
Method Article
使用大鼠对象定位任务的主体内实验设计
* 这些作者具有相同的贡献
摘要
此协议为使用同一组大鼠重复的对象定位任务提供了详细的步骤。弱而强的编码可以产生短期和长期的记忆。重复协议的灵活性可以通过节省时间和劳动力来促进涉及手术的研究。
摘要
物体位置识别是研究啮齿动物空间记忆的一种突出方法。此对象放置识别内存是对象位置任务的基础。本文提供了一个广泛的协议,以指导建立一个对象定位任务,选择使用同一组老鼠最多四次重复。弱编码协议和强编码协议可用于研究强度不同的短期和长期空间记忆,并能够实施相关的内存抑制或增强操作。此外,重复此处介绍的反平衡测试允许将两个或多个测试的结果组合起来进行主题内比较,以减少大鼠之间的变异性。这种方法有助于提高统计能力,并强烈推荐,尤其是当运行实验,产生高变化的个人行为。这直接通过增加从每种动物获得的数据和减少所需的动物总数来完善研究。最后,通过节省时间和劳动力,实施重复的对象定位任务,提高了涉及外科手术的研究效率。
引言
自发识别任务(如物体识别、对象位置识别)在啮齿动物记忆的调查中得到了很大程度的利用。这些测试不同于用于评估基于恐惧调理或奖励动机的记忆的各种测试,因为自发识别任务仅基于针对新刺激的自发探索行为。这种行为,被称为"新偏好"1,是内在的啮齿动物,以及其他哺乳动物物种和一些非哺乳动物,如鸟类和鱼类2。对象位置识别,这取决于空间内存,可以使用对象位置任务(也称为空间对象识别任务)3来观察。病变研究表明,物体位置识别需要一个完整的海马体4,5。由于相对简单的培训协议和没有任何增援,这项任务在许多研究中是可取的。缺乏正增援和负强化将可能驱动行为的其他参数和大脑区域最小化。因此,这里的行为是中立的,基于好奇心和空间记忆,允许调查参与空间记忆编码、整合和检索的机制。
对象定位任务的规程通常包括习惯会话,然后是单个编码和测试试验会话,除以延迟期,延迟期从几分钟到数小时不等。强烈建议事先处理老鼠,以尽量减少动物的压力水平,因此,行为可能会影响识别记忆,如厌恶新奇。同样,精心设计的习惯协议在防止压力方面起着至关重要的作用,这种压力可能会阻碍大鼠在任务期间的自然行为。然而,处理和习惯的程度因实验室和实验者而异,这可能导致6、7、8的可复制性低。在编码试验中,大鼠有时间探索一个竞技场,两个相同的物体位于两个指定的角落。在测试试验中,大鼠被给予了时间用同一对物体探索竞技场,但这次其中一个被移到了一个新的位置。大鼠表现出的自发偏好以及由此导致在新位置探索物体所花费时间的增加,都表明空间识别和物体位置的记忆3。编码试用的修改(持续时间和重复次数)会影响记忆的强度。
根据研究目的,编码和测试试验之间的延迟长度可以修改为模拟蛋白质合成独立的短期记忆或蛋白质合成依赖的长期记忆。因此,对象定位任务可用于各种研究,根据需要调整协议。此外,在这些试验之间也有可能实施实验性操作,如药理学和光遗传学干预,就像在活体成像中一样。有几项研究9,10报告在同一大鼠群中的物体位置任务的重复迭代。这与传统用途形成鲜明对比,即一种动物有一个会话,没有重复。然而,这些范式的有效性尚未得到彻底调查,也没有描述这些范式的任何方法性文件。据我们所知,这是第一次报告的对协议的描述,该协议详细描述了使用同一鼠群重复最多四次的对象定位任务,其中还系统地比较了每次重复的结果。重复可用于平衡实验条件,以便在主体内与测试之间的变异性降低进行比较。任务的可靠重复允许数据进行汇集,这意味着使用相对较少的鼠标可以生成足够多的数据。最后,重复使用同一只大鼠可以有利于在涉及手术和植入的实验中降低所需的大鼠数量,从而节省时间和人工成本。
这项研究提出了一个广泛的协议,详细说明了如何使用强弱编码试验在成年大鼠中执行对象定位任务,然后以1小时和24小时延迟进行试验。强编码协议在测试1小时和24小时延迟时产生具有统计学意义的识别记忆,因此可用于研究实施操作时的短期和长期记忆,以抑制这些记忆11。相比之下,弱编码协议仅在 1 小时延迟测试时产生显著的短期内存。缺乏长期记忆可用于研究增强记忆保留的操作。此协议还包括详细的处理和习惯会话,旨在提高对象定位任务的可复制性。本文还演示了使用弱编码协议的同一组大鼠在四个不同的上下文中重复任务,该协议被确认每次都能产生可复制和一致的结果。
研究方案
根据丹麦和欧盟动物福利立法,这里描述的所有方法都得到了丹麦国家当局的批准(许可证编号:2018-15-0201-01405)。
1. 实验设置和准备不同的上下文
- 具有上下文的对象位置竞技场
注:下面的设置在一个封闭的隔音盒(图1B)中显示,光源位于天花板的边缘,相机位于盒子的天花板中心。竞技场,60厘米×60厘米,墙壁是100厘米高(图1B),被放置在盒子内,并与周围的房间完全隔离。所有空间线索都在竞技场内。这简化了创建不同上下文的过程。通过在墙壁周围围住一个带统一窗帘的正常露天竞技场,可以达到与周围房间类似的隔离程度。- 获得一个方形竞技场,由不透明、无孔硬塑料制成,最小宽度为 60 厘米,高度最小为 50 厘米。选择与大鼠颜色对比的地板颜色,以便自动软件成功记录大鼠运动(如适用)。将竞技场放在一个盒子内(图1B)或一个被窗帘包围的平台上。
- 要创建上下文,请获取第二层可插入墙(例如, 由与竞技场相同的材料制成的墙面覆盖物,或易于清洁的塑料墙纸)以不同颜色和/或图案(例如黑色、白色、 条纹或圆点)。在竞技场上插入第二层墙壁,使它们彼此与众不同。
- 获得三维 (3D) 空间提示(每个上下文 1-2),尺寸在 10 厘米 x 10 厘米 x 5 厘米和 20 厘米 x 15 厘米 x 15 厘米 x 15 厘米(宽度 x 长度 x 高度)之间,并且具有 (i) 独特的几何形状和 (ii) 颜色对比墙壁颜色。把它们挂在足够高的墙上,这样老鼠就达不到这些线索。
- 获得不同对的对象(如上下文编号),这些对象是无孔的、不可咀嚼的、易于清洁的。旨在为每个新对象提供不同的几何形状和纹理。选择宽度和高度在 5 到 15 厘米之间的对象(避免任何更高的对象)。请参阅 图 1D, 了解四个不同对象(圆锥体、足球、矩形棱镜和三角棱镜)示例。
注:每个物体都应与大鼠具有相似的兴趣,以便所有物体的总探测时间具有可比性。 - 找到将物体连接到竞技场地板上的最佳解决方案(例如,使用粘垫、双面胶带、在物体下方附加金属板和竞技场下方配对磁铁等)。
- 在创建另一个上下文时,重创建墙壁,以便对比墙壁的颜色和图案的分布与以前的上下文。使用与之前所有提示不同的新 3D 空间提示,并与之形成鲜明对比。有关四种不同上下文的示例,请参阅图 1C。
- 获得光源,确保竞技场内的扩散和均等照明,并具有调光选项。创建每个上下文后,将竞技场角落的光强度调整到大约 100-120 lux。获取相机并将其放置在盒子的天花板中央。
注意:如果不使用自动评分软件,光强度可以调整到较低的水平。
- 对象桶
- 获取一个桶(直径>50厘米)。不要选择方形,以避免与实验竞技场有任何相似之处。装满床上用品材料。
- 获取不同形状和大小的 5-10 个对象(与实验中要使用的对象不同),并随机将其全部放入桶中(图 1A)。

图1:实验设置,包括四个不同的上下文和对象。 (A) 对象习惯的对象桶。(B) 实验装置(左),包围物体位置竞技场、照相机和光源。上下文设置前的实验框和竞技场(中)和带上下文设置的竞技场(右)。(C) 四个上下文 (1-4) 具有不同的墙壁颜色和图案,以及三维空间线索。(D) 分别在上下文 1-4 中使用的四个对象。 请单击此处查看此图的较大版本。
{kind=link}
- 相机和跟踪软件(可选)
- 获取可用于远程控制相机记录器和跟踪鼠鼻的软件。每次实验前,对每个特定上下文和鼠株进行软件调整。
- 对象位置和实验组的对比
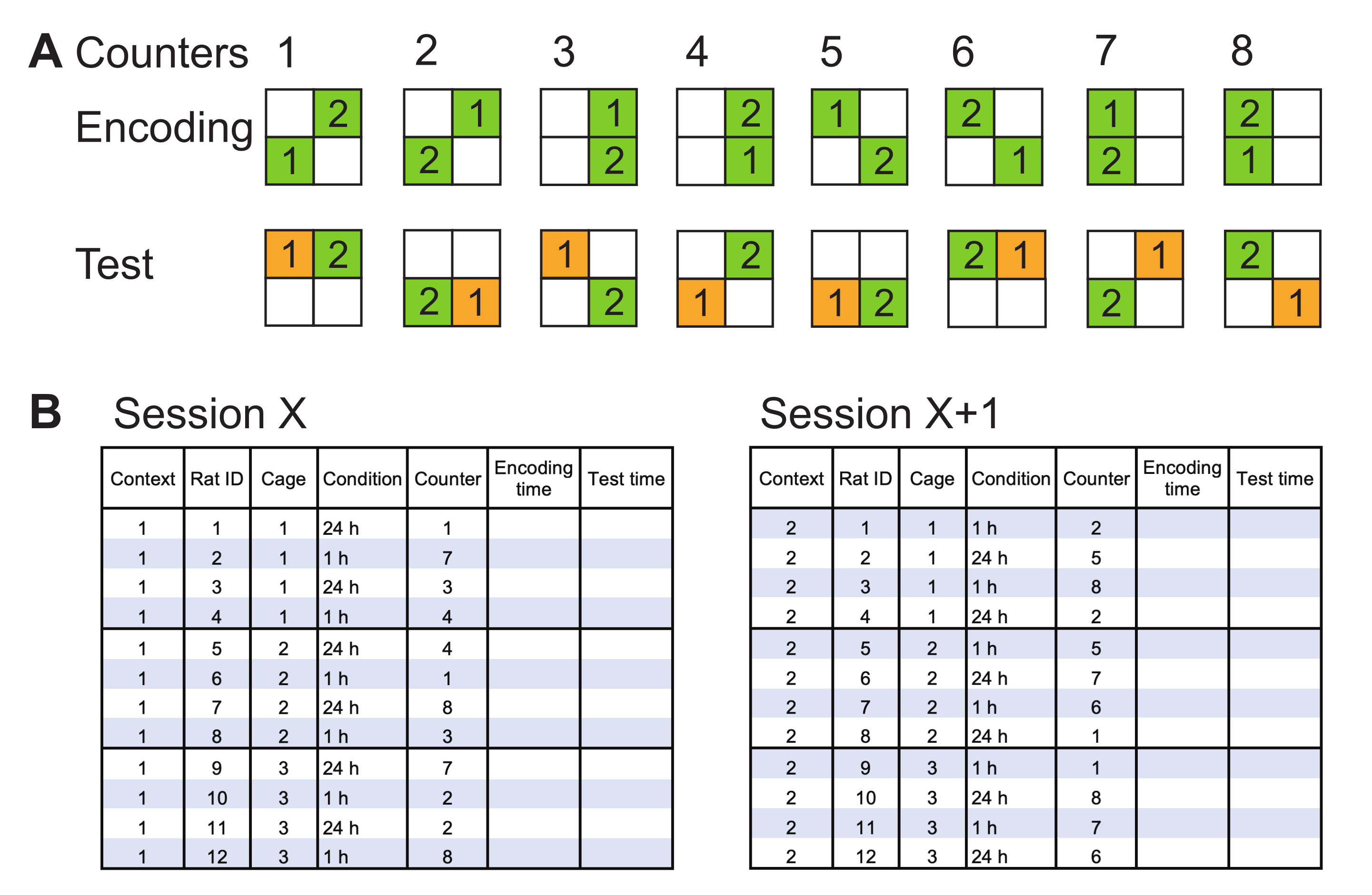
- 准备可能的对象位置组合进行编码和测试,并将它们命名为计数器。创建组合,使它们覆盖所有角落作为对象位置,对象从相邻对角移动,反之亦然(图2A)。
- 为特定实验准备时间表,将实验组中的每只大鼠与计数器进行匹配。如果有足够的老鼠,请在一组内使用两个配对计数器(图2A)中的每个对。在单个编码/测试会话(图 2B)中,为两个实验组使用同一组计数器。为以下会话(即 每个新上下文)重新分配计数器。
注:在编码/测试过程中,以混合顺序运行大鼠(例如,不要将所有老鼠一个接一个地关在笼子里;相反,旋转笼子以确保在一个多只老鼠的笼子内有一个平静的环境)。 - 当使用两个或两个以上的上下文来平衡实验组(例如,1小时内存与24小时记忆组)时,将鼠分配给每个组,并在以下上下文中更改组(图2B)。

图2:代表反平衡方法。(A)在编码和测试试验中竞技场上物体的可能方向被命名为计数器。对象 1 始终是移动对象。每两个计数器都进行制衡,以便移动对象的位置发生变化。每个角被占用两次,对象 1 从对角线移动到相邻,反之亦然,以等多次。(B) 两个制衡会话(例如上下文 1 和 2)的编码/测试时间表示例。大鼠被分配到实验条件上下文 1 (会话 X, 左).一组计数器对(即1-2、3-4、5-6和7-8)被选定并分配给一个实验组中的每个大鼠。同一组计数器被分配给两个实验组的老鼠。在上下文 2 中的下一节话(会话 X+1;右),实验组中的鼠被更改以进行反平衡,并分配了一组新的计数器对。应注意编码和测试试验开始的时间。请单击此处查看此图的较大版本。
{kind=link}
注:本协议中的所有处理、习惯和编码/测试会话在 12 小时光/暗周期的光相期间进行了优化,因此建议在光相期间进行实验。
2. 处理和习惯
- 开始处理从断奶开始的老鼠(如果大鼠是在家庭设施中繁殖的)或在实验开始前2-3周(如果大鼠是从外部设施订购的,在允许它们在到达后适应一周后)。
- 每周花至少10-15分钟在4只老鼠的每个笼子上2到3天,直到实验者舒适地触摸和接走老鼠。根据笼子里的老鼠数量调整每个笼子分配的时间。
注:重要的是,所有希望与大鼠合作的实验者在处理过程中都存在。 - 如果处理从断奶开始,一旦达到此级别,将处理减少到最低(可选)。如果在实验前 2-3 周开始,请继续处理,直到习惯会话开始。
- 把笼子里的老鼠带到实验室,让老鼠习惯运输,也把老鼠带到实验室。让老鼠坐至少30分钟,让他们有时间冷静下来,习惯。在此时间之后,将鼠/笼返回到住房房间。
注:步骤 2.4 可与处理相结合,并根据需要重复多次。如果协议包含任何进一步操作(例如, 对注射程序的处理等),则在此步骤中可以实施其他习惯。 - 进行对象习惯,使大鼠习惯与物体相互作用,并降低新环境体验产生的一般应力水平。
- 对于第1节,把所有的家笼带到实验室,让老鼠习惯到房间,并定居至少30分钟。将来自同一笼子的老鼠(2-4只大鼠)放在桶里20分钟。通过去除每组大鼠之间的任何粪便来清洁水桶。重复所有笼子的程序。把所有的老鼠放在家里的笼子里,然后回到房里。
- 对于第 2 节,在单独的一天将所有笼子带到实验室,并离开至少 30 分钟。将每只老鼠单独放入桶中10分钟。将鼠放回家庭笼子中,并在每只老鼠之后清洁水桶。将所有笼子都送回住房室。
- 对于会话 3,在单独的一天重复步骤 2.5.2。
- 如果实验装置是一个封闭的盒子(图1B),选择执行空盒子习惯,以习惯老鼠到新的实验仪器。在第4节课中,将所有笼子带到实验室,至少离开30分钟。将来自同一笼子的老鼠(2-4只大鼠)放在空旷的竞技场上,没有上下文或空间线索(图1B,中间),20分钟。将所有老鼠放回家庭笼中,每组大鼠后用70%的乙醇擦拭竞技场。
注:步骤 2.5 和 2.6 应在上下文习惯周之前的一周内执行(步骤 2.7;参见 图 3)。在这些步骤中休息几天是可以接受的。但是,在开始第 2.7 步后,每一步应按规定连续执行日期,直到测试试验结束(第 2.9 步)。 - 执行上下文习惯,使大鼠习惯上下文和 3D 提示,以降低一般压力水平,并支持环境的空间学习。
- 修改空竞技场以创建第 1.1 节中描述的第一个上下文,但不要将对象放在竞技场中。准备录音设备。
- 对于第 1 节,将所有笼子带到实验室,并离开至少 30 分钟。手动操作时启动录音机。将第一只老鼠放在竞技场中央,让老鼠探索竞技场10分钟。然后,停止录音机(如果手动),并将鼠放回家庭笼子。每只老鼠后用70%的乙醇彻底擦拭竞技场,完工后将所有笼子送回屋内。
- 对于第 2 和第 3 节,连续两天为每只大鼠重复步骤 2.7.2,这样每只大鼠总共有 3 次上下文习惯。
注意:考虑洗牌大鼠进入竞技场的顺序,尤其是在与一大群人打交道时。这样可以避免在一天中的同一时间反复运行特定的老鼠。

图3:行为实验的设计,包括处理、习惯和对象定位任务协议。 鼠应从习惯周前几周开始定期处理。在第 0 周,对象和实验框习惯在 4 个会话中执行,中间至少间隔 24 小时。在第 1 周,上下文习惯连续 3 次,中间间隔 24 小时,然后是编码和测试试验。在继续下一个会话之前,应至少间隔 48 小时和最多 1 周(例如, 在第 2 周或第 3 周开始习惯下一个上下文)。缩写:哈布,习惯。 请单击此处查看此图的较大版本。
{kind=link}
- 编码试验(第4期)
注:在药理操作的情况下,根据药理剂的性质,在编码试验之前或之后,以及/或在试用之前,可以有一个合理的时间来管理药剂。- 把所有的笼子都带到实验室,至少离开30分钟。使用事先准备的时间表(图2B),使用粘垫或双面胶带将第一对相同的物体放置在指定位置(在2个角落,距离每个墙壁>10厘米:L形纸板可用于每次保持相同的距离)。
- 启动录音机(如果为手动)。将第一只老鼠放在竞技场上,面对一堵墙或一个没有物体占据的角落(与每个物体的距离相等)。
注意:请按照下面的步骤进行弱编码或强编码。 - 对于弱编码(1试验),让大鼠探索竞技场和物体20分钟。然后,停止录音机(如果手动),并将鼠放回家庭笼子。取出物体,用70%的乙醇彻底擦拭物体和竞技场。
- 对所有大鼠重复步骤 2.8.3,使每只大鼠接受 1 次编码试验,每次 20 分钟。
- 对于强编码(3试验),让大鼠探索竞技场和物体5分钟。然后,停止录音机(如果手动),并将鼠放回家庭笼子。不要删除对象。用 70% 乙醇擦拭竞技场和物体。
- 重复步骤 2.8.5 两次与同一大鼠,使总共有 3 个试验。时间到了,把老鼠放回家里的笼子里。取出物体进行彻底清洁,用 70% 乙醇擦拭物体和竞技场。
注:大鼠的试用间隔应约为1-2分钟。 - 每只大鼠重复步骤 2.8.5-2.8.6。
- 如果延迟时间短于 24 小时,请将笼子放在实验室中直到试用。如果没有,完成所有笼子后返回到住房室。
- 测试试验(会话 4)
注:延迟期应从编码试用开始计算。- 如果出现 24 小时延迟(或任何延迟(要求第二天进行测试试验),请将所有笼子带到实验室,在第一次测试前留出足够的时间,以便大鼠至少可以离开 30 分钟。根据时间表,将对象放置在指定位置(新位置的对象之一)。
- 到时候,请启动录音机(如果是手动录音机)。将第一只老鼠放在竞技场上,面对一堵墙或一个没有物体占据的角落(与每个物体的距离相等)。
- 让老鼠探索竞技场和物体5分钟。然后,停止录音机(如果手动)。把老鼠放回家里的笼子里。取出物体,用70%的乙醇彻底擦拭物体和竞技场。
- 重复步骤 2.9.2-2.9.3 每只大鼠。将所有笼子送回住房室。
注:在以下每个编码/测试会话中,在间隔至少 48 小时和长达 1 周后,从步骤 2.7(上下文习惯)开始习惯协议。
3. 数据分析
- 对于每只大鼠,使用为此目的设计的软件或使用手动设置,在编码和测试试验中为每个对象的探索时间打分。在整个持续时间内进行评分编码试验。评分测试试验2分钟的最佳歧视表现3。如果使用自动在线软件评分,则从软件中导出评分数据。
- 计算大鼠与物体接触、嗅探物体或在距离小于 2 厘米的距离上面对物体时的探索时间。包括攀爬和坐在物体上作为探索,除非老鼠的注意力似乎在物体以外的某个地方(例如, 远离物体)。
- 计算每只大鼠两个物体的总探索时间。考虑将试验中总探索时间小于 10 秒(得分为 2 分钟)的任何大鼠排除在本次测试之外,因为这可能反映了不可靠的探索。
- 计算每个物体(方程1)或每只大鼠的分辨指数(DI)的勘探百分比(方程2),并计算组的平均值。
 (1)
(1)
注意:如果%的探索是50%或DI是0,这意味着性能是在机会水平,和老鼠没有偏好的任一对象。编码试验中的平均勘探百分比应分别为 +50% 或 0。在编码试验中,任何一个物体的偏好高于[平均±(2×SD)]的,应排除在相应测试的分析之外。这允许在测试试验中将偏好作为稳定对象位置的记忆进行可靠的解释。此值可用于单独测试或从多个测试中计算组合编码数据。 - 通过最适合实验设置的方法分析数据。使用单样本 t测试检测高于机会级别的重大偏好。
- 在使用多个上下文与反平衡时,将相同实验条件的结果组合在上下文中。
注:这将产生由相同大鼠组成的组,使用两组的配对 t测试进行主体内比较,并使用对两组以上组的方差 (ANOVA) 进行重复测量分析。
结果
这里显示的是使用雄性酪氨酸羟基酶(Th)-Cre转基因大鼠13 与长埃文斯菌株背对四次李斯特胡德菌株和野生型李斯特胡德大鼠的强和弱编码协议的代表性结果。Th-Cre转基因大鼠被使用,因为这种大鼠系将用于未来涉及光遗传学的研究。使用每个协议,内存测试延迟为 1 小时和 24 小时。1 小时的测试显示短期记忆,而 24 小时测试显示长期记忆。编码首选项的排除值按协议中描述计算,使用来自五个测试(强和弱编码协议)的组合数据作为 [50.8% ±(2×10.8%)。在这些值之上和下方有编码偏好的鼠被排除在相关测试的分析之外。
用于强编码实验,使用了16只大鼠,用于弱编码实验,使用了19只大鼠。在强编码试验期间(3×5分钟编码: 图4A),没有显著偏爱任一对象(52.0±1.9%,n = 16,t15 = 1.1,p = 0.29;单样本 t测试与机会水平)。这种强大的编码协议导致在新位置对对象的偏好, 如平均百分比勘探所示,这明显高于1小时和24小时延迟(1小时内存,77.9±2.4%、n = 8、t7 = 11.8、p <0.001;24小时内存的测试中的机会水平(50%), 65.2 ± 5.3%, n = 8, t7 = 2.8, p = 0.025;一个示例 t测试与机会水平)。1 小时和 24 小时内存 (p = 0.056; 未修复的韦尔奇 t- 测试) 之间没有显著差异。
在弱编码试验期间(20分钟编码;结果汇集在四个上下文中; 图4B),没有显著偏爱任一对象(51.1±1.0%,n = 66,t65 = 1.2,p = 0.24;一个样本 t测试与机会水平)。与延迟 1 小时的测试中的机会水平相比,此弱编码协议显著增加了对新位置对象的偏好, 但不是 24 小时延迟 (来自所有四个上下文的组合数据; 1 小时内存, 66.7 ± 2.0%, n = 32, t31 = 8.2, p < 0.001; 24 小时内存, 49.6 ± 2.6%, n = 34, t33 = 0.16, p = 0.87;一个示例 t测试与机会水平)。1 小时和 24 小时延迟的测试性能存在显著差异(1 小时内存:n = 32,24 小时内存:n = 34,t61.5 = 5.2,p < 0.001;未修修的 Welch 的 t- 测试)。
在 24 小时延迟测试中未观察到按偶然级别性能索引的组级内存,但显示单个变异。由于对物体的随机探索更多,通常观察到弱到无记忆条件的这种更高的变异(例如,24小时测试)。因此,重要的是不要单独解释大鼠的表现。相反,单个数据点的分布可以与组平均值一起用作测试的可靠结果。编码越强,大鼠的行为就越统一,达到统计意义所需的大鼠数量就越少,如图4A中所观察到的强编码协议。相比之下,需要较大的群体来获得可靠的结果,以弱的条件(图4B)。

图4:强弱编码后的记忆性能。(A )强编码试验(3×5分钟编码),然后是1小时或24小时测试试验。在编码试验期间,没有显著偏爱任何对象(n = 16)。与机会级别(1-h 和 24 小时内存:n = 8)相比,强编码在测试中新位置对对象的偏好显著增加,延迟为 1 小时和 24 小时。各组之间没有显著差异。(B) 弱编码试验(20分钟编码),然后是1小时或24小时测试试验。在编码试验期间(n = 66),这两个对象作为一个组没有显著的偏好。与机会级别(1 小时内存:n = 32;24 小时内存:n = 34)相比,弱编码在测试中新位置显著增加了对对象的偏好,延迟为 1 小时,但不是 24 小时延迟。1 小时和 24 小时延迟的测试性能存在显著差异。结果从四个上下文中汇集而来。单个数据点以点形式显示。所有条显示在新位置对物体的探索百分比为平均± SEM. *p < 0.05, ***p < 0.001;一个样本t测试与机会水平 (50%, 虚线) 。##p< 0.001;ns,不重要;未修复的韦尔奇的t测试。请单击此处查看此图的较大版本。
{kind=link}
此既定协议的一个显著优点是,它可以使用四个不同的上下文(图 1C)与同一组大鼠执行四次。图5中显示的结果表明,与两个实验组(1-h和24-h记忆组)使用反平衡的一种可能方法。这两组在两个上下文(上下文 1 和 2)中进行了平衡,并在两个额外的上下文(上下文 3 和 4) 中重复了这一点:图5A)。这四个上下文的结果分别在图 5BD中显示,其中通过比较每个上下文中的偏好和机会级别(1-h 内存:上下文 1、69.9 ± 3.6%、n = 9、t 8 = 5.5、p < 0.001 来评估每个实验组的内存;上下文 2, 65.6 ± 3.9%, n = 9, t8 = 4.0, p = 0.004;上下文 3, 65.2 ± 3.8%, n = 7, t6 = 4.0, p = 0.007;上下文 4, 65.3 ± 5.6%, n = 7, t6 = 2.7, p = 0.035;24 小时内存: 上下文 1, 45.1 ± 6.4%, n = 9, t8 = 0.77, p = 0.46;上下文 2, 49.1 ± 4.9%, n = 9, t8 = 0.18, p = 0.86;上下文 3, 57.2 ± 4.1%, n = 8, t7 = 1.7, p = 0.12;上下文 4, 47.6 ± 4.7%, n = 8, t7 = 0.52, p = 0.62;一个示例t测试与机会水平)。
在上下文 1、2 和 4 中,各组的主题比较显示 1 小时和 24 小时内存(1 小时内存与 24 小时内存:上下文 1、t12.7 = 3.4、p = 0.005;上下文 2, t15.2 = 2.6, p = 0.019;上下文 3, t13.0 = 1.4, p = 0.17;上下文 4, t12.2 = 2.4, p = 0.032;未修复的韦尔奇的t测试) 。为了更好地表示和对数据进行主题内比较,将两个平衡上下文的结果(图 5C,E)结合起来。合并后的实验组再次单独与机会水平进行比较(上下文 1 和 2 组合:1-h 内存, 67.8 ± 2.6%, n = 18, t17 = 6.7, p < 0.001; 24 小时内存, 47.1 ± 3.9%, n = 18, t17 = 0.74, p = 0.47;上下文 3 和 4 组合: 1 小时内存, 65.3 ± 3.3%, n = 14, t13 = 4.7, p < 0.001;24 小时内存, 52.4 ± 3.2%, n = 16, t15 = 0.73, p = 0.48;一个示例t测试与机会水平)。然后,实验组相互比较。
在两个上下文对中,主题内比较(1-h 内存与 24-h 内存:上下文 1 和 2 组合、t16 = 3.5、p = 0.003)所揭示的组之间存在显著差异;上下文 3 和 4 组合, t13 = 2.4, p = 0.032;配对 t- 测试)。野生型李斯特帽鼠也获得了类似的结果,在弱编码协议中,使用上下文1和4进行两个平衡会话(数据未显示)。通过使用单向 ANOVA 比较每个数据集,验证了结果的可复制性和可靠性。在四个上下文中未检测到显著差异(1 小时内存:F3,28 = 0.31,p = 0.81;24 小时内存:F3,30 = 0.99,p = 0.41)。因此,对象位置测试可以可靠地重复,并具有最小重复的影响,因为遵循此协议中的说明。

图5:用两个实验组在两个实验组中对弱编码协议的结果进行演示和分析的不同方法。 (A)两个实验组(1-h和24-h记忆组)在两个实验组(上下文1和2)中进行反平衡的实验设计。在另外两个会话(上下文 3 和 4)中重复了反平衡。(B 和 D)每个上下文和实验组的结果分别与机会水平和彼此进行比较。在所有四种上下文中,与机会级别 [上下文 1 和 2:n = 9 每组/B)相比,在延迟 1 小时的测试中对新位置对象的偏好显著增加;上下文 3 和 4: n = 每组 7 个组(D)] 。在 24 小时延迟测试中,新位置对对象的偏好与偶然性没有区别(上下文 1 和 2:n = 每组 9;上下文 3 和 4: n = 每组 8 个)。实验组在上下文 1、2 和 4 中的偏好之间存在显著差异,但主题间比较所揭示的上下文 3 则没有显著差异。*p < 0.05, **p < 0.01, ***p < 0.001;一个样本 t测试与机会水平 (50%, 虚线) 。 #p < 0.05; ##p < 0.01;ns,不重要;未修复的韦尔奇的 t测试。(C 及 E)结果在结合了两个平衡上下文的实验组后提出 [上下文 1 和 2 组合, n = 每个组 17(C);上下文 3 和 4 组合, n = 每组 14(E)] 。与 1 小时(但不是 24 小时延迟)的测试中的机会级别相比,在两个上下文对中,对新位置对象的偏好显著增加。实验组的主体内比较显示,在测试中,在新位置对物体的偏好存在显著差异,两个上下文对的延迟为 1 小时和 24 小时。p < 0.001:一个样本 t测试与机会水平 (50%, 虚线) 。 #p < 0.05, ##p < 0.01;配对 t- 测试。单个数据点以点形式显示。所有条条显示在新位置对对象的探索百分比为平均± SEM。 请单击此处查看此图的较大版本。
{kind=link}
讨论
对象定位任务可用于各种研究,以调查前面描述的空间记忆。设置的灵活性使不同优势的短期和长期记忆建模,并且可以轻松地以低成本实现。但是,由于协议中有许多参数可以影响结果,并且这些参数6中不同的研究略有不同,因此首次成功执行任务可能会遇到困难。上述协议旨在引导读者顺利地完成此过程。下文将讨论在成功执行具有高度可复制性的任务方面可能具有重大意义的进一步关键步骤。
虽然编码/测试会话往往是运行对象位置实验时的焦点,处理和习惯协议对这类行为测试的结果有深远的影响,其结果取决于不受干扰的自然大鼠行为14,15。因此,编码/测试会话前的步骤应谨慎设计,因为它们会影响鼠的行为和记忆,从而影响最终结果。良好的处理和习惯水平,使大鼠熟悉实验者,任务将尽量减少压力因素的影响,同时增加表现出自然行为的可能性8。如协议中所述,如果在家庭设施中保持鼠株,处理可以尽早开始断奶幼崽。根据以前的经验(数据没有显示)和从以前的几个研究16,17,这种早期处理导致低焦虑和增强的好奇心,在随后的几个月。
由于物体定位任务完全取决于大鼠的内在探索驱动,如果大鼠不急于探索或不愿接近新奇事物,预期行为很容易受到阻碍,即所谓的"新恐惧行为"因此,强烈建议根据研究的具体需要,包括一个彻底的处理和习惯协议。此协议可用作最低要求指南,并可以实施进一步步骤(例如,如果研究要在稍后阶段包括注射,则需要习惯注射程序和特定持有位置)。实验鼠的应变和年龄是另外两个影响因素,在计划实验之前应考虑避免结果不理想。不同的大鼠菌株可能有不同的行为和基线焦虑水平18,19,20,因此,根据使用的菌株,可能需要对协议进行具体调整。
该协议被证实与Th-Cre转基因大鼠配合良好,长埃文斯菌株与李斯特胡德菌株和野生型李斯特胡德大鼠背对四次。在行为实验中,大鼠在逻辑上理想的起始年龄在12周20左右,但应考虑应考虑间应变异性和任务的具体要求。如果对研究感兴趣,也可以使用发育中的大鼠,尽管可能需要对协议进行调整,但此处未涵盖。然而,重要的是要考虑在给定年龄的老鼠是否已经发展了成功执行这项任务所需的认知功能。一项21日 对此进行的调查报告说,只有产后第38天而不是之前的青春期大鼠,显示出同心空间记忆反映在偏爱物体的新地点,如成年大鼠所观察到的。这里提出的协议是成功的使用鼠是15-16周大,在第一次编码/测试会议开始。以前,同样的强编码协议在使用23周大的老鼠时,由于在足够小的时候缺乏处理和习惯,没有达到最佳的适应水平,结果会低于最佳到负。这些大鼠要么没有表现与偶然水平不同,要么事实上表现出对新奇事物的厌恶,如对稳定物体的偏好,而不是对被移位物体的偏好(未显示数据)。这些结果提供了证据,证明处理习惯的年龄和时间可能对习惯的有效性产生影响,因此有助于在测试中观察焦虑和新恐惧行为。
在此,概述了两个不同的协议,确保对象位置任务中的强或弱编码。在这些协议的建立过程中,人们观察到,在单次长时间试验(例如20分钟编码)中,对这些物体的兴趣在5-10分钟的探索后下降, 大鼠最终停止了探索。这会导致对象位置的内存变弱。一种编码协议,将编码试验与短的休息时间(例如,3 x 5 分钟的编码)交织在一起,克服了这一点,并导致在整个试验过程中进行高度探索。因此,这两个编码协议的主动探索时间和不同的布局会影响内存的强度,在 3 x 5 分钟编码后,内存的强度比 20 分钟编码协议后更强。类似的结果也可以使用略有不同的持续时间与单一试验与交错试验协议,并可以作出调整,以适应研究的需要和大鼠应变。
与使用仅带有外部提示的纯白色开放字段的协议相反,此处介绍的协议使用具有不同上下文和迷宫内提示的竞技场,可能需要更多时间来学习。因此,建议在编码试用之前在协议中添加上下文习惯步骤。这将允许大鼠在习惯期间形成每个上下文的空间地图,并缩短以下编码试验的持续时间,因为大鼠只需对与此地图相关的对象位置进行编码。此外,上下文习惯将允许大鼠在每个上下文中习惯任何可能的注意力干扰器,如 3D 空间提示,以尽量减少编码/测试会话中对象探索以外的行为。随着一个彻底的平衡方法的实施,包括几个级别(即 广泛的对象位置组合(计数器)和对象位移的方向),由于光强度和竞技场角落的墙壁颜色/图案的变化,可能会上升的不需要的偏好被最小化。
重复任务时应考虑几个因素,以增加编码/测试会话之间的可重复性,并最大限度地减少重复的影响。首先,需要设计不同的上下文(编码/测试会话的重复次数)以避免使用相同上下文执行重复会话可能造成的空间内存积累。为此,使用了不同颜色和图案的可更换墙壁的装置(图1B,C)。墙上悬挂的不同墙壁和 3D 物体(如玩具或不同颜色和形状的小日常物品、参见协议和图 1C)是老鼠可能用来了解与其上下文相关的对象位置的空间线索和地标。如果测试未能产生对移动对象的偏好,则可以考虑更改上下文的这些参数(墙面设计和空间提示)。或者,矩形或圆形竞技场可用于对象定位任务,而不是此协议中那样的方形竞技场。据报道,圆形竞技场可以消除在有角落的竞技场中经常观察到的角落偏好22,因此,当处理特别焦虑的老鼠或老鼠菌株时,它可以是有益的。虽然在此协议中创建四个不同上下文的要求与四边形最为最佳,但经过一些调整后,也可以使圆形竞技场发挥作用。
其次,应确定每个编码/测试会话之间的间隔,以便鼠每次都保持相同的兴趣水平,同时避免因密集的重复时间表而产生累积学习的风险。通常,编码和测试之间的延迟时间至少延长一倍的间隔就足够了,更长的间隔更有利于两次以上的重复。这意味着,虽然在 24 小时测试后,至少 48 小时间隔足以重复一到两次,但建议使用 1 周间隔进行四次重复。图 5 的结果和使用ANOVA的比较显示,任务可以成功地重复四次。在此基础上,已建立的协议可用于制衡多达四个实验条件。实验组的数量决定在不同上下文中编码/试验会话的重复次数。 图5 的结果是使用两个实验组协议的一种可能方法。两届会议对这些小组进行了制衡,在另外两届会议中重复了同样的条件(为了验证目的)。第二组制衡会话也可用于制衡新条件。同样,可以分别使用三到四个平衡会话比较三到四个实验条件。
在这些情况下,应设计上下文以适应协议中描述的对比特征。值得注意的是,平衡设计可能不适合使用其他操作的实验,例如可能留下长期效果或损害的药理干预。为了保持测试的有效性和可复制性,应相应地设计实验。重复测试的数据可以通过多种方式呈现和分析,如图 5所示。对于初始分析,每个上下文中的实验组可以单独比较机会水平,使用一个样本t测试来确定任何重要的偏好(图5B,D)。这有助于快速了解数据,但它只确保对组进行间接比较。因此,对于比较两个或两个以上组,应分别使用双样本t测试(配对或未修复)或 ANOVA 分析数据。这可以以单个编码/测试会话(图 4A和图 5B,D)中的组之间的主体比较或来自两个(或更多)制衡上下文的组的主体内比较的形式(图 5C,E)。强烈推荐后一种方法,尤其是在处理弱记忆条件时,如前所述,由于行为随机性,这些情况会导致高差异。
结合平衡上下文,需要更大的组以最小的变化可靠地可视化组的行为。使用在制衡会话中重复的协议,可以预期使用具有相同统计能力的单个测试所需的鼠数量将减少约三分之一。通常,在 7 到 15 只大鼠(总计)的范围内进行平衡会话,在 20 到 50 只大鼠(每组 10 到 25 只)的范围内,效果大小和功率均大于 0.8 的样本量就足够了。需要的动物数量的减少和我们使用此协议从每种动物那里获得的信息的增加,都完善了研究,并符合研究中动物伦理用途的 3R 原则。在这一步中,重要的是要记住,随机的老鼠行为,不伴有强烈的记忆力,可能会导致个人强烈的偏好低于和高于机会,但组平均应产生一个偏好,与机会没有显著区别。应仔细解释单个数据。小组中各个数据点的分布也可以为解释结果提供信息。如 图4 和 图5所见,分布会根据记忆的强度而变化。总体而言,这里提出的协议可以很容易地遵循,以实现对象定位任务与重复建模短期和/或长期空间内存。简单而灵活的培训协议以及实施进一步操作的可能性使此任务成为热门选择。对协议的这些修改使调查能够调查特定步骤,如内存获取、整合和召回。
披露声明
作者没有什么可透露的。
致谢
我们要感谢安东尼奥斯·阿西米纳斯、多萝西·谢、小原诚司和大卫·贝特的有见地的意见和建议。这项研究得到了伊拉斯谟®(对G.B和L.N.) 的支持;奥胡斯大学卫生研究生院(到K.H.):诺和诺德基金会青年研究员奖2017年(NNF17OC0026774),伦德贝克方登(DANDRITE-R248-2016-2518)和PROMEMO - 记忆中的蛋白质中心,由丹麦国家研究基金会(DNRF133)资助的卓越中心(T.T.)。
材料
| Name | Company | Catalog Number | Comments |
| Open-field/experimental box | O'Hara & Co (Japan) | OF-3001 | Open-field box for the object location task |
| Object 1: cones | O'Hara & Co (Japan) | ORO-RR | |
| Object 2: footballs | O'Hara & Co (Japan) | ORO-RB | |
| Object 3: rectangular blocks | O'Hara & Co (Japan) | ORO-RC | Rectangular blocks were modified after purchase |
| Object location task apparatus | O'Hara & Co (Japan) | SPP-4501 | Sound attenuating box that contains the open-field box for the object location task |
| Tracking software | O'Hara & Co (Japan) | TimeSSI | For movement tracking and automated camera functions |
| Wild-type Lister Hooded rats | Charles River | 603 |
参考文献
- Hughes, R. N. Neotic preferences in laboratory rodents: issues, assessment and substrates. Neuroscience and Biobehavioral Reviews. 31 (3), 441-464 (2007).
- Blaser, R., Heyser, C. Spontaneous object recognition: a promising approach to the comparative study of memory. Frontiers in Behavioral Neuroscience. 9, 183 (2015).
- Dix, S. L., Aggleton, J. P. Extending the spontaneous preference test of recognition: evidence of object-location and object-context recognition. Behavioral Brain Research. 99 (2), 191-200 (1999).
- Barker, G. R., Warburton, E. C. When is the hippocampus involved in recognition memory. Journal of Neuroscience. 31 (29), 10721-10731 (2011).
- Mumby, D. G., Gaskin, S., Glenn, M. J., Schramek, T. E., Lehmann, H. Hippocampal damage and exploratory preferences in rats: memory for objects, places, and contexts. Learning & Memory. 9 (2), 49-57 (2002).
- Gulinello, M., et al. Rigor and reproducibility in rodent behavioral research. Neurobiology of Learning and Memory. 165, 106780 (2019).
- Rudeck, J., Vogl, S., Banneke, S., Schonfelder, G., Lewejohann, L. Repeatability analysis improves the reliability of behavioral data. PLoS One. 15 (4), 0230900 (2020).
- Gouveia, K., Hurst, J. L. Optimising reliability of mouse performance in behavioural testing: the major role of non-aversive handling. Scientific Reports. 7, 44999 (2017).
- Migues, P. V., et al. Blocking synaptic removal of GluA2-containing AMPA receptors prevents the natural forgetting of long-term memories. Journal of Neuroscience. 36 (12), 3481-3494 (2016).
- Maingret, N., Girardeau, G., Todorova, R., Goutierre, M., Zugaro, M. Hippocampo-cortical coupling mediates memory consolidation during sleep. Nature Neuroscience. 19 (7), 959-964 (2016).
- Chao, O. Y., de Souza Silva, M. A., Yang, Y. M., Huston, J. P. The medial prefrontal cortex - hippocampus circuit that integrates information of object, place and time to construct episodic memory in rodents: Behavioral, anatomical and neurochemical properties. Neuroscience and Biobehavioral Reviews. 113, 373-407 (2020).
- Takeuchi, T., et al. Locus coeruleus and dopaminergic consolidation of everyday memory. Nature. 537 (7620), 357-362 (2016).
- Witten, I. B., et al. Recombinase-driver rat lines: tools, techniques, and optogenetic application to dopamine-mediated reinforcement. Neuron. 72 (5), 721-733 (2011).
- Costa, R., Tamascia, M. L., Nogueira, M. D., Casarini, D. E., Marcondes, F. K. Handling of adolescent rats improves learning and memory and decreases anxiety. Journal of the American Association for Labaratory Animal Science. 51 (5), 548-553 (2012).
- Schmitt, U., Hiemke, C. Strain differences in open-field and elevated plus-maze behavior of rats without and with pretest handling. Pharmacology Biochemistry and Behavior. 59 (4), 807-811 (1998).
- Kosten, T. A., Kim, J. J., Lee, H. J. Early life manipulations alter learning and memory in rats. Neuroscience and Biobehavioral Reviews. 36 (9), 1985-2006 (2012).
- Denenberg, V. H., Grota, L. J. Social-seeking and novelty-seeking behavior as a function of differential rearing histories. Journal of Abnormal and Social Psychology. 69 (4), 453-456 (1964).
- Clemens, L. E., Jansson, E. K., Portal, E., Riess, O., Nguyen, H. P. A behavioral comparison of the common laboratory rat strains Lister Hooded, Lewis, Fischer 344 and Wistar in an automated homecage system. Genes, Brain, and Behavior. 13 (3), 305-321 (2014).
- Ennaceur, A., Michalikova, S., Bradford, A., Ahmed, S. Detailed analysis of the behavior of Lister and Wistar rats in anxiety, object recognition and object location tasks. Behavioral Brain Research. 159 (2), 247-266 (2005).
- Deacon, R. M. Housing, husbandry and handling of rodents for behavioral experiments. Nature Protocols. 1 (2), 936-946 (2006).
- Contreras, M. P., Born, J., Inostroza, M. The expression of allocentric object-place recognition memory during development. Behavioral Brain Research. 372, 112013 (2019).
- Yaski, O., Eilam, D. How do global and local geometries shape exploratory behavior in rats. Behavioral Brain Research. 187 (2), 334-342 (2008).
转载和许可
请求许可使用此 JoVE 文章的文本或图形
请求许可探索更多文章
This article has been published
Video Coming Soon
版权所属 © 2025 MyJoVE 公司版权所有,本公司不涉及任何医疗业务和医疗服务。