
Method Article
Eye Tracking au cours de la compréhension du langage visuel situé : Flexibilité et Limitations en découvrant des effets de contexte visuel
Dans cet article
Résumé
Le présent article examine une méthodologie de suivi oculaire pour les études sur la compréhension de la langue. Pour obtenir des données fiables, des étapes clés du protocole doivent être respectées. Parmi ceux-ci figurent la mise en place correcte du Traqueur d’oeil (par exemple, assurer la bonne qualité des images oeil et tête) et un étalonnage précis.
Résumé
Le présent ouvrage est une description et une évaluation d’une méthodologie visant à quantifier les différents aspects de l’interaction entre le traitement du langage et la perception du monde visuel. L’enregistrement de modèles d’yeux-regard a fourni des preuves suffisantes pour la contribution du contexte visuel et connaissances linguistiques/world à la compréhension de la langue. Recherche initiale évalué les effets de contexte de l’objet pour tester des théories de la modularité dans le traitement du langage. Dans l’introduction, les auteurs décrivent comment des enquêtes ultérieures ont pris le rôle du contexte visuel plus large dans la langue de traitement comme un sujet de recherche à part entière, poser des questions telles que la façon dont notre perception visuelle des événements et des orateurs contribue à compréhension informée par expérience des comprehenders. Parmi les aspects examinés du contexte visuel sont des actions, événements, d’un haut-parleur regard et des expressions faciales émotionnelles, ainsi que des configurations spatiales objet. Après un aperçu de la méthode de suivi du regard et de ses différentes applications, nous listons les principales étapes de la méthodologie dans le protocole, illustrant la façon de l’utiliser avec succès pour étudier la compréhension de la langue trouve visuellement. Une dernière section présente trois ensembles de résultats représentatifs et illustre les avantages et les limites de suivi oculaire pour étudier l’interaction entre la perception de la compréhension mondiale et le langage visuelle.
Introduction
Recherche psycholinguistique a mis en évidence l’importance des analyses des mouvements oculaires dans la compréhension des processus impliqués dans la compréhension de la langue. Au cœur du processus de compréhension de l’enregistrement en regard de la déduction est une hypothèse qui relie la cognition et de mouvements oculaires5. Il existe trois grands types de mouvements oculaires : saccades, mouvements vestibulo-oculaire et sans heurt de poursuite. Saccades sont rapides et balistiques des mouvements qui se produisent plus souvent inconsciemment et ont été sûrement associés aux déplacements attention6. Les moments de regard relative stabilité entre les saccades, connu comme les fixations, sont considérés comme attention visuelle actuelle index. Le locus des fixations et leur durée en ce qui concerne les processus cognitifs de mesure est connue comme la « méthode d’eye-tracking ». Premières implémentations de cette méthode a servi à examiner la compréhension de la lecture dans des contextes strictement linguistiques (voir Rayner7 pour un examen). Dans cette approche, la durée d’inspecter un mot ou une phrase région est associée au traitement des difficultés. Cependant, oculométrique a également été appliquée pour examiner la compréhension de la langue parlée au cours de l’inspection d’objets dans le monde (ou sur un ordinateur affichage2). Dans cette version d’oculométrie « univers visuel », l’inspection d’objets est guidée par la langue. Quand les comprehenders entendent le zèbre, par exemple, l’inspection d’un zèbre à l’écran est censée refléter qu’ils pensent sur l’animal. Dans ce qui est connu comme le paradigme de l’univers visuel, regard oeil d’un comprehender est censée refléter la compréhension de la langue parlée et l’activation des savoirs associés (p. ex., les auditeurs aussi inspectent le zèbre quand ils entendent le pâturage, ce qui indique une action effectuée par le zèbre)2. Ces inspections suggèrent un lien systématique entre les relations langue-monde et de mouvements oculaires2. Un moyen courant de quantifier ce lien est en calculant la proportion de regards vers différentes régions prédéterminées sur un écran. Cela permet aux chercheurs de comparer directement (dans des conditions, par les participants et éléments) la quantité d’attention accordée à des objets différents à un moment donné et comment ces valeurs changent dans la résolution de la milliseconde.
Recherches en psycholinguistique a exploité la suivi des yeux dans des mondes visuels pour taquiner apart concurrentes hypothèses théoriques sur l’architecture de l' esprit1. Fixations d’oeil sur les objets représentés ont, en outre, révélé que comprehenders peut — en supposant un contexte linguistique suffisamment restrictif — effectuer une interprétation sémantique différentiel8 et même développer des attentes sur les caractères à venir 9. ces données de regard yeux ont également fait la lumière sur une gamme de plus les processus de compréhension, comme ambiguïté lexicale résolution10,11, pronom résolution12, la désambiguïsation du rôle structurel et thématique cession par le biais de l’information dans le contexte visuel13,14,16et processus pragmatique15, parmi beaucoup d’autres4. De toute évidence, les mouvements de le œil aux objets au cours de la compréhension de la langue peuvent être informatives des processus impliqués.
La méthode de l’oculométrie est non invasif et peut être utilisée avec les nourrissons, les utilisateurs des langues des jeunes et plus âgés. Un avantage clé est que, contrairement aux réponses ponctuées de sondes ou de pressions sur la touche de réponse dans les tâches de vérification, il donne un aperçu au fil du temps dans une résolution de milliseconde dans Comment langue guides attention et comment le contexte visuel (sous la forme d’objets, actions, événements, d’un orateur regard et des expressions faciales émotionnelles, ainsi des configurations spatiales objet) contribue au traitement du langage. La continuité de la mesure au cours de la compréhension de la phrase complète bien avec les autres mesures postpénale et après expérience comme vérification de photo/vidéo-phrase manifeste, questions de compréhension et tâches de rappel de mémoire. Des réponses ouvertes à ces tâches peuvent enrichir l’interprétation de l’enregistrement de regard yeux en fournissant la perspicacité dans le résultat de la processus de compréhension, la mémoire et d’apprentissage2. Combinant la suivi des yeux avec ces autres tâches a permis de découvrir dans quelle mesure différents aspects du contexte visuel modulent l’attention visuelle et la compréhension (immédiate, ainsi que retardée) toutes les étapes de la vie.
La présentation de la langue (parlée ou écrite) et des scènes peuvent être simultanée ou séquentielle. Par exemple, Knoeferle et collaborateurs17 présenté la scène 1 000 ms avant la phrase parlée, et il est resté présent au cours de la compréhension. Ils ont signalé la preuve clipart représentations des événements d’action contribuant à la résolution de l’ambiguïté structurelle locale allemande sujet-verbe-objet (SVO) par rapport aux phrases sujet-verbe-objet (OVS). Knoeferle et Crocker18 présenté une scène clipart avant une phrase écrite et testé l’intégration progressive des cliparts événements au cours de la compréhension de la phrase. Ils ont observé des effets de congruence supplémentaires, ce qui signifie que les participants lecture des constituants de la phrase était plus long lorsque ceux-ci correspondent pas (vs appariés) l’événement représenté dans la scène précédente. Dans une autre variante de présentation de stimulation, les participants d’abord lire une phrase décrivant une relation spatiale et puis vu une scène d’une disposition spatiale particulière impliquant l’objet des dessins au trait19. Cette étude a évalué les prédictions des modèles de calcul langue spatiale en demandant aux participants d’évaluer l’adéquation de la phrase donnée à la scène, avec les mouvements de le œil étant enregistrées au cours de l’interrogatoire de la scène. Modèles de regard des participants ont été modulées par la forme de l’objet qu’ils ont été confrontés — partiellement confirmant les prédictions du modèle et en fournissant des données pour l’affinement du modèle.
Alors que de nombreuses études ont utilisé des cliparts représentations17,18,19,20,21,22,23, il est également possible de combiner le monde réel objets, des vidéos de ces objets, ou des photos statiques avec langue parlée1,21,24,25,26,46. Knoeferle et collègues ont utilisé un contexte réel24 et Abachidzé et collègues utilisaient un format de présentation enregistrée sur bande magnétoscopique pour l’examen des événements d’action et effets tendue25. Variant le contenu précis des scènes (par exemple, illustrant les actions ou non)22,27,38 est possible et peut également révéler des effets de contexte visuel. Une étude connexe par Rodríguez et collaborateurs26 a étudié l’influence des signaux sur bande vidéo sexe visuel sur la compréhension des présenté par la suite les phrases parlées. Participants ont regardé les vidéos montrant des mains mâles ou femelles qui exécute une action stéréotype sexiste. Puis, ils ont entendu une phrase sujet soit un événement d’action stéréotype masculin ou féminin lors de l’inspection en même temps un affichage montrant deux photos côte à côte, l’un de l’homme et l’autre d’une femme. Ce riche environnement visuel et linguistique a permis aux auteurs de distinguer les effets des connaissances stéréotypée véhiculée par la langue sur la compréhension des effets des signaux entre les sexes visuellement présentés (main).
Une autre demande de ce paradigme a ciblé des changements développementaux dans le traitement du langage. Mouvements oculaires aux objets au cours de la compréhension de la langue parlée a révélé les effets des événements représentés dans 4 - 5 - ans27,28 et d’adultes plus âgés29 en temps réel, mais un peu retardé par rapport aux jeunes adultes. Kröger et collaborateurs22 a examiné les effets des indices prosodiques et cas marquant au sein d’une expérience et comparé ces travers expériences chez les adultes et les enfants. Participants ont inspecté une scène d’action-événement ambigu pendant l’écoute d’une phrase allemande connexe clairement marquées en cas. Mouvements oculaires ont révélé que les profils prosodiques distincts a aidé ni adultes, ni les 4 ou 5-ans quand qui-est-ce que-à qui diriger. Phrase initiale cas marquant, mais influencé des adultes mais pas les mouvements des yeux des enfants. Ceci suggère que la compréhension des 5-year-olds de marquage affaire n’est pas suffisamment robuste pour permettre l’attribution de rôle thématique (Voir l’étude de Özge et collaborateurs30), au moins pas quand événements action ne pas lever l’ambiguïté entre rôle thématique relations. Ces résultats sont intéressants, étant donné qu’ils sont en contraste avec les résultats antérieurs des effets prosodiques le rôle thématique affectation31. Kröger et collaborateurs22 a proposé que le contexte visuel (plus ou moins favorable) est responsable des résultats contrastés. Dans la mesure où ces interprétations tiennent, elles mettent en évidence le rôle du contexte dans la compréhension de la langue toutes les étapes de la vie.
La méthode de l’oculométrie combine bien avec les mesures de la photo (ou vidéo) phrase vérification tâches18,20,26, image vérification tâches32, corpus études24, cotation tâches19, ou études expérimentales de rappel des tâches25,33. Abachidzé et collaborateurs34 et Kreysa et collaborateurs33 a étudié le jeu de regard de haut-parleur et action réelle vidéos34 et haut-parleur regard et action représentations33, respectivement, comme repères pour contenu de la phrase à venir. En combinant le suivi du regard des yeux dans une scène au cours de la compréhension de la langue avec une tâche de mémoire après expérimentation, ils ont acquis une meilleure compréhension de la façon dont perception de l’auditeur du regard du conférencier et les actions représentées interagissent et affectent traitement du langage immédiat et mémorisation. Les résultats ont révélé la contribution distincte des actions par rapport aux haut-parleurs regard aux processus de rappel compréhension en temps réel par rapport à post-l’expérience mémoire.
Alors que la méthode de suivi oculaire peut être employée avec beaucoup de souplesse, certaines normes sont essentielles. Le protocole suivant résume une procédure généralisée qui peut être réglée à différents types de questions de recherche selon les besoins spécifiques des chercheurs. Ce protocole est une procédure normalisée utilisée dans le laboratoire de psycholinguistique à la Humboldt-Universität zu Berlin, ainsi que dans l’ancienne langue et laboratoire Cognition à la Cognitive Interaction technologie Excellence Cluster (CITEC) à Université de Bielefeld. Le protocole décrit un ordinateur de bureau et d’une installation à distance. Ce dernier est recommandé pour une utilisation dans les études avec des enfants ou des adultes plus âgés. Toutes les expériences mentionnées dans les Résultats représentant utilisent un appareil de traqueur d’oeil qui a une fréquence d’échantillonnage de 1 000 Hz et est utilisé conjointement avec un stabilisateur de tête, un PC pour tester les participants (écran PC) et un PC de surveillance de l’expérience et la mouvements oculaires des participants (PC hôte). La différence principale de cet appareil à son prédécesseur, c’est qu’il permet un suivi oculaire binoculaire. Le protocole est destiné à être suffisamment générales pour une utilisation avec d’autres dispositifs de poursuite oculaire qui incluent un stabilisateur de la tête et de faire usage d’un PC dual setup (hôte + affichage). Cependant, il est important de garder à l’esprit que les autres configurations auront probablement des méthodes différentes pour traiter des problemes tels que les échecs de calibrage ou de la perte de la piste, dans lequel cas l’expérimentateur doit faire référence à l’utilisateur manuelle d’un périphérique spécifique.
Protocole
Ce protocole suit les directives d’éthique de l’institution où les données ont été recueillies, c'est-à-direle cognitif Interaction technologie Excellence Cluster (CITEC) de l’Université de Bielefeld et Humboldt-Universität zu Berlin. Les expériences menées à l’Université de Bielefeld ont été approuvées individuellement par le Comité d’éthique de l’Université de Bielefeld. Le laboratoire de psycholinguistique à la Humboldt-Universität zu Berlin comporte un protocole laboratoire éthique a été approuvé par le Comité d’éthique de la Deutsche Gesellschaft für Sprachwissenschaft, la société de linguistique de l’allemand (DGfS).
1. Bureau Setup
NOTE : Voici les principales étapes dans une expérience de suivi du regard.
- Préparation de l’instrument
- Allumez la caméra eye-tracking et le PC hôte (voir la Figure 1 pour une illustration de la collecte des données en laboratoire et l’installation de pré-traitement).
- Lancer le logiciel de traqueur oculaire.
- Activer l’affichage du PC. Ouvrez le dossier qui contient les expériences.
- Démarrer la version « déployée » avec une extension .exe en double-cliquant dessus.
- Selon le paramétrage, une invite de sélection une liste expérimentale peut apparaître, qui est généralement un fichier délimité par des tabulations.csv/.txt contenant les conditions, les noms de fichier audio, phrases écrites et/ou images qui est exposé à un participant. Sélectionnez la liste et le programme va commencer. Nommez le fichier de sortie, où les résultats seront conservés.
Remarque : Le fichier de sortie est sauvegardé sur le PC d’affichage et une copie de sauvegarde est enregistré sur le PC hôte. - Entrouvrir le premier écran de l’expérience (l’introduction ou l’écran de bienvenue).
- Retirez le couvercle de protection de l’appareil de traqueur oculaire.
- À des fins hygiéniques, placez un mouchoir en papier sur le support de menton.
- Facultatif : Préparer un tampon de réponse et/ou un clavier tel qu’exigé par l’expérience.
- Facultatif : Si la présentation de stimuli auditifs, régler le volume des haut-parleurs et testez-les avant d’exécuter l’expérience. Vous pouvez également tester la fonctionnalité du casque d’écoute pour être utilisé par le participant.
- Préparer les formulaires nécessaires doit être signé par le participant.
- Régler l’intensité lumineuse en laboratoire afin d’avoir une pièce faiblement éclairée avec une luminance constante pendant toute la durée de la procédure de collecte de données.
- Préparation pour les participants
- Après que les participants sont arrivés, présentez-vous.
- Place un ne pas déranger signe sur la porte du laboratoire.
- Demander au participant de prendre un siège.
- Guide du participant par le biais de la fiche d’information et le consentement nécessaire et formes démographiques.
- Laisser le participant lire et signer le formulaire de consentement.
- Expliquer brièvement les aspects généraux de l’expérience et de sa durée. N’informent pas trop avant l’expérience, car cela pourrait influencer comportement regard du participant et les données qui en résulte.
- Fournit des instructions écrites et donne le participant la possibilité de poser des questions.
- Expliquer brièvement la fonction du Traqueur oculaire.
- Le cas échéant, préciser la tâche et signaler toute boutons/touches qui devront être pressé pendant l’expérience.
- Expliquer comment la mentonnière est destinée à minimiser les mouvements de la tête au cours de l’expérience. Mentionner que le dispositif fonctionne mieux si le participant évite tout mouvement.
- Mise en place le traqueur d’oeil
- Préparer le participant à l’expérience : leur demander de s’asseoir à la table et placer leur menton sur la mentonnière. Leur demander d’appuyer leur front contre l’appui-tête.
- Demander au participant d’ajuster la hauteur et la position de la chaise si nécessaire : le participant doit se sentir à l’aise avec leur menton sur la mentonnière et leur front contre l’appui-tête.
- Expliquez qu’il est fréquent de passer accidentellement la tête pendant l’expérience et que cela devrait être évité. Expliquer que la posture de tête peut-être avoir à être corrigé au cours de l’expérience.
- Si l’expérience nécessite une touche (par exemple, via la touche de réponse), demander au participant de laisser leurs doigts reposant sur les boutons à presser et d’éviter en regardant vers le bas le tampon de la réponse lorsque vous appuyez sur un bouton.
- Demander aux participants de lire l’écran de bienvenue/introduction.
- Assis devant l’ordinateur hôte. Si l’écran n’est pas déjà sur la configuration de la caméra, cliquez sur configuration de la caméra pour accéder à l’écran de droite. Si le couvercle protecteur a été retiré de la lentille de la caméra et le participant est bien positionné sur la mentonnière, l’écran devrait afficher trois images des yeux du participant : une image plus grande en haut et deux plus petits en bas à gauche et à droite. Ces petites images montrent un œil chacun, correspondant à la gauche et le œil droit.
- Sélectionnez le œil à suivre. Il est de coutume pour suivre le œil dominant du participant. Si le participant ne sait pas que l’oeil est dominante, effectuer un test de dominance oculaire (étape 1.3.8).
- Déterminer la dominance oculaire. Demander au participant de s’étirer un bras et d’aligner le pouce avec un objet éloigné avec les deux yeux ouverts. Demander au participant de rechange fermer le œil gauche ou à droite. L’oeil dominant est celui pour lequel le pouce reste aligné avec l’objet lorsque le œil est ouvert35,36.
- Cliquez sur l’Image | Écran pc (ou appuyez sur entrée) et les images décrits à l’étape 1.3.6 apparaîtront sur l’écran d’affichage du participant, mais un seul à la fois.
- Appuyez sur la flèche gauche/droite sur le clavier de l’ordinateur de l’expérimentateur ou du participant pour basculer entre l’image plus petite et plus grande de l’oeil. Mettre l’accent sur la petite image (le œil).
- Appuyez sur A (fenêtre œil Align) sur un clavier afin de centrer la zone de limite de recherche relative à la position de la pupille. Ensuite, un carré rouge autour de le œil doit apparaître un cercle turquoise [le « reflet cornéen », (cr)] au bas de la pupille. L’élève lui-même doit être bleue.
- S’assurer que les deux croix (« collimateur ») apparaître sur l’écran, un au centre de la pupille et l’autre dans le centre du reflet cornéen. La zone rouge et les deux croix signifie que le traqueur d’oeil détecte la pupille et la République tchèque.
Remarque : Si la zone rouge ou les croix sont absents, l’oeil n'est pas sur chenilles — dans ce cas, aucun élève ne s’affiche sur l’ordinateur de l’expérimentateur. - Ajuster mise au point de la caméra en tournant manuellement la lentille de focalisation. Veillez à ne pas toucher l’extrémité de l’objectif. Tourner l’objectif jusqu'à ce que le meilleur point de focus est atteint.
Remarque : Le meilleur point de focus est atteinte lorsque le cercle turquoise (le reflet cornéen) est aussi petit que possible (c'est-à-dire, lorsque ce cercle est mise au point). - Définissez le seuil de l’élève. S’assurer que seule l’image de la pupille est bleue (par exemple, que les cils ne doivent pas être bleus) sur le PC hôte. En outre, assurez-vous que l’élève entière (pas seulement sa partie centrale) est bleu. Seulement vous inquiétez pas tout ce qui est à l’intérieur de la place rouge.
- Appuyez sur A. Cela définit automatiquement le seuil de l’élève. Si l’élève n’est pas correctement affiché en bleu, ajuster le seuil manuellement à l’aide de la touche vers le haut pour augmenter et la touche bas pour diminuer la quantité de la partie bleue de la surface de l’image.
NOTE : Mascara (qui est habituellement noire, comme la pupille) peut interférer avec la fixation du seuil — le traqueur d’oeil pourrait prendre les cils sombres pour l’élève. Dans ce cas, demander au participant d’enlever leur maquillage en leur fournissant de maquillage tissus remover. - Définissez le seuil de la cr. Si A a été choisie à l’étape 1.3.15, le seuil de cr doit ont automatiquement été fixé.
Remarque : Les valeurs numériques pour tous les paramètres de seuil doivent être visibles. Si un point d’interrogation apparaît dans un d’eux, il y avait un problème dans l’une des étapes précédentes et les seuils devraient être fixés manuellement.
- Calibrer le traqueur d’oeil
Remarque : Vérifiez si le traqueur d’oeil peut déceler constamment la position de le œil lorsque le participant se penche sur les autres parties de l’écran.- Demander au participant de regarder aux quatre coins de l’écran une à la fois, tandis que la fenêtre de paramètres de caméra est en vue. Recherchez attentivement toute réflexions irrégulières (ce seront affiché comme turquoise « blobs » sur l’écran) qui interfèrent avec le reflet cornéen lorsque le regard de le œil est ordonné à l’angle.
- Demander au participant de regarder au centre de l’écran et puis diriger leur regard vers l’angle problématique si la zone rouge autour de le œil et l’autre de la ligne de mire n’est pas visible à tout moment au cours de l’étape 1.4.1. Cela aidera à déterminer la source du problème.
- Réajustez la position de tête du participant et vérifier si cela donne une amélioration. Répétez cette étape si nécessaire. Si l’appareil est toujours incapable de suivre avec précision le regard du participant après plusieurs tentatives, abandonner l’expérience.
- Informer le participant que le traqueur d’oeil sera calibré et qu’ils vont voir un cercle noir (avec un petit point gris) se déplaçant à différentes parties de l’écran. Demandez aux participants de se focaliser le cercle jusqu'à ce qu’il se déplace vers un nouvel emplacement. Instruire le participant afin d’éviter de forcer leurs yeux et se concentrer sur le petit point gris à l’intérieur du cercle noir pour des résultats optimaux.
- Dire le participant qu’il est important de rester tranquille et ne pas tenter d’anticiper la position du cercle suivant lors de l’étalonnage. Instruire à suivre les cercles avec les yeux et pas leur tête. Cliquez sur calibrer pour démarrer le processus d’étalonnage. Normalement, une procédure d’étalonnage de 9 points est utilisée dans laquelle le cercle noir se déplace à neuf endroits de manière série.
- Pour un étalonnage automatique, appuyez sur entrée après que le participant a fixé précisément le premier point au milieu de l’écran. Pour l’étalonnage manuel (p. ex., lorsqu’il y a des problèmes de suivi oculaire du participant ou lors du participant spécial qui traite les groupes tels que les enfants), accepter chaque fixation en appuyant sur entrée (ou en cliquant sur accepter fixation/ en appuyant sur la barre d’espace).
Remarque : À la fin du processus d’étalonnage, un modèle presque rectangulaire sur l’écran de l’expérimentateur doit être visible. Cela représente les patrons de regard yeux du participant. En outre, les résultats d’un étalonnage bon devraient être surlignés en vert. Si ils ne le sont pas, répétez la procédure d’étalonnage (c'est-à-dire, cliquez sur l’étalonnage). - Valider les résultats. Dire le participant de passer par la même procédure (en regardant points) afin de valider les résultats de l’étalonnage. Rappelez-leur de regarder le point et d’être toujours.
Remarque : Le processus de validation est semblable à celui de l’étalonnage et les deux résultats sont comparés par le logiciel de traqueur de œil pour s’assurer que l’oeil est suivi avec précision. - Cliquez sur valider.
- Accepter chaque fixation en appuyant sur entrée (ou en cliquant sur accepter lafixation/en appuyant sur la barre d’espace).
- Après la validation, les résultats apparaîtront sur l’écran de l’expérimentateur. Une attention particulière aux mesures deux erreur, l’erreur moyenne (p. ex., ° 0,23) et l’erreur maximale (par exemple, 0,70 °). Ceux-ci représentent les degrés auxquels l’image chenilles s’écarte de la position de regard réel d’un participant.
- Lorsque vous utilisez un paradigme de l’univers visuel, gardez l’erreur moyenne (le premier nombre) sous 0,5 ° et l’erreur maximale (le second nombre) moins de 1°.
- Si les valeurs d’erreur sont au-dessus du seuil, demander au participant pour réajuster la position de leur tête et recommencer la procédure d’étalonnage. Si aucune amélioration n’est constatée, abandonner l’expérience.
Remarque : Il est fréquent d’observer des erreurs de calibration supérieur lorsque le participant porte des lentilles de contact. Le participant devrait demander à l’avance pour mettre leurs lunettes au lieu de leurs lentilles de contact. - Après avoir réussi le processus de calibrage, cliquez sur Sortie/Record pour commencer l’expérience. Informer le participant que l’expérience va maintenant commencer.
- Au cours de l’expérience
Remarque : Lors de l’expérience (selon comment une expérience individuelle est programmée, mais en général avant chaque essai expérimental), un écran cocher la dérive ou dérive correct affiche un point dans le centre de l’écran. Son but est de rendre compte de l’erreur calculée de fixation pour le courant du procès et, selon le modèle de traqueur oculaire, de l’ajuster automatiquement.- Pendant la phase d’instruction, le participant a été dit de fixer le point central lorsqu’il apparaît. S’assurer qu’au cours de chaque phase correcte de cocher/dérive de dérive, les participants sont fixer à nouveau le point. Cela peut être fait en suivant le regard du participant sur le PC hôte, où le regard du participant apparaît comme un cercle vert mobile.
- Une fois la bonne dérive cocher/dérive terminée, appuyez sur entrée (ou la barre d’espace) pour faire le point disparaissent et afficher le prochain procès.
- Déterminer comment faire face à l’échec à la phase de contrôle de dérive selon le modèle du Traqueur oculaire utilisé. Selon le modèle, le traqueur d’oeil soit interprétera un automatique, correction de la dérive en ajustant les coordonnées du regard pour correspondre à celles du point central, ou elle fera un bip sonore pour inviter l’expérimentateur pour ré-étalonner avant de poursuivre le expérience (cocher la dérive).
- Si vous utilisez une correction de dérive automatique, n’oubliez pas que trop de dérive corrections aux essais consécutifs et/ou trop grand un degré de correction de la dérive seront fausser les résultats et nécessiter un ré-étalonnage de l’appareil.
- Ré-étalonnage lors de l’expérience
- Il est possible de re-calibrer à tout moment pendant l’expérience. Lors de la présentation de l’écran de Drift correction/dérive cocher , cliquez sur configuration de la caméra, puis cliquez sur étalonner. Passer par les processus d’étalonnage et de validation, jusqu'à atteindre une valeur satisfaisante, puis cliquez sur sortie/enregistrement. L’expérience reprendra à partir du point de sortie de la séquence du procès.
- Après l’expérience
- Fournir au participant un questionnaire afin de déterminer s’ils ont été capables de deviner les clé manipulations expérimentales. Ici, il est aussi important de poser des questions sur les stratégies potentielles qui pourraient ont été développés tout au long de l’expérience.
- Debrief du participant sur le but de l’expérience. Les remercier pour leur participation et fournir la compensation monétaire nécessaire ou assigner du cours, le cas échéant.
2. remote Setup : Réglage de la configuration pour les études avec les enfants et les adultes plus âgés
Remarque : Cette section décrit uniquement les différences entre une installation à distance et une configuration du bureau, tel que décrit à l’étape 1. Points non explicitement mentionnés ici doivent être considérés comme étant identique à la procédure décrite à l’étape 1.
- Change la lentille de caméra standard 35 mm oeil tracker pour une lentille de 16 mm.
- Brancher tout l’équipement nécessaire (PC hôte, conférenciers, Traqueur d’oeil et portable si on utilise un ordinateur portable).
- Placez l’ordinateur portable sur un socle d’ordinateur portable et le traqueur d’oeil devant lui (le participant doit être en mesure de voir les 75 % de l’écran).
- Placer un autocollant « cible » (disponible sur fabricant du tracker) sur le front du participant (au-dessus du sourcil de l’oeil droit ou sur la joue droite si le front est trop petit (c'est-à-dire, dans le cas de nourrissons) ; cette remplace autocollant le menton le repos de la configuration du bureau et il permet le traqueur oculaire déterminer avec précision la position de tête du participant.
- S’assurer que le participant est assis 550-600 mm loin de la caméra (la distance de la vignette de la cible de la caméra).
- S’assurer que les mots « grand angle » ou « près des yeux » n’apparaissent pas sur le PC hôte. S’ils le font, cela signifie que la position de l’étiquette de la cible n’est pas idéale. Dans ce cas, réajustez l’autocollant de la cible. Il peut aussi signifier que le front du participant est particulièrement faible. Si c’est le cas, placez l’autocollant sur la joue du participant.
Remarque : Si l’autocollant est placé trop près de l’oreille, le message « grand angle » est susceptible d’apparaître et la vignette doit être repositionnée. - Avant de commencer le processus d’étalonnage décrit à l’étape 1.4, assurez-vous que le participant est confortablement assis. Leur demander de maintenir la même position tout au long de l’expérience entière et d’expliquer que le traqueur d’oeil est très sensible aux mouvements du corps. Demandez-leur de tenir leur tête toujours. Si le participant se déplace trop, l’appareil émet un bruit de ronflement.
Remarque : Si la configuration de traqueur oculaire distant est utilisée pour tester les populations sensibles, comme les enfants ou les adultes plus âgés, il est conseillé d’utiliser une procédure de calibration manuelle.
3. réglage de la configuration pour la lecture des études
Remarque : Lors d’enquêtes sur les effets de contexte visuel en lecture, il est nécessaire d’accorder une attention particulière aux mécanismes d’étalonnage et de réétalonnage. Par opposition aux études de l’univers visuel, oculométrique lors de lecture exige un degré beaucoup plus élevé de précision de l’appareil, compte tenu de la précision nécessaire pour suivre les habitudes de lecture mot à mot et lettre pour lettre.
- Veillez à ce que tant l’erreur moyenne et maximale affichée pendant la phase de validation reste moins de 0,5 °.
- Vérifiez que vous utilisez au moins une échelle de 9 points pour l’étalonnage. Ceci s’assure d’un suivi plus précis de la position de regard des yeux, qui est essentiel, étant donné la petite taille des domaines d’intérêt au cours de la lecture.
Résultats
Une étude de Münster et collaborateurs37 a étudié l’interaction de la structure de la phrase, dépeint les actions et les indices émotionnels du visage au cours de la compréhension de la langue. Cette étude est bien adaptée pour illustrer les avantages et les limites de la méthode, car elle démontre que les deux robustes dépeint les effets de l’action et les effets marginaux de repères émotionnels du visage sur la compréhension de la phrase. Les auteurs ont créé 5 vidéos de s d’expression du visage de femme qui a changé depuis une position de repos dans un heureux ou dans une expression triste. Ils ont aussi créé avec émotion positive des allemand objet-verbe-adverbe-sujet (OVAdvS) des phrases de la forme ' le [objet/patientaccusatif] [verbe] [adverbe positive] le [objet/agentnominatif].' Via l’adverbe positive, les phrases égalé la vidéo « heureuse » et correspondent pas la vidéo « malheureuse », permettant en prévision du principe de l’agent (qui était souriant et décrit comme agissant avec bonheur par l’adverbe positive). Après la vidéo le Président, la phrase est apparu avec l’une des deux versions d’une scène de clipart agent-patient-distracteur. Dans une version, l’agent a été dépeinte comme en exécutant l’action mentionnée sur le patient, tandis que le caractère distracteur effectué une action différente. L’autre version de la scène ne dépeinte aucuns actions entre les personnages. Mouvements oculaires de la scène a révélé les effets des mesures et de l’expression faciale de l’orateur sur la compréhension de la phrase.
La représentation de l’action affectée rapidement l’attention visuelle des participants, ce qui signifie que les participants ressemblait plus à l’agent que le distracteur lorsque l’action mentionnée était (vs n’était pas) dépeint. Ces regards étaient anticipées (c'est-à-diresurvenant avant que l’agent a été mentionné), ce qui suggère que la représentation de l’action a précisé l’agent avant la phrase. L’effet plus tôt de la représentation de l’action a émergé pendant le verbe (c'est-à-dire, le verbe médiée par l’agent de l’action associée). En revanche, si l’orateur précédent sourit ou qu’il avait l’air malheureux a eu aucun effet évident sur l’anticipation de l’agent (Figure 2). Ce dernier résultat pourrait refléter le lien plus ténu entre le sourire de conférencier et d’un adverbe phraséologiques positif relatives à l’action de l’agent représenté (par rapport à une référence directe-l’action du verbe médiant un agent lié à l’action). Sinon, ça pourrait être spécifique à la présentation de la tâche et de stimulation : peut-être effets d’émotion seraient ont été plus prononcés dans une tâche plus socialement interactive ou dans celle qui présente le compréhension de phrase pour le visage au cours (et non avant) de l’orateur. Cependant, présentant le visage souriant de conférencier au cours de compréhension pourrait causer aux participants de se concentrer sur le visage au détriment de tout autre contenu de la scène, peut-être autrement avec effets de masquage des variables manipulées (source : données non publiées).
Dans une autre variante du paradigme, Guerra et Knoeferle32 a demandé si les relations spatiales-sémantiques de langue mondiale peuvent moduler la compréhension du contenu sémantique abstraite lors de lecture. Guerra et Knoeferle ont emprunté l’idée de la théorie de la métaphore conceptuelle38 que la distance spatiale (p. ex., proximité) terrain sens de relations sémantiques abstraites (p. ex., similitude). Conformément à cette hypothèse, les participants lire coordonné substantifs abstraits plus vite lorsqu’ils étaient similaires (vs opposé) en sens et avaient été précédées d’une proximité transport vidéo (par rapport à distance, cartes à jouer déménagement plus près ensemble vs. plus loin dehors). Dans une seconde série d’études39, phrases décrit l’interaction entre deux personnes comme intime ou inamical, conduisant à la découverte que les vidéos de deux cartes approchant un de l’autre accélèrent la lecture des régions de phrase qui véhiculé social proximité/intimité. Notez que la distance spatiale affectées à peine lire rapidement et progressivement, même quand les phrases ne mentionnaient pas les objets dans la vidéo. Les vidéos modulé distinctement des temps de lecture en fonction de la congruence entre la distance spatiale et aspects sociaux mais aussi sémantiques du sens de la phrase. Ces effets ont semblé aussi bien dans les temps de lecture de premier passage (la durée de la première inspection d’une région à peine prédéterminé) et le temps total passé sur cette région de la phrase (voir la Figure 3 pour une illustration des résultats des études par Guerra et Knoeferle)32. Toutefois, l’analyse a également révélé une variation importante entre les participants, menant à la conclusion que ces effets subtils de la carte-distance ne sont peut-être pas aussi robustes que les effets des relations de verbe-action, pour citer un exemple.
Une autre série d’études illustre comment la variation dans la structure de la phrase peut aider à évaluer la portée générale des effets de contexte visuel. Abachidzé et collaborateurs34 et Rodríguez et collaborateurs26 a examiné les effets des actions récentes sur le traitement ultérieur des phrases parlées. Dans les deux études, les participants inspecté tout d’abord une vidéo de l’action (par exemple, un concombre d’assaisonnement expérimentateur, ou les mains féminines cuire un gâteau). Ensuite, ils ont écouté une phrase allemande qui a été soit liée à l’action récente ou à une autre action qui pourrait être interprétée suivant (assaisonnement tomates34; construire un modèle26). Au cours de la compréhension, les participants ont inspecté une scène montrant deux objets (concombres, tomates)34 ou deux photographies d’agent faces (une femelle et un visage masculin agent, nommé « Susanna » et « Thomas », respectivement)26. Dans l’étude par Abachidzé et collaborateurs34, l’orateur a mentionné tout d’abord l’expérimentateur, puis le verbe (p. ex., arômes), suscitant des attentes quant à un thème (par exemple, les concombres ou les tomates). Dans l’étude de Rodríguez et collaborateurs26, l’enceinte pour la première fois un thème (le gâteau), puis le verbe (cuisson), suscitant des attentes au sujet de l’agent de l’action (féminin : Susanna, ou un homme : Thomas, représenté par les photos d’une femelle et un mâle visage).
Dans les deux études, la question en litige était si les gens seraient attendrait (visuellement) le thème ou l’agent de l’événement récent d’action ou de l’autre thème/agent issu des autres indices contextuels fournis au cours de la compréhension. Abachidzé et collaborateurs34, regard de l’expérimentateur a repéré l’objet futur thème (les tomates) depuis l’apparition du verbe (littéralement traduit de l’allemand : « l’agent de l’expérimentateur saveurs bientôt... »). En26Rodríguez et collaborateurs, connaissance des sexes des actions stéréotypées devenue disponible lorsque le thème et le verbe sont mentionnés (par exemple, la traduction littérale des stimuli allemandes était : « thème du gâteau cuit bientôt... »). Dans les deux séries d’études, les participants ont inspecté préférentiellement la cible ou l’agent de l’action récente (concombres34 ou Susanna26) au-dessus de la cible (futur/autres-sexe) alternative (tomates34 ou Thomas26) au cours de la phrase.
Ce que l'on appelle l’événement récent » préférence «, semble donc être solide à travers une variation importante dans la structure de la phrase et supports expérimentaux. Il a été modulé, cependant, par les contraintes visuelles de la scène simultanées26, tel que présentant photographies plausibles des thèmes verbe photographies en outre à sexué des agents réduit la dépendance sur les événements d’action récemment inspectés et attention modulée issue des connaissances entre les sexes-stéréotype véhiculé par la langue. La figure 4 illustre les principales conclusions des expériences par Rodríguez et collaborateurs26.
Bien que cette version du paradigme visual-monde a donné des résultats robustes, d’autres études ont mis en évidence la complexité (et les limites) de l’hypothèse de la liaison. Burigo et Knoeferle20 a découvert que les participants — lorsque vous écoutez des déclarations telles que der d’über Die Box ist Wurst (« la boîte est au-dessus de la saucisse ») — pour la plupart suivi l’énoncé en inspectant les représentations d’images clipart de ces objets. Mais sur une partie des essais, regard des participants dissociée de ce qui a été mentionné. Après avoir entendu « saucisse » et après avoir inspecté la saucisse au moins une fois, le prochain contrôle des participants revenez à la boîte sur environ 21 % des essais de vérification accélérée (expérience 1) et dans 90 % des essais dans la phrase après vérification ( Expérience 2). Ce motif de regard suggère que la référence (audience « saucisse ») dirigés uniquement certains la saucisse (inspection), mais pas tous les yeux des mouvements (inspection de la boîte). Ce genre de conception pourrait être utilisé pour taquiner apart processus lexicale référentielle des autres (y compris le niveau de la phrase interprétatif) processus. Toutefois, les chercheurs doivent être prudent quand faire des revendications sur les différents niveaux de traitement linguistique basée sur des différences relatives dans des proportions des mouvements oculaires, compte tenu de l’ambiguïté en reliant les yeux regard vers cognitive et les processus de compréhension.

Figure 1 : vue d’ensemble de la collecte de données environnement. Le graphique montre comment les différents logiciels et éléments matériels utilisés pour la collecte de données et de prétraitement se rapportent à un autre. S’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
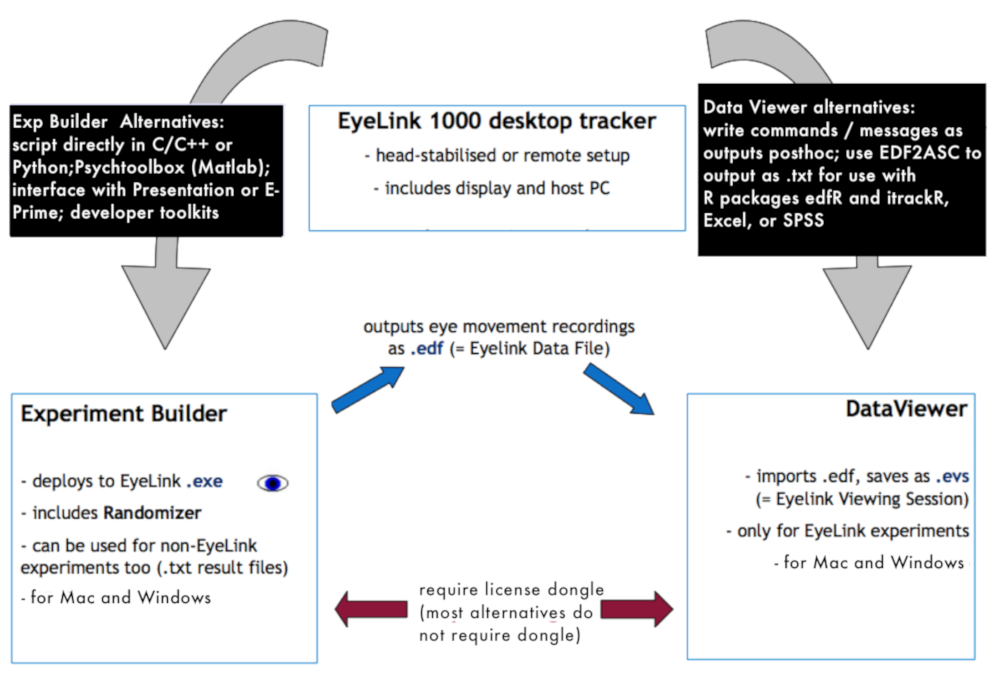{kind=link}

Figure 2 : Résultats représentatifs de Münster et collaborateurs37. Ces panneaux montrent le journal moyenne par-sujets-regard ratios de probabilité par l’État dans la région de verbe (pour l’action représentée) et dans la région de verbe-adverbe combinés (pour l’effet du premier émotionnelle). Les résultats montrent une proportion considérablement plus élevée de regards vers l’image cible lorsque l’action mentionnée dans la phrase a été dépeint que lorsqu’il n’était pas représenté. Les résultats de l’effet des primes faciales émotionnelles ont été moins concluantes : ils ne suggèrent qu’une légère augmentation du ratio de la moyenne-journal de regards à la cible lorsque le premier visage avait une valence émotionnelle positive (sourire) que quand il y avait une valence négative (un visage triste). Les barres d’erreur représentent l’écart-type de la moyenne. Ce chiffre a été modifié de Münster et al. 37. s’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
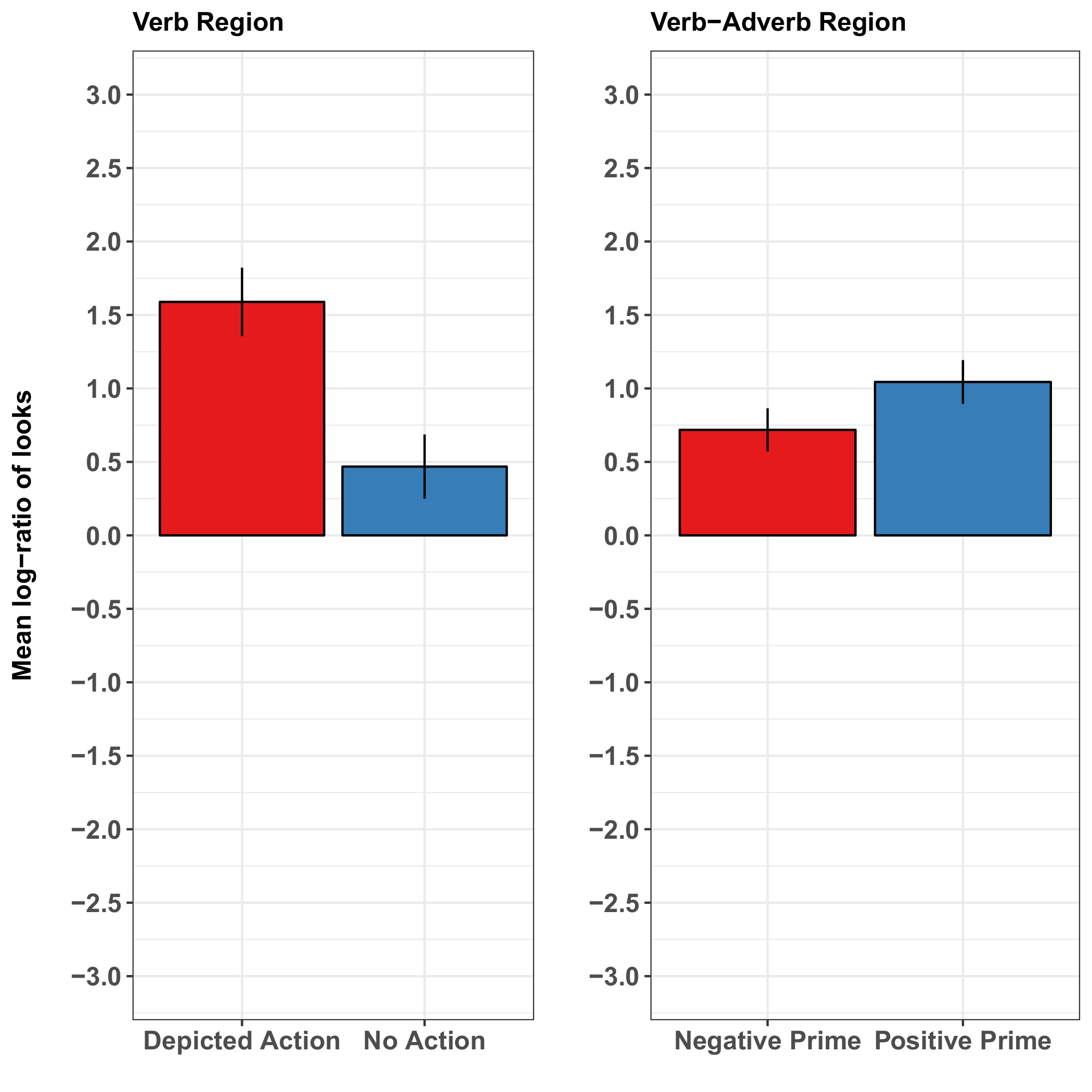{kind=link}

Figure 3 : Résultats représentatifs de la Guerra et Knoeferle32. Ce panneau affiche les temps de lecture de premier passage moyenne (en millisecondes) de l’adjectif de similitude (dis). Les résultats montrent des temps plus courts de lecture pour les phrases de similitude après que voir les deux cartes de lecture à se rapprocher ensemble comparée plus loin dehors. Les barres d’erreur représentent l’écart-type de la moyenne. Ce chiffre a été modifié par Guerra et Knoeferle32. S’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
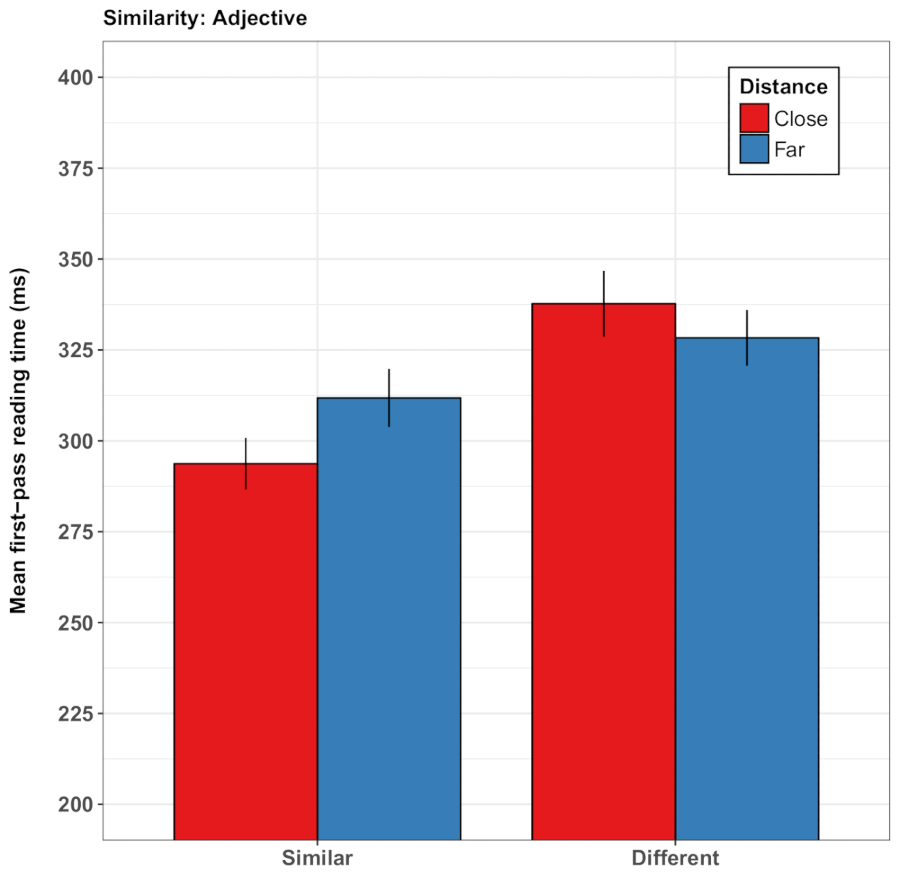{kind=link}

Figure 4 : Résultats représentatifs de Rodríguez et collaborateurs26. Ce panneau montre le regard journal moyenne par matière ratios de probabilité par l’État dans la région de verbe. Les proportions de regarde ci-dessus 0 montrent une préférence pour l’image cible de l’agent et les proportions ci-dessous 0 montrent une préférence pour l’image d’agent concurrent. Les résultats montrent que les participants étaient plus susceptibles d’inspecter l’image cible de l’agent lorsque l’objet et le verbe mentionnée dans la phrase les événements enregistrés sur bande magnétoscopique précédents que quand ils n’ont pas mis en correspondance. En outre, il y avait plus de regards vers l’image cible de l’agent lorsque l’action décrite par la phrase était conforme aux stéréotypes sexuels. Les barres d’erreur représentent l’écart-type de la moyenne. Ce chiffre a été modifié par Rodríguez et al. 26. s’il vous plaît cliquez ici pour visionner une version agrandie de cette figure.
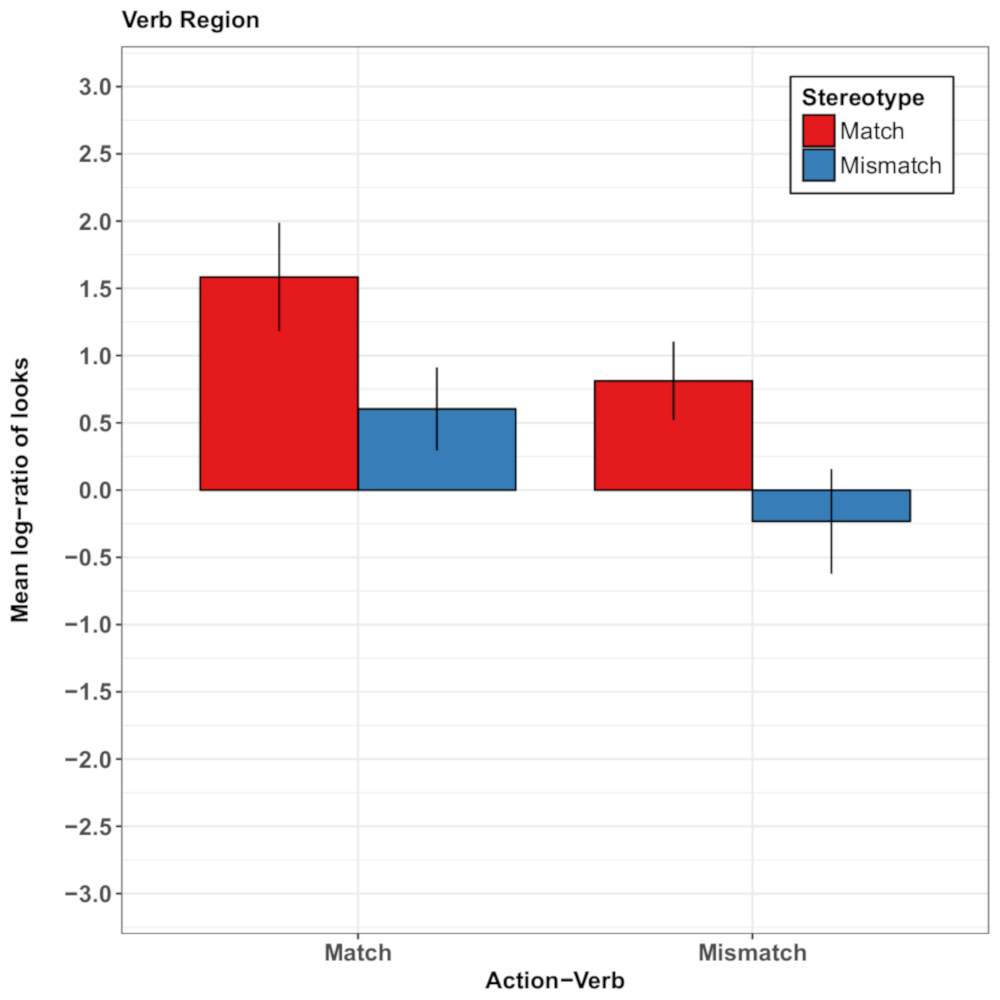{kind=link}
Discussion
En résumé, les variantes révisés d’oculométrique dans des contextes visuels ont découvert plusieurs façons dans lequel une scène visuelle peut affecter la compréhension de la langue. Cette méthode offre des avantages cruciaux par rapport aux méthodes comme la mesure des temps de réaction. Par exemple, les mouvements oculaires en cours nous fournissent une fenêtre dans le processus de compréhension de langue et comment ceux-ci interagissent avec notre perception du monde visuel au fil du temps. En outre, les participants ne doivent pas forcément pour effectuer une tâche explicite au cours de la compréhension de la langue (par exemple, à en juger la grammaticalité d’une phrase par une presse de bouton). Cela permet aux chercheurs d’utiliser la méthode avec les populations qui pourraient lutter avec des réponses comportementales manifestes, autres que le regard de le œil, comme les nourrissons, enfants et, dans certains cas, les personnes âgées. Oculométrique est écologiquement valable en ce qu’elle reflète les réponses des participants attention — pas contrairement aux interrogatoires visuelle des humains de communication les choses dans le monde autour d’eux pendant plus ou moins attentif, écouter les énoncés qui se déroule.
Une des limites (ou peut-être caractéristiques) du paradigme univers visuel est que pas tous les événements peuvent être présentés directement et sans ambiguïté. Événements et objets concrets peuvent, bien sûr, être présentés. Mais comment les concepts abstraits sont les mieux représentés est moins claire. Cela peut limiter (ou définir) aperçus de l’interaction entre le traitement du langage et la perception de l’univers visuel à l’aide d’un paradigme de l’oculométrie monde visuel. Autant les défis concernent les hypothèses reliant entre processus de compréhension et de comportement observé. Fixations oculaires sont une réponse comportementale unique qui reflète probablement les nombreux sous-processus au cours de la compréhension de la langue (par exemple, accès lexical, processus référentielles, induite par la langue des attentes, des effets de contexte visuel, entre autres). Compte tenu de cette idée, les chercheurs doivent être prudents pas de sur - ou de mal interpréter le modèle regard observées. Pour résoudre ce problème, la recherche antérieure a mis en évidence le rôle de la compréhension des sous-tâches pour clarifier l’interprétation du regard record40.
Améliorer l’intelligibilité des mouvements oculaires consiste à les intégrer à d’autres mesures telles que les potentiels de cerveau liées à l’événement (ERPs). En enquêtant sur le même phénomène avec deux méthodes qui soient comparables dans leur granularité temporelle et complémentaires dans leurs hypothèses reliant, les chercheurs peuvent exclure d’autres explications de leurs résultats et enrichir l’interprétation de chacun 41de mesure individuelle. Cette démarche a été poursuivie à travers des expériences43, mais, plus récemment, également au sein d’une seule expérience (bien que dans des contextes strictement linguistiques)44. Recherches futures pourraient bénéficier grandement d’une telle intégration méthodologique et a continué de combinaison avec les tâches après le procès et études expérimentales.
La méthode de suivi oculaire peut reproduire les résultats établis, ainsi que tester de nouvelles hypothèses, sur l’interaction de l’attention visuelle dans les scènes avec la compréhension de la langue. La procédure décrite dans le protocole doit être soigneusement suivie puisque même mineures expérimentateur erreurs peuvent affecter la qualité des données. En lisant les études, par exemple, les régions d’analyse pertinents sont souvent des mots individuels ou même des lettres, ce qui signifie que l’étalonnage même de petites erreurs pourraient fausser les résultats (Voir l’article de Raney et collègues42). Marches 1.4 et 1.5 du protocole, l’étalonnage de la Traqueur oculaire et la dérive cocher/dérive correcte, sont d’une importance particulière puisqu’ils ont un impact direct sur l’exactitude de l’enregistrement. Pour calibrer correctement le traqueur oculaire peut entraîner dans le tracker pas correctement suivi les mouvements des yeux aux domaines d’intérêt préétablis. Ce défaut de suivi emmènera en manque de points de données et une perte de puissance statistique qui peut être problématique lors d’enquêtes sur le monde-à-langue des relations qui sont très subtiles et qui produisent des tailles petit effet statistique (voir la description de la expériences de Guerra et Knoeferle32 et Münster et collègues37 Résultats représentant, entre autres).
Compte tenu de la nécessité de maximiser la puissance et la sensibilité de l’appareil, il est important que les expérimentateurs savent comment traiter les problèmes qui se produisent régulièrement lors d’une séance expérimentale. Par exemple, la position de l’élève et le mouvement de participants portant des lunettes peuvent entraîner des difficultés de calibration en raison des reflets lumineux sur les verres de lunettes d’un participant. Pour résoudre ce problème consiste à refléter l’image de le œil du participant sur le PC de l’affichage et les encourager à bouger leur tête jusqu'à ce que la réflexion de la lumière sur les lunettes n’est plus visible sur son écran, ce qui signifie qu’il est n’est plus capturée par la caméra. Une autre cause de l’échec de l’étalonnage peut être constriction de pupille, qui peut être une conséquence d’une surexposition à la lumière. Dans ce cas, gradation de la lumière dans le laboratoire augmentera dilatation de la pupille et, ainsi, aider le traqueur d’oeil de détecter avec précision la pupille.
Comme une dernière pensée, nous aimerions aborder le potentiel que le paradigme de visual-monde a pour la recherche sur l’apprentissage de la langue seconde. Le paradigme a déjà été avec succès utilisé en recherche psycholinguistique pour enquêter sur des phénomènes tels qu’interlangage lexicale et phonologique interaction46,47,48. En outre, le lien étroit qui existe entre l’attention visuelle et l’apprentissage des langues a fréquemment été mis en évidence dans la littérature linguistique appliquée sur une langue seconde49,50,,51. Les recherches futures sur l’apprentissage de la langue seconde continuera probablement à bénéficier de la position avantageuse de suivi oculaire comme une méthode qui fournit un indice d’attention visuelle dans la résolution de la milliseconde.
Déclarations de divulgation
Les auteurs n’ont rien à divulguer.
Remerciements
Cette recherche a été financée par le ZuKo (Initiative d’Excellence, Humboldt-Universität zu Berlin), l’Excellence Cluster 277 « Cognitive Interaction technologie » Conseil allemand de la recherche (DFG) et par le septième programme-cadre de l’Union européenne pour la recherche, développement technologique et démonstration en vertu de l’accord de subvention n° 316748 (LanPercept). Les auteurs reconnaissent également le soutien des fonds basale des centres d’Excellence, FB0003 projet du programme de la recherche Associative de CONICYT (gouvernement du Chili), ainsi que du projet « FoTeRo » dans le centre de mise au point XPrag (DFG). Pia Knoeferle pourvu par un protocole de laboratoire, une première ébauche de l’article a informé que Helene Kreysa instancié à l’Université de Bielefeld et qui continue d’être utilisé à la Humboldt-Universität zu Berlin. Tous les auteurs ont contribué au contenu en fournissant des entrées sur les méthodes et les résultats sous une forme ou une autre. Camilo Rodríguez Ronderos et Pia Knoeferle a coordonné la contribution des auteurs et, dans deux itérations, révision substantielle du projet initial. Ernesto Guerra produit Figures 2 - 4 basé sur la contribution de Katja Münster, Alba Rodríguez et Ernesto Guerra. Helene Kreysa fourni Figure 1 et Pia Knoeferle mis à jour. Pièces des résultats rapportés ont été publiés dans le compte rendu de la réunion annuelle de la société des sciences cognitives.
matériels
| Name | Company | Catalog Number | Comments |
| Desktop mounted eye-tracker including head/chin rest | SR Research Ltd. | EyeLink 1000 plus | http://www.sr-research.com/eyelink1000plus.html |
| Software for the design and execution of an eye-tracking experiment | SR Research Ltd. | Experiment Builder | http://www.sr-research.com/eb.html |
Références
- Tanenhaus, M. K., Spivey-Knowlton, M. J., Eberhard, K. M., Sedivy, J. C. Integration of visual and linguistic information in spoken language comprehension. Science. 268 (5217), 1632-1634 (1995).
- Cooper, R. M. The control of eye fixation by the meaning of spoken language: A new methodology for the real-time investigation of speech perception, memory, and language processing. Cognitive Psychology. 6 (1), 84-107 (1974).
- Knoeferle, P., Guerra, E. What is non-linguistic context? A view from language comprehension. In What is a Context? Linguistic Approaches and Challenges. Finkbeiner, R., Meibauer, J., Schumacher, P. B. , John Benjamins Publishing Company. Amsterdam, The Netherlands. 129-150 (2012).
- Knoeferle, P., Guerra, E. Visually situated language comprehension. Language and Linguistics Compass. 10 (2), 66-82 (2016).
- Just, M. A., Carpenter, P. A. A theory of reading: From eye fixations to comprehension. Psychological Review. 87 (4), 329-354 (1980).
- Deubel, H., Schneider, W. X. Saccade target selection and object recognition: Evidence for a common attentional mechanism. Vision Research. 36 (12), 1827-1837 (1996).
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychological Bulletin. 124 (3), 372-422 (1998).
- Sedivy, J. C., Tanenhaus, M. K., Chambers, C. G., Carlson, G. N. Achieving incremental semantic interpretation through contextual representation. Cognition. 71 (2), 109-147 (1999).
- Kamide, Y., Scheepers, C., Altmann, G. T. Integration of syntactic and semantic information in predictive processing: Cross-linguistic evidence from German and English. Journal of Psycholinguistic Research. 32 (1), 37-55 (2003).
- Allopenna, P. D., Magnuson, J. S., Tanenhaus, M. K. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language. 38 (4), 419-439 (1998).
- Tanenhaus, M. K., Magnuson, J. S., Dahan, D., Chambers, C. Eye movements and lexical access in spoken-language comprehension: Evaluating a linking hypothesis between fixations and linguistic processing. Journal of Psycholinguistic Research. 29 (6), 557-580 (2000).
- Arnold, J. E., Eisenband, J. G., Brown-Schmidt, S., Trueswell, J. C. The rapid use of gender information: Evidence of the time course of pronoun resolution from eyetracking. Cognition. 76 (1), B13-B26 (2000).
- Chambers, C. G., Tanenhaus, M. K., Magnuson, J. S. Actions and affordances in syntactic ambiguity resolution. Journal of Experimental Psychology: Learning, Memory, and Cognition. 30 (3), 687-696 (2004).
- Spivey, M. J., Tanenhaus, M. K., Eberhard, K. M., Sedivy, J. C. Eye movements and spoken language comprehension: Effects of visual context on syntactic ambiguity resolution. Cognitive Psychology. 45 (4), 447-481 (2002).
- Huang, Y. T., Snedeker, J. Online interpretation of scalar quantifiers: Insight into the semantics-pragmatics interface. Cognitive Psychology. 58 (3), 376-415 (2009).
- Trueswell, J. C., Sekerina, I., Hill, N. M., Logrip, M. L. The kindergarten-path effect: studying online sentence processing in young children. Cognition. 73 (2), 89-134 (1999).
- Knoeferle, P., Crocker, M. W., Scheepers, C., Pickering, M. J. The influence of the immediate visual context on incremental thematic role-assignment: evidence from eye movements in depicted events. Cognition. 95 (1), 95-127 (2005).
- Knoeferle, P., Crocker, M. W. Incremental Effects of Mismatch during Picture-Sentence Integration: Evidence from Eye-tracking. Proceedings of the 26th Annual Conference of the Cognitive Science Society. , Stresa, Italy. 1166-1171 (2005).
- Kluth, T., Burigo, M., Schultheis, H., Knoeferle, P. The role of the center-of-mass in evaluating spatial language. Proceedings of the 13th Biannual Conference of the German Society for Cognitive Science. , Bremen, Germany. 11-14 (2016).
- Burigo, M., Knoeferle, P. Visual attention during spatial language comprehension. PLoS One. 10 (1), (2015).
- Münster, K., Carminati, M. N., Knoeferle, P. How Do Static and Dynamic Emotional Faces Prime Incremental Semantic Interpretation? Comparing Older and Younger Adults. Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 2675-2680 (2014).
- Kroeger, J. M., Münster, K., Knoeferle, P. Do Prosody and Case Marking influence Thematic Role Assignment in Ambiguous Action Scenes? Proceedings of the 39th Annual Meeting of the Cognitive Science Society. , London, UK. 2463-2468 (2017).
- Knoeferle, P., Crocker, M. W. The influence of recent scene events on spoken comprehension: evidence from eye movements. Journal of Memory and Language. 57 (4), 519-543 (2007).
- Knoeferle, P., Carminati, M. N., Abashidze, D., Essig, K. Preferential inspection of recent real-world events over future events: evidence from eye tracking during spoken sentence comprehension. Frontiers in Psychology. 2, 376(2011).
- Abashidze, D., Knoeferle, P., Carminati, M. N. How robust is the recent-event preference? Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 92-97 (2014).
- Rodríguez, A., Burigo, M., Knoeferle, P. Visual constraints modulate stereotypical predictability of agents during situated language comprehension. Proceedings of the 38th Annual Meeting of the Cognitive Science Society. , Philadelphia, USA. 580-585 (2016).
- Zhang, L., Knoeferle, P. Visual Context Effects on Thematic Role Assignment in Children versus Adults: Evidence from Eye Tracking in German. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 2593-2598 (2012).
- Zhang, L., Kornbluth, L., Knoeferle, P. The role of recent versus future events in children's comprehension of referentially ambiguous sentences: Evidence from eye tracking. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 1227-1232 (2012).
- Münster, K., Knoeferle, P. Situated language processing across the lifespan: A review. International Journal of English Linguistics. 7 (1), 1-13 (2017).
- Özge, D., et al. Predictive Use of German Case Markers in German Children. Proceedings of the 40th Annual Boston University Conference on Language Development. , Somerville, USA. 291-303 (2016).
- Weber, A., Grice, M., Crocker, M. W. The role of prosody in the interpretation of structural ambiguities: A study of anticipatory eye movements. Cognition. 99 (2), B63-B72 (2006).
- Guerra, E., Knoeferle, P. Effects of object distance on incremental semantic interpretation: similarity is closeness. Cognition. 133 (3), 535-552 (2014).
- Kreysa, H., Knoeferle, P., Nunnemann, E. Effects of speaker gaze versus depicted actions on visual attention during sentence comprehension. Proceedings of the 36th Annual Meeting of the Cognitive Science Society. , Quebec City, Canada. 2513-2518 (2014).
- Abashidze, D., Knoeferle, P., Carminati, M. N. Eye-tracking situated language comprehension: Immediate actor gaze versus recent action events. Proceedings of the 37th Annual Meeting of the Cognitive Science Society. , Pasadena, USA. 31-36 (2015).
- Crovitz, H. F., Zener, K. A Group-Test for Assessing Hand- and Eye-Dominance. The American Journal of Psychology. 75 (2), 271-276 (1962).
- Ehrenstein, W. H., Arnold-Schulz-Gahmen, B. E., Jaschinski, W. Eye preference within the context of binocular functions. Graefe's Arch Clin Exp Ophthalmol. 243, 926(2005).
- Münster, K., Carminati, M. N., Knoeferle, P. The Effect of Facial Emotion and Action Depiction on Situated Language Processing. Proceedings of the 37th Annual Meeting of the Cognitive Science Society. , Pasadena, USA. 1673-1678 (2015).
- Lakoff, G., Johnson, M. Metaphors We Live By. , University of Chicago Press. Chicago, USA. (1980).
- Guerra, E., Knoeferle, P. Visually perceived spatial distance affects the interpretation of linguistically mediated social meaning during online language comprehension: An eye tracking reading study. Journal of Memory and Language. 92, 43-56 (2017).
- Kreysa, H., Knoeferle, P. Effects of speaker gaze on spoken language comprehension: task matters. Proceedings of the Annual Meeting of the Cognitive Science Society. , Boston, USA. 1557-1562 (2012).
- Knoeferle, P. Language comprehension in rich non-linguistic contexts: Combining eye tracking and event-related brain potentials. Towards a cognitive neuroscience of natural language use. Roel, W. , Cambridge University Press. Cambridge, UK. 77-100 (2015).
- Raney, G. E., Campell, S. J., Bovee, J. C. Using eye movements to evaluate cognitive processes involved in text comprehension. Journal of Visualized Experiments. (83), e50780(2014).
- Knoeferle, P., Habets, B., Crocker, M. W., Muente, T. F. Visual scenes trigger immediate syntactic reanalysis: evidence from ERPs during situated spoken comprehension. Cerebral Cortex. 18 (4), 789-795 (2008).
- Dimigen, O., Sommer, W., Hohlfeld, A., Jacobs, A. M., Kliegl, R. Coregistration of eye movements and EEG in natural reading: Analyses and review. Journal of Experimental Psychology: General. 140 (4), 552-572 (2011).
- Knoeferle, P., Kreysa, H. Can speaker gaze modulate syntactic structuring and thematic role assignment during spoken sentence comprehension? Frontiers in Psychology. 3, 538(2012).
- Chambers, C. G., Cooke, H. Lexical competition during second-language listening: Sentence context, but not proficiency, constrains interference from the native lexicon. Journal of Experimental Psychology: Learning, Memory, and Cognition. 35 (4), 1029(2009).
- Duyck, W., Van Assche, E., Drieghe, D., Hartsuiker, R. J. Visual word recognition by bilinguals in a sentence context: Evidence for nonselective lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition. 33 (4), 663(2007).
- Weber, A., Cutler, A. Lexical competition in non-native spoken-word recognition. Journal of Memory and Language. 50 (1), 1-25 (2004).
- Verhallen, M. J., Bus, A. Young second language learners' visual attention to illustrations in storybooks. Journal of Early Childhood Literacy. 11 (4), 480-500 (2011).
- Robinson, P., Mackey, A., Gass, S. M., Schmidt, R. Attention and awareness in second language acquisition. The Routledge Handbook of Second Language Acquisition. , 247-267 (2012).
- Tomlin, R. S., Villa, V. Attention in cognitive science and second language acquisition. Studies in Second Language Acquisition. 16 (2), 183-203 (1994).
Réimpressions et Autorisations
Demande d’autorisation pour utiliser le texte ou les figures de cet article JoVE
Demande d’autorisationThis article has been published
Video Coming Soon
À PROPOS DE JoVE
Copyright © 2025 MyJoVE Corporation. Tous droits réservés.