
Method Article
개의 눈을 통해: 개 피질의 자연주의적 비디오의 fMRI 디코딩
요약
기계 학습 알고리즘은 인간에게 제시된 자극을 "디코딩"하기 위해 뇌 활동 패턴을 사용하도록 훈련되었습니다. 여기에서는 동일한 기술이 두 마리의 반려견의 뇌에서 추출한 자연주의적 비디오 콘텐츠를 디코딩할 수 있음을 보여줍니다. 우리는 비디오의 행동을 기반으로 한 디코더가 개에서 성공적이라는 것을 발견했습니다.
초록
최근 머신 러닝과 기능적 자기 공명 영상(fMRI)을 사용하여 인간 및 비인간 피질의 시각적 자극을 해독하는 발전은 지각의 본질에 대한 새로운 통찰력을 가져왔습니다. 그러나 이 접근법은 아직 영장류 이외의 동물에 실질적으로 적용되지 않았기 때문에 동물계 전반에 걸쳐 이러한 표현의 본질에 대한 의문이 제기되고 있습니다. 여기에서는 두 마리의 집에서 기르는 개와 두 명의 인간을 대상으로 특별히 제작된 개에 적합한 자연주의 비디오를 시청하면서 얻은 깨어 있는 fMRI를 사용했습니다. 그런 다음 신경망(Ivis)을 훈련시켜 각 뇌 활동에서 총 90분 동안 기록된 뇌 활동에서 비디오 콘텐츠를 분류했습니다. 우리는 개, 사람, 자동차와 같은 범주를 구별하려고 시도하는 객체 기반 분류자와 먹고, 냄새 맡고, 말하기와 같은 범주를 구별하려고 시도하는 행동 기반 분류기를 모두 테스트했습니다. 두 가지 유형의 분류기가 모두 우연을 훨씬 능가하는 성능을 보인 두 인간 피험자와 비교했을 때, 행동 기반 분류기만이 개의 비디오 콘텐츠를 성공적으로 해독했습니다. 이러한 결과는 육식 동물의 뇌에서 자연주의적 비디오를 디코딩하기 위해 기계 학습이 최초로 적용된 것으로 알려져 있음을 보여주며, 개의 눈으로 보는 세상이 우리의 관점과 상당히 다를 수 있음을 시사합니다.
서문
다른 영장류와 마찬가지로 인간의 뇌는 뚜렷하고 잘 알려진 기능,즉 물체의 "무엇"과 "위치"1를 통해 시각적 흐름을 등쪽과 복쪽 경로로 나누는 것을 보여줍니다. 이 무엇을/어디서 이분법은 수십 년 동안 유용한 휴리스틱이었지만, 해부학적 기초는 이제 훨씬 더 복잡한 것으로 알려져 있으며, 많은 연구자들은 인식 대 행동("무엇" 대 "어떻게")에 기반한 소포를 선호합니다2,3,4,5. 또한, 영장류의 시각 체계의 조직에 대한 우리의 이해는 계속해서 개선되고 논쟁이 되고 있지만, 다른 포유류 종의 뇌가 시각 정보를 어떻게 표현하는지에 대해서는 많은 것이 알려지지 않았습니다. 부분적으로, 이러한 빈틈은 역사적으로 시각 신경과학에서 소수의 종에 초점을 맞춘 결과입니다. 그러나 뇌 영상에 대한 새로운 접근 방식은 더 넓은 범위의 동물의 시각 시스템을 비침습적으로 연구할 수 있는 가능성을 열어주고 있으며, 이는 포유류 신경계의 조직에 대한 새로운 통찰력을 제공할 수 있습니다.
개(Canis lupus familiaris)는 진정제나 구속 없이 MRI 촬영에 협력적으로 참여할 수 있도록 훈련받을 수 있는 유일한 동물이기 때문에 영장류와 진화적으로 멀리 떨어져 있는 종의 시각적 자극 표현을 연구할 수 있는 풍부한 기회를 제공합니다 6,7,8. 지난 15,000년 동안 인간과의 공진화로 인해 개도 우리 환경에 서식하며 MRI 스캐너에서 자극을 표시하는 데 선호되는 방법인 비디오 화면을 포함하여 인간이 매일 접하는 많은 자극에 노출됩니다. 그렇다 하더라도, 개는 이러한 일반적인 환경 자극을 인간과는 상당히 다른 방식으로 처리할 수 있으며, 이는 시각 피질이 어떻게 구성되어 있는지에 대한 질문을 불러일으킨다. 중심와(fovea)가 없거나 이염색체(dichromat)가 되는 것과 같은 기본적인 차이점은 낮은 수준의 시각적 인식뿐만 아니라 더 높은 수준의 시각적 표현에도 상당한 다운스트림 결과를 초래할 수 있습니다. 개를 대상으로 한 여러 fMRI 연구는 영장류에서 볼 수 있는 일반적인 등쪽/복부 흐름 구조를 따르는 것으로 보이는 얼굴 처리 영역과 객체 처리 영역이 모두 존재한다는 것을 입증했지만, 개가 그 자체로 얼굴 처리 영역을 가지고 있는지 또는 이러한 영역이 머리의 형태에 선택적인지(예: 개 대 인간)9, 10,11,12,13. 어쨌든, 대부분의 영장류보다 작은 개의 뇌는 덜 모듈화될 것으로 예측될 수 있다14, 따라서 흐름에서 정보 유형의 혼합이 더 많거나 행동과 같은 특정 유형의 정보에 대한 특권이 부여될 수 있다. 예를 들어, 움직임은 질감이나 색깔보다 개의 시각적 지각에서 더 두드러진 특징일 수 있다고 제안되었다15. 또한 개는 우리가 세상과 상호 작용하는 주요 수단 중 하나인 손이 없기 때문에 특히 물체에 대한 시각적 처리는 영장류와 상당히 다를 수 있습니다. 이와 일치하여, 우리는 최근에 발과 입으로 물체와 상호 작용하면 개의 뇌에서 물체 선택 영역이 더 많이 활성화된다는 증거를 발견했습니다16.
개는 가정 환경에서 비디오 화면에 익숙할 수 있지만 그렇다고 해서 인간과 같은 방식으로 실험 환경에서 이미지를 보는 데 익숙하다는 의미는 아닙니다. 좀 더 자연주의적인 자극을 사용하면 이러한 질문 중 일부를 해결하는 데 도움이 될 수 있습니다. 지난 10년 동안 머신 러닝 알고리즘은 인간의 뇌 활동에서 자연주의적 시각 자극을 해독하는 데 상당한 성공을 거두었습니다. 초기의 성공은 개인이 보고 있는 자극의 유형을 분류하기 위해 뇌 활동을 사용하기 위해 고전적이고 차단된 디자인을 적용하는 데 초점을 맞췄고, 이러한 표현을 인코딩하는 뇌 네트워크를 분류했습니다 17,18,19. 더 강력한 알고리즘, 특히 신경망이 개발됨에 따라 자연주의적 비디오를 포함하여 더 복잡한 자극을 해독할 수 있었습니다20,21. 일반적으로 이러한 비디오에 대한 신경 반응에 대해 훈련된 이러한 분류기는 새로운 자극으로 일반화되어 fMRI 반응 당시 특정 피험자가 관찰한 내용을 식별할 수 있습니다. 예를 들어, 영화에 나오는 점프와 회전과 같은 특정 유형의 동작은 인간의 뇌에서 정확하게 해독할 수 있는 반면, 다른 동작(예: 드래그)은 해독할 수 없습니다22. 마찬가지로, fMRI 응답에서 많은 유형의 객체를 디코딩할 수 있지만 일반적인 범주는 더 어려운 것으로 보입니다. 뇌 해독은 인간에만 국한되지 않으며, 다른 종의 뇌에서 정보가 어떻게 구성되어 있는지 이해할 수 있는 강력한 도구를 제공합니다. 인간이 아닌 영장류를 대상으로 한 유사한 fMRI 실험은 측두엽에서 적대감(animacy)과 겉모습(faciness)/몸매(bodiness)의 차원에 대한 뚜렷한 표현을 발견했는데, 이는 인간과 유사하다23.
자연주의적 시각 자극에 대한 개의 표현을 이해하기 위한 첫 번째 단계로, 깨어 있는 fMRI는 MRI에 능숙한 두 마리의 집에서 개에게 적합한 비디오에 대한 피질 반응을 측정하는 데 사용되었습니다. 이 연구에서는 자연주의적 비디오가 개에게 잠재적으로 더 큰 생태학적 타당성과 개의 움직임에 비디오 콘텐츠를 매핑하는 신경망의 성공을 입증했기 때문에 자연주의적 비디오를 사용했습니다24. 세 번의 개별 세션에 걸쳐 256개의 고유한 비디오 클립에 대한 각 개의 응답에서 90분 분량의 fMRI 데이터를 얻었습니다. 비교를 위해, 두 명의 인간 지원자에 대해 동일한 절차를 수행했습니다. 그런 다음 신경망을 사용하여 다양한 수의 클래스를 사용하여 "물체"(예: 인간, 개, 자동차) 또는 "행동"(예: 말하기, 먹기, 냄새 맡기)을 구별하도록 분류기를 훈련하고 테스트했습니다. 이 연구의 목표는 두 가지였습니다 : 1) 자연주의적 비디오 자극이 개 피질에서 해독 될 수 있는지 여부를 결정합니다. 2) 그렇다면, 그 조직이 인간의 조직과 유사한지 여부를 먼저 살펴볼 수 있습니다.
프로토콜
개 연구는 Emory University IACUC (PROTO201700572)의 승인을 받았으며 모든 소유자는 개의 연구 참여에 대한 서면 동의를했습니다. 인체 대상 연구 절차는 에모리 대학 IRB의 승인을 받았으며 모든 참가자는 스캔 전에 서면 동의서를 제공했습니다(IRB00069592).
1. 참가자
- 연구에서 제시된 자극에 이전에 노출된 적이 없는 참가자(개 및 인간)를 선택합니다.
참고: 개 참가자는 앞서 설명한 것과 일치하는 fMRI 교육 및 스캔에 참여하기 위해 주인이 자발적으로 참여한 두 마리의 지역 애완견이었습니다7. 부보는 4살짜리 수컷 복서 믹스견이었고, 데이지는 11살짜리 암컷 보스턴 테리어 믹스견이었다. 두 개 모두 이전에 여러 fMRI 연구(Bhubo: 8건, Daisy: 11건)에 참여했으며, 그 중 일부는 스캐너에 있는 동안 화면에 투사된 시각적 자극을 보는 것과 관련이 있습니다. 그들은 주인이 보이지 않는 상태에서 오랜 시간 동안 움직이지 않고 스캐너에 머물 수 있는 입증된 능력 때문에 선택되었습니다. 두 명의 사람(34세 남성 1명과 25세 여성 1명)도 연구에 참여했습니다. 개도 사람도 이 연구에서 나타난 자극에 이전에 노출된 적이 없었다.
2. 자극
- 휴대용 안정화 짐벌에 장착된 비디오(1920픽셀 x 1440픽셀, 초당 60프레임[fps])를 촬영합니다.
참고: 이 연구에서 비디오는 2019년 조지아주 애틀랜타에서 촬영되었습니다.- "개의 시선"에서 짐벌을 대략 무릎 높이로 잡고 자연주의적 비디오를 촬영합니다. 반려견의 일상 생활 속 시나리오를 포착할 수 있도록 동영상을 디자인하세요.
참고: 여기에는 걷는 장면, 먹이를 주는 장면, 노는 장면, 인간이 상호 작용하는 장면(서로 및 개와 상호 작용), 개가 서로 상호 작용하는 개, 움직이는 차량, 개가 아닌 동물이 포함된 장면이 포함되었습니다(그림 1A; 보충 영화 1). 일부 클립에서는 비디오의 피사체가 카메라를 쓰다듬거나, 냄새를 맡거나, 가지고 노는 등 카메라와 직접 상호 작용한 반면, 다른 클립에서는 카메라가 무시되었습니다. 사슴의 추가 영상은 현지에 배치된 카메라 트랩(1920 픽셀 x 1080 픽셀, 30fps)에서 얻었습니다. - 비디오를 256개의 고유한 7초 "장면"으로 편집합니다. 각 장면은 인간이 포옹하거나, 개가 달리거나, 사슴이 걷는 것과 같은 단일 이벤트를 묘사했습니다. 각 장면에 내용에 따라 고유 번호와 레이블을 할당합니다(아래 참조).
- "개의 시선"에서 짐벌을 대략 무릎 높이로 잡고 자연주의적 비디오를 촬영합니다. 반려견의 일상 생활 속 시나리오를 포착할 수 있도록 동영상을 디자인하세요.
- 장면을 각각 약 6분 분량의 5개의 더 큰 편집 비디오로 편집합니다. 하나의 긴 필름보다는 컴필레이션 비디오를 사용하여 다양한 자극을 순서대로 제시합니다.
참고: 다양한 자극을 제시하는 것은 비디오가 하나의 긴 "테이크"로 캡처되는 경우 달성하기 어려울 것입니다. 이는 인간을 대상으로 한 fMRI 디코딩 연구와 일치합니다 20,22. 또한 짧은 클립의 편집을 제시하면 하나의 긴 동영상 대신 개별 클립을 유지할 수 있었기 때문에 훈련된 알고리즘을 테스트할 수 있는 홀드아웃 세트를 더 쉽게 만들 수 있었습니다(아래 섹션 7, 분석 참조). 4개의 편집 비디오에는 51개의 고유한 장면이 있었고 1개에는 52개의 장면이 있었습니다. 장면 사이에 휴식이나 빈 화면이 없었습니다. - 장면을 반 무작위로 선택하여 각 비디오에 개, 인간, 차량, 비인간 동물 및 상호 작용과 같은 모든 주요 레이블 범주의 예시가 포함되도록 합니다.
참고: 컴파일 과정에서 모든 장면은 MRI 프로젝터의 해상도와 일치하도록 30fps에서 1920픽셀 x 1080픽셀로 다운샘플링되었습니다.
3. 실험적인 디자인
- 3T MRI 스캐너로 참가자를 스캔하면서 MRI 보어 후면에 장착된 스크린에 투사된 편집 비디오를 시청합니다.
- 소리 없이 동영상을 재생합니다.
- 개의 경우, 중간에서 하악골 뒤까지 아래턱에 맞게 성형된 맞춤형 턱 받침대에 머리를 배치하기 위해 사전 훈련을 통해 머리의 안정적인 위치를 확보하십시오.
- 코일에 걸쳐있는 나무 선반에 턱 받침대를 부착하지만 그 아래에 발을 위한 충분한 공간을 허용하여 각 개가 "스핑크스" 위치를 가정하도록 합니다(그림 1B). 구속구는 사용되지 않았습니다. 훈련 프로토콜에 대한 자세한 내용은 이전의 깨어 있는 fMRI 개 연구7을 참조하십시오.
- 피험자가 세션당 5개의 실행에 참여하게 하고, 각 실행은 처음부터 끝까지 시청하는 하나의 편집 비디오로 구성되며 무작위 순서로 제시됩니다. 반려견의 경우, 달리기를 할 때마다 짧은 휴식을 취한다. 이 휴식 시간 동안 개에게 음식 보상을 제공하십시오.
- 각 피험자가 2주에 걸쳐 세 번의 세션에 참여하게 합니다. 이를 통해 피험자는 5개의 고유한 편집 비디오를 각각 3번씩 시청할 수 있으며, 개인당 총 90분의 fMRI 시간을 산출할 수 있다.
4. 이미징
- 이전의 깨어 있는 fMRI 개 연구 7,25에서 사용된 프로토콜과 일치하는 프로토콜에 따라 개 참가자를 스캔합니다.
- 싱글샷 에코 평면 이미징 시퀀스를 사용하여 20% 간격(TE = 28ms, TR = 1,430ms, 플립 각도 = 70°, 64 x 64 매트릭스, 2.5mm 평면 복셀 크기, FOV = 160mm)으로 22개의 순차적인 2.5mm 슬라이스 부피를 획득합니다.
- 개의 경우, 개가 목을 뇌와 일직선상에 두고 "스핑크스" 자세로 MRI에 앉을 때 위상 인코딩 방향을 오른쪽에서 왼쪽으로 하여 슬라이스를 뇌 쪽으로 등쪽으로 향하게 합니다. 오른쪽에서 왼쪽으로 위상 인코딩은 목에서 머리 앞쪽으로 랩어라운드 아티팩트를 방지합니다. 또한, 개를 스캔할 때 주요 감수성 아티팩트는 전두동에서 발생하여 전두엽의 왜곡을 초래합니다.
- 인간의 경우, 전방-후방 방향으로 위상 인코딩을 사용하여 축 슬라이스를 얻습니다.
- 개 스캔(동일한 TR/TE)과 비교하기 위해 다대역 가속 계수가 2(GRAPPA = 2, TE = 28ms, TR = 1,430ms, 플립 각도 = 55°, 88 x 88 매트릭스, 2.5mm 평면 복셀, 20% 간격이 있는 44개의 2.5mm 슬라이스)인 인간에 대해 다중 대역 슬라이스 획득(CMRR, University of Minnesota)을 사용합니다.
- 개의 경우, 1.5mm 등방성 복셀이 있는 터보 스핀-에코 시퀀스를 사용하여 각 참가자에 대한 전체 뇌의 T2 가중치 구조 이미지도 획득합니다. 인간 참가자의 경우 1mm 등방성 복셀이 있는 T1 가중 MPRAGE 시퀀스를 사용합니다.
참고: 세 번의 세션 동안 각 참가자에 대해 약 4,000개의 기능 볼륨을 얻었습니다.
5. 경기 부양 라벨
- 동영상에 표시되는 콘텐츠를 분류하도록 모델을 학습시키려면 먼저 장면에 레이블을 지정합니다. 이렇게 하려면 각 편집 비디오를 구성하는 7초 장면을 1.4초 클립으로 나눕니다. 스틸 프레임으로 캡처할 수 없는 비디오 요소가 있으므로 개별 프레임보다 짧은 클립에 레이블을 지정합니다. 그 중 일부는 개에게 특히 두드러질 수 있으므로 움직임과 같은 디코딩에 유용할 수 있습니다.
참고: 1.4초의 클립 길이가 선택된 이유는 이러한 동적 요소를 캡처하기에 충분히 길고 1.43초의 TR과 거의 일치하여 볼륨별로 분류를 수행할 수 있기 때문입니다. - 이 1.4s 클립(n = 1,280)을 실험실 구성원에게 무작위로 배포하고 사전 프로그래밍된 확인란 스타일 제출 양식을 사용하여 각 클립에 수동으로 레이블을 지정합니다.
참고: 피사체(예: 개, 인간, 고양이), 피사체 수(1, 2, 3+), 물체(예: 자동차, 자전거, 장난감), 동작(예: 먹기, 냄새 맡기, 말하기), 상호 작용(예: 인간-인간, 인간-개) 및 설정(실내, 실외) 등 비디오의 가능한 많은 주요 기능을 포괄하기 위해 94개의 레이블이 선택되었습니다. 이를 통해 각 클립에 대해 94차원 라벨 벡터가 생성되었습니다(보충 표 1). - 일관성 검사로, 두 번째 랩 구성원이 다시 레이블을 지정할 수 있도록 임의의 하위 집합을 선택합니다. 여기에서 레이블은 개인(>95%)에 걸쳐 매우 일관된 것으로 나타났습니다. 일관성이 없는 레이블의 경우 두 실험실 구성원이 문제의 클립을 다시 보고 레이블에 대한 합의에 도달할 수 있도록 합니다.
- 각 실행에 대해 타임스탬프가 지정된 로그 파일을 사용하여 첫 번째 스캔 볼륨을 기준으로 비디오 자극의 시작을 확인합니다.
- 자극 제시와 BOLD 반응 사이의 지연을 설명하려면 이중 감마 혈역학적 반응 함수(HRF)로 레이블을 컨벌루션하고 Python 함수 numpy.convolve() 및 interp()를 사용하여 기능 이미지의 TR(1,430ms)로 보간합니다.
참고: 최종 결과는 각 참가자의 총 스캔 볼륨 수(Daisy, Bhubo, Human 1 및 Human 2에 대해 각각 94개의 라벨 x 3,932, 3,920, 3,939 및 3,925 볼륨)에 의한 컨볼루션된 라벨 매트릭스였습니다. - 추가 분석을 위한 매크로 레이블을 만들기 위해 필요한 경우 이러한 레이블을 그룹화합니다. 예를 들어 걷기의 모든 인스턴스(개 산책, 사람 산책, 당나귀 산책)를 결합하여 "걷기" 레이블을 만듭니다.
- 레이블 세트에서 중복성을 추가로 제거하려면 명백히 상관관계가 높은 매크로 레이블을 제외한 각 레이블에 대한 분산 팽창 계수(VIF)를 계산합니다.
참고: VIF는 예측 변수의 다중 공선성을 측정한 것으로, 각 예측 변수를 다른 예측 변수에 대해 회귀 분석하여 계산됩니다. VIF가 높을수록 상관관계가 높은 예측 변수를 나타냅니다. 이 연구에서는 VIF 임계값 2를 사용하여 94개의 레이블을 52개의 고유하고 대체로 상관관계가 없는 레이블로 줄였습니다(보충 표 1).
6. fMRI 전처리
- 전처리에는 AFNI 제품군(NIH) 및 관련 기능을 사용한 모션 보정, 중도절단 및 정규화가 포함됩니다26,27. 2패스, 6개 매개변수의 강체 모션 보정을 사용하여 런 전반에 걸쳐 참가자의 평균 머리 위치를 나타내는 목표 볼륨에 볼륨을 정렬합니다.
- 중도절단을 수행하여 스캔 간 변위가 1mm를 초과하는 볼륨과 0.1%보다 큰 이상치 복셀 신호 강도를 가진 볼륨을 제거합니다. 두 개 모두 검열 후 볼륨의 80% 이상이 유지되었으며 인간의 경우 90% 이상이 유지되었습니다.
- 개별 복셀의 신호 대 잡음 비율을 개선하려면 3dmerge와 4mm 가우스 커널을 사용하여 전체 너비의 절반 최대로 가벼운 공간 평활화를 수행합니다.
- 자극에 따라 달라질 수 있는 움직임 또는 속도와 같은 낮은 수준의 시각적 특징의 효과를 제어하기 위해, 비디오 클립의 연속된 프레임들 사이의 광학적 흐름을 계산한다(22,28). 초당 10프레임으로 다운샘플링한 후 OpenCV의 Farneback 알고리즘을 사용하여 광학 흐름을 계산합니다29.
- 각 프레임의 모션 에너지를 추정하려면 각 픽셀의 광학 흐름의 제곱합을 계산하고 결과의 제곱근을 취하여 한 프레임에서 다음28,30까지의 유클리드 평균 광학 흐름을 효과적으로 계산합니다. 이것은 각 편집 비디오에 대해 모션 에너지의 시간 코스를 생성합니다.
- 위와 같이 이중 감마 혈류역학적 반응 함수(HRF)로 컨볼루션되고 각 피험자에 대한 자극 제시와 정렬되도록 연결된 fMRI 데이터의 시간 해상도와 일치하도록 이를 재샘플링합니다.
- 위에서 설명한 모션 보정에서 생성된 모션 매개변수와 함께 이 시간 과정을 AFNI의 3dDeconvolve를 사용하여 각 복셀에 대해 추정된 일반 선형 모델(GLM)에 대한 유일한 회귀 변수로 사용하십시오. 이 모델의 잔차를 아래에 설명된 기계 학습 알고리즘에 대한 입력으로 사용합니다.
7. 분석
- 시각적 자극의 분류에 크게 기여하는 뇌 영역을 해독하고, 참가자의 뇌 데이터를 기반으로 비디오 콘텐츠를 분류하는 데 사용할 수 있는 각 개별 참가자에 대한 모델을 훈련합니다. 고차원 생물학적 데이터에서 성공을 거둔 샴 신경망(SNN)을 기반으로 하는 비선형 방법인 Ivis 기계 학습 알고리즘을 사용합니다31.
참고: SNN에는 지도 모드 또는 비지도 모드에서 입력의 유사성을 학습하는 데 사용되는 두 개의 동일한 하위 네트워크가 포함되어 있습니다. 신경망은 일반적으로 SVM(Support Vector Machine)과 같은 선형 방법보다 더 강력하기 때문에 브레인 디코딩에 대한 인기가 높아졌지만, 클래스 불균형에 대한 견고성과 더 적은 모범이 필요하기 때문에 여기서는 SNN을 사용했습니다. 동일한 데이터에 대해 훈련된 SVM(Support Vector Machine) 및 RF(Random Forest) 분류기와 비교했을 때, Ivis는 평균 F1 점수, 정밀도, 재현율 및 테스트 정확도(아래 참조)를 포함한 다양한 지표에 의해 결정된 여러 레이블 조합에 걸쳐 뇌 데이터를 분류하는 데 더 성공적이라는 것을 발견했습니다. - 각 참가자에 대해 전체 뇌 잔차를 Ivis 신경망에 입력하기에 적합한 형식으로 변환합니다. 세 번의 세션 각각에서 5개의 실행을 연결하고 마스킹하여 뇌 복셀만 유지합니다.
- 공간 차원을 평면화하여 시간별 복셀의 2차원 행렬을 만듭니다.
- 각 실행에 표시된 비디오의 컨볼루션된 레이블을 연결하여 fMRI 실행에 해당합니다.
- fMRI 데이터와 해당 레이블을 전처리에서 플래그 지정된 볼륨에 따라 모두 검열합니다.
- 디코딩할 대상 레이블(이하 "클래스"라고 함)을 선택하고 이러한 클래스를 포함하는 볼륨만 유지합니다. 단순화를 위해 클래스를 상호 배타적인 것으로 취급하고 디코딩을 위해 여러 클래스에 속하는 볼륨을 포함하지 않고 순수한 예시만 남깁니다.
- 데이터를 훈련 세트와 테스트 세트로 분할합니다. 5중 분할을 사용하여 장면의 20%를 테스트 세트로 사용할 장면을 무작위로 선택합니다.
참고: 즉, 테스트 세트에 대해 지정된 장면을 선택하면 이 장면에서 얻은 모든 클립과 기능 볼륨이 훈련 세트에서 제외됩니다. 분할이 장면과 독립적으로 수행되었다면 동일한 장면의 볼륨이 훈련 세트와 테스트 세트 모두에 나타났을 것이며 분류기는 이를 특정 장면과 일치시키기만 하면 성공적으로 분류할 수 있었을 것입니다. 그러나 새 장면에서 보류된 볼륨을 올바르게 분류하려면 분류기가 이를 보다 일반적인 장면 독립적 클래스와 일치시켜야 했습니다. 이것은 개별 클립을 유지하는 것과 비교하여 분류기의 성공의 일반화 가능성에 대한 더 강력한 테스트였습니다. - scikit-learn 패키지 imbalanced-learn을 사용하여 가장 작은 클래스의 볼륨 수와 일치하도록 각 클래스의 볼륨 수를 언더샘플링하여 훈련 세트의 균형을 맞춥니다.
- 각 참가자에 대해 고유한 테스트-학습 분할(Ivis 매개 변수: k = 5, model = "maaten", n_epochs_without_progress = 30, supervision_weight = 1)을 사용하여 100회 반복하여 Ivis 알고리즘을 학습시키고 테스트합니다. 이러한 매개변수 값은 알고리즘 작성자가 문서32에서 권장한 대로 데이터 세트 크기와 복잡성을 기반으로 크게 선택되었습니다. "진행되지 않는 epoch 수" 및 "감독 가중치"(비지도 가중치 0, 감독 가중치 1)는 모델을 최적화하기 위해 추가 매개변수 조정을 거쳤습니다.
- 전체 브레인에서 가장 유익한 복셀로만 분류자를 훈련하는 데 사용되는 기능 수를 줄이려면 scikit-learn을 사용하여 RFC(임의 포리스트 분류자)를 사용하여 기능 중요도에 따라 각 복셀의 순위를 지정합니다.
참고: RFC는 그 자체로 위의 기회를 수행하지는 않았지만 Ivis 알고리즘에 노이즈만 기여했을 수 있는 정보가 없는 복셀을 선별하는 유용한 목적을 수행했습니다. 이는 분류기33에 전달하기 전에 특징 선택을 위해 F-테스트를 사용하는 것과 유사합니다. 훈련 세트에서 상위 5%의 복셀만 훈련 및 테스트에 사용되었습니다. 선호되는 복셀 수는 신경망을 훈련시키기 전에 정보가 없는 복셀의 수를 줄이기 위한 노력의 일환으로 보수적 임계값으로 5%로 선택되었습니다. 더 많은 비율의 복셀을 사용할 때 인간과 개 모두에 대해서도 질적으로 유사한 결과가 얻어졌습니다. 인간의 뇌는 개의 뇌보다 크지만, 인간 모델은 개 모델에 포함된 것과 동일한 절대 수의 복셀로 훈련되었을 때도 성공적이었으며, 이는 복셀의 5%(~250 복셀, 모든 평균 LRAP 점수>99번째 백분위수)보다 훨씬 작습니다. 따라서 일관성을 위해 두 종 모두에 대한 상위 5%의 복셀을 사용하여 결과를 제시합니다. - 100개의 모든 실행에서 평균 5%의 가장 유익한 복셀을 정규화하고, 각 참가자의 구조 공간으로 변환한 다음 그룹 아틀라스 공간(아틀라스: 인간34 명, 개35명)으로 변환하고, 각 종에 대한 참가자 간에 합산합니다. 아틀라스에 기능 중요도를 오버레이하고 ITK-SNAP36을 사용하여 중요도 점수에 따라 색상을 지정합니다.
결과
기계 학습 분석에서 모델 성능을 평가하는 가장 일반적인 메트릭에는 정밀도, 정확도, 재현율 및 F1 점수가 포함됩니다. 정확도는 실제 데이터가 제공된 경우 올바른 모델 예측의 전체 백분율입니다. 정밀도는 모델의 긍정 예측에서 실제로 긍정(즉, 참 긍정 비율)인 비율이고, 재현율은 모델이 성공적으로 예측할 수 있는 원본 데이터의 참 긍정 비율입니다. F1 점수는 정밀도 및 재현율의 가중 평균이며 클래스 불균형에 더 강력한 정확도의 대체 척도 역할을 합니다. 그러나 Ivis는 출력이 바이너리가 아니라는 점에서 일반적으로 사용되는 다른 기계 학습 알고리즘과 다릅니다. 브레인 복셀의 특정 입력이 주어지면 각 출력 요소는 각 클래스에 해당하는 확률을 나타냅니다. 이러한 출력에 대한 정확도, 정밀도, 재현율 및 F1을 계산하려면 "승자 독식" 방식으로 이진화해야 했으며, 여기서 가장 높은 확률을 가진 클래스가 해당 볼륨에 대해 예측된 것으로 간주되었습니다. 이 접근 방식은 모델의 품질을 평가하는 것과 관련된 이러한 확률의 순위에 대한 중요한 정보를 제거했습니다. 따라서 이러한 기존 메트릭을 계속 계산하면서 LRAP(Label Ranking Average Precision) 점수를 기본 메트릭으로 사용하여 테스트 세트에서 모델의 정확도를 계산했습니다. 이 메트릭은 본질적으로 분류기가 실제 레이블37에 더 높은 확률을 할당한 정도를 측정합니다.
정도는 다르지만, 신경망 분류기는 인간과 개 모두에게 성공적이었다. 인간의 경우, 이 알고리즘은 객체와 행동을 모두 분류할 수 있었으며, 둘 다에 대한 3클래스 모델을 통해 평균 70%의 정확도를 달성했습니다. LRAP 점수는 테스트 세트에서 모델의 정확도를 계산하기 위한 기본 메트릭으로 사용되었습니다. 이 메트릭은 분류기가 실제 레이블37에 더 높은 확률을 할당한 정도를 측정합니다. 두 사람 모두에게, LRAP 점수의 중앙값은 테스트된 모든 모델에 대해 무작위로 치환된 레이블 세트의 99번째 백분위수보다 컸습니다(표 1; 그림 2). 개의 경우, 두 참가자 모두에서 행동 모델만이 확률보다 훨씬 큰 LRAP 백분위수 순위의 중앙값을 가졌습니다(표 1; P = 객체의 경우 0.13, 동작의 경우 P < 0.001입니다. 개에 대한 평균 3등급 행동 모델 LRAP 점수 = 78번째 백분위수). 이러한 결과는 모든 피험자에게 개별적으로 적용되었을 뿐만 아니라 종별로 그룹화할 때도 마찬가지였습니다.
분류기의 성공을 감안하여 모델의 한계를 결정하기 위해 추가 클래스로 훈련하고 테스트했습니다. 여기에는 Python 패키지 scipy의 계층적 클러스터링 알고리즘을 사용하여 관심 있는 전체 52개의 클래스에 대한 비유사성 행렬을 계산하는 것이 포함되었으며, 이는 쌍별 상관에 의해 정의된 대로 각각에 대한 개인의 뇌 반응의 유사성을 기반으로 클래스를 클러스터링했습니다. 테스트된 추가 모델 중 두 개 모두에서 LRAP 백분위수 중앙값이 가장 높은 모델은 원래의 "말하기", "먹기", "킁킁거리기"의 5가지 클래스와 "쓰다듬기" 및 "놀기"의 두 가지 새로운 클래스를 가지고 있었습니다(그림 2). 이 모델은 모든 참가자에 대해 우연히 예측한 것보다 훨씬 더 큰 LRAP 백분위수 순위의 중앙값을 가졌습니다(표 1; P < 개와 인간 모두 0.001; 개에 대한 평균 5등급 행동 모델 LRAP 점수 = 81번째 백분위수).
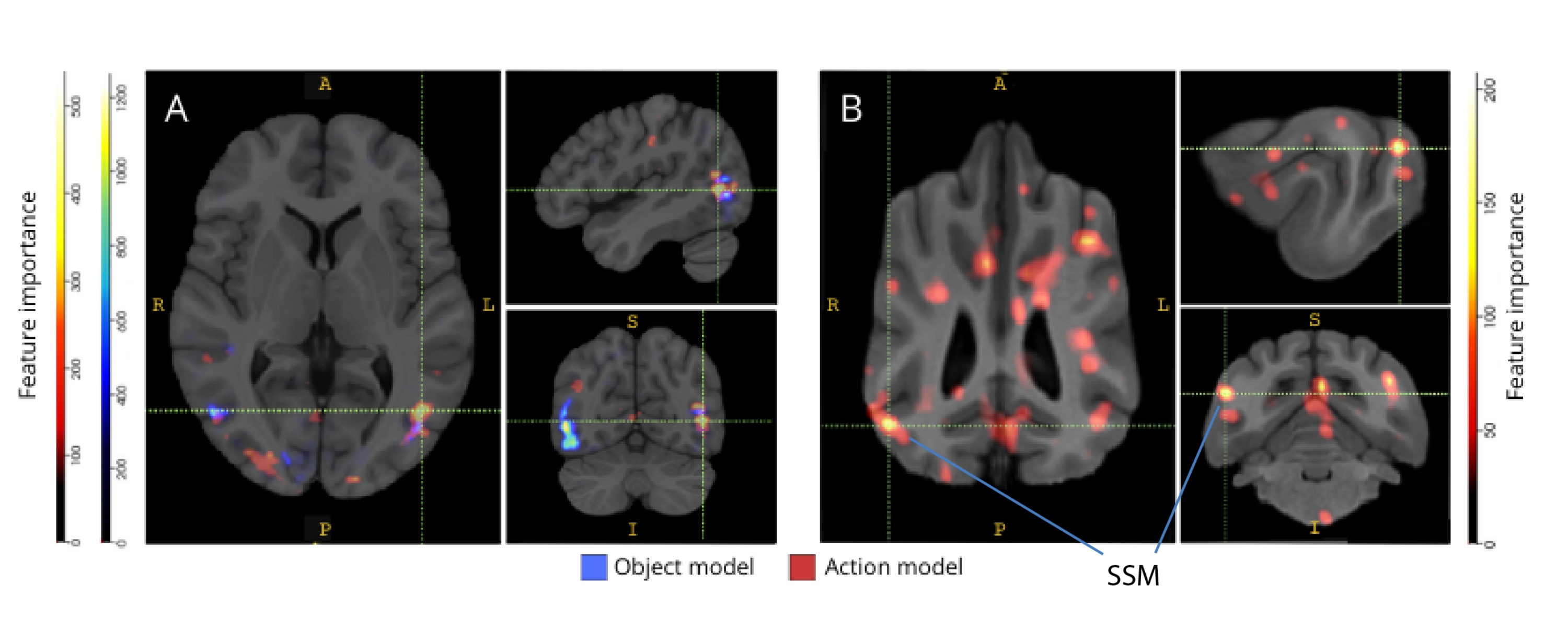
각각의 뇌 지도에 역매핑했을 때, 복셀의 기능 중요도 점수는 개와 인간 모두의 후두부, 두정엽 및 측두엽 피질에 있는 많은 정보 복셀 클러스터를 보여주었습니다(그림 3). 인간의 경우, 객체 기반 및 행동 기반 모델은 객체 기반 복셀과 행동 기반 복셀의 공간적 위치에는 약간의 차이가 있었지만 개와 일반적으로 객체 인식과 관련된 영역보다 더 집중적인 패턴을 보여주었습니다.
우리는 이러한 종 차이가 개가 다른 유형의 비디오보다 특정 유형의 비디오(예: 개가 아닌 다른 비디오, 예를 들어 자동차)로 더 많이 이동하는 작업의 상관 관련 동작의 결과가 아님을 확인했습니다. 6개의 모션 매개변수의 유클리드 노름을 계산하고 R 패키지 lme4를 사용하여 클래스를 고정 효과로, 런 번호를 각 개에 대한 무작위 효과로 사용하여 선형 혼합 효과 모델을 피팅했습니다. 각 최종 모델에 대해 Daisy(F(2, 2252) = 0.83, p = 0.44(객체 기반, F(4, 1235) = 1.87, p = 0.11(액션 기반) 또는 Bhubo(F(2, 2231) = 1.71, p = 0.18(객체 기반, F(4, 1221) = 0.94, p = 0.45)의 모션에 대한 클래스 유형의 유의미한 영향은 발견되지 않았습니다.

그림 1: MRI 보어로 표현한 자연주의적 비디오 및 프레젠테이션. (A) 참가자에게 보여준 비디오 클립의 예시 프레임. (B) 4세 복서 믹스견 Bhubo가 깨어 있는 fMRI를 받으면서 비디오를 보고 있습니다. 이 그림의 더 큰 버전을 보려면 여기를 클릭하십시오.
{kind=link}

그림 2: 개와 인간의 성능을 모델링합니다. null 분포의 백분위수 순위로 제시된 LRAP 점수의 분포, 3클래스 객체 기반 모델, 3클래스 액션 기반 모델 및 5클래스 액션 기반 모델에 대한 Ivis 머신 러닝 알고리즘의 100회 이상의 학습 및 테스트 반복, 여기서 모델은 다음을 통해 얻은 자연주의적 비디오 자극에 대한 대담한 반응을 분류하려고 시도했습니다. 개와 인간의 깨어 있는 fMRI. 점수는 종별로 집계됩니다. 백분위수 순위가 매우 높은 LRAP 점수는 모델이 우연히 해당 LRAP 점수를 달성할 가능성이 매우 낮다는 것을 나타냅니다. 우연보다 성능이 좋지 않은 모델은 LRAP 점수 백분위수 순위의 중앙값이 ~50입니다. 파선은 100개의 모든 실행에서 각 종에 대한 중앙값 LRAP 점수 백분위수 순위를 나타냅니다. 이 그림의 더 큰 버전을 보려면 여기를 클릭하십시오.
{kind=link}

그림 3: 3등급 객체 및 5등급 액션 모델의 구별에 중요한 영역. (A) 인간 및 (B) 개 참가자. 복셀은 모델의 모든 반복에서 평균화된 랜덤 포레스트 분류기를 사용하여 기능 중요도에 따라 순위가 매겨졌습니다. 상위 5%의 복셀(즉, 모델을 훈련하는 데 사용되는 복셀)이 여기에 표시되며, 종별로 집계되고 시각화 목적을 위한 그룹 공간으로 변환됩니다(아틀라스: 인간34 및 개35). 라벨은 Johnson et al.35에 의해 확인된 것을 기반으로 높은 기능 중요도 점수를 가진 개의 뇌 영역을 보여줍니다. 약어 : SSM = suprasylvian gyrus. 이 그림의 더 큰 버전을 보려면 여기를 클릭하십시오.
{kind=link}
| 모델 유형 | 훈련 정확도 | 테스트 정확도 | F1 점수 | 정밀 | 기억 | LRAP 점수 중앙값 백분위수 | |
| 인간 1 | 객체(3 클래스) | 0.98 | 0.69 | 0.48 | 0.52 | 0.49 | >99 |
| 액션(3개 클래스) | 0.98 | 0.72 | 0.51 | 0.54 | 0.54 | >99 | |
| 액션(5개 클래스) | 0.97 | 0.51 | 0.28 | 0.37 | 0.27 | >99 | |
| 인간 2 | 객체(3 클래스) | 0.98 | 0.68 | 0.45 | 0.5 | 0.47 | >99 |
| 액션(3개 클래스) | 0.98 | 0.69 | 0.46 | 0.5 | 0.48 | >99 | |
| 액션(5개 클래스) | 0.97 | 0.53 | 0.3 | 0.4 | 0.27 | >99 | |
| 부보 | 객체(3 클래스) | 0.99 | 0.61 | 0.38 | 0.41 | 0.39 | 57 |
| 액션(3개 클래스) | 0.98 | 0.63 | 0.38 | 0.4 | 0.4 | 87 | |
| 액션(5개 클래스) | 0.99 | 0.45 | 0.16 | 0.29 | 0.13 | 88 | |
| 데이지 | 객체(3 클래스) | 1 | 0.61 | 0.38 | 0.43 | 0.39 | 43 |
| 액션(3개 클래스) | 0.97 | 0.62 | 0.35 | 0.38 | 0.35 | 60 | |
| 액션(5개 클래스) | 0.99 | 0.44 | 0.16 | 0.27 | 0.13 | 76 |
표 1: 개와 인간의 깨어 있는 fMRI를 통해 얻은 자연주의적 비디오 자극에 대한 볼드 반응에 대한 훈련 및 테스트를 100회 이상 반복한 Ivis 머신 러닝 알고리즘의 집계 메트릭. 오브젝트 모델에는 3개의 대상 클래스("개", "인간", "자동차")가 있었고, 액션 모델에는 3개 또는 5개의 클래스(3개의 클래스: "말하기", "먹기", "킁킁거리", 5개의 클래스: "말하기", "먹기", "스니핑", "쓰다듬기", "놀이")가 있었습니다. 우연보다 훨씬 큰 값은 굵게 표시됩니다.
보충 표 1: 클래스 레이블. 이 파일을 다운로드하려면 여기를 클릭하십시오.
보충 영화 1: 샘플 비디오 클립. 이 파일을 다운로드하려면 여기를 클릭하십시오.
토론
이 연구의 결과는 자연주의적 비디오가 여러 이미징 세션에 걸쳐 충분히 안정적인 개의 뇌에 표현을 유도하여 인간과 원숭이에서 얻은 결과와 유사한 fMRI로 디코딩할 수 있음을 보여줍니다20,23. 개의 시각 시스템에 대한 이전의 fMRI 연구는 중립적인 배경에 얼굴이나 물체와 같은 벗겨진 자극을 제시했지만, 여기의 결과는 여러 사람과 물체가 서로 상호 작용하는 자연주의적 비디오가 개의 피질에서 활성화 패턴을 유도하여 인간의 피질에서 볼 수 있는 신뢰성에 접근하는 신뢰성으로 해독할 수 있음을 보여줍니다. 이 접근법은 개의 시각 체계가 어떻게 구성되어 있는지에 대한 새로운 연구 길을 열어준다.
개 fMRI 분야가 빠르게 성장했지만 현재까지 이러한 실험은 중립적인 배경에 대한 사람이나 물체의 사진과 같은 상대적으로 빈곤한 자극에 의존해 왔습니다 10,12,13. 또한, 이러한 실험은 얼굴 처리에 관여하는 영장류 방추형 얼굴 영역(FFA) 및 물체 처리를 위한 외측 후두 피질(LOC)과 유사한 뇌 영역을 식별하기 시작했지만, 개가 영장류와 유사한 두드러진 특징에 반응하는 얼굴 영역 자체를 가지고 있는지 또는 개와 사람 또는 얼굴과 머리에 대한 별도의 표현을 가지고 있는지 여부와 같은 이러한 표현의 본질에 대해서는 의견이 분분합니다. 예를 들어 9,13입니다. 물론 개는 영장류가 아니며, 우리는 그들이 일반적인 다감각적 맥락에서 분리된 이러한 인공 자극을 소리와 냄새로 어떻게 해석하는지 알지 못한다. 일부 증거에 따르면 개는 사물의 이미지를 실제 사물의 표상으로 취급하지 않는다12. 스캐너에서 진정한 다감각 경험을 만드는 것은 불가능하지만, 자연주의적 비디오를 사용하면 적어도 개에게는 현실 세계와 더 가까운 동적 자극을 제공함으로써 인공적인 요소를 일부 완화할 수 있습니다. 같은 이유로, 인간 fMRI 연구에서 자연주의적 자극을 사용하는 것이 인기를 얻고 있는데, 예를 들어, 영화의 일련의 사건이 피질에서 여러 시간 척도에 걸쳐 표현되고 영화가 신뢰할 수 있는 감정 활성화를 유도하는 데 효과적이라는 것을 입증했다38. 따라서 자연주의적 비디오는 상대적으로 빈곤한 자극으로 남아 있지만, 인간 신경 과학에서의 성공은 개에서도 유사한 결과를 얻을 수 있는지에 대한 질문을 제기합니다.
우리의 결과는 신경망 분류기가 개의 뇌에서 일부 유형의 자연주의적 콘텐츠를 성공적으로 디코딩했음을 보여줍니다. 이 성공은 자극의 복잡성을 감안할 때 인상적인 위업입니다. 중요한 것은 분류자가 보이지 않는 비디오 클립에서 테스트되었기 때문에 디코딩 모델이 개별 장면에 특정한 속성이 아닌 클립에서 식별할 수 있는 광범위한 범주를 선택했다는 것입니다. 기계 학습 분류기의 성능을 정량화하기 위한 여러 메트릭이 있다는 점에 유의해야 합니다(표 1). 자연주의적 비디오는 본질적으로 모든 클래스가 동일하게 발생하지 않기 때문에 레이블의 무작위 순열에서 null 분포를 구성하고 이에 참조된 중요성을 평가하여 신중한 접근 방식을 취했습니다. 그런 다음 개 모델의 성공이 통계적으로 유의미하여 75-90번째 백분위수 점수를 달성했지만 이는 놀이나 말하기와 같은 현재 행동을 기반으로 비디오를 코딩한 경우에만 해당됩니다.
테스트 세트는 훈련 세트와 달리 클래스 간에 균형이 맞지 않았습니다. 데이터의 20%만 구성되는 경우 가장 작은 클래스 크기로 언더샘플링하면 각 클래스에 대한 샘플 크기가 매우 작아져 계산된 통계를 신뢰할 수 없게 됩니다. 이러한 불균형으로 인한 정확도 부풀려진 가능성을 피하기 위해 LRAP의 null 분포는 각 모델 반복에 대해 클래스 순서를 1,000번 무작위로 치환하여 계산되었습니다. 이 귀무 분포는 모델이 우연히 얼마나 잘 수행될 수 있는지에 대한 참조 역할을 했습니다. 그런 다음 실제 LRAP는 이 null 분포에서 백분위수 순위로 변환되었습니다. 예를 들어 95%와 같이 매우 높은 백분위수 순위는 1,000개의 무작위 순열에서 5%만 높은 점수가 발생했음을 나타냅니다. 따라서 이러한 모델은 우연을 훨씬 뛰어넘는 성과를 내는 것으로 간주될 수 있습니다. 이러한 백분위수 순위가 우연히 예상된 것보다 유의하게 큰지 확인하기 위해(즉, 통계적으로 50번째 백분위수) 각 모델에 대한 100회 반복 모두에서 중앙값 LRAP 백분위수 순위를 계산하고 1표본 Wilcoxon 부호 순위 테스트를 수행했습니다.
주요 목표는 개를 위한 자연주의적 시각 자극의 디코더를 개발하는 것이었지만 인간과의 비교는 피할 수 없습니다. 여기서 우리는 두 가지 주요 차이점을 주목할 수 있습니다: 각 유형의 분류자에 대해, 인간 모델이 개 모델보다 더 나은 성능을 보였습니다. 그리고 인간 모델은 객체 기반 모델과 행동 기반 모델 모두에서 좋은 성능을 보인 반면, 개 모델은 행동 기반 모델에서만 수행되었습니다. 인간 모델의 우수한 성능은 몇 가지 요인에 기인할 수 있습니다. 인간의 뇌는 개의 뇌보다 약 10배 더 크기 때문에 분류기를 만들기 위해 선택할 수 있는 복셀이 더 많습니다. 모델을 동등한 위치에 놓으려면 동일한 수의 복셀을 사용해야 하지만 이는 절대적 또는 상대적 의미일 수 있습니다. 최종 모델은 각 뇌에서 상위 5%의 정보 복셀(상대적 측정)을 기반으로 했지만, 고정된 수의 복셀을 사용하여 유사한 결과를 얻었습니다. 따라서 성능 차이는 인간과 개가 비디오 자극을 인식하는 방식과 관련이 있을 가능성이 더 높은 것으로 보입니다. 위에서 언급했듯이 개와 인간은 모두 지각에 있어 다감각적이지만, 자극은 인간보다 개에게 더 빈곤할 수 있습니다. 예를 들어, 크기 단서가 손실되어 모든 것이 현실 세계의 장난감 버전으로 보일 수 있습니다. 개가 모양보다 크기와 질감에 따라 물체를 분류한다는 증거가 있는데, 이는 인간과 거의 반대입니다39. 또한, 여기에서 고려하지 않은 냄새는 개의 객체 식별, 특히 동종 또는 인간을 식별하는 데 중요한 정보 소스일 수 있습니다 40,41,42. 그러나 크기나 냄새 단서가 없는 경우에도, MRI 스캐너의 특이한 환경에서, 분류기가 작동했다는 사실은 그들의 뇌에서 회수할 수 있는 개와 관련된 정보가 여전히 존재한다는 것을 말해준다. 개 두 마리와 인간 두 마리뿐인 이 종의 차이는 개인차에 기인할 수도 있다. 그러나 두 마리의 개는 MRI 훈련을 받은 개 중 최고를 대표했으며 비디오를 보면서 가만히 있는 데 탁월했습니다. 표본 크기가 클수록 종 간에 더 신뢰할 수 있는 구별을 할 수 있지만, 깨어 있는 fMRI를 수행할 수 있고 일정 시간 동안 비디오를 시청할 수 있는 개의 수가 적기 때문에 항상 모든 개에 대한 일반화 가능성이 제한됩니다. 시각 추적견과 같은 특수 품종이 더 미세하게 조정된 시각적 뇌 반응을 가질 수 있지만, 우리는 개인의 기질과 훈련이 개의 뇌에서 회복할 수 있는 것의 주요 결정 요인일 가능성이 더 높다고 믿습니다.
이러한 종의 차이는 개들이 비디오의 어떤 측면에 주의를 기울였는지에 대한 의문을 제기한다. 이 질문에 답하는 한 가지 접근 방식은 더 간단한 비디오 자극에 의존합니다. 그런 다음 인간, 개, 자동차의 분리된 이미지를 중립적인 배경에 개별적으로 또는 함께 사용함으로써 개의 두드러진 치수를 리버스 엔지니어링할 수 있습니다. 그러나 이것은 방법론적으로 비효율적일 뿐만 아니라 현실 세계의 자극을 더욱 빈곤하게 만듭니다. 주의의 문제는 디코딩 접근법만으로도 해결할 수 있으며, 사실상 모델 성능을 사용하여43에 주의를 기울이고 있는 것이 무엇인지 결정할 수 있습니다. 이러한 맥락에서, 여기서의 결과는 인간이 행위자와 행동 모두에 주의를 기울이는 반면, 개는 행동 자체에 더 집중한다는 것을 시사한다. 이는 개인이 놀 때와 먹을 때의 움직임 빈도와 같은 낮은 수준의 동작 기능의 차이 때문일 수도 있고, 더 높은 수준에서 이러한 활동을 범주적으로 표현하기 때문일 수도 있습니다. 개의 피질 전체에 걸쳐 유익한 복셀이 분포되어 있다는 것은 이러한 표현이 시각 영역에 국한될 수 있는 낮은 수준의 특징이 아니라는 것을 시사합니다. 더 다양한 비디오 자극을 사용한 추가 연구는 개에 의한 범주 차별에서 움직임의 역할을 조명할 수 있습니다.
요약하면, 이 연구는 인간의 피질에 대해 수행되는 것과 동일한 방식으로 fMRI를 사용하여 개의 피질에서 자연주의적 시각 정보를 복구하는 것의 타당성을 입증했습니다. 이 시연은 소리나 냄새가 없어도 비디오를 보는 개에 의해 복잡한 장면의 돌출된 차원이 암호화되고 이러한 차원이 뇌에서 복구될 수 있음을 보여줍니다. 둘째, 이러한 유형의 작업을 수행할 수 있는 소수의 개에 기초하여 정보는 일반적으로 인간에서 볼 수 있는 것보다 피질에 더 널리 분포될 수 있으며, 행동 유형은 행위자나 물체의 신원보다 더 쉽게 복구되는 것처럼 보입니다. 이러한 결과는 비디오 화면을 포함하여 개가 인간과 공유하는 환경을 어떻게 인식하는지 조사하는 새로운 방법을 열어주며, 개와 다른 영장류가 아닌 동물이 세상을 어떻게 "보는지"에 대한 향후 탐구를 위한 풍부한 길을 제시합니다.
공개
없음.
감사의 말
이 분석을 개발하는 데 도움이 된 통찰력을 제공해 준 Kate Revill, Raveena Chhibber, Jon King, MRI를 위한 개를 모집하고 훈련하는 데 도움을 준 Mark Spivak, 비디오 제작 및 라벨링에 도움을 준 Phyllis Guo에게 감사드립니다. 우리는 또한 헌신적인 개 주인인 Rebecca Beasley(Daisy)와 Ashwin Sakhardande(Bhubo)에게 감사드립니다. 인체 연구는 국립 안과 연구소(National Eye Institute)의 보조금(Grant R01 EY029724 to D.D.D.D.)의 지원으로 이루어졌습니다.
자료
| Name | Company | Catalog Number | Comments |
| 3 T MRI Scanner | Siemens | Trio | |
| Audio recordings of scanner noise | homemade | none | |
| Camera gimbal | Hohem | iSteady PRO 3 | |
| Dog-appropriate videos | homemade | none | |
| fMRI processing software | AFNI | 20.3.01 | |
| Mock scanner components | homemade | none | Mock head coil and scanner tube |
| Neural net software | Ivis | 1.7.1 | |
| Optical flow software | OpenCV | 4.2.0.34 | |
| Projection system for scanner | homemade | none | |
| Trophy Cam HD | Bushnell | 119874 | |
| Video camera | GoPro | HERO7 | |
| Visualization software | ITK-SNAP | 3.6.0 | |
| Windows Video Editor | Microsoft | Windows 11 version |
참고문헌
- Mishkin, M., Ungerleider, L. G., Macko, K. A. Object vision and spatial vision: Two cortical pathways. Trends in Neurosciences. 6, 414-417 (1983).
- de Haan, E. H. F., Cowey, A. On the usefulness of 'what' and 'where' pathways in vision. Trends in Cognitive Sciences. 15 (10), 460-466 (2011).
- Freud, E., Plaut, D. C., Behrmann, M. What' is happening in the dorsal visual pathway. Trends in Cognitive Sciences. 20 (10), 773-784 (2016).
- Goodale, M. A., Milner, A. D. Separate visual pathways for perception and action. Trends in Neurosciences. 15 (1), 20-25 (1992).
- Schenk, T., McIntosh, R. D. Do we have independent visual streams for perception and action? Do we have independent visual streams for perception and action. Cognitive Neuroscience. 1 (1), 52-78 (2010).
- Andics, A., Gácsi, M., Faragó, T., Kis, A., Miklós, &. #. 1. 9. 3. ;. Report voice-sensitive regions in the dog and human brain are revealed by comparative fMRI. Current Biology. 24 (5), 574-578 (2014).
- Berns, G. S., Brooks, A. M., Spivak, M. Functional MRI in awake unrestrained dogs. PLoS One. 7 (5), 38027 (2012).
- Karl, S., et al. Training pet dogs for eye-tracking and awake fMRI. Behaviour Research Methods. 52, 838-856 (2019).
- Bunford, N., et al. Comparative brain imaging reveals analogous and divergent patterns of species and face sensitivity in humans and dogs. Journal of Neuroscience. 40 (43), 8396-8408 (2020).
- Cuaya, L. V., Hernández-Pérez, R., Concha, L. Our faces in the dog's brain: Functional imaging reveals temporal cortex activation during perception of human faces. PLoS One. 11 (3), 0149431 (2016).
- Dilks, D. D., et al. Awake fMRI reveals a specialized region in dog temporal cortex for face processing. PeerJ. 2015 (8), 1115 (2015).
- Prichard, A., et al. 2D or not 2D? An fMRI study of how dogs visually process objects. Animal Cognition. 24 (5), 1143-1151 (2021).
- Thompkins, A. M., et al. Separate brain areas for processing human and dog faces as revealed by awake fMRI in dogs (Canis familiaris). Learning & Behavior. 46 (4), 561-573 (2018).
- Zhang, K., Sejnowski, T. J. A universal scaling law between gray matter and white matter of cerebral cortex. Proceedings of the National Academy of Sciences of the United States of America. 97 (10), 5621-5626 (2000).
- Bradshaw, J., Rooney, N., Serpell, J. Dog Social Behavior and Communication. The Domestic Dog: Its Evolution, Behavior and Interactions with People. , 133-160 (2017).
- Prichard, A., et al. The mouth matters most: A functional magnetic resonance imaging study of how dogs perceive inanimate objects. The Journal of Comparative Neurology. 529 (11), 2987-2994 (2021).
- Haxby, J. V., Connolly, A. C., Guntupalli, J. S. Decoding neural representational spaces using multivariate pattern analysis. Annual Review of Neuroscience. 37, 435-456 (2014).
- Kamitani, Y., Tong, F. Decoding the visual and subjective contents of the human brain. Nature Neuroscience. 8 (5), 679-685 (2005).
- Kay, K. N., Naselaris, T., Prenger, R. J., Gallant, J. L. Identifying natural images from human brain activity. Nature. 452 (7185), 352-355 (2008).
- Nishimoto, S., et al. Reconstructing visual experiences from brain activity evoked by natural movies. Current Biology. 21 (19), 1641-1646 (2011).
- vander Meer, J. N., Breakspear, M., Chang, L. J., Sonkusare, S., Cocchi, L. Movie viewing elicits rich and reliable brain state dynamics. Nature Communications. 11 (1), 5004 (2020).
- Huth, A. G., De Heer, W. A., Griffiths, T. L., Theunissen, F. E., Gallant, J. L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature. 532 (7600), 453-458 (2016).
- Kriegeskorte, N., et al. Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron. 60 (6), 1126-1141 (2008).
- Ehsani, K., Bagherinezhad, H., Redmon, J., Mottaghi, R., Farhadi, A. Who let the dogs out? Modeling dog behavior from visual data. Proceedings of the IEEE Conference on Computer Vision and Pattern. 2018, 4051-4060 (2018).
- Berns, G. S., Brooks, A., Spivak, M. Replicability and heterogeneity of awake unrestrained canine fMRI responses. PLoS One. 9 (5), 98421 (2013).
- Cox, R. W. AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research. 29 (3), 162-173 (1996).
- Prichard, A., Chhibber, R., Athanassiades, K., Spivak, M., Berns, G. S. Fast neural learning in dogs: A multimodal sensory fMRI study. Scientific Reports. 8, 14614 (2018).
- Russ, B. E., Kaneko, T., Saleem, K. S., Berman, R. A., Leopold, D. A. Distinct fMRI responses to self-induced versus stimulus motion during free viewing in the macaque. The Journal of Neuroscience. 36 (37), 9580-9589 (2016).
- Farnebäck, G., Bigun, J., Gustavsson, T. Two-Frame Motion Estimation Based on Polynomial Expansion. In Image Analysis. Scandinavian Conference on Image Analysis. Lecture Notes in Computer Science. 2749, 363-370 (2003).
- Elias, D. O., Land, B. R., Mason, A. C., Hoy, R. R. Measuring and quantifying dynamic visual signals in jumping spiders). Journal of Comparative Physiology A. 192, 799-800 (2006).
- Szubert, B., Cole, J. E., Monaco, C., Drozdov, I. Structure-preserving visualisation of high dimensional single-cell datasets. Scientific Reports. 9, 8914 (2019).
- Tian, H., Tao, P. IVIS dimensionality reduction framework for biomacromolecular simulations. Journal of Chemical Information and Modeling. 60 (10), 4569-4581 (2020).
- Hebart, M. N., Gorgen, K., Haynes, J. The decoding toolbox (TDT): A versatile software package for multivariate analyses of functional imaging data. Frontiers in Neuroinformatics. 8, 88 (2015).
- Mazziotta, J., et al. A probabilistic atlas and reference system for the human brain: International Consortium for Brain Mapping (ICBM). Philosophical Transactions of the Royal Society B: Biological Sciences. 356 (1412), 1293-1322 (2001).
- Johnson, P. J., et al. Stereotactic cortical atlas of the domestic canine brain. Scientific Reports. 10, 4781 (2020).
- Yushkevich, P. A., et al. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. NeuroImage. 31 (3), 1116-1128 (2006).
- Fürnkranz, J., Hüllermeier, E., Loza Mencía, E., Brinker, K. Multilabel classification via calibrated label ranking. Machine Learning. 73 (2), 133-153 (2008).
- Sonkusare, S., Breakspear, M., Guo, C. Naturalistic stimuli in neuroscience: Critically acclaimed. Trends in Cognitive Sciences. 23 (8), 699-714 (2019).
- vander Zee, E., Zulch, H., Mills, D. Word generalization by a dog (Canis familiaris): Is shape important. PLoS One. 7 (11), 49382 (2012).
- Bekoff, M. Observations of scent-marking and discriminating self from others by a domestic dog (Canis familiaris): Tales of displaced yellow snow. Behavioural Processes. 55 (2), 75-79 (2001).
- Berns, G. S., Brooks, A. M., Spivak, M. Scent of the familiar: An fMRI study of canine brain responses to familiar and unfamiliar human and dog odors. Behavioural Processes. 110, 37-46 (2015).
- Schoon, G. A. A., de Bruin, J. C. The ability of dogs to recognize and cross-match human odours. Forensic Science International. 69 (2), 111-118 (1994).
- Kamitani, Y., Tong, F. Decoding seen and attended motion directions from activity in the human visual cortex. Current Biology. 16 (11), 1096-1102 (2006).
재인쇄 및 허가
JoVE'article의 텍스트 или 그림을 다시 사용하시려면 허가 살펴보기
허가 살펴보기더 많은 기사 탐색
This article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. 판권 소유