
Method Article
Eye Tracking durante la comprensione del linguaggio visivo situato: Flessibilità e limitazioni a scoprire gli effetti di contesto visivo
In questo articolo
Riepilogo
Il presente articolo esamina una metodologia di eye tracking per gli studi sulla comprensione del linguaggio. Per ottenere dati affidabili, passaggi chiave del protocollo devono essere seguiti. Tra questi vi sono il corretto set-up dell'inseguitore dell'occhio (per esempio, garantire la buona qualità delle immagini dell'occhio e testa) ed una calibrazione accurata.
Abstract
Il presente lavoro è una descrizione e una valutazione di una metodologia progettata per quantificare i diversi aspetti dell'interazione tra elaborazione del linguaggio e la percezione del mondo visivo. La registrazione dei modelli di sguardo fisso dell'occhio ha fornito buone prove per il contributo di conoscenza linguistica/mondo di comprensione del linguaggio sia il contesto visivo. Ricerca iniziale valutato gli effetti del contesto dell'oggetto per testare le teorie di modularità nell'elaborazione linguistica. Nell'introduzione, descriviamo come le indagini successive hanno preso il ruolo del più ampio contesto visivo nella lingua di elaborazione come un argomento di ricerca a se stante, fare domande così come la nostra percezione visiva degli eventi e degli altoparlanti contribuisce alla comprensione informata dall'esperienza degli comprehenders. Tra gli aspetti esaminati del contesto visivo sono azioni, eventi, un altoparlante lo sguardo ed espressioni facciali emotive, come pure le configurazioni oggetto spaziale. A seguito di una panoramica delle sue varie applicazioni e il metodo di eye tracking, vi elenchiamo i passaggi chiave della metodologia nel protocollo, che illustrano come utilizzare correttamente per studiare la comprensione del linguaggio visivo situato. Una sezione finale presenta tre insiemi di risultati rappresentativi e illustra i vantaggi ei limiti di rilevamento di occhio per indagare l'interazione tra la percezione della comprensione mondiale e linguaggio visual.
Introduzione
Ricerca psicolinguistica ha evidenziato l'importanza di analisi di movimento di occhio nella comprensione dei processi implicati nella comprensione del linguaggio. Il nucleo di inferenza di processi di comprensione del record di sguardo è un'ipotesi che collega cognizione a occhio movimenti5. Ci sono tre principali tipi di movimenti oculari: saccadi, riflesso vestibulo-oculare movimenti e movimenti regolari di inseguimento. Saccadi sono movimenti balistici e veloci che accadono principalmente inconsciamente e sono stati associati in modo affidabile con turni in attenzione6. I momenti di stabilità relativo sguardo tra saccadi, noto come fissazioni, sono considerati attenzione visiva attuale indice. Il locus delle fissazioni e la loro durata in relazione ai processi cognitivi di misura è noto come il 'metodo di eye-tracking'. Prime implementazioni di questo metodo è servito per esaminare la comprensione della lettura in contesti strettamente linguistici (cfr. Rayner7 per una recensione). In tale approccio, la durata di ispezionare una regione di parola o frase è associata a difficoltà di elaborazione. Eye-tracking, tuttavia, è anche stato applicato per esaminare la comprensione del linguaggio parlato durante l'ispezione di oggetti del mondo (o su un computer visualizzare2). In questa versione di eye tracking 'mondo visivo', l'ispezione di oggetti è guidato dalla lingua. Quando il comprehenders sente la zebra, per esempio, l'ispezione di una zebra sullo schermo è preso per riflettere che pensano circa l'animale. In che cosa è conosciuto come il paradigma del mondo visivo, sguardo degli occhi di un comprehender è preso per riflettere la comprensione del linguaggio parlato e l'attivazione di conoscenze associate (ad es., gli ascoltatori anche ispezionare la zebra quando sentono al pascolo, che indica un azione eseguita dalla zebra)2. Tali ispezioni suggeriscono un collegamento sistematico tra linguaggio-mondo relazioni e occhio movimenti2. Un modo comune per quantificare questo link è calcolando la percentuale di sguardi tra cui diverse regioni pre-determinate su uno schermo. Questo permette ai ricercatori di confrontare direttamente (attraverso condizioni, dai partecipanti ed elementi) la quantità di attenzione a oggetti diversi in un momento particolare e come questi valori cambiano in risoluzione di millisecondo.
Ricerca in psicolinguistica ha sfruttato il tracciamento dell'occhio in mondi visivi per stuzzicare apart concorrenti ipotesi teoriche per quanto riguarda l'architettura della mente1. Fissazioni occhio sugli oggetti raffigurati hanno, inoltre, ha rivelato che comprehenders può — assumendo un contesto linguistico sufficientemente restrittivo — eseguire incrementale interpretazione semantica8 e anche sviluppare aspettative sui prossimi caratteri 9. tali dati lo sguardo dell'occhio inoltre hanno fatto luce su una serie di ulteriori processi di comprensione, come ambiguità lessicale risoluzione10,11, pronome risoluzione12, il chiarimento delle ambiguità di ruolo strutturale e tematico assegnazione per mezzo di informazioni nel contesto visivo13,14,16e pragmatico processi15, tra molti altri4. Chiaramente, i movimenti di occhio agli oggetti durante la comprensione del linguaggio possono essere informativi dei processi implicati.
Il metodo di eye tracking è invasivo e può essere utilizzato con i neonati, gli utenti di lingua giovani e anziani. Un vantaggio chiave è che, a differenza delle risposte punctate per sonde o pressioni di tasto di risposta in attività di verifica, esso fornisce le comprensioni nel tempo in una risoluzione di millisecondo in quanto lingua Guida l'attenzione e come il contesto visivo (sotto forma di oggetti, azioni, eventi, un altoparlante lo sguardo ed espressioni facciali emotive, come pure le configurazioni oggetto spaziale) contribuisce all'elaborazione del linguaggio. La continuità della misura durante la comprensione di frase si integra bene con altre misure di post- frase e post-esperimento, come da evidente foto/video-frase verifica, domande di comprensione e attività di richiamo della memoria. Risposte evidenti in queste mansioni possono arricchire l'interpretazione del record lo sguardo dell'occhio fornendo spaccato l'esito del processo di comprensione, memoria e apprendimento2. Combinando il tracciamento dell'occhio con queste altre attività ha scoperto fino a che punto diversi aspetti del contesto del visual modulano l'attenzione visiva e la comprensione (immediata, come pure in ritardo) in tutta la durata della vita.
La presentazione del linguaggio (parlato o scritto) e scene possono essere simultanea o sequenziale. Per esempio, Knoeferle e collaboratori17 ha presentato la scena 1.000 ms prima la frase parlata, e rimase presente durante la comprensione. Hanno riferito prove che clipart rappresentazioni di eventi azione contribuiscono alla risoluzione di ambiguità strutturali locali in tedesco soggetto-verbo-oggetto (SVO) confrontata con frasi oggetto-verbo-oggetto (OVS). Knoeferle e Crocker18 ha presentato una scena di clipart prima una frase scritta e testato l'integrazione incrementale di clipart eventi durante la comprensione della frase. Essi hanno osservato gli effetti incrementali congruenza, che significa che i tempi di lettura dei partecipanti dei costituenti di frase erano più lunghi quando questi non corrispondono (vs abbinati) l'evento raffigurato nella scena precedente. In un'altra variante di presentazione dello stimolo, i partecipanti prima leggere una frase che descrive un rapporto spaziale e poi visto una scena di una particolare disposizione spaziale che coinvolgono oggetto disegni linea19. Questo studio ha valutato le previsioni dei modelli computazionali linguaggio spaziale chiedendo ai partecipanti di votare la vestibilità della frase data alla scena, con i movimenti dell'occhio viene registrati durante l'interrogatorio di scena. Modelli di sguardo dei partecipanti sono stati modulati dalla forma dell'oggetto che sono stati confrontati con — parzialmente confermando le previsioni del modello e fornire i dati per il perfezionamento del modello.
Mentre molti studi hanno utilizzato clipart raffigurazioni17,18,19,20,21,22,23, è anche possibile combinare reali oggetti, video di questi oggetti, o di fotografie statiche con lingua parlata1,21,24,25,26,46. Knoeferle e colleghi hanno usato un mondo reale impostazione24 e Abashidze e colleghi hanno usato un formato di presentazione videoregistrato per esaminare gli eventi azione ed effetti tesa25. Variando il contenuto preciso delle scene (ad es., raffiguranti azioni o non)22,27,38 è possibile e può anche rivelare effetti di contesto visivo. Uno studio relativo da Rodríguez e collaboratori26 studiato l'influenza di spunti videoregistrato genere visual sulla comprensione del successivamente presentato frasi parlate. I partecipanti guardato i video visualizzati sia maschile o femminile mani eseguendo un'azione stereotypically legate al genere. Poi, hanno sentito una frase neanche di un evento di azione lo stereotipo maschile o femminile durante l'ispezione simultaneamente un display che mostra due fotografie fianco a fianco, tra l'altro di una donna e un uomo. Questo ricco ambiente visual e linguistico ammessi gli autori a prendere in giro a parte gli effetti della lingua-mediata stereotypical conoscenza sulla comprensione dagli effetti dei suggerimenti di genere visivamente presentato (a mano).
Un'applicazione ulteriore di questo paradigma ha preso di mira cambiamenti inerenti allo sviluppo nell'elaborazione linguistica. I movimenti di occhio agli oggetti durante la comprensione del linguaggio parlato hanno rivelato gli effetti degli eventi raffigurati in 4 - 5 - anni27,28 e in adulti più anziani29 in tempo reale, ma un po' in ritardo rispetto ai giovani adulti. Kröger e collaboratori22 ha esaminato gli effetti di spunti prosodiche e caso marcatura all'interno di un esperimento e rispetto questi attraverso esperimenti negli adulti e nei bambini. I partecipanti ispezionato una scena ambigua azione-evento mentre si ascolta una frase di tedesco relative al caso-contrassegnato in modo non ambiguo. Movimenti oculari ha rivelato che i modelli distinti prosodici ha aiutato né gli adulti né il 4 - o 5-year-olds quando evitare ambiguità tra chi-fa-cosa-a-chi. Caso di frase iniziale marcatura, influenzato tuttavia, degli adulti, ma non i movimenti di occhio dei bambini. Ciò suggerisce che la comprensione di 5-anno-olds della marcatura di caso non è sufficientemente robusto per consentire l'assegnazione di ruolo tematico (Vedi lo studio di Özge e collaboratori30), almeno non quando eventi action non risolvere l'ambiguità tematiche ruolo rapporti. Questi risultati sono interessanti, dato che sono in contrasto con i precedenti risultati di effetti prosodici su ruolo tematico assegnazione31. Kröger e collaboratori22 proposto che il contesto visivo (più o meno favorevole) è responsabile per i risultati contrastanti. Nella misura in cui queste interpretazioni valgono, essi sottolineano il ruolo del contesto nella comprensione del linguaggio in tutta la durata della vita.
Il metodo di eye tracking combina bene con le misure da foto (o video) frase verifica attività18,20,26, immagine-verifica attività32, corpus studia24, Voto attività19, o richiamo post-sperimentale attività25,33. Abashidze e collaboratori34 e Kreysa e collaboratori33 studiato l'interazione dello sguardo fisso altoparlante e mondo reale azione video34 e altoparlante lo sguardo e azione raffigurazioni33, rispettivamente, come spunti per contenuto di prossima frase. Combinando l'allineamento di sguardo fisso dell'occhio in una scena durante la comprensione del linguaggio con un compito di memoria post-sperimentale, hanno acquisito una migliore comprensione del modo in cui la percezione degli ascoltatori dello sguardo fisso di un altoparlante e le azioni raffigurate interagire e colpiscono sia elaborazione del linguaggio immediato e richiamo della memoria. I risultati hanno rivelato il contributo distinto di azioni contro altoparlante lo sguardo a processi di richiamo di comprensione in tempo reale contro post-esperimento memoria.
Mentre il metodo di eye tracking può essere impiegato con grande flessibilità, talune norme sono la chiave. Il seguente protocollo riassume una routine generalizzata che può essere registrata per diversi tipi di domande di ricerca secondo le specifiche esigenze dei ricercatori. Questo protocollo è una procedura standardizzata, un impiego in laboratorio psicolinguistica presso la Humboldt-Universität zu Berlin, così come nella lingua e nella cognizione laboratorio presso il Cognitive interazione tecnologia Excellence Cluster (CITEC) presso ex Università di Bielefeld. Il protocollo descrive un desktop e un'impostazione remota. Quest'ultimo è consigliato per l'uso negli studi con bambini o anziani. Tutti gli esperimenti citati nei Risultati rappresentante utilizzano un dispositivo di tracking di occhio che ha una frequenza di campionamento di 1.000 Hz e viene utilizzato insieme a un testa stabilizzatore, un PC per testare i partecipanti (Display PC) e un PC per l'esperimento di monitoraggio e la movimenti di occhio dei partecipanti (PC Host). La differenza principale di questo dispositivo al suo predecessore è che permette il tracciamento dell'occhio binoculare. Il protocollo è destinato ad essere sufficientemente generali per l'utilizzo con altri dispositivi di eye tracking che includono uno stabilizzatore testa e fare uso di un PC dual installazione (Host + Display). Tuttavia, è importante tenere a mente che altre configurazioni probabilmente avrà diversi metodi per la gestione di problemi quali errori di calibrazione o perdita di pista, in cui caso lo sperimentatore deve fare riferimento per l'utente manuale del loro dispositivo specifico.
Protocollo
Questo protocollo segue le linee guida di etica dell'istituzione dove i dati sono stati raccolti, vale a dire, l'interazione cognitiva eccellenza tecnologia Cluster (CITEC) dell'Università di Bielefeld e Humboldt-Universität zu Berlin. Gli esperimenti condotti all'Università di Bielefeld sono stati approvati singolarmente dal comitato etico dell'Università di Bielefeld. Il laboratorio di psicolinguistica presso la Humboldt-Universität zu Berlin dispone di un protocollo di etica di laboratorio che è stato approvato dal comitato etico della Deutsche Gesellschaft für Sprachwissenschaft, società tedesca di linguistica (DGfS).
1. configurazione desktop
Nota: Di seguito sono i passaggi chiave in un esperimento di eye tracking.
- Preparazione dello strumento
- Accendere la fotocamera di eye tracking e il PC Host (vedere la Figura 1 per un'illustrazione della raccolta dati in laboratorio e il programma di installazione di pre-elaborazione).
- Avviare il software di eye tracking.
- Attivare la visualizzazione PC. Aprire la cartella che contiene gli esperimenti.
- Avviare la versione 'distribuita' con un estensione di .exe facendo doppio clic su esso.
- A seconda della configurazione, potrebbe apparire un prompt dei comandi per la selezione di un elenco sperimentale, che è in genere un file delimitato da tabulazioni.csv/.txt che contiene le condizioni, i nomi dei file audio, frasi scritte o immagini che un partecipante sarà esposti a. Selezionare l'elenco, e il programma verrà avviato. Nome del file di uscita in cui verranno archiviati i risultati.
Nota: Il file di output viene salvato sul PC di visualizzazione e un back-up viene salvato sul PC Host. - Lasciare aperta la prima schermata dell'esperimento (l'introduzione o la schermata di benvenuto).
- Rimuovere la copertura protettiva dalla telecamera eye tracking.
- Per scopi igienici, mettete un fazzoletto di carta sul supporto mento.
- Opzionale: Preparare un pad di risposta e/o una tastiera come richiesto dall'esperimento.
- Facoltativo: Se presentare stimoli uditivi, regolare il volume degli altoparlanti e testarli prima di eseguire l'esperimento. In alternativa, verificare la funzionalità delle cuffie per essere utilizzato dal partecipante.
- Preparare i moduli necessari per essere firmato dal partecipante.
- Regolare l'intensità luminosa in laboratorio al fine di avere una stanza poco illuminata con una luminanza costante per tutta la durata del processo di raccolta dati.
- Preparazione per i partecipanti
- Dopo che i partecipanti sono arrivati, presentatevi.
- Un non disturbare segno sulla porta del laboratorio.
- Chiedere al partecipante di prendere un posto a sedere.
- Guidare il partecipante attraverso il foglio informativo e il necessario consenso e forme demografiche.
- Lasciate che il partecipante leggere e firmare il modulo di consenso.
- Spiegare brevemente gli aspetti generali dell'esperimento e la sua durata. Non forniscono troppe informazioni prima dell'esperimento, poiché questo potrebbe influenzare il comportamento di sguardo del partecipante e i dati risultanti.
- Fornire istruzioni scritte e dare al partecipante la possibilità di porre domande.
- Spiegare brevemente la funzione dell'inseguitore dell'occhio.
- Se necessario, il compito di chiarire e precisare qualsiasi bottoni/tasti che dovrà essere premuto durante l'esperimento.
- Spiegare come il resto di mento è destinato per minimizzare il movimento della testa durante l'esperimento. Ricordare che il dispositivo funzioni meglio se il partecipante consente di evitare eventuali movimenti.
- Configurare il tracker di occhio
- Preparare il partecipante per l'esperimento: chiedere loro di sedersi al tavolo e posizionare il mento sul resto di mento. Chiedere loro di appoggiarsi sulla loro fronte contro il poggiatesta.
- Chiedere al partecipante di regolare l'altezza e la posizione della sedia, se necessario: il partecipante deve sentirsi a proprio agio con il mento sulla loro fronte contro il poggiatesta e il resto di mento.
- Spiegare che è comune per spostare accidentalmente la testa durante l'esperimento e che questo dovrebbe essere evitato. Spiegare che la postura della testa potrebbe dover essere corretta durante l'esperimento.
- Se l'esperimento richiede una pressione del pulsante (ad esempio, tramite il pad di risposta), indicare al partecipante di lasciare le dita che riposa sui pulsanti da premere e per evitare di guardare il pad di risposta quando si preme un pulsante.
- Chiedere al partecipante di leggere la schermata di benvenuto/introduzione.
- Sedersi davanti al PC Host. Se lo schermo non è già su installazione della telecamera, fare clic su configurazione della telecamera per visualizzare la schermata di destra. Se il coperchio di protezione è stato rimosso dalla lente della fotocamera e il partecipante sia posizionato correttamente sul resto di mento, lo schermo dovrebbe mostrare tre immagini degli occhi del partecipante: un'immagine più grande nella parte superiore e due più piccoli nella parte inferiore a sinistra e a destra. Queste immagini più piccole mostrano un occhio ciascuna, corrispondente a sinistra e l'occhio destro.
- Selezionare l'occhio deve essere rilevata. Si è soliti tenere traccia occhio dominante del partecipante. Se il partecipante non sa che l'occhio è dominante, condurre un test di dominanza oculare (punto 1.3.8).
- Determinare la dominanza oculare. Chiedere al partecipante di allungare un braccio e allineare il pollice con un oggetto distante con entrambi gli occhi aperti. Chiedere al partecipante di alternativo chiudendo l'occhio sinistro o destro. L'occhio dominante è quello per il quale il pollice rimane allineato con l'oggetto quando l'occhio è aperto35,36.
- Clicca sull'immagine | Display pc (o premere invio) e le immagini descritte nel passaggio 1.3.6 apparirà anche su schermo di visualizzazione del partecipante, ma solo uno alla volta.
- Premere la freccia sinistra/destra sulla tastiera del computer o lo sperimentatore o del partecipante per commutare tra l'immagine più piccola e più grande dell'occhio. Concentrarsi sull'immagine più piccola (l'occhio).
- Premere A (finestra occhio Align) sulla tastiera al fine di centrare la casella limiti di ricerca relativa alla posizione della pupilla. Quindi, un quadrato rosso intorno all'occhio dovrebbe apparire con un cerchio turchese [il 'riflesso cornea', (cr)] nella parte inferiore della pupilla. La pupilla stessa dovrebbe essere blu.
- Assicurarsi che le due croci ('Croce') vengano visualizzati sullo schermo — uno al centro della pupilla e uno nel centro del riflesso cornea. La scatola rossa e le due croci significa che l'inseguitore dell'occhio sta rilevando la pupilla e il cr.
Nota: Se la casella rossa o le croci sono assenti, l'occhio non viene rilevata — se questo accade, nessun allievo apparirà sul computer dello sperimentatore. - Regolare messa a fuoco della fotocamera ruotando manualmente la messa a fuoco. Fare attenzione a non toccare la parte frontale della lente. Ruotare l'obiettivo fino a quando non viene raggiunto il punto di messa a fuoco migliore.
Nota: Il miglior punto di messa a fuoco viene raggiunta quando il cerchio turchese (il riflesso cornea) è il più piccolo possibile (cioè, quando questo cerchio è a fuoco). - Impostare la soglia di pupilla. Assicurarsi che solo l'immagine della pupilla è blu (ad es., le ciglia non dovrebbero essere blue) sul PC Host. Inoltre, assicurarsi che l'alunno intero (non solo la sua parte centrale) è blu. Solo preoccuparti di cosa c'è dentro il quadrato rosso.
- Premere A. Questo automaticamente imposta la soglia di pupilla. Se la pupilla con precisione non viene visualizzata in blu, regolare la soglia manualmente utilizzando il tasto UP per aumentare e il tasto giù per diminuire la quantità di blu parte della superficie dell'immagine.
Nota: Mascara (che è solitamente nero, come la pupilla) può interferire con l'impostazione della soglia — l'inseguitore dell'occhio potrebbe prendere la ciglia scure per la pupilla. In questo caso, chiedere al partecipante di rimuovere il loro trucco, fornendo loro trucco tessuti remover. - Impostare la soglia di cr. Se A è stato premuto nel passaggio 1.3.15, la soglia di cr dovrebbe automaticamente impostati.
Nota: I valori numerici per tutte le impostazioni di soglia dovrebbero essere visibili. Se viene visualizzato un punto interrogativo in nessuno di essi, c'era un problema in uno dei passaggi precedenti e le soglie devono essere impostate manualmente.
- Calibrare il tracker di occhio
Nota: Controllare se il tracker di occhio costantemente può identificare la posizione dell'occhio quando il partecipante Guarda altre parti dello schermo.- Chiedere al partecipante di guardare ai quattro angoli dello schermo uno alla volta, mentre la finestra di setup della macchina fotografica è in vista. Guarda con attenzione per eventuali riflessi irregolari (questi verranno visualizzati come turchese 'blob' sullo schermo) che interferiscono con il riflesso cornea quando lo sguardo dell'occhio è rivolto all'angolo.
- Chiedere al partecipante di guardare al centro dello schermo e quindi indirizzare lo sguardo verso l'angolo problematico se il riquadro rosso intorno all'occhio e uno dei puntatori a croce non è visibile in qualsiasi punto durante il passaggio 1.4.1. Questo vi aiuterà a determinare l'origine del problema.
- Ri-regolare la posizione della testa del partecipante e verifica se questo produce alcun miglioramento. Se necessario, ripetere questo passaggio. Se il dispositivo è ancora in grado di monitorare con precisione lo sguardo del partecipante dopo diversi tentativi, interrompere l'esperimento.
- Informare il partecipante che sarà calibrato l'inseguitore dell'occhio e che stanno andando a vedere un cerchio nero (con un piccolo puntino grigio) trasferirsi in diverse parti dello schermo. Istruire il partecipante di fissarsi il cerchio fino a quando non si muove in una nuova posizione. Istruire il partecipante per evitare di sforzare gli occhi e mettere a fuoco il piccolo puntino grigio all'interno del cerchio nero per ottenere risultati ottimali.
- Raccontare il partecipante che è importante per mantenere ancora e non per cercare di anticipare la posizione del cerchio successivo durante la calibrazione. Indicare loro di seguire i cerchi con i loro occhi e non la testa. Fare clic su Calibra per avviare il processo di calibrazione. Normalmente, una procedura di calibrazione del punto 9 è utilizzata in cui il cerchio nero si muove a nove posizioni in modo seriale.
- Per una calibrazione automatica, è necessario premere invio dopo il partecipante ha accuratamente fissato il primo punto al centro dello schermo. Per calibrazione manuale (ad esempio, quando ci sono problemi di rilevamento del partecipante dell'occhio o quando si occupano di partecipante speciale gruppi come i bambini), accettare ogni fissazione premendo invio (o facendo clic su Accept fissazione/ Premere la barra spaziatrice).
Nota: Al termine del processo di calibrazione, un modello quasi rettangolare sullo schermo dello sperimentatore deve essere visibile. Questo rappresenta i modelli di sguardo fisso dell'occhio del partecipante. Inoltre, i risultati di una buona taratura dovrebbero essere evidenziati in verde. Se non lo sono, ripetere la procedura di calibrazione (cioè, fare clic su calibrazione). - Convalidare i risultati. Dica al partecipante di passare attraverso la stessa procedura (guardando puntini) al fine di convalidare i risultati del processo di calibrazione. Ricordare loro di guardare il punto e di essere ancora.
Nota: Il processo di convalida è simile a quella di taratura ed entrambi i risultati vengono confrontati dal software eye tracking per garantire che l'occhio è registrato con precisione. - Fare clic su convalidare.
- Accettare ogni fissazione premendo invio (oppure cliccando accettarefissazione/premere la barra spaziatrice).
- Dopo la convalida, i risultati verranno visualizzati sullo schermo dello sperimentatore. Prestare particolare attenzione alle misure di due errore, l'errore medio (ad es., 0,23 °) e l'errore massimo (ad es., 0,70 °). Questi rappresentano i gradi a cui l'immagine rilevata si discosta dalla posizione di sguardo effettivo di un partecipante.
- Quando si utilizza un paradigma del mondo visivo, tenere l'errore medio (il primo numero) sotto 0,5 ° e l'errore massimo (il secondo numero) sotto 1°.
- Se i valori di errore sono sopra la soglia, chiedere al partecipante di regolare nuovamente la posizione della loro testa e riavviare la procedura di calibrazione. Se non si osserva alcun miglioramento, interrompere l'esperimento.
Nota: È comune osservare gli errori di calibratura alta quando il partecipante indossa lenti a contatto. Il partecipante deve essere chiesto in anticipo per portare loro occhiali da vista invece di loro lenti a contatto. - Dopo aver completato il processo di calibrazione, fare clic su Output/Record per iniziare l'esperimento. Informare il partecipante che l'esperimento inizierà ora.
- Durante l'esperimento
Nota: Durante l'esperimento (a seconda di come si programma un esperimento individuo, ma in genere prima di ogni prova sperimentale), deriva il controllo o drift corretta verrà visualizzata una schermata un punto al centro dello schermo. Il suo scopo è di segnalare l'errore calcolato fissazione per la corrente di prova e, a seconda del modello di eye tracking, di regolare automaticamente.- Durante la fase di istruzione, il partecipante è stato detto di fissare il punto centrale, ogni volta che appare. Assicurarsi che, durante ogni fase corretta del controllo/drift drift, i partecipanti sono ancora fissazione il puntino. Questo può essere fatto seguendo lo sguardo del partecipante sul PC Host, dove lo sguardo del partecipante appare come un cerchio verde commovente.
- Una volta completata la deriva check/deriva corretta, premere invio (o la barra spaziatrice) per fare il punto scompaiono e visualizzare la prova successiva.
- Determinare come affrontare se non si passa la fase di verifica della deriva secondo il modello dell'inseguitore dell'occhio utilizzato. A seconda del modello, il tracker di occhio neanche eseguirà un automatico deriva correzione regolando le coordinate di sguardo affinché corrispondano a quelle del punto centrale, o farà un rumore bip per richiedere lo sperimentatore per ri-calibrare prima di continuare il esperimento (drift check).
- Se utilizzando una correzione automatica deriva, tenere a mente che troppe correzioni di drift in prove consecutive e/o troppo grande un grado di correzione deriva saranno falsare i risultati e richiedono una ri-calibrazione del dispositivo.
- Ri-calibrazione durante l'esperimento
- È possibile calibrare nuovamente in qualsiasi momento durante l'esperimento. Durante la presentazione dello schermo Drift correzione/drift controllo , fare clic su configurazione della videocamera, quindi fare clic su Calibra. Passare attraverso i processi di calibrazione e validazione, fino a quando non viene raggiunto un valore soddisfacente, quindi fare clic su Output/record. L'esperimento verrà ripresa dal punto di uscita nella sequenza di prova.
- Dopo l'esperimento
- Fornire al partecipante un questionario per valutare se sono stati in grado di indovinare la chiave manipolazioni sperimentali. Qui, è anche importante chiedere informazioni su possibili strategie che potrebbero sono state sviluppate in tutto l'esperimento.
- Debriefing il partecipante circa lo scopo dell'esperimento. Li ringrazio per la loro partecipazione e fornire la necessaria compensazione monetaria o assegnare credito corso se applicabile.
2. installazione remoto: Regolare il programma di installazione per gli studi con i bambini e gli adulti più anziani
Nota: Questa sezione descrive solo le differenze tra un programma di installazione remota e un desktop come descritto nel passaggio 1. Punti non esplicitamente menzionato qui dovrebbero essere assunti in modo identico alla procedura descritta nel passaggio 1.
- Scambiare la lente di fotocamera standard da 35 mm eye tracking per un obiettivo da 16 mm.
- Collegare tutte le apparecchiature necessarie (Host PC, altoparlanti, tracking di occhio e computer portatile se viene utilizzato un computer portatile).
- Collocare il portatile su un supporto per notebook e il tracker di occhio di fronte ad essa (il partecipante dovrebbe essere in grado di vedere il 75% dello schermo).
- Collocare un "bersaglio adesivo" (disponibili dal produttore del tracker) sulla fronte del partecipante (sopra il sopracciglio dell'occhio destro o sulla guancica di destra se la fronte è troppo piccolo (cioè, in caso di neonati); questo sostituisce la vignetta il mento il resto della configurazione desktop e permette il tracking di occhio determinare con precisione la posizione della testa del partecipante.
- Accertarsi che il partecipante è assestato 550-600 mm distanza dalla fotocamera (la distanza dell'autoadesivo della destinazione alla fotocamera).
- Assicurarsi che le parole "grande angolo" o "vicino a occhio" non vengono visualizzati sul PC Host. Se lo fanno, vuol dire che la posizione dell'adesivo di destinazione non è l'ideale. In questo caso, regolare di nuovo l'adesivo di destinazione. Può anche significare che il fronte del partecipante è particolarmente piccola. Se questo è il caso, è possibile collocare l'adesivo sulla guancia del partecipante.
Nota: Se l'adesivo è posizionato troppo vicino all'orecchio, il messaggio di "grande angolo" rischia di apparire e l'adesivo deve essere riposizionato. - Prima di iniziare il processo di calibrazione descritto al punto 1.4, assicurarsi che il partecipante è comodamente seduti. Chiedere loro di mantenere la stessa posizione durante l'intero esperimento e spiegare che l'inseguitore dell'occhio è molto sensibile ai movimenti corporei. Insistere che tengono ferma la loro testa. Se il partecipante si muove troppo, il dispositivo emette un ronzio.
Nota: Se l'installazione di tracking occhio remoto viene utilizzato per testare le popolazioni sensibili, come i bambini o adulti più anziani, è consigliabile utilizzare una procedura di calibrazione manuale.
3. regolare l'impostazione per la lettura di studi
Nota: Quando si esamina gli effetti del contesto visivo sulla lettura, è necessario prestare particolare attenzione ai processi di calibrazione e ri-calibrazione. In contrasto con gli studi del mondo visivo, eye-tracking durante lettura richiede un grado molto più alto di precisione del dispositivo, dato la precisione necessaria per tracciare gli schemi di lettura parola per parola e lettera per lettera.
- Assicurarsi che sia l'errore medio e massimo visualizzato durante la fase di convalida rimanga sotto 0,5 °.
- Assicurarsi di utilizzare almeno una scala di 9 punti per la calibrazione. Questo assicura un monitoraggio più accurato della posizione di sguardo fisso dell'occhio, che è essenziale, date le piccole dimensioni delle aree di interesse durante la lettura.
Risultati
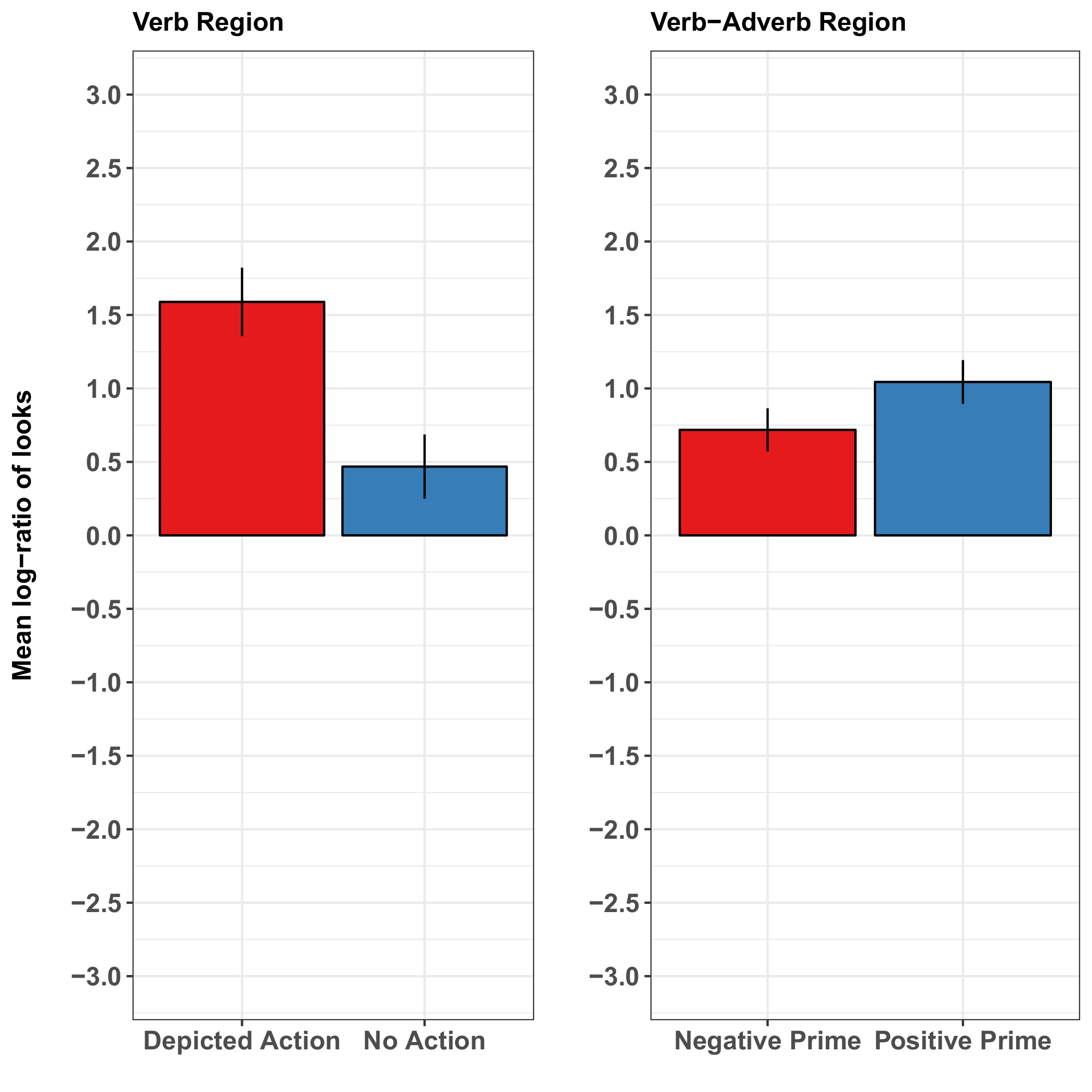
Uno studio condotto da Münster e collaboratori37 studiato l'interazione della struttura della frase, ritraeva le azioni e spunti emotivi facciale durante la comprensione del linguaggio. Questo studio è perfetto per illustrare i vantaggi e le limitazioni del metodo, poiché ha mostrato che entrambi robusto raffigurati degli effetti dell'azione e gli effetti marginali di spunti emotivi facciale sulla comprensione della frase. Gli autori hanno creato 5 s video di espressione del viso di una donna che ha cambiato da una posizione di riposo in un felice o in un'espressione triste. Crearono anche emotivamente positivamente sarebbe tedesco oggetto-verbo-avverbio-soggetto (OVAdvS) frasi del modulo ' [oggetto/pazientecaso accusativo] [verbo] [avverbio positivo] [oggetto/agentecaso nominativo].' Via l'avverbio positivo, le frasi abbinate il video 'felice' e non corrispondenti il video 'triste', permettendo in previsione di principio dell'agente (che era sempre sorridente e descritto come recitazione felicemente dall'avverbio positivo). In seguito l'altoparlante dei video, la frase è apparso con una delle due versioni di una scena di agente-paziente-distractor clipart. In una versione, l'agente è stato raffigurato come eseguendo l'azione accennato sul paziente, mentre il personaggio di distrattore eseguita un'azione diversa. L'altra versione di scena non raffigurata alcuna azione tra i caratteri. Movimenti oculari nella scena hanno rivelato gli effetti delle azioni e dell'espressione facciale dell'altoparlante sulla comprensione della frase.
La raffigurazione di azione colpite rapidamente l'attenzione visiva dei partecipanti, che significa che i partecipanti sembrava più presso l'agente rispetto al distrattore quando l'azione accennato era (vs non era) raffigurato. Questi sguardi erano anticipatori (cioè, che si verificano prima che l'agente è stato citato), suggerendo che la raffigurazione di azione chiarito l'agente prima che la frase ha fatto. L'effetto più in anticipo nella raffigurazione di azione emerse durante il verbo (cioè, il verbo ha mediato l'agente azione-associato). Al contrario, se l'oratore precedente ha sorriso o sembrava infelice non ha avuto chiaro effetto sulla previsione agente (Figura 2). Il risultato di quest'ultimo potrebbe riflettere il più tenue legame tra sorriso di un altoparlante e un avverbio sentenziale positivo relativi all'azione dell'agente raffigurati (rispetto a un riferimento di verbo-azione diretta un agente di azione-associato di mediazione). In alternativa, potrebbe essere specifico per la presentazione di attività e di stimolo: forse gli effetti emotion sarebbero state più marcati in un'attività più socialmente interattiva o in quella che presenta la comprensione di frase faccia durante (anziché prima) dell'altoparlante. Tuttavia, che presenta il volto sorridente dell'altoparlante durante la comprensione potrebbe causare i partecipanti a concentrarsi sul viso a scapito di altri contenuti di scena, forse mascheramento altrimenti osservabili effetti delle variabili manipolate (fonte: dati non pubblicati).
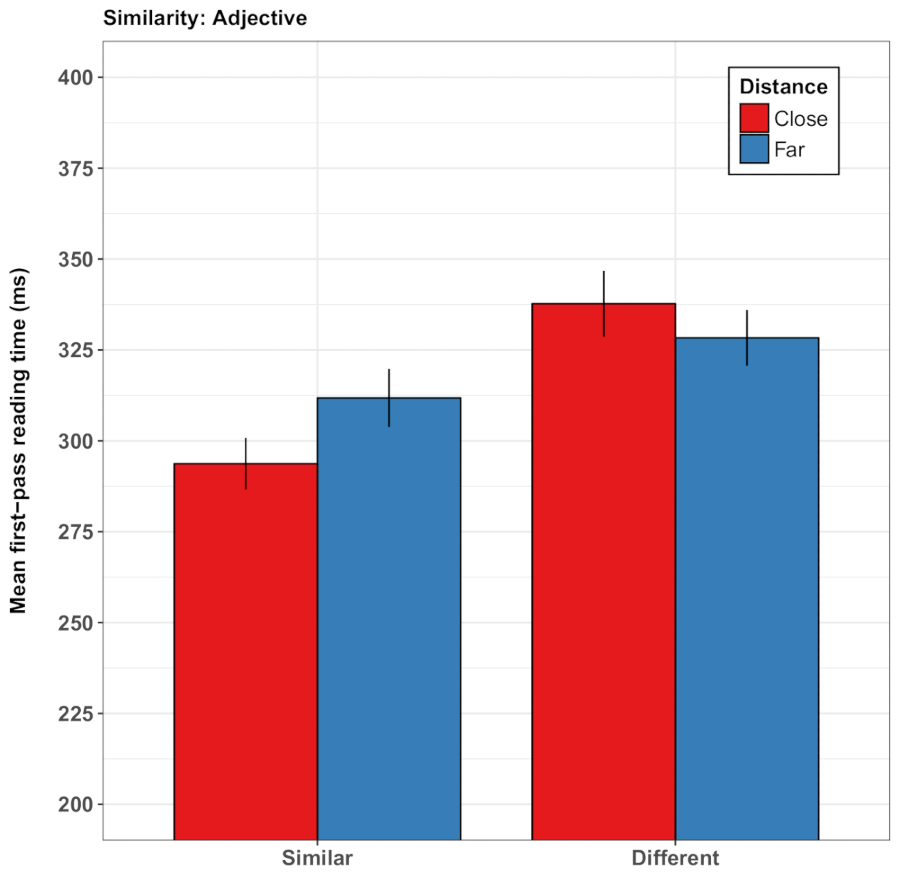
In una variante ulteriore del paradigma, Guerra e Knoeferle32 chiesto se relazioni spaziali-semantiche di lingua di mondo possono modulare la comprensione del contenuto semantico astratto durante la lettura. Guerra e Knoeferle preso in prestito l'idea dal metafora concettuale teoria38 che distanza spaziale (ad es., prossimità) motivi il significato di astratte relazioni semantiche (ad es., somiglianza). In linea con questa ipotesi, i partecipanti lettura coordinato nomi astratti più velocemente quando erano simili (vs opposto) nel significato ed era stata precedute da una vicinanza di trasporto video (vs distanza; carte da gioco mossa più vicino insieme vs. più distanti). In una seconda serie di studi39, frasi descritto l'interazione tra due persone come intimo o scortese, leader per la scoperta che i video delle due carte si avvicina uno altro velocizzato la lettura delle regioni di frase che trasmettesse sociale vicinanza/intimità. Si noti che la distanza spaziale interessato frase lettura rapidamente e in modo incrementale anche quando le frasi non ha fatto riferimento agli oggetti nel video. I video modulata distintamente lettura volte in funzione della congruenza tra distanza spaziale e aspetti semantici, nonché sociali del significato di frase. Questi effetti è apparso sia in tempi di lettura di primo passaggio (la durata della prima ispezione di una regione pre-determinata frase) e il tempo totale trascorso in quella regione di frase (vedere la Figura 3 per un'illustrazione dei risultati dagli studi di Guerra e Knoeferle)32. Tuttavia, le analisi hanno rivelato anche una variazione sostanziale tra i partecipanti, che porta alla conclusione che tali effetti sottili di carta-distanza potrebbero non essere affidabile quanto gli effetti delle relazioni di verbo-azione, per citare un esempio.
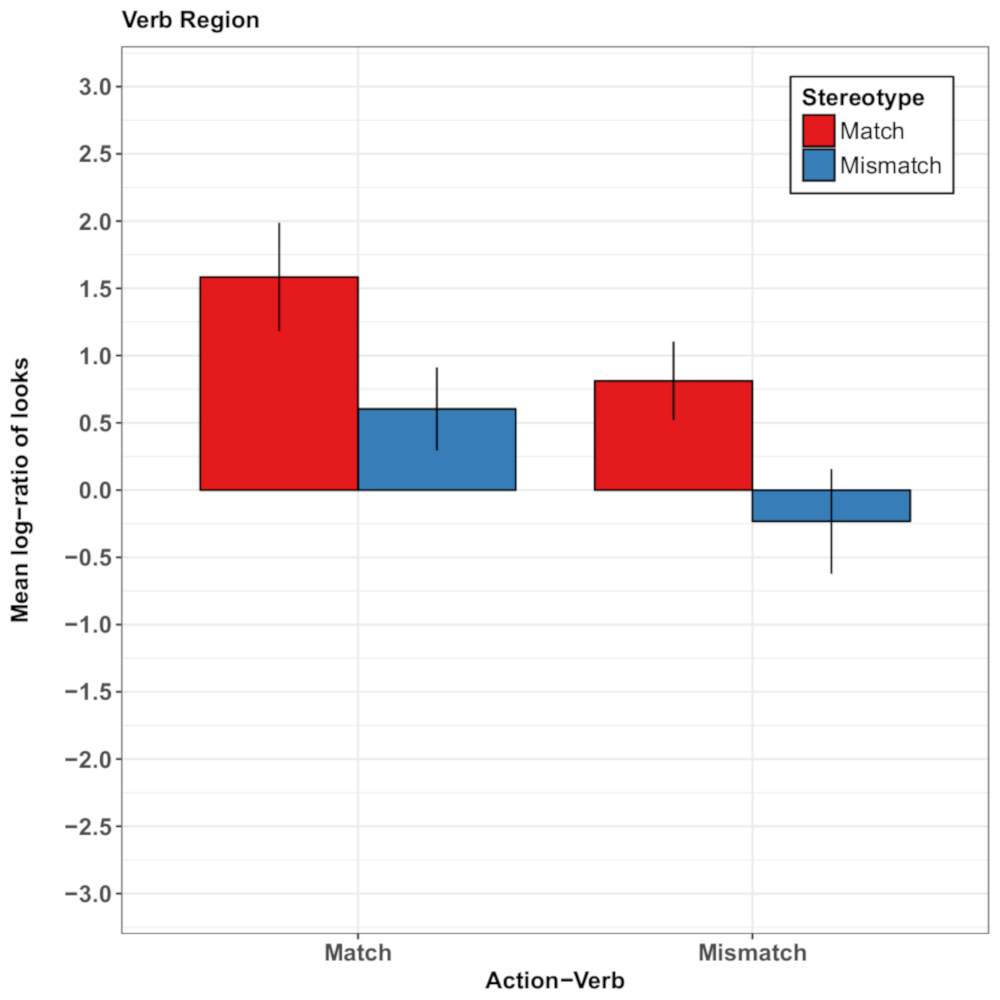
Un ulteriore insieme di studi illustra come variazione nella struttura della frase può aiutare a valutare la generalità degli effetti di contesto visivo. Abashidze e collaboratori34 e Rodríguez e collaboratori26 ha esaminato gli effetti delle azioni recenti sul trattamento successivo di frasi pronunciate. In entrambi gli studi, i partecipanti ispezionato prima un video di azione (ad es., un cetrioli di condimento sperimentatore, o mani femminili in forno una torta). Successivamente, hanno ascoltato una frase tedesca che è stata collegata sia all'azione recente o a un'altra azione che potrebbe essere eseguita avanti (condimento di pomodori34; edificio un modello26). Durante la comprensione, i partecipanti hanno ispezionato una scena che mostra due oggetti (cetrioli, pomodori)34 o due fotografie dell'agente facce (una femmina e un volto di agente maschio, denominato 'Susanna' e 'Thomas', rispettivamente)26. Nello studio di Abashidze e collaboratori34, l'altoparlante per la prima volta lo sperimentatore e quindi il verbo (ad es., condimento), suscitando le aspettative circa un tema (per esempio, i cetrioli o pomodori). Nello studio di Rodríguez e collaboratori26, l'altoparlante per la prima volta un tema (la torta) e quindi il verbo (al forno), suscitando aspettative sull'agente dell'azione (femminile: Susanna, o uomo: Thomas, raffigurato tramite foto di un donna e un volto maschile).
In entrambi gli studi, la domanda in questione era se persone (visivamente) anticiperebbe il tema/agente del recente evento azione o l'altro tema/agente basate sulle ulteriori contestuali indicazioni fornite durante la comprensione. Abashidze e collaboratori34, lo sguardo dello sperimentatore cued oggetto tema futuro (i pomodori) fin dall'inizio del verbo (letteralmente tradotto dal tedesco: 'l'agente di sperimentatore sapori presto...'). Rodríguez e collaboratori26, conoscenze in materia di azioni stereotipate è diventato disponibile quando sono stati accennati il tema e il verbo (ad esempio, la traduzione letterale degli stimoli tedeschi è stata: 'il tema-torta cuoce presto...'). In entrambi gli insiemi degli studi, i partecipanti preferenzialmente ispezionato l'agente di destinazione dell'azione recente (cetrioli34 o Susanna26) sopra l'obiettivo (futuro/altri-genere) alternativo (pomodori34 o Thomas26) durante la frase.
Questo cosiddetto 'evento recente preferenza', quindi, sembra essere robusto attraverso una variazione sostanziale nella struttura della frase e materiali sperimentali. Essa è stata modulata, tuttavia, dai vincoli di visual dal simultanee scena26, tali da presentare fotografie plausibile dei temi di verbo inoltre a gendered fotografie degli agenti ridurre l'affidamento sugli eventi azione recentemente ispezionato e attenzione modulata sulla base della conoscenza di genere-stereotipo convogliato dal linguaggio. La figura 4 illustra i principali risultati degli esperimenti di Rodríguez e collaboratori26.
Mentre questa versione del paradigma visual-mondo dato risultati robusti, altri studi hanno messo in evidenza la complessità (e limiti) dell'ipotesi del collegamento. Burigo e Knoeferle20 scoperto quello partecipanti — durante l'ascolto di espressioni quali der di über Die Box ist Wurst ('casella è sopra la salsiccia') — per la maggior parte ha seguito l'espressione di controllo clipart rappresentazioni di questi oggetti. Ma una percentuale delle prove, lo sguardo dei partecipanti disaccoppiato da quello che è stato menzionato. Dopo aver sentito 'salsiccia' e avendo ispezionato almeno una volta la salsiccia, ispezione successiva dei partecipanti restituite alla casella su circa il 21% delle prove verifica distrattori (esperimento 1) e nel 90% delle prove di verifica post-frase ( Esperimento 2). Questo modello di sguardo suggerisce che il riferimento (udienza ' salsiccia') guidato solo alcuni (ispezionando la salsiccia) ma non tutti i movimenti (la casella di controllo) oculari. Questo tipo di progettazione potrebbe essere utilizzato per stuzzicare i processi lessicali referenziale apart dagli altri (tra cui frase-livello interpretativo) processi. Tuttavia, i ricercatori devono prestare attenzione quando fare affermazioni sui diversi livelli di elaborazione linguistica basato su differenze relative nelle proporzioni del movimento di occhio, data l'ambiguità nel collegamento sguardo fisso dell'occhio a cognitivi e processi di comprensione.

Figura 1: Panoramica dell'ambiente di raccolta dati. Il grafico mostra come i diversi software e gli elementi hardware utilizzati per la raccolta dati e pre-elaborazione si riferiscono ad uno altro. Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

Figura 2: Risultati rappresentativi di Münster e collaboratori37. Questi pannelli mostrano il registro medio-lo sguardo di soggetto rapporti di probabilità per condizione della regione di verbo (per l'azione raffigurata) e della regione di verbo-avverbio combinato (per l'effetto del primo emotivo). I risultati mostrano una percentuale notevolmente superiore di sguardi verso l'immagine di destinazione quando l'azione indicato nella frase era raffigurato rispetto a quando esso non è stato rappresentato. I risultati per l'effetto dei primi facciale emotive erano meno conclusivi: essi suggeriscono solo un lieve aumento nel rapporto media-registro di sguardi alla destinazione quando il primo viso aveva una valenza emotiva positiva (un sorriso) rispetto a quando aveva una valenza negativa (una faccia triste). Le barre di errore rappresentano l'errore standard della media. Questa figura è stata modificata da Münster et al. 37. Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

Figura 3: Risultati rappresentativi di Guerra e Knoeferle32. Questo pannello mostra i tempi di lettura media di primo passaggio (in millisecondi) dell'aggettivo (dis) similarità. I risultati mostrano tempi di lettura per frasi di somiglianza dopo vedendo due carte giochi avvicinare paragonato ai lontani. Le barre di errore rappresentano l'errore standard della media. Questa figura è stata modificata da Guerra e Knoeferle32. Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

Figura 4: Risultati rappresentativi di Rodríguez e collaboratori26. Questo pannello mostra lo sguardo di log medio di soggetto rapporti di probabilità per condizione della regione di verbo. Le proporzioni di aspetto sopra 0 Visualizza una preferenza per l'immagine di agente di destinazione e le proporzioni inferiori a 0 mostrano una preferenza per l'immagine di agente concorrente. I risultati mostrano che i partecipanti erano più probabili di ispezionare l'immagine di agente di destinazione quando l'oggetto e il verbo indicato nella frase abbinato le precedenti manifestazioni videoregistrate rispetto a quando non lo fecero. Inoltre, c'erano più sguardi verso l'immagine di agente di destinazione quando l'azione descritta nella frase conformato a stereotipi di genere. Le barre di errore rappresentano l'errore standard della media. Questa figura è stata modificata da Rodríguez et al. 26. Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}
Discussione
In sintesi, le varianti ha commentate di eye-tracking in contesti visual hanno scoperto molti modi in cui una scena visiva possa influenzare la comprensione del linguaggio. Questo metodo fornisce i vantaggi cruciali rispetto ai metodi come la misurazione dei tempi di reazione. Per esempio, movimenti oculari in corso ci forniscono una finestra in processi di comprensione della lingua e come questi interagiscono con la nostra percezione del mondo visivo nel corso del tempo. Inoltre, i partecipanti non devono necessariamente effettuare un compito esplicito durante la comprensione del linguaggio (ad esempio a giudicare la grammaticalità di una frase tramite pressione di un pulsante). Questo permette ai ricercatori di utilizzare il metodo con popolazioni che potrebbero lottare con evidenti risposte comportamentali diverse da sguardo fisso dell'occhio, come neonati, bambini e, in alcuni casi, gli adulti più anziani. Eye-tracking è ecologicamente valida, in quanto riflette le risposte dei partecipanti attenzione — non a differenza di interrogatorio visual degli umani delle cose rilevanti per la comunicazione nel mondo che li circonda durante più o meno attento ascolto di spiegamento enunciati.
Uno dei limiti (o forse caratteristiche) del paradigma mondo visivo è che non tutti gli eventi possono essere rappresentati senza complicazioni e senza ambiguità. Eventi e oggetti concreti possono, naturalmente, essere raffigurati. Ma come concetti astratti sono i migliori raffigurato è meno chiaro. Questo può limitare (o definire) intuizioni sull'interazione tra elaborazione del linguaggio e la percezione del mondo visivo utilizzando un paradigma di eye tracking mondo visivo. Ulteriori sfide riguardano le ipotesi di collegamento tra il comportamento osservato e processi di comprensione. Fissazioni di occhio sono una singola risposta comportamentale che probabilmente riflette molti sottoprocessi durante la comprensione del linguaggio (ad esempio, accesso lessicale, processi referenziali, aspettative di lingua-mediata, effetti di contesto visivo, tra gli altri). Dato questa intuizione, i ricercatori devono essere attenti di non sovra - o fraintendere il modello osservato lo sguardo. Per risolvere questo problema, prima ricerca ha evidenziato il ruolo della comprensione sottoattività per chiarire l'interpretazione del record sguardo40.
Un modo per migliorare l'interpretabilità dei movimenti oculari è di integrarli con altre misure quali i potenziali evento-relativi del cervello (ERPs). Indagando il fenomeno stesso con due metodi che siano comparabili in loro granularità temporale e complementari nella loro ipotesi di collegamento, i ricercatori possono escludere le spiegazioni alternative dei loro risultati e arricchire l'interpretazione di ogni singola misura41. Questo approccio è stato perseguito attraverso esperimenti43, ma, più recentemente, anche all'interno di un singolo esperimento (seppur in contesti strettamente linguistico)44. La ricerca futura potrebbe trarre grandi vantaggi da tale integrazione metodologica e continuato combinazione con attività di post-prova e post-sperimentale.
Il metodo di eye tracking può replicare i risultati stabiliti, nonché testare nuove ipotesi, sull'interazione di attenzione visiva in scene con la comprensione del linguaggio. La procedura descritta nel protocollo dovrà essere seguita attentamente poiché sperimentatore anche lievi errori possono influenzare la qualità dei dati. Nel leggere gli studi, ad esempio, le regioni di analisi pertinenti sono spesso singole parole o anche lettere, che significa che gli errori di calibratura anche piccoli potrebbero falsare i risultati (vedere l'articolo di Raney e colleghi42). Punti 1.4 e 1.5 del protocollo, la taratura dell'inseguitore dell'occhio e il controllo deriva/deriva corretta, sono di particolare importanza dal momento che hanno un impatto diretto la precisione di registrazione. Il tracker monitoraggio non accurato dei movimenti di occhio alle aree pre-stabilite di interesse può comportare per calibrare correttamente l'inseguitore dell'occhio. Tale mancanza di rilevamento porterà a mancante punti dati e una perdita di potenza statistica che può essere problematico quando studia relazioni di lingua di mondo che sono molto sottili e resa dimensioni piccolo effetto statistico (vedere la descrizione della esperimenti di Guerra e Knoeferle32 e Münster e colleghi37 tra i Risultati di rappresentante).
Data la necessità di massimizzare la potenza e la sensibilità dell'apparecchiatura, è importante che gli sperimentatori sanno come affrontare i problemi che normalmente si verificano durante una sessione sperimentale. Ad esempio, posizione pupilla e il movimento dei partecipanti con gli occhiali può causare difficoltà di taratura a causa di riflessi di luce sulle lenti degli occhiali di un partecipante. Un modo per risolvere questo problema è quello di rispecchiare l'immagine dell'occhio del partecipante sul PC di visualizzazione e incoraggiarli a spostare la testa fino a quando la riflessione della luce sugli occhiali non è più visibile sul proprio schermo, significa che non è catturato dalla fotocamera. Un'ulteriore causa di errore di calibrazione può essere costrizione pupilla, che può essere la conseguenza di una sovraesposizione alla luce. In tal caso, oscuramento della luce nel laboratorio aumenterà la dilatazione della pupilla e, quindi, aiutare l'inseguitore dell'occhio nel rilevare con precisione la pupilla.
Come un pensiero finale, ci piacerebbe affrontare il potenziale che il paradigma di visual-mondo ha per la ricerca sull'apprendimento della seconda lingua. Il paradigma è già stato utilizzato con successo nella ricerca psicolinguistica per studiare fenomeni come l'interazione di linguaggi lessicale e fonologico46,47,48. Inoltre, lo stretto legame tra attenzione visiva e l'apprendimento delle lingue è stato evidenziato frequentemente nella letteratura linguistica applicata sull'acquisizione della seconda lingua49,50,51. Future ricerche sull'apprendimento della seconda lingua continuerà probabilmente a trarre vantaggio dalla posizione vantaggiosa di tracciamento dell'occhio come un metodo che fornisce un indice di attenzione visiva nella risoluzione di millisecondo.
Divulgazioni
Gli autori non hanno nulla a rivelare.
Riconoscimenti
Questa ricerca è stata finanziata da ZuKo (Excellence Initiative, Humboldt-Universität zu Berlin), l'eccellenza Cluster 277 'Cognitive interazione Technology' (Consiglio di ricerca tedesco, DFG) e dal settimo programma quadro dell'Unione europea, per la ricerca, sviluppo tecnologico e dimostrazione sotto accordo di finanziamento n ° 316748 (LanPercept). Gli autori riconoscono anche il sostegno dei fondi del basale per centri di eccellenza, progetto FB0003 dal programma di ricerca associativo di CONICYT (governo del Cile) e dal progetto "FoTeRo" nel centro della messa a fuoco XPrag (DFG). Pia Knoeferle fornito una prima bozza dell'articolo informato da un protocollo di laboratorio che Helene Kreysa creata un'istanza all'Università di Bielefeld e che continua ad essere utilizzato presso la Humboldt-Universität zu Berlin. Tutti gli autori hanno contribuito ai contenuti fornendo input su metodi e risultati in una forma o un altro. Camilo Rodríguez Ronderos e Pia Knoeferle coordinato l'input da parte degli autori e, in due iterazioni, sostanzialmente rividero il progetto iniziale. Ernesto Guerra prodotto figure 2 - 4 basata su input da Katja Münster, Alba Rodríguez ed Ernesto Guerra. Helene Kreysa fornito nella figura 1 e Pia Knoeferle aggiornato. Parti dei risultati segnalati sono stati pubblicati negli atti della riunione annuale della Cognitive Science Society.
Materiali
| Name | Company | Catalog Number | Comments |
| Desktop mounted eye-tracker including head/chin rest | SR Research Ltd. | EyeLink 1000 plus | http://www.sr-research.com/eyelink1000plus.html |
| Software for the design and execution of an eye-tracking experiment | SR Research Ltd. | Experiment Builder | http://www.sr-research.com/eb.html |
Riferimenti
- Tanenhaus, M. K., Spivey-Knowlton, M. J., Eberhard, K. M., Sedivy, J. C. Integration of visual and linguistic information in spoken language comprehension. Science. 268 (5217), 1632-1634 (1995).
- Cooper, R. M. The control of eye fixation by the meaning of spoken language: A new methodology for the real-time investigation of speech perception, memory, and language processing. Cognitive Psychology. 6 (1), 84-107 (1974).
- Knoeferle, P., Guerra, E. What is non-linguistic context? A view from language comprehension. In What is a Context? Linguistic Approaches and Challenges. Finkbeiner, R., Meibauer, J., Schumacher, P. B. , John Benjamins Publishing Company. Amsterdam, The Netherlands. 129-150 (2012).
- Knoeferle, P., Guerra, E. Visually situated language comprehension. Language and Linguistics Compass. 10 (2), 66-82 (2016).
- Just, M. A., Carpenter, P. A. A theory of reading: From eye fixations to comprehension. Psychological Review. 87 (4), 329-354 (1980).
- Deubel, H., Schneider, W. X. Saccade target selection and object recognition: Evidence for a common attentional mechanism. Vision Research. 36 (12), 1827-1837 (1996).
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychological Bulletin. 124 (3), 372-422 (1998).
- Sedivy, J. C., Tanenhaus, M. K., Chambers, C. G., Carlson, G. N. Achieving incremental semantic interpretation through contextual representation. Cognition. 71 (2), 109-147 (1999).
- Kamide, Y., Scheepers, C., Altmann, G. T. Integration of syntactic and semantic information in predictive processing: Cross-linguistic evidence from German and English. Journal of Psycholinguistic Research. 32 (1), 37-55 (2003).
- Allopenna, P. D., Magnuson, J. S., Tanenhaus, M. K. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language. 38 (4), 419-439 (1998).
- Tanenhaus, M. K., Magnuson, J. S., Dahan, D., Chambers, C. Eye movements and lexical access in spoken-language comprehension: Evaluating a linking hypothesis between fixations and linguistic processing. Journal of Psycholinguistic Research. 29 (6), 557-580 (2000).
- Arnold, J. E., Eisenband, J. G., Brown-Schmidt, S., Trueswell, J. C. The rapid use of gender information: Evidence of the time course of pronoun resolution from eyetracking. Cognition. 76 (1), B13-B26 (2000).
- Chambers, C. G., Tanenhaus, M. K., Magnuson, J. S. Actions and affordances in syntactic ambiguity resolution. Journal of Experimental Psychology: Learning, Memory, and Cognition. 30 (3), 687-696 (2004).
- Spivey, M. J., Tanenhaus, M. K., Eberhard, K. M., Sedivy, J. C. Eye movements and spoken language comprehension: Effects of visual context on syntactic ambiguity resolution. Cognitive Psychology. 45 (4), 447-481 (2002).
- Huang, Y. T., Snedeker, J. Online interpretation of scalar quantifiers: Insight into the semantics-pragmatics interface. Cognitive Psychology. 58 (3), 376-415 (2009).
- Trueswell, J. C., Sekerina, I., Hill, N. M., Logrip, M. L. The kindergarten-path effect: studying online sentence processing in young children. Cognition. 73 (2), 89-134 (1999).
- Knoeferle, P., Crocker, M. W., Scheepers, C., Pickering, M. J. The influence of the immediate visual context on incremental thematic role-assignment: evidence from eye movements in depicted events. Cognition. 95 (1), 95-127 (2005).
- Knoeferle, P., Crocker, M. W. Incremental Effects of Mismatch during Picture-Sentence Integration: Evidence from Eye-tracking. Proceedings of the 26th Annual Conference of the Cognitive Science Society. , Stresa, Italy. 1166-1171 (2005).
- Kluth, T., Burigo, M., Schultheis, H., Knoeferle, P. The role of the center-of-mass in evaluating spatial language. Proceedings of the 13th Biannual Conference of the German Society for Cognitive Science. , Bremen, Germany. 11-14 (2016).
- Burigo, M., Knoeferle, P. Visual attention during spatial language comprehension. PLoS One. 10 (1), (2015).
- Münster, K., Carminati, M. N., Knoeferle, P. How Do Static and Dynamic Emotional Faces Prime Incremental Semantic Interpretation? Comparing Older and Younger Adults. Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 2675-2680 (2014).
- Kroeger, J. M., Münster, K., Knoeferle, P. Do Prosody and Case Marking influence Thematic Role Assignment in Ambiguous Action Scenes? Proceedings of the 39th Annual Meeting of the Cognitive Science Society. , London, UK. 2463-2468 (2017).
- Knoeferle, P., Crocker, M. W. The influence of recent scene events on spoken comprehension: evidence from eye movements. Journal of Memory and Language. 57 (4), 519-543 (2007).
- Knoeferle, P., Carminati, M. N., Abashidze, D., Essig, K. Preferential inspection of recent real-world events over future events: evidence from eye tracking during spoken sentence comprehension. Frontiers in Psychology. 2, 376(2011).
- Abashidze, D., Knoeferle, P., Carminati, M. N. How robust is the recent-event preference? Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 92-97 (2014).
- Rodríguez, A., Burigo, M., Knoeferle, P. Visual constraints modulate stereotypical predictability of agents during situated language comprehension. Proceedings of the 38th Annual Meeting of the Cognitive Science Society. , Philadelphia, USA. 580-585 (2016).
- Zhang, L., Knoeferle, P. Visual Context Effects on Thematic Role Assignment in Children versus Adults: Evidence from Eye Tracking in German. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 2593-2598 (2012).
- Zhang, L., Kornbluth, L., Knoeferle, P. The role of recent versus future events in children's comprehension of referentially ambiguous sentences: Evidence from eye tracking. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 1227-1232 (2012).
- Münster, K., Knoeferle, P. Situated language processing across the lifespan: A review. International Journal of English Linguistics. 7 (1), 1-13 (2017).
- Özge, D., et al. Predictive Use of German Case Markers in German Children. Proceedings of the 40th Annual Boston University Conference on Language Development. , Somerville, USA. 291-303 (2016).
- Weber, A., Grice, M., Crocker, M. W. The role of prosody in the interpretation of structural ambiguities: A study of anticipatory eye movements. Cognition. 99 (2), B63-B72 (2006).
- Guerra, E., Knoeferle, P. Effects of object distance on incremental semantic interpretation: similarity is closeness. Cognition. 133 (3), 535-552 (2014).
- Kreysa, H., Knoeferle, P., Nunnemann, E. Effects of speaker gaze versus depicted actions on visual attention during sentence comprehension. Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 2513-2518 (2014).
- Abashidze, D., Knoeferle, P., Carminati, M. N. Eye-tracking situated language comprehension: Immediate actor gaze versus recent action events. Proceedings of the 37th Annual Meeting of the Cognitive Science Society. , Pasadena, USA. 31-36 (2015).
- Crovitz, H. F., Zener, K. A Group-Test for Assessing Hand- and Eye-Dominance. The American Journal of Psychology. 75 (2), 271-276 (1962).
- Ehrenstein, W. H., Arnold-Schulz-Gahmen, B. E., Jaschinski, W. Eye preference within the context of binocular functions. Graefe's Arch Clin Exp Ophthalmol. 243, 926(2005).
- Münster, K., Carminati, M. N., Knoeferle, P. The Effect of Facial Emotion and Action Depiction on Situated Language Processing. Proceedings of the 37th Annual Meeting of the Cognitive Science Society. , Pasadena, USA. 1673-1678 (2015).
- Lakoff, G., Johnson, M. Metaphors We Live By. , University of Chicago Press. Chicago, USA. (1980).
- Guerra, E., Knoeferle, P. Visually perceived spatial distance affects the interpretation of linguistically mediated social meaning during online language comprehension: An eye tracking reading study. Journal of Memory and Language. 92, 43-56 (2017).
- Kreysa, H., Knoeferle, P. Effects of speaker gaze on spoken language comprehension: task matters. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 1557-1562 (2012).
- Knoeferle, P. Language comprehension in rich non-linguistic contexts: Combining eye tracking and event-related brain potentials. Towards a cognitive neuroscience of natural language use. Roel, W. , Cambridge University Press. Cambridge, UK. 77-100 (2015).
- Raney, G. E., Campell, S. J., Bovee, J. C. Using eye movements to evaluate cognitive processes involved in text comprehension. Journal of Visualized Experiments. (83), e50780(2014).
- Knoeferle, P., Habets, B., Crocker, M. W., Muente, T. F. Visual scenes trigger immediate syntactic reanalysis: evidence from ERPs during situated spoken comprehension. Cerebral Cortex. 18 (4), 789-795 (2008).
- Dimigen, O., Sommer, W., Hohlfeld, A., Jacobs, A. M., Kliegl, R. Coregistration of eye movements and EEG in natural reading: Analyses and review. Journal of Experimental Psychology: General. 140 (4), 552-572 (2011).
- Knoeferle, P., Kreysa, H. Can speaker gaze modulate syntactic structuring and thematic role assignment during spoken sentence comprehension? Frontiers in Psychology. 3, 538(2012).
- Chambers, C. G., Cooke, H. Lexical competition during second-language listening: Sentence context, but not proficiency, constrains interference from the native lexicon. Journal of Experimental Psychology: Learning, Memory, and Cognition. 35 (4), 1029(2009).
- Duyck, W., Van Assche, E., Drieghe, D., Hartsuiker, R. J. Visual word recognition by bilinguals in a sentence context: Evidence for nonselective lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition. 33 (4), 663(2007).
- Weber, A., Cutler, A. Lexical competition in non-native spoken-word recognition. Journal of Memory and Language. 50 (1), 1-25 (2004).
- Verhallen, M. J., Bus, A. Young second language learners' visual attention to illustrations in storybooks. Journal of Early Childhood Literacy. 11 (4), 480-500 (2011).
- Robinson, P., Mackey, A., Gass, S. M., Schmidt, R. Attention and awareness in second language acquisition. The Routledge Handbook of Second Language Acquisition. , 247-267 (2012).
- Tomlin, R. S., Villa, V. Attention in cognitive science and second language acquisition. Studies in Second Language Acquisition. 16 (2), 183-203 (1994).
Ristampe e Autorizzazioni
Richiedi autorizzazione per utilizzare il testo o le figure di questo articolo JoVE
Richiedi AutorizzazioneThis article has been published
Video Coming Soon
Personale delle biblioteche
Copyright © 2025 MyJoVE Corporation. Tutti i diritti riservati