
Method Article
Eyetracking während visuell liegt Sprachverständnis: Flexibilität und Einschränkungen bei der Aufdeckung visuellen Kontext Effekte
In diesem Artikel
Zusammenfassung
Der vorliegende Artikel Bewertungen eine Eyetracking-Methodik für Studien über Sprachverständnis. Um verlässliche Daten zu erhalten, sind die wichtigsten Schritte des Protokolls einzuhalten. Dazu gehören die richtigen Aufbau des Eye Trackers (z.B., gute Qualität der Augen- und Kopfbewegungen Bilder) und genaue Kalibrierung.
Zusammenfassung
Das vorliegende Werk ist eine Beschreibung und eine Bewertung der eine Methodik entwickelt, um verschiedene Aspekte der Interaktion zwischen Sprachverarbeitung und die Wahrnehmung der visuellen Welt zu quantifizieren. Die Aufzeichnung der Auge-Blickmustern hat für den Beitrag der visuellen Kontext und sprachliche/Weltwissen zum Sprachverständnis gut belegt. Erste Untersuchungen beurteilt Objektkontext Effekte, Theorien der Modularität bei der Sprachverarbeitung zu testen. In der Einführung beschrieben, wie nachfolgende Untersuchungen Sprachverarbeitung als ein Forschungsthema aus eigenem Recht die Rolle der visuellen Kontext teilgenommen haben, Fragen, Fragen so wie unsere visuelle Wahrnehmung der Ereignisse und der Lautsprecher zur trägt Verständnis von Comprehenders Erfahrung unterrichtet. Die untersuchten Aspekte der visuellen Kontext gehören, Aktionen, Veranstaltungen, eines Sprechers Blick, und emotionale Mimik, sowie räumliches Objekt Konfigurationen. Nach einem Überblick über die Eye-Tracking-Methode und seinen verschiedenen Anwendungen Listen wir die wichtigsten Schritte der Methodik des Protokolls zur Veranschaulichung, wie man erfolgreich verwenden, um visuell befindet sich Sprachverständnis zu untersuchen. Ein letzte Abschnitt drei Sätze von repräsentative Ergebnisse präsentiert und zeigt die vor- und Nachteile von Eyetracking für untersucht das Zusammenspiel zwischen der Wahrnehmung der visuellen Welt und Sprache verstehen.
Einleitung
Psycholinguistische Forschung hat die Bedeutung der Augenbewegungen Analysen im Verständnis der Prozesse verwickelt im Sprachverständnis hervorgehoben. Der Kern der Ableitung Verständnis Prozesse aus dem Blick-Datensatz ist eine Hypothese, die Kognition mit Auge Bewegungen5verbindet. Es gibt drei große Arten von Augenbewegungen: Sakkaden, Vestibulo-Okular Bewegungen und glatte Verfolgung Bewegungen. Sakkaden sind schnelle und ballistischen Bewegungen, die meist unbewusst passieren und Verschiebungen in Aufmerksamkeit6zuverlässig zugeordnet wurden. Die Momente der relativen Blick Stabilität zwischen Sakkaden, bekannt als Festlegungen gelten Index aktuelle visuelle Aufmerksamkeit. Messung der Nenner für die Fixierungen und ihre Dauer im Hinblick auf kognitive Prozesse ist bekannt als die "Eye-Tracking-Methode". Frühen Implementierungen dieser Methode diente, Leseverständnis in rein sprachlichen Kontexten zu untersuchen (siehe Rayner7 für eine Überprüfung). In diesem Ansatz ist die Dauer der Inspektion einer Wort oder einen Satz Region mit Verarbeitung Schwierigkeiten verbunden. Eye-tracking wurde jedoch auch angewandt, um gesprochene Sprache verstehen zu untersuchen, während der Inspektiondes von Objekten in der Welt (oder auf einem Computer anzeigen2). In dieser "Bilderwelt" Eyetracking-Version wird die Inspektion von Objekten durch Sprache geführt. Wenn die Comprehenders hören, das Zebra, zum Beispiel, deren Prüfung eines Zebras auf dem Bildschirm werden genommen, zu reflektieren, dass sie an das Tier denken. In Bildwelt Paradigma sogenannten ein Comprehender Auge Blick versteht man gesprochene Sprache verstehen und die Aktivierung des damit verbundenen Wissens widerspiegeln (z. B. Zuhörer auch das Zebra überprüfen, wenn sie, Beweidung hören, zeigt eine Aktion durch das Zebra)2. Solche Inspektionen empfehlen eine systematische Verbindung zwischen Sprache-Welt-Beziehungen und Auge Bewegungen2. Eine gängige Methode, diesen Link zu quantifizieren ist durch Berechnung des Anteils der verschiedenen vorgegebenen Regionen auf einem Bildschirm sieht. Dies erlaubt Forschern, direkt (über Bedingungen, von den Teilnehmern und Artikel) zu vergleichen die Menge an Aufmerksamkeit auf verschiedene Objekte in einer bestimmten Zeit und wie diese Werte in Millisekunden Auflösung ändern.
Forschung in der Psycholinguistik ist Eyetracking in Bildwelten zu necken auseinander konkurrierende theoretischen Hypothesen über die Architektur des Geistes1genutzt. Auge Fixierungen auf abgebildeten Objekte haben, darüber hinaus gezeigt, dass Comprehenders können – vorausgesetzt, einen hinreichend restriktiven sprachlichen Kontext – inkrementelle semantische Interpretation8 führen und entwickeln sogar Erwartungen über zukünftige Charaktere 9. solche Augen-Blick-Daten haben auch Aufschluss über eine Reihe weiterer Verständnis Prozesse, wie lexikalische Mehrdeutigkeit Auflösung10,11, Pronomen Auflösung12, Disambiguierung von strukturellen und thematischen Rolle Zuordnung von Informationen in der visuellen Kontext13,14,16und pragmatische Prozesse15, unter vielen anderen bedeutet4. Natürlich können die Augenbewegungen auf Objekte im Sprachverständnis der betroffenen Prozesse informativ sein.
Die Eye-Tracking-Methode ist nicht invasiv und kann mit Kleinkindern, junge und ältere Sprache Benutzer verwendet werden. Ein entscheidender Vorteil ist, dass, im Gegensatz zu punctata Antworten auf Sonden oder Antwort-Taste drückt in Überprüfungsaufgaben, es gibt Einblicke im Laufe der Zeit in einer Millisekunde Auflösung in wie Sprache Aufmerksamkeit zu widmen und wie führt die visuellen Kontext (in Form von Objekten, Aktionen, Veranstaltungen, eines Lautsprechers Blick, und emotionale Mimik, sowie räumliches Objekt Konfigurationen) trägt zur Sprachverarbeitung. Die Kontinuität der Maßnahme während Satz Verständnis ergänzt gut mit anderen Post-Satz und nach dem Experiment Maßnahmen wie z. B. offene Bild/Video-Satz Überprüfung, Fragen zum Textverständnis und Rückruf Gedächtnisaufgaben. Offene Antworten in diesen Aufgaben können die Interpretation des Auges Blick Datensatzes durch Einblicke in das Ergebnis der Verständnis Prozess, Gedächtnis und lernen2bereichern. Kombination von Eyetracking mit diesen anderen Aufgaben hat aufgedeckt, inwieweit verschiedene Aspekte der visuellen Kontext visuelle Aufmerksamkeit und (sofortige sowie verzögerte) Verständnis über die Lebensspanne modulieren.
Die Darstellung der Sprache (gesprochen oder geschrieben) und Szenen können entweder simultan oder sequenziell sein. Beispielsweise Knoeferle und Mitarbeiter17 präsentiert die Szene 1.000 ms vor der gesprochene Satz, und es blieb beim Verständnis. Sie meldeten die Auflösung von lokalen strukturelle Ambiguität in deutschen Subjekt-Verb-Objekt (SVO) im Vergleich zu Objekt-Verb-Gegenstand (OVS) Sätze Beweise, die Clipart Darstellungen von Action-Events beitragen. Knoeferle und Crocker18 präsentiert eine Clipart-Szene vor einem geschriebenen Satz und die inkrementelle Integration von Clipart Ereignisse während Satz Verständnis getestet. Sie beobachteten inkrementelle Kongruenz Effekte, was bedeutet, dass die Teilnehmer lesen Zeiten Satz Bestandteile länger waren, wenn diese falsch zugeordnet (vs. abgestimmt) der Veranstaltung, die in der vorherigen Szene dargestellt. In einer anderen Stimulus-Präsentation-Variante die Teilnehmer zunächst einen Satz beschreibt eine räumliche Beziehung zu lesen und dann sah eine Szene von einer bestimmten räumlichen Anordnung mit Objekt Strichzeichnungen19. Diese Studie bewertet die Vorhersagen der rechnerische räumliche Sprachmodelle bitten die Teilnehmer, den Anfall von der Strafe für die Szene mit den Augenbewegungen aufgezeichnet während des Verhörs Szene zu bewerten. Die Teilnehmer Blickmustern waren moduliert durch die Form des Objekts, mit denen sie konfrontiert wurden – teilweise bestätigen die Modellvorhersagen und Bereitstellung von Daten zur Verfeinerung des Modells.
Während viele Studien Clipart Darstellungen17,18,19,20,21,22,23verwendet haben, ist es auch möglich, reale zu kombinieren Objekte, Videos von diesen Objekten oder statische Fotos mit gesprochener Sprache1,21,24,25,26,46. Knoeferle und Kollegen einer realen Umgebung24 und Abashidze und Kollegen verwendet ein Videoaufnahmen Darstellungsformat für Action-Events und spannende Effekte25untersucht. Variation des genauen Inhalts der Szenen (z. B.Darstellung von Aktionen oder nicht)22,27,38 ist möglich und kann auch visuellen Kontext Auswirkungen zeigen. Eine ähnliche Studie von Rodríguez und Mitarbeiter26 untersuchten den Einfluss von Videoaufnahmen visuelle Geschlecht Cues auf das Verständnis der gesprochene Sätzen dargestellt. Teilnehmer sahen die Videos anzeigen entweder männlich oder weiblich Hände eine Stereotyp geschlechtsspezifische Aktion auszuführen. Hörten sie einem Satz über entweder ein Stereotyp männliche oder weibliche Action-Event während gleichzeitig Inspektion ein Display zeigt zwei Fotos nebeneinander, einem Mann und einer Frau. Diese reiche visuelle und sprachliche Umgebung erlaubt die Autoren, die Auswirkungen der Sprache vermittelte Stereotype wissen auf das Verständnis von den Auswirkungen der visuell präsentiert (Hand) Geschlecht Cues auseinander zu necken.
Eine weitere Anwendung dieses Paradigma hat Entwicklungsstörungen Änderungen bei der Sprachverarbeitung gezielt. Augenbewegungen auf Objekte während der gesprochenen Sprachverständnis zeigte die Auswirkungen der dargestellten Ereignisse in 4 - 5 - jährigen27,28 und ältere Erwachsene29 in Echtzeit, aber etwas verzögert im Vergleich zu jungen Erwachsenen. Kröger und Mitarbeiter22 untersuchte die Auswirkungen der prosodischen Cues und Fall markieren im Rahmen eines Experiments und verglich diese über Experimente bei Erwachsenen und Kindern. Teilnehmer inspiziert eine mehrdeutige Action-Event-Szene beim Hören eines damit verbundenen eindeutig Fall markiert deutschen Satzes. Augenbewegungen ergab, dass die unterschiedliche prosodische Muster weder die Erwachsenen noch die 4 - oder 5-jährigen geholfen, wenn wer-macht-was-zu-wen vereindeutigenden. Satz-Initial Fall markieren, beeinflusst jedoch Erwachsenen aber nicht Kinder-Augenbewegungen. Dies deutet darauf hin, dass 5-Year-Olds Verständnis der Fall Markierung nicht robust genug, um thematische Rollenzuweisung zu ermöglichen (siehe Studie von Özge und Mitarbeiter30), zumindest nicht als Action-Events nicht eindeutig thematische Rolle Beziehungen. Diese Ergebnisse sind interessant, da sie im Gegensatz zu früheren Ergebnisse der prosodischen Auswirkungen auf thematische Rolle Zuordnung31sind. Kröger und Mitarbeiter22 vorgeschlagen, die (mehr oder weniger unterstützende) visuelle Kontext für die gegensätzlichen Ergebnisse verantwortlich ist. In dem Maße, in diese Interpretationen zu halten, unterstreichen sie die Rolle des Kontextes im Sprachverständnis über die Lebensspanne.
Die Eye-Tracking-Methode lässt sich gut mit den Maßnahmen von Bild (oder Video) Satz Überprüfung Aufgaben18,20,26, Bild Überprüfung Aufgaben32, Korpus Studien24, rating Aufgaben19, oder Post-experimentelle Rückruf Aufgaben25,33. Abaschidse und Mitarbeiter34 und Kreysa und Kollaborateure33 untersucht das Zusammenspiel von Lautsprecher Blick und Real-World-Action Videos34 und Lautsprecher Blick und Aktion Darstellungen33, bzw. als Hinweise für nächsten Satz Inhalt. Durch die Kombination der Verfolgung von Auge Blick in einer Szene während Sprachverständnis mit einer Post-experimentelle Speicher Aufgabe, bekamen sie ein besseres Verständnis für die Art und Weise, in der die Zuhörer Wahrnehmung des Sprechers Blick und die abgebildeten Aktionen interagieren und beeinflussen beide sofortige Sprachverarbeitung und Gedächtnis. Die Ergebnisse zeigten deutlichen Beitrag von Aktionen gegen Lautsprecher Blick auf Echtzeit-Verständnis gegenüber Post-Experiment Rückruf Gedächtnisprozesse.
Während die Eyetracking-Methode sehr flexibel eingesetzt werden kann, sind bestimmte Standards der Schlüssel. Das folgende Protokoll fasst ein generalisiertes Verfahren, das auf verschiedene Arten von Forschungsfragen die Forscher Bedürfnissen angepasst werden kann. Dieses Protokoll ist ein standardisiertes Verfahren beschäftigt in der Psycholinguistik Laboratory an der Humboldt-Universität Zu Berlin sowie in der ehemaligen Sprache und Kognition Labor an der kognitiven Interaktion Technologie Exzellenz Cluster (CITEC) bei Universität Bielefeld. Das Protokoll beschreibt einen Desktop-PC und eine remote-Installation. Letzteres ist für den Einsatz in Studien mit Kindern oder älteren Erwachsenen empfohlen. Alle Experimente erwähnt in den Vertreter Ergebnisse verwenden eine Auge-Tracker-Gerät, das hat einer Abtastrate von 1.000 Hz und dient zusammen mit einem Kopf Stabilisator, einen PC für die Prüfung der Teilnehmer (Display PC) und ein PC für die Überwachung des Experiments und der Teilnehmer Augenbewegungen (Host-PC). Der Hauptunterschied zum Vorgänger dieses Gerätes ist, dass es binokularen Eyetracking ermöglicht. Das Protokoll soll hinreichend allgemein für die Verwendung mit anderen Augen-Tracking-Geräte sein, die einen Kopf Stabilisator und nutzen Sie einen dual PC Setup (Host + Display). Es ist jedoch wichtig zu beachten, die andere Setups werden wahrscheinlich haben verschiedene Methoden für den Umgang mit Problemen wie Kalibrierung Fehler oder Track-Verlust, in dem Fall der Experimentator an den Benutzer verweisen sollten manuelle ihrer spezifischen Gerät.
Protokoll
Dieses Protokoll folgt den Ethikrichtlinien der Institution wo die Daten erhoben wurden, d. h., die kognitiven Interaktion Technology Excellence Cluster (CITEC) der Universität Bielefeld und Humboldt-Universität Zu Berlin. Die Experimente an der Universität Bielefeld wurden individuell von der Universität Bielefeld Ethikkommission genehmigt. Die Psycholinguistik Laboratory an der Humboldt-Universität Zu Berlin hat eine Labor-Ethik-Protokoll, die von der Ethikkommission der deutschen Gesellschaft Für Studienfinanzierung, der deutschen Gesellschaft für Sprachwissenschaft (DGfS) genehmigt wurde.
1. Desktop-Setup
Hinweis: Im folgenden werden die wichtigsten Schritte in einem Eyetracking-Experiment.
- Instrumenten-Aufbereitung
- Schalten Sie die Eye-Tracking-Kamera und dem Host-PC (siehe Abbildung 1 zur Veranschaulichung der im Labor Datenerhebung und das Pre-processing-Setup).
- Der Eye-Tracker-Software zu initiieren.
- Aktivieren Sie die Anzeige PC. Öffnen Sie den Ordner mit den Experimenten.
- Starten Sie die "bereitgestellte" Version mit einer .exe-Erweiterung, indem sie darauf doppelklicken.
- Abhängig von der Einrichtung möglicherweise eine Eingabeaufforderung für die Auswahl einer experimentellen Liste angezeigt, die in der Regel eine tabulatorgetrennte.csv/.txt Datei mit ist, die Bedingungen, sound-Dateinamen/schriftliche Sätze oder Bilder, denen ein Teilnehmer ausgesetzt wird. Wählen Sie die Liste, und das Programm startet. Benennen Sie die Ausgabe-Datei, wo die Ergebnisse gespeichert werden.
Hinweis: Die Ausgabe-Datei wird auf dem Display PC gespeichert und eine Back-Up auf dem Host-PC gespeichert ist. - Lassen Sie den ersten Bildschirm des Experiments (die Einführung oder die Willkommensseite) geöffnet.
- Entfernen Sie die Schutzabdeckung von der Eye-Tracker-Kamera.
- Hygienischen Gründen legen Sie eine Gewebe am Kinn Halter.
- Optional: Bereiten Sie eine Antwort-Pad und/oder eine Tastatur je nach Bedarf durch das Experiment.
- Optional: Wenn auditive Reize zu präsentieren, stellen Sie die Lautstärke der Lautsprecher und testen sie vor der Durchführung des Experiments. Alternativ testen Sie die Funktionalität des Kopfhörers vom Teilnehmer verwendet werden.
- Bereiten Sie die notwendigen Formulare durch den Teilnehmer angemeldet sein.
- Stellen Sie die Lichtintensität im Labor einen schwach beleuchteten Raum mit einer konstanten Helligkeit für die gesamte Dauer der Sammlung von Daten haben.
- Vorbereitung für die Teilnehmer
- Nachdem die Teilnehmer angekommen sind, stellen Sie sich vor.
- Stelle eine nicht stören Schild an der Labortür.
- Bitten Sie die Teilnehmer Platz zu nehmen.
- Führen Sie die Teilnehmer durch das Informationsblatt und die erforderlichen Zustimmungen und demografischen Formen.
- Lassen Sie die Teilnehmer lesen und die Einverständniserklärung unterschreiben.
- Erklären Sie kurz die allgemeinen Aspekte des Experiments und ihrer Dauer. Bieten Sie nicht zu viele Informationen vor dem Experiment, da das Blickverhalten der Teilnehmer und die daraus resultierenden Daten beeinflussen könnten.
- Schriftliche Anweisungen und geben Sie die Teilnehmer die Möglichkeit, Fragen zu stellen.
- Erklären Sie kurz die Funktion des Eye-Trackers.
- Falls erforderlich, die Aufgabe zu klären und darauf hin keine Knöpfe/Tasten, die während des Experiments gedrückt werden müssen.
- Erläutern Sie, wie die Kinnstütze Kopfbewegungen während des Experiments zu minimieren soll. Erwähnen Sie, dass das Gerät am besten, funktioniert wenn der Teilnehmer keine Bewegungen vermeidet.
- Einrichten des Eye-Trackers
- Vorbereitung den Teilnehmer für das Experiment: bitten, sitzen am Tisch und legen Sie ihr Kinn auf den Kinnhalter. Fragen sie ihre Stirn gegen die Kopfstütze zu lehnen.
- Bitten Sie die Teilnehmer die Höhe und Position des Stuhls gegebenenfalls anpassen: die Teilnehmer sollen sich wohlfühlen mit ihrem Kinn auf den Kinnhalter und ihre Stirn gegen die Kopfstütze.
- Erklären Sie, dass es allgemein um versehentlich den Kopf während des Experiments ist und dass dies sollte vermieden werden. Erklären Sie, dass der Kopf Körperhaltung haben könnte, während des Tests korrigiert werden.
- Wenn das Experiment erfordert einen Knopf drücken (z. B. über die Antwort-Pad), weisen Sie die Teilnehmer, ihre Finger auf den Tasten ruhen lassen gedrückt werden und um zu vermeiden, blickte auf das Pad Reaktion beim Betätigen einer Taste.
- Bitten Sie die Teilnehmer den Bildschirm Willkommen/Einführung zu lesen.
- Setzen Sie sich vor dem Host-PC. Wenn der Bildschirm nicht auf Kamera-Setupist, klicken Sie auf Kamera-Setup kommt man zu der rechten Bildschirmseite. Wenn die Schutzkappe vom Objektiv Kamera entfernt wurde und die Teilnehmer auf den Kinnhalter korrekt positioniert ist, sollte der Bildschirm drei Bilder des Teilnehmers Augen zeigen: ein größeres Bild oben und unten links und rechts zwei kleinere. Diese kleineren Bilder zeigen ein Auge, jeweils die linke und das rechte Auge.
- Wählen Sie das Auge verfolgt werden. Es ist üblich, dominante Auge des Teilnehmers zu verfolgen. Wenn der Teilnehmer nicht weiß, welches Auge dominant ist, durchführen Sie einen augenfällige Dominanz-Test (Schritt 1.3.8).
- Augenfällige Herrschaft zu bestimmen. Bitten Sie die Teilnehmer, einen Arm ausstrecken und richten Sie den Daumen mit ein entferntes Objekt mit beiden Augen offen. Bitten Sie die Teilnehmer zu alternativen schließen das linke oder rechte Auge. Das dominante Auge ist wofür der Daumen mit dem Objekt ausgerichtet, bleibt wenn das Auge geöffnet35,36ist.
- Klicken Sie auf Bild | Display pc (oder drücken Sie die Eingabetaste) und die Bilder im Schritt 1.3.6 beschrieben erscheinen auch auf der Teilnehmer-Bildschirm, sondern nur eine zu einem Zeitpunkt.
- Drücken Sie links/rechts-Pfeil auf des Experimentators oder des Teilnehmers Computer-Tastatur umschalten zwischen kleineren und größeren Bild des Auges. Konzentrieren Sie sich auf das kleinere Bild (das Auge).
- Drücken Sie A (Align Auge Fenster) auf beiden Tastatur um das Suchfeld Grenzen auf die Pupille Position zentrieren. Dann erscheint ein rotes Quadrat um das Auge mit einem türkisen Kreis ["Hornhaut Reflexion", (Cr)] am unteren Rand der Pupille. Die Schüler selbst sollte blau sein.
- Stellen Sie sicher, dass zwei Kreuze ("Fadenkreuz") auf dem Bildschirm angezeigt werden – in der Mitte der Pupille und eine in der Mitte der Hornhaut Reflexion. Das rote Feld und die beiden Kreuze bedeuten, dass die Eye-Tracker erkennt der Schüler und der Tschechischen Republik.
Hinweis: Wenn das rote Feld oder die Kreuze nicht vorhanden sind, das Auge wird nicht verfolgt – in diesem Fall wird kein Schüler auf der Experimentator Computer angezeigt. - Stellen Sie den Fokus der Kamera durch manuelles Drehen der Fokus-Objektiv. Achten Sie darauf, dass Sie nicht vor das Objektiv zu berühren. Drehen Sie das Objektiv, bis die besten Fokus-Punkt erreicht ist.
Hinweis: Die besten Fokus-Punkt ist erreicht, wenn der türkisfarbene Kreis (die Hornhaut Reflexion) so klein ist wie möglich (d.h., wenn dieser Kreis im Fokus ist). - Festlegen Sie die Schüler-Schwellenwert. Stellen Sie sicher, dass nur das Bild des Schülers blau ist (z. B.die Wimpern sollten nicht blau sein) auf dem Host-PC. Stellen Sie außerdem sicher, dass die gesamte Schüler (nicht nur der zentrale Teil) blau ist. Nur sorgen Sie, was sich innerhalb des Roten Platzes befindet.
- Drücken Sie A. Dadurch wird automatisch die Pupille-Schwelle. Wenn die Schüler in blau nicht korrekt angezeigt wird, passen Sie den Schwellenwert manuell mit der auf -Taste zu erhöhen und der DOWN -Taste, um den blauen Teil der Bildfläche verringern.
Hinweis: Mascara (das ist in der Regel schwarz, wie die Pupille) beeinträchtigen festlegen des Schwellenwerts-Eye-Tracker dauern die dunklen Wimpern für den Schüler. In diesem Fall bitten Sie die Teilnehmer, ihr Make-up zu entfernen, indem Sie sie mit Make-up Entferner Gewebe. - Festlegen Sie die Cr-Schwellenwert. Wenn A in Schritt 1.3.15 gedrückt wurde, wurde der Cr-Schwelle sollte automatisch eingestellt.
Hinweis: Numerische Werte für alle Schwellenwerteinstellungen sollte sichtbar sein. Erscheint ein Fragezeichen in einer von ihnen, es gab ein Problem in einer der vorhergehenden Schritte und die Schwellenwerte sollten manuell eingestellt werden.
- Kalibrierung des Eye-Trackers
Hinweis: Überprüfen Sie, ob der Eye-Tracker die Position des Auges konsequent identifizieren kann, wenn der Teilnehmer auf andere Teile des Bildschirms sieht.- Bitten Sie die Teilnehmer an den vier Ecken des Bildschirms eine zu einem Zeitpunkt aussehen, während die Kamera-Setup-Fenster angezeigt wird. Suchen Sie sorgfältig nach unregelmäßigen Reflexionen (diese werden als Türkis "Blobs" auf dem Bildschirm angezeigt), die die Hornhaut Reflexion beeinträchtigen, wenn die Augen Blick sich an der Ecke richtet.
- Bitten Sie die Teilnehmer in der Mitte des Bildschirms schauen und dann direkt den Blick auf die problematischen Ecke, wenn das rote Feld rund um das Auge und entweder des Fadenkreuzes während Schritt 1.4.1 nicht jederzeit sichtbar sind. Dies wird helfen, die Ursache des Problems zu bestimmen.
- Erneut passen Sie die Position des Leiters des Teilnehmers an und überprüfen Sie, ob dies eine Verbesserung ergibt. Wiederholen Sie diesen Schritt, falls erforderlich. Wenn das Gerät immer noch nicht genau verfolgen des Teilnehmers Blick nach mehreren versuchen, abzubrechen Sie das Experiment.
- Informieren Sie die Teilnehmer, dass der Eye-Tracker kalibriert werden und dass sie gehen, um einen schwarzen Kreis (mit einem kleinen grauen Punkt) in verschiedene Teile des Bildschirms zu sehen. Weisen Sie den Teilnehmer, den Kreis zu fixieren, bis es an eine neue Position bewegt. Weisen Sie die Teilnehmer, um zu vermeiden, ihre Augen und konzentrieren sich auf den kleinen grauen Punkt innerhalb des schwarzen Kreises für ein optimales Ergebnis.
- Erzählen Sie die Teilnehmer, ist es wichtig, noch zu halten und nicht zu versuchen, die Position des nächsten Kreises während der Kalibrierung zu antizipieren. Weisen sie auf die Kreise mit ihren Augen und nicht den Kopf zu folgen. Klicken Sie auf kalibrieren , um die Kalibrierung zu starten. Normalerweise wird ein 9-Punkt-Kalibrierung verwendet, in dem der schwarze Kreis an neun Standorten in gewissem Sinne seriellen bewegt.
- Drücken Sie für eine automatische Kalibrierung die Eingabetaste , nachdem der Teilnehmer genau den ersten Punkt in der Mitte des Bildschirms fixiert hat. Für die manuelle Kalibrierung (z. B., wenn es Probleme tracking des Teilnehmers Auge oder beim Umgang mit speziellen Teilnehmer Gruppen wie z. B. Kinder), akzeptieren jede Fixierung durch Drücken der Eingabetaste (oder durch Klicken auf Accept Fixierung/ Drücken der Leertaste).
Hinweis: Am Ende der Kalibrierung sollte eine fast rechteckige Anordnung auf der Experimentator Bildschirm sichtbar sein. Dies entspricht die Auge Blickmustern des Teilnehmers. Darüber hinaus sollten die Ergebnisse eine gute Kalibrierung grün hervorgehoben werden. Wenn sie nicht sind, wiederholen Sie den Kalibriervorgang (d.h., klicken Sie auf Kalibrierung). - Überprüfen Sie die Ergebnisse. Sagen Sie die Teilnehmer durch das gleiche Verfahren (Blick auf Punkte) zu gehen, um die Ergebnisse der Kalibrierung zu validieren. Erinnern sie auf den Punkt schauen, um leise sein.
Hinweis: Der Prozess der Validierung ist ähnlich dem der Kalibrierung und beide Ergebnisse werden verglichen, indem die Eye-Tracker-Software um sicherzustellen, dass das Auge genau nachverfolgt wird. - Klicken Sie auf überprüfen.
- Akzeptieren Sie jede Fixierung durch Drücken der Eingabetaste (oder per Klick akzeptierenFixierung/Drücken der Leertaste).
- Nach der Validierung werden die Ergebnisse auf der Experimentator Bildschirm angezeigt. Besonderes Augenmerk auf die zwei Fehler Maßnahmen, den durchschnittlichen Fehler (z.B. 0,23 °) und der maximale Fehler (z.B. 0,70 °). Diese stellen den Grad, die nachverfolgte Bild von der tatsächlichen Blick Position eines Teilnehmers abweicht.
- Wenn Sie eine visuelle Welt Paradigma zu verwenden, halten den durchschnittlichen Fehler (die erste Zahl) unter 0,5 ° und der maximale Fehler (die zweite Zahl) unter 1°.
- Wenn Fehlerwerte oberhalb der Schwelle sind, bitten Sie die Teilnehmer, passen Sie die Position ihres Kopfes und starten die Kalibrierung. Wenn keine Besserung beobachtet wird, abzubrechen Sie das Experiment.
Hinweis: Es ist üblich, hohe Kalibrierung Fehler zu beobachten, wenn der Teilnehmer Kontaktlinsen trägt. Die Teilnehmer sollten im Voraus aufgefordert werden, ihre Brille anstelle der Kontaktlinsen zu bringen. - Klicken Sie nach erfolgreichem Abschluss der Kalibrierung, Ausgabedatensatz/um das Experiment zu beginnen. Informieren Sie die Teilnehmer, dass das Experiment nun beginnen wird.
- Während des Experiments
Hinweis: Während des Experiments (je nachdem, wie ein einzelner Experiment programmiert ist, aber in der Regel vor jeder experimentellen Studie) wird eine drift Check oder Drift korrekt einen Punkt in der Mitte des Bildschirms Bildschirm. Gesellschaftszweck ist die berechnete Fixierung Fehlerbericht für die aktuelle Testversion, und je nach Tracker Augenmodell automatisch angepasst.- Während die Instruktionsphase teilte der Teilnehmer an den zentralen Punkt zu fixieren, wenn es angezeigt wird. Stellen Sie sicher, dass in jeder Drift Check/Drift korrekt Phase Teilnehmer wieder den Punkt fixiert sind. Dies kann erfolgen, indem Sie Blick des Teilnehmers auf der Host-PC, dem Blick des Teilnehmers als bewegliche grüne Kreis angezeigt wird.
- Nach Abschluss der Drift Check/Drift korrekt drücken Sie Eingabetaste (oder die Leertaste) um den Punkt verschwinden und zeigt die nächste Prüfung zu machen.
- Umgang mit Versagen die Drift-Check-Phase nach dem Vorbild der Eye-Tracker verwendet übergeben zu bestimmen. Je nach Modell, der Eye-Tracker entweder führt eine automatische Korrektur drift durch die Anpassung des Blicks Koordinaten um den zentralen Punkt übereinstimmen, oder es wird ein Piepton aufgefordert, den Experimentator, bevor Sie fortfahren neu zu kalibrieren die Experimentieren Sie (drift Check).
- Wenn Sie eine automatische Drift-Korrektur verwenden, denken Sie daran, dass zu viele Drift Korrekturen in aufeinander folgenden Studien und/oder zu groß ein Maß an Drift-Korrektur werden die Ergebnisse verzerren und erfordern eine erneute Kalibrierung des Gerätes.
- Re-Kalibrierung während des Experiments
- Es ist möglich, während das Experiment jederzeit neu zu kalibrieren. Während der Präsentation des Bildschirms Drift Korrektur/Drift überprüfen klicken Sie auf Kamera-Setup, und klicken Sie dann auf kalibrieren. Die Kalibrierung und Validierung Prozesse durchlaufen Sie, bis ein zufriedenstellender Wert erreicht ist, dann klicken Sie auf Ausgabe/Record. Das Experiment wird an der Austrittsstelle in der Testversion Sequenz fortgesetzt.
- Nach dem experiment
- Bieten Sie die Teilnehmer mit einem Fragebogen zu beurteilen, ob sie in der Lage, die wichtigsten experimentellen Manipulationen zu erraten waren. Hier ist es auch wichtig, über mögliche Strategien zu Fragen, die während des Experiments erarbeitet werden konnte.
- Nachbesprechung des Teilnehmers über den Zweck des Experiments. Danke ihnen für ihre Teilnahme und bieten die notwendige finanzielle Entschädigung oder Kurs Kredit vergeben, falls zutreffend.
2. remote Setup: Anpassung der Setup für Studien mit Kindern und ältere Erwachsene
Hinweis: Dieser Abschnitt beschreibt nur die Unterschiede zwischen einer remote-Installation und ein Desktop-Setup wie in Schritt 1 beschrieben. Punkte erwähnt nicht ausdrücklich, hier sollte davon ausgegangen werden, identisch mit dem in Schritt 1 beschriebenen Verfahren werden.
- Tauschen Sie die standard 35 mm Eye Tracker Kameralinse für ein 16 mm-Objektiv.
- Schließen Sie alle notwendige Ausrüstung (Host-PC, Lautsprecher, Eye-Tracker und Laptop wenn ein Laptop verwendet wird).
- Legen Sie den Laptop auf ein Laptopständer und der Eye-Tracker davor (der Teilnehmer sollte in der Lage, den Top 75 % des Bildschirms zu sehen sein).
- Legen Sie einen "Ziel-Aufkleber" (der Tracker Hersteller erhältlich) auf Stirn des Teilnehmers (oberhalb der Augenbraue des rechten Auges oder auf die rechte Wange ist die Stirn zu klein (z.B.bei Säuglingen); diese Aufkleber ersetzt das Kinn rest der Desktop-Setup und es erlaubt den Eye-Tracker, die Position des Leiters der Teilnehmer genau zu bestimmen.
- Stellen Sie sicher, dass der Teilnehmer 550-600 mm Entfernung von der Kamera (der Abstand von der Ziel-Aufkleber an der Kamera) sitzt.
- Stellen Sie sicher, dass die Worte "großen Winkel" oder "in der Nähe von Auge" erscheinen nicht auf dem Host-PC. Wenn sie es tun, bedeutet dies, dass die Position des Aufklebers Ziel nicht ideal ist. In diesem Fall passen Sie den Ziel-Aufkleber. Es kann auch bedeuten, dass der Teilnehmer Stirn besonders klein ist. Wenn dies der Fall ist, legen Sie den Aufkleber auf Wange des Teilnehmers.
Hinweis: Wenn der Aufkleber angebracht ist zu nah an das Ohr, die Meldung "großen Winkel" ist wahrscheinlich erscheinen und die Aufkleber muss neu positioniert werden. - Stellen Sie vor Beginn der Kalibrierung im Schritt 1.4 beschrieben sicher, dass die Teilnehmer bequem sitzt. Bitten sie erhalten die gleiche Position in das ganze Experiment und erklären, dass die Eye-Tracker sehr empfindlich auf Körperbewegungen. Bestehen Sie darauf, dass sie ihren Kopf still halten. Wenn der Teilnehmer zu viel bewegt, sendet das Gerät ein summendes Geräusch.
Hinweis: Wenn das remote Eye Tracker Setup verwendet wird, um empfindliche Bevölkerungsgruppen, wie Kinder oder ältere Erwachsene testen ist es ratsam, eine manuelle Kalibrierung verwenden.
3. Einstellen der Setup für das Lesen von Studien
Hinweis: Bei der Untersuchung von visuellen Kontext Auswirkungen auf die Lesung ist es notwendig, besonderes Augenmerk auf die Kalibrierung und Rekalibrierung Prozesse. Im Gegensatz zu visuellen Welt Studien erfordert Eye-tracking beim Lesen ein viel höheres Maß an Gerät Präzision, angesichts der Genauigkeit, Wort für Wort und Buchstabe für Buchstabe lesen Muster zu verfolgen.
- Stellen Sie sicher, dass sowohl die durchschnittliche und maximale Fehler während der Validierungsphase angezeigt unter 0,5 ° bleiben.
- Achten Sie darauf, mindestens eine 9-Punkte-Skala für die Kalibrierung. Dies sichert eine genauere Nachverfolgung der Augenposition Blick, das wesentliche, angesichts der geringen Größe der Bereiche von Interesse beim Lesen ist.
Ergebnisse
Eine Studie von Münster und Mitarbeiter37 untersucht das Zusammenspiel von Satzbau, Aktionen und Gesichts emotionale Signale während Sprachverständnis dargestellt. Diese Studie ist gut geeignet, um die Vorzüge und Grenzen der Methode zu veranschaulichen, wie es zeigte sich, dass beide robuste Aktion und marginale Effekte des Gesichts emotionale Hinweise auf Satz Verständnis abgebildet. Die Autoren erstellt 5 s Videos der Gesichtsausdruck einer Frau, die von einer Ruheposition in eine glückliche oder in einen traurigen Ausdruck geändert. Sie schufen auch emotional positiv valenced deutschen Objekt-Verb-Adverb-Thema (OVAdvS) Sätze der Form "[Objekt/PatientAkkusativ Fall] [Verb] [positive Adverb] [Thema/AgentNominativ Fall]." Über die positive Adverb Sätze 'glückliche' Video abgestimmt und übereinstimmende "traurige" Video, schönem im Prinzip Vorgriff auf den Agent (wer lächelte und glücklich von der positiven Adverb als Handeln beschrieben). Im Anschluss an die Lautsprecher video erschien der Satz mit einem von zwei Versionen einer Agenten-Patient-Distraktor Clipart-Szene. In einer einzigen Version wurde der Agent dargestellt, wie die Durchführung der genannten Maßnahmen am Patienten, während der Distraktor Charakter eine andere Aktion ausgeführt. Die andere Version der Szene dargestellt, keine Aktionen zwischen den Charakteren. Augenbewegungen in der Szene zeigte die Auswirkungen der Maßnahmen und des Gesichtsausdrucks des Sprechers auf Satz Verständnis.
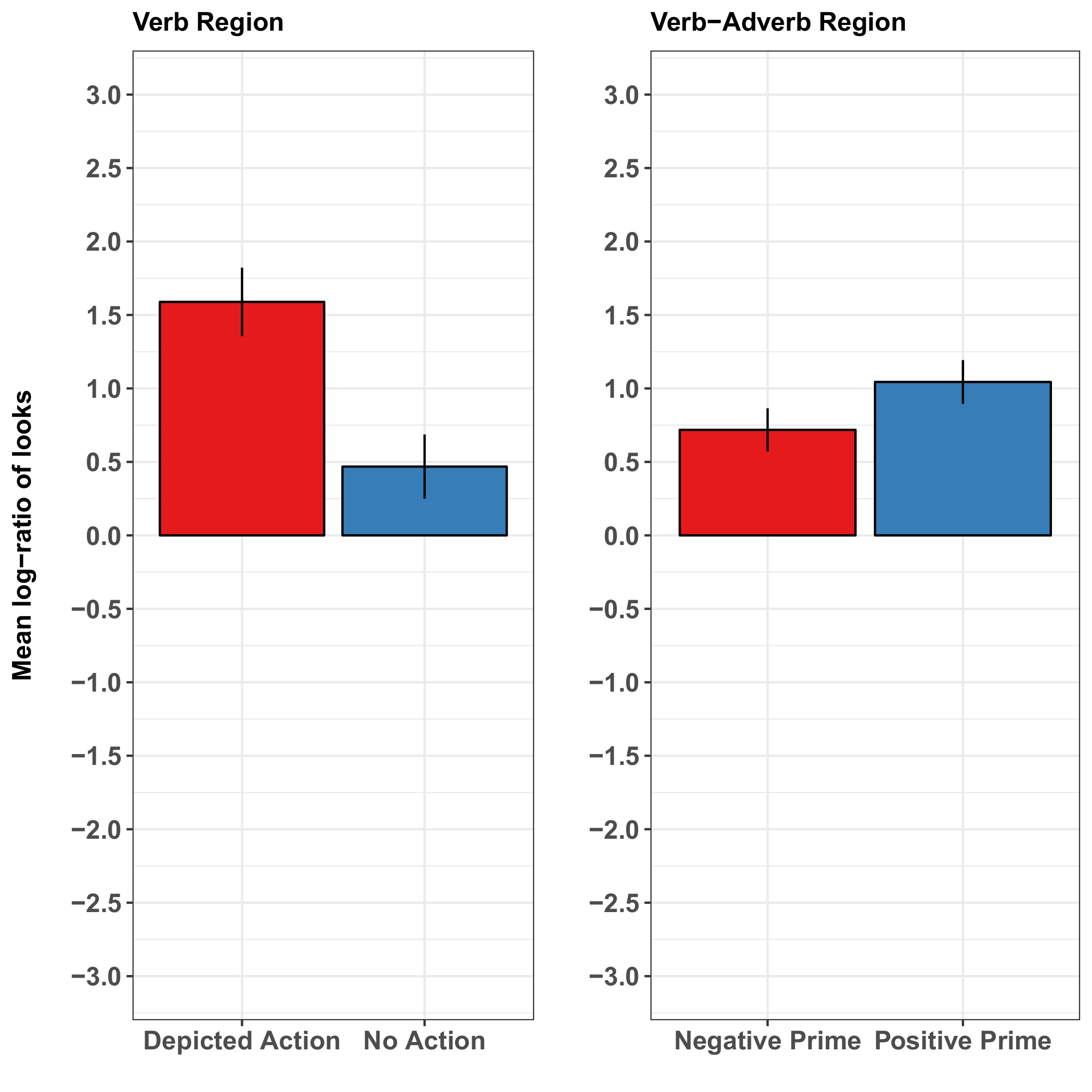
Die Aktion Darstellung schnell visuelle Aufmerksamkeit der Teilnehmer, was bedeutet, dass die Teilnehmer eher an den Agent als bei der Distraktor, sah als die genannte Aktion war betroffen (vs. war nicht) dargestellt. Diese Blicke waren vorausschauend (d.h.auftreten, bevor der Agent erwähnt wurde), was darauf hindeutet, dass die Aktion Darstellung den Agent geklärt, bevor der Satz hat. Die früheste Wirkung der Aktion Darstellung entstanden, während das Verb (d.h.das Verb vermittelt den Aktion verbundenen Agent). Im Gegensatz dazu, ob Vorredner lächelte oder unglücklich aussah hatte keine klare Auswirkungen auf die Agenten Vorfreude (Abbildung 2). Das letztere Ergebnis könnte mehr tenuous Verbindung zwischen eines Sprechers Lächeln und einer positiven sentential Adverb im Zusammenhang mit der abgebildeten Agent Maßnahme (im Vergleich mit einem direkten Verb-Aktion Bezug vermitteln einen Aktion-assoziierten Agent) widerspiegeln. Alternativ könnte es werden speziell für die Aufgabe und Ansporn Präsentation: vielleicht Emotion-Effekte würde haben wurde stärker ausgeprägt in einer sozial interaktive Aufgabe oder das Gesicht während (und nicht vor) Satz Verständnis des Sprechers präsentiert. Präsentieren referiert lächelnden Gesicht während Verständnis kann jedoch führen Teilnehmer zu konzentrieren auf das Gesicht auf Kosten der anderen Szeneninhalt vielleicht Maskierung sonst beobachtbaren Effekte von der Stellgrößen (Quelle: unveröffentlichte Daten).
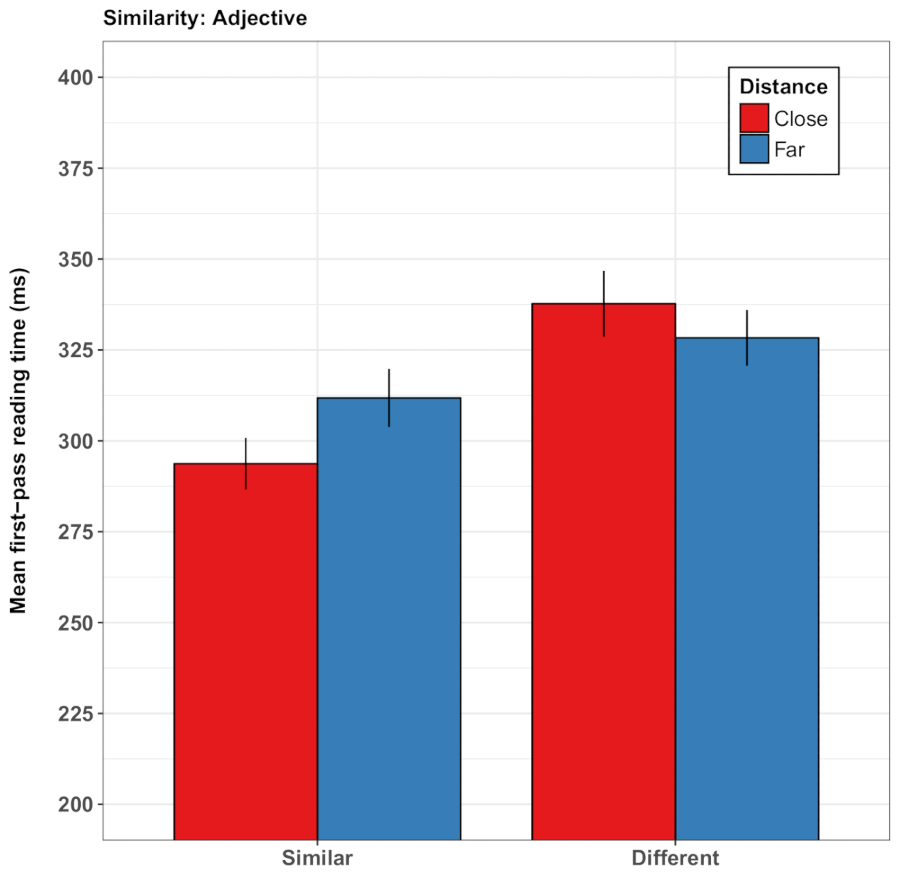
In einer weiteren Variante des Paradigmas Guerra und Knoeferle32 gefragt ob räumliche semantische Weltsprache Beziehungen beim Lesen das Verständnis der abstrakte Bedeutungsgehalt modulieren können. Guerra und Knoeferle lieh die Idee von der konzeptuellen Metapher Theorie38 , dass räumliche Distanz (z.B. Nähe) die Bedeutung der abstrakte semantische Beziehungen (z.B.Ähnlichkeit) Gründen. Im Einklang mit dieser Hypothese koordiniert Teilnehmer lesen Abstrakte Substantive schneller als sie ähnliche (vs. gegenüberliegenden) in der Bedeutung und durch ein video vermitteln Nähe (vs. Entfernung, Spielkarten Schritt näher zusammen Vs vorausgegangen. weiter auseinander). In einer zweiten Reihe von Studien39beschriebenen Sätze die Interaktion zwischen zwei Menschen als intime oder unfreundlich, führend zu die Entdeckung, dass das Lesen der Satz Regionen Videos von zwei Karten aufeinander zugehen beschleunigt, die soziale vermittelt Nähe/Intimität. Beachten Sie, dass die räumliche Distanz Satz schnell und inkrementell lesen betroffen, selbst wenn die Sätze nicht auf die Objekte in das Video ansprach. Die Videos moduliert unverwechselbar Lesung Zeiten in Abhängigkeit von der Kongruenz zwischen räumlichen Distanz und semantische sowie soziale Aspekte der Satz Sinn. Diese Effekte erschien sowohl in der First-Pass-Lesung Zeit (die Dauer der ersten Inspektion einer vorher festgelegten Satz-Region) und die gesamte Zeit verbracht in diesem Satz-Bereich (siehe Abbildung 3 eine Darstellung der Ergebnisse aus den Studien von Guerra und Knoeferle)32. Die Analysen zeigten jedoch auch erhebliche Unterschiede zwischen den Teilnehmern, was zu dem Schluss, dass solche subtilen Karte-Entfernung-Effekte möglicherweise nicht so robust wie die Auswirkungen der Handlung Beziehungen, um ein Beispiel zu nennen.
Eine weitere Reihe von Studien zeigt wie Variation im Satzbau helfen kann, die Allgemeingültigkeit des visuellen Kontext Auswirkungen zu bewerten. Abaschidse und Mitarbeiter34 und Rodríguez und Mitarbeiter26 untersuchte die Auswirkungen der jüngsten Maßnahmen auf die Weiterverarbeitung der gesprochenen Sätzen. In beiden Studien Teilnehmer zunächst inspiziert eine Action-Video (z.B., ein Experimentator Würze Gurken oder weibliche Hände einen Kuchen zu backen). Als nächstes hörte sie einen deutschen Satz, der entweder verwandt war, um die jüngsten Maßnahmen oder eine andere Aktion, die ausgeführt werden könnte weiter (würzen Tomaten34; bauen ein Modell26). Während Verständnis, inspiziert die Teilnehmer eine Szene zeigt zwei Objekte (Gurken, Tomaten)34 oder zwei Fotos von Agent Gesichter (eine weibliche und eine männliche Agent Gesicht, namens "Susanna" und "Thomas", beziehungsweise)26. In der Studie von Abashidze und Mitarbeiter34, der Redner erstmals erwähnt, der Experimentator und dann das Verb (z.B. Geschmack), Erwartungen über ein Thema (z.B., die Gurken oder Tomaten) zu entlocken. In der Studie von Rodríguez und Mitarbeiter26, die Lautsprecher erstmals erwähnt ein Thema (Kuchen), und dann das Verb (Backen), Erwartungen an den Agenten der Aktion zu entlocken (weiblich: Susanna oder männlich: Thomas, dargestellt über Fotos von einer weibliche und männliche Gesicht).
In beiden Studien war die Frage, ob Menschen (visuell) Thema/Agent der jüngsten Aktion Veranstaltung oder das andere Thema/Agent basierend auf weitere inhaltliche Hinweise während Verständnis erwarten würde. Der Experimentator Blick vorgehört Abashidze und Mitarbeiter34, das zukünftige Theme-Objekt (die Tomaten) aus dem Beginn des Verbs (wörtlich übersetzt aus dem deutschen: "der Experimentator-Agent Aromen bald..."). Rodríguez und Mitarbeiter26, Geschlecht wissen Stereotype Handlungen wurde zur Verfügung, wenn das Thema und das Verb erwähnt wurden (z.B., die wörtliche Übersetzung der deutschen Stimuli war: "Themas Kuchen backt bald..."). In beiden Studien kontrolliert die Teilnehmer bevorzugt den Ziel /-Agent der letzten Aktion (die Gurken34 oder Susanna26) über die alternative (Zukunft/andere-Geschlecht) Ziel (die Tomaten34 oder Thomas26) während der Satz.
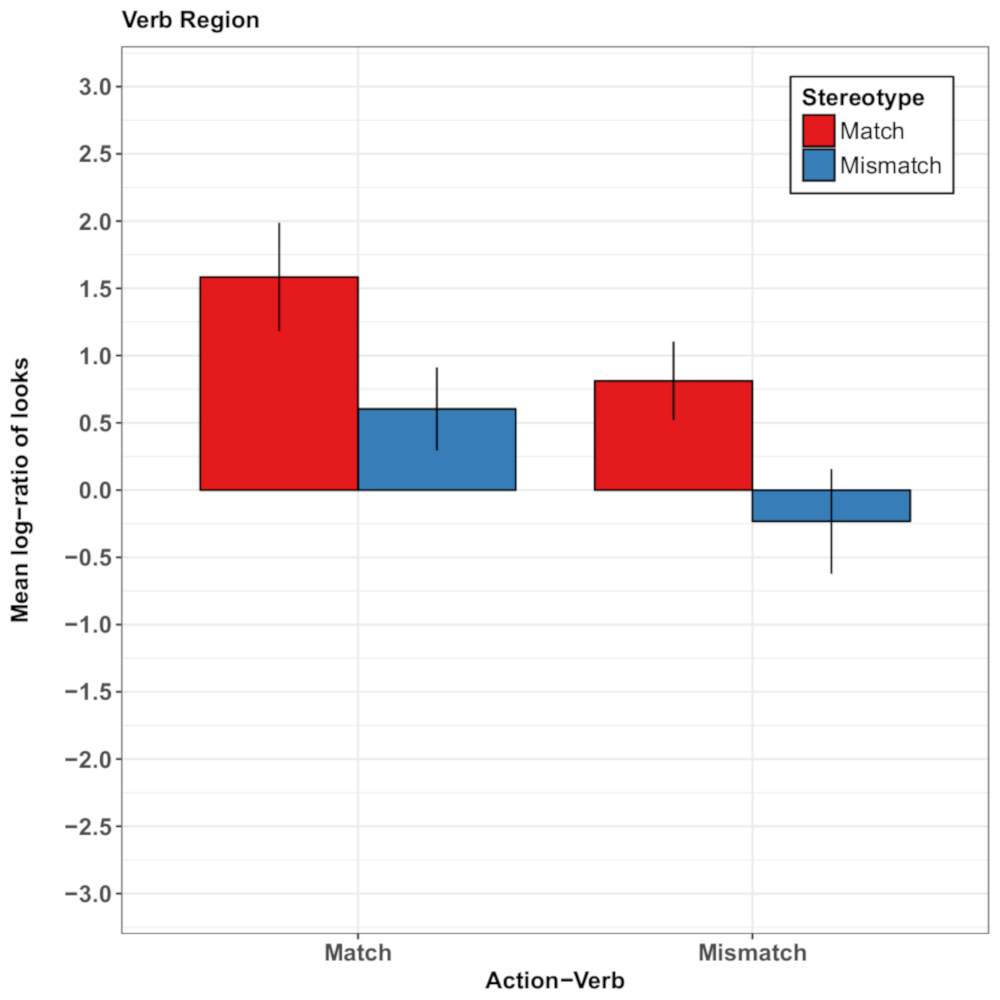
Dieser so genannte "aktuelles Ereignis Bevorzugung" scheint so robust über erhebliche Unterschiede im Satzbau und experimentelle Materialien. Es wurde moduliert, jedoch durch visuelle Zwänge aus der gleichzeitigen Szene26, sodass präsentiert plausibel Fotografien von Verb Themen zusätzlich zu vergeschlechtlichte Fotografien von Agenten die Abhängigkeit von den vor kurzem inspiziert Action-Events reduziert und modulierte Aufmerksamkeit basierend auf Geschlecht-Stereotyp wissen durch Sprache vermittelt. Abbildung 4 zeigt die wichtigsten Ergebnisse der Experimente von Rodríguez und Mitarbeiter26.
Während diese Version des Visual-Welt Paradigmas robuste Ergebnisse gezeitigt, haben andere Studien die Komplexität (und Grenzen) der Verknüpfung Hypothese hervorgehoben. Burigo und Knoeferle20 aufgedeckt, dass die Teilnehmer – beim hören von Äußerungen wie sterben Box ist Über der Wurst ("das Feld ist über die Wurst") – meist folgte die Äußerung in Inspektion Clipart Darstellungen dieser Objekte. Aber auf einen Anteil der Studien, die Teilnehmer Blick was entkoppelt wurde erwähnt. Nach Anhörung "Wurst" und die Wurst mindestens einmal kontrolliert haben, nächste Inspektion der Teilnehmer in die Schachtel auf ca. 21 % der Studien an beschleunigte Prüfung (Experiment 1) und in 90 % der Versuche in Post-Satz Überprüfung (zurückgelegt Experiment 2). Dieser Blick Muster deutet darauf hin, dass die Referenz (Anhörung "Wurst") geführt, nur einige (Inspektion der Wurst), aber nicht alle Augenbewegungen (Inspektion der Box). Diese Art von Design könnte verwendet werden, um auseinander lexikalische referentielle Prozesse voneinander (einschließlich Satzebene interpretativen) necken Prozesse. Jedoch Forscher müssen vorsichtig sein wenn, Behauptungen über verschiedene Ebenen der sprachlichen Verarbeitung basierend auf relative Unterschiede in der Augenbewegung Proportionen, angesichts der Unklarheiten bei der Verknüpfung von Augen-Blick auf kognitive und Verständnis Prozesse.

Abbildung 1: Überblick über die Sammlung Datenumgebung. Das Diagramm zeigt, wie die verschiedenen Software- und Hardware-Elemente für die Datensammlung verwendet und Vorverarbeitung zueinander. Bitte klicken Sie hier für eine größere Version dieser Figur.
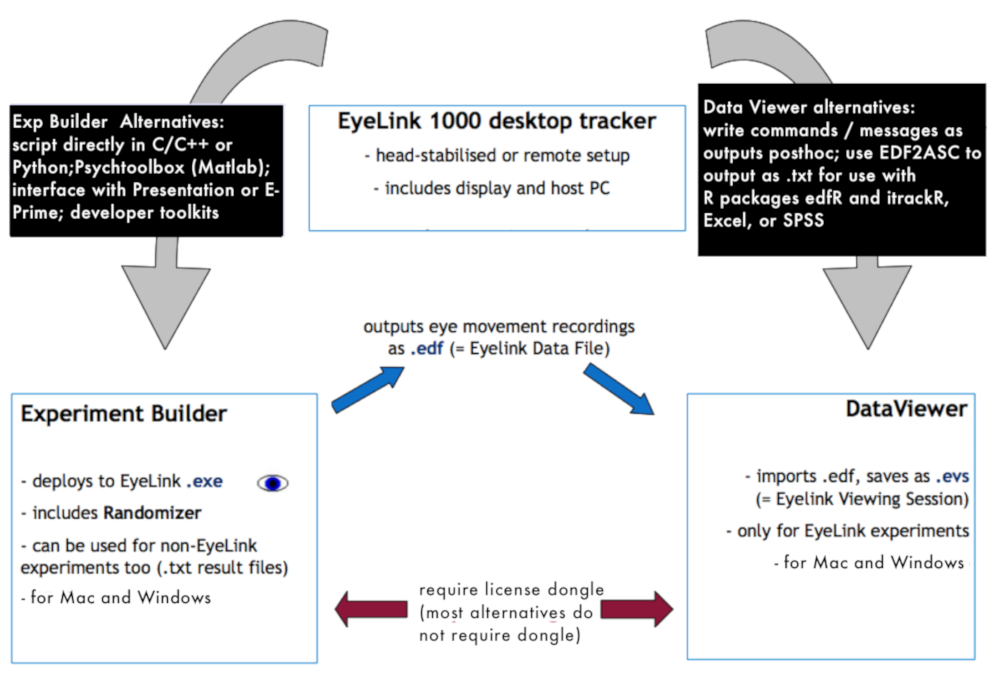{kind=link}

Abbildung 2: Repräsentative Ergebnisse von Münster und Mitarbeiter37. Diese Tafeln zeigen des Sachgebietes mittlere Log-Blick Wahrscheinlichkeit Verhältnisse pro Zustand in der Verb-Region (für die dargestellte Handlung) und in der Verb-Adverb-Region (für den Effekt von emotionalen Prime) kombiniert. Die Ergebnisse zeigen einen deutlich höheren Anteil an Blicke auf das Zielbild, wenn die Handlung im Satz genannten als dargestellt wurde, wenn es nicht abgebildet war. Die Ergebnisse für die Wirkung der emotionalen Gesichts Primzahlen wurden weniger schlüssig: sie schlagen nur eine leichte Erhöhung im Verhältnis bedeuten-Log sieht das Ziel als das Gesicht Prime eine positive emotionale Wertigkeit (ein Lächeln hatte) als wenn es eine negative Valenz (ein trauriges Gesicht) hatte. Die Fehlerbalken repräsentieren den Standardfehler des Mittelwerts. Diese Zahl wurde von Münster Et Al. modifiziert 37. Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}

Abbildung 3: Repräsentative Ergebnisse von Guerra und Knoeferle32. Dieses Fenster zeigt die mittlere First-Pass-Lesung Zeit (in Millisekunden) des Adjektivs (Dis) Ähnlichkeit. Die Ergebnisse zeigen kürzere Lesung Zeiten für Ähnlichkeit Sätze nach sehen zwei Spielkarten näher zusammenrücken mit weiter auseinander verglichen. Die Fehlerbalken repräsentieren den Standardfehler des Mittelwerts. Diese Zahl wurde von Guerra und Knoeferle32geändert. Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}

Abbildung 4: Repräsentative Ergebnisse von Rodríguez und Mitarbeiter26. Dieses Panel zeigt den Blick des Sachgebietes mittlere Log Wahrscheinlichkeit Verhältnisse pro Zustand in der Verb-Region. Die Proportionen der sieht oben 0 zeigen eine Vorliebe für das Zielbild Agent und die Proportionen unterhalb 0 zeigen eine Vorliebe für die Wettbewerber-Agent-Image. Die Ergebnisse zeigen, dass Teilnehmer wahrscheinlicher waren, das Zielbild Agent zu überprüfen, wenn Sie das Objekt und das Verb im Satz genannten die Vorveranstaltungen Videoaufnahmen abgestimmt als wenn dies nicht der Fall. Darüber hinaus gab es weitere Blicke auf das Zielbild Agent, wenn die Aktion beschrieben durch den Satz Geschlechterstereotypen gleichgestaltet. Die Fehlerbalken repräsentieren den Standardfehler des Mittelwerts. Diese Zahl wurde von Rodríguez Et Al. modifiziert 26. Bitte klicken Sie hier für eine größere Version dieser Figur.
{kind=link}
Diskussion
Zusammenfassend lässt sich sagen haben bewerteten Varianten von Eye tracking im visuellen Kontext viele Möglichkeiten entdeckt, in denen visuelle Szene Sprachverständnis beeinflussen kann. Diese Methode bietet entscheidende Vorteile im Vergleich zu Methoden wie Reaktionszeiten zu messen. Zum Beispiel bieten laufende Augenbewegungen mit einem Fenster in die Sprache verstehen Prozesse und wie diese interagieren mit unserer Wahrnehmung der visuellen Welt im Laufe der Zeit. Darüber hinaus sind die Teilnehmer nicht unbedingt erforderlich, um eine explizite Aufgabe während Sprachverständnis (z. B. Beurteilung der Grammaticality einen Satz über einen Knopf drücken). Dies erlaubt Forschern, die Methode mit einer Bevölkerung zu verwenden, die mit offener Verhaltensreaktionen als Auge Blick, wie Säuglinge, kämpfen könnten Kinder und in einigen Fällen, ältere Erwachsene. Eye-tracking ist ökologisch gültig, dass sie Teilnehmer Aufmerksamkeit Antworten widerspiegelt – nicht anders als Menschen visuelle Vernehmung Kommunikationsrelevante Dinge in der Welt um sie herum beim mehr oder weniger aufmerksam zuhören, sich entfaltenden Äußerungen.
Die Grenzen (oder vielleicht Merkmale) der visuellen Welt Paradigma gehört, dass nicht alle Veranstaltungen unkompliziert und eindeutig dargestellt werden können. Konkrete Objekte und Ereignisse, natürlich darstellbar. Aber wie abstrakte Konzepte am besten sind dargestellt ist weniger klar. Dies kann zu begrenzen (Einblicke in das Zusammenspiel von Sprachverarbeitung und die Wahrnehmung der visuellen Welt mit einem Eyetracking-Bildwelt Paradigma oder definieren). Weitere Herausforderungen beziehen sich auf die Verknüpfungen Hypothesen zwischen beobachteten Verhalten und Verständnis Prozesse. Auge Fixierungen sind ein einziges Verhaltensreaktion, die wahrscheinlich viele Teilprozesse im Sprachverständnis (z.B., lexikalische Zugriff, referentielle Prozesse, Sprache-vermittelten Erwartungen, visuellen Kontext Effekte, unter anderem) widerspiegelt. Angesichts dieser Erkenntnis, Forscher müssen vorsichtig sein, nicht zu über- oder fehlinterpretiert werden die beobachteten Blick-Muster. Um dieses Problem zu beheben, hat frühere Forschung die Rolle von Verständnis Teilaufgaben zu klären, die Interpretation der Blick Rekord40hervorgehoben.
Eine Möglichkeit, die Interpretierbarkeit der Augenbewegungen zu verbessern ist, sie mit anderen Maßnahmen wie veranstaltungsbezogenen Gehirn Potentiale (ERPs) zu integrieren. Durch die Untersuchung des gleichen Phänomens mit zwei Methoden, die in ihrer zeitlichen Granularität vergleichbar und ergänzen sich in ihrer Verknüpfungen Hypothesen sind, können Forscher alternative Erklärungen ihrer Ergebnisse ausschließen und bereichern die Interpretation der einzelnen Einzelmaßnahme41. Dieser Ansatz wurde verfolgt über Experimente43aber vor kurzem auch in einem einzigen Experiment (wenn auch in rein sprachlichen Kontexten)44. Zukunftsforschung könnte profitieren von solchen methodischen Integration und Kombination mit Post-Prozess und Post-experimentellen Aufgaben weiter.
Die Eye-Tracking-Methode kann etablierte Ergebnisse zu replizieren sowie neue Hypothesen über die Interaktion der visuellen Aufmerksamkeit in Szenen mit Sprachverständnis zu testen. Das Verfahren des Protokolls muss sorgfältig beachtet werden, da auch kleine Experimentator Fehler Datenqualität beeinträchtigen können. Lesen Sie Studien, z. B. sind die entsprechenden Analysen-Regionen oft einzelne Wörter oder auch Buchstaben, was bedeutet, dass selbst kleine Kalibrierung Fehler die Ergebnisse verzerren könnten (siehe den Artikel von Raney und Kollegen42). Schritte 1.4 und 1.5 des Protokolls, die Kalibrierung des Eye-Trackers und Drift Check/Drift korrekt ist, sind von besonderer Bedeutung, da sie direkten Einfluss auf die Genauigkeit der Aufzeichnung. Nichtbeachtung des Eye-Trackers korrekt kalibrieren kann der Tracker nicht präzise tracking Augenbewegungen zu den vorher festgelegten Bereichen von Interesse. Diese Tracking-Ausfall führt zu fehlenden Datenpunkte und einem Verlust an statistische Aussagekraft, was problematisch sein kann, bei der Untersuchung von Sprache-Welt-Beziehungen, die sind sehr subtil und kleinen statistischen Effekt Größen (siehe die Beschreibung von der Experimente von Guerra und Knoeferle32 und Münster und Kollegen37 unter den Vertreter Ergebnisse).
Angesichts der Notwendigkeit, Kraft und Sensibilität des Gerätes zu maximieren, ist es wichtig, dass die Experimentatoren wissen, wie man mit Problemen umzugehen, die routinemäßig während einer experimentellen Sitzung auftreten. Beispielsweise können die Schüler Position und Bewegung der Teilnehmer, die das Tragen einer Brille Kalibrierung Schwierigkeiten durch Lichtreflexionen auf den Linsen eines Teilnehmers Gläser führen. Eine Möglichkeit zur Lösung dieses Problems ist spiegeln das Bild des Teilnehmers Auge auf dem Display PC und ermutigen sie, ihren Kopf bewegen, bis die Reflexion des Lichtes auf den Gläsern ist nicht mehr sichtbar auf dem Bildschirm, was bedeutet, dass es nicht mehr von der Kamera eingefangen wird. Eine weitere Ursache des Scheiterns der Kalibrierung kann Verengung der Pupille, die eine Folge von einer Überbelichtung Licht sein kann. In diesem Fall wird Dimmen des Lichtes im Labor Erweiterung der Pupille zu erhöhen und so helfen, den Eye-Tracker bei der Aufdeckung von genau der Schüler.
Als ein letzter Gedanke möchten wir das Potenzial zu befassen, das die visuelle Welt Paradigma für die Forschung auf das zweite Sprachenlernen hat. Das Paradigma wurde bereits erfolgreich in die psycholinguistische Forschung verwendet, um wie z. B. sprachübergreifende lexikalischen und phonologischen Interaktion46,47,48Phänomene zu untersuchen. Darüber hinaus wurde die enge Verbindung zwischen visuelle Aufmerksamkeit und Sprachenlernen häufig in die angewandte Linguistik Literatur zum zweiten Spracherwerb49,50,51hervorgehoben. Zukünftige Forschung zum zweiten Sprachenlernen wird wahrscheinlich weiterhin profitieren von vorteilhaften Position Eye Tracking als eine Methode, die ein Index der visuellen Aufmerksamkeit in Millisekunden Auflösung sorgt.
Offenlegungen
Die Autoren haben nichts preisgeben.
Danksagungen
Diese Forschung wurde finanziert durch die ZuKo (Exzellenzinitiative, Humboldt-Universität Zu Berlin), die Exzellenz-Cluster-277 'kognitiven Interaktion-Technologie"(Deutschen Forschungsgemeinschaft, DFG) und der Europäischen Union siebte Rahmenprogramm für Forschung, technologische Entwicklung und Demonstration unter Förderung Vereinbarung n ° 316748 (LanPercept). Die Autoren erkennen auch Unterstützung aus den basalen Fonds für Centers of Excellence, Projekt FB0003 von assoziativen Forschung Programm von CONICYT (Regierung von Chile), und aus dem Projekt "FoTeRo" in der Focus-Center XPrag (DFG). Pia Knoeferle vorausgesetzt, ein erster Entwurf des Artikels mit einem Laborprotokoll teilte mit, Universität Bielefeld und die Helene Kreysa instanziiert, weiterhin an der Humboldt-Universität Zu Berlin verwendet werden. Alle Autoren trugen zu den Inhalt durch Eingabe über Methoden und Ergebnisse im einen oder anderen Form. Camilo Rodríguez Ronderos und Pia Knoeferle koordiniert die Beiträge der Autoren und in zwei Iterationen wesentlich überarbeitet den ersten Entwurf. Ernesto Guerra produziert Abbildungen 2 - 4 am Eingang von Katja Münster, Alba Rodríguez und Ernesto Guerra. Helene Kreysa vorausgesetzt, Abbildung 1 und Pia Knoeferle es aktualisiert. Teile der gemeldeten Ergebnisse wurden in den Proceedings of Annual Meeting der Cognitive Science Societyveröffentlicht.
Materialien
| Name | Company | Catalog Number | Comments |
| Desktop mounted eye-tracker including head/chin rest | SR Research Ltd. | EyeLink 1000 plus | http://www.sr-research.com/eyelink1000plus.html |
| Software for the design and execution of an eye-tracking experiment | SR Research Ltd. | Experiment Builder | http://www.sr-research.com/eb.html |
Referenzen
- Tanenhaus, M. K., Spivey-Knowlton, M. J., Eberhard, K. M., Sedivy, J. C. Integration of visual and linguistic information in spoken language comprehension. Science. 268 (5217), 1632-1634 (1995).
- Cooper, R. M. The control of eye fixation by the meaning of spoken language: A new methodology for the real-time investigation of speech perception, memory, and language processing. Cognitive Psychology. 6 (1), 84-107 (1974).
- Knoeferle, P., Guerra, E. What is non-linguistic context? A view from language comprehension. In What is a Context? Linguistic Approaches and Challenges. Finkbeiner, R., Meibauer, J., Schumacher, P. B. , John Benjamins Publishing Company. Amsterdam, The Netherlands. 129-150 (2012).
- Knoeferle, P., Guerra, E. Visually situated language comprehension. Language and Linguistics Compass. 10 (2), 66-82 (2016).
- Just, M. A., Carpenter, P. A. A theory of reading: From eye fixations to comprehension. Psychological Review. 87 (4), 329-354 (1980).
- Deubel, H., Schneider, W. X. Saccade target selection and object recognition: Evidence for a common attentional mechanism. Vision Research. 36 (12), 1827-1837 (1996).
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychological Bulletin. 124 (3), 372-422 (1998).
- Sedivy, J. C., Tanenhaus, M. K., Chambers, C. G., Carlson, G. N. Achieving incremental semantic interpretation through contextual representation. Cognition. 71 (2), 109-147 (1999).
- Kamide, Y., Scheepers, C., Altmann, G. T. Integration of syntactic and semantic information in predictive processing: Cross-linguistic evidence from German and English. Journal of Psycholinguistic Research. 32 (1), 37-55 (2003).
- Allopenna, P. D., Magnuson, J. S., Tanenhaus, M. K. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language. 38 (4), 419-439 (1998).
- Tanenhaus, M. K., Magnuson, J. S., Dahan, D., Chambers, C. Eye movements and lexical access in spoken-language comprehension: Evaluating a linking hypothesis between fixations and linguistic processing. Journal of Psycholinguistic Research. 29 (6), 557-580 (2000).
- Arnold, J. E., Eisenband, J. G., Brown-Schmidt, S., Trueswell, J. C. The rapid use of gender information: Evidence of the time course of pronoun resolution from eyetracking. Cognition. 76 (1), B13-B26 (2000).
- Chambers, C. G., Tanenhaus, M. K., Magnuson, J. S. Actions and affordances in syntactic ambiguity resolution. Journal of Experimental Psychology: Learning, Memory, and Cognition. 30 (3), 687-696 (2004).
- Spivey, M. J., Tanenhaus, M. K., Eberhard, K. M., Sedivy, J. C. Eye movements and spoken language comprehension: Effects of visual context on syntactic ambiguity resolution. Cognitive Psychology. 45 (4), 447-481 (2002).
- Huang, Y. T., Snedeker, J. Online interpretation of scalar quantifiers: Insight into the semantics-pragmatics interface. Cognitive Psychology. 58 (3), 376-415 (2009).
- Trueswell, J. C., Sekerina, I., Hill, N. M., Logrip, M. L. The kindergarten-path effect: studying online sentence processing in young children. Cognition. 73 (2), 89-134 (1999).
- Knoeferle, P., Crocker, M. W., Scheepers, C., Pickering, M. J. The influence of the immediate visual context on incremental thematic role-assignment: evidence from eye movements in depicted events. Cognition. 95 (1), 95-127 (2005).
- Knoeferle, P., Crocker, M. W. Incremental Effects of Mismatch during Picture-Sentence Integration: Evidence from Eye-tracking. Proceedings of the 26th Annual Conference of the Cognitive Science Society. , Stresa, Italy. 1166-1171 (2005).
- Kluth, T., Burigo, M., Schultheis, H., Knoeferle, P. The role of the center-of-mass in evaluating spatial language. Proceedings of the 13th Biannual Conference of the German Society for Cognitive Science. , Bremen, Germany. 11-14 (2016).
- Burigo, M., Knoeferle, P. Visual attention during spatial language comprehension. PLoS One. 10 (1), (2015).
- Münster, K., Carminati, M. N., Knoeferle, P. How Do Static and Dynamic Emotional Faces Prime Incremental Semantic Interpretation? Comparing Older and Younger Adults. Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 2675-2680 (2014).
- Kroeger, J. M., Münster, K., Knoeferle, P. Do Prosody and Case Marking influence Thematic Role Assignment in Ambiguous Action Scenes? Proceedings of the 39th Annual Meeting of the Cognitive Science Society. , London, UK. 2463-2468 (2017).
- Knoeferle, P., Crocker, M. W. The influence of recent scene events on spoken comprehension: evidence from eye movements. Journal of Memory and Language. 57 (4), 519-543 (2007).
- Knoeferle, P., Carminati, M. N., Abashidze, D., Essig, K. Preferential inspection of recent real-world events over future events: evidence from eye tracking during spoken sentence comprehension. Frontiers in Psychology. 2, 376(2011).
- Abashidze, D., Knoeferle, P., Carminati, M. N. How robust is the recent-event preference? Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 92-97 (2014).
- Rodríguez, A., Burigo, M., Knoeferle, P. Visual constraints modulate stereotypical predictability of agents during situated language comprehension. Proceedings of the 38th Annual Meeting of the Cognitive Science Society. , Philadelphia, USA. 580-585 (2016).
- Zhang, L., Knoeferle, P. Visual Context Effects on Thematic Role Assignment in Children versus Adults: Evidence from Eye Tracking in German. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 2593-2598 (2012).
- Zhang, L., Kornbluth, L., Knoeferle, P. The role of recent versus future events in children's comprehension of referentially ambiguous sentences: Evidence from eye tracking. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 1227-1232 (2012).
- Münster, K., Knoeferle, P. Situated language processing across the lifespan: A review. International Journal of English Linguistics. 7 (1), 1-13 (2017).
- Özge, D., et al. Predictive Use of German Case Markers in German Children. Proceedings of the 40th Annual Boston University Conference on Language Development. , Somerville, USA. 291-303 (2016).
- Weber, A., Grice, M., Crocker, M. W. The role of prosody in the interpretation of structural ambiguities: A study of anticipatory eye movements. Cognition. 99 (2), B63-B72 (2006).
- Guerra, E., Knoeferle, P. Effects of object distance on incremental semantic interpretation: similarity is closeness. Cognition. 133 (3), 535-552 (2014).
- Kreysa, H., Knoeferle, P., Nunnemann, E. Effects of speaker gaze versus depicted actions on visual attention during sentence comprehension. Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 2513-2518 (2014).
- Abashidze, D., Knoeferle, P., Carminati, M. N. Eye-tracking situated language comprehension: Immediate actor gaze versus recent action events. Proceedings of the 37th Annual Meeting of the Cognitive Science Society. , Pasadena, USA. 31-36 (2015).
- Crovitz, H. F., Zener, K. A Group-Test for Assessing Hand- and Eye-Dominance. The American Journal of Psychology. 75 (2), 271-276 (1962).
- Ehrenstein, W. H., Arnold-Schulz-Gahmen, B. E., Jaschinski, W. Eye preference within the context of binocular functions. Graefe's Arch Clin Exp Ophthalmol. 243, 926(2005).
- Münster, K., Carminati, M. N., Knoeferle, P. The Effect of Facial Emotion and Action Depiction on Situated Language Processing. Proceedings of the 37th Annual Meeting of the Cognitive Science Society. , Pasadena, USA. 1673-1678 (2015).
- Lakoff, G., Johnson, M. Metaphors We Live By. , University of Chicago Press. Chicago, USA. (1980).
- Guerra, E., Knoeferle, P. Visually perceived spatial distance affects the interpretation of linguistically mediated social meaning during online language comprehension: An eye tracking reading study. Journal of Memory and Language. 92, 43-56 (2017).
- Kreysa, H., Knoeferle, P. Effects of speaker gaze on spoken language comprehension: task matters. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 1557-1562 (2012).
- Knoeferle, P. Language comprehension in rich non-linguistic contexts: Combining eye tracking and event-related brain potentials. Towards a cognitive neuroscience of natural language use. Roel, W. , Cambridge University Press. Cambridge, UK. 77-100 (2015).
- Raney, G. E., Campell, S. J., Bovee, J. C. Using eye movements to evaluate cognitive processes involved in text comprehension. Journal of Visualized Experiments. (83), e50780(2014).
- Knoeferle, P., Habets, B., Crocker, M. W., Muente, T. F. Visual scenes trigger immediate syntactic reanalysis: evidence from ERPs during situated spoken comprehension. Cerebral Cortex. 18 (4), 789-795 (2008).
- Dimigen, O., Sommer, W., Hohlfeld, A., Jacobs, A. M., Kliegl, R. Coregistration of eye movements and EEG in natural reading: Analyses and review. Journal of Experimental Psychology: General. 140 (4), 552-572 (2011).
- Knoeferle, P., Kreysa, H. Can speaker gaze modulate syntactic structuring and thematic role assignment during spoken sentence comprehension? Frontiers in Psychology. 3, 538(2012).
- Chambers, C. G., Cooke, H. Lexical competition during second-language listening: Sentence context, but not proficiency, constrains interference from the native lexicon. Journal of Experimental Psychology: Learning, Memory, and Cognition. 35 (4), 1029(2009).
- Duyck, W., Van Assche, E., Drieghe, D., Hartsuiker, R. J. Visual word recognition by bilinguals in a sentence context: Evidence for nonselective lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition. 33 (4), 663(2007).
- Weber, A., Cutler, A. Lexical competition in non-native spoken-word recognition. Journal of Memory and Language. 50 (1), 1-25 (2004).
- Verhallen, M. J., Bus, A. Young second language learners' visual attention to illustrations in storybooks. Journal of Early Childhood Literacy. 11 (4), 480-500 (2011).
- Robinson, P., Mackey, A., Gass, S. M., Schmidt, R. Attention and awareness in second language acquisition. The Routledge Handbook of Second Language Acquisition. , 247-267 (2012).
- Tomlin, R. S., Villa, V. Attention in cognitive science and second language acquisition. Studies in Second Language Acquisition. 16 (2), 183-203 (1994).
Nachdrucke und Genehmigungen
Genehmigung beantragen, um den Text oder die Abbildungen dieses JoVE-Artikels zu verwenden
Genehmigung beantragenThis article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. Alle Rechte vorbehalten