
Для просмотра этого контента требуется подписка на Jove Войдите в систему или начните бесплатную пробную версию.
Method Article
Применение программы настройки eMASS в качестве исследовательского инструмента для оценки потребительских выгод
В этой статье
Резюме
Представлен протокол для изучения реакции потребителей на массовую настройку в контексте онлайн-ритейла. Протокол подробно описывает процедуру онлайн-опроса и как анализировать данные с помощью структурного моделирования уравнений и групповых различий с помощью скрытого среднего анализа.
Аннотация
Поскольку многие ученые и практики изучают персонализацию и маркетинг отношений, важно обеспечить персонализацию, такую как массовая настройка с помощью маркетинговых технологий. Цель этого исследования состоит в том, чтобы изучить, как проводить исследования потребителей с помощью онлайн-опроса и анализа данных. Это исследование рассматривает потребителей воспринимается выгоды при настройке продукта, а также эмоциональные привязанности продукта, отношение к программе настройки, и лояльность намерениях в контексте онлайн-розничной торговли. Кроме того, это исследование исследует, как потребительские ответы отличаются на основе индивидуальных характеристик, таких как мода инновационность. Онлайн-опрос компании в Корее набрал 290 женщин-покупателей одежды, которые приобрели одежду в Интернете. Для повышения внешней достоверности, это исследование использовало существующий розничный веб-сайт с хорошо зарекомендовавшей себя программой массовой настройки. После завершения программы настройки участники заполняют онлайн-опросник. Затем для анализа проводится анализ структурного моделирования уравнений (SEM) и скрытых средних анализов (LMAs). Это исследование подчеркивает важность тестирования инвариантности измерения для средних сравнений. До SEM и LMA, это исследование следует иерархии инвариантных тестов (конфигуральный тест на инвариантность, метрический тест на инвариантность, и тест на скалантарную инвариантность), которые не рассматриваются традиционными подходами, такими как ANOVA. Эти статистические анализы обеспечивают применимость процедур тестирования инвариантности и LMA к поведению потребителей. Выводы о средних различиях имеют целостность и обоснованность, поскольку они руководствуются сложной статистической процедурой для обеспечения инвариантности измерений.
Введение
Массовая настройка относится к способности электронного ритейлера адаптировать продукты, услуги и транзакционную среду для отдельных клиентов1. Сегодняшние потребители не удовлетворены стандартными продуктами, и многие розничные торговцы признали это. Предлагая вариант массовой настройки является одним из методов для получения лояльности клиентов и конкурентных преимуществ2. Массовая настройка как маркетинговая тактика позволяет потребителям создавать свои собственные продукты на основе особых потребностей и, таким образом, предоставляет индивидуальные продукты или услуги3. Например, потребители могут не только приобрести пару обуви, которые массового производства, но они также могут создать новую и уникальную пару обуви, которые не доступны на регулярных розничных веб-сайтов, выбрав цвет, ткань и другие компоненты дизайна. В результате потребители могут приобрести более выгодные продукты, а их удовлетворенность индивидуальным продуктом, а также рост лояльности к бренду4,5.
С увеличением использования Интернета, процесс массовой настройки стал более быстрым и эффективным с точки зрения снижения времени производства и предоставления более вариантов дизайна с теми же затратами. Кроме того, розничные торговцы могут получить информацию о том, что их целевые клиенты предпочитают и таким образом построить прочные отношения с ними6,7. Таким образом, многие отрасли промышленности (например, одежда, обувь, автомобили и компьютеры) приняли программы настройки. Хотя массовая настройка приносит пользу как потребителям, так и розничным торговцам, некоторые розничные торговцы сталкиваются с проблемами8. Поэтому необходимо изучить, как потребители воспринимают преимущества и как эти преимущества влияют на другие торговые ответы для долгосрочного успеха.
Опираясь на иерархию эффектов (HOE) модель из теорий убеждения9, это исследование предлагает, чтобы потребители обрабатывать информацию на основе познания-аффект-конации последовательности. В частности, это исследование рассматривает (после создания массового настроенного продукта), влияют ли предполагаемые потребительские преимущества (познание) на намерения лояльности (конация) через вложение продукта и отношение к программе массовой настройки (влияет) . На основе теории мотивации10, воспринимается выгоды делятся на внутренние и внутренние преимущества11.
Экстримвые выгоды относится к потребительской воспринимается значение, полученное от использования продукта12 (таким образом, близко по стоимости к качеству продукта11), в то время как внутренняя выгода указывает приятный опыт при использовании продукта11. В контексте массовой настройки, экстренная выгода связана с продуктом, который создает потребитель, и внутренняя выгода связана с опытом настройки, удовлетворяющей гедонистические и эмпирические потребности13,14. Предварительное исследование показало, что потребители воспринимается выгоды повышения эмоционального продукта привязанности15 и позитивное отношение к массовой программы настройки16. Эмоциональная привязанность продукта относится к эмоциональной связи, что потребители подключаются к продукту17, что положительно влияет на отношение к программе настройки18 и лояльность намерения19. Кроме того, отношение к программе настройки положительно влияет на намерения лояльности20.
Наконец, это исследование рассматривает, как индивидуальная характеристика (т.е. мода инновационность) влияет на реакцию потребителей по-разному. Мода инновационность относится к степени, в которой инновационная тенденция человека влияет на принятие нового элемента моды21. Результаты исследований показывают, что потребители, желающие избежать соответствия (т.е. высоко модных инновационных потребителей) мотивированы на приобретение уникальных продуктов, что указывает на то, что массовая настройка может быть эффективной тактикой дифференцировать себя от других 22. Таким образом, это исследование предполагает, что большее количество положительных ответов будет генерироваться для высокой моды инновационных потребителей.
На основе предыдущих обзоров литературы, это исследование рассматривает следующие гипотезы исследования. H1: Воспринимаемые преимущества (a: экстренная польза, b: внутренняя выгода) массового индивидуального продукта положительно повлияют на эмоциональную привязанность продукта; H2: Предполагаемые преимущества (a: экстренная польза, b: внутренняя выгода) массового индивидуального продукта положительно повлияют на отношение к программе массовой настройки; H3: Эмоциональная привязанность продукта положительно повлияет на отношение к программе массовой настройки; H4: Эмоциональная привязанность к продукту положительно повлияет на намерения лояльности; H5: Отношение к программе массовой настройки положительно повлияет на намерения лояльности; и H6: По сравнению с низкой модой инновационность, высокая мода новаторов будет иметь более положительные ответы на а) воспринимается выгоды, b) эмоциональная привязанность продукта, (с) отношения, и (d) поведенческие намерения.
Для повышения внешней достоверности в этом исследовании используется существующая программа настройки массы. Потенциальные участники в корее набираются для этого исследования и просят создать свои собственные траншеи пальто с помощью программы, как если бы они на самом деле приобрели продукт. Для изучения ответов участников на основе их настройки опытом, это исследование использует онлайн-опрос. Участники могут получить доступ к анкете сразу после использования программы настройки онлайн. После сбора данных, исследование использует одногрупповую SEM для изучения влияния потребительских выгод на вложение продукта, отношение, и намерения лояльности. Для изучения модерирующих ролей моды инновационность, исследование использует LMAs.
Access restricted. Please log in or start a trial to view this content.
протокол
Это исследование было исключено из IRB Обзор в Ewha Womans University и был назначен номер протокола #143-18.
1. Набор участников
- Приготовьтесь к проведению онлайн-опроса.
ПРИМЕЧАНИЕ: Онлайн-опрос был проведен с помощью опроса компании в корее. Исследовательская компания имеет крупнейшую группу потребителей с высоким итоговым уровнем реагирования в Корее. Возрастное и гендерное распределение в группе отражает состояние корейского населения. Потребительская панель имеет высокую степень надежности через проверку реальных имен. Так как исследовательская компания управляет панелью непрерывно с различными инновационными методами, лояльность группы к исследовательской компании высока; таким образом, результаты опроса, полученные компанией, как известно, являются весьма надежными. - Набирать женщин-потребителей, которые имеют опыт покупки одежды в Интернете.
ПРИМЕЧАНИЕ: Потребители женского пола в Корее тратят высокий процент дохода на покупки одежды, и торговые поведения происходят в основном онлайн23. Поэтому выбор этой группы в качестве участников для данного исследования подходит. - Отправьте участникам письмо с приглашением, включав в которое содержится информация о цели исследования и гарантия конфиденциальности их ответов.
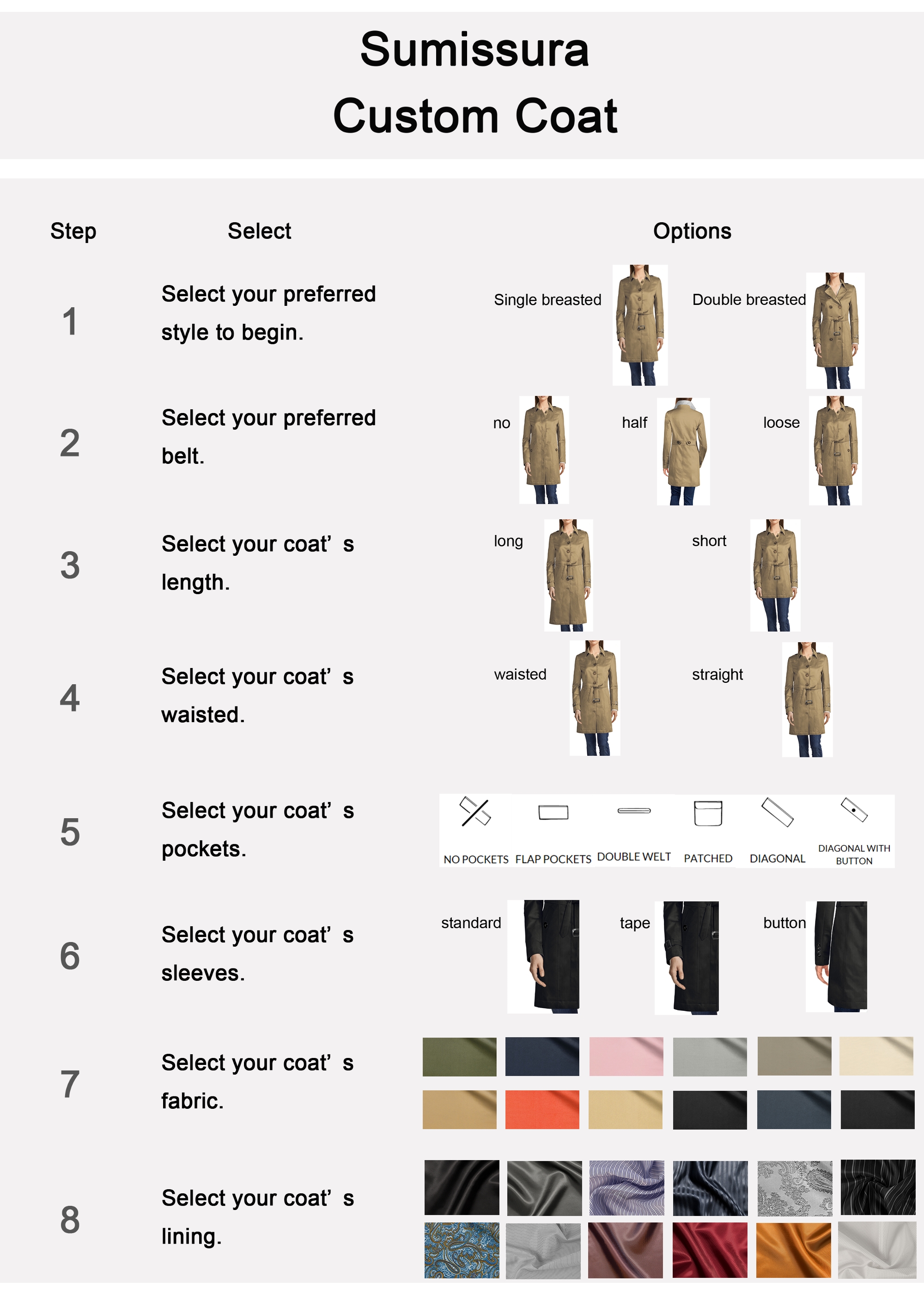
- Отправить руководящие принципы для тех, кто согласен принять участие в опросе, показывающие, как создать траншеи пальто с помощью программы настройки (см. Рисунок 1).
ПРИМЕЧАНИЕ: Чтобы избежать потенциальных ситуаций, в которых участники могут столкнуться с трудностями с помощью программы настройки, модератор из исследовательской компании послал руководящие принципы. Кроме того, модератор позвонил участникам и разъяснил процедуру настройки, в то время как участники рассмотрели руководящие принципы. - Попросите участников запечатлеть скриншот созданного плаща и предоставить цену за пальто, чтобы убедиться, что они на самом деле создают плащ в программе настройки.
- Отправить ссылку, подключенную к программе настройки электронной массы, на существующем веб-сайте по покупкам, когда участники поймут процедуру.
- Предоставьте участникам следующий сценарий: «Пожалуйста, представьте, что вы достаточно состоятельны, чтобы приобрести симпатичную одежду и приобрести плащ для участия в важном собрании. Вы хотите создать уникальный плащ. При просмотре в Интернете, вы столкнетесь с совершенным одежды веб-сайт, который имеет программу массовой настройки ".
ПРИМЕЧАНИЕ: Этот шаг необходим для повышения уровня вовлеченности и контроля типа продукта и восприятия потребителями цены продукта. - Разрешить участникам 24 ч, чтобы создать траншею пальто после прочтения сценария.
ПРИМЕЧАНИЕ: Участники могут свободно создавать траншеи пальто, выбрав предпочтительный общий стиль, воротник, длина пальто, длина рукава, карманы, ткань, и подкладка в случае, если они будут на самом деле купить его. Если у них есть проблемы с созданием пальто в программе настройки, они могут позвонить и спросить модератора в любое время в течение 24 часов. - Активировать ссылку опроса после 24 ч, чтобы участники, которые готовы принять участие в опросе (т.е. те, кто закончил захват скриншот траншеи пальто они создали) можно нажать на ссылку обследования.

Рисунок 1: Направления для использования программы настройки электронной массы. Участники онлайн-опроса читают направления о том, как создать траншеи с помощью программы настройки и следовать шагам 1-8. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}
2. Процедура обследования
- Попросите участников загрузить скриншот и цену плаща, который они создали, на первую страницу опроса (см. рисунок 2).
ПРИМЕЧАНИЕ: Доступ к анкете могут получить только участники, которые загружают скриншот. - Попросите участников заполнить онлайн-опрос, касающийся предполагаемых преимуществ, эмоциональной привязанности к индивидуальному продукту, отношения к программе настройки, намерений лояльности и демографических вопросов (см. таблицу 1).
- Дайте вознаграждение тем, кто завершит опрос.
ПРИМЕЧАНИЕ: Здесь участники получили вознаграждение в размере 10 000 фунтов стерлингов (около 10 долларов США) за участие. Участники, которые покинули опрос или не предоставили скриншот и цену, получили 1000 фунтов стерлингов (около 1 доллара США).

Рисунок 2: Примеры траншеи пальто, созданные с помощью программы настройки электронной массы. Участники создали траншеи пальто, выбрав предпочтительный воротник, длина, ткань и т.д., а затем загрузив скриншот создания траншеи пальто. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}
| Экстрим-выгода (Franke et al., 2009) |
| по сравнению со стандартным продуктом, настраиваемый продукт будет |
| 1. Лучше удовлетворять мои требования |
| 2. Лучше удовлетворить мои личные предпочтения |
| 3. Более вероятно, будет лучшим решением для меня |
| Внутреннее пособие (Франк и Шрайер, 2010) |
| 1. Я наслаждался этой деятельности дизайн очень много |
| 2. Я думал, проектирование продукта было довольно приятным |
| 3. Проектирование этого продукта было очень интересно |
| Эмоциональное присоединение продукта (Thomson et al., 2005) |
| По сравнению со стандартным продуктом этого бренда, мое чувство по отношению к его индивидуальный продукт может быть охарактеризована как «Я» . |
| 1. Аффективность |
| 2. Подключение |
| 3. Страсть |
| 4. Пленитель |
| Отношение к программе массовой настройки (Li et al., 2001) |
| Программа массовой настройки на этом веб-сайте была «я» . |
| 1. Непривлекательный электронный привлекательный |
| 2. Неприятно е приятно |
| 3. Непривлекательный e привлекательный |
| 4. Неприязненный e симпатичный |
| Намерения лояльности (Квон и Леннон, 2009) |
| 1. Я хотел бы приобрести индивидуальный продукт в этой программе настройки в ближайшем будущем |
| 2. Я рекомендовал бы эту программу настройки друзьям или родственникам |
| 3. Я хотел бы вернуться на этот сайт и настроить продукт в ближайшем будущем |
| Участие в продуктах (Зайчковский, 1985) |
| Для меня, одежда является " » . |
| 1. Неважно е важно |
| 2. Скучно е интересно |
| 3. Непривлекательный электронный привлекательный |
| 4. Не нужно e необходимо |
| 5. Неинтересно е exciting6. Worthless e ценный |
| Модная инновационность (Park et al., 2007) |
| 1. В общем, я последний в моем кругу друзей, чтобы знать имена последней новой моды (R) |
| 2. В общем, я один из последних в моем кругу друзей, чтобы купить новый элемент моды, когда он появляется (R) |
| 3. По сравнению с моими друзьями, у меня есть новые предметы моды. |
| 4. Я знаю имена новых модельеров раньше других людей. |
| 5. Если бы я услышал, что новый элемент моды был доступен в магазине, я был бы заинтересован, чтобы купить его. |
| 6. Я куплю новый пункт моды, даже если я не видел его раньше. |
| (R) Обратный код |
Таблица 1: Масштаб измерения. Эта таблица была использована ранее29.
3. Подготовка данных
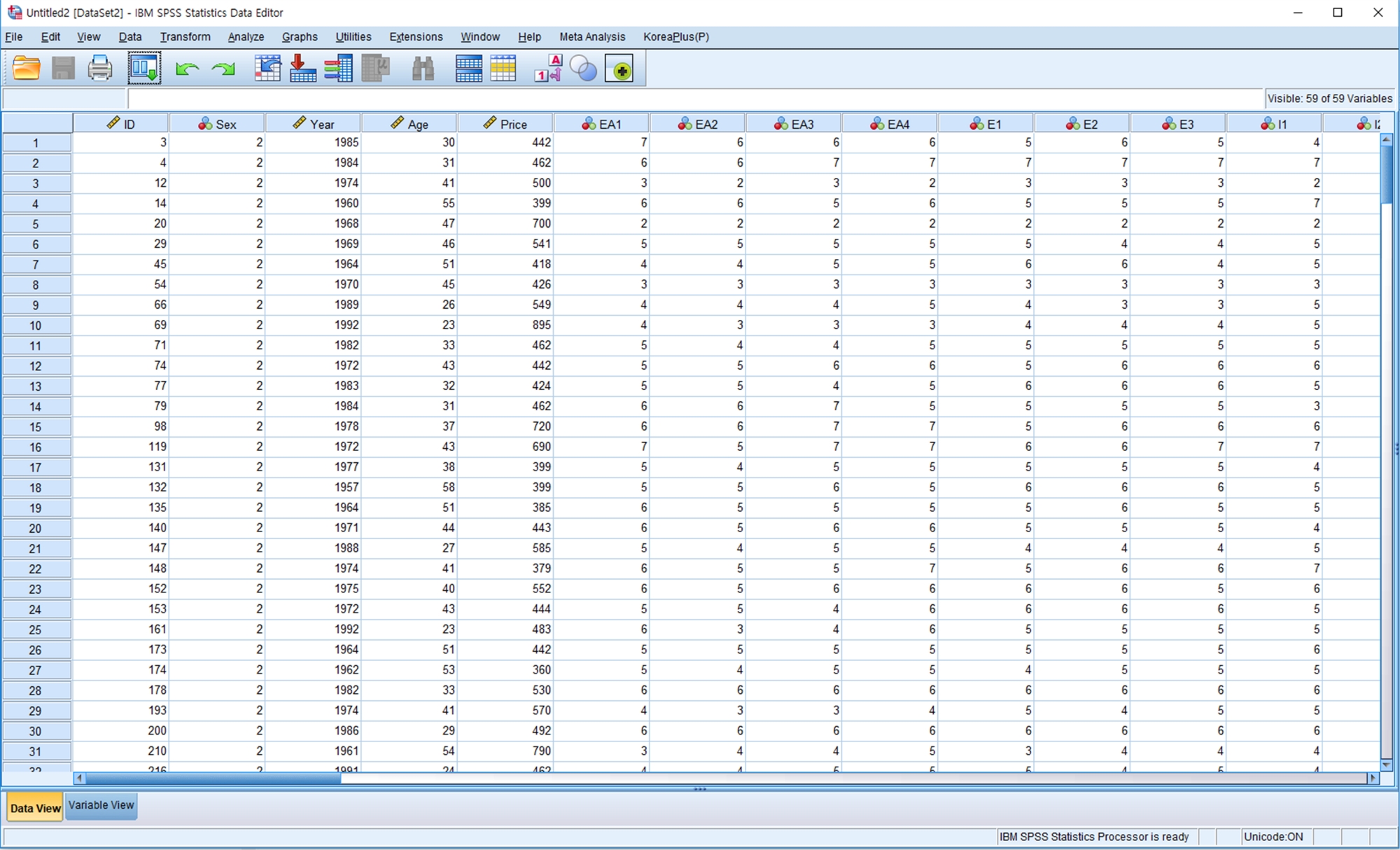
- Сохраните данные опроса в файле SPSS как "Data-TOTAL.sav" (см. рисунок 3), который содержит все ответы участников опроса. Удаление случаев, включающих недостающие значения. Используйте очищенные данные для проведения анализа SEM.
- Разделите общие данные на два файла данных: высокой и низкой моды инновационных групп. Используйте медианный раскол. Сумма и средние баллы шести пунктов моды инновационности, и рассчитать средний балл моды инновационность (мед 4,17).
ПРИМЕЧАНИЕ: Медианный раскол часто используется в психологии и маркетинговых исследованиях, и использование медианного раскола для непрерывной переменной для изучения групповых различий является действительным24. - Нажмите кнопку "Перекодирование в различные переменные" в меню "Преобразование". Создайте новую переменную, "мода инновационной группы (FIG)", путем кодирования "1 (низкая мода инновационной группы)" если средний балл ниже, чем средний (например, средний 4,17), или путем кодирования "2 (высокая мода инновационной группы)" если она выше, чем медиана (см. рисунок 4 ).
- Нажмите "Сплит в файлы" в меню "Данные", дважды щелкните переменную "мода инновационной группы (FIG)", чтобы переместить его в поле "Сплит-кейсы" и назначить "Выход файла каталога" место, чтобы сохранить файлы (см. Рисунок 5).
- Сохранить "1.sav" и "2.sav" в назначенном каталоге. Измените имена файлов на "Data » low fashion innovativeness.sav" и "Data-high fashion innovativeness.sav", чтобы использовать как для LMA.

Рисунок 3: Данные И ТОТАЛИза. Данные включают ответы всех участников (n No 290), используемые для анализа SEM. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}

Рисунок 4: Создание новой переменной "мода инновационной группы (FIG)". Новая переменная (FIG) была сделана путем кодирования "1 (инновационная группа низкой моды)" и "2 (высокая инновационная группа)". Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}

Рисунок 5: Разделение набора данных на два файла данных. Общий файл данных, "Data-TOTAL", был разделен на "Data -low fashion innovativeness.sav" и "Data-high fashion innovativeness.sav" файлы для последующего использования в LMA. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}
4. Проведение анализа подтверждающих факторов (CFA)
-
Провести единую группу CFA с пятифакторной моделью измерения для подтверждения конвергентной достоверности. Нажмите кнопку "Выберите файл данных (ы) Данные-TOTAL.sav". Разработайте модель измерений на основе вопросов исследования.
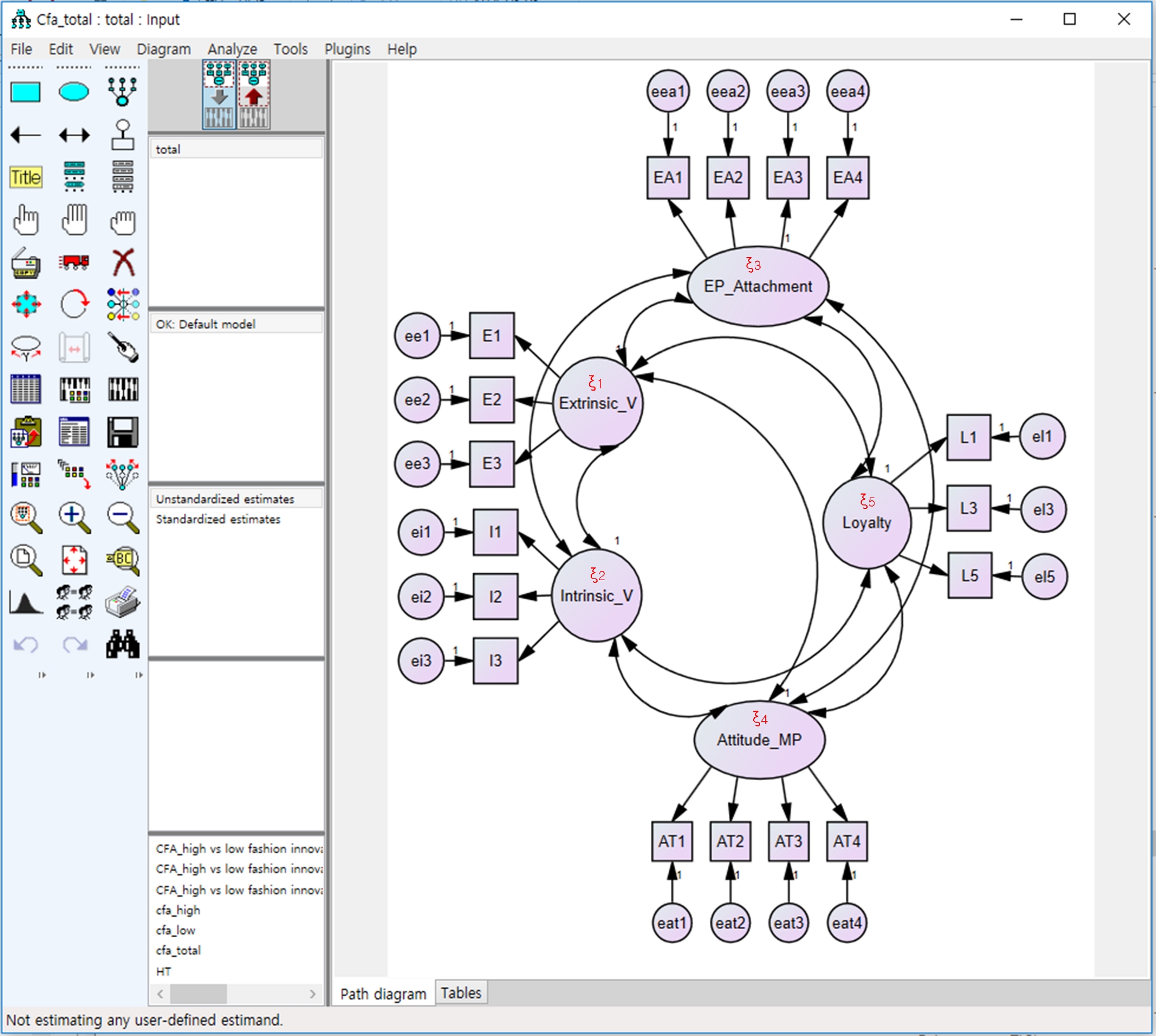
- Модель измерения включает пять скрытых переменных (т.е. экстренную пользу, внутреннюю пользу, эмоциональную привязанность к продукту, отношение к программе массовой настройки и намерения лояльности) и 17 наблюдаемых переменных (три наблюдаемых переменных для экстреманное преимущество, 3 для внутренней выгоды, 4 для эмоциональной привязанности продукта, 4 для ориентации к программе массового customization, и 3 для намерий верноподданности). Установить различия скрытых переменных как "1" (см. Рисунок 6 и рисунок 7). Нажмите "Рассчитать оценки".
- Проверьте подходящие индексы модели измерений по результатам единой группы CFA: индекс доброго соответствия (GFI), скорректированный индекс добра в соответствии (AGFI), индекс соответствия нормой (NFI), индекс Такера-Льюиса (TLI), сравнительный индекс соответствия (CFI) и корневая квадратная ошибка приближения (RMSEA).

Рисунок 6: Спецификация модели для подтверждаемого анализа факторов. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}

Рисунок 7: Модель измерения для подтверждаемого анализа факторов. Модель измерения cfA была создана с помощью программы AMOS. Разница скрытых переменных была установлена как "1". Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}
5. Запуск SEM
- Чтобы проверить взаимосвязь между скрытыми переменными, проведите SEM. Нажмите кнопку "Выберите файл данных (ы) Данные-TOTAL.sav". Разработка SEM на основе вопросов исследования, включая пять скрытых переменных и 17 наблюдаемых переменных.
- Нарисуйте стрелки от "Extrinsic'V" и "Intrinsic'V" до "EP-Attachment" и "Attitude-MP", а также от "EP-Attachment" и "Отношение" к "Лояльность". Добавьте три ненаблюдаемые переменные, а именно: "z1" в качестве предсказателя "EP-Attatchment", "z2" в качестве предсказателя "Attitude"MP, и "z3" в качестве предиктора "Лояльность" (см. Рисунок 8, Рисунок 9). Нажмите "Рассчитать оценки". Проверьте "Оценки" и подходят индексы модели.

Рисунок 8: Спецификация модели для моделирования структурного уравнения. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}

Рисунок 9: Анализ моделирования структурного уравнения. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}
6. Проведение испытаний инвариантной ассоциации для LMA
- Для сравнения высокой и низкой моды инновационных групп, провести LMA на основе многогруппового подтверждаемого анализа факторов (MGCFA). Перед LMA, тест конфигуральной инвариантности, метрической инвариантности, и scalar инвариантности между обеими группами25.
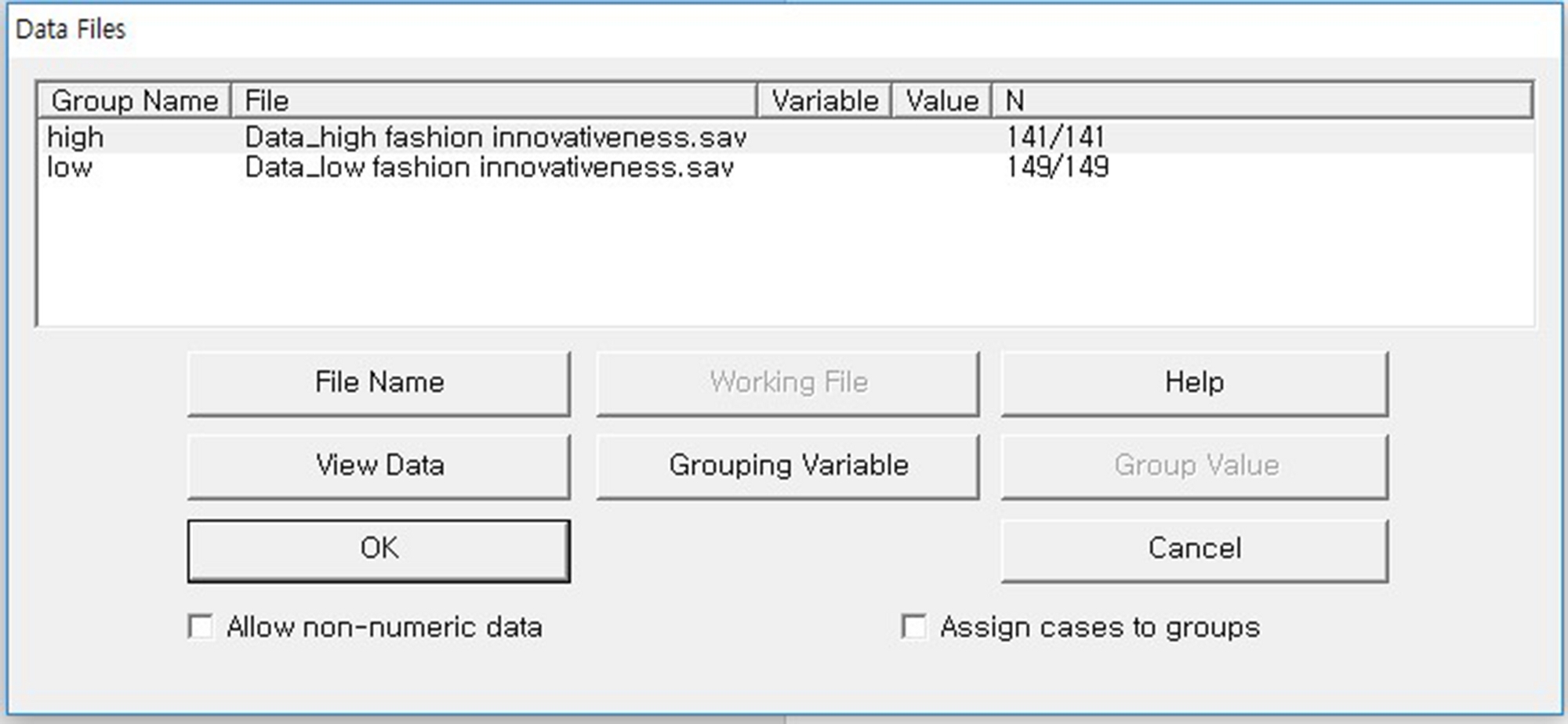
- Создание многогрупповой модели измерения: создание модели измерения (т.е. модели MGCFA) с двумя группами, названными "высоким" и "низким" в рамках "Группы управления". Выберите файлы данных для групп в следующем порядке: "Data 'низкая мода innovativeness.sav" для низкой моды инновационной группы и "Data 'высокая мода innovativeness.sav" для высокой моды инновационной группы (см. Рисунок 10).

Рисунок 10: Выбор файлов данных для групп. Была создана модель измерения для MGCFA, и были загружены два файла данных («Data»low fashion innovativeness.sav» и «Data»high fashion innovativeness.sav). Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}
-
Тестирование конфигуральной инвариантности
ПРИМЕЧАНИЕ: Если структура моделей измерений в обеих группах имеет одинаковую форму (т.е. одинаковые размеры и одинаковые модели фиксированных и нефиксированных значений), то конфигуральная инвариантность удовлетворяется (см. рисунок 11). Если припадок модели измерения является удовлетворительным, перейдите к следующему шагу для проверки метрической инвариантности26.- Выполните CFA с ранее предложенной пятифакторной моделью измерения для каждой группы. Нажмите "Рассчитать оценки". Проверьте "Оценки" и подходят индексы обеих моделей. Если соответствие обеих моделей является удовлетворительным и коэффициенты коэффициентов являются значительными, перейдите к следующему шагу.
- Ведите MGCFA с пятифакторной моделью измерения в качестве базовой модели. Исправьте "1" для коэффициента фактора от каждой скрытой переменной к первой наблюдаемой переменной и освободите другие коэффициенты фактора. Нажмите "Рассчитать оценки".
- Проверьте "Оценки" двух групп и вписываются в индексы модели. Если припадок модели является удовлетворительным и коэффициенты коэффициентов коэффициентов значительны, конфигуральная инвариантность удовлетворяется. Затем перейдите к следующему шагу, связанного с тестом на инвариантность метрики.

Рисунок 11: Равные размеры и формы моделей измерений в двух группах. (A) Модель для высокой моды инновационной группы и (B) модель для низкой моды инновационной группы. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
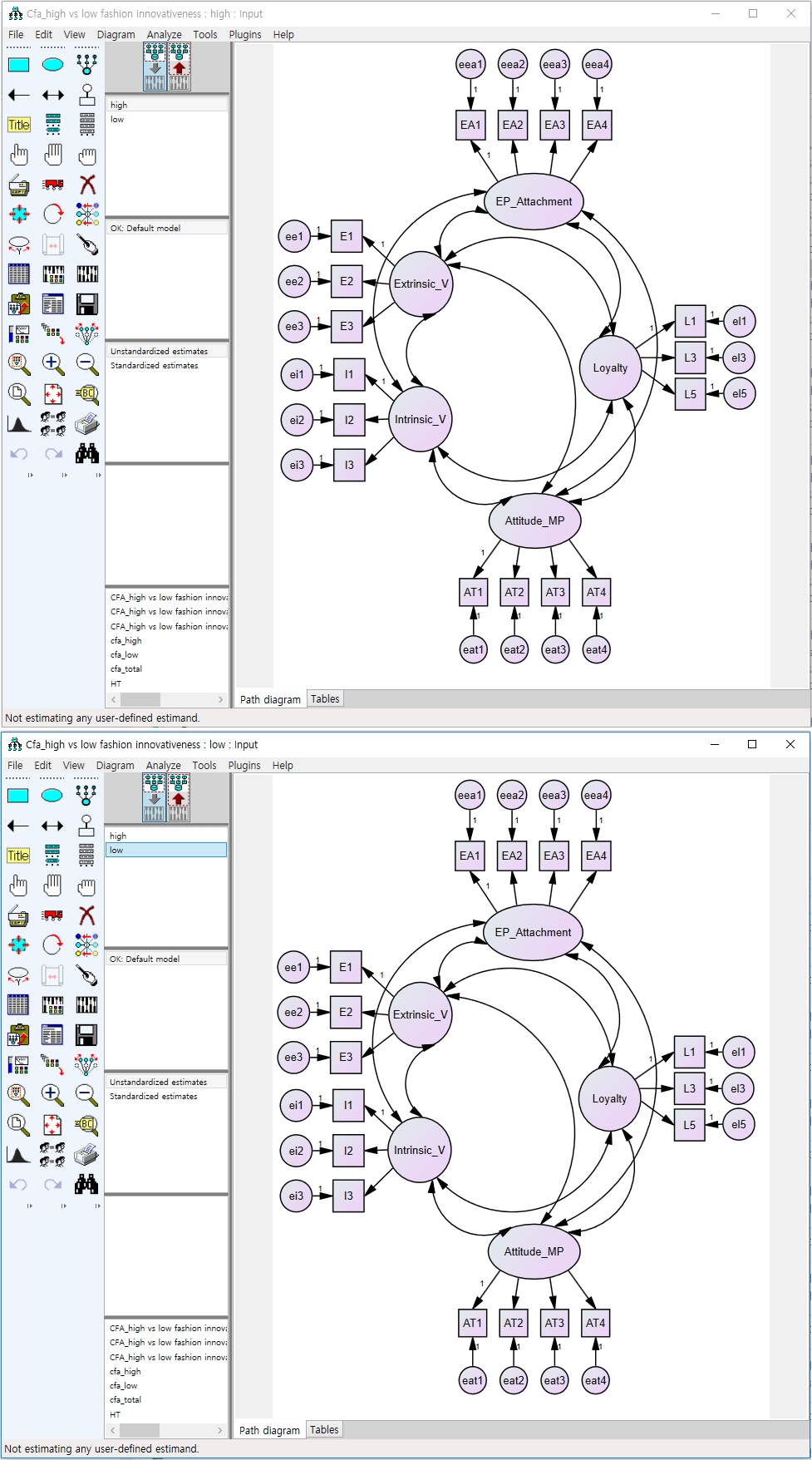{kind=link}
-
Тестирование метрической инвариантности
ПРИМЕЧАНИЕ: Тест метрической инвариантности оценивает, являются ли коэффициенты факторов, связывающих скрытые переменные с наблюдаемыми переменными, равными между группами.- Для проверки метрической инвариантности исправьте коэффициенты коэффициентов в разных группах. Введите одно и то же имя для одних и тех же коэффициентов в разных группах (например, "a" для Extrinsic-V E2, "j" для EP-Приложения EA4, см. Рисунок 12). Нажмите "Рассчитать оценки". Проверьте "Оценки" двух групп и вписываются в индексы модели.
- Проведите тест разницы в чи-квадрате, сравнив полную модель инвариантной связи (т.е. модель с фиксированными коэффициентами коэффициентов коэффициентов в разных группах) с моделью конфигурированной инвариантности (т.е. модель юаней со свободными коэффициентами коэффициентов коэффициентов в разных группах). Если разница в чи-квадрате незначительна, то метрическая инвариантность удовлетворяется. Затем приступаем к следующему шагу, связанного с тестом на скалантарную инвариантность25,26,27.

Рисунок 12: Фиксация коэффициентов коэффициентов между группами. При вводе одного и того же имени для одних и тех же коэффициентов между группами факторные коэффициенты были ограничены. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
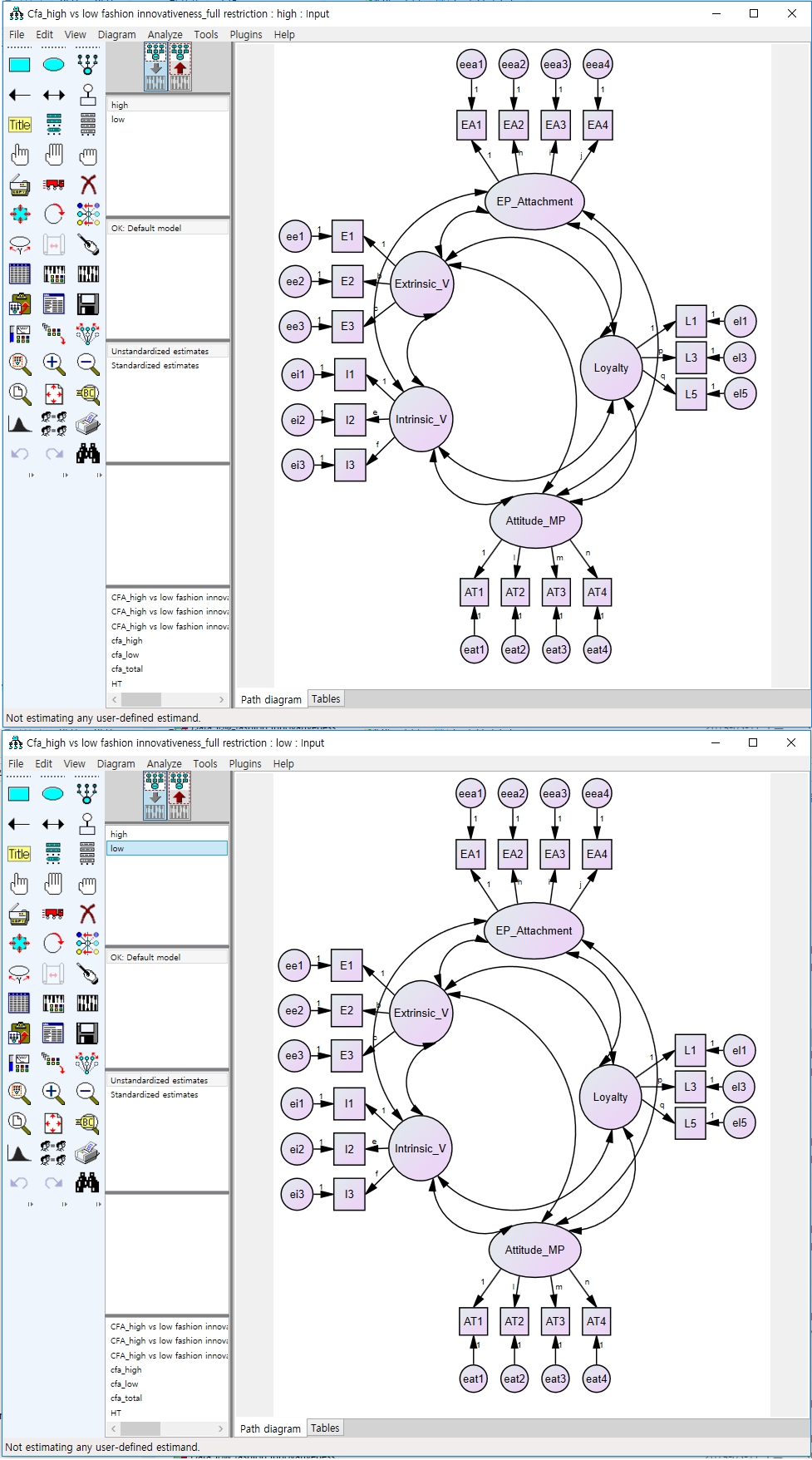{kind=link}
-
Тестирование масштабирования инвариантности
ПРИМЕЧАНИЕ: Инвариантность Scalar означает, что 1) те же значения на скрытой конструкции связаны с теми же значениями на наблюдаемой переменной и 2) различия в средствах наблюдаемых переменных вытекают из средних различий скрытых переменных. Чтобы проверить масштабную инвариантность, ограничьте перехватнаблюдаемых переменных таким образом, чтобы они были равны между группами28.- Нажмите "Анализ свойств" в меню "Вид". Нажмите на вкладку "Оценка" и проверьте "Оценить средства и перехваты". Правый щелчок каждой наблюдаемой переменной и выберите "Объект Свойства". Выберите вкладку "Параметры" и введите имена параметров, такие как "int'e1" и "int'ea1" в текстовых ящиках перехвата (см. рисунок 13).
- Проведите тест разницы в чи-квадрате, сравнив полную модель инклярной инвариантности (т.е. модель с фиксированными перехватами наблюдаемых переменных и коэффициентами фиксированного фактора в разных группах) с полной метрической моделью инвариантности (т.е. моделью с коэффициенты фиксированного коэффициента в разных группах). Если разница в чи-квадрате незначительна, то полное инвариантное сравливость метрики/полный масштаб является удовлетворенным.
ПРИМЕЧАНИЕ: Здесь используется определенная иерархия (конфигуральный тест на инвариантность, метрический тест инвариантности, тест на акварельное инвариантность). Как только каждый тест invariance будет удовлетворен, проведите LMA, используя окончательно выбранную модель (т.е. полную модель инкровой/полной масштабирования).

Рисунок 13: Ввод имен параметров в текстовую коробку перехвата.
Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
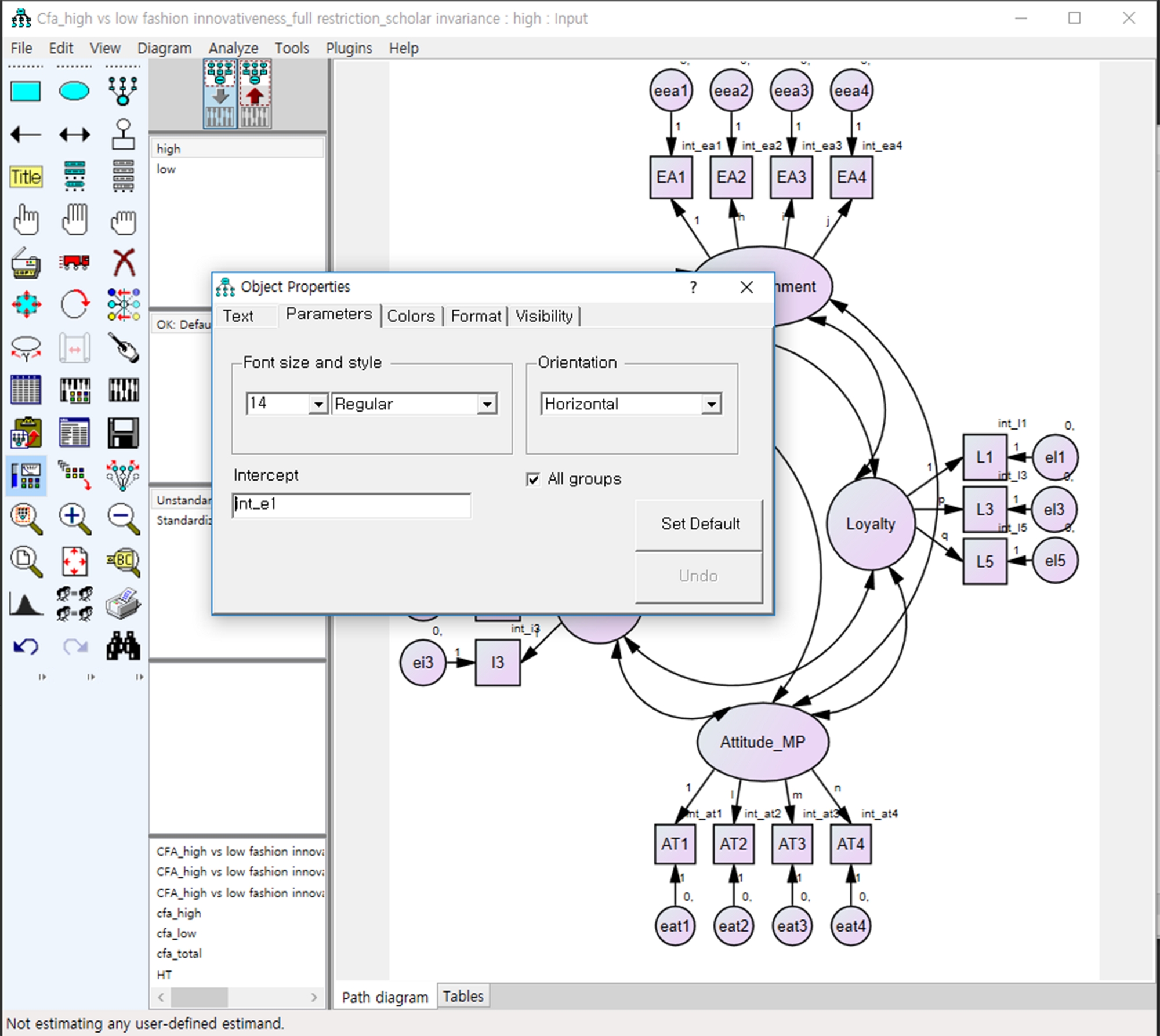{kind=link}
7. Запуск LMA
- Провести LMA, используя полный scalar / полный метрической модели инвариантности27,28. Чтобы сравнить средства скрытых переменных, исправьте средства скрытых переменных в одной группе и позвольте им быть свободными в другой группе.
- Оцените средние различия между группами, зафиксировав одно из средств к нулю для референтной группы, а затем оцените средние значения для другой группы. Таким образом, исправить средства всех скрытых переменных в низкой моды инновационной группы на нуле. Важно обеспечить, чтобы средства скрытых переменных в высокой моде инновационной группы являются бесплатными и их отклонения в обеих группах являются бесплатными (см. Рисунок 14).
- Нажмите "Рассчитать оценки". Проверьте "Оценки" двух групп и вписываются в индексы модели.
- Нажмите "Посмотреть текст" и проверить средства скрытых переменных в высокой моды инновационной группы в соответствии с "Оценки" (см. Рисунок 15).

Рисунок 14: Установка скрытых переменных средств и отклонений. (A) Высокая мода инновационной группы и (B) низкая мода инновационной группы. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
{kind=link}

Рисунок 15: Выход для скрытого анализа средств. Пожалуйста, нажмите здесь, чтобы просмотреть большую версию этой цифры.
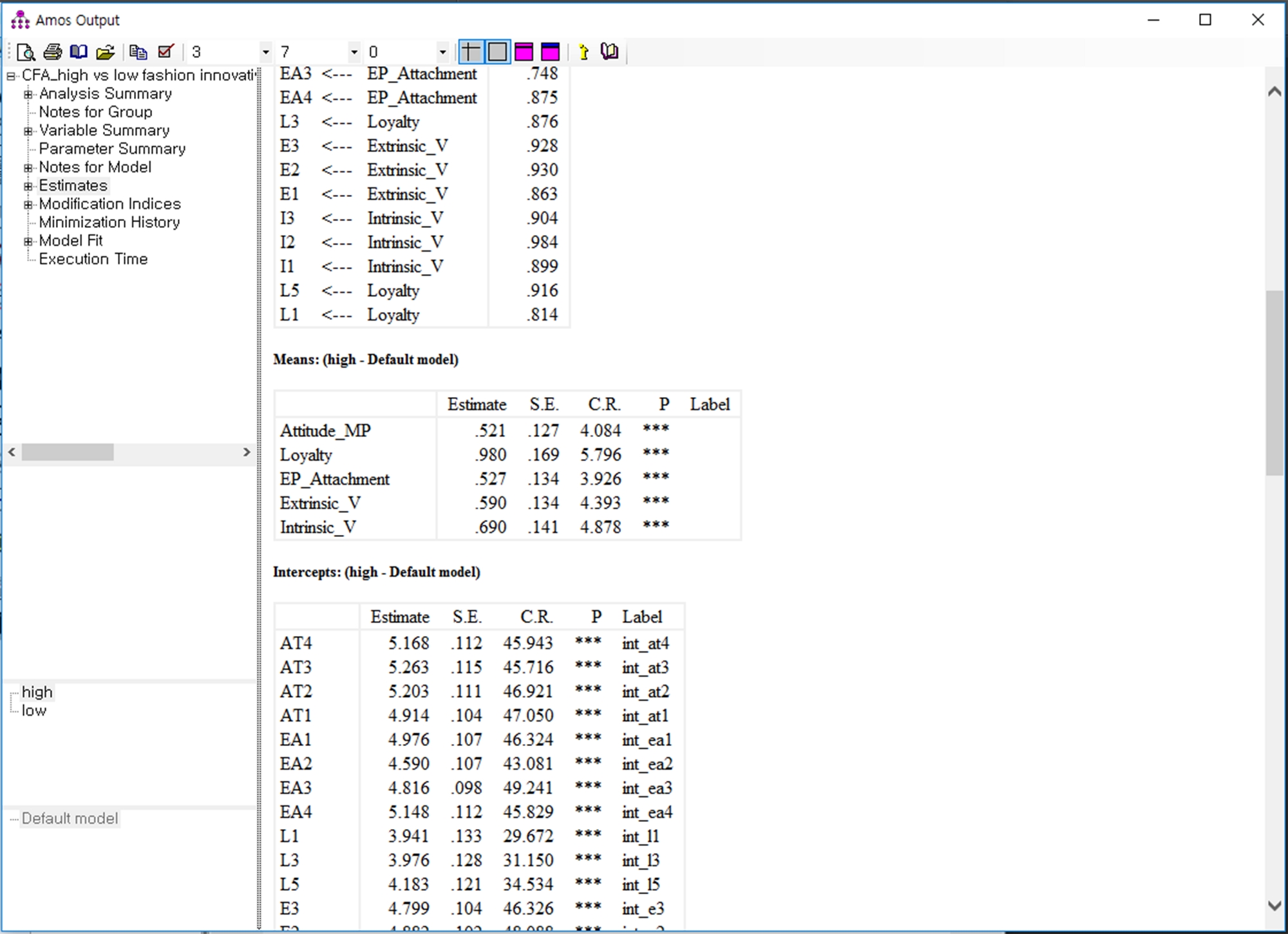{kind=link}
Access restricted. Please log in or start a trial to view this content.
Результаты
Частотная статистика предлагает характеристики выборки. В общей сложности 290 женщин онлайн-потребителей завершили процесс покупки с помощью программы настройки электронной массы. Демографические характеристики выборки были равномерно распределены. В возрастной группе 23,1% были в воз...
Access restricted. Please log in or start a trial to view this content.
Обсуждение
Последствия выводов
Результаты этого исследования показывают, что внутренние и внутренние преимущества потребителей, полученные от создания массового индивидуального продукта, помогают росту эмоциональной привязанности к продукту, созданию позитивного отношения к прогр...
Access restricted. Please log in or start a trial to view this content.
Раскрытие информации
Авторам нечего раскрывать.
Благодарности
Данные были изменены из исследования Парка и Yoo29. Эта работа была поддержана Министерством образования Республики Корея и Национальным исследовательским фондом КОРЕА (NRF No 2016S1A5A2A03927809).
Access restricted. Please log in or start a trial to view this content.
Материалы
| Name | Company | Catalog Number | Comments |
| SPSS AMOS 22 | IBM Corporation, Data Solution Inc. | used for confirmatory factor analyses, structural equation modeling analyses, and latent means analyses |
Ссылки
- Srinivasan, S. S., Anderson, R., Ponnavolu, K. Customer loyalty in e-commerce: an exploration of its antecedents and consequences. Journal of Retailing. 78 (1), 41-50 (2002).
- Mouw, R. Biggest challenges of mass customization and tips for addressing these challenges. Manufacturing Tomorrow. , Available from: http://www.manufacturingtomorrow.com/article/2016/05/biggest-challenges-of-mass-customization-and-tips-for-addressing-these-challenges-/8047 (2005).
- Fiore, A. M., Lee, S. E., Kunz, G. Individual differences, motivations, and willingness to use a mass customization option for fashion products. European Journal of Marketing. 38 (7), 835-849 (2004).
- Pine, B. J., Gilmore, J. H. The Experience Economy: Work is Theater and Every Business a Stage. , Harvard Business School Press. Boston, MA. (1999).
- Yoo, J., Park, M. The effects of e-mass customization on consumer perceived value, satisfaction, and loyalty toward luxury brands. Journal of Business Research. 69 (12), 5775-5784 (2016).
- Endo, S., Kincade, D. H. Mass customization for long-term relationship development: why consumers purchase mass customized products again. Qualitative Market Research: An International Journal. 11 (3), 275-294 (2008).
- Spiegel, E. How the U.S. can be a leader in the factory of the future. , Available from: http://blogs.wsj.com/experts/2015/06/04/how-the-u-s-can-be-a-leader-in-the-factory-of-the-future (2015).
- Franke, N., Piller, F. T. Value creation by toolkits for user innovation and design: the case of the watch market. The Journal of Product Innovation Management. 21 (6), 401-415 (2004).
- Lavidge, R. J., Steiner, G. A. A model for predictive measurements of advertising effectiveness. Journal of Marketing. 25, 59-62 (1961).
- Deci, E. L. Intrinsic Motivation. , Plenum Press. New York, NY. (1975).
- Kim, H. W., Chan, H. C., Gupta, S. Value-based adoption of mobile internet: an empirical investigation. Decision Support System. 43 (1), 111-126 (2007).
- Rogers, E. M. Diffusion of Innovations, 4th Edition. , The Free Press. New York, NY. (1995).
- Fiore, A. M., Lee, S. E., Kunz, G. Individual differences, motivations, and willingness to use a mass customization option for fashion products. European Journal of Marketing. 38 (7), 835-849 (2004).
- Franke, N., Piller, F. T. Key research issues in user interaction with configuration toolkits in a mass customization system. International Journal of Technology Management. 26 (5/6), 578-599 (2003).
- Grisaffe, D. B., Nguyen, H. P. Antecedents of emotional attachment to brands. Journal of Business Research. 64 (10), 1052-1059 (2011).
- Lee, M. Factors influencing the adoption of internet banking: an integration of TAM and TPB with perceived risk and perceived benefit. Electronic Commerce Research and Applications. 8 (3), 130-141 (2009).
- Pedeliento, G., Andreini, D., Bergamaschi, M., Salo, J. Brand and product attachment in an industrial context: the effects on brand loyalty. Industrial Marketing Management. 53, 194-206 (2016).
- Ilicic, J., Webster, C. M. Effects of multiple endorsements and consumer celebrity attachment on attitude and purchase intention. Australasian Marketing Journal. 19 (4), 230-237 (2011).
- Koo, G. Y., Hardin, R. Difference in interrelationship between spectators’ motives and behavioral intentions based on emotional attachment. Sport Marketing Quarterly. 17 (1), (2008).
- Kang, J. M., Kim, E. e-Mass customization apparel shopping: effects of desire for unique consumer products and perceived risk on purchase intentions. International Journal of Fashion Design, Technology and Education. 5 (2), 91-103 (2012).
- Kim, J. B., Rhee, D. The relationship between psychic distance and foreign direct investment decisions: a Korean study. International Journal of Management. 18 (3), 286-293 (2001).
- Simonson, I. Determinants of customers' responses to customized offers: conceptual framework and research propositions. Journal of Marketing. 69 (1), 32-45 (2005).
- Consumer behavior study reveals South Korean online shopping habits. FedEx. , Available from: http://about.van.fedex.com/newsroom/asia-english/consumer-behavior-study-reveals-south-korean-online-shopping-habits/ (2015).
- Iacobucci, D., Posavac, S. S., Kardes, F. R., Schneider, M. J., Popovich, D. L. Toward a more nuanced understanding of the statistical properties of a median split. Journal of Consumer Psychology. 25 (4), 652-665 (2015).
- Steenkamp, J. B. E. M., Baumgartner, H. Assessing measurement invariance in cross-national consumer research. Journal of Consumer Research. 25 (1), 78-90 (1998).
- Bollen, K. A. Structural Equation with Latent Variables. , Wiley. New York, NY. (1989).
- Sass, D. A. Testing measurement invariance and comparing latent factor means within a confirmatory factor analysis framework. Journal of Psychoeducational Assessment. 29 (4), 347-363 (2011).
- Hong, S., Malik, M. L., Lee, M. K. Testing configural, metric, scalar, and latent mean invariance across genders in sociotropy and autonomy using a non-western sample. Educational and Psychological Measurement. 63 (4), 636-654 (2003).
- Park, M., Yoo, J. Benefits of mass customized products: moderating role of product involvement and fashion innovativeness. Heliyon. 4, 00537(2018).
- Neuman, W. L. Social Research Methods: Qualitative and Quantitative Approaches, 6th Edition. , Allyn and Bacon. Boston, MA. (2006).
- Kim, J. H., Jang, S. A scenario-based experiment and a field study: a comparative examination for service failure and recovery. International Journal of Hospitality Management. 41, 125-132 (2014).
- Hancock, G. R., Lawrence, F. R., Nevitt, J. Type I error and power of latent mean methods and MANOVA in factorial invariant and noninvariant latent variable systems. Structural Equation Modeling. 7 (4), 534-556 (2000).
Access restricted. Please log in or start a trial to view this content.
Перепечатки и разрешения
Запросить разрешение на использование текста или рисунков этого JoVE статьи
Запросить разрешениеСмотреть дополнительные статьи
This article has been published
Video Coming Soon
Авторские права © 2025 MyJoVE Corporation. Все права защищены