
Method Article
Frase di Cloud-Based Mining e analisi dell'associazione di categoria-frase definita dall'utente in pubblicazioni biomediche
* Questi autori hanno contribuito in egual misura
In questo articolo
Riepilogo
Vi presentiamo un protocollo e codice di programmazione associato, nonché esempi di metadati per supportare un'identificazione automatizzata basata su cloud dell'associazione di categoria di frasi che rappresentano concetti unici nel dominio selezionato conoscenza utente nella letteratura biomedica. L'associazione di frase-categoria quantificata dal presente protocollo può facilitare un'analisi approfondita del dominio di conoscenza selezionato.
Abstract
Il rapido accumulo di dati testuali biomedicali ha superato la capacità umana di curatela manuale e analisi, che richiedono nuovi strumenti di text mining per estrarre intuizioni biologiche da grandi volumi di relazioni scientifiche. La pipeline di Context-aware semantico Online Analytical Processing (CaseOLAP), sviluppata nel 2016, quantifica con successo relazioni di frase-categoria definita dall'utente attraverso l'analisi dei dati testuali. CaseOLAP ha molte applicazioni biomediche.
Abbiamo sviluppato un protocollo per un ambiente basato su cloud supporta la-to-end frase-estrazione mineraria e la piattaforma di analisi. Il nostro protocollo include dati di pre-elaborazione (ad esempio, scaricare, l'estrazione e l'analisi di documenti di testo), indicizzazione e ricerca con Elasticsearch, creazione di una struttura funzionale documento chiamato testo-Cube e quantificare le relazioni frase-categoria utilizzando l'algoritmo di CaseOLAP di nucleo.
I nostri dati di pre-elaborazione genera mapping di chiave-valore per tutti i documenti interessati. I dati pre-elaborati vengono indicizzati per effettuare una ricerca dei documenti, comprese le persone giuridiche, che facilita ulteriormente la creazione di testo-cubo e calcolo del Punteggio di CaseOLAP. I punteggi grezzi ottenuti di CaseOLAP vengono interpretati utilizzando una serie di analisi integrative, compresa la riduzione della dimensionalità, clustering, temporale e analisi geografiche. Inoltre, i punteggi di CaseOLAP vengono utilizzati per creare un database grafico, che consente il mapping semantico dei documenti.
CaseOLAP definisce la frase-categoria relazioni in modo accurato (identifica relazioni), coerente (altamente riproducibili) e in modo efficiente (processi 100.000 parole/sec). A seguito di questo protocollo, gli utenti possono accedere un ambiente di cloud computing per supportare le proprie configurazioni e applicazioni di CaseOLAP. Questa piattaforma offre una maggiore accessibilità e autorizza la comunità biomedica con strumenti di frase-mining applications diffusa ricerca biomedica.
Introduzione
Valutazione manuale di milioni di file di testo per lo studio dell'associazione frase-categoria (ad es.., età gruppo all'associazione di proteine) è incomparabile con l'efficienza fornita da un metodo di calcolo automatico. Vogliamo introdurre la piattaforma di cloud-based Context-aware semantico Online Analytical Processing (CaseOLAP) come un metodo di frase-minerario per calcolo automatico dell'associazione di categoria di frase in ambito biomedico.
La piattaforma CaseOLAP, che è stata definita in primo luogo nel 20161, è molto efficiente rispetto ai metodi tradizionali di gestione dei dati e calcolo a causa della sua gestione funzionale documento chiamato testo-Cube2,3, 4, che distribuisce i documenti pur mantenendo la sottostante gerarchia e quartieri. È stato applicato nella ricerca biomedica5 per studiare entità-categoria associazione. La piattaforma CaseOLAP è costituito da sei passaggi principali, tra cui download ed estrazione di dati, l'analisi, indicizzazione, creazione del testo-cubo, conteggio delle entità e calcolo di Punteggio CaseOLAP; che è l'obiettivo principale del protocollo (Figura 1, figura 2, tabella 1).
Per implementare l'algoritmo di CaseOLAP, l'utente imposta la categoria di interesse (ad es., malattia, segni e sintomi, fasce d'età, diagnosi) e le entità di interesse (ad es., proteine, farmaci). Un esempio di una categoria inclusa in questo articolo è il 'Età', che ha 'Neonato', 'bambino', 'adolescenziale', e 'adulte' sottocategorie come celle di testo-cubo e proteina nomi (sinonimi) e abbreviazioni come entità. Medical Subject Headings (MeSH) vengono implementati per recuperare le pubblicazioni corrispondenti alle categorie definite (tabella 2). Descrittori di maglia sono organizzati in una struttura gerarchica ad albero per consentire la ricerca di pubblicazioni a diversi livelli di specificità (un esempio è mostrato nella Figura 3). La piattaforma CaseOLAP utilizza la funzionalità di indicizzazione e ricerca di dati per la curatela dei documenti associati a un'entità che favoriscano ulteriormente documento di mapping di entità conteggio e calcolo del Punteggio di CaseOLAP.
I dettagli del calcolo punteggio CaseOLAP è disponibile in precedenti pubblicazioni1,5. Questo punteggio viene calcolato utilizzando i criteri di classificazione specifico basati sulla struttura di documento di testo-cubo sottostante. Il Punteggio finale è il prodotto di integrità, la popolaritàe carattere distintivo. L'integrità descrive se un'entità rappresentativa è un'unità integrale semantica che collettivamente si riferisce ad un concetto significativo. L' integrità della frase definita dall'utente viene considerato come 1.0 perché si erge come una frase standard nella letteratura. Carattere distintivo rappresenta l'importanza relativa di una frase in un sottoinsieme di documenti rispetto al resto delle altre cellule. Prima calcola la pertinenza di un'entità a una cella specifica confrontando l'occorrenza del nome della proteina nel set di dati di destinazione e fornisce un punteggio normalizzato di carattere distintivo . Popolarità rappresenta il fatto che la frase con un punteggio più alto gradimento compare più frequentemente in un sottoinsieme di documenti. Nomi di proteina rara in una cella vengono classificati in basso, mentre un aumento della loro frequenza di menzione ha un ritorno diminuzione grazie all'implementazione della funzione logaritmica di frequenza. Questi tre concetti di misura quantitativamente dipende dalla frequenza (1) termine dell'entità su una cella e tra le cellule e (2) numero di documenti aventi tale entità (frequenza documento) all'interno della cellula e attraverso le cellule.
Abbiamo studiato due scenari rappresentativi utilizzando un set di dati di PubMed e il nostro algoritmo. Siamo interessati in proteine mitocondriali come sono associati due categorie univoche dei descrittori MeSH; "Età" e "malattie nutrizionali e metaboliche". In particolare, abbiamo recuperato 15,728,250 pubblicazioni da pubblicazioni di 20 anni raccolti da PubMed (1998 a 2018), fra loro, 8.123.458 unici estratti hanno avuto completo maglia descrittori. Di conseguenza, 1.842 proteina mitocondriale umana nomi (abbreviazioni e sinonimi), acquistati da UniProt (http://www.UniProt.org/) come pure da MitoCarta2.0 (http://mitominer.mrc-mbu.cam.ac.uk/release-4.0/begin.do >), sono sistematicamente esaminato. Loro associazioni con questi 8.899.019 pubblicazioni ed entità sono stati studiati usando il nostro protocollo; Abbiamo costruito un testo-cubo e calcolati i rispettivi punteggi di CaseOLAP.
Protocollo
Nota: Abbiamo sviluppato questo protocollo basato su linguaggio di programmazione Python. Per eseguire questo programma, che Anaconda Python e Git pre-installato sul dispositivo. I comandi forniti in questo protocollo sono basati sull'ambiente Unix. Questo protocollo fornisce il dettaglio di download di dati dal database di PubMed (MEDLINE), l'analisi dei dati e creazione di una piattaforma di cloud computing per il data mining frase e la quantificazione dell'associazione di categoria-entità definita dall'utente.
1. ottenere installazione ambiente codice e python
- Scarica o clonare il repository di codice da Github (https://github.com/CaseOLAP/caseolap) oppure digitando 'git clone https://github.com/CaseOLAP/caseolap.git' nella finestra del terminale.
- Spostarsi nella directory 'caseolap'. Questa è la directory radice del progetto. All'interno di questa directory, la directory 'dati' verrà popolata con più insiemi di dati come lei progressi attraverso questi passaggi nel protocollo. La directory 'input' è per i dati forniti dall'utente. La directory 'log' ha i file di registro per la risoluzione dei problemi. La directory 'risultato' è dove verranno archiviati i risultati finali.
- Utilizzando la finestra di terminale, passare alla directory dove hai clonato il nostro repository di GitHub. Creare l'ambiente di CaseOLAP utilizzando il file 'environment.yml' digitando 'conda env creare -f environment.yaml' nel terminale. Quindi attivare l'ambiente digitando 'origine attivare caseolap' nel terminale.
2. download di documenti
- Assicurarsi che l'indirizzo FTP in 'ftp_configuration.json' nella directory config è lo stesso come indirizzo del collegamento previsione annuale o i file di aggiornamento quotidiano, trovata il link (https://www.nlm.nih.gov/databases/download/pubmed_medline.html) .
- Per scaricare la previsione solo o aggiornamento file impostato solo, 'true' nel file 'download_config.json' nella directory 'config'. Per impostazione predefinita, Scarica ed estrae file della linea di base e di aggiornamento. Un campione di dati estratti XML può essere visionato a (https://github.com/CaseOLAP/caseolap-pipelines/blob/master/data/extracted-data-sample.xml)
- Digitare 'run_download.py python' nella finestra del terminale per scaricare estratti dal database di Pubmed. Questo creerà una directory chiamata 'ftp.ncbi.nlm.nih.gov' nella directory corrente. Questo processo controlla l'integrità dei dati scaricati e gli estratti nella directory di destinazione.
- Vai alla directory 'log' a leggere i messaggi di log in 'download_log.txt' nel caso in cui il processo di download non riesce. Se il processo viene completato correttamente, i messaggi di debug del processo di download verranno stampati in questo file di registro.
- Quando il download è completo, navigare attraverso 'ftp.ncbi.nlm.nih.gov' per assicurarsi che ci sia 'updatefiles' o 'basefiles' o entrambe le directory basate su Scarica configurazione in 'download_config.json'. Le statistiche del file diventano disponibili a 'filestat.txt' nella directory 'dati'.
3. l'analisi di documenti
- Assicurarsi che i dati scaricati ed estratti sono disponibili nella directory 'ftp.ncbi.nlm.nih.gov' dal passaggio 2. Questa è la directory di dati di input in questo passaggio.
- Per modificare lo schema di analisi di dati, è necessario selezionare i parametri nel file 'parsing_config.json' nella directory 'config' impostando il valore su 'true'. Per impostazione predefinita, viene analizzata la PMID, autori, abstract, MeSH, posizione, journal, data di pubblicazione.
- Digitare 'run_parsing.py python' nel terminale per analizzare i documenti inviati da file scaricati (o estratti). Questo passaggio analizza tutti scaricati i file XML e crea un dizionario di python per ogni documento con chiavi (ad es.., PMID, autori, astratto, MeSH del file basato su analisi installazione dello schema al punto 3.2).
- Una volta completata l'analisi dei dati, assicurarsi che i dati analizzati viene salvati nel file chiamato 'pubmed.json' nella directory dei dati. Un campione di dati analizzati è disponibile presso Figura 3.
- Vai alla directory 'log' a leggere i messaggi di log in 'parsing_log.txt' nel caso in cui il processo di analisi ha esito negativo. Se il processo viene completato correttamente, i messaggi di debug verranno stampati nel file di registro.
4. mesh al mapping PMID
- Assicurarsi che i dati analizzati ('pubmed.json') sono disponibili presso la directory 'dati'.
- Digitare 'run_mesh2pmid.py python' nel terminale per eseguire MeSH al mapping PMID. Questo crea una tabella di mapping dove ciascuno della MeSH raccoglie PMIDs associato. Un singolo PMID potrebbe cadere sotto i termini della maglia più.
- Una volta completata la mappatura, assicurarsi che ci sia 'mesh2pmid.json' nella directory dei dati. Un esempio delle statistiche mappatura top 20 è disponibile in tabella 2, Figura 4 e 5.
- Vai alla directory 'log' a leggere i messaggi di log in 'mesh2pmid_mapping_log.txt' nel caso in cui questo processo ha esito negativo. Se il processo viene completato correttamente, i messaggi di debug del mapping verranno stampati in questo file di registro.
5. documento di indicizzazione
- Scaricare l'applicazione Elasticsearch da https://www.elastic.co. Attualmente, il download è disponibile presso (https://www.elastic.co/downloads/elasticsearch). Per scaricare il software nel cloud remoto, digitare 'wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-x.x.x.tar.gz' nel terminale. Assicurarsi che 'x.x.x' nel comando precedente viene sostituita dal numero di versione corretto.
- Assicurarsi che il file scaricato 'elasticsearch-x.x.x.tar.gz' visualizzato nella directory principale, quindi estrarre i file digitando 'tar xvzf elasticsearch-0.5 ' nella finestra del terminale.
- Aprite un terminale e passare alla directory bin ElasticSearch digitando 'cd Elasticsearch/bin' nel terminale dalla directory principale.
- Avviare il server Elasticsearch digitando '. / Elasticsearch' nella finestra del terminale. Assicurarsi che il server è avviato senza messaggi di errore. In caso di errore su avvio Elasticsearch server, seguire le istruzioni a (https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html).
- Modificare il contenuto in 'index_init_config.json' nella directory 'config' per impostare l'inizio indice. Per impostazione predefinita, verranno selezionate tutte le voci presenti.
- Digitare 'run_index_init.py python' nel terminale per avviare un database di indice nel server Elasticsearch. Questo Inizializza l'indice con una serie di criteri noto come indice informazioni (ad es., nome indice, digitare il nome, numero di frammenti, numero di repliche). Si vedrà il messaggio di menzionare l'indice viene creato correttamente.
- Selezionare gli elementi in 'index_populate_config.json' nella directory 'config' impostando il valore su 'true'. Per impostazione predefinita, verranno selezionate tutte le voci presenti.
- Assicurarsi che i dati analizzati ('pubmed.json') sono presenti nella directory 'dati'.
- Digitare 'run_index_populate.py python' nel terminale per popolare l'indice con la creazione di dati per operazioni bulk con due componenti. Un primo componente è un dizionario con metadati informazioni sul nome indice, digitare il nome e l' Identificativo di massa (ad es., 'PMID'). A secondo componente è un dizionario di dati contenente tutte le informazioni sui tag (ad es., 'title', 'astratta', 'Maglia').
- Vai alla directory 'log' a leggere i messaggi di log in 'indexing_log.txt' nel caso in cui questo processo ha esito negativo. Se il processo viene completato correttamente, i messaggi di debug dell'indicizzazione verranno stampati nel file di registro.
6. creazione di testo-cubi
- Scarica l'ultimo albero MeSH disponibili presso (https://www.nlm.nih.gov/mesh/filelist.html). La versione corrente del codice utilizza MeSH Tree 2018 come 'meshtree2018.bin' nella directory di input.
- Definire le categorie di interesse (ad esempio, nomi di malattia, fasce di età, sesso). Una categoria può includere uno o più descrittori MeSH (https://meshb-prev.nlm.nih.gov/treeView). Raccogliere gli ID MeSH per una categoria. Salvare i nomi delle categorie nel file 'textcube_config.json' nella directory config (Vedi un campione della categoria in 'Età' nella versione scaricata del file 'textcube_config.json').
- Mettere le categorie raccolte di MeSH ID in una riga separata da uno spazio. Salvare il file di categoria come 'categories.txt' nella directory 'input' (vedere un esempio di 'Età' MeSH ID nella versione scaricata del file 'categories.txt'). Questo algoritmo seleziona automaticamente tutti i descrittori MeSH discendenti. Un esempio di nodi radice e discendenti sono presentati in Figura 4.
- Assicurarsi che 'mesh2pmid.json' sia nella directory 'dati'. Se l'albero della maglia è stato aggiornato con un nome diverso (ad es., 'meashtree2019.bin') nella directory 'input', assicurarsi che questo sia correttamente rappresentato nel percorso dati di input nel file 'run_textube.py'.
- Digitare 'run_textcube.py python' nel terminale per creare una struttura di dati documento chiamata testo-cubo. Questo crea una raccolta di documenti (PMIDs) per ogni categoria. Un unico documento (PMID) può rientrare in più categorie, (vedere tabella 3A, 3B tabella, Figura 6A e figura 7A).
- Una volta completato il passaggio della creazione di testo-Cube, assicurarsi che i seguenti file di dati vengono salvati nella directory 'dati': (1) una cella di tabella PMID come "textcube_cell2pmid.json", (2) un PMID alla tabella di mapping di cella come "textcube_pmid2cell.json", (3) un raccolta di termini tutti i discendenti della maglia per una cella come "meshterms_per_cat.json" (4) le statistiche di dati di testo-cubo come "textcube_stat.txt".
- Vai alla directory 'log' a leggere i messaggi di log in 'textcube_log.txt' nel caso in cui questo processo ha esito negativo. Se il processo viene completato correttamente, i messaggi di debug della creazione testo-cubo verranno stampati nel file di registro.
7. conteggio entità
- Creare entità definite dall'utente (ad esempio, nomi di proteina, geni, prodotti chimici). Mettere un soggetto e sue abbreviazioni in una singola riga, separata da "|". Salvare il file di entità come 'entities.txt' nella directory 'input'. Un esempio di entità è reperibile tabella 4.
- Assicurarsi che Elasticsearch il server è in esecuzione. In caso contrario, andare al punto 5.2 e 5.3 per riavviare il server Elasticsearch. Si prevede di avere un database indicizzato chiamato 'pubmed' nel tuo server di Elasticsearch che è stato istituito nel passaggio 5.
- Assicurarsi che 'textcube_pmid2cell.json' sia nella directory 'dati'.
- Digitare 'run_entitycount.py python' nel terminale per eseguire operazione di conteggio delle entità. Questo cerca i documenti dal database indicizzato e conta l'entità in ogni documento nonché raccoglie il PMIDs in cui le entità sono state trovate.
- Una volta completato il conteggio delle entità, assicurarsi che i risultati finali vengono salvati come 'entitycount.txt' e 'entityfound_pmid2cell.json' nella directory 'dati'.
- Vai alla directory 'log' a leggere i messaggi di log in 'entitycount_log.txt' nel caso in cui questo processo ha esito negativo. Se il processo viene completato correttamente, i messaggi di debug del conteggio entità verranno stampati nel file di registro.
8. metadati aggiornamento
- Assicurarsi che tutti i dati di input ('entitycount.txt', 'textcube_pmid2cell.json', 'entityfound_pmid2cell.txt') si trovano nella directory 'dati'. Questi sono i dati di input per l'aggiornamento dei metadati.
- Digitare 'run_metadata_update.py python' nel terminale per aggiornare i metadati. Questo prepara un insieme di metadati (ad es., nome di cella, MeSH associata, PMIDs) che rappresenta ogni documento di testo nella cella. Un esempio di testo-Cube metadati è presentato in tabella 3A e tabella 3B.
- Una volta completato l'aggiornamento dei metadati, assicurarsi che il file 'metadata_pmid2pcount.json' e 'metadata_cell2pmid.json' vengono salvati nella directory 'dati'.
- Vai alla directory 'log' a leggere i messaggi di log in 'metadata_update_log.txt' nel caso in cui questo processo ha esito negativo. Se il processo viene completato correttamente, i messaggi di debug dell'aggiornamento metadati verranno stampati nel file di registro.
9. CaseOLAP conteggio dei punti
- Assicurarsi che siano presenti nella directory 'dati' file 'metadata_pmid2pcount.json' e 'metadata_cell2pmid.json'. Questi sono i dati di input per il calcolo del punteggio.
- Digitare 'run_caseolap_score.py python' nel terminale per eseguire il calcolo del Punteggio di CaseOLAP. Questo calcola il Punteggio di CaseOLAP dell'entità in base alle categorie definite dall'utente. Il Punteggio di CaseOLAP è il prodotto di integrità, la popolaritàe carattere distintivo.
- Una volta completato il calcolo del punteggio, assicurarsi che questo Salva i risultati in più file (ad esempio, la popolarità come 'pop.csv', carattere distintivo come 'dist.csv', CaseOLAP Punteggio come 'caseolap.csv'), nella directory 'risultato'. Il riepilogo del calcolo di Punteggio di CaseOLAP inoltre è presentato nella tabella 5.
- Vai alla directory 'log' a leggere i messaggi di log in 'caseolap_score_log.txt' nel caso in cui questo processo ha esito negativo. Se il processo viene completato correttamente, i messaggi di debug del calcolo punteggio CaseOLAP verranno stampati nel file di registro.
Risultati
Per produrre i risultati dei campioni, abbiamo implementato l'algoritmo di CaseOLAP in due rubriche/descrittori di soggetto: "Età" e "Nutrizionali e malattie del metabolismo" come casi di utilizzo.
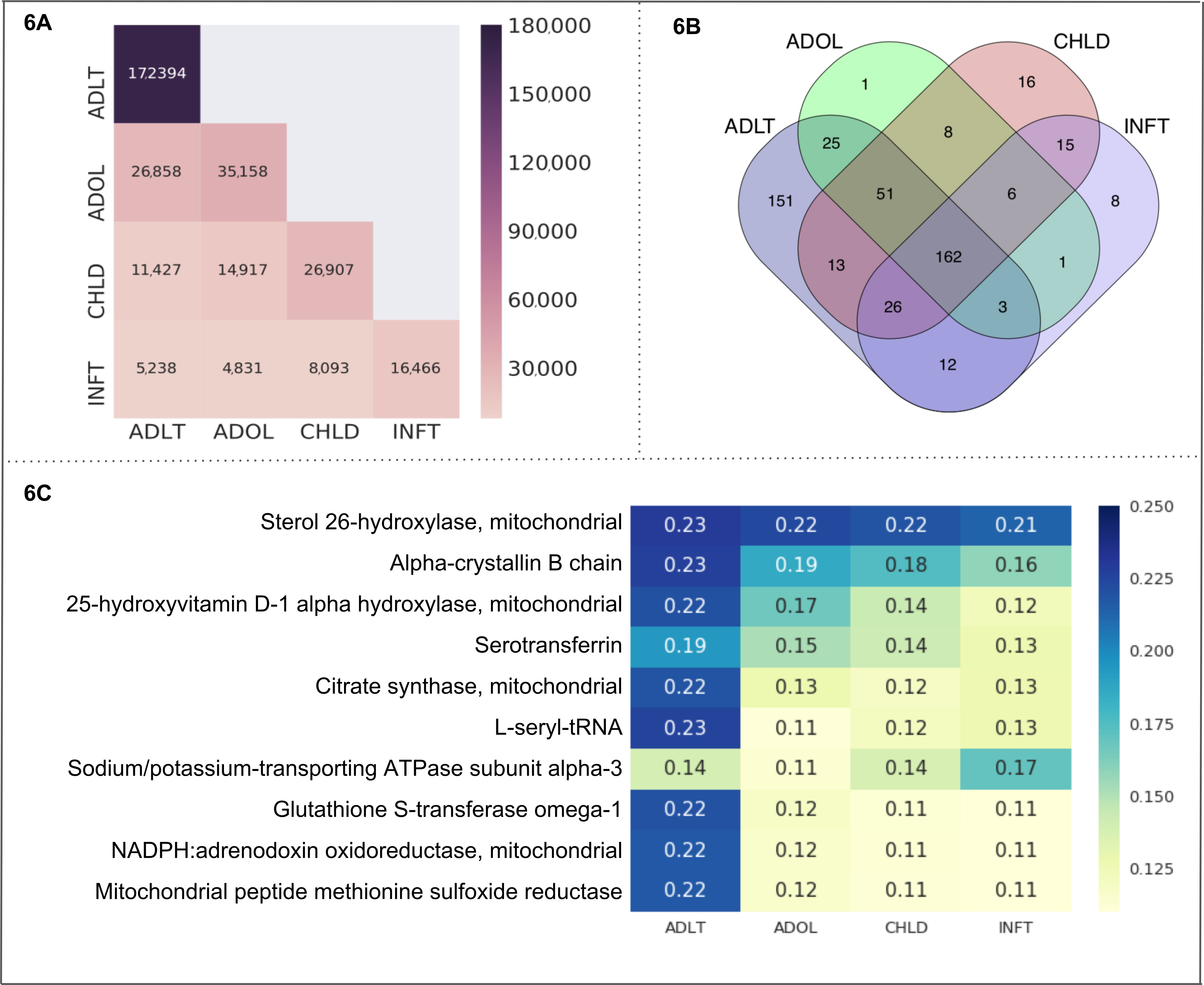
Gruppi di età. Abbiamo selezionato 4 tutte le sottocategorie di "Età" (infante, bambino, adolescente e adulto) come le cellule in un testo-cubo. I metadati ottenuti e le statistiche sono mostrate in tabella 3A. Il confronto del numero di documenti tra le celle di testo-cubo viene visualizzato in Figura 6A. Adulto contiene 172.394 documenti che è il numero più alto tra tutte le celle. Le sottocategorie di adulte e adolescenti hanno il maggior numero di documenti condivisi (26.858 documenti). In particolare, questi documenti inclusi l'entità del nostro interesse solo (vale a dire, proteine mitocondriali). Il diagramma di Venn in Figura 6B rappresenta il numero di entità (cioè, proteine mitocondriali) all'interno di ogni cellula, e all'interno di più sovrapposizioni fra le cellule. Il numero delle proteine condivisi all'interno di tutte le fasce d'età sottocategorie è 162. La sottocategoria adulta raffigura il più alto numero di proteine uniche (151) seguita da bambino (16), infante (8) e dell'adolescenza (1). Abbiamo calcolato l'associazione del gruppo di proteina-età come un punteggio di CaseOLAP. Le proteine di top 10 (basate sul loro Punteggio medio CaseOLAP) associate sottocategorie infante, bambino, adolescente e adulto sono 26-idrossilasi dello sterolo, catena alfa-crystallin B, 25 hydroxyvitamin D-1 alfa-idrossilasi, Serotransferrin, citrato sintasi, L-seryl-tRNA, ATPasi sodio/potassio-trasporto subunità alfa-3, Glutathione S-transferasi omega-1, NADPH: adrenodoxina ossidoriduttasi e riduttasi del solfossido della metionina del peptide mitocondriale (mostrato in Figura 6). La sottocategoria adulta Visualizza 10 heatmap celle con un'intensità più elevata rispetto alle cellule heatmap del adolescente, bambino e neonato sottocategoria, che indica che la top 10 proteine mitocondriali presentano le associazioni più forti alla sottocategoria adulto. La proteina mitocondriale dello sterolo 26-idrossilasi ha alte associazioni in tutte le sottocategorie di età quale è dimostrato da heatmap cellule con intensità più elevate rispetto alle cellule heatmap delle altre 9 proteine mitocondriali. La distribuzione statistica della differenza assoluta nel punteggio tra due gruppi Mostra la seguente gamma per differenza media con un intervallo di confidenza del 99%: (1) la differenza media tra 'ADLT' e 'INFT' si trova nella gamma (0,029 a 0,042), (2) la media differenza tra 'ADLT' e 'CHLD' si trova nell'intervallo (0,021 a 0.030), (3) la differenza media tra 'ADLT' e 'ADOL' si trova nell'intervallo (0,020 a 0,029), (4) la differenza media tra 'ADOL' e 'INFT' si trova nell'intervallo (0.015 a 0,022), (5) la differenza media tra 'ADOL' e 'CHLD' si trova nell'intervallo (0,007 a 0.010), (6) la differenza media tra 'CHLD' e 'INFT' si trova nell'intervallo (0,011 a 0,016).
Malattie nutrizionali e metaboliche. Abbiamo selezionato 2 sottocategorie di "Nutrizionali e malattie del metabolismo" (cioè, malattia metabolica e disordini nutrizionali) per creare 2 celle in un cubo di testo. I metadati ottenuti e le statistiche sono mostrate nella tabella 3B. Il confronto del numero di documenti tra le celle di testo-cubo viene visualizzato nella figura 7A. La malattia metabolica sottocategoria contiene 54.762 documenti seguite da 19.181 documenti in disordini nutrizionali. La malattia metabolica sottocategorie e disordini nutrizionali hanno 7.101 documenti condivisi. In particolare, questi documenti inclusi l'entità del nostro interesse solo (vale a dire, proteine mitocondriali). Il diagramma di Venn in figura 7B rappresenta il numero di entità all'interno di ogni cellula, e all'interno di più sovrapposizioni tra le cellule. Abbiamo calcolato la proteina - associazione "Nutrizionale e malattie metaboliche" come un punteggio di CaseOLAP. Le proteine di top 10 (basate sul loro Punteggio medio CaseOLAP) associate a questo caso di utilizzo sono steroli 26-idrossilasi, alfa-crystallin B catena, L-seryl-tRNA, dello synthase del citrato, tRNA sintetasi trasportante A 25-idrossivitamina D-1 alfa-idrossilasi, Glutathione S-transferasi omega-1, NADPH: adrenodoxina ossidoriduttasi, riduttasi del solfossido della metionina del peptide mitocondriale, inibitore dell'attivatore del plasminogeno 1 (illustrato nella Figura 7). Più della metà (54%) di tutte le proteine sono condivise tra le malattie metaboliche sottocategorie e disordini nutrizionali (397 proteine). È interessante notare che, quasi la metà (43%) delle proteine ad esso associate nella sottocategoria malattia metabolica sono unici (300 proteine), considerando che disordini nutrizionali presentano solo poche proteine uniche (35). Alfa-crystallin B catena Visualizza l'associazione più forte per le malattie metaboliche di sottocategoria. 26-idrossilasi dello sterolo, mitocondriale Visualizza l'associazione più forte nella sottocategoria disordini nutrizionali, che indica che questa proteina mitocondriale è molto rilevante negli studi che descrivono disordini nutrizionali. La distribuzione statistica della differenza assoluta nel punteggio tra i due gruppi 'MBD' e 'NTD' Mostra la gamma (0,046 a 0,061) per la differenza media come un intervallo di confidenza del 99%.

Figura 1. Visualizzazione dinamica del flusso di lavoro CaseOLAP. Questa figura rappresenta le 5 fasi principali del flusso di lavoro CaseOLAP. Nel passaggio 1, il flusso di lavoro inizia con il download e l'estrazione di documenti testuali (ad esempio, da PubMed). Nel passaggio 2, i dati estratti vengono analizzati per creare un dizionario di dati per ogni documento, nonché una MeSH per mappatura PMID. Nel passaggio 3, indicizzazione dei dati è condotto per facilitare la ricerca di entità veloce ed efficiente. Nel passaggio 4, implementazione delle informazioni fornite dall'utente categoria (es.., radice MeSH per ogni cella) viene effettuata per costruire un testo-cubo. Nel passaggio 5, l'operazione di conteggio di entità viene implementato sui dati di indice per calcolare i punteggi di CaseOLAP. Questi passaggi vengono ripetuti in modo iterativo per aggiornare il sistema con le ultime informazioni disponibili in un database pubblico (ad es., PubMed). Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

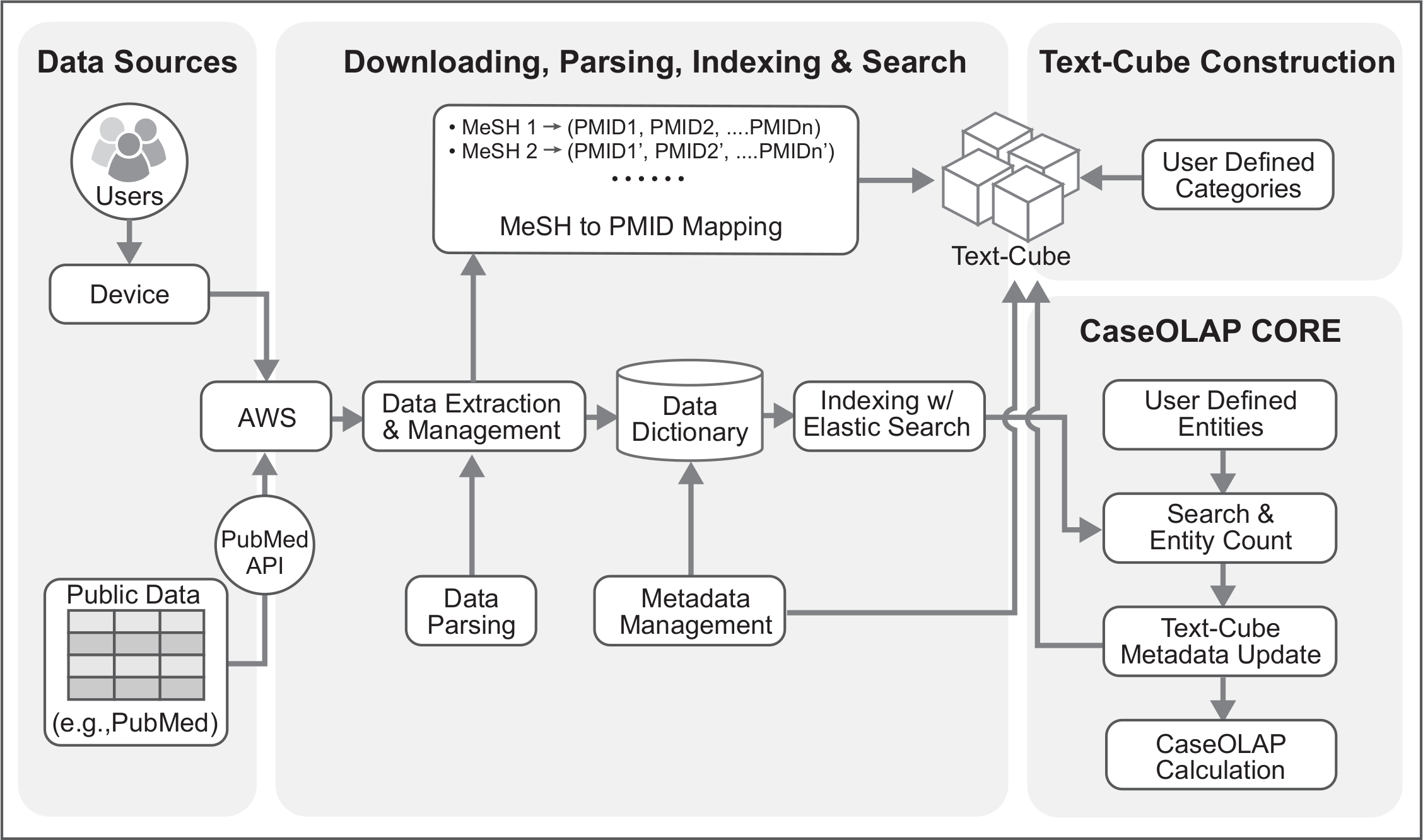
Figura 2. Architettura tecnica del flusso di lavoro CaseOLAP. Questa figura rappresenta i dettagli tecnici del flusso di lavoro CaseOLAP. Dati dal repository di PubMed sono ottenuti dal server FTP di PubMed. L'utente si connette al cloud server (ad es., connettività AWS) tramite il loro dispositivo e crea una Pipeline scaricare download che estrae i dati da un repository locale nel cloud. Dati estratti sono strutturati, verificati e portati in un formato corretto con una Pipeline di analisi di dati. Contemporaneamente, viene creata una MeSH alla tabella di mapping PMID durante la fase di analisi, che viene utilizzata per la costruzione del testo-cubo. Dati analizzati vengono memorizzati come un JSON come formato di dizionario chiave-valore con i metadati del documento (ad es., anno di pubblicazione di PMID, MeSH,). Il passaggio di indicizzazione più ulteriormente migliora i dati implementando Elasticsearch per gestire dati per operazioni bulk. Successivamente, il testo-cubo viene creato con categorie definite dall'utente implementando MeSH al mapping PMID. Quando la formazione di testo-cubo e indicizzazione passaggi sono stati completati, è condotto un conteggio di entità. I dati di conteggio di entità vengono implementati per i metadati del testo-cubo. Infine, il Punteggio di CaseOLAP viene calcolato in base la struttura del testo-cubo sottostante. Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

Figura 3. Un esempio di un documento analizzato. In questa figura è presentato un campione di dati analizzati. I dati analizzati sono disposti come una coppia chiave-valore che è compatibile con la creazione di metadati di indicizzazione e documento. In questa figura, un PMID (ad es., "25896987") è utilizzata come chiave di e raccolta di informazioni associate (ad esempio, titolo, rivista, data, Abstract, MeSH, sostanze, reparto e posizione) sono come valore. La prima applicazione di tali metadati documento è la costruzione di MeSH PMID mapping (Figura 5 e tabella 2), che viene successivamente implementata per creare il testo-cubo e per calcolare il Punteggio di CaseOLAP con entità fornito dall'utente e Categorie. Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

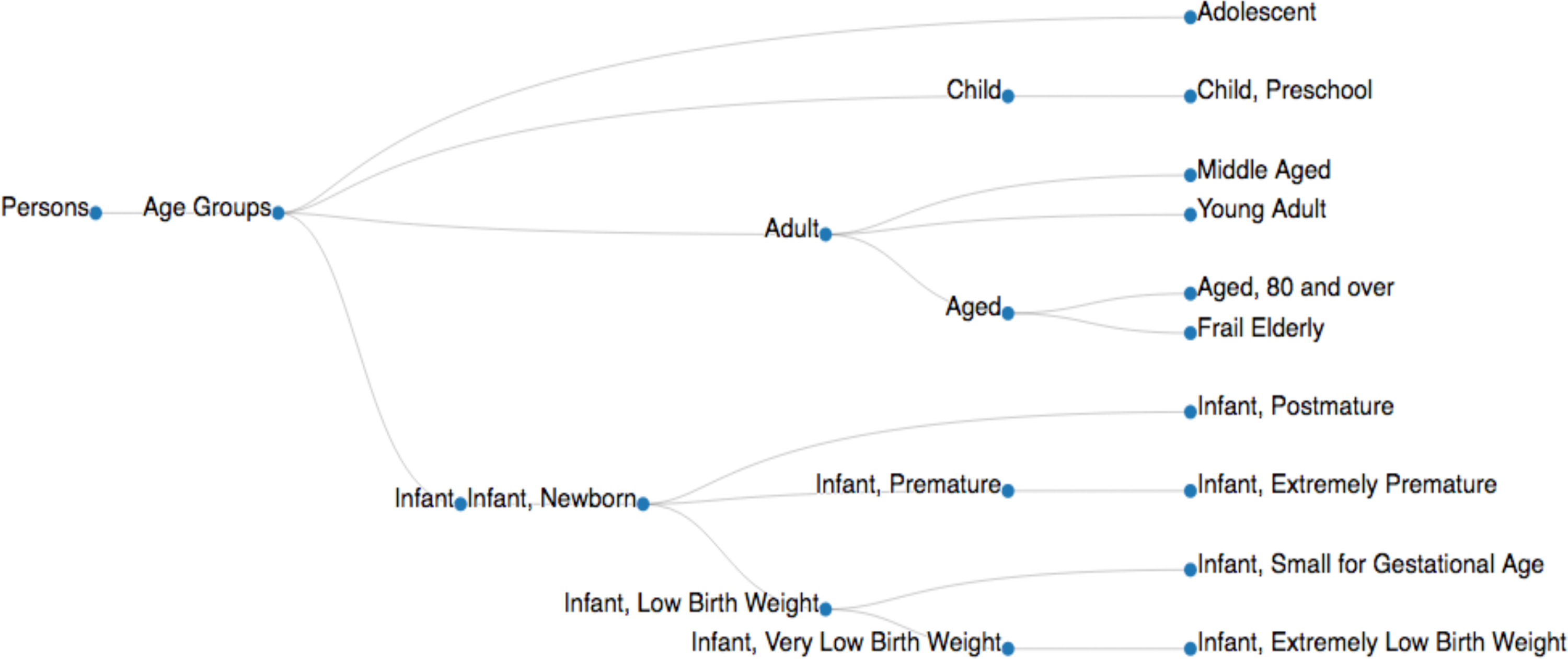
Figura 4. Un esempio di un albero di MeSH. Albero MeSH dei gruppi 'età è adattato dalla struttura di dati disponibile nel database di NIH (MeSH Tree 2018, < https://meshb.nlm.nih.gov/treeView>). I descrittori meSH vengono implementati con loro nodo IDs (ad es., persone [M01], gruppi di età [M01.060], adolescente [M01.060.057], adulto [M01.060.116], bambino [M01.060.406], infante [M01.060.703]) per raccogliere i documenti rilevanti per un specifico descrittore di MeSH ( Tabella 3A). Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

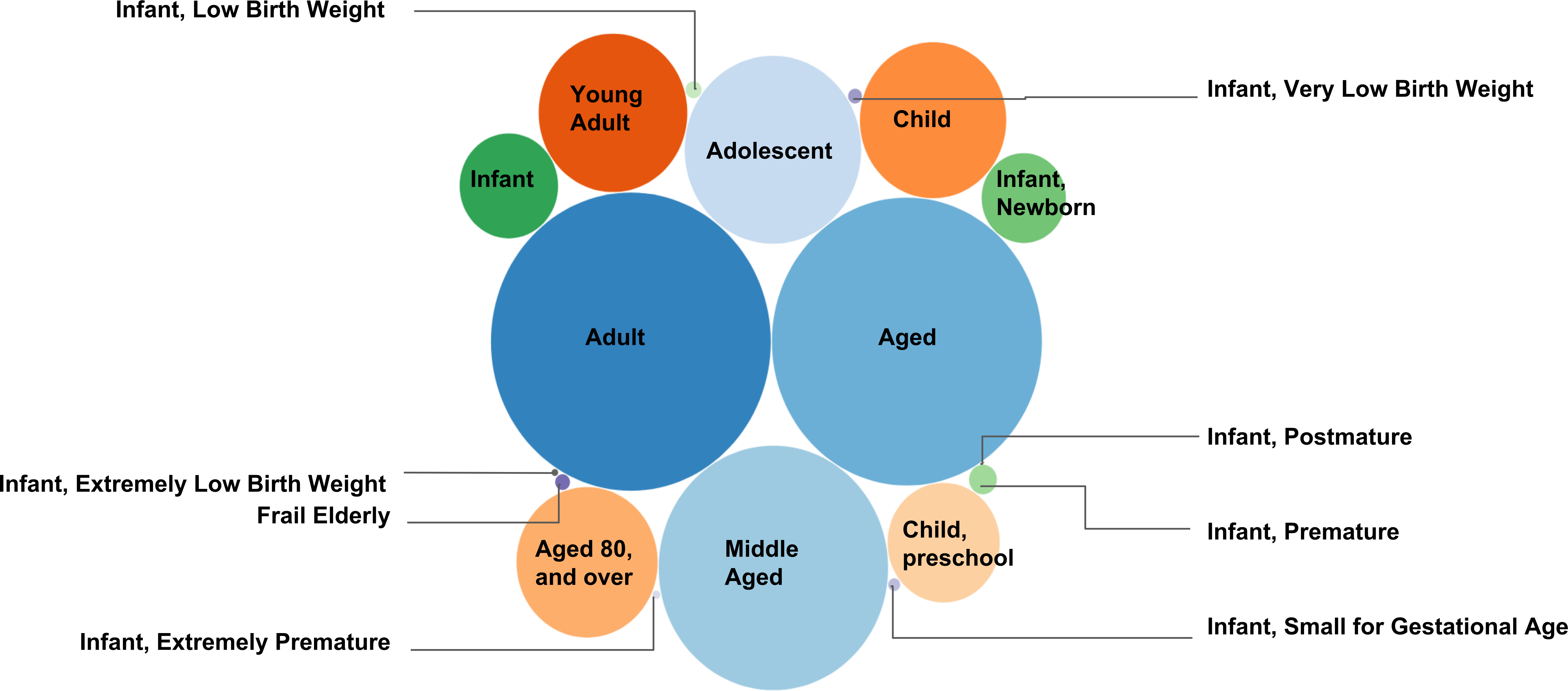
Figura 5. MeSH in mappatura PMID in gruppi di età. Questa figura presenta il numero di documenti di testo (ciascuno collegato con un PMID) raccolto sotto i descrittori MeSH in "Gruppi di età" come un grafico a bolle. La MeSH al mapping PMID viene generata per fornire il numero esatto di documenti raccolti sotto i descrittori MeSH. 3.062.143 documenti unici in totale sono stati raccolti sotto i 18 descrittori MeSH discendenti (Vedi tabella 2). Più alto il numero di PMIDs selezionata in un specifico descrittore di MeSH, il più grande il raggio della bolla che rappresenta il descrittore di MeSH. Per esempio, il maggior numero di documenti sono stati raccolti sotto il descrittore di MeSH "Adulto" (1.786.371 documenti), mentre il minor numero di documenti di testo sono stati raccolti sotto il descrittore di MeSH "Infante, Postmature" (62 documenti).
Un ulteriore esempio di MeSH al mapping PMID è dato per "Nutrizionali e malattie del metabolismo" (https://caseolap.github.io/mesh2pmid-mapping/bubble/meta.html). 422.039 documenti unici in totale sono stati raccolti sotto i 361 descrittori MeSH discendenti in "Malattie del metabolismo e della nutrizione". Il maggior numero di documenti sono stati raccolti sotto il descrittore di MeSH "Obesità" (77.881 documenti) seguirono da "diabete mellito di tipo 2" (61.901 documenti), considerando che "Glicogenosi, tipo VIII" hanno esibito il minor numero di documenti (1 documento ). Una tabella correlata è anche disponibile online presso (https://github.com/CaseOLAP/mesh2pmid-mapping/blob/master/data/diseaseall.csv). Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

Nella figura 6. "Età" come un caso d'uso. Questa figura presenta i risultati di un caso di utilizzo della piattaforma CaseOLAP. In questo caso, i nomi di proteine e loro abbreviazioni (vedere esempio in tabella 4) vengono implementate come entità e "Età", comprese le cellule: infante (INFT), bambino (CHLD), adolescenti (Nik) e adulti (ADLT), vengono implementate come sottocategorie (Vedi Tabella 3A). (A) Numero di documenti in "Gruppi di età": Questa mappa di calore indica il numero di documenti distribuiti in cellule di "Gruppi di età" (per dettagli vedere la creazione testo-cubo protocollo 4 e tabella 3A). Un numero maggiore di documenti è presentato con un'intensità più scura dell'heatmap delle cellule (Vedi la scala). Un singolo documento può essere incluso in più di una cella. L'heatmap presenta il numero di documenti all'interno di una cella lungo la posizione diagonale (ad es., l'ADLT contiene 172.394 documenti che è il numero più alto tra tutte le celle). La posizione come rappresenta il numero di documenti che rientrano nell'ambito di due celle (ad esempio, ADLT e ADOL hanno 26.858 documenti condivisi). (B) . Conteggio delle entità in "Gruppi di età": il diagramma di Venn rappresenta il numero di proteine che si trovano in quattro celle che rappresentano i "Gruppi di età" (INFT, CHLD, ADOL e ADLT). Il numero delle proteine condivisi all'interno di tutte le cellule è 162. Gruppo d'età ADLT raffigura il più alto numero di proteine uniche (151) seguita da CHLD (16), INFT (8) e Luca (1). (C) CaseOLAP presentazione di punteggio in "Gruppi di età": La top 10 proteine con i punteggi medi più alti di CaseOLAP in ogni gruppo sono presentate in una mappa di calore. Un punteggio più alto di CaseOLAP è presentato con un'intensità più scura dell'heatmap delle cellule (Vedi la scala). Sulla colonna di sinistra vengono visualizzati i nomi di proteine e le cellule (INFT, CHLD, ADOL ADLT) vengono visualizzate lungo l'asse x. Alcune proteine mostrano una forte associazione a uno specifico gruppo di età (ad es., 26-idrossilasi dello sterolo, alfa-crystallin catena B e L-seryl-tRNA hanno forti associazioni con ADLT, mentre ATPasi sodio/potassio-trasporto subunità alfa-3 ha una forte associazione con INFT). Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

Figura 7. "Nutrizionale e malattie metaboliche" come un caso d'uso: questa figura presenta i risultati di un altro caso di utilizzo della piattaforma CaseOLAP. In questo caso, i nomi di proteine e loro abbreviazioni (Vedi esempio nella tabella 4) vengono implementati come entità e "Malattia nutrizionale e metabolico" comprese le due cellule: malattia metabolica (MBD) e disordini nutrizionali (NTD) sono implementati come sottocategorie (vedere la tabella 3B). (A). numero di documenti in "Malattie del metabolismo e della nutrizione": questo heatmap raffigura il numero di documenti di testo nelle celle di "Malattie del metabolismo e della nutrizione" (per informazioni dettagliate sulla creazione di testo-cubo vedere protocollo n. 4 e tabella 3B ). Un numero maggiore di documenti è presentato con un'intensità più scura dell'heatmap delle cellule (Vedi scala). Un singolo documento può essere incluso in più di una cella. L'heatmap presenta il numero totale di documenti all'interno di una cella lungo la posizione diagonale (ad es., il MBD contiene 54.762 documenti che è il numero più alto tra le due celle). La posizione come rappresenta il numero di documenti condivisi dalle due cellule (ad es., MBD e NTD hanno 7.101 documenti condivisi). (B). conteggio delle entità in "Malattie del metabolismo e della nutrizione": il diagramma di Venn rappresenta il numero di proteine che si trovano nelle due celle che rappresentano "Nutrizionali e malattie del metabolismo" (MBD e NTD). Il numero delle proteine ha condiviso all'interno delle due cellule è 397. La cella MBD raffigura 300 proteine uniche, e la cella NTD raffigura 35 proteine uniche. (C). CaseOLAP presentazione di punteggio in "Malattie del metabolismo e della nutrizione": le proteine 10 migliori con i punteggi medi più alti di CaseOLAP in "Malattie del metabolismo e della nutrizione" sono presentate in una mappa di calore. Un punteggio più alto di CaseOLAP è presentato con un'intensità più scura dell'heatmap delle cellule (Vedi scala). Sulla colonna di sinistra vengono visualizzati i nomi di proteine e cellule (MBD e NTD) sono visualizzate lungo l'asse x. Alcune proteine mostrano una forte associazione a una categoria specifica di malattia (ad es., alfa-crystallin B catena ha un'alta associazione con la malattia metabolica e steroli 26-idrossilasi ha un'alta associazione con disordini nutrizionali). Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}
| Tempo trascorso (percentuale del tempo totale) | Passaggi nella piattaforma CaseOLAP | Algoritmo e struttura dei dati della piattaforma CaseOLAP | Complessità dell'algoritmo e struttura dei dati | Particolari dei punti |
| 40% | Download in corso e L'analisi | Albero di algoritmi di analisi e di iterazione | Iterazione con ciclo nidificato e moltiplicazione costante: O(n^2), O (log n). Dove ' n'è no di iterazioni. | La pipeline di Downloading scorre ogni procedura per più file. L'analisi di un singolo documento, viene eseguito ogni procedura sopra la struttura ad albero di dati XML non elaborati. |
| 30% | L'indicizzazione, la ricerca e la creazione di cubi di testo | Iterazione, algoritmi di ricerca di Elasticsearch (ordinamento, indice di Lucene, code di priorità, macchine a stati finiti, bit giocherellando hack, query regex) | Complessità legate alla Elasticsearch (https://www.elastic.co/) | I documenti vengono indicizzati implementando il processo di iterazione sopra il dizionario dei dati. La creazione di testo-cubo implementa documento meta-dati e informazioni di categoria fornito dall'utente. |
| 30% | Entità di conteggio e calcolo CaseOLAP | Iterazione nell'integrità, popolarità, calcolo di carattere distintivo | O (1), O(n^2), più complessità legate alla caseOLAP calcolo punteggio basato sui tipi di iterazione. | Operazione di conteggio di entità sono elencati i documenti e fare un'operazione di conteggio sopra la lista. I dati di conteggio di entità viene utilizzati per calcolare il Punteggio CaseOLAP. |
Tabella 1. Algoritmi e complessità. Questa tabella presenta informazioni sul tempo impiegato (percentuale del tempo totale trascorso) sulle procedure (ad es., download, analisi), struttura di dati e informazioni dettagliate su algoritmi implementati nella piattaforma CaseOLAP. CaseOLAP implementa l'indicizzazione professionale e l'applicazione di ricerca chiamato Elasticsearch. Ulteriori informazioni su complessità relazionati al Elasticsearch e algoritmi interni possono essere trovati alla (https://www.elastic.co).
| Descrittori di maglia | Numero di PMIDs raccolti |
| Adulto | 1.786.371 |
| Medio Evo | 1.661.882 |
| Di età compresa tra | 1.198.778 |
| Adolescente | 706.429 |
| Giovane adulto | 486.259 |
| Bambino | 480.218 |
| Invecchiato, 80 e oltre | 453.348 |
| Bambino in età prescolare | 285.183 |
| Neonato | 218.242 |
| Neonato, neonato | 160.702 |
| Neonato prematuro | 17.701 |
| Neonato sottopeso | 5.707 |
| Anziani fragili | 4.811 |
| Peso alla nascita neonato, molto basso | 4.458 |
| Infante, piccolo per l'età gestazionale | 3.168 |
| Neonato estremamente prematuro | 1.171 |
| Peso alla nascita estremamente basso, neonato | 1.003 |
| Neonato, Postmature | 62 |
Tabella 2. MeSH in statistiche mappatura PMID. Questa tabella presenta tutti i descrittori MeSH discendenti da "Età" e il loro numero di raccolti PMIDs (documenti di testo). La visualizzazione di queste statistiche è presentata nella Figura 5.
| A | Infante (INFT) | Bambino (CHLD) | Adolescente (FRE) | Adulto (ADLT) |
| Radice ID di meSH | M01.060.703 | M01.060.406 | M01.060.057 | M01.060.116 |
| Numero di descrittori MeSH discendenti | 9 | 2 | 1 | 6 |
| Numero di PMIDs selezionato | 16.466 | 26.907 | 35.158 | 172.394 |
| Numero delle entità trovate | 233 | 297 | 257 | 443 |
| B | Malattie metaboliche (MBD) | Disordini nutrizionali (NTD) | ||
| Radice ID di meSH | C18.452 | C18.654 | ||
| Numero di MeSH discendente descrittori | 308 | 53 | ||
| Numero di PMIDs raccolti | 54.762 | 19.181 | ||
| Numero delle entità trovate | 697 | 432 |
Tabella 3. Testo-Cube metadati. Una visualizzazione tabulare dei metadati testo-Cube è presentata. Le tabelle forniscono informazioni sulle categorie e MeSH descrittore radici e discendenti, che vengono implementati per raccogliere i documenti in ogni cella. La tabella fornisce anche le statistiche di entità e i documenti raccolti. (A) "Età": si tratta di una rappresentazione tabellare di "Età" tra cui infante (INFT), bambino (CHLD), adolescenti (Nik) e adulti (ADLT) e trovato loro radice MeSH ID, numero di discendenti descrittori MeSH, numero di PMIDs selezionato e il numero di entità. (B) "Malattie del metabolismo e della nutrizione": si tratta di una rappresentazione tabellare delle "Malattie nutrizionali e metaboliche" compreso la malattia metabolica (MBD) e disordini nutrizionali (NTD) con il loro radice MeSH ID, numero di discendenti descrittori MeSH, numero di PMIDs selezionato e il numero delle entità trovate.
| Nomi di proteina e sinonimi | Abbreviazioni |
| N-acetilglutammato sintasi, mitocondriale, aminoacido acetiltransferasi, forma lunga di N-acetilglutammato sintasi; Forma abbreviata di N-acetilglutammato sintasi; Modulo di N-acetilglutammato sintasi conservata dominio] | (CE 2.3.1.1) |
| Deglycase acido nucleico/proteina DJ-1 (Maillard deglycase) (Oncogene DJ1) (proteina di malattia di Parkinson 7) (parkinsonismo-associated deglycase) (proteina DJ-1) | (EC 3.1.2.-) (EC 3.5.1.-) (EC 3.5.1.124) (DJ-1) |
| Piruvato carbossilasi, mitocondriale (piruvico carbossilasi) | (EC 6.4.1.1) (PCB) |
| BCL-2-Associazione componente 3 (p53 up-regolato modulatore dell'apoptosi) | (JFY-1) |
| BH3-interazione agonista morte dominio [BH3-interazione dominio morte agonista p15 (p15 BID); BH3-interazione dominio morte agonista p13; Dominio BH3-interacting morte agonista p11] | (p22 BID) (OFFERTA) (p13 BID) (p11 BID) |
| ATP sintasi subunità alfa, mitocondriale (ATP sintasi F1 subunità alfa) | |
| Citocromo P450 11B2, mitocondriale (Aldosterone sintasi) (Angiotensina Aldosterone-sintetizzazione) (CYPXIB2) (citocromo P-450Aldo) (citocromo P-450_C_18) (idrossilasi dello steroide 18) | (ALDOS) (EC 1.14.15.4) (EC 1.14.15.5) |
| 60 kDa heat shock proteins, mitocondriale (il 60 kDa chaperonin) (il Chaperonin 60) (CPN60) (Heat shock protein 60) (proteina di matrice mitocondriale P1) (proteina del linfocita di P60) | (HSP-60) (Hsp60) (HuCHA60) (EC 3.6.4.9) |
| Caspasi-4 (ghiaccio e Ced-3 dell'omologo 2) (proteasi TX) [scisso in: Caspase-4 subunità 1; Caspasi-4 subunità 2] | (CASP-4) (EC 3.4.22.57) (ICH-2) (ICE(rel)-II) (Mih1) |
Tabella 4. Entità tabella di esempio. Questa tabella presenta il campione di entità implementata nei nostri casi di due uso: "Età" e "Malattie del metabolismo e della nutrizione" (Figura 6 e Figura 7, tabella 3A,B). Le entità includono proteine nomi, sinonimi e abbreviazioni. Ogni entità (con i suoi sinonimi e abbreviazioni) è selezionato uno ad uno e viene passato attraverso l'operazione di ricerca di entità su dati indicizzati (Vedi protocollo 3 e 5). La ricerca produce un elenco di documenti che favoriscano ulteriormente l'operazione di conteggio di entità.
| Quantità | Definito dall'utente | Calcolato | Equazione della quantità | Significato della quantità |
| Integrità | Sì | No | Integrità dell'utente definito entità considerata 1.0. | Rappresenta una frase significativa. Valore numerico è 1.0, quando è già una frase stabilita. |
| Popolarità | No | Sì | Equazione di popolarità nella figura 1 (flusso di lavoro e algoritmo) da riferimento 5, sezione "Materiali e metodi". | Basato sulla frequenza di termine della frase all'interno di una cella. Normalizzato di frequenza del termine totale della cella. Aumento della frequenza di termine è risultato in diminuzione. |
| Carattere distintivo | No | Sì | Equazione di carattere distintivo nella figura 1 (flusso di lavoro e algoritmo) da riferimento 5, sezione "Materiali e metodi". | Basato su durata e frequenza di documento all'interno di una cella e tra le cellule vicine. Normalizzati dal termine totale frequenza e frequenza di documento. Quantitativamente, è la probabilità che una frase è unica in una cella specifica. |
| Punteggio di CaseOLAP | No | Sì | Equazione di Punteggio CaseOLAP in figura 1 (flusso di lavoro e algoritmo) da riferimento 5, sezione "Materiali e metodi". | Basato su integrità, popolarità e carattere distintivo. Valore numerico rientra sempre da 0 a 1. Quantitativamente il Punteggio di CaseOLAP rappresenta l'associazione di frase-categoria |
Tabella 5. Equazioni di CaseOLAP: CaseOLAP l'algoritmo è stato sviluppato da Fangbo Tao e Jiawei Han et nel 20161. Questa tabella presenta brevemente, il calcolo del Punteggio di CaseOLAP composto da tre componenti: integrità, popolarità e carattere distintivo e il loro significato matematico associato. Nei nostri casi di utilizzo, il Punteggio di integrità per le proteine è 1.0 (il punteggio massimo) perché si levano in piedi come i nomi di entità stabilita. I punteggi di CaseOLAP nei nostri casi di utilizzo possono essere visto in Figura 6 e Figura 7.
Discussione
Abbiamo dimostrato che l'algoritmo di CaseOLAP possibile creare un'associazione quantitativa di frase basata a una categoria basata sulla conoscenza sopra grandi volumi di dati testuali per l'estrazione di approfondimenti significativi. Seguendo il nostro protocollo, uno può costruire il quadro di CaseOLAP per creare un cubo di testo desiderato e quantificare le associazioni di entità-categoria attraverso il calcolo del Punteggio di CaseOLAP. I punteggi grezzi ottenuti di CaseOLAP possono essere adottati per analisi integrative, compresa la riduzione della dimensionalità, clustering, l'analisi temporale e geografica, nonché la creazione di un database grafico che consente la mappatura semantica dei documenti.
Applicabilità dell'algoritmo. Esempi di entità definite dall'utente, diverse proteine, potrebbero essere un elenco di nomi di gene, droghe, segni e sintomi specifici comprese le loro abbreviazioni e sinonimi. Inoltre, ci sono molte scelte per la selezione di categoria facilitare analisi biomediche definito dall'utente specifiche (ad es., anatomia [A], disciplina e occupazione [H], fenomeni e processi [G]). Nei nostri due casi d'uso, tutte le pubblicazioni scientifiche e loro dati testuali vengono recuperati dal database MEDLINE utilizzando PubMed come motore di ricerca, entrambi gestiti dalla National Library of Medicine. Tuttavia, la piattaforma di CaseOLAP può essere applicata ad altri database di interesse contenente documenti biomedici con dati testuali quali la FDA negativi eventi Reporting System (FAERS). Si tratta di un database aperto contenente informazioni sul medicali eventi avversi e report di errore farmaco presentato alla FDA. In contrasto con MEDLINE e FAERS, database negli ospedali contenenti electronic health record da pazienti non siano aperte al pubblico e sono limitati dall'Health Insurance Portability and Accountability Act conosciuto come HIPAA.
Algoritmo di CaseOLAP è stato applicato con successo per i diversi tipi di dati (ad es., articoli di notizie)1. L'implementazione di questo algoritmo in biomedical documenti compiuto nel 20185. I requisiti per l'applicabilità dell'algoritmo di CaseOLAP è che ciascuno dei documenti deve essere assegnato con parole chiave associate con i concetti (ad esempio i descrittori MeSH in pubblicazioni biomediche, parole chiave in articoli di notizie). Se non si trovano parole chiave, si può applicare Autophrase6,7 per raccogliere frasi rappresentative superiori e creare un elenco di entità prima di implementare il nostro protocollo. Il nostro protocollo non prevede il passaggio per eseguire Autophrase.
Confronto con altri algoritmi di. Il concetto dell'utilizzo di un cubo di dati8,9,10 e un testo-Cube2,3,4 si è evoluto dal 2005 con nuovi progressi per rendere il data mining dei dati più applicabile. Il concetto di elaborazione analitica Online (OLAP)11,12,13,14,15 in business intelligence e data mining dati risale al 1993. OLAP, in generale, aggrega le informazioni provenienti da più sistemi e lo memorizza in un formato multi-dimensionale. Ci sono diversi tipi di sistemi OLAP implementati nel data mining. Ad esempio elaborazione delle transazioni/analitica (1) ibrido (HTAP)16,17, (2) OLAP multidimensionale (MOLAP)18,19-cubo OLAP relazionale (ROLAP) fondate e (3)20.
In particolare, l'algoritmo di CaseOLAP è stato confrontato con numerosi algoritmi esistenti, in particolare, con i miglioramenti della segmentazione loro frase, tra cui TF-IDF + Seg, MCX + Seg, MCX e SegPhrase. Inoltre, RepPhrase (RP, noto anche come SegPhrase +) è stato confrontato con un proprio variazioni di ablazione, inclusi (1) RP senza la misura di integrità incorporata (RP INT n), (2) RP senza misura la popolarità incorporata (RP No POP) e (3) RP senza il Misura di carattere distintivo incorporato (RP No DIS). I risultati dei benchmark sono mostrati nello studio di Fangbo Tao et al.1.
Ci sono ancora sfide sul data mining, che possono aggiungere funzionalità aggiuntive nel corso di salvataggio e recupero dei dati dal database. Consapevoli del contesto semantico Analytical Processing (CaseOLAP) implementa sistematicamente la Elasticsearch per costruire un database di indicizzazione di milioni di documenti (protocollo n. 5). Il testo-cubo è una struttura di documento costruita sopra i dati indicizzati con categorie fornito dall'utente (protocollo n. 6). Questo migliora la funzionalità per i documenti all'interno e attraverso la cella del testo-cubo e ci permettono di calcolare la frequenza di termine delle entità sopra un documento e il documento frequenza sopra una cella specifica (protocollo n. 8). Il Punteggio finale di CaseOLAP utilizza questi calcoli di frequenza per un punteggio finale di uscita (protocollo n. 9). Nel 2018, abbiamo implementato questo algoritmo per lo studio di proteine ECM e sei cuore malattie per analizzare le associazioni proteina-malattia. I dettagli di questo studio possono essere trovati nello studio di Liem, D.A. et al.5. che indica che il CaseOLAP potrebbe essere ampiamente usato nella comunità biomedica esplorare una varietà di malattie e meccanismi.
Limiti dell'algoritmo. Data mining di frase stessa è una tecnica per gestire e recuperare i concetti importanti da dati testuali. Scoprendo l'associazione di categoria di entità come una quantità matematica (vettore), questa tecnica è in grado di capire la polarità (ad es., inclinazione positiva o negativa) dell'associazione. Uno può costruire il Riepilogo quantitativo dei dati che utilizza la struttura del documento di testo-Cude con casi assegnati e categorie, ma un concetto qualitativo con granularità microscopica non può essere raggiunto. Alcuni concetti sono in continua evoluzione dal passato fino ad ora. Il riepilogo presentato per un'associazione di categoria di entità specifica include tutte le incidenze in tutta la letteratura. Questo può mancare la propagazione temporale dell'innovazione. In futuro, prevediamo di risolvere queste limitazioni.
Future applicazioni. Circa il 90% dei dati accumulati nel mondo è nei dati di testo non strutturati. Trovare una frase rappresentativa e la relazione con le entità incorporati nel testo è un compito molto importante per l'implementazione delle nuove tecnologie (ad es., Machine Learning, estrazione di informazioni, l'intelligenza artificiale). Per rendere i dati di testo macchina leggibile, i dati devono essere organizzate nel database su cui lo strato successivo di strumenti potrebbe essere implementato. In futuro, questo algoritmo può essere un passo cruciale nel rendere più funzionale per il recupero di informazioni e la quantificazione delle associazioni di categoria di entità datamining.
Divulgazioni
Gli autori non hanno nulla a rivelare.
Riconoscimenti
Questo lavoro è stato supportato in parte dal National Heart, Lung e Blood Institute: HL135772 R35 (a P. Ping); Istituto nazionale di scienze mediche generali: U54 GM114833 (a P. Ping, K. Watson e Wang W.); U54 GM114838 (per J. Han); un regalo dal Hellen & Larry Hoag Foundation e Setty Dr. S.; e l'investitura del T.C. Laubisch presso la UCLA (a P. Ping).
Materiali
| Name | Company | Catalog Number | Comments |
Riferimenti
- Tao, F., Zhuang, H., et al. Phrase-Based Summarization in Text Cubes. IEEE Data Engineering Bulletin. , 74-84 (2016).
- Ding, B., Zhao, B., Lin, C. X., Han, J., Zhai, C. TopCells: Keyword-based search of top-k aggregated documents in text cube. IEEE 26th International Conference on Data Engineering (ICDE). , 381-384 (2010).
- Ding, B., et al. Efficient Keyword-Based Search for Top-K Cells in Text Cube. IEEE Transactions on Knowledge and Data Engineering. 23 (12), 1795-1810 (2011).
- Liu, X., et al. A Text Cube Approach to Human, Social and Cultural Behavior in the Twitter Stream.Social Computing, Behavioral-Cultural Modeling and Prediction. Lecture Notes in Computer Science. 7812, (2013).
- Liem, D. A., et al. Phrase Mining of Textual Data to analyze extracellular matrix protein patterns across cardiovascular disease. American Journal of Physiology-Heart and Circulatory. , (2018).
- Shang, J., et al. Automated Phrase Mining from Massive Text Corpora. IEEE Transactions on Knowledge and Data Engineering. 30 (10), 1825-1837 (2018).
- Liu, J., Shang, J., Wang, C., Ren, X., Han, J. Mining Quality Phrases from Massive Text Corpora. Proceedings ACM-Sigmod International Conference on Management of Data. , 1729-1744 (2015).
- Lee, S., Kim, N., Kim, J. A Multi-dimensional Analysis and Data Cube for Unstructured Text and Social Media. IEEE Fourth International Conference on Big Data and Cloud Computing. , 761-764 (2014).
- Lin, C. X., Ding, B., Han, J., Zhu, F., Zhao, B. Text Cube: Computing IR Measures for Multidimensional Text Database Analysis. IEEE Data Mining. , 905-910 (2008).
- Hsu, W. J., Lu, Y., Lee, Z. Q. Accelerating Topic Exploration of Multi-Dimensional Documents Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE International. , 1520-1527 (2017).
- Chaudhuri, S., Dayal, U. An overview of data warehousing and OLAP technology. SIGMOD Record. 26 (1), 65-74 (1997).
- Ravat, F., Teste, O., Tournier, R. Olap aggregation function for textual data warehouse. ICEIS - 9th International Conference on Enterprise Information Systems, Proceedings. , 151-156 (2007).
- Ho, C. T., Agrawal, R., Megiddo, N., Srikant, R. Range Queries in OLAP Data Cubes. SIGMOD Conference. , (1997).
- Saxena, V., Pratap, A. Olap Cube Representation for Object- Oriented Database. International Journal of Software Engineering & Applications. 3 (2), (2012).
- Maniatis, A. S., Vassiliadis, P., Skiadopoulos, S., Vassiliou, Y. Advanced visualization for OLAP. DOLAP. , (2003).
- Bog, A. . Benchmarking Transaction and Analytical Processing Systems: The Creation of a Mixed Workload Benchmark and its Application. , 7-13 (2013).
- Özcan, F., Tian, Y., Tözün, P. Hybrid Transactional/Analytical Processing: A Survey. In Proceedings of the ACM International Conference on Management of Data (SIGMOD). , 1771-1775 (2017).
- Hasan, K. M. A., Tsuji, T., Higuchi, K. An Efficient Implementation for MOLAP Basic Data Structure and Its Evaluation. International Conference on Database Systems for Advanced Applications. , 288-299 (2007).
- Nantajeewarawat, E. Advances in Databases: Concepts, Systems and Applications. DASFAA 2007. Lecture Notes in Computer Science. 4443, (2007).
- Shimada, T., Tsuji, T., Higuchi, K. A storage scheme for multidimensional data alleviating dimension dependency. Third International Conference on Digital Information Management. , 662-668 (2007).
Ristampe e Autorizzazioni
Richiedi autorizzazione per utilizzare il testo o le figure di questo articolo JoVE
Richiedi AutorizzazioneThis article has been published
Video Coming Soon
Personale delle biblioteche
Copyright © 2025 MyJoVE Corporation. Tutti i diritti riservati