
Method Article
Combinée des nucléotides et des Extractions de protéine chez Caenorhabditis elegans
Dans cet article
Résumé
Nous présentons ici un protocole pour l’isolement de l’ARN, ADN et protéines de l’échantillon même, dans un effort pour réduire la variation, améliorer la reproductibilité et faciliter les interprétations.
Résumé
Un seul échantillon biologique est titulaire d’une multitude d’informations, et il est maintenant pratique courante d’étudier simultanément plusieurs macromolécules pour capturer une image complète des multiples niveaux de transformation moléculaire et les changements entre les différentes conditions. Ce protocole présente la méthode d’isoler l’ADN, ARN et protéines de l’échantillon même du nématode Caenorhabditis elegans pour éliminer la variation introduite lors de ces biomolécules sont isolés des répétitions de traités de la même façon mais finalement différents échantillons. Acides nucléiques et des protéines sont extraites de la nématode utilisant la méthode de thiocyanate-phénol-chloroforme extraction acide guanidinium, avec précipitation subséquente, lavage et solubilisation de chacun. Nous montrons la réussite de l’isolement de l’ARN, ADN et protéines à partir d’un seul échantillon de trois souches de nématodes et les cellules HeLa, avec de meilleurs résultats d’isolement de protéines chez les animaux adultes. En outre, guanidinium thiocyanate-phénol-chloroforme-extrait de protéines de nématodes améliore la résolution de protéines plus gros, avec des niveaux détectables améliorées tel qu’observé par immunoblotting, par rapport à l’extraction de RIPA traditionnelle de protéine.
La méthode présentée ici est utile lors d’enquêtes sur des échantillons à l’aide d’une approche multiomic, spécifiquement pour l’exploration du transcriptome et du protéome. Les techniques qui permettent d’évaluer en même temps multiomics sont attrayants parce que moléculaires sous-jacents signalisation complexes phénomènes biologiques est pensé pour se produire aux niveaux complémentaires ; Cependant, il est devenu plus en plus fréquent de voir que les changements dans les niveaux d’ARNm ne reflètent pas toujours le même changement dans les taux de protéines et que le moment de la collecte est pertinent dans le contexte du règlement circadienne. Cette méthode supprime toute variation intersample lors du dosage des matières différentes au sein d’un même échantillon (intrasample).
Introduction
Multiomics, l’approche analytique qui utilise une combinaison d’omics, comme génome, protéome, transcriptome, épigénome, microbiome ou lipidome, est devenu plus en plus populaire lors du traitement de grands volumes de données pour la caractérisation de la maladie1, 2. Montage des éléments de preuve a montré que limitant les approches à une seule « ome » fournit une analyse moléculaire incomplète (évaluée par Rotroff et Motsinger-Reif1). Grands ensembles de données sont générés, en particulier lors de l’exécution des écrans à l’aide de techniques de haut-débit, mais afin de brosser un tableau complet ou d’identifier les cibles plus pertinentes, multiomic approches sont préférables. Avec l’utilisation des approches multiomics, cependant, il y a l’observation fréquente de contradictions entre l’ARNm et protéines niveaux3,4,5,6. Notamment, ARNm et protéines utilisées pour side-by-side transcriptomique et proteomic analyses avec le séquençage de RNA (RNAseq) et spectrométrie de masse en tandem par chromatographie liquide (LC-MS/MS), respectivement, sont souvent obtenus à partir des échantillons de même traités de différents réplicats, potentiellement présentant des variations entre les mêmes conditions de3,4,5,6. Harvald et coll. effectué un élégant worms de c. elegans famine temporelle étude qui a comparé le transcriptome et le protéome de type sauvage (WT) à celle de hlh-30 vers mutant qui n’ont pas un facteur de transcription important dans la longévité 7. de la note, l’ARN et des protéines ont été récoltés sur les réplicats condition même, afin de ne pas partir du même échantillon. Leurs résultats montrent une faible corrélation entre les niveaux d’ARNm et des niveaux de protéine à chaque instant (r = 0.559 à 0,628). En fait, leur heatmap formé quatre groupes : Cluster, j’ai eu une forte baisse dans l’ARNm niveaux mais peu ou pas de diminution des taux de protéines correspondantes, Cluster II avait peu ou aucune augmentation dans les niveaux d’ARNm mais une augmentation des niveaux de protéine, module III a eu une augmentation de mRNA niveaux mais une baisse de taux de protéines et module IV avait une augmentation des niveaux d’ARNm, mais seulement un changement subtil dans la protéine niveaux4. En outre, cette variation intersample peut-être être introduite dans les cas où les échantillons de la même condition ne sont pas collectées au même moment. Par exemple, l’ARNm et protéines régulés par le cycle circadien fluctuent selon l’heure de la journée8,9, ou, plus précisément, l’exposition de c. elegans à lumière9; expression de ces protéines circadiens pourrait être retardée jusqu'à 8 h après gene expression induction10. Néanmoins, la prévalence de cette observation ne signifie pas nécessairement que c’est une erreur ; en fait, cela pourrait pour être instructif. ARNm et protéines sont dans un état dynamique constant entre la formation et la dégradation. En outre, les protéines sont modifiées souvent après pour accroître la stabilité ou d’induire leur dégradation11. Par exemple, leur statut d’ubiquitination peut conduire à activation ou ciblant le protéasome ou lysosome pour dégradation12. En outre, les ARN non codants joue un rôle important dans la régulation de l’expression des gènes à l' étapes transcriptionnelle et post-transcriptionnelle13. Ainsi, la question est comment faire pour limiter les variables afin de confirmer que les divergences que nous observons dans ces études de nématodes sont réels.
Ici, nous proposons une méthode qui supprime la variable intersample en permettant des analyses de macromolécules différentes du même échantillon. Le but du présent protocole est de proposer une méthode pour isoler systématiquement ADN, d’ARN et protéine provenant d’un seul échantillon c. elegans (aussi dénommé "vers") dans le but de réduire la variation, d’améliorer la reproductibilité et de faciliter les interprétations. Également d’utiliser le même échantillon l’épargne du temps et de ressources au cours du prélèvement, facilitant l’analyse transversale des échantillons précieuses et limitées, y compris les souches qui sont difficiles à cultiver et à entretenir et à acquérir aperçus de la régulation différentielle des macromolécules basé sur intrasample variations dans les niveaux d’ARNm et de protéines.
Cette méthode est pertinente pour évaluer les expressions génétiques et des niveaux de protéine d’un seul échantillon de worms, permettant une évaluation plus détaillée de plusieurs niveaux de traitement moléculaire. Guanidinium thiocyanate-phénol-chloroforme (CGA) réactif14, un chimique couramment utilisé pour isoler l’ARN, est utilisé pour l’extraction des acides nucléiques et des protéines vers, avec précipitation subséquente, lavage et solubilisation de chacun. Ce protocole est une compilation de divers protocoles15,16 , avec des modifications mineures, conçu en mettant l’accent sur c. elegans, mais nous avons également avec succès isolé des ARN, protéines et l’ADN d’un culot de cellules HeLa suite à la mêmes étapes. Bien que ne pas testé ici, ce protocole est susceptible de travailler sur les tissus ainsi17,18.
Protocole
Remarque : Chaque étape de précipitation de macromolécule est exécutée séquentiellement, suivie de lavages faits simultanément ; Toutefois, il est conseillé de compléter l’ARN tout d’abord car il est intrinsèquement instable.
1. le prélèvement
- Graines de 1 000 œufs de ver par plaque de 10 cm avec des conditions de croissance approprié19. Incuber à 20 ° C pendant 72 h.
Remarque : Eau de Javel œuvée adultes afin de ramasser les œufs comme précédemment décrit19. - Laver la plaque avec environ 5 mL de tampon de M9 et collectez 1 000 vers adultes dans un tube.
Remarque : Tampon de M9 est composé de 35 mM phosphate dibasique de sodium, chlorure de sodium de 102 mM, 22 mM de phosphate de potassium monobasique et 1 mM le sulfate de magnésium dans l’eau stérile,19. - Centrifuger les vers à 1 000 x g pendant 1 min, jeter le surnageant et transférer les granulés vers avec 1 mL de tampon de M9 dans un tube de microtubes de 1,5 mL.
- Centrifuger à nouveau à 845 x g pendant 1 min et jeter la majeure partie du liquide surnageant. Stocker les granulés vers à-80 ° C pendant au moins 4 h.
Remarque : Avec une boulette de congelés produit un rendement plus élevé qu’un tourteau frais. Une série de cycles de gel/dégel à l’aide d’éthanol 95 % ou de l’azote liquide sur la glace sèche pour casser la cuticule de ver est recommandée si vous utilisez un tourteau frais. Laisser une petite quantité de M9 sur le culot aidera à briser la cuticule en gelant.
2. séquences de nucléotides et d’isolement de protéine
- Supprimer un surnageant de la pastille décongelée et ajouter 1 mL de réactif de CGA froid. Bien mélanger en pipetage de haut en bas. Placer l’échantillon sur la glace pendant 10 min et mélangez-le occasionnellement en le tournant à l’envers.
Mise en garde : Phénol est corrosif, neurotoxiques et hautement toxique et peut provoquer des brûlures chimiques et la cécité.
Remarque : Nous avons utilisé vers adultes pouvant atteindre 5 000 comme produit de départ avec les volumes déclarés ; chaque volume est fondé sur l’utilisation de 1 mL de réactif de CGA. Lorsque vous utilisez un échantillon plus large, il peut être nécessaire à l’échelle. - À la solution vers et des CGA, ajouter 200 µL de chloroforme froid. Tenez le tube entre les doigts et agiter vigoureusement pendant 15 s. congé il à température ambiante (RT) pendant 3 min.
Mise en garde : Chloroforme est un toxique irritant et peut provoquer des ulcérations cutanées et autres dommages d’organe-cible est un cancérogène possible. - Centrifuger le tube à 13 500 g pendant 15 min à 4 ° C.
Remarque : Trois couches sont formées après ce spin : haut, phase aqueuse limpide, au fond, Rose phase organique et l’interphase petit, nuageux qui contient des lipides et l’ADN. - À l’aide d’une micropipette, déplacer la couche claire (phase aqueuse) à un nouveau tube exempt de RNase 1,5 mL microcentrifuge (tube A) pour isoler l’ARN par précipitation alcoolique (comme décrit à l’étape 2.5) et déplacer la couche rose (phase organique) de la granule restant à une (nouvelle) tube tube B) et placez-le sur la glace.
Remarque : La phase organique rose peut être congelée à-80 ° C jusqu'à ce que l’isolement de l’ADN et de protéines à partir de cet échantillon. Plus grands échantillons produira une épaisse couche blanche entre la phase aqueuse et organique. Cette fraction contient de l’ADN. Si cette couche peut être enlevée sans déranger les autres phases, faites-le et mettez-le dans une éprouvette (tube B2). -
Isoler l’ARN comme suit.
- De la phase aqueuse limpide dans le tube A, précipiter l’ARN avec 500 µL d’isopropanol 100 %. Incuber pendant 10 min à température ambiante. Puis, centrifugeuse tube A à 13 500 x g pendant 10 min à 4 ° C.
Remarque : Une petite pastille blanche de l’ARN doit être visible au fond du tube. - Décanter la majorité du liquide surnageant. Retirer le reste avec une seringue de 1 mL avec une aiguille et éliminer le surnageant.
Remarque : La taille de l’aiguille n’est pas importante ; Cependant, une plus grande mesure d’aiguille offrira davantage de contrôle pour ne pas déranger le culot. Une micropipette peut être utilisée si les aiguilles ne sont pas disponibles. - Ajouter 1 mL d’éthanol 75 % au tube A pour laver le culot. Tourner le tube à 5 300 x g pendant 5 min à 4 ° C.
- Retirez le surnageant de la pastille par décantation et à l’aide d’une seringue de 1 mL avec une aiguille, comme indiqué au point 2.5.2 et jetez-le.
- Laisser le diabolo sécher à l’air pendant 5 – 10 min, mais ne le laissez pas sèchent. 50 µL d’eau exempte de RNase permet de reconstituer le culot d’ARN avant qu’il devienne complètement transparent.
Remarque : Il s’agit d’un volume suffisant de départ pour les 1 000 – 3 000 vers, mais elle peut devoir être ajustée selon la quantité des matériaux a été utilisé. - Incuber le culot à 55 – 60 ° C pendant 10 min pour le dissoudre.
- Mesurer la concentration et la pureté à l’aide d’un spectrophotomètre. Enregistrer les absorbances à 260 nm pour la concentration en ARN et à 230 et 280 nm pour identifier toutes les impuretés.
- Nettoyer l’ARN pour enlever les contaminants, tels que les résidus de phénol ou de l’ADN, purification colonne soit avec les lavages ultérieurs de l’éthanol et le traitement de la DNase.
Remarque : À ce stade, l’ARN est prêt à être envoyé pour analyse RNAseq ou peut être utilisé pour faire des ADNc à utiliser pour la RT-qPCR (voir la section 3.1 pour plus de détails). RNA peut être conservée à-80 ° C jusqu'à l’utilisation supplémentaire.
- De la phase aqueuse limpide dans le tube A, précipiter l’ARN avec 500 µL d’isopropanol 100 %. Incuber pendant 10 min à température ambiante. Puis, centrifugeuse tube A à 13 500 x g pendant 10 min à 4 ° C.
-
Isoler l’ADN comme suit.
- De la phase organique rose en tube B et l’échantillon dans le tube B2, le cas échéant, précipiter l’ADN en ajoutant 300 µL d’éthanol à 100 % et mélanger par retournement. Laisser les tubes à ta pendant 2 à 3 min.
- Centrifuger les tubes B et B2 à 375 x g pendant 5 min à 4 ° C pour granuler ADN.
- Déplacer le surnageant de tubes B et B2 en le versant dans un nouveau tube 2 mL (tube C) et laisser sur la glace pour l’isolement des protéines ultérieures. Laver le culot d’ADN dans le tube B ou B2 avec 1 mL de citrate de sodium 0,1 M à 10 % d’éthanol pour tubes de centrifugeuse de 30 min. B et B2 à 375 x g pendant 5 min à 4 ° C.
Remarque : Sodium se lie à la colonne vertébrale de l’ADN, rendant l’ADN précipité plus facilement en citrate de sodium et d’éthanol, ce qui permet des impuretés est retiré par centrifugation à basse vitesse. - Répétez l’étape de lavage comme indiqué au point 2.6.3. Resuspendre le culot dans 1,5 mL d’éthanol 75 % et sortir à RT pendant 20 min, avec mélange occasionnelle de bouleversement.
- Centrifugeuse tube B et B2 à 375 x g pendant 5 min à 4 ° C.
- Jeter le surnageant et laisser sécher pendant 5 à 10 min.
- Dissoudre les granulés dans 150 µL d’hydroxyde de sodium 8 mM. Ajuster le pH désiré avec HEPES si nécessaire. Faire tourner l’échantillon à 375 x g pendant 5 min à 4 ° C.
- À l’aide d’une micropipette, déplacez le surnageant (ADN) dans un nouveau tube. Mesure de la concentration et de déterminer la pureté à l’aide d’un spectrophotomètre. Enregistrer les absorbances à 260 nm pour la concentration de l’ADN et à 230 et 280 nm pour identifier toutes les impuretés.
-
Isolat de protéine comme suit.
- Pour précipiter les protéines, ajouter jusqu'à 1,5 mL d’isopropanol 100 % dans le surnageant rose en tube C, mélanger en retournant plusieurs fois et incuber à ta pendant 10 min.
- Centrifuger le tube C à 13 500 x g pendant 10 min à 4 ° C.
- Jeter le surnageant et le culot avec 2 mL de chlorhydrate de guanidine 0,3 M de lavage dans l’éthanol à 95 % pendant 20 min à tube à centrifuger de RT. C à 5 300 x g pendant 5 min à 4 ° C.
- Répétez l’étape de lavage comme indiqué au point 2.7.3 x 2.
- Le culot de protéine dans un nouveau tube de 1,5 mL (tube C2) et ajoutez jusqu'à 1,5 mL d’éthanol à 95 %. Vortex et laissez reposer pendant 20 min à ta.
- Centrifuger le tube C2 à 5 300 x g pendant 5 min à 4 ° C. Jeter le surnageant et sécher le culot pendant 10 min à RT. dissoudre le culot dans 300 µL du SDS de 5 % à 50 ° C pendant 60 min.
NOTE : Un temps d’incubation plus longs peut devoir dissoudre complètement le culot de protéine. Dans le passé, le pellet a mis à incuber pendant 6 h sans sacrifier la qualité. - Centrifuger tube C2 à 13 500 g pendant 10 min à 17 ° C. Déplacez le surnageant dans un nouveau tube.
- Mesurer la concentration à l’aide d’un essai de quantification de protéine préférée qui est compatible avec un détergent.
Remarque : La protéine est prête à être utilisé en SDS-PAGE et transfert Western. Il peut être conservé à-20 ° C pour une utilisation future. D’autres techniques, telles que LC-MS/MS, le détergent devront être dialysé hors tension.
3. évaluation des niveaux de protéines et de l’ARNm
-
RT-qPCR
- Préparer des ADNc par transcription inverse avec 1 ng d’ARN, en utilisant le protocole thermocycleur suivant : amorçage (5 min à 25 ° C), la transcriptase inverse (20 min à 46 ° C) et l’inactivation de RT (1 min à 95 ° C).
- Faire une plaque stock de cDNA en ajoutant 100 µL de la dilution au 1/100 de chaque échantillon d’ADNc à chaque puits d’une plaque de 96 puits. Inclure des contrôles appropriés, tels qu’aucun puits modèle / l’eau seulement et les échantillons dilués en série de 01:25 1 : 400 (pour origine des ADNc mise en commun de tous les échantillons analysés) afin de permettre une courbe d’étalonnage établir l’efficacité d’apprêt pour chaque gène analysé.
Remarque : Ce format peut être utilisé avec le Microdoseur de 96 puits, ce qui permet le transfert de tous les échantillons dans une plaque sur une plaque de la RT-qPCR et de réduire les variations de pipetage puits à puits. Le mélange maître approprié (par exemple, SYBR + amorces) peut être ajouté à chaque bien par la suite, avec une pipette multicanaux. Dans l’ensemble, cette approche réduit les erreurs introduites lors du main-pipetage chaque échantillon, ce qui réduit encore la variabilité. - Ajouter 3 µL de l’ADNc de la plaque de stock dans les puits de la plaque de la RT-qPCR.
- Faire un mélange maître pour chaque série d’amorces qui comprend 1 supermix x contenant un colorant intercalant de l’ADN de cyanine, 5 µM de chaque de transmettre et inverser les amorces et jusqu'à 7 µL par échantillon d’eau. Ajouter 7 µL dans les puits d’une plaque de la RT-qPCR et agiter légèrement pour mélanger.
Remarque : Inclure des échantillons afin de mesurer les gènes domestiques à utiliser comme référence pour normaliser les résultats20. - Exécutez la plaque à l’aide d’un protocole de RT-qPCR qui convient pour les amorces utilisées.
-
Tache occidentale
Remarque : Pour obtenir des informations détaillées sur les transferts western, veuillez consulter Mahmood et Yang21.- Préparer les échantillons pour SDS-PAGE en combinant 20 µg de protéines avec un volume égal de 2 x solution tampon de Laemmli et faites bouillir à 95 ° C pendant 10 min.
- Charger les échantillons sur un gel de Tris-glycine 4 – 15 % et de les exécuter à 150 V pendant 1 h ou jusqu'à ce que le front de colorant atteigne le bas du gel.
- Protéines de transfert du gel sur une membrane de nitrocellulose à 25 V pendant 30 min dans un appareil de transfert semi Etanche.
- Confirmer le transfert par la coloration de la membrane avec la tache de Ponceau S.
- Laver soigneusement la tache de la membrane avec tampon Tris salin (TBS) avec 0,01 % polysorbate 20 (SCT-T).
- Bloquer la membrane avec 5 % de lait dans TBS-T pendant 1 h à température ambiante.
- Incuber la membrane à l’anticorps primaire à la dilution appropriée conformément aux recommandations du fournisseur. Laisser sur le balancier à 4 ° C durant la nuit.
- Laver la membrane 3 x, de 5 min chacun, avec TBS-T.
- Incuber la membrane dans l’anticorps secondaire approprié à la dilution appropriée conformément aux recommandations du fournisseur. Laisser sur le rocker pendant 1 h à température ambiante.
- Laver la membrane 3 x, de 5 min chacun, avec TBS-T.
- Image et quantifier la tache occidentale, à l’aide de méthodes préférées.
Résultats
On a analysé les échantillons d’ARN, ADN et protéine, et des résultats représentatifs à l’aide de l’ARN et protéine isolats sont présentés ici. En outre, nous comparons l’échantillon de protéine récoltée en utilisant la méthode de CGA à la commune RIPA lysis méthode22. Notre expérience, nous avons utilisé quatre réplicats indépendantes de chaque vers WT (N2) et les deux vers mutant longue durée de vie, manger-2 et les rsks-123,24.
Qualité et la quantité d’ARN et d’ADN
La concentration d’ARN lorsque remis en suspension dans 50 µL d’eau varie de 0,2 à 2 µg/µL, à l’aide d’environ 3 000 adultes worms comme des matériaux. Les ratios d’absorbance, qui indiquent la pureté, varient de 2,0 à 2,2 pour A260/A280 et de 1,9 à 2,5 pour A260/A230 (tableau 1), indiquant l’extraction réussie de l’ARN sans contamination avec des composants de CGA, tels que le chlorhydrate de guanidine ou de phénol.
L’extraction de l’ADN a été un succès, mais la qualité était variable. La concentration d’ADN lorsque resuspendues dans 150 µL de NaOH variait entre 0,04 et 1,1 µg/µL. Les ratios d’absorbance varies de 1,8 à 2,1 pour A260/A280 et 0,9 à 1,6 pour A260/A230 (tableau 1), indiquant l’extraction réussie de l’ADN ; Toutefois, certains des échantillons étaient contaminés par des composants de CGA, comme chlorhydrate de guanidine ou de phénol. Si l’isolement d’ADN est nécessaire, il faut en séparant la couche du milieu de la séparation de phase de CGA, et plusieurs lavages peuvent être nécessaires.
RT-qPCR de cibles choisies
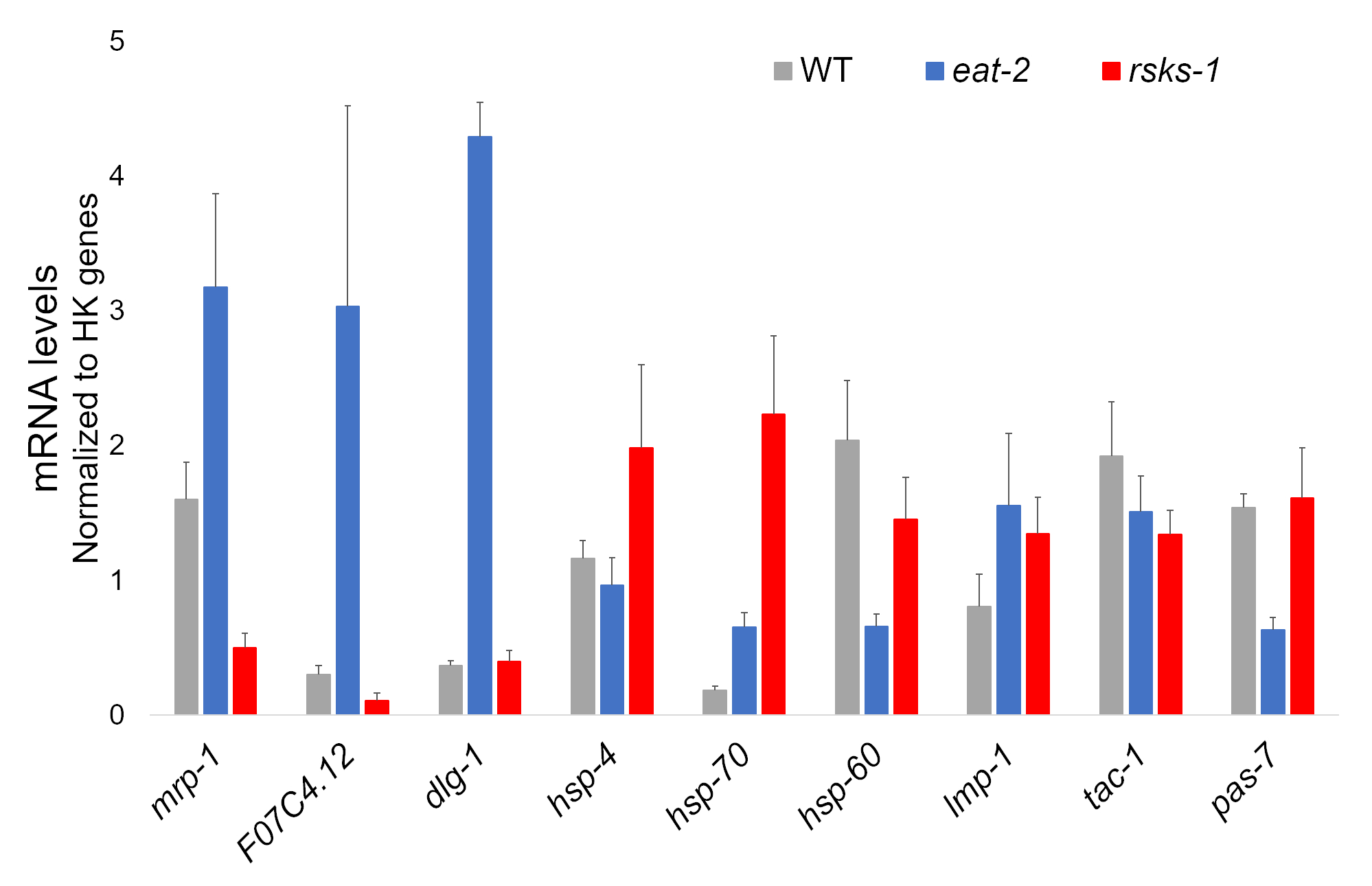
L’ARN de quatre échantillons indépendants de chaque souche de ver a été un succès et a été envoyé pour analyse de RNAseq, avec le RT-qPCR ultérieur effectuée à l’aide d’un supermix contenant un colorant cyanine. Cibles analysés par RT-qPCR ont été sélectionnés parmi un grand dataset RNAseq basé sur les gènes plus différemment réglementés fréquents chez les deux mutants contre les vers WT. F07C4.1225, un homologue d’humain neuroligines 3, l’isoforme b, a été la cible de surexprimés partagés sélectionnés. Nous avons également inclus un gène réglementé différemment entre les deux mutants, mrp-126, pour une analyse complémentaire, qui était augmentée à worms eat-2 mais réprimés dans les vers de rsks-1 . Modifications de l’expression du mrp-1 ont été confirmées par l’intermédiaire de RT-qPCR ; Toutefois, l’upregulation F07C4.12 à rsks-1 worms prédite par l’analyse de RNAseq n’était pas considérée par la RT-qPCR (Figure 1).
Des cibles supplémentaires avec des anticorps validés pour les vers ont été étudiées aussi bien. Il s’agissait de plusieurs marqueurs organelle caractérisés chez Hadwiger et al.,27. Un certain nombre de ces marqueurs ont été exprimé à l’échelle de l’ARNm dans les vers mutants. Comme on le voit à la Figure 1, lmp-128 et dlg-129 étaient surexprimés dans les vers mangent-2 ; HSP-4 30, hsp-7030et lmp-1 ont été positivement en vers rsks-1 ; HSP-60 31 et pas-732 ont été réprimés dans les vers mangent-2 ; HSP-60 et tac-133 ont été réprimés dans les vers de rsks-1 .
Préparation de protéine simultanée vs RIPA
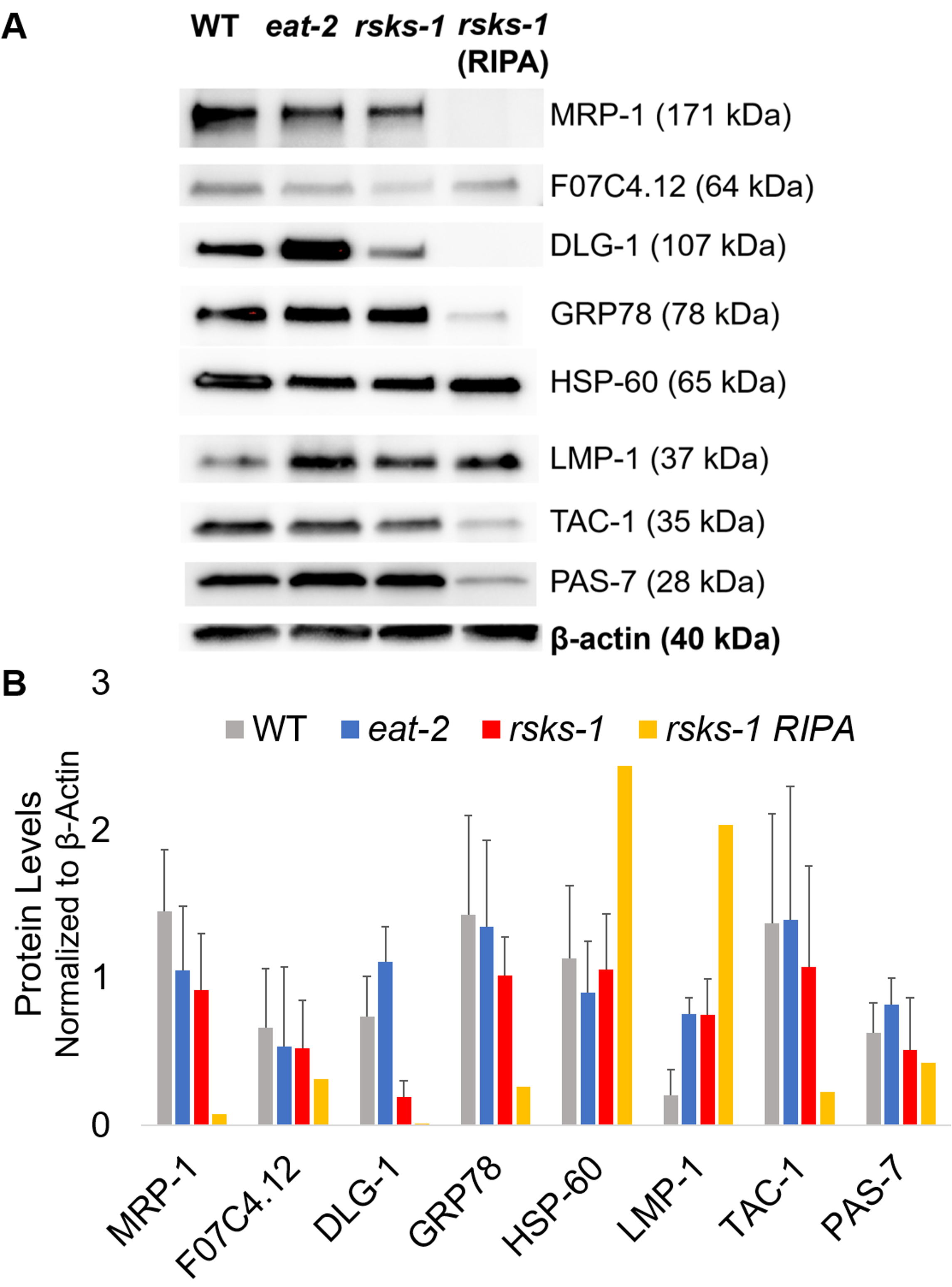
Pour affirmer l’efficacité et la qualité de la protéine avec la méthode de CGA comme décrit ci-dessus, nous avons comparé à protéine recueillie à l’aide de la méthode plus traditionnelle de RIPA lysis22. En utilisant la même quantité de matière, à savoir soit adultes seulement (environ 10 000 vers), soit une population mixte d’adultes, les larves et les œufs (environ 130 000 vers), première la quantité globale recueillie avec CGA a été moins en resuspendues dans des volumes égaux de fin (tableau 1 ); Toutefois, l’extraction d’une population adulte seule a plus de succès que d’une population mixte. En outre, la qualité des protéines était similaire, quoique les protéines extraites à l’aide de CGA a montré une meilleure résolution des protéines plus grandes lors du chargement égal de protéine totale, comme en témoigne la tache de bleu de Coomassie dans la Figure 2. En effet, objectifs évalués par western blot à la Figure 3 montrent des niveaux similaires dans la plupart des cas ; Cependant, les protéines de plus de 75 kDa ont montré des niveaux inférieurs dans la protéine RIPA-extrait par rapport à la protéine extraite CGA (Figure 3 a, voie de droite ; Figure 3 b, jaune bar).
La méthode d’extraction présentée ici a également été évaluée dans la lignée de cellules mammaliennes HeLa. Pour référence, la quantité de protéines extraites avec RIPA une pastille compacte de cellules HeLa 6 millions (une pastille de ~ 25 µL) était comparable à celle extraite d’une population mixte 130 000 de worms (une pastille compacte ~ 75 µL), ou près de la moitié de ce qui est extrait de 10 000 vers adultes (une pastille ~ 100 µL réglés en gravité), comme on le voit dans le tableau 1. Nous montrons que l’efficacité de l’extraction de protéines (tableau 1) et la résolution des grandes protéines (Figure 2) a été réduites en CGA comparée à RIPA-extraits de protéines dans les cellules HeLa, suggérant que cette technique fonctionne mieux dans une population adulte de vers. La solubilisation incomplète de l’extrait concentré de protéine de protéines extraites à l’aide de CGA HeLa peut être une limitation de cette méthode dans les cellules de mammifères.
Immunoblotting cibles analysés par RT-qPCR
Ensuite, nous avons étudié les taux de protéines des produits géniques testés par RT-qPCR afin de déterminer si les taux d’ARNm en corrélation avec le taux de protéines. Comme on le voit à la Figure 3, les modifications de moyen d’expression de protéine en corrélation avec les expressions d’ARNm moyenne a changé pour de nombreux objectifs ; Cependant, certains niveaux de la protéine ne reflète pas les changements dans les niveaux d’ARNm. Souvent, les taux d’ARNm à worms eat-2 ont été plus élevées que celles des autres souches, mais le taux de protéines était équivalentes ou plus bas que les autres souches de la même cible. L’observation plus remarquable a été les niveaux très élevés de dlg-1 ARNm à worms eat-2 , qui ne s’est pas traduit à plus de protéines ; en fait, il y a des dlg-1 protéine plus faibles comparativement aux autres souches (Figure 3).
Enfin, les niveaux dans les protéines extraites à l’aide de CGA et les protéines extraites à l’aide de RIPA a montré une différence frappante. L’ARN a été extrait de la même manière pour les deux ; Toutefois, l’échantillon similaire mais distinct recueilli par RIPA lysis a montré nettement réduit les taux de protéines, particulièrement pour ceux de plus de 75 kDa (Figure 3 a, voie de droite ; Figure 3 b, jaune bar).
Intrasample comparaison des niveaux d’ARNm et de protéines
Un des objectifs du présent protocole était de déterminer si la variation que nous avons vu à l’ARNm et teneur en protéines était réel, ou si elle pouvait être un artefact de la variation intersample. Dans la Figure 4, un sous-ensemble des cibles a été comparé dans les échantillons individuels. Chaque échantillon individuel est montré comme la même teinte et la couleur de la dot, avec échantillon 1 étant l’ombre plus sombre et l’échantillon 4 comme la plus légère nuance de gris (WT), bleu (eat-2) ou rouge (rsks-1). Dans la plupart des échantillons, il y avait une faible variabilité des teneurs en ARNm, avec une plus grande variabilité au niveau de la protéine, une faille potentielle de l’analyse semi-quantitative des transferts western. En regardant la position de chacun des points colorés entre les paires d’ARNm et de protéines, l’ordre du plus haut-de-bas souvent ne correspond pas ; par exemple, chez le WT, l’ordre d’ARNm hsp-60 était d’échantillon 4, 3, 2, 1, mais le taux de protéines était 1, 2, 3, 4. Ainsi, il existe certainement des différences entre les niveaux d’ARNm et de protéines dans un échantillon, mais la méthode présentée permet aux utilisateurs de supprimer le temps de collection comme une source possible de la différence observée.

Tableau 1 : Concentrations et des rapports de l’absorption. Concentrations de l’ARN et l’ADN et des rapports de pureté ont été mesurés sur un spectrophotomètre. Des concentrations de protéines ont été déterminées à l’aide d’un test de dosage colorimétrique protéine. Le gris, bleu et rouge mettent en évidence les échantillons utilisés pour la RT-qPCR et tache occidentale. Le jaune indique les échantillons utilisés pour comparer des CGA à extraction de protéine RIPA ou ver protéine protéine HeLa. S’il vous plaît cliquez ici pour télécharger ce fichier.

Figure 1 : l’expression des gènes de la RT-qPCR. RT-qPCR analyse de l’ARNm obtenu par cette méthode, confirmant les objectifs identifiés de RNAseq données et des gènes marqueurs organite. Les barres d’erreur représentent déviation standard ; n = 4. La concentration de l’ARNm a été définie contre une courbe d’étalonnage pour chaque série d’amorces. Tous les niveaux d’ARNm ont été normalisés à la moyenne d’un ensemble de six gènes domestiques utilisés comme des gènes de référence, qui comprennent act-1, cdc-42, ama-1, nhr-23, pmp-3et cyn-1. S’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
{kind=link}

Figure 2 : comparaison des CGA-versus RIPA-extrait de protéine dans les vers et les cellules HeLa. Protéines totales de type sauvage (WT) vers ou des cellules HeLa récoltées via la méthode de CGA ou RIPA lysis, séparés par SDS-PAGE et colorées au bleu de Coomassie. Chaque piste contient 25 µg de protéines totales. S’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
{kind=link}

Figure 3 : taux de protéines dans les worms. (A) la tache occidentale des cibles étudiées par analyse de densitométrie RT-qPCR et (B) de l’intensité du signal. Chaque piste contient 20 μg de protéines extraites à l’aide de CGA de type sauvage (WT), eat-2ou rsks-1 vers mutant. L’image affichée est une représentation de quatre répétitions indépendantes par souche ver. Β-actine (en bas) a été utilisé au contrôle pour le chargement égal pour chaque cible ; seulement un ensemble représentatif est montré. La voie de droite contient 20 μg de protéines totales de RIPA-extrait de : rsks-1 mutant worms. (B) intensités du signal correspondant ont été quantifiées à l’aide de ImageJ. Les barres d’erreur représentent déviation standard ; n = 4. S’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
{kind=link}

Figure 4 : comparaison de niveau Intrasample ARNm et protéines. Les niveaux d’ARNm et de protéines provenant d’échantillons individuels d’un sous-ensemble des cibles pour chaque souche sont alignés. La couleur est le représentant de la Table 1. Le gris/noir est WT, le bleu est manger-2et le rouge est rsks-1. ARNm et protéines de la même cible sont jumelés à côté de l’autre et séparés par des nématode souche. S’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
{kind=link}
Discussion
Méthodes pour biomolécule isolements, telles que l’ADN, l’ARN et des protéines, sont souvent optimisées sans chevauchement technique ou combinaisons. C’est particulièrement défavorable lorsque les échantillons sont difficiles à obtenir, qui pourrait conduire à la récolte des échantillons dans les mêmes conditions à des moments différents. Selon les voies cellulaires, prélevées à différents moments de répétitions peuvent générer variation. Ce manuscrit est une méthode pour contourner cet obstacle en permettant l’isolation simultanée et la purification de chaque biomolécule partir du même échantillon de worms, réduisant les modifications introduites par des techniques différentes d’isolement, le moment de la récolte de l’échantillon, ou de la récolte inégal. Contrôler ces variables non seulement économise temps et ressources, mais aussi facilite la reproductibilité. Ici, nous démontrons une approche combinatoire qui évite les ARN compromettante et la qualité des protéines, mais avec des résultats variables avec l’ADN. Préparations peuvent être optimisées en utilisant l’ADN procédures de nettoyage. Nous avons démontré l’approche à l’aide de matériel des cellules nématodes c. elegans et HeLa.
Des travaux antérieurs, explorant le transcriptome et le protéome des animaux N2 WT et mutants de eat-2 et rsks-1 ont offert aperçu de diverses voies, y compris les mécanismes qui se prolongent la durée de vie4,34,35 ,,36. Dans le but d’étudier le mécanisme de la restriction calorique en prolongeant la durée de vie, un Isotope Stable étiquetant par/avec des acides aminés dans les cellules (SILAC) la culture analyse a révélé que manger-2 worms ont une diminution globale de la synthèse protéique globale 36. les données présentées ici sont conformes à cette conclusion, alors même que les taux d’ARNm des mêmes cibles sont grandement augmentés. Un autre groupe visait à identifier les effecteurs de la médiation S6K longévité et, ainsi, effectué un écran de protéomique du rsks-1 vers34. Partir des données de RNAseq trouvées à la présente étude, nous avons identifié au moins trois gènes qui corroborent avec les protéines identifiées à partir de cet écran ; MRP-1 et les homologues de CPA et neuroligines (F07C4.12) ont été découverts comme étant exprimés dans les vers de rsks-1 par rapport au WT N234.
Les données générées à l’aide de cette méthode sont compatibles avec les enquêtes précédentes de multiomic. Les taux d’ARNm de neuf cibles furent utilisées pour prédire le taux de protéines dans chaque échantillon. De ces objectifs, plusieurs avaient des taux de protéine prévisible compte tenu des niveaux d’ARNm. Néanmoins, il y avait des différences notables entre les niveaux d’ARNm et de protéines. Ce qui est important, le protocole présenté ici permet aux scientifiques de toute confiance, évaluer et interpréter ces différences en supprimant la variabilité intersample collecte d’ARNm et protéines par le même échantillon. En outre, nous avons comparé les taux d’ARNm pour les niveaux de protéines collectées à partir du même échantillon ou recueillies auprès d’un échantillon de semblable mais différent récolté avec RIPA. Nous avons démontré que pour un certain nombre d’objectifs, il y avait des concentrations beaucoup plus faibles de protéines dans l’échantillon extrait RIPA. Sans contrôle la variation intersample, il serait impossible de savoir si cette différence est due à la régulation différentielle d’ARNm et de protéines.
Il est important de garder à l’esprit qu’il existe des protocoles spécialement optimisées pour ces différentes macromolécules, donc si une analyse transversale n’est pas le but final de l’expérience, alors il serait judicieux d’employer ces méthodes au lieu de cela. L’utilisation de CGA pour isoler l’ADN et les protéines provoque ils deviennent moins solubles, exiger la reconstitution de l’ADN dans une base faible, tels que NaOH et solubilisation de la protéine dans un tampon avec une forte concentration de détergent avec chauffage, au risque d’incomplète solubilisation. En outre, CGA contient guanidinium thiocyanate et acide phénol, qui inactive les enzymes comme les protéases, mais se dégradent lentement protéine au fil du temps, sauf congelée. Il sera à la discrétion du chercheur de décider si le contournement de ces limitations sera utile.
Ce qui est important, lorsque vous travaillez avec l’ARN, une technique stérile, garder l’échantillon sur la glace, sauf indication contraire et l’utilisation de décontamination disponibles dans le commerce réactif est recommandé pour maintenir l’ARN intact. Notamment, plus grands échantillons devront plus CGA, dans lequel chaque solvant d’extraction devront également être entartré. Ce protocole ne nécessite pas de n’importe quel manuelle homogénéisation des échantillons ver ou cellule lorsque le montant correct de CGA est utilisé. Dans le contexte d’isolement de l’ADN, le rendement est fortement tributaire de l’aptitude à récupérer la couche organique (rose). Enfin, pour améliorer la solubilisation des protéines au cours de l’isolement, augmenter le volume de mémoire tampon resolubilization ou l’ajout d’autres détergents outre SDS peut être nécessaire. En effet, les protéines provenant d’une population adulte uniquement vers au lieu d’un mélange de œufs, larves et adultes sont beaucoup plus faciles à resolubilize.
Dans l’ensemble, à l’aide de ce protocole offre une approche intégrée à l’isolement de la biomolécule et facilite l’interprétation des corrélations, ou l’absence, entre les niveaux d’ARNm et de protéines qui peuvent en découler récolte séparément des biomolécules de différents échantillons. En utilisant cette méthode peut aider les scientifiques à identifier correctement les cas où la traduction de l’ARNm à la protéine n’est pas corrélative et peut conduire à l’enquête plus profonde des mécanismes de régulation post-transcriptionnelle et post-traductionnelles dans diverses conditions.
Déclarations de divulgation
Les auteurs n’ont rien à divulguer.
Remerciements
L.R.L. a été financé par des subventions de la NIH/NIA (R00 AG042494 et AG051810 R01), un Glenn Foundation for Medical Research Award for Research in mécanismes biologiques du vieillissement et une subvention de faculté de Junior de la Fédération américaine for Aging Research. Les auteurs aimeraient remercier Anita Kumar et Shi Quan Wong pour leurs commentaires utiles à la rédaction de ce manuscrit.
matériels
| Name | Company | Catalog Number | Comments |
| 4–15% Mini-PROTEAN® TGX Stain-Free™ Protein Gels | BIORAD | 4568084 | |
| Antibodies: | |||
| CePAS7-s | DHSB- U of Iowa | ||
| CeTAC1-s | DHSB- U of Iowa | ||
| DLG1-s | DHSB- U of Iowa | ||
| GRP78 | Novus Bio. | NBp1-06274 | |
| HRP Goat Anti-Mouse | Li-Cor | 926-80010 | |
| HRP Goat Anti-Rabbit | Li-Cor | 92680011 | |
| HSP60-s | DHSB- U of Iowa | ||
| LMP1-s | DHSB- U of Iowa | ||
| MRP-1 | Abcam | ab24102 | |
| Neuroligin 3 | Abcam | ab172798 | |
| β-actin | Millipore | MAB1501R | |
| ChemiDoc MP Imaging System | BIORAD | ||
| Chloroform | Fisher | C298-500 | Health hazard, Irritant, Toxic |
| Coomassie Brilliant Blue | ThermoSci | 20279 | |
| DC Protein assay | BIORAD | 500-0116 | |
| Epoch 2 microplate reader | BioTek | ||
| Ethanol (200 proof) | Fisher | 04-355-223 | Flammable, health hazard |
| HeLa cells | ATCC | CCL-2 | BSL2 |
| iScript Reverse Transcription Supermix | BIORAD | 1708840 | |
| Hydra microdispenser: Matrix Hydra | Robbins/ThermoFisher | ||
| Isopropanol | Fisher | A516-4 | Flammable, health hazard |
| M9 buffer: 3 g KH2PO4 6 g Na2HPO4 5 g NaCl Add H2O to 1 liter. Sterilize by autoclaving. After solution cools down, add 1 mL sterile 1 M MgSO4 | |||
| Laemmli Sample Buffer (2x) | BIORAD | 161-0737 | |
| NanoDrop One | ThermoSci | ||
| PAGE apparatus | BIORAD | ||
| Ponceau S | Alfa Aesar | J60744 | |
| Primers | IDT | 25 nmole DNA Oligo with Standard Desalting | |
| dlg-1: F (5'-GGTCCTACCA GGCAGTTGAG-3') R (5'-CACGTCCGTT AACCTCTCCC-3') | |||
| hsp-4: F (5'-AGAGGGCTTT GTCAACCCAG-3') R (5'-TCGTCAGGGT TGATTCCACG-3') | |||
| hsp-70: F (5'-CGGCATGTGA ACGTGCTAAG-3') R (5'-GAGCAGTTGA GGTCCTTCCC-3') | |||
| hsp-60: F (5'-ATTGAGCAAT CGACGAGCGA-3') R (5'-CAACACCTCC TCCTGGAACG-3') | |||
| lmp-1: F (5'-ACAACAACAC CGGACTCACG-3') R (5'-ATCGAGCTCC CACTCTTTGG-3') | |||
| tac-1: F (5'-AGTGGCAGGC AAAGTTCCTC-3') R (5'-TGAGCACCTT GATCTCGTCG-3') | |||
| pas-7: F (5'-GTACGCTCAA AAGGCTGTCG-3') R (5'-CTGAATCGGC ATTGGCTCAC-3') | |||
| mrp-1: F (5'-TTTGCCTTGC GCTTGTTCTG-3') R (5'-AGTTCCAGTG CGGAGCATAC-3') | |||
| F07C4.12: F (5'-TGCTGAGCAT GAAGGACTGT-3') R (5'-TGGCAATAGC TCCTCCGTTG-3') | |||
| HK Actin: F (5'-CTACGAACTT CCTGACGGACAAG-3') R (5'-CCGGCGGACT CCATACC-3') | |||
| HK cyn-1: F (5'-GTGTCACCAT GGAGTTGTTC-3') R (5'-TCCGTAGATT GATTCACCAC-3') | |||
| HK nhr-23: F (5'-CAGAAACACT GAAGAACGCG-3') R (5'-CGATCTGCAG TGAATAGCTC-3') | |||
| HK ama-1: F (5'-TGGAACTCTG GAGTCACACC-3') R (5'-CATCCTCCTT CATTGAACGG-3') | |||
| HK cdc-42: F (5'-CTGCTGGACA GGAAGATTACG-3') R (5'-CTCGGACATT CTCGAATGAAG-3') | |||
| HK pmp-3: F (5'-GTTCCCGTGT TCATCACTCAT-3') R (5'-ACACCGTCGA GAAGCTGTAGA-3') | |||
| LightCycler 96 qPCR machine | Roche | ||
| RIPA buffer: 10 mM Tris-Cl (pH 8.0) 1 mM EDTA 1% Triton X-100 0.2% SDS 140 mM NaCl 1 tablet of Roche protease inhibitor per 20 mL | |||
| SsoAdvanced Universal SYBR Supermix | BIORAD | 1725274 | |
| SuperSignal West Femto Max Sens Substrate | ThermoSci | 34095 | |
| Trans-Blot Transfer apparatus | BIORAD | ||
| Trans-Blot Turbo Transfer Pack | BIORAD | 170-4159 | |
| TRIzol reagent | Invitrogen | 15596026 | Health hazard (skin, eyes) |
| Worm strains: | Caenorhabditis Genetics Center (CGC) | ||
| N2 (wild type) | Caenorhabditis Genetics Center (CGC) | ||
| eat-2 (MAH95) | Caenorhabditis Genetics Center (CGC) | ||
| rsks-1 (VB633) | Caenorhabditis Genetics Center (CGC) |
Références
- Rotroff, D. M., Motsinger-Reif, A. A. Embracing Integrative Multiomics Approaches. International Journal of Genomics. 2016, 1715985 (2016).
- Chen, R., Snyder, M. Promise of personalized omics to precision medicine. Wiley Interdisciplinary Reviews: System Biology and Medicine. 5 (1), 73-82 (2013).
- Anderson, L., Seilhamer, J. A comparison of selected mRNA and protein abundances in human liver. Electrophoresis. 18 (3-4), 533-537 (1997).
- Harvald, E. B., et al. Multi-omics Analyses of Starvation Responses Reveal a Central Role for Lipoprotein Metabolism in Acute Starvation Survival in C. elegans. Cell Systems. 5 (1), (2017).
- Griffin, T. J., et al. Complementary profiling of gene expression at the transcriptome and proteome levels in Saccharomyces cerevisiae. Molecular and Cell Proteomics. 1 (4), 323-333 (2002).
- Greenbaum, D., Colangelo, C., Williams, K., Gerstein, M. Comparing protein abundance and mRNA expression levels on a genomic scale. Genome Biology. 4 (9), 117 (2003).
- Lapierre, L. R., et al. The TFEB orthologue HLH-30 regulates autophagy and modulates longevity in Caenorhabditis elegans. Nature Communications. 4, 2267 (2013).
- Doherty, C. J., Kay, S. A. Circadian control of global gene expression patterns. Annual Reviews Genetics. 44, 419-444 (2010).
- Goya, M. E., Romanowski, A., Caldart, C. S., Benard, C. Y., Golombek, D. A. Circadian rhythms identified in Caenorhabditis elegans by in vivo long-term monitoring of a bioluminescent reporter. Proceedings of the National Academy of Sciences USA. 113 (48), E7837-E7845 (2016).
- Dalvin, L. A., Fautsch, M. P. Analysis of Circadian Rhythm Gene Expression With Reference to Diurnal Pattern of Intraocular Pressure in Mice. Investigative Ophthalmology and Visual Science. 56 (4), 2657-2663 (2015).
- Narayanan, A., Jacobson, M. P. Computational studies of protein regulation by post-translational phosphorylation. Current Opinion in Structural Biology. 19 (2), 156-163 (2009).
- Swatek, K. N., Komander, D. Ubiquitin modifications. Cell Research. 26 (4), 399-422 (2016).
- Cech, T. R., Steitz, J. A. The noncoding RNA revolution-trashing old rules to forge new ones. Cell. 157 (1), 77-94 (2014).
- Chomczynski, P., Sacchi, N. Single-step method of RNA isolation by acid guanidinium thiocyanate-phenol-chloroform extraction. Analytical Biochemistry. 162 (1), 156-159 (1987).
- Triant, D. A., Whitehead, A. Simultaneous Extraction of High-Quality RNA and DNA from Small Tissue Samples. Journal of Heredity. 100 (2), 246-250 (2009).
- Liu, X., Harada, S. RNA Isolation from Mammalian Samples. Current Protocols in Molecular Biology. 103 (1), 11-14 (2013).
- Hummon, A. B., Lim, S. R., Difilippantonio, M. J., Ried, T. Isolation and solubilization of proteins after TRIzol extraction of RNA and DNA from patient material following prolonged storage. Biotechniques. 42 (4), 467-470 (2007).
- Kopec, A. M., Rivera, P. D., Lacagnina, M. J., Hanamsagar, R., Bilbo, S. D. Optimized solubilization of TRIzol-precipitated protein permits Western blotting analysis to maximize data available from brain tissue. Journal of Neuroscience Methods. 280, 64-76 (2017).
- Stiernagle, T. Maintenance of C. elegans. WormBook. , (2006).
- Hoogewijs, D., Houthoofd, K., Matthijssens, F., Vandesompele, J., Vanfleteren, J. R. Selection and validation of a set of reliable reference genes for quantitative sod gene expression analysis in C. elegans. BMC Molecular Biology. 9 (1), 9 (2008).
- Mahmood, T., Yang, P. -. C. Western blot: technique, theory, and trouble shooting. North American Journal of Medical Sciences. 4 (9), 429-434 (2012).
- Peach, M., Marsh, N., MacPhee, D. J., Kurien, B. T., Scofield, R. H. Protein solubilization: Attend to the choice of lysis buffer. Protein Electrophoresis: Methods and Protocols. , 37-47 (2012).
- Lakowski, B., Hekimi, S. The genetics of caloric restriction in Caenorhabditis elegans. Proceedings of the National Academy of Science USA. 95 (22), 13091-13096 (1998).
- Pan, K. Z., et al. Inhibition of mRNA translation extends lifespan in Caenorhabditis elegans. Aging Cell. 6 (1), 111-119 (2007).
- Gaudet, P., Livstone, M. S., Lewis, S. E., Thomas, P. D. Phylogenetic-based propagation of functional annotations within the Gene Ontology consortium. Briefings in Bioinformatics. 12 (5), 449-462 (2011).
- Broeks, A., Gerrard, B., Allikmets, R., Dean, M., Plasterk, R. H. Homologues of the human multidrug resistance genes MRP and MDR contribute to heavy metal resistance in the soil nematode Caenorhabditis elegans. The EMBO Journal. 15 (22), 6132-6143 (1996).
- Hadwiger, G., Dour, S., Arur, S., Fox, P., Nonet, M. L. A Monoclonal Antibody Toolkit for C. elegans. PLoS One. 5 (4), e10161 (2010).
- Kostich, M., Fire, A., Fambrough, D. M. Identification and molecular-genetic characterization of a LAMP/CD68-like protein from Caenorhabditis elegans. Journal of Cell Science. 113 (14), 2595 (2000).
- Firestein, B. L., Rongo, C. DLG-1 is a MAGUK similar to SAP97 and is required for adherens junction formation. Molecular Biology of the Cell. 12 (11), 3465-3475 (2001).
- Heschl, M. F., Baillie, D. L. Characterization of the hsp70 multigene family of Caenorhabditis elegans. DNA. 8 (4), 233-243 (1989).
- Yoneda, T., et al. Compartment-specific perturbation of protein handling activates genes encoding mitochondrial chaperones. Journal of Cell Science. 117 (18), 4055 (2004).
- Takahashi, M., Iwasaki, H., Inoue, H., Takahashi, K. Reverse Genetic Analysis of the Caenorhabditis elegans 26S Proteasome Subunits by RNA Interference. Biological Chemistry. 383, 1263 (2002).
- Le Bot, N., Tsai, M. C., Andrews, R. K., Ahringer, J. TAC-1, a regulator of microtubule length in the C. elegans embryo. Current Biology. 13 (17), 1499-1505 (2003).
- McQuary, P. R., et al. C. elegans S6K Mutants Require a Creatine-Kinase-like Effector for Lifespan Extension. Cell Reports. 14 (9), 2059-2067 (2016).
- Larance, M., et al. Global Proteomics Analysis of the Response to Starvation in C. elegans . Molecular and Cell Proteomics. 14 (7), 1989-2001 (2015).
- Yuan, Y., et al. Enhanced energy metabolism contributes to the extended life span of calorie-restricted Caenorhabditis elegans. Journal of Biological Chemistry. 287 (37), 31414-31426 (2012).
Réimpressions et Autorisations
Demande d’autorisation pour utiliser le texte ou les figures de cet article JoVE
Demande d’autorisationThis article has been published
Video Coming Soon
À PROPOS DE JoVE
Copyright © 2025 MyJoVE Corporation. Tous droits réservés.