
Method Article
Progettazione e analisi per la semplificazione del sistema di rilevamento delle cadute
In questo articolo
Riepilogo
Presentiamo una metodologia basata su sensori multimodali per configurare un sistema di rilevamento delle cadute semplice, comodo e veloce e di riconoscimento dell'attività umana. L'obiettivo è quello di costruire un sistema per il rilevamento accurato delle cadute che possa essere facilmente implementato e adottato.
Abstract
Questo documento presenta una metodologia basata su sensori multimodali per configurare un sistema di rilevamento delle cadute semplice, confortevole e veloce e un sistema di riconoscimento dell'attività umana che può essere facilmente implementato e adottato. La metodologia si basa sulla configurazione di tipi specifici di sensori, metodi e procedure di apprendimento automatico. Il protocollo è suddiviso in quattro fasi: (1) creazione di database (2) semplificazione del sistema (3) e (4) valutazione. Utilizzando questa metodologia, abbiamo creato un database multimodale per il rilevamento delle cadute e il riconoscimento dell'attività umana, vale a dire UP-Fall Detection. Comprende campioni di dati di 17 soggetti che eseguono 5 tipi di cadute e 6 diverse attività semplici, durante 3 prove. Tutte le informazioni sono state raccolte utilizzando 5 sensori indossabili (accelerometro a tre assi, giroscopio e intensità della luce), 1 casco elettroencefalografo, 6 sensori a infrarossi come sensori ambientali e 2 telecamere nei punti di vista laterali e anteriori. La nuova metodologia proposta aggiunge alcune fasi importanti per eseguire un'analisi approfondita dei seguenti problemi di progettazione al fine di semplificare un sistema di rilevamento delle cadute: a) selezionare quali sensori o combinazione di sensori devono essere utilizzati in un semplice sistema di rilevamento delle cadute, b) determinare il miglior posizionamento delle fonti di informazione, e c) selezionare il metodo di classificazione di apprendimento automatico più adatto per la caduta e il rilevamento e il riconoscimento dell'attività umana. Anche se alcuni approcci multimodali riportati in letteratura si concentrano solo su uno o due dei problemi di cui sopra, la nostra metodologia consente di risolvere contemporaneamente questi tre problemi di progettazione relativi a una caduta umana e al sistema di rilevamento e riconoscimento dell'attività.
Introduzione
Dal momento che il fenomeno mondiale dell'invecchiamento della popolazione1, la prevalenza caduta è aumentata ed è in realtà considerato un grave problema di salute2. Quando si verifica una caduta, le persone richiedono un'attenzione immediata per ridurre le conseguenze negative. I sistemi di rilevamento delle cadute possono ridurre la quantità di tempo in cui una persona riceve un'attenzione medica inviando un avviso quando si verifica una caduta.
Ci sono varie categorizzazioni di sistemi di rilevamento delle cadute3. I primi lavori4 classificano i sistemi di rilevamento delle cadute con il loro metodo di rilevamento, metodi approssimativamente analitici e metodi di apprendimento automatico. Più recentemente, altri autori3,5,6 hanno considerato i sensori di acquisizione dei dati come la caratteristica principale per classificare i rilevatori di caduta. Igual et al.3 divide i sistemi di rilevamento delle cadute in sistemi consapevoli del contesto, che includono approcci basati su sensori di vista e ambientali e sistemi di dispositivi indossabili. Mubashir et al.5 classifica i rilevatori di caduta in tre gruppi basati sui dispositivi utilizzati per l'acquisizione dei dati: dispositivi indossabili, sensori di atmosfera e dispositivi basati sulla visione. Perry et al.6 prende in considerazione metodi per misurare l'accelerazione, metodi per misurare l'accelerazione combinati con altri metodi e metodi che non misurano l'accelerazione. Da queste indagini, possiamo determinare che sensori e metodi sono gli elementi principali per classificare la strategia di ricerca generale.
Ognuno dei sensori ha punti deboli e punti di forza discussi in Xu et al.7. Gli approcci basati sulla visione utilizzano principalmente telecamere normali, telecamere di sensori di profondità e/o sistemi di motion capture. Le normali telecamere web sono a basso costo e facili da usare, ma sono sensibili alle condizioni ambientali (variazione di luce, occlusione, ecc.), possono essere utilizzate solo in uno spazio ridotto e hanno problemi di privacy. Le videocamere di profondità, come il Kinect, forniscono movimento 3D a tutto corpo7 e sono meno influenzate dalle condizioni di illuminazione rispetto alle normali telecamere. Tuttavia, gli approcci basati sul Kinect non sono così robusti e affidabili. I sistemi di motion capture sono più costosi e difficili da usare.
Gli approcci basati su dispositivi accelerometro e smartphone/orologi con accelerometri incorporati sono molto comunemente utilizzati per il rilevamento delle cadute. Lo svantaggio principale di questi dispositivi è che devono essere indossati per lunghi periodi. Disagio, invadente, posizionamento del corpo e orientamento sono problemi di progettazione da risolvere in questi approcci. Anche se gli smartphone e gli orologi intelligenti sono dispositivi meno invadenti che sensori, le persone anziane spesso dimenticano o non sempre indossano questi dispositivi. Tuttavia, il vantaggio di questi sensori e dispositivi è che possono essere utilizzati in molte stanze e / o all'aperto.
Alcuni sistemi utilizzano sensori posizionati intorno all'ambiente per riconoscere cadute/attività, in modo che le persone non debbano indossare i sensori. Tuttavia, questi sensori sono anche limitati ai luoghi in cui sono distribuiti8 e a volte sono difficili da installare. Recentemente, i sistemi multimodali di rilevamento delle cadute includono diverse combinazioni di sensori di visione, indossabili e ambientali al fine di ottenere maggiore precisione e robustezza. Possono anche superare alcune delle limitazioni del singolo sensore.
La metodologia utilizzata per il rilevamento delle cadute è strettamente correlata alla catena di riconoscimento dell'attività umana (ARC) presentata da Bulling et al.9, che consiste in fasi per l'acquisizione dei dati, la pre-elaborazione e la segmentazione dei segnali, l'estrazione e la selezione delle caratteristiche, la formazione e la classificazione. I problemi di progettazione devono essere risolti per ognuna di queste fasi. In ogni fase vengono utilizzati metodi diversi.
Presentiamo una metodologia basata su sensori multimodali per configurare una caduta umana semplice, confortevole e veloce e un sistema di rilevamento/riconoscimento dell'attività umana. L'obiettivo è quello di costruire un sistema per il rilevamento accurato delle cadute che possa essere facilmente implementato e adottato. La nuova metodologia proposta si basa su ARC, ma aggiunge alcune fasi importanti per eseguire un'analisi approfondita dei seguenti problemi al fine di semplificare il sistema: (a) selezionare quali sensori o combinazioni di sensori devono essere utilizzati in un semplice sistema di rilevamento delle cadute; b) determinare il miglior posizionamento delle fonti di informazione ; e (c) selezionare il metodo di classificazione di apprendimento automatico più adatto per il rilevamento delle cadute e il riconoscimento dell'attività umana per creare un sistema semplice.
Ci sono alcune opere correlate in letteratura che affrontano uno o due dei problemi di progettazione di cui sopra, ma a nostra conoscenza, non c'è nessun lavoro che si concentra su una metodologia per superare tutti questi problemi.
Le opere correlate utilizzano approcci multimodali per il rilevamento delle cadute e il riconoscimento dell'attività umana10,11,12 al fine di ottenere robustezza e aumentare la precisione. Kwolek et al.10 ha proposto la progettazione e l'implementazione di un sistema di rilevamento delle cadute basato su dati accelerometrici e mappe di profondità. Hanno progettato un'interessante metodologia in cui viene implementato un accelerometro a tre assi per rilevare una potenziale caduta e il movimento della persona. Se la misura di accelerazione supera una soglia, l'algoritmo estrae una persona che differenzia la mappa di profondità dalla mappa di riferimento della profondità aggiornata online. Un'analisi delle combinazioni di profondità e accelerometro è stata effettuata utilizzando un classificatore di macchine vettoriali di supporto.
Ofli et al.11 ha presentato un database multimodale delle azioni umane (MHAD) al fine di fornire un banco di prova per i nuovi sistemi di riconoscimento delle attività umane. Il set di dati è importante poiché le azioni sono state raccolte simultaneamente utilizzando 1 sistema di motion capture ottico, 4 telecamere multi-vista, 1 sistema Kinect, 4 microfoni e 6 accelerometri wireless. Gli autori hanno presentato i risultati per ogni modalità: il Kinect, il mocap, l'accelerometro e l'audio.
Dovgan etal. 12 propose un prototipo per rilevare comportamenti anomali, comprese le cadute, negli anziani. Hanno progettato test per tre sistemi di sensori al fine di trovare l'attrezzatura più appropriata per il rilevamento delle cadute e del comportamento insolito. Il primo esperimento consiste di dati provenienti da un sistema di sensori intelligenti con 12 tag attaccati ai fianchi, alle ginocchia, alle caviglie, ai polsi, ai gomiti e alle spalle. Hanno anche creato un set di dati di test utilizzando un sistema di sensori Ubisense con quattro tag attaccati alla vita, al torace e alle due caviglie e un accelerometro Xsens. In un terzo esperimento, quattro soggetti utilizzano solo il sistema Ubisense durante l'esecuzione di 4 tipi di cadute, 4 problemi di salute come comportamento anomalo e diverse attività della vita quotidiana (ADL).
Altri lavori nella letteratura13,14,15 affrontare il problema di trovare il miglior posizionamento di sensori o dispositivi per il rilevamento delle cadute confrontando le prestazioni di varie combinazioni di sensori con diversi classificatori. Santoyo et al.13 ha presentato una valutazione sistematica valutando l'importanza della posizione di 5 sensori per il rilevamento delle cadute. Hanno confrontato le prestazioni di queste combinazioni di sensori utilizzando i vicini k-nearest (KNN), le macchine vettoriali di supporto (SVM), le baie ingenue (NB) e i classificatori di alberi delle decisioni (DT). Essi concludono che la posizione del sensore sul soggetto ha un'influenza importante sulle prestazioni del rilevatore di caduta indipendentemente dal classificatore utilizzato.
Il confronto dei posizionamenti dei sensori indossabili sul corpo per il rilevamento delle cadute è stato presentato da zdemir14. Al fine di determinare il posizionamento del sensore, l'autore ha analizzato 31 combinazioni di sensori delle seguenti posizioni: testa, vita, petto, polso destro, caviglia destra e coscia destra. Quattordici volontari hanno eseguito 20 cadute simulate e 16 ADL. Ha scoperto che le migliori prestazioni sono state ottenute quando un singolo sensore è posizionato sulla vita da questi esperimenti di combinazione esaustivi. Un altro confronto è stato presentato da Ntanasis15 utilizzando il set di dati di zzdemir. Gli autori hanno confrontato singole posizioni su testa, petto, vita, polso, caviglia e coscia utilizzando i seguenti classificatori: J48, KNN, RF, random committee (RC) e SVM.
I benchmark delle prestazioni dei diversi metodi computazionali per il rilevamento delle cadute si trovano anche nella letteratura16,17,18. Bagala et al.16 ha presentato un confronto sistematico per confrontare le prestazioni di tredici metodi di rilevamento autunnali testati su cadute reali. Hanno preso in considerazione solo gli algoritmi basati sulle misurazioni dell'accelerometro posizionate sulla vita o sul tronco. 17 Bourke17 et al. Kerdegari18 ha fatto anche un confronto delle prestazioni di diversi modelli di classificazione per una serie di dati di accelerazione registrati. Gli algoritmi utilizzati per il rilevamento delle cadute erano zeroR, oneR, NB, DT, perceptron multistrato e SVM.
Una metodologia per il rilevamento delle cadute è stata proposta da Alazrai et al.18 utilizzando il descrittore geometrico di posa del movimento per costruire una rappresentazione accumulata dell'istogramma dell'attività umana. Hanno valutato il framework utilizzando un set di dati raccolto con sensori Kinect.
In sintesi, abbiamo trovato il rilevamento multimodale delle cadute relative alle opere10,11,12 che confrontano le prestazioni di diverse combinazioni di modalità. Alcuni autori affrontano il problema di trovare il miglior posizionamento dei sensori13,,14,,15,o combinazioni di sensori13 con diversi classificatori13,15,16 con più sensori della stessa modalità e accelerometri. Nella letteratura non è stato trovato alcun lavoro che affrontasse il posizionamento, le combinazioni multimodali e il benchmark del classificatore allo stesso tempo.
Protocollo
Tutti i metodi qui descritti sono stati approvati dal Comitato di Ricerca della Scuola di Ingegneria dell'Università Panamericana.
NOTA: Questa metodologia si basa sulla configurazione dei tipi specifici di sensori, metodi e procedure di apprendimento automatico al fine di configurare un sistema di riconoscimento delle cadute semplice, veloce e multimodale e di riconoscimento dell'attività umana. Per questo motivo, il seguente protocollo è suddiviso in fasi: (1) creazione di database (2) semplificazione del sistema (3) e (4) valutazione.
1. Creazione di database
- Impostare il sistema di acquisizione dati. In questo modo verranno raccolti tutti i dati dai soggetti e le informazioni verranno archiviate in un database di recupero.
- Selezionare i tipi di sensori indossabili, sensori ambientali e dispositivi basati sulla visione richiesti come fonti di informazioni. Assegnare un ID per ogni fonte di informazioni, il numero di canali per fonte, le specifiche tecniche e la frequenza di campionamento di ciascuno di essi.
- Collegare tutte le fonti di informazioni (ad esempio, dispositivi indossabili e sensori ambientali e dispositivi basati sulla visione) a un computer centrale o a un sistema informatico distribuito:
- Verificare che i dispositivi cablati siano collegati correttamente a un computer client. Verificare che i dispositivi wireless siano completamente caricati. Si consideri che la batteria insufficiente potrebbe influire sulle connessioni wireless o sui valori dei sensori. Inoltre, le connessioni intermittenti o perse aumenteranno la perdita di dati.
- Configurare ciascuno dei dispositivi per recuperare i dati.
- Configurare il sistema di acquisizione dati per l'archiviazione dei dati nel cloud. A causa della grande quantità di dati da archiviare, il cloud computing è considerato in questo protocollo.
- Verificare che il sistema di acquisizione dati soddisfi la sincronizzazione dei dati e la coerenza dei datidi 20 proprietà. In questo modo viene mantenuta l'integrità dell'archiviazione dei dati da tutte le fonti di informazioni. Potrebbe richiedere nuovi approcci nella sincronizzazione dei dati. Ad esempio, vedere Peafort-Asturiano etal.
- Iniziare a raccogliere alcuni dati con le fonti di informazioni e memorizzare i dati in un sistema preferito. Includere timestamp in tutti i dati.
- Eseguire una query sul database e determinare se tutte le origini di informazioni vengono raccolte con le stesse frequenze di campionamento. Se fatto correttamente, andare al passo 1.1.6. In caso contrario, eseguire il campionamento di up o down utilizzando i criteri riportati in Peafort-Asturiano, et al.20.
- Impostare l'ambiente (o laboratorio) considerando le condizioni richieste e le restrizioni imposte dall'obiettivo del sistema. Impostare le condizioni per l'attenuazione della forza d'impatto nelle cadute simulate come sistemi di pavimentazione conformi suggeriti in Lachance, et al.23 per garantire la sicurezza dei partecipanti.
- Utilizzare un materasso o qualsiasi altro sistema di pavimentazione conforme e posizionarlo al centro dell'ambiente (o laboratorio).
- Tenere tutti gli oggetti lontano dal materasso per dare almeno un metro di spazio sicuro tutto intorno. Se necessario, preparare attrezzature protettive personali per i partecipanti (ad esempio guanti, berretto, occhiali, supporto al ginocchio, ecc.).
NOTA: il protocollo può essere messo in pausa qui.
- Determinare le attività umane e cade che il sistema rileverà dopo la configurazione. È importante tenere a mente lo scopo del sistema di rilevamento delle cadute e di riconoscimento dell'attività umana, nonché della popolazione bersaglio.
- Definire l'obiettivo del sistema di rilevamento delle cadute e dell'attività umana. Annottale in un foglio di pianificazione. Per questo caso di studio, l'obiettivo è quello di classificare i tipi di cadute umane e attività eseguite in una base quotidiana interna di persone anziane.
- Definire la popolazione di destinazione dell'esperimento in base all'obiettivo del sistema. Annotino nella scheda di pianificazione. Nello studio, considerare gli anziani come la popolazione bersaglio.
- Determinare il tipo di attività quotidiane. Includere alcune attività non-fall che sembrano cadute al fine di migliorare il rilevamento caduta reale. Assegnare un ID per tutti e descriverli nel modo più dettagliato possibile. Impostare il periodo di tempo per ogni attività da eseguire. Scrivere tutte queste informazioni nella scheda di pianificazione.
- Determinare il tipo di cadute umane. Assegnare un ID per tutti e descriverli nel modo più dettagliato possibile. Impostare il periodo di tempo per ogni caduta da eseguire . Considerare se le cadute saranno auto-generate dai soggetti o generate da altri (ad esempio, spingendo il soggetto). Scrivere tutte queste informazioni nella scheda di pianificazione.
- Nella scheda di pianificazione, annotare le sequenze di attività e le cadute che un soggetto eseguirà. Specificare il periodo di tempo, il numero di prove per attività/caduta, la descrizione per eseguire l'attività/caduta e gli ID attività/caduta.
NOTA: il protocollo può essere messo in pausa qui.
- Selezionare i soggetti pertinenti allo studio che eseguirà le sequenze di attività e cadute. Le cadute sono eventi rari da catturare nella vita reale e di solito si verificano a persone anziane. Tuttavia, per motivi di sicurezza, non includere persone anziane e con disabilità nella simulazione caduta sotto la consulenza medica. Le acrobazie sono state usate per evitare lesioni22.
- Determinare il sesso, la fascia di età, il peso e l'altezza dei soggetti. Definire eventuali condizioni di compromissione richieste. Inoltre, definire il numero minimo di soggetti necessari per l'esperimento.
- Selezionare casualmente l'insieme di soggetti richiesti, seguendo le condizioni indicate nel passaggio precedente. Usa una chiamata per i volontari per reclutarli. Adempiere a tutte le linee guida etiche applicabili dall'istituzione e dal paese, così come qualsiasi regolamentazione internazionale quando si sperimenta con gli esseri umani.
NOTA: il protocollo può essere messo in pausa qui.
- Recuperare e archiviare i dati dai soggetti. Queste informazioni saranno utili per ulteriori analisi sperimentali. Completare i seguenti passaggi sotto la supervisione di un esperto clinico o di un ricercatore responsabile.
- Iniziare a raccogliere dati con il sistema di acquisizione dati configurato nel passaggio 1.1.Start collecting data with the data acquisition system configured in Step 1.1.
- Chiedi a ciascuno dei soggetti di eseguire le sequenze di attività e le cadute dichiarate al punto 1.2. Salvare chiaramente i timestamp dell'inizio e della fine di ogni attività/caduta. Verificare che i dati di tutte le origini di informazioni vengano salvati nel cloud.
- Se le attività non sono state eseguite correttamente o si sono verificati problemi con i dispositivi (ad esempio, connessione persa, batteria scarica, connessione intermittente), eliminare i campioni e ripetere il passaggio 1.4.1 fino a quando non vengono rilevati problemi del dispositivo. Ripetere il passaggio 1.4.2 per ogni prova, per argomento, dichiarata nella sequenza del passaggio 1.2.
NOTA: il protocollo può essere messo in pausa qui.
- Pre-elaborare tutti i dati acquisiti. Applicare il campionamento e l'alto per ciascuna delle fonti di informazioni. Vedere i dettagli sui dati di pre-elaborazione per il rilevamento delle cadute e il riconoscimento dell'attività umana in Martènez-Villaseoor et al.21.
NOTA: il protocollo può essere messo in pausa qui.
2. Analisi dei dati
- Selezionare la modalità di trattamento dei dati. Selezionare Dati non elaborati se i dati archiviati nel database verranno utilizzati a titolo definitivo (ad esempio, utilizzando il deep learning per l'estrazione automatica delle funzionalità) e andare al passaggio 2.2. Selezionare Dati feature se l'estrazione delle feature verrà utilizzata per un'ulteriore analisi e andare al passaggio 2.3.
- Per i dati nonelaborati , non sono necessari passaggi aggiuntivi, quindi andare al passaggio 2.5.
- Per Dati entità geografiche, estrarre feature dai dati non elaborati.
- Segmentare i dati non elaborati in intervalli di tempo. Determinare e correggere la lunghezza della finestra temporale (ad esempio, fotogrammi di dimensioni di un secondo). Inoltre, determinare se queste finestre temporali saranno sovrapposte o meno. Una buona pratica è scegliere il 50% di sovrapposizione.
- Estrarre feature da ogni segmento di dati. Determinare l'insieme di feature temporali e frequenti da estrarre dai segmenti. Per l'estrazione di caratteristiche comuni,vedere Martènez-Villaseor et al.
- Salvare il set di dati di estrazione delle entità geografiche nel cloud in un database indipendente.
- Se verranno selezionati intervalli di tempo diversi, ripetere i passaggi da 2.3.1 a 2.3.3 e salvare ogni set di dati di entità geografiche in database indipendenti.
NOTA: il protocollo può essere messo in pausa qui.
- Selezionare le funzioni più importanti estratte e ridurre il set di dati delle entità geografiche. Applicare alcuni metodi di selezione delle funzionalità comunemente utilizzati (adesempio, selezione univariata, analisi dei componenti principali, eliminazione ricorsiva delle funzionalità, importanza delle funzionalità, matrice di correlazione e così via).
- Selezionare un metodo di selezione delle funzioni. Qui, abbiamo usato l'importanza delle funzionalità.
- Utilizzare ogni funzione per eseguire il training di un determinato modello (abbiamo impiegato RF) e misurare l'accuratezza (vedere L'equazione 1).
- Classificare le feature ordinando le funzioni in ordine di precisione.
- Selezionare le funzioni più importanti. Qui, abbiamo usato le prime dieci caratteristiche classificate.
NOTA: il protocollo può essere messo in pausa qui.
- Selezionare un metodo di classificazione di Machine Learning ed eseguire il training di un modello. Esistono metodi di apprendimento automatico ben noti16,17,18,21, ad esempio: support vector machines (SVM), random forest (RF), multilayer perceptron (MLP) e k-nearest neighbors (KNN), tra molti altri.
- Facoltativamente, se viene selezionato un approccio di deep learning, considerare21: reti neurali convoluzionali (CNN), reti neurali di memoria a breve termine (LSTM), tra gli altri.
- Selezionare un set di metodi di apprendimento automatico. Qui, abbiamo usato i seguenti metodi: SVM, RF, MLP e KNN.
- Correggere i parametri di ognuno dei metodi di apprendimento automatico, come suggerito nella letteratura21.
- Creare un set di dati di entità geografiche combinato (o set di dati non elaborati) utilizzando i set di dati di entità geografiche indipendenti (o set di dati non elaborati) per combinare i tipi di origini di informazioni. Ad esempio, se è necessaria una combinazione di un sensore indossabile e di una telecamera, combinare i set di dati delle entità geografiche di ognuna di queste origini.
- Dividere il set di dati delle entità geografiche (o set di dati non elaborati) nei set di training e test. Una buona scelta è quella di dividere casualmente il 70% per l'allenamento e il 30% per il test.
- Eseguire un k-fold cross-validation21 utilizzando il set di dati di funzionalità (o set di dati non elaborati), per ogni metodo di apprendimento automatico. Usare una metrica comune di valutazione, ad esempio la precisione (vedere L'equazione 1) per selezionare il modello migliore sottoposto a training per metodo. Si consigliano anche esperimenti LOSO (Leave-one subject-out)3.
- Aprire il set di dati delle funzionalità di training (o set di dati non elaborati) nel software del linguaggio di programmazione preferito. Python è consigliato. Per questo passaggio, utilizzare la libreria pandas per leggere un file CSV come segue:
training_set : pandas.csv(). - Dividere il set di dati della funzionalità (o set di dati non elaborati) in coppie di input-output. Ad esempio, usare Python per dichiarare i valori x (input) e i valori y (output):
training_set_X training_set.drop('tag',axis'1), training_set_Y training_set.tag
dove tag rappresenta la colonna del set di dati della funzionalità che include i valori di destinazione. - Selezionare un metodo di apprendimento automatico e impostare i parametri. Ad esempio, utilizzare SVM in Python con la libreria sklearn come il comando seguente:
classificatore - sklearn. SVC(kernel - 'poly')
in cui la funzione del kernel viene selezionata come polinomiale. - Eseguire il training del modello di apprendimento automatico. Ad esempio, usare il classificatore precedente in Python per eseguire il training del modello SVM:For example, use the above classifier in Python to train the SVM model:
classificatore.fit(training_set_X,training_set_Y). - Calcolare i valori delle stime del modello utilizzando il set di dati della funzionalità di test (o il set di dati non elaborati). Ad esempio, utilizzare la funzione stima in Python come segue: estimates : classifier.predict(testing_set_X) dove testing_set_X rappresenta i valori x del set di test.
- Ripetere i passaggi da 2.5.6.1 a 2.5.6.5, il numero di volte specificato k nella convalida trasversale k-fold (o il numero di volte necessario per l'approccio LOSO).
- Ripetere i passaggi da 2.5.6.1 a 2.5.6.6 per ogni modello di apprendimento automatico selezionato.
NOTA: il protocollo può essere messo in pausa qui.
- Aprire il set di dati delle funzionalità di training (o set di dati non elaborati) nel software del linguaggio di programmazione preferito. Python è consigliato. Per questo passaggio, utilizzare la libreria pandas per leggere un file CSV come segue:
- Confrontare i metodi di apprendimento automatico testando i modelli selezionati con il set di dati di test. È possibile utilizzare altre metriche di valutazione: precisione (Equazione 1), precisione (Equazione 2), sensibilità (Equazione 3), specificità (Equazione 4) o Punteggio F1 (Equazione 5), dove TP sono i veri positivi, TN sono i veri negativi, FP sono i falsi positivi e FN sono i falsi negativi.





- Usare altre metriche di prestazioni utili, ad esempio la matrice di confusione9 per valutare l'attività di classificazione dei modelli di apprendimento automatico o una curva ROC (Precision-recall9) indipendente dalla decisione o una caratteristica di funzionamento del ricevitore9 (ROC). In questa metodologia, richiamo e sensibilità sono considerati equivalenti.
- Usare le funzionalità qualitative dei modelli di apprendimento automatico per confrontarli tra di essi, ad esempio: facilità di interpretazione dell'apprendimento automatico; prestazioni in tempo reale; risorse limitate di tempo, memoria ed elaborazione di calcolo; e facilità di distribuzione di apprendimento automatico in dispositivi perimetrali o sistemi embedded.
- Selezionare il modello di apprendimento automatico migliore utilizzando le informazioni di: Le metriche di qualità (Equazioni 1-5), le metriche delle prestazioni e le caratteristiche qualitative della fattibilità dell'apprendimento automatico dei passaggi 2.5.6, 2.5.7 e 2.5.8.
NOTA: il protocollo può essere messo in pausa qui.
3. Semplificazione del sistema
- Selezionare i posizionamenti adatti delle fonti di informazione. A volte, è necessario determinare il miglior posizionamento delle fonti di informazioni (ad esempio, quale posizione di un sensore indossabile è migliore).
- Determinare il sottoinsieme di fonti di informazioni che verranno analizzate. Ad esempio, se ci sono cinque sensori indossabili nel corpo e solo uno deve essere selezionato come miglior sensore posizionato, ognuno di questi sensori farà parte del sottoinsieme.
- Per ogni origine di informazioni in questo sottoinsieme, creare un set di dati separato e archiviarlo separatamente. Tenere presente che questo set di dati potrebbe essere il set di dati della funzionalità precedente o il set di dati non elaborati.
NOTA: il protocollo può essere messo in pausa qui.
- Selezionare un metodo di classificazione di Machine Learning ed eseguire il training di un modello per una fonte di inserimento delle informazioni. Completare i passaggi da 2.5.1 a 2.5.6 utilizzando ognuno dei set di dati creati nel passaggio 3.1.2.Complete Steps from 2.5.1 to 2.5.6 using each of the data sets created in Step 3.1.2. Rileva la fonte più adatta di posizionamento delle informazioni in base alla classificazione. Per questo caso di studio, utilizziamo i seguenti metodi: SVM, RF, MLP e KNN.
Nota: il protocollo può essere messo in pausa qui. - Selezionare i posizionamenti adatti in un approccio multimodale se è necessaria una combinazione di due o più fonti di informazioni per il sistema (ad esempio, la combinazione di un sensore indossabile e di una telecamera). In questo caso di studio, utilizzare sensore indossabile in vita e fotocamera 1 (vista laterale) come modalità.
- Selezionare la migliore fonte di informazioni di ogni modalità nel sistema e creare un set di dati di entità geografiche combinate (o set di dati non elaborati) utilizzando i set di dati indipendenti di queste origini di informazioni.
- Selezionare un metodo di classificazione di Apprendimento automatico ed eseguire il training di un modello per queste fonti combinate di informazioni. Completare i passaggi da 2.5.1 a 2.5.6 utilizzando il set di dati delle entità geografiche combinate (o set di dati non elaborati). In questo studio, utilizzare i seguenti metodi: SVM, RF, MLP e KNN.
NOTA: il protocollo può essere messo in pausa qui.
4. Valutazione
- Preparare un nuovo set di dati con gli utenti in condizioni più realistiche. Utilizzare solo le fonti di informazioni selezionate nel passaggio precedente. Preferibile, implementare il sistema nel gruppo target (ad esempio, gli anziani). Raccogliere dati in periodi di tempo più lunghi.
- Facoltativamente, se il gruppo target viene utilizzato solo, creare un protocollo di gruppo di selezione che includa i termini di esclusione (ad esempio, eventuali menomazioni fisiche o psicologiche) e interrompere la prevenzione dei criteri (ad esempio, rilevare eventuali lesioni fisiche durante le prove; subendo nausea, vertigini e/o vomito; svenimento). Considerare anche le preoccupazioni etiche e le questioni relative alla privacy dei dati.
- Valutare le prestazioni del sistema di rilevamento delle cadute e dell'attività umana sviluppato finora. Utilizzare le equazioni 1-5 per determinare l'accuratezza e la potenza predittiva del sistema o qualsiasi altra metrica delle prestazioni.
- Discutere dei risultati degli esperimenti.
Risultati
Creazione di un database
Abbiamo creato un set di dati multimodale per il rilevamento delle cadute e il riconoscimento delle attività umane, vale a dire UP-Fall Detection21. I dati sono stati raccolti per un periodo di quattro settimane presso la School of Engineering dell'Universidad Panamericana (Città del Messico, Messico). Lo scenario di test è stato selezionato considerando i seguenti requisiti: (a) uno spazio in cui i soggetti potevano eseguire comodamente e in modo sicuro cadute e attività, e (b) un ambiente interno con luce naturale e artificiale che è adatto per le impostazioni dei sensori multimodali.
Ci sono campioni di dati da 17 soggetti che hanno eseguito 5 tipi di cadute e 6 diverse attività semplici, durante 3 prove. Tutte le informazioni sono state raccolte utilizzando un sistema di acquisizione dati interno con 5 sensori indossabili (accelerometro a tre assi, giroscopio e intensità della luce), 1 casco elettroencefalografo, 6 sensori a infrarossi come sensori ambientali e 2 telecamere nei punti di vista laterali e anteriori. Figura 1 Mostra il layout del posizionamento del sensore nell'ambiente e sul corpo. La frequenza di campionamento dell'intero set di dati è 18 Hz. Il database contiene due set di dati: il set di dati non elaborati consolidato (812 GB) e un set di dati di entità geografiche (171 GB). Tutti i database archiviati nel cloud per l'accesso pubblico: https://sites.google.com/up.edu.mx/har-up/. Ulteriori dettagli sull'acquisizione, la pre-elaborazione, il consolidamento e l'archiviazione di questo database, nonché i dettagli sulla sincronizzazione e la coerenza dei dati sono disponibili in Martènez-Villaseor etal.
Per questa banca dati, tutti i soggetti erano giovani volontari sani (9 maschi e 8 femmine) senza alcuna menomazione, di età compresa tra i 18 e i 24 anni, con un'altezza media di 1,66 m e un peso medio di 66,8 kg. Durante la raccolta dei dati, il ricercatore tecnico responsabile stava supervisionando che tutte le attività sono state eseguite dai soggetti correttamente. I soggetti hanno eseguito cinque tipi di cadute, ognuna per 10 secondi, come caduta: in avanti con le mani (1), in avanti con le ginocchia (2), all'indietro (3), seduto su una sedia vuota (4) e lateralmente (5). Hanno anche condotto sei attività quotidiane per 60 s ciascuna tranne che per saltare (30 s): camminare (6), in piedi (7), raccogliere un oggetto (8), sedersi (9), saltare (10) e posare (11). Sebbene le cadute simulate non siano in grado di riprodurre tutti i tipi di cadute reali, è importante almeno includere tipi rappresentativi di cadute che consentano la creazione di modelli di rilevamento delle cadute migliori. È anche rilevante utilizzare ADL e, in particolare, attività che di solito possono essere scambiate con cadute come la raccolta di un oggetto. I tipi di caduta e ADL sono stati selezionati dopo una revisione dei relativi sistemi di rilevamento delle cadute21. Ad esempio, Figura 2 Mostra una sequenza di immagini di uno studio quando un soggetto cade lateralmente.
Abbiamo estratto 12 temporali (media, deviazione standard, ampiezza massima, ampiezza minima, quadrato medio radice, mediana, numero di incrocio zero, asimmetria, curtosi, primo quartile, terzo quartile e autocorrelazione) e 6 frequenti (media, mediana, entropia, energia, frequenza principale e centroide spettrale) caratteristiche21 da ogni canale del tagliabile e sensori comprendente 756 in totale. Abbiamo anche calcolato 400 funzioni visive21 per ogni telecamera sul movimento relativo dei pixel tra due immagini adiacenti nei video.
Analisi dei dati tra approcci unimodali e multimodali
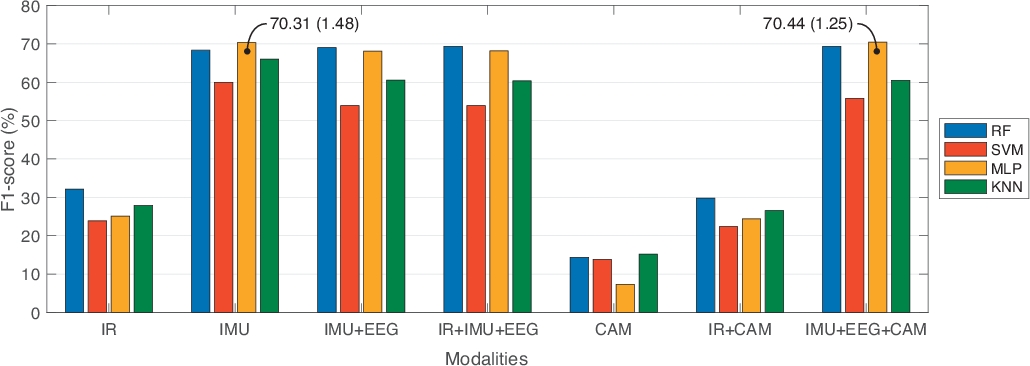
Dal database UP-Fall Detection, abbiamo analizzato i dati a scopo di confronto tra approcci unimodali e multimodale. In questo senso, abbiamo confrontato sette diverse combinazioni di fonti di informazione: solo sensori a infrarossi (IR); sensori indossabili (IMU); sensori indossabili e casco (IMU-EEG); sensori a infrarossi e indossabili e casco (IR-IMU-EEG); solo telecamere (CAM); sensori a infrarossi e telecamere (IR-CAM); e sensori indossabili, casco e telecamere (IMU-EEG-CAM). Inoltre, abbiamo confrontato tre diverse dimensioni dell'intervallo di tempo con il 50% di sovrapposizione: un secondo, due secondi e tre secondi. Ad ogni segmento, abbiamo selezionato le funzioni più utili applicando la selezione e la classificazione delle funzioni. Utilizzando questa strategia, abbiamo impiegato solo 10 funzionalità per modalità, ad eccezione della modalità IR utilizzando 40 funzionalità. Inoltre, il confronto è stato fatto su quattro classificatori di apprendimento automatico ben noti: RF, SVM, MLP e KNN. Abbiamo impiegato una convalida incrociata di 10 volte, con set di dati del 70% di training e test del 30%, per addestrare i modelli di apprendimento automatico. La tabella 1 mostra i risultati di questo benchmark, segnalando le migliori prestazioni ottenute per ogni modalità a seconda del modello di apprendimento automatico e della migliore configurazione della lunghezza della finestra. Le metriche di valutazione segnalano precisione, precisione, sensibilità, specificità e punteggio F1. Figura 3 Mostra questi risultati in una rappresentazione grafica, in termini di F1-score.
Dalla Tabella 1, gli approcci multimodali (sensori a infrarossi e indossabili e casco, IR-IMU-EEG; e sensori indossabili e casco e telecamere, IMU-EEG-CAM) hanno ottenuto i migliori valori di Punteggio F1, rispetto agli approcci unimodali (solo infrarossi, IR; e solo telecamere, CAM). Abbiamo anche notato che solo i sensori indossabili (IMU) hanno ottenuto prestazioni simili rispetto a un approccio multimodale. In questo caso, abbiamo optato per un approccio multimodale perché diverse fonti di informazioni possono gestire le limitazioni da altri. Ad esempio, l'invadente nelle telecamere può essere gestita da sensori indossabili e non utilizzando tutti i sensori indossabili può essere completata da telecamere o sensori ambientali.
In termini di benchmark dei modelli basati sui dati, gli esperimenti nella Tabella 1 hanno dimostrato che la RF presenta i migliori risultati in quasi tutti gli esperimenti; mentre MLP e SVM non erano molto coerenti nelle prestazioni (ad esempio, la deviazione standard in queste tecniche mostra una variabilità maggiore rispetto alla RF). Per quanto riguarda le dimensioni della finestra, queste non hanno rappresentato alcun miglioramento significativo tra di loro. È importante notare che questi esperimenti sono stati fatti per la caduta e la classificazione dell'attività umana.
Posizionamento del sensore e migliore combinazione multimodale
D'altra parte, abbiamo mirato a determinare la migliore combinazione di dispositivi multimodali per il rilevamento delle cadute. Per questa analisi, abbiamo limitato le fonti di informazioni ai cinque sensori indossabili e alle due telecamere. Questi dispositivi sono i più comodi per l'approccio. Inoltre, abbiamo considerato due classi: caduta (qualsiasi tipo di caduta) o no-fall (qualsiasi altra attività). Tutti i modelli di apprendimento automatico e le dimensioni delle finestre rimangono le stesse dell'analisi precedente.
Per ogni sensore indossabile, abbiamo creato un modello di classificatore indipendente per ogni lunghezza della finestra. Abbiamo eseguito il training del modello usando la convalida incrociata di 10 volte con il 70% di training e il 30% di set di dati di test. Nella Tabella 2 sono riepilogati i risultati per la classificazione dei sensori indossabili per classificatore di prestazioni, in base al punteggio F1. Questi risultati sono stati ordinati in ordine decrescente. Come si è visto nella tabella 2, le migliori prestazioni si ottengono quando si utilizza un singolo sensore alla vita, collo o stretta tasca destra (regione ombreggiata). Inoltre, i sensori indossabili per caviglie e polsi e polsi hanno ottenuto il peggio. La tabella 3 mostra la preferenza della lunghezza della finestra per sensore indossabile per ottenere le migliori prestazioni in ogni classificatore. Dai risultati, i sensori per la vita, il collo e la tasca destra stretti con classificatore RF e le dimensioni della finestra a 3 s con una sovrapposizione del 50% sono i sensori indossabili più adatti per il rilevamento delle cadute.
Abbiamo condotto un'analisi simile per ogni telecamera nel sistema. È stato creato un modello di classificazione indipendente per ogni dimensione della finestra. Per il training, abbiamo esito una convalida incrociata di 10 volte con il 70% di training e il 30% di set di dati di test. La tabella 4 mostra la classifica del miglior punto di vista della telecamera per classificatore, in base al punteggio F1. Come osservato, la vista laterale (telecamera 1) ha eseguito il miglior rilevamento di caduta. Inoltre, RF ha sovraperformato rispetto agli altri classificatori. Inoltre, la tabella 5 mostra la preferenza della lunghezza della finestra per punto di vista della fotocamera. Dai risultati, abbiamo scoperto che la migliore posizione di una fotocamera è in punto di vista laterale utilizzando RF in 3 s dimensione della finestra e 50% sovrapposti.
Infine, abbiamo scelto due possibili posizionamenti di sensori indossabili (ad esempio, vita e tasca destra stretta) da combinare con la fotocamera del punto di vista laterale. Dopo la stessa procedura di formazione, abbiamo ottenuto i risultati dalla tabella 6. Come illustrato, il classificatore del modello RF ha ottenuto le migliori prestazioni in termini di precisione e punteggio F1 in entrambe le multimodalità. Inoltre, la combinazione tra vita e telecamera 1 classificata in prima posizione ottenendo il 98,72% di precisione e il 95,77% nel punteggio di F1.

Figura 1: Layout dei sensori indossabili (a sinistra) e ambientali (a destra) nel database UP-Fall Detection. I sensori indossabili sono posizionati sulla fronte, sul polso sinistro, sul collo, sulla vita, sulla tasca destra dei pantaloni e sulla caviglia sinistra. I sensori ambientali sono sei sensori a infrarossi accoppiati per rilevare la presenza di soggetti e due telecamere. Le telecamere si trovano alla vista laterale e alla vista frontale, sia per quanto riguarda la caduta umana. Fare clic qui per visualizzare una versione più grande di questa figura.
{kind=link}

Figura 2: Esempio di una registrazione video estratta dal database UP-Fall Detection. Nella parte superiore, c'è una sequenza di immagini di un soggetto che cade lateralmente. Nella parte inferiore, c'è una sequenza di immagini che rappresentano le caratteristiche di visione estratte. Queste caratteristiche sono il movimento relativo dei pixel tra due immagini adiacenti. I pixel bianchi rappresentano un movimento più veloce, mentre i pixel neri rappresentano un movimento più lento (o prossimo allo zero). Questa sequenza viene ordinata da sinistra a destra, in ordine cronologico. Fare clic qui per visualizzare una versione più grande di questa figura.
{kind=link}

Figura 3: Risultati comparativi che riportano il miglior punteggio F1 di ogni modalità rispetto al modello di apprendimento automatico e la migliore lunghezza della finestra. Le barre rappresentano i valori medi del punteggio F1. Il testo nei punti dati rappresenta la media e la deviazione standard tra parentesi. Fare clic qui per visualizzare una versione più grande di questa figura.
{kind=link}
| Modalità | Modello | Precisione (%) | Precisione (%) | Sensibilità (%) | Specificità (%) | Punteggio F1 (%) |
| Ir | RF (3 sec) | 67,38 : 0,65 | 36,45 x 2,46 | 31,26 - 0,89 | 96,63 x 0,07 | 32,16 - 0,99 |
| SVM (3 sec) | 65,16 x 0,90 | 26,77 x 0,58 | 25,16 x 0,29 | 96,31 - 0,09 | 23,89 x 0,41 | |
| MLP (3 sec) | 65,69 x 0,89 | 28,19 x 3,56 | 26.40 - 0,71 | 96.41 - 0,08 | 25,13 x 1,09 | |
| kNN (3 sec) | 61,79 x 1,47 | 30,04 x 1,44 | 27,55 x 0,97 | 96,05 x 0,16 | 27,89 x 1,13 | |
| Imu | RF (1 sec) | 95,76 x 0,18 | 70,78 x 1,53 | 66,91 x 1,28 | 99,59 x 0,02 | 68,35 x 1,25 |
| SVM (1 sec) | 93,32 x 0,23 | 66,16 x 3,33 | 58,82 x 1,53 | 99,32 - 0,02 | 60,00 x 1,34 | |
| MLP (1 sec) | 95,48 x 0,25 | 73,04 - 1,89 | 69,39 x 1,47 | 99,56 - 0,02 | 70.31 - 1,48 | |
| kNN (1 sec) | 94,90 x 0,18 | 69,05 x 1,63 | 64,28 x 1,57 | 99,50 x 0,02 | 66,03 x 1,52 | |
| IMU-EEG | RF (1 sec) | 95,92 x 0,29 | 74,14 x 1,29 | 66,29 x 1,66 | 99,59 x 0,03 | 69.03 - 1,48 |
| SVM (1 sec) | 90,77 x 0,36 | 62,51 - 3,34 | 52,46 x 1,19 | 99.03 - 0,03 | 53,91 - 1,16 | |
| MLP (1 sec) | 93,33 x 0,55 | 74.10 - 1,61 | 65,32 x 1,15 | 99,32 x 0,05 | 68.13 - 1,16 | |
| kNN (1 sec) | 92,12 x 0,31 | 66,86 x 1,32 | 58,30 x 1,20 | 98,89 x 0,05 | 60,56 x 1,02 | |
| IR-IMU-EEG | RF (2 sec) | 95,12 x 0,36 | 74,63 x 1,65 | 66,71 - 1,98 | 99,51 - 0,03 | 69,38 x 1,72 |
| SVM (1 sec) | 90,59 x 0,27 | 64,75 x 3,89 | 52,63 x 1,42 | 99.01 - 0,02 | 53,94 x 1,47 | |
| MLP (1 sec) | 93,26 - 0,69 | 73,51 - 1,59 | 66,05 x 1,11 | 99,31 - 0,07 | 68,19 x 1,02 | |
| kNN (1 sec) | 92,24 x 0,25 | 67,33 x 1,94 | 58.11 - 1,61 | 99.21 - 0,02 | 60,36 x 1,71 | |
| Cam | RF (3 sec) | 32,33 X 0,90 | 14,45 x 1,07 | 14.48 - 0,82 | 92,91 - 0,09 | 14,38 - 0,89 |
| SVM (2 sec) | 34,40 x 0,67 | 13,81 - 0,22 | 14,30 : 0,31 | 92,97 - 0,06 | 13,83 x 0,27 | |
| MLP (3 sec) | 27,08 x 2,03 | 8.59 x 1,69 | 10,59 x 0,38 | 92,21 - 0,09 | 7.31 - 0,82 | |
| kNN (3 sec) | 34.03 - 1,11 | 15,32 x 0,73 | 15,54 x 0,57 | 93.09 - 0,11 | 15,19 x 0,52 | |
| IR-CAM | RF (3 sec) | 65,00 - 0,65 | 33,93 x 2,81 | 29.02 - 0,89 | 96,34 x 0,07 | 29,81 x 1,16 |
| SVM (3 sec) | 64,07 - 0,79 | 24,10 - 0,98 | 24.18 x 0,17 | 96,17 x 0,07 | 22,38 x 0,23 | |
| MLP (3 sec) | 65,05 - 0,66 | 28,25 x 3,20 | 25.40 - 0,51 | 96,29 x 0,06 | 24,39 x 0,88 | |
| kNN (3 sec) | 60,75 x 1,29 | 29,91 x 3,95 | 26,25 x 0,90 | 95,95 x 0,11 | 26,54 x 1,42 | |
| IMU-EEG-CAM | RF (1 sec) | 95.09 - 0,23 | 75,52 x 2,31 | 66,23 x 1,11 | 99,50 x 0,02 | 69,36 x 1,35 |
| SVM (1 sec) | 91,16 - 0,25 | 66,79 x 2,79 | 53,82 : 0,70 | 99.07 - 0.02 | 55,82 x 0,77 | |
| MLP (1 sec) | 94,32 x 0,31 | 76,78 x 1,59 | 67.29 x 1,41 | 99,42 - 0,03 | 70,44 x 1,25 | |
| kNN (1 sec) | 92,06 - 0,24 | 68,82 x 1,61 | 58,49 x 1,14 | 99,19 - 0,02 | 60,51 - 0,85 |
Tabella 1: risultati comparativi che riportano le migliori prestazioni di ogni modalità rispetto al modello di apprendimento automatico e la migliore lunghezza della finestra (tra parentesi). Tutti i valori delle prestazioni rappresentano la media e la deviazione standard.
| # | Tipo IMU | |||
| Rf | Svm | Mlp | KNN (KNN) | |
| 1 | (98.36) Vita | (83.30) Tasca destra | (57.67) Tasca destra | (73.19) Tasca destra |
| 2 | (95.77) Collo | (83.22) Vita | (44.93) Collo | (68,73) Vita |
| 3 | (95.35) Tasca destra | (83.11) Collo | (39.54) Vita | (65.06) Collo |
| 4 | (95.06) Caviglia | (82,96) Caviglia | (39.06) Polso sinistro | (58.26) Caviglia |
| 5 | (94.66) Polso sinistro | (82.82) Polso sinistro | (37.56) Caviglia | (51.63) Polso sinistro |
Tabella 2: Classificazione del miglior sensore indossabile per classificatore, ordinato in base al punteggio F1 (tra parentesi). Le aree in ombra rappresentano i primi tre classificatori per il rilevamento delle cadute.
| Tipo IMU | Lunghezza finestra | |||
| Rf | Svm | Mlp | KNN (KNN) | |
| Caviglia sinistra | 2 secondi | 3-sec | 1-sec | 3-sec |
| Vita | 3-sec | 1-sec | 1-sec | 2 secondi |
| Collo | 3-sec | 3-sec | 2 secondi | 2 secondi |
| Tasca destra | 3-sec | 3-sec | 2 secondi | 2 secondi |
| Polso sinistro | 2 secondi | 2 secondi | 2 secondi | 2 secondi |
Tabella 3: Lunghezza della finestra temporale preferita nei sensori indossabili per classificatore.
| # | Vista Fotocamera | |||
| Rf | Svm | Mlp | KNN (KNN) | |
| 1 | (62.27) Vista laterale | (24.25) Vista laterale | (13.78) Vista frontale | (41.52) Vista laterale |
| 2 | (55.71) Vista frontale | (0.20) Vista frontale | (5.51) Vista laterale | (28.13) Vista frontale |
Tabella 4: Classificazione del miglior punto di vista della telecamera per classificatore, ordinato in base al punteggio F1 (tra parentesi). Le aree in ombra rappresentano il classificatore superiore per il rilevamento delle cadute.
| Fotocamera | Lunghezza finestra | |||
| Rf | Svm | Mlp | KNN (KNN) | |
| Vista laterale | 3-sec | 3-sec | 2 secondi | 3-sec |
| Vista frontale | 2 secondi | 2 secondi | 3-sec | 2 secondi |
Tabella 5: Lunghezza della finestra temporale preferita nei punti di vista della telecamera per classificatore.
| Multimodale | Classificatore | Precisione (%) | Precisione (%) | Sensibilità (%) | Punteggio F1 (%) |
| Vita + Vista laterale | Rf | 98,72 x 0,35 | 94.01 - 1,51 | 97,63 x 1,56 | 95,77 x 1,15 |
| Svm | 95,59 x 0,40 | 100 | 70,26 x 2,71 | 82,51 - 1,85 | |
| Mlp | 77,67 x 11,04 | 33,73 x 11,69 | 37.11 - 26,74 | 29.81 - 12,81 | |
| KNN (KNN) | 91,71 - 0,61 | 77,90 x 3,33 | 61,64 x 3,68 | 68,73 x 2,58 | |
| Tasca destra + Vista laterale | Rf | 98.41 - 0,49 | 93,64 x 1,46 | 95,79 x 2,65 | 94,69 x 1,67 |
| Svm | 95,79 x 0,58 | 100 | 71,58 x 3,91 | 83,38 x 2,64 | |
| Mlp | 84,92 x 2,98 | 55,70 x 11,36 | 48,29 x 25,11 | 45.21 - 14,19 | |
| KNN (KNN) | 91,71 - 0,58 | 73,63 x 3,19 | 68,95 x 2,73 | 71.13 - 1,69 |
Tabella 6: Risultati comparativi del sensore indossabile combinato e del punto di vista della fotocamera utilizzando la lunghezza della finestra di 3 secondi. Tutti i valori rappresentano la media e la deviazione standard.
Discussione
È comune incontrare problemi dovuti a problemi di sincronizzazione, organizzazione e incoerenza dei dati20 quando viene creato un set di dati.
Sincronizzazione
Nell'acquisizione dei dati, sorgono problemi di sincronizzazione, dato che più sensori funzionano comunemente a diverse frequenze di campionamento. I sensori con frequenze più alte raccolgono più dati rispetto a quelli con frequenze più basse. Pertanto, i dati provenienti da origini diverse non verranno abbinati correttamente. Anche se i sensori funzionano alle stesse frequenze di campionamento, è possibile che i dati non vengano allineati. A questo proposito, le seguenti raccomandazioni potrebbero aiutare a gestire questi problemi di sincronizzazione20: (i) registrare timestamp, soggetto, attività e prova in ogni campione di dati ottenuto dai sensori; ii) la fonte di informazioni più coerente e meno frequente deve essere utilizzata come segnale di riferimento per la sincronizzazione; e (iii) utilizzare procedure automatiche o semiautomatiche per sincronizzare le registrazioni video che l'ispezione manuale sarebbe impraticabile.
Pre-elaborazione dei dati
Anche la pre-elaborazione dei dati deve essere eseguita e le decisioni critiche influenzano questo processo: (a) determinare i metodi per l'archiviazione dei dati e la rappresentazione dei dati di origini multiple ed eterogenee (b) decidere i modi per archiviare i dati nell'host locale o sul cloud (c) selezionare l'organizzazione dei dati, inclusi i nomi dei file e le cartelle (d) gestire i valori mancanti dei dati, nonché i redeventuali trovati nei sensori , tra gli altri. Inoltre, per il cloud di dati, il buffering locale è consigliato quando possibile per ridurre la perdita di dati al momento del caricamento.
Incoerenza dei dati
L'incoerenza dei dati è comune tra le prove che individuano variazioni nelle dimensioni del campione di dati. Questi problemi sono correlati all'acquisizione di dati nei sensori indossabili. Brevi interruzioni dell'acquisizione dei dati e collisione dei dati da più sensori portano a incoerenze dei dati. In questi casi, gli algoritmi di rilevamento delle incoerenze sono importanti per gestire i guasti online nei sensori. È importante sottolineare che i dispositivi basati su wireless devono essere monitorati frequentemente durante l'esperimento. Una batteria scarica potrebbe influire sulla connettività e causare la perdita di dati.
Etico
Il consenso a partecipare e l'approvazione etica sono obbligatori in ogni tipo di sperimentazione in cui le persone sono coinvolte.
Per quanto riguarda le limitazioni di questa metodologia, è importante notare che è progettata per approcci che considerano diverse modalità per la raccolta dei dati. I sistemi possono includere sensori indossabili, ambientali e/o di visione. Si consiglia di considerare il consumo di energia dei dispositivi e la durata delle batterie nei sensori wireless, a causa di problemi come la perdita di raccolta dei dati, la diminuzione della connettività e il consumo di energia nell'intero sistema. Inoltre, questa metodologia è destinata a sistemi che utilizzano metodi di apprendimento automatico. Un'analisi della selezione di questi modelli di apprendimento automatico deve essere eseguita in anticipo. Alcuni di questi modelli potrebbero essere accurati, ma molto dispendiosi in termini di tempo ed energia. È necessario prendere in considerazione un compromesso tra una stima accurata e una disponibilità limitata delle risorse per l'elaborazione nei modelli di apprendimento automatico. È inoltre importante osservare che, nella raccolta dei dati del sistema, le attività sono state condotte nello stesso ordine; inoltre, le prove sono state eseguite nella stessa sequenza. Per motivi di sicurezza, un materasso protettivo è stato utilizzato per i soggetti a cadere su. Inoltre, le cadute sono state auto-iniziate. Si tratta di una differenza importante tra cadute simulate e reali, che generalmente si verificano nei confronti dei materiali duri. In questo senso, questo set di dati registrato cade con una reazione intuitiva che cerca di non cadere. Inoltre, ci sono alcune differenze tra le cadute reali nelle persone anziane o con disabilità e le cadute della simulazione; e questi devono essere presi in considerazione quando si progetta un nuovo sistema di rilevamento delle cadute. Questo studio si è concentrato sui giovani senza alcuna menomazione, ma è notevole dire che la selezione dei soggetti dovrebbe essere allineata all'obiettivo del sistema e alla popolazione target che lo utilizzerà.
Dalle opere correlate descritte in precedenza10,11,12,13,14,15,16,1717,18, possiamo osservare che ci sono autori che utilizzano approcci multimodali che si concentrano nell'ottenere robusti rilevatori di caduta o concentrarsi sul posizionamento o sulle prestazioni del classificatore. Di conseguenza, affrontano solo uno o due dei problemi di progettazione per il rilevamento delle cadute. La nostra metodologia consente di risolvere contemporaneamente tre dei principali problemi di progettazione di un sistema di rilevamento delle cadute.
Per il lavoro futuro, suggeriamo di progettare e implementare un semplice sistema di rilevamento delle cadute multimodale basato sui risultati ottenuti seguendo questa metodologia. Per l'adozione nel mondo reale, per l'apprendimento dei trasferimenti, la classificazione gerarchica e gli approcci di deep learning dovrebbero essere utilizzati per sviluppare sistemi più solidi. La nostra implementazione non ha preso in considerazione le metriche qualitative dei modelli di apprendimento automatico, ma le risorse di elaborazione in tempo reale e limitate devono essere prese in considerazione per l'ulteriore sviluppo della caduta umana e dei sistemi di rilevamento/riconoscimento delle attività. Infine, al fine di migliorare il nostro set di dati, inciampare o quasi cadere attività e monitoraggio in tempo reale dei volontari durante la loro vita quotidiana può essere considerato.
Divulgazioni
Gli autori non hanno nulla da rivelare.
Riconoscimenti
Questa ricerca è stata finanziata dall'Universidad Panamericana attraverso la sovvenzione "Fomento a la Investigaciàn UP 2018", sotto il codice del progetto UP-CI-2018-ING-MX-04.
Materiali
| Name | Company | Catalog Number | Comments |
| Inertial measurement wearable sensor | Mbientlab | MTH-MetaTracker | Tri-axial accelerometer, tri-axial gyroscope and light intensity wearable sensor. |
| Electroencephalograph brain sensor helmet MindWave | NeuroSky | 80027-007 | Raw brainwave signal with one forehand sensor. |
| LifeCam Cinema video camera | Microsoft | H5D-00002 | 2D RGB camera with USB cable interface. |
| Infrared sensor | Alean | ABT-60 | Proximity sensor with normally closed relay. |
| Bluetooth dongle | Mbientlab | BLE | Dongle for Bluetooth connection between the wearable sensors and a computer. |
| Raspberry Pi | Raspberry | Version 3 Model B | Microcontroller for infrared sensor acquisition and computer interface. |
| Personal computer | Dell | Intel Xeon E5-2630 v4 @2.20 GHz, RAM 32GB |
Riferimenti
- United Nations. World Population Prospects: The 2017 Revision, Key Findings and Advance Tables. United Nations. Department of Economic and Social Affairs, Population Division. , (2017).
- World Health Organization. Ageing, and Life Course Unit. WHO Global Report on Falls Prevention in Older Age. , (2008).
- Igual, R., Medrano, C., Plaza, I. Challenges, Issues and Trends in Fall Detection Systems. Biomedical Engineering Online. 12 (1), 66 (2013).
- Noury, N., et al. Fall Detection-Principles and Methods. 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 1663-1666 (2007).
- Mubashir, M., Shao, L., Seed, L. A Survey on Fall Detection: Principles and Approaches. Neurocomputing. 100, 144-152 (2002).
- Perry, J. T., et al. Survey and Evaluation of Real-Time Fall Detection Approaches. Proceedings of the 6th International Symposium High-Capacity Optical Networks and Enabling Technologies. , 158-164 (2009).
- Xu, T., Zhou, Y., Zhu, J. New Advances and Challenges of Fall Detection Systems: A Survey. Applied Sciences. 8 (3), 418 (2018).
- Rougier, C., Meunier, J., St-Arnaud, A., Rousseau, J. Robust Video Surveillance for Fall Detection Based on Human Shape Deformation. IEEE Transactions on Circuit Systems for Video Technologies. 21, 611-622 (2011).
- Bulling, A., Blanke, U., Schiele, B. A Tutorial on Human Activity Recognition Using Body-Worn Inertial Sensors. ACM Computing Surveys. 46 (3), 33 (2014).
- Kwolek, B., Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Computational Methods and Programs in Biomedicine. 117, 489-501 (2014).
- Ofli, F., Chaudhry, R., Kurillo, G., Vidal, R., Bajcsy, R. Berkeley MHAD: A Comprehensive Multimodal Human Action Database. Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision. , 53-60 (2013).
- Dovgan, E., et al. Intelligent Elderly-Care Prototype for Fall and Disease Detection. Slovenian Medical Journal. 80, 824-831 (2011).
- Santoyo-Ramón, J., Casilari, E., Cano-García, J. Analysis of a Smartphone-Based Architecture With Multiple Mobility Sensors for Fall Detection With Supervised Learning. Sensors. 18 (4), 1155 (2018).
- Özdemir, A. An Analysis on Sensor Locations of the Human Body for Wearable Fall Detection Devices: Principles and Practice. Sensors. 16 (8), 1161 (2016).
- Ntanasis, P., Pippa, E., Özdemir, A. T., Barshan, B., Megalooikonomou, V. Investigation of Sensor Placement for Accurate Fall Detection. International Conference on Wireless Mobile Communication and Healthcare. , 225-232 (2016).
- Bagala, F., et al. Evaluation of Accelerometer-Based Fall Detection Algorithms on Real-World Falls. PLoS One. 7, 37062 (2012).
- Bourke, A. K., et al. Assessment of Waist-Worn Tri-Axial Accelerometer Based Fall-detection Algorithms Using Continuous Unsupervised Activities. Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 2782-2785 (2010).
- Kerdegari, H., Samsudin, K., Ramli, A. R., Mokaram, S. Evaluation of Fall Detection Classification Approaches. 4th International Conference on Intelligent and Advanced Systems. , 131-136 (2012).
- Alazrai, R., Mowafi, Y., Hamad, E. A Fall Prediction Methodology for Elderly Based on a Depth Camera. 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. , 4990-4993 (2015).
- Peñafort-Asturiano, C. J., Santiago, N., Núñez-Martínez, J. P., Ponce, H., Martínez-Villaseñor, L. Challenges in Data Acquisition Systems: Lessons Learned from Fall Detection to Nanosensors. 2018 Nanotechnology for Instrumentation and Measurement. , 1-8 (2018).
- Martínez-Villaseñor, L., et al. UP-Fall Detection Dataset: A Multimodal Approach. Sensors. 19 (9), 1988 (2019).
- Rantz, M., et al. Falls, Technology, and Stunt Actors: New approaches to Fall Detection and Fall Risk Assessment. Journal of Nursing Care Quality. 23 (3), 195-201 (2008).
- Lachance, C., Jurkowski, M., Dymarz, A., Mackey, D. Compliant Flooring to Prevent Fall-Related Injuries: A Scoping Review Protocol. BMJ Open. 6 (8), 011757 (2016).
Ristampe e Autorizzazioni
Richiedi autorizzazione per utilizzare il testo o le figure di questo articolo JoVE
Richiedi AutorizzazioneThis article has been published
Video Coming Soon
Personale delle biblioteche
Copyright © 2025 MyJoVE Corporation. Tutti i diritti riservati