
Method Article
通过狗的眼睛:来自狗皮层的自然视频的 fMRI 解码
摘要
机器学习算法已经过训练,可以使用大脑活动模式来“解码”呈现给人类的刺激。在这里,我们证明了相同的技术可以解码来自两只家犬大脑的自然视频内容。我们发现基于视频中动作的解码器在狗身上是成功的。
摘要
使用机器学习和功能磁共振成像 (fMRI) 来解码来自人类和非人类皮层的视觉刺激的最新进展,为感知的本质带来了新的见解。然而,这种方法尚未实质性地应用于灵长类动物以外的动物,这引发了对整个动物王国中此类表征性质的质疑。在这里,我们在两只家犬和两只人类中使用了清醒 fMRI,这些 MRI 是在每只狗观看专门制作的适合狗的自然主义视频时获得的。然后,我们训练了一个神经网络 (Ivis),从每个网络总共 90 分钟的大脑活动记录中对视频内容进行分类。我们测试了基于对象的分类器,试图区分狗、人类和汽车等类别,以及基于动作的分类器,试图区分吃、闻和说话等类别。与两种类型分类器的表现都远高于偶然性的人类受试者相比,只有基于动作的分类器才能成功解码来自狗的视频内容。这些结果证明了机器学习的首次已知应用,用于解码食肉动物大脑中的自然视频,并表明狗对世界的看法可能与我们自己的完全不同。
引言
与其他灵长类动物一样,人类的大脑展示了将视觉流分为背侧和腹侧通路的过程,这些通路具有独特而众所周知的功能——物体的“什么”和“哪里”1。几十年来,这种什么/在哪里二分法一直是一种有用的启发式方法,但现在已知其解剖学基础要复杂得多,许多研究人员赞成基于识别与行动(“什么”与“如何”)的划分2,3,4,5。此外,虽然我们对灵长类动物视觉系统组织的理解不断得到完善和争论,但关于其他哺乳动物物种的大脑如何表示视觉信息,仍有许多未知数。在某种程度上,这种空白是视觉神经科学中历史上对少数物种的关注的结果。然而,新的脑成像方法为无创研究更广泛动物的视觉系统提供了可能性,这可能会对哺乳动物神经系统的组织产生新的见解。
狗 (Canis lupus familiaris) 为研究进化上远离灵长类动物的物种中视觉刺激的表现提供了丰富的机会,因为它们可能是唯一可以被训练合作参与 MRI 扫描而无需镇静或约束的动物 6,7,8.由于它们在过去 15,000 年中与人类共同进化,狗也居住在我们的环境中,并暴露在人类每天遇到的许多刺激中,包括视频屏幕,这是在 MRI 扫描仪中呈现刺激的首选方式。即便如此,狗可能会以与人类完全不同的方式处理这些常见的环境刺激,这就引出了它们的视觉皮层是如何组织的问题。基本差异(例如缺少中央凹或成为双色性)可能不仅对较低级别的视觉感知产生重大的下游影响,而且对较高级别的视觉表示也有影响。几项针对狗的 fMRI 研究表明,面部和物体加工区域的存在似乎都遵循灵长类动物中常见的背侧/腹侧流结构,尽管目前尚不清楚狗本身是否具有面部处理区域,或者这些区域是否对头部的形态具有选择性(例如,狗与人类)9, 10,11,12,13。无论如何,狗的大脑比大多数灵长类动物都小,预计它的模块化程度会更低14,因此在流中可能会有更多的信息类型混合,甚至某些类型的信息(如动作)的特权。例如,有人提出,运动可能是犬类视觉感知中比纹理或颜色更突出的特征15。此外,由于狗没有手,而手是我们与世界互动的主要方式之一,它们的视觉处理,尤其是对物体的视觉处理,可能与灵长类动物完全不同。与此一致,我们最近发现证据表明,与爪子相比,口腔与物体的相互作用会导致狗大脑中物体选择性区域的激活更大16。
尽管狗可能已经习惯了家庭环境中的视频屏幕,但这并不意味着它们习惯于像人类一样在实验环境中查看图像。使用更自然的刺激可能有助于解决其中一些问题。在过去十年中,机器学习算法在解码来自人脑活动的自然视觉刺激方面取得了相当大的成功。早期的成功集中在调整经典的、受阻的设计,以使用大脑活动来分类个体所看到的刺激类型,以及编码这些表征的大脑网络 17,18,19。随着更强大的算法的发展,尤其是神经网络,可以解码更复杂的刺激,包括自然视频20,21。这些分类器通常根据对这些视频的神经反应进行训练,推广到新的刺激,使它们能够识别特定对象在 fMRI 反应时观察到的内容。例如,电影中某些类型的动作可以从人脑中准确解码,例如跳跃和转弯,而其他类型的动作(例如拖动)则无法22.同样,尽管可以从 fMRI 反应中解码许多类型的对象,但一般类别似乎更加困难。大脑解码不仅限于人类,它提供了一个强大的工具来理解信息在其他物种的大脑中是如何组织的。对非人类灵长类动物进行的类似 fMRI 实验发现,颞叶的有灵性和面貌/身体的维度有明显的表示,这与人类的相似23.
作为了解狗对自然视觉刺激的表征的第一步,清醒 fMRI 被用于两只高度熟练的家犬,以测量皮层对适合狗的视频的反应。在这项研究中,使用自然主义视频是因为它们对狗的潜在生态有效性更高,并且因为它们在将视频内容映射到狗运动的神经网络方面取得了成功24。在三个单独的会话中,从每只狗对 256 个独特视频剪辑的反应中获得 90 分钟的 fMRI 数据。为了进行比较,对两名人类志愿者进行了相同的程序。然后,使用神经网络,我们训练和测试了分类器,以使用不同数量的类来区分“对象”(例如,人、狗、汽车)或“动作”(例如,说话、吃、闻)。这项研究的目标有两个:1) 确定是否可以从狗皮层解码自然视频刺激;2) 如果是这样,请初步了解该组织是否与人类相似。
研究方案
该狗研究得到了埃默里大学 IACUC (PROTO201700572) 的批准,所有主人都书面同意他们的狗参与该研究。人体研究程序已获得埃默里大学 IRB 的批准,所有参与者在扫描前均提供书面同意书 (IRB00069592)。
1. 参与者
- 选择以前没有接触过研究中呈现的刺激的参与者(狗和人类)。
注意:狗参与者是两只当地宠物狗,由主人自愿参加 fMRI 训练和扫描,与之前描述的7 一致。Bhubo 是一只 4 岁的雄性拳击手混血儿,而 Daisy 是一只 11 岁的雌性波士顿梗犬混血儿。这两只狗之前都参加了几项 fMRI 研究(Bhubo:8 项研究,Daisy:11 项研究),其中一些涉及在扫描仪中观看投射到屏幕上的视觉刺激。之所以选择它们,是因为它们能够在主人不在视线范围内的情况下留在扫描仪中而不会长时间移动。两名人类(一名男性,34 岁,一名女性,25 岁)也参与了这项研究。狗和人类以前都没有接触过本研究中显示的刺激。
2. 刺激
- 拍摄安装在手持式稳定云台上的视频(1920 像素 x 1440 像素,每秒 60 帧 [fps])。
注意:在这项研究中,这些视频于 2019 年在佐治亚州亚特兰大拍摄。- 从“狗的眼睛”拍摄自然主义视频,将万向节保持在大约膝盖的高度。设计视频以捕捉狗生活中的日常场景。
注意:这些场景包括走路、喂食、玩耍、人类互动(彼此之间以及与狗互动)、狗彼此互动、运动中的车辆和非狗动物(图 1A; 补充电影 1)。在某些剪辑中,视频中的主体直接与摄像头互动,例如,抚摸、嗅探或玩耍摄像头,而在其他剪辑中,摄像头被忽略。从本地放置的相机陷阱(1920 像素 x 1080 像素,30 fps)获得鹿的额外镜头。 - 将视频编辑成 256 个独特的 7 秒“场景”。每个场景都描绘了一个事件,例如人类拥抱、狗跑或鹿走路。根据场景的内容为每个场景分配一个唯一的编号和标签(请参阅下文)。
- 从“狗的眼睛”拍摄自然主义视频,将万向节保持在大约膝盖的高度。设计视频以捕捉狗生活中的日常场景。
- 将场景编辑成五个较大的编译视频,每个视频大约 6 分钟。使用汇编视频而不是一部长电影来按顺序呈现各种刺激。
注意:如果视频是在一个长 “镜头 ”中捕捉的,将很难实现呈现各种各样的刺激。这与人类的 fMRI 解码研究一致20,22。此外,呈现短片的汇编可以更轻松地创建一个维持集,在该集上可以测试经过训练的算法(请参阅下面的第 7 节,分析),因为可以保留单个剪辑而不是一个长电影。四个合辑视频有 51 个独特的场景,一个有 52 个。场景之间没有中断或空白屏幕。 - 半随机选择场景,以确保每个视频都包含来自所有主要标签类别(狗、人类、车辆、非人类动物和交互)的示例。
注意:在编译过程中,所有场景都以 30 fps 的速度缩减像素采样到 1920 像素 x 1080 像素,以匹配 MRI 投影仪的分辨率。
3. 实验设计
- 在 3T MRI 扫描仪中扫描参与者,同时观看投影在安装在 MRI 孔后部的屏幕上的汇编视频。
- 无声播放视频。
- 对于狗,通过事先训练将头部放在定制的下巴托中,从鼻子中部到下颌骨后面模制到下颌骨后面,从而实现头部的稳定定位。
- 将下巴托固定在横跨线圈的木架上,但为下面的爪子留出足够的空间,从而使每只狗都处于“狮身人面像”位置(图 1B)。没有使用任何约束装置。有关训练方案的更多信息,请参阅以前的清醒 fMRI 狗研究7。
- 让受试者每次运行五次,每次运行包括一个从头到尾观看的汇编视频,以随机顺序呈现。对于狗,在每次跑步之间短暂休息。在这些休息时间向狗提供食物奖励。
- 让每个受试者在 2 周内参加三个会议。这允许受试者观看五个独特编译视频中的每一个 3 次,每人的总 fMRI 时间为 90 分钟。
4. 成像
- 按照与之前清醒 fMRI 狗研究中采用的方案一致的方案扫描狗参与者 7,25。
- 使用单次回波平面成像序列获得功能扫描,以采集 22 个连续的 2.5 毫米切片,间隙为 20%(TE = 28 毫秒,TR = 1,430 毫秒,翻转角度 = 70°,64 x 64 矩阵,2.5 毫米平面内体素大小,FOV = 160 毫米)。
- 对于狗,将切片背侧定向到大脑,相位编码方向从右到左,因为狗以“狮身人面像”位置坐在 MRI 中,颈部与大脑对齐。从右到左的相位编码可避免从颈部到头部前部的环绕伪影。此外,扫描犬的主要易感性伪影来自额窦,导致额叶变形。
- 对于人类,获得前后方向具有相位编码的轴向切片。
- 为了与狗扫描(相同的 TR/TE)进行比较,对多波段加速因子为 2(GRAPPA = 2,TE = 28 ms,TR = 1,430 ms,翻转角度 = 55°,88 x 88 矩阵,2.5 mm 平面内体素,44 个 2.5 mm 切片,间隙为 20%)的人类使用多波段切片(CMRR,明尼苏达大学)。
- 对于狗,还可以使用具有 1.5 毫米各向同性体素的涡轮自旋回波序列为每个参与者获取整个大脑的 T2 加权结构图像。对于人类参与者,使用具有 1 毫米各向同性体素的 T1 加权 MPRAGE 序列。
注意:在三个会议的过程中,每个参与者获得了大约 4,000 个功能体积。
5. 刺激标签
- 为了训练模型对视频中呈现的内容进行分类,请先标记场景。为此,请将构成每个汇编视频的 7 秒场景划分为 1.4 秒的剪辑。标记短剪辑而不是单个帧,因为视频中的某些元素无法通过静止帧捕获,其中一些元素可能对狗特别突出,因此在解码(如运动)时很有用。
注意:选择 1.4 秒的剪辑长度,因为它足够长来捕获这些动态元素,并且与 1.43 秒的 TR 非常匹配,这允许逐个体积地执行分类。 - 将这些 1.4 秒的剪辑 (n = 1,280) 随机分发给实验室成员,以使用预编程的复选框样式提交表单手动标记每个剪辑。
注意:选择了 94 个标签来包含视频的尽可能多的关键特征,包括主题(例如,狗、人、猫)、主题数量(1、2、3+)、对象(例如,汽车、自行车、玩具)、动作(例如,吃、闻、说话)、互动(例如,人与人、人与狗)和环境(室内、室外)等。这为每个剪辑产生了一个 94 维标签向量(补充表 1)。 - 作为一致性检查,选择一个随机子集,以便由第二个实验室成员重新标记。在这里,发现标签在个体之间高度一致 (>95%)。对于那些不一致的标签,允许两位实验室成员重新观看有问题的剪辑,并就标签达成共识。
- 对于每次运行,使用带时间戳的日志文件来确定视频刺激相对于第一个扫描卷的开始时间。
- 为了解释刺激呈现和 BOLD 响应之间的延迟,使用双伽马血流动力学响应函数 (HRF) 对标签进行卷积,并使用 Python 函数 numpy.convolve() 和 interp() 插入功能图像的 TR(1,430 毫秒)。
注意:最终结果是一个卷积标签矩阵,每个参与者的扫描体积总数(Daisy、Bhubo、Human 1 和 Human 2 分别为 94 个标签 x 3,932、3,920、3,939 和 3,925 个体积)。 - 在必要时对这些标签进行分组,以创建宏标签以进行进一步分析。例如,合并所有 walking 实例(dog walking、human walking、donkey walking)以创建 “walking” 标签。
- 要进一步消除标签集中的冗余,请计算每个标签的方差膨胀因子 (VIF),不包括宏标签,这些标签显然是高度相关的。
注意:VIF 是预测变量中多重共线性的度量,通过对每个预测变量进行回归计算得出。VIF 越高,表示预测变量高度相关。本研究采用 2 的 VIF 阈值,将 94 个标签减少到 52 个唯一且基本不相关的标签(补充表 1)。
6. fMRI 预处理
- 预处理涉及使用 AFNI 套件 (NIH) 及其相关函数进行运动校正、删失和归一化26,27。使用两遍、六参数刚体运动校正,将体积与代表参与者在跑步中平均头部位置的目标体积对齐。
- 执行删失以删除扫描之间位移超过 1 mm 的体积,以及异常体素信号强度大于 0.1% 的体积。对于这两只狗,删失后保留了超过 80% 的体积,而对于人类,保留了超过 90% 的体积。
- 要提高单个体素的信噪比,请使用 3dmerge 和 4 mm 高斯核在全宽半高值处执行温和的空间平滑。
- 为了控制可能因刺激而异的低级视觉特征(例如运动或速度)的效果,请计算视频剪辑连续帧之间的光流22,28。在下采样到每秒 10 帧后,使用 OpenCV 中的 Farneback 算法计算光流29。
- 要估计每帧中的运动能量,请计算每个像素的光流平方和,并取结果的平方根,从而有效地计算从一帧到下一帧的欧几里得平均光流28,30。这会为每个合辑视频生成运动能量的时间进程。
- 对这些进行重新采样以匹配 fMRI 数据的时间分辨率,如上所述与双 γ 血流动力学反应函数 (HRF) 进行卷积,并连接以与每个主题的刺激呈现保持一致。
- 使用这个时间过程,以及从上述运动校正生成的运动参数,作为使用 AFNI 的 3dDeconvolve为每个体素估计的一般线性模型 (GLM) 的唯一回归量。使用此模型的残差作为机器学习算法的输入,如下所述。
7. 分析
- 解码大脑中对视觉刺激分类有重大贡献的区域,为每个参与者训练一个模型,然后可以使用该模型根据参与者的大脑数据对视频内容进行分类。使用 Ivis 机器学习算法,这是一种基于 Siamese 神经网络 (SNN) 的非线性方法,已在高维生物数据上取得成功31。
注意: SNN 包含两个相同的子网络,用于学习有监督或无监督模式下输入的相似性。尽管神经网络在大脑解码中越来越受欢迎,因为它们通常比支持向量机 (SVM) 等线性方法更强大,但我们在这里使用 SNN,因为它对类不平衡的鲁棒性,并且需要更少的示例。与在相同数据上训练的支持向量机 (SVM) 和随机森林 (RF) 分类器相比,我们发现 Ivis 在跨多个标签组合对大脑数据进行分类方面更成功,这取决于各种指标,包括平均 F1 分数、精度、召回率和测试准确性(见下文)。 - 对于每个参与者,将全脑残差转换为适合输入到 Ivis 神经网络的格式。在他们的三个会话中,每个会话中都连接并屏蔽 5 个运行,仅保留大脑体素。
- 展平空间维度,从而生成按时间划分的体素的二维矩阵。
- 连接每次运行中显示的视频的卷积标签,从而对应于 fMRI 运行。
- 根据预处理中标记的卷审查 fMRI 数据和相应的标签。
- 选择要解码的目标标签(以下称为 “类”),并仅保留包含这些类的卷。为简单起见,请将类视为互斥的,并且不包括属于多个类的卷进行解码,只留下纯示例。
- 将数据拆分为训练集和测试集。使用 5 重拆分,随机选择 20% 的场景作为测试集。
注意:这意味着,如果为测试集选择了给定的场景,则在此场景中获得的所有剪辑和功能体积都会从训练集中保留。如果拆分是独立于场景执行的,则来自同一场景的卷将同时出现在训练集和测试集中,并且分类器只需将它们与该特定场景匹配即可成功分类。但是,为了正确分类来自新场景的保留体积,分类器必须将它们与更通用的、独立于场景的类匹配。与保留单个剪辑相比,这是对分类器成功的泛化性的更有力的测试。 - 通过使用 scikit-learn 包 imbalanced-learn 对每个类中的卷数进行欠采样以匹配最小类的卷数来平衡训练集。
- 对于每个参与者,在 100 次迭代中训练和测试 Ivis 算法,每次使用唯一的测试训练拆分(Ivis 参数:k = 5,model = “maaten”,n_epochs_without_progress = 30,supervision_weight = 1)。这些参数值主要是根据算法作者在其文档中推荐的数据集大小和复杂性选择的32.“Number of epochs without progress” 和 “supervision weight” (0 表示无监督,1 表示监督)进行了额外的参数调整以优化模型。
- 要将用于训练分类器的特征数量从整个大脑减少到仅提供信息量最大的体素,请使用 scikit-learn 的随机森林分类器 (RFC) 根据每个体素的特征重要性对每个体素进行排名。
注意:尽管 RFC 本身并没有执行上述机会,但它确实起到了筛选出非信息性体素的有用目的,这些体素只会给 Ivis 算法带来噪声。这类似于在传递给分类器33之前使用 F 检验进行特征选择。只有训练集中前 5% 的体素被用于训练和测试。首选的体素数量被选为 5% 作为保守阈值,以便在训练神经网络之前减少非信息性体素的数量。当使用较大比例的体素时,人类和狗也获得了定性相似的结果。尽管人类大脑比狗的大脑大,但人类模型在训练的体素绝对数量等于狗模型中包含的体素时也取得了成功,远小于 5% 的体素(~250 个体素;均平均 LRAP 分数>第 99 个百分位数)。因此,为了保持一致性,我们使用两个物种的前 5% 的体素来呈现结果。 - 对所有 5 次运行中平均 100% 信息量最大的体素进行标准化,转换为每个参与者的结构空间,然后对图集空间进行分组(图集:人类34 个,狗35 个),并在每个物种的参与者之间求和。叠加图集上的重要性,并使用 ITK-SNAP36 根据重要性评分为它们着色。
结果
在机器学习分析中评估模型性能的最常见指标包括精度、准确率、召回率和 F1 分数。准确率是指在给定真实数据的情况下,模型预测正确的总体百分比。精度是模型的实际正预测的百分比(即真阳性率),而召回率是模型能够成功预测的原始数据中真阳性的百分比。F1 分数是精确率和召回率的加权平均值,可作为准确率的替代度量,对类不平衡更可靠。但是,Ivis 与其他常用的机器学习算法的不同之处在于它的输出不是二进制的。给定大脑体素的特定输入,每个输出元素都表示对应于每个类的概率。计算这些输出的准确率、精度、召回率和 F1 需要以 “赢家通吃” 的方式将它们二值化,其中概率最高的类别被认为是该数量的预测类别。这种方法消除了有关这些概率排名的重要信息,这些信息与评估模型的质量有关。因此,虽然我们仍然计算这些传统指标,但我们使用标签排名平均精度 (LRAP) 分数作为主要指标来计算模型在测试集上的准确性。该指标本质上衡量分类器在多大程度上为真实标签分配了更高的概率37。
在不同程度上,神经网络分类器对人类和狗都取得了成功。对于人类,该算法能够对物体和动作进行分类,三类模型的平均准确率都达到了 70%。LRAP 分数被用作计算模型在测试集上的准确性的主要指标;该指标衡量分类器为 true 标签分配更高概率的程度37.对于这两个人,对于所有测试的模型,LRAP 分数的中位数都大于随机排列标签集的第 99 个百分位数(表 1; 图 2)。对于狗,只有动作模型的中位 LRAP 百分位排名在两个参与者中都明显大于机会(表 1; 对象 p = 0.13, 作 p < 0.001;狗的平均三类动作模型 LRAP 评分 = 第 78 个百分位数)。这些结果适用于所有受试者单独以及按物种分组时。
鉴于分类器的成功,我们使用其他类进行了训练和测试,以确定模型的极限。这包括使用 Python 包 scipy 的分层聚类算法计算整个 52 个潜在感兴趣类别的不相似性矩阵,该算法根据个体大脑对每个类别的反应的相似性对类别进行聚类,如成对相关所定义。在测试的其他模型中,两只狗中 LRAP 百分位数排名中位数的模型有五个类别:原来的 “说话”、“吃 ”和 “嗅”,加上两个新类别 “抚摸 ”和 “玩耍”(图 2)。该模型的 LRAP 百分位中位数排名显着大于所有参与者随机预测的百分位(表 1; 狗 和人类的 p < 0.001;狗的平均五类动作模型 LRAP 评分 = 第 81 个百分位数)。
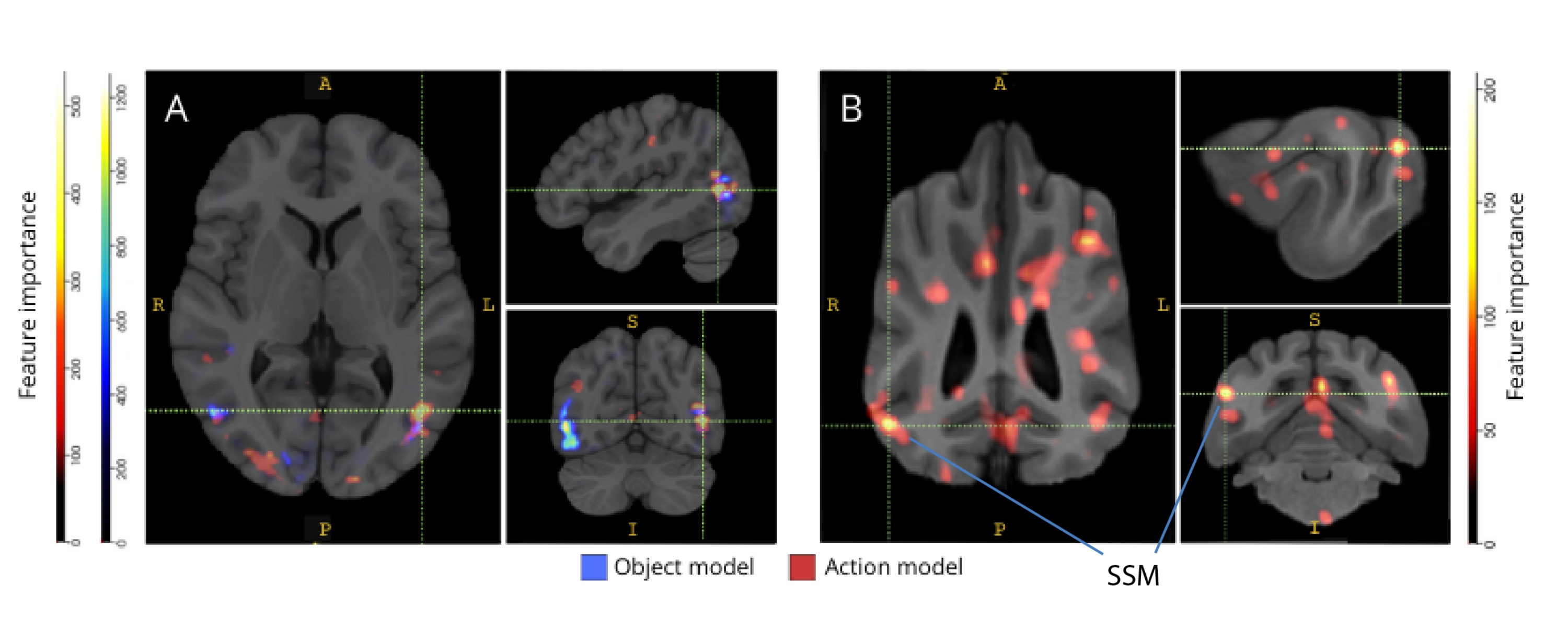
当反向映射到它们各自的大脑图谱时,体素的特征重要性分数揭示了狗和人类的枕叶、顶叶和颞叶皮层中的许多信息体素集群(图 3)。在人类中,基于对象和基于动作的模型比狗和通常与对象识别相关的区域显示出更聚焦的模式,尽管基于对象的体素和基于动作的体素的空间位置略有不同。
我们检查了这些物种差异不是狗比其他类型视频更多地移动到某些类型的视频(例如,狗以外的视频,例如汽车)的任务相关运动的结果。我们计算了六个运动参数的欧几里得范数,并使用 R 包 lme4 拟合了一个线性混合效应模型,其中类是固定效应,游程数是每只狗的随机效应。对于每个最终模型,我们发现类别类型对 Daisy(F(2, 2252) = 0.83, 基于对象的 p = 0.44,F(4, 1235) = 1.87, 基于 动作的 p = 0.11)或 Bhubo(F(2, 2231) = 1.71,基于对象的 p = 0.18 和 F(4, 1221) = 0.94,基于动作的 p = 0.45)的运动没有显着影响。

图 1:MRI 钻孔中的自然视频和演示。 (A) 向参与者展示的视频剪辑中的示例帧。(B) Bhubo,一只 4 岁的拳击手混血儿,一边看视频,一边接受清醒的 fMRI。 请单击此处查看此图的较大版本。
{kind=link}

图 2:模型在狗和人类中的性能。 LRAP 分数的分布,表示为其零分布的百分位排名,针对三类基于对象的模型、三类基于动作的模型和五类基于动作的模型对 Ivis 机器学习算法进行 100 多次迭代的训练和测试,其中模型试图对 通过以下方式 获得的自然主义视频刺激的 BOLD 反应进行分类狗和人类的清醒 fMRI。分数按物种汇总。具有非常高百分位排名的 LRAP 分数表明该模型不太可能偶然获得该 LRAP 分数。表现不优于偶然性的模型的 LRAP 分数百分位排名中位数为 ~50。虚线表示所有 100 次运行中每个物种的 LRAP 分数百分位排名中位数。 请单击此处查看此图的较大版本。
{kind=link}

图 3:区分三类对象和五类动作模型的重要区域。 (A) 人类和 (B) 狗参与者。使用随机森林分类器根据体素的特征重要性对体素进行排名,并在模型的所有迭代中取平均值。此处显示了前 5% 的体素(即用于训练模型的体素),按物种聚合并转换为组空间以进行可视化(图集:人类34 和狗35)。标签显示具有高特征重要性分数的狗脑区域,基于 Johnson 等人确定的区域35。缩写:SSM = 外侧上回。 请单击此处查看此图的较大版本。
{kind=link}
| 型号类型 | 训练准确性 | 测试精度 | F1 分数 | 精度 | 召回 | LRAP 评分中位百分位数 | |
| 人类 1 | 对象 (3 类) | 0.98 | 0.69 | 0.48 | 0.52 | 0.49 | >99 |
| 动作 (3 类) | 0.98 | 0.72 | 0.51 | 0.54 | 0.54 | >99 | |
| 动作 (5 类) | 0.97 | 0.51 | 0.28 | 0.37 | 0.27 | >99 | |
| 人类 2 | 对象 (3 类) | 0.98 | 0.68 | 0.45 | 0.5 | 0.47 | >99 |
| 动作 (3 类) | 0.98 | 0.69 | 0.46 | 0.5 | 0.48 | >99 | |
| 动作 (5 类) | 0.97 | 0.53 | 0.3 | 0.4 | 0.27 | >99 | |
| 布博 | 对象 (3 类) | 0.99 | 0.61 | 0.38 | 0.41 | 0.39 | 57 |
| 动作 (3 类) | 0.98 | 0.63 | 0.38 | 0.4 | 0.4 | 87 | |
| 动作 (5 类) | 0.99 | 0.45 | 0.16 | 0.29 | 0.13 | 88 | |
| 雏菊 | 对象 (3 类) | 1 | 0.61 | 0.38 | 0.43 | 0.39 | 43 |
| 动作 (3 类) | 0.97 | 0.62 | 0.35 | 0.38 | 0.35 | 60 | |
| 动作 (5 类) | 0.99 | 0.44 | 0.16 | 0.27 | 0.13 | 76 |
表 1:Ivis 机器学习算法对 通过 清醒 fMRI 在狗和人类中通过清醒 fMRI 获得的自然视频刺激的 BOLD 反应进行 100 次迭代训练和测试的汇总指标。 对象模型有三个目标类别(“狗”、“人”、“汽车”),动作模型有三个或五个类别(三个类别:“说话”、“吃”、“闻”;五个类别:“说话”、“吃”、“嗅”、“抚摸”、“玩耍”)。显著大于机会的值以粗体显示。
补充表 1:类标签。请点击此处下载此文件。
补充影片 1:示例视频剪辑。请点击此处下载此文件。
讨论
这项研究的结果表明,自然主义视频在狗的大脑中诱导了表征,这些表征在多次成像过程中足够稳定,可以用 fMRI 解码——类似于在人类和猴子中获得的结果20,23。虽然之前对犬视觉系统的 fMRI 研究呈现了剥离的刺激,例如中性背景下的面部或物体,但这里的结果表明,多个人和物体相互交互的自然视频会在狗皮层中诱导激活模式,这些模式可以以接近人类皮层中看到的可靠性进行解码。这种方法为研究狗的视觉系统的组织方式开辟了新的途径。
尽管犬 fMRI 领域发展迅速,但迄今为止,这些实验都依赖于相对贫乏的刺激,例如中性背景下的人或物体的图片 10,12,13。此外,虽然这些实验已经开始识别类似于灵长类动物梭形面部区域 (FFA) 的大脑区域,参与面部处理,以及用于对象处理的枕外侧皮层 (LOC),但对这些表征的性质仍然存在分歧,例如狗本身是否具有与灵长类动物相似的显着特征反应的面部区域,或者它们是否对狗和人类或面部和头部有单独的表征, 例如 9,13。当然,狗不是灵长类动物,我们不知道它们是如何通过声音和气味来解读这些脱离它们通常的多感官背景的人工刺激的。一些证据表明,狗不会将物体的图像视为真实事物的代表12。虽然不可能在扫描仪中创建真正的多感官体验,但使用自然主义视频可能会通过提供更接近现实世界的动态刺激来减轻一些人工现象,至少对狗来说是这样。出于同样的原因,在人类 fMRI 研究中使用自然刺激已经越来越受欢迎,例如,证明电影中的事件序列在多个时间尺度上在皮层中表示,并且电影可以有效地诱导可靠的情绪激活38。因此,虽然自然主义视频确实仍然是相对贫乏的刺激,但它们在人类神经科学中的成功引出了一个问题,即是否可以在狗身上获得类似的结果。
我们的结果表明,神经网络分类器成功地解码了来自狗大脑的某些类型的自然内容。考虑到刺激措施的复杂性,这一成功是一项令人印象深刻的壮举。重要的是,由于分类器是在看不见的视频剪辑上测试的,因此解码模型选择了可在剪辑中识别的广泛类别,而不是特定于单个场景的属性。我们应该注意,有多个指标可用于量化机器学习分类器的性能(表 1)。由于自然主义视频本质上不会所有类的出现次数相等,因此我们采取了谨慎的方法,从标签的随机排列中构建一个空分布,并评估与之相关的显著性。然后,我们发现狗模型的成功具有统计学意义,达到第 75-90 个百分位分数,但前提是视频是根据存在的动作(例如玩耍或说话)进行编码的。
与训练集不同,测试集在类之间不平衡。仅包含 20% 的数据,欠采样到最小的类大小将导致每个类的样本量非常小,因此计算的任何统计数据都是不可靠的。为了避免这种不平衡导致准确性膨胀的可能性,LRAP 的零分布是通过在每次模型迭代中随机排列类的顺序 1,000 次来计算的。此 null 分布可作为模型偶然执行情况的参考。然后,将真实的 LRAP 转换为此 null 分布中的百分位排名。非常高的百分位排名(例如 95%)表示在 1,000 次随机排列中,如此高的分数仅出现 5% 的时间。因此,这样的模型可以被认为表现得远高于偶然性。为了确定这些百分位排名是否显著大于偶然预期的排名,即统计上的第 50 个百分位,计算了每个模型所有 100 次迭代的中位 LRAP 百分位排名,并执行了单样本 Wilcoxon 有符号排名检验。
尽管主要目标是为狗开发自然视觉刺激的解码器,但与人类的比较是不可避免的。在这里,我们注意到两个主要差异:对于每种类型的分类器,人类模型的表现优于狗模型;人类模型在基于对象和动作的模型中都表现良好,而狗模型仅对基于动作的模型表现良好。人类模型的卓越性能可能是由于几个因素。人脑大约比狗脑大 10 倍,因此有更多的体素可供选择来构建分类器。为了将模型置于平等的地位,应该使用相同数量的体素,但这可以是绝对意义上的,也可以是相对意义上的。尽管最终模型基于每个大脑中前 5% 的信息体素(相对度量),但使用固定数量的体素可以获得类似的结果。因此,性能差异似乎更有可能与人类和狗如何感知视频刺激有关。如上所述,虽然狗和人类的感知都是多感官的,但狗的刺激可能比人类更贫乏。例如,大小提示可能会丢失,所有内容看起来都是现实世界的玩具版本。有一些证据表明,狗根据大小和质地对物体进行分类,然后再根据形状进行分类,这与人类几乎相反39.此外,此处未考虑的气味可能是狗物体辨别的重要信息来源,尤其是在识别同种动物或人类时 40,41,42。然而,即使没有大小或气味线索,在 MRI 扫描仪的不寻常环境中,分类器完全有效的事实表明,仍然有与狗相关的信息可以从它们的大脑中恢复。由于只有两只狗和两个人类,物种差异也可能是由于个体差异造成的。然而,这两只狗代表了受过 MRI 训练的狗中最好的,并且在观看视频时擅长保持静止。虽然较大的样本量肯定会允许在物种之间做出更可靠的区分,但能够进行清醒 fMRI 并且会观看视频足够长的狗数量很少,这总是限制了对所有狗的普遍性。虽然像猎犬这样的特殊品种可能具有更精细的视觉大脑反应,但我们认为个体的气质和训练更有可能成为从狗的大脑中恢复的主要决定因素。
这些物种差异提出了一个问题,即狗关注了视频的哪个方面。回答这个问题的一种方法依赖于更简单的视频刺激。然后,通过使用人类、狗和汽车的孤立图像,无论是单独还是一起在中性背景下,我们或许能够将突出的维度逆向工程到狗身上。然而,这在方法上既是低效的,又进一步使来自现实世界的刺激贫乏。注意力问题可以单独通过解码方法来解决,实际上,使用模型性能来确定正在关注的内容43。沿着这些思路,这里的结果表明,虽然人类同时关注演员和动作,但狗更关注动作本身。这可能是由于低级运动特征的差异,例如个人玩耍与进食时的运动频率,也可能是由于这些活动在更高级别上的分类表示。信息体素在整个狗皮层的分布表明,这些表示不仅仅是低级特征,否则它们将局限于视觉区域。使用更广泛的视频刺激的进一步研究可能会阐明运动在狗的类别区分中的作用。
总之,这项研究证明了使用 fMRI 从狗皮层恢复自然视觉信息的可行性,其方式与人类皮层相同。这个演示表明,即使没有声音或气味,复杂场景的突出维度也会由观看视频的狗编码,并且这些维度可以从它们的大脑中恢复。其次,基于能够完成此类任务的狗数量较少,信息在皮层中的分布可能比人类通常看到的更广泛,并且动作类型似乎比演员或物体的身份更容易恢复。这些结果开辟了一种研究狗如何感知它们与人类共享的环境(包括视频屏幕)的新方法,并为未来探索它们和其他非灵长类动物如何“看到”世界提出了丰富的途径。
披露声明
没有。
致谢
我们感谢 Kate Revill、Raveena Chhibber 和 Jon King 在开发此分析时提供的有益见解,感谢 Mark Spivak 协助招募和训练犬只进行 MRI,感谢 Phyllis Guo 在视频创建和标记方面的帮助。我们还要感谢我们敬业的狗主人 Rebecca Beasley (Daisy) 和 Ashwin Sakhardande (Bhubo)。人体研究得到了美国国家眼科研究所的资助(DDD 的 R01 EY029724 的资助)。
材料
| Name | Company | Catalog Number | Comments |
| 3 T MRI Scanner | Siemens | Trio | |
| Audio recordings of scanner noise | homemade | none | |
| Camera gimbal | Hohem | iSteady PRO 3 | |
| Dog-appropriate videos | homemade | none | |
| fMRI processing software | AFNI | 20.3.01 | |
| Mock scanner components | homemade | none | Mock head coil and scanner tube |
| Neural net software | Ivis | 1.7.1 | |
| Optical flow software | OpenCV | 4.2.0.34 | |
| Projection system for scanner | homemade | none | |
| Trophy Cam HD | Bushnell | 119874 | |
| Video camera | GoPro | HERO7 | |
| Visualization software | ITK-SNAP | 3.6.0 | |
| Windows Video Editor | Microsoft | Windows 11 version |
参考文献
- Mishkin, M., Ungerleider, L. G., Macko, K. A. Object vision and spatial vision: Two cortical pathways. Trends in Neurosciences. 6, 414-417 (1983).
- de Haan, E. H. F., Cowey, A. On the usefulness of 'what' and 'where' pathways in vision. Trends in Cognitive Sciences. 15 (10), 460-466 (2011).
- Freud, E., Plaut, D. C., Behrmann, M. What' is happening in the dorsal visual pathway. Trends in Cognitive Sciences. 20 (10), 773-784 (2016).
- Goodale, M. A., Milner, A. D. Separate visual pathways for perception and action. Trends in Neurosciences. 15 (1), 20-25 (1992).
- Schenk, T., McIntosh, R. D. Do we have independent visual streams for perception and action? Do we have independent visual streams for perception and action. Cognitive Neuroscience. 1 (1), 52-78 (2010).
- Andics, A., Gácsi, M., Faragó, T., Kis, A., Miklós, &. #. 1. 9. 3. ;. Report voice-sensitive regions in the dog and human brain are revealed by comparative fMRI. Current Biology. 24 (5), 574-578 (2014).
- Berns, G. S., Brooks, A. M., Spivak, M. Functional MRI in awake unrestrained dogs. PLoS One. 7 (5), 38027 (2012).
- Karl, S., et al. Training pet dogs for eye-tracking and awake fMRI. Behaviour Research Methods. 52, 838-856 (2019).
- Bunford, N., et al. Comparative brain imaging reveals analogous and divergent patterns of species and face sensitivity in humans and dogs. Journal of Neuroscience. 40 (43), 8396-8408 (2020).
- Cuaya, L. V., Hernández-Pérez, R., Concha, L. Our faces in the dog's brain: Functional imaging reveals temporal cortex activation during perception of human faces. PLoS One. 11 (3), 0149431 (2016).
- Dilks, D. D., et al. Awake fMRI reveals a specialized region in dog temporal cortex for face processing. PeerJ. 2015 (8), 1115 (2015).
- Prichard, A., et al. 2D or not 2D? An fMRI study of how dogs visually process objects. Animal Cognition. 24 (5), 1143-1151 (2021).
- Thompkins, A. M., et al. Separate brain areas for processing human and dog faces as revealed by awake fMRI in dogs (Canis familiaris). Learning & Behavior. 46 (4), 561-573 (2018).
- Zhang, K., Sejnowski, T. J. A universal scaling law between gray matter and white matter of cerebral cortex. Proceedings of the National Academy of Sciences of the United States of America. 97 (10), 5621-5626 (2000).
- Bradshaw, J., Rooney, N., Serpell, J. Dog Social Behavior and Communication. The Domestic Dog: Its Evolution, Behavior and Interactions with People. , 133-160 (2017).
- Prichard, A., et al. The mouth matters most: A functional magnetic resonance imaging study of how dogs perceive inanimate objects. The Journal of Comparative Neurology. 529 (11), 2987-2994 (2021).
- Haxby, J. V., Connolly, A. C., Guntupalli, J. S. Decoding neural representational spaces using multivariate pattern analysis. Annual Review of Neuroscience. 37, 435-456 (2014).
- Kamitani, Y., Tong, F. Decoding the visual and subjective contents of the human brain. Nature Neuroscience. 8 (5), 679-685 (2005).
- Kay, K. N., Naselaris, T., Prenger, R. J., Gallant, J. L. Identifying natural images from human brain activity. Nature. 452 (7185), 352-355 (2008).
- Nishimoto, S., et al. Reconstructing visual experiences from brain activity evoked by natural movies. Current Biology. 21 (19), 1641-1646 (2011).
- vander Meer, J. N., Breakspear, M., Chang, L. J., Sonkusare, S., Cocchi, L. Movie viewing elicits rich and reliable brain state dynamics. Nature Communications. 11 (1), 5004 (2020).
- Huth, A. G., De Heer, W. A., Griffiths, T. L., Theunissen, F. E., Gallant, J. L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature. 532 (7600), 453-458 (2016).
- Kriegeskorte, N., et al. Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron. 60 (6), 1126-1141 (2008).
- Ehsani, K., Bagherinezhad, H., Redmon, J., Mottaghi, R., Farhadi, A. Who let the dogs out? Modeling dog behavior from visual data. Proceedings of the IEEE Conference on Computer Vision and Pattern. 2018, 4051-4060 (2018).
- Berns, G. S., Brooks, A., Spivak, M. Replicability and heterogeneity of awake unrestrained canine fMRI responses. PLoS One. 9 (5), 98421 (2013).
- Cox, R. W. AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research. 29 (3), 162-173 (1996).
- Prichard, A., Chhibber, R., Athanassiades, K., Spivak, M., Berns, G. S. Fast neural learning in dogs: A multimodal sensory fMRI study. Scientific Reports. 8, 14614 (2018).
- Russ, B. E., Kaneko, T., Saleem, K. S., Berman, R. A., Leopold, D. A. Distinct fMRI responses to self-induced versus stimulus motion during free viewing in the macaque. The Journal of Neuroscience. 36 (37), 9580-9589 (2016).
- Farnebäck, G., Bigun, J., Gustavsson, T. Two-Frame Motion Estimation Based on Polynomial Expansion. In Image Analysis. Scandinavian Conference on Image Analysis. Lecture Notes in Computer Science. 2749, 363-370 (2003).
- Elias, D. O., Land, B. R., Mason, A. C., Hoy, R. R. Measuring and quantifying dynamic visual signals in jumping spiders). Journal of Comparative Physiology A. 192, 799-800 (2006).
- Szubert, B., Cole, J. E., Monaco, C., Drozdov, I. Structure-preserving visualisation of high dimensional single-cell datasets. Scientific Reports. 9, 8914 (2019).
- Tian, H., Tao, P. IVIS dimensionality reduction framework for biomacromolecular simulations. Journal of Chemical Information and Modeling. 60 (10), 4569-4581 (2020).
- Hebart, M. N., Gorgen, K., Haynes, J. The decoding toolbox (TDT): A versatile software package for multivariate analyses of functional imaging data. Frontiers in Neuroinformatics. 8, 88 (2015).
- Mazziotta, J., et al. A probabilistic atlas and reference system for the human brain: International Consortium for Brain Mapping (ICBM). Philosophical Transactions of the Royal Society B: Biological Sciences. 356 (1412), 1293-1322 (2001).
- Johnson, P. J., et al. Stereotactic cortical atlas of the domestic canine brain. Scientific Reports. 10, 4781 (2020).
- Yushkevich, P. A., et al. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. NeuroImage. 31 (3), 1116-1128 (2006).
- Fürnkranz, J., Hüllermeier, E., Loza Mencía, E., Brinker, K. Multilabel classification via calibrated label ranking. Machine Learning. 73 (2), 133-153 (2008).
- Sonkusare, S., Breakspear, M., Guo, C. Naturalistic stimuli in neuroscience: Critically acclaimed. Trends in Cognitive Sciences. 23 (8), 699-714 (2019).
- vander Zee, E., Zulch, H., Mills, D. Word generalization by a dog (Canis familiaris): Is shape important. PLoS One. 7 (11), 49382 (2012).
- Bekoff, M. Observations of scent-marking and discriminating self from others by a domestic dog (Canis familiaris): Tales of displaced yellow snow. Behavioural Processes. 55 (2), 75-79 (2001).
- Berns, G. S., Brooks, A. M., Spivak, M. Scent of the familiar: An fMRI study of canine brain responses to familiar and unfamiliar human and dog odors. Behavioural Processes. 110, 37-46 (2015).
- Schoon, G. A. A., de Bruin, J. C. The ability of dogs to recognize and cross-match human odours. Forensic Science International. 69 (2), 111-118 (1994).
- Kamitani, Y., Tong, F. Decoding seen and attended motion directions from activity in the human visual cortex. Current Biology. 16 (11), 1096-1102 (2006).
转载和许可
请求许可使用此 JoVE 文章的文本或图形
请求许可探索更多文章
This article has been published
Video Coming Soon
版权所属 © 2025 MyJoVE 公司版权所有,本公司不涉及任何医疗业务和医疗服务。