
A subscription to JoVE is required to view this content. Sign in or start your free trial.
Method Article
בחינת עיבוד תחבירי מקוון של משפטים מורכבים ומדוברים בסינית באמצעות משימות התערבות כפולות-מודאליות
In This Article
Summary
כאן, אנו מציגים פרוטוקול המעסיק משימות התערבות כפולות-מודאליות כדי לבחון עיבוד מקוון של משפטים יחסיים של משפט בסינית מדוברת. שני מחקרים מבוססי עיבוד שמיעתי עם הפרעות פנים וחוץ מתוארים. הפרדיגמה מספקת מתודולוגיה לטיפול באופיו של זיכרון העבודה והשפעותיו על עיבוד משפטים.
Abstract
זיכרון עבודה (WM) ממלא תפקיד מרכזי בהבנת משפטים מורכבים. תפקידה בעיבוד של משפטים מורכבים מדוברים ברור במיוחד מכיוון שעיבוד משפט מורכב מדובר הוא עתיר זיכרון. פרדיגמת ההתערבות הכפולה-מודאלית שימש לבדיקת האופן שבו מערכת WM מעורבת בעיבוד תחבירי מורכב. מאמר זה מציג שני ניסויים הקשורים לעיבוד שמיעתי עם הפרעות פנים או חוץ. בניסוי הראשון, גירויים שמיעתית [המשפט היחסי הסיני הדובר (RC) משפטים עם שני סוגים תחבילי: כפופים (SRC) לעומת האובייקט-כפיפות (אורק)] מתערבים באמצעות משימת החלטה לקסיקלית מוצגת ויזואלית בתוך משפט ו מניפולציות באמצעות שלושה נקודות זמן שונות של הפרעות. בניסוי השני, את אותו גירוי שמיעתי, הציג דרך חלון השמיעה הנעה הטכניקה, הם הפריעו באמצעות משימה חזותית הציג זיכרון דיגיטלי מעבר לגזר הדין מניפולציות באמצעות שלושה מטענים דיגיטליים. על-ידי הערכת האופן שבו המשימה העיקרית של ההבנה של משפטי ה-RC מושפעת מהפעילות המשנית, אנו יכולים להתמודד עם הסוגיה השנויה במחלוקת בנוגע לעיבוד א-סימטריה של הסינים. התוצאות שלנו מגלות דפוסים שונים של עיבוד RC לעומת אלה שדווחו במחקרים קודמים. הניסוי 1 מתבטא לא ברור יתרונות עיבוד RC ב SRC או אורק; עם זאת, העדפה של אורק הוא נצפתה בקצות משפטים, ו העדפה עבור SRC נמצא באתר הפועל הראשי. כמו כן, ניסוי 2 מציג דפוס דינמי. תחת עומס לא-ספרתי, SRCs מראה יתרונות עיבוד באזור הסמן של RC. עם זאת, תחת הפרעה בעלת ספרה גבוהה יותר, האורקים מציגים יתרונות עיבוד באותו אזור. התוצאות הללו מובילות לניחושים שאין ברור או מהותי עיבוד סימטריה קיימת בעיבוד של RCs סינית. באמצעות גישה של הערכת הפרעות ספציפיות במהלך עיבוד תחבירי, ניסויים אלה להפגין מחקר עתידי יישומים החוקרים את מדדי העיבוד של משפטים מדוברים הכרוכים בזיכרון עבודה.
Introduction
התפקיד של זיכרון העבודה (WM) במהלך עיבוד משפט מדוברת הוא ברור מאליו: עקב האופי הארעי של הדיבור, על המאזינים לשמור על הטפסים האקוסטיים של הרכיבים בזיכרונותיהם עד שיעובדו. היבט זה הופך להיות חשוב עוד יותר במהלך העיבוד של משפטים תחבירית מורכבים. הקצאת יחסים תחביטיים למילים במשפטים מורכבים כרוכה בביצוע פעולות חישוביות בפריטים הנשמרים בזיכרון לפרקי זמן קצרים, והתוצאה היא דרישת זיכרון גבוהה יותר. עם זאת, כיצד מערכת WM מעורבת בעיבוד משפט מדוברת שנויה במחלוקת.
מחלוקת זו כרוכה בשני חילוקי דעות עיקריים: מספר חוקרים טוענים כי קיים מערכת WM אחת המשמשת עבור כל המשימות המילולית1,2— במילים אחרות, עיבוד תחבירי מסתמך על משאבי זיכרון זהה בשימוש על ידי יותר תהליכים קוגניטיביים כלליים. זהו המודל של משאב יחיד. אחרים טענו כי קביעת משמעות המשפט המבוסס על מבנה הסינטקטיק כרוכה במערכת WM מיוחדת הנפרדת ממשימות מילוליות אחרות3,4. בתוך וריד זה, עיבוד תחבירי הוא מודולרי. זהו מודל המשאב הנפרד לפענוח משפט.
במחקר פסיכובלשנות, הפרדיגמה של ההפרעות הדו-מודאליות שימש לבדיקת שני החשבונות המתחרים. מבוסס על ההנחה שקיבולת האחסון של WM מוגבלת ב-5,6, כתובות הפרדיגמה על-ידי מסבך משימה ראשית עם משימה משנית. בהתחשב בכך שהמשימה העיקרית מתחרה על משאבים מוגבלים עם הפעילות המשנית, הקושי גדל והמשימה העיקרית מציגה זמני תגובה ארוכים יותר. בהתחשב במצב זה, גישת ההפרעות הדו-מודאליות מאפשרת להעריך את עומס העיבוד והיקף המעורבות של ה-WM כאשר משתתף מקבל משימה המחייבת קיום שתי משימות בו.
משפטים המכילים רכיבי RC, הגורמים לקשיי הבנה רבים יותר בשל מבנה הסינטקטיקה הידוע שלהם, נמצאים בשימוש נרחב כדי לחקור כיצד מערכת WM מעורבת בעיבוד משפטים מורכבים. עם זאת, למרות שעיבוד משפטים מורכבים מציב דרישה גבוהה יותר על משאבי WM המשויכים לעיבוד דיבור, פחות ברור אם ה-WM שנחשב לתורם לעלויות של תנועות תחביריות בשפות עם הראש-RC הראשונית מבנים (כגון אנגלית) משקפים את המורכבות הסינטקטיקה של שפות עם הראש-סופי RCs (כגון סינית). באמצעות שימוש בפרדיגמת הפרעה כפולה מודאלית, המחקר הנוכחי שופך אור בנושא זה.
הקשיים הקשורים לעיבוד שני מבני RC, כפופים ומשפטים יחסיים של האובייקט (SRCs נגד האורקים), היו הנושא של דיון נרחב. המחלוקות הללו נצפו בעיקר בשפות שונות לוגית. בשפות ראש-ראשוניות כגון אנגלית, שבה משפט יחסי מלווה את שם העצם הראשי שהוא משנה, הממצא הכללי הוא ש-SRCs כגון בדוגמה 1 (א) להלן מעובדים בקלות רבה יותר מאשר אורקים בדוגמה 1 (ב).

כפי שמוצג לדוגמה (1), באנגלית, מיקום פני השטח של הפער שונה מינימלית בין SRCs ואורקים. פער זה נכלל באינדקס כ- e1, התנוחה הריקה שלאחר הפעולה 'שחקן' שנקרא ' מילוי' (המכונה ' פילר ') שנותרה על-ידי הסרתה מהrc. עם זאת, SRCs ואורקים נבדלים באופן משמעותי במונחים של המבנה הדקדוקי ותפקודו של הפער בתחום ה-RC. עלות הזיכרון לשילוב ולפתרון התלות המבנית בין המילוי לבין הפער היא יעד מתאים למחקר ניסיוני ומשמשת רבות להשגת תובנות לתפקיד WM בעיבוד ובהבנת השפה.
לדוגמה, ההבנה והעיבוד של מערכות הדואר האלקטרוני הללו מחייבת יצירת אינדקס לסמלהשחקןהראשי כנושא פונקציונלי או כאובייקט של הפועל 'ביקורת' ב-SRC ו-אורק ולאחר מכן אחסון העצם הראשי ב-WM כך שיהיה מאוחר יותר ל הוקצה לנושא הדקדוקי של הפועל 'הודה' בסעיף הראשי.
בניגוד לממצא העקבי עם הראש-השפות הראשוניות שבין SRCs קל יותר מאשר ההבנה של אורקים, תוצאות מעורבות דווחו לגבי העיבוד של ה-RC סימטריה לסינית, שהיא שפה בראש ובראשונה שבה קרוב משפחה מקדים את שם העצם של הראש. חלקם נצפו יתרון עיבוד SRC, בעוד אחרים דיווחו על הדפוס הנגדי (כלומר, יתרון עיבוד אורק). הקווים האחרונים של מחקר גם הציעו כי RC עיבוד סימטריה יכול להיות מאופנן על ידי WM, כפי שהוצע על ידי תוצאות שהתקבלו ממחקרים של ביצועים בקצב הקריאה העצמי7,8,9.
כפי שהוזכר לעיל, ישנם שני מודלים מתחרים לגבי התפקיד ש-WM מנגן בעיבוד הסינטקטיק (המורכב). האחד הוא כי "עיבוד תחבירי הוא מודולרי", והשני הוא כי "עיבוד תחבירי הוא כללי". משפטים מורכבים עם הבדלים ידועים בקושי הבנה, כלומר, srcs נגד האורקים באנגלית, משמשים לעתים קרובות במשימות הפרעה dual-מודאליות (DMI) כדי לבחון את שתי הטענות הללו ביחס לשאלה של מודולריות משום ש מעורבות של WM נטען במקביל לעיבוד א-סימטריה. כך, גרימת עומס זיכרון בו באמצעות משימות מפריעות מדגים אפקטי WM על עיבוד תחבירי. הרציונל הוא שאם מערכת מילולית אחת או מערכות סינטקטיקה מודולרית קיימות, מעורבות במערכת עם משימה מפריעה הופכת את עיבוד הסינטקטיק ליעיל פחות עקב מגבלות משאבי WM. הדרך שבה עיבוד משפטים תחבירית יותר מורכבים (אורק, באנגלית) סובלת במשימות DMI משווה לעיבוד משפטים מבחינה תחבירית פשוטים (SRC, באנגלית) מספק ראיות לגבי ההשפעה הספציפית של WM ומציין את המידה של בו מעורב WM.
לעומת ראש-השפות הראשוניות כגון אנגלית, RCs הסינית מבטאת היווצרות ראש-סופי ומציג קשר מילוי פערים . הרכיב שהועבר באינדקס, הפער, מופיע לפני שם העצם הראשי השייך לו, כפי שמודגם ב-2 (א), SRC ו-2 (ב), אורק.

המחלוקת הנובעת מעיבוד RCs סינית היא כי SRCs לא דיווחו בעקביות קל יותר לעבד מאשר אורקים, ופער זה הציב אתגר עבור תיאוריות של עיבוד שפה והבנה. מכיוון שהתוכן הפרימאני לפני הצורך המפעם בתהליך חייב להיות מאוחסן ב-WM עד לאחר הפער-השחקן ' שחקן הראש המוזז ', מקושר ומאוחזר-הבנת תהליך זה עדיין מסייעת בהשגת תובנות לתפקיד WM בעיבוד השפה.
במחקר הנוכחי, עיבוד משפט ה-RC המדוברת נבדק מכיוון שהקשבה היא במידה רבה במהלך העיבוד והיא קשורה היטב לתפקוד של WM. משתמשים בפרדיגמת ההתערבות המודאלית הכפולה מכיוון שהפרעה היא פונקציית שכחה מבוססת היטב בזיכרון שמיעתי לטווח קצר. הייצוגים המאוחסנים בזיכרון יכולים להיות מוקטנים ואבודים לאחר מכן כאשר האירועים מפריעים מתרחשים10. שחקנים שמשתנים לאורך היבטים שונים (במקרה הנוכחי: intralinguistic ואקסטרדיגיטלי, ראו להלן) למשפט הדובר הקאנוני מאפשרים לנו למדוד את העלות של שילוב הקלט המצטבר במהלך שלבי עיבוד שונים ומתחת תנאי הפרעה שונים.
בהתבסס על המיקום המעבד יותר מורכבים תחבירית יותר משפטים הטוען את WM יותר מאשר עיבוד משפטים פשוטים יותר, אחד יכול ההשערה כי מניפולציה את סוג ההפרעה במהלך ההבנה צריך להיות השפעות על עיבוד משפט. על ידי משתמע, עיבוד משפטים תחבירית יותר מורכבים ידרוש באופן יחסי הקשבה גבוהה יותר או באופן לא פרופורציונלי יותר באינטרנט ולהראות ביצועים גרועים יותר בהערכת משפט postonline מאשר יהיה עיבוד מבנים פשוט תחבירית. המחקר הנוכחי בוחן את ההשערה כי הפרעה במהלך עיבוד משפט יכול ליצור אינדקס מעורבות WM ולמעשה מציב את הערך שלה מעבר לנושא של מודולריות תחבירי: הוא מציע את הרעיון כי המחלוקת על עיבוד ה-RC הסינית יכול להיות הובהר באמצעות חקירת WM בשל תפקידה הבסיסי בהבנת השפה. לפיכך, המשמעות המצורפת לשימוש במשימות DMI בעיבוד של RC סינית מספקת נתיב לפתרון הויכוח המתמשך בנוגע לעיבוד א-סימטריה של הסינים.
מאמר זה מציג שני ניסויים מבוססי עיבוד שמיעתי באמצעות הפרעה פנים וחוץ. המטרה של שני הניסויים האלה הייתה לחקור באיזו מידה ה-WM עוסק בעיבוד ה-RC הסינית תחת סוגים שונים של הפרעות.
בניסוי הראשון, משימת החלטה מלקסיקלית שהוצגה באופן חזותי שימש כהפרעה התוך-הבית. כמשימה מתערבת משנית, המילה/משימת החלטה לקסיקלית (LDT) הוצגה בשלוש נקודות במהלך הצגת השמיעה של משפט המשפט היחסי המיועד, ובכך מאפשרת למדוד את קושי העיבוד בנקודות אלה. הדאגה העיקרית בניסוי זה היא האופן שבו הפער במשפט היחסי (RC) משויך למילוי בפסוקית המטריצה (MC) והאם הוא משפיע על העיבוד של ה-MC הבאים. לפיכך, שלושת אתרי הגישוש שנמדדו הוגדרו לאחר אזור ה-MC. דוגמה, המשוכפלת מ-(2), משלושת האתרים הנמצאים בבדיקה המסומנים בחצים ומיושרים עם שרשור תחבירי מתאים, מומחש בדוגמה 3, כאשר 3 (א) מציג SRC ו-3 (ב) מראה אורק.

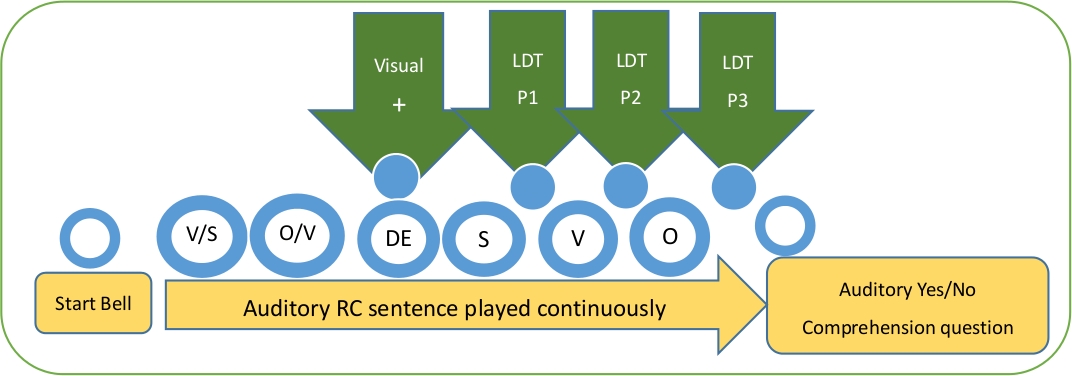
איור 1 מציג את ההליך של הפרעה למצגת ה-RC השמיעתית הרציפה על-ידי ה-ldt בכל אחד משלושת אתרי הגישוש. עיצוב העיתוי מלווה את הפרוטוקול המקובל של משימה LDT במחקר הסיני הקודם עיבוד11. לדוגמה, כל משפט של LDT חזותי מתחיל עם סימן צלב "+" המציין נקודת קיבוע במרכז הצג עבור 500 ms, ואחריו גירוי LDT חזותי, אשר מוצג על המסך עבור 3,000 ms ונעלם מיד לאחר הנושא עושה ההחלטה הקסיקלית. נושא אופייני משלים את ניסוי 1, כולל התרגול, תוך 30 – 35 דקות.

איור 1: הליך התערבות פנימי עם משימת החלטה לקסיקלית.
אנא לחץ כאן כדי להציג גירסה גדולה יותר של איור זה.
{kind=link}
שלושת אתרי הגישוש יחד עם משימת LDT:
1. תנוחה 1 (P1): לאחר-SMC אזור
המיקום הראשון (P1) שנמדד מיד לאחר הנושא של ה-MC באזור לאחר הגבול של RC. עומס העיבוד צפוי לחול באתר זה. קודם כל, לפני נקודה זו (SMC), הפער הנושא והפער האובייקט בתוך הטופס התחום של RC היוצר (VO) ומבנה הנושא-פועל (SV), בהתאמה. לאחר, כדי לשלב את המרכיבים באזור ה-RC עם שם הראש ב-MC, המאזינים חייבים לזהות את התפקיד הדקדוקי של הפער ולקשר אותו עם שם העצם המתקרב הקרוב
2. תנוחה 2 (P2): לאחר VMC אזור
המיקום השני (P2) שנמדד מיד לאחר הפועל בפסוקית המטריצה (VMC). אתר זה מניחים גם כדי לגרום לעומס העיבוד. שילוב המידע המילולי דורש מאזינים לאחזר את ארגומנטי שם העצם במשפט ולזהות את הסוכן של פועל המטריצה מהתחום הקודם של ה-RC או מתוך שם העצם הראשי שאותו משנה ה-RC.
3. תנוחה 3 (P3): אזור משפט הדואר
התנוחה השלישית (P3) נמדדת מיד לאחר תום המשפט. המחקרים הקודמים בתהליך הצעת הנישואין שקיים הסכם סיום משפט – תופעה שבה מידע שאינו תחבירי (למשל, השיח והרמה הסמנטית) נחשבים בסוף משפט להפעלת ולהשלמת הבנת12 ,13. לפיכך, טעינת העיבוד צריכה להיות מעלה לקראת סוף המשפט בשל הצורך לשלב מידע זה בלתי תחבירי14,15. ההנחה היא שמיקום 3 מראה השפלה בעומס העיבוד מאחר שנעשה ניסיון לפענוח משפט ברחבי אתר זה.
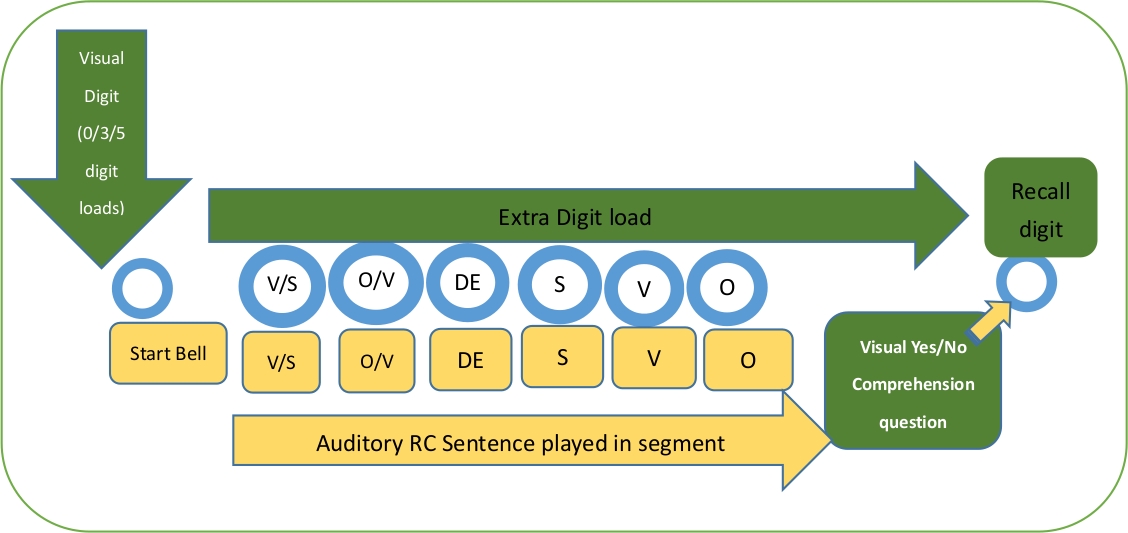
בניסוי השני, משימה של חלון שמיעתי (AMW) אומצה. טכניקת ה-amw נחשבת ליכולת ללכוד תבניות של הקצאת משאבים במהלך עיבוד לשוני מקוון ומשמשת רבות בניסיונות להבחין בין שתי הגישות המתחרות ב-16,17. יש להניח כי הפרעה נוספת צריכה לעלות מאזינים זמן נוסף במהלך עיבוד המשפט הארעי המתקרב הקרובה. תחת הפרדיגמה של AMW, המשתתפים שמעו משפטים שהיו מחולקים למילים, והם לוחצים על מקש במקלדת כדי ליזום משחק של הקטע הבא. לפיכך, משכי ההפסקות בין מקשים לאתחול המקטע העוקב ושליטה בזרימת המידע הנכנס משקפים את ההיענות של המשתתפים לתכונות הלשוני המיוחדות הנמצאות בנדון. לדוגמה, אם להפרעות הנוספות יש השפעות מסוימות על עיבוד משפטים של מורכבות תחביריות שונות, המשתתפים יוצגו בהתאמה משכי הפסקה ארוכים יותר לפני שיוזמים את הקטעים הבאים. ההליכים מוצגים באיור 2.

איור 2: הליך הפרעה מחוץ לשני עם משימת אחזור ספרות.
אנא לחץ כאן כדי להציג גירסה גדולה יותר של איור זה.
{kind=link}
הפרוטוקול הבא מציג את האופן שבו חוקרים משתמשים במשימת החלטה לקסיקלית שהוצגה באופן חזותי כהפרעה מחובית ובעומס ההפרעות האריתמטי המקביל כהפרעה מחוץ לחקירת מעורבות WM והעיבוד סימטריה של RCs סינית ולהרחיב את הלוגיקה הבסיסית.
Access restricted. Please log in or start a trial to view this content.
Protocol
הממשל של ניסויים אלה הלווה בכל התקנות האתיקה של המחקר. כל הנבדקים סיפקו הסכמה מילולית ובכתב לפני הניסויים. כל ההליכים, טופסי הסכמה, ואת הפרוטוקול הניסיוני אושרו על ידי ועדת האתיקה מחקר של האוניברסיטה הלאומית קונג צ'נג בטייוואן.
1. התנסות 1 – משימת הפרעה מודלית כפולה
- לגייס 97 סטודנטים, 54 נקבות ו42 זכרים, ממכון טלאן הלאומי לסיעוד ובית הספר הלאומי התיכון טמשני להשתתף בניסוי 1.
הערה: כל המשתתפים נדרשים להיות דוברי סינית שוטפת עם חזון רגיל או מתוקן לקדמותו וללא ליקוי שמיעתי באמצעות דוח עצמי. - הכנה חומרית
- בחר מילים ולא מילים עבור ה-LDT. כלול סך של 48 bisyllabic (שני תווים) מילים סיניות, אשר 24 היו מילים ו -24 היו לא מילים.
הערה: דמות סינית מייצגת הברה, שהיא בדרך כלל מורפמה (כלומר, המרכיב המשמעותי ביותר). מילות המטרה כאן הן. מילים מורכבות מדבקות נא עיין בקובץ המשלים לקבלת רשימה של מילות היעד החזותיות/שאינן מילים המשמשות עבור משימת ldt.- בחר את 24 המילים מתוך הדוח הטכני של Sinica משנת18, וודא שכל מילות היעד הן בתדר בינוני. חיפוש מילים של אחוזי התדר הממוצע כ-0.00030 וסדר הדירוג כ-4,000 במסד הנתונים.
הערה: בחירת מילים בתדר בינוני כאשר מילות היעד מיועדת להפחית את אפקט התדר, דבר המביא לזמני תגובה קצרים יותר (RTs) למילים בתדר גבוה ולעוד RTs ממילים בתדר נמוך. - צור את 24 המילים שאינן מילים על-ידי שימוש בשתי תווים חד-מונותיים המשמעותיים באופן אינדיבידואלי, אך השילוב שלהם אינו חריג. כדי למנוע הפעלות פוטנציאליות, הימנע ממילים בעלות אופי ביאיללמית עם רדיקלים זהים (למשל, haiyang, כלומר 'ocean ', מיוצג במילה תו ביאילמית סינית
 כמו
כמו  , שם המרכיב הרדיקלי מים משותפים בדמויות
, שם המרכיב הרדיקלי מים משותפים בדמויות  ו
ו  -).
-). - מאתר באופן ידני את 24 המילים הלא מילים במשפטים מילוי ו-24 המילים במשפטים RC היעד.
הערה: לאתר מילים עם RCs ולא מילים עם מילוי היה הכרחי כי רק RTs של LDT מ 24 מילים עם RCs צריך להיחשב וכלול בניתוחים סטטיסטיים.
- בחר את 24 המילים מתוך הדוח הטכני של Sinica משנת18, וודא שכל מילות היעד הן בתדר בינוני. חיפוש מילים של אחוזי התדר הממוצע כ-0.00030 וסדר הדירוג כ-4,000 במסד הנתונים.
- RC שמיעתי ועונשי מילוי
הערה: נא עיין בקובץ המשלים לקבלת דוגמאות של משפטים SRC, אורק ומילוי.- להלחין את גירוי השמיעה לתוך 72 משפטים, מעורבים שלושה סוגים של משפטים: 24 SRCs, 24 אורקים, ו 24 משפטי מילוי.
- לחלק את 48 RC משפטים באופן שווה לתוך שתי קבוצות כדי ליצור עיצוב לא שלם מאוזן, יוצרים 48 מבחנים (12 SRCs, 12 אורקים, ו 24 מילוי) ב 2 (SRC, אורק) * 3 (אתר בודק) * 2 (מילה/nonword) תנאים.
- בחר מילים ולא מילים עבור ה-LDT. כלול סך של 48 bisyllabic (שני תווים) מילים סיניות, אשר 24 היו מילים ו -24 היו לא מילים.
- הגדרת התוכנה הניסיונית
- השתמש בתוכנה ניסיונית סטנדרטית (כלומר, E-Prime19) כדי לתכנת את הניסוי בהתאם לפרוטוקולי התוכנה.
- באקראי את כל הגירויים באמצעות התוכנה הניסיונית.
- הגדר את מערכת התוכנה כך שתתעד את הנתונים הבאים: (1) זמן התגובה, (2) שיעור הדיוק של התגובות של המשתתף ב-LDT, ו-(3) הבנת משפט הדואר בהתבסס על הקשות המקלדת של המשתתפים.
- כלול משוב לגבי החלטה שגויה של המשתתפים או ללא תגובה. הצגת משוב על מסך הצג מיד לאחר התגובה השגויה או החסרה של המשתתף. כאשר תגובת המשתתף היתה נכונה, לא מופיעה משוב.
- ספק מקטע תרגול הכולל מבחנים עם משוב.
- לאחר הפעלת התרגול, הפעל את משימת ההפרעות הדו-מודאלית הכפולה של LDT. במהלך המפגשים הניסיוניים, אפשר למשתתפים לקחת הפסקה בין כל 24 מבחנים.
- כל משתתף יבצע את המשימה בנפרד. ראשית, מספקים למשתתפים הוראות הן בצורת כתב על מסך המחשב והן בצורה מילולית על ידי הנסניסה. יש להושיב את המשתתפים מול המחשב ולצייד אותם באוזניות.
- הנחה את המשתתפים להאזין למשפטים המושמעים באמצעות האוזניות שלהם, ובמקביל, בשלב מסוים במהלך תהליך ההאזנה, לביצוע משימת החלטה לקסיקלית.
- בקש מהמשתתפים להחליט אם המכשיר החזותי המפריע המוצג על המסך היה מילה או אי-מילים והורה להם ללחוץ על מפתח התגובה ' כן ' עבור מילה או ' לא ' עבור מילה שאינה מהירה ומדויקת ככל האפשר.
- הודיעו למשתתפים ששאלת הבנה תעקוב מיד אחרי המשפט. הזכר להם להקשיב בתשומת לב למשפט השמיעה בזמן שהוא מבצע את משימת LDT בו.
2. ניסוי 2 – משימת הפרעה כפולה ומודאלית
- גייס 61 סטודנטים לקולג ', 40 נשים ו -21 גברים, מאוניברסיטת הרפובליקה הלאומית של טאיוואן והמכללה הלאומית לסיעוד בטקן ג'וניור כמשתתפים בניסוי 2.
הערה: כל המשתתפים נדרשים להיות דוברי סינית מקורית עם חדות ראייה רגילה או מתוקנת לרגילה וללא ליקוי שמיעתי באמצעות דוח עצמי. - הכנה חומרית
- RC שמיעתי ועונשי מילוי
- להלחין את גירוי השמיעה לשלושה סוגים של משפטים: SRCs, אורקים, ומשפטים המילוי. חלוקת 48 RC משפטים באופן שווה לשתי קבוצות כדי ליצור עיצוב מאוזן מלאה עם 96 הכולל מבחנים (24 SRCs, 24 אורקים, ו 48 מילוי) עבור 2 (סוג משפט: SRC, אורק) * 3 (עומס הספרה) תנאים.
הערה: נא עיין בקובץ המשלים לקבלת דוגמאות לניסיון שמיעתי של SRC, אורק ועונשי מילוי.
- להלחין את גירוי השמיעה לשלושה סוגים של משפטים: SRCs, אורקים, ומשפטים המילוי. חלוקת 48 RC משפטים באופן שווה לשתי קבוצות כדי ליצור עיצוב מאוזן מלאה עם 96 הכולל מבחנים (24 SRCs, 24 אורקים, ו 48 מילוי) עבור 2 (סוג משפט: SRC, אורק) * 3 (עומס הספרה) תנאים.
- 0/3/5 ספרות
- בניית סך של 96 פריטים דיגיטליים, המורכב מ-0/3/5 שילובי ספרות. הקצה כל אחד מ-0, 3 או 5 ספרות באופן שווה לכל משפטי המשפט.
- RC שמיעתי ועונשי מילוי
- משימת הפרעה דיגיטלית מודאלית כפולה עם פרדיגמה של AMW
- השתמש בתוכנה ניסיונית סטנדרטית (כלומר, E-Prime19) כדי לתכנת את הניסוי בהתאם לפרוטוקולי התוכנה.
- באופן אקראי להקצות את המשתתפים לאחד משני סטים גירוי המייצג שילובים של שני גורמים בתוך הנושא של סוג משפט (SRC vs. אורק) ואת טעינת הזיכרון (ללא עומס, 3-לטעון, 5-הספרה-לטעון). ספק למשתתפים את המצגת החזותית 1,500 ms של הספרות לפני משימת AMW.
- לאחר מכן, הפעל את משימת AMW.
הערה: פעילות ה-AMW20 היא משימת האזנה בקצב אישי.- הנחה את המשתתפים להחזיק בזיכרון את המצגת החזותית הקודמת (ספרות או ללא ספרות).
- לאחר מכן, הורה למשתתפים להאזין למשפטים שהיו מחולקים למילים ושיחקו באוזניות שלהם. אמור להם לפייס את עצמם מהר ככל האפשר על ידי לחיצה על המקלדת כדי ליזום משחק של המילה הבאה מקוטע.
- הורה למשתתפים לענות על שאלת ההבנה של כן/לא הופיעה על מסך המחשב לאחר שהם הקשיבו לכל משפט משפט. הודע למשתתפים כי השאלה מופיעה לפני סימן שאלה "?" במסך המחשב ושהשאלה קשורה למידע ששמעו במשפט הקודם.
- צליל "צפצוף" קצר מושמע כאשר המשתתפים מקישים על המפתח כן/לא כדי לענות על שאלת ההבנה. לאחר הצפצוף, בעקבות ההוראה המופיעה על המסך, בקש מהמשתתפים לחזור על הספרה שראו לפני ההקשבה לגזר הדין.
- יש לרשום את התגובות לאחזור הספרות של המשתתפים בגיליון ניקוד.
Access restricted. Please log in or start a trial to view this content.
תוצאות
אפקט ההפרעות נצפה הן בתוך ה-LDT הכפולה והן בפעילויות העומס החוץ-ספרתי. בהתחשב בשלושת אתרי הגישוש בניסוי 1, תוצאות ה-RT של הפעילות בפנים-LDT מתבטאת בתבנית דינמית של עיבוד RC כפונקציה של שני סוגי RC. כפי שמוצג באיור 3, הסוג אורק מציג יתרון עיבוד בעמדה להציב את הנושא מטריצה (SMC) לא...
Access restricted. Please log in or start a trial to view this content.
Discussion
מחקר זה ממחיש כי שימוש בשיטות DMI עם משימות הפרעה פנים וחוץ, יכולות לסייע להבהיר את תפקיד ה-WM בעיבוד משפט מדובר ולשפוך אור על סוגיית ה-RC הסינית לעיבוד א-סימטריה. כצפוי, על-ידי מדידת המידה שבה הפרעה מפעילות משנית השפיעו על עיבוד משפט ראשוני, אנו יכולים להסיק את דפוסי עיבוד ה-RC הסינית ולהגיע לפת?...
Access restricted. Please log in or start a trial to view this content.
Disclosures
. למחברים אין מה לגלות
Acknowledgements
מחקר זה היה נתמך על ידי מענקים ממשרד המדע והטכנולוגיה, טייוואן, R.O.C. [לבטחון לאומי-101-2410-H-439-001] המחבר הראשון, Tuyuan צ'נג. המחברים מודים לחברי המעבדה, יאנג יה-הואי וחן פיי-האן, בשנת NTIN, על עזרתם בהכנה ובניהול הניסוי.
Access restricted. Please log in or start a trial to view this content.
Materials
| Name | Company | Catalog Number | Comments |
| E-Prime | Psychology Software Tools | version Professional 2.0 | |
| Headphone | Logitech | ||
| Praat | Praat | 5.3.43 | The online software used to edit the sound files for listening; http://www.fon.hum.uva.nl/praat/ |
| Serial Response Box | Psychology Software Tools | ||
| Standard PC | ASUS K42Jv laptop |
References
- Just, M. A., Carpenter, P. A. A capacity theory of comprehension: Individual differences in working memory. Psychological Review. 99, 122-149 (1992).
- King, J., Just, M. A. Individual differences in syntactic processing: The role of working memory. Journal of Memory and Language. 30, 580-602 (1991).
- Caplan, D., Waters, G. S. Verbal working memory and sentence comprehension. Behavioral & Brain Sciences. 22, 77-94 (1999).
- Waters, G., Caplan, D., Yampolsky, S. On-line syntactic processing under concurrent memory load. Psychonomic Bulletin & Review. 10 (1), 88-95 (2003).
- Cowan, N. Working Memory Capacity. , Psychology Press. New York, NY. (2005).
- Miller, G. A. The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychological Review. 63, 81-97 (1956).
- Chen, B., Ning, A., Bi, H., Dunlap, S. Chinese subject-relative clauses are more difficult to process than the object-relative clauses. Acta Psychologica. 129, 61-65 (2008).
- Gibson, E., Wu, H. H. Processing Chinese relative clauses in context. Language and Cognitive Processes. 28, 125-155 (2013).
- Hsiao, F., Gibson, E. Processing relative clauses in Chinese. Cognition. 90, 3-27 (2003).
- Lewandowsky, S., Oberauer, K., Brown, G. D. A. No temporal decay in verbal short-term memory. Trends in Cognitive Science. 13, 120-126 (2009).
- Wu, J. T., Chou, T. L., Liu, I. M. The locus of the character/word frequency effect. Advances in the study of Chinese language processing. Chang, H. W., Huang, J. T., Hue, C. W., Tzeng, O. J. L. , Taipei. Taipei: National Taiwan University (in Chinese) 31-58 (1994).
- Fodor, J. D., Ni, W., Crain, S., Shankweiler, D. Tasks and timing in the perception of linguistic anomaly. Journal of Psycholinguistic Research. 25 (1), 25-57 (1996).
- Swinney, D., Zurif, E. Syntactic processing in aphasia. Brain and Language. 50 (2), 225-239 (1995).
- Balogh, J., Zurif, E., Prather, P., Swinney, D., Finkel, L. Gap-filling and end-of-sentence effects in real-time language processing: implications for modeling sentence comprehension in aphasia. Brain and Language. 61 (2), 169-182 (1998).
- Granier, J. P., Robin, D. A., Shapiro, L. P., Peach, R. K., Zimba, L. D. Measuring processing load during sentence comprehension: visuomotor tracking. Aphasiology. 14 (5-6), 501-513 (2000).
- Waters, G. S., Caplan, D. Age, working memory, and on-line syntactic processing in sentence comprehension. Psychology and Aging. 16, 128-144 (2001).
- Waters, G. S., Caplan, D. Working memory and online syntactic processing in Alzheimer’s disease: Studies with auditory moving window presentation. Journal of Gerontology: Psychological Sciences. 57B, 298-311 (2002).
- Cheng, T., Cheung, H., Wu, J. Spoken relative clause processing in Chinese: measure from an alternative task. Language and Linguistics. 12 (3), 669-705 (2011).
- Cheng, T., Wu, J., Huang, S. Use of Memory-Load Interference in Processing Spoken Chinese Relative Clauses. Journal of Psycholinguistic Research. 47 (5), https://doi.org/10.1007/s10936-018-9576-5 1035-1055 (2018).
- CKIP. Zhongwen shumianyu pinlü cidian [Dictionary of Chinese written word frequency], CKIP Technical Report, No. 94-01. , Institute of Information Science, Academia Sinica. Taipei. (1994).
- MacWhinney, B., James, J., Schunn, C., Li, P., Schneider, W. Step—A system for teaching experimental psychology using E-Prime. Behavior Research Methods, Instruments, and Computers. 33 (2), 287-296 (2001).
- Ferreira, F., Henderson, J., Anes, M., Weeks, P., McFarlane, D. Effects of lexical frequency and syntactic complexity in spoken language comprehension: Evidence from the auditory moving-window technique. Journal of Experimental Psychology: Learning, Memory, and Cognition. 22, 324-335 (1996).
- Daneman, M., Carpenter, P. A. Individual differences in working memory and reading. Journal of Verbal Learning and Verbal Behavior. 19, 450-466 (1980).
- Bulut, T., Cheng, S. K., Xu, K. Y., Hung, D. L., Wu, D. H. Is there a processing preference for object relative clauses in Chinese? Evidence from ERPs. Frontiers in Psychology. 9, 1-18 (2018).
- Mitchell, D. C., Green, D. W. The effects of context and content on immediate processing in reading. Quarterly Journal of Experimental Psychology. 30 (4), 609-636 (1978).
Access restricted. Please log in or start a trial to view this content.
Reprints and Permissions
Request permission to reuse the text or figures of this JoVE article
Request PermissionThis article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. All rights reserved