
Method Article
צירוף המבוסס על ענן צמתים הכרייה וניתוח של ההתאגדות הביטוי-הקטגוריה מוגדרת על-ידי המשתמש בפרסומים ביו
* These authors contributed equally
In This Article
Summary
אנו מציגים פרוטוקול ו משויך קוד תיכנות, כמו גם דגימות מטה-נתונים כדי לתמוך מזהה אוטומטי המבוסס על ענן צמתים אגודת משפטים-קטגוריה מייצגת קונספט יחודי בתחום הידע שנבחר משתמש בספרות הביו-רפואית. האגודה הביטוי-קטגוריה לכמת על ידי פרוטוקול זה יכול להקל על בניתוחי עומק בתחום הידע שנבחר.
Abstract
הצטברות מהירה של נתונים טקסטואליים ביו חרגה בהרבה את היכולת האנושית של curation ידנית וניתוח, המחייב כלי כריית טקסט הרומן לחלץ תובנות ביולוגי כמויות גדולות של דו חות מדעיים. צינור הקשר-מודעות סמנטי מקוון אנליטי לעיבוד (CaseOLAP), שפותח בשנת 2016, בהצלחה מכמתת קשרים הביטוי-הקטגוריה מוגדרת על-ידי המשתמש באמצעות הניתוח של נתונים טקסטואליים. CaseOLAP יש הרבה יישומים ביו-רפואי.
פיתחנו פרוטוקול עבור סביבת המבוסס על ענן צמתים תומך מכרות הביטוי קצה-לקצה של ניתוחים פלטפורמה. פרוטוקול שלנו כוללת נתונים preprocessing (למשל, הורדת החילוץ, ניתוח של מסמכי טקסט), של יצירת אינדקס וחיפוש עם Elasticsearch, יצירת מבנה המסמך פונקציונלי שנקרא טקסט-קוביה, וכימות יחסים הביטוי-קטגוריה באמצעות האלגוריתם CaseOLAP הליבה.
הנתונים שלנו preprocessing מפיק מיפויי מפתח-ערך עבור כל המסמכים מעורב. הנתונים עיבוד מקדים באינדקס כדי לבצע חיפוש של מסמכים כולל ישויות, אשר בהמשך מקלה על יצירת טקסט-קוביית וחישוב הציון CaseOLAP. ציוני הגלם שהושג CaseOLAP מפורשים באמצעות סדרה של ניתוחים אינטגרטיבית, כולל הפחתת dimensionality, קיבוץ באשכולות, הזמני, וניתוחים גיאוגרפי. בנוסף, הציונים CaseOLAP משמשים כדי ליצור מסד נתונים גרפיים, אשר מאפשר מיפוי סמנטי של המסמכים.
CaseOLAP מגדיר את הביטוי-קטגוריה יחסים ב מדויקת (מזהה מערכות יחסים) ועקבי (מאוד לשחזור), ולא באופן יעיל (תהליכים 100,000 מילים/שניה). בעקבות פרוטוקול זה, משתמשים יכולים לגשת סביבת מחשוב ענן כדי לתמוך משלהם תצורות ויישומים של CaseOLAP. פלטפורמה זו מציע נגישות משופרת, מסמיכה את הקהילה הביו-רפואית עם כלי הביטוי כריית ליישומים המחקר הביו-רפואי נרחב.
Introduction
הערכה ידנית של מיליוני קבצי טקסט לצורך המחקר ההתאגדות הביטוי-קטגוריה (למשל., קבוצת גיל להתאחדות חלבון) אין מה להשוות עם יעילות המסופקים על ידי שיטה חישובית אוטומטית. אנחנו רוצים להציג את הפלטפורמה המבוססת על ענן צמתים ההקשר-aware סמנטי באינטרנט אנליטי לעיבוד (CaseOLAP) כשיטה כריית הביטוי עבור חישוב אוטומטי של שיוך הקטגוריה הביטוי בהקשר ביו.
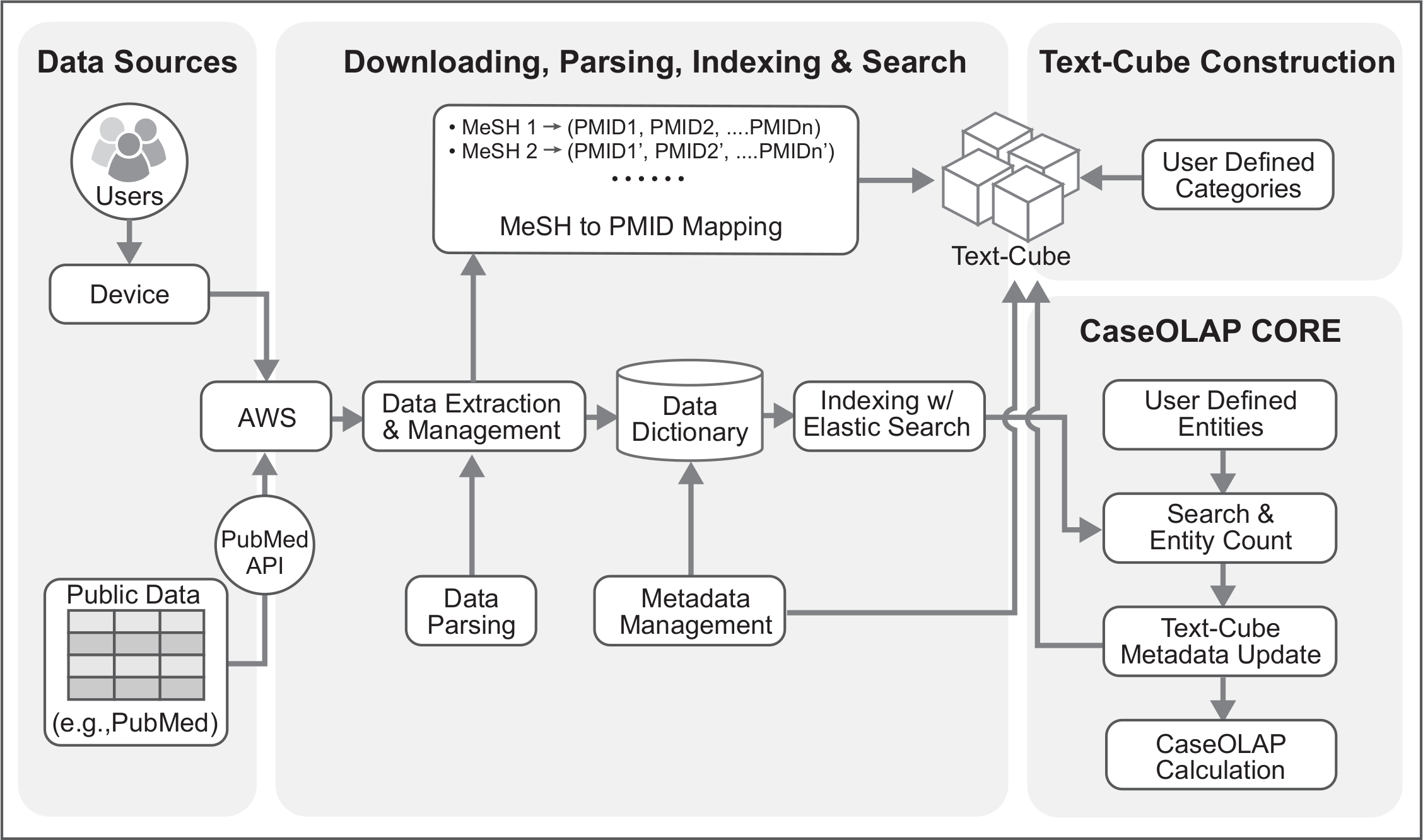
פלטפורמת CaseOLAP, שהוגדרה לראשונה בשנת 20161, היא יעילה מאוד לעומת השיטות המסורתיות של ניהול נתונים וחישוביות בגלל שלה ניהול מסמכים פונקציונלי שנקרא טקסט-קיוב2,3, 4, המשווקת את המסמכים תוך שמירה על היררכיה הבסיסית ואת השכונות. זה הוחל המחקר הביו-רפואי5 ללמוד ישות-קטגוריה האגודה. פלטפורמת CaseOLAP מורכב שישה שלבים עיקריים לרבות להורדה, מיצוי של נתונים, ניתוח, אינדקס, יצירת טקסט-קוביה, ישות ספירת חישוב הציון CaseOLAP; אשר הוא המוקד העיקרי של הפרוטוקול(איור 1, איור 2, טבלה 1).
כדי ליישם את האלגוריתם CaseOLAP, המשתמש מגדיר קטגוריות עניין (למשל, מחלות, אבחון סימנים וסימפטומים, קבוצות הגיל,) וישויות עניין (כגון: חלבונים, תרופות). דוגמה אחת של קטגוריה כלולים במאמר זה הוא 'קבוצות' אשר 'התינוק', 'הילד', 'גיל ההתבגרות', 'למבוגרים' קטגוריות משנה כתאים של טקסט-קוביה, שמות חלבון (מילים נרדפות), קיצורים כישויות. כותרות נושאים רפואיים (MeSH) מיושמים לאחזר פרסומים התואם הקטגוריות מוגדרת (טבלה 2). רשת מתארי מאורגנים במבנה עץ היררכי להתיר חיפוש עבור פרסומים שונים רמות של ירידה לפרטים (מדגם בתרשים 3). פלטפורמת CaseOLAP מנצל את הנתונים יצירת אינדקס וחיפוש הפונקציונליות עבור curation של המסמכים הקשורים עם ישות אשר להמשיך לקדם את המסמך כדי ישות ספירת מיפוי וחישוב הציון CaseOLAP.
הפרטים של חישוב הציון CaseOLAP זמין פרסומים קודמים1,5. ציון זה מחושב באמצעות קריטריונים ספציפיים הדירוג מבוסס על מבנה מסמך טקסט-קוביה. הציון הסופי הוא התוצר של שלמות, הפופולריות הייחוד. שלמות מתאר ישות נציג יחידת סמנטי אינטגרלי מתייחסת קונספט משמעותי. שלמות של הביטוי על-ידי המשתמש נלקח להיות 1.0, כי הוא עומד בתור ביטוי רגיל בספרות. הייחוד מייצג את הרלוונטיות היחסי של ביטוי בקבוצת משנה אחד מהמסמכים לעומת שאר התאים האחרים. תחילה היא מחשבת את הרלוונטיות של ישות לתא מסוים על ידי השוואת המופע של חלבון על שם ערכת הנתונים היעד ומספקת תוצאה מנורמלת הייחוד . הפופולריות מייצג למעשה את הביטוי עם ניקוד גבוה יותר פופולריות מופיע בתדירות גבוהה יותר בקבוצת משנה אחד מהמסמכים. שמות נדירים החלבון בתא מדורגים נמוך, ואילו עלייה התדר שלהם שהזכרת יש תשואה שמפחית עקב היישום של הפונקציה לוגריתמי של תדר. באופן כמותי מודדים אלה למושגים שלושה תלוי בתדר (1) לטווח של הישות מעל תא על פני תאים (2) מספר המסמכים שיש ישות זו (מסמך תדירות) בתוך התא, על-פני התאים.
למדנו שני תרחישים נציג PubMed dataset באמצעות אלגוריתם שלנו. אנו מעוניינים בחלבונים מיטוכונדריאלי איך הם קשורים לשתי קטגוריות הייחודי של רשת מתארי; "קבוצות גיל", "מחלות תזונתי". באופן ספציפי, אחזרנו פרסומים 15,728,250 מפרסומים 20 שנה שנאספו על ידי PubMed (1998 עד 2018), ביניהם, תקצירים ייחודי 8,123,458 היו מתארי רשת מלאה. בהתאם לכך, 1,842 חלבון מיטוכונדריאלי אנושי שמות (כולל ראשי תיבות, מילים נרדפות), רכשה מ- UniProt (uniprot.org) כמו גם MitoCarta2.0 (http://mitominer.mrc-mbu.cam.ac.uk/release-4.0/begin.do >), הן באופן שיטתי בחן. שלהם שיוכים אלה פרסומים 8,899,019 וישויות נחקרו באמצעות פרוטוקול שלנו; אנו נבנה קוביה-טקסט, מחושבים הציונים CaseOLAP בהתאמה.
Protocol
הערה: פיתחנו פרוטוקול זה בהתאם לשפת התכנות פייתון. כדי להפעיל תוכנית זו, יש אנקונדה פייתון ו לגית מותקנת מראש על המכשיר. הפקודות המסופקות ב פרוטוקול זה מבוססים על סביבת Unix. פרוטוקול זה מספק את הפירוט של הורדת נתונים ממסד PubMed (MEDLINE), ניתוח הנתונים והגדרת מחשוב פלטפורמה עבור הביטוי הכרייה ו כימות של האגודה ישות-הקטגוריה מוגדרת על-ידי המשתמש.
1. הגעה ההתקנה סביבת קוד ופיתון
- להוריד או לשכפל את מאגר קוד Github (https://github.com/CaseOLAP/caseolap) או על-ידי הקלדת 'לגית לשבט https://github.com/CaseOLAP/caseolap.git' בחלון המסוף.
- נווט אל הספריה 'caseolap'. זה השורש של הפרויקט. בתוך בספריה, הספריה 'נתונים' יאוכלסו עם ערכות נתונים מרובים כמו שאתה התקדמות דרך השלבים בפרוטוקול. הספריה 'קלט' היא עבור נתונים שסופקו על-ידי המשתמש. הספריה 'יומן' יש קבצי יומן רישום לצורך פתרון בעיות. הספריה 'תוצאה' היא היכן יאוחסן התוצאות הסופיות.
- שימוש בחלון המסוף, ללכת לספרייה איפה שכפלת מאגר GitHub שלנו. ליצור את הסביבה CaseOLAP באמצעות הקובץ 'environment.yml' על-ידי הקלדת "conda env ליצור -f environment.yaml' בתוך הטרמינל. ואז להפעיל את הסביבה על-ידי הקלדת 'מקור להפעיל caseolap' בתוך הטרמינל.
2. הורדת מסמכים
- ודא כי כתובת FTP 'ftp_configuration.json' בספריה config הוא זהה בסיסית שנתית או קבצי עדכון יומי הכתובת קישור, נמצאו ב הקישור (https://www.nlm.nih.gov/databases/download/pubmed_medline.html) .
- להורדת תוכנית בסיסית בלבד או עדכון בלבד, להגדיר קבצים 'true' בקובץ 'download_config.json' בספריה 'config'. כברירת מחדל, הוא מוריד, מחלץ קבצים בסיסית ו- update. מדגם של נתוני XML שחולץ ניתן לצפות ב (https://github.com/CaseOLAP/caseolap-pipelines/blob/master/data/extracted-data-sample.xml)
- הקלד 'run_download.py פייתון' בחלון המסוף להורדת התקצירים ממסד הנתונים Pubmed. פעולה זו תיצור ספריה בשם 'ftp.ncbi.nlm.nih.gov' בספריה הנוכחית. תהליך זה בודק את תקינות הנתונים שהורדו, מחלצת אותה לספריית היעד.
- ללכת לספרייה 'יומן' כדי לקרוא את ההודעות יומן ב- 'download_log.txt', למקרה תהליך ההורדה נכשל. אם התהליך הושלם בהצלחה, יודפס הודעות איתור באגים של תהליך ההורדה בקובץ יומן רישום זה.
- עם השלמת ההורדה, לנווט דרך 'ftp.ncbi.nlm.nih.gov' כדי לוודא כי אין 'updatefiles' או 'basefiles' או שתי ספריות מבוסס על להוריד את התצורה של 'download_config.json'. הנתונים הסטטיסטיים קובץ יהפכו לזמינים ב- 'filestat.txt' בספריה 'נתונים'.
3. ניתוח מסמכים
- ודא כי נתוני שהורדו שחולצו הינו זמין 'ftp.ncbi.nlm.nih.gov' מדריך של שלב 2. ספריה זו היא הספריה נתוני הקלט בשלב זה.
- כדי לשנות את הסכימה ניתוח נתונים, בחר פרמטרים בקובץ 'parsing_config.json' בספריה 'config' על-ידי הגדרת הערך שלהם כדי 'true'. כברירת מחדל, זה מנתח רמב"ם, מחברים, מופשט, רשת שינוי, מיקום, יומן, תאריך הפרסום.
- הקלד 'run_parsing.py פייתון' הטרמינל לנתח את המסמכים מקבצים שהורדו (או חילוץ). שלב זה מנתח קבצי XML שהורדת הכל ויוצר מילון פיתון עבור כל מסמך עם מפתחות (למשל., רמב"ם, מחברים, מופשט, רשת שינוי של הקובץ מבוסס על ניתוח של סכימת ההתקנה בשלב 3.2).
- סיום של ניתוח הנתונים, ודא כי נתוני שנותחה נשמרים בקובץ שנקרא 'pubmed.json' בספריה נתונים. מדגם של נתונים שנותחה הינה זמינה במלון איור 3-
- ללכת לספרייה 'יומן' כדי לקרוא את ההודעות יומן ב- 'parsing_log.txt', למקרה תהליך הניתוח נכשל. אם התהליך הושלם בהצלחה, יודפס הודעות איתור באגים בקובץ יומן הרישום.
4. רשת שינוי כדי מיפוי רמב"ם
- ודא כי הנתונים שנותחה ('pubmed.json') הינו זמין בספריה 'נתונים'.
- הקלד 'run_mesh2pmid.py פייתון' בטרמינל שיש לבצע עם רשת שינוי כדי מיפוי רמב"ם. זה יוצר טבלת מיפוי שבו כל אחד רשת השינוי אוספת PMIDs המשויך. רמב"ם יחיד יפלו תחת תנאי רשת מרובים.
- סיום המיפוי, ודא כי יש 'mesh2pmid.json' בספריה נתונים. מדגם של הנתונים הסטטיסטיים למעלה 20 מיפוי זמין בטבלה-2, דמויות 4 ו -5.
- ללכת לספרייה 'יומן' כדי לקרוא את ההודעות יומן ב- 'mesh2pmid_mapping_log.txt', אם תהליך זה נכשל. אם התהליך הושלם בהצלחה, הודעות איתור באגים של המיפוי יודפס בקובץ יומן רישום זה.
5. המסמך יצירת האינדקסים
- להוריד את היישום Elasticsearch https://www.elastic.co. ההורדה זמינה כיום, (https://www.elastic.co/downloads/elasticsearch). כדי להוריד את התוכנה בענן מרוחק, הקלד 'wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-x.x.x.tar.gz' בתוך הטרמינל. ודא כי 'x.x.x' בפקודה לעיל מוחלף על-ידי מספר הגירסה הנכונה.
- ודא שהקובץ שהורדת 'elasticsearch-x.x.x.tar.gz' מופיע בספריית הבסיס ולאחר מכן לחלץ את הקבצים על-ידי הקלדת "טאר xvzf elasticsearch-x.x.x.tar.gz' בחלון המסוף.
- פתיחת הטרמינל החדש, ללכת לספרייה סל ElasticSearch על-ידי הקלדת 'cd Elasticsearch/bin' בטרמינל מספריית הבסיס.
- להפעיל את שרת Elasticsearch על-ידי הקלדת ". / Elasticsearch' בחלון המסוף. ודא כי השרת מופעל ללא הודעות שגיאה. במקרה של שגיאה על הקמת שרת Elasticsearch, בצע את ההוראות ב (https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html).
- לשנות את התוכן הנמצא 'index_init_config.json' בספריה 'config' כדי להגדיר אינדקס חניכה. כברירת מחדל, זה יבחר נוכח כל הפריטים.
- הקלד 'run_index_init.py פייתון' הטרמינל ליזום אינדקס-מסד נתונים בשרת Elasticsearch. ערך זה מאתחל את האינדקס עם קבוצת קריטריונים המכונה אינדקס מידע (למשל, שם אינדקס, הקלד שם, מספר רסיסי, מספר העותקים המשוכפלים). תראה את ההודעה להזכיר אינדקס נוצר בהצלחה.
- בחר את הפריטים 'index_populate_config.json' בספריה 'config' על-ידי הגדרת הערך שלהם כדי 'true'. כברירת מחדל, זה יבחר נוכח כל הפריטים.
- ודא כי הנתונים שנותחה ('pubmed.json') קיים בספריה 'נתונים'.
- הקלד 'run_index_populate.py פייתון' הטרמינל כדי לאכלס את האינדקס על-ידי יצירת נתונים בצובר עם שני רכיבים. רכיב הראשון הינו מילון עם מטא-נתונים על שם אינדקס, הקלד שם, בצובר מזהה (למשל, 'רמב"ם'). A רכיב השני הוא מילון נתונים המכיל את כל המידע על התגים (למשל, 'כותרת', 'מופשט', 'רשת').
- ללכת לספרייה 'יומן' כדי לקרוא את ההודעות יומן ב- 'indexing_log.txt', אם תהליך זה נכשל. אם התהליך הושלם בהצלחה, יודפס הודעות איתור באגים של בניית אינדקס בקובץ יומן הרישום.
6. קוביות טקסט היצירה
- הורד האחרונה MeSH העץ לרשותכם (https://www.nlm.nih.gov/mesh/filelist.html). הגירסה הנוכחית של הקוד משתמש MeSH 2018 עץ כמו 'meshtree2018.bin' בספריה קלט.
- הגדר את הקטגוריות של עניין (למשל, מחלה שמות, קבוצות גיל, מין). קטגוריית עשויים לכלול מתארי רשת שינוי אחת או יותר (https://meshb-prev.nlm.nih.gov/treeView). לאסוף חתימות MeSH בקטגוריה. לשמור את שמות הקטגוריות בקובץ ה-'textcube_config.json' של הספריה config (ראה מדגם של הקטגוריה בקבוצת גיל' בגירסה שהורדת קובץ 'textcube_config.json').
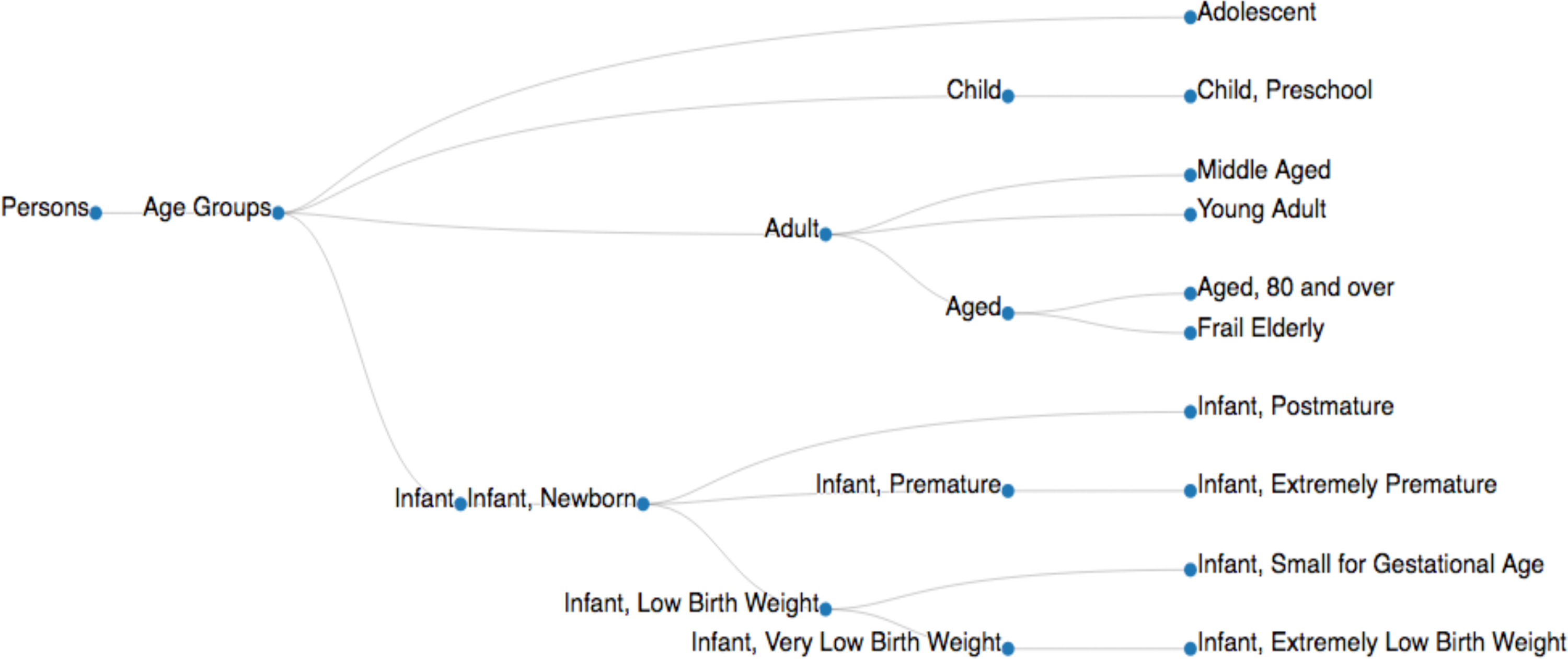
- הנח את הקטגוריות שנאספו של מזהי רשת שינוי בשורה כשהם מופרדים באמצעות רווח. שמור את הקובץ קטגוריה בשם 'categories.txt' בספריה 'קלט' (ראה מדגם של 'קבוצת גיל' רשת שינוי של מזהי גירסת שהורדת קובץ 'categories.txt'). אלגוריתם זה בוחר באופן אוטומטי כל מתארי רשת צאצא. דוגמה לצמתי בסיס צאצאים מוצגים איור 4.
- ודא כי 'mesh2pmid.json' בספריה 'נתונים'. אם העץ MeSH עודכן בשם אחר (לדוגמה, 'meashtree2019.bin') בספריית 'קלט', ודא כי זה מיוצג כראוי הנתיב נתוני הקלט בקובץ ה-'run_textube.py'.
- הקלד 'פייתון run_textcube.py' הטרמינל כדי ליצור מבנה נתונים מסמך בשם טקסט-קוביה. זה יוצר אוסף של מסמכים (PMIDs) עבור כל קטגוריה. מסמך יחיד (PMID) יפלו תחת קטגוריות מרובות, (ראה טבלה 3A, טבלה 3B, איור 6A , איור 7 א).
- עם סיום שלב יצירת טקסט-קוביה, לוודא כי קבצי הנתונים הבאים שמורים בספריה 'נתונים': (1) תאים לטבלה רמב"ם כמו"textcube_cell2pmid.json", (2) בית החולים רמב"ם לטבלה מיפוי תא כמו "textcube_pmid2cell.json", (3) אוסף של כל צאצא תנאי רשת עבור תא כמו "meshterms_per_cat.json" (4) טקסט-קוביית נתונים סטטיסטיים כמו "textcube_stat.txt".
- ללכת לספרייה 'יומן' כדי לקרוא את ההודעות יומן ב- 'textcube_log.txt', אם תהליך זה נכשל. אם התהליך הושלם בהצלחה, הודעות איתור באגים של יצירת טקסט-קוביית יודפס בקובץ יומן הרישום.
7. ישות ספירה
- ליצור ישויות על-ידי המשתמש (לדוגמה, שמות חלבון, גנים, כימיקלים). להכניס שורה אחת, מופרדים על-ידי ישות אחת וקיצורים שלה "|". שמור את הקובץ ישות בשם 'entities.txt' בספריה 'קלט'. מדגם של ישויות ניתן למצוא בטבלה 4.
- ודא כי שרת Elasticsearch הזה פועל. אחרת, עבור לשלב 5.2 ו 5.3 כדי להפעיל מחדש את השרת Elasticsearch. הוא צפוי לעשות מסד באינדקס הנקרא 'pubmed' בשרת שלך Elasticsearch שהוקמה בשלב 5.
- ודא כי 'textcube_pmid2cell.json' בספריה 'נתונים'.
- הקלד 'פייתון run_entitycount.py' הטרמינל כדי לבצע פעולת ספירה ישות. זה מחפש את המסמכים הכלולים באינדקס במסד הנתונים של סופרת את הישות בכל מסמך וכן אוסף את PMIDs שבה נמצאו ישויות.
- עם סיום הספירה ישות, ודא כי התוצאות הסופיות נשמרים 'entitycount.txt', 'entityfound_pmid2cell.json' בספריה 'נתונים'.
- ללכת לספרייה 'יומן' כדי לקרוא את ההודעות יומן ב- 'entitycount_log.txt', אם תהליך זה נכשל. אם התהליך הושלם בהצלחה, הודעות איתור באגים של הרוזן ישות יודפס בקובץ יומן הרישום.
8. עדכון מטה-נתונים
- ודא כי כל נתוני הקלט ('entitycount.txt', 'textcube_pmid2cell.json', 'entityfound_pmid2cell.txt') הן בספריה 'נתונים'. אלה הם נתוני הקלט עבור עדכון המטה-נתונים.
- הקלד 'run_metadata_update.py פייתון' הטרמינל כדי לעדכן את המטה-נתונים. זה מכין אוסף של מטה-נתונים (למשל, תא שם, רשת משויכים, PMIDs) המייצג כל מסמך טקסט בתא. מדגם של טקסט-הקוביה מטה מוצג בטבלה 3A ו- טבלה 3B.
- עם סיום העדכון מטה-נתונים, ודא כי 'metadata_pmid2pcount.json' ו- 'metadata_cell2pmid.json' קבצים שמורים בספריה 'נתונים'.
- ללכת לספרייה 'יומן' כדי לקרוא את ההודעות יומן ב- 'metadata_update_log.txt', אם תהליך זה נכשל. אם התהליך הושלם בהצלחה, יודפס הודעות איתור באגים של העדכון מטה-נתונים בקובץ יומן הרישום.
9. חישוב הציון CaseOLAP
- ודא כי קבצי 'metadata_pmid2pcount.json' ו- 'metadata_cell2pmid.json' נמצאים בספריה 'נתונים'. אלה הם נתוני הקלט לחישוב הציון.
- הקלד 'run_caseolap_score.py פייתון' הטרמינל כדי לבצע חישוב הניקוד CaseOLAP. זה מחשב את התוצאה CaseOLAP של ישויות בהתבסס על קטגוריות על-ידי המשתמש. התוצאה CaseOLAP הוא התוצר של שלמות, הפופולריות הייחוד.
- עם סיום חישוב הציון, ודא כי זה חוסך את התוצאות של קבצים מרובים (למשל, פופולריות כמו 'pop.csv', את הייחוד כמו 'dist.csv', CaseOLAP ניקוד כמו 'caseolap.csv'), בספריה 'תוצאה'. התקציר של חישוב הציון CaseOLAP מוצג גם טבלה 5.
- ללכת לספרייה 'יומן' כדי לקרוא את ההודעות יומן ב- 'caseolap_score_log.txt', אם תהליך זה נכשל. אם התהליך הושלם בהצלחה, יודפס הודעות איתור באגים של חישוב הציון CaseOLAP בקובץ יומן הרישום.
תוצאות
כדי להפיק תוצאות המדגם, אנחנו מיושם האלגוריתם CaseOLAP נושא שתי כותרות/מתארי: "קבוצות הגיל" ומחלות "תזונתי ואת חילוף החומרים" כפי מקרי שימוש.
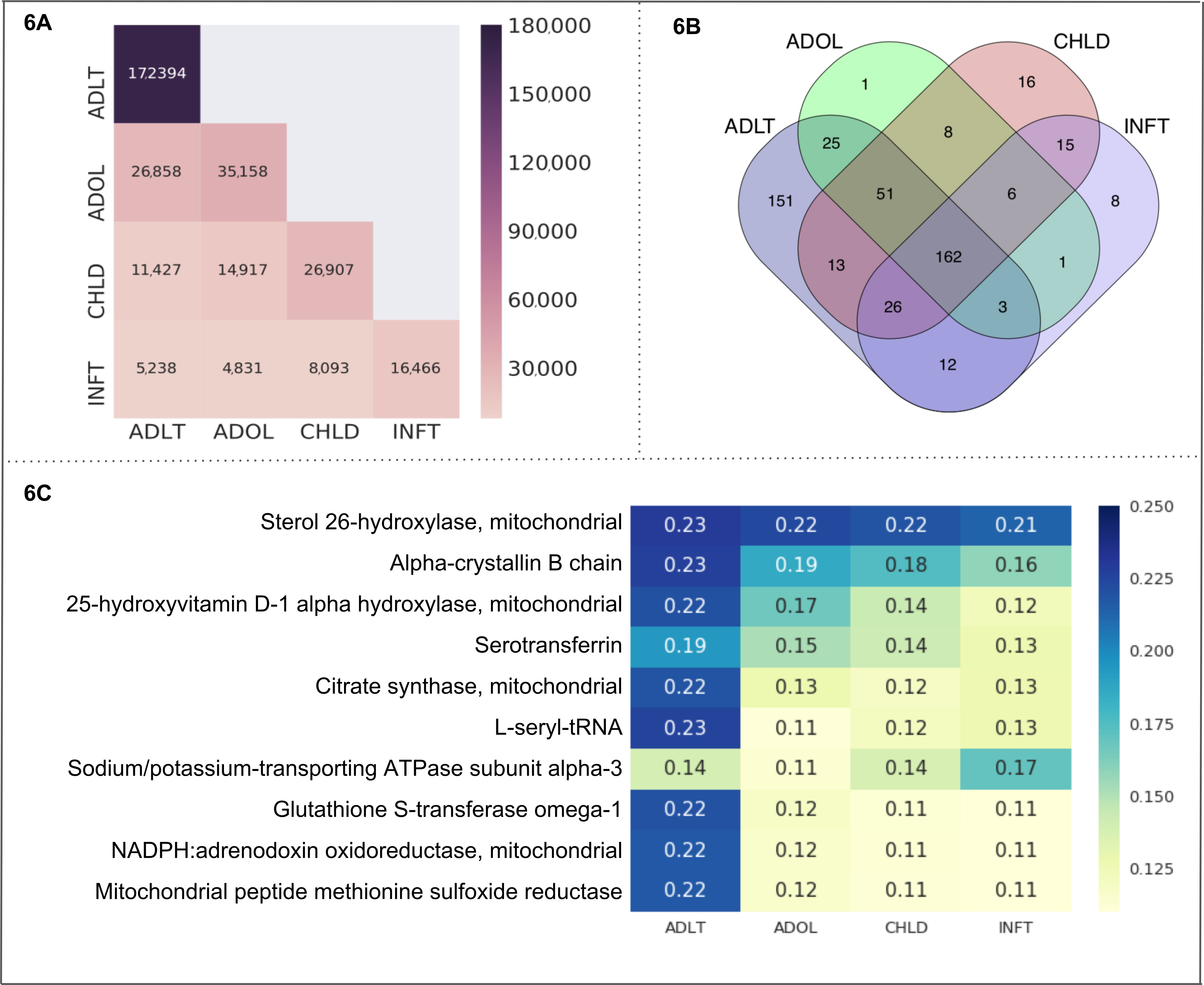
קבוצות הגיל. בחרנו כל 4 תתי-קטגוריות של "קבוצות גיל" (התינוק, הילד, מתבגרים ומבוגרים) כתאים בקוביה של טקסט. שהושג מטא-נתונים וסטטיסטיקות מוצגים בטבלה 3A. ההשוואה של מספר מסמכים בין התאים קוביות טקסט מוצג באיור 6A. מבוגר מכיל מסמכים 172,394 וזה המספר הגבוה ביותר על פני כל התאים. קטגוריות מבוגרים, מתבגרים יש את המספר הגבוה ביותר של מסמכים משותפים (26,858 מסמכים). ראוי לציין, מסמכים אלה כללו את הישות שלנו הריבית בלבד (קרי, מיטוכונדריאלי חלבונים). דיאגרמת ון ב- 6B איור מייצג את מספר ישויות (קרי, מיטוכונדריאלי חלבונים) נמצאו בתוך כל תא, ובתוך מספר חפיפות בין התאים. המספר של חלבונים משותפים בתוך כל הקטגוריות קבוצות הגיל הוא 162. קטגוריית המשנה למבוגרים מתאר המספר הגבוה ביותר של חלבונים ייחודיים (151) ולאחריו הילד (16), התינוק (8) ונוער (1). אנחנו מחושב האגודה קבוצה חלבון-גיל כמו ניקוד CaseOLAP. חלבונים העליון 10 (מבוסס על הציון הממוצע שלהם CaseOLAP) המשויך קטגוריות משנה של התינוק, הילד, המתבגר, מבוגרים הם סטרול 26-hydroxylase, שרשרת B אלפא-crystallin, 25-hydroxyvitamin D-1 אלפא-hydroxylase, Serotransferrin, ציטרט סינתאז. L-seryl-tRNA, ATPase נתרן/אשלגן-הובלת יחידה משנית אלפא-3 גלוטתיון S-טרנספראז אומגה-1, nadph ל: adrenodoxin oxidoreductase, פפטיד מיטוכונדריאלי מתיונין סולפוקסיד רדוקטאז (מוצג ב- 6C איור). קטגוריית המשנה למבוגרים מציג 10 תאים heatmap בעוצמה גבוהה יותר לעומת התאים heatmap של המתבגר, הילדה הפעוטה קטגוריית משנה, המציין החלבונים מיטוכונדריאלי העליון 10 בנספח החזק ביותר השיוכים קטגוריית המשנה למבוגרים. חלבון מיטוכונדריאלי סטרול 26-hydroxylase יש עמותות גבוהה בכל הקטגוריות גיל אשר מומחש heatmap תאים עם עוצמות גבוהות יותר לעומת תאי heatmap של החלבונים מיטוכונדריאלי 9 אחרים. התפלגות סטטיסטית של ההבדל מוחלטת ציון בין שתי קבוצות מציג את הטווח הבאים להבדל מרושע עם בר-סמך 99%: (1) ההבדל הממוצע בין 'ADLT' 'INFT' טמון הטווח (0.029 כדי 0.042), (2) הממוצע ההבדל טמון הטווח (0.021 כדי 0.030), (3) 'ADLT' ו- 'קיד' לבין 'ADLT' אומר ושקרים 'עידן אראל' בטווח (0.020 כדי 0.029), (4) לבין שקרים 'עידן אראל' ו- 'INFT' בטווח (0.015 כדי 0.022), (5) כלומר ההבדל מרושע בין 'עידן אראל' 'קיד' שוכן בטווח (0.007 כדי 0.010), (6) רשע לבין שקרים 'קיד' ו- 'INFT' בטווח (0.011 כדי 0.016).
תזונה ומחלות מטבוליות- בחרנו 2 קטגוריות משנה של "תזונתי מטבוליות ומחלות" (קרי, מחלות מטבוליות, הפרעות תזונה) ליצירת תאים 2 בקוביה של טקסט. שהושג מטא-נתונים וסטטיסטיקות מוצגים בטבלה 3B. ההשוואה של מספר מסמכים בין התאים קוביות טקסט מוצג איור 7 א. המחלה המטבולית קטגוריית משנה מכיל מסמכים 54,762 ואחריו מסמכים 19,181 בהפרעות תזונתי. קטגוריות משנה של מחלות מטבוליות והפרעות תזונתיים יש 7,101 במסמכים משותפים. ראוי לציין, מסמכים אלה כללו את הישות שלנו הריבית בלבד (קרי, מיטוכונדריאלי חלבונים). דיאגרמת ון ב 7 ב איור מייצג את מספר ישויות נמצאו בתוך כל תא, ובתוך מספר חפיפות בין התאים. אנחנו מחושב חלבון-"תזונתי ומחלות מטבוליות" האגודה כמו ניקוד CaseOLAP. חלבונים העליון 10 (מבוסס על הציון הממוצע שלהם CaseOLAP) המשויך זה מקרה שימוש הם סטרול 26-hydroxylase, אלפא-crystallin B שרשרת, L-seryl-tRNA, ציטרט סינתאז, tRNA pseudouridine סינתאז A, אלפא D-1 25-hydroxyvitamin-hydroxylase, גלוטתיון S-טרנספראז אומגה-1, nadph ל: adrenodoxin oxidoreductase, פפטיד מיטוכונדריאלי מתיונין סולפוקסיד רדוקטאז, Plasminogen activator מעכב 1 (מוצג באיור 7C). יותר ממחצית (54 אחוז) של כל החלבונים משותפים בין קטגוריות משנה במחלות מטבוליות והפרעות תזונתי (חלבונים 397). מעניין לציין, כמעט מחצית (43%) חלבונים הקשורים כולם את קטגוריית המשנה מחלה מטבולית הם ייחודיים (חלבונים 300), ואילו הפרעות תזונה מוצג רק כמה ייחודי חלבונים (35). שרשרת B אלפא-crystallin מציגה את הקשר החזק ביותר למחלות מטבוליות קטגוריית משנה. סטרול 26-hydroxylase, מיטוכונדריאלי מציגה את הקשר החזק ביותר את קטגוריית המשנה של הפרעות תזונתיות, המציינת כי חלבון מיטוכונדריאלי זה מאוד רלוונטי מחקרים המתארים הפרעות תזונה. ההתפלגות הסטטיסטית של ההבדל מוחלטת ציון בין שתי קבוצות 'מבד' 'NTD' מציג את הטווח (0.046 כדי 0.061) את ההבדל מרושע כמו בר-סמך 99%.

איור 1. תצוגה דינאמית של זרימת העבודה CaseOLAP. הדמות הזו מייצגת את 5 שלבים עיקריים בתהליך העבודה CaseOLAP. בשלב 1, זרימת העבודה מתחיל הורדה וחילוץ טקסטואליים מסמכים (למשל, PubMed). בשלב 2, נותחו הנתונים שחולצו כדי ליצור מילון נתונים עבור כל מסמך, כמו גם רשת שינוי כדי מיפוי רמב"ם. בשלב 3, יצירת האינדקסים הנתונים מבוצע כדי להקל על חיפוש מהיר ויעיל ישות. בשלב 4, יישום של מידע שסופק על-ידי המשתמש קטגוריה (למשל., שורש רשת עבור כל תא) מבוצע כדי לבנות קוביית הטקסט. בשלב 5, מתבצעת פעולת ספירה ישות על נתוני מדד לחישוב הציונים CaseOLAP. שלבים אלה חוזרים על עצמם בצורה איטרטיבית כדי לעדכן את המערכת עם המידע העדכני ביותר הזמינות במסד נתונים לציבור (למשל, PubMed). אנא לחץ כאן כדי להציג גירסה גדולה יותר של הדמות הזאת.
{kind=link}

באיור 2. ארכיטקטורה טכני של זרימת העבודה CaseOLAP. הדמות הזו מייצגת את הפרטים הטכניים של זרימת העבודה CaseOLAP. נתונים מהמאגר PubMed מתקבלים מן שרת ה-PubMed FTP. המשתמש מתחבר לשרת הענן (למשל, קישוריות AWS) באמצעות המכשיר שלהם ויוצר קו צינור הורדה הורדות, מחלץ את הנתונים ולמאגר המקומית בענן הצמתים. הנתונים שחולצו הם מובנים, לאמת, הביא לתבנית הנכונה עם צינור של ניתוח נתונים. במקביל, רשת שינוי בטבלת מיפוי רמב"ם נוצר במהלך השלב הניתוח, אשר משמש לבניית קוביות טקסט. שנותחה נתונים מאוחסנים של JSON כמו מפתח-ערך במילון תבנית עם מטא-נתונים (למשל, רמב"ם, רשת, שנת הוצאה). הצעד אינדקס נוסף משפר את הנתונים על-ידי יישום Elasticsearch להתמודד עם נתונים בצובר. בשלב הבא, הטקסט-קוביית נוצר עם קטגוריות על-ידי המשתמש על-ידי יישום רשת שינוי כדי מיפוי רמב"ם. לאחר השלמת טקסט-קוביית היווצרות והשלבים אינדקס, ספירה ישות מתנהל. ישות ספירת נתונים מוטמעים המטא-נתונים טקסט-קוביה. בסופו של דבר, התוצאה CaseOLAP מחושב בהתבסס על המבנה הבסיסי של טקסט-קוביה. אנא לחץ כאן כדי להציג גירסה גדולה יותר של הדמות הזאת.
{kind=link}

איור 3. דגימה של מסמך שנותחה. מדגם של נתונים שנותחה מוצג באיור זה. הנתונים שנותחה מסודרים כמו זוג מפתח-ערך אשר תואמת יצירת מטא-נתונים אינדקס במסמך. באיור זה רמב"ם (למשל," 25896987") הוא מרצה כמפתח, איסוף מידע המשויך (למשל, כותרת, יומן, פרסום תאריך, מופשט, רשת, חומרים, מחלקת ומיקום) כערך. היישום הראשון של כזה מטא-נתונים הוא הקמת רשת שינוי כדי רמב"ם מיפוי (איור 5 ו לטבלה 2), המיושמת מאוחר יותר כדי ליצור את הקוביה-הטקסט וכדי לחשב את הציון CaseOLAP עם ישויות שסופק על-ידי המשתמש, קטגוריות. אנא לחץ כאן כדי להציג גירסה גדולה יותר של הדמות הזאת.
{kind=link}

באיור 4. דגימה של עץ רשת. של הקבוצות 'גיל רשת עץ הוא ממאמרו של מבנה עץ נתונים זמינים במסד הנתונים NIH (MeSH העצים 2018, < https://meshb.nlm.nih.gov/treeView>). רשת מתארי מיושמים עם צומת שלהם מזהים (למשל, אנשים [M01], קבוצות גיל [M01.060], המתבגר [M01.060.057], מבוגר [M01.060.116], הילד [M01.060.406], התינוק [M01.060.703]) כדי לאסוף את המסמכים הרלוונטיים מתאר רשת ספציפיות ( טבלה 3 א). אנא לחץ כאן כדי להציג גירסה גדולה יותר של הדמות הזאת.
{kind=link}

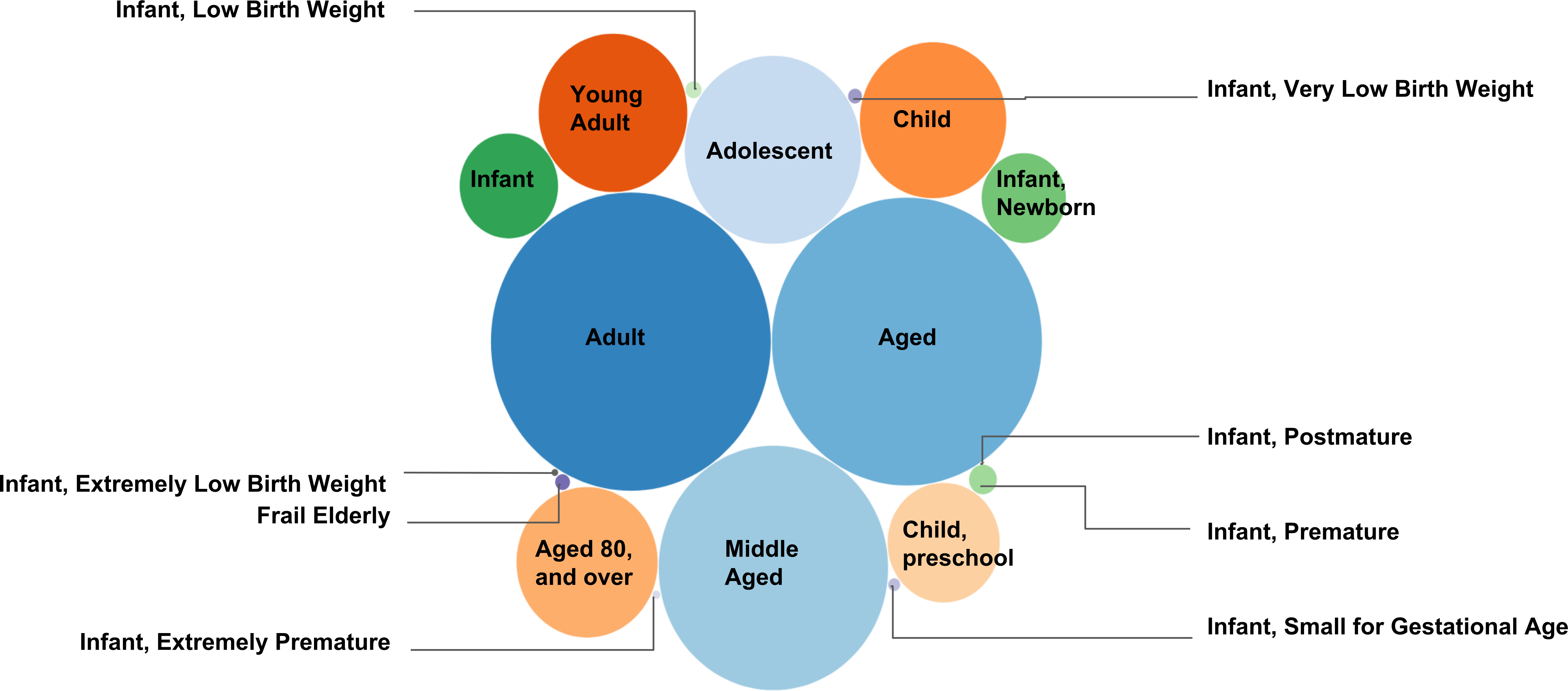
איור 5. רשת שינוי כדי מיפוי רמב"ם קבוצות הגיל. איור זה מציג את מספר מסמכי טקסט (אחד מקושר עם רמב"ם) שנגבו תחת מתארי רשת"קבוצות הגיל"כמו מגרש בועה. רשת השינוי רמב"ם ממיפוי ל נוצר כדי לספק את המספר המדויק של מסמכים שנאספו תחת מתארי רשת. המספר הכולל של מסמכים ייחודי 3,062,143 נאספו תחת מתארי 18 רשת צאצא (ראה טבלה 2). גבוה יותר מספר PMIDs הנבחר תחת מתאר רשת מסוים, גדול יותר הרדיוס של הבועה המייצג את מתאר רשת. למשל, המספר הגבוה ביותר של מסמכים שנאספו תחת מתאר רשת "מבוגרים" (מסמכים 1,786,371), ואילו המספר הנמוך ביותר של מסמכי טקסט נאספו תחת מתאר רשת "יינג, Postmature" (62 מסמכים).
דוגמא נוספת של רשת מיפוי רמב"ם ניתנת על"תזונה מטבוליות ומחלות"(https://caseolap.github.io/mesh2pmid-mapping/bubble/meta.html). המספר הכולל של מסמכים ייחודי 422,039 נאספו תחת מתארי רשת צאצא 361 ב- "תזונה מטבוליות ומחלות". המספר הגבוה ביותר של מסמכים שנאספו תחת מתאר רשת "השמנה" (מסמכים 77,881) ואחריו "סוכרת, סוג 2" (61,901 מסמכים), ואילו "מחלת אגירת גליקוגן, הקלד השמיני" הציג את המספר הנמוך ביותר של מסמכים (מסמך 1 ). טבלה קשורה זמין גם באינטרנט (https://github.com/CaseOLAP/mesh2pmid-mapping/blob/master/data/diseaseall.csv). אנא לחץ כאן כדי להציג גירסה גדולה יותר של הדמות הזאת.
{kind=link}

איור 6. "קבוצות גיל" כמו מקרה שימוש. איור זה מציג את התוצאות של מקרה שימוש של פלטפורמת CaseOLAP. במקרה זה, שמות חלבון וקיצורים שלהם (ראה לדוגמה בטבלה4) מיושמות כאובייקטי ישויות, "קבוצות הגיל" כולל את התאים: התינוק (INFT), הילד (ראסל), המתבגר (עידן אראל), מבוגר (ADLT), מיושמות כקטגוריות (ראה טבלה 3 א). (א) מספר המסמכים "קבוצות הגיל": המפה הזו חום מראה מספר המסמכים מופץ על-פני התאים של "קבוצות בגילאים" (לפירוט על טקסט-קוביית הבריאה ראה פרוטוקול 4 ועל השולחן 3A). מספר גבוה יותר של מסמכים מוצגים כהה יותר עוצמת heatmap התא (ראה את קנה המידה). מסמך יחיד עשוי להיכלל בתא אחד או יותר. Heatmap מציג מספר המסמכים בתוך תא לאורך המיקום אלכסוני (למשל, ADLT מכיל מסמכים 172,394 וזה המספר הגבוה ביותר על פני כל התאים). המיקום nondiagonal מייצג את מספר המסמכים נופל תחת שני תאים (למשל, ADLT, עידן אראל יש במסמכים משותפים 26,858). (B) . ישות ספירת "קבוצות הגיל": דיאגרמת מייצג את מספר חלבונים הנמצאים בארבעת התאים המייצגים "קבוצות גיל" (INFT, ראסל, עידן אראל ו ADLT). המספר של חלבונים משותפים בתוך כל התאים הוא 162. בקבוצת הגיל ADLT מתאר את המספר הגבוה ביותר של חלבונים ייחודיים (151) ואחריה ראסל (16), INFT (8), עידן אראל (1). (ג) CaseOLAP מצגת הציון "קבוצות הגיל": החלבונים 10 העליון עם הציונים CaseOLAP הממוצע הגבוה ביותר בכל קבוצה מוצגים במפה חום. ניקוד גבוה יותר CaseOLAP מוצג עם עוצמת heatmap כהה יותר תא (ראה את קנה המידה). שמות חלבון מוצגים בעמודה הימנית, התאים (INFT, ראסל, עידן אראל, ADLT) מוצגות לאורך ציר ה-x. חלבונים מסוימים להראות קשר חזק כדי לקבוצת גיל מסוימת (למשל, סטרול 26-hydroxylase, שרשרת B אלפא-crystallin, L-seryl-tRNA יש אסוציאציות חזקות עם ADLT, ואילו ATPase נתרן/אשלגן-הובלת יחידה משנית אלפא 3 יש קשר חזק עם INFT). אנא לחץ כאן כדי להציג גירסה גדולה יותר של הדמות הזאת.
{kind=link}

איור 7. "תזונתי ומחלות מטבוליות" בתור מקרה שימוש: איור זה מציג את התוצאות מחקירה שימוש אחרת של פלטפורמת CaseOLAP. במקרה זה, שמות חלבון וקיצורים שלהם (ראה לדוגמה בטבלה4) מיושמות כאובייקטי ישויות, "התזונה ואת חילוף החומרים מחלת" כולל את שני התאים: מחלות מטבוליות (מבד) והפרעות תזונתי (NTD) מיושמות כאובייקטי קטגוריות משנה (ראה טבלה 3B). (א). מספר מסמכים ב- "תזונה מטבוליות ומחלות": heatmap זו מתארת את מספר מסמכי טקסט בתאים של "התזונה מטבוליות ומחלות" (לקבלת פרטים על יצירת טקסט-קוביית ראה פרוטוקול 4 ו- טבלה 3B ). מספר גבוה יותר של מסמכים מוצגים כהה יותר עוצמת heatmap התא (ראו סולם). מסמך יחיד עשוי להיכלל בתא אחד או יותר. Heatmap מציג את המספר הכולל של מסמכים בתוך תא לאורך המיקום אלכסוני (למשל, מבד מכיל מסמכים 54,762 וזה המספר הגבוה ביותר על-פני התאים שני). המיקום nondiagonal מייצג את מספר מסמכים המשותפים את שני התאים (למשל, מבד, NTD יש 7,101 במסמכים משותפים). (B). ישות רוזן ב "תזונתי מטבוליות ומחלות": דיאגרמת מייצג את מספר חלבונים הנמצאים את שני התאים המייצגים "תזונתי מטבוליות ומחלות" (מבד ו- NTD). המספר של חלבונים משותפים בתוך התאים שני הוא 397. התא מבד מתארת 300 חלבונים ייחודיים, ומתאר התא NTD 35 חלבונים ייחודיים. (ג). CaseOLAP מצגת הציון ב- "תזונה מטבוליות ומחלות": החלבונים העליון 10 עם הציונים CaseOLAP הממוצע הגבוה ביותר ב- "תזונה מטבוליות ומחלות" מוצגים במפה חום. ניקוד גבוה יותר CaseOLAP מוצג עם עוצמת heatmap כהה יותר תא (ראה סולם). שמות חלבון מוצגים בעמודה הימנית, תאים (מבד ו- NTD) מוצגות לאורך ציר ה-x. חלבונים מסוימים להראות קשר חזק לקטגוריה מחלות ספציפיות (למשל, אלפא-crystallin B שרשרת יש אגודה גבוהה עם מחלה מטבולית ויש סטרול 26-hydroxylase אגודה גבוהה עם הפרעות תזונה). אנא לחץ כאן כדי להציג גירסה גדולה יותר של הדמות הזאת.
{kind=link}
| הזמן המושקע (אחוז מהזמן סה כ) | צעדים ברציף CaseOLAP | אלגוריתם ומבנה נתונים של פלטפורמת CaseOLAP | המורכבות של אלגוריתם ומבנה נתונים | פרטים על המדרגות |
| 40% | הורדת ו ניתוח | איטראציה ועץ של ניתוח אלגוריתמים | איטראציה עם לולאה מקוננת וכפל קבוע: O(n^2), O (log n). איפה רול הוא לא של חזרות. | הצינור והורדת מבצע איטראציה של כל הליך על קבצים מרובים. ניתוח מבנה טקסט של מסמך יחיד פועל כל הליך על עץ מבנה של נתוני XML גולמיים. |
| 30% | יצירת אינדקס, חיפוש ויצירת טקסט קוביה | איטראציה, אלגוריתמי החיפוש על-ידי Elasticsearch (מיון, אינדקס ' לוקנה ', תורים, מכונות המדינה סופיים, קצת twiddling פריצות, שאילתות regex של האימות) | המורכבות הקשורה Elasticsearch (https://www.elastic.co/) | המסמכים הכלולים באינדקס על-ידי יישום תהליך איטרציה על מילון הנתונים. יצירת טקסט-קוביית מיישמת המסמך מטה-נתונים ומידע קטגוריה שסופק על-ידי המשתמש. |
| 30% | ישות ספירת וחישוב CaseOLAP | איטראציה של שלמות, הפופולריות, חישוב הייחוד | O(1), O(n^2), המורכבות מרובים הקשורים caseOLAP חישוב הציון מבוסס על סוגי איטראציה. | פעולת הספירה ישות מפרט את המסמכים ולעשות פעולת ספירה על הרשימה. הנתונים ספירת הישות משמשת לחישוב הציון CaseOLAP. |
טבלה 1. אלגוריתמים, המורכבות. השולחן הזה מציג מידע על הזמן המושקע (אחוזי הזמן הכולל) על ההליכים (למשל, הורדה, ניתוח), מבנה נתונים ופרטים אודות האלגוריתמים מיושמים ברציף CaseOLAP. CaseOLAP מיישמת את יצירת האינדקסים המקצועיים ואת יישום חיפוש בשם Elasticsearch. ניתן למצוא פרטים נוספים על המורכבות הקשורה Elasticsearch ואלגוריתמים פנימי-(https://www.elastic.co).
| רשת מתארי | מספר של PMIDs אסף |
| מבוגר | 1,786,371 |
| בגיל העמידה | 1,661,882 |
| בגילאי | 1,198,778 |
| המתבגר | 706,429 |
| למבוגרים צעירים | 486,259 |
| הילד | 480,218 |
| בני, 80, ומעל | 453,348 |
| ילדתי, גן | 285,183 |
| התינוק | 218,242 |
| הפעוט הרך הנולד | 160,702 |
| תינוקות, מוקדם מדי | 17,701 |
| משקל לידה תינוקות, נמוך | 5,707 |
| קשישים שבריריים | 4,811 |
| משקל לידה תינוקות, נמוך מאוד | 4,458 |
| יינג, קטן לגיל ההיריון | 3,168 |
| תינוקות, מאוד מוקדמת | 1,171 |
| משקל לידה תינוקות, נמוך מאוד | 1,003 |
| תינוקות, Postmature | 62 |
בטבלה 2. רשת שינוי לנתוני מיפוי רמב"ם. השולחן הזה מציג כל מתארי צאצא של רשת "קבוצות גיל", שלהם מספר שנאספו PMIDs (מסמכי טקסט). החזיית נתונים אלה מוצג באיור5.
| A | התינוק (INFT) | הילד (קיד) | המתבגר (עידן אראל) | מבוגר (ADLT) |
| זיהוי שורש רשת | M01.060.703 | M01.060.406 | M01.060.057 | M01.060.116 |
| מספר מתארי רשת צאצא | 9 | 2 | 1 | 6 |
| מספר PMIDs נבחר | 16,466 | 26,907 | 35,158 | 172,394 |
| מספר ישויות נמצאו | 233 | 297 | 257 | 443 |
| B | מחלות מטבוליות (מבד) | הפרעות תזונה (NTD) | ||
| זיהוי שורש רשת | C18.452 | C18.654 | ||
| מספר רשת צאצא מתארי | 308 | 53 | ||
| אספתי מספר PMIDs | 54,762 | 19,181 | ||
| מספר ישויות נמצאו | 697 | 432 |
בטבלה 3. טקסט-הקוביה מטה-נתונים. תצוגה טבלאית של מטה-נתונים טקסט-הקוביה מוצג. הטבלאות לספק מידע על הקטגוריות, רשת שינוי מתאר שורשים, צאצאים, אשר מיושמות כדי לאסוף את המסמכים בכל תא. הטבלה מספקת גם את הסטטיסטיקה של מסמכים שנאספו, ישויות. (א) "קבוצות הגיל": זוהי תצוגה טבלאית של "קבוצות הגיל" כולל התינוק (INFT), הילד (ראסל), המתבגר (עידן אראל) של מבוגר (ADLT) ומצאתי את שורש הבעיה של רשת תעודות זהות, מספר מתארי רשת צאצא, מספר PMIDs שנבחרו ואת מספר ישויות. (B) "תזונה מטבוליות ומחלות": זוהי תצוגה טבלאית של "התזונה מטבוליות ומחלות" כולל מחלות מטבוליות (מבד) והפרעות תזונתי (NTD) עם רשת שינוי שלהם שורש תעודות זהות, מספר מתארי רשת צאצא, מספר PMIDs שנבחרו ואת המספר של ישויות שנמצאו.
| חלבון שמות, מילים נרדפות | קיצורים |
| N-acetylglutamate סינתאז, מיטוכונדריאלי, חומצת אמינו acetyltransferase, N-acetylglutamate סינתאז תבנית ארוכה; N-acetylglutamate סינתאז טופס קצר; N-acetylglutamate סינתאז והתפאורה תחום טופס] | (EC 2.3.1.1) |
| חלבון/nucleic חומצה deglycase DJ-1 (Maillard deglycase) (אונקוגן DJ1) (חלבון מחלת פרקינסון 7) (Parkinsonism-הקשורים deglycase) (חלבון DJ-1) | (EC 3.1.2.-) (EC 3.5.1.-) (EC 3.5.1.124) (DJ-1) |
| פירובט קרבוקסילאז מיטוכונדריאלי (Pyruvic קרבוקסילאז) | (EC 6.4.1.1) (PCB) |
| רכיב Bcl-2-איגוד 3 (p53 מוסדר למעלה אפנן של אפופטוזיס) | (JFY-1) |
| אינטראקציה BH3 תחום המוות אגוניסט [אינטראקציה BH3 תחום המוות אגוניסט p15 (הצעת מחיר p15); אינטראקציה BH3 תחום המוות אגוניסט p13; אינטראקציה BH3 תחום המוות אגוניסט p11] | (p22 הצעת מחיר) (הצעת מחיר) (p13 הצעת מחיר) (p11 הצעת מחיר) |
| ATP סינתאז יחידה משנית, אלפא מיטוכונדריאלי (ATP סינתאז F1 יחידה משנית אלפא) | |
| ציטוכרום P450 11B2, מיטוכונדריאלי (סינתאז אלדוסטרון) (אנזים סינתזה-אלדוסטרון) (CYPXIB2) (ציטוכרום P-450Aldo) (ציטוכרום P-450_C_18) (18 סטרואידים-hydroxylase) | (ALDOS) (EC 1.14.15.4) (EC 1.14.15.5) |
| 60 kDa חום הלם חלבון, מיטוכונדריאלי (kDa 60 שפרון) (60 שפרון) (CPN60) (חום הלם חלבון 60) (מיטוכונדריאלי מטריקס חלבון P1) (P60 לימפוציט חלבון) | (HSP-60) (Hsp60) (HuCHA60) (EC 3.6.4.9) |
| קספאז-4 (קרח, סיד-3 homolog 2) (פרוטאז TX) [ביקע לתוך: יחידה משנית קספאז-4 1; יחידת משנה קספאז-4 2] | (CASP-4) (EC 3.4.22.57) (ICH-2) (ICE(rel)-II) (Mih1) |
בטבלה 4. לטעום שולחן ישות. טבלה זו מציגה המדגם של ישויות מיושם במקרים שימוש שני שלנו: "קבוצות הגיל" ו- "תזונה מטבוליות ומחלות" (איור 6 ו 7 איור, טבלה 3A,B). הישויות כוללים חלבון שמות, מילים נרדפות, קיצורים. כל ישות (עם מילים נרדפות, קיצורים) אחד נבחר, הוא עבר מבצע חיפוש ישות בנתונים הכלולים באינדקס (ראה פרוטוקול 3 ו- 5). החיפוש מפיק רשימה של מסמכים, אשר להמשיך לקדם את פעולת הספירה ישות.
| כמויות | המשתמש הגדיר | החישוב | המשוואה של הכמות | המשמעות של הכמות |
| שלמות | כן | לא | שלמות של המשתמש מוגדרת על ידי ישויות נחשבת 1.0. | מייצג ביטוי משמעותי. הערך המספרי הוא 1.0 כאשר זה כבר ביטוי הוקמה. |
| הפופולריות | לא | כן | משוואת הפופולריות באיור 1 (זרימת עבודה, אלגוריתם) מהפניית 5, סעיף 'חומרים ושיטות'. | מבוסס על המונח תדר של הביטוי בתוך תא. מנורמל מאת סה כ המונח תדר של התא. עלייה המונח תדר יש צמצום תוצאה. |
| הייחוד | לא | כן | משוואת הייחוד באיור 1 (זרימת עבודה, אלגוריתם) מהפניית 5, סעיף 'חומרים ושיטות'. | מבוסס על המונח תדר התדירות המסמך בתוך תא על-פני התאים הסמוכים. מנורמל מאת מונח הכולל תדירות ותדירות המסמך. באופן כמותי, זה ההסתברות כי צירוף מילים ייחודי בתא מסוים. |
| CaseOLAP ציון | לא | כן | CaseOLAP ציון משוואת באיור 1 (זרימת עבודה, אלגוריתם) מהפניית 5, סעיף 'חומרים ושיטות'. | מבוסס על תקינות, פופולריות, הייחוד. הערך המספרי תמיד נופל בתוך 0 ל- 1. באופן כמותי הציון CaseOLAP מייצג את העמותה הביטוי-קטגוריה |
טבלה 5. משוואות CaseOLAP: CaseOLAP אלגוריתם פותח על ידי Fangbo טאו, Jiawei האן ואח ב 20161. בקצרה, השולחן הזה מציג את חישוב הציון CaseOLAP בהיקף של שלושה מרכיבים: שלמות, הפופולריות, ואת הייחוד ומשמעות שלהם הקשורים מתמטית. המקרים השימוש שלנו, התוצאה שלמות חלבונים היא 1.0 (את הציון המקסימלי) כי הם עומדים כשמות ישות הוקמה. ניתן לראות הציונים CaseOLAP במקרים שלנו השתמש ב- 6C איור , איור 7C.
Discussion
הראו כי האלגוריתם CaseOLAP יכולים ליצור אגודה כמותיים הביטוי מבוסס על קטגוריה מבוססת ידע על כמויות גדולות של נתונים טקסטואליים עבור הפקת תובנות משמעותיות. בעקבות הפרוטוקול שלנו אחד יכול לבנות את המסגרת CaseOLAP כדי ליצור קוביה-הטקסט הרצוי ולכמת ישות-קטגוריה שיוכים באמצעות חישוב הניקוד CaseOLAP. ציוני הגלם שהושג CaseOLAP שניתן לנקוט כדי ניתוח אינטגרטיבי כולל הפחתת dimensionality, קיבוץ באשכולות, זמני וניתוח גיאוגרפי, וכן על הקמת מסד נתונים גרפיים המאפשרת מיפוי סמנטי של המסמכים.
הישימות של אלגוריתם ה- דוגמאות של ישויות על-ידי המשתמש, מלבד חלבונים, יכול להיות רשימה של שמות ג'ין, סמים, סימנים ספציפיים, סימפטומים כולל שלהם קיצורים, מילים נרדפות. יתר על כן, קיימות אפשרויות רבות לבחירת קטגוריה להקל על ספציפיים על-ידי המשתמש ביו ניתוחים (למשל, אנטומיה [A], משמעת, הכיבוש [H], התופעות והתהליכים [G]). שלנו שני מקרי השימוש, כל הפרסומים המדעיים והנתונים טקסטואליים מאוחזרות ממסד הנתונים של MEDLINE באמצעות PubMed כמו מנוע החיפוש, שניהם מנוהל על ידי הספריה הלאומית של הרפואה. עם זאת, ניתן להחיל את הפלטפורמה CaseOLAP למסדי נתונים אחרים של עניין המכיל מסמכים ביו עם נתונים טקסטואליים כמו ה-FDA שלילית האירוע דיווח מערכת (FAERS). זהו בסיס נתונים פתוח המכיל מידע על אירועים קשים רפואי, דוחות שגיאה תרופות ל- FDA. בניגוד MEDLINE, FAERS, מסדי נתונים בבתי חולים המכיל רשומות אלקטרוניות בריאות מחולים לא פתוח לציבור, מוגבלים על ידי ביטוח בריאות הטלטלות דין וחשבון המעשה הידוע בשם HIPAA.
CaseOLAP אלגוריתם הוחלה בהצלחה על סוגים שונים של נתונים (למשל, מאמרי חדשות)1. מימוש אלגוריתם זה במסמכים ביו הפך בשנת 20185. הדרישות הישימות של אלגוריתם CaseOLAP הוא כל אחד מהמסמכים להקצותם עם מילות המפתח המשויך המושגים (למשל, רשת מתארי בפרסומים ביו, מילות מפתח במאמרים חדשות). אם לא נמצאו מילות מפתח, אפשר לייחס Autophrase6,,7 , כדי לאסוף את ביטויים הנציגה העליונה ולבנות את הרשימה ישות לפני יישום פרוטוקול שלנו. פרוטוקול שלנו אינו מספק את הצעד כדי לבצע Autophrase.
השוואה עם אלגוריתמים אחרים. כבר מתפתח המושג באמצעות נתונים-קוביה8,9,10 ו-3,2,4 קוביות טקסט מאז 2005 עם הפיתוחים החדשים כדי להפוך כריית מידע רלוונטי יותר. הרעיון של עיבוד אנליטי מקוון (OLAP)11,12,13,14,15 כריית מידע ומודיעין עסקי חוזר עד 1993. OLAP, באופן כללי, אגרגטים את המידע במערכות מרובות, ומאחסן אותה בתבנית רב-מימדי. ישנם סוגים שונים של מערכות OLAP מיושם כריית נתונים. כך למשל עיבוד טרנזקציות/האנליטי (1) היברידית (HTAP)16,17, OLAP רב-ממדי (MOLAP) (2)18,19-קוביית OLAP יחסיים (ROLAP) בסיס, ו- (3)20.
באופן ספציפי, האלגוריתם CaseOLAP הושוותה עם אלגוריתמים רבים הקיימים, באופן ספציפי, עם שיפורים פילוח הביטוי שלהם, כולל TF-צה ל + Seg, MCX + Seg, MCX ו- SegPhrase. יתר על כן, RepPhrase (RP, הידוע גם בשם SegPhrase +) הושוותה עם וריאציות אבלציה משלו, כולל RP (1) בלי המדד שלמות שולבו (RP לא INT), (2) RP ללא מדד הפופולריות שולבו (RP לא פופ) ו- (3) RP בלי הייחוד מדד משולב (RP לא דיס). תוצאות בחינת ביצועים מוצגות במחקר על-ידי Fangbo טאו ואח '1.
יש עדיין אתגרים על כריית מידע אשר יכול להוסיף פונקציונליות נוספת על שמירה של מאחזר את הנתונים ממסד הנתונים. מודעות הקשר סמנטי אנליטי לעיבוד (CaseOLAP) מיישם באופן שיטתי את Elasticsearch כדי לבנות מסד נתונים יצירת אינדקס של מיליוני מסמכים (5 לפרוטוקול). הקוביה-הטקסט הוא מבנה המסמך בנתונים הכלולים באינדקס עם קטגוריות שסופק על-ידי המשתמש (6 לפרוטוקול). זה משפר את הפונקציונליות על מסמכי בתוך ועל -פני התא של הקוביה הטקסט, מאפשרות לנו לחשב את המונח תדר של הישויות מעל המסמך מסמך תדירות מעל תא מסוים (8 לפרוטוקול). הניקוד הסופי CaseOLAP מנצל חישובים אלה בתדר פלט ציון סופי (9 לפרוטוקול). ב 2018, נוכל ליישם אלגוריתם זה ללמוד ECM חלבונים ומחלות לב 6 כדי לנתח עמותות חלבון-מחלה. ניתן למצוא את הפרטים של מחקר זה במחקר על ידי Liem, התובע המחוזי ואח '5. המציין כי CaseOLAP יכול להיות בשימוש נרחב הקהילה הביו-רפואית חקר מגוון של מחלות, מנגנונים.
מגבלות של האלגוריתם. כריית הביטוי עצמו היא טכניקה לניהול של מושגים חשובים לאחזר נתונים טקסטואליים. תוך גילוי ישות הקטגוריה שיוך להוסיף1כמו כמות מתמטית (וקטורית), טכניקה זו אין אפשרות להבין את הקוטביות (למשל, הנטייה חיובי או שלילי) של האגודה. אחד יכול לבנות את סיכום כמותי של נתוני שימוש במבנה המסמך הטקסט-Cude עם ישויות שהוקצו, קטגוריות, אך לא ניתן להשיג תפיסה איכותי עם granularities מיקרוסקופיים. כמה מושגים מתפתחים באופן רציף מן העבר עד עכשיו. סיכום מוצג עבור שיוך ישות-קטגוריה ספציפית כולל מקרים כל ברחבי הספרות. זה אולי חוסר התפשטות הטמפורלי של החידוש. בעתיד, אנו מתכננים לפנות מגבלות אלה.
יישומים עתידיים. כ 90% מהמידע שנצבר בעולם נמצא נתוני הטקסט לא מובנים. מציאת של הביטוי נציג והקשר הישויות המוטבעים בטקסט היא משימה חשובה מאוד עבור היישום של טכנולוגיות חדשות (למשל, האינטליגנציה המלאכותית של למידה חישובית, שאיבת מידע,). כדי להפוך את נתוני הטקסט מכונה לקריא, הנתונים צריך להיות מאורגנים במסד הנתונים שעליהם ניתן ליישום השכבה הבאה של כלים. בעתיד, אלגוריתם זה יכול להיות צעד מכריע בהפיכת כריית נתונים יותר פונקציונלי דליית מידע, כימות של השיוכים ישות-קטגוריה.
Disclosures
המחברים אין לחשוף.
Acknowledgements
עבודה זו נתמכת באופן חלקי על ידי הלאומי ללב, ריאות ודם המכון: R35 HL135772 (כדי פינג פ); לאומי כללי לרפואה למדעי: U54 GM114833 (כדי פינג פ ק ווטסון, וואנג ו); U54 GM114838 (כדי ג'יי האן); מתנה של אויגן & קרן הוג. לארי, ד ר ס סטי; התרומה T.C. Laubisch ב UCLA (כדי פינג עמ').
Materials
| Name | Company | Catalog Number | Comments |
References
- Tao, F., Zhuang, H., et al. Phrase-Based Summarization in Text Cubes. IEEE Data Engineering Bulletin. , 74-84 (2016).
- Ding, B., Zhao, B., Lin, C. X., Han, J., Zhai, C. TopCells: Keyword-based search of top-k aggregated documents in text cube. IEEE 26th International Conference on Data Engineering (ICDE). , 381-384 (2010).
- Ding, B., et al. Efficient Keyword-Based Search for Top-K Cells in Text Cube. IEEE Transactions on Knowledge and Data Engineering. 23 (12), 1795-1810 (2011).
- Liu, X., et al. A Text Cube Approach to Human, Social and Cultural Behavior in the Twitter Stream.Social Computing, Behavioral-Cultural Modeling and Prediction. Lecture Notes in Computer Science. 7812, (2013).
- Liem, D. A., et al. Phrase Mining of Textual Data to analyze extracellular matrix protein patterns across cardiovascular disease. American Journal of Physiology-Heart and Circulatory. , (2018).
- Shang, J., et al. Automated Phrase Mining from Massive Text Corpora. IEEE Transactions on Knowledge and Data Engineering. 30 (10), 1825-1837 (2018).
- Liu, J., Shang, J., Wang, C., Ren, X., Han, J. Mining Quality Phrases from Massive Text Corpora. Proceedings ACM-Sigmod International Conference on Management of Data. , 1729-1744 (2015).
- Lee, S., Kim, N., Kim, J. A Multi-dimensional Analysis and Data Cube for Unstructured Text and Social Media. IEEE Fourth International Conference on Big Data and Cloud Computing. , 761-764 (2014).
- Lin, C. X., Ding, B., Han, J., Zhu, F., Zhao, B. Text Cube: Computing IR Measures for Multidimensional Text Database Analysis. IEEE Data Mining. , 905-910 (2008).
- Hsu, W. J., Lu, Y., Lee, Z. Q. Accelerating Topic Exploration of Multi-Dimensional Documents Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE International. , 1520-1527 (2017).
- Chaudhuri, S., Dayal, U. An overview of data warehousing and OLAP technology. SIGMOD Record. 26 (1), 65-74 (1997).
- Ravat, F., Teste, O., Tournier, R. Olap aggregation function for textual data warehouse. ICEIS - 9th International Conference on Enterprise Information Systems, Proceedings. , 151-156 (2007).
- Ho, C. T., Agrawal, R., Megiddo, N., Srikant, R. Range Queries in OLAP Data Cubes. SIGMOD Conference. , (1997).
- Saxena, V., Pratap, A. Olap Cube Representation for Object- Oriented Database. International Journal of Software Engineering & Applications. 3 (2), (2012).
- Maniatis, A. S., Vassiliadis, P., Skiadopoulos, S., Vassiliou, Y. Advanced visualization for OLAP. DOLAP. , (2003).
- Bog, A. . Benchmarking Transaction and Analytical Processing Systems: The Creation of a Mixed Workload Benchmark and its Application. , 7-13 (2013).
- Özcan, F., Tian, Y., Tözün, P. Hybrid Transactional/Analytical Processing: A Survey. In Proceedings of the ACM International Conference on Management of Data (SIGMOD). , 1771-1775 (2017).
- Hasan, K. M. A., Tsuji, T., Higuchi, K. An Efficient Implementation for MOLAP Basic Data Structure and Its Evaluation. International Conference on Database Systems for Advanced Applications. , 288-299 (2007).
- Nantajeewarawat, E. Advances in Databases: Concepts, Systems and Applications. DASFAA 2007. Lecture Notes in Computer Science. 4443, (2007).
- Shimada, T., Tsuji, T., Higuchi, K. A storage scheme for multidimensional data alleviating dimension dependency. Third International Conference on Digital Information Management. , 662-668 (2007).
Reprints and Permissions
Request permission to reuse the text or figures of this JoVE article
Request PermissionExplore More Articles
This article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. All rights reserved