
Method Article
Frase baseada em nuvem mineração e análise de associação de frase-categoria definida pelo usuário em publicações biomédicas
* Estes autores contribuíram igualmente
Neste Artigo
Resumo
Apresentamos um protocolo e código de programação associado, bem como amostras de metadados para apoiar uma identificação automatizada baseada em nuvem de associação de frases-categoria representando conceitos exclusivos no domínio de usuário selecionado conhecimento na literatura biomédica. A associação de frase-categoria quantificada pelo presente protocolo pode facilitar na análise de profundidade no domínio do conhecimento selecionado.
Resumo
A acumulação rápida de dados textuais biomédicos longe excedeu a capacidade humana de curadoria manual e análise, necessitando de novas ferramentas de mineração de texto para extrair ideias biológicas de grandes volumes de relatórios científicos. O pipeline de reconhecimento de contexto semântico Online Analytical Processing (CaseOLAP), desenvolvido em 2016, com êxito quantifica relacionamentos frase-categoria definida pelo usuário através da análise de dados textuais. CaseOLAP tem muitas aplicações biomédicas.
Temos desenvolvido um protocolo para um ambiente baseado em nuvem, apoiando a frase de fim-de-final-mineração e plataforma de análises. Nosso protocolo inclui pré-processamento de dados (por exemplo, transferindo, extração e análise de documentos de texto), indexação e pesquisa com Elasticsearch, criando uma estrutura de documento funcional chamado texto-cubo e quantificar as relações de frase-categoria usando o algoritmo de CaseOLAP do núcleo.
Nossa pré-processamento de dados gera mapeamentos chave-valor para todos os documentos envolvidos. Os dados pré-processado são indexados para efectuar uma pesquisa de documentos, incluindo as entidades, o que facilita ainda mais a criação de texto-cubo e cálculo de Pontuação de CaseOLAP. Os escores brutos obtidos do CaseOLAP são interpretados usando uma série de análises Integrativa, incluindo a redução de dimensionalidade, clusterização, temporal e de análises geográficas. Além disso, os escores de CaseOLAP são usados para criar um banco de dados gráfico, que permite o mapeamento de semântico dos documentos.
CaseOLAP define a frase-categoria relações em um exato (identifica as relações), consistente (altamente reprodutível) e de forma eficiente (processos 100.000 palavras/seg). Na sequência deste protocolo, os usuários podem acessar um ambiente de computação em nuvem para oferecer suporte a suas próprias configurações e aplicações de CaseOLAP. Esta plataforma oferece maior acessibilidade e capacita a Comunidade biomédica com ferramentas de mineração de frase para aplicações de pesquisa biomédica generalizada.
Introdução
Avaliação manual de milhões de arquivos de texto para o estudo da Associação de frase-categoria (por exemplo., faixa etária para associação de proteína) é incomparável com a eficiência fornecida por um método computacional automatizado. Queremos introduzir a plataforma baseada em nuvem sensível ao contexto semântico Online Analytical Processing (CaseOLAP) como um método de mineração de frase para computação automatizada da associação da categoria-frase no contexto biomédico.
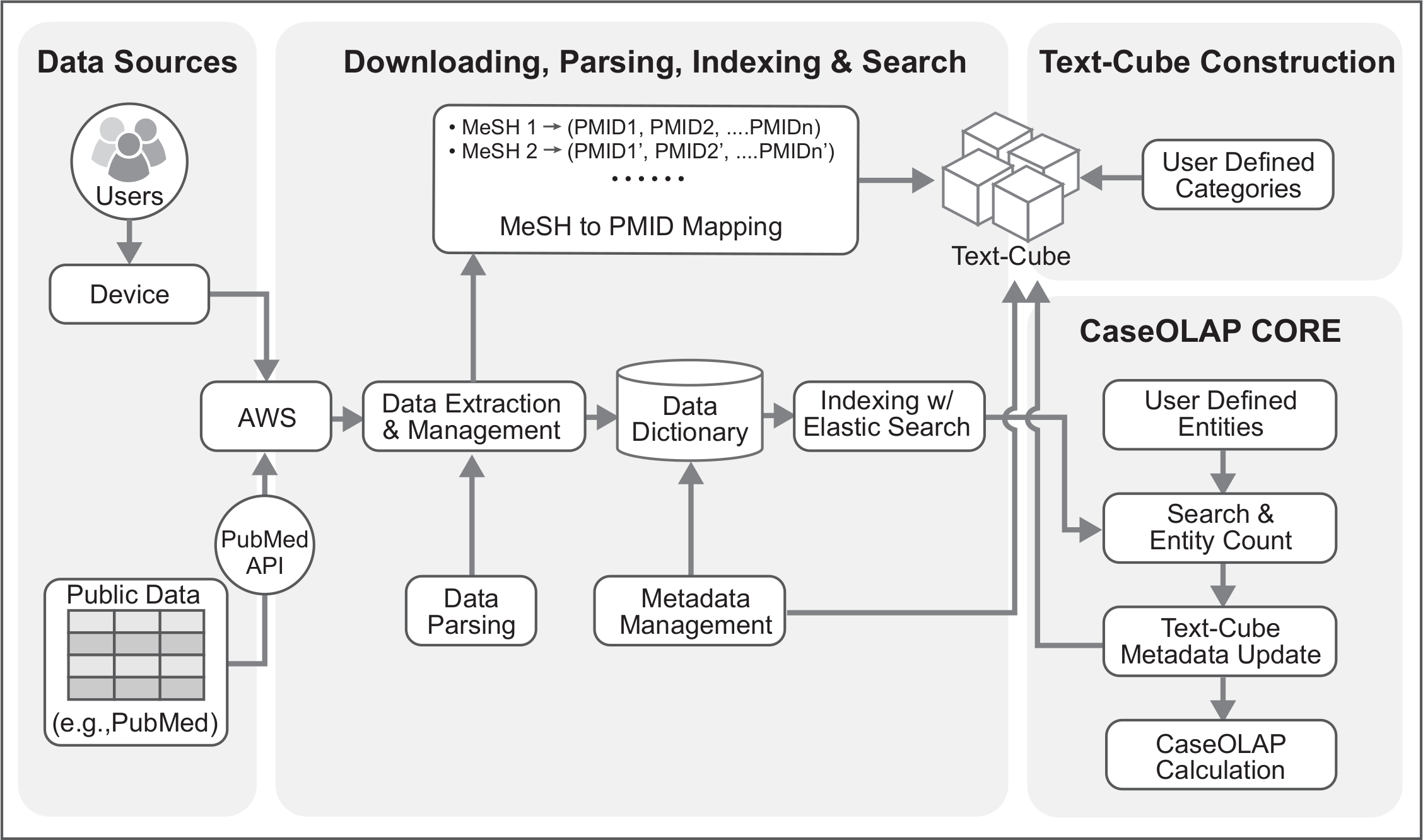
A plataforma CaseOLAP, que primeiro foi definida em 20161, é muito eficiente em comparação com os métodos tradicionais de gerenciamento de dados e computação por causa de sua gestão de documento funcional chamado texto-cubo2,3, 4, que distribui os documentos, mantendo a hierarquia e bairros subjacentes. Tiver sido aplicado em investigação biomédica5 para estudar a associação entidade-categoria. A plataforma de CaseOLAP consiste em seis etapas principais, incluindo download e extração de dados, análise, indexação, criação de texto-cubo, contagem de entidade e cálculo de Pontuação de CaseOLAP; Qual é o foco principal do protocolo (Figura 1, Figura 2, tabela 1).
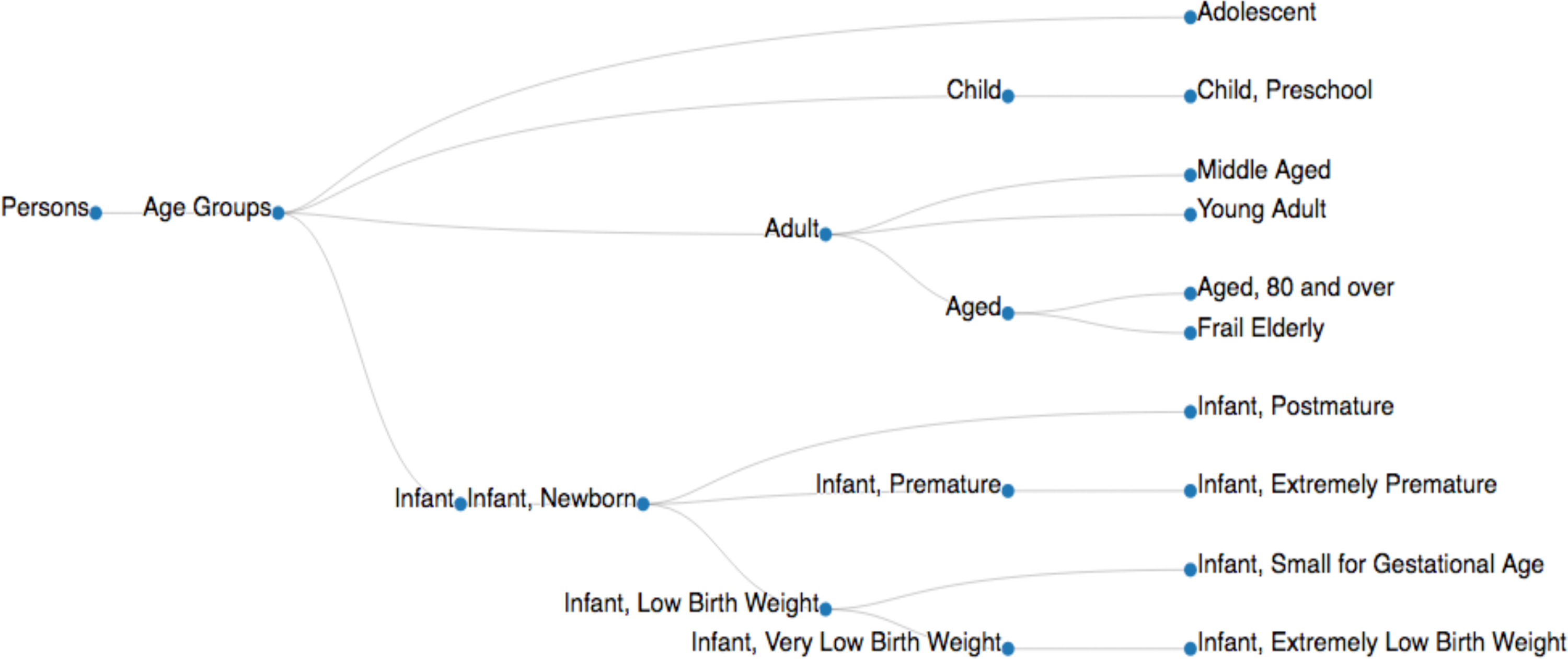
Para implementar o algoritmo de CaseOLAP, o usuário configura a categorias de interesse (por exemplo, doença, sinais e sintomas, grupos de idade, diagnóstico) e entidades de interesse (por exemplo, proteínas, drogas). Um exemplo de uma categoria incluída neste artigo é a 'Grupos de idade', que tem 'Infantil', 'criança', 'adolescente', e 'adultas' subcategorias como células do cubo-texto e nomes de proteína (sinônimos) e abreviaturas como entidades. Medical Subject Headings (MeSH) são implementados para recuperar publicações correspondentes às categorias definidas (tabela 2). Descritores de malha são organizados em uma estrutura de árvore hierárquica para permitir a busca de publicações em diferentes níveis de especificidade (um exemplo mostrado na Figura 3). A plataforma CaseOLAP utiliza a funcionalidade de indexação e busca de dados para a curadoria dos documentos associados a uma entidade que facilitar ainda mais o documento de mapeamento de entidade contagem e cálculo de Pontuação de CaseOLAP.
Os detalhes do cálculo CaseOLAP Pontuação está disponível em anteriores Publicações1,5. Esta pontuação é calculada usando critérios específicos de classificação com base na estrutura de documento subjacente do texto-cubo. O resultado final é o produto de integridade, popularidadee distinção. Integridade descreve-se uma entidade representativa é uma unidade semântica integral que coletivamente se refere a um conceito significativo. A integridade da frase definida pelo usuário é levado para ser 1.0 porque ele permanece como uma frase padrão na literatura. Distintividade representa a importância relativa de uma frase em um subconjunto dos documentos em comparação com o resto das outras células. Primeiro calcula a relevância de uma entidade para uma célula específica, comparando a ocorrência do nome proteína no conjunto de dados de destino e fornece uma pontuação normalizada de distintividade . Popularidade representa o fato de que a frase com uma pontuação mais elevada de popularidade aparece mais frequentemente em um subconjunto dos documentos. Nomes raros de proteína em uma célula são classificados em baixo, enquanto um aumento na sua frequência de menção tem um retorno decrescente devido a implementação da função logarítmica da frequência. Estes três conceitos de medição quantitativa depende da frequência de (1) o termo da entidade sobre uma célula e entre as células e (2) o número de documentos com essa entidade (frequência de documento) dentro da célula e entre as células.
Temos estudado dois cenários representativos usando um conjunto de dados PubMed e nosso algoritmo. Estamos interessados em proteínas como mitocondriais estão associados com duas categorias únicas de descritores de malha; "Faixas etárias" e "doenças nutricionais e metabólicas". Especificamente, nós obtida 15,728,250 publicações de publicações de 20 anos, coletadas pelo PubMed (1998 a 2018), entre eles, 8.123.458 resumos originais tem tido descritores de malha completo. Por conseguinte, 1.842 proteína mitocondrial humano nomes (incluindo abreviações e sinônimos), adquiridas de UniProt (uniprot.org) bem como de MitoCarta2.0 (http://mitominer.mrc-mbu.cam.ac.uk/release-4.0/begin.do >), são sistematicamente examinados. Suas associações com essas 8.899.019 publicações e entidades foram estudadas usando nosso protocolo; Temos construído um texto-cubo e calculadas as respectivas pontuações CaseOLAP.
Protocolo
Nota: Nós desenvolvemos este protocolo baseado na linguagem de programação Python. Para executar este programa, ter Anaconda Python e Git pre-instalado no dispositivo. Os comandos fornecidos neste protocolo são baseados em ambiente Unix. Este protocolo fornece os detalhes de download de dados de banco de dados PubMed (MEDLINE), analisando os dados e criação de uma plataforma para a mineração de frase e quantificação de associação entidade-categoria definida pelo usuário de computação em nuvem.
1. se a configuração do ambiente de código e python
- Baixar ou clonar o repositório de código de Github (https://github.com/CaseOLAP/caseolap) ou digitando 'git clone https://github.com/CaseOLAP/caseolap.git' na janela do terminal.
- Navegue até o diretório 'caseolap'. Este é o diretório raiz do projeto. Dentro deste diretório, diretório de 'dados' será preenchido com vários conjuntos de dados como você progressos através desses passos no protocolo. O diretório 'entrado' é para dados fornecidos pelo usuário. O diretório de 'log' tem arquivos de log para fins de solução de problemas. O diretório 'resultado' é onde serão armazenados os resultados finais.
- Usando a janela de terminal, vá para o diretório onde você clonou nosso repositório GitHub. Criar o ambiente de CaseOLAP usando o arquivo 'environment.yml' digitando 'conda env criar -f environment.yaml' no terminal. Em seguida, ative o ambiente digitando 'fonte ativar caseolap' no terminal.
2. baixar documentos
- Certifique-se de que o endereço FTP no 'ftp_configuration.json' no diretório config é o mesmo que o endereço do link de base anual ou arquivos de atualização diária, encontrado no link (https://www.nlm.nih.gov/databases/download/pubmed_medline.html) .
- Para baixar a atualização ou linha de base apenas arquivos apenas, conjunto 'verdadeiros' no arquivo 'download_config.json' no diretório 'config'. Por padrão, ele baixa e extrai arquivos de base e de atualização. Uma amostra de dados extraídos de XML pode ser vista em (https://github.com/CaseOLAP/caseolap-pipelines/blob/master/data/extracted-data-sample.xml)
- Digite 'run_download.py python' na janela do terminal para baixar resumos de banco de dados Pubmed. Isso criará um diretório chamado 'ftp.ncbi.nlm.nih.gov' no diretório atual. Este processo verifica a integridade dos dados baixados e extrai-lo para o diretório de destino.
- Vá para o diretório de 'log' para ler as mensagens de log em 'download_log.txt', no caso de falha o processo de download. Se o processo for concluído com êxito, as mensagens de depuração do processo de download serão impresso nesse arquivo de log.
- Quando o download for concluído, navegue através de 'ftp.ncbi.nlm.nih.gov' para certificar-se que há 'updatefiles' ou 'basefiles' ou baixar de ambos os diretórios com base na configuração em 'download_config.json'. As estatísticas de arquivo tornam-se disponíveis em 'filestat.txt' no diretório 'dados'.
3. analisar os documentos
- Certifique-se que baixado e extraídos de dados estão disponíveis no diretório 'ftp.ncbi.nlm.nih.gov' da etapa 2. Este diretório é o diretório de dados de entrada nesta etapa.
- Para modificar o esquema de análise de dados, selecionar parâmetros no arquivo 'parsing_config.json' no diretório 'config', definindo seu valor para 'true'. Por padrão, ele analisa o PMID, autores, resumo, malha, localização, jornal, data da publicação.
- Digite 'run_parsing.py python' no terminal para analisar os documentos dos arquivos baixados (ou extraídos). Esta etapa analisa tudo baixados arquivos XML e cria um dicionário de python para cada documento com chaves (por exemplo., PMID, autores, resumo, malha do arquivo baseado na análise de configuração do esquema no passo 3.2).
- Uma vez que a análise de dados é concluída, certifique-se de que os dados analisados é salvo no arquivo chamado 'pubmed.json' no diretório de dados. Uma amostra de dados analisados está disponível em Figura 3.
- Vá para o diretório de 'log' para ler as mensagens de log em 'parsing_log.txt', no caso de falha o processo de análise. Se o processo for concluído com êxito, as mensagens de depuração serão impresso para fora no arquivo de log.
4. mesh para mapeamento PMID
- Certifique-se de que os dados analisados ('pubmed.json') estão disponíveis no diretório 'dados'.
- Digite 'run_mesh2pmid.py python' no terminal para realizar a malha para mapeamento PMID. Isso cria uma tabela de mapeamento, onde cada um da malha recolhe PMIDs associados. Um único PMID pode cair sob os vários termos de malha.
- Uma vez que o mapeamento é concluído, certifique-se que há 'mesh2pmid.json' no diretório de dados. Uma amostra das estatísticas do mapeamento de top 20 está disponível na tabela-2, figuras 4 e 5.
- Vá para o diretório de 'log' para ler as mensagens de log em 'mesh2pmid_mapping_log.txt', no caso desse processo falha. Se o processo for concluído com êxito, as mensagens de depuração do mapeamento serão impresso nesse arquivo de log.
5. documento de indexação
- Baixe o aplicativo de Elasticsearch de https://www.elastic.co. Atualmente, o download está disponível em (https://www.elastic.co/downloads/elasticsearch). Para baixar o software na nuvem remoto, digite 'wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-x.x.x.tar.gz' no terminal. Certifique-se de que 'x.x.x' no comando acima é substituído pelo número de versão apropriada.
- Verifique se esse arquivo baixado 'elasticsearch-x.x.x.tar.gz' aparece no diretório raiz, em seguida, extrair os arquivos, digitando 'tar xvzf elasticsearch-x.x.x.tar.gz' na janela do terminal.
- Abra um novo terminal e vá para o diretório bin ElasticSearch digitando 'cd Elasticsearch/bin' no terminal do diretório raiz.
- Inicie o servidor Elasticsearch digitando '. / Elasticsearch' na janela do terminal. Certifique-se de que o servidor é iniciado sem mensagens de erro. Em caso de erro no servidor Elasticsearch, siga as instruções no (https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html).
- Modifica o conteúdo no 'index_init_config.json' no diretório 'config' para definir o início do índice. Por padrão, ele irá selecionar todos os itens de presentes.
- Digite 'run_index_init.py python' no terminal para iniciar um índice-banco de dados no servidor Elasticsearch. Isso inicializa o índice com um conjunto de critérios, conhecido como informações de índice (por exemplo, o nome do índice, tipo nome, número de fragmentos, o número de réplicas). Você verá a mensagem mencionando o índice é criado com êxito.
- Selecione os itens do 'index_populate_config.json' no diretório 'config', definindo seu valor para 'true'. Por padrão, ele irá selecionar todos os itens de presentes.
- Certifique-se de que os dados analisados ('pubmed.json') estão presentes no diretório 'dados'.
- Digite 'run_index_populate.py python' no terminal para preencher o índice através da criação de grandes volumes de dados com dois componentes. Um primeiro componente é um dicionário com informações de metadados sobre o nome do índice, nome de tipo e identificação em massa (por exemplo, 'PMID'). A segundo componente é um dicionário de dados que contém todas as informações sobre as marcas (por exemplo, 'title', 'Resumo', 'MeSH').
- Vá para o diretório de 'log' para ler as mensagens de log em 'indexing_log.txt', no caso desse processo falha. Se o processo for concluído com êxito, as mensagens de depuração da indexação serão impresso para fora no arquivo de log.
6. criação de texto-cubo
- Baixe a árvore de malha mais recente disponível em (https://www.nlm.nih.gov/mesh/filelist.html). A versão atual do código está usando MeSH árvore 2018 como 'meshtree2018.bin' no diretório de entrada.
- Defina as categorias de interesse (por exemplo, doença nomes, grupos de idade, sexo). Uma categoria pode incluir um ou mais descritores de malha (https://meshb-prev.nlm.nih.gov/treeView). Colete IDs de malha para uma categoria. Guarde os nomes das categorias no arquivo 'textcube_config.json' no diretório config (ver uma amostra da categoria 'Faixa etária' na versão para download do arquivo 'textcube_config.json').
- Colocar as categorias coletadas de IDs de malha em uma linha separada por um espaço. Salve o arquivo de categoria como 'categories.txt' no diretório 'input' (ver uma amostra da ' idade ' malha as IDs de grupo na versão para download do arquivo 'categories.txt'). Este algoritmo seleciona automaticamente todos os descritores de malha descendentes. Um exemplo de nós raiz e descendentes são apresentados em Figura 4.
- Certifique-se de que 'mesh2pmid.json' está no diretório 'dados'. Se a árvore de malha foi atualizada com um nome diferente (por exemplo, 'meashtree2019.bin') no diretório 'input', certifique-se de que isto é devidamente representado no caminho de entrada de dados no arquivo 'run_textube.py'.
- Digite 'run_textcube.py python' no terminal para criar uma estrutura de dados do documento chamada texto-cubo. Isso cria uma coleção de documentos (PMIDs) para cada categoria. Um único documento (PMID) pode cair em várias categorias, (ver tabela 3A, 3B tabela, figura 6A e Figura 7A).
- Concluída a etapa de criação de texto-cubo, certifique-se que os seguintes arquivos de dados são salvos no diretório 'dados': (1) uma célula de tabela PMID como "textcube_cell2pmid.json", (2) um PMID à tabela de mapeamento de célula como "textcube_pmid2cell.json", (3) um coleção de termos tudo descendentes de malha para uma célula como estatísticas de dados de texto-cubo de "meshterms_per_cat.json" (4) como "textcube_stat.txt".
- Vá para o diretório de 'log' para ler as mensagens de log em 'textcube_log.txt', no caso desse processo falha. Se o processo for concluído com êxito, as mensagens de depuração da criação texto-cubo serão impresso para fora no arquivo de log.
7. contagem de entidade
- Crie entidades definidas pelo usuário (por exemplo, nomes de proteínas, genes, produtos químicos). Colocar uma entidade e suas abreviaturas em uma única linha, separada por "|". Salve o arquivo de entidade como 'entities.txt' no diretório 'input'. Um exemplo de entidades pode ser encontrado em tabela 4.
- Certifique-se de que Elasticsearch o servidor está executando. Caso contrário, vá para a etapa 5.2 e 5.3 para reiniciar o servidor de Elasticsearch. Espera-se que tem um banco de dados indexado chamado 'pubmed' em seu servidor de Elasticsearch que foi criada na etapa 5.
- Certifique-se de que 'textcube_pmid2cell.json' está no diretório 'dados'.
- Digite 'run_entitycount.py python' no terminal para executar a operação de contagem de entidade. Esta procura os documentos do banco de dados indexado e conta a entidade em cada documento bem como recolhe os PMIDs em que entidades foram encontradas.
- Uma vez que é concluída a contagem de entidade, certifique-se que os resultados finais são salvos como 'entitycount.txt' e 'entityfound_pmid2cell.json' no diretório 'dados'.
- Vá para o diretório de 'log' para ler as mensagens de log em 'entitycount_log.txt', no caso desse processo falha. Se o processo for concluído com êxito, as mensagens de depuração de contagem da entidade serão impressas no arquivo de log.
8. metadados atualização
- Certifique-se de que todos os dados de entrada ('entitycount.txt', 'textcube_pmid2cell.json', 'entityfound_pmid2cell.txt') estão no diretório 'dados'. Estes são os dados de entrada para a actualização de metadados.
- Digite 'run_metadata_update.py python' no terminal para atualizar os metadados. Isso prepara uma coleção de metadados (por exemplo, célula de nome, malha associada, PMIDs) que representa cada documento de texto na célula. Uma amostra de metadados de texto-cubo é apresentada na tabela 3A e tabela 3B.
- Uma vez que a actualização de metadados é concluída, certifique-se de que 'metadata_pmid2pcount.json' e 'metadata_cell2pmid.json' arquivos são salvos no diretório 'dados'.
- Vá para o diretório de 'log' para ler as mensagens de log em 'metadata_update_log.txt', no caso desse processo falha. Se o processo for concluído com êxito, as mensagens de depuração da atualização metadados serão impressas no arquivo de log.
9... cálculo de Pontuação de CaseOLAP
- Certifique-se de que os arquivos 'metadata_pmid2pcount.json' e 'metadata_cell2pmid.json' estão presentes no diretório 'dados'. Estes são os dados de entrada para o cálculo da pontuação.
- Digite 'run_caseolap_score.py python' no terminal para executar o cálculo de Pontuação de CaseOLAP. Este calcula a pontuação de CaseOLAP das entidades com base nas categorias definidas pelo usuário. A pontuação de CaseOLAP é o produto de integridade, popularidadee distinção.
- Uma vez que o cálculo da pontuação é concluído, certifique-se que esta salva os resultados em vários arquivos (por exemplo, em termos de popularidade como 'pop.csv', distintividade como 'dist.csv', CaseOLAP Pontuação como 'caseolap.csv'), no diretório 'resultado'. O resumo do cálculo de Pontuação de CaseOLAP também é apresentado na tabela 5.
- Vá para o diretório de 'log' para ler as mensagens de log em 'caseolap_score_log.txt', no caso desse processo falha. Se o processo for concluído com êxito, as mensagens de depuração do cálculo CaseOLAP Pontuação serão impresso para fora no arquivo de log.
Resultados
Para produzir resultados de amostra, implementamos o algoritmo de CaseOLAP em duas rubricas/descritores de assunto: "Faixas etárias" e "Nutricional e doenças metabólicas" como casos de uso.
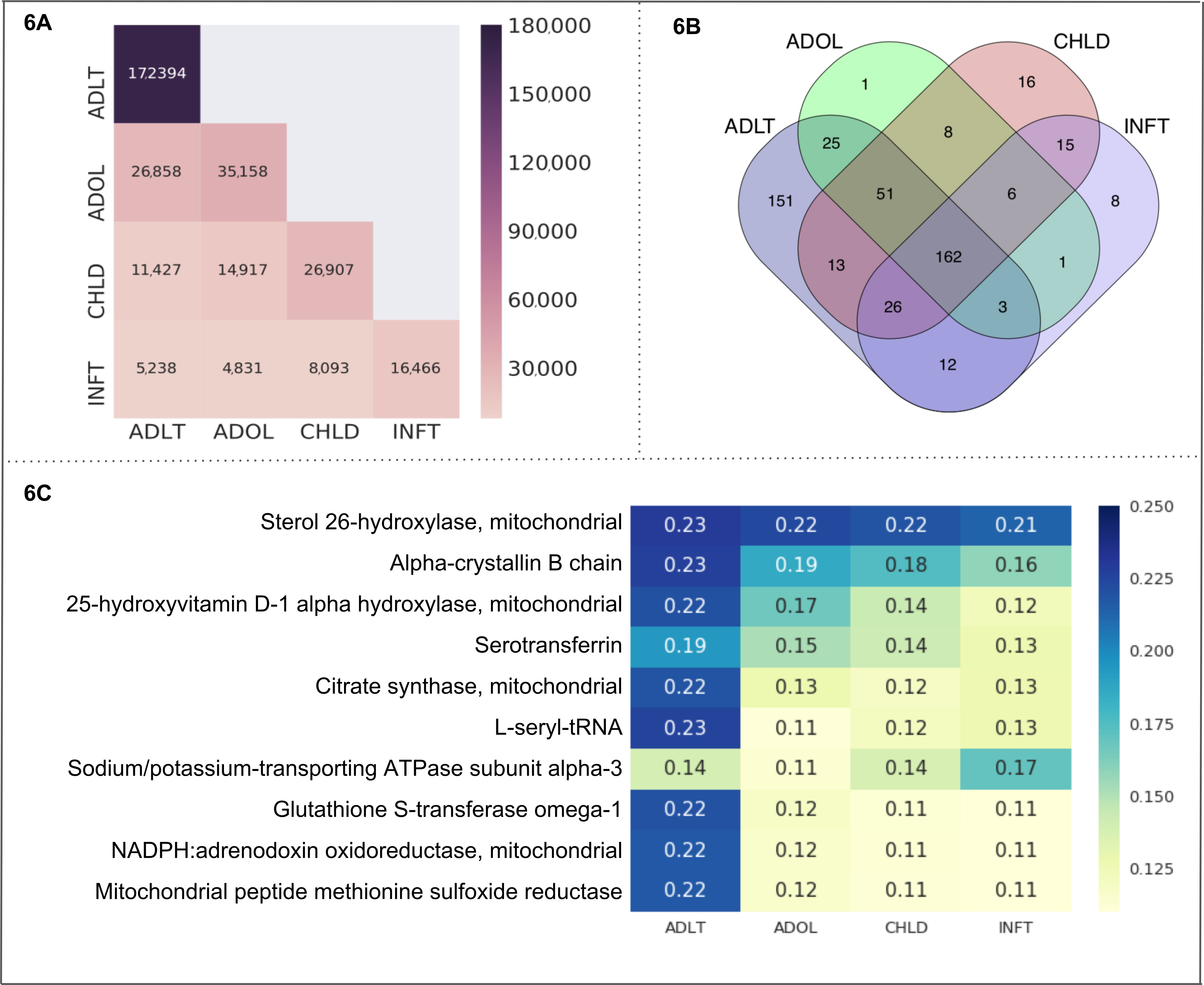
Grupos de idade. Nós selecionamos todas as 4 subcategorias de "Grupos etários" (infantil, criança, adolescente e adulto) como células em um texto-cubo. Os metadados obtidos e estatísticas são mostradas na tabela 3A. A comparação do número de documentos entre as células de cubo de texto é exibida na figura 6A. Adulto contém 172.394 documentos que é o número mais alto em todas as células. As subcategorias de adultas e adolescentes têm o maior número de documentos compartilhados (26.858 documentos). Notadamente, estes documentos incluíam a entidade de nosso interesse apenas (ou seja, proteínas mitocondriais). O diagrama de Venn na Figura 6B representa o número de entidades (ou seja, proteínas mitocondriais) encontrado dentro de cada célula e dentro de várias sobreposições entre as células. O número de proteínas compartilhado dentro de todos os grupos etários subcategorias é 162. A subcategoria adulta retrata o maior número de proteínas únicas (151) seguido por criança (16), infantil (8) e do adolescente (1). Calculamos a associação de grupo de proteínas-idade como uma pontuação de CaseOLAP. As proteínas de top 10 (com base na sua pontuação média de CaseOLAP) associadas com criança, criança, adolescente e adulto subcategorias são esterol 26-hidroxilase, cadeia alfa-CRYGS B, D-1 de 25-hidroxivitamina alfa-hidroxilase, Serotransferrin, citrato sintase, L-seryl-tRNA, transporte de sódio/potássio ATPase subunidade alfa-3, Glutathione S-transferase Ômega-1, NADPH: adrenodoxina oxidorredutase e peptídeo mitocondrial metionina sulfóxido redutase (mostrado na Figura 6). A subcategoria adulta exibe 10 heatmap células com uma intensidade mais elevada em comparação com as células heatmap da criança, adolescente e infantil subcategoria, indicando que o top 10 proteínas mitocondriais apresentam as associações mais fortes para a subcategoria de adulta. A proteína mitocondrial esterol 26-hidroxilase tem associações de altas em todas as subcategorias de idade que é demonstrado pelas células heatmap com intensidades mais elevadas em comparação com as células heatmap das outras 9 proteínas mitocondriais. A distribuição estatística da absoluta diferença na pontuação entre dois grupos mostra o seguinte intervalo de diferença de média, com um intervalo de confiança de 99%: (1) a diferença média entre 'ADLT' e 'INFT' encontra-se no intervalo (0,029 a 0.042), média (2) diferença entre 'ADLT' e 'CHLD' encontra-se no intervalo (0.021 para 0,030), (3) a diferença média entre 'ADLT' e 'ADOL' encontra-se no intervalo (0.020 a 0,029), (4) a diferença média entre 'ADOL' e 'INFT' encontra-se no intervalo (0.015 a 0,022), (5) a diferença média entre 'ADOL' e 'CHLD' situa-se no intervalo (0,007 a 0,010), (6) a diferença média entre 'CHLD' e 'INFT' encontra-se no intervalo (0.011 para 0.016).
Doenças nutricionais e metabólicas. Nós selecionamos 2 subcategorias de "Nutricional e doenças metabólicas" (ou seja, doença metabólica e distúrbios nutricionais) para criar 2 células em um texto-cubo. Os metadados obtidos e estatísticas são mostradas na tabela 3B. A comparação do número de documentos entre as células de cubo de texto é exibida na Figura 7A. A doença metabólica subcategoria contém 54.762 documentos seguidos por 19.181 documentos em distúrbios nutricionais. A doença metabólica de subcategorias e distúrbios nutricionais têm 7.101 documentos compartilhados. Notadamente, estes documentos incluíam a entidade de nosso interesse apenas (ou seja, proteínas mitocondriais). O diagrama de Venn na Figura 7B representa o número de entidades encontradas dentro de cada célula e dentro de várias sobreposições entre as células. Calculamos a proteína-"Nutricional e doenças metabólicas" associação como uma pontuação de CaseOLAP. As proteínas de top 10 (com base na sua pontuação média de CaseOLAP) associadas com este caso de uso são esterol 26-hidroxilase, alfa-CRYGS B cadeia, L-seryl-tRNA, citrato sintase, tRNA pseudouridine sintase A 25-hidroxivitamina D-1 alfa-hidroxilase, Glutathione S-transferase Ômega-1, NADPH: adrenodoxina oxidorredutase, redutase de sulfóxido de metionina peptídeo mitocondrial, inibidor do ativador do plasminogênio 1 (mostrado na Figura 7). Mais da metade (54%) de todas as proteínas são compartilhados entre as doenças metabólicas subcategorias e distúrbios nutricionais (397 proteínas). Curiosamente, quase metade (43%) de proteínas está associadas na subcategoria doença metabólica são exclusivas (300 proteínas), Considerando que distúrbios nutricionais apresentam apenas algumas proteínas únicas (35). Cadeia B de alfa-CRYGS exibe a associação mais forte para as doenças metabólicas subcategoria. Esterol 26-hidroxilase, mitocondrial exibe a associação mais forte na subcategoria transtornos nutricionais, indicando que esta proteína mitocondrial é altamente relevante em estudos descrevendo desordens nutricionais. A distribuição estatística da absoluta diferença na pontuação entre dois grupos 'MBD' e 'NTD' mostra o intervalo (0,046 a 0.061) para a diferença média como um intervalo de confiança de 99%.

Figura 1. Modo de exibição dinâmico de fluxo de trabalho CaseOLAP. Esta figura representa as 5 principais etapas do fluxo de trabalho CaseOLAP. Na etapa 1, o fluxo de trabalho começa por baixar e extrair documentos textuais (por exemplo, a partir de PubMed). Na etapa 2, os dados extraídos são analisados para criar um dicionário de dados para cada documento, bem como uma malha para mapeamento PMID. Na etapa 3, indexação de dados é realizado para facilitar a busca rápida e eficiente da entidade. Na etapa 4, implementação de informação fornecido pelo usuário de categoria (ex.., raiz de malha para cada célula) é realizada para construir um texto-cubo. Na etapa 5, a operação de contagem de entidade é implementada sobre dados de índice, para calcular a pontuação de CaseOLAP. Essas etapas são repetidas de forma iterativa para actualizar o sistema com as últimas informações disponíveis em uma base de dados pública (por exemplo, PubMed). Clique aqui para ver uma versão maior desta figura.
{kind=link}

Figura 2. Arquitetura técnica do fluxo de trabalho CaseOLAP. Esta figura representa os detalhes técnicos do fluxo de trabalho CaseOLAP. Dados do repositório PubMed são obtidos do servidor de FTP do PubMed. O usuário se conecta ao servidor nuvem (por exemplo, conectividade AWS) através do seu dispositivo e cria um Pipeline de Download que faz o download e extrai os dados de um repositório local na nuvem. Dados extraídos são estruturados, verificados e trouxe para um formato adequado com um Pipeline de análise de dados. Simultaneamente, uma malha para a tabela de mapeamento PMID é criada durante a etapa de análise, que é usada para construção de texto-cubo. Dados analisados são armazenados como um JSON como formato de chave-valor dicionário com metadados do documento (por exemplo, PMID, malha, publicação ano). A etapa de indexação mais melhora os dados implementando Elasticsearch para lidar com grandes volumes de dados. Em seguida, o texto-cubo é criado com categorias definidas pelo usuário através da implementação de malha para mapeamento PMID. Quando a formação do texto-cubo e indexação passos forem concluídos, uma contagem de entidade é conduzida. Dados de contagem de entidade são implementados para os metadados de texto-cubo. Finalmente, a pontuação de CaseOLAP é calculada com base na estrutura subjacente do texto-cubo. Clique aqui para ver uma versão maior desta figura.
{kind=link}

Figura 3. Uma amostra de um documento analisado. Uma amostra de dados analisados é apresentada nesta figura. Os dados analisados são organizados como um par chave-valor que é compatível com a criação de metadados de documentos e indexação. Nesta figura, uma PMID (por exemplo, "25896987") está servindo como uma chave e coleta de informações associadas (por exemplo, título, revista, data, abstrato, MeSH, substâncias, departamento e local de publicação) como valor. A primeira aplicação de tal documento metadados é a construção da malha para PMID mapeamento (Figura 5 e tabela 2), que mais tarde é implementado para criar o texto-cubo e para calcular a pontuação de CaseOLAP com entidades fornecido pelo usuário e categorias. Clique aqui para ver uma versão maior desta figura.
{kind=link}

Figura 4. Um exemplo de uma árvore de malha. Árvore de malha de 'idade dos grupos é adaptado a partir da estrutura de dados árvore disponível no banco de dados do NIH (MeSH árvore 2018, < https://meshb.nlm.nih.gov/treeView>). Descritores de malha são implementados com seu IDs (por exemplo, pessoas [M01], idades [M01.060], adolescente [M01.060.057], adulto [M01.060.116], criança [M01.060.406], infantil [M01.060.703]) para coletar os documentos relevantes para um descritor específico de malha ( de nó 3A da tabela). Clique aqui para ver uma versão maior desta figura.
{kind=link}

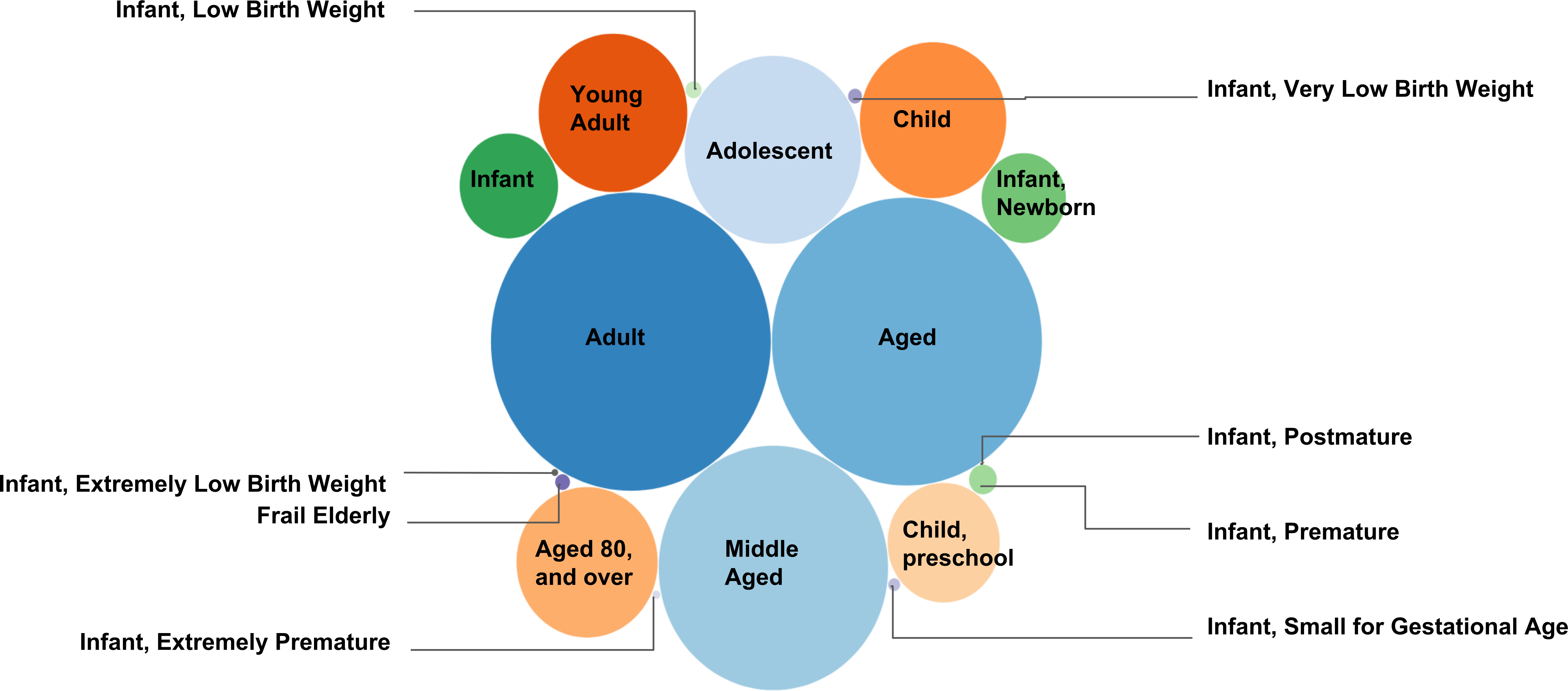
Figura 5. MeSH para mapeamento PMID em faixas etárias. Essa figura apresenta o número de documentos de texto (cada um ligado com um PMID) coletado sob os descritores de malha em "Faixas etárias" como um enredo de bolha. A malha para mapeamento PMID é gerada para fornecer o número exato dos documentos recolhidos sob os descritores de malha. Um número total de 3.062.143 documentos originais foram coletado sob os descritores de malha 18 descendentes (ver tabela 2). Quanto maior o número de PMIDs selecionada sob um descritor de malha específico, quanto maior o raio da bolha que representa o descritor de malha. Por exemplo, o maior número de documentos foram coletado sob o descritor de malha "Adulto" (1.786.371 documentos), Considerando que o menor número de documentos de texto foram coletado sob o descritor de malha "Infante, Postmature" (62 documentos).
Um exemplo adicional de malha para mapeamento PMID é dada para "Doenças nutricionais e metabólicas" (https://caseolap.github.io/mesh2pmid-mapping/bubble/meta.html). Um número total de 422.039 documentos originais foram coletado sob os 361 descritores MeSH descendentes em "Doenças nutricionais e metabólicas". O maior número de documentos foram coletado sob o descritor de malha "Obesidade" (77.881 documentos) seguiram por "Diabetes Mellitus tipo 2" (61.901 documentos), Considerando que "doença do armazenamento de glicogênio, digite VIII" exibiu o menor número de documentos (1 documento ). Uma tabela relacionada também está disponível online em (https://github.com/CaseOLAP/mesh2pmid-mapping/blob/master/data/diseaseall.csv). Clique aqui para ver uma versão maior desta figura.
{kind=link}

Figura 6. "Faixas etárias" como um caso de uso. Essa figura apresenta os resultados de um caso de uso da plataforma de CaseOLAP. Neste caso, nomes de proteína e suas abreviaturas (ver exemplo no quadro 4) são implementadas como entidades e "Faixas etárias", incluindo as células: Infante (INFT), criança (CHLD), adolescente (ADOL) e adulto (ADLT), são implementados como subcategorias (ver Tabela 3A). () Número de documentos em "Faixas etárias": Este mapa de calor mostra o número de documentos distribuídos entre as células dos "Grupos de idade" (para obter detalhes sobre o texto-cubo criação ver protocolo 4 e a tabela 3A). Um maior número de documentos é apresentado com uma intensidade mais escura do heatmap célula (veja a escala). Um único documento pode ser incluído em mais de uma célula. O heatmap apresenta o número de documentos dentro de uma célula ao longo da posição diagonal (por exemplo, ADLT contém 172.394 documentos que é o número mais alto em todas as células). A posição nondiagonal representa o número de documentos, caindo em duas células (por exemplo, ADLT e ADOL tem 26.858 documentos compartilhados). (B) . Contagem de entidade em "Faixas etárias": o diagrama de Venn representa o número de proteínas encontradas nas quatro células representando "Faixas etárias" (INFT, CHLD, ADOL e ADLT). O número de proteínas compartilhados em todas as células é 162. O grupo de idade ADLT retrata o maior número de proteínas únicas (151) seguido por CHLD (16), INFT (8) e ADOL (1). (C) CaseOLAP apresentação de pontuação em "Faixas etárias": As top 10 proteínas com as maiores pontuações CaseOLAP médias de cada grupo são apresentadas em um mapa de calor. Uma maior pontuação CaseOLAP é apresentada com uma intensidade mais escura do heatmap célula (veja a escala). Os nomes de proteína são exibidos na coluna da esquerda e as células (INFT CHLD, ADOL, ADLT) são exibidas ao longo do eixo x. Algumas proteínas mostram uma forte associação a um grupo etário específico (por exemplo, esterol 26-hidroxilase, Cadeia de alfa-CRYGS B e L-seryl-tRNA tem fortes associações com ADLT, Considerando que o transporte de sódio/potássio ATPase subunidade alfa-3 tem uma forte associação com INFT). Clique aqui para ver uma versão maior desta figura.
{kind=link}

Figura 7. "Nutricional e doenças metabólicas" como um caso de uso: esta figura apresenta os resultados de outro caso de uso da plataforma de CaseOLAP. Neste caso, nomes de proteína e suas abreviaturas (ver exemplo no quadro 4) são implementadas como entidades e "Nutricional e doença metabólica" incluindo as duas células: doença metabólica (MBD) e distúrbios nutricionais (NTD) são implementados como subcategorias (consulte a tabela 3B). (A). número de documentos em "Doenças nutricionais e metabólicas": este heatmap retrata o número de documentos de texto nas células de "Doenças nutricionais e metabólicas" (para obter detalhes sobre a criação de texto-cubo, consulte protocolo 4 e tabela 3B ). Um maior número de documentos é apresentado com uma intensidade mais escura do heatmap celular (ver escala). Um único documento pode ser incluído em mais de uma célula. O heatmap apresenta o número total de documentos dentro de uma célula ao longo da posição diagonal (por exemplo, MBD contém 54.762 documentos que é o número mais alto entre as duas células). A posição nondiagonal representa o número de documentos compartilhada por duas células (por exemplo, MBD e NTD tem 7.101 documentos compartilhados). (B). contagem de entidade em "Doenças nutricionais e metabólicas": o diagrama de Venn representa o número de proteínas encontradas nas duas células representando "Nutricional e doenças metabólicas" (MBD e NTD). O número de proteínas compartilhada dentro das duas células é 397. A célula MBD retrata 300 proteínas únicas, e a célula NTD retrata 35 proteínas únicas. (C). CaseOLAP apresentação de pontuação em "Doenças nutricionais e metabólicas": as proteínas de top 10 com as maiores pontuações médias de CaseOLAP em "Doenças nutricionais e metabólicas" são apresentadas em um mapa de calor. Uma maior pontuação CaseOLAP é apresentada com uma intensidade mais escura do heatmap celular (ver escala). Os nomes de proteína são exibidos na coluna esquerda e células (MBD e NTD) são exibidas ao longo do eixo x. Algumas proteínas mostram uma forte associação a uma categoria de doença específica (por exemplo, alfa-CRYGS B cadeia tem uma alta associação com doença metabólica e esterol 26-hidroxilase tem uma alta associação com distúrbios nutricionais). Clique aqui para ver uma versão maior desta figura.
{kind=link}
| Tempo gasto (porcentagem do tempo total) | Passos na plataforma CaseOLAP | Algoritmo e estrutura de dados da plataforma CaseOLAP | Complexidade do algoritmo e estrutura de dados | Detalhes das etapas |
| 40% | Transferindo e Análise | Iteração e árvore de análise de algoritmos | Iteração com loop aninhado e multiplicação constante: O(n^2), O (logn). Onde ' n'é não de iterações. | O pipeline de Downloading itera cada procedimento em vários arquivos. Análise de um único documento executa cada procedimento sobre a estrutura de árvore de dados brutos de XML. |
| 30% | Indexação, pesquisa e criação de cubo de texto | Iteração, algoritmos de busca por Elasticsearch (classificação, índice Lucene, filas de prioridade, as máquinas de estado finito, bit sem fazer cortes, consultas de regex) | Complexidade relacionada com Elasticsearch (https://www.elastic.co/) | Documentos são indexados pela implementação do processo de iteração sobre o dicionário de dados. A criação de texto-cubo implementa documento meta-dados e informações fornecidos pelo usuário da categoria. |
| 30% | Entidade contagem e cálculo CaseOLAP | Iteração na integridade, popularidade, cálculo de distintividade | (1), O(n^2), múltiplas complexidades relacionadas com caseOLAP cálculo de pontuação com base nos tipos de iteração. | Operação de contagem de entidade lista os documentos e fazer uma operação de contagem a lista. Os dados de contagem de entidade são usados para calcular a pontuação de CaseOLAP. |
Tabela 1. Algoritmos e complexidades. Esta tabela apresenta as informações sobre o tempo gasto (porcentagem do tempo total gasto) sobre os procedimentos (por exemplo, transferindo, análise), estrutura de dados e detalhes sobre os algoritmos implementados na plataforma CaseOLAP. CaseOLAP implementa a indexação profissional e aplicação de pesquisa chamado Elasticsearch. Informações adicionais sobre complexidades relacionadas com Elasticsearch e algoritmos internos podem ser encontradas em (https://www.elastic.co).
| Descritores de malha | Número de PMIDs coletados |
| Adulto | 1.786.371 |
| Com idade média | 1.661.882 |
| Com idade | 1.198.778 |
| Adolescente | 706.429 |
| Jovem adulto | 486.259 |
| Criança | 480.218 |
| Com a idade, 80 e mais | 453.348 |
| Criança, pré-escolar | 285.183 |
| Infante | 218.242 |
| Recém | 160.702 |
| Infante, prematuro | 17.701 |
| Nascimento de criança, baixo peso | 5.707 |
| Idosos frágeis | 4.811 |
| Nascimento de criança, muito baixo peso | 4.458 |
| Infantil, pequeno para a idade gestacional, | 3.168 |
| Criança, extremamente prematura | 1.171 |
| Peso de nascimento de criança, extremamente baixa | 1.003 |
| Infante, Postmature | 62 |
Tabela 2. MeSH para estatísticas de mapeamento PMID. Esta tabela apresenta todos os descritores de malha descendentes de "Faixas etárias" e seu número de PMIDs coletados (documentos de texto). A visualização destas estatísticas é apresentada na Figura 5.
| A | Infante (INFT) | Criança (CHLD) | Adolescente (ADOL) | Adulto (ADLT) |
| ID de raiz de malha | M01.060.703 | M01.060.406 | M01.060.057 | M01.060.116 |
| Número de descritores de malha descendentes | 9 | 2 | 1 | 6 |
| Número de PMIDs selecionada | 16.466 | 26.907 | 35.158 | 172.394 |
| Número de entidades encontradas | 233 | 297 | 257 | 443 |
| B | Doenças metabólicas (MBD) | Distúrbios nutricionais (NTD) | ||
| ID de raiz de malha | C18.452 | C18.654 | ||
| Número de descendentes de malha descritores de | 308 | 53 | ||
| Número de PMIDs coletados | 54.762 | 19.181 | ||
| Número de entidades encontradas | 697 | 432 |
Tabela 3. Metadados de texto-cubo. Uma exibição tabular metadados de texto-cubo é apresentada. As tabelas fornecem informações sobre as categorias e malha raízes descritor e descendentes, que são implementados para coletar os documentos em cada célula. A tabela também fornece as estatísticas dos documentos recolhidos e entidades. () "Grupos etários": é uma exibição tabular das "Faixas etárias", incluindo o Infante (INFT), criança (CHLD), adolescente (ADOL) e adulto (ADLT) e sua raiz malha IDs, o número de descritores de malha descendente, número de PMIDs selecionados e número de encontrada de entidades. (B) "Doenças nutricionais e metabólicas": é uma exibição tabular de "Nutricional e doenças metabólicas" incluindo doença metabólica (MBD) e distúrbios nutricionais (NTD) com sua raiz de malha IDs, número de descritores de malha descendentes, número de PMIDs selecionados e o número de entidades encontradas.
| Nomes de proteína e sinônimos | Abreviaturas |
| N-acetylglutamate sintase, mitocondrial, aminoácido acetiltransferase, N-acetylglutamate sintase forma longa; N-acetylglutamate sintase forma abreviada; N-acetylglutamate sintase conservado domínio formulário] | (CE 2.3.1.1) |
| Proteínas e ácidos nucleicos/ácido deglycase DJ-1 (deglycase de Maillard) (Oncogene DJ1) (proteína de doença de Parkinson 7) (parkinsonismo associado deglycase) (DJ de proteína-1) | (CE-3.1.2.-) (CE-3.5.1.-) (CE 3.5.1.124) (DJ-1) |
| Carboxilase do piruvato, mitocondrial (piruvato carboxilase) | (CE 6.4.1.1) (PCB) |
| Componente de vinculação Bcl-2 3 (p53 acima-regulada modulador da apoptose) | (JFY-1) |
| BH3-interação agonista de morte de domínio [BH3-interagindo domínio morte agonista p15 (p15 oferta); BH3-interagindo domínio morte agonista p13; BH3-interagindo domínio morte agonista p11] | (p22) oferta (OFERTA) (p13) oferta (p11) oferta |
| ATP sintase subunidade alfa, mitocondrial (ATP sintase F1 subunidade alfa) | |
| Citocromo P450 11B2, mitocondrial (aldosterona sintase) (enzima de síntese de aldosterona) (CYPXIB2) (citocromo P-450Aldo) (citocromo P-450_C_18) (esteroide 18-hidroxilase) | (ALDOS) (CE 1.14.15.4) (CE 1.14.15.5) |
| 60 kDa calor choque proteína mitocondrial (60 kDa Chaperona) (Chaperona 60) (CPN60) (proteínas de choque 60 de calor) (proteína matriz mitocondrial P1) (proteína de linfócitos P60) | (HSP-60) (Hsp60) (HuCHA60) (CE 3.6.4.9) |
| Caspase-4 (gelo e Ced-3 do homólogo 2) (TX de Protease) [clivada em: subunidade 4 Caspase 1; Subunidade de caspase-4 2] | (CASP-4) (CE 3.4.22.57) (ICH-2) (ICE(rel)-II) (Mih1) |
Tabela 4. Entidade tabela de exemplo. Esta tabela apresenta a amostra de entidades implementado em nossos casos de dois uso: "Faixas etárias" e "Doenças nutricionais e metabólicas" (Figura 6 e Figura 7, tabela 3A,B). As entidades incluem nomes de proteína, sinónimos e abreviaturas. Cada entidade (com seus sinónimos e abreviaturas) é selecionado um por um e é passada através da operação de busca de entidade sobre dados indexados (ver protocolo de 3 e 5). A pesquisa produz uma lista de documentos que facilitar ainda mais a operação de contagem de entidade.
| Quantidades | Definidos pelo usuário | Calculado | Equação da quantidade | Significado da quantidade |
| Integridade | Sim | Não | Integridade do usuário definidas entidades consideradas 1.0. | Representa uma frase significativa. Valor numérico é 1.0, quando já é uma frase estabelecida. |
| Em termos de popularidade | Não | Sim | Equação de popularidade na Figura 1 (fluxo de trabalho e algoritmo) de referência 5, seção "Materiais e métodos". | Com base na frequência de termo da frase dentro de uma célula. Normalizados pela frequência prazo total da célula. Aumento da frequência do termo tem que diminuir o resultado. |
| Distintividade | Não | Sim | Equação de distintividade na Figura 1 (fluxo de trabalho e algoritmo) de referência 5, seção "Materiais e métodos". | Com base no termo frequência e frequência de documento dentro de uma célula e entre as células vizinhas. Normalizado pelo prazo total de frequência e frequência de documento. Quantitativamente, é a probabilidade de que uma frase é exclusiva em uma célula específica. |
| Pontuação CaseOLAP | Não | Sim | Equação de Pontuação de CaseOLAP na Figura 1 (fluxo de trabalho e algoritmo) de referência 5, seção "Materiais e métodos". | Com base na integridade, popularidade e distinção. Valor numérico sempre cai dentro de 0 para 1. Quantitativamente, a pontuação de CaseOLAP representa a associação de frase-categoria |
Tabela 5. Equações CaseOLAP: CaseOLAP o algoritmo foi desenvolvido pelo Fangbo Tao e Jiawei Han et al. em 20161. Brevemente, esta tabela apresenta o cálculo de Pontuação de CaseOLAP constituído por três componentes: integridade, popularidade e distintividade e seu significado matemático associado. Em nossos casos de uso, a pontuação de integridade para proteínas é 1.0 (a máxima pontuação) porque eles ficam como nomes de entidade estabelecida. As contagens de CaseOLAP em nossos casos de uso podem ser vistas na Figura 6 e Figura 7.
Discussão
Nós demonstramos que o algoritmo de CaseOLAP pode criar uma associação de frase com base quantitativa para uma categoria de conhecimento sobre grandes volumes de dados textuais para extração de insights significativos. Seguindo o nosso protocolo, pode-se construir o quadro de CaseOLAP para criar um cubo de texto desejado e quantificar associações de entidade-categoria através do cálculo de Pontuação de CaseOLAP. Os escores brutos obtidos de CaseOLAP podem ser tomados para análises Integrativa, incluindo a redução de dimensionalidade, cluster, análise temporal e geográfica, bem como a criação de um banco de dados gráfico que permite o mapeamento de semântico dos documentos.
Aplicabilidade do algoritmo. Exemplos de entidades definidas pelo usuário, além de proteínas, podem ser uma lista de nomes de gene, drogas, sinais específicos e sintomas, incluindo suas siglas e sinônimos. Além disso, há muitas escolhas para a seleção de categoria facilitar o usuário-definido biomédicas análises específicas (por exemplo, anatomia [A], disciplina e ocupação [H], fenômenos e processos [G]). Em nossos dois casos de uso, todas as publicações científicas e seus dados textuais são recuperados do banco de dados MEDLINE, usando o PubMed como o motor de busca, ambos geridos pela Biblioteca Nacional de medicina. No entanto, a plataforma de CaseOLAP pode ser aplicada a outros bancos de dados de interesse contendo documentos biomédicos com dados textuais tais como o FDA adversos evento Reporting System (fazendas). Este é um banco de dados aberto, contendo informações sobre eventos adversos médicos e relatórios de erros de medicação submetidos ao FDA. Em contraste com o MEDLINE e fazendas, bancos de dados contendo registros eletrônicos de saúde de pacientes de hospitais são não aberto ao público e são restritos pelo Health Insurance Portability and Accountability Act, conhecido como HIPAA.
CaseOLAP algoritmo foi aplicado com sucesso para os diferentes tipos de dados (por exemplo, artigos de notícias)1. A implementação deste algoritmo em documentos biomédicos foi feita em 20185. Os requisitos para a aplicabilidade do algoritmo de CaseOLAP é que cada um dos documentos deve ser atribuído com palavras-chave associadas os conceitos (por exemplo, descritores MeSH em publicações biomédicas, palavras-chave em artigos de notícias). Se não se encontram palavras-chave, um pode aplicar Autophrase6,7 para coletar top frases representativas e construir a lista de entidades antes de implementar nosso protocolo. Nosso protocolo não fornece o passo para executar Autophrase.
Comparação com outros algoritmos. O conceito de uso de um cubo de dados8,9,10 e um texto-cubo2,3,4 tem vindo a evoluir desde 2005 com novos avanços para tornar mais aplicável a mineração de dados. O conceito de processamento analítico Online (OLAP)11,12,13,14,15 em mineração de dados e business intelligence remonta a 1993. OLAP, em geral, agrega as informações de vários sistemas e armazena-lo em um formato multidimensional. Existem diferentes tipos de sistemas OLAP implementados em mineração de dados. Por exemplo, processamento de transação/analítica de híbrido (1) (HTAP)16,17, (2) Multidimensional OLAP (MOLAP)18,19-cubo OLAP relacional (ROLAP) de base e (3)20.
Especificamente, o algoritmo de CaseOLAP tem sido comparado com numerosos algoritmos existentes, especificamente, com suas melhorias de segmentação de frase, incluindo TF-IDF + Seg, MCX + Seg, MCX e SegPhrase. Além disso, RepPhrase (RP, também conhecido como SegPhrase +) tem sido comparado com suas próprias variações de ablação, incluindo (1) RP sem a medida de integridade incorporada (RP n INT), RP (2), sem a medida de popularidade incorporada (RP n POP) e (3) RP sem o Medida da distintividade incorporada (RP n DIS). Os resultados de benchmark são mostrados no estudo por Fangbo Tao et al1.
Existem ainda desafios na mineração de dados que pode adicionar funcionalidade adicional sobre salvando e recuperando os dados do banco de dados. Sensível ao contexto semântico Analytical Processing (CaseOLAP) sistematicamente implementa o Elasticsearch para construir um banco de dados de indexação de milhões de documentos (protocolo 5). O texto-Cube é uma estrutura de documento construída sobre os dados indexados com categorias fornecido pelo usuário (protocolo 6). Isto melhora a funcionalidade aos documentos dentro e através de célula do texto-cubo e permitir-nos calcular a frequência do termo das entidades sobre um documento e a frequência de documento sobre uma célula específica (8 do protocolo). O resultado final de CaseOLAP utiliza esses cálculos de frequência para uma pontuação final de saída (protocolo 9). Em 2018, implementamos este algoritmo para estudar proteínas ECM e seis doenças de coração, para analisar as associações de proteína-doença. Os detalhes deste estudo podem ser encontrados no estudo por Liem, D.A. et al.5. indicando que o CaseOLAP podia ser amplamente utilizado na Comunidade biomédica, explorando uma variedade de doenças e mecanismos.
Limitações do algoritmo. Mineração de frase em si é uma técnica para gerenciar e recuperar conceitos importantes de dados textuais. Descobrindo a associação entidade-categoria como uma quantidade matemática (vetor), essa técnica é incapaz de perceber a polaridade (por exemplo, a inclinação positiva ou negativa) da associação. Se pode construir a sumarização quantitativa dos dados utilizando a estrutura do documento de texto-Cude com entidades afectadas e categorias, mas um conceito qualitativo com granularidades microscópicas não pode ser alcançado. Alguns conceitos estão em constante evolução do passado até agora. O resumo apresentado por uma associação de entidade específica-categoria inclui todas as incidências em toda a literatura. Este pode faltar a propagação temporal da inovação. No futuro, pretendemos abordar estas limitações.
Aplicações futuras. Cerca de 90% dos dados acumulados no mundo é nos dados de texto não estruturados. Encontrar uma frase representativa e relação com as entidades incorporadas no texto é uma tarefa muito importante para a implementação de novas tecnologias (por exemplo, aprendizagem de máquina, extração de informações, Artificial Intelligence). Para os dados de texto da máquina legível, dados precisam ser organizados em banco de dados sobre os quais a próxima camada de ferramentas poderia ser implementada. No futuro, este algoritmo pode ser um passo crucial na tomada mais funcional para a recuperação da informação e a quantificação das associações entidade-categoria de mineração de dados.
Divulgações
Os autores não têm nada para divulgar.
Agradecimentos
Este trabalho foi financiado em parte pelo nacional do coração, pulmão e sangue Instituto: R35 HL135772 (a P. Ping); Instituto Nacional de ciências médicas do General: U54 GM114833 (a P. Ping, K. Watson e W. Wang); U54 GM114838 (para J. Han); um presente da Hellen & Larry Hoag Foundation e Dr. S. Soares; e a doação de T.C. Laubisch na UCLA (a P. Ping).
Materiais
| Name | Company | Catalog Number | Comments |
Referências
- Tao, F., Zhuang, H., et al. Phrase-Based Summarization in Text Cubes. IEEE Data Engineering Bulletin. , 74-84 (2016).
- Ding, B., Zhao, B., Lin, C. X., Han, J., Zhai, C. TopCells: Keyword-based search of top-k aggregated documents in text cube. IEEE 26th International Conference on Data Engineering (ICDE). , 381-384 (2010).
- Ding, B., et al. Efficient Keyword-Based Search for Top-K Cells in Text Cube. IEEE Transactions on Knowledge and Data Engineering. 23 (12), 1795-1810 (2011).
- Liu, X., et al. A Text Cube Approach to Human, Social and Cultural Behavior in the Twitter Stream.Social Computing, Behavioral-Cultural Modeling and Prediction. Lecture Notes in Computer Science. 7812, (2013).
- Liem, D. A., et al. Phrase Mining of Textual Data to analyze extracellular matrix protein patterns across cardiovascular disease. American Journal of Physiology-Heart and Circulatory. , (2018).
- Shang, J., et al. Automated Phrase Mining from Massive Text Corpora. IEEE Transactions on Knowledge and Data Engineering. 30 (10), 1825-1837 (2018).
- Liu, J., Shang, J., Wang, C., Ren, X., Han, J. Mining Quality Phrases from Massive Text Corpora. Proceedings ACM-Sigmod International Conference on Management of Data. , 1729-1744 (2015).
- Lee, S., Kim, N., Kim, J. A Multi-dimensional Analysis and Data Cube for Unstructured Text and Social Media. IEEE Fourth International Conference on Big Data and Cloud Computing. , 761-764 (2014).
- Lin, C. X., Ding, B., Han, J., Zhu, F., Zhao, B. Text Cube: Computing IR Measures for Multidimensional Text Database Analysis. IEEE Data Mining. , 905-910 (2008).
- Hsu, W. J., Lu, Y., Lee, Z. Q. Accelerating Topic Exploration of Multi-Dimensional Documents Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE International. , 1520-1527 (2017).
- Chaudhuri, S., Dayal, U. An overview of data warehousing and OLAP technology. SIGMOD Record. 26 (1), 65-74 (1997).
- Ravat, F., Teste, O., Tournier, R. Olap aggregation function for textual data warehouse. ICEIS - 9th International Conference on Enterprise Information Systems, Proceedings. , 151-156 (2007).
- Ho, C. T., Agrawal, R., Megiddo, N., Srikant, R. Range Queries in OLAP Data Cubes. SIGMOD Conference. , (1997).
- Saxena, V., Pratap, A. Olap Cube Representation for Object- Oriented Database. International Journal of Software Engineering & Applications. 3 (2), (2012).
- Maniatis, A. S., Vassiliadis, P., Skiadopoulos, S., Vassiliou, Y. Advanced visualization for OLAP. DOLAP. , (2003).
- Bog, A. . Benchmarking Transaction and Analytical Processing Systems: The Creation of a Mixed Workload Benchmark and its Application. , 7-13 (2013).
- Özcan, F., Tian, Y., Tözün, P. Hybrid Transactional/Analytical Processing: A Survey. In Proceedings of the ACM International Conference on Management of Data (SIGMOD). , 1771-1775 (2017).
- Hasan, K. M. A., Tsuji, T., Higuchi, K. An Efficient Implementation for MOLAP Basic Data Structure and Its Evaluation. International Conference on Database Systems for Advanced Applications. , 288-299 (2007).
- Nantajeewarawat, E. Advances in Databases: Concepts, Systems and Applications. DASFAA 2007. Lecture Notes in Computer Science. 4443, (2007).
- Shimada, T., Tsuji, T., Higuchi, K. A storage scheme for multidimensional data alleviating dimension dependency. Third International Conference on Digital Information Management. , 662-668 (2007).
Reimpressões e Permissões
Solicitar permissão para reutilizar o texto ou figuras deste artigo JoVE
Solicitar PermissãoThis article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. Todos os direitos reservados