
Un abonnement à JoVE est nécessaire pour voir ce contenu. Connectez-vous ou commencez votre essai gratuit.
Method Article
Utilisation de la décomposition de Cholesky pour explorer les différences individuelles dans les relations longitudinales entre les compétences en lecture
Dans cet article
Résumé
Cet article démontre l'utilisation de la méthode d'étalon-or en génétique comportementale, la méthode de décomposition de Cholesky, pour estimer les influences génétiques et environnementales uniques et qui se chevauchent sur différentes variables pour répondre à la recherche motivée par la longitudinale Questions.
Résumé
La méthode de décomposition Cholesky est l'étalon-or utilisé dans le domaine de la génétique comportementale. La méthode est populaire parce qu'elle est facile à programmer et à résoudre. En utilisant cette méthode, les chercheurs peuvent explorer les différences individuelles dans les relations longitudinales de différentes variables à travers plusieurs points de temps. La méthode permet aux chercheurs de décomposer la variance en (1) des effets génétiques, partagés et non partagés uniques sur l'environnement qui surviennent à des moments précis ainsi que (2) des effets génétiques, partagés et non partagés qui se répertèquent d'un temps point à un autre. Cependant, la méthode n'identifie pas les mécanismes ou les origines sous-jacents à ces effets. Le présent rapport se concentre sur l'application de la méthode de décomposition Cholesky dans le domaine de la psychologie de l'éducation. Plus précisément, il traite des différences individuelles dans les relations longitudinales entre la connaissance de la lettre de maternelle, la conscience phonologique de la maternelle, les compétences de lecture de premier niveau de mot, et la compréhension de la lecture de septième année.
Introduction
Devenir un lecteur qualifié avec la capacité de lire et de comprendre couramment le texte est important pour les résultats scolaires des enfants. Pour prévenir le développement de problèmes de lecture, il est essentiel de comprendre dans quelle mesure différentes compétences en lecture prédisent la compréhension de la lecture. La recherche existante a montré que la pré-lecture et les compétences de lecture au niveau des mots à l'école primaire longitudinalement prédire la compréhension de la lecture au collège1,2. Les différences individuelles dans ces prédictions indiquent principalement des facteurs génétiques sous-jacents (et, dans une certaine mesure, environnementaux) de la maternelle jusqu'à la quatrième année3,4. Cependant, il est nécessaire d'examiner si ces mêmes facteurs génétiques et environnementaux continuent d'influencer ces prédictions jusqu'aux notes du collège.
Une méthode pour acquérir une meilleure compréhension des différences individuelles sous-jacentes aux associations entre les compétences de lecture primaire et intermédiaire est d'utiliser la méthodologie génétique comportementale, en particulier la méthode de décomposition Cholesky. La méthode de décomposition de Cholesky est considérée comme l'une des analyses de l'étalon-or en génétique comportementale. Cette méthode est facile à programmer et à résoudre et permet la décomposition de la variance et de la covariance en (A) génétique, (C) partagelage des influences environnementales, et (E) des influences environnementales non partagées, généralement dans un échantillon de jumeaux. Un exemple de décomposition univariée (une variable) de Cholesky est indiqué à la figure 1. Le facteur latent A fait référence aux effets génétiques, qui sont des influences génétiques héritées des parents. Le facteur latent C fait référence aux effets environnementaux partagés, qui sont des aspects de l'environnement qui servent à rendre les jumeaux plus semblables, comme les milieux familial et scolaire. Enfin, le facteur latent E fait référence aux effets environnementaux non partagés, qui sont des influences environnementales qui sont uniques à chaque jumeau et qui contribuent à des différences entre les jumeaux, comme l'expérience de chacun. Le facteur E capture également l'erreur de mesure.

Figure 1 : Décomposition en (A) génétique, (C) influences environnementales partagées et (E) influences environnementales non partagées. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
Les facteurs A, C et E de la figure 1 estiment à quel point les gènes et les environnements influencent une variable (lecture). Cependant, pour étudier les différences individuelles sous-jacentes aux associations longitudinales entre plus d'une compétence de lecture du primaire au collège, une analyse longitudinale est nécessaire. Pour répondre aux questions de recherche longitudinalement motivées, une méthode de décomposition cholesky multivariée est utilisée ici5. Conceptuellement, la méthode de décomposition multivariée de Cholesky est semblable à la régression multiple hiérarchique, de sorte que la contribution indépendante des facteurs génétiques et environnementaux est évaluée après que les contributions des facteurs précédents aient été prises en compte-rendu.
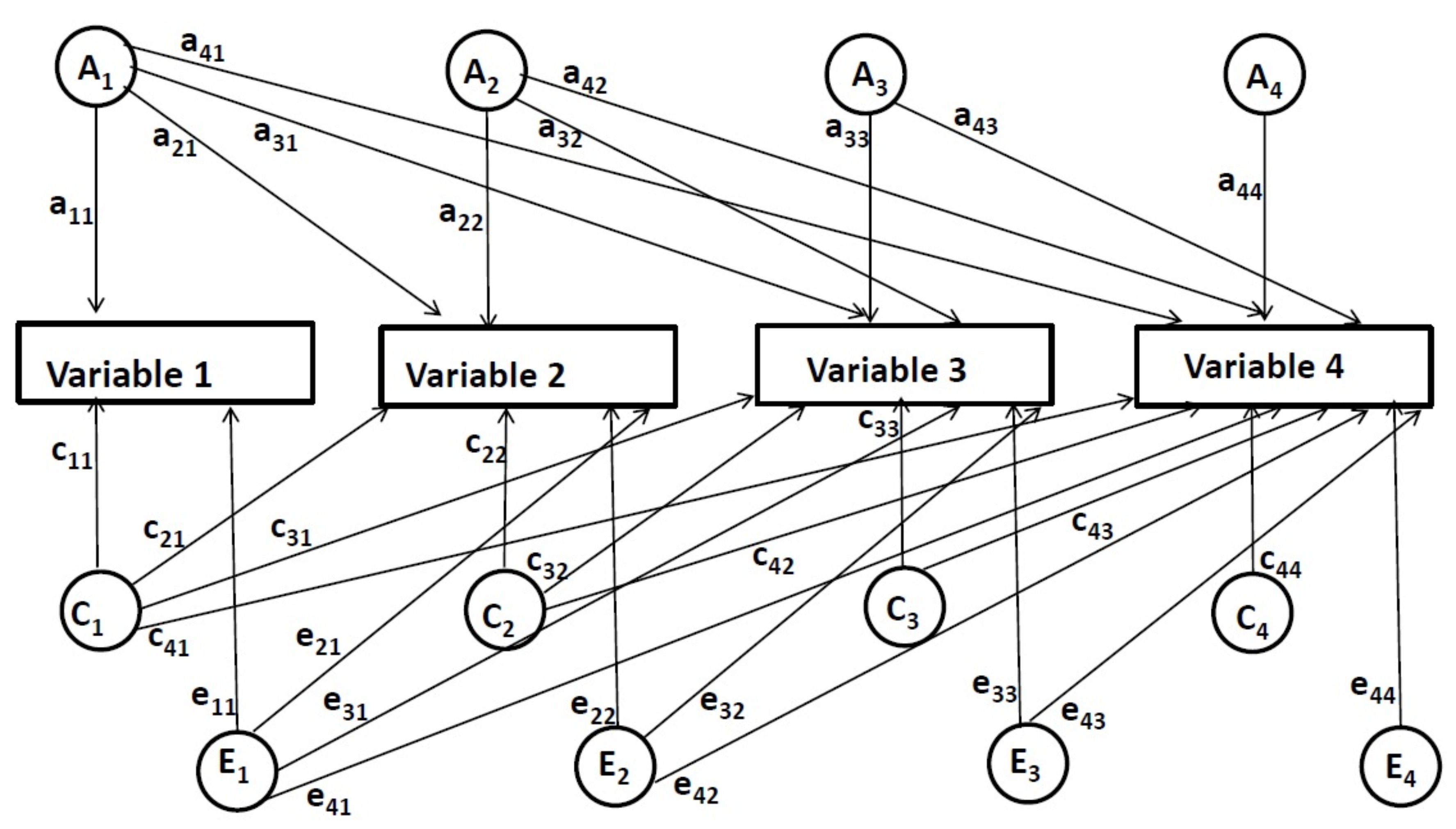
Par exemple, dans une décomposition cholesky multivariée avec des données longitudinales à quatre points de temps (voir la figure 2), la première ensemble de facteurs [génétique (A1), environnemental partagé (C1), et l'environnement non partagé (E1)] contribue à la variance de toutes les variables, représentées comme des chemins un11, un21, un31, un41, c11, c21, ..., e11, etc, de A1, C1, E1 facteurs à chaque variable . La deuxième ensemble de facteurs (A2, C2, E2) contribue à la variance des variables deuxièmes et suivantes après contrôle pour la première fois. La deuxième ensemble de facteurs est représenté comme des chemins un22, un32, un42, c22, c32, ..., e22, etc. Ensuite, les influences de la troisième ensemble de facteurs (A3, C3, E3) sont estimées pour les troisième et quatrième variables après contrôle pour les deux points de temps précédents. Ils sont représentés comme des chemins un33, un43, c33, c43, e33, e43. Enfin, les influences de la quatrième ensemble de facteurs (A4, C4, E4) sont mesurées pour le point de temps final après contrôle pour tous les points de temps précédents. Ils sont représentés comme des chemins un44, c44, e44.

Figure 2 : Modèle de décomposition Cholesky multivarié pour quatre points de temps. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
Dans cette application longitudinale de la méthode de décomposition multivariée de Cholesky, les influences génétiques et environnementales à chaque moment sont estimées après que les effets des points de temps précédents ont été contrôlés pour. En tant que tel, cette méthode permet de déterminer dans quelle mesure les influences génétiques et environnementales uniques sont en ligne à chaque moment particulier, indépendamment des influences des moments précédents (ces effets sont estimés par les chemins un11, un 22, un33, un44, c11, c22, ..., e11, e22, etc.). En outre, la méthode permet également d'examiner dans quelle mesure les mêmes influences génétiques et environnementales sont partagées entre les points de temps et les mêmes influences génétiques et environnementales. En d'autres termes, on peut déterminer dans quelle mesure les influences génétiques et environnementales se reportent d'un point à l'autre (c'est-à-dire que ces effets sont estimés par chemins un21, un31, un41, un32, un42, un 43, c21, c31, ..., e21, etc.). Il convient de noter que les chemins un11, c11, et e11 représentent toutes les influences génétiques et environnementales possibles jusqu'au premier point de temps, qui peut être soit unique ou chevauchant avec les points de temps précédents. Toutefois, les points de temps avant le premier point de temps ne sont pas estimés; par conséquent, il n'est pas possible de déterminer avec précision s'ils représentent des influences uniques ou qui se chevauchent. À des fins de simplification, elles sont incluses comme influences uniques dans le présent rapport.
L'ordre des variables mesurées entrées dans une décomposition de Cholesky est arbitraire. Cependant, l'ordre est généralement conduit par une perspective théorique. C'est également le cas dans la présente étude, dans laquelle l'ordre était basé sur le développement des compétences en lecture, de sorte que les compétences en lecture à l'école primaire sont prédictives de la compréhension de la lecture au collège.
Il y a plusieurs rapports dans la littérature étudiant les facteurs génétiques et environnementaux sous-jacents aux associations longitudinales des qualifications de lecture utilisant la méthode de décomposition de Cholesky. Ces études antérieures se sont surtout concentrées sur l'étude des relations entre les compétences en lecture chez les élèves du primaire6,7. Il n'y a qu'une seule étude publiée examinant les différences individuelles associées à la lecture des classes élémentaires dans les classes intermédiaires en utilisant la méthode de décomposition multivariée Cholesky8. Ce protocole détaille la méthode de décomposition multivariée de Cholesky de ce rapport spécifique pour explorer les différences individuelles dans les relations longitudinales entre la connaissance de lettre de jardin d'enfants, la conscience phonologique de jardin d'enfants, le niveau de mot de première année compétences en lecture, et la compréhension de la lecture de septième année.
Les résultats de l'étude se concentrent sur l'utilisation de la méthode de décomposition cholesky multivariée pour distinguer deux types d'influences génétiques et environnementales. Tout d'abord, il est montré comment estimer les influences génétiques et environnementales qui se reportent (overlap) de la lecture primaire au collège (par exemple, l'estimation des chemins un43, c43, et e43, qui sont des influences génétiques et environnementales sur compétences en lecture de niveau mot de la première année qui affectent la compréhension de la lecture en septième année). Deuxièmement, il est démontré comment estimer les influences génétiques et environnementales uniques qui entrent en ligne à chaque grade particulier (par exemple, estimer les chemins un33, c33, et e33, qui sont des influences génétiques et environnementales uniques sur compétences en lecture de niveau mot qui se posent en première année).
Access restricted. Please log in or start a trial to view this content.
Protocole
Les étapes ci-dessous décrivent le processus d'estimation des différences individuelles sous-jacentes aux associations longitudinales entre les compétences en lecture du primaire et du collège en (A) génétique, (C) partageant les facteurs environnementaux et (E) non partagés à l'aide d'un programme de modélisation statistique, traitement de texte et logiciel doté d'une interface utilisateur graphique (GUI). Cette étude a été approuvée par l'Institutional Review Board de la Florida State University.
1. Préparation des données pour le programme de modélisation statistique
- Préparer les données dans un format qui peut être lu par le programme de modélisation statistique de choix. Les programmes de modélisation statistique les plus populaires comprennent Mx, OpenMx dans la plate-forme R, et MPlus9. Mx peut lire des fichiers de données dans des formats de données .vl ou .dat, OpenMx dans n'importe quel format de données, et Mplus dans un format de données .dat. L'exemple démontré ici est exécuté dans le programme MPlus9.
REMARQUE : Un fichier de données échantillondans un format .dat pour six participants choisis au hasard est disponible dans les fichiers supplémentaires. Les variables utilisées dans un fichier de données d'échantillon reflètent les variables utilisées dans le fichier de codage d'entrée.
2. Lecture des données dans le programme de modélisation statistique, exécution du script et estimation des effets
- Ouvrez le programme de modélisation statistique.
- Localisez le fichier de données pertinent à lire dans le programme de modélisation statistique en tapant « Le fichier est [insérer l'emplacement de votre fichier de données sur votre ordinateur] ».
- Cliquez sur l'icône RUN sur le ruban du programme de modélisation statistique pour obtenir des estimations des influences génétiques, environnementales partagées et non partagées de la méthode de décomposition multivariée Decomposition Cholesky. Le script d'entrée annoté pour le modèle de décomposition multivarié Cholesky pour quatre points de temps ainsi que sa sortie en utilisant MPlus peut être trouvé dans les fichiers de codage supplémentaires.
- Une fois que le programme de modélisation statistique génère des estimations des influences génétiques, environnementales partagées et non partagées, localisez les estimations dans le fichier de sortie sous stx11 pour le chemin un11, stx21 pour le chemin un21, ..., sty11 pour le chemin c11, sty21 pour le chemin c21, ..., stz11 pour le chemin e11, stz21 pour le chemin e21, etc.
3. Création d'un tableau avec estimations générées
- Ouvrez le traitement de texte.
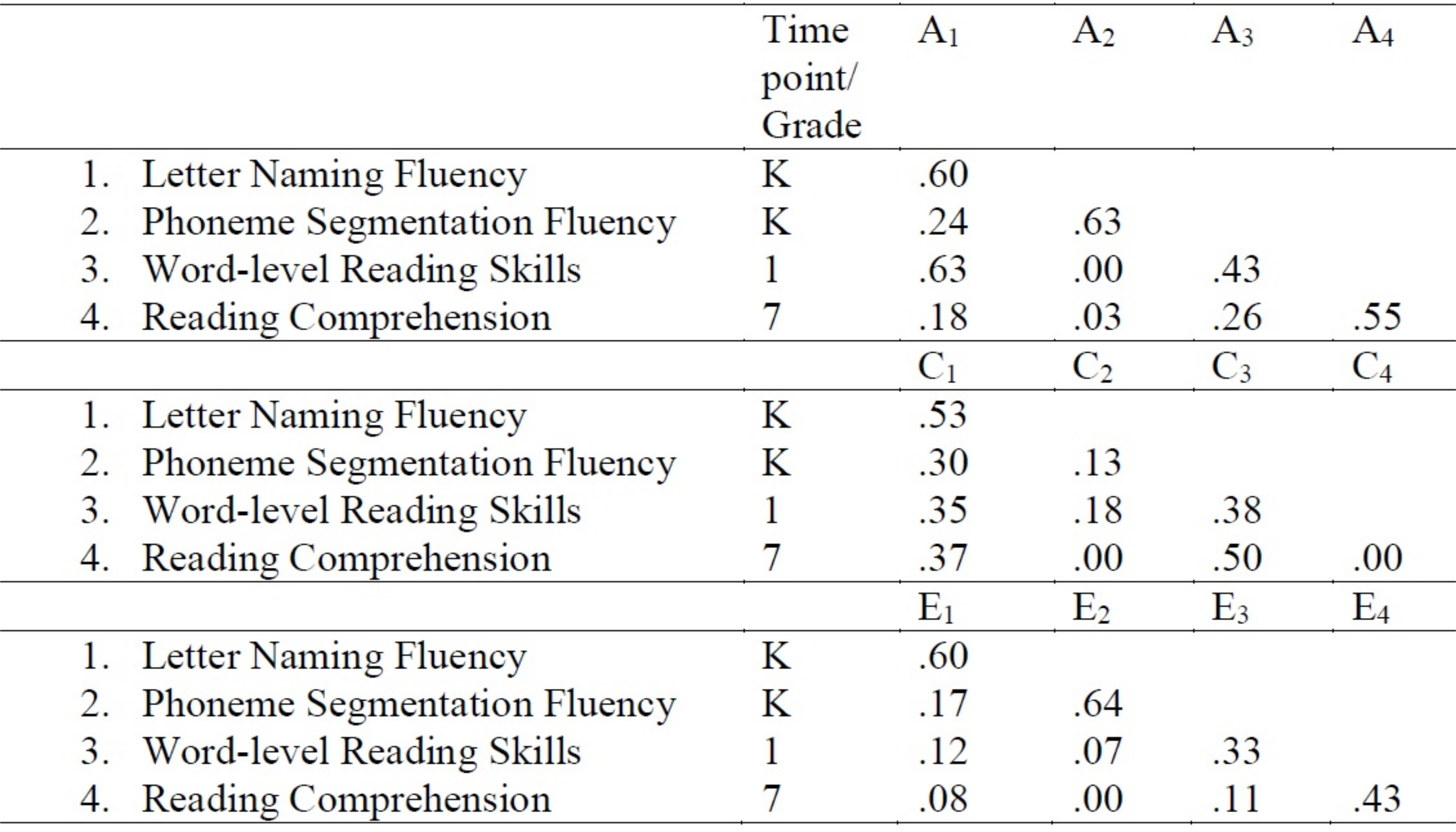
- Copiez les estimations générées dans une table dans un traitement de texte. Le tableau peut être créé dans un format indiqué à la figure 3. Par exemple, dans ce cas, les estimations pour les chemins un11, un21, un31, et un41 ont des valeurs de 0,60, 0,24, 0,63 et 0,18, respectivement.

Figure 3 : Décomposition multivariée de Cholesky modélisant des estimations normalisées des influences génétiques et environnementales. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
4. Tracer des influences génétiques, environnementales partagées et non partagées
- Ouvrez le logiciel avec une interface graphique.
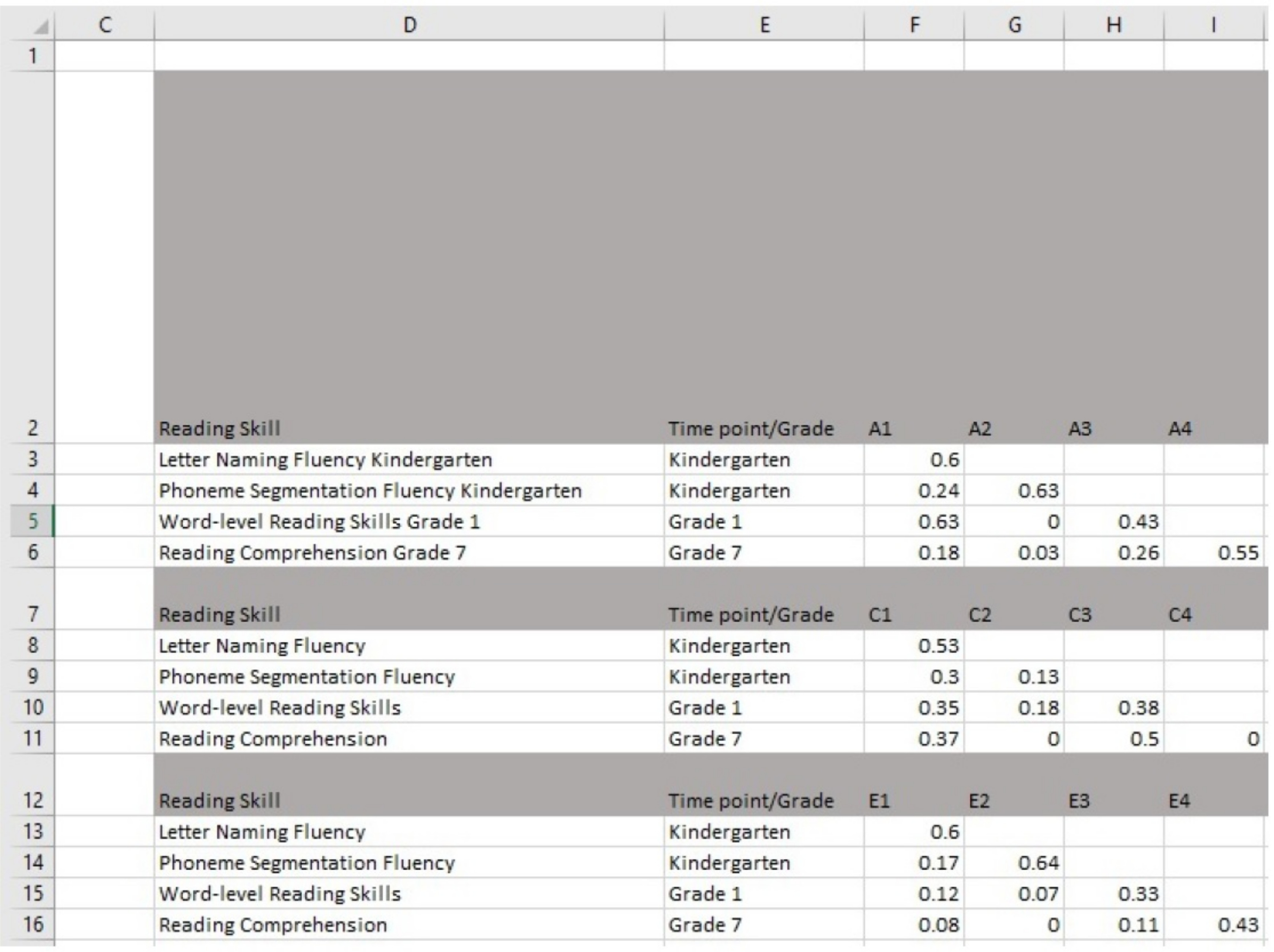
- Entrez les estimations de la table créée dans les cellules F3-F16, G4-G16, H5-H16 et I6-I16. Une capture d'écran du logiciel avec une interface graphique est représentée dans la figure 4.

Figure 4 : Saisie d'estimations dans le logiciel avec une interface graphique. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
- Calculez la variance des influences génétiques, environnementales partagées et non partagées en quadrant les estimations dans les cellules F3-F16, G4-G16, H5-H16 et I6-I16. Tapez les valeurs carrées dans les cellules J3-J16, K4-K16, L5-L16 et M6-M16.
- Calculez la variance en pourcentage en multipliant les valeurs dans les cellules J3-J16, K4-K16, L5-L16 et M6-M16 par 100. Tapez les valeurs de pourcentage dans les cellules N3-N16, O4-O16, P5-P16 et Q6-Q16. Les étapes 4.3 et 4.4 sont représentées dans la figure 5.

Figure 5 : Illustration des étapes 4.3 et 4.4. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
- Calculer dans quelle mesure les influences génétiques se reportent (overlap) du primaire au collège.
- Dans la cellule R3, tapez "0".
- Dans la cellule R4, tapez « N4 ». C'est dans quelle mesure les influences génétiques du premier point de temps se reportent au deuxième point de temps. Dans ce cas, il indique des influences génétiques de la maîtrise de nom de lettre dans la maternelle portant plus à la fluidité de segmentation phonème dans la maternelle.
- Dans la cellule R5, tapez « N5 o5 ». C'est dans quelle mesure les influences génétiques des deux premiers temps se reportent au troisième point. Dans ce cas, il indique les influences génétiques de la lettre nommant la maîtrise de la maternelle et la segmentation phonétique de la maîtrise de la maternelle portant sur les compétences de lecture au niveau du mot en première année.
- Dans la cellule R6, tapez « N6-O6-P6 ». C'est dans quelle mesure les influences génétiques des trois premiers points de temps se reportent au quatrième point de temps. Dans ce cas-ci, il indique des influences génétiques de la maîtrise de nom de lettre dans la maternelle, de la maîtrise de segmentation de phonème dans la maternelle, et des qualifications de lecture de mot-niveau dans la catégorie 1 portant plus à la compréhension de lecture dans la catégorie 7.
- Calculer dans quelle mesure les influences environnementales partagées et non partagées se reportent (overlap) du primaire au collège, tout comme à l'étape 4.5.
- Calculer dans quelle mesure des facteurs génétiques, environnementaux partagés et non partagés uniques sont mis en ligne à chaque moment donné (c.-à-d. grade).
- Copiez les pourcentages des cellules N3, O4, P5 et Q6 dans les cellules S3, S4, S5 et S6, respectivement, afin d'obtenir la mesure dans laquelle des facteurs génétiques uniques sont mis en ligne à chaque grade.
- Copiez les pourcentages des cellules N8, O9, P10 et Q11 dans les cellules U3, U4, U5 et U6, respectivement, afin d'obtenir la mesure dans laquelle des facteurs environnementaux partagés uniques sont mis en ligne à chaque catégorie.
- Copiez les pourcentages des cellules N13, O14, P15 et Q16 dans les cellules W3, W4, W5 et W6, respectivement, afin d'obtenir la mesure dans laquelle des facteurs environnementaux non partagés uniques sont mis en ligne à chaque catégorie.
- Pour s'assurer que tous les calculs sont corrects, les valeurs dans les cellules R3-W3, R4-W4, R5-W5 et R6-W6 devraient chacune s'ajouter jusqu'à 100. Les étapes 4.5 à 4.7 sont représentées dans la figure 6.

Figure 6 : Illustration des étapes 4.5-4.8. Veuillez cliquer ici pour voir une version plus grande de ce chiffre.
{kind=link}
- Tracez les chevauchements génétiques ainsi que les influences génétiques uniques en cliquant et en faisant glisser la souris sur les cellules R2-R6 et S2-S6 pour mettre en évidence les données.
- Cliquez sur le menu Insérer.
- Cliquez sur les graphiques 'gt; Colonne empilée.
- Répéter les étapes 4.9-4.11 pour les chevauchements environnementaux partagés et non partagés ainsi que les influences uniques. Choisissez les cellules T2-T6 et U2-U6 pour tracer les influences environnementales partagées, et choisissez les cellules V2-V6 et W2-W6 pour les influences environnementales non partagées.
Access restricted. Please log in or start a trial to view this content.
Résultats
Les estimations normalisées des influences génétiques, environnementales partagées et non partagées du modèle de décomposition multivarié de Cholesky sont représentées à la figure 7. En général, les résultats ont révélé que les différences individuelles dans les compétences en lecture de la maternelle en prélecture et en première année représentaient une grande proportion de la variance de la génétique (40 %) ainsi que l'environnement partagé (39...
Access restricted. Please log in or start a trial to view this content.
Discussion
L'objectif de cette étude était de démontrer comment la méthode bien établie dans la génétique comportementale, la méthode multivariée de décomposition de Cholesky, peut effectivement être employée pour comprendre des relations entre les variables dans le contexte temporel. Plus précisément, cette méthode permet d'estimer dans quelle mesure des influences génétiques et environnementales uniques surgissent à des moments particuliers (p. ex., l'école), ainsi que de démontrer le chevauchement des influen...
Access restricted. Please log in or start a trial to view this content.
Déclarations de divulgation
Les auteurs n'ont rien à divulguer.
Remerciements
Cette recherche a été soutenue en partie par une subvention de l'Institut national de la santé de l'enfant et du développement humain (P50 HD052120). Les points de vue exprimés dans les présentes sont ceux des auteurs et n'ont ni été examinés ni approuvés par les organismes subventionnaires.
Access restricted. Please log in or start a trial to view this content.
matériels
| Name | Company | Catalog Number | Comments |
| Microsoft Office Excel | Microsoft | ||
| Microsoft Office Powerpoint | Microsoft | ||
| Microsoft Office Visio | Microsoft | ||
| Microsoft Office Word | Microsoft | ||
| Mplus Statistical Program | Mplus |
Références
- Muter, V., Hulme, C., Snowling, M. J., Stevenson, J. Phonemes, rimes, vocabulary and grammatical skills as foundations of early reading development: Evidence from a longitudinal study. Developmental Psychology. 40 (5), 665-681 (2004).
- Schatschneider, C., Fletscher, J. M., Francis, D. J., Carlson, C. D., Foorman, B. R. Kindergarten prediction of reading skills: A longitudinal comparative analysis. Journal of Educational Psychology. 96 (2), 265-282 (2004).
- Byrne, B., et al. Longitudinal twin study of early literacy development: Preschool and kindergarten phases. Scientific Studies of Reading. 9 (3), 219-235 (2005).
- Christopher, M. E., et al. Genetic and environmental etiologies of the longitudinal relations between prereading skills and. Child Development. 86 (2), 342-361 (2015).
- Neale, M. C., Cardon, L. R. Methodology for Genetic Studies of Twins and Families. , Springer Science. Kluwer Academic Publishers B.V. Dordrecht, Netherlands. (1992).
- Byrne, B., et al. Genetic and environmental influences on early literacy. Journal of Research in Reading. 29 (1), 33-49 (2006).
- Byrne, B., et al. Genetic and environmental influences on aspects of literacy and language in early childhood: Continuity and change from preschool to grade 2. Journal of Neurolinguistics. 22 (3), 219-236 (2009).
- Erbeli, F., Hart, S. A., Taylor, J. Longitudinal associations among reading related skills and reading comprehension: A twin study. Child Development. 89 (6), e480-e493 (2018).
- Muthén, L. K., Muthén, B. O. Mplus. The comprehensive modeling program for applied researchers: User’s guide. , Muthén and Muthén. Los Angeles, CA. (2012).
- Hart, S. A., et al. Exploring how nature and nurture affect the development of reading: An analysis of the Florida Twin Project on Reading. Developmental Psychology. 49 (10), 1971-1981 (2013).
- Taylor, J., Roehrig, A. D., Hensler, B. S., Connor, C. M., Schatschneider, C. Teacher quality moderates the genetic effects on early reading. Science. 328 (5977), 512-514 (2010).
Access restricted. Please log in or start a trial to view this content.
Réimpressions et Autorisations
Demande d’autorisation pour utiliser le texte ou les figures de cet article JoVE
Demande d’autorisationExplorer plus d’articles
This article has been published
Video Coming Soon
À PROPOS DE JoVE
Copyright © 2025 MyJoVE Corporation. Tous droits réservés.