
Un abonnement à JoVE est nécessaire pour voir ce contenu. Connectez-vous ou commencez votre essai gratuit.
Method Article
Cartographie dynamique corticales à l'aide MEG / EEG simultanés et anatomique contrainte minimum-norm Budget: un exemple L'attention auditive
Dans cet article
Résumé
Nous utilisons et magnéto-électroencéphalographie (MEG / EEG), combinées avec des informations anatomiques capturée par imagerie par résonance magnétique (IRM), pour cartographier la dynamique du réseau cortical associé à l'attention auditive.
Résumé
Magnéto-et électro-encéphalographie (MEG / EEG) sont techniques de neuroimagerie offrant une haute résolution temporelle particulièrement adapté pour enquêter sur les réseaux corticaux impliqués dans la dynamique des tâches perceptives et cognitives, telles que la participation à des sons différents dans un cocktail. De nombreuses études antérieures ont utilisé des données enregistrées au niveau du capteur uniquement, c'est à dire., Les champs magnétiques ou les potentiels électriques enregistrés à l'extérieur et sur le cuir chevelu, et ont généralement porté sur une activité qui prend beaucoup de temps enfermé à la présentation du stimulus. Ce type d'événement lié terrain / analyse du potentiel est particulièrement utile quand il ya seulement un petit nombre de modèles distincts dipolaires qui peut être isolée et identifiée dans l'espace et le temps. Sinon, en utilisant des informations anatomiques, ces modèles de terrain distinctes peuvent être localisés en tant que sources actuelles sur le cortex. Cependant, pour une intervention plus soutenue que ne peut-être temps-verrouillé à un stimulus spécifique (p. ex.,en préparation pour l'écoute de l'un des deux simultanément présentés chiffres énoncés basés sur la fonction auditive indicé) ou peuvent être réparties sur plusieurs emplacements spatiaux inconnus a priori, le recrutement d'un réseau distribué corticale peut pas être pris en considération par l'aide d'un nombre limité de sources focales.
Ici, nous décrivons une procédure qui utilise des données d'IRM anatomiques individuelles d'établir une relation entre l'information et l'activation du capteur dipôle sur le cortex grâce à l'utilisation d'un minimum-norm estimations (MNE). Cette approche d'imagerie inverse nous fournit un outil pour l'analyse des sources distribuées. À titre d'illustration, nous allons décrire toutes les procédures à l'aide du logiciel Freesurfer et les entreprises multinationales, à la fois disponibles gratuitement. Nous allons résumer les séquences d'IRM et les étapes d'analyse nécessaires pour produire un modèle direct qui nous permet de relier la forme du champ prévu causés par les dipôles distribués sur le cortex sur les capteurs M / EEG. Next, nous allons passer en revue les processus nécessaires qui nous facilitent en débruitage des données du capteur de contaminants environnementaux et physiologiques. Nous allons ensuite décrire la procédure permettant de combiner et de cartographie MEG / EEG données des capteurs sur l'espace cortical, produisant ainsi une famille de séries chronologiques de l'activation corticale dipôle à la surface du cerveau (ou "films du cerveau») liés à chaque condition expérimentale. Enfin, nous mettrons en évidence quelques techniques statistiques qui nous permettent de tirer toute conclusion scientifique à travers une population de sujets (p. ex., Effectuer l'analyse au niveau du groupe) basée sur un espace de coordonnées corticale commune.
Protocole
1. Anatomique Acquisition et traitement des données
- Acquérir une aimantation préparé gradient rapide d'écho (MPRAGE) IRM du sujet. Cela peut prendre 5-10 minutes selon le protocole de numérisation spécifique est utilisé.
- L'acquisition de deux autres fast low-angle shot (FLASH) IRM (angles de bascule = 5 ° et 30 °) si les données EEG sont utilisés pour l'analyse d'imagerie inverse, comme des séquences FLASH offrent un contraste des tissus différents à partir des séquences MPRAGE standard 1.
- Utilisez Freesurfer logiciel (voir le tableau) 2, 3 de reconstruire la surface corticale et de mettre en place individuelle M / EEG espace source dipôle.
- Cet espace source est contraint à la frontière matière grise / blanche segmentée de l'analyse MPRAGE. Chaque hémisphère contient environ 100.000 sommets potentiels, espacés de ~ 1 mm. Pour l'estimation d'amplitude dipolaire (voir ci-dessous), utilisez un espacement de grille de 7 mm, ce qui donne ~ 3000 dipôles par hémisphère.
- Reconstruirela peau, le crâne externe et des surfaces intérieures du crâne à partir des images MPRAGE et FLASH utilisant MNE (voir tableau) et Freesurfer. Utiliser ces surfaces pour générer un modèle à trois couches limites élément (BEM).
2. M / EEG d'acquisition de données
- Préparer sujet de M / EEG enregistrement.
- Reportez-vous à Liu et al 4 pour les détails de électrooculogramme et la préparation électrode de référence ainsi que la numérisation des monuments les repères du sujet, bobines indicateur de position de tête (HPI) et les électrodes EEG.
- Une fois que l'objet est placé dans le MEG, mesurer la position de la tête en utilisant les bobines de HPI.
- Démarrez l'enregistrement. Début de la présentation de stimuli auditifs et visuels.
- De nombreux matériels et logiciels sont disponibles pour effectuer la présentation du stimulus (p. ex., Présentation, E-Prime). Nous utilisons une Tucker-Davis Technologies Rż6 pour la présentation du stimulus auditif et déclenchement d'emboutissage, avec Psychtoolbox 5 pour visuelles sprésentation timulus, toutes deux contrôlées par MATLAB. Test des latences auditives et visuelles à l'aide d'un microphone et une photodiode attaché à l'écran, puis s'assurer qu'il n'ya pas de gigue observable (ce qui peut nécessiter la mise au projecteur de présentation à sa résolution native) avant l'expérience permet de garantir l'intégrité de synchronisation.
- Sujet répond à des stimuli auditifs et visuels par l'intermédiaire d'une boîte à boutons optique tout en effectuant des tâches comportementales.
- Conservez tous les stimuli, les paramètres expérimentaux et les fichiers de données pour l'analyse hors ligne.
3. M / EEG Co-inscription avec IRM et de traitement des données
- Utilisation du logiciel sur les EMN, charger des données numériseur et reconstruite sujet du modèle social IRM. Choisissez sites repères pour initier la co-registration processus et procéder à recourir à la procédure d'alignement automatique pour compléter la transformation de coordonnées (Figure 2).
- Pour relier l'emplacement de chaque dipôle dans la source de space à l'emplacement de chaque capteur, combiner les données enregistrées HPI (voir 2.2) pour calculer une solution de l'avant avec le BEM trois couches (voir 1.4)
- Inspectez tous enregistrés M / EEG données et d'identifier les canaux qui n'ont écart exceptionnellement élevé ou qui sont complètement à plat. Définissez ces canaux comme canaux mauvaises.
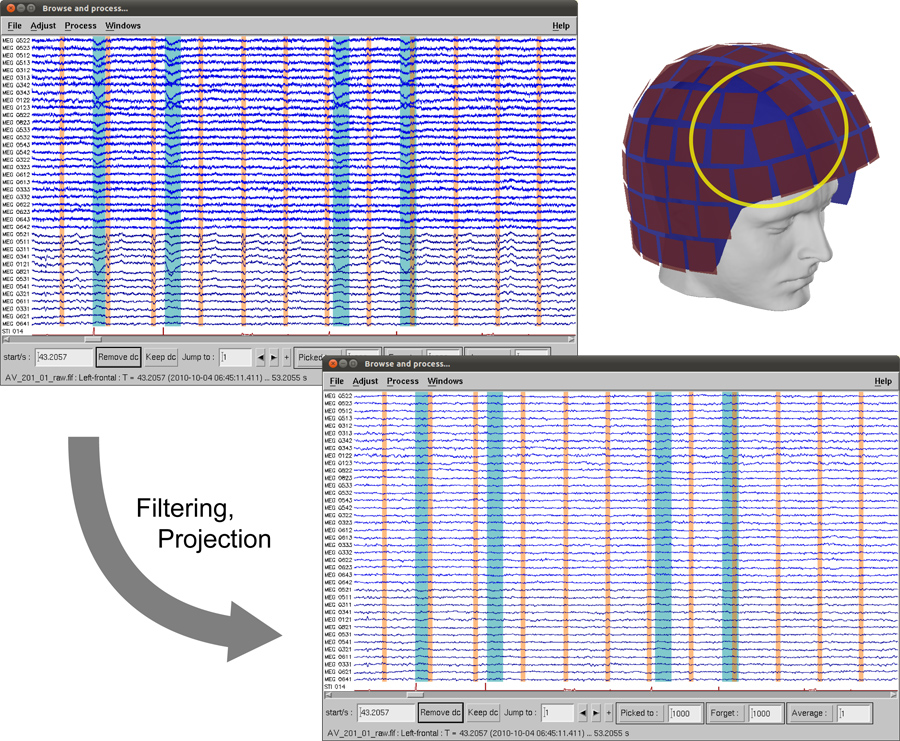
- Utilisez signal-espace de projection 6 ou d'autres techniques de réduction du bruit (comme la séparation d'espace de signal 7) pour projeter ou séparer les modèles de champ spatial origine de la contamination champ ambiant de l'environnement ou d'autres signaux physiologiques indésirables, tels que ceux liés aux oculaires clignote et artefacts cardiaques (Figure 3).
- Appliquer l'élimination des artefacts dans le domaine temporel (p. ex., En supprimant les époques contenant des signaux d'amplitude anormalement élevés en raison de dopage d'un canal) et l'élimination des artefacts dans le domaine fréquentiel (p. ex., Bande-cran filtrage à 50 ou 60 Hz fréquence de ligne) pour augmenter encore rapport signal-bruit.
- Identifier une période de référence où le sujet n'était pas d'effectuer une tâche (p. ex., 200 ms Délai avant le début de chaque essai). Générer une moyenne de ces époques de base afin d'obtenir une estimation de bruit (également connu sous le nom de matrice de covariance).
- Identifier les époques d'intérêt (par exemple, seulement la collecte époques avec bonnes réponses comportementales.) Et définir les conditions de contrastes expérimentales (par exemple, les époques associée à l'objet ayant tourné leur attention auditive à l'hémichamp opposé à l'origine indicé -. "Switch" état - par rapport à l'objet maintien de l'attention sur l'hémichamp originale - "Hold" condition). Générer une réponse moyenne pour chacun de la condition définie.
- Ces moyennes peuvent être corrigées de base-ou non en fonction des paramètres expérimentaux (voir 8), les données présentées ici sont la ligne de base corrigée.
- Combiner la matrice de covariance (3,5) et la solution calculée avant (3,2) pour obtenir unedistribué corticale contraint l'opérateur inverse minimale norme qui concerne les mesures de capteur de dipôles estimations actuelles de l'espace source.
- Vous pouvez soit environ limiter ou corriger l'orientation des dipôles à la direction corticale normale 9.
- Générer un «film cerveau" de l'estimation distribuée dipôle (c'est à dire., L'estimation courante à chaque emplacement dans l'espace de dipôle de source dans le temps) pour chaque condition expérimentale (figure 4).
- Selon les caractéristiques temporelles de votre plan expérimental, vous pouvez bin vos données en temps par la moyenne des estimations actuelles utilisant des méthodes non-chevauchement des fenêtres temporelles.
4. Inférence statistique basée sur un système de coordonnées de surface à base commune
- Morph les films "cerveau" pour chaque sujet sur une commune (en moyenne) d'espace cortical basées sur un système de coordonnées surface qui ne aligne de manière optimale individuelle sulcal-gysieurs modèles 3. Cela nous permet de comparer ou de moyenne activité corticale dans toutes les matières. (Figure 5).
- Il ya beaucoup de différentes approches d'inférence statistique. Nous soulignerons ici trois approches possibles. Les approches qui ne sont pas mises en œuvre dans le progiciel peut être écrite avec le logiciel, personnalisée et nos exemples, nous utilisons MATLAB pour effectuer le test non paramétrique spatio-temporelle de clustering test de permutation. En dépit de la forte dimensionnalité (espace x temps x Sujets) de ces données, l'ensemble de ces approches peuvent être réalisées en utilisant du matériel standard moderne ordinateur de bureau en quelques secondes (ROI; 4.3 Approche) à des heures (non-paramétrique de clustering; 4,5).
- Région d'intérêt (ROI) approche
- Vous pouvez définir le retour sur investissement anatomique (p. ex., Définie par l'algorithme de parcellisation automatique 1) et / ou fonctionnelle (p. ex., En enregistrant une tâche fonctionnelle de localisation, comme un Go / No Go tâche d'identifier la saccade oculomotorégions R).
- Vous pouvez limiter davantage votre analyse à un temps spécifique d'intérêt qui convient à votre paradigme expérimental (p. ex., Une période de temps immédiatement avant et après l'apparition des stimuli sonores). Vous pouvez également utiliser d'autres inférence statistique associée à une analyse chronologique.
- L'ensemble du cerveau Bonferroni ou faux-Discovery-Rate (FDR) de correction
- Employer correction de Bonferroni ou FDR si vous avez besoin du cerveau entier, de tous les temps d'analyse.
- Générer une carte statistique à chaque emplacement dipôle et chaque point à l'aide de tests statistiques appropriés, tels que des t-test ou intra-sujets ANOVA pour les données à peu près normalement distribuée. Par exemple, z-scores de la cartographie des paramètres dynamiques statistique des estimations de sources fixes MNE du dipôle 10 peut être utilisé lorsqu'il est associé à une correction des corrélations dans les estimations (par exemple, le conservateur Greenhouse-Geisser correction).
- Pour Bonferronicorrection, obtenir significatifs espace-temps de points par application d'un seuil à un niveau de signification de 0,05 divisé par le nombre de comparaisons (nombre de dipôles multiplié par le nombre de points dans le temps). Pour une approche moins conservatrice, utilisez FDR p-valeur de correction 11.
- Non-paramétrique de regroupement spatio-temporelle
- Utilisez cette méthode (basée sur une simple extension de 12) pour trouver les régions du grand activation spatiale et temporelle cohérente tout en étant moins conservatrice que la correction de Bonferroni, et moins sujettes à des erreurs statistiques de type I que FDR en contrôlant le taux d'erreur famille-sage .
- Parce que cette approche utilise permutation ou Monte Carlo techniques de ré-échantillonnage, il ne repose pas sur des hypothèses de normalité des données, et suppose seulement que les étiquettes de condition sont échangeables sous l'hypothèse nulle. Bien qu'il soit plus beaucoup de calculs que les deux approches précédentes, il peut encore être effectué en heures sur uneseule machine en utilisant du matériel moderne ordinateur de bureau.
- Générer une carte statistique à chaque emplacement dipôle et chaque point à l'aide des statistiques de test appropriées, comme un t-test.
- Seuil cette carte à un seuil de signification préliminaire, par exemple, p <0,05.
- Cluster ces points putatifs significatives basées sur la proximité spatio-temporelle, par exemple. les points importants à moins de 5 ms et 5 mm de distance géodésique de l'autre sont mis dans le même cluster. Note chaque groupe résultant en utilisant hypervolume ou la signification totale (par ex. Somme de t-scores de points dans le cluster).
- Effectuer un ré-échantillonnage standard de permutation (ou ré-échantillonnage de Monte Carlo pour les grands ensembles de données, par exemple. Certain nombre de sujets N> 10, pour sauver le calcul) test avec une statistique maximale (voir 12 pour des exemples de tests de permutation). En bref, pour un sous-ensemble aléatoire des sujets (choix allant de 0 à N sujets), ré-étiqueter les conditions being comparés avant l'obtention de la carte statistique, effectuez le regroupement sur la nouvelle carte statistique, et obtenir la note maximale de cluster pour que le nouvel étiquetage. Effectuer cette procédure sur de nouveaux relabelings aléatoires jusqu'à 2 N permutations pour obtenir une distribution de la statistique maximale; effectuer tout 2 N relabelings possibles on obtient le test de permutation et en utilisant un sous-ensemble aléatoire de moins de 2 N relabelings donne un Monte Carlo (ou aléatoire ) test de permutation.
- Obtenir la signification d'un groupe donné d'origine (à partir de l'étiquetage d'origine), en déterminant la proportion de temps les dimensions maximales sont de cluster supérieure à celle de la grappe d'origine, par exemple. groupes qui sont plus grandes que 95% des grappes statistiques maximales peut être déclaré significatif.
- Pour une discussion approfondie sur l'inférence statistique en imagerie MEG source distribué, voir 13.
- Utilisez cette méthode (basée sur une simple extension de 12) pour trouver les régions du grand activation spatiale et temporelle cohérente tout en étant moins conservatrice que la correction de Bonferroni, et moins sujettes à des erreurs statistiques de type I que FDR en contrôlant le taux d'erreur famille-sage .
- Les fichiers de données qui en résultent peuvent être vi sualized à bien des égards, notamment en utilisant les formats nativement utilisés par le logiciel MNE pour stocker spatio-temporelles des estimations corticales, nommément limes STC. Ceux-ci, aux côtés des étiquettes qui peuvent être produits correspondant aux régions importantes, peuvent être générés en utilisant des boîtes à outils MATLAB multinationales prévues et Python.
5. Les résultats représentatifs
La figure 6 montre un ensemble de résultats représentatifs en utilisant le paradigme comportemental montre la figure 4. En utilisant la procédure non paramétrique regroupement spatio-temporel (4,5), la FEF droit est considéré comme significatif lorsque le sujet effectue une tâche réorientation par rapport à une tâche standard (figure 6 gauche). En utilisant l'approche ROI (4,3), l'évolution dans le temps de la FEF droite est indiqué, ainsi que la période de temps que ces deux conditions sont sensiblement différentes.
p_upload/4262/4262fig1.jpg "/>
Figure 1. Workflow pour générer un "film cerveau» à l'aide corticale-contrainte minimale norme estimations dipôle (cf. figure 1 de Liu et al., 2010).

Figure 2. MNE logiciels utilisés pour faciliter canaux d'EEG et des lieux HPI co-registration sur un sujet IRM de coordonner l'espace.

Figure 3. Données MEG avant et après l'utilisation de SSP pour enlever cardiaque (surligné en orange) et des yeux clignote (surligné en bleu-vert) des artefacts et filtrage passe-bas pour supprimer la ligne de fréquence. Cliquez ici pour agrandir la figure .
{kind=link}

Figure 4 Un "film cerveaux» natif sujet d'espace cortical et le moment de la présentation audio-visuelle (avec des stimuli auditifs présentés à 600 ms et d'un stimulus visuel présenté à -600 ms) dans un paradigme expérimental (Remarque:. Ce sera présenté comme un film dans le clip final)

Figure 5. Comparaison entre un retour sur investissement hypothétique mappé sur un sujet natif espace cortical et après transformé sur un espace commun corticale.

Figure 6. Représentant spatio-temporelle cluster et évolution temporelle associée à la condition expérimentale deuxtions testé.
Discussion
Afin d'estimer l'activation dipôle sur le cortex des MEG acquis / données EEG, nous avons besoin de résoudre un problème inverse, qui n'a pas de solution unique stable à moins appropriées anatomiquement et physiologiquement contraintes sonores sont appliquées. En utilisant la contrainte anatomique acquis pour les sujets individuels utilisant l'IRM et l'adoption de la norme minimale comme critère d'estimation, nous pouvons arriver à une estimation inverse source de courant qui corticale e...
Déclarations de divulgation
Aucun conflit d'intérêt déclaré.
Remerciements
Les auteurs tiennent à remercier Matti S. Hämäläinen, Lilla Zöllei et trois relecteurs anonymes pour leurs précieux commentaires. Sources de financement: R00DC010196 (AKCL); T32DC000018 (EDL); T32DC005361 (RKM).
matériels
| Name | Company | Catalog Number | Comments |
| Nom du matériel / logiciel | Société / source | ||
| 306-canal Vectorview MEG système | Eleka-Neuromag Ltd, | ||
| 1,5-T scanner IRM Avanto | Siemens Medical Solutions | ||
| Freesurfer | http://freesurfer.net/ | ||
| MNE logiciel | http://www.nmr.mgh.harvard.edu/martinos/userInfo/data/sofMNE.php | ||
| Électrodes EEG | Produits du cerveau, Easycap GmbH | ||
| 3Space Fastrak système | Polhemus | ||
| Boîte à boutons optique (CRF-932) | Current Designs |
Références
- Fischl, B. Automatically parcellating the human cerebral cortex. Cerebral Cortex. 14, 11-22 (2004).
- Dale, A., Sereno, M. Improved localization of cortical activity by combining EEG and MEG with MRI cortical surface reconstruction: A linear approach. Journal of Cognitive Neuroscience. 5, 162-176 (1993).
- Fischl, B., Sereno, M. I., Dale, A. M. Cortical surface-based analysis. II: Inflation, flattening, and a surface-based coordinate system. NeuroImage. 9, 195-207 (1999).
- Liu, H. Functional Mapping with Simultaneous MEG and EEG. Journal of Visualized Experiments. (40), e1668 (2010).
- Brainard, D. H. The Psychophysics Toolbox. Spatial Vision. 10, 433-436 (1997).
- Uusitalo, M. A., Ilmoniemi, R. J. Signal-space projection method for separating MEG or EEG into components. Med. Biol. Eng. Comput. 35, 135-140 (1997).
- Taulu, S., Simola, J., Kajola, M. Applications of the signal space separation method. IEEE Transactions on Signal Processing. 53, 3359-3372 (2005).
- Urbach, T. P., Kutas, M. Interpreting event-related brain potential (ERP) distributions: Implications of baseline potentials and variability with application to amplitude normalization by vector scaling. Biological Psychology. 72, 333-343 (2006).
- Lin, F. -. H., Belliveau, J. W., Dale, A. M., Hämäläinen, M. S. Distributed current estimates using cortical orientation constraints. Human Brain Mapping. 27, 1-13 (2006).
- Dale, A. Dynamic statistical parametric mapping: combining fMRI and MEG for high-resolution imaging of cortical activity. Neuron. 26, 55-67 (2000).
- Nichols, T., Hayasaka, S. Controlling the familywise error rate in functional neuroimaging: a comparative review. Statistical Methods in Medical Research. 12, 419-446 (2003).
- Nichols, T. E., Holmes, A. P. Nonparametric permutation tests for functional neuroimaging: a primer with examples. Human Brain Mapping. 15, 1-25 (2001).
- Pantazis, D., Leahy, R. M., Hansen, P., Kringelbach, M., Salmelin, R. Statistical Inference in MEG Distributed Source Imaging. MEG: An Introduction to Methods. , 245-272 (2010).
- Ahveninen, J. Attention-driven auditory cortex short-term plasticity helps segregate relevant sounds from noise. Proceedings of the National Academy of Sciences. , 1-6 (2011).
- Sharon, D. The advantage of combining MEG and EEG: comparison to fMRI in focally stimulated visual cortex. Neuroimage. 36, 1225-1235 (2007).
- Herrmann, B., Maess, B., Hasting, A. S., Friederici, A. D. Localization of the syntactic mismatch negativity in the temporal cortex: An MEG study. NeuroImage. 48, 590-600 (2009).
- Baillet, S., Hansen, P., Kringelbach, M., Salmelin, R. The Dowser in the Fields: Searching for MEG Sources. MEG: An Introduction to Methods. , 83-123 (2010).
- Gutschalk, A., Micheyl, C., Oxenham, A. J. Neural correlates of auditory perceptual awareness under informational masking. PLoS Biology. 6, e138 (2008).
Réimpressions et Autorisations
Demande d’autorisation pour utiliser le texte ou les figures de cet article JoVE
Demande d’autorisationThis article has been published
Video Coming Soon
À PROPOS DE JoVE
Copyright © 2025 MyJoVE Corporation. Tous droits réservés.