
需要订阅 JoVE 才能查看此. 登录或开始免费试用。
Method Article
使用胆汁分解探索阅读技能之间纵向关系中的个体差异
摘要
本文演示了金标准法在行为遗传学中的运用,Cholesky分解法,以估计不同变量的独特、重叠遗传和环境影响,以回答纵向动机的研究问题。
摘要
胆汁分解法是行为遗传学领域使用的黄金标准。该方法很受欢迎,因为它易于编程和解决。使用这种方法,研究人员可以探索不同变量在多个时间点的纵向关系中的个体差异。该方法允许调查人员将方差分解为 (1) 在特定时间点产生的独特遗传、共享和非共享环境影响,以及 (2) 从一个点延续的重叠遗传、共享和非共享环境影响时间指向另一个。但是,该方法不识别这些影响背后的机制或来源。本报告着重论述了科尔斯基分解方法在教育心理学领域的应用。具体来说,论述了幼儿园字母知识、幼儿园语音意识、一年级单词水平阅读技巧和七年级阅读理解之间纵向关系的差异。
引言
成为一名熟练的读者,能够流利地阅读和理解文本,对于孩子的学习成绩非常重要。为了防止阅读问题的发展,了解不同的阅读技能在多大程度上预测阅读理解至关重要。现有研究表明,小学的阅读前和单词水平阅读能力纵向预测中学1、2的阅读理解能力。这些预测的个体差异主要指向从幼儿园到四年级三年级、四年级的基本遗传(以及在某种程度上是环境)因素。然而,有必要探讨这些相同的遗传和环境因素是否继续影响这些预测,到中学成绩。
更好地了解中小学阅读技能之间关联个体差异的一种方法是使用行为遗传方法,特别是Cholesky分解方法。胆汁分解法被认为是行为遗传学中的金标准分析之一。该方法易于编程和求解,并允许将方差和协方差分解为 (A) 遗传、(C) 共享环境以及 (E) 非共享环境影响,通常以双胞胎样本的形式进行。图1中所示的单变量(一个变量)胆囊分解的例子。A潜在因素是指遗传效应,遗传效应是从父母遗传的遗传影响。C潜在因素是指共同的环境影响,这是环境的各个方面,使双胞胎更相似,如家庭和学校环境。最后,E潜移默化因素是指非共享的环境影响,这是每个双胞胎所特有的环境影响,并造成双胞胎之间的差异,例如每个双胞胎自己的经验。E 因子还捕获测量误差。

图1:分解为(A)遗传、(C)共享环境和(E)非共享环境影响。请点击此处查看此图的较大版本。
{kind=link}
图 1中的 A、C 和 E 因子估计了基因和环境对一个(读数)变量的影响程度。然而,要调查从小学到中学多个阅读技能之间的纵向关联背后的个体差异,纵向分析是必要的。为了回答纵向动机的研究问题,这里使用了多变量Cholesky分解方法5。从概念上讲,多变量Cholesky分解方法类似于分层多重回归,因此,在将先前因素的贡献纳入后,对遗传和环境因素的独立贡献进行评估帐户。
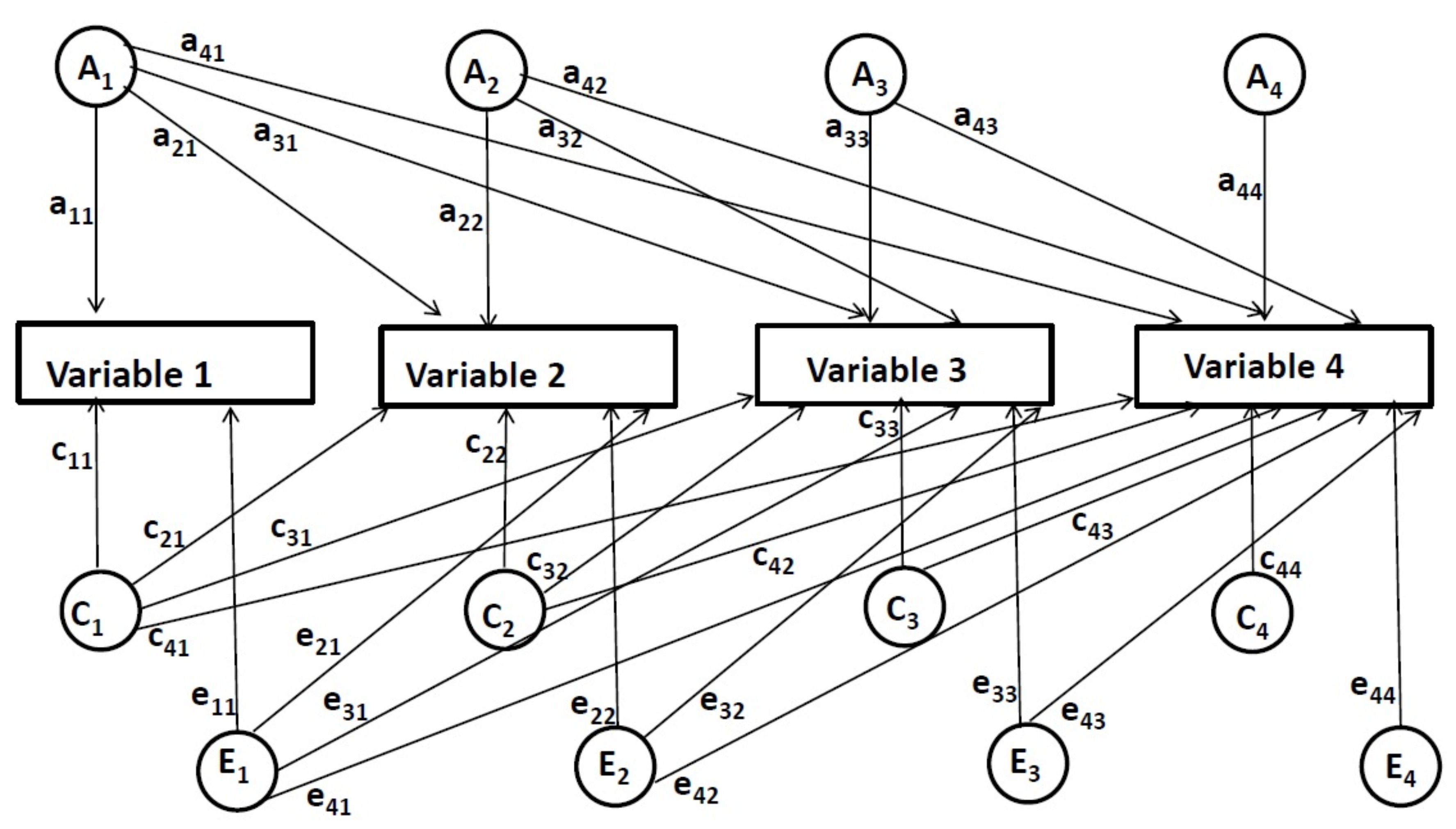
例如,在四个时间点的纵向数据(参见图2)的多变量Cholesky分解中,第一组因子[遗传(A1)、共享环境(C1)和非共享环境(E1)]。所有变量的方差,表示为路径 a11、a21、a31、a41、c11、c21、...、e11等,从 A1、C1、E1因子到每个变量.第二组因子(A2、C2、E2)在第一次控制点后,会促成第二个和后续变量的方差。第二组因子表示为路径 a22、32、42、c22、c32、...、e22等。然后,在第三组因子(A3、C3、E3)的控制前两个时间点后,估计第三和第四个变量的影响。它们代表为路径a33,a43,c33,c43,e33,e 43。 最后,对控制所有先前时间点后的最后一个时间点测量第四组因子(A4、C4、E4)的影响。它们被表示为路径 a44,c44,e44。

图2:四个时间点的多变量Cholesky分解模型。请点击此处查看此图的较大版本。
{kind=link}
在多变量Cholesky分解法的纵向应用中,在控制前时间点的影响后,估计每个时间点对遗传和环境影响的影响。因此,此方法允许确定独特的遗传和环境影响在每个特定时间点在线的程度,而与以前时间点的影响无关(这些影响由路径 11、a 22,a33,a 44,c11, c22, ..., e11, e22,等等).此外,该方法还能够检查相同(重叠)遗传和环境影响在时间点之间共享的程度。换句话说,可以确定遗传和环境影响从一个时间点到另一个时间点的程度(即,这些影响是由路径 21、31、41、32、a42、aa a) 估计的。43,c21,c31, ..., e21等).需要注意的是,路径11,c11和e11表示所有可能的遗传和环境影响,最多包括第一时间点,它可以是唯一的或与以前的时间点重叠。但是,不估计第一时间点之前的时间点;因此,不能准确地确定它们代表唯一的影响还是重叠的影响。为简化起见,它们作为独特影响列入本报告。
输入到 Cholesky 分解中的测量变量的顺序是任意的。但是,顺序通常由理论视角驱动。在目前的研究中,情况也如此,其顺序是基于阅读技能的发展,因此,小学的阅读技能是中学阅读理解的预测。
文献中有几份报告,利用Cholesky分解方法,调查了阅读技能纵向关联背后的遗传和环境因素。这些先前的研究主要集中于调查小学生阅读技能之间的关系。只有一项已发表的研究,用多变量Cholesky分解方法8,检验了从小学到中学年级的阅读与个人差异。本协议详细介绍了该具体报告中的多变量Cholesky分解方法,以探讨幼儿园字母知识、幼儿园语音意识、一年级字级之间纵向关系的差异阅读技巧,七年级阅读理解。
研究结果侧重于使用多变量Cholesky分解方法来区分两种类型的遗传和环境影响。首先,它展示了如何估计遗传和环境影响,从小学到中学阅读(例如,估计路径43,c43和e43,这是遗传和环境影响一年级影响阅读理解的一年级阅读技能)。其次,它展示了如何估计在每个特定级别上出现的独特遗传和环境影响(例如,估计路径为 33、c33和 e33,这些路径是独特的遗传和环境影响。一年级产生的字级阅读技能)。
Access restricted. Please log in or start a trial to view this content.
研究方案
以下步骤描述了将小学和中学阅读技能之间的纵向关联估计到 (A) 遗传、(C) 共享环境以及 (E) 使用统计建模程序、字处理器和具有图形用户界面 (GUI) 的软件。这项研究已经获得佛罗里达州立大学机构审查委员会的批准。
1. 为统计建模程序准备数据
- 以可由所选择的统计建模程序读取的格式准备数据。流行的统计建模程序包括Mx、平台R中的OpenMx和MPlus9。Mx 可以读取 .vl 或 .dat 数据格式的数据文件,以任何数据格式读取 OpenMx,以 .dat 数据格式读取 Mplus。此处演示的示例在程序 MPlus9中执行。
注: 补充文件中提供了六个随机选择的参与者的 .dat 格式的示例数据文件。示例数据文件中使用的变量反映输入编码文件中使用的变量。
2. 将数据读取到统计建模程序,运行脚本,并估计效果
- 打开统计建模程序。
- 通过键入"文件是 [在计算机上插入数据文件的位置]",找到要读取到统计建模程序中的相关数据文件。
- 单击统计建模程序功能区上的图标RUN,从多变量 Cholesky 分解方法获取遗传、共享环境和非共享环境影响的估计值。在补充编码文件中可以找到四个时间点的多变量 Cholesky 分解模型及其输出的符号输入脚本。
- 一旦统计建模程序生成遗传、共享环境和非共享环境影响的估计值,请在 stx11下的输出文件中为路径 a11,stx21为路径 a21找到估计值。,sty11表示路径 c11,sty 21表示路径 c21,...,stz11表示路径 e11,stz21表示路径 e21,等等。
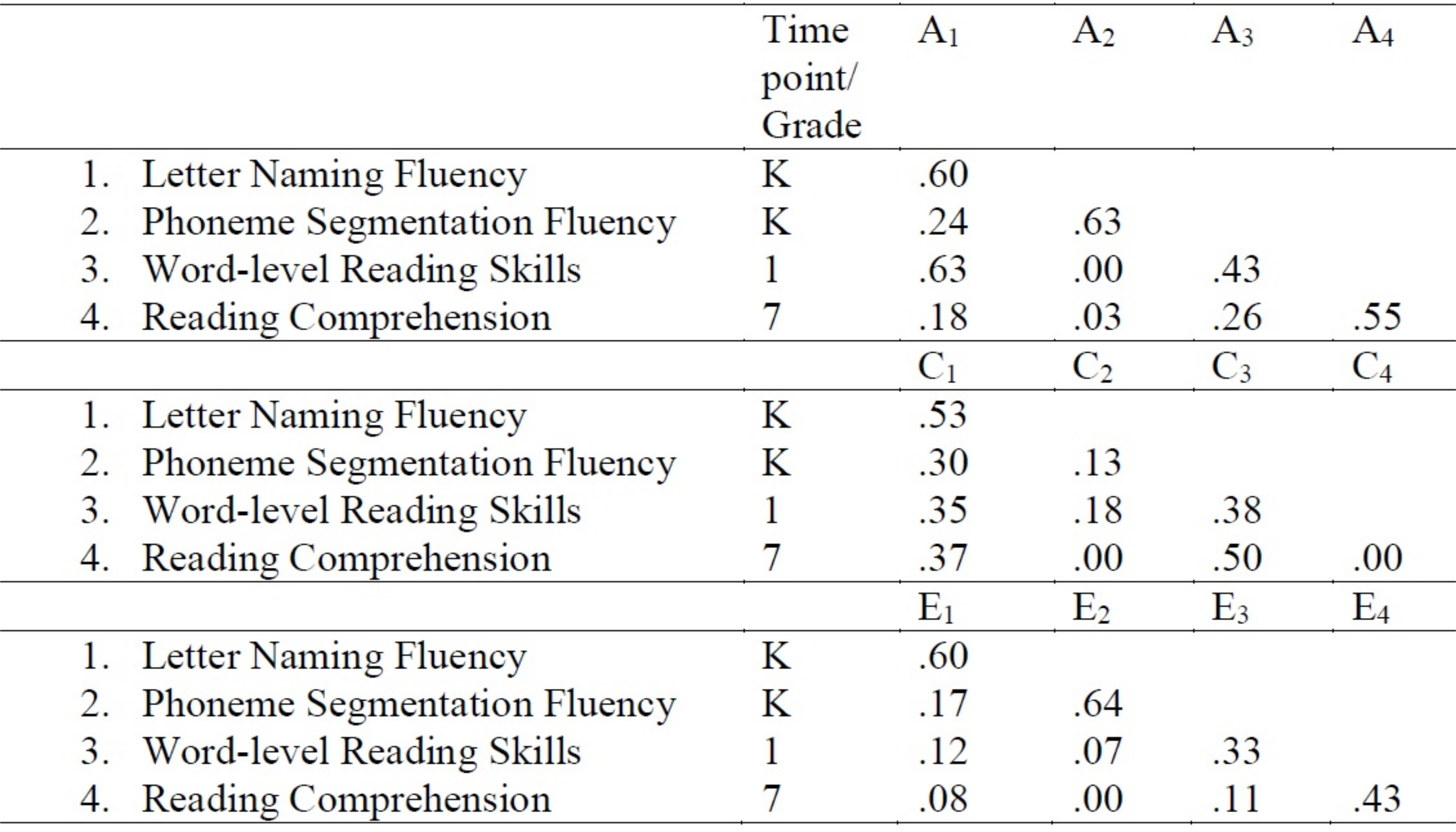
3. 创建具有生成的估计值的表
- 打开字处理器。
- 将生成的估计值复制到字处理器中的表中。该表可以创建为如图 3所示的格式。例如,在本例中,路径 a11、a21、a31和41的估计值分别为 0.60、0.24、0.63 和 0.18。

图3:多变量Cholesky分解建模标准化路径估计遗传和环境影响。请点击此处查看此图的较大版本。
{kind=link}
4. 绘制遗传、共享环境和非共享环境影响图
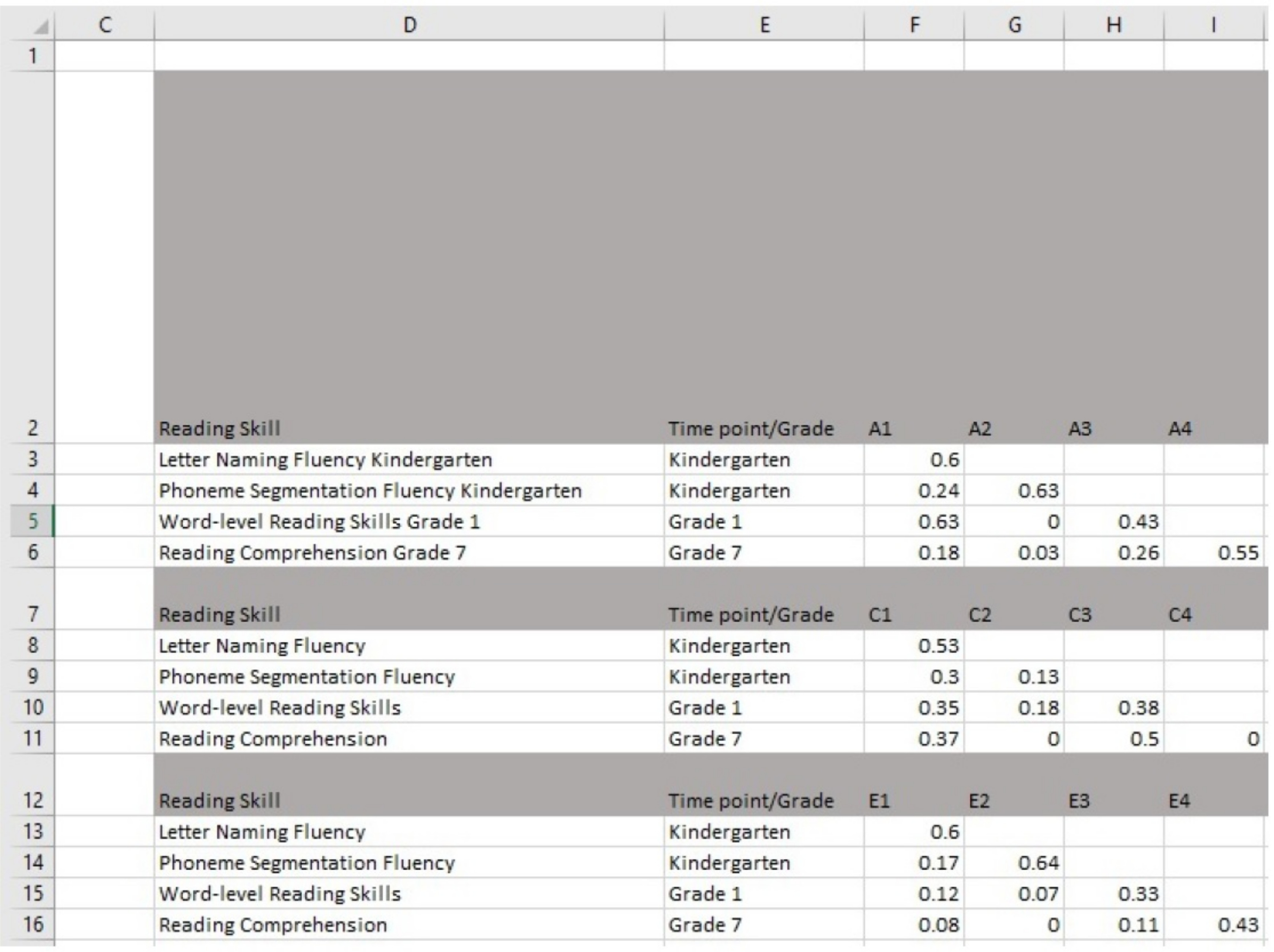
- 使用 GUI 打开软件。
- 将创建的表中的估计值输入单元格 F3-F16、G4-G16、H5-H16 和 I6-I16。图 4中描述了带有 GUI 的软件中的屏幕截图。

图 4:使用 GUI 在软件中输入估计值。请点击此处查看此图的较大版本。
{kind=link}
- 通过在细胞 F3-F16、G4-G16、H5-H16 和 I6-I16 中计算估计值,计算遗传、共享环境和非共享环境影响的方差。在单元格 J3-J16、K4-K16、L5-L16 和 M6-M16 中键入平方值。
- 通过将单元格 J3-J16、K4-K16、L5-L16 和 M6-M16 中的值乘以 100 来计算百分比方差。在单元格 N3-N16、O4-O16、P5-P16 和 Q6-Q16 中键入百分比值。步骤 4.3 和 4.4 如图5所示。

图 5:步骤 4.3 和 4.4 的插图。请点击此处查看此图的较大版本。
{kind=link}
- 计算遗传影响从小学到中学的延续(重叠)程度。
- 在单元格 R3 中,键入"0"。
- 在单元格 R4 中,键入"_N4"。这是从第一个时间点到第二个时间点的基因影响的程度。在这种情况下,它表明遗传影响从字母命名流利在幼儿园进行到音标分割流利在幼儿园。
- 在单元格 R5 中,键入"= N5_O5"。这是遗传影响从前两个时间点延续到第三个时间点的程度。在这种情况下,它表明遗传影响从字母命名流利在幼儿园和音线细分流利在幼儿园进行字级阅读技能在一年级。
- 在单元格 R6 中,键入"= N6_O6_P6"。这是遗传影响从前三个时间点延续到第四个时间点的程度。在这种情况下,它表明遗传影响从字母命名流利在幼儿园,音线细分流利在幼儿园,字级阅读技能在一年级进行阅读理解在7年级。
- 计算共同的环境和非共享环境影响在小学到中学的延续(重叠)程度,就像第4.5步一样。
- 计算每个特定时间点(即等级)中独特的遗传、共享环境和非共享环境因素在线的程度。
- 将细胞N3、O4、P5和Q6的百分比分别复制到细胞S3、S4、S5和S6中,以获得每个等级的独特遗传因子在线的程度。
- 将单元格 N8、O9、P10 和 Q11 中的百分比分别复制到单元格 U3、U4、U5 和 U6 中,以获得每个级别中独特的共享环境因素在线的程度。
- 将单元 N13、O14、P15 和 Q16 中的百分比分别复制到单元格 W3、W4、W5 和 W6 中,以获得每个级别中独特的非共享环境因素联机的程度。
- 为了确保所有计算都正确,单元格 R3-W3、R4-W4、R5-W5 和 R6-W6 中的值应相加为 100。步骤 4.5_4.7 如图6所示。

图 6:步骤 4.5-4.8 的插图。请点击此处查看此图的较大版本。
{kind=link}
- 通过单击鼠标并将鼠标拖动到单元格 R2_R6 和 S2+S6 以突出显示数据,绘制遗传重叠以及遗传独特影响。
- 单击"插入"菜单。
- 单击图表>堆叠列。
- 对于共享的环境和非共享环境重叠以及独特的影响,重复步骤 4.9_4.11。选择单元格 T2_T6 和 U2+U6 来绘制共享的环境影响图,并选择单元格 V2_V6 和 W2+W6 作为非共享环境影响。
Access restricted. Please log in or start a trial to view this content.
结果
图7描述了多变量Cholesky分解模型中遗传、共享环境和非共享环境影响的标准化估计。总体而言,结果显示,幼儿园预读和一年级字级阅读技能的个体差异占遗传差异的很大比例(40%)以及共享环境 (39%)对七年级阅读理解的影响。此外,结果还暗示了每个年级的每个人阅读技能的一定程度的独特来源。
Access restricted. Please log in or start a trial to view this content.
讨论
本研究的目的是展示行为遗传学中公认的方法,即多变量Cholesky分解方法,如何有效地用于理解时间语境中变量之间的关系。具体而言,这种方法可以估计特定时间点(例如,学校年级)中产生独特遗传和环境影响的程度,并证明许多时间点之间的遗传和环境影响的重叠时间点。
协议中有一个关键步骤,即估计多变量Cholesky分解模型。有时,统计建模程序脚本需要根据输入的?...
Access restricted. Please log in or start a trial to view this content.
披露声明
作者没有什么可透露的。
致谢
这项研究部分得到了国家儿童健康和人类发展研究所(P50 HD052120)的资助。本文表达的观点是作者的观点,既未经授权机构审查,也未获批准。
Access restricted. Please log in or start a trial to view this content.
材料
| Name | Company | Catalog Number | Comments |
| Microsoft Office Excel | Microsoft | ||
| Microsoft Office Powerpoint | Microsoft | ||
| Microsoft Office Visio | Microsoft | ||
| Microsoft Office Word | Microsoft | ||
| Mplus Statistical Program | Mplus |
参考文献
- Muter, V., Hulme, C., Snowling, M. J., Stevenson, J. Phonemes, rimes, vocabulary and grammatical skills as foundations of early reading development: Evidence from a longitudinal study. Developmental Psychology. 40 (5), 665-681 (2004).
- Schatschneider, C., Fletscher, J. M., Francis, D. J., Carlson, C. D., Foorman, B. R. Kindergarten prediction of reading skills: A longitudinal comparative analysis. Journal of Educational Psychology. 96 (2), 265-282 (2004).
- Byrne, B., et al. Longitudinal twin study of early literacy development: Preschool and kindergarten phases. Scientific Studies of Reading. 9 (3), 219-235 (2005).
- Christopher, M. E., et al. Genetic and environmental etiologies of the longitudinal relations between prereading skills and. Child Development. 86 (2), 342-361 (2015).
- Neale, M. C., Cardon, L. R. Methodology for Genetic Studies of Twins and Families. , Springer Science. Kluwer Academic Publishers B.V. Dordrecht, Netherlands. (1992).
- Byrne, B., et al. Genetic and environmental influences on early literacy. Journal of Research in Reading. 29 (1), 33-49 (2006).
- Byrne, B., et al. Genetic and environmental influences on aspects of literacy and language in early childhood: Continuity and change from preschool to grade 2. Journal of Neurolinguistics. 22 (3), 219-236 (2009).
- Erbeli, F., Hart, S. A., Taylor, J. Longitudinal associations among reading related skills and reading comprehension: A twin study. Child Development. 89 (6), e480-e493 (2018).
- Muthén, L. K., Muthén, B. O. Mplus. The comprehensive modeling program for applied researchers: User’s guide. , Muthén and Muthén. Los Angeles, CA. (2012).
- Hart, S. A., et al. Exploring how nature and nurture affect the development of reading: An analysis of the Florida Twin Project on Reading. Developmental Psychology. 49 (10), 1971-1981 (2013).
- Taylor, J., Roehrig, A. D., Hensler, B. S., Connor, C. M., Schatschneider, C. Teacher quality moderates the genetic effects on early reading. Science. 328 (5977), 512-514 (2010).
Access restricted. Please log in or start a trial to view this content.
转载和许可
请求许可使用此 JoVE 文章的文本或图形
请求许可探索更多文章
This article has been published
Video Coming Soon
版权所属 © 2025 MyJoVE 公司版权所有,本公司不涉及任何医疗业务和医疗服务。