
Method Article
视觉语言理解中的眼动追踪: 发现视觉语境效果的灵活性和局限性
摘要
本文综述了一种用于语言理解研究的眼动追踪方法。为了获得可靠的数据, 必须遵循协议的关键步骤。其中包括眼动仪的正确设置 (例如, 确保眼睛和头部图像的高质量) 和准确的校准。
摘要
本工作是对一种方法的描述和评估, 该方法旨在量化语言处理与视觉世界感知之间相互作用的不同方面。眼睛注视模式的记录为视觉语境和语言世界知识对语言理解的贡献提供了很好的证据。初步研究评估了对象上下文效应, 以检验语言处理中的模块化理论。在导言中, 我们描述了随后的调查如何将更广泛的视觉背景在语言处理中的作用本身作为一个研究主题, 并提出了我们对事件和说话者的视觉感知如何有助于理解的基础上, 了解理解的理解。视觉语境的研究方面包括动作、事件、说话者的目光、情感面部表情, 以及空间物体的配置。在概述了眼动追踪方法及其不同应用之后, 我们列出了该方法在协议中的关键步骤, 说明了如何成功地将其用于研究视觉位置的语言理解。最后一节介绍了三套具有代表性的结果, 并说明了眼动追踪在调查视觉世界感知与语言理解之间的相互作用方面的好处和局限性。
引言
心理语言学研究强调了眼睛运动分析在理解语言理解中所涉及的过程中的重要性。从凝视记录推断理解过程的核心是将认知与眼动联系起来的假设.有三种主要类型的眼动: 囊, 前庭眼动, 和流畅的追求运动。saccades 速度快, 大部分发生在不知不觉中的弹道运动, 并与注意力的转移可靠地联系在一起。在囊之间相对注视稳定的时刻, 也就是所谓的固定时刻, 被认为是对当前视觉注意力的指数。测量固定点的位点及其与认知过程的持续时间被称为 "眼动追踪方法"。这种方法的早期实现有助于考察严格语言语境中的阅读理解 (请参见 rayner7 的回顾)。在这种方法中, 检查单词或句子区域的持续时间与处理难度有关。然而, 眼动追踪也被用来检查世界上的物体检查期间的口语理解 (或在计算机显示器2上)。在这个 "视觉世界" 的眼动跟踪版本中, 对物体的检查是以语言为指导的。例如, 当理解者听到斑马的声音时, 他们对屏幕上斑马的检查就会反映出他们在想这只动物。在所谓的视觉世界范式中, 一个理解的目光被用来反映口语理解和相关知识的激活 (例如,听众在听到放牧时也会检查斑马, 这表明斑马所做的动作)2。这种检查表明, 语言世界关系与眼球运动之间存在着系统的联系。量化此链接的常用方法是计算外观与屏幕上不同预定区域的比例。这使得研究人员能够直接 (跨条件, 通过参与者和项目) 比较特定时间对不同对象的关注程度, 以及这些值在毫秒分辨率下的变化情况。
心理语言学的研究利用视觉世界中的眼动追踪来区分关于思维结构的相互竞争的理论假设1。此外, 对所描绘的物体的眼睛固定也表明, 假设语言环境具有足够的限制性, 理解者可以对即将到来的字符进行增量语义解释,甚至对即将到来的字符产生期望9. 这些眼睛注视数据也揭示了一系列进一步的理解过程, 如词汇歧义分辨率10,11, 代词分辨率 12, 消除歧义的结构和主题作用通过信息分配在视觉上下文 13、14、16和语用过程15, 除其他许多4。显然, 在语言理解过程中, 对物体的眼球运动可以提供所涉及的过程的信息。
这种眼动追踪方法是非侵入性的, 可用于婴儿、年轻和年龄较大的语言使用者。一个关键的优点是, 与验证任务中对探测器或响应按钮按下的点点响应不同, 它以毫秒的分辨率提供了对语言如何引导注意力以及视觉上下文如何的洞察 (以对象、操作的形式,事件、说话者的注视、情感面部表情以及空间对象的配置) 有助于语言处理。句子理解过程中的连续性与其他句子后和实验后的测量方法有很好的配合, 如公开的图片句子验证、理解问题和记忆回忆任务。在这些任务中, 公开的反应可以通过深入了解理解过程、记忆和学习2的结果来丰富对眼睛注视记录的解释。将眼动追踪与这些其他任务结合起来, 揭示了视觉语境在多大程度上调节视觉注意力和 (即时以及延迟) 整个生命周期的理解。
语言 (口头或书面) 和场景的呈现可以是同步的, 也可以是顺序的。例如, Knoeferle 和合作者17在口语句之前呈现了 1, 000 毫秒的场景, 它在理解过程中仍然存在。他们报告的证据表明, 与对象动词-宾语 (ovs) 相比, 对动作事件的剪裁描述有助于解决德语动词-动词-对象 (svo) 中的局部结构歧义。Knoeferle 和 crocker18在写句子之前呈现了一个剪贴画场景, 并测试了句子理解过程中剪贴画事件的增量集成。他们观察到了增量一致性效应, 这意味着当这些不匹配 (与前一幕中描述的事件相匹配) 时, 参与者对句子成分的阅读时间会更长。在另一个刺激呈现变体中, 参与者首先阅读描述空间关系的句子, 然后看到一个特定空间排列的场景, 其中涉及对象线图19。这项研究评估了计算空间语言模型的预测, 要求参与者对给场景的句子的拟合进行评分, 并在现场审讯过程中记录眼动。参与者的凝视模式被他们所面对的物体的形状所调节--部分确认模型预测并为模型细化提供数据。
虽然许多研究使用了剪贴画17、18、19、20、21、22、23,但也可以结合现实世界对象、这些对象的视频或使用口语的静态照片1、21、24、25、26、46。Knoeferle 和他的同事使用了现实世界的环境24和 abashidze 和他的同事使用了一个录像演示格式来检查行动事件和紧张的影响25。改变场景的精确内容 (例如, 描述动作与否)22、27、38 是可能的, 也可以揭示视觉背景效果。rodríguez 和合作者26的一项相关研究调查了录像的视觉性别暗示对随后提出的口语句子理解的影响。参与者观看了显示男性或女性手的视频, 表演了与性别有关的陈规定型行动。然后, 他们听到一句关于男女动作事件的句子, 同时检查一个显示两张照片并排的显示, 一张是一张是男性照片, 另一张是一张是一张是一张是一张。这种丰富的视觉和语言环境使作者能够将语言介导的陈规定型知识对理解的影响与视觉呈现的 (手) 性别暗示的影响区分开来。
这种范式的进一步应用针对语言处理的发展变化。在口语理解过程中对物体的眼睛运动显示了描述事件的影响,在4-5岁的 27岁, 28岁和老年人 29岁的实时, 但与年轻成年人相比有些延迟。kröger 和合作者22在实验中研究了韵律提示和病例标记的影响, 并在成人和儿童的实验中对这些效果进行了比较。参与者在听一个明确的带有明显大小写的德语句子时, 检查了一个不明确的动作事件场景。眼睛的运动显示, 独特的韵律模式对成年人和4岁或5岁的孩子在消除对谁做什么的歧义时, 既没有帮助。然而, 最初的句子病例标记影响的是成年人的眼睛运动, 但并没有影响到儿童的眼睛运动。这表明, 5岁儿童对案例标记的理解不够有力, 无法进行专题角色分配 (见厄兹格和合作者30的研究), 至少在行动事件没有消除专题角色关系的情况下是如此。这些结果很有趣, 因为它们与以前对专题角色分配31的韵律效应结果形成鲜明对比。kröger 和合作者22提出, (或多或少支持) 视觉背景负责对比结果。在这些解释成立的程度上, 它们突出了上下文在整个生命周期中在语言理解中的作用。
眼动追踪方法很好地结合了从图片 (或视频) 句子验证任务18,20, 26, 图片图像验证任务32, 语料库研究 24, 评级的措施任务19, 或实验后召回任务25,33。abashidze 和合作者34和 kreysa 和合作者33分别调查了扬声器凝视和现实世界动作视频34和扬声器凝视和动作描述33之间的相互作用, 作为即将到来的句子内容。通过将语言理解过程中对场景中的眼视跟踪与实验后的记忆任务结合起来, 他们更好地了解了听众对说话者注视和所描述的行为的感知如何相互作用并影响两者即时语言处理和记忆召回。结果表明, 与实验后记忆回忆过程相比, 动作与说话人的注视对实时理解的贡献是显著的。
虽然可以非常灵活地使用眼动追踪方法, 但某些标准是关键。下面的协议总结了一个通用的过程, 可以根据研究人员的具体需要调整到不同类型的研究问题。该协议是柏林洪堡大学心理语言学实验室以及认知技术卓越集群 (citec) 前语言和认知实验室采用的标准化程序。比勒费尔德大学。该协议描述了桌面和远程设置。后者建议用于儿童或老年人的研究。代表性结果中提到的所有实验都使用一个眼动仪设备, 采样率为 1, 000 赫兹, 并与头部稳定器、用于测试参与者的 pc (显示 pc) 和用于监测实验的 pc 一起使用。参与者的眼动 (主机)。这个设备的主要区别是, 它允许双目眼动追踪。该协议旨在足够通用, 可用于其他眼动追踪设备, 包括头部稳定器, 并使用双 pc 设置 (主机 + 显示)。但是, 请务必记住, 其他设置可能会有不同的方法来处理校准失败或轨道丢失等问题, 在这种情况下, 实验者应参考其特定设备的用户手册。
研究方案
该议定书遵循收集数据的机构的道德准则,即bielefeld 大学和柏林洪堡大学的认知交互技术卓越集群 (citec)。在 bielefeld 大学进行的实验得到了 bielefeld 大学伦理委员会的单独批准。柏林洪堡大学的心理语言学实验室有一项实验室伦理规程, 该规程得到了德国语言学学会德国语言学会 (dgfs) 德国语言学委员会伦理委员会的批准。
1. 桌面设置
注: 以下是眼动追踪实验中的关键步骤。
- 仪器制备
- 打开眼动跟踪摄像头和主机 pc (有关实验室内数据收集和预处理设置的说明, 请参见图 1 )。
- 启动眼动仪软件。
- 打开 "显示电脑"。打开包含实验的文件夹。
- 通过双击 "已部署" 版本, 以. exe 扩展名启动该版本。
- 根据设置, 可能会出现选择实验列表的提示, 该列表通常是一个制表符分隔的. csv/t. txt 文件, 其中包含参与者将向其公开的条件、声音文件名、书面句子和图像。选择列表, 程序将启动。命名将在其中存储结果的输出文件。
注: 输出文件保存在显示 pc 上, 备份保存在主机上。 - 保持实验的第一个屏幕 (介绍或欢迎屏幕) 打开。
- 从眼动仪相机上取下保护盖。
- 为卫生起见, 请将纸巾放在下巴支架上。
- 可选: 根据实验要求准备响应垫和键盘。
- 可选: 如果显示听觉刺激, 请调整扬声器的音量, 并在运行实验之前对其进行测试。或者, 测试参与者要使用的耳机的功能。
- 准备必要的表格, 由参与者签署。
- 调整实验室中的光强, 以便在整个数据收集过程中拥有一个光线变暗、亮度恒定的房间。
- 为与会者做准备
- 参与者到达后, 介绍一下你自己。
- 在实验室门上放置 a . 不要打扰指示牌。
- 请与会者坐下。
- 指导参与者通过信息表和必要的同意和人口形式。
- 让参与者阅读并签署同意书。
- 简要说明实验的一般方面及其持续时间。不要在实验前提供太多信息, 因为这可能会影响参与者的凝视行为和由此产生的数据。
- 提供书面指示, 并给参与者提问的机会。
- 简要说明眼动仪的功能。
- 如有必要, 澄清任务并指出在实验过程中需要按下的任何按钮。
- 解释如何在实验过程中将下巴休息的目的是为了最大限度地减少头部运动。如果参与者避免任何移动, 请注意设备的功能最佳。
- 设置眼动仪
- 为实验的参与者做好准备: 让他们坐在桌旁, 把下巴放在下巴上休息。让他们把额头靠在头枕上。
- 如有必要, 请参与者调整椅子的高度和位置: 参与者下巴休息, 额头靠头, 感觉很舒服。
- 解释在实验过程中不小心移动头部是很常见的, 应该避免这种情况。解释在实验过程中, 头部姿势可能需要纠正。
- 如果实验需要按下按钮 (例如, 通过响应板), 请指示参与者将手指放在要按下的按钮上, 并避免在按下按钮时向下看响应垫。
- 请参与者阅读欢迎介绍屏幕。
- 坐在主机电脑前。如果屏幕尚未在 "相机设置"上, 请单击"相机设置"以进入正确的屏幕。如果保护盖已从相机镜头中取下, 并且参与者正确地放置在下巴休息上, 则屏幕应显示参与者眼睛的三个图像: 顶部有一个较大的图像, 左侧和右侧的底部有两个较小的图像。这些较小的图像显示, 每个眼睛都有一只眼睛, 与左眼和右眼相对应。
- 选择要跟踪的眼睛。按照惯例, 跟踪参与者的优势眼睛。如果参与者不知道哪只眼睛是显性的, 就进行眼睛优势测试 (步骤 1.3.8)。
- 确定眼睛的优势。让参与者伸出一只手臂, 用眼睛睁开的远处物体对齐拇指。要求参与者交替关闭左眼或右眼。占主导地位的眼睛是当眼睛打开35,36时拇指保持与物体对齐的眼睛。
- 点击图片显示电脑(或按enter), 步骤1.3.6 中描述的图像也将显示在参与者的显示屏上, 但一次只显示一个。
- 按实验者或参与者的计算机键盘上的左/右箭头, 在较小和较大的眼睛图像之间切换。聚焦在较小的图像 (眼睛) 上。
- 按任意一个键盘上的a (对齐眼睛窗口), 以便将搜索限制框居中放在瞳孔位置上。然后, 眼睛周围的一个红色正方形应该出现一个绿松石圆圈 (' 角膜反射 ', (cr)) 靠近瞳孔的底部。瞳孔本身应该是蓝色的。
- 确保屏幕上出现两个交叉 ("十字线")-一个在瞳孔的中心, 一个在角膜反射的中心。红色的盒子和两个交叉意味着眼动仪正在检测瞳孔和 cr。
注: 如果红色框或十字架不存在, 则不会跟踪眼睛, 如果发生这种情况, 实验者的计算机上将出现无瞳孔。 - 手动转动对焦镜头, 调整相机的对焦。注意不要触摸镜头的前部。转动镜头, 直到达到最佳焦点。
注: 当绿松石圆 (角膜反射) 尽可能小 (即当这个圆处于焦点时), 就会达到最佳的焦点。 - 设置瞳孔阈值。确保主机 pc 上只有瞳孔的图像是蓝色的 (例如, 睫毛不应是蓝色的)。另外, 要确保整个瞳孔 (不仅仅是它的中心部分) 是蓝色的。只担心红色广场里面是什么。
- 按a。这将自动设置瞳孔阈值。如果瞳孔未准确显示为蓝色, 请使用up键手动调整阈值以增加, 向下键调整阈值以减少图像表面的蓝色部分的数量。
注: 睫毛膏 (通常是黑色的, 像瞳孔) 可能会干扰设置阈值-眼动仪可能会采取黑暗睫毛的瞳孔。在这种情况下, 要求参与者通过为他们提供卸妆组织来卸妆。 - 设置cr 阈值。如果在1.3.15 的步骤中按下 a, 则应自动设置cr 阈值。
注: 所有阈值设置的数值都应可见。如果其中任何一个中出现问号, 则前面的步骤之一存在问题, 应手动设置阈值。
- 校准眼动仪
注: 当参与者查看屏幕的其他部分时, 检查眼动仪是否能够一致地识别眼睛的位置。- 让参与者在看到相机设置窗口时, 一次看一个屏幕的四个角。仔细寻找任何不规则的反射 (这些将显示为绿松石 "斑点" 在屏幕上), 干扰角膜反射时, 眼睛的目光是指向角落。
- 如果眼睛周围的红色框和任何一个十字线在步骤1.4.1 的任何时间点都看不到, 请让参与者查看屏幕的中心, 然后将他们的目光定向到有问题的角落。这将有助于确定问题的根源。
- 重新调整参与者头部的位置, 并检查这是否会产生任何改进。如有必要, 请重复此步骤。如果设备在几次尝试后仍无法准确跟踪参与者的凝视, 请中止实验。
- 通知参与者, 眼动仪将被校准, 他们将看到一个黑色圆圈 (带有一个小的灰色点) 移动到屏幕的不同部分。指示参与者固定圆圈, 直到它移动到新位置。指示参与者避免紧张他们的眼睛, 并专注于黑色圆圈内的小灰点, 以获得最佳效果。
- 告诉参与者, 在校准过程中保持静止是很重要的, 不要试图预测下一个圆的位置。告诉他们用眼睛而不是头跟着圆圈走。单击"校准"开始校准过程。通常情况下, 使用9点校准过程, 其中黑圈以串行方式移动到9个位置。
- 对于自动校准, 在参与者准确地固定屏幕中间的第一个点之后, 按enter.对于手动校准 (例如, 当跟踪参与者的眼睛时, 或在处理特殊参与者组 (如儿童) 时, 通过按enter 接受每种固定 (或单击 "接受固定/按空格键)。
注: 在校准过程结束时, 实验者屏幕上几乎是矩形的图案应该是可见的。这代表了参与者的眼睛注视模式。此外, 良好校准的结果应以绿色突出显示。如果不是, 请重复校准过程 (即, 单击"校准")。 - 验证结果。告诉参与者通过相同的过程 (查看点), 以验证校准过程的结果。提醒他们看点, 并保持静止。
注: 验证过程与校准过程相似, 眼动仪软件会对这两个结果进行比较, 以确保准确跟踪眼睛。 - 单击 "验证".
- 通过按enter (或单击 "接受固定 ")接受每个固定。
- 验证后, 结果将显示在实验者的屏幕上。请特别注意两个错误度量, 平均误差 (例如0.23°) 和最大误差 (例如0.70°)。这些表示跟踪图像偏离参与者实际凝视位置的程度。
- 使用可视世界范例时, 将平均误差 (第一个数字) 保持在0.5°以下, 最大误差 (第二个数字) 保持在1°以下。
- 如果错误值高于阈值, 请要求参与者重新调整其头部的位置并重新启动校准过程。如果没有观察到改进, 中止实验。
注: 当参与者佩戴隐形眼镜时, 通常会观察到较高的校准错误。应提前要求参与者携带处方眼镜, 而不是隐形眼镜。 - 成功完成校准过程后, 单击 "输出记录" 开始实验。通知参与者实验现在将开始。
- 在实验过程中
注: 在实验过程中 (取决于单个实验的编程方式, 但通常在每次实验试验之前),漂移检查或漂移正确的屏幕将在屏幕中心显示一个点。其目的是报告当前试验的计算固定误差, 并根据眼动仪模型自动调整。- 在指令阶段, 参与者被告知在中心点出现时固定它。确保在每个漂移检查/漂移正确的阶段, 参与者再次固定点。这可以通过跟随参与者对主机 pc 的注视来实现, 参与者的注视显示为一个移动的绿色圆圈。
- 漂移检查/漂移正确完成后, 按enter (或空格键) 使点消失并显示下一个试验。
- 根据所使用的眼动仪模型, 确定如何处理通过漂移检查阶段的故障。根据型号的不同, 眼动仪将通过调整凝视坐标以匹配中心点的坐标来执行自动漂移校正,或者发出蜂鸣声, 提示实验者在继续实验 (漂移检查)。
- 如果使用自动漂移校正, 请记住, 在连续试验中, 过多的漂移校正和/或过大程度的漂移校正会扭曲结果, 需要重新校准设备。
- 实验期间的重新校准
- 在实验期间的任何时候都可以重新校准。在介绍漂移更正/漂移检查屏幕的过程中, 单击"相机设置", 然后单击 "校准"。完成校准和验证过程, 直到达到满意的值, 然后单击output/记录.实验将从试验序列中的退出点恢复。
- 实验结束后
- 向参与者提供一份调查问卷, 以评估他们是否能够猜测关键的实验操作。在这里, 询问可能在整个实验过程中开发的策略也很重要。
- 向参与者简要说明实验的目的。感谢他们的参与, 并提供必要的货币补偿或分配课程学分 (如果适用)。
2. 远程设置: 调整儿童和老年人学习设置
注: 本节仅介绍远程安装和桌面安装之间的差异, 如步骤1中所述。此处未明确提到的要点应假定与步骤1中描述的过程相同。
- 将标准的35毫米眼动仪相机镜头更换为16毫米镜头。
- 连接所有必要的设备 (主机电脑、扬声器、眼动仪和笔记本电脑 (如果使用笔记本电脑)。
- 将笔记本电脑放在笔记本电脑支架上, 眼前的眼动仪 (参与者应该能够看到屏幕的前 75%)。
- 在参与者的额头上放置 "目标贴纸" (可从跟踪器制造商处获得) (右眼眉毛上方或右脸颊上, 如果额头太小 (即婴儿); 如果是婴儿); 该贴纸取代了其余的下巴。桌面设置, 它允许眼动仪准确地确定参与者的头部的位置。
- 确保参与者坐在距离相机550-600 毫米的地方 (目标贴纸与相机的距离)。
- 确保主机上的 "大角度" 或 "近眼" 这两个词不会出现。如果他们这样做了, 就意味着目标贴纸的位置并不理想。在这种情况下, 请重新调整目标贴纸。这也可能意味着参与者的额头特别小。如果是这种情况, 请将贴纸放在参与者的脸颊上。
注: 如果贴纸放置在离耳朵太近的地方, 则可能会出现 "大角度" 消息, 并且贴纸必须重新定位。 - 在开始步骤1.4 中描述的校准过程之前, 请确保参与者舒适地坐着。让他们在整个实验过程中保持相同的位置, 并解释眼动仪对身体运动非常敏感。坚持让他们保持清醒的头脑。如果参与者移动太多, 设备将发出嗡嗡声。
注: 如果远程眼动仪设置用于测试敏感人群 (如儿童或老年人), 建议使用手动校准过程。
3. 调整阅读研究的设置
注: 在调查视觉上下文对阅读的影响时, 有必要特别注意校准和重新校准过程。与视觉世界研究不同的是, 考虑到跟踪单词对单词和信对字的阅读模式所需的准确性, 阅读过程中的眼动跟踪需要更高的设备精度。
- 确保验证阶段显示的平均和最大误差都保持在0.5°以下。
- 确保至少使用9点刻度进行校准。这确保了更准确地跟踪眼睛注视的位置, 这一点是必不可少的, 因为阅读过程中感兴趣的区域规模很小。
结果
明斯特和合作者37的一项研究调查了语言理解过程中句子结构的相互作用, 描述了动作和面部情感暗示。本研究非常适合于说明该方法的优点和局限性, 因为它既显示了有力的描述动作效果和边缘效应的面部情感暗示句子理解。作者制作了5个视频, 视频中的女性的面部表情从休息的位置变成了快乐或悲伤的表情。他们还创造了情感上积极的积极的德国对象 ver-adwd-主题 (ovadvs) 句子形式 ' [对象/病人指控案件] [动词] [副词 b] [主体/名义的情况]。通过正面副词, 句子匹配的 "快乐" 视频和不匹配的 "悲伤" 视频, 原则上允许期待的代理 (谁是微笑, 并被描述为快乐的正面副词)。在演说者视频之后, 这个句子出现了两个版本中的一个, 一个是病人分心的剪辑场景。在一个版本中, 代理被描述为对患者执行上述操作, 而干扰角色则执行不同的动作。另一个场景版本描述了角色之间的任何操作。场景中的眼动揭示了动作和说话人面部表情对句子理解的影响。
动作描述迅速影响了参与者的视觉注意力, 这意味着参与者更多的是看着代理, 而不是在描述所述动作时的干扰者 。这些表情是预特长的 (即发生在提到代理人之前), 表明行动描述在判决之前澄清了代理人。动作描述的最早效果出现在动词 (即动词介导动作关联的代理) 中。相比之下, 前一位说话者是微笑还是看起来不开心, 对代理预期没有明显的影响 (图 2)。后一个结果可能反映了说话者的微笑与与被描述的代理人的行为有关的积极的句子副词之间更为脆弱的联系 (与调解与行动相关的代理人的直接动词-动作参考相比)。或者, 它可以是特定于任务和刺激的介绍: 也许情绪影响会更明显地在一个更具社会互动的任务, 或在一个显示说话人的脸在句子理解期间 (而不是之前)。然而 , 在理解过程中呈现微笑的说话者的脸可能会导致参与者以牺牲其他场景内容为代价地关注脸 , 也许掩盖纵变量的其他可观察到的效果 ( 来源 : 未公布的数据 ) 。
在范式的另一个变种中, guerra 和 noeferle32询问了空间语义世界-语言关系是否可以调节阅读过程中对抽象语义内容的理解。guerra 和 Knoeferle 从概念隐喻理论38中借用了这一观点, 即空间距离 (如接近) 是抽象语义关系 (如相似) 的基础。根据这一假设, 当抽象名词在意义上相似 (相对于相反) 时, 参与者阅读协调抽象名词的速度更快, 并且之前有一个视频传递接近度 (相对于距离; 扑克牌移动得更近) 与. 更远的距离)。在第二组研究中, 句子将两个人之间的互动描述为亲密或不友好, 导致发现两张卡片相互接近的视频加速了表达社会的句子区域的阅读亲密的亲密。请注意, 即使句子未引用视频中的对象, 空间距离也会快速、增量地影响句子读取。视频独特地调节了阅读时间, 作为空间距离与语义的一致性以及句子意义的社会方面的函数。这些影响既出现在第一次通过的阅读时间 (对预先确定的句子区域进行第一次检查的时间) 中, 也出现在该句子区域上的总时间 (关于 guerra 研究结果的说明, 见图 3 )和 Knoeferle)32。然而, 分析还揭示了参与者之间的巨大差异, 从而得出的结论是, 例如, 这种微妙的卡距离效应可能不如动词-行动关系的影响那么有力。
进一步的研究表明, 句子结构的变化如何有助于评价视觉语境效果的普遍性。abashidze 和合作者34和 rodríguez 和合作者26审查了最近的行动对随后处理口语句子的影响。在这两项研究中, 参与者首先检查了一个动作视频 (例如, 实验者调味黄瓜, 或女性手烤蛋糕)。接下来, 他们听了一句德语句子, 这句话要么与最近的行动有关, 要么与接下来可能执行的另一项行动有关 (调味西红柿34; 建造一个模型26)。在理解过程中, 参与者视察了一个场景, 展示了两个物体 (黄瓜, 西红柿)34或两张代理脸的照片 (一个女性和一个男性的代理脸, 分别叫 "苏珊娜" 和 "托马斯")26。在 abashidze 和合作者34 的研究中, 发言者首先提到实验者, 然后提到动词 (例如, 调味), 引起人们对一个主题 (例如黄瓜或西红柿) 的期望。在 rodríguez 和合作者26的研究中, 发言者首先提到了一个主题 (蛋糕), 然后提到了动词 (烘烤), 引起了人们对动作代理人的期望 (女性: 苏珊娜, 或男:托马斯, 通过照片描绘的女性和男性的面孔)。
在这两项研究中, 争论的问题是人们是否会 (视觉上) 根据理解过程中提供的进一步语境暗示来预测最近动作事件的主体或其他主体。在 abashidze 和合作者34中, 实验者的目光从动词的开头就吸引了未来的主题对象 (西红柿) (从字面上翻译为德语: "实验者代理的味道很快......")。在 rodríguez 和合作者26中, 当提到主题和动词时, 就可以获得对陈规定型行为的性别知识 (例如, 德语刺激的直译是: "蛋糕主题烤面包很快.")。在这两组研究中, 参与者优先考察了最近行动的目标 (黄瓜34或苏珊娜 26) 的替代目标 (未来/性别) 目标 (西红柿34或托马斯26).在句子中。
因此, 这种所谓的 "事件偏好" 在句子结构和实验材料的实质性变化中似乎是稳健的。然而, 由于同时出现的场景26的视觉限制, 它得到了调整, 因此, 除了代理的性别照片外, 还提出了动词主题的可信照片, 从而减少了对最近检查的行动事件的依赖。根据语言所传达的性别陈规定型知识来调整注意力。图 4显示了 rodríguez 和合作者26实验的主要结果。
虽然这个版本的视觉世界范式产生了稳健的结果, 但其他研究也强调了链接假设的复杂性 (和局限性)。布里戈和诺埃弗20发现, 参与者--在听诸如模盒列表über der wurst ("盒子在香肠上方") 等话语时--大多是在检查这些物体的剪贴画中的话语。但在一定比例的试验中, 参与者的目光与提到的分离。在听到 "香肠" 并至少检查过一次香肠后, 参与者的下一次检查返回到盒子里, 对大约21% 的试验进行了快速核查 (实验 1), 在判决后核查中进行了90% 的试验 (实验 2)。这种注视模式表明, 参考 (听到 ' 香肠 ') 只引导一些 (检查香肠), 但不是所有的眼睛运动 (检查盒子)。这种设计可以用来区分词汇引用过程和其他 (包括句子级的解释) 过程。然而, 研究人员在根据眼睛运动比例的相对差异对不同程度的语言处理提出主张时必须小心, 因为眼睛注视与认知和理解过程之间的联系是模糊的。

图 1: 数据收集环境概述.该图显示了用于数据收集和预处理的不同软件和硬件元素之间的相互关系。请点击这里查看此图的较大版本.
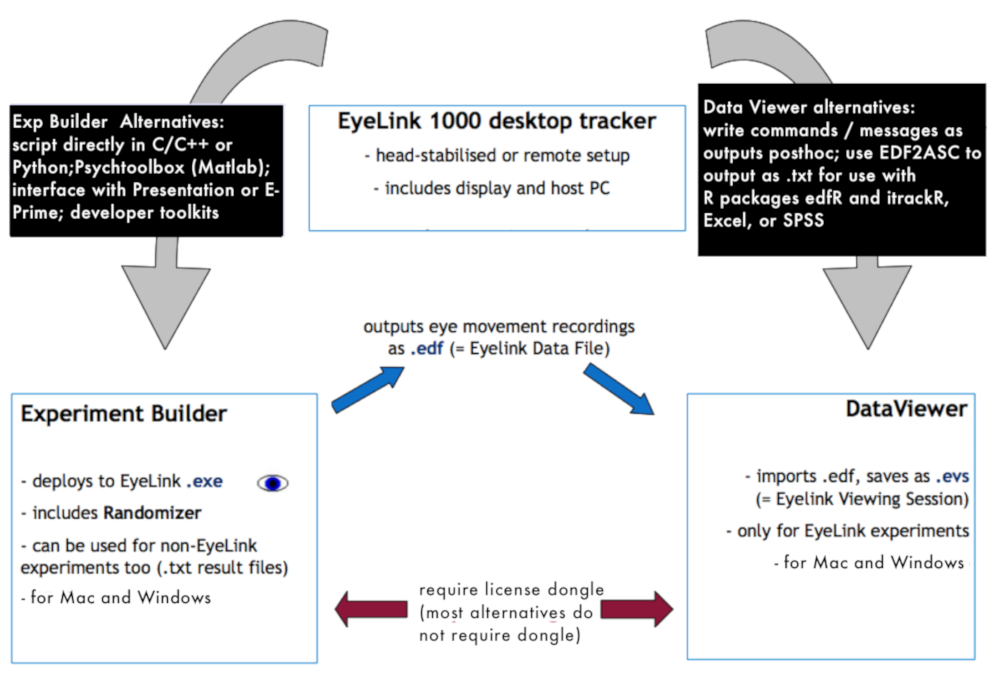{kind=link}

图 2: 明斯特和合作者的代表性结果 37.这些面板显示了每个主题的平均对数凝视概率比率, 每个条件在动词区域 (对于所描绘的动作) 和在动词副词区域组合 (情感素数的效果)。结果显示, 当句子中提到的动作被描绘时, 对目标图像的看目光比例要比没有描述时高得多。情绪面部原值效应的结果并不那么确定: 它们表明, 与负性情绪价值 (悲伤的脸) 相比, 当面部原值有积极的情绪价值 (微笑) 时, 外观与目标的平均日志比例只略有增加。误差线表示平均值的标准误差。明斯特等人对这一数字作了修改.37.请点击此处查看此图的较大版本.
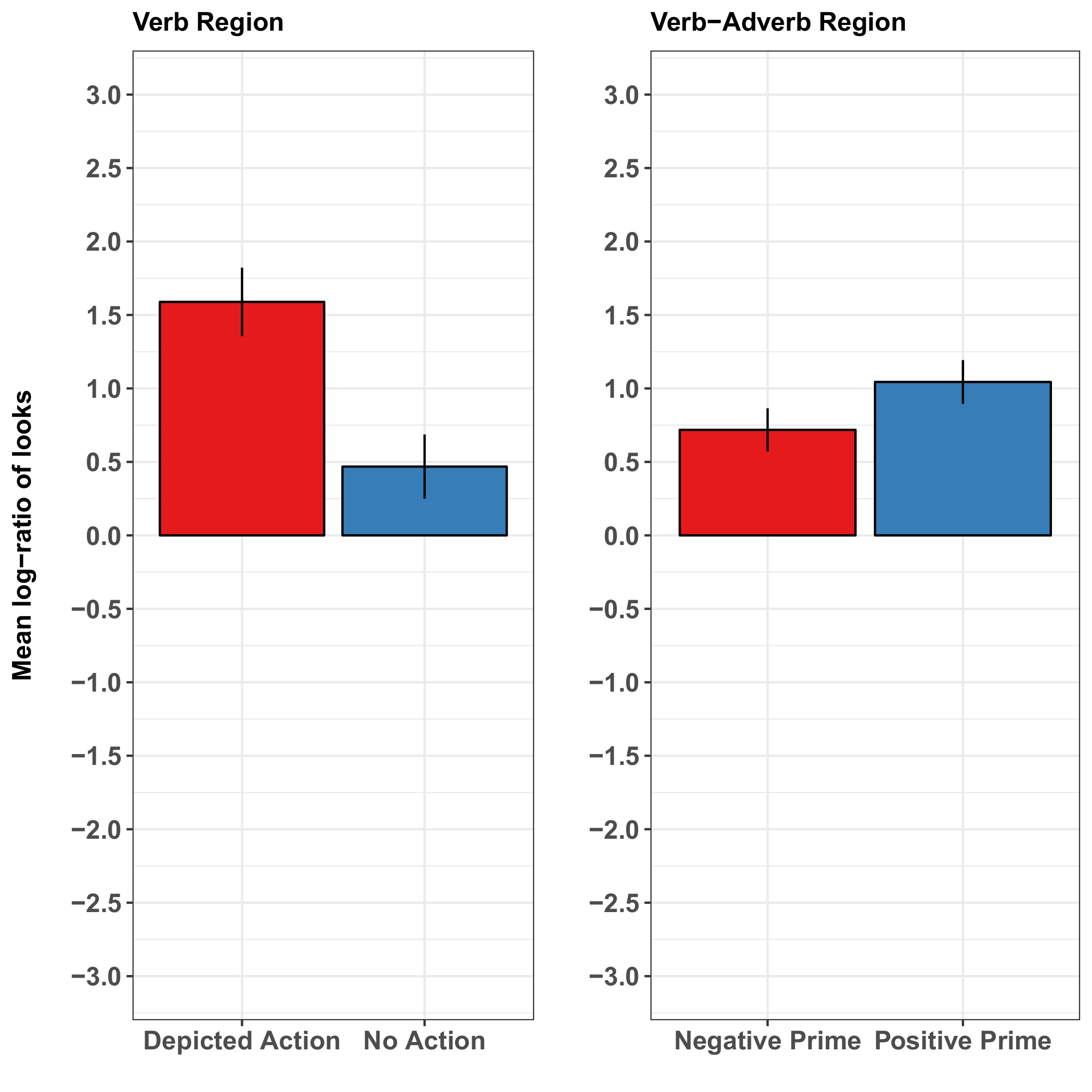{kind=link}

图 3: guerra 和 kneferle32的代表性结果.此面板显示 (dis) 相似形容词的平均第一道次读时数 (以毫秒为单位)。结果显示, 在看到两张扑克牌与距离较远的扑克牌移动得更近之后, 相似句子的阅读时间较短。误差线表示平均值的标准误差。这一数字已从 guerra 和 knefer32修改。请点击这里查看此图的较大版本.
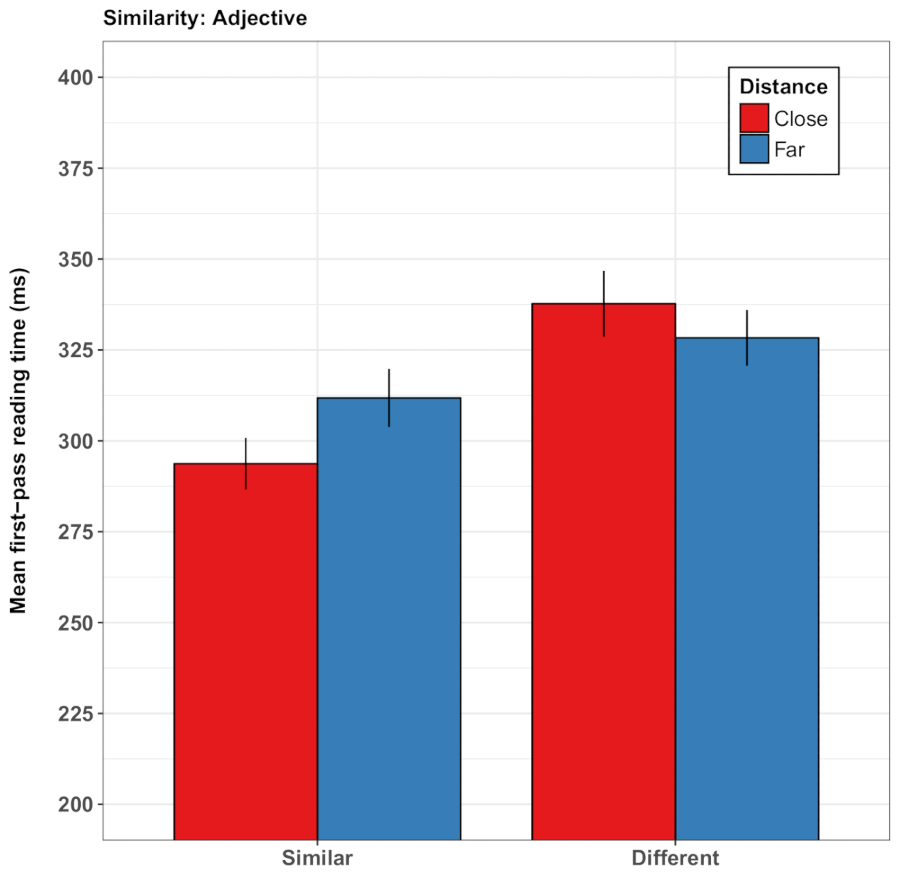{kind=link}

图 4: 罗德里格斯和合作者的代表性结果 26.此面板显示动词区域中每个条件的按主题的平均日志凝视概率比率。0以上的外观比例显示目标代理映像的首选项, 0 以下的比例显示竞争对手代理映像的首选项。结果表明, 当句子中提到的对象和动词与之前的录像事件相匹配时, 参与者更容易检查目标代理映像, 而不是不匹配的对象。此外, 当句子所描述的动作符合性别陈规定型观念时, 对目标代理形象的看法也会更多。误差线表示平均值的标准误差。这一数字已从 rodríguez等人处修改。26.请点击此处查看此图的较大版本.
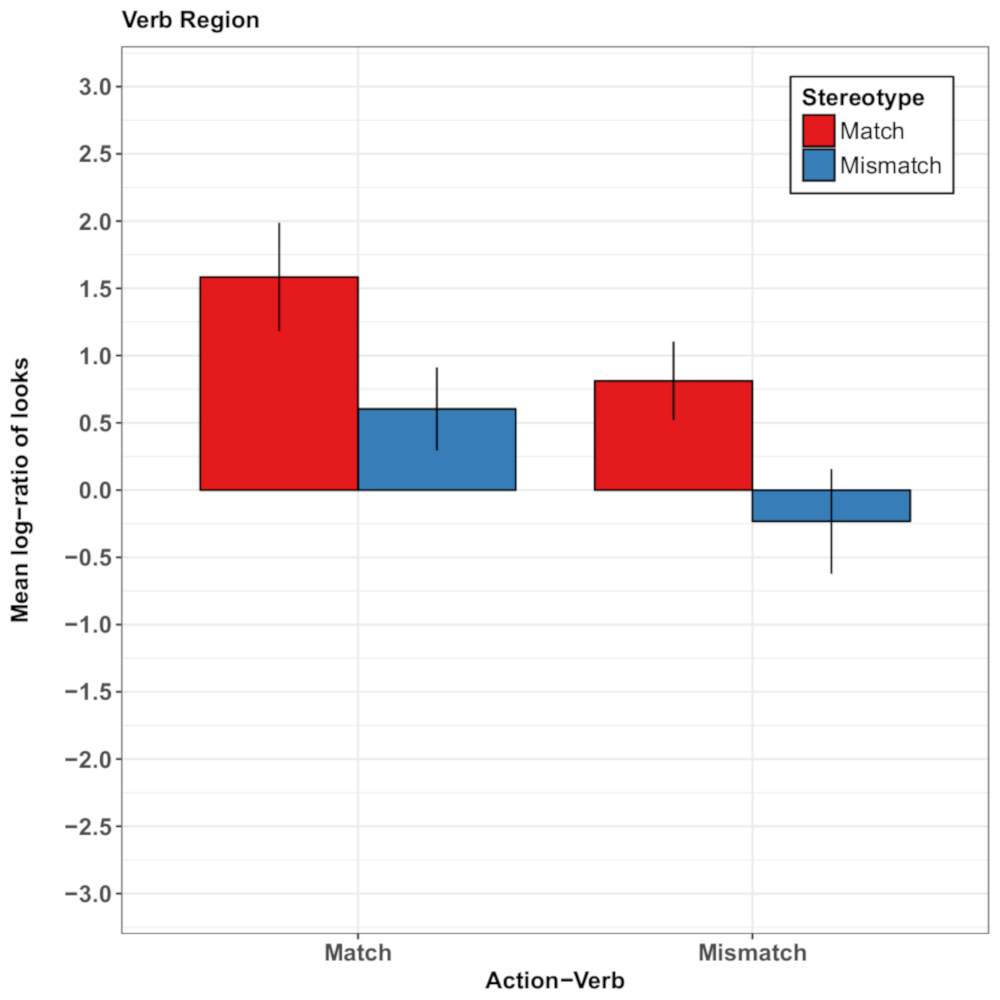{kind=link}
讨论
总之, 所回顾的视觉环境中眼动追踪的变体已经揭示了视觉场景影响语言理解的多种方式。与测量反应时间等方法相比, 这种方法提供了至关重要的优势。例如, 持续的眼动为我们提供了一个了解语言理解过程的窗口, 以及这些过程如何随着时间的推移与我们对视觉世界的感知相互作用。此外, 在语言理解过程中, 不一定要求参与者执行明确的任务 (例如通过按钮按下来判断句子的语法性)。这使得研究人员能够对可能难以与眼睛注视以外的公开行为反应的人群使用这种方法, 如婴儿、儿童, 在某些情况下还有老年人。眼动追踪在生态上是有效的, 因为它反映了参与者的注意力反应--与人类在他们周围的世界中对与通信相关的事物的视觉询问并无不同。
视觉世界范式的边界之一 (或许是特征) 是, 并不是所有的事件都能直接、明确地描述。当然, 可以描述具体的物体和事件。但抽象概念是如何最好地描述的并不那么清楚。这可以限制 (或定义) 对语言处理与使用眼动视觉世界范式感知视觉世界之间互动的洞察。进一步的挑战涉及到观察到的行为和理解过程之间的联系假设。眼睛固定是一种单一的行为反应, 可能反映了语言理解过程中的许多子过程 (例如, 词汇访问、引用过程、语言中介的期望、视觉语境效果等)。鉴于这种洞察, 研究人员必须小心, 不要过度或误解观察到的凝视模式。为了解决这个问题, 先前的研究强调了理解子任务的作用, 以澄清对凝视记录40的解释.
提高眼动可解释性的一个方法是将它们与其他措施 (如事件相关的大脑电位) 结合起来。通过用两种在时间粒度上具有可比性和在连接假设上互补的方法来研究同一现象, 研究人员可以排除对其结果的替代解释, 并丰富对每种方法的解释个别措施41。这种方法已在实验43中采用, 但最近也在一个单一的实验中 (尽管是在严格的语言背景下)44。今后的研究可大大受益于这种方法整合以及与试验后和实验后任务的持续结合。
眼动追踪方法可以复制已建立的结果, 也可以测试关于场景中视觉注意力与语言理解相互作用的新假设。必须仔细遵循协议中概述的过程, 因为即使是轻微的实验错误也会影响数据质量。例如, 在阅读研究中, 相关的分析区域往往是个别单词甚至字母, 这意味着即使是很小的校准错误也可能扭曲结果 (见 raney 和同事42的文章)。协议的步骤1.4 和1.5、眼动仪的校准和漂移检查/漂移的正确性尤其重要, 因为它们直接影响记录的准确性。如果不能正确校准眼动仪, 可能会导致跟踪器无法准确跟踪眼动到预先确定的感兴趣的区域。这种跟踪失败将导致数据点缺失和统计能力的丧失, 这在调查非常微妙的世界与语言的关系时可能会出现问题, 并产生较小的统计效果大小 (请参见由 guerra 和 Knoeferle 和 münster和同事 37的实验)。
鉴于需要最大限度地提高设备的功率和灵敏度, 实验者必须知道如何处理实验期间经常发生的问题。例如, 戴眼镜的参与者的瞳孔位置和运动可能会由于参与者眼镜镜片上的光线反射而导致校准困难。解决此问题的一种方法是在 "显示 pc" 上镜像参与者的眼睛图像, 并鼓励他们移动头部, 直到眼镜上的光线反射在屏幕上不再可见, 这意味着相机不再捕捉到光线。校准失败的另一个原因可能是瞳孔收缩, 这可能是过度暴露在光线下的结果。在这种情况下, 调光实验室中的光线将增加瞳孔扩张, 从而帮助眼动仪准确地检测瞳孔。
作为最后的想法, 我们要讨论视觉世界范式对第二语言学习研究的潜力。该范式已成功地应用于心理语言学研究中, 以调查跨语言词汇和语音互动等现象 46、47、48。此外, 视觉注意力与语言学习之间的密切联系在关于第二语言习得的应用语言学文献中也经常凸显, 49、50、51.今后对第二语言学习的研究很可能继续受益于眼动追踪作为一种以毫秒分辨率提供视觉注意力指标的方法的有利位置。
披露声明
作者没有什么可透露的。
致谢
这项研究是由柏林洪堡大学 (emboldt-t ' t ' t 大学)、第2业集群 277 "认知相互作用技术" (德国研究理事会) 和欧洲联盟第七个研究框架方案资助的,技术发展, 以及在授予协议下的示范 n°316748 (lanpercept)。作者还感谢基础卓越中心基金、智利政府联合研究项目 fb0003 项目和 xprag (dfg) 焦点中心的 "fotero" 项目的支持。pia Knoeferle 提供了一份由实验室协议通报的文章初稿, helene kreysa 在 bielefeld 大学实例化, 并继续在柏林洪堡大学继续使用。所有作者都通过以这样或那样的形式提供方法和结果的输入, 为内容做出了贡献。camilo rodríguez ronderos 和 pia Knoeferle 协调了作者的投入, 并在两次迭代中对初稿作了实质性修订。 ernesto guerra 根据 katja münster、alba rodríguez 和 ernesto guerra 的投入制作了图 2-4 。helene kreysa 提供了图 1 , pia Knoeferle 对其进行了更新。所报告的部分结果已发表在认知科学学会年会论文集上。
材料
| Name | Company | Catalog Number | Comments |
| Desktop mounted eye-tracker including head/chin rest | SR Research Ltd. | EyeLink 1000 plus | http://www.sr-research.com/eyelink1000plus.html |
| Software for the design and execution of an eye-tracking experiment | SR Research Ltd. | Experiment Builder | http://www.sr-research.com/eb.html |
参考文献
- Tanenhaus, M. K., Spivey-Knowlton, M. J., Eberhard, K. M., Sedivy, J. C. Integration of visual and linguistic information in spoken language comprehension. Science. 268 (5217), 1632-1634 (1995).
- Cooper, R. M. The control of eye fixation by the meaning of spoken language: A new methodology for the real-time investigation of speech perception, memory, and language processing. Cognitive Psychology. 6 (1), 84-107 (1974).
- Knoeferle, P., Guerra, E. What is non-linguistic context? A view from language comprehension. In What is a Context? Linguistic Approaches and Challenges. Finkbeiner, R., Meibauer, J., Schumacher, P. B. , John Benjamins Publishing Company. Amsterdam, The Netherlands. 129-150 (2012).
- Knoeferle, P., Guerra, E. Visually situated language comprehension. Language and Linguistics Compass. 10 (2), 66-82 (2016).
- Just, M. A., Carpenter, P. A. A theory of reading: From eye fixations to comprehension. Psychological Review. 87 (4), 329-354 (1980).
- Deubel, H., Schneider, W. X. Saccade target selection and object recognition: Evidence for a common attentional mechanism. Vision Research. 36 (12), 1827-1837 (1996).
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychological Bulletin. 124 (3), 372-422 (1998).
- Sedivy, J. C., Tanenhaus, M. K., Chambers, C. G., Carlson, G. N. Achieving incremental semantic interpretation through contextual representation. Cognition. 71 (2), 109-147 (1999).
- Kamide, Y., Scheepers, C., Altmann, G. T. Integration of syntactic and semantic information in predictive processing: Cross-linguistic evidence from German and English. Journal of Psycholinguistic Research. 32 (1), 37-55 (2003).
- Allopenna, P. D., Magnuson, J. S., Tanenhaus, M. K. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language. 38 (4), 419-439 (1998).
- Tanenhaus, M. K., Magnuson, J. S., Dahan, D., Chambers, C. Eye movements and lexical access in spoken-language comprehension: Evaluating a linking hypothesis between fixations and linguistic processing. Journal of Psycholinguistic Research. 29 (6), 557-580 (2000).
- Arnold, J. E., Eisenband, J. G., Brown-Schmidt, S., Trueswell, J. C. The rapid use of gender information: Evidence of the time course of pronoun resolution from eyetracking. Cognition. 76 (1), B13-B26 (2000).
- Chambers, C. G., Tanenhaus, M. K., Magnuson, J. S. Actions and affordances in syntactic ambiguity resolution. Journal of Experimental Psychology: Learning, Memory, and Cognition. 30 (3), 687-696 (2004).
- Spivey, M. J., Tanenhaus, M. K., Eberhard, K. M., Sedivy, J. C. Eye movements and spoken language comprehension: Effects of visual context on syntactic ambiguity resolution. Cognitive Psychology. 45 (4), 447-481 (2002).
- Huang, Y. T., Snedeker, J. Online interpretation of scalar quantifiers: Insight into the semantics-pragmatics interface. Cognitive Psychology. 58 (3), 376-415 (2009).
- Trueswell, J. C., Sekerina, I., Hill, N. M., Logrip, M. L. The kindergarten-path effect: studying online sentence processing in young children. Cognition. 73 (2), 89-134 (1999).
- Knoeferle, P., Crocker, M. W., Scheepers, C., Pickering, M. J. The influence of the immediate visual context on incremental thematic role-assignment: evidence from eye movements in depicted events. Cognition. 95 (1), 95-127 (2005).
- Knoeferle, P., Crocker, M. W. Incremental Effects of Mismatch during Picture-Sentence Integration: Evidence from Eye-tracking. Proceedings of the 26th Annual Conference of the Cognitive Science Society. , Stresa, Italy. 1166-1171 (2005).
- Kluth, T., Burigo, M., Schultheis, H., Knoeferle, P. The role of the center-of-mass in evaluating spatial language. Proceedings of the 13th Biannual Conference of the German Society for Cognitive Science. , Bremen, Germany. 11-14 (2016).
- Burigo, M., Knoeferle, P. Visual attention during spatial language comprehension. PLoS One. 10 (1), (2015).
- Münster, K., Carminati, M. N., Knoeferle, P. How Do Static and Dynamic Emotional Faces Prime Incremental Semantic Interpretation? Comparing Older and Younger Adults. Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 2675-2680 (2014).
- Kroeger, J. M., Münster, K., Knoeferle, P. Do Prosody and Case Marking influence Thematic Role Assignment in Ambiguous Action Scenes? Proceedings of the 39th Annual Meeting of the Cognitive Science Society. , London, UK. 2463-2468 (2017).
- Knoeferle, P., Crocker, M. W. The influence of recent scene events on spoken comprehension: evidence from eye movements. Journal of Memory and Language. 57 (4), 519-543 (2007).
- Knoeferle, P., Carminati, M. N., Abashidze, D., Essig, K. Preferential inspection of recent real-world events over future events: evidence from eye tracking during spoken sentence comprehension. Frontiers in Psychology. 2, 376(2011).
- Abashidze, D., Knoeferle, P., Carminati, M. N. How robust is the recent-event preference? Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 92-97 (2014).
- Rodríguez, A., Burigo, M., Knoeferle, P. Visual constraints modulate stereotypical predictability of agents during situated language comprehension. Proceedings of the 38th Annual Meeting of the Cognitive Science Society. , Philadelphia, USA. 580-585 (2016).
- Zhang, L., Knoeferle, P. Visual Context Effects on Thematic Role Assignment in Children versus Adults: Evidence from Eye Tracking in German. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 2593-2598 (2012).
- Zhang, L., Kornbluth, L., Knoeferle, P. The role of recent versus future events in children's comprehension of referentially ambiguous sentences: Evidence from eye tracking. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 1227-1232 (2012).
- Münster, K., Knoeferle, P. Situated language processing across the lifespan: A review. International Journal of English Linguistics. 7 (1), 1-13 (2017).
- Özge, D., et al. Predictive Use of German Case Markers in German Children. Proceedings of the 40th Annual Boston University Conference on Language Development. , Somerville, USA. 291-303 (2016).
- Weber, A., Grice, M., Crocker, M. W. The role of prosody in the interpretation of structural ambiguities: A study of anticipatory eye movements. Cognition. 99 (2), B63-B72 (2006).
- Guerra, E., Knoeferle, P. Effects of object distance on incremental semantic interpretation: similarity is closeness. Cognition. 133 (3), 535-552 (2014).
- Kreysa, H., Knoeferle, P., Nunnemann, E. Effects of speaker gaze versus depicted actions on visual attention during sentence comprehension. Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 2513-2518 (2014).
- Abashidze, D., Knoeferle, P., Carminati, M. N. Eye-tracking situated language comprehension: Immediate actor gaze versus recent action events. Proceedings of the 37th Annual Meeting of the Cognitive Science Society. , Pasadena, USA. 31-36 (2015).
- Crovitz, H. F., Zener, K. A Group-Test for Assessing Hand- and Eye-Dominance. The American Journal of Psychology. 75 (2), 271-276 (1962).
- Ehrenstein, W. H., Arnold-Schulz-Gahmen, B. E., Jaschinski, W. Eye preference within the context of binocular functions. Graefe's Arch Clin Exp Ophthalmol. 243, 926(2005).
- Münster, K., Carminati, M. N., Knoeferle, P. The Effect of Facial Emotion and Action Depiction on Situated Language Processing. Proceedings of the 37th Annual Meeting of the Cognitive Science Society. , Pasadena, USA. 1673-1678 (2015).
- Lakoff, G., Johnson, M. Metaphors We Live By. , University of Chicago Press. Chicago, USA. (1980).
- Guerra, E., Knoeferle, P. Visually perceived spatial distance affects the interpretation of linguistically mediated social meaning during online language comprehension: An eye tracking reading study. Journal of Memory and Language. 92, 43-56 (2017).
- Kreysa, H., Knoeferle, P. Effects of speaker gaze on spoken language comprehension: task matters. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 1557-1562 (2012).
- Knoeferle, P. Language comprehension in rich non-linguistic contexts: Combining eye tracking and event-related brain potentials. Towards a cognitive neuroscience of natural language use. Roel, W. , Cambridge University Press. Cambridge, UK. 77-100 (2015).
- Raney, G. E., Campell, S. J., Bovee, J. C. Using eye movements to evaluate cognitive processes involved in text comprehension. Journal of Visualized Experiments. (83), e50780(2014).
- Knoeferle, P., Habets, B., Crocker, M. W., Muente, T. F. Visual scenes trigger immediate syntactic reanalysis: evidence from ERPs during situated spoken comprehension. Cerebral Cortex. 18 (4), 789-795 (2008).
- Dimigen, O., Sommer, W., Hohlfeld, A., Jacobs, A. M., Kliegl, R. Coregistration of eye movements and EEG in natural reading: Analyses and review. Journal of Experimental Psychology: General. 140 (4), 552-572 (2011).
- Knoeferle, P., Kreysa, H. Can speaker gaze modulate syntactic structuring and thematic role assignment during spoken sentence comprehension? Frontiers in Psychology. 3, 538(2012).
- Chambers, C. G., Cooke, H. Lexical competition during second-language listening: Sentence context, but not proficiency, constrains interference from the native lexicon. Journal of Experimental Psychology: Learning, Memory, and Cognition. 35 (4), 1029(2009).
- Duyck, W., Van Assche, E., Drieghe, D., Hartsuiker, R. J. Visual word recognition by bilinguals in a sentence context: Evidence for nonselective lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition. 33 (4), 663(2007).
- Weber, A., Cutler, A. Lexical competition in non-native spoken-word recognition. Journal of Memory and Language. 50 (1), 1-25 (2004).
- Verhallen, M. J., Bus, A. Young second language learners' visual attention to illustrations in storybooks. Journal of Early Childhood Literacy. 11 (4), 480-500 (2011).
- Robinson, P., Mackey, A., Gass, S. M., Schmidt, R. Attention and awareness in second language acquisition. The Routledge Handbook of Second Language Acquisition. , 247-267 (2012).
- Tomlin, R. S., Villa, V. Attention in cognitive science and second language acquisition. Studies in Second Language Acquisition. 16 (2), 183-203 (1994).
转载和许可
请求许可使用此 JoVE 文章的文本或图形
请求许可探索更多文章
This article has been published
Video Coming Soon
版权所属 © 2025 MyJoVE 公司版权所有,本公司不涉及任何医疗业务和医疗服务。