
Method Article
Une approche d’Extraction de métadonnées pour des rapports de cas cliniques permettre Advanced compréhension des Concepts biomédicales
Dans cet article
Résumé
Nous présentons un protocole et un modèle de métadonnées associée pour l’extraction de texte décrivant les concepts biomédicales dans les rapports de cas cliniques. Les valeurs de texte structuré, produits par le biais de ce protocole peuvent prendre en charge une analyse approfondie des milliers de récits cliniques.
Résumé
Rapports de cas cliniques (CCT) sont un moyen précieux de partage des observations et des idées en médecine. Varie selon la forme de ces documents et leur contenu comprend des descriptions de nombreux, nouvelle maladie des présentations et des traitements. Jusqu’ici, les données de texte au sein de la CCT sont très peu structurées, exigeant un effort humain et de calcul important pour rendre ces données utiles pour une analyse approfondie. Dans ce protocole, nous décrivons des méthodes pour identifier les métadonnées correspondant aux concepts biomédicales spécifiques fréquemment observées au sein de la CCT. Nous fournissons un modèle de métadonnées comme un guide pour l’annotation de document, reconnaissant qu’imposant structure sur CCT peut-être être poursuivi par des combinaisons d’efforts manuels et automatiques. L’approche présentée ici est approprié pour l’organisation du texte axés sur la notion d’un corpus de littérature importante (p. ex., des milliers de CCT) mais peut être facilement adapté pour faciliter plus ciblées tâches ou petites séries de rapports. Les données de texte structuré qui comprennent un contexte sémantique suffisant pour prendre en charge une variété de flux de travail analyse ultérieure du texte : meta-analyses afin de déterminer comment maximiser CCR détail, études épidémiologiques sur les maladies rares et l’élaboration de modèles de langage médical peut-être tous être fait plus réalisable et gérable par l’utilisation de données textuelles structurées.
Introduction
Rapports de cas cliniques (CCT) sont un moyen fondamental de partager des observations et connaissances en médecine. Ceux-ci servent comme un mécanisme de base de communication et d’éducation pour les cliniciens et étudiants en médecine. Historiquement, les CCT ont également fourni comptes des maladies émergentes, leurs traitements et leurs antécédents génétiques1,2,3,4. Par exemple, le premier traitement de la rage humaine par Louis Pasteur en 18855,6 et la première application de pénicilline chez les patients étaient de7 ont tous deux signalé par le Centre canadien de télédétection. Plus de 1,87 millions CCT ont été publiés en avril 2018, avec plus d’un demi-million dans la dernière décennie ; revues continuent à fournir de nouveaux lieux pour ces rapports8. Bien qu’unique dans la forme et le contenu, CCT contiennent des données de texte qui sont très peu structurées, contiennent un vaste vocabulaire et concerne des phénomènes interdépendants, limitant leur utilisation comme une ressource structurée. Un effort important est nécessaire à l’extraction de métadonnées détaillées (c.-à-d., « données sur les données », ou dans ce cas, les descriptions du contenu du document) du CCT et leur conférer une données trouvable, accessible, interopérable et réutilisables (FAIR)9 ressources.
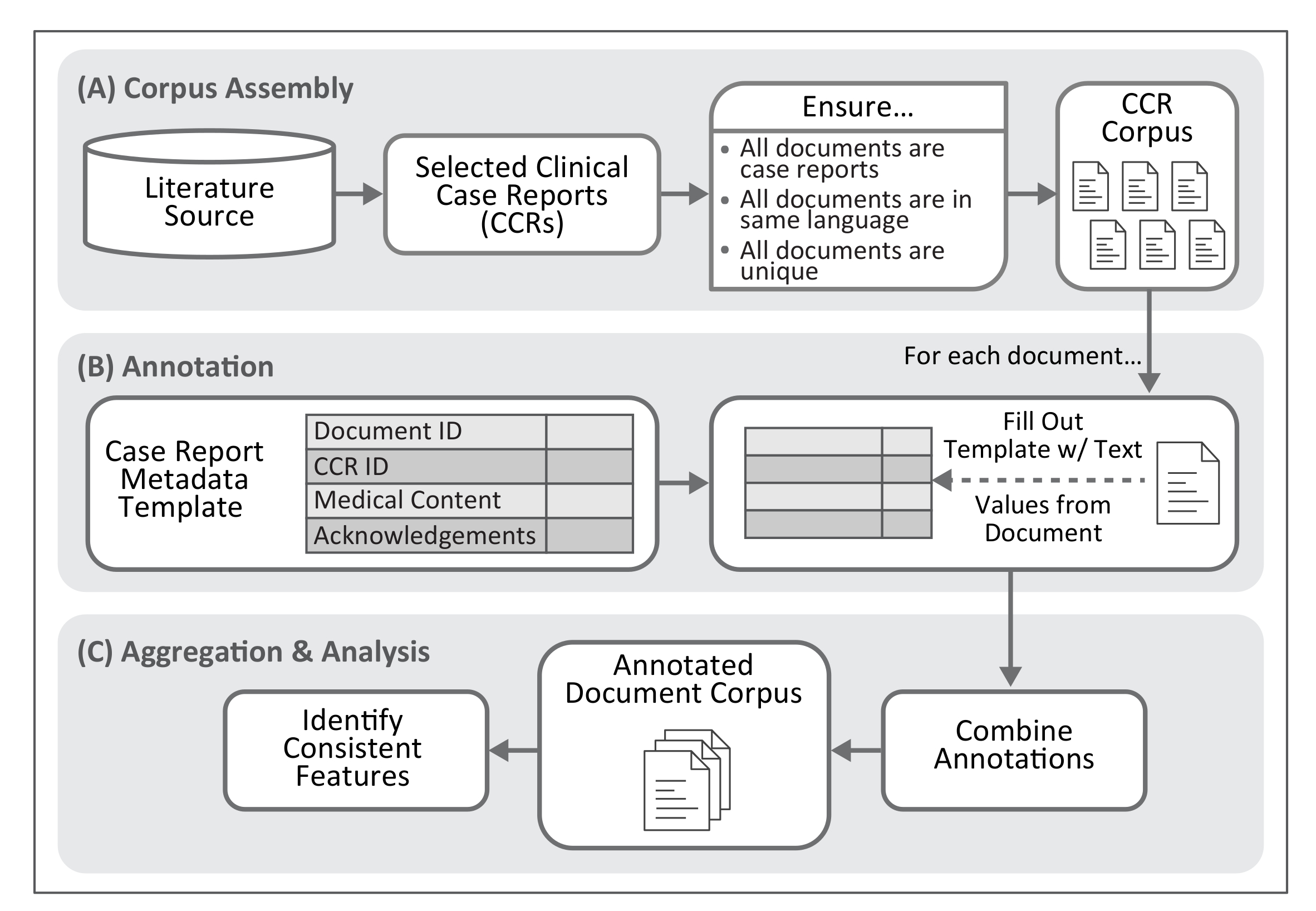
Nous décrivons ici un procédé d’extraction de texte et des valeurs numériques de standardiser la description des concepts biomédicales spécifiques au sein de la CCT publiées. Cette méthodologie comprend un modèle de métadonnées pour guider l’annotation en question ; Voir la Figure 1 pour une vue d’ensemble de ce processus. Application du processus d’annotation à une vaste collection de rapports (par exemple, plusieurs milliers d’un type spécifique de présentation de la maladie) permet montage d’un ensemble de textes cliniques annotés, gérable et structuré atteindre lisible par une machine documentation et phénomènes biomédicaux incorporé dans chaque clinique de la présentation. Bien que les formats de données tels que ceux fournis par HL7 (e.g., Version 3 de la norme de messagerie10 ou le Fast Healthcare Interoperability Resources [FHIR]11), LOINC12et révision 10 de la statistique internationale Classification des maladies et des problèmes de santé connexes (CIM-10)13 fournissent des normes pour la description et d’échange d’observations cliniques, ils ne saisissent pas le texte qui entoure ces données, ni sont qu’ils veulent. Les résultats de notre méthodologie sont mieux utilisées pour appliquer la structure sur les CCT et faciliteraient l’analyse ultérieure, normalisation par le biais de systèmes de codage et de vocabulaires contrôlés (e.g., CIM-10), ou la conversion vers les formats de données cliniques mentionnés ci-dessus .
Exploitation minière CCT est un domaine actif de travail au sein de l’informatique biomédicale et clinique. Bien que les propositions précédentes de standardiser la structure de rapports de cas (p. ex.., à l’aide de HL7 v2.514 ou normalisés phénotype terminologie15) sont louables, il est probable que la CCT continuera à suivre une variété de différents formes de langage naturel et document mises en page, car ils ont pour une grande partie du siècle passé. Dans des conditions idéales, les auteurs des nouveaux cas signalés suivre soins orientations16 pour s’assurer qu’ils sont complets. Les approches sensibles à la fois de langage naturel et de sa relation avec concepts médicaux peuvent donc être plus efficaces en travaillant avec des rapports nouveaux et archivées. Ressources telles que l’artisanat17 et celles produites par informatique pour intégrer la biologie et la curation de18 de chevet (i2b2) soutenir les approches de traitement du langage naturel (NLP) mais ne sont pas spécifiquement l’accent sur la CCT ou récits cliniques. De même, les outils PNL médicaux tels que le cTAKES19 et20 de la pince ont été développés mais généralement définir des mots ou des phrases (c'est-à-dire, des entités) dans le cadre de documents plutôt que les concepts généraux attachés habituellement décrits dans CCT.
Nous avons conçu un modèle de métadonnées normalisées pour fonctionnalités généralement incluses au sein de la CCT. Ce modèle définit les fonctionnalités d’imposer la structure sur la CCT — un précurseur essentiel de comparaison approfondie du contenu du document-permet encore de suffisamment de souplesse pour conserver le contexte sémantique. Bien que nous avons conçu le format associé à ce modèle convient pour les annotation manuelle et la fouille de textes assistée par le calcul, nous nous sommes assurés que c’est particulièrement facile à utiliser pour manuels annotators. Notre approche diffère nettement de plus complexe (et, par conséquent, moins immédiatement compréhensible aux chercheurs) cadres tels que FHIR21. Le protocole suivant explique comment isoler les caractéristiques de document correspondant à chaque type de données de modèle, avec un ensemble unique de valeurs correspondant à celles dans un seul CCR.
Les types de données dans le modèle de ceux plus descriptive de CCT et documents médicaux centrés sur le patient sont en général. Annotation de ces fonctionnalités favorise findability, l’accessibilité, l’interopérabilité et réutilisabilité du texte CCR, principalement en lui donnant une structure. Les types de données sont en quatre catégories générales : identification de document et d’annotation, identification de rapport de cas (c'est-à-dire, les propriétés au niveau du document), concepts contenus médicaux (propriétés principalement au niveau de concept) et remerciements (par exemple fonctionnalités fournissant des preuves de financement). Dans ce processus d’annotation, chaque document contient le texte intégral d’un CCR, l’omission de tout document contenu matériel indépendant pour le cas (par exemple, les protocoles expérimentaux). Centre canadien de télédétection sont généralement moins de 1 000 mots chacun ; un corpus unique devrait idéalement être indexé par la même base de données bibliographique et être dans la même langue écrite.
Le produit de l’approche décrite ici, lorsqu’il est appliqué à un corpus CCR, est un ensemble structuré de texte annoté de clinique. Bien que cette méthodologie est entièrement manuelle et a été conçue pour être effectués par des experts de domaine sans aucune expérience de l’informatique, il vient compléter les approches de traitement du langage naturel mentionnés ci-dessus et fournit des données appropriées pour analyse computationnelle. Ces analyses peuvent être d’intérêt à un public de chercheurs au-delà de ceux qui lisent souvent CCT, y compris :
- personnes concernées par les présentations de la maladie, leur symptomatologie clé, approches diagnostiques habituelles et traitements
- ceux qui souhaitent comparer les résultats des essais cliniques avec les événements décrits dans la littérature clinique, potentiellement fournir des observations supplémentaires et une plus grande puissance statistique.
- bio-informatique, informatique biomédicale et chercheurs en sciences informatiques qui ont besoin d’ensembles de données structurées langage médical ou haut niveau compréhension des récits médicaux
- Chercheurs du gouvernement politique mettant l’accent sur les essais cliniques comment peuvent refléter mieux comment le diagnostic et le traitement qu’elle se produit en réalité
Application de la structure sur la CCT peut supporter des nombreux efforts ultérieurs pour mieux comprendre la langue médicale et biomédicales phénomènes.
Protocole
1. le document et l’Identification de l’Annotation
Remarque : Les valeurs dans cette catégorie prend en charge le processus d’annotation.
- L’aide du modèle de l’annotation, fournir qu'un identificateur spécifique à ces métadonnées définie, par exemple, Case123. Le format de l’identificateur doit être cohérent tout au long du projet (p. ex., Case001 par l’intermédiaire de Case500).
- Spécifiez la date à laquelle un document a été lu et annoté. Utiliser un format ressemblant à « 10 janvier 2018 » pour la cohérence et la lisibilité.
2. case Report Identification
Remarque : Les valeurs dans cette catégorie fournissent des fonctionnalités au niveau du document et contribuent à la trouvabilité un document.
- Être compatible avec le format de chaque champ à travers toutes les annotations, par exemple, les valeurs individuelles doivent être séparés par des points-virgules sans espaces suivants dans toutes les entrées. Utilisez des formats identiques à ceux utilisés dans le document d’origine ou ceux utilisés dans une base de données bibliographique MEDLINE.
- Indiquer le titre du document.
- Fournir les noms de tous les auteurs du document dans l’ordre prévu. Normaliser le format de tous les noms, tels que tous les noms prennent la forme d’un nom de famille unique suivie de n’importe quel nombre d’initiales, par exemple Jane B. Park devient Parc JB. N’incluez pas les titres. Séparez plusieurs auteurs par un point-virgule sans ponctuation supplémentaire, tels que John A. Smith, Jane B. Park prend une forme de JA Smith ; Parc JB.
- Fournir l’année de publication du document.
- Indiquer le titre complet du journal dans lequel le document a été publié. Une liste de noms de journal contrôlé est fournie par le catalogue de la NLM (https://www.ncbi.nlm.nih.gov/nlmcatalog).
- Indiquez l’adresse de l’établissement d’attache des auteurs du document, tel que spécifié dans le document. Ceci peut inclure des ministères, des emplacements géographiques et détails de l’adresse postale.
- Si plusieurs sites sont fournis (par exemple, si les affiliations diffèrent entre les auteurs), spécifiez uniquement les détails pour l’auteur-correspondant. Si un auteur ne peut pas être identifié, utilisez celui du premier auteur, ou ne spécifiez pas une institution. Si un auteur correspondant a des appartenances multiples, spécifier à la fois et séparée par un point-virgule.
- Fournir à l’auteur correspondant du document, tel que spécifié dans l’en-tête de document en utilisant le même format que celui utilisé dans le type de données d’auteurs.
- Fournir un identificateur de document (p. ex., un PMID).
- Fournir un identificateur d’objet numérique, si possible et disponible, peut être résolue au document URL (via https://www.doi.org/), pas un PubMed Central page.
- Fournir une URL stable vers le texte intégral du document, s’il est disponible. Afin de maximiser l’accessibilité, cela peut se référer à la version de PubMed Central.
- Fournir la langue du document. Pour les documents disponibles en plusieurs langues, offrir à la fois, séparés par un point-virgule.
3. contenu médical
Remarque : Les valeurs dans cette catégorie identifient les fonctionnalités au niveau du document, niveau du concept et texte-niveau. Ils servent à améliorer l’accessibilité, l’interopérabilité et réutilisabilité un document. Ces fonctionnalités permettent d’observer des similitudes conceptuelles et sémantiques entre le contenu du document, en mettant l’accent sur les thèmes biomédicaux et événements. Plupart des catégories dans la présente section peuvent inclure plusieurs instructions texte et chacun doit être séparé par un point-virgule.
- Inclure des détails contextuels dans chaque domaine (par exemple, « la mère avait le cancer du sein à 50 ans ») plutôt que de fournir uniquement des termes d’un vocabulaire contrôlé (par exemple, pas « le cancer du sein » seul). N’incluez pas de détail étendu au-delà de chaque observation.
- Omettre des mots souvent répétés et des phrases (par exemple, les pronoms, mot « patient » et les phrases « s’est plaints de » ou « présenté avec »). Bien que subjectivité à travers de multiples annotators est susceptible, elle peut être réduite par la présence de plusieurs annotators pour chaque document et par le biais de normalisation automatique après la collecte de données. Approches de traitement informatiques varieront selon les besoins de l’analyse ultérieure et ne sont pas discutés ici en détail.
- Fournir les renseignements suivants dans le modèle de l’annotation.
- Fournir des termes spécifiques, identifiés dans un document, habituellement dans son en-tête, comme termes clés. Séparer par un point-virgule, comme modalités peuvent prévoir d’autres signes de ponctuation.
- Fournir des valeurs démographiques, notamment des déclarations de texte décrivant les antécédents du patient, y compris le sexe et/ou sexe, âge, origine ethnique ou nationalité.
- Fournir des emplacements géographiques mentionnées dans le récit clinique, autre que les adresses des institutions spécifiques. Cela ne devrait pas inclure les lieux/parties anatomiques, mais peut-être inclure n’importe quel lieu géographique où le patient réside ou se déplace.
- Fournir des valeurs de style de vie, y compris les déclarations de texte décrivant les activités patients fréquentes ou des comportements pertinents à leur état de santé général. Dans la pratique, ceci souvent consiste à fumer ou habitudes de consommation d’alcool, mais peut-être également inclure, exposition au soleil, alimentation ou la fréquence de certains types d’activité physique.
- Fournir des valeurs d’antécédents médicaux faisant référence aux antécédents familiaux. Inclure toutes affirmations de texte décrivant les observations cliniques d’et les événements vécus par les frères et sœurs, parents et autres membres de la famille. Cela inclut les maladies génétiques et des observations négatives (c.-à-d., antécédents familiaux a été négatif pour une maladie).
- Fournir des valeurs se référant à l’histoire sociale, y compris les déclarations de texte décrivant le contexte patient non couvert dans la démographie ou Style de vie. Il peut y avoir des chevauchements dans le contenu entre ces catégories. Les déclarations peuvent inclure des antécédents professionnels et les habitudes sociales.
- Fournir des valeurs se référant aux antécédents médicaux et chirurgicaux du patient. Inclure des déclarations de texte décrivant les observations médicales, les traitements ou autres événements qui se déroulent avant le début de la présentation clinique. Cela comprend les antécédents obstétricaux et les périodes de bonne santé, lorsque cela est indiqué.
- Spécifiez un ou plusieurs des catégories suivantes 16 maladie système. Notez que ces valeurs sont catégoriques plutôt que de texte libre. Catégories ne sont pas exhaustives mais devraient indiquer la plupart des systèmes affectés par les événements décrits dans le tableau clinique et diagnostiquée la maladie.
- Suivre un ensemble de catégories, basées sur les catégories spécifiques utilisés dans la Classification statistique internationale des maladies et des problèmes de santé connexes, révision 10 système de code (ICD-10). Voir le tableau 1 pour la liste des catégories de maladies système ainsi que les plages correspondantes de code CIM-10.
- Fournir des détails sur tous les signes et les symptômes. Inclure des déclarations de texte décrivant les observations médicales des signes ou symptômes dès la présentation initiale, y compris leur apparition, durée, sévérité et la résolution, si elle est fournie. N’incluez pas les symptômes décrits dans le document final. Ces valeurs peuvent se chevaucher avec d’autres types, si les symptômes persistent de l’histoire à la présentation initiale.
- Fournir les détails de toute maladies concomitantes. Inclure les termes ou les expressions décrivant les maladies distinctes présents au moment de la présentation clinique initiale. Il est susceptible de chevauchement entre ces valeurs et celles de l’histoire clinique, si comorbidité n’inclue pas les termes identiques à ceux dans le diagnostic.
- Fournir les détails de toutes les techniques de diagnostic et de procédures. Inclure les noms de procédures médicales menées à des fins diagnostiques, y compris les examens, épreuves et l’imagerie, ainsi que les conditions dans lesquelles ces tests ont été exécutées et les emplacements anatomiques (p. ex., « membre supérieur veineux « « « ultrasons »). Exclure les résultats des tests.
- Fournir les détails du diagnostic. Inclure des déclarations de texte décrivant le diagnostic de la maladie, même si le diagnostic final est ambigu.
- Fournir toutes les valeurs de laboratoire et les résultats des tests. Inclure les noms de tests diagnostiques, leurs valeurs et les conditions dans lesquelles elles ont été effectuées. Il s’agira de chevauchement avec les termes utilisés dans les Techniques de Diagnostic et le type de données de procédures. Les valeurs numériques et qualitatifs (p. ex., numération formule sanguine était dans les limites normales) sont acceptables. Si les noms des tests de diagnostic ne sont pas fournis, utiliser des termes décrivant les résultats (p. ex., leucopénie), bien qu’ils devraient également figurer dans les signes et les symptômes.
- Fournir les détails de la pathologie. Inclure des déclarations de texte décrivant les résultats des études de pathologie et de l’histologie, y compris les études de pathologie et immunologie microscopie bruts. Conditions pourraient correspondre à ceux utilisés dans les Techniques de Diagnostic et de procédures (étape 3.11), par exemple, avec les procédures effectuées pour obtenir des échantillons comme la biopsie.
- Fournir toutes les thérapies pharmacologiques. Inclure des déclarations de texte décrivant les traitements médicamenteux utilisés dans le cadre du traitement, y compris des termes généraux tels que les antibiotiques ou les noms de médicaments spécifiques. En outre, comprennent des descriptions de quand et comment les traitements médicamenteux ont été arrêtés.
- Fournir toutes les procédures interventionnelles. Inclure des déclarations de texte décrivant les procédures thérapeutiques utilisés dans le cadre du traitement, y compris les procédures invasives, l’implantation de dispositifs médicaux et les procédures prises pour faciliter les autres thérapies. En outre, comprennent des descriptions de quand et comment les procédures thérapeutiques en cours ont été arrêtées, si nécessaire.
- Fournir les résultats pour les patients. Inclure des déclarations de texte décrivant la santé du patient à la fin de la présentation clinique décrite dans le rapport, y compris des tests de suivi.
- Fournir des chefs d’accusation de toutes les images diagnostiques, les illustrations, vidéos/animations et tables. Inclure tous les chefs des médias visuels inclus dans le rapport, selon le format suivant : nombre d’images ; Nombre de chiffres ; Nombre des vidéos ou des animations ; Nombre de tables.
- Faire la distinction entre les images et les chiffres de cette manière : images comprennent tous les produits de diagnostic clinique, y compris les photographies, les micrographies, électrocardiogramme rythme images et autres produits d’imagerie diagnostique, tandis que les chiffres sont toutes les autres images, généralement y compris les emplacements de données et illustrations.
- Fournir la preuve de relations aux autres CCT. Ce champ peut inclure des identificateurs (par exemple, PMIDs) d’autres rapports dans l’ensemble des données citées par ou faisant référence à ce rapport.
- Fournir la preuve de relations aux essais cliniques. Ce champ peut inclure des identificateurs des essais cliniques, citant ce CCR. Identifier les essais par leur identificateur ClinicalTrials.gov, précédée par la NCT, ou tout autre identifiant stable.
- Inclure des croisements de base de données correspondant à ce document, y compris les identificateurs, de préférence sous les noms de base de données et stable URL.
4. remerciements
Notes : Valeurs dans cette catégorie identifient les fonctionnalités au niveau du document, mais ont peu de structure cohérente à travers des publications. Ils fournissent des détails concernant les organisations fournit un appui pour un CCR et travaux connexes. Cette catégorie comprend également un champ pour le nombre total de références citées par un article : il est destiné à fournir une mesure approximative du degré auquel un document possède des relations conceptuelles avec d’autres documents de recherche biomédicales de n’importe quel type. Dans les quatre types dans cette section, fournir les renseignements suivants.
- Indiquez toutes les sources de financement appuyant les travaux et correspondant PI ainsi que les numéros de prix pertinents. La première valeur, Source de financement, doit inclure les noms de toutes les organisations apportant un soutien financier pour le travail.
- Organisations séparées par des points-virgules et espaces, par exemple, Instituts nationaux de santé/National Cancer Institute; DOE; Smith-Park Foundation .
- Pour la valeur suivante, le nombre de prix, indiquer n’importe quel nombre de prix ou désignations spécifiques ainsi que les récipiendaires des prix, le cas échéant, comme initiales des bénéficiaires entre parenthèses, par exemple, R01HL123123 (pour JP) , NS12312 (pour JP, JS), bourse de formation de recherche (de JS). Auteurs peuvent indiquer explicitement qu’aucune information correspondante est disponible (par exemple, « aucun financement n’a été reçu ») ; dans ces cas, utilisez le texte fourni par les auteurs comme la valeur de la Source de financement. Dans le cas contraire, la valeur doit être na
- Spécifier les divulgations et les conflits d’intérêt tel que spécifié par les auteurs, par exemple, JP est consultant pour DrugCo. Auteurs peuvent indiquer explicitement qu’aucune information correspondante est disponible (par exemple, « aucun conflit d’intérêts n’est déclaré ») ; dans ces cas, utilisez le texte fourni par les auteurs comme le divulgations/conflit de valeur de l’intérêt. Dans le cas contraire, comme ci-dessus, la valeur doit être na
- Spécifiez un compte numérique de toutes les références citées par le document, sans compter celles qui sont prévues dans les documents supplémentaires. Aucun texte de référence ne devrait être inclus dans ce domaine.
Résultats
Un exemple du processus d’annotation est illustré à la Figure 2. Cette affaire22 décrit une présentation de l’infection par la bactérie pathogène de Burkholderia thailandensis. Pour référence, la partie pertinente de cette CCR est fournie au format texte brut supplémentaire 1 fichier; certains résultats de la recherche sont également présentées dans le présent rapport et sont inclus à titre de comparaison. Dans la pratique, la conversion de rapports fournis au format HTML ou PDF en texte brut peut améliorer l’efficacité et la facilité d’extraction de métadonnées.
Des exemples de deux ensembles d’annotations de métadonnées CCR remplies figurent au tableau 2. Le premier de ces exemples est données fictives pour illustrer le format idéal de chaque valeur, tandis que le deuxième exemple contient des valeurs extraites d’un CCR publié sur une maladie rare, Acrodermatite enteropathica23.

Figure 1. Flux de travail pour l’Annotation de rapport de cas. Le protocole décrit ici fournit une méthode pour l’identification des caractéristiques textuelles souvent présents dans les rapports de cas cliniques. Ce processus exige l’assemblage d’un corpus de document. Le produit du processus d’annotation, une fois regroupé en un seul fichier, permet l’identification des fonctionnalités de texte associées à des concepts médicaux et leur description dans les rapports de cas. S’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
{kind=link}

Figure 2. Identification du Concept spécifique dans un rapport de cas clinique. En commençant par le texte d’un rapport de cas, un annotateur manuelle peut évoluer à travers le document, identifier les segments de texte correspondant à chaque élément du modèle de métadonnées. Éléments d’identification sont surlignées en bleu. Texte correspondant aux concepts médicaux est en rouge et marqués avec leur type ; tout le texte en surbrillance dans la troisième colonne désigne le type de pathologie. S’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
{kind=link}
| Catégorie | Description | CIM-10 chapitre | Plage de codes CIM-10 |
| cancer | N’importe quel type de cancer ou tumeurs malignes. | II | C00-D49 |
| nerveux | Toute maladie du cerveau, colonne vertébrale ou de nerfs. | VI | G00-G99 |
| cardiovasculaire | Toute maladie du cœur ou du système vasculaire. N’inclut pas les maladies hématologiques. | IX | I00-I99 |
| musculo-squelettiques et rhumatismales | Toute maladie des muscles, système squelettique, articulations et les tissus conjonctifs. | XIII | M00-M99 |
| digestif | Toute maladie du tube digestif et organes digestifs, y compris le foie et le pancréas. | XI | K00-K95 |
| obstétricale et gynécologique | Toute maladie relatifs à la grossesse, l’accouchement, le système reproducteur féminin ou les seins. | XIV ; XV | O00-O9A ; N60-N98 |
| infectieuses | Toute cause de maladie par les microorganismes infectieux. | J’ai | A00-B99 |
| respiratoire | Toute maladie des poumons et des voies respiratoires. | X | J00-J99 |
| hématologique | Toute maladie du sang, moelle osseuse, ganglions lymphatiques ou rate. | III | D50-D89 |
| rénaux et urologiques | Une maladie des reins ou la vessie, y compris les uretères, ainsi que les organes reproducteurs mâles, y compris la prostate. | XIV | N00-N53 ; N99 |
| système endocrinien | Toute maladie de la glandes endocrines, mais aussi des troubles métaboliques. | IV | E00-E89 |
| buccale et maxillofaciale | Toute condition impliquant la bouche, mâchoires, tête, visage ou cou. | XI ; XIII | K00-K14 ; M26-M27 |
| œil | Toute condition faisant intervenir les yeux, y compris la cécité. | VII | H00-H59 |
| oto-rhino-laryngologiques | Toute condition de l’oreille, nez ou de la gorge. | VIII | H60-H95 ; J30-J39 |
| peau | Toute maladie de la peau. | XII | L00-L99 |
| rare | Une catégorie spéciale réservée aux rapports des maladies rares, définies comme celles ayant une incidence sur moins de 200 000 personnes aux États-Unis (Voir https://rarediseases.info.nih.gov/diseases) | NA | NA |
Tableau 1. Catégories de maladies pour l’Annotation de Document. Les catégories répertoriées ici sont celles à utiliser pour le type de données du système de la maladie dans le modèle de métadonnées du document. Car chaque présentation de maladies peut-être provoquer des systèmes organiques ou des étiologies multiples, un seul rapport de cas clinique peut correspondre à plusieurs catégories. Ces catégories suivent en grande partie celles qui sont utilisées pour différencier les sections de la Classification statistique internationale des maladies et des problèmes de santé connexes, révision 10 (CIM-10) code système : CIM-10 chapitres et gammes de code sont fournis. Certaines catégories, comme celle de maladie buccale et maxillofaciale , correspondent à plusieurs sections du système CIM-10.
| Type de données | Exemple #1 | Exemple #2 (Cameron et McClain 1986) |
| Document et Identification de l’Annotation | ||
| ID interne | CCR005 | CCR2000 |
| Date de l’annotation | 2 mars 2018 | 1er mars 2018 |
| Identification de rapport de cas | ||
| Titre | Un cas d’endocardite. | Oculaire histopathologie du col Acrodermatite enteropathica. |
| Auteurs | Grant AB ; CD de Chang | Cameron JD ; McClain CJ |
| Année | 2017 | 1986 |
| Journal | Journal du monde de la médecine et les rapports de cas | British Journal of Ophthalmology |
| Institution | Département de médecine, Division de cardiologie, premier General Hospital, Boston, Massachusetts, é.-u. | Département d’ophtalmologie, Faculté de médecine de l’Université du Minnesota, Minneapolis, Minnesota 55455 |
| Auteur correspondant | Grant AB | Cameron JD |
| PMID | 25555555 | 3756122 |
| DOI | 10.1011/wjmcr.2017.11.001 | NA |
| Lien | https://www.ncbi.nlm.nih.gov/PMC/Articles/PMC9555555/ | https://www.ncbi.nlm.nih.gov/PMC/Articles/PMC1040795/ |
| Langue | Anglais | Anglais |
| Contenu médical | ||
| Mots clés | brucellose ; endocardite ; valve mitrale | NA |
| Démographie | homme de 37 ans | enfant de sexe masculin |
| Emplacements géographiques | La Floride ; Rio de Janeiro, Brésil | NA |
| Style de vie | fumeur ; boit de l’alcool occasionnellement | NA |
| Antécédents familiaux | troisième des cinq enfants de parents consanguins ; frère cadet a eczéma chronique | NA |
| Histoire sociale | travailleur de la construction | NA |
| Antécédents médicaux/chirurgicaux | histoire de la fatigue | 8 livres 9 onces (3884 g) produit d’une grossesse sans complication nés à terme ; en bonne santé jusqu'à l’âge de 1 mois quand il a développé une éruption cutanée cloques sur ses joues ; éruption cutanée se propager d’impliquer la peau autour des yeux, le nez et la bouche ; lésions cutanées ont également été observées sur l’abdomen et des extrémités ; diarrhée et retard staturo-pondéral ; biopsie de la peau à ce moment-là a montré parakeratosis typique d’Acrodermatite enteropathica ; traitée pendant les six prochaines années, avec des cours intermittents des antibiotiques à large spectre, le lait maternel et diodoquin ; partiellement répondu ; mis au point l’alopécie totale, Acrodermatite intermittent et diarrhée intermittente avec gain de poids sous-optimale ; spasticité attribuée à l’implication du système nerveux central par l’ae a mis au point par 8 mois d’âge ; plusieurs épisodes d’un arrêt cardiorespiratoire à 11 mois ; manque de coordination de ses cordes vocales ; trachéotomie ; Selon l’âge de 18 mois, l’enfant a développé la recherche un nystagmus associé à une atrophie optique bilatérale et légère atténuation des vaisseaux rétiniens, ainsi que des signes de retard psychomoteur ; kératoconjonctivite bilatérale ; éruption cutanée ; deuxième biopsie cutanée effectuée à 3 ans de plus montré parakeratosis typique pour ae ; éruption cutanée sévère et la diarrhée ; bilatéraux bruts antérieur les opacités cornéennes ont été vus qui avait complètement résolue au moment où qu'il a été réexaminé à l’âge de cinq ; infections fréquentes, notamment les otites, infections des voies urinaires et infections de la peau |
| Système de maladie | cardiovasculaire ; infectieuses | digestif ; peau ; œil ; rare |
| Signes et symptômes | palpitations et dyspnée la semaine précédente ; présenté avec frissons, maux de tête et léthargie | blepharoconjunctivitis sévère et bilatérale vascularisation cornéenne antérieure ; éruption cutanée sévère et la diarrhée ; septicémie bactérienne Gram négative ; lésions cutanées typiques d’Acrodermatite enteropathica, absence de tissu thymique, marqué la dégénérescence des nerfs optiques, chiasma et tractus optiques et dégénérescence cérébelleuse étendue |
| Comorbidité | hypertension ; hyperlipidémie | NA |
| Procédures et Techniques diagnostiques | Examen physique ; Électrocardiographie ; hémocultures | Examen oculaire ; nécropsie |
| Diagnostic | Endocardite Brucella | Acrodermatite enteropathica |
| Valeurs de laboratoire | augmentation de la protéine c - réactive (9 mg/dl) ; phosphatase alcaline (250 u/l) | NA |
| Pathologie | Brucella melitensis a été cultivé à partir des échantillons de sang | les yeux droit et gauche sont semblables en apparence ; l’épithélium cornéen est réduite en épaisseur d’un à trois couches de cellules des cellules épithéliales squameuses aplaties sur toute la surface de la cornée ; toutes les polarités de l’épithélium a été perdue. membrane de Bowman pourrait être identifié que dans la périphérie de la cornée droite. membrane de bowman, pas pu être identifié dans la cornée gauche. pannus, ni dégénérative inflammatoire pouvait être identifié dans chaque œil ; une atrophie des muscles circulaires et obliques du corps ciliaire ; certaines migrations postérieures de lentille épithélium capsulaire et premières modifications dégénératives corticales ; une dégénérescence de l’épithélium pigmentaire rétinien dans l’ensemble du pôle postérieur ; rétine était attaché et a montré de légers changements autolytiques tout au long ; certains préservation du cône et la tige des segments externes au pôle postérieur, cependant, ces structures ont été complètement perdus antérieur à l’Équateur ; perte importante des ganglion cellule nerveuse fibre couches et des deux yeux ; atrophie presque complète du disque et adjacent nerf optique |
| Thérapie pharmacologique | gentamycine 240 mg/iv/jour | NA |
| Inverventional thérapie | remplacement valvulaire prothétique | NA |
| Évaluation des résultats pour les patients | récupération se déroule sans incident ; maison déchargée | mort en 1971 (7 ans) |
| Diagnostic Imaging/bande vidéo enregistrement | 2, 1, 0, 1 | 7 ; 0 ; 0 ; 0 |
| Relation avec les autres rapports de cas | 5555555 | 23430849 |
| Relation avec le procès Clinial | NCT05555123 | NA |
| Crosslink avec base de données | Information sur la santé de MedlinePlus : https://medlineplus.gov/ency/article/000597.htm | HighWire - PDF : http://bjo.bmj.com/cgi/pmidlookup?view=long&pmid=3756122; L’Europe PubMed Central : http://europepmc.org/abstract/MED/3756122; Alliance de génétique : http://www.diseaseinfosearch.org/result/143 |
| Remerciements | ||
| Source de financement | National Institutes of Health/National Heart, Lung, and Blood Institute | Le Lions Club de Minnesota ; Recherche pour prévenir la cécité ; Administration des anciens combattants ; Office of Alcohol and Other Drug Abuse de programmation de l’état du Minnesota |
| Nombre de prix | R01HL123123 (à l’AG) | NA |
| Divulgations/conflit d’intérêts | Dr. Grant est un porte-parole payé pour DrugCo. | NA |
| Références | 4 | 27 |
Le tableau 2. Modèle de métadonnées normalisées pour cas clinique recense avec Annotations exemple. Un ensemble de caractéristiques communes aux cas clinique rapports et faciliter leurs annotations au niveau concept est illustré ici. Ce modèle est organisé en trois sections principales : Identification, contenu médical et les accusés de réception, indiquant l’objet et la valeur ajoutée offerte par chaque type de fonctionnalité de rapport de cas. Ce tableau contient deux jeux d’annotations d’exemple, l’un d’un rapport de cas romancé, et une autre série dérivée d’un rapport sur l’État Acrodermatite enteropathica23.
Fichier complémentaire 1. Texte d’un rapport de cas clinique (Chang et al. 2017). s’il vous plaît cliquez ici pour télécharger ce fichier.
Discussion
Mise en œuvre d’un modèle de métadonnées normalisées pour la CCT peut faire leur juste plus contenu, élargir leur audience et étendre leurs applications. Suite à l’utilisation traditionnelle du CCT comme outils pédagogiques en communication médicale, stagiaires de soins de santé (p. ex., les étudiants en médecine, stagiaires et boursiers) et des chercheurs biomédicaux peuvent trouver que contenu Résumé rapport cas permettre plus rapide compréhension. La plus grande force de la normalisation des métadonnées avec la CCT, cependant, est que l’indexation de ces transformations de données sinon isolé observations en motifs interprétables. Le protocole fourni ici peut servir comme la première étape dans un flux de travail pour travailler avec la CCT, si ce flux de travail se compose d’analyse épidémiologique, drogue après la commercialisation ou surveillance de traitement des enquêtes plus larges de pathogénie ou efficacité thérapeutique. Caractéristiques structurées identifiées au sein de la CCT peuvent fournir une ressource utile pour les chercheurs en se concentrant sur les présentations de la maladie et les traitements, en particulier pour les maladies rares. Cliniciens-chercheurs peuvent trouver des données sur les schémas thérapeutiques passées à analyser les symptômes enregistrés ou effets secondaires et le degré d’amélioration en vertu des anciennes normes de soins. Les données peuvent conduire également des analyses plus larges d’un nouveaux traitements base efficacité, absence de toxicité, ou les effets indésirables ou de médicament ciblant les différences de sexe, groupe d’âge ou les antécédents génétiques.
Les avantages de métadonnées structurées sont de même applicables aux flux de travail informatique conçu pour analyser ou modéliser le langage médical. Caractéristiques CCR structurés peuvent également fournir des teneur en évidence des domaines où les auteurs du rapport peuvent fournir plus facilement lisible par une machine (et dans certains cas, lisible par l’homme). Écart entre la CCT peut résulter d’un manque d’observations explicitement fournis : par exemple, âge exact du patient ne peut pas être spécifié. De même, les cliniciens ne devez mentionner essais si les diagnostics ou leurs résultats étaient considérés comme triviales. En fournissant des exemples de lacunes nécessaires à une analyse approfondie, application de la structure sur la CCT met en évidence les améliorations potentielles. Dans une perspective plus large, une plus grande disponibilité des données de texte structuré de documents médicaux soutient des efforts (PNL) pour en tirer des données volumineuses dans les soins de santé24,25de traitement du langage naturel.
Déclarations de divulgation
Les auteurs n’ont rien à divulguer.
Remerciements
Ce travail a été soutenu en partie par le National Heart, Lung, and Blood Institute : R35 HL135772 (à la P. Ping) ; National Institute of General Medical Sciences : U54 GM114833 (à la P. Ping, K. Watson et Wang W.) ; National Institute of Biomedical Imaging and Bioengineering : T32 EB016640 (d’a. Bui) ; un don de la Fondation de Hoag et Dr. S. Setty ; et la dotation de T.C. Laubisch à UCLA (à la P. Ping).
matériels
| Name | Company | Catalog Number | Comments |
| A corpus of clinical case reports | n/a | n/a | Full texts of case reports may be accessed through PubMed (e.g., using the search query "Case Reports"[Filter]), other citation databases such as Europe PMC (https://europepmc.org/) or directly through publishers. |
Références
- Ban, T. A. The role of serendipity in drug discovery. Dialogues in Clinical Neuroscience. 8 (3), 335-344 (2006).
- Cabán-Martinez, A. J., García-Beltrán, W. F. Advancing medicine one research note at a time: the educational value in clinical case reports. BMC Research Notes. 5 (1), 293(2012).
- Vandenbroucke, J. P. In Defense of Case Reports and Case Series. Annals of Internal Medicine. 134 (4), 330(2001).
- Bayoumi, A. M. The storied case report. Canadian Medical Association Journal. 171 (6), 569-570 (2004).
- Pasteur, L. Méthode pour prévenir la rage après morsure. Comptes rendus de l'Académie des Sciences. 101, 765-774 (1885).
- Pearce, J. Louis Pasteur and Rabies: a brief note. Journal of Neurology, Neurosurgery & Psychiatry. 73 (1), 82-82 (2002).
- Keefer, C. S., Blake, F. G., Marshall, E. K. J., Lockwood, J. S., Wood, W. B. J. PENICILLIN IN THE TREATMENT OF INFECTIONS. Journal of the American Medical Association. 122 (18), 1217(1943).
- Akers, K. G. New journals for publishing medical case reports. Journal of the Medical Library Association JMLA. 104 (2), 146-149 (2016).
- Wilkinson, M. D., et al. The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data. 3, 160018(2016).
- Beeler, G. W. HL7 Version 3-An object-oriented methodology for collaborative standards development. International Journal of Medical Informatics. 48 (1-3), 151-161 (1998).
- HL7 FHIR Release 3 (STU; v3.0.1-11917). , Available from: http://hl7.org/implement/standards/fhir/ (2018).
- McDonald, C. J. LOINC, a Universal Standard for Identifying Laboratory Observations: A 5-Year Update. Clinical Chemistry. 49 (4), 624-633 (2003).
- CDC/National Center for Health Statistics ICD-10-CM Official Guidelines for Coding and Reporting. , Available from: https://www.cdc.gov/nchs/data/icd/10cmguidelines_fy2018_final.pdf (2017).
- Rajeev, D., et al. Development of an electronic public health case report using HL7 v2.5 to meet public health needs. Journal of the American Medical Informatics Association. 17 (1), 34-41 (2010).
- Biesecker, L. Mapping phenotypes to language: a proposal to organize and standardize the clinical descriptions of malformations. Clinical Genetics. 68 (4), 320-326 (2005).
- Riley, D. S., et al. CARE guidelines for case reports: explanation and elaboration document. Journal of Clinical Epidemiology. 89, 218-235 (2017).
- Cohen, K. B., et al. Coreference annotation and resolution in the Colorado Richly Annotated Full Text (CRAFT) corpus of biomedical journal articles. BMC Bioinformatics. 18 (1), 372(2017).
- Sun, W., Rumshisky, A., Uzuner, O. Evaluating temporal relations in clinical text: 2012 i2b2 Challenge. Journal of the American Medical Informatics Association. 20 (5), 806-813 (2013).
- Savova, G. K., et al. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): architecture, component evaluation and applications. Journal of the American Medical Informatics Association. 17 (5), 507-513 (2010).
- Soysal, E., et al. CLAMP - a toolkit for efficiently building customized clinical natural language processing pipelines. Journal of the American Medical Informatics Association. 25 (3), 331-336 (2018).
- Bender, D., Sartipi, K. HL7 FHIR: An Agile and RESTful approach to healthcare information exchange. Proceedings of the 26th IEEE International Symposium on Computer-Based Medical Systems. , 326-331 (2013).
- Chang, K., et al. Human Infection with Burkholderia thailandensis, China, 2013. Emerging Infectious Diseases. 23 (8), 1416-1418 (2013).
- Cameron, J. D., McClain, C. J. Ocular histopathology of acrodermatitis enteropathica. British Journal of Ophthalmology. 70 (9), 662-667 (1986).
- Maddox, T. M., Matheny, M. A. Natural Language Processing and the Promise of Big Data. Circulation: Cardiovascular Quality and Outcomes. 8 (5), 463-465 (2015).
- Kreimeyer, K., et al. Natural language processing systems for capturing and standardizing unstructured clinical information: A systematic review. Journal of Biomedical Informatics. 73, 14-29 (2017).
Réimpressions et Autorisations
Demande d’autorisation pour utiliser le texte ou les figures de cet article JoVE
Demande d’autorisationThis article has been published
Video Coming Soon
À PROPOS DE JoVE
Copyright © 2025 MyJoVE Corporation. Tous droits réservés.