
- Kurniawan, I. T., Guitart-Masip, M., Dolan, R. J. Dopamine and Effort-Based Decision Making. Frontiers in Neuroscience. 5, 81 (2011).
- Izquierdo, A., Belcher, A. M. Rodent models of adaptive decision making. Methods Mol Biol. 829, 85-101 (2012).
- Thiebot, M. H., Le Bihan, C., Soubrie, P., Simon, P. Benzodiazepines reduce the tolerance to reward delay in rats. Psychopharmacology. 86 (1-2), 147-152 (1985).
- Green, M. F., Horan, W. P., Barch, D. M., Gold, J. M. Effort-Based Decision Making: A Novel Approach for Assessing Motivation in Schizophrenia. Schizophr Bull. 41 (5), 1035-1044 (2015).
- Fatahi, Z., Sadeghi, B., Haghparast, A. Involvement of cannabinoid system in the nucleus accumbens on delay-based decision making in the rat. Behav Brain Res. 337, 107-113 (2018).
- Iodice, P., et al. Fatigue modulates dopamine availability and promotes flexible choice reversals during decision making. Sci Rep. 7 (1), (2017).
- Rudebeck, P. H., Walton, M. E., Smyth, A. N., Bannerman, D. M., Rushworth, M. F. Separate neural pathways process different decision costs. Nat Neurosci. 9 (9), 1161-1168 (2006).
- Bonnelle, V., et al. Characterization of reward and effort mechanisms in apathy. J Physiol Paris. 109 (1-3), 16-26 (2015).
- Hartmann, M. N., et al. Apathy but not diminished expression in schizophrenia is associated with discounting of monetary rewards by physical effort. Schizophr Bull. 41 (2), 503-512 (2015).
- Lockwood, P. L., et al. Prosocial apathy for helping others when effort is required. Nat Hum Behav. 1 (7), (2017).
- Kobayashi, Y., et al. Genetic dissection of medial habenula-interpeduncular nucleus pathway function in mice. Frontiers in behavioral neuroscience. 7 (17), (2013).
- Hanks, T. D., Summerfield, C. Perceptual Decision Making in Rodents, Monkeys, and Humans. Neuron. 93 (1), 15-31 (2017).
- Lee, D. Decision Making: from Neuroscience to Psychiatry. Neuron. 78 (2), 233-248 (2013).
- Carandini, M., Churchland, A. K. Probing perceptual decisions in rodents. Nature Neuroscience. 16 (7), 824-831 (2013).
- Denk, F., et al. Differential involvement of serotonin and dopamine systems in cost-benefit decisions about delay or effort. Psychopharmacology. 179 (3), 587-596 (2005).
- Walton, M. E., Bannerman, D. M., Rushworth, M. F. S. The Role of Rat Medial Frontal Cortex in Effort-Based Decision Making. The Journal of Neuroscience. 22 (24), 10996-11003 (2002).
- Bardgett, M. E., Depenbrock, M., Downs, N., Points, M., Green, L. Dopamine Modulates Effort-Based Decision-Making in Rats. Behavioral Neuroscience. 123 (2), 242-251 (2009).
- Floresco, S. B., Tse, M. T., Ghods-Sharifi, S. Dopaminergic and glutamatergic regulation of effort- and delay-based decision making. Neuropsychopharmacology. 33 (8), 1966-1979 (2008).
- Assadi, S. M., Yucel, M., Pantelis, C. Dopamine modulates neural networks involved in effort-based decision-making. Neuroscience & Biobehavioral Reviews. 33 (3), 383-393 (2009).
Reimpresiones y Permisos
Solicitar permiso para reutilizar el texto o las figuras de este JoVE artículos
Solicitar permisoThis article has been published
Video Coming Soon
ACERCA DE JoVE
Copyright © 2025 MyJoVE Corporation. Todos los derechos reservados