
Zum Anzeigen dieser Inhalte ist ein JoVE-Abonnement erforderlich. Melden Sie sich an oder starten Sie Ihre kostenlose Testversion.
Method Article
Verwenden von Cholesky-Zersetzung, um individuelle Unterschiede in den Längsbeziehungen zwischen Lesefähigkeiten zu erforschen
In diesem Artikel
Zusammenfassung
Dieses Papier zeigt die Verwendung der Goldstandardmethode in der Verhaltensgenetik, der Cholesky-Zersetzungsmethode, um einzigartige, überlappende genetische und Umwelteinflüsse auf verschiedene Variablen zu schätzen, um längs motivierte Forschung zu beantworten. Fragen.
Zusammenfassung
Die Cholesky Zersetzungsmethode ist der Goldstandard, der im Bereich der Verhaltensgenetik verwendet wird. Die Methode ist beliebt, weil sie einfach zu programmieren und zu lösen ist. Mit dieser Methode können Forscher individuelle Unterschiede in Längsverhältnisbeziehungen verschiedener Variablen über mehrere Zeitpunkte hinweg untersuchen. Die Methode ermöglicht es den Forschern, Varianz in (1) einzigartige genetische, gemeinsame und nicht gemeinsam genutzte Umweltauswirkungen zu zersetzen, die zu bestimmten Zeitpunkten auftreten, sowie (2) sich überschneidende genetische, gemeinsame und nicht gemeinsame Umweltauswirkungen, die von einem Zeitpunkt zu einem anderen. Die Methode identifiziert jedoch nicht die Mechanismen oder Ursprünge, die diesen Effekten zugrunde liegen. Der aktuelle Bericht konzentriert sich auf die Anwendung der Cholesky Zersetzungsmethode im Bereich der pädagogischen Psychologie. Konkret geht es um individuelle Unterschiede in den Längszusammenhängen zwischen Kindergartenbriefwissen, Kindergarten-Phonologiebewusstsein, Lesekompetenz der ersten Klasse und Leseverständnis der siebten Klasse.
Einleitung
Ein erfahrener Leser zu werden, der textfließend lesen und verstehen kann, ist wichtig für die Schulergebnisse der Kinder. Um die Entwicklung von Leseproblemen zu verhindern, ist es wichtig zu verstehen, inwieweit unterschiedliche Lesefähigkeiten das Leseverständnis vorhersagen. Bestehende Forschungen haben gezeigt, dass Vorlese- und Lesefähigkeiten in der Grundschule längs das Leseverständnis in der Mittelschule1,2vorhersagen. Individuelle Unterschiede in diesen Vorhersagen deuten meist auf zugrunde liegende genetische (und bis zu einem gewissen Grad, Umwelt-)Faktoren vom Kindergarten bis zur 4. Klasse3,4hin. Es muss jedoch untersucht werden, ob dieselben genetischen und ökologischen Faktoren diese Vorhersagen bis hin zu den mittleren Schulnoten weiterhin beeinflussen.
Eine Methode, um ein besseres Verständnis der individuellen Unterschiede zu gewinnen, die den Assoziationen zwischen den Lesefähigkeiten der Grund- und Mittelschule zugrunde liegen, ist die Verwendung der verhaltensgenetischen Methodik, insbesondere der Cholesky-Zersetzungsmethode. Die Cholesky-Zersetzungsmethode gilt als eine der Goldstandardanalysen in der Verhaltensgenetik. Diese Methode ist einfach zu programmieren und zu lösen und ermöglicht die Zersetzung von Varianz und Kovarianz in (A) genetische, (C) gemeinsame Umwelteinflüsse und (E) nicht gemeinsame Umwelteinflüsse, in der Regel in einer Zwillingsprobe. Ein Beispiel für eine univariate (eine Variable) Cholesky Zersetzung ist in Abbildung 1angegeben. Der latente Faktor bezieht sich auf genetische Effekte, bei denen es sich um genetische Einflüsse handelt, die von Eltern vererbt wurden. Der latente Faktor C bezieht sich auf gemeinsame Umweltauswirkungen, die Aspekte der Umwelt sind, die dazu dienen, Zwillinge ähnlicher zu machen, wie z. B. häusliche und schulische Umgebungen. Schließlich bezieht sich der E-latente Faktor auf nicht gemeinsame Umweltauswirkungen, bei denen es sich um Umwelteinflüsse handelt, die für jeden Zwilling einzigartig sind und zu Unterschieden zwischen Zwillingen, wie z. B. jeder eigenen Erfahrung, beitragen. Der E-Faktor erfasst auch Messfehler.

Abbildung 1: Zersetzung in (A) genetische, (C) gemeinsame Umwelteinflüsse und (E) nicht gemeinsame Umwelteinflüsse. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}
Die A-, C- und E-Faktoren in Abbildung 1 schätzen das Ausmaß, in dem Gene und Umgebungen eine (Lesen)-Variable beeinflussen. Um jedoch individuelle Unterschiede zu untersuchen, die Längsverbänden zwischen mehr als einer Lesefähigkeit von der Grund- bis zur Mittelschule zugrunde liegen, ist eine Längsanalyse erforderlich. Um längs motivierte Forschungsfragen zu beantworten, wird hier eine multivariate Cholesky Zersetzungsmethode verwendet5. Konzeptionell ähnelt die multivariate Cholesky-Zersetzungsmethode der hierarchischen Multiple-Regression, so dass der unabhängige Beitrag genetischer und ökologischer Faktoren bewertet wird, nachdem die Beiträge früherer Faktoren in rechnung.
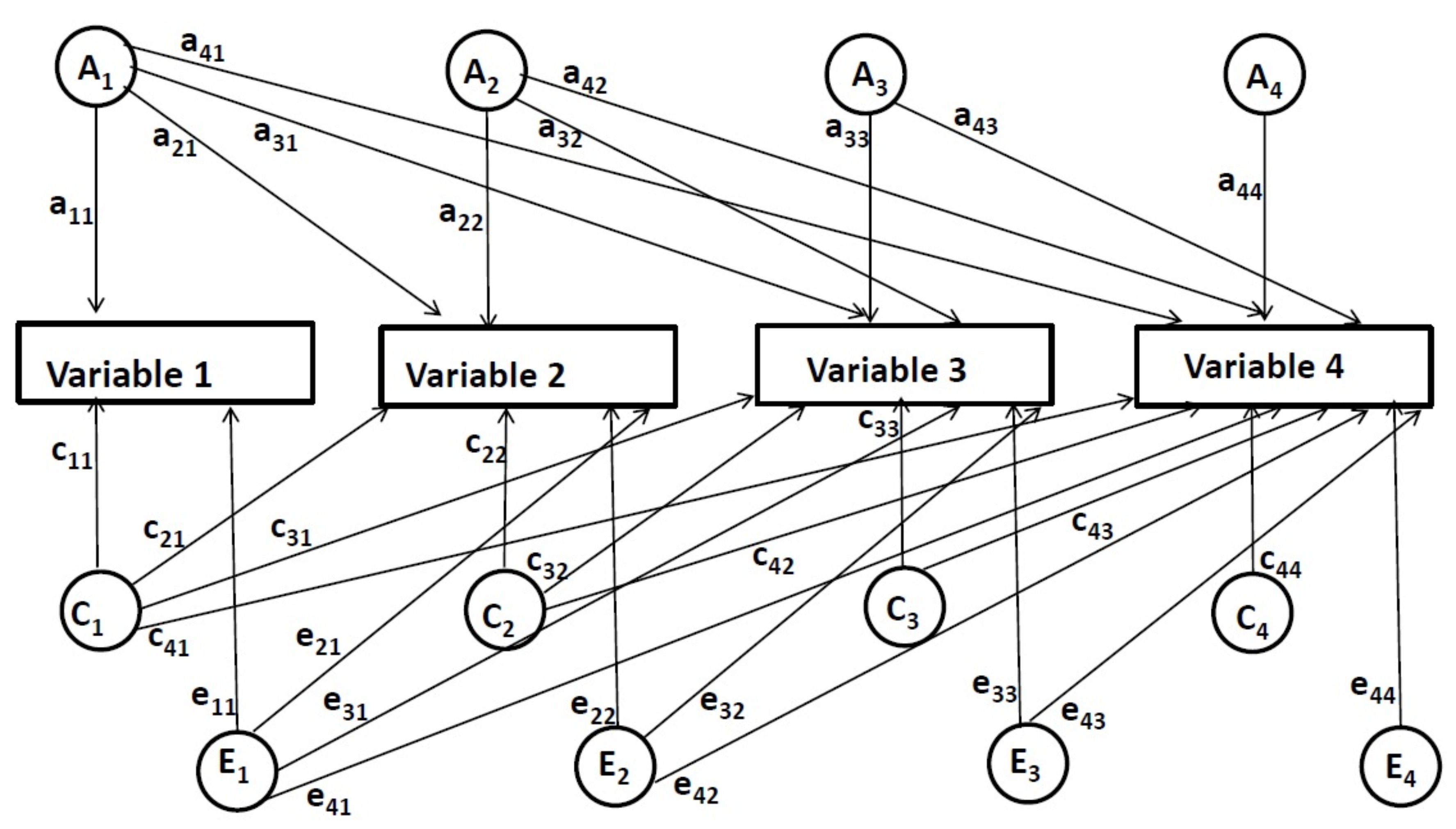
Zum Beispiel in einer multivariaten Cholesky-Zersetzung mit Längsschnittdaten zu vier Zeitpunkten (siehe Abbildung 2), dem ersten Satz von Faktoren [genetisch (A1), gemeinsamer Umwelt (C1) und nicht gemeinsam erdender Umwelt (E1)] trägt zur Varianz aller Variablen bei, dargestellt als Pfade a11, a21, a31, a41, c11, c21, ..., e11, etc., von A1, C1, E1 Faktoren zu jeder Variablen . Der zweite Satz von Faktoren (A2, C2, E2) trägt zur Varianz der zweiten und nachfolgenden Variablen nach der ersten Steuerung des ersten Zeitpunkts bei. Der zweite Satz von Faktoren wird als Pfadea 22, a32, a42, c22, c32, ..., e22, etc. dargestellt. Anschließend werden die Einflüsse des dritten Satzes von Faktoren (A3, C3, E3) für die dritte und vierte Variable nach der Steuerung für die letzten beiden Zeitpunkte geschätzt. Sie werden als Pfadea 33, a43, c33, c43, e33, e43dargestellt. Schließlich werden die Einflüsse des vierten Satzes von Faktoren (A4, C4, E4) für den letzten Zeitpunkt gemessen, nachdem alle vorherigen Zeitpunkte kontrolliert wurden. Sie werden als Pfadea 44, c44, e44dargestellt.

Abbildung 2: Multivariate Cholesky Zersetzungsmodell für vier Zeitpunkte. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}
Bei dieser Längsanwendung der multivariaten Cholesky-Zersetzungsmethode werden genetische und Umwelteinflüsse zu jedem Zeitpunkt geschätzt, nachdem die Auswirkungen früherer Zeitpunkte kontrolliert wurden. Daher ermöglicht diese Methode die Bestimmung des Ausmaßes, in dem einzigartige genetische und Umwelteinflüsse zu jedem bestimmten Zeitpunkt online gehen, unabhängig von Einflüssen aus früheren Zeitpunkten (diese Effekte werden durch Pfade a11, a 22, a33, a44, c11, c22, ..., e11, e22, etc.). Darüber hinaus ermöglicht das Verfahren auch die Untersuchung des Grades, in dem die gleichen (überlappenden) genetischen und ökologischen Einflüsse zwischen Zeitpunkten geteilt werden. Mit anderen Worten, es kann bestimmt werden, inwieweit genetische und ökologische Einflüsse von einem Zeitpunkt zum anderen übertragen werden (d.h. diese Effekte werden durch Pfade a21, a31, a41, a32, a42, a geschätzt). 43, c21, c31, ..., e21, etc.). Es sei darauf hingewiesen, dass Pfadea 11, c11und e11 alle möglichen genetischen und ökologischen Einflüsse bis einschließlich des ersten Zeitpunkts darstellen, die entweder eindeutig sein oder sich mit früheren Zeitpunkten überlappen können. Zeitpunkte vor dem ersten Zeitpunkt werden jedoch nicht geschätzt. Daher kann nicht genau bestimmt werden, ob sie eindeutige oder überlappende Einflüsse darstellen. Aus Vereinfachungsgründen werden sie als einzigartige Einflüsse in den aktuellen Bericht aufgenommen.
Die Reihenfolge der gemessenen Variablen, die in eine Cholesky-Zersetzung eingegeben werden, ist willkürlich. Die Reihenfolge wird jedoch in der Regel von einer theoretischen Perspektive gesteuert. Dies gilt auch für die aktuelle Studie, in der die Reihenfolge auf der Entwicklung von Lesefähigkeiten beruhte, so dass Lesefähigkeiten in der Grundschule das Leseverständnis in der Mittelschule vorhersagen.
Es gibt mehrere Berichte in der Literatur, die genetische und Umweltfaktoren untersuchen, die Längsschnittassoziationen von Lesefähigkeiten unter Verwendung der Cholesky-Zersetzungsmethode zugrunde liegen. Diese früheren Studien konzentrierten sich hauptsächlich auf die Untersuchung der Beziehungen zwischen den Lesefähigkeiten zwischen Grundschülern6,7. Es gibt nur eine veröffentlichte Studie, die individuelle Unterschiede im Zusammenhang mit dem Lesen von Grundschulklassen in Mittelschulnoten mit der multivariaten Cholesky Zersetzungsmethode8untersucht. Dieses Protokoll beschreibt die multivariate Cholesky Zersetzungsmethode aus diesem spezifischen Bericht, um individuelle Unterschiede in den Längszusammenhängen zwischen Kindergartenbriefwissen, phonologischem Bewusstsein des Kindergartens, Wortebene der ersten Klasse zu untersuchen. Lesefähigkeiten und Leseverständnis der siebten Klasse.
Die Studienergebnisse konzentrieren sich auf die Verwendung der multivariaten Cholesky Zersetzungsmethode, um zwischen zwei Arten von genetischen und Ökologischen Einflüssen zu unterscheiden. Zunächst wird gezeigt, wie genetische und ökologische Einflüsse abgeschätzt werden können, die vom Lesen der Grundschule bis zur Mittelschule (z. B. Schätzung von Pfadena 43, c43und e43, die genetische und ökologische Einflüsse auf Lesefähigkeiten auf Wortebene ab der ersten Klasse, die sich auf das Leseverständnis in der siebten Klasse auswirken). Zweitens wird gezeigt, wie man einzigartige genetische und Umwelteinflüsse, die in jedem bestimmten Grad online kommen, abschätzen kann (z. B. Schätzung von Pfaden a33, c33und e33, die einzigartige genetische und Umwelteinflüsse auf Lesefähigkeiten auf Wortebene, die in der ersten Klasse entstehen).
Access restricted. Please log in or start a trial to view this content.
Protokoll
Die folgenden Schritte beschreiben den Prozess der Schätzung individueller Unterschiede, die Längsschnittassoziationen zwischen den Lesefähigkeiten der Grund- und Mittelschule in (A) genetische, (C) gemeinsame Umweltfaktoren und (E) nicht gemeinsam genutzte Umweltfaktoren unter Verwendung eines statistischemodellierung, Textverarbeitungsprogramm und Software mit einer grafischen Benutzeroberfläche (GUI). Diese Studie wurde vom Institutional Review Board der Florida State University genehmigt.
1. Vorbereiten von Daten für das statistische Modellierungsprogramm
- Bereiten Sie die Daten in einem Format vor, das vom statistischen Modellierungsprogramm Ihrer Wahl gelesen werden kann. Beliebte statistische Modellierungsprogramme sind Mx, OpenMx in der Plattform R und MPlus9. Mx kann Datendateien in .vl- oder .dat-Datenformaten, OpenMx in jedem Datenformat und Mplus im DAT-Datenformat lesen. Das hier gezeigte Beispiel wird im Programm MPlus9ausgeführt.
HINWEIS: Eine Beispieldatendatei im .dat-Format für sechs zufällig ausgewählte Teilnehmer ist in ergänzenden Dateien verfügbar. Variablen, die in einer Beispieldatendatei verwendet werden, spiegeln Variablen wider, die in der Eingabecodierungsdatei verwendet werden.
2. Daten in das statistische Modellierungsprogramm lesen, das Skript ausführen und die Auswirkungen schätzen
- Öffnen Sie das statistische Modellierungsprogramm.
- Suchen Sie die relevante Datendatei, die in das statistische Modellierungsprogramm eingelesen werden soll, indem Sie "Datei ist [Speicherort Ihrer Datendatei auf Ihrem Computer einfügen]" eingeben.
- Klicken Sie auf das Symbol RUN auf dem Band des statistischen Modellierungsprogramms, um Schätzungen für genetische, gemeinsame Umwelteinflüsse und nicht gemeinsam genutzte Umwelteinflüsse aus der multivariaten Cholesky-Zersetzungsmethode zu erhalten. Das benotete Eingabeskript für das multivariate Cholesky Zerlegungsmodell für vier Zeitpunkte sowie seine Ausgabe mit MPlus finden Sie in ergänzenden Codierungsdateien.
- Sobald das statistische Modellierungsprogramm Schätzungen für genetische, gemeinsame Umwelteinflüsse und nicht gemeinsam genutzte Umwelteinflüsse generiert, suchen Sie die Schätzungen in der Ausgabedatei unter stx11 für Pfad11, stx21 für Pfad a21, ..., sty11 für Pfad c11, sty21 für Pfad c21, ..., stz11 für Pfad e11, stz21 für Pfad e21, etc.
3. Erstellen einer Tabelle mit generierten Schätzungen
- Öffnen Sie die Textverarbeitung.
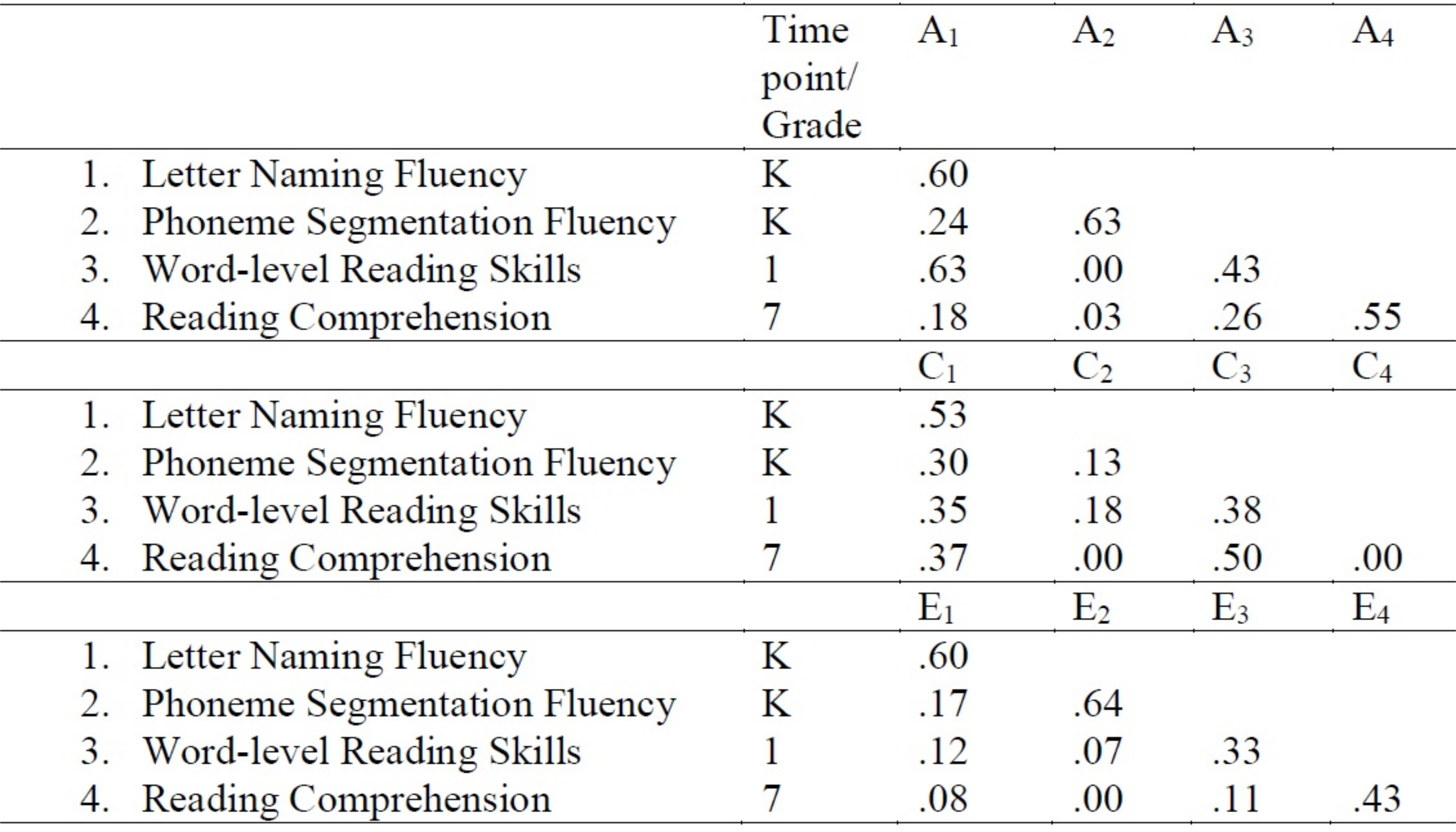
- Kopieren Sie die generierten Schätzungen in eine Tabelle in einem Textverarbeitungsprogramm. Die Tabelle kann in einem Format erstellt werden, wie in Abbildung 3angegeben. In diesem Fall weisen die Schätzungen für die Pfadea 11, a21, a31und a41 beispielsweise Werte von 0,60, 0,24, 0,63 bzw. 0,18 auf.

Abbildung 3: Multivariate Cholesky Zersetzung Modellierung standardisierte PfadSchätzungen von genetischen und Umwelteinflüssen. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}
4. Plotten genetischer, gemeinsamer Umwelteinflüsse und nicht gemeinsamer Umwelteinflüsse
- Öffnen Sie die Software mit einer GUI.
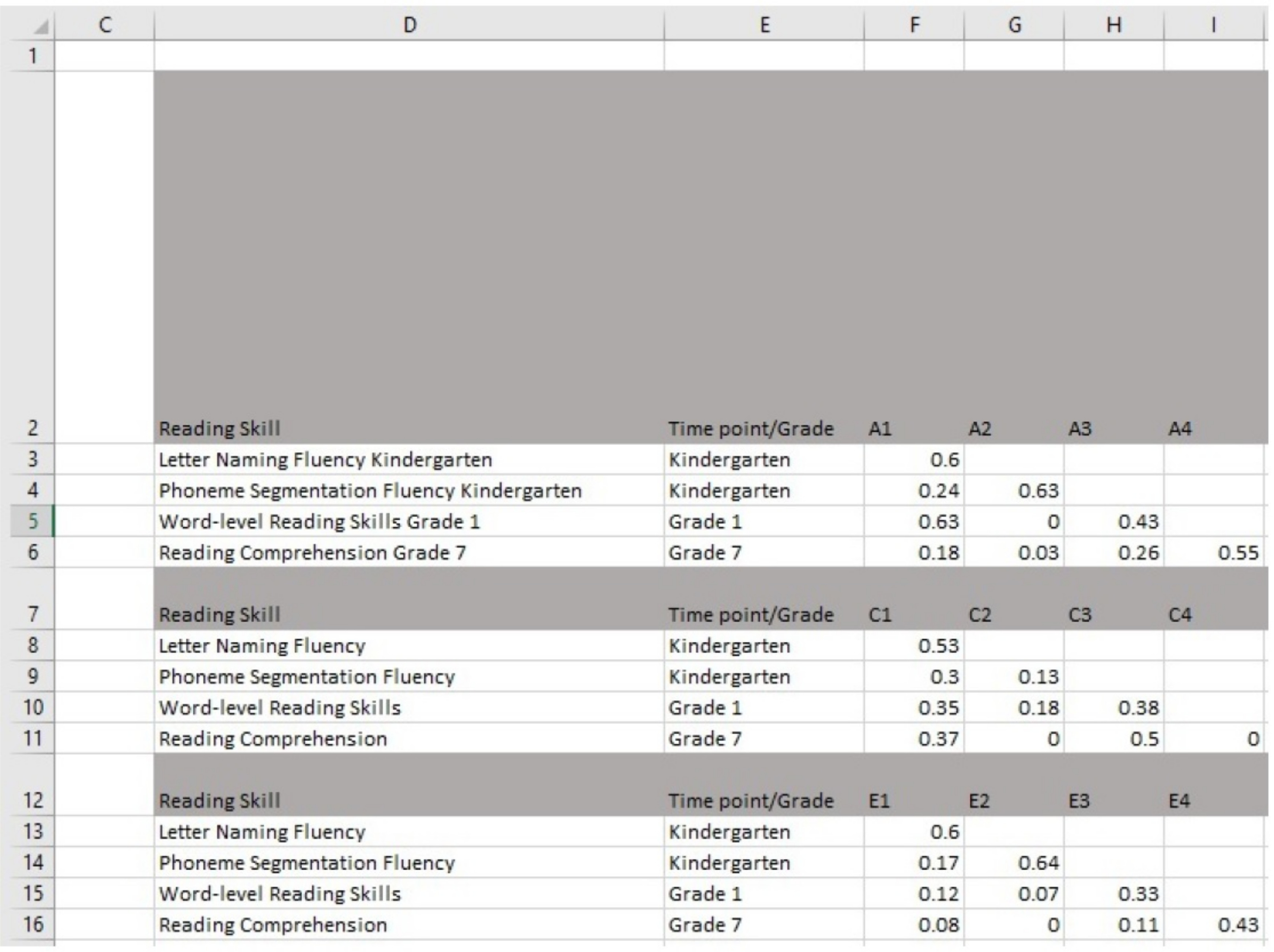
- Geben Sie die Schätzungen aus der erstellten Tabelle in die Zellen F3-F16, G4-G16, H5-H16 und I6-I16 ein. Ein Screenshot der Software mit GUI ist in Abbildung 4dargestellt.

Abbildung 4: Eingabe von Schätzungen in die Software mit einer GUI. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}
- Berechnen Sie die Varianz genetischer, gemeinsamer Umwelteinflüsse und nicht gemeinsam genutzter Umwelteinflüsse, indem Sie die Schätzungen in den Zellen F3-F16, G4-G16, H5-H16 und I6-I16 skalieren. Geben Sie die quadrierten Werte in die Zellen J3-J16, K4-K16, L5-L16 und M6-M16 ein.
- Berechnen Sie die prozentuale Varianz, indem Sie die Werte in den Zellen J3-J16, K4-K16, L5-L16 und M6-M16 mit 100 multiplizieren. Geben Sie die Prozentwerte in die Zellen N3-N16, O4-O16, P5-P16 und Q6-Q16 ein. Die Schritte 4.3 und 4.4 sind in Abbildung 5dargestellt.

Abbildung 5: Abbildung der Schritte 4.3 und 4.4. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}
- Berechnen Sie das Ausmaß, in dem genetische Einflüsse von der Grundschule zur Mittelschule übertragen werden (Überlappung).
- Geben Sie in Zelle R3 "0" ein.
- Geben Sie in Zelle R4 "=N4" ein. Dies ist das Ausmaß, in dem genetische Einflüsse vom ersten Zeitpunkt auf den zweiten Zeitpunkt übertragen werden. In diesem Fall weist es auf genetische Einflüsse hin, die von der Buchstabenbenennung im Kindergarten bis hin zur Phoneme-Segmentierungsfluenz im Kindergarten führen.
- Geben Sie in Zelle R5 "= N5+O5" ein. Dies ist der Grad, in dem genetische Einflüsse von den ersten beiden Zeitpunkten auf den dritten Zeitpunkt übertragen werden. In diesem Fall weist es auf genetische Einflüsse hin, die von der Buchstabenbenennung stritten fließend im Kindergarten und phoneme segmentierenim Kindergarten über die Lesefähigkeiten auf Wortniveau in Der 1. Klasse.
- Geben Sie in Zelle R6 "= N6+O6+P6" ein. Dies ist das Ausmaß, in dem genetische Einflüsse von den ersten drei Zeitpunkten auf den vierten Zeitpunkt übertragen werden. In diesem Fall zeigt es genetische Einflüsse von Buchstabenbenennung fließend im Kindergarten, Phoneme Segmentierung Fluency im Kindergarten, und Wort-Ebene Lesefähigkeiten in Klasse 1 über das Leseverständnis in Klasse 7.
- Berechnen Sie, inwieweit gemeinsame Umwelteinflüsse und nicht gemeinsame Umwelteinflüsse von der Grundschule zur Mittelschule übertragen werden, ähnlich wie in Schritt 4.5.
- Berechnen Sie, inwelchem Umfang eindeutige genetische, gemeinsame Umweltfaktoren und nicht gemeinsam genutzte Umweltfaktoren zu jedem bestimmten Zeitpunkt (d. h. Grad) online gehen.
- Kopieren Sie die Prozentsätze aus den Zellen N3, O4, P5 und Q6 in die Zellen S3, S4, S5 und S6, um das Ausmaß zu ermitteln, in dem eindeutige genetische Faktoren bei jeder Stufe online gehen.
- Kopieren Sie die Prozentsätze aus den Zellen N8, O9, P10 und Q11 in die Zellen U3, U4, U5 und U6, um das Ausmaß zu ermitteln, in dem eindeutige gemeinsame Umgebungsfaktoren bei jeder Klasse online gehen.
- Kopieren Sie die Prozentsätze aus den Zellen N13, O14, P15 und Q16 in die Zellen W3, W4, W5 und W6, um das Ausmaß zu ermitteln, in dem eindeutige nicht gemeinsam genutzte Umgebungsfaktoren bei jeder Klasse online gehen.
- Um sicherzustellen, dass alle Berechnungen korrekt sind, sollten die Werte in den Zellen R3-W3, R4-W4, R5-W5 und R6-W6 jeweils bis zu 100 addieren. Die Schritte 4.5–4.7 sind in Abbildung 6dargestellt.

Abbildung 6: Abbildung der Schritte 4.5-4.8. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}
- Zeichnen Sie genetische Überlappung sowie genetische einzigartige Einflüsse, indem Sie mit der Maus auf die Zellen R2–R6 und S2–S6 klicken und ziehen, um die Daten hervorzuheben.
- Klicken Sie auf das Menü Einfügen.
- Klicken Sie auf Diagramme > Gestapelte Spalte.
- Wiederholen Sie die Schritte 4.9–4.11 für gemeinsame Umweltüberschneidungen und eindeutige Einflüsse. Wählen Sie die Zellen T2–T6 und U2–U6 aus, um gemeinsame Umwelteinflüsse darzustellen, und wählen Sie die Zellen V2–V6 und W2–W6 für nicht gemeinsam genutzte Umwelteinflüsse aus.
Access restricted. Please log in or start a trial to view this content.
Ergebnisse
Standardisierte Schätzungen für genetische, gemeinsame Umwelteinflüsse und nicht gemeinsame Umwelteinflüsse aus dem multivariaten Cholesky-Zersetzungsmodell sind in Abbildung 7dargestellt. Im Allgemeinen zeigten die Ergebnisse, dass individuelle Unterschiede in der Vorlesezeit im Kindergarten und bei den Lesefertigkeiten auf der ersten Klasse einen großen Teil der Varianz der genetischen (40%) sowie gemeinsame Umwelt (39%) Einfluss auf das Leseverständnis der siebte...
Access restricted. Please log in or start a trial to view this content.
Diskussion
Ziel dieser Studie war es, zu zeigen, wie die etablierte Methode in der Verhaltensgenetik, die multivariate Cholesky-Zersetzungsmethode, effektiv zum Verständnis von Beziehungen zwischen Variablen im zeitlichen Kontext eingesetzt werden kann. Insbesondere ermöglicht diese Methode die Abschätzung des Ausmaßes, in dem während bestimmter Zeitpunkte (z. B. Schulnoten) einzigartige genetische und ökologische Einflüsse auftreten, sowie die Überschneidung von genetischen und ökologischen Einflüssen über viele Zeitpun...
Access restricted. Please log in or start a trial to view this content.
Offenlegungen
Autoren haben nichts zu verraten.
Danksagungen
Diese Forschung wurde teilweise durch ein Stipendium des National Institute of Child Health and Human Development (P50 HD052120) unterstützt. Die hierin zum Ausdruck gebrachten Ansichten sind die der Verfasser und wurden weder von den Bewilligungsstellen überprüft noch gebilligt.
Access restricted. Please log in or start a trial to view this content.
Materialien
| Name | Company | Catalog Number | Comments |
| Microsoft Office Excel | Microsoft | ||
| Microsoft Office Powerpoint | Microsoft | ||
| Microsoft Office Visio | Microsoft | ||
| Microsoft Office Word | Microsoft | ||
| Mplus Statistical Program | Mplus |
Referenzen
- Muter, V., Hulme, C., Snowling, M. J., Stevenson, J. Phonemes, rimes, vocabulary and grammatical skills as foundations of early reading development: Evidence from a longitudinal study. Developmental Psychology. 40 (5), 665-681 (2004).
- Schatschneider, C., Fletscher, J. M., Francis, D. J., Carlson, C. D., Foorman, B. R. Kindergarten prediction of reading skills: A longitudinal comparative analysis. Journal of Educational Psychology. 96 (2), 265-282 (2004).
- Byrne, B., et al. Longitudinal twin study of early literacy development: Preschool and kindergarten phases. Scientific Studies of Reading. 9 (3), 219-235 (2005).
- Christopher, M. E., et al. Genetic and environmental etiologies of the longitudinal relations between prereading skills and. Child Development. 86 (2), 342-361 (2015).
- Neale, M. C., Cardon, L. R. Methodology for Genetic Studies of Twins and Families. , Springer Science. Kluwer Academic Publishers B.V. Dordrecht, Netherlands. (1992).
- Byrne, B., et al. Genetic and environmental influences on early literacy. Journal of Research in Reading. 29 (1), 33-49 (2006).
- Byrne, B., et al. Genetic and environmental influences on aspects of literacy and language in early childhood: Continuity and change from preschool to grade 2. Journal of Neurolinguistics. 22 (3), 219-236 (2009).
- Erbeli, F., Hart, S. A., Taylor, J. Longitudinal associations among reading related skills and reading comprehension: A twin study. Child Development. 89 (6), e480-e493 (2018).
- Muthén, L. K., Muthén, B. O. Mplus. The comprehensive modeling program for applied researchers: User’s guide. , Muthén and Muthén. Los Angeles, CA. (2012).
- Hart, S. A., et al. Exploring how nature and nurture affect the development of reading: An analysis of the Florida Twin Project on Reading. Developmental Psychology. 49 (10), 1971-1981 (2013).
- Taylor, J., Roehrig, A. D., Hensler, B. S., Connor, C. M., Schatschneider, C. Teacher quality moderates the genetic effects on early reading. Science. 328 (5977), 512-514 (2010).
Access restricted. Please log in or start a trial to view this content.
Nachdrucke und Genehmigungen
Genehmigung beantragen, um den Text oder die Abbildungen dieses JoVE-Artikels zu verwenden
Genehmigung beantragenWeitere Artikel entdecken
This article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. Alle Rechte vorbehalten