
Method Article
gP2S,冷冻实验信息管理系统
摘要
gP2S 是跟踪低温实验的网络应用程序。其主要功能被描述,安装和配置应用程序所需的步骤也被描述。一旦配置,应用程序允许准确记录与负污渍和低温EM实验相关的元数据。
摘要
低温电子显微镜(低温显微镜)已成为许多药物发现项目不可或缺的一部分,因为蛋白质靶点的晶体学并不总是可以实现的,低温电子显微镜为支持基于结构的配体设计提供了替代手段。当处理大量不同的项目时,在每个项目中,潜在的大量配体蛋白共构,准确记录的保存会很快变得具有挑战性。许多实验参数针对每个目标进行调整,包括样品准备、网格准备和显微镜阶段。因此,准确记录保存对于实现长期可重复性以及促进高效团队合作至关重要,尤其是在不同操作员执行低温EM工作流程步骤时。为了帮助应对这一挑战,我们开发了一个基于网络的低温信息管理系统,称为gP2S。
该应用程序跟踪每个实验,从样品到最终原子模型,在项目的背景下,在应用中或外部在一个单独的系统中保留一个列表。用户定义的消耗品、设备、协议和软件的受控词汇有助于以结构化的方式描述低温EM工作流程的每一步。gP2S 可广泛配置,根据团队的需求,可能作为独立产品存在,或成为更广泛的科学应用生态系统的一部分,通过 REST API 与项目管理工具集成,跟踪蛋白质或小分子配体生产的应用程序,或自动收集和存储数据的应用程序。用户可以注册每个网格和显微镜会话的详细信息,包括关键实验元数据和参数值,并记录每个实验物的血统(示例、网格、显微镜会话、地图等)。gP2S 是一个低温EM 实验工作流组织者,可为团队提供准确的记录保存,并可在开源许可证下获得。
引言
冷冻机设施的信息管理
从2014年开始,低温电子显微镜(低温EM)1 设施的数量呈爆炸式增长,全球至少安装了300个高端系统2个,其中包括制药公司的一些系统,反映出低温电子显微镜在药物发现3中的作用日益增强。这些设施的任务及其对数据跟踪和管理的要求各有不同。例如,一些国家的低温中心负责接收 EM 网格、收集数据集以及将数据返回给用户进行结构确定,也许在经过一些自动图像处理之后。在此类设施中,跟踪网格的来源、网格与用户建议或授予的关联以及从网格到数据集的血统至关重要,但其他因素(如蛋白质样本的纯化方法或最终结构确定过程)则不太相关,或者根本不相关。在其他设施(如当地学术设施)中,每个最终用户负责准备自己的样品和网格、进行显微镜检查、管理原始数据及其处理和公布结果。此类设施没有严格的元数据跟踪需求,因为此角色由最终用户或其首席调查员履行。
在我们的低温EM设施中,样品、网格、数据收集和处理协议以及结果(地图、模型)的处理和优化将集中在许多项目中,并集中到一小群从业者身上。这给实验(元)数据管理带来了挑战。必须通过网格制备参数和数据收集协议,准确捕获和保存结构的实验系,从原子模型一直到蛋白质和配体的确切身份。这些元数据必须提供给一些人工操作员。例如,进行图像处理的人可能需要知道使用了蛋白质的哪个构造以及成像参数是什么,即使他们既没有纯化蛋白质,也没有自己收集低温EM数据:信息学系统,如自动数据管理,需要识别显微镜目前正在收集数据的项目,以便正确和系统地分配目录名称。
有几个信息管理系统可用于支持低温EM设施。其中最完整的可能是EMEN25,它结合了电子实验室笔记本、信息管理系统和业务流程管理工具的某些元素。ISPyB6用于许多同步加速器,最初用于支持用于晶体学的 X 射线光束线,现在也支持低温图像数据收集。Scipion7 是围绕图像处理包的丰富而强大的包装,允许用户记录图像处理工作流程并共享它们,例如通过公共存储库 EMPIAR8、9,并且还与 ISPyB 集成,以便进行即时低温EM 数据处理。
在这里,我们描述了gP2S(Genentech蛋白质到结构),这是一个现代和轻量级的低温EM信息管理系统,用于支持从纯化蛋白和小分子配体到最终原子模型的工作流程。
gP2S 概述
gP2S 是一种用户友好型网络低温信息管理系统,为低温实验室和多用户、多项目设施提供准确的记录保存。跟踪以下实体、它们的关系和相关元数据:项目、设备、消耗品、协议、样品、网格、显微镜会话、图像处理会话、地图和原子模型。用户还可以添加免费文本评论,可选地包括文件附件,允许对在 gP2S 中注册的任何实体进行丰富的注释。前端设计用于触摸屏设备,并在 12.9" iPad Pros 上进行了广泛的测试,因此在准备样品和网格(图 1)时,以及在计算机操作显微镜、处理图像或沉积模型时,可以在实验室的长凳上使用 gP2S。前端的每一页都旨在尽可能通过预先设置参数来将手动数据输入降低到合理的默认值。
gP2S 的后端具有多个 REST API(REpentent 国家传输应用程序编程接口)端点,因此能够将 gP2S 集成到现有工作流程和脚本中。数据模型旨在准确捕获负污渍和低温EM工作流程,例如,在多个网格上使用一个示例、多个显微镜会话的数据合并为单个数据处理会话,或生成多个地图的一个数据处理会话。
系统架构
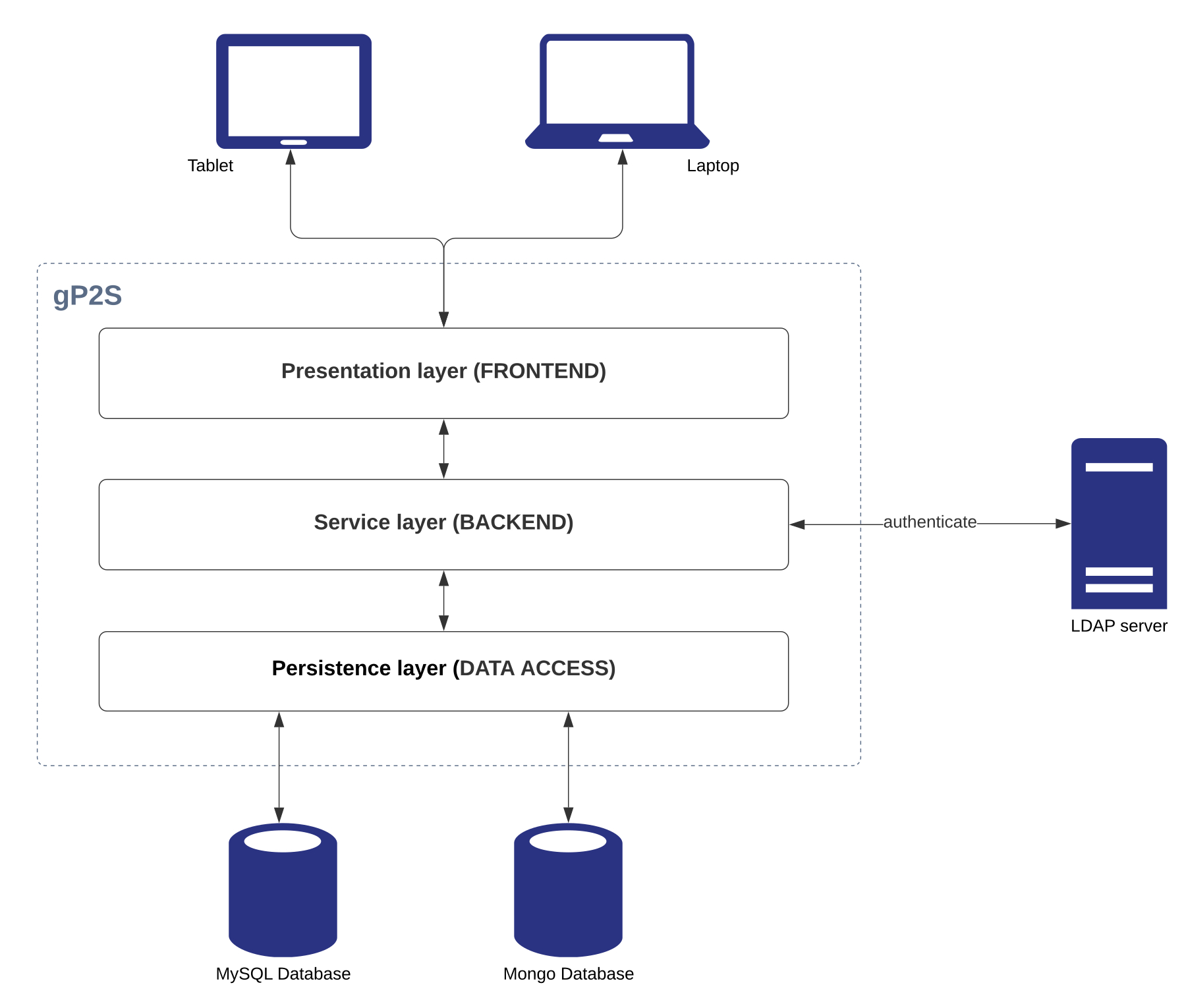
gP2S 是一个经典的三层应用程序 (图 2)。在此模块化架构中,系统被分成三个独立的层,每个层负责执行不同的职责,每个层可替换或可修改,独立于其他层。(1) 演示层(或前端)通过 Web 浏览器(使用 Chrome 和 Safari 进行广泛测试)提供用户访问权限,允许创建和修改工作流元素(包括数据验证),并将实验数据显示为单个实体、基于项目的列表和完整的工作流程报告。(2) 服务层(或后端)是用户界面和存储系统之间的中间层 - 它具有核心业务逻辑,暴露了前端使用的服务 API,与数据存储和 LDAP(轻量级目录访问协议)系统集成,用于用户身份验证,并为与外部系统进行额外集成提供了基础。(3) 持久性层(数据访问)负责存储实验数据、用户评论和文件附件。
关键技术和框架
为了促进gP2S应用的开发、建设和维护,该项目使用了若干技术和框架。最重要的是: Vue .js 2.4.210 前端和 Springboot 1.311 与嵌入式 Tomcat 8 服务器为后端。该应用程序使用 MySQL 5.7 和蒙哥德布 4.0.6 数据库进行存储,使用 LDAP12 进行身份验证。默认情况下,所有这些组件都作为一个应用程序进行发货和部署。
该应用程序总共直接或间接地使用数百个不同的库。最突出的列在 表1中。
数据模型
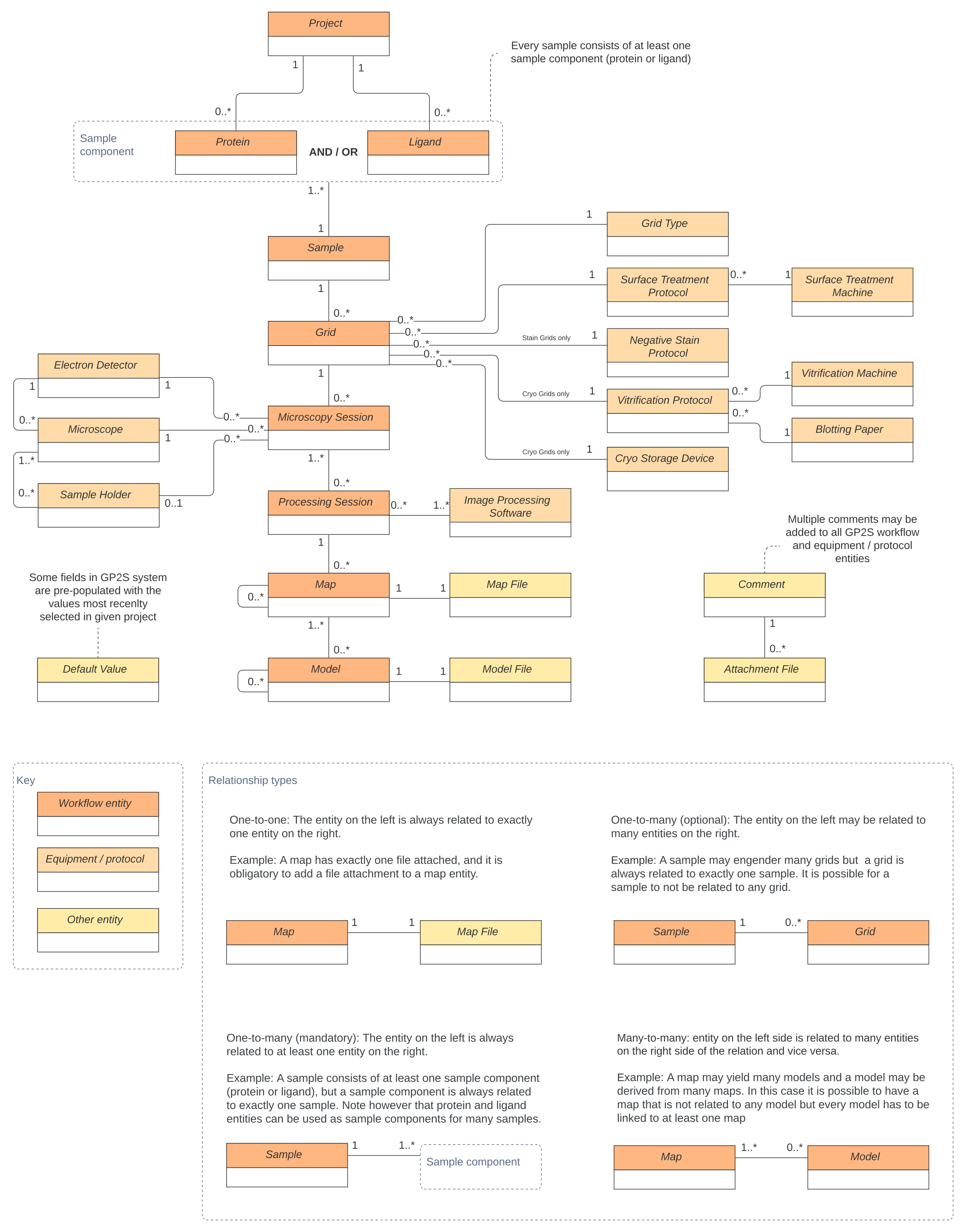
在 gP2S 数据模型(图 3)中可以区分三种类型的实体:与实验期间收集的数据相关的工作流实体(例如样本或显微镜会话):描述所有项目中常见的数据(例如显微镜或玻璃化协议)的设备和协议实体;在系统中发挥支持性或技术作用的其他实体(例如评论或默认值)。
工作流数据树的根源是项目实体。每个项目都包含一些蛋白质和/或利甘德,它们是创建示例实体的构建基块。每个示例可用于创建多个网格,这些网格又用于显微镜会话(每个显微镜会话一个网格)。后者被分配到可以生成一张或多张地图的处理会话。树上的最后一个实体是原子模型,使用一个或多个地图创建。因此,从蛋白质到模型,每个与工作流程相关的实体总是通过其祖先受制于特定的项目。这种设计可创建数据聚合,这些聚合体可以通过前端模块或使用 API 的外部系统轻松处理。
除了工作流程数据之外,还有一些实体描述在准备网格时遵循的实验或协议中使用的设备。定义这些实体是创建实验工作流实体(如网格、显微镜和处理会话)的先决条件。
最后一种类型的数据实体,统称为"其他",用于技术目的(例如,文件附件或默认值)。此类别包括可链接到任何工作流程或设备/协议实体的评论实体。
软件可用性
gP2S 的开源版本可在阿帕奇许可证版本 2.026下提供,从 https://github.com/arohou/gP2S。运行gP2S的码头图像可从 https://hub.docker.com/r/arohou/gp2s。gP2S的一个封闭源分支机构正在罗氏和基因科技继续开发中。
运行gP2S应用程序
运行 gP2S 有两种方法:作为码头容器或独立 Java 应用程序。最佳选择将取决于目标部署环境。例如,如果需要自定义或增强代码以适应用户特定需求的能力,则必须首先重新构建整个应用程序。在这种情况下,可能会建议将 gP2S 作为独立应用程序运行。
码头集装箱
开始使用 gP2S 应用程序的最简单方法是将其作为码头服务运行。为此,在 Docker Hub 存储库("https://hub.docker.com/r/arohou/gp2s")中编写并发布了专用的 Docker 图像。运行 gP2S 图像取决于对 MySQL 和蒙哥德布数据库的访问以及 LDAP 服务器的访问。对于非生产环境,建议将所有这些依赖项与 gP2S 应用程序一起作为多容器 Docker 应用程序运行。为了实现此无缝,在 gP2S GitHub 存储库(https://github.com/arohou/gP2S)中已准备并提供了包含最终环境所有所需配置的码头工人组合文件(https://github.com/arohou/gP2S/blob/master/docker-compose.yml)。以下码头工人图像是依赖性:mysql27,蒙戈德布28,阿帕切德29。
在默认配置中,删除码头容器后,将删除所有存储的数据、实体和文件附件。为了保留数据,应使用码头工人卷,或者应将 gP2S 应用程序连接到专用数据库实例 (MySQL 和 MongoDB)。ApacheDS LDAP 服务器容器附带预配置的管理员用户(密码:密)。这些凭据应用于登录 gP2S 应用程序,当它作为码头服务运行。对于生产环境,可以使用相同的码头工人组合文件来部署 gP2S(如果需要的话,还有其他容器)作为服务到 Docker Swarm 容器编排平台。
将 gP2S 作为 Docker 容器运行的完整过程,包括有关正确配置的所有详细信息,在 gP2S GitHub 存储库中进行了描述,并涵盖以下主题:
•运行与所有依赖的码头化gP2S应用程序。
• 访问gP2S应用程序、数据库和LDAP。
•使用新版本更新gP2S服务。
•删除gP2S应用程序。
•配置数据持久性。
•将焊接的gP2S应用程序连接到专用数据库或LDAP服务器。
• 配置详细信息
独立爪哇应用程序
运行 gP2S 应用程序的另一个选项是构建一个自成一体的 Java 包。如果无法运行 Docker 容器,则应采用此方法。构建 gP2S 应用程序需要安装 Java 开发套件版本 8 或以上。整个构建过程由 Maven 工具管理,该工具在 GitHub 存储库中的代码库中提供。构建配置准备先构建前端部分,然后将其复制到后端源,然后将其构建为最终应用程序。这样,就无需安装任何其他工具或库,以便准备功能齐全的 gP2S 包。默认情况下,生成的结果是 JAR 包(本地存储)和 Docker 图像(推送到配置在 Maven pom .xml 文件中的存储库)。重要的是要记住,连接到外部系统(数据库和LDAP服务器)所需的信息需要在构建包之前以适当的配置文件提供。
创建 gP2S JAR 封装后,它将包含运行应用程序所需的所有依赖关系和配置信息,包括托管系统的 Tomcat 应用程序服务器。如果包是用多个配置文件构建的,则可以在不同模式下运行,而无需重建。
gP2S GitHub 存储库包括构建和运行 gP2S 作为独立应用程序的过程的完整描述,并涵盖以下主题:
•使用马文工具构建gP2S
• 使用嵌入式数据库构建和运行
• 以码头集装箱部署的依赖关系构建和运行
• 使用专用数据库进行构建和运行
• 配置身份验证
研究方案
1. 设置gP2S以供工作
- 登录到gP2S。成功登录后,将显示主屏幕。
注:在右上角显示用户名 - 单击此显示以注销。左侧导航条包括项目选择器(上图)、列出定义低温EM工作流程的实验实体类型(示例、网格、显微镜会话、处理会话、地图和模型)的一组导航项目,以及应用程序设置部分的链接。 - 在记录任何实验之前,在"设置"部分填充有关低温EM设施中使用的项目、设备、消耗品、软件和协议的信息。可以通过添加新的工具和项目以及编辑现有条目随时更新设置:但是,与 gP2S 中的所有实体一样,设置实体一旦创建,就无法删除。
2. 配置至少一个项目
- 导航到 设置>项目。
- 点击 创建新项目。
- 键入项目标签。
- 单击 "保存"。
3. 配置至少一台表面处理机。
注意:表面处理机用于修改 EM 网格的表面特性 - 最常见的是发光放电器或等离子清洁剂。
- 从 设备 部分,选择 表面处理机。
- 点击 创建新机器。
- 输入一个标签,该标签将在以后识别机器。
- 提供其制造商、型号和位置。
- 单击 "保存"。
4. 注册至少一种网格类型。
注:网格类型旨在识别网格模型(例如,"300 网铜网格上的 2-μm 孔状碳膜"),而不是特定批次或大量网格
- 从 消耗品 部分选择 网格类型。
- 单击 "创建新网格类型"。
- 输入网格类型标签、制造商和说明。
- 单击 "保存"。
5. 注册至少一台振动机
- 从 设备 部分,选择 玻璃化机器。
- 点击 创建新机器。
- 提供其制造商、型号和位置。
- 单击 "保存"。
6. 注册至少一张印花纸
- 从 消耗品 部分选择 印迹纸。
- 点击 创建新的印迹纸。
- 键入"印纸"标签、制造商和型号。
- 单击 "保存"。
7. 注册至少一个冷冻存储设备
- 从 设备 部分,选择 冷冻存储设备。
- 单击 "创建新存储设备"。
- 输入设备的制造商、型号和位置。
- 设置切换开关以指定添加的存储设备是否具有气缸、管和/或盒子。
注:如果确实如此,gP2S 将允许用户在用户记录单个网格的存储位置时指定相关的气缸、管和/或框标识符。通过设置上述设备和消耗品,可以创建三种类型的协议 - 表面处理、负污渍和振动。
8. 注册至少一个表面处理协议
- 从 协议 部分,选择 表面处理。
- 点击 创建新协议。
- 输入标签以识别协议。
- 选择一台表面处理机。
- 指定在此协议中使用的设置:放电的持续时间、电流和极性、压力以及大气中的任何添加剂。
- 单击 "保存"。
9. 创建至少一个负污渍协议
- 从 协议 部分,选择 负污渍。
- 点击 创建新协议。
- 输入协议标签。
- 描述污渍,给出其名称、pH值和重金属盐浓度的值。
- 在涂抹前指定污渍的潜伏时间。
- 输入协议的自由文本描述。
- 单击 "保存"。
10. 注册至少一个网格冻结协议
- 从 协议 部分,选择 维他化。
- 点击 创建新协议。
- 输入协议标签。
- 从下拉列表中选择相关的振动机。
- 选择本协议中使用的印迹纸。
- 然后,提供剩余的实验信息:相对湿度、温度、污点力、斑点数量、污点时间、等待时间、排水时间、样品应用次数。
- 输入免费文本描述。
- 单击 "保存"。
注意:在配置了协议后,可以同时创建低温和负污格格。要使用 gP2S 记录工作流程中的后续步骤,从显微镜会话开始,必须配置显微镜、电子探测器和样品保持器。
11. 注册至少一台显微镜
- 从 设备 部分,选择 显微镜。
- 单击 "创建新显微镜"。
- 键入显微镜标签。
- 提供其制造商、型号和位置。
- 从预设的 80、120、200 和 300 kV 列表中选择此显微镜上配置和可用的加速电压。
- 指定已安装的凝结器 ("C2") 和目标孔径列表。注意:对于每种类型,最多可配置 4 个光圈槽,其中一个槽被指定为此显微镜的默认光圈。在客观光圈的情况下,指示一个或多个插槽被相板占用,在这种情况下,直径参数被禁用。
- 指示此显微镜是否配备自动加载器或需要侧入支架。
- 指示显微镜是否装有能量过滤器。
- 为提取电压、枪镜头设置、点大小和能量滤光片狭缝宽度(如果相关)提供默认值。当用户创建显微镜会话时,将使用所提供的值。
12. 注册至少一个电子探测器
- 从 设备 部分,选择 电子探测器。
- 点击 创建新的电子探测器。
- 输入标签、制造商和型号。
- 从安装该探测器的显微镜下拉列表中进行选择。
- 为此显微镜-探测器组合添加至少一个放大校准:
- 在放大倍数下,选择 "添加新"。
- 提供名义放大和校准的放大值。
- 对于预期的所有放大设置,重复这些步骤。这些放大设置稍后将以下拉选择器提供,供记录显微镜会话的用户使用。
- 使用复选框指定探测器是否能够进行电子计数、剂量分馏和超分辨率。
- 最后,提供探测器的其他规格:每个电子数因子计数(事件电子记录的平均计数数)、每个像素的线性维度(以μm计),以及像素的行和柱数。
- 单击 "保存"
13. 如果有一个或多个显微镜需要侧入口样本持有人,请在 gP2S 中注册可用的样本持有人。
- 从 设备 部分,选择 样品持有人。
- 点击 创建新支架。
- 输入标签、制造商、型号和位置。
- 指定样本持有人的最大倾斜度(以度)。
- 使用复选框指定它是否能够保持低温 EM 网格,以及它是否能够双轴倾斜。
- 从下拉列表中,选择使用此支架的所有显微镜。
注意:这将确保只有相关持有人在用户使用侧入显微镜注册显微镜会话时才会列出。 - 单击 "保存"。
14. 指定 gP2S 在设置与每个显微镜会话相关的目录名称时将遵循的模式。
注意:让 gP2S 自动生成目录名称以存储显微镜会话期间记录的图像数据是非常有用的。这确保了存储目录的系统化、信息丰富化命名。指定 gP2S 在设置与每个显微镜会话相关的目录名称时将遵循的模式。
- 从管理员部分,选择 设置。
- 编辑目录名称模式字符串。
注意:此字符串可能包含以下变量:项目标签、网格 ID、网格标签、显微镜会话标签、显微镜会话 ID、显微镜会话开始日期、显微镜会话开始时间以及显微镜标签,按 $\}划定。除了这些变量,目录名称模式可能包含大多数字符。例如,默认目录名称模式是 $[GridLabel] $[显微镜开始更新] [项目标签] [显微镜标签] _格莱格_$[GridID] 会话_$[显微镜研究]。现在,已配置了足够的设置,以便能够注册最多和包括显微镜会话的实验实体。
15. 注册可供用户使用的图像处理软件。
注:这将启用处理会话和以后实体类型(地图和模型)的注册。
- 选择 图像处理。
- 点击 创建新的图像处理软件。
- 键入软件名称
- 列出用户可用的所有版本:
- 在软件版本下,选择 "添加新"。
- 输入软件版本。
注:这将使用户能够在注册图像处理会话时准确指定他们用于达到其结果的软件的哪个版本。这完成了 gP2S 的必要配置。用户现在应该能够准确地捕获描述其电子显微镜实验的关键元数据,如下部分所述。
结果
整体设计和导航模式
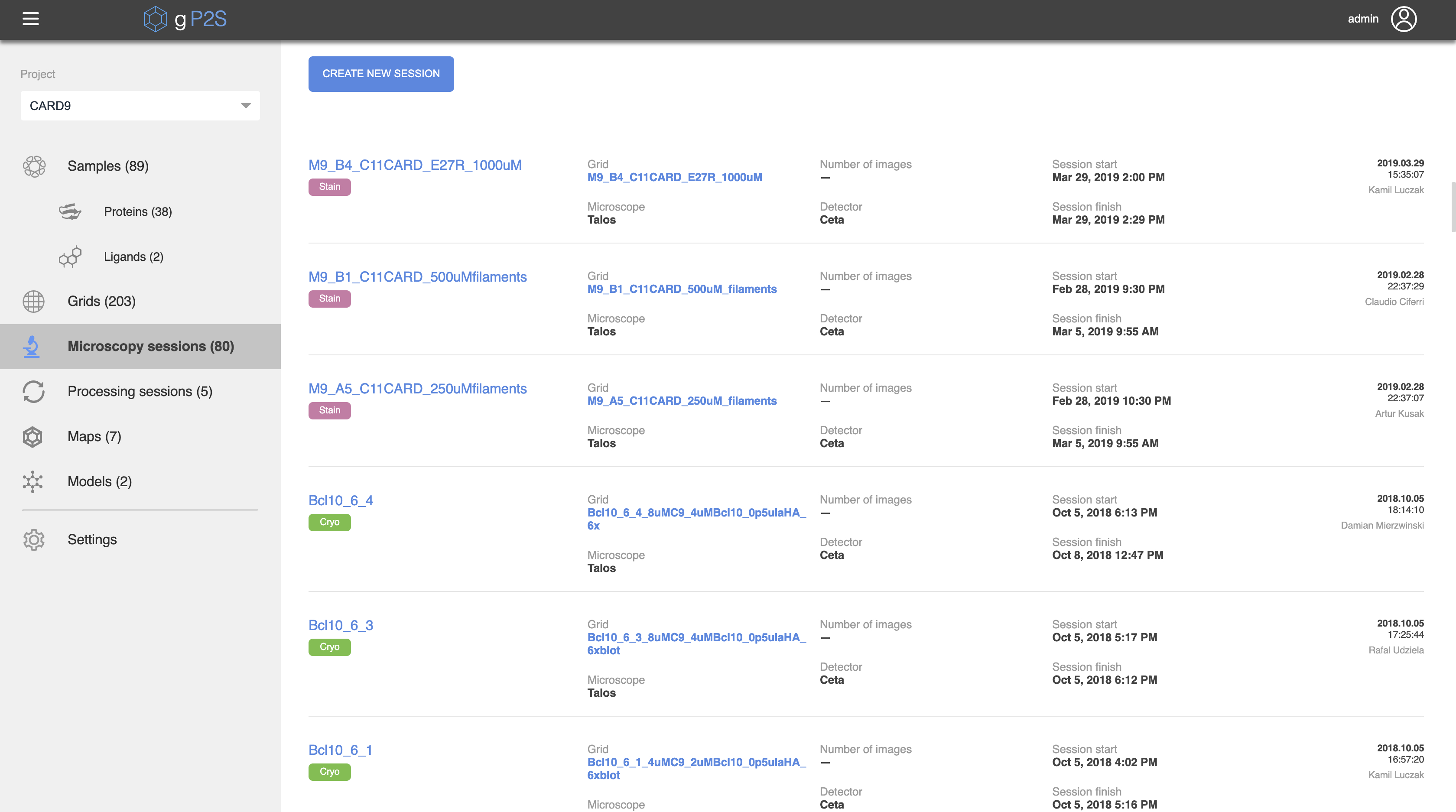
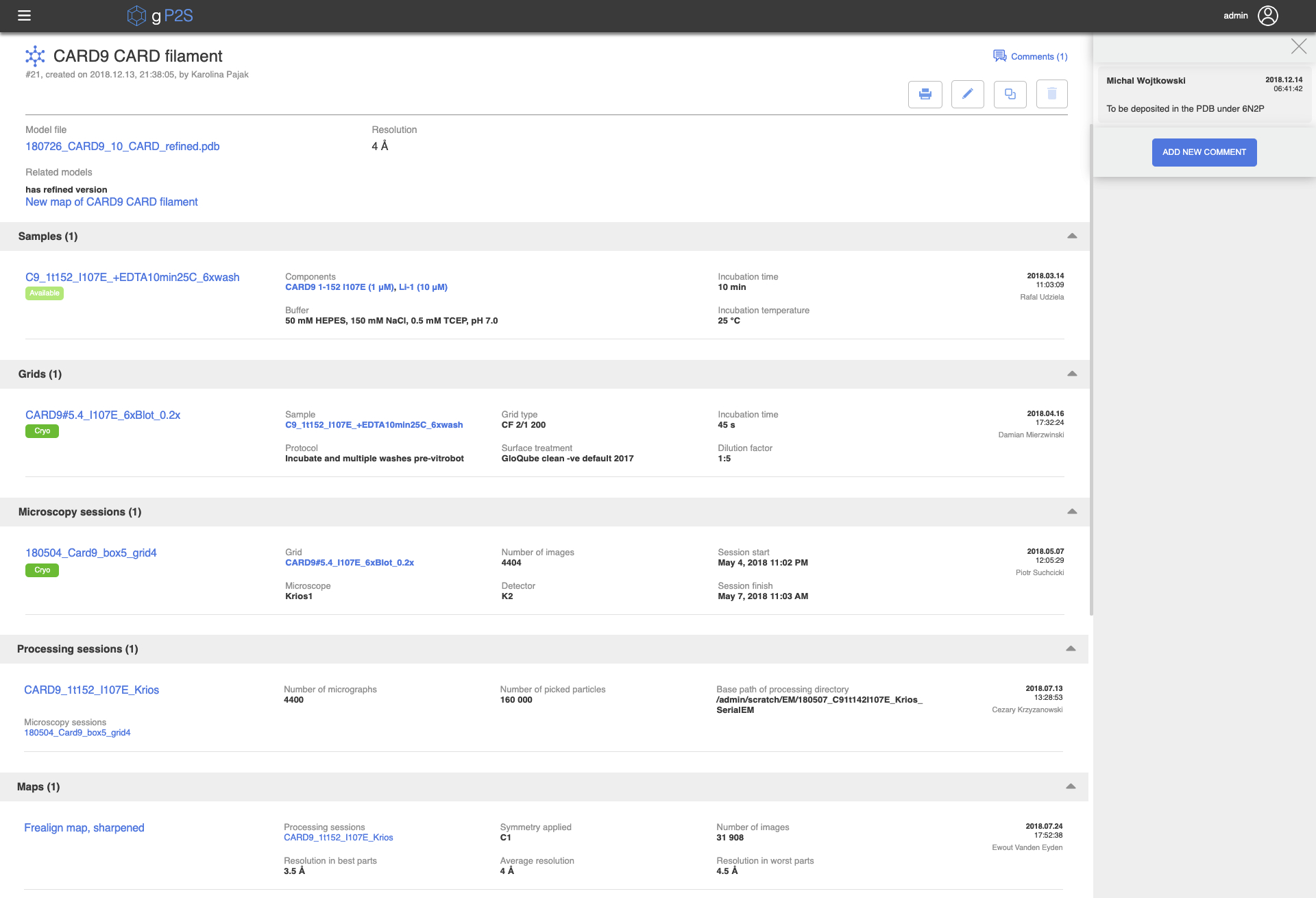
gP2S 应用程序面向项目,因此实体只能在项目上下文中创建。相关项目首先从应用程序左上角附近的下拉下取。为了方便起见,项目列表是可过滤的,并且它与顶部显示的最近使用的项目进行排序。在选择项目时,在左侧导航栏的工作流部分显示与此项目相关的各类型实体的数量。然后,用户可以单击任何工作流实体类型(例如显微镜会话),以显示所选项目中的这些实体列表(图 4)。此列表包括每个实体的标签、创建日期和时间、创建该实体的用户名称、是否对该实体发表了任何评论的指示,以及最多六个关键元数据字段(例如,每个显微镜会话:网格、图像数量、开始和完成时间以及使用了显微镜和探测器)。选择其中一个列出的实体打开一个详细信息页面,列出此项目可用的所有信息,包括所有祖先实体的摘要列表(例如,显微镜会话、其母网格和示例已列出)。这允许通过实体的"血统"进行非常快速的导航,例如允许从原子模型单击导航到示例(图 5)的详细信息。此外,可以通过在其详细信息页面右上角选择"注释"、输入免费文本评论以及可选地附加一个或多个文件来评论 gP2S 中的任何实体。
样品准备
在工作流程的第一步中描述示例。为此,首先定义至少一个成分:蛋白质或利甘德。
添加新的蛋白质只需要一个蛋白质标签,但为了帮助更好地描述蛋白质添加PUR ID(用于纯化标识符)。此字段接受任何文本,例如可以包含大量/批次编号或用作条形码标签的位置。如果 gP2S 已定制为与蛋白质注册系统集成(参见讨论),PUR ID 可以自动验证,并用于检索和显示有关这批蛋白质的详细信息。对于利甘兹来说,标签和库存集中度是强制性信息。所有其他字段都是可选的,包括:概念(条形码、通用名称或其他配体标识符)和批次/批次标识符。同样,如果 gP2S 已配置为与配体注册系统集成,则概念和批次标识符可用于提取和显示描述配体的外部存储数据(例如其化学结构、检测结果)。
样本由蛋白质和利根德及其最终浓度的任何组合定义。可选地指定样品的其他实验细节,如孵化时间和温度、缓冲区和自由文本协议描述。
网格准备
样品准备好后,导航到网格。在列表中,在每个 Grid 的标签下找到一个或两个指示网格类型(低温或污渍)以及该网格是否可供使用的彩色标签。要创建新网格,请选择 创建新网格。键入标签,选择所使用的网格类型和表面处理协议(例如发光放电)。然后,指示是准备低温网格还是负污渍网格,并根据之前选择的网格准备类型,从下拉列表中选择一个预配置的准备协议,该列表中填充了负污渍协议或 Vitration 协议。接下来,从下拉列表中选择适当的示例,并使用切换开关指示样本是否仍然可用(详情请如下)。如果选择稀释或浓缩选定的样品,使用"稀释/浓缩"来表示此情况,并指定相关的稀释或浓度因子。指定应用于网格(μL)的音量,并可选地记录孵化时间。最后,定义网格的存储位置。对于负污渍网格,记录存储箱标签/编号和网格在框中的位置。对于低温网格,首先从列表中选择存储设备,然后根据"设置"中先前定义的 Cryo 存储设备属性为可用和适当的字段(气缸、管和/或框)提供信息。
上述工作流程的各个部分,示例和网格,是库存管理系统的一部分。此功能可跟踪组件是否仍可供使用。
- 蛋白质或利甘德可以从样品水平不可用。创建示例时,为该示例的任何组件选择"最后一滴"标记这些组件无法供将来使用:它们在创建示例时将不再在下降中可用,并且不会在列表视图中标注"可用"标记它们。
- 选定的示例可以通过使用两个切换开关之一标记为不可用 - "可用于网格制作?(根据示例)或"样品可供进一步使用?"(网格下)。
- 要管理网格的可用性,请使用"网格返回存储?" 切换(在显微镜会话下)。默认情况下,此值设置为所有负污渍网格的"是"和低温EM网格的"否"。
数据采集
网格注册后,通过在 gP2S 中创建显微镜会话来注册数据收集实验。显微镜会话是应用跟踪的最复杂的实验实体,分为四个部分:基本信息、显微镜设置、曝光设置和显微镜控制。
第一部分包含基本信息:显微镜会话标签、其开始和结束日期和时间、网格图像、使用显微镜、探测器和样品持有人(如果适用)以及收集了多少图像。创建新的显微镜会话时,系统会自动填写开始日期和时间。完成日期和时间是可选的。这是因为在实验仍在进行中时,会话可能会在系统中注册,因此其结束时间不会确切地知道。如果完成日期和时间不详,请手动键入或使用"现在"按钮输入当前日期和时间。另一种方法是利用 gP2S 不允许在任何给定显微镜上进行多个未完成的显微镜会话这一事实。在同一显微镜上启动新的显微镜会话会话会自动标记任何先前启动的会话是否已完成。
在下一步,选择网格。下拉列表将具有当前项目中的所有可用网格。选择网格后,将看到一些基本信息:创建者和时间,以及应用了什么示例。根据选择的网格类型,显微镜会话将在列表视图上标记为"污渍"或"cryo"。
默认情况下,当前项目中最近使用的显微镜是预先选定的。如果特定显微镜具有定义为自动加载器的样品插入机制,则这是显示为样品持有人的信息。但是,如果选定的显微镜需要使用侧入口持有人,请从配置使用此显微镜的样本持有人列表中选择使用该显微镜的支架(如果选定的网格是低温网格,则仅列出具有低温功能的支架)。
显微镜会话表形式的第二部分包含有关显微镜设置的信息,如提取和加速电压、枪镜头、C2 光圈直径、客观光圈和能量滤光片狭缝宽度。在常规使用期间,这些设置很少更改,因为用户通常不必偏离默认值。
显微镜会话的第三部分包含有关曝光设置的信息。在此部分中,记录以下元数据:放大(像素大小)、点大小、照明区域直径、曝光持续时间以及是否使用了纳米探头、计数模式、剂量分馏和超分辨率(仅在选定的探测器具有这些功能的情况下才能启用计数模式、剂量分馏和超分辨率设置)。如果使用剂量分馏,帧数和暴露率也会记录下来。
为了方便起见,在飞行中计算了一些具有实验重要性的参数,并在表单中显示:最终图像像素大小 (+)、曝光率(电子/+2/s)、总曝光(电子/+2)、帧持续时间(s) 和每帧曝光(电子/+ 2)。
显微镜会话的第四节也是最后一节可用于记录最小和最大目标下聚焦,以及每个孔的暴露次数。
虽然 gP2S 中的显微镜会话可用于注册任何类型的显微镜工作,无论是用于筛选还是数据收集目的,我们发现要求用户专注于注册数据收集会话已经足够且效率更高,并且筛选会话(其中网格仅被短暂检查以进行质量控制)不一定需要注册为显微镜会话。
图像处理
图像处理工作记录在 gP2S 中,作为处理会话实体。每个处理会话都与一个或多个显微镜会话相关,该会话必须从下拉列表中选择。指示使用了哪些软件包(程序和版本),缩微图的数量和拾取的粒子数量。可选地记录处理目录的名称。
地图沉积
一旦获得一个或多个三维重建,地图可以沉积到gP2S中。每个地图都与处理会话关联,包括实际地图文件(通常是 MRC 格式的文件,但 gP2S 允许任何文件类型)和关键元数据:像素大小 (é),建议用于表面渲染的等离子水平、应用什么对称性、用于创建地图的图像数量和估计分辨率:在其最好的和最坏的部分,以及全球平均分辨率。地图可能使用以下类型的关系相互关联:过滤、蒙面、重新采样或精制版本。注册此类关联时,请选择关系类型(例如,"已过滤版本"或"已过滤版本")。
模型沉积
获得原子模型后,可以将其存入 gP2S 的模型部分,用于相关项目。gP2S 第一版中的模型功能是裸骨:除了实际模型文件(通常是 PDB 或 mmCIF 文件),只需要从模型中获取的分辨率(在 é) 和地图(或地图列表)。此外,还可以指示模型是先前存入的模型的精炼版本。其他功能(包括模型验证)正在开发中,将来可能会添加到 gP2S 的开源版本中。
报告
可能需要生成摘要文档,以便分发给协作者,协作者可能无法访问 gP2S,或在文件系统上存档。gP2S 为此提供了报告功能,可通过每个实体详细信息查看页面右上角的打印机图标获得。这将生成一个可打印的 PDF 文件,其中包括描述实体及其每个祖先实体的所有元数据,包括所有注释。此功能在模型沉积后特别有价值,因为所有跟踪最终原子模型血统的数据和元数据都将通过显微镜会话和 Grid(s) 在单个文档中提供。

图1。gP2S在玻璃化实验室的长凳上运行在iPad上。 用户界面设计用于使用触摸屏操作,便于实验室内使用和准确输入元数据。 请单击此处查看此图的较大版本。
{kind=link}

图2:gP2S系统架构。 gP2S遵循经典的三级组织,依靠两个数据库服务器进行数据存储,并依靠LDAP服务器进行用户身份验证。 请单击此处查看此图的较大版本。
{kind=link}

图3:gP2S数据模型。 实体被描绘成矩形(工作流程实体为深橙色,设备和协议为橙色,其他实体类型为黄色),其关系(一对一、一对多、多对多)表示连续行。 请单击此处查看此图的较大版本。
{kind=link}

图4。显微镜会话列表视图。 在此视图中,列出了在选定项目下注册的所有显微镜会话(此屏幕截图中的"CARD9")。绿色或紫色标签区分室温(负污渍)和低温显微镜会话,并列出描述每个会话的一些关键元数据(例如,在最右边注册该标记的用户)。单击显微镜会话的名称可打开该会话的详细视图(模型的详细视图见 图 5中显示)。 请单击此处查看此图的较大版本。
{kind=link}

图5。模型详细信息视图。 页面的上部显示了所选型号的可用元数据。右侧的评论窗格可以通过单击十字架(右上角)或左侧的"注释 (1)"来隐藏。下面,一组图标可生成 PDF 报告(打印机图标,参见主文本)、编辑条目(铅笔图标)或复制条目(双矩形图标)。页面的下半部分包含该模型从示例到地图的所有实体的结构列表。 请单击此处查看此图的较大版本。
{kind=link}
| 库或框架的名称 | 类型 | 版本 |
| 阿帕奇德斯 | LDAP 服务器 | 0.7.0 |
| 码头工人 | 开发工具 | 不适用 |
| 元素 | 图书馆 | 1.4.10 |
| 冬眠 | 图书馆 | 5.0.12 |
| 爪哇岛 | 程序设计语言 | 1.8+ |
| 爪哇脚本 | 程序设计语言 | EcmaScript 2017 |
| 联合 | 图书馆 | 4.12 |
| 业 | 图书馆 | 1.4.1 |
| 马文 | 开发工具 | 3+ |
| 蒙哥德布 | 数据库服务器 | 4.0.6 |
| 迈斯克尔数据库 | 数据库服务器 | 5.7 |
| 节点.js | 框架 | 6.9.1 |
| 萨斯 (节点- 萨斯) | 图书馆 | 4.5.3 |
| 弹簧重新启动 | 框架 | 1.3 |
| 挥舞用户界面 | 图书馆 | 2.6.1 |
| 汤姆卡特 | 应用程序服务器 | 8.5.15 |
| Vue.js | 框架 | 2.4.2 |
| 维埃克利 | 开发工具 | 2.6.12 |
表1。gP2S 使用的库和框架
讨论
如果正确和一致地使用,gP2S 通过使用结构化的数据模型和定义的词汇强制执行关键实验元数据的记录,从而有助于实现高质量元数据的正确记录保存,但只有在实验室中实现高水平合规性时,才能完全实现该数据的附加值。上述协议不包括如何实现此目标。我们发现,有效的执法技术是让显微镜操作员拒绝收集未在 gP2S 中注册的网格上的数据。这迅速推动了合规性的发展,并为在接下来的几个月中出现大量详细准确的实验细节和企业记忆奠定了基础。经过几个月的使用,gP2S 中存储的元数据语料库的价值对大多数用户来说非常明显,以至于在没有明确干预的情况下,合规性仍然很高。
充分利用这种集体存储器,需要存储在 gP2S 中的元数据可供外部系统访问,并且容易与实验数据(微图)和结果(地图和模型)相关联。上述协议没有描述如何将 gP2S 与其他信息学和数据处理系统集成。最直接的是通过gP2S的后端 REST API 进行的潜在集成,不需要对 gP2S 进行任何修改。例如,控制我们数据收集探测器的每台计算机都运行一个脚本,定期在显微镜会话管理 REST 控制器下查询 gP2S 的端点"getItemBy显微镜",以检查显微镜会话是否在其显微镜上进行。如果是这样,脚本从 gP2S 检索到适当的数据存储目录名称(如"设置"页面中配置的,见上文),并使用此名称在本地数据存储设备上创建目录。这确保了数据存储目录的系统命名,并降低了因拼写错误而出错的风险。
虽然在 gP2S 的公共版本源中已对此进行了评论,但还需要进一步集成 gP2S 消耗外部系统的数据。在我们的实验室中,我们部署的 gP2S 与 (i) 项目管理系统集成,以便配置在 gP2S 中的每个项目都可以链接到全公司范围的投资组合项目,并且投资组合中的元数据可以在 gP2S 中显示:(二) 蛋白质登记系统,以便通过当地储存的身份识别器将添加到gP2S中的每一种蛋白质与一整套详细记录联系起来,详细说明蛋白质的来源,包括相关分子生物学、表达系统和纯化的细节:(iii) 一个小分子化合物管理系统,允许gP2S显示有关每个配体的关键信息,如其化学结构。启用这些集成所需的代码修改在从 gP2S 存储库 (https://github.com/arohou/gP2S) 提供的 README-BUILD.md 文档的"集成"部分中进行了描述。
当前版本的 gP2S 有局限性,首先是过于简单化的数据模型和结构(模型)沉积的前端。这是故意留在"裸骨"状态在发布的版本的gP2S,因为一个成熟的结构沉积和验证功能目前正在开发中,同时支持X射线晶体学。另一个设计决定是不实施任何特权或权限系统:gP2S 中的所有用户都可以平等地访问其功能和数据。对于为具有竞争利益和保密要求的用户群体提供服务的设施来说,这可能是一个糟糕的选择,但这不是我们设施所关心的问题。
我们内部版本的 gP2S 正在开发中,我们希望此处描述的开源版本将对其他低温EM组有所帮助,并且一些版本将来可能会提出建议或代码改进。例如,未来的高价值发展可以侧重于与实验室设备(玻璃化机器人、电子显微镜)、软件(例如收集图像处理元数据)和外部公共存储库(例如促进结构沉积)的集成。
通过在实验室和低温EM设施中常规使用 gP2S 实现的高质量元数据的系统收集,可对多年来同时起诉多个项目的能力产生重大而积极的影响。随着越来越多的共享和集中的低温组和设施的建立,我们预计对 gP2S 等信息管理系统的需求将继续增长。
披露声明
所有作者都是罗氏或其子公司Genetech的承包商或雇员。
致谢
作者感谢自项目启动以来一直从事该项目的 gP2S 开发团队的所有其他成员:拉法·乌齐埃拉, 塞扎里·克日尼亚诺夫斯基、普热米索夫·斯坦科夫斯基、雅切克·齐姆斯基、皮奥特·苏奇基、卡罗琳娜·Pająk、埃瓦特·范登·艾登、达米安·米尔兹维斯基、米查·沃伊特科夫斯基、皮奥特·皮库萨、安娜·苏尔达卡卡、卡米尔·乌恰克和阿图尔·库萨克。我们还感谢雷蒙德·哈和克劳迪奥·西费里帮助组建团队并塑造项目。
材料
| Name | Company | Catalog Number | Comments |
| n/a | n/a | n/a | n/a |
参考文献
- Cheng, Y., Grigorieff, N., Penczek, P. A., Walz, T. A Primer to Single-Particle Cryo-Electron Microscopy. Cell. 161 (3), 438-449 (2015).
- . High-End Cryo-EMs Worldwide Available from: https://www.google.com/maps/d/u/0/viewer?mid=1eQ1r8BiDYfaK7D1S9EeFJEgkLggMyoaT (2021)
- Renaud, J. -. P., et al. Cryo-EM in drug discovery: achievements, limitations and prospects. Nature Reviews Drug Discovery. 17 (7), 471-492 (2018).
- Alewijnse, B., et al. Best practices for managing large CryoEM facilities. Journal of Structural Biology. 199 (3), 225-236 (2017).
- Rees, I., Langley, E., Chiu, W., Ludtke, S. J. EMEN2: An Object Oriented Database and Electronic Lab Notebook. Microscopy and Microanalysis. 19 (1), 1-10 (2013).
- Delagenière, S., et al. ISPyB: an information management system for synchrotron macromolecular crystallography. Bioinformatics. 27 (22), 3186-3192 (2011).
- dela Rosa-Trevín, J. M., et al. Scipion: A software framework toward integration, reproducibility and validation in 3D electron microscopy. Journal of Structural Biology. 195 (1), 93-99 (2016).
- . EMPIAR deposition manual Available from: https://www.ebi.ac.u/pdbe/emdb/empiar/depostion/manual/#manScipion (2021)
- Iudin, A., Korir, P. K., Salavert-Torres, J., Kleywegt, G. J., Patwardhan, A. EMPIAR: a public archive for raw electron microscopy image data. Nature Methods. 13 (5), 387-388 (2016).
- . Vue.js Available from: https://vuejs.org (2021)
- . Spring Boot Available from: https://spring.io/projects/spring-boot (2021)
- . Lightweight Directory Access Protocol Available from: https://ldap.com (2021)
- . Vue CLI Available from: https://cli.vuejs.org (2021)
- . Element, A Desktop UI Library Available from: https://element.eleme.io (2021)
- . Sass Available from: https://sass-lang.com/ (2021)
- . Node.js Available from: https://nodejs.org/ (2021)
- . Java Available from: https://www.java.com/ (2021)
- . Hibernate Available from: https://hibernate.org (2021)
- . Swagger UI Available from: https://swagger.io/tools/swagger-ui/ (2021)
- . JUnit Available from: https://junit.org/junit4/ (2020)
- . Apache Maven Project Available from: https://maven.apache.org/ (2020)
- . MySQL Available from: https://www.mysql.com/ (2020)
- . mongoDB Available from: https://www.mongodb.com/ (2020)
- . Apache license, version 2.0 Available from: https://www.apache.org/licenses/license-2.0 (2004)
- . mysql Docker Official Image Available from: https://hub.docker.com/_/mysql (2021)
- . mongo Docker Official Image Available from: https://hub.docker.com/_/mongo (2021)
- . openmicroscopy apacheds Available from: https://hub.docker.com/r/openmicroscopy/apacheds (2021)
转载和许可
请求许可使用此 JoVE 文章的文本或图形
请求许可探索更多文章
This article has been published
Video Coming Soon
版权所属 © 2025 MyJoVE 公司版权所有,本公司不涉及任何医疗业务和医疗服务。