
Method Article
Minería de frase basado en la nube y el análisis de Asociación de categoría de frase definida por el usuario en publicaciones biomédicas
* Estos autores han contribuido por igual
En este artículo
Resumen
Presentamos un protocolo y código de programación asociada así como muestras de metadatos para soportar una identificación automatizada basada en nube de Asociación de la categoría frases que representan conceptos únicos en dominio de conocimiento seleccionado usuario en literatura biomédica. La Asociación de categoría de frase cuantificada por este protocolo puede facilitar en el análisis de la profundidad en el dominio del conocimiento seleccionado.
Resumen
La rápida acumulación de datos textuales biomédicas ha superado la capacidad humana de curación manual y análisis, que requiere de nuevas herramientas de minería de textos para extraer ideas biológicas de grandes volúmenes de informes científicos. La tubería del contexto semántico Online Analytical Processing (CaseOLAP), desarrollada en el año 2016, cuantifica con éxito relaciones de categoría de frase definida por el usuario a través del análisis de datos textuales. CaseOLAP tiene muchas aplicaciones biomédicas.
Hemos desarrollado un protocolo para un entorno basado en la nube, apoyando la plataforma de análisis y minería de frase end-to-end. Nuestro protocolo incluye preprocesado de datos (por ejemplo, descarga, extracción y análisis de documentos de texto), indexación y búsqueda con Elasticsearch, creando una estructura funcional documento llaman texto-Cube y cuantificar las relaciones de categoría de frase utilizando el algoritmo de CaseOLAP de base.
El preprocesamiento de datos genera asignaciones de clave y valor para todos los documentos involucrados. Los datos preprocesados sea indexados para llevar a cabo una búsqueda de documentos, incluidas las entidades, que facilita aún más la creación de texto-Cube y cálculo de puntuación de CaseOLAP. Los puntajes crudos obtenidos de la CaseOLAP se interpretan utilizando una serie de análisis integrados, incluyendo la reducción de dimensionalidad, clustering, temporal y análisis geográficos. Además, las puntuaciones de CaseOLAP se utilizan para crear una base de datos gráfica, que permite la asignación semántica de los documentos.
CaseOLAP define las relaciones de categoría de frase en una exacta (identifica relaciones), consistente (altamente reproducible) y de manera eficiente (procesos 100.000 palabras por segundo). Siguiendo este protocolo, los usuarios pueden acceder a un entorno de cloud computing para apoyar sus propias configuraciones y aplicaciones de CaseOLAP. Esta plataforma ofrece mayor accesibilidad y empodera a la comunidad biomédica con herramientas de minería de frase para aplicaciones de investigación biomédica generalizada.
Introducción
Manual evaluación de millones de archivos de texto para el estudio de la Asociación de categoría de frase (por ejemplo., grupo de edad a la Asociación de la proteína) es incomparable con la eficacia de un método computacional automatizado. Queremos presentarle la plataforma en la nube de contexto semántico Online Analytical Processing (CaseOLAP) como un método de extracción de frase para cómputo automatizado de Asociación de categoría de frase en el contexto biomédico.
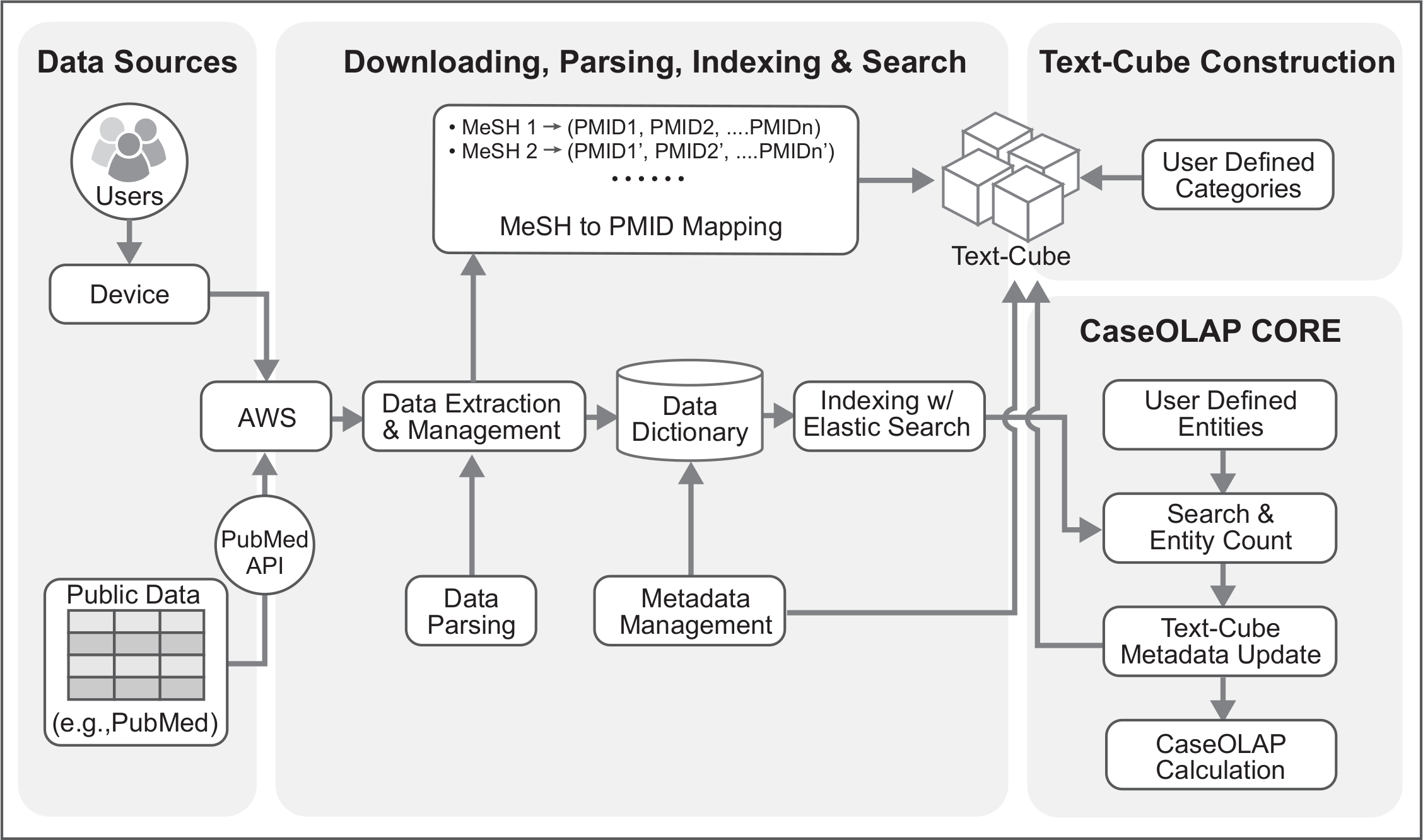
La plataforma CaseOLAP, que primero fue definida en 20161, es muy eficiente comparado con los métodos tradicionales de gestión de datos y computación por su gestión funcional llamado texto-cubo2,3, 4, que distribuye los documentos manteniendo la jerarquía y barrios subyacentes. Se ha aplicado en la investigación biomédica5 para estudiar asociación de categoría de la entidad. La plataforma de CaseOLAP consiste en seis pasos principales, incluyendo descarga y extracción de datos, análisis, indexación, creación de texto-cubo, cuenta de la entidad y cálculo de puntaje de CaseOLAP; cual es el objetivo principal del Protocolo (figura 1, figura 2, tabla 1).
Para implementar el algoritmo de CaseOLAP, el usuario establece las categorías de interés (p. ej., enfermedad, signos y síntomas, grupos de edad, diagnóstico) y entidades de interés (por ejemplo, proteínas, medicamentos). Un ejemplo de una categoría incluida en este artículo es el 'Las edades', que tiene 'Infantil', 'niño', 'adolescente', y 'adultos' subcategorías como las células de la texto-Cube y proteína nombres (sinónimos) y abreviaturas como entidades. Medical Subject Headings (MeSH) se implementan para recuperar publicaciones correspondientes a las categorías definidas (tabla 2). Descriptores meSH se organizan en una estructura de árbol jerárquica para permitir la búsqueda de publicaciones en diferentes niveles de especificidad (un ejemplo que se muestra en la figura 3). La plataforma de CaseOLAP utiliza la funcionalidad de indización y búsqueda de datos para la conservación de los documentos relacionados con una entidad que facilitar aún más el documento que la entidad cuenta cartografía y cálculo de puntuación de CaseOLAP.
Los detalles del cálculo de puntuación de CaseOLAP está disponible en anteriores publicaciones1,5. Esta puntuación se calcula utilizando criterios de clasificación específica basados en estructura de documento de texto-cubo subyacente. El resultado final es el producto de la integridad, popularidady carácter distintivo. Integridad describe una entidad representativa sea una integral unidad semántica que colectivamente se refiere a un concepto significativo. La integridad de la frase definida por el usuario es llevado a ser 1.0 porque se destaca como una frase estándar en la literatura. Carácter distintivo representa la importancia relativa de una frase en un subconjunto de documentos en comparación con el resto de las otras células. Primero calcula la relevancia de una entidad a una célula específica mediante la comparación de la ocurrencia del nombre proteína del objetivo conjunto de datos y proporciona una puntuación normalizada de carácter distintivo . Popularidad representa el hecho de que la frase con una puntuación de popularidad aparece más con frecuencia en un subconjunto de documentos. Nombres raros de la proteína en una célula se alinean bajo, mientras que un aumento en su frecuencia de mención tiene un retorno decreciente debido a la implementación de la función logarítmica de frecuencia. Medir cuantitativamente estos tres conceptos depende de la frecuencia (1) término de la entidad sobre una celda y a través de las células y (2) número de documentos que tengan esa entidad (frecuencia de documento) dentro de la célula y a través de las células.
Hemos estudiado dos escenarios representativos mediante un conjunto de datos de PubMed y nuestro algoritmo. Estamos interesados en cómo mitocondriales proteínas se asocian a dos únicas categorías de descriptores MeSH; "Los grupos de edad" y "enfermedades nutricionales y metabólicas". Concretamente, hemos obtenido 15,728,250 publicaciones de publicaciones 20 años recogidos por PubMed (1998 a 2018), entre ellos, resúmenes únicos 8.123.458 han tenido completos descriptores MeSH. Por consiguiente, 1.842 proteína mitocondrial humano nombres (incluyendo las abreviaturas y sinónimos), adquiridos de UniProt (uniprot.org) y MitoCarta2.0 (http://mitominer.mrc-mbu.cam.ac.uk/release-4.0/begin.do >), son sistemáticamente examinado. Sus asociaciones con estas 8.899.019 publicaciones y entidades fueron estudiados usando nuestro protocolo; construye un cubo de texto y calcula los puntajes respectivos de CaseOLAP.
Protocolo
Nota: Hemos desarrollado este protocolo basado en el lenguaje de programación Python. Para ejecutar este programa, tener Python Anaconda y Git instalado en el dispositivo. Los comandos indicados en este protocolo se basan en entorno Unix. Este protocolo proporciona los detalles de la descarga de datos desde la base de datos PubMed (MEDLINE), analizar los datos y establecer una plataforma para la frase minería y cuantificación de la Asociación de la categoría de entidad definidos por el usuario de computación en nube.
1 obtener código y python la configuración de entorno
- Descargar o clonar el repositorio de código en Github (https://github.com/CaseOLAP/caseolap) o escribiendo 'git clone https://github.com/CaseOLAP/caseolap.git' en la ventana de terminal.
- Desplácese hasta el directorio 'caseolap'. Este es el directorio raíz del proyecto. Dentro de este directorio, el directorio de 'datos' se popularán con múltiples conjuntos de datos como usted progresa a través de estos pasos en el protocolo. El directorio 'input' es para los datos proporcionado por el usuario. El directorio de 'registro' tiene archivos de registro para fines de solución de problemas. El directorio de 'resultado' es donde se almacenarán los resultados finales.
- Usando la ventana de terminal, ir al directorio donde usted clonado el repositorio de GitHub. Crear el entorno de CaseOLAP usando el archivo 'environment.yml' escribiendo 'conda env crear -f environment.yaml' en la terminal de. Luego activar el entorno tecleando 'fuente activar caseolap' en el terminal.
2. descarga de documentos
- Asegúrese de que la dirección FTP en 'ftp_configuration.json' en el directorio config es la misma que la dirección de enlace base anual o los archivos de actualización diaria, en el enlace (https://www.nlm.nih.gov/databases/download/pubmed_medline.html) .
- Para descargar sólo línea base o actualización archivos sólo, establecer 'true' en el archivo 'download_config.json' en el directorio 'config'. Por defecto, descarga y extrae los archivos base de referencia y actualización. Una muestra de los datos extraídos de XML puede ser consultada en (https://github.com/CaseOLAP/caseolap-pipelines/blob/master/data/extracted-data-sample.xml)
- Tipo 'python run_download.py' en la ventana de terminal para descargar los resúmenes de la base de datos de Pubmed. Esto creará un directorio llamado 'ftp.ncbi.nlm.nih.gov' en el directorio actual. Este proceso comprueba la integridad de los datos descargados y extractos para el directorio de destino.
- Vaya al directorio de 'registro' para leer los mensajes de registro en 'download_log.txt' en caso de que falle el proceso de descarga. Si el proceso se ha completado con éxito, los mensajes de depuración del proceso de descarga se va a imprimir en archivo de registro.
- Cuando la descarga haya finalizado, navegar a través de 'ftp.ncbi.nlm.nih.gov' para asegurarse de que hay 'updatefiles' o 'basefiles' o ambos directorios basados en descargar la configuración en 'download_config.json'. Las estadísticas de archivo se convierten en 'filestat.txt' en el directorio 'data'.
3. Análisis de documentos
- Asegúrese de que descargado y extraídos datos están disponibles en el directorio 'ftp.ncbi.nlm.nih.gov' en el paso 2. Este directorio es el directorio de datos de entrada en este paso.
- Para modificar el esquema de análisis de datos, ajustar parámetros en el archivo 'parsing_config.json' en el directorio 'config' su valor 'true'. De forma predeterminada, analiza la PMID, autores, Resumen, malla, ubicación, revista, fecha de publicación.
- Tipo 'python run_parsing.py' en el terminal para analizar los documentos de los archivos descargados (o extraídos). Este paso analiza todo descargados archivos XML y crea un diccionario de python para cada documento con las teclas (por ejemplo., PMID, autores, Resumen, malla de archivo basado en análisis de configuración de esquema en el paso 3.2).
- Una vez terminado el análisis de datos, asegúrese de que los datos analizados se guardan en el archivo llamado 'pubmed.json' en el directorio de datos. Una muestra de datos analizados está disponible en figura 3.
- Vaya al directorio de 'registro' para leer los mensajes de registro en 'parsing_log.txt' en caso de falla el proceso de análisis. Si el proceso se ha completado con éxito, los mensajes de depuración se va a imprimir en el archivo de registro.
4. acoplamiento del mapeo de PMID
- Asegúrese de que los datos analizados ('pubmed.json') están disponibles en el directorio 'data'.
- Tipo 'python run_mesh2pmid.py' en el terminal para llevar a cabo acoplamiento para traz PMID. Esto crea una tabla de mapeo donde cada una de la malla recoge PMIDs asociados. Un PMID sola puede caer bajo los términos de acoplamiento múltiple.
- Una vez terminado el trazado, asegúrese de que hay 'mesh2pmid.json' en el directorio de datos. Una muestra de las estadísticas de asignación top 20 está disponible en la tabla 2, figuras 4 y 5.
- Vaya al directorio de 'registro' para leer los mensajes de registro en 'mesh2pmid_mapping_log.txt' en caso de falla de este proceso. Si el proceso se ha completado con éxito, los mensajes de depuración de la asignación se va a imprimir en archivo de registro.
5. documento indexado
- Descargar la aplicación de Elasticsearch de https://www.elastic.co. Actualmente, la descarga está disponible en (https://www.elastic.co/downloads/elasticsearch). Para descargar el software en la nube remota, escriba 'wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-x.x.x.tar.gz' en el terminal. Asegúrese de que 'x.x.x' en el comando anterior es sustituida por la versión correcta.
- Asegúrese de que el archivo descargado "elasticsearch-x.x.x.tar.gz' aparece en el directorio raíz y luego extraer los archivos escribiendo 'tar xvzf elasticsearch-x.x.x.tar.gz' en la ventana de terminal.
- Abra una nueva terminal e ir al directorio bin de ElasticSearch escribiendo 'cd Elasticsearch/bin' en el terminal en el directorio raíz.
- Inicie el servidor de Elasticsearch escribiendo '. / Elasticsearch' en la ventana de terminal. Asegúrese de que el servidor se inició sin mensajes de error. En caso de error en iniciar servidor de Elasticsearch, siga las instrucciones en (https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html).
- Modificar el contenido de la 'index_init_config.json' en el directorio 'config' para establecer el inicio del índice. Por defecto, seleccionará todos los elementos presentes.
- Tipo 'python run_index_init.py' en el terminal para iniciar una base de datos de índice en el servidor de Elasticsearch. Esto inicializa el índice con un conjunto de criterios conocidos como información de índice (p. ej., Índice nombre, tipo, número de fragmentos, número de réplicas). Verá el mensaje mencionar índice es creado.
- Seleccione los elementos de la 'index_populate_config.json' en el directorio 'config' por su valor 'true'. Por defecto, seleccionará todos los elementos presentes.
- Asegúrese de que los datos analizados ('pubmed.json') están presentes en el directorio 'data'.
- Tipo 'python run_index_populate.py' en el terminal para llenar el índice mediante la creación de datos a granel con dos componentes. Un primer componente es un diccionario con información de metadatos en el Índice nombre, tipo y el id a granel (por ejemplo, 'Pertenece'). A segundo componente es un diccionario de datos que contiene toda la información sobre las etiquetas (por ejemplo, 'título', 'Resumen', 'MeSH').
- Vaya al directorio de 'registro' para leer los mensajes de registro en 'indexing_log.txt' en caso de falla de este proceso. Si el proceso se ha completado con éxito, los mensajes de depuración de la indexación de direcciones se va a imprimir en el archivo de registro.
6. creación de texto-cubo
- Descargar el árbol de malla más reciente disponible en (https://www.nlm.nih.gov/mesh/filelist.html). La versión actual del código utiliza acoplamiento árbol de 2018 como 'meshtree2018.bin' en el directorio de entrada.
- Definir las categorías de interés (por ejemplo, nombres de enfermedad, grupos de edad, género). Una categoría puede incluir uno o más descriptores MeSH (https://meshb-prev.nlm.nih.gov/treeView). Recoger identificadores de malla para una categoría. Guardar los nombres de las categorías en el archivo 'textcube_config.json' en el directorio de configuración (vea una muestra de la categoría de 'Edad' en la versión descargada del archivo 'textcube_config.json').
- Poner las categorías recogidas de IDs de malla en una línea separada por un espacio. Guarde el archivo de la categoría como 'categories.txt' en el directorio 'input' (vea una muestra de 'Edad' malla de identificadores de la versión descargada del archivo 'categories.txt'). Este algoritmo selecciona automáticamente todos los descriptores MeSH descendientes. Un ejemplo de los nodos raíz y descendientes se presentan en figura 4.
- Asegúrese de que 'mesh2pmid.json' está en el directorio 'data'. Si el árbol de la malla se ha actualizado con un nombre diferente (por ejemplo, 'meashtree2019.bin') en el directorio 'input', asegúrese de que esto se representa correctamente en la ruta de entrada de datos en el archivo 'run_textube.py'.
- Tipo 'python run_textcube.py' en el terminal para crear una estructura de datos de documento llamada cubo de texto. Esto crea una colección de documentos (PMIDs) para cada categoría. Un solo documento (PMID) puede caer en varias categorías, (ver tabla 3A, 3B de la tabla, figura 6A y Figura 7A).
- Una vez terminado el paso de creación de texto-Cube, asegúrese de que los siguientes archivos de datos se guardan en el directorio 'data': (1) una célula tabla PMID como "textcube_cell2pmid.json", (2) pertenece a la tabla de asignación de celda como "textcube_pmid2cell.json", (3) colección de todo descendientes términos MeSH para una celda como "meshterms_per_cat.json" (4) estadísticas de datos de texto-Cube como "textcube_stat.txt".
- Vaya al directorio de 'registro' para leer los mensajes de registro en 'textcube_log.txt' en caso de falla de este proceso. Si el proceso se ha completado con éxito, los mensajes de depuración de la creación de texto-cubo se va a imprimir en el archivo de registro.
7. cuenta de la entidad
- Crear entidades definidas por el usuario (por ejemplo, nombres de proteínas, genes, productos químicos). Poner una entidad y sus abreviaturas en una sola línea separada por "|". Guarde el archivo de la entidad como 'entities.txt' en el directorio 'input'. Una muestra de entidades se puede encontrar en cuadro 4.
- Asegúrese de que está ejecutando el servidor de Elasticsearch. De lo contrario, vaya al paso 5.2 y 5.3 para reiniciar el servidor de Elasticsearch. Se espera tener una base de datos indexada llamado 'pubmed' en el servidor de Elasticsearch que se estableció en el paso 5.
- Asegúrese de que 'textcube_pmid2cell.json' está en el directorio 'data'.
- Tipo 'python run_entitycount.py' en el terminal para realizar la operación de la cuenta de la entidad. Esto busca los documentos de la base de datos indexada y cuenta de la entidad en cada documento como recoge PMIDs en que entidades se encontraron.
- Una vez completada la cuenta de la entidad, asegúrese de que los resultados finales se guardan como 'entitycount.txt' y 'entityfound_pmid2cell.json' en el directorio 'data'.
- Vaya al directorio de 'registro' para leer los mensajes de registro en 'entitycount_log.txt' en caso de falla de este proceso. Si el proceso se ha completado con éxito, los mensajes de depuración de la cuenta de la entidad se va a imprimir en el archivo de registro.
8. metadatos actualización
- Asegúrese de que todos los datos de entrada ('entitycount.txt', 'textcube_pmid2cell.json', 'entityfound_pmid2cell.txt') en el directorio 'data'. Estos son los datos de entrada para la actualización de metadatos.
- Tipo 'python run_metadata_update.py' en el terminal para actualizar los metadatos. Esto prepara una colección de metadatos (por ejemplo, celda nombre, malla asociado, PMIDs) que representa cada documento de texto en la celda. Una muestra de texto-Cube metadatos se presenta en la tabla 3A y tabla 3B.
- Una vez completada la actualización de metadatos, asegúrese de que 'metadata_pmid2pcount.json' y 'metadata_cell2pmid.json' los archivos se guardan en el directorio 'data'.
- Vaya al directorio de 'registro' para leer los mensajes de registro en 'metadata_update_log.txt' en caso de falla de este proceso. Si el proceso se ha completado con éxito, los mensajes de depuración de la actualización de metadatos se va a imprimir en el archivo de registro.
9. cálculo de puntuación de CaseOLAP
- Asegúrese de que los archivos 'metadata_pmid2pcount.json' y 'metadata_cell2pmid.json' están presentes en el directorio 'data'. Estos son los datos de entrada para el cálculo de la puntuación.
- Tipo 'python run_caseolap_score.py' en el terminal para realizar cálculo de puntuación de CaseOLAP. Esto calcula la puntuación de CaseOLAP de las entidades basadas en categorías definidas por el usuario. La puntuación de CaseOLAP es el producto de la integridad, popularidady carácter distintivo.
- Una vez terminado el cómputo de la puntuación, asegúrese de que esto guarda los resultados en varios archivos (por ejemplo, popularidad como 'pop.csv', carácter distintivo como 'dist.csv', CaseOLAP puntuación como 'caseolap.csv'), en el directorio 'resultado'. El resumen del cálculo de puntuación de CaseOLAP también se presenta en la tabla 5.
- Vaya al directorio de 'registro' para leer los mensajes de registro en 'caseolap_score_log.txt' en caso de falla de este proceso. Si el proceso se ha completado con éxito, los mensajes de depuración del cálculo de puntuación de CaseOLAP se va a imprimir en el archivo de registro.
Resultados
Para producir resultados de la muestra, hemos implementado el algoritmo de CaseOLAP en dos partidas/descriptores de asunto: "Las edades" y "Nutrición y enfermedades metabólicas" como casos de uso.
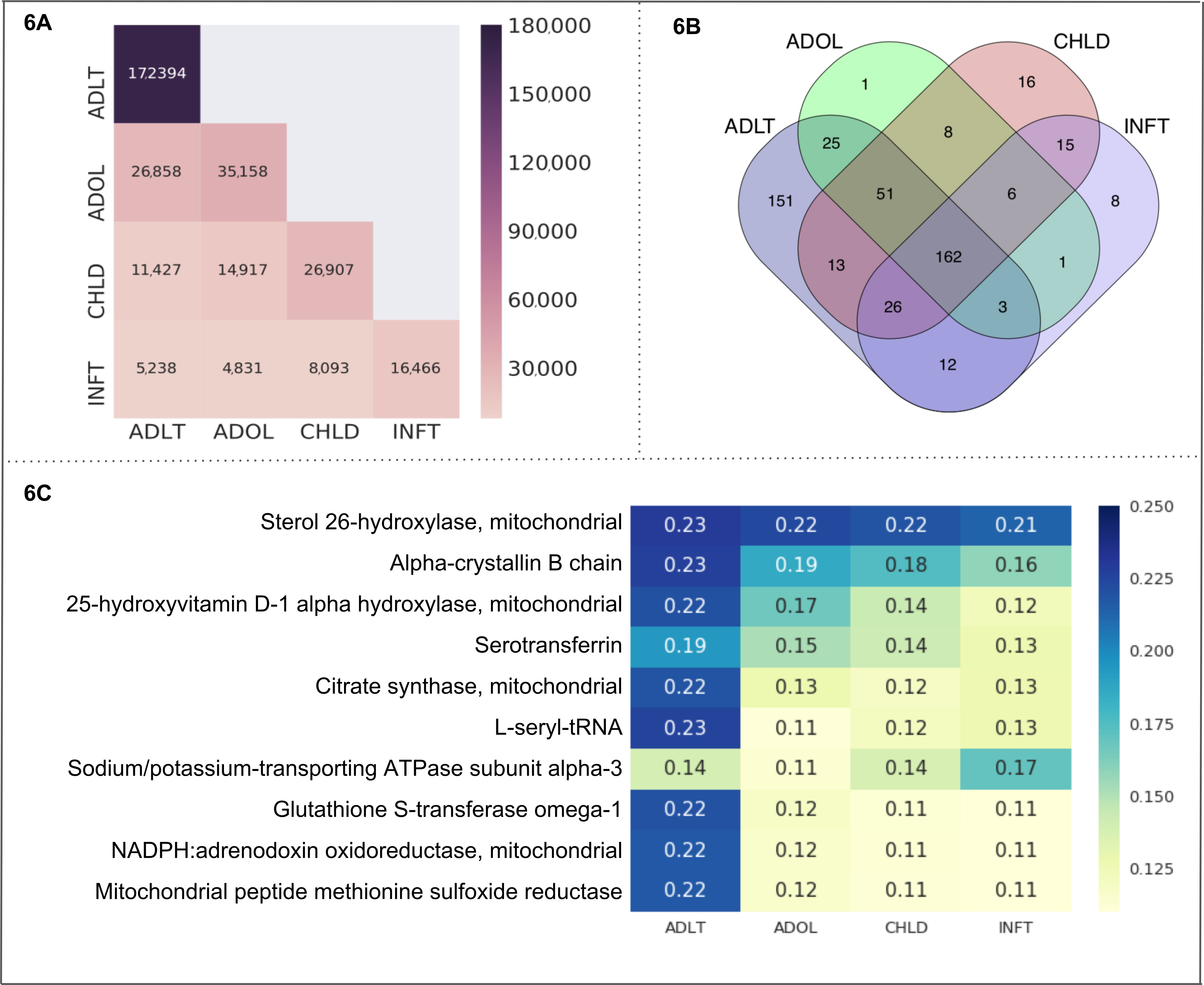
Grupos de edad. Se seleccionaron todos 4 subcategorías de "Las edades" (bebé, niño, adolescente y adulto) como células en un cubo de texto. Las estadísticas y los metadatos obtenidos se muestran en la tabla 3A. La comparación del número de documentos entre las celdas de texto-cubo se muestra en la figura 6A. Adulto contiene 172.394 documentos que es el número más alto en todas las células. Las subcategorías de adultas y adolescentes tienen el mayor número de documentos compartidos (26.858 documentos). En particular, estos documentos incluyen la entidad de nuestro interés solamente (es decir, proteínas mitocondriales). El diagrama de Venn de la Figura 6B representa el número de entidades (es decir, proteínas mitocondriales) encontrado dentro de cada célula y dentro de múltiples superposiciones entre las células. El número de proteínas compartida dentro de todos los grupos de edad subcategorías es 162. La subcategoría adultos representa el mayor número de proteínas únicas (151) seguido del niño (16), niño (8) y el adolescente (1). Se calculó la Asociación de grupo de edad de proteína como un puntaje de CaseOLAP. Las proteínas del top 10 (basadas en su puntaje CaseOLAP) asociadas con subcategorías de bebé, niño, adolescente y adulto son 26-hidroxilasa del esterol, cadena B de alfa-cristalina, 25-hidroxivitamina D-1 alfa-hidroxilasa, Serotransferrin, citrato sintasa, L-seril-tRNA, ATPasa de sodio/potasio-transporte de subunidad alfa-3, Glutathione S-transferase omega-1, NADPH: adrenodoxina oxidorreductasa y reductasa de sulfóxido de metionina péptido mitocondrial (ver figura 6). La subcategoría adultos muestra 10 de heatmap de células con una mayor intensidad en comparación con las células del mapa de calor de la adolescente, el niño y la subcategoría infantil, indicando que las proteínas mitocondriales 10 superior muestran las asociaciones más fuertes a la subcategoría adultos. La proteína mitocondrial esterol 26-hidroxilasa tiene altas asociaciones en todas las subcategorías de edad que se demuestra por las células del mapa de calor con intensidades más altas en comparación con las células del mapa de calor de las otras proteínas mitocondriales 9. La siguiente gama de diferencia de medias con un intervalo de confianza del 99% muestra la distribución estadística de la diferencia absoluta en la puntuación entre dos grupos: (1) la diferencia media entre 'ADLT' y 'INFT' miente en la gama (0.029 a 0,042), (2) la media la diferencia entre 'ADLT' y 'CHLD' se encuentra en el rango (0.021 a 0.030), (3) la diferencia media entre 'ADLT' y 'ADOL' miente en la gama (0.020 a 0.029), (4) la diferencia media entre 'ADOL' y 'INFT' se encuentra en el rango (0.015 a 0.022), (5) la diferencia de medias entre 'ADOL' y 'CHLD' miente en la gama (0.007 a 0.010), (6) la diferencia media entre 'CHLD' y 'INFT' se encuentra en el rango (0.011 a 0.016).
Enfermedades nutricionales y metabólicas. Se seleccionaron 2 subcategorías de "Nutrición y enfermedades metabólicas" (es decir, enfermedad metabólica y trastornos nutricionales) para crear 2 celdas en un cubo de texto. Las estadísticas y los metadatos obtenidos se muestran en la tabla 3B. La comparación del número de documentos entre las celdas de texto-cubo se muestra en la Figura 7A. La enfermedad metabólica de subcategoría contiene 54.762 documentos 19.181 documentos en trastornos nutricionales. La enfermedad metabólica de subcategorías y trastornos nutricionales tienen 7.101 documentos compartidos. En particular, estos documentos incluyen la entidad de nuestro interés solamente (es decir, proteínas mitocondriales). El diagrama de Venn de la figura 7B representa el número de entidades que se encuentran dentro de cada célula y dentro de múltiples superposiciones entre las células. Se calculó la proteína-"Nutrición y enfermedades metabólicas" Asociación como un puntaje de CaseOLAP. Las proteínas del top 10 (basadas en su puntaje CaseOLAP) asociadas con este caso son 26-hidroxilasa del esterol, B de alfa-cristalina L-seril-tRNA synthase del citrato, tRNA pseudouridina sintetasa A, 25-hidroxivitamina D-1 alfa-hidroxilasa, de la cadena Glutathione S-transferasa omega-1, NADPH: adrenodoxina oxidorreductasa, reductasa de sulfóxido de metionina péptido mitocondrial, inhibidor del activador del plasminógeno 1 (se muestra en la figura 7). Más de la mitad (54%) de todas las proteínas se comparten entre las enfermedades metabólicas de subcategorías y trastornos nutricionales (397 proteínas). Curiosamente, casi la mitad (43%) de proteínas asociadas en la subcategoría de enfermedad metabólica son únicas (300 proteínas), mientras que trastornos nutricionales muestran sólo algunas proteínas únicas (35). Cadena B de alfa-cristalina muestra la asociación más fuerte a las enfermedades metabólicas de la subcategoría. Esterol 26-hidroxilasa, mitocondrial muestra la asociación más fuerte en la subcategoría de trastornos nutricionales, lo que indica que esta proteína mitocondrial es altamente relevante en estudios que describen los trastornos nutricionales. La distribución estadística de la diferencia absoluta en la puntuación entre dos grupos 'MBD' y 'NTD' muestra la gama (0.046 a 0.061) para la diferencia de medias como un intervalo de confianza del 99%.

Figura 1. Vista dinámica de flujo de trabajo CaseOLAP. Esta figura representa los 5 pasos principales en el flujo de trabajo de CaseOLAP. En el paso 1, el flujo de trabajo comienza por descargar y extraer documentos textuales (por ejemplo, a partir de PubMed). En el paso 2, los datos extraídos son analizados para crear un diccionario de datos para cada documento, así como una malla para mapeo PMID. En el paso 3, indexación de datos se lleva a cabo para facilitar la búsqueda rápida y eficiente de la entidad. En el paso 4, aplicación de la información suministrada por el usuario categoría (por ejemplo,., raíz malla para cada célula) se lleva a cabo para construir un cubo de texto. En el paso 5, se implementa la operación de la cuenta de la entidad sobre los datos de índice para calcular la puntuación de CaseOLAP. Estos pasos se repiten de manera iterativa para actualizar el sistema con la última información disponible en bases de datos públicas (por ejemplo, PubMed). Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 2. Arquitectura técnica del flujo de trabajo CaseOLAP. Esta figura representa los detalles técnicos del flujo de trabajo CaseOLAP. Datos del repositorio PubMed se obtienen desde el servidor FTP de PubMed. El usuario se conecta con el servidor de la nube (por ejemplo, la conectividad de AWS) a través de su dispositivo y crea una tubería de descarga que descarga y extrae los datos a un repositorio local en la nube. Los datos extraídos son estructurados, verificados y trajo a un formato adecuado con una tubería de análisis de datos. Simultáneamente, se crea una malla a la tabla de asignación de PMID durante la etapa de análisis, que se utiliza para la construcción del texto-Cube. Analizados los datos se almacenan como un JSON como formato de Diccionario de clave y valor con metadatos (por ejemplo, año de PMID, malla, la editorial). El paso de indexación más mejora los datos mediante la aplicación de Elasticsearch para el manejo de datos a granel. A continuación, el texto-cubo se crea con categorías definidas por el usuario poniendo malla a asignación PMID. Cuando se ha completado la formación de texto-Cube y pasos de la indexación, se lleva a cabo un conteo de la entidad. Datos de la cuenta de la entidad se aplican a los metadatos de texto-Cube. Finalmente, la puntuación de CaseOLAP se calcula basándose en la estructura del texto-cubo subyacente. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 3. Una muestra de un documento analizado. Una muestra de los datos analizados se presenta en esta figura. Los datos analizados están dispuestos como un par de clave y valor que es compatible con la indexación y documento la creación de metadatos. En esta figura, un PMID (por ejemplo, "25896987") es que sirve como llave y colección de información asociada (por ejemplo, título, revista, publicación fecha, Resumen, malla, sustancias, Departamento y ubicación) son como valor. La primera aplicación de estos metadatos de documento es la construcción de la malla a PMID mapeo (figura 5 y tabla 2), que más tarde se pone en ejecución para crear el cubo de texto y para calcular el puntaje de CaseOLAP con entidades suministrada por el usuario y categorías. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

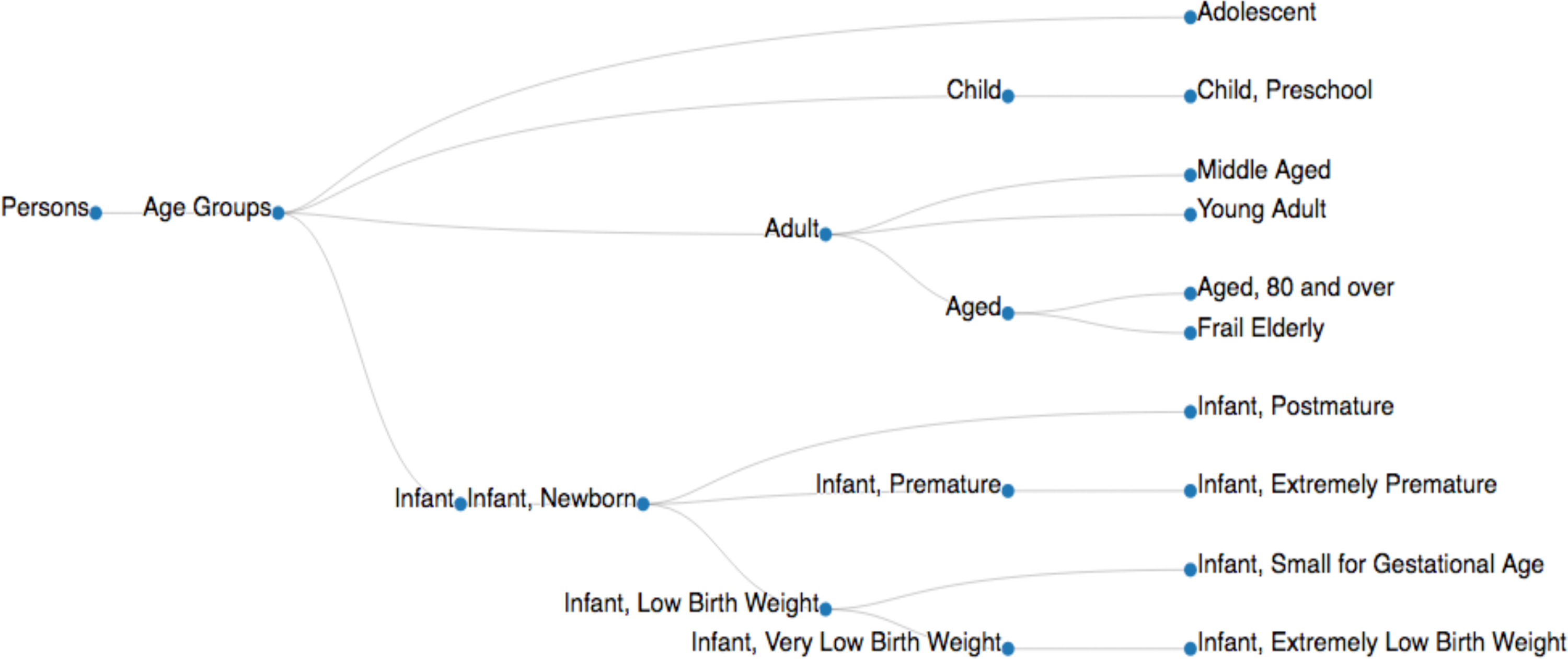
Figura 4. Una muestra de un árbol de la malla. Árbol de acoplamiento de los grupos 'edad es una adaptación de la estructura de datos árbol disponible en la base de datos de NIH (acoplamiento árbol 2018, < https://meshb.nlm.nih.gov/treeView>). Descriptores meSH se implementan con su nodo ID (por ejemplo, personas [M01], [M01.060] los grupos de edad, adolescente [M01.060.057], adulto [M01.060.116], infantil [M01.060.406], infantil [M01.060.703]) para recoger los documentos pertinentes a un descriptor específico de malla ( Tabla 3A). Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

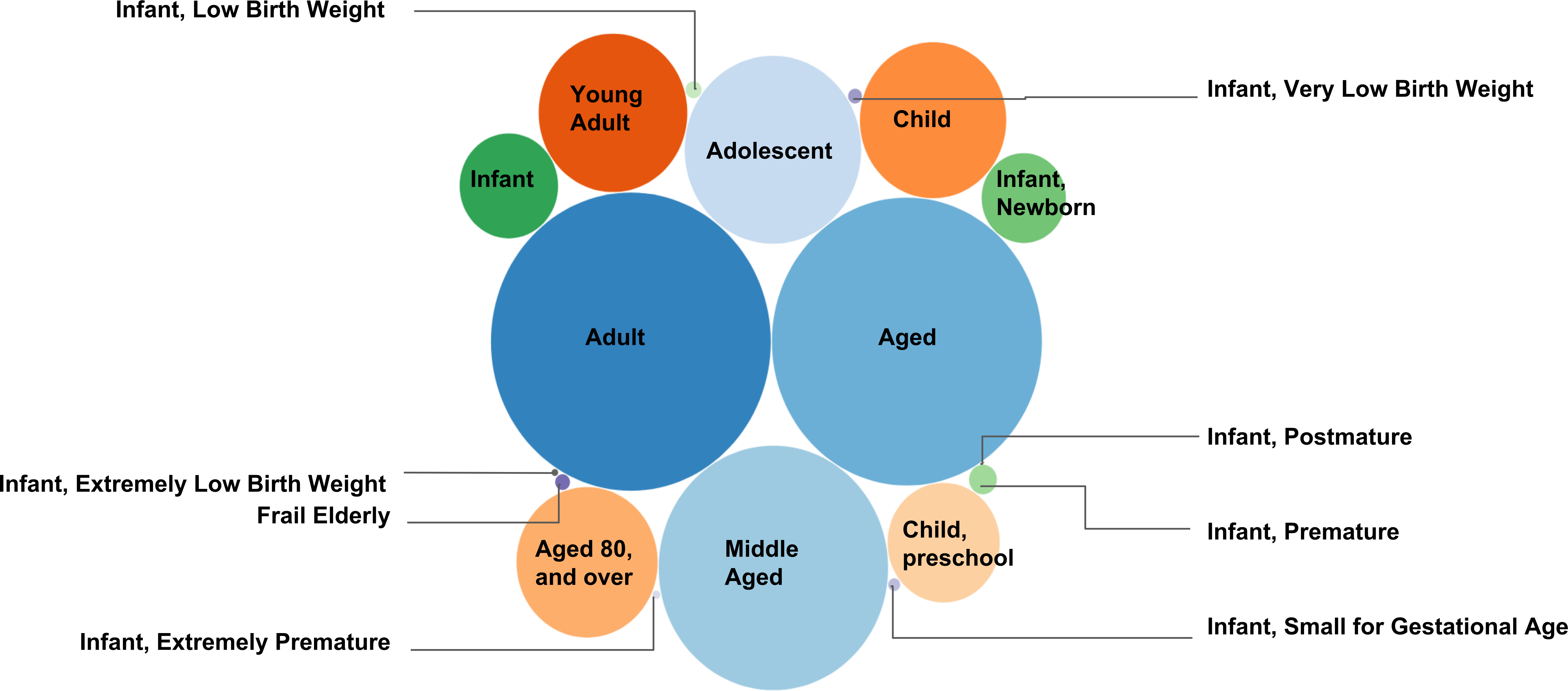
Figura 5. Acoplamiento del mapeo PMID en grupos de edad. Esta figura presenta el número de documentos de texto (cada uno vinculado con un PMID) recogido bajo los descriptores de acoplamiento en "Edades" como un diagrama de burbuja. La malla a los mapas de PMID es generada para proporcionar el número exacto de documentos recogidos bajo los descriptores MeSH. Un total de 3.062.143 documentos únicos fueron recogido bajo los descriptores de malla descendientes 18 (ver tabla 2). Cuanto mayor sea el número de PMIDs seleccionado bajo un descriptor específico de malla, el más grande el radio de la burbuja que representa el descriptor de la malla. Por ejemplo, el mayor número de documentos fueron recogido bajo el descriptor MeSH "Adulto" (1.786.371 documentos), mientras que el menor número de documentos de texto se recolectaron con el descriptor MeSH "Infant, Postmature" (62 documentos).
Se da un ejemplo adicional de malla para mapeo PMID de "Nutrición y enfermedades metabólicas" (https://caseolap.github.io/mesh2pmid-mapping/bubble/meta.html). Se recolectaron un total de 422.039 documentos únicos bajo los 361 descriptores de malla descendentes en "Enfermedades nutricionales y metabólicas". El mayor número de documentos fueron recogido bajo el descriptor MeSH "Obesidad" (77.881 documentos) seguido de "Diabetes Mellitus, tipo 2" (61.901 documentos), mientras que "enfermedad por almacenamiento de glucógeno tipo VIII" exhibió el menor número de documentos (1 documento ). Una tabla relacionada está también disponible en (https://github.com/CaseOLAP/mesh2pmid-mapping/blob/master/data/diseaseall.csv). Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 6. "Las edades" como un caso de uso. Esta figura presenta los resultados de un caso de uso de la plataforma CaseOLAP. En este caso, nombres de proteína y sus abreviaturas (ver muestra en la tabla 4) se implementan como entidades y "Edades", incluyendo las células: infantil (INFT), niño (CHLD), adolescente (ADOL) y adulto (ADLT), se implementan como subcategorías (véase Tabla 3A). (A) Número de documentos en "Edades": Este mapa muestra el número de documentos distribuidos a través de las células de "Grupos de edad" (para los detalles en el texto-Cube creación ver protocolo 4 y tabla 3A). Un mayor número de documentos se presenta con una intensidad más oscura del mapa de calor (véase la escala) de la célula. Un solo documento puede incluirse en más de una celda. El mapa de calor presenta el número de documentos dentro de una célula a lo largo de la posición diagonal (por ejemplo, ADLT contiene 172.394 documentos que es el número más alto en todas las células). La posición nondiagonal representa el número de documentos, cayendo en dos células (por ejemplo, ADLT y ADOL tienen 26.858 documentos compartidos). (B) . Cuenta de la entidad en "Edades": el diagrama de Venn representa el número de proteínas que se encuentran en las cuatro casillas que representan a "Los grupos de edad" (INFT CHLD, ADOL y ADLT). El número de proteínas compartida dentro de todas las células es 162. El grupo de edad ADLT representa el mayor número de proteínas únicas (151) seguido por CHLD (16), INFT (8) y ADOL (1). (C) CaseOLAP puntuación presentación en "Edades": Las top 10 proteínas con las puntuaciones promedio más altas de la CaseOLAP en cada grupo se presentan en un mapa de calor. Una puntuación de CaseOLAP se presenta con una intensidad más oscura del mapa de calor (véase la escala) de la célula. En la columna de la izquierda aparecen los nombres de la proteína y las células (INFT CHLD, ADOL, ADLT) aparecen a lo largo del eje x. Algunas proteínas muestran una fuerte asociación a un grupo específico de edad (p. ej., 26-hidroxilasa del esterol, cadena B de alfa-cristalina y L-seril-tRNA tienen fuertes asociaciones con ADLT, mientras que la ATPasa sodio/potasio-transporte de subunidad alfa-3 tiene una fuerte asociación con INFT). Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 7. "Nutrición y enfermedades metabólicas" como un caso de uso: esta figura presenta los resultados de otro caso de uso de la plataforma CaseOLAP. En este caso, nombres de proteína y sus abreviaturas (ver muestra en el cuadro 4) se implementan como entidades y "Nutrición y enfermedad metabólica" entre las dos células: enfermedad metabólica (MBD) y trastornos nutricionales (DTN) se implementan como subcategorías (ver tabla 3B). (A). número de documentos en "Enfermedades nutricionales y metabólicas": este mapa de calor muestra el número de documentos de texto en las celdas de "Enfermedades nutricionales y metabólicas" (para más detalles sobre la creación de texto-cubo 4 protocolo y tabla 3B ). Un mayor número de documentos se presenta con una intensidad más oscura del mapa de calor (ver escala) de la célula. Un solo documento puede incluirse en más de una celda. El mapa de calor presenta el número total de documentos dentro de una célula a lo largo de la posición diagonal (por ejemplo, MBD contiene 54.762 documentos cuál es el número más alto en las dos células). La posición nondiagonal representa el número de documentos compartidos por las dos células (por ejemplo, MBD y NTD tienen 7.101 documentos compartidos). (B). entidad cuenta en "Enfermedades nutricionales y metabólicas": el diagrama de Venn representa el número de proteínas que se encuentran en las dos celdas que representan a "Nutrición y enfermedades metabólicas" (MBD y NTD). El número de proteínas compartida dentro de las dos células es 397. La célula MBD representa 300 proteínas únicas, y la célula NTD representa 35 proteínas únicas. (C). CaseOLAP puntuación presentación en "Enfermedades nutricionales y metabólicas": las proteínas del top 10 con las puntuaciones más altas de CaseOLAP media en "Enfermedades nutricionales y metabólicas" se presentan en un mapa de calor. Una puntuación de CaseOLAP se presenta con una intensidad más oscura del mapa de calor (ver escala) de la célula. En la columna de la izquierda aparecen los nombres de proteínas y células (MBD y NTD) aparecen a lo largo del eje x. Algunas proteínas muestran una fuerte asociación a una categoría de enfermedad específica (p. ej., cadena B de alfa-cristalina tiene una alta asociación con enfermedad metabólica y 26-hidroxilasa del esterol tiene una alta asociación con trastornos nutricionales). Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}
| Tiempo (porcentaje del tiempo total) | Pasos en la plataforma de CaseOLAP | Algoritmo y estructura de datos de la plataforma CaseOLAP | Complejidad del algoritmo y estructura de datos | Detalles de los pasos |
| 40% | Descargando y Análisis sintáctico | Iteración y el árbol de análisis de algoritmos | Iteración de bucle anidado y multiplicación de constante: O(n^2), O (log n). Donde n es no de iteraciones. | La tubería de descarga recorre en cada procedimiento en varios archivos. Análisis de un único documento funciona cada procedimiento sobre la estructura de datos XML. |
| 30% | Indexación, búsqueda y creación de cubo de texto | Iteración, algoritmos de búsqueda por Elasticsearch (clasificación, índice de Lucene, colas de prioridad, máquinas de estado finito, poco jugar hacks, regex consultas) | Complejidad, relacionadas con la Elasticsearch (https://www.elastic.co/) | Los documentos están indexados por implementar el proceso de iteración en el Diccionario de datos. La creación de texto-Cube implementa documento meta-datos e información suministrada por el usuario de la categoría. |
| 30% | Entidad de conteo y cálculo de CaseOLAP | Iteración en integridad, popularidad, cálculo de carácter distintivo | O, O(n^2), múltiples complejidades relacionadas con caseOLAP cálculo de puntuación basado en tipos de iteración ¡(1). | Operación de cuenta de entidad enumera los documentos y hacer una operación de cuenta sobre la lista. Los datos de la cuenta de la entidad se utilizan para calcular la puntuación de CaseOLAP. |
Tabla 1. Algoritmos y complejidad. Esta tabla presenta información sobre el tiempo pasado (porcentaje de tiempo total) en los procedimientos (por ejemplo, descargando, análisis), estructura de datos y detalles acerca de los algoritmos implementados en la plataforma CaseOLAP. CaseOLAP implementa la indización profesional y la aplicación de búsqueda denominada Elasticsearch. Información adicional sobre complejidades relacionadas con algoritmos internos y Elasticsearch se puede encontrar en (https://www.elastic.co).
| Descriptores meSH | Número de PMIDs |
| Adulto | 1.786.371 |
| Media edad | 1.661.882 |
| De años | 1.198.778 |
| Adolescente | 706.429 |
| Adulto joven | 486.259 |
| Niño | 480.218 |
| De edad, 80 y más | 453.348 |
| Niño, preescolar | 285.183 |
| Niño | 218.242 |
| Bebé, recién nacido | 160.702 |
| Prematuro | 17.701 |
| Infantil, bajo peso | 5.707 |
| Ancianos frágiles | 4.811 |
| Nacimiento de bebé, muy bajo peso | 4.458 |
| Niño, pequeño para edad gestacional | 3.168 |
| Extremadamente prematuro | 1.171 |
| Infantil, de muy bajo peso | 1.003 |
| Infantil, Postmature | 62 |
Tabla 2. Estadísticas de asignación PMID del acoplamiento. Esta tabla presenta todos los descriptores MeSH descendiente de "Edades" y su número de recogidas PMIDs (documentos de texto). La visualización de estas estadísticas se presenta en la figura 5.
| A | Niño (INFT) | Niño (CHLD) | Adolescente (ADOL) | Adulto (ADLT) |
| Malla de raíz ID | M01.060.703 | M01.060.406 | M01.060.057 | M01.060.116 |
| Número de descriptores MeSH descendiente de | 9 | 2 | 1 | 6 |
| Número de PMIDs seleccionado | 16.466 | 26.907 | 35.158 | 172.394 |
| Número de entidades que se encuentran | 233 | 297 | 257 | 443 |
| B | Enfermedades metabólicas (Mbj) | Trastornos nutricionales (NTD) | ||
| Malla de raíz ID | C18.452 | C18.654 | ||
| Número de malla descendiente descriptores de | 308 | 53 | ||
| Número de PMIDs | 54.762 | 19.181 | ||
| Número de entidades que se encuentran | 697 | 432 |
Tabla 3. Metadatos de texto-Cube. Se presenta una vista tabular de metadatos de texto-Cube. Las tablas proporcionan información sobre las categorías y descriptor raíces y descendientes, que se implementan para recoger los documentos en cada celda de la malla. La tabla también proporciona las estadísticas de las entidades y documentos recogidos. (A) "Los grupos de edad": esta es una presentación tabular de "Las edades" como niño (INFT), niño (CHLD), adolescente (ADOL) y adulto (ADLT) y su raíz malla ID, número de descendiente descriptores MeSH, número de PMIDs seleccionados y número de encontrar entidades. (B) "Enfermedades nutricionales y metabólicas": esta es una presentación tabular de "Nutrición y enfermedades metabólicas" como enfermedad metabólica (MBD) y trastornos nutricionales (NTD) con su raíz de malla ID, el número de descriptores de malla descendiente, de PMIDs seleccionados y el número de entidades encontradas.
| Proteína nombres y sinónimos | Abreviaturas |
| N-acetilglutamato sintasa, mitocondrial, aminoácido acetiltransferasa, forma larga de N-acetilglutamato sintasa; N-acetilglutamato sintasa forma corta; N-acetilglutamato sintasa conservada dominio formulario] | (CE 2.3.1.1) |
| Deglycase ácido nucleico/proteína DJ-1 (deglycase de Maillard) (Oncogene DJ1) (proteína de la enfermedad de Parkinson 7) (asociada a parkinsonismo deglycase) (DJ-1 de proteína) | (EC 3.1.2.-) (EC 3.5.1.-) (CE 3.5.1.124) (DJ-1) |
| Carboxilasa de piruvato mitocondrial (pirúvico carboxilasa) | (EC 6.4.1.1) (PCB) |
| Componente de bcl-2-enlace 3 (p53 regula para arriba modulador de la apoptosis) | (JFY-1) |
| BH3-interacción agonista de muerte de dominio [BH3-interacción dominio muerte agonista p15 (p15 BID); BH3-interacción dominio muerte agonista p13; BH3-interacción dominio muerte agonista p11] | (22 ofertas) (BID) (p13 BID) (oferta de p11) |
| ATP sintasa subunidad alfa, mitocondrial (ATP sintasa F1 subunidad alfa) | |
| Citocromo P450 11B2, mitocondrial (aldosterona sintasa) (enzima de la síntesis de aldosterona) (CYPXIB2) (citocromo P-450Aldo) (citocromo P-450_C_18) (18-hidroxilasa) | (ALDOS) (CE 1.14.15.4) (CE 1.14.15.5) |
| 60 kDa proteína de choque térmico, mitocondrial (60 kDa chaperonin) (chaperonina 60) (CPN60) (proteína 60 de choque de calor) (proteína de la matriz mitocondrial P1) (proteína P60 de linfocito) | (HSP-60) (Hsp60) (HuCHA60) (CE 3.6.4.9) |
| Caspasa-4 (hielo y Ced-3 homólogo 2) (proteasa TX) [divididos en: caspasas-4 subunidad 1; Caspasa-4 subunidad 2] | (CASP-4) (CE 3.4.22.57) (ICH-2) (ICE(rel)-II) (Mih1) |
Tabla 4. Muestra la tabla de la entidad. Esta tabla presenta la muestra de entidades que en nuestros casos de dos uso: "Las edades" y "Enfermedades nutricionales y metabólicas" (figura 6 y figura 7, tabla 3A,B). Las entidades incluyen abreviaturas, sinónimos y nombres de proteína. Cada entidad (con sus sinónimos y abreviaturas) es seleccionado uno por uno y se pasa a través de la operación de búsqueda de entidad de datos indexados (ver protocolo de 3 y 5). La búsqueda produce una lista de documentos que facilitan aún más la operación de la cuenta de la entidad.
| Cantidades | Definidos por el usuario | Calcula | Ecuación de la cantidad | Significado de la cantidad |
| Integridad | Sí | No | Integridad de usuario define entidades consideradas 1.0. | Representa una frase significativa. Valor numérico es de 1,0 cuando ya es una frase establecida. |
| Popularidad | No | Sí | Ecuación de Popularidad en la figura 1 (flujo de trabajo y algoritmo) de la referencia 5, sección "Materiales y métodos". | Basado en la frecuencia del término de la frase dentro de una célula. Normalizado por frecuencia de plazo total de la célula. Aumento en la frecuencia de término tiene disminución de resultado. |
| Carácter distintivo | No | Sí | Ecuación de carácter distintivo en la figura 1 (flujo de trabajo y algoritmo) de la referencia 5, sección "Materiales y métodos". | Basado en plazo y frecuencia del documento dentro de una célula y a través de las células vecinas. Normalizado por el plazo total y frecuencia de documento. Cuantitativamente, es la probabilidad de que una frase es única en una celda concreta. |
| Puntuación CaseOLAP | No | Sí | Ecuación de resultado CaseOLAP en la figura 1 (flujo de trabajo y algoritmo) de referencia 5, sección "Materiales y métodos". | Basada en integridad, popularidad y carácter distintivo. Valor numérico siempre cae dentro de 0 a 1. Cuantitativamente la puntuación de CaseOLAP representa la Asociación de categoría de frase |
Tabla 5. Ecuaciones de CaseOLAP: CaseOLAP el algoritmo fue desarrollado por Fangbo Tao y Jiawei Han et al. en el 20161. Brevemente, esta tabla muestra el cálculo de la puntuación de CaseOLAP que consta de tres componentes: integridad, popularidad y un carácter distintivo y su significado matemático asociado. En nuestros casos de uso, la puntuación de la integridad de las proteínas es 1.0 (la máxima puntuación) porque están parados como nombres de entidades establecidas. Las puntuaciones de CaseOLAP en nuestros casos de uso pueden verse en la figura 6 y figura 7.
Discusión
Hemos demostrado que el algoritmo de CaseOLAP puede crear una asociación cuantitativa frase basada en una categoría basada en el conocimiento sobre grandes volúmenes de datos textuales para la extracción de información significativa. Siguiendo nuestro protocolo, uno puede construir el marco de CaseOLAP para crear un cubo de texto deseado y cuantificar asociaciones de categoría de la entidad a través del cálculo de puntuación de CaseOLAP. Los puntajes crudos obtenidos de la CaseOLAP pueden tomarse para análisis integrantes incluyendo la reducción de dimensionalidad, clustering, análisis temporal y geográfico, así como la creación de una base de datos gráfica que permite la asignación semántica de los documentos.
Aplicabilidad del algoritmo de. Ejemplos de entidades definidas por el usuario, diferentes proteínas, podrían ser una lista de nombres de gene, drogas, específicos signos y síntomas incluyendo sinónimos y abreviaturas. Además, hay muchas opciones para la selección de categoría facilitar la definida por el usuario biomédicos análisis específicos (por ejemplo, anatomía [A], disciplina y ocupación [H], fenómenos y procesos [G]). En nuestros dos casos de uso, todas las publicaciones científicas y sus datos textuales se recuperan de la base de datos MEDLINE mediante PubMed como el motor de búsqueda, ambos gestionados por la Biblioteca Nacional de medicina. Sin embargo, la plataforma de CaseOLAP puede aplicarse a otras bases de datos de interés que contienen documentos biomédicos con datos textuales como la FDA adversos evento informes sistema (FAERS). Se trata de una base de datos abierta que contiene información sobre eventos adversos clínicos y de informes de errores de medicación presentados a la FDA. A diferencia de MEDLINE y FAERS, bases de datos que contiene registros electrónicos de salud de pacientes de hospitales no abiertas al público y se limitan por la Health Insurance Portability y Accountability Act, conocida como HIPAA.
Algoritmo de CaseOLAP se ha aplicado con éxito a los diferentes tipos de datos (por ejemplo, noticias)1. La implementación de este algoritmo en documentos biomédicos realizada en 20185. Los requisitos para la aplicabilidad del algoritmo CaseOLAP es que cada uno de los documentos debe asignarse con palabras clave asociada con los conceptos (por ejemplo, descriptores MeSH en publicaciones biomédicas, palabras clave en artículos de prensa). Si no se encuentran palabras, uno puede aplicar Autophrase6,7 para recoger mejores frases representativas y construir la lista de personas antes de implementar el protocolo. Nuestro protocolo no proporciona el paso para realizar Autophrase.
Comparación con otros algoritmos de. El concepto de usar un cubo de datos8,9,10 y texto-cubo2,3,4 ha ido evolucionando desde el año 2005 con nuevos avances para hacer minería de datos más aplicable. El concepto de procesamiento analítico en línea (OLAP)11,12,13,14,15 en minería de datos e inteligencia de negocios se remonta a 1993. OLAP, en general, agrega la información de múltiples sistemas y almacena en un formato multidimensional. Hay diferentes tipos de sistemas OLAP en minería de datos. Por ejemplo procesamiento de transacción/analítica (1) híbrido (HTAP)16,17, de18,de OLAP Multidimensional (MOLAP) (2)19-cubo OLAP relacional (ROLAP) de base y (3)20.
Específicamente, el algoritmo de CaseOLAP se ha comparado con numerosos algoritmos existentes, específicamente, con sus mejoras de segmentación de la frase, incluyendo TF-IDF + Seg, MCX + Seg, MCX y SegPhrase. Por otra parte, RepPhrase (RP, también conocido como SegPhrase +) ha sido comparado con sus propias variaciones de ablación, incluyendo (1) RP sin la medida de integridad incorporada (RP No INT), (2) RP sin la medida de popularidad incorporada (RP No POP) y (3) RP sin la Medida de carácter distintivo incorporado (RP No DIS). Los resultados se muestran en el estudio por Fangbo Tao et al.1.
Todavía hay retos en minería de datos que puede Agregar funcionalidad adicional sobre guardar y recuperar los datos de la base de datos. Sensibles al contexto semántico Analytical Processing, (CaseOLAP) implementa sistemáticamente el Elasticsearch para construir una base de datos de indexación de millones de documentos (protocolo 5). El texto-cubo es una estructura de documento construida sobre los datos indexados con categorías suministrada por el usuario (Protocolo de 6). Esto aumenta la funcionalidad de los documentos dentro y a través de la celda del cubo de texto y nos permiten calcular frecuencia de término de las entidades en un documento y documento frecuencia sobre una celda concreta (protocolo 8). La puntuación final de CaseOLAP utiliza estos cálculos de frecuencia para un marcador final de salida (9 del Protocolo). En el 2018, hemos implementado este algoritmo para estudiar proteínas ECM y seis enfermedades cardiacas para analizar asociaciones de proteína-enfermedad. Los detalles de este estudio pueden encontrarse en el estudio por Liem, D.A. et al.5. lo que indica que CaseOLAP podía ser ampliamente utilizado en la comunidad biomédica, explorando una variedad de enfermedades y mecanismos.
Limitaciones del algoritmo de. Explotación minera de la frase sí mismo es una técnica para administrar y recuperar conceptos importantes de datos textuales. Descubrir la Asociación entidad categoría como una cantidad matemática (vector), esta técnica es incapaz de averiguar la polaridad (por ejemplo, inclinación positiva o negativa) de la asociación. Uno puede construir la síntesis cuantitativa de los datos utilizando la estructura del documento texto-Cude con categorías y entidades asignadas, pero no se logra un concepto cualitativo resulta microscópica. Algunos conceptos están evolucionando continuamente desde pasado hasta ahora. El resumen presentado por la Asociación de una categoría específica de entidad incluye todas las incidencias a lo largo de la literatura. Esto puede carecer la propagación temporal de la innovación. En el futuro, planeamos abordar estas limitaciones.
Aplicaciones futuro. Cerca del 90% de los datos acumulados en el mundo está en los datos de texto no estructurado. Encontrar una frase representativa y relación con las entidades en el texto es una tarea muy importante para la aplicación de nuevas tecnologías (por ejemplo, en el aprender de máquina, extracción de información, Inteligencia Artificial). Para hacer que los datos de texto máquina legible, datos que se organizó en la base de datos sobre los que podría aplicarse la siguiente capa de herramientas. En el futuro, este algoritmo puede ser un paso crucial en la fabricación de minería de datos más funcional para la recuperación de la información y la cuantificación de las asociaciones de categoría de la entidad.
Divulgaciones
Los autores no tienen nada que revelar.
Agradecimientos
Este trabajo fue financiado en parte por el National Heart, Lung and Blood Institute: HL135772 R35 (al P. Ping); Instituto Nacional de Ciencias de Medicina General: GM114833 U54 (a Ping P., K. Watson y W. Wang); U54 GM114838 (a J. Han); un regalo de la Hellen & Larry Hoag Foundation y el Dr. S. Setty; y la dotación de T.C. Laubisch en UCLA (al P. Ping).
Materiales
| Name | Company | Catalog Number | Comments |
Referencias
- Tao, F., Zhuang, H., et al. Phrase-Based Summarization in Text Cubes. IEEE Data Engineering Bulletin. , 74-84 (2016).
- Ding, B., Zhao, B., Lin, C. X., Han, J., Zhai, C. TopCells: Keyword-based search of top-k aggregated documents in text cube. IEEE 26th International Conference on Data Engineering (ICDE). , 381-384 (2010).
- Ding, B., et al. Efficient Keyword-Based Search for Top-K Cells in Text Cube. IEEE Transactions on Knowledge and Data Engineering. 23 (12), 1795-1810 (2011).
- Liu, X., et al. A Text Cube Approach to Human, Social and Cultural Behavior in the Twitter Stream.Social Computing, Behavioral-Cultural Modeling and Prediction. Lecture Notes in Computer Science. 7812, (2013).
- Liem, D. A., et al. Phrase Mining of Textual Data to analyze extracellular matrix protein patterns across cardiovascular disease. American Journal of Physiology-Heart and Circulatory. , (2018).
- Shang, J., et al. Automated Phrase Mining from Massive Text Corpora. IEEE Transactions on Knowledge and Data Engineering. 30 (10), 1825-1837 (2018).
- Liu, J., Shang, J., Wang, C., Ren, X., Han, J. Mining Quality Phrases from Massive Text Corpora. Proceedings ACM-Sigmod International Conference on Management of Data. , 1729-1744 (2015).
- Lee, S., Kim, N., Kim, J. A Multi-dimensional Analysis and Data Cube for Unstructured Text and Social Media. IEEE Fourth International Conference on Big Data and Cloud Computing. , 761-764 (2014).
- Lin, C. X., Ding, B., Han, J., Zhu, F., Zhao, B. Text Cube: Computing IR Measures for Multidimensional Text Database Analysis. IEEE Data Mining. , 905-910 (2008).
- Hsu, W. J., Lu, Y., Lee, Z. Q. Accelerating Topic Exploration of Multi-Dimensional Documents Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE International. , 1520-1527 (2017).
- Chaudhuri, S., Dayal, U. An overview of data warehousing and OLAP technology. SIGMOD Record. 26 (1), 65-74 (1997).
- Ravat, F., Teste, O., Tournier, R. Olap aggregation function for textual data warehouse. ICEIS - 9th International Conference on Enterprise Information Systems, Proceedings. , 151-156 (2007).
- Ho, C. T., Agrawal, R., Megiddo, N., Srikant, R. Range Queries in OLAP Data Cubes. SIGMOD Conference. , (1997).
- Saxena, V., Pratap, A. Olap Cube Representation for Object- Oriented Database. International Journal of Software Engineering & Applications. 3 (2), (2012).
- Maniatis, A. S., Vassiliadis, P., Skiadopoulos, S., Vassiliou, Y. Advanced visualization for OLAP. DOLAP. , (2003).
- Bog, A. . Benchmarking Transaction and Analytical Processing Systems: The Creation of a Mixed Workload Benchmark and its Application. , 7-13 (2013).
- Özcan, F., Tian, Y., Tözün, P. Hybrid Transactional/Analytical Processing: A Survey. In Proceedings of the ACM International Conference on Management of Data (SIGMOD). , 1771-1775 (2017).
- Hasan, K. M. A., Tsuji, T., Higuchi, K. An Efficient Implementation for MOLAP Basic Data Structure and Its Evaluation. International Conference on Database Systems for Advanced Applications. , 288-299 (2007).
- Nantajeewarawat, E. Advances in Databases: Concepts, Systems and Applications. DASFAA 2007. Lecture Notes in Computer Science. 4443, (2007).
- Shimada, T., Tsuji, T., Higuchi, K. A storage scheme for multidimensional data alleviating dimension dependency. Third International Conference on Digital Information Management. , 662-668 (2007).
Reimpresiones y Permisos
Solicitar permiso para reutilizar el texto o las figuras de este JoVE artículos
Solicitar permisoThis article has been published
Video Coming Soon
ACERCA DE JoVE
Copyright © 2025 MyJoVE Corporation. Todos los derechos reservados