
Method Article
Modélisation immunitaire prédictive des tumeurs solides
Dans cet article
Résumé
L’utilisation d’une approche basée sur l’ARN pour déterminer les profils immunitaires quantitatifs des tissus tumoraux solides et tirer parti des cohortes cliniques pour la découverte de biomarqueurs immuno-oncologie est décrite au moyen d’un protocole moléculaire et informatique.
Résumé
Les immunothérapies montrent la promesse dans le traitement des patients d’oncologie, mais l’hétérogénéité complexe du microenvironnement de tumeur rend la réponse de traitement de prévision provocante. La capacité de résoudre les populations relatives des cellules immunitaires présentes dans et autour du tissu de tumeur s’est avérée médicalement pertinente pour comprendre la réponse, mais est limitée par des techniques traditionnelles telles que la cytométrie de flux et l’immunohistochimie ( IHC), en raison de la grande quantité de tissu nécessaire, l’absence de marqueurs de type cellulaire précis, et de nombreux obstacles techniques et logistiques. Un essai (p. ex., l’immunoprisme ImmunoPrism Immune Profiling Assay) surmonte ces défis en accommodant à la fois de petites quantités d’ARN et d’ARN hautement dégradé, caractéristiques communes de l’ARN extraitdu du tissu tumoral solide cliniquement archivé. L’essai est accessible via un kit réactif et une informatique basée sur le cloud qui fournit une solution d’immunoprofiling quantitative à haut débit de bout en bout pour les plates-formes de séquençage Illumina. Les chercheurs commencent avec aussi peu que deux sections de tissu paraffine-intégré (FFPE) de formaline-fixe (FFPE) ou 20-40 ng de l’ARN total (selon la qualité d’échantillon), et le protocole génère un rapport de profil immunitaire quantifiant huit types de cellules immunitaires et dix évasion immunisée gènes, capturant une vue complète du microenvironnement tumoral. Aucune analyse bioinformatique supplémentaire n’est requise pour utiliser les données obtenues. Avec les cohortes d’échantillon appropriées, le protocole peut également être utilisé pour identifier des biomarqueurs statistiquement significatifs au sein d’une population de patients d’intérêt.
Introduction
Quantification des lymphocytes infiltrants tumorales (TIL) et d’autres molécules liées au système immunitaire dans des échantillons de tissus humains tumeur savants (FFPE) corrigés de la formaline et de la paraffine (FFPE) a démontré de la valeur dans la recherche clinique1,2,3. Les techniques courantes telles que la cytométrie du débit et le séquençage de l’acide ribonucléique unicellulaire (ARN) sont utiles pour les tissus frais et le sang4, mais ne conviennent pas à l’analyse des matériaux FFPE en raison de l’incapacité de créer des suspensions cellulaires viables. Les méthodes actuelles qui ont été employées pour quantifier ces cellules dans le tissu de FFPE souffrent des défis principaux. L’immunohistochimie (IHC) et d’autres flux de travail d’imagerie similaires nécessitent des anticorps spécifiques pour détecter les protéines de surface cellulaire, qui peuvent être difficiles à normaliser entre les laboratoires pour permettre une quantification reproductible5. Les plates-formes telles que le système nCounter s’appuient sur l’expression de gènes uniques pour définir les cellules immunitaires clés6, limitant la sensibilité et la spécificité de la détection. Des méthodes de séquençage plus génériques de l’ARN, couplées à des outils logiciels autonomes, sont disponibles mais nécessitent une optimisation et une validation significatives avant d’utiliser7,8,9,10,11,12. Les progrès récents dans la combinaison de la microdissection de capture de laser (LCM) avec le séquençage d’ARN pour le tissu de FFPE s’est avéré prometteur ; cependant, une solution clé en main plus haut débit est nécessaire pour les études translationnelles visant à identifier les biomarqueurs robustes13,14. Les méthodes pour générer des biomarqueurs multidimensionnels, tels que la modélisation immunitaire prédictive, qui définissent les cohortes de patients, y compris les répondeurs thérapeutiques, les sous-types de cancer, ou les résultats de survie avec une précision prédictive élevée et une signification statistique sont de plus en plus importants à l’ère de la médecine de précision et de l’immunothérapie15,16.
Pour répondre à ce besoin, un test de profilage immunitaire a été développé pour permettre la quantification sensible et spécifique des cellules immunitaires dans le tissu FFPE de tumeur solide utilisant les réactifs normalisés de Séquençage d’ARN et l’informatique basée sur le nuage. En plus d’accommoder l’ARN dégradé du tissu FFPE, le protocole est capable d’adapter l’ARN dérivé des échantillons de tissu limitants tels que des biopsies d’aiguille de noyau, des aspirates d’aiguille, et le tissu micro- ou macro-disséqué. Les données de l’ARN de chaque échantillon sont comparées à une base de données de modèles d’expression génique de cellules immunitaires, appelées modèles immunitaires d’expression de la santé, pour quantifier les cellules immunitaires en pourcentage du total des cellules présentes dans l’échantillon. En bref, ces modèles ont été construits à l’aide de méthodes d’apprentissage automatique pour identifier les modèles d’expression multigéniques uniques à partir de données de transcriptome entier générées à partir de populations de cellules immunitaires purifiées (isolées à l’aide de marqueurs canoniques de surface cellulaire)17,18. Les modèles multidimensionnels d’expression de santé sous-jacents à la technologie permettent à l’analyse de quantifier chaque cellule immunitaire en pourcentage du total des cellules présentes dans le mélange hétérogène. Cela permet au chercheur de générer des comparaisons de cellules immunitaires inter-échantillon et intra-échantillon, qui ont été montrés pour avoir une valeur clinique19,20. D’autres applications incluent la quantification de la réponse immunitaire avant et après le traitement, comme décrit dans les résultats représentatifs. L’analyse rend compte de multiples caractéristiques de la contexture immunitaire de la tumeur et du microenvironnement tumoral, y compris les pourcentages absolus de huit types de cellules immunitaires (dérivés de modèles d’expression génique) : CD4- lymphocytes T, CD8et lymphocytes T, CD56et cellules tueuses naturelles, cD19et cellules B, CD14, monocytes, Tregs, Macrophages M1 et macrophages M2. En outre, l’analyse rapporte l’expression (dans les transcriptions par million, ou TPM) de dix gènes d’évasion immunitaire : PD-1, PD-L1, CTLA4, OX40, TIM-3, BTLA, ICOS, CD47, IDO1, et ARG1.
Le kit de réactif est utilisé pour préparer les bibliothèques de haute qualité à se séquencer sur une plate-forme Illumina selon une méthode hybride de préparation de la bibliothèque basée sur la capture, comme le montre la figure 1. Si un chercheur n’a pas de plate-forme de séquençage de l’illumine dans son laboratoire, il peut soumettre ses échantillons à un laboratoire de base pour le séquençage. Une fois générées, les données de séquençage sont téléchargées sur le portail Prism pour analyse automatisée, et un profil quantitatif complet pour chaque échantillon individuel, sous la forme du rapport immunitaire (figure 2A), est retourné à l’utilisateur. Les utilisateurs peuvent également définir des groupes d’échantillons dans le portail Prism pour générer un rapport sur les biomarqueurs (figure 2B), mettant en évidence des biomarqueurs statistiquement significatifs qui distinguent deux cohortes de patients. Il est important de noter que les données générées par le kit de réactif sont destinées à une utilisation de recherche seulement et ne peuvent pas être utilisées à des fins diagnostiques.

Figure 1 : Aperçu du flux de travail. Dans ce protocole, l’ARN est d’abord converti en cDNA. Les adaptateurs de séquençage sont ligatés, et l’ADNc à ligature adaptateur est amplifié et codé à barres par PCR pour créer une bibliothèque de pré-capture. Les sondes biotinylated sont ensuite hybridées à des cibles spécifiques d’ADNc qui sont ensuite capturées à l’aide de perles de streptavidin. L’ADNc non lié et non ciblé est éliminé par lavage. Un enrichissement final de PCR donne une bibliothèque de poteau-capture prête pour le séquençage. L’ARN total doit être à partir d’échantillons humains; peut être intact ou dégradé (FFPE). Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}

Figure 2 : Rapports immunisés représentatifs. Le flux de travail génère deux rapports, un rapport immunitaire individuel (A) pour chaque échantillon traité, et un rapport de biomarqueur (B) pour les cohortes de patients définies. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
Le protocole nécessite environ 16 h de temps de préparation (de l’ARN total aux bibliothèques prêtes pour le séquençage); cependant, il existe un certain nombre de points d’arrêt facultatifs, comme indiqué dans le protocole. L’analyse utilise la nature riche et dynamique de la transcriptomique pour aller au-delà des biomarqueurs mono-analytes hérités pour les modèles multidimensionnels d’expression génique, permettant ainsi une caractérisation biologique complète des échantillons de tissus avec des modèles normalisés réactifs et des outils logiciels faciles à utiliser. Il permet aux chercheurs d’utiliser une technologie contemporaine dans leur propre laboratoire, en tirant parti de l’apprentissage automatique et d’une base de données de modèles d’expression de la santé pour obtenir des profils immunitaires plus précis et quantitatifs de précieux échantillons cliniques, et découvrir biomarqueurs multidimensionnels de l’ARN avec une analyse statistique complète.
Protocole
Les échantillons de tissus humains utilisés dans les résultats représentatifs présentés ici ont été achetés auprès d’une entité de bonne réputation (TriStar Technology Group) et ont informé le consentement des donateurs permettant la recherche universitaire et commerciale, ainsi que l’approbation d’une éthique compétente Comité.
Partie I : Préparation de la bibliothèque pré-capture
1. Quantification et qualification de l’ARN
- Quantifier l’ARN à l’aide d’un présodiste fluorométrique pour déterminer l’apport approprié à l’organisme. Évaluer la qualité de l’ARN d’entrée à l’aide d’électrophorèse pour déterminer le nombre d’intégrité de l’ARN (RIN) et le pourcentage de fragments de 200 nucléotides (DV200) valeurs.
- Pour les échantillons d’ARN intacts (RIN et 7) ou partiellement dégradés (RIN 2 à 7) suivez les étapes de préparation de la bibliothèque pour l’ARN de haute qualité/intact, en commençant par l’étape 2.1. La qualité de l’ARN est importante pour sélectionner le temps de fragmentation correct dans le programme de cycle thermique #1 (tableau supplémentaire 2).
- Pour les échantillons fortement dégradés (p. ex., RIN 1 à 2 ou FFPE), déterminez la valeur DV200. Ces échantillons ne nécessitent pas de fragmentation et suivront les instructions pour l’ARN dégradé, en commençant par l’étape 2.2.
- Préparer la quantité appropriée d’ARN total pour chaque échantillon pour en diluant 20 ng d’ARN (High-Quality/Intact RNA avec RIN 'gt; 2) ou 40 ng d’ARN (ARN dégradé / FFPE avec DV200 'gt; 20%) à 5 l l dans de l’eau sans nucléane. Le traitement des échantillons avec DV200 lt; 20% n’est pas recommandé. Pour les échantillons d’ARN de contrôle fournis avec le kit, diluer 1 'L de l’ARN approprié dans 4 'L d’eau nucléane. Les échantillons témoins suivront le même traitement que celui décrit pour les matériaux d’ARN de haute qualité (Intact) ou dégradés (FFPE), comme l’étiquette. Voir tableau supplémentaire 1 pour tous les réactifs inclus dans le kit.
2. Fragmentation et primage de l’ARN
- Suivez l’étape 2.1.1 pour l’ARN de haute qualité/Intact avec RIN et 2.
- Pour l’ARN de haute qualité, assemblez la fragmentation et la réaction d’amorçage sur la glace dans un tube PCR sans nucléane selon le tableau 1.
- Mélanger soigneusement en faisant monter et descendre plusieurs fois. Ensuite, faites tourner brièvement les échantillons dans un microcentrifuge
REMARQUE : Pour toutes les rotations de centrifugeuse dans le protocole, une vitesse de 1 000 x g pour au moins 3 s est recommandée. - Placer les échantillons dans un cycleur thermique et utiliser le programme #1 (Tableau supplémentaire 2).
- Transférez immédiatement les tubes sur la glace et passez à la synthèse de l’ADNc First Strand pour l’ARN de haute qualité (étape 3.1). Pour la préparation simultanée de l’ARN de haute qualité et ffPE, commencez la préparation de l’ARN FFPE (Étape 2.2) pendant l’incubation de fragmentation.
- Mélanger soigneusement en faisant monter et descendre plusieurs fois. Ensuite, faites tourner brièvement les échantillons dans un microcentrifuge
- Pour l’ARN de haute qualité, assemblez la fragmentation et la réaction d’amorçage sur la glace dans un tube PCR sans nucléane selon le tableau 1.
| Fragmentation et mélange de priming | Volume (L) |
| ARN intact ou partiellement dégradé (20 ng) | 5 |
| Premier tampon de réaction de synthèse Strand | 4 |
| Amorces aléatoires | 1 |
| Total Volume | 10 |
Tableau 1 : Réaction de fragmentation et d’amorçage pour l’ARN de haute qualité. Les composants de la fragmentation et de la réaction d’amorçage pour l’ARN de haute qualité doivent être assemblés et mélangés sur de la glace en fonction des volumes indiqués. Un mélange maître de First Strand Synthesis Reaction Buffer et Random Primers peut être fait et ajouté aux échantillons d’ARN.
- Suivez l’étape 2.2.1 pour l’ARN dégradé/FFPE avec DV200 -gt; 20%.
- Pour l’ARN fortement dégradé (FFPE) qui ne nécessite pas de fragmentation, assemblez la réaction d’amorçage telle que décrite dans le tableau 2. Pour l’ARN intact, n’oubliez pas de suivre l’étape 2.1.
- Mélanger soigneusement en faisant monter et descendre plusieurs fois. Ensuite, faites tourner brièvement les échantillons dans un microcentrifugeur.
- Placer les échantillons dans un cycleur thermique et utiliser le programme #2 (Tableau supplémentaire 2).
- Transférer les tubes sur la glace et passer à la synthèse de l’ADNc First Strand pour l’ARN hautement dégradé (FFPE) (étape 3.2).
- Pour l’ARN fortement dégradé (FFPE) qui ne nécessite pas de fragmentation, assemblez la réaction d’amorçage telle que décrite dans le tableau 2. Pour l’ARN intact, n’oubliez pas de suivre l’étape 2.1.
| Réaction d’amorçage | Volume (L) |
| ARN FFPE (40 ng) | 5 |
| Amorces aléatoires | 1 |
| Total Volume | 6 |
Tableau 2 : Réaction d’amorçage aléatoire pour l’ARN fortement dégradé. Les composants de la réaction d’amorçage pour l’ARN fortement dégradé devraient être assemblés sur la glace dans un tube PCR nucléal-libre.
3. First Strand cDNA Synthesis
- Suivez l’étape 3.1.1 pour l’ARN de haute qualité/Intact avec RIN et 2.
- Pour l’ARN intact (haute qualité), assemblez la première réaction de synthèse de brin sur la glace dans un tube PCR nucléal-libre selon le tableau 3.
- Garder les réactions sur la glace, bien mélanger en pipetting de haut en bas à plusieurs reprises. Faites brièvement tourner les échantillons dans un microcentrifugeur, et passez directement à l’incubation de synthèse du premier brin (étape 4).
- Pour l’ARN intact (haute qualité), assemblez la première réaction de synthèse de brin sur la glace dans un tube PCR nucléal-libre selon le tableau 3.
| Première synthèse strand | Volume (L) |
| ARN fragmenté et amorcé (étape 2.1.3) | 10 |
| Réactif de la première synthèse strand Specificity | 8 |
| Premier strand Synthesis Enzyme Mix | 2 |
| Total Volume | 20 |
Tableau 3 : Réaction de synthèse du premier brin pour l’ARN de haute qualité. Les composants de la fragmentation et de la réaction d’amorçage pour l’ARN de haute qualité doivent être assemblés et mélangés sur la glace en fonction des volumes donnés. Un mélange maître de First Strand Synthesis Specificity Reagent et First Strand Synthesis Enzyme Mix peut être fait et ajouté aux échantillons d’ARN fragmentés et apprêtés.
- Suivez l’étape 3.2.1 pour l’ARN dégradé/FFPE avec DV200 -gt; 20%.
- Pour l’ARN fortement dégradé (FFPE), assemblez la réaction de synthèse de première ligne sur la glace dans un tube PCR nucléal-libre selon le tableau 4.
- Garder les réactions sur la glace, bien mélanger en pipetting de haut en bas à plusieurs reprises. Faites brièvement tourner les échantillons dans un microcentrifugeur, et passez directement à l’incubation de synthèse du premier brin (étape 4).
- Pour l’ARN fortement dégradé (FFPE), assemblez la réaction de synthèse de première ligne sur la glace dans un tube PCR nucléal-libre selon le tableau 4.
| Première synthèse strand | Volume (L) |
| ARN d’apprêt (étape 2.2.3) | 6 |
| Premier tampon de réaction de synthèse Strand | 4 |
| First Strand Specificity Reagent | 8 |
| Premier strand Synthesis Enzyme Mix | 2 |
| Total Volume | 20 |
Tableau 4 : Première réaction de synthèse des brins pour l’ARN fortement dégradé. Les composantes de la fragmentation et de la réaction d’amorçage de l’ARN fortement dégradé doivent être assemblées et mélangées sur de la glace en fonction des volumes indiqués. Un mélange maître de First Strand Synthesis Reaction Buffer, First Strand Synthesis Specificity Reagent et First Strand Synthesis Enzyme Mix peut être fait et ajouté aux échantillons d’ARN apprêtés.
4. Incubation de synthèse de premier brin
- Garder les tubes sur la glace, bien mélanger en faisant monter et descendre plusieurs fois. Faites brièvement tourner les échantillons dans un microcentrifugeur. Incuber les échantillons dans un cycleur thermique préchauffé suivant le programme #3 (Tableau supplémentaire 2).
5. Deuxième brin cDNA Synthèse
- Préparer la réaction de synthèse de l’ADNc du deuxième brin sur la glace en assemblant les composants énumérés dans le tableau 5, y compris le premier produit de réaction de brin de l’étape 4.1.
| Réaction de synthèse du deuxième brin | Volume (L) |
| Premier produit de synthèse strand (étape 4.1) | 20 |
| Deuxième tampon de réaction de synthèse strand | 8 |
| Deuxième Strand Synthesis Enzyme Mix | 4 |
| Eau sans nucléane | 48 |
| Total Volume | 80 |
Tableau 5 : Réaction de synthèse du deuxième brin. Les composants de la réaction de synthèse de l’ADNc du deuxième brin doivent être assemblés et mélangés sur de la glace en fonction des volumes indiqués. Un mélange maître du second tampon de réaction de synthèse de brin, du mélange d’enzymede de synthèse de deuxième brin, et de l’eau nucléane-libre peut être fait et ajouté au produit de synthèse de premier brin.
- Garder les tubes sur la glace, bien mélanger en faisant monter et descendre plusieurs fois. Incuber dans un cycleur thermique suivant le programme #4 (Tableau supplémentaire 2).
6. Nettoyage de cDNA utilisant des perles SPRI (Solid Phase Reversible Immobilization)
- Laisser les perles SPRI se réchauffer à température ambiante pendant au moins 30 minutes avant utilisation, puis vortex Perles SPRI pour environ 30 s à suspendre.
- Ajouter 144 l de perles resuspensionnées à la réaction de synthèse du deuxième brin (80 l). Bien mélanger en faisant monter et descendre au moins 10 fois et incuber 5 min à température ambiante.
- Faites tourner brièvement les tubes dans un microcentrifugeet placez les tubes sur un support magnétique pour séparer les perles du supernatant. Une fois que la solution est claire, retirez soigneusement et jetez le supernatant. Veillez à ne pas déranger les perles, qui contiennent de l’ADN.
- Ajouter 180 l d’éthanol fraîchement préparé à 80 % dans les tubes sur le support magnétique. Incuber à température ambiante pendant 30 s, puis retirer soigneusement et jeter le supernatant.
- Répétez l’étape 6.4 une fois pour un total de 2 étapes de lavage.
- Retirez complètement l’éthanol résiduel. Laissez les tubes sur le support magnétique et séchez les perles à l’air pendant environ 3 min avec le couvercle ouvert, ou jusqu’à ce qu’ils soient visiblement secs. Ne pas trop sécher les perles, car cela peut entraîner une récupération plus faible de l’ADN.
- Retirez les tubes de l’aimant et ajoutez 53 tampons TE L 0,1x (inclus dans le kit réactif, voir Tableau supplémentaire 1) aux perles. Pipette de haut en bas au moins 10 fois pour bien mélanger. Incuber 2 min à température ambiante.
- Placez les tubes sur un support magnétique, ce qui permet aux perles de se séparer complètement du supernatant. Transférer 50 L du supernatant pour nettoyer les tubes PCR sans nauséabondes. Veillez à ne pas déranger les perles. Il s’agit d’un point d’arrêt facultatif dans le protocole, les échantillons d’ADNc peuvent être stockés à -20 oC.
7. Fin de la réparation de la bibliothèque de l’ADNc
- Assembler la réaction de réparation finale sur la glace en assemblant les composants énumérés dans le tableau 6 au produit de synthèse du deuxième brin de l’étape 6.8.
| Réaction de réparation de fin | Volume (L) |
| Deuxième produit de synthèse strand (étape 6.8) | 50 |
| Tampon de réaction de réparation de fin | 7 |
| Mélange d’enzymes de réparation de fin | 3 |
| Total Volume | 60 |
Tableau 6 : Fin de la réaction de réparation. Les composants de la réaction de réparation final doivent être assemblés et mélangés sur de la glace en fonction des volumes indiqués. Un mélange maître du tampon de réaction de réparation d’extrémité et du mélange d’enzyme de réparation de fin peut être fait et ajouté au produit de synthèse de deuxième brin.
- Placez une pipette à 50 l, puis pipette le volume entier de haut en bas au moins 10 fois pour bien mélanger. Brièvement centrifugeuse pour recueillir tout le liquide sur les côtés des tubes. Il est important de bien mélanger. La présence d’une petite quantité de bulles n’interfère pas avec les performances.
- Incuber les échantillons dans un cycleur thermique suivant le programme #5 (Tableau supplémentaire 2).
8. Ligation adaptateur
- Avant de configurer la réaction de ligature, diluer l’adaptateur dans un tampon de dilution adaptateur glacé comme le montre le tableau 7,en se multipliant par le nombre requis d’échantillons, plus 10 % de plus. Maintenir l’adaptateur dilué sur la glace.
| Ligation Dilution | Volume (L) |
| Adaptateur | 0.5 |
| Tampon de dilution adaptateur | 2 |
| Total Volume | 2.5 |
Tableau 7 : Dilution de l’adaptateur. L’adaptateur doit être dilué sur la glace avec tampon de dilution adaptateur en fonction des volumes indiqués.
- Assembler la réaction de ligature sur la glace en ajoutant les composants décrits dans le tableau 8, dans l’ordre indiqué, au produit de réaction de préparation finale de l’étape 7.3. Notez que le Ligation Master Mix et Ligation Enhancer peuvent être mélangés à l’avance. Ce mélange est stable pendant au moins 8 h à 4 oC. Ne prémélangez pas le Ligation Master Mix, ligation Enhancer et Adaptor avant de l’utiliser dans l’étape de ligation adaptateur.
| Réaction de ligation | Volume (L) |
| Adn préparé de fin (étape 7.3) | 60 |
| Adaptateur dilué (étape 8.1) | 2.5 |
| Améliorateur de ligation | 1 |
| Ligation Master Mix | 30 |
| Total Volume | 93.5 |
Tableau 8 : Réaction de ligation. Les composants de la réaction de ligature de l’adaptateur doivent être assemblés sur glace en fonction des volumes indiqués dans l’ordre indiqué. Un mélange maître de Ligation Enhancer et Ligation Master Mix peut être fait et ajouté à l’ADN prepped fin avec adaptateur dilué. Ne mélangez pas l’Adaptor dilué et le Ligation Master Mix ou Ligation Enhancer avant de mélanger l’ADN final préparé.
- Placez une pipette à 80 l, puis pipette le volume entier de haut en bas au moins 10 fois pour bien mélanger. Effectuer une rotation rapide pour recueillir tout le liquide sur les côtés des tubes. Le Ligation Master Mix est très visqueux. Veillez à un mélange adéquat de la réaction de ligature, car un mélange incomplet se traduira par une efficacité de ligature réduite. La présence d’une petite quantité de bulles n’interfère pas avec les performances.
- Incuber les #6 suivantes du programme (Tableau supplémentaire 2), puis retirer le mélange de ligature du cycle thermique et ajouter 3 l d’Enzyme de traitement adaptateur, résultant en un volume total de 96,5 l.
- Pipette de haut en bas plusieurs fois pour bien mélanger, puis incuber suivant le programme #7 (tableau supplémentaire 2) avant de procéder immédiatement à la purification de la réaction de ligation.
9. Purification de la réaction de ligation à l’aide de neads SPRI
- Laisser les perles SPRI se réchauffer à température ambiante pendant au moins 30 minutes avant utilisation, puis vortex Perles SPRI pour environ 30 s à suspendre.
- Ajouter 87 l de perles SPRI remises en suspension et bien mélanger en faisant monter et descendre au moins 10 fois. Incuber 10 min à température ambiante.
- Faites tourner brièvement les tubes dans un microcentrifugeet placez les tubes sur un support magnétique pour séparer les perles du supernatant. Une fois que la solution est claire (5 min), retirez soigneusement et jetez le supernatant. Ne jetez pas les perles.
- Ajouter 180 l d’éthanol fraîchement préparé à 80 % dans les tubes sur le support magnétique. Incuber à température ambiante pendant 30 s, puis retirer soigneusement et jeter le supernatant. Répétez l’étape 9.4 une fois pour un total de 2 étapes de lavage.
- Retirez complètement l’éthanol résiduel. Laissez les tubes sur le support magnétique et séchez les perles à l’air pendant environ 3 min avec le couvercle ouvert, ou jusqu’à ce qu’ils soient visiblement secs. Ne pas trop sécher les perles, car cela peut entraîner une récupération plus faible de l’ADN.
- Retirez les tubes de l’aimant et ajoutez 17 l de tampon 0,1x TE aux perles. Pipette de haut en bas au moins 10 fois pour bien mélanger. Incuber pendant 2 min à température ambiante, puis placer les tubes sur un support magnétique, permettant aux perles de se séparer complètement du supernatant.
- Transférer 15 l de la supernatante pour nettoyer les tubes PCR sans nauséabondes. Veillez à ne pas déranger les perles. Il s’agit d’un point d’arrêt facultatif dans le protocole, l’ADN adaptateur-ligated peut être stocké à -20 oC.
10. P.R. Enrichissement de l’ADN Ligadis Adaptor
- Configurez la réaction PCR telle que décrite dans le tableau 9. Un Master Mix contenant le Pre-Capture PCR Master Mix et l’Universal Primer peut être fabriqué et ajouté à l’ADN ligaté adaptateur. Pour le séquençage multiplexé, utilisez des amorces d’index uniques pour chaque réaction et ajoutez à chaque échantillon individuellement.
| Enrichissement PCR | Volume (L) |
| Adaptateur d’ADN ligaté (étape 10.1) | 15 |
| Pré-Capture PCR Master Mix | 25 |
| Amorce PCR universelle | 5 |
| Indice (X) Amorce | 5 |
| Total Volume | 50 |
Tableau 9 : Enrichissement PCR de l’ADN ligaté adaptateur. Les composants de l’enrichissement PCR de la réaction d’ADN ligaté de l’adaptateur doivent être assemblés et mélangés sur de la glace en fonction des volumes indiqués. Un mélange maître du Pre-Capture PCR Master Mix et de l’Universal PCR Primer peut être fait et ajouté à l’ADN ligaté de l’adaptateur. Pour le séquençage multiplexé, chaque échantillon doit recevoir une primeur d’index unique.
- Bien mélanger en faisant un tuyauterie en douceur 10 fois. Faites tourner brièvement les tubes dans un microcentrifugeur et placez-les dans un cycleur thermique et effectuez l’amplification de PCR en utilisant le programme #8 (tableau supplémentaire 2).
11. Purification de la réaction PCR à l’aide de perles SPRI
- Laisser les perles SPRI se réchauffer à température ambiante pendant au moins 30 minutes avant utilisation, puis vortex Perles SPRI pour environ 30 s à suspendre.
- Ajouter 45 l de perles resuspendues à chaque réaction PCR (50 l). Bien mélanger en faisant monter et descendre au moins 10 fois, avant d’incuber pendant 5 minutes à température ambiante.
- Faites tourner brièvement les tubes dans un microcentrifugeet placez les tubes sur un support magnétique pour séparer les perles du supernatant. Une fois que la solution est claire (5 min), retirez soigneusement et jetez le supernatant. Veillez à ne pas déranger les perles qui contiennent de l’ADN.
- Ajouter 180 l d’éthanol fraîchement préparé à 80 % dans les tubes dans le support magnétique. Incuber à température ambiante pendant 30 s, puis retirer soigneusement et jeter le supernatant. Répétez l’étape 11.4 une fois pour un total de 2 étapes de lavage.
- Retirez complètement l’éthanol résiduel. Laissez les tubes sur le support magnétique et séchez les perles à l’air pendant environ 3 min avec le couvercle ouvert, ou jusqu’à ce qu’ils soient visiblement secs. Ne pas trop sécher les perles, car cela peut entraîner une récupération plus faible de l’ADN.
- Retirez les tubes de l’aimant et ajoutez un tampon TE de 23 l 0,1x aux perles. Pipette de haut en bas au moins 10 fois pour bien mélanger. Incuber 2 min à température ambiante.
- Placez les tubes sur un support magnétique, ce qui permet aux perles de se séparer complètement du supernatant. Transférer 20 l de la supernatante pour nettoyer les tubes PCR sans nauséabondes. Veillez à ne pas déranger les perles. Il s’agit d’un point d’arrêt facultatif dans le protocole, les bibliothèques pré-capture peuvent être stockées à -20 oC.
12. Valider et quantifier la bibliothèque pré-capture
- Mesurer la concentration de la bibliothèque pré-capture à l’aide d’un fluoromètre et d’une trousse d’analyse à haute sensibilité. Un rendement minimum de 200 ng est requis pour passer à la partie II : Hybridation et capture.
- Exécuter 1 l de bibliothèque sur un système d’électrophoresis numérique. Si nécessaire, diluer l’échantillon pour éviter de surcharger la puce à haute sensibilité, selon les recommandations du protocole du fabricant.
- Vérifier que l’électrophétoygramme montre une distribution étroite avec une taille maximale d’environ 250-400 pb (voir Résultats représentatifs, Figure 3 et Figure 4).
- Si un pic de 128 pb (adaptateur-dimer) est visible dans les traces de Bioanalyzer, et que l’intensité du signal est de 250 à 400 bp de signal de bibliothèque (voir Résultats représentatifs, figure 5), puis faites passer le volume de l’échantillon (de l’étape 11,7) à 50 oL avec 0,1 x TE Buffer et répétez la purification des perles SPRI (étape 11). Il s’agit d’un point d’arrêt facultatif dans le protocole, les bibliothèques de pré-capture peuvent être stockées à -20 oC avant de passer à la partie II: ImmunoPrism Hybridization and Capture.
Partie II : Hybridation et capture
13. Combiner les oligos bloquants, l’ADN Cot-1, l’ADN de la bibliothèque pré-capture et le
- Mélanger la bibliothèque à code-barres préparée à l’étape 11 et Quantifiée à l’étape 12, avec l’ADN Cot-1 et les oligos bloquants dans un tube PCR sans nucléane ou un microtube de 1,5 ml, comme le montre le tableau 10.
| Réactif | Quantité/Volume |
| Bibliothèque à code à barres de l’étape 10.10 | 200 ng |
| Adn Cot-1 | 2 g |
| Blocage des Oligos | 2 l |
Tableau 10 : Préparation et séchage de l’hybridation. Les composants à combiner pour le séchage des bibliothèques en vue de l’hybridation doivent être assemblés en fonction des quantités indiquées.
- Séchez le contenu du tube à l’aide d’un concentrateur à vide réglé à 30-45 oC. Il s’agit d’un point d’arrêt facultatif dans le protocole. Après le séchage, les tubes peuvent être entreposés toute la nuit à température ambiante (15-25 oC) ou plus longtemps à -20 oC.
14. Hybrider les sondes de capture d’ADN avec la bibliothèque
- Dégel 2x Tampon de lavage de perles et tampon d’hybridation, amélioration de tampon d’hybridation, panneau de sonde immunoPrism, 10x tampon de lavage 1, 10x tampon de lavage 2, 10x tampon de lavage 3, et tampon de lavage strict 10x à température ambiante. Avant d’utiliser, inspectez le tampon d’hybridation pour la cristallisation des sels. Si des cristaux sont présents, chauffer le tube à 65 oC, en secouant par intermittence, jusqu’à ce que le tampon soit complètement solubilisé.
- À température ambiante, créez le Master Mix d’hybridation dans un tube. Multipliez les volumes par le nombre d’échantillons et ajoutez 10 % de plus, suivant le tableau 11.
| Mix Maître d’Hybridation | Volume (L) |
| Tampon d’hybridation | 8.5 |
| Amélioration de la mémoire tampon d’hybridation | 2.7 |
| Panneau de sonde ImmunoPrism | 5 |
| Eau sans nucléane | 0.8 |
| Total Volume | 17 |
Tableau 11 : Mix Maître d’hybridation. Les composants du Master Mix d’hybridation doivent être assemblés et mélangés à température ambiante en fonction des volumes indiqués.
- Vortex ou pipette de haut en bas pour bien mélanger. Ensuite, ajoutez 17 L du Master Mix d’hybridation à chaque tube contenant de l’ADN séché. Sceller les tubes et couver pendant 5 min à température ambiante.
- Vortex les échantillons, en s’assurant qu’ils sont complètement mélangés, et faire tourner les échantillons brièvement dans un microcentrifuge. Le cas échéant, transférer chaque échantillon d’un microtube de 1,5 ml à un tube PCR sans nucléane.
- Placer les échantillons dans un cycleur thermique et exécuter le programme #9 (Tableau supplémentaire 2).
- Pendant l’incubation, préparer les tampons de lavage (étape 15) et les perles de streptavidin (étape 16), ce qui laisse suffisamment de temps pour préchauffer les tampons et réquilibrer les perles de streptavidin.
15. Préparer les tampons de lavage
REMARQUE : Les tampons de lavage sont fournis sous forme de solutions concentrées 2x (Tampon de lavage de perles) ou 10fois (tous les autres tampons de lavage).
- Pendant l’incubation de l’hybridation, diluer le tampon de lavage 2x Perles et les tampons de lavage 10x pour créer des solutions de travail 1x, en multipliant par le nombre requis d’échantillons et en ajoutant 10 % de plus, suivant le tableau 12. Si 10x Wash Buffer 1 est nuageux, chauffer la bouteille dans un bain d’eau ou un bloc de chauffage de 65 oC pour resuspendre les particules. Les tampons de lavage 1x congelés doivent être mélangés après la décongélation.
| Laver les tampons | Tampon concentré (L) | Eau sans nucléane (L) | Total (L) |
| Tampon de lavage de perle | 150 | 150 | 300 |
| Laver le tampon 1 | 25 | 225 | 250 |
| Laver le tampon 2 | 15 | 135 | 150 |
| Laver le tampon 3 | 15 | 135 | 150 |
| Tampon de lavage rigoureux | 30 | 270 | 300 |
Tableau 12 : Laver la dilution tampon. Les tampons de lavage de concentration doivent être dilués avec de l’eau sans nucléane à température ambiante en fonction des volumes indiqués.
- Aliquot le 1x Wash Buffers dans des tubes PCR sans nucléane et placer aux températures appropriées comme indiqué dans le tableau 13. Assurez-vous d’inclure un surmenage suffisant pour le tuyauterie. Pour les tampons chauffés, utilisez un cycleur thermique réglé à 65 oC avec le couvercle réglé à 70 oC.
| Laver les tampons | Température de maintien | Volume/Tube (L) | Nombre de tubes/échantillon |
| Tampon de lavage de perle | RT (15-25 oC) | 100 | 3 |
| Laver le tampon 1 | 65 oC | 100 | 1 |
| Laver le tampon 1 | RT (15-25 oC) | 150 | 1 |
| Laver le tampon 2 | RT (15-25 oC) | 150 | 1 |
| Laver le tampon 3 | RT (15-25 oC) | 150 | 1 |
| Tampon de lavage rigoureux | 65 oC | 150 | 2 |
Tableau 13 : Tampons de lavage dilués. Les tampons de lavage dilués doivent être aliquoted dans des tubes séparés en fonction des volumes et du nombre de tubes par échantillon montré. Les tampons de lavage doivent être maintenus à la température indiquée avant utilisation.
- Préparer le mélange de suspension de perles à température ambiante, comme le montre le tableau 14,en multipliant le nombre requis d’échantillons et en ajoutant 10 % de plus.
| Mélange de résuspension de perles | Volume (L) |
| Tampon d’hybridation | 8.5 |
| Amélioration de la mémoire tampon d’hybridation | 2.7 |
| Eau sans nucléane | 5.8 |
| Total Volume | 17 |
Tableau 14 : Mélange de résuspension de perles. Les composants du mélange de resuspension de perle doivent être assemblés et mélangés à température ambiante en fonction des volumes indiqués.
16. Préparer les perles Streptavidin
- Perles de streptavidin equilibrate à température ambiante pendant au moins 30 minutes avant utilisation. Mélanger les perles à fond en vortexant pendant 15 s et aliquot 50 l de perles par capture dans un tube PCR sans nauséabondes.
- Ajouter 100 l de tampon de lavage de perles 1x (préparé à l’étape 15.1) à chaque tube. Doucement pipette de haut en bas 10 fois pour mélanger. Placez le tube sur un support magnétique, ce qui permet aux perles de se séparer complètement du supernatant.
- Retirez et jetez le supernatant clair. Veillez à ne pas déranger les perles.
- Effectuer le lavage suivant.
- Retirer du support magnétique. Ajouter 100 l de tampon de lavage de perles 1x à chaque tube contenant des perles, puis pipette de haut en bas 10 fois pour mélanger.
- Placez le tube dans le support magnétique, permettant aux perles de se séparer complètement du supernatant.
- Retirez soigneusement et jetez le supernatant clair.
- Répétez l’étape 16.4 une fois pour un total de deux lavages.
- Retirer du support magnétique. Ajouter 17 lde de mélange de suspension de perles à partir de l’étape 15.3 à chaque tube. Pipette de haut en bas plusieurs fois pour bien mélanger. Assurez-vous que les perles ne sont pas collées sur les côtés des tubes. Si nécessaire, faites-tourner brièvement les tubes pour recueillir les perles au fond.
17. Lier la cible hybridée aux perles Streptavidin
- Une fois l’incubation de 4 heures d’hybridation terminée, retirez les échantillons du cycleur thermique et fixez le cycleur thermique pour les incuber à 65 oC avec le couvercle chauffé réglé à 70 oC.
- À l’aide d’une pipette multicanal, transférer 17 l de perles entièrement homogénéisées aux échantillons. Mélanger soigneusement en faisant monter et descendre 10 fois.
- Lier l’ADN aux perles en plaçant les tubes dans le cycleur thermique suivant le programme #10 (Tableau supplémentaire 2). Pendant l’incubation, retirer brièvement les tubes à bande toutes les 10-12 min et faire un vortex en douceur pendant 3 s pour s’assurer que les perles restent en suspension. Alternativement, mélanger en pipetting de haut en bas plusieurs fois. Procédez immédiatement à Wash Streptavidin Beads (Étape 18).
18. Laver les perles de Streptavidin pour enlever l’ADN non lié
- Utilisez les tampons de lavage 1x de l’étape 15.2 et entreposez les tampons chauffés dans le cycleur thermique pendant les lavages.
- Ajouter 100 l préchauffés 1x Wash Buffer 1 aux tubes de l’étape 17.3. Mélanger soigneusement en faisant monter et descendre 10 fois. Placez les tubes sur un support magnétique, ce qui permet aux perles de se séparer complètement du supernatant.
- Pipette et jeter le supernatant, qui contient de l’ADN non lié. Retirer du support magnétique.
- Effectuer le lavage suivant de 65 oC.
- Ajouter 150 l de tampon de lavage préchauffé 1x Stringent.
- Mélanger soigneusement en faisant monter et descendre au moins 10 fois. Évitez les bulles pendant le tuyauterie. Assurez-vous que les perles sont complètement remises en suspension dans tous les tubes.
- Incuber dans le cycleur thermique à 65 oC pendant 5 min.
- Placez les tubes sur un support magnétique, ce qui permet aux perles de se séparer complètement du supernatant. Pipette et jeter le supernatant, qui contient de l’ADN non lié. Retirer du support magnétique.
- Répétez l’étape 18.4 pour un total de deux lavages rigoureux.
- Effectuer le premier lavage à température ambiante.
- Ajouter 150 l de température ambiante 1x Tampon de lavage 1.
- Pipette de haut en bas 10 à 20 fois pour resuspendre complètement les perles.
- Sceller les tubes et incuber pendant 2 min, en alternant entre le vortex doucement pendant 30 s et le repos pendant 30 secondes. Assurez-vous que les perles dans tous les puits restent complètement suspendues dans tous les tubes tout au long de l’incubation.
- Brièvement centrifuger les tubes.
- Placez les tubes sur un support magnétique, ce qui permet aux perles de se séparer complètement du supernatant. Pipette et jeter le supernatant.
- Sceller les tubes et brièvement la centrifugeuse. Retournez à la grille magnétique et utilisez une pipette de 10 l pour enlever tout tampon de lavage résiduel.
- Effectuer le lavage à température de la deuxième pièce.
- Ajouter 150 l de température ambiante 1x Tampon de lavage 2.
- Pipette de haut en bas 10 à 20 fois pour resuspendre complètement les perles.
- Sceller les tubes et incuber pendant 2 min, en alternant entre le vortex doucement pendant 30 s et le repos pendant 30 secondes. Assurez-vous que les perles dans tous les puits restent complètement suspendues dans tous les tubes tout au long de l’incubation.
- Brièvement centrifuger les tubes.
- Transférer tout le volume de perles resuspendues dans Wash Buffer 2 pour nettoyer les tubes PCR sans nauséabondes. Important : Il est important de transférer les perles dans des tubes neufs afin d’éviter la contamination hors cible.
- Placez les tubes sur un support magnétique, ce qui permet aux perles de se séparer complètement du supernatant. Pipette et jeter le supernatant.
- Sceller les tubes et brièvement la centrifugeuse. Retournez à la grille magnétique et utilisez une pipette de 10 l pour enlever tout tampon de lavage résiduel.
- Effectuer le lavage de température de la troisième pièce.
- Ajouter 150 l de température ambiante 1x Tampon de lavage 3.
- Pipette de haut en bas 10 à 20 fois pour resuspendre complètement les perles.
- Sceller les tubes et incuber pendant 2 min, en alternant entre le vortex doucement pendant 30 s et le repos pendant 30 secondes. Assurez-vous que les perles dans tous les puits restent complètement suspendues dans tous les tubes tout au long de l’incubation.
- Brièvement centrifuger les tubes.
- Placez les tubes sur un support magnétique, ce qui permet aux perles de se séparer complètement du supernatant. Pipette et jeter le supernatant.
- Sceller les tubes et brièvement la centrifugeuse. Retournez à la grille magnétique et utilisez une pipette de 10 l pour enlever tout tampon de lavage résiduel.
- Retirer de la grille magnétique et ajouter 20 l’eau sans nucléane aux perles.
- Pipette de haut en bas 10 fois pour s’assurer que les perles collées sur le côté des tubes ont été suspendues.
- Important: Ne pas jeter les perles. Utilisez l’ensemble des 20 l de perles rechargées avec de l’ADN capturé à l’étape 19.
19. Effectuer final, Post-capture PCR Enrichment
- Préparer le Post-Capture PCR Master Mix selon le tableau suivant, en multipliant par le nombre requis d’échantillons et en ajoutant 10% de plus, selon le tableau 15.
| Composant de mixage PCR Master | Volume (L) |
| Post-Capture PCR MasterMix | 25 |
| Post-Capture PCR Primer Mix | 1.25 |
| Eau sans nucléane | 3.75 |
| Total Volume | 30 |
Tableau 15 : Mix Master PCR post-capture. Les composants du Master Mix PCR post-capture doivent être assemblés et mélangés sur glace en fonction des volumes indiqués.
- Ajouter 30 L du mix pcR Master Post-Capture à chaque échantillon pour un volume de réaction final de 50 L. Mélanger soigneusement en faisant monter et descendre 10 fois.
- Placez les tubes PCR dans le cycleur thermique et incuber les #11 du programme suivant(tableau supplémentaire 2).
20. Purify Post-capture PCR Fragments
- Laisser les perles SPRI se réchauffer à température ambiante pendant au moins 30 minutes avant utilisation, puis vortex Perles SPRI pour environ 30 s à suspendre.
- Ajouter 75 l de perles resuspendues à chaque capture enrichie de PCR (50 l). Bien mélanger en faisant monter et descendre au moins 10 fois. Les perles de streptavidin n’interféreront pas avec la purification de perles de SPRI. Incuber 5 min à température ambiante.
- Faites tourner brièvement les tubes dans un microcentrifugeet placez les tubes sur un support magnétique pour séparer les perles du supernatant. Une fois que la solution est claire, retirez soigneusement et jetez le supernatant. Veillez à ne pas déranger les perles, qui contiennent de l’ADN.
- Ajouter 180 l d’éthanol fraîchement préparé à 80 % dans le tube dans le support magnétique. Incuber à température ambiante pendant 30 s, puis retirer soigneusement et jeter le supernatant.
- Répétez l’étape 20.4 une fois pour un total de 2 étapes de lavage.
- Retirez complètement l’éthanol résiduel. Laissez le tube sur le support magnétique et sécher à l’air 3 min avec le couvercle ouvert, ou jusqu’à ce qu’il soit visiblement sec. Ne pas trop sécher les perles. Ceci peut avoir comme conséquence la récupération inférieure de l’ADN.
- Retirez le tube de l’aimant. Éluter l’ADN des perles en ajoutant 22 L de 0,1x TE Buffer. Bien mélanger en faisant monter et descendre plusieurs fois. Incuber 2 min à température ambiante. Placez le tube sur le support magnétique jusqu’à ce que la solution soit claire.
- Retirez 20 L du supernatant et transférez-le dans un tube PCR sans nauséabonde propre, en prenant soin de ne pas déranger les perles. Il s’agit d’un point d’arrêt facultatif dans le protocole, les bibliothèques peuvent être stockées à -20 oC.
21. Valider et quantifier la bibliothèque
- Mesurer la concentration de la bibliothèque capturée à l’aide d’un fluoromètre et d’une trousse d’analyse à haute sensibilité.
- Mesurez la longueur moyenne du fragment de la bibliothèque capturée à l’aide d’une puce d’ADN à haute sensibilité électrophorésise numérique et calculez la taille moyenne du fragment pour chaque bibliothèque à l’aide du logiciel système. La taille moyenne des fragments devrait être d’environ 250 à 400 pb (voir Résultats représentatifs, figure 6 et figure 7). Il s’agit d’un point d’arrêt facultatif dans le protocole, les bibliothèques terminées peuvent être stockées à -20 oC.
22. Séquençage sur une plate-forme de séquençage
- Pour le séquençage, diluer les bibliothèques à 2 nM et suivre les directives du fabricant pour le chargement et l’exploitation du séquenceur. Les bibliothèques de séquence à une profondeur minimale de 15 millions de lectures à extrémité unique d’au moins 50 bp de longueur.
23. Analyse des données de séquençage pour générer des profils immunitaires et découvrir des biomarqueurs avec le portail Prism, un outil informatique basé sur le cloud
- Créez un compte Prism en visitant https://prism.cofactorgenomics.com/
- Une fois connecté, cliquez sur Soumettre nouveau projet dans la barre d’outils supérieure à partir de n’importe quelle page dans Prism pour télécharger les fichiers de séquençage FASTQ démultiplexé, ou télécharger des fichiers stockés sur BaseSpace avec le compte Prism.
- Remplissez le nouveau formulaire de projet, y compris le nom du projet et les échantillons par groupe ou cohorte. Le regroupement des échantillons et les noms de groupement correspondants sont nécessaires pour générer le rapport de découverte des biomarqueurs. Notez qu’un minimum de 3 échantillons par groupe sont nécessaires pour produire le rapport de découverte des biomarqueurs. Cliquez sur le bouton Demande de lancement pour soumettre le formulaire; une page de confirmation apparaîtra en cas de succès.
- Lorsque vous vous connectez, cliquez sur Voir Les résultats dans la barre d’outils supérieure ou n’importe quelle page de Prism. Prism permet à un utilisateur de voir l’état des projets soumis et de consulter les rapports d’échantillons et de biomarqueurs par projet. Il y aura une table de projets que l’utilisateur a créé sur Prism. Le tableau comporte trois colonnes pour le statut, le nom et la date de soumission.
REMARQUE : L’état de chaque projet peut être :
« Exécution », où l’analyse de projet est en cours d’exécution, ou,
« Succès », où l’analyse du projet est terminée et où des rapports sont disponibles. - Si un projet a terminé l’analyse (indiquée par un statut de « succès »), consultez les rapports d’échantillons individuels et un rapport de découverte de biomarqueurs. Notez que le rapport de découverte des biomarqueurs ne sera disponible que si le projet comprend le minimum requis de trois échantillons par groupe.
- Pour accéder à ces rapports, retournez à la table des projets et cliquez sur le nom du projet. Sur cette page de projet, il y aura une table avec une rangée pour chaque échantillon dans le projet. Cliquez sur le lien dans chaque ligne, sous la colonne Rapport, pour accéder au rapport individuel de chaque échantillon. Immédiatement au-dessous du tableau, cliquez sur le lien pour le rapport de découverte des biomarqueurs. Si aucun lien n’est dans cette page, votre projet n’a pas terminé l’analyse.
Résultats
Il existe un certain nombre de points de contrôle tout au long du protocole qui permettent à un utilisateur d’évaluer la qualité et la quantité des matériaux générés. Après l’étape 12 décrite dans le protocole, un électrophétogramme est généré comme le montre la figure 3, représentant d’une bibliothèque pré-capture typique pour un échantillon d’ARN intact (RIN 7,8).

Figure 3 : Trace typique de bioanalyseur de la bibliothèque de pré-capture pour un échantillon d’ARN intact. Les bibliothèques pré-captureapparaissent comme un large pic d’environ 250 à 400 paires de base (bp). Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
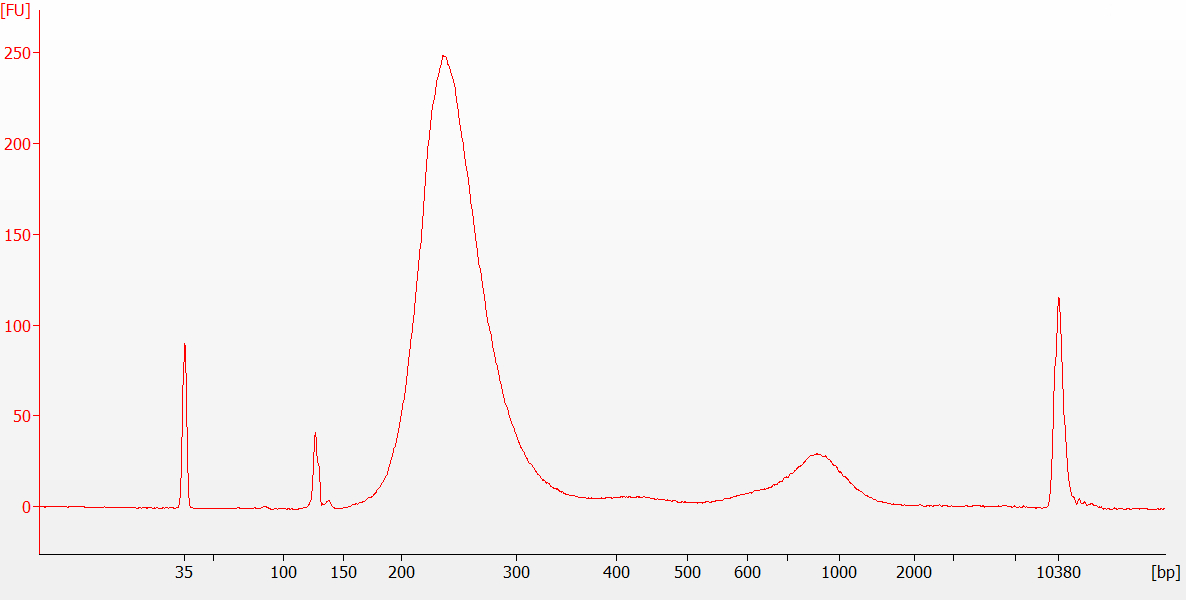
Il faut prendre soin d’éviter la suramplification, comme l’indique le deuxième pic d’environ 1 000 pb indiqué à la figure 4, un électrophétigramme représentatif d’une bibliothèque pré-capture générée à partir d’un échantillon d’ARN FFPE (DV200 à 46). Si ce pic est faible par rapport au pic principal (environ 250-400 paires de base (bp), comme indiqué), il n’interfèrera pas avec les étapes en aval ou l’analyse. Si le deuxième pic est important par rapport au pic de 250-400 pb, la bibliothèque de pré-capture peut être refaite avec moins de cycles PCR afin de réduire la suramplification.

Figure 4 : Trace typique de bioanalyseur de la bibliothèque pré-capture pour un échantillon d’ARN FFPE. Le deuxième pic autour de 1000 bp est révélateur d’une sur-amplification. Si ce pic est faible par rapport au pic principal autour de 250-400 bp (comme indiqué), il n’interférera pas avec les étapes en aval ou l’analyse. Si le deuxième pic est important par rapport au pic de 250-400 pb, la bibliothèque de pré-capture peut être refaite avec moins de cycles PCR afin de réduire la sur-amplification. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
Comme décrit à l’étape 12.1.3, la présence de dieux adaptateurs devrait être évaluée afin de déterminer si un nettoyage supplémentaire est nécessaire. Les électrophétographies présentées à la figure 5 sont représentatives des niveaux inacceptables(figure 5A, DV200 et 33) et acceptables(figure 5B, DV200 à 46) des niveaux de dimère adaptateur, apparaissant comme le pic fort autour de 128 pb.

Figure 5 : Pré-capture de la bibliothèque Bioanalyser traces. Le dimère adaptateur apparaît comme un pic abrupt autour de 128 bp. (A) Des dimères adaptateurs excessifs sont présents dans cet électrophétigramme. (B) Les niveaux acceptables de dimère adaptateur sont représentés dans cette trace. Les deux traces montrent des signes de légère sur-amplification, mais cela ne devrait pas interférer avec l’immunoprisme Assay. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
À l’achèvement du protocole, avant le séquençage, les bibliothèques finales sont à nouveau évaluées à l’aide d’électrophoresis numériques. Les bibliothèques faites à partir de l’ARN FFPE ont tendance à avoir une distribution de taille moyenne plus petite que les bibliothèques faites à partir d’ARN intact. Pour les échantillons d’ARN intacts, la trace résultante devrait ressembler à la figure 6 (RIN no 9,5). Pour l’ARN dégradé ou FFPE, la trace résultante devrait ressembler à la figure 7 (DV200 -36).

Figure 6 : Trace de bioanalyseur de bibliothèque finale typique pour un échantillon d’ARN intact. Les bibliothèques finales apparaissent comme un large pic autour de 250-400 paires de base (bp) de taille. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
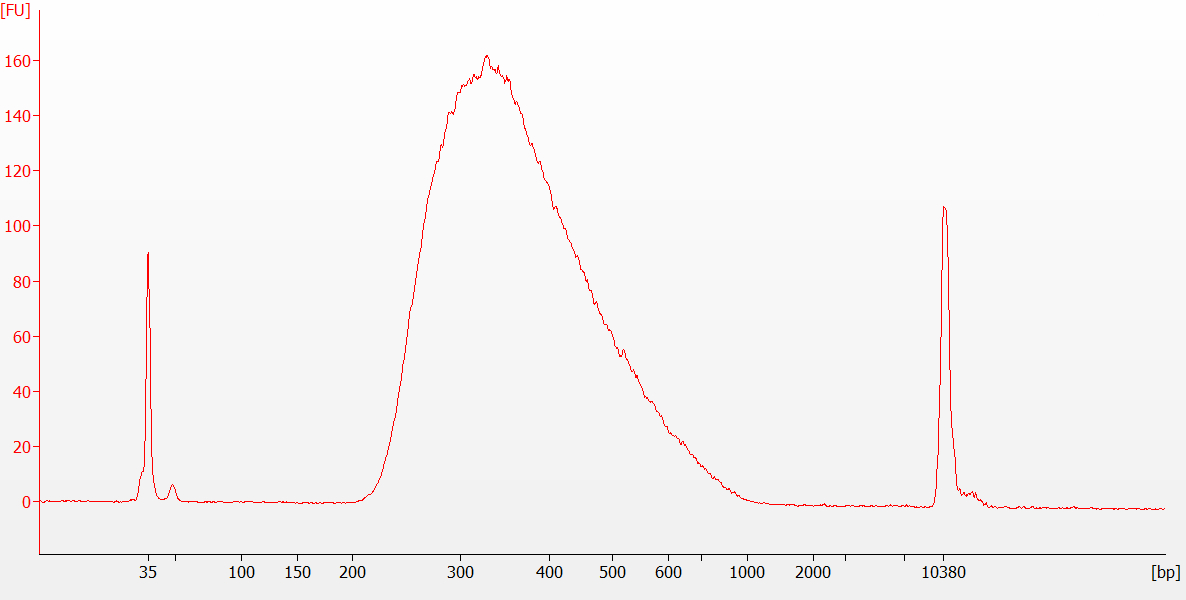{kind=link}

Figure 7 : Trace typique de bioanalyseur de bibliothèque finale pour un échantillon d’ARN de FFPE. Les bibliothèques faites à partir de l’ARN FFPE ont tendance à avoir une distribution de taille moyenne plus petite que les bibliothèques faites à partir d’ARN intact. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
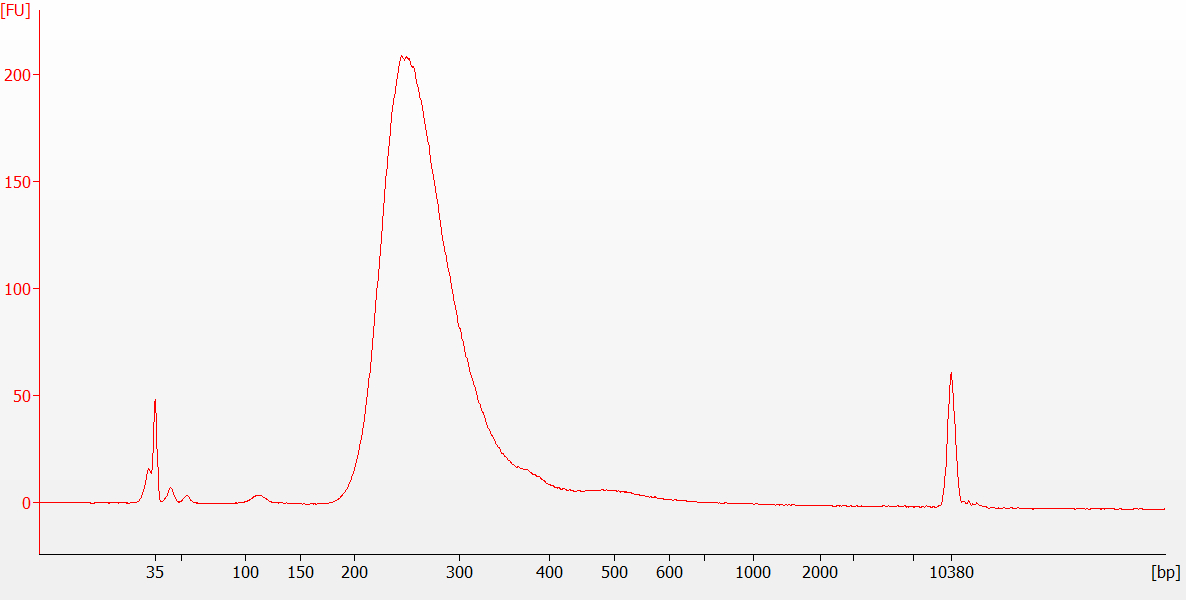{kind=link}
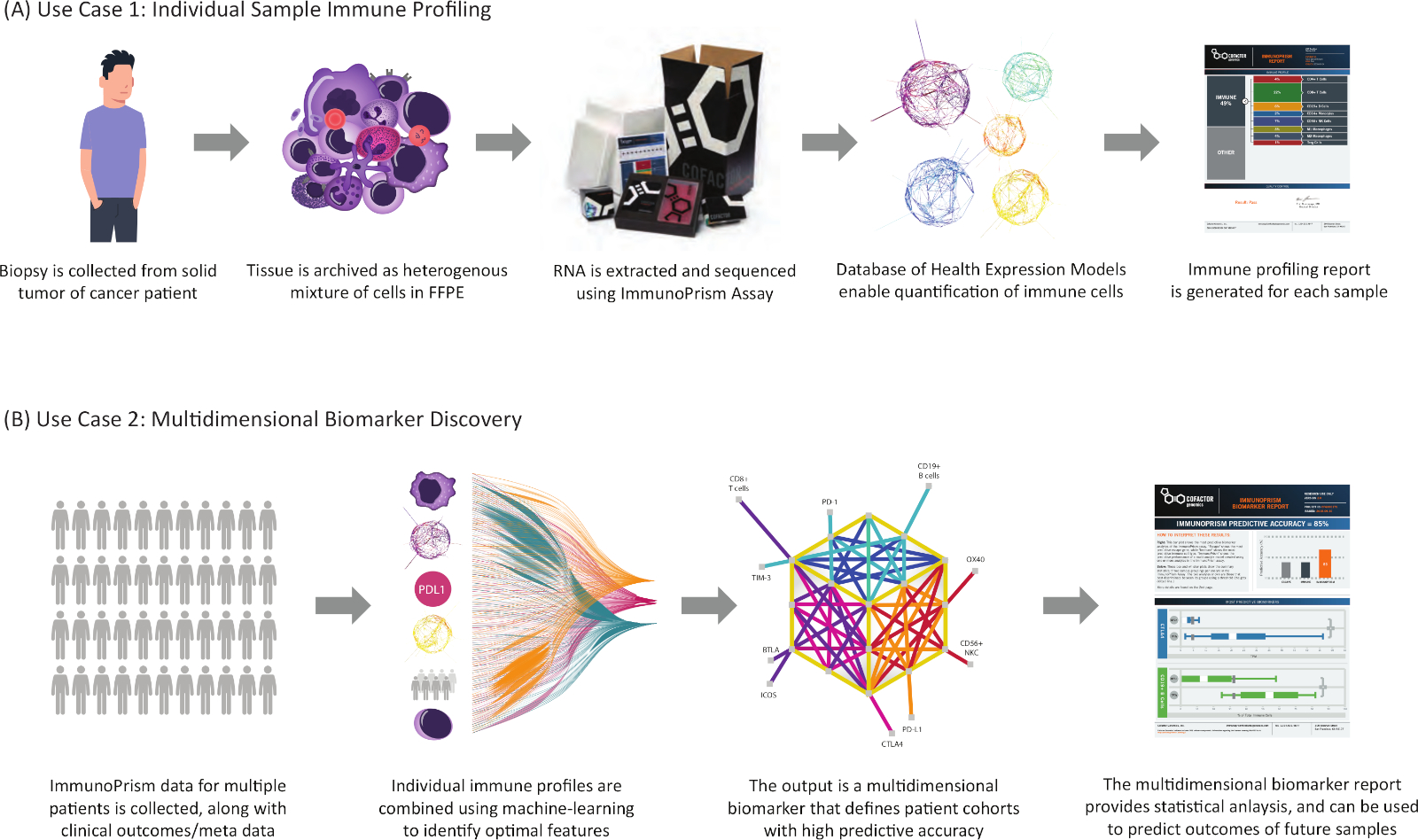
Tel que décrit, les résultats générés par ce protocole peuvent être appliqués de deux façons clés, comme le montre la figure 8.

Figure 8 : Deux cas d’utilisation du protocole. Les résultats générés par cet analyse de profilage immunitaire sont appliqués dans deux applications translationnelles clés. (A) Le premier cas d’utilisation commence à partir du tissu humain solide de tumeur (y compris des archives de FFPE) et génère un profil immunitaire individuel pour l’échantillon. (B) Une fois générées pour une cohorte d’échantillons humains, les données sont combinées à l’aide du portail Prism pour générer un biomarqueur multidimensionnel et un rapport de biomarqueur correspondant. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
Pour démontrer chacun de ces cas d’utilisation, les données représentatives d’une petite étude translationnelle sont incluses21. Les échantillons utilisés dans cette étude sont un ensemble de spécimens de 7 patients diagnostiqués et traités pour un cancer du poumon non à petites cellules (NSCLC). Les échantillons sont des tissus tumoraux solides appariés par le patient provenant de biopsies avant et après le traitement. Premièrement, des échantillons individuels ont été analysés pour générer un profil immunitaire, comme le rapport d’exemple présenté à la figure 9.

Figure 9 : Exemple de rapport immunitaire individuel pour un échantillon de NSCLC. Le pipeline Prism Portal génère un rapport graphique pour chaque échantillon traité, avec un rapport représentatif généré pour un échantillon de tumeur solide NSCLC montré ici. (A) La partie avant du rapport représente graphiquement la dégradation des cellules immunitaires présentes dans l’échantillon d’ARN extrait du tissu FFPE. (B) L’envers du rapport comprend un tableau des cellules immunitaires (en pourcentages absolus) et l’expression des gènes d’évasion (dans les transcriptions par million, ou TPM), ainsi qu’une déclaration de performance pour l’analyse. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
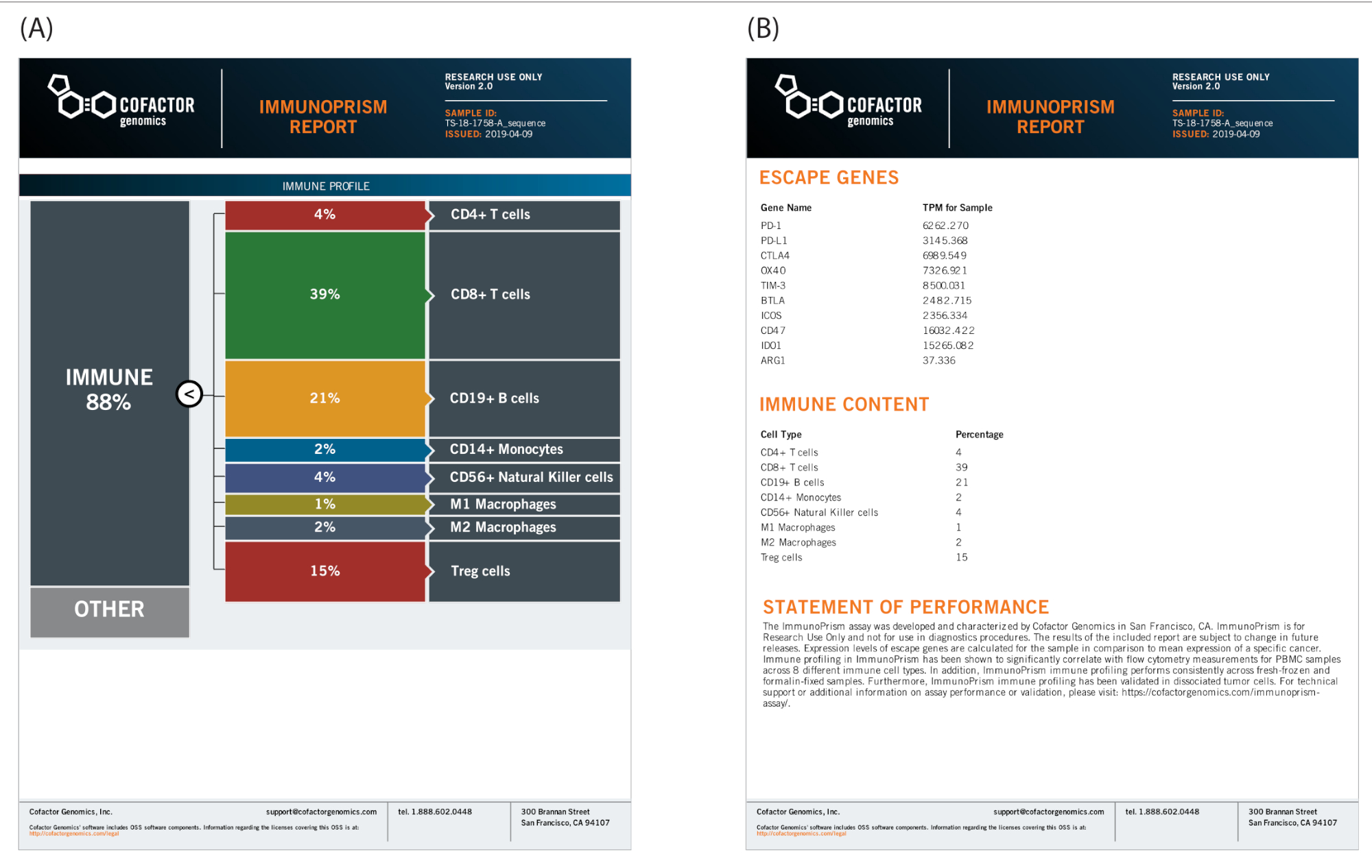{kind=link}
Les profils immunitaires avant et après le traitement peuvent être utilisés pour comprendre comment une thérapie (chimiothérapie ou radiothérapie, dans cette étude) a modifié le microenvironnement tumoral. Un exemple est montré à la figure 10, où les changements en pourcentage pour chaque cellule immunitaire et le contenu immunitaire total sont montrés avant et après la chimiothérapie, pour un seul patient.

Figure 10 : Exemple de résultats avant et après le traitement. Des données individuelles sur les cellules immunitaires et le contenu immunitaire total générées à partir d’échantillons avant et après le traitement d’un seul patient de NSCLC sont montrées. Dans cet exemple, le patient a reçu un régime de chimiothérapie comme traitement. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
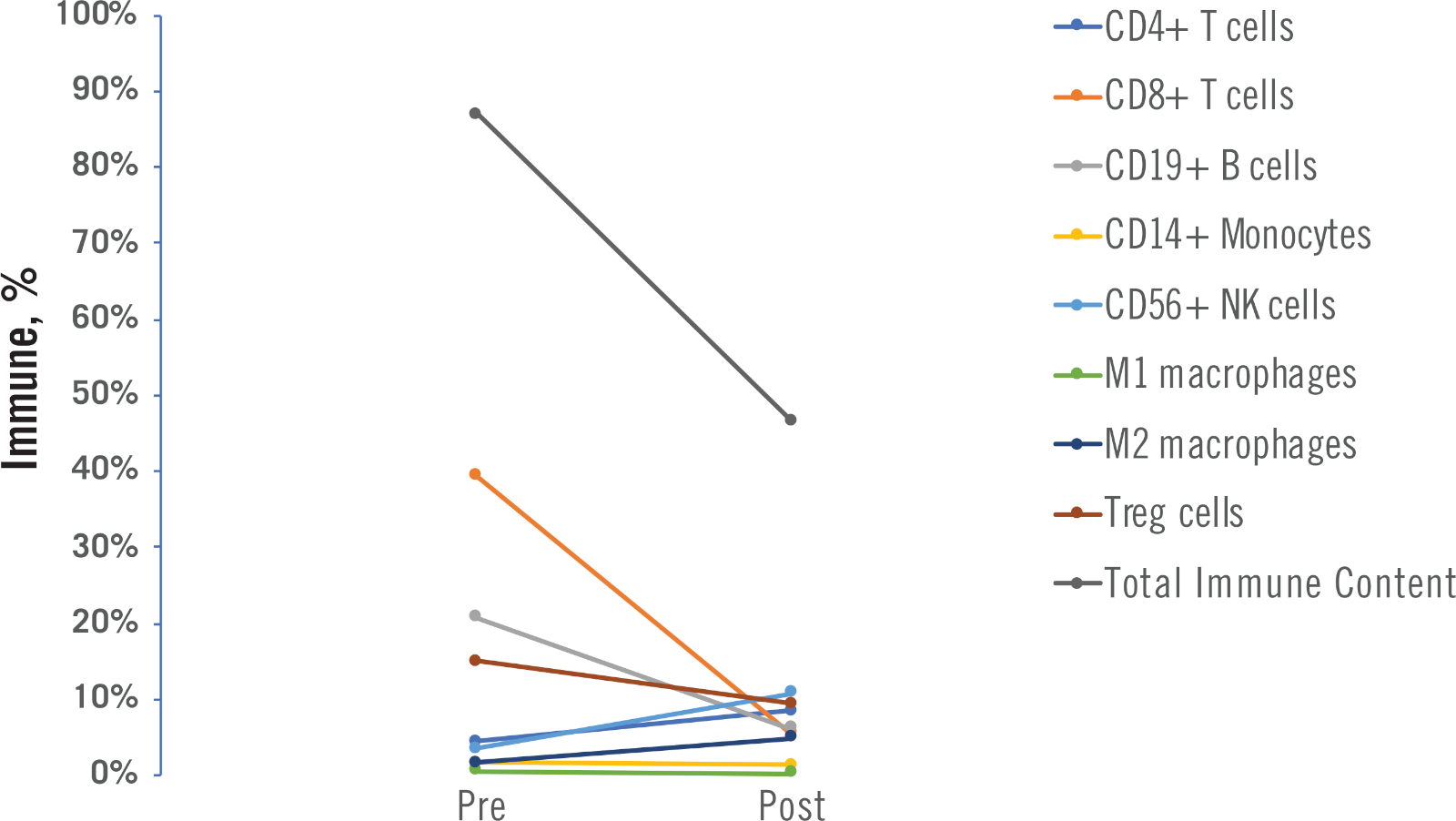{kind=link}
Les patients peuvent être regroupés par des critères tels que les résultats cliniques ou les phénotypes à des fins de comparaison. Par exemple, à la figure 11, les échantillons de l’étude du NSCLC ont été comparés en fonction du temps à la progression de la maladie après le traitement. Un sous-ensemble des patients a montré la répétition de la maladie dans les mois de 'gt;18, et un autre sous-ensemble a progressé plus rapidement, en '18 mois. La valeur médiane du delta (différence entre les valeurs avant et après le traitement) est comparée pour chaque échantillon afin d’identifier les biomarqueurs putatifs de la progression de la maladie.

Figure 11 : Exemple de comparaison des résultats cliniques. Les variations quantitatives entre les pourcentages de cellules immunitaires dans les échantillons de NSCLC avant et après le traitement ont été calculées et déclarées comme la valeur « delta ». Ceux qui sont mis en évidence en jaune montrent des changements de signal clairs entre l’état de survie. Les barres bleues représentent les valeurs médianes du delta pendant 18 mois jusqu’à la progression de la maladie, les barres oranges représentent les valeurs médianes du delta pendant 18 mois jusqu’à la progression de la maladie. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
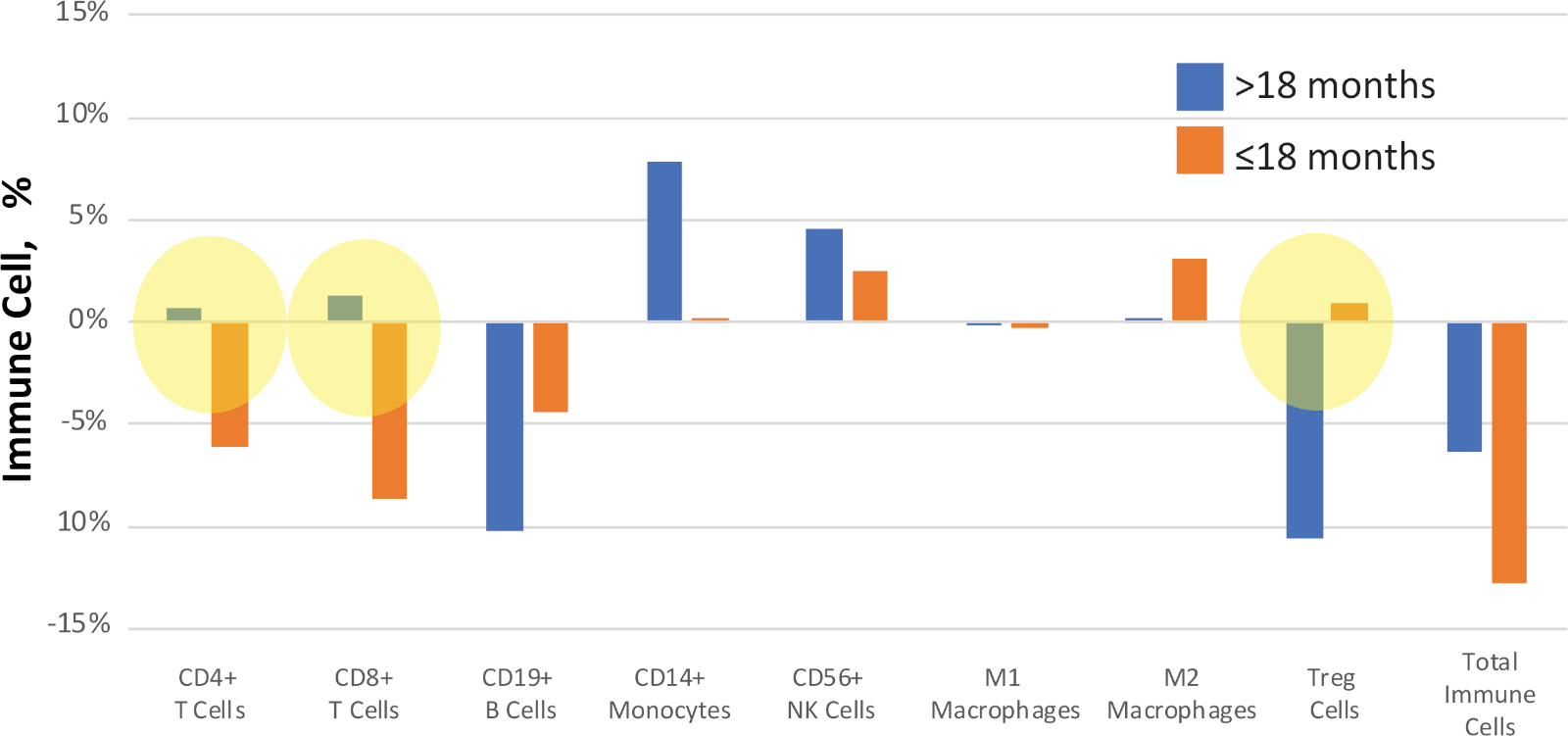{kind=link}
Enfin, des groupes d’échantillons similaires peuvent être utilisés pour examiner spécifiquement les échantillons de prétraitement afin d’identifier les biomarqueurs prédictifs en utilisant le portail Prism pour produire un rapport sur les biomarqueurs. Montré à la figure 12, le même phénotype clinique (progression de la maladie) comme décrit ci-dessus définit les groupes d’échantillons. Dans cet exemple, deux gènes d’évasion immunitaire ont été identifiés comme des différenciateurs statistiquement significatifs des groupes d’échantillons (CD47 et OX40, indiqués dans le panneau inférieur de la figure 12A). Dans cet exemple, parce que les biomarqueurs génétiques individuels sont robustes avec une signification statistique claire, le biomarqueur multidimensionnel n’ajoute pas de valeur prédictive significative (ImmunoPrism, tel qu’il est étiqueté dans le graphique de la barre supérieure droite de la figure 12B). Le tableau complet des données, y compris les résultats des 18 analytes pour l’analyse, est résumé à l’envers du rapport, y compris l’analyse statistique et un bref résumé des méthodes.

Figure 12 : Exemple de rapport de biomarqueur pour les échantillons du NSCLC. Le pipeline Biomarker Discovery fournit un rapport visuel de biomarqueurs individuels et un biomarqueur multidimensionnel à apprentissage automatique, avec des statistiques détaillées. (A) Dans le cadre de cette étude, le pipeline a identifié deux biomarqueurs individuels (CD47 et OX40) comme statistiquement significatifs pour définir la progression de la maladie avec un seuil de 18 mois. (B) Les détails sur la méthode et les résultats complets sont inclus sur le revers du rapport. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
Tableau supplémentaire 1 : Matériaux de kit de réactif. Une liste des documents fournis dans le kit ImmunoPrism sont énumérés, ainsi que les numéros de pièces qui ont fait référence dans le protocole du fabricant. Tous les autres équipements et matériaux requis sont répertoriés dans le Tableau des matériaux. Visitez https://cofactorgenomics.com/product/immunoprism-kit/ pour les fiches de données de sécurité (SDS). S’il vous plaît cliquez ici pour voir ce fichier (Clic droit pour télécharger).
Tableau supplémentaire 2 : Programmes de cycle thermique. Les programmes de cycler recommandés référencés tout au long du protocole sont résumés pour faciliter la programmation. S’il vous plaît cliquez ici pour voir ce fichier (Clic droit pour télécharger).
Tableau supplémentaire 3 : Guide de l’indice de séquençage. Les amorces d’index fournies dans le kit de réactif sont énumérées ; une amorce unique est ajoutée à chaque réaction pour le démultiplexage post-séquençage. Des combinaisons de multiplexage de bas niveau recommandées sont également fournies. S’il vous plaît cliquez ici pour voir ce fichier (Clic droit pour télécharger).
Discussion
Le protocole exige 20 ng intacts ou 40 ng fortement dégradés (FFPE) ARN. L’échantillon d’ARN doit être exempt d’ADN, de sels (p. ex. Mg2MDou sels de guanidinium), d’agents chélateurs divalents (p. ex. EDTA, EGTA, citrate) ou de matières organiques (p. ex. phénol et éthanol). Il n’est pas recommandé de procéder à des échantillons d’ARN qui ont un DV200 lt;20%. L’utilisation de l’ARN témoin en kit est fortement recommandée car ces contrôles fournissent un moyen d’évaluer les performances tout au long du protocole, de la préparation de la bibliothèque à l’analyse.
Le protocole est conçu pour être exécuté à l’aide de tubes à bande PCR de 0,2 mL. Si vous préférez, le protocole peut également être exécuté à l’aide des puits dans une plaque PCR de 96 puits. Il suffit d’utiliser les puits d’une plaque PCR de 96 puits à la place de toutes les références aux tubes PCR ou aux tubes à bande. Utilisez des plaques PCR avec des puits clairs seulement, car il est essentiel de confirmer visuellement la résuspension complète des perles pendant les purifications de perles et les étapes de lavage.
Tout au long du protocole, garder les réactifs congelés ou sur la glace, sauf indication contraire. N’utilisez pas de réactifs jusqu’à ce qu’ils soient complètement décongelés. Assurez-vous de bien mélanger tous les réactifs avant utilisation.
Maintenir les enzymes à -20 oC jusqu’à ce qu’elles soient prêtes à l’emploi et revenir rapidement à -20 oC après utilisation. N’utilisez que de l’eau sans nucléane de qualité moléculaire; il n’est pas recommandé d’utiliser de l’eau traitée par LE DEPC. Lors de la pipeàminage pour mélanger, aspirez doucement et distribuez au moins 50% du volume total jusqu’à ce que les solutions soient bien mélangées. Pipette mélanger tous les mélanges maîtres contenant des enzymes. L’utilisation du vortex pour mélanger les enzymes pourrait conduire à la dénaturation et compromettre leurs performances. Pendant les purifications de perles, utilisez des solutions d’éthanol fraîchement fabriquées à 80 % à partir d’éthanol de qualité moléculaire. L’utilisation de solutions d’éthanol qui ne sont pas fraîches peut entraîner des rendements plus faibles. Évitez de sécher les perles, car cela peut réduire l’efficacité de l’élution (les perles semblent fissurées si elles sont trop séchées).
Comme décrit à l’étape 10, des amorces d’index uniques sont ajoutées à chaque réaction. Sur la base des séquences de ces indices, pour le multiplexage de bas niveau, certaines combinaisons d’indices sont optimales. Les séquences de ces indices sont nécessaires pour démultiplexer les données post-séquençage. Les séquences et les combinaisons de multiplexage recommandées sont fournies dans le tableau supplémentaire 3. Dans cette même étape, il est important de noter que le nombre de cycles PCR recommandés varie en fonction de la qualité de l’ARN utilisé, et, une certaine optimisation peut être nécessaire pour prévenir la sur-amplification PCR. Pour l’ARN ImmunoPrism Intact Control et d’autres ARN de haute qualité, commencez l’optimisation avec 10 cycles PCR. Pour l’ARN de contrôle ImmunoPrism FFPE et d’autres ARN fortement dégradés/FFPE, commencez l’optimisation avec 15 cycles PCR. Il est recommandé de produire une bibliothèque d’essai à l’aide d’ARN représentant le matériau à analyser afin d’optimiser les cycles de PCR. Le nombre minimum de cycles PCR qui donnent constamment des rendements suffisants de bibliothèque pré-capture (-200 ng) devrait être utilisé. Un pic secondaire d’environ 1000 pb sur la trace de Bioanalyzer est révélateur d’une suramplification (figure 4). La suramplification doit être réduite au minimum, mais la présence d’un petit pic secondaire n’interfère pas avec les résultats d’analyse.
Pour minimiser la perte d’échantillon et éviter les tubes de commutation, l’étape 13 peut être effectuée dans des tubes PCR, des tubes à bande ou une plaque PCR de 96 puits au lieu de 1,5 ml de microtubes, si votre concentrateur à vide le permet. Le rotor peut être enlevé sur de nombreux concentrateurs. Cela permet aux tubes ou plaques à bande de s’insérer dans le vide. La concentration sous vide peut alors être exécuté en utilisant le réglage de dessiccation aqueuse sans centrifugation. Consultez le manuel pour votre concentrateur à vide pour les instructions. Si les échantillons sont séchés dans des tubes à bande ou une plaque de 96 puits, l’étape d’hybridation peut être effectuée dans le même récipient.
Au cours de l’étape 17, assurez-vous de vortex toutes les 10-12 min pour augmenter l’efficacité de capture de perles. Tenez soigneusement les bouchons des tubes à bande chaude lors du mélange pour empêcher les tubes de s’ouvrir.
Les lavages décrits à l’étape 18 sont essentiels pour éviter une contamination non spécifique élevée et doivent être suivis de près. Assurez-vous de resuspendre complètement les perles à chaque lavage, retirez complètement les tampons de lavage, et pendant le lavage de la tampon de lavage 2, transférez les échantillons dans un tube à bande fraîche (étape 18.6.5). Assurez-vous que les perles de streptavidin sont complètement suspendues et restent en suspension pendant toute l’incubation. Les éclaboussures sur les bouchons du tube n’auront pas d’impact négatif sur la capture. Pendant les lavages à température ambiante, un mélangeur de vortex microplaque peut être utilisé pour vortexles les échantillons pour l’ensemble de la période d’incubation de deux minutes pour une résuspension plus facile. Ne laissez pas sécher les perles de streptavidin. Au besoin, prolonger les incubations dans les tampons pour éviter de sécher les perles. Si vous utilisez plus d’un tube à bande, travaillez avec un tube à bande à la fois pour chaque lavage tandis que les autres tubes à bande sont assis dans le thermocycleur. Cela peut aider à éviter de sécher les perles ou de se précipiter, ce qui entraîne une mauvaise suspension ou d’autres techniques sous-optimales. Pour les utilisateurs débutants, il n’est pas recommandé de traiter plus de 8 réactions de bibliothèque à la fois.
Les techniques actuelles de profilage immunitaire fournissent un continuum d’information - de milliers de points de données qui nécessitent une interprétation significative (séquençage de l’ARN) à un point de données individuel et discret (IHC à plex unique). Le protocole décrit ici représente une approche qui se situe quelque part au milieu, avec une portée focalisée permettant une sensibilité élevée, mais ne capturant qu’un sous-ensemble de données transcriptomiques cliniquement pertinentes. En raison de la nature de l’extraction d’ARN en vrac, ce protocole ne fournit pas d’informations sur les relations spatiales entre les cellules immunitaires et le microenvironnement tumoral, cependant, les résultats peuvent être complétés par des technologies d’imagerie pour ajouter cette information. Il existe une myriade d’applications pour les données générées par ce protocole, car il ya beaucoup à apprendre sur la biologie du cancer comme une maladie, et les thérapies en cours de développement pour le traiter. Comme le montrent les résultats représentatifs, le rapport immunitaire individuel est utile pour comprendre comment le profil immunitaire d’un patient peut changer en réponse à des événements tels que la progression de la maladie ou le traitement. Bien que les résultats présentés ici fournissent quelques exemples de cas d’utilisation, d’autres applications, y compris l’étude du mécanisme d’action d’un traitement et l’identification des biomarqueurs putatifs des résultats cliniques tels que la progression libre et la survie globale sont également Pratique. Lorsque vous utilisez ce protocole pour les applications de découverte de biomarqueurs, il est important de pratiquer une bonne conception d’étude pour s’assurer que les populations homogènes sont analysées, que des échantillons suffisants sont inclus pour la puissance statistique et que des sources de biais sont prises en considération. En raison de la nature ciblée et rationalisée de l’analyse, il est possible d’imaginer une voie vers la validation clinique et l’application en aval de ces biomarqueurs une fois découverts.
Déclarations de divulgation
Tous les auteurs sont employés par Cofactor Genomics, Inc., la société qui a développé et produit le kit de réactifs ImmunoPrism et les outils informatiques utilisés dans cet article. L’analyse ImmunoPrism est pour l’utilisation de la recherche seulement, et n’est pas pour une utilisation dans les procédures diagnostiques.
Remerciements
Les auteurs tiennent à remercier TriStar Technology Group d’avoir fourni les spécimens biologiques pour les résultats représentatifs, ainsi que l’ensemble des équipes moléculaires, d’analyse, de produits et commerciaux de Cofactor Genomics pour leur expertise technique et Soutien.
matériels
| Name | Company | Catalog Number | Comments |
| 0.2 mL PCR 8 tube strip | USA Scientific | 1402-2700 | USA Scientific 0.2 mL PCR 8-tube strip |
| 200 Proof Ethanol | MilliporeSigma | EX0276-1 | Prepare 80% by mixing with nuclease-free water on the day of the experiment |
| 96-well thermal cyclers | BioRad | 1861096 | |
| Solid-phase Reversible Immobilization (SPRI) Beads | Beckman-Coulter | A63882 | Agencourt AMPure XP – PCR Purification beads |
| Digital electrophoresis chips and kit | Agilent Technologies | 5067-4626 | Agilent High Sensitivity DNA chips and kit |
| Digital electrophoresis system | Agilent Technologies | G2939AA | Agilent 2100 Electrophoresis Bioanalyzer |
| Streptavidin Beads | ThermoFisher Scientific | 65306 | Dynabeads M-270 Streptavidin |
| ImmunoPrism Kit – 24 reaction | Cofactor Genomics | CFGK-302 | Cofactor ImmunoPrism Immune Profiling Kit – 24 reactions |
| Human Cot-1 DNA | ThermoFisher Scientific | 15279011 | Invitrogen brand |
| Magnetic separation rack | Alpaqua/Invitrogen | A001322/12331D | 96-well Magnetic Ring Stand |
| Microcentrifuge | Eppendorf | 22620701 | |
| Microcentrifuge tubes | USA Scientific | 1415-2600 | USA Scientific 1.5 mL low-adhesion microcentrifuge tube |
| NextSeq550 | Illumina | SY-415-1002 | Any Illumina sequencer may be used for this protocol |
| Nuclease-free water | ThermoFisher Scientific | AM9937 | |
| Prism Extraction Kit | Cofactor Genomics | CFGK-401 | Cofactor Prism FFPE Extraction Kit – 24 samples |
| Purified RNA | - | - | Purified from human tissue samples |
| Fluorometer | ThermoFisher Scientific | Q33226 | Qubit 4 System |
| Fluorometric Assay Tubes | Axygen | PCR-05-C | 0.5mL Thin Wall PCR Tubes with Flat Caps |
| High Sensitivity Fluorometric Reagent Kit | Life Technologies | Q32854 | Qubit dsDNA HS Assay Kit |
| Vacuum concentrator | Eppendorf | 22820001 | VacufugePlus |
| Vortex mixer | VWR | 10153-838 | |
| Water bath or heating block | VWR/USA Scientific | NA/2510-1102 | VWR water bath/USA Scientific heating block |
Références
- Brambilla, E., et al. Prognostic Effect of Tumor Lymphocytic Infiltration in Resectable Non-Small-Cell Lung Cancer. Journal of Clinical Oncology. 34 (11), 1223-1230 (2016).
- Iacono, D., et al. Tumour-infiltrating lymphocytes, programmed death ligand 1 and cyclooxygenase-2 expression in skin melanoma of elderly patients: clinicopathological correlations. Melanoma Research. 28 (6), 547-554 (2018).
- Fridman, W. H., Zitvogel, L., Sautes-Fridman, C., Kroemer, G. The immune contexture in cancer prognosis and treatment. Nature Reviews Clinical Oncology. 14 (12), 717-734 (2017).
- Sierant, M. C., Choi, J. Single-Cell Sequencing in Cancer: Recent Applications to Immunogenomics and Multi-omics Tools. Genomics Inform. 16, (2018).
- Klauschen, F., et al. Scoring of tumor-infiltrating lymphocytes: From visual estimation to machine learning. Seminars in Cancer Biology. 52 (Pt 2), 151-157 (2018).
- Danaher, P., et al. Gene expression markers of Tumor Infiltrating Leukocytes. Journal for ImmunoTherapy of Cancer. 5, 18(2017).
- Aran, D., Hu, Z., Butte, A. J. xCell: digitally portraying the tissue cellular heterogeneity landscape. Genome Biology. 18 (1), 220(2017).
- Newman, A. M., et al. Robust enumeration of cell subsets from tissue expression profiles. Nature Methods. 12 (5), 453-457 (2015).
- Becht, E., et al. Estimating the population abundance of tissue-infiltrating immune and stromal cell populations using gene expression. Genome Biology. 17 (1), 218(2016).
- Newman, A. M., Gentles, A. J., Liu, C. L., Diehn, M., Alizadeh, A. A. Data normalization considerations for digital tumor dissection. Genome Biology. 18 (1), 128(2017).
- Chen, S. H., et al. A gene profiling deconvolution approach to estimating immune cell composition from complex tissues. BMC Bioinformatics. 19 (Suppl 4), 154(2018).
- Yoshihara, K., et al. Inferring tumour purity and stromal and immune cell admixture from expression data. Nature Communications. 4, 2612(2013).
- Foley, J. W., et al. Gene-expression profiling of single cells from archival tissue with laser-capture microdissection and Smart-3SEQ. Genome Research. , (2019).
- Civita, P., et al. Laser Capture Microdissection and RNA-Seq Analysis: High Sensitivity Approaches to Explain Histopathological Heterogeneity in Human Glioblastoma FFPE Archived Tissues. Front Oncol. 9, 482(2019).
- PD-L1 in cancer: ESMO Biomarker Factsheet | OncologyPRO. , OncologyPRO. https://oncologypro.esmo.org/Education-Library/Factsheets-on-Biomarkers/PD-L1-in-Cancer (2019).
- Haslam, A., Prasad, V. Estimation of the Percentage of US Patients With Cancer Who Are Eligible for and Respond to Checkpoint Inhibitor Immunotherapy Drugs. JAMA Network Open. 2 (5), e192535(2019).
- Maecker, H. T., McCoy, J. P., Nussenblatt, R. Standardizing immunophenotyping for the Human Immunology Project. Nature Reviews Immunology. 12 (3), 191-200 (2012).
- Schillebeeckx, I., et al. Analytical Performance of an Immunoprofiling Assay Based on RNA Models. Association for Molecular Pathology 2019 Annual Meeting. Journal of Molecular Diagnostics. 21, Baltimore, MD. (2019).
- Uryvaev, A., Passhak, M., Hershkovits, D., Sabo, E., Bar-Sela, G. The role of tumor-infiltrating lymphocytes (TILs) as a predictive biomarker of response to anti-PD1 therapy in patients with metastatic non-small cell lung cancer or metastatic melanoma. Medical Oncology. 35 (3), 25(2018).
- Wang, K., Shen, T., Siegal, G. P., Wei, S. The CD4/CD8 ratio of tumor-infiltrating lymphocytes at the tumor-host interface has prognostic value in triple-negative breast cancer. Human Pathology. 69, 110-117 (2017).
- Carney, W. P., Bhagat, M., LaFranzo, N. Multidimensional gene expression models for characterizing response and metastasis in solid tumor samples [abstract]. American Association for Cancer Research Annual Meeting. Cancer Research. 79 (13 Suppl), Atlanta, GA. (2019).
Réimpressions et Autorisations
Demande d’autorisation pour utiliser le texte ou les figures de cet article JoVE
Demande d’autorisationThis article has been published
Video Coming Soon
À PROPOS DE JoVE
Copyright © 2025 MyJoVE Corporation. Tous droits réservés.