
JoVE 비디오를 활용하시려면 도서관을 통한 기관 구독이 필요합니다. 전체 비디오를 보시려면 로그인하거나 무료 트라이얼을 시작하세요.
Method Article
Cholesky 분해를 사용하여 읽기 기술 간의 세로 관계의 개인 차이 탐색
요약
이 논문은 행동 유전학, Cholesky 분해 방법에서 금 표준 방법의 사용을 보여줍니다, 세로 동기 연구에 응답하기 위해 다른 변수에 고유, 중복 유전 및 환경 영향을 추정하기 위해 질문.
초록
Cholesky 분해 방법은 행동 유전학 분야에서 사용되는 금 표준입니다. 이 방법은 프로그래밍및 해결이 용이하기 때문에 인기가 있습니다. 이 방법을 사용하여 연구원은 여러 시간 지점에 걸쳐 서로 다른 변수의 세로 관계의 개별 차이를 탐색 할 수 있습니다. 이 방법을 통해 조사자들은 (1) 특정 시점에서 발생하는 고유한 유전적, 공유 및 비공유 환경 적 효과뿐만 아니라 (2) 중첩되는 유전적, 공유 및 비공유 환경 효과로 분산을 분해할 수 있습니다. 다른 시점. 그러나 메서드는 이러한 효과의 기본 메커니즘 또는 기원을 식별 하지 않습니다. 현재 보고서는 교육 심리학 분야에서 Cholesky 분해 방법의 적용에 초점을 맞추고 있습니다. 구체적으로는 유치원 편지 지식, 유치원 음운 인식, 1학년 단어 수준 읽기 능력, 7학년 독해 능력 사이의 종적 관계의 개인적 차이에 대해 설명합니다.
서문
텍스트를 유창하게 읽고 이해할 수있는 숙련 된 독자가되는 것은 아이들의 학교 결과에 중요합니다. 독서 문제의 개발을 방지하기 위해, 다른 독서 능력이 독침을 예측하는 정도를 이해하는 것이 중요합니다. 기존 연구에 따르면 초등학교의 사전 읽기 및 단어 수준 읽기 능력은 중학교1,2에서독해력을 예측하는 것으로 나타났습니다. 이 예측에 있는 개별적인 다름은 주로 유치원에서 4 학년3,4까지근본적인 유전 (그리고 어느 정도, 환경) 요인을 가리킵니다. 그러나, 이 동일 유전과 환경 요인이 중학교 학년까지 이 예측에 계속 영향을 미치는지 여부를 탐구할 필요가 있습니다.
초등학교와 중학교 독서 능력 사이의 연관성에 기초한 개인의 차이를 더 잘 이해하는 한 가지 방법은 행동 유전 적 방법론, 특히 Cholesky 분해 방법을 사용하는 것입니다. Cholesky 분해 방법은 행동 유전학에 있는 금 표준 분석의 한개입니다. 이 방법은 프로그래밍 및 해결이 용이하며 (A) 유전, (C) 공유 환경 및 (E) 비 공유 환경 영향, 일반적으로 쌍둥이 샘플로 분산 및 공분산의 분해를 허용합니다. 일변량(하나의 변수) Cholesky 분해의 예는 그림 1에표시됩니다. 잠복 인자는 부모에게서 승계된 유전 영향인 유전 효력을 나타납니다. C 잠재 요인은 가정 및 학교 환경과 같이 쌍둥이를 더 유사하게 만드는 환경의 측면인 공유 환경 효과를 말합니다. 마지막으로, E 잠재 요인은 각 쌍둥이에게 고유하고 쌍둥이 사이의 차이에 기여하는 환경 영향인 비 공유 환경 효과를 말합니다. E 계수는 측정 오차도 캡처합니다.

그림 1: (A) 유전으로 분해, (C) 공유 환경, 및 (E) 비공유 환경 영향. 이 그림의 더 큰 버전을 보려면 여기를 클릭하십시오.
{kind=link}
그림 1의 A, C 및 E 계수는 유전자와 환경이 하나의 (읽기) 변수에 영향을 미치는 정도를 추정합니다. 그럼에도 불구하고 초등학교에서 중학교까지 하나 이상의 독서 기술 사이의 기본 세로 연관의 개인 차이를 조사하기 위해서는 세로 분석이 필요합니다. 세로 동기 연구 질문에 대답하기 위해, 다변량 Cholesky 분해 방법은 여기에사용된다 5. 개념적으로, 다변량 Cholesky 분해 방법은 이전 요인의 기여가 취해진 후에 유전적 및 환경적 요인의 독립적인 기여가 평가되도록 계층적 다중 회귀와 유사합니다. 계정.
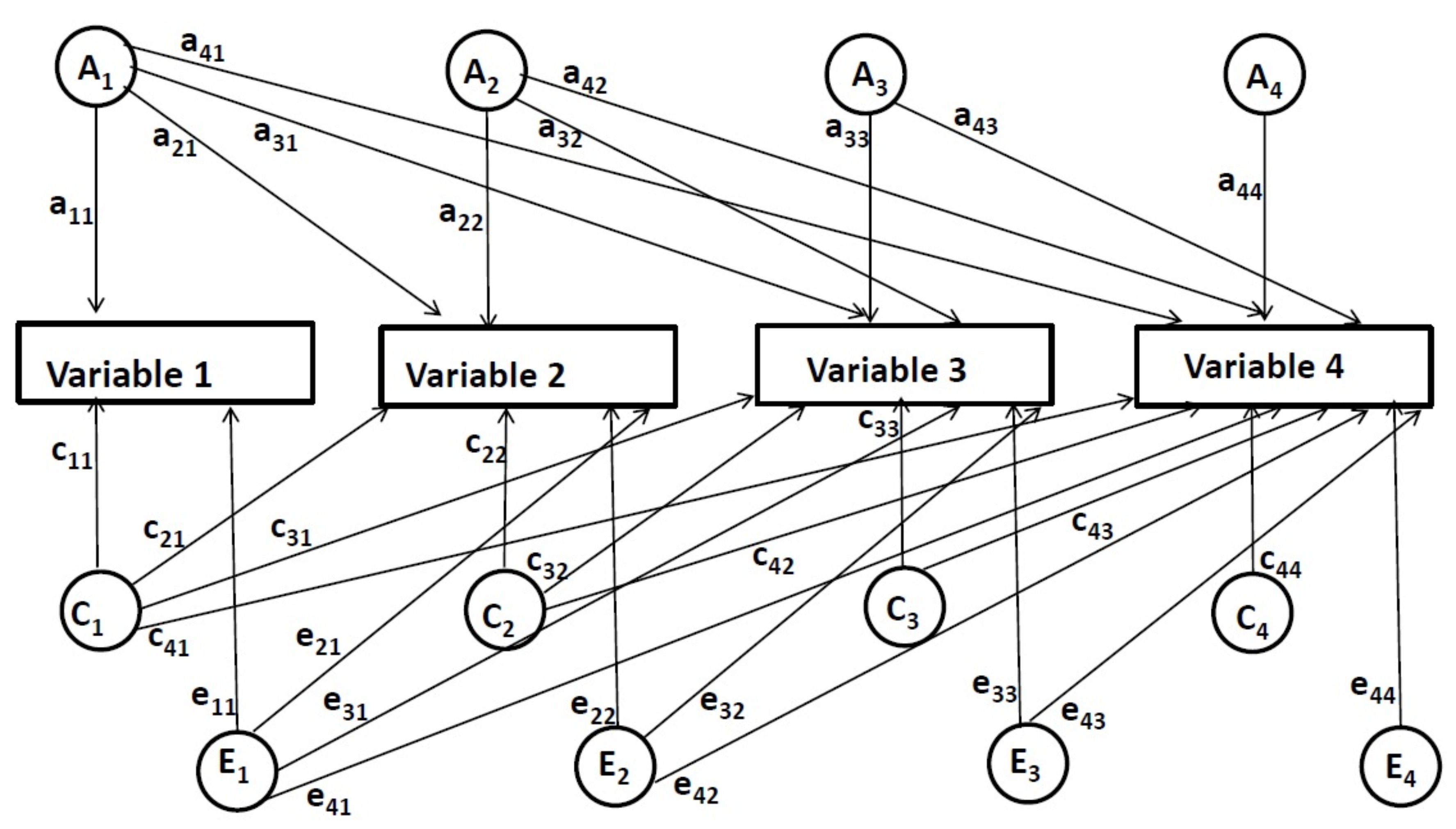
예를 들어, 4개의 시점에서 세로 데이터를 가진 다변량 Cholesky 분해에서(그림 2참조), 요인의 첫 번째 세트 [유전(A1),공유 환경(C1),및 비공유 환경(E1)] 경로로 표현 되는 모든 변수의 차이에 기여11,a21,a 31,a 41, c11, c21, ..., e11, 등,A에서 1,C1,E1 각 변수에 요인 . 요인의 두 번째 세트(A2,C2,E2)는첫 번째 시점 동안 제어 한 후 두 번째 및 후속 변수의 분산에 기여합니다. 요인의 두 번째 세트는 경로로 표시됩니다22,a 32,a 42,c22,c32, ..., e22,기타. 그런 다음, 제3 계수세트(A3,C3,E3)의영향은 이전 두 시간 포인트를 제어한 후 제3 및 제4 변수에 대해 추정된다. 그들은 경로로 표시됩니다33,a 43,c33, c43, e33,e43. 마지막으로, 네 번째 요인 세트의영향(A4,C4,E4)은이전의 모든 시간 포인트를 제어한 후 최종 시점까지 측정됩니다. 그들은 경로로 표시됩니다44,c44,전자44.

그림 2: 4개의 시간점에 대한 다변량 Cholesky 분해 모델입니다. 이 그림의 더 큰 버전을 보려면 여기를 클릭하십시오.
{kind=link}
다변량 Cholesky 분해 방법의 이러한 종방향 적용에서, 각 시점에서유전적 및 환경적 영향은 이전 시점의 영향이 제어된 후에 추정된다. 이와 같이, 이 방법은 독특한 유전적 및 환경적 영향이 이전 시점의 영향과 무관하게 각 특정 시점에서 온라인 상태가 되는 정도를 결정할 수 있게 합니다(이러한 효과는 경로11에 의해 추정됩니다. 22,33,44, c11, c22, ..., e11, e22, 등). 또한, 이 방법은 또한 동일한(중첩) 유전적 및 환경적 영향이 시점 간에 공유되는 정도를 검사할 수 있게 한다. 즉, 유전적 및 환경적 영향이 한 시점에서 다른 시점으로 어느 정도 이월되는지를 결정할 수 있습니다(즉, 이러한 효과는 경로21, 31,41,a32,a 42, 42, a 43, c21, c31, ..., e21, 등). 경로11,c11및 e11은 고유하거나 이전 시점과 겹칠 수 있는 첫 번째 시점까지 가능한 모든 유전 및 환경 영향을 나타냅니다. 그러나 첫 번째 시점 이전의 시점은 추정되지 않습니다. 따라서 고유한 영향을 나타내는지 또는 겹치는 영향을 나타내는지 여부를 정확하게 결정할 수 없습니다. 단순화를 위해 현재 보고서에 고유한 영향으로 포함됩니다.
Cholesky 분해에 입력된 측정된 변수의 순서는 임의입니다. 그러나 순서는 일반적으로 이론적 관점에 의해 구동됩니다. 초등학교에서의 독해 능력이 중학교의 독해력을 예측하는 등 독해능력의 발달에 기초한 현행 연구의 경우도 마찬가지다.
Cholesky 분해 방법을 활용하는 독서 기술의 세로 협회의 근본적인 유전적 및 환경적 요인을 조사하는 문헌에 몇 가지 보고서가 있습니다. 이러한 선행 연구는 주로 초등학생 들 사이의 독서 능력 사이의 관계를 조사에 초점을 맞추고6,7. 다변량 Cholesky 분해 방법을 사용하여 초등학교 학년에서 중학교 학년으로의 독서와 관련된 개인의 차이를 조사하는 연구는 단 한 번뿐입니다8. 이 프로토콜은 유치원 편지 지식, 유치원 음운 인식, 1 학년 워드 레벨 사이의 종적 관계의 개인 차이를 탐구하기 위해 특정 보고서에서 다변량 Cholesky 분해 방법을 자세히 설명합니다. 독서 능력, 그리고 7 학년 독해.
연구 결과는 유전과 환경 영향의 2가지의 모형 을 구별하기 위하여 다변량 Cholesky 분해 방법을 사용하여 집중합니다. 첫째, 초등학교에서 중학교까지(중첩) 이월되는 유전적 및 환경적 영향을 추정하는 방법을 보여 주며(예: 경로 추정경로 43,c43,및 e43,유전 및 환경 영향 7학년 의 독해력에 영향을 미치는 1학년의 단어 수준의 독해 능력). 둘째, 각 특정 등급에서 온라인으로 제공되는 고유한 유전 및 환경 적 영향을 추정하는 방법(예: 경로 추정경로 33,c33및 e33,고유한 유전 및 환경 적 영향 1 학년에서 발생하는 단어 수준의 읽기 능력).
Access restricted. Please log in or start a trial to view this content.
프로토콜
아래 단계는 (A) 유전, (C) 공유 환경, (E) 비 공유 환경 요인으로 초등학교와 중학교 독서 능력 사이의 기본 세로 연관을 추정하는 과정을 설명합니다. 그래픽 사용자 인터페이스(GUI)를 갖춘 통계 모델링 프로그램, 워드 프로세서 및 소프트웨어. 이 연구는 플로리다 주립 대학의 기관 검토 위원회에 의해 승인되었습니다.
1. 통계 모델링 프로그램에 대한 데이터 준비
- 선택한 통계 모델링 프로그램에서 읽을 수 있는 형식으로 데이터를 준비합니다. 인기있는 통계 모델링 프로그램은 Mx, 플랫폼 R의 OpenMx 및 MPlus9을포함합니다. Mx는 .vl 또는 .dat 데이터 형식으로 데이터 파일을 읽을 수 있습니다. 여기에 설명된 예제는 프로그램 MPlus9에서실행됩니다.
참고: 임의로 선택한 6명의 참가자를 위한 .dat 형식의 샘플 데이터 파일은 추가 파일에서 사용할 수 있습니다. 샘플 데이터 파일에 사용되는 변수는 입력 코딩 파일에 사용되는 변수를 반영합니다.
2. 통계 모델링 프로그램에 데이터를 읽고, 스크립트를 실행하고, 효과를 추정
- 통계 모델링 프로그램을 엽니다.
- "파일은 [컴퓨터에 데이터 파일의 삽입 위치]"를 입력하여 통계 모델링 프로그램에 읽을 관련 데이터 파일을 찾습니다.
- 통계 모델링 프로그램의 리본에서 RUN 아이콘을 클릭하여 다변량 Cholesky 분해 방법에서 유전, 공유 환경 및 비공유 환경 영향에 대한 추정치를 얻을 수 있습니다. MPlus를 사용한 출력뿐만 아니라 4개의 시점의 다변량 Cholesky 분해 모델에 대한 추가된 입력 스크립트는 추가 코딩 파일에서 찾을 수 있습니다.
- 통계 모델링 프로그램이 유전적, 공유 환경 적 영향 및 비공유 환경 영향에 대한 추정치를 생성하면 경로 a11,경로21의stx21에 대한 stx11 아래의 출력 파일에서 추정치를 찾습니다. ..., 경로 c11에 대한 sty11,경로 c21에 대한 sty21, 경로 e11에 대한 stz11,경로 e21에 대한 stz21, 기타.
3. 생성된 예상을 가진 테이블 만들기
- 워드 프로세서를 엽니다.
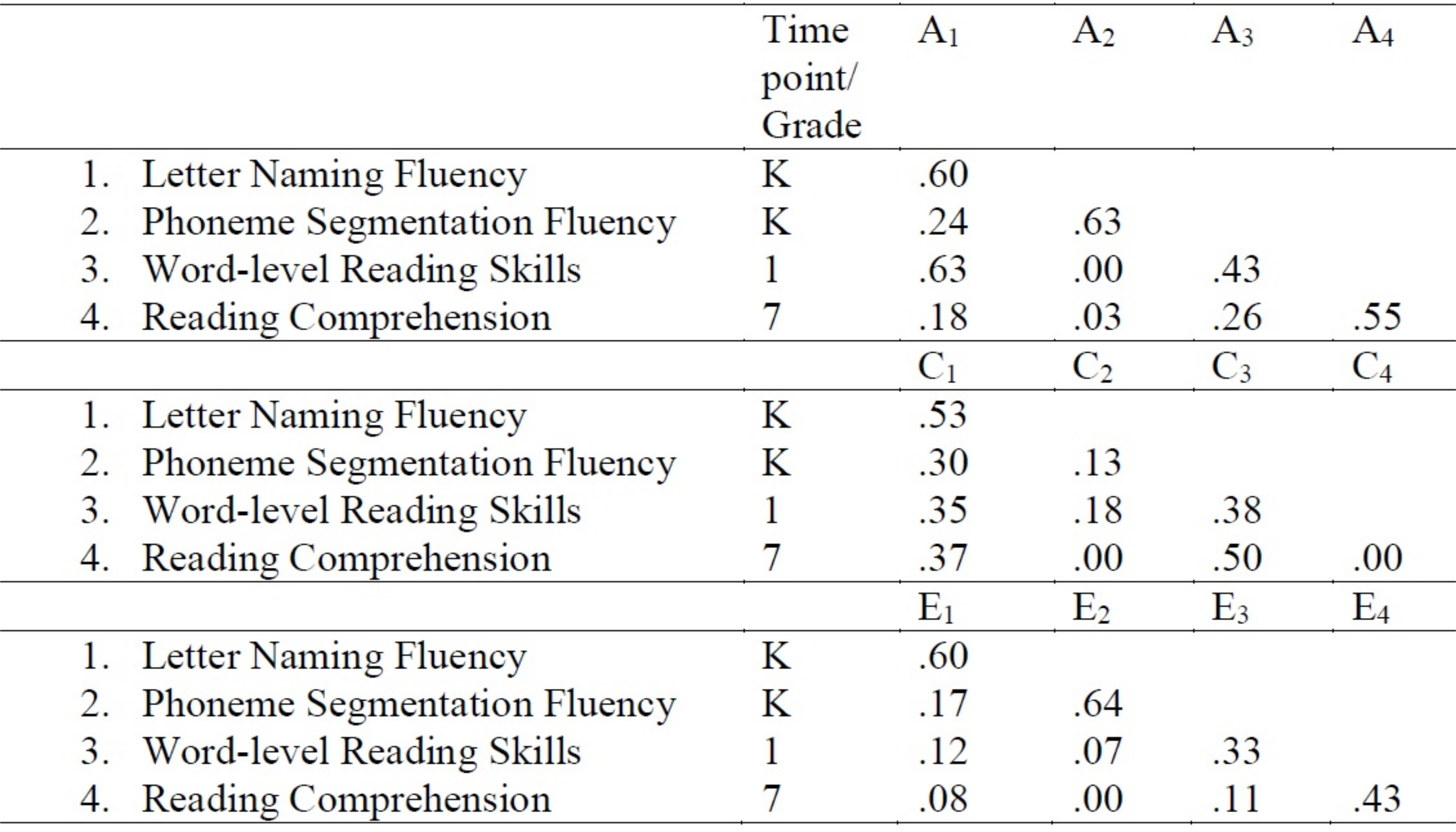
- 생성된 예상을 워드 프로세서의 테이블에 복사합니다. 그림은 3에표시된 형식으로 테이블을 만들 수 있습니다. 예를 들어, 이 경우 경로에 대한 추정값은11, a21,31및41값은 각각 0.60, 0.24, 0.63 및 0.18입니다.

그림 3: 다변량 Cholesky 분해 모델링 은 유전 및 환경 영향의 표준화 된 경로 추정. 이 그림의 더 큰 버전을 보려면 여기를 클릭하십시오.
{kind=link}
4. 유전적, 공유된 환경 및 비공유 환경 영향 의 플롯
- GUI를 가진 소프트웨어를 엽니다.
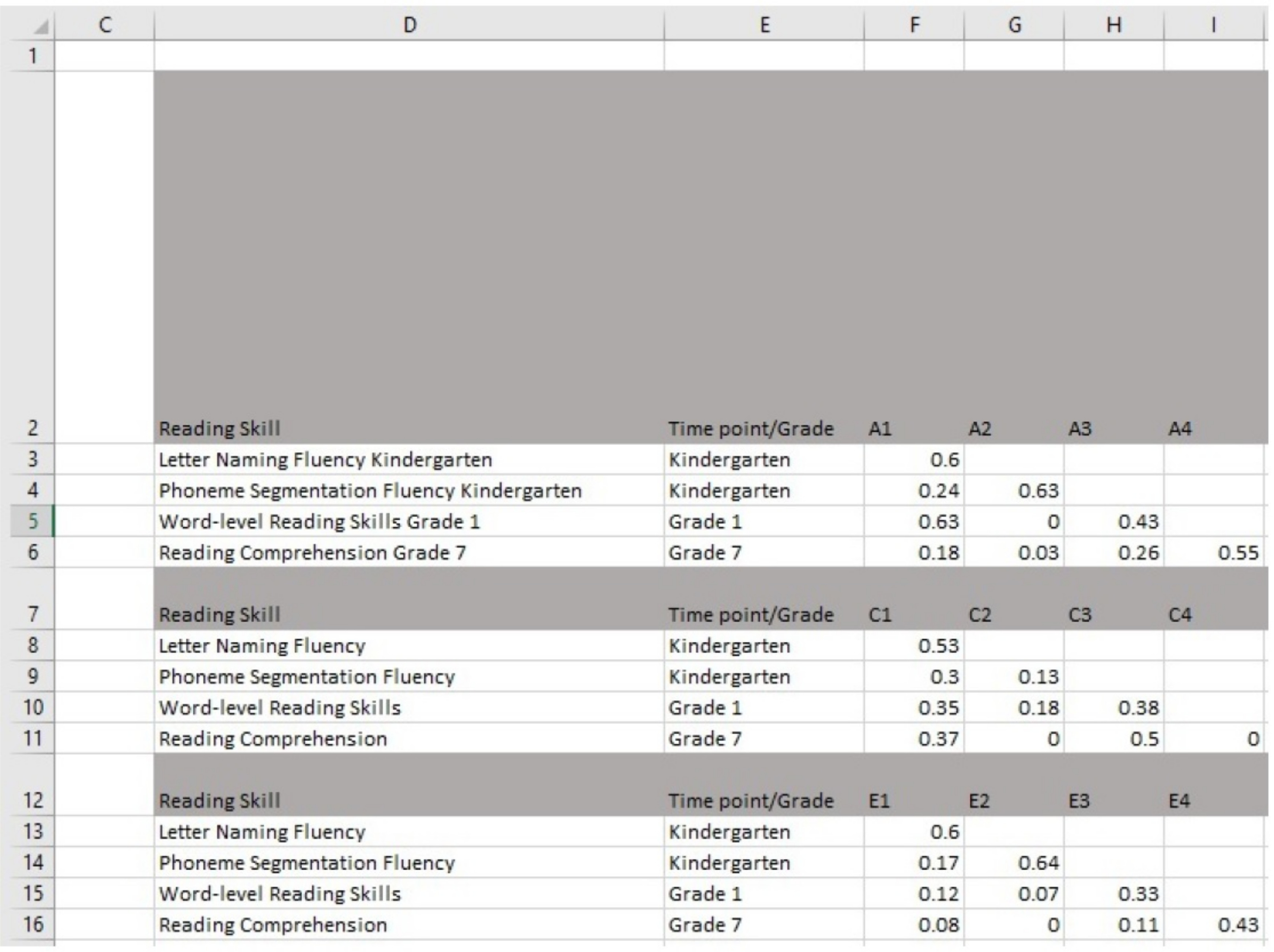
- 생성된 테이블에서 F3-F16, G4-G16, H5-H16 및 I6-I16에 대한 추정치를 입력합니다. 그림 4에는GUI가 있는 소프트웨어의 스크린샷이 표시됩니다.

그림 4: GUI를 가진 소프트웨어에 견적을 입력합니다. 이 그림의 더 큰 버전을 보려면 여기를 클릭하십시오.
{kind=link}
- F3-F16, G4-G16, H5-H16 및 I6-I16의 추정치를 제곱하여 유전적, 공유 환경 및 비공유 환경 영향의 차이를 계산합니다. 셀 J3-J16, K4-K16, L5-L16 및 M6-M16에 제곱 값을 입력합니다.
- J3-J16, K4-K16, L5-L16 및 M6-M16의 값을 100으로 곱하여 백분율 분산을 계산합니다. 셀 N3-N16, O4-O16, P5-P16 및 Q6-Q16의 백분율 값을 입력합니다. 4.3 단계와 4.4단계는 그림 5에도시되어 있습니다.

그림 5: 단계 4.3 및 4.4의 그림. 이 그림의 더 큰 버전을 보려면 여기를 클릭하십시오.
{kind=link}
- 유전적 영향이 초등학교에서 중학교까지(겹치는) 정도를 계산합니다.
- 셀 R3에서 "0"을 입력합니다.
- 셀 R4에서 "=N4"를 입력합니다. 이것은 첫번째 시점시점부터 두 번째 시점까지 유전적 영향이 이월되는 정도입니다. 이 경우, 유치원에서 전화 분할 유창에 이월 편지 명명 유창에서 유전 적 영향을 나타냅니다.
- 셀 R5에서 "= N5+O5"를 입력합니다. 이것은 처음 두 시간 포인트에서 유전적 영향이 세 번째 시점까지 이월되는 정도입니다. 이 경우 유치원에서 편지 명명 유창성에서 유전적 영향을 나타내며 유치원의 음소 세분화 유창성은 1학년의 워드 레벨 읽기 능력으로 이월됩니다.
- 셀 R6에서 "= N6+O6+P6"를 입력합니다. 이것은 처음 세 번의 시점으로부터 유전적 영향이 네 번째 시점까지 이월되는 정도입니다. 이 경우 유치원의 문자 명명 유창성, 유치원의 음소 세분화 유창성, 1학년의 워드 레벨 읽기 능력에서 7학년의 독해로 인한 유전적 영향을 나타냅니다.
- 4.5단계에서와 같이 초등학교에서 중학교까지 환경 및 비공유 환경 영향이 어느 정도 이월(중복)되는정도를 계산합니다.
- 고유한 유전적, 공유 환경 적 요인 및 공유되지 않는 환경 요인이 각 특정 시점(예: 등급)에서 온라인으로 제공되는 정도를 계산합니다.
- 세포 N3, O4, P5 및 Q6에서 백분율을 세포 S3, S4, S5 및 S6로 복사하여 각 등급에서 고유한 유전 적 요인이 온라인으로 제공되는 정도를 얻습니다.
- 셀 N8, O9, P10 및 Q11의 백분율을 각각 셀 U3, U4, U5 및 U6에 복사하여 각 등급에서 고유한 공유 환경 요인이 온라인 상태가 되는 정도를 얻습니다.
- 셀 N13, O14, P15 및 Q16의 백분율을 각각 W3, W4, W5 및 W6셀에 복사하여 각 등급에서 고유한 비공유 환경 요인이 온라인 상태가 되는 정도를 얻습니다.
- 모든 계산이 올바른지 확인하려면 셀 R3-W3, R4-W4, R5-W5 및 R6-W6의 값이 각각 100까지 추가되어야 합니다. 단계 4.5-4.7은 그림 6에설명되어 있습니다.

그림 6: 단계 4.5-4.8의 그림. 이 그림의 더 큰 버전을 보려면 여기를 클릭하십시오.
{kind=link}
- 데이터를 강조하기 위해 R2-R6 및 S2-S6 위에 마우스를 클릭하고 드래그하여 유전적 중복과 유전적 고유 영향을 플롯합니다.
- 삽입 메뉴를 클릭합니다.
- 차트 > 누적 열을클릭합니다.
- 4.9-4.11 단계를 반복하여 환경 및 비공유 환경이 중복되고 고유한 영향이 있는 경우를 반복합니다. 셀 T2-T6 및 U2-U6을 선택하여 공유 환경 영향을 플롯하고 비공유 환경 영향에 대해 셀 V2-V6 및 W2-W6을 선택합니다.
Access restricted. Please log in or start a trial to view this content.
결과
다변량 Cholesky 분해 모델에서 유전, 공유 환경 및 비공유 환경 영향에 대한 표준화된 추정치는 그림 7에도시되어 있습니다. 일반적으로, 결과는 유치원 사전 읽기와 1 학년 단어 수준의 읽기 능력에 개인 차이가 유전의 차이의 큰 비율을 차지하는 것으로 나타났다 (40%) 뿐만 아니라 공유 환경 (39%) 7 학년 독해력에 영향을 미칩니다. 또한, 결과는 각 학년의 각 개?...
Access restricted. Please log in or start a trial to view this content.
토론
이 연구의 목적은 행동 유전학 내에서 잘 확립 된 방법, 다변량 Cholesky 분해 방법, 효과적으로 시간적 맥락에서 변수에 걸쳐 관계를 이해하는 데 사용할 수있는 방법을 설명하는 것이었습니다. 구체적으로, 이 방법은 특정 시점 (예 : 학교 학년)에서 독특한 유전 적 및 환경적 영향이 발생하는 정도를 추정할 뿐만 아니라 많은 사람들에게 유전 적 및 환경적 영향의 중첩을 입증 할 수 있습니다. 시간 ...
Access restricted. Please log in or start a trial to view this content.
공개
저자는 공개 할 것이 없습니다.
감사의 말
이 연구는 부분적으로 아동 건강 및 인간 개발의 국립 연구소에서 보조금에 의해 지원 되었다 (P50 HD052120). 본 명세서에 명시된 견해는 저자의 견해이며, 허가 기관에 의해 검토되거나 승인되지 않았습니다.
Access restricted. Please log in or start a trial to view this content.
자료
| Name | Company | Catalog Number | Comments |
| Microsoft Office Excel | Microsoft | ||
| Microsoft Office Powerpoint | Microsoft | ||
| Microsoft Office Visio | Microsoft | ||
| Microsoft Office Word | Microsoft | ||
| Mplus Statistical Program | Mplus |
참고문헌
- Muter, V., Hulme, C., Snowling, M. J., Stevenson, J. Phonemes, rimes, vocabulary and grammatical skills as foundations of early reading development: Evidence from a longitudinal study. Developmental Psychology. 40 (5), 665-681 (2004).
- Schatschneider, C., Fletscher, J. M., Francis, D. J., Carlson, C. D., Foorman, B. R. Kindergarten prediction of reading skills: A longitudinal comparative analysis. Journal of Educational Psychology. 96 (2), 265-282 (2004).
- Byrne, B., et al. Longitudinal twin study of early literacy development: Preschool and kindergarten phases. Scientific Studies of Reading. 9 (3), 219-235 (2005).
- Christopher, M. E., et al. Genetic and environmental etiologies of the longitudinal relations between prereading skills and. Child Development. 86 (2), 342-361 (2015).
- Neale, M. C., Cardon, L. R. Methodology for Genetic Studies of Twins and Families. , Springer Science. Kluwer Academic Publishers B.V. Dordrecht, Netherlands. (1992).
- Byrne, B., et al. Genetic and environmental influences on early literacy. Journal of Research in Reading. 29 (1), 33-49 (2006).
- Byrne, B., et al. Genetic and environmental influences on aspects of literacy and language in early childhood: Continuity and change from preschool to grade 2. Journal of Neurolinguistics. 22 (3), 219-236 (2009).
- Erbeli, F., Hart, S. A., Taylor, J. Longitudinal associations among reading related skills and reading comprehension: A twin study. Child Development. 89 (6), e480-e493 (2018).
- Muthén, L. K., Muthén, B. O. Mplus. The comprehensive modeling program for applied researchers: User’s guide. , Muthén and Muthén. Los Angeles, CA. (2012).
- Hart, S. A., et al. Exploring how nature and nurture affect the development of reading: An analysis of the Florida Twin Project on Reading. Developmental Psychology. 49 (10), 1971-1981 (2013).
- Taylor, J., Roehrig, A. D., Hensler, B. S., Connor, C. M., Schatschneider, C. Teacher quality moderates the genetic effects on early reading. Science. 328 (5977), 512-514 (2010).
Access restricted. Please log in or start a trial to view this content.
재인쇄 및 허가
JoVE'article의 텍스트 или 그림을 다시 사용하시려면 허가 살펴보기
허가 살펴보기더 많은 기사 탐색
This article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. 판권 소유