
Method Article
Mit den Augen eines Hundes: fMRT-Dekodierung naturalistischer Videos aus der Hunderinde
In diesem Artikel
Zusammenfassung
Algorithmen des maschinellen Lernens wurden so trainiert, dass sie Muster der Gehirnaktivität verwenden, um Reize, die dem Menschen präsentiert werden, zu "entschlüsseln". Hier zeigen wir, dass die gleiche Technik naturalistische Videoinhalte aus dem Gehirn von zwei Haushunden entschlüsseln kann. Wir stellen fest, dass Decoder, die auf den Aktionen in den Videos basieren, bei Hunden erfolgreich waren.
Zusammenfassung
Jüngste Fortschritte beim Einsatz von maschinellem Lernen und funktioneller Magnetresonanztomographie (fMRT) zur Entschlüsselung visueller Reize aus dem menschlichen und nichtmenschlichen Kortex haben zu neuen Erkenntnissen über die Natur der Wahrnehmung geführt. Dieser Ansatz wurde jedoch noch nicht im Wesentlichen auf andere Tiere als Primaten angewendet, was Fragen über die Art solcher Darstellungen im gesamten Tierreich aufwirft. Hier haben wir die Wach-fMRT bei zwei Haushunden und zwei Menschen verwendet, die jeweils beim Anschauen speziell erstellter hundegerechter naturalistischer Videos aufgenommen wurden. Anschließend trainierten wir ein neuronales Netz (Ivis), um den Videoinhalt von insgesamt 90 Minuten aufgezeichneter Gehirnaktivität von jedem zu klassifizieren. Wir testeten sowohl einen objektbasierten Klassifikator, der versuchte, Kategorien wie Hund, Mensch und Auto zu unterscheiden, als auch einen handlungsbasierten Klassifikator, der versuchte, Kategorien wie Essen, Schnüffeln und Sprechen zu unterscheiden. Im Vergleich zu den beiden menschlichen Probanden, bei denen beide Arten von Klassifikatoren weit über dem Zufall lagen, waren nur handlungsbasierte Klassifikatoren erfolgreich bei der Dekodierung von Videoinhalten der Hunde. Diese Ergebnisse zeigen die erste bekannte Anwendung des maschinellen Lernens zur Entschlüsselung naturalistischer Videos aus dem Gehirn eines Fleischfressers und deuten darauf hin, dass die Sicht des Hundes auf die Welt ganz anders sein könnte als unsere eigene.
Einleitung
Das Gehirn des Menschen zeigt, wie andere Primaten auch, die Aufteilung des visuellen Stroms in dorsale und ventrale Bahnen mit unterschiedlichen und bekannten Funktionen - das "Was" und "Wo" von Objekten1. Diese Was/Wo-Dichotomie war jahrzehntelang eine nützliche Heuristik, aber ihre anatomische Grundlage ist heute als viel komplexer bekannt, da viele Forscher eine Parzellierung bevorzugen, die auf Erkennen und Handeln basiert ("was" vs. "wie")2,3,4,5. Während unser Verständnis der Organisation des visuellen Systems von Primaten weiter verfeinert und diskutiert wird, ist noch viel darüber unbekannt, wie die Gehirne anderer Säugetierarten visuelle Informationen repräsentieren. Diese Lücke ist zum Teil ein Ergebnis der historischen Fokussierung auf eine Handvoll Arten in den visuellen Neurowissenschaften. Neue Ansätze in der Bildgebung des Gehirns eröffnen jedoch die Möglichkeit, das visuelle System eines breiteren Spektrums von Tieren nichtinvasiv zu untersuchen, was neue Einblicke in die Organisation des Nervensystems von Säugetieren liefern könnte.
Hunde (Canis lupus familiaris) bieten eine reichhaltige Gelegenheit, die Repräsentation visueller Reize bei einer Spezies zu untersuchen, die evolutionär von Primaten entfernt ist, da sie möglicherweise das einzige Tier sind, das darauf trainiert werden kann, kooperativ an MRT-Scans teilzunehmen, ohne dass eine Sedierung oder Fixierung erforderlich ist 6,7,8. Aufgrund ihrer Koevolution mit dem Menschen in den letzten 15.000 Jahren bewohnen Hunde auch unsere Umwelt und sind vielen der Reize ausgesetzt, denen Menschen täglich begegnen, einschließlich Videobildschirmen, die die bevorzugte Art der Darstellung von Reizen in einem MRT-Scanner sind. Trotzdem können Hunde diese üblichen Umweltreize auf eine Weise verarbeiten, die sich stark von der des Menschen unterscheidet, was die Frage aufwirft, wie ihr visueller Kortex organisiert ist. Grundlegende Unterschiede - wie das Fehlen einer Fovea oder die Tatsache, dass sie ein Dichromat sind - können nicht nur für die visuelle Wahrnehmung auf niedrigerem Niveau, sondern auch für die visuelle Repräsentation auf höherer Ebene erhebliche nachgelagerte Folgen haben. Mehrere fMRT-Studien an Hunden haben gezeigt, dass sowohl gesichts- als auch objektverarbeitende Regionen vorhanden sind, die der allgemeinen dorsalen/ventralen Strömungsarchitektur bei Primaten zu folgen scheinen, obwohl unklar bleibt, ob Hunde per se gesichtsverarbeitende Regionen haben oder ob diese Regionen für die Morphologie des Kopfes selektiv sind (z. B. Hund vs. Mensch)9, 10,11,12,13. Unabhängig davon würde vorhergesagt, dass das Gehirn eines Hundes, da es kleiner ist als das der meisten Primaten, weniger modularisiert ist14, so dass es zu einer stärkeren Vermischung der Arten von Informationen in den Strömen oder sogar zur Privilegierung bestimmter Arten von Informationen, wie z. B. Handlungen, kommen könnte. Es wurde zum Beispiel vermutet, dass Bewegung ein hervorstechenderes Merkmal bei der visuellen Wahrnehmung von Hunden sein könnte als Textur oder Farbe15. Da Hunde keine Hände haben, eines der wichtigsten Mittel, durch die wir mit der Welt interagieren, kann ihre visuelle Verarbeitung, insbesondere von Objekten, ganz anders sein als die von Primaten. In Übereinstimmung damit fanden wir kürzlich Hinweise darauf, dass die Interaktion mit Objekten durch Mund und Pfote zu einer stärkeren Aktivierung in objektselektiven Regionen im Hundegehirn führte16.
Obwohl Hunde in ihrer häuslichen Umgebung an Videobildschirme gewöhnt sind, bedeutet das nicht, dass sie es gewohnt sind, Bilder in einer Versuchsumgebung auf die gleiche Weise zu betrachten, wie es ein Mensch tun würde. Die Verwendung naturalistischerer Reize kann helfen, einige dieser Fragen zu klären. In den letzten zehn Jahren haben Algorithmen des maschinellen Lernens beachtliche Erfolge bei der Entschlüsselung naturalistischer visueller Reize aus der menschlichen Gehirnaktivität erzielt. Frühe Erfolge konzentrierten sich auf die Adaption klassischer, blockierter Designs, um die Gehirnaktivität zu nutzen, um sowohl die Arten von Reizen zu klassifizieren, die ein Individuum sah, als auch die Gehirnnetzwerke, die diese Repräsentationen kodierten 17,18,19. Mit der Entwicklung leistungsfähigerer Algorithmen, insbesondere neuronaler Netze, konnten komplexere Reize entschlüsselt werden, einschließlich naturalistischer Videos20,21. Diese Klassifikatoren, die in der Regel auf neuronale Reaktionen auf diese Videos trainiert werden, verallgemeinern sich auf neuartige Stimuli und ermöglichen es ihnen, zu identifizieren, was ein bestimmtes Subjekt zum Zeitpunkt der fMRT-Reaktion beobachtet hat. Zum Beispiel können bestimmte Arten von Aktionen in Filmen vom menschlichen Gehirn genau entschlüsselt werden, wie z. B. Springen und Drehen, während andere (z. B. Ziehen) dies nicht können22. Obwohl viele Arten von Objekten aus fMRT-Antworten dekodiert werden können, scheinen allgemeine Kategorien schwieriger zu sein. Die Entschlüsselung des Gehirns ist nicht auf den Menschen beschränkt und bietet ein leistungsfähiges Werkzeug, um zu verstehen, wie Informationen in den Gehirnen anderer Spezies organisiert sind. Analoge fMRT-Experimente mit nichtmenschlichen Primaten haben im Temporallappen unterschiedliche Repräsentationen für die Dimensionen von Lebendigkeit und Faszination/Körperlichkeit gefunden, die denen beim Menschen entsprechen23.
Als erster Schritt zum Verständnis der Repräsentationen naturalistischer visueller Reize bei Hunden wurde die Wach-fMRT bei zwei sehr MRT-versierten Haushunden eingesetzt, um die kortikalen Reaktionen auf hundegeeignete Videos zu messen. In dieser Studie wurden naturalistische Videos aufgrund ihrer potenziell größeren ökologischen Validität für einen Hund und aufgrund ihres nachgewiesenen Erfolgs mit neuronalen Netzen, die Videoinhalte auf die Bewegung von Hunden abbilden24, verwendet. In drei separaten Sitzungen wurden 90 Minuten fMRT-Daten aus den Reaktionen jedes Hundes auf 256 einzigartige Videoclips gewonnen. Zum Vergleich: Das gleiche Verfahren wurde an zwei menschlichen Freiwilligen durchgeführt. Dann trainierten und testeten wir mit einem neuronalen Netzwerk Klassifikatoren, um entweder "Objekte" (z. B. Mensch, Hund, Auto) oder "Aktionen" (z. B. Sprechen, Essen, Schnüffeln) mit einer unterschiedlichen Anzahl von Klassen zu unterscheiden. Die Ziele dieser Studie waren zweierlei: 1) festzustellen, ob naturalistische Videoreize aus dem Hundekortex dekodiert werden können; und 2) wenn ja, geben Sie einen ersten Einblick, ob die Organisation der des Menschen ähnlich war.
Protokoll
Die Hundestudie wurde von der Emory University IACUC (PROTO201700572) genehmigt, und alle Besitzer gaben ihre schriftliche Zustimmung zur Teilnahme ihres Hundes an der Studie. Die Studienverfahren am Menschen wurden vom IRB der Emory University genehmigt, und alle Teilnehmer gaben vor dem Scannen eine schriftliche Einwilligung ab (IRB00069592).
1. Teilnehmer
- Wählen Sie die Teilnehmer (Hunde und Menschen) aus, die zuvor den in der Studie vorgestellten Reizen nicht ausgesetzt waren.
HINWEIS: Bei den teilnehmenden Hunden handelte es sich um zwei einheimische Hunde, die von ihren Besitzern freiwillig für die Teilnahme an fMRT-Training und -Scans in Übereinstimmung mit dem zuvor beschriebenen Training und Scannen zur Verfügung gestelltwurden 7. Bhubo war ein 4-jähriger Boxer-Mix und Daisy war eine 11-jährige Boston Terrier-Mischlingshündin. Beide Hunde hatten zuvor an mehreren fMRT-Studien teilgenommen (Bhubo: 8 Studien, Daisy: 11 Studien), von denen einige visuelle Reize beobachteten, die auf einen Bildschirm projiziert wurden, während sie sich im Scanner befanden. Sie wurden ausgewählt, weil sie nachweislich in der Lage sind, lange Zeit im Scanner zu bleiben, ohne sich zu bewegen, ohne dass ihr Besitzer außer Sichtweite ist. Zwei Menschen (ein Mann im Alter von 34 Jahren und eine Frau von 25 Jahren) nahmen ebenfalls an der Studie teil. Weder Hunde noch Menschen waren zuvor den in dieser Studie gezeigten Reizen ausgesetzt.
2. Reize
- Filmen Sie die Videos (1920 Pixel x 1440 Pixel, 60 Bilder pro Sekunde [fps]), die auf einem tragbaren Stabilisierungs-Gimbal montiert sind.
HINWEIS: In dieser Studie wurden die Videos 2019 in Atlanta, Georgia, gefilmt.- Filmen Sie naturalistische Videos aus der "Hundeperspektive", indem Sie den Gimbal etwa auf Kniehöhe halten. Gestalten Sie die Videos so, dass sie alltägliche Szenarien im Leben eines Hundes festhalten.
HINWEIS: Dazu gehörten Szenen mit Spazierengehen, Füttern, Spielen, Menschen, die miteinander interagieren (miteinander und mit Hunden), Hunden, die miteinander interagieren, Fahrzeuge in Bewegung und Tiere, die keine Hunde sind (Abbildung 1A; Ergänzender Film 1). In einigen Clips interagierten die Personen im Video direkt mit der Kamera, z. B. Streicheln, Schnüffeln oder Spielen mit ihr, während in anderen die Kamera ignoriert wurde. Zusätzliche Aufnahmen von Hirschen wurden von einer lokal platzierten Kamerafalle (1920 Pixel x 1080 Pixel, 30 fps) aufgenommen. - Bearbeiten Sie die Videos in 256 einzigartige 7-Sekunden-"Szenen". Jede Szene stellte ein einzelnes Ereignis dar, z. B. Menschen, die sich umarmen, einen rennenden Hund oder ein laufendes Reh. Weisen Sie jeder Szene eine eindeutige Nummer und Beschriftung entsprechend ihrem Inhalt zu (siehe unten).
- Filmen Sie naturalistische Videos aus der "Hundeperspektive", indem Sie den Gimbal etwa auf Kniehöhe halten. Gestalten Sie die Videos so, dass sie alltägliche Szenarien im Leben eines Hundes festhalten.
- Schneiden Sie die Szenen in fünf größere Kompilationsvideos von jeweils ca. 6 Minuten. Verwenden Sie Kompilationsvideos anstelle eines langen Films, um eine Vielzahl von Reizen nacheinander zu präsentieren.
HINWEIS: Die Darstellung einer Vielzahl von Reizen wäre schwierig zu erreichen, wenn die Videos in einem langen "Take" aufgenommen würden. Dies stimmt mit fMRT-Dekodierungsstudien am Menschenüberein 20,22. Darüber hinaus ermöglichte die Präsentation von Zusammenstellungen kurzer Clips die Erstellung eines Hold-Out-Sets, an dem der trainierte Algorithmus getestet werden konnte (siehe Abschnitt 7, Analysen, unten), da es möglich war, die einzelnen Clips anstelle eines langen Films auszuhalten. Vier Kompilationsvideos hatten 51 einzigartige Szenen und eines hatte 52. Es gab keine Pausen oder leere Bildschirme zwischen den Szenen. - Wählen Sie die Szenen halbzufällig aus, um sicherzustellen, dass jedes Video Beispiele aus allen wichtigen Label-Kategorien enthält: Hunde, Menschen, Fahrzeuge, nichtmenschliche Tiere und Interaktionen.
HINWEIS: Während des Kompilierungsprozesses wurden alle Szenen auf 1920 Pixel x 1080 Pixel bei 30 fps heruntergerechnet, um der Auflösung des MRT-Projektors zu entsprechen.
3. Versuchsplanung
- Scannen Sie die Teilnehmer in einem 3T-MRT-Scanner, während Sie sich die Zusammenstellungsvideos ansehen, die auf eine Leinwand projiziert werden, die an der Rückseite der MRT-Bohrung angebracht ist.
- Spielen Sie die Videos ohne Ton ab.
- Bei Hunden sollten Sie eine stabile Positionierung des Kopfes erreichen, indem Sie vorher trainieren, ihren Kopf in eine maßgeschneiderte Kinnstütze zu legen, die von der Mitte der Schnauze bis hinter den Unterkiefer an den Unterkiefer angeformt ist.
- Befestigen Sie den Kinnhalter an einer Holzablage, die die Spule überspannt, aber genügend Platz für die Pfoten darunter lässt, was dazu führt, dass jeder Hund eine "Sphinx"-Position einnimmt (Abbildung 1B). Es wurden keine Fesseln verwendet. Weitere Informationen zum Trainingsprotokoll finden Sie in früheren Wach-fMRT-Studien an Hunden7.
- Lassen Sie die Probanden an fünf Durchläufen pro Sitzung teilnehmen, wobei jeder Durchlauf aus einem Kompilationsvideo besteht, das von Anfang bis Ende angesehen und in zufälliger Reihenfolge präsentiert wird. Für Hunde sollten Sie zwischen jedem Lauf kurze Pausen einlegen. Liefern Sie dem Hund in diesen Pausen Futterbelohnungen.
- Lassen Sie jedes Fach an drei Sitzungen über 2 Wochen teilnehmen. Dies ermöglicht es dem Probanden, jedes der fünf einzigartigen Kompilationsvideos dreimal anzusehen, was zu einer aggregierten fMRT-Zeit von 90 Minuten pro Person führt.
4. Bildgebung
- Scannen Sie die Hundeteilnehmer nach einem Protokoll, das mit dem in früheren fMRT-Studien an Hunden im Wachzustand verwendeten übereinstimmt 7,25.
- Erhalten Sie die funktionellen Scans mit einer echoplanaren Einzelbildsequenz zur Erfassung von Volumina von 22 sequenziellen 2,5-mm-Schichten mit einem Abstand von 20 % (TE = 28 ms, TR = 1.430 ms, Flip-Winkel = 70°, 64 x 64 Matrix, 2,5 mm Voxelgröße in der Ebene, FOV = 160 mm).
- Bei Hunden richten Sie die Schnitte dorsal zum Gehirn mit der phasenkodierenden Richtung von rechts nach links aus, da Hunde im MRT in einer "Sphinx"-Position sitzen, wobei der Hals in einer Linie mit dem Gehirn liegt. Die Phasencodierung von rechts nach links vermeidet Wrap-around-Artefakte vom Hals bis zur Vorderseite des Kopfes. Darüber hinaus stammt das Hauptanfälligkeitsartefakt bei scannenden Hunden aus der Stirnhöhle, was zu einer Verzerrung des Frontallappens führt.
- Für den Menschen erhalten Sie axiale Schnitte mit Phasenkodierung in anterior-posteriorer Richtung.
- Um einen Vergleich mit den Hundescans (gleicher TR/TE) zu ermöglichen, verwenden Sie die Multiband-Schichterfassung (CMRR, University of Minnesota) für den Menschen mit einem Multiband-Beschleunigungsfaktor von 2 (GRAPPA = 2, TE = 28 ms, TR = 1.430 ms, Flip-Winkel = 55°, 88 x 88 Matrix, 2,5 mm Voxel in der Ebene, vierundvierzig 2,5-mm-Schichten mit einem Abstand von 20 %).
- Für die Hunde wird für jeden Teilnehmer auch ein T2-gewichtetes Strukturbild des gesamten Gehirns unter Verwendung einer Turbo-Spin-Echo-Sequenz mit 1,5 mm isotropen Voxeln erstellt. Verwenden Sie für die menschlichen Teilnehmer eine T1-gewichtete MPRAGE-Sequenz mit 1 mm isotropen Voxeln.
HINWEIS: Im Laufe von drei Sitzungen wurden für jeden Teilnehmer ca. 4.000 Funktionsvolumina erhalten.
5. Labels für Stimulus
- Um ein Modell so zu trainieren, dass es die in den Videos dargestellten Inhalte klassifiziert, beschriften Sie zuerst die Szenen. Teilen Sie dazu die 7 Szenen, aus denen jedes Compilation-Video besteht, in 1,4 s Clips auf. Beschriften Sie kurze Clips anstelle einzelner Frames, da es Elemente im Video gibt, die nicht mit Standbildern erfasst werden können, von denen einige für Hunde besonders auffällig und daher für die Dekodierung nützlich sein können, wie z. B. Bewegungen.
HINWEIS: Es wurde eine Cliplänge von 1,4 s gewählt, da dies lang genug war, um diese dynamischen Elemente zu erfassen, und der TR von 1,43 s sehr nahe kam, was eine Klassifizierung auf Volumenbasis ermöglicht. - Verteilen Sie diese 1,4-Sekunden-Clips (n = 1.280) nach dem Zufallsprinzip an die Labormitglieder, um jeden Clip manuell mit einem vorprogrammierten Einreichungsformular im Kontrollkästchenstil zu beschriften.
HINWEIS: Es wurden 94 Labels ausgewählt, um so viele wichtige Merkmale wie möglich zu erfassen, darunter Themen (z. B. Hund, Mensch, Katze), Anzahl der Personen (1, 2, 3+), Objekte (z. B. Auto, Fahrrad, Spielzeug), Aktionen (z. B. Essen, Schnüffeln, Sprechen), Interaktionen (z. B. Mensch-Mensch, Mensch-Hund) und Umgebung (drinnen, draußen). Dies ergab einen 94-dimensionalen Label-Vektor für jeden Clip (Ergänzende Tabelle 1). - Wählen Sie als Konsistenzprüfung eine zufällige Teilmenge aus, die von einem zweiten Lab-Mitglied neu beschriftet werden soll. Hier wurde festgestellt, dass die Labels bei allen Individuen sehr konsistent sind (>95 %). Bei den Labels, die nicht konsistent waren, erlauben Sie den beiden Labormitgliedern, den betreffenden Clip erneut anzusehen und zu einem Konsens über das Label zu kommen.
- Verwenden Sie für jeden Lauf Protokolldateien mit Zeitstempel, um den Beginn des Videostimulus relativ zum ersten Scan-Volumen zu bestimmen.
- Um die Verzögerung zwischen der Stimuluspräsentation und der BOLD-Antwort zu berücksichtigen, falten Sie die Markierungen mit einer doppelten gamma-hämodynamischen Antwortfunktion (HRF) und interpolieren Sie mit den Python-Funktionen numpy.convolve() und interp() auf die TR der Funktionsbilder (1.430 ms).
HINWEIS: Das Endergebnis war eine Matrix aus gefalteten Beschriftungen nach der Gesamtzahl der Scan-Volumina für jeden Teilnehmer (94 Beschriftungen x 3.932, 3.920, 3.939 bzw. 3.925 Bände für Daisy, Bhubo, Mensch 1 bzw. Mensch 2). - Gruppieren Sie diese Beschriftungen nach Bedarf, um Makrobeschriftungen für die weitere Analyse zu erstellen. Kombinieren Sie beispielsweise alle Instanzen des Gehens (Ausführen des Hundes, Ausführen eines Menschen, Ausführen eines Esels), um ein "Gehen"-Label zu erstellen.
- Um Redundanzen im Beschriftungssatz weiter zu entfernen, berechnen Sie den Varianzinflationsfaktor (VIF) für jedes Label, mit Ausnahme der Makrobeschriftungen, die offensichtlich stark korreliert sind.
HINWEIS: VIF ist ein Maß für die Multikollinearität in Prädiktorvariablen, das berechnet wird, indem jeder Prädiktor gegen jeden anderen regressiert wird. Höhere VIFs weisen auf stärker korrelierte Prädiktoren hin. In dieser Studie wurde ein VIF-Schwellenwert von 2 verwendet, wodurch die 94 Markierungen auf 52 einzigartige, weitgehend unkorrelierte Markierungen reduziert wurden (Ergänzende Tabelle 1).
6. fMRT-Vorverarbeitung
- Die Vorverarbeitung umfasst die Korrektur, Zensur und Normalisierung von Bewegungen unter Verwendung der AFNI-Suite (NIH) und der zugehörigen Funktionen26,27. Verwenden Sie eine Starrkörper-Bewegungskorrektur mit zwei Durchgängen und sechs Parametern, um die Volumina an einem Zielvolumen auszurichten, das für die durchschnittliche Kopfposition des Teilnehmers über die Durchläufe hinweg repräsentativ ist.
- Führen Sie eine Zensur durch, um Volumina mit einer Verschiebung von mehr als 1 mm zwischen den Scans sowie solche mit einer Voxelsignalintensität von mehr als 0,1 % zu entfernen. Bei beiden Hunden wurden mehr als 80 % der Volumina nach der Zensur beibehalten, bei Menschen waren es mehr als 90 %.
- Um das Signal-Rausch-Verhältnis einzelner Voxel zu verbessern, führen Sie eine leichte räumliche Glättung mit 3dmerge und einem 4-mm-Gaußschen Kern bei voller Breite und halbem Maximum durch.
- Um die Wirkung visueller Merkmale auf niedriger Ebene, wie z. B. Bewegung oder Geschwindigkeit, zu kontrollieren, die je nach Reiz unterschiedlich sein können, ist der optische Fluss zwischen aufeinanderfolgenden Bildern von Videoclipszu berechnen 22,28. Berechnen Sie den optischen Fluss mit dem Farneback-Algorithmus in OpenCV nach dem Downsampling auf 10 Bilder pro Sekunde29.
- Um die Bewegungsenergie in jedem Frame zu schätzen, berechnen Sie die Summe der Quadrate des optischen Flusses jedes Pixels und ziehen Sie die Quadratwurzel des Ergebnisses, wodurch der euklidische durchschnittliche optische Fluss von einem Frame zum nächsten effektiv berechnetwird 28,30. Dadurch werden Zeitverläufe von Bewegungsenergie für jedes Kompilationsvideo erzeugt.
- Wiederholen Sie diese Stichproben, um sie an die zeitliche Auflösung der fMRT-Daten anzupassen, gefaltet mit einer doppelten hämodynamischen Gamma-Reaktionsfunktion (HRF) wie oben und verkettet, um sie mit der Stimuluspräsentation für jedes Subjekt in Einklang zu bringen.
- Verwenden Sie diesen Zeitverlauf zusammen mit den Bewegungsparametern, die aus der oben beschriebenen Bewegungskorrektur generiert wurden, als einzige Regressoren zu einem allgemeinen linearen Modell (GLM), das für jedes Voxel mit AFNIs 3dDeconvolve geschätzt wird. Verwenden Sie die Residuen dieses Modells als Eingaben für den unten beschriebenen Machine Learning-Algorithmus.
7. Analysen
- Entschlüsseln Sie die Regionen des Gehirns, die wesentlich zur Klassifizierung visueller Reize beitragen, und trainieren Sie für jeden einzelnen Teilnehmer ein Modell, das dann zur Klassifizierung von Videoinhalten auf der Grundlage der Gehirndaten der Teilnehmer verwendet werden kann. Verwenden Sie den Ivis-Algorithmus für maschinelles Lernen, eine nichtlineare Methode, die auf siamesischen neuronalen Netzen (SNNs) basiert und sich bei hochdimensionalen biologischen Daten als erfolgreich erwiesen hat31.
HINWEIS: SNNs enthalten zwei identische Subnetzwerke, die verwendet werden, um die Ähnlichkeit von Eingaben im überwachten oder unüberwachten Modus zu ermitteln. Obwohl neuronale Netze für die Dekodierung des Gehirns aufgrund ihrer im Allgemeinen größeren Leistungsfähigkeit gegenüber linearen Methoden wie Support Vector Machines (SVMs) immer beliebter werden, haben wir hier ein SNN verwendet, da es gegenüber Klassenungleichgewichten robust ist und weniger Exemplare benötigt wird. Im Vergleich zu Support Vector Machines (SVM) und Random Forest (RF)-Klassifikatoren, die mit denselben Daten trainiert wurden, stellten wir fest, dass Ivis erfolgreicher bei der Klassifizierung von Gehirndaten über mehrere Label-Kombinationen hinweg ist, die durch verschiedene Metriken bestimmt werden, darunter der mittlere F1-Score, die Präzision, der Abruf und die Testgenauigkeit (siehe unten). - Konvertieren Sie für jeden Teilnehmer die Residuen des gesamten Gehirns in ein Format, das für die Eingabe in das neuronale Netzwerk von Ivis geeignet ist. Verketten und maskieren Sie die fünf Durchläufe in jeder ihrer drei Sitzungen, wobei nur die Gehirnvoxel beibehalten werden.
- Glätten Sie die räumliche Dimension, was zu einer zweidimensionalen Matrix von Voxeln nach Zeit führt.
- Verketten Sie die gefalteten Beschriftungen der Videos, die in jedem Lauf gezeigt werden, und entsprechen Sie somit den fMRT-Läufen.
- Zensieren Sie sowohl die fMRT-Daten als auch die entsprechenden Markierungen entsprechend den in der Vorverarbeitung gekennzeichneten Volumina.
- Wählen Sie die Zielbeschriftungen aus, die dekodiert werden sollen - im Folgenden als "Klassen" bezeichnet - und behalten Sie nur die Datenträger bei, die diese Klassen enthalten. Der Einfachheit halber sollten Sie Klassen als sich gegenseitig ausschließend behandeln und keine Volumes einschließen, die zu mehreren Klassen für die Decodierung gehören, sodass nur reine Exemplare übrig bleiben.
- Teilen Sie die Daten in Trainings- und Testsätze auf. Verwenden Sie eine fünffache Aufteilung und wählen Sie nach dem Zufallsprinzip 20 % der Szenen aus, die als Testset dienen sollen.
HINWEIS: Dies bedeutete, dass, wenn eine bestimmte Szene für den Testsatz ausgewählt wurde, alle Clips und Funktionsvolumen, die während dieser Szene erhalten wurden, aus dem Trainingssatz herausgehalten wurden. Wäre die Aufteilung unabhängig von der Szene durchgeführt worden, wären Volumina aus derselben Szene sowohl im Trainingssatz als auch im Testsatz erschienen, und der Klassifizierer hätte sie nur mit dieser bestimmten Szene abgleichen müssen, um sie erfolgreich klassifizieren zu können. Um jedoch zurückgehaltene Volumina aus neuen Szenen korrekt zu klassifizieren, musste der Klassifikator sie einer allgemeineren, szenenunabhängigen Klasse zuordnen. Dies war ein robusterer Test für die Generalisierbarkeit des Erfolgs des Klassifikators im Vergleich zum Zurückhalten einzelner Clips. - Gleichen Sie den Trainingssatz aus, indem Sie die Anzahl der Volumina in jeder Klasse mit dem scikit-learn-Paket imbalanced-learn so unterbewerten, dass sie der der kleinsten Klasse entspricht.
- Trainieren und testen Sie den Ivis-Algorithmus für jeden Teilnehmer in 100 Iterationen, jedes Mal mit einem eindeutigen Test-Train-Split (Ivis-Parameter: k = 5, model = "maaten", n_epochs_without_progress = 30, supervision_weight = 1). Diese Parameterwerte wurden weitgehend auf der Grundlage der Größe und Komplexität des Datensatzes ausgewählt, wie von den Autoren des Algorithmus in seiner Dokumentationempfohlen 32. "Anzahl der Epochen ohne Fortschritt" und "Aufsichtsgewichtung" (0 für unüberwacht, 1 für überwacht) wurden einer zusätzlichen Parameteranpassung unterzogen, um das Modell zu optimieren.
- Um die Anzahl der Merkmale, die zum Trainieren des Klassifikators vom gesamten Gehirn verwendet werden, auf die informativsten Voxel zu reduzieren, verwenden Sie einen Random Forest Classifier (RFC) mit scikit-learn, um jedes Voxel nach seiner Merkmalsbedeutung zu ordnen.
ANMERKUNG: Obwohl der RFC nicht über den Zufall hinaus funktionierte, diente er dem nützlichen Zweck, nicht-informative Voxel auszusortieren, die nur zum Rauschen des Ivis-Algorithmus beigetragen hätten. Dies ist vergleichbar mit der Verwendung von F-Tests für die Merkmalsauswahl, bevor sie an den Klassifikator33 übergeben werden. Nur die besten 5 % der Voxel aus dem Trainingssatz wurden beim Training und Testen verwendet. Die bevorzugte Anzahl von Voxeln wurde mit 5 % als konservativer Schwellenwert gewählt, um die Anzahl der nicht-informativen Voxel vor dem Training des neuronalen Netzes zu reduzieren. Qualitativ ähnliche Ergebnisse wurden auch für Menschen und Hunde erzielt, wenn ein größerer Anteil an Voxeln verwendet wurde. Obwohl menschliche Gehirne größer sind als Hundegehirne, waren menschliche Modelle auch erfolgreich, wenn sie mit einer absoluten Anzahl von Voxeln trainiert wurden, die denen in Hundemodellen entspricht, weit kleiner als 5% der Voxel (~250 Voxel; alle mittleren LRAP-Werte >99. Perzentil). Aus Gründen der Konsistenz präsentieren wir daher die Ergebnisse unter Verwendung der oberen 5% der Voxel für beide Arten. - Normalisieren Sie die durchschnittlichen 5 % der informativsten Voxel über alle 100 Durchläufe, transformieren Sie in den Strukturraum jedes Teilnehmers und dann in den Gruppenatlasraum (Atlanten: Mensch34 und Hund35) und summieren Sie ihn über die Teilnehmer für jede Spezies. Überlagern Sie die Wichtigkeit der Merkmale auf den Atlanten und färben Sie sie entsprechend der Wichtigkeitsbewertung mit ITK-SNAP36 ein.
Ergebnisse
Zu den gebräuchlichsten Metriken zum Bewerten der Modellleistung in Machine Learning-Analysen gehören Präzision, Genauigkeit, Abruf und F1-Bewertung. Genauigkeit ist der Gesamtprozentsatz der Modellvorhersagen, die unter Berücksichtigung der wahren Daten richtig sind. Die Genauigkeit ist der Prozentsatz der positiven Vorhersagen des Modells, die tatsächlich positiv sind (d. h. die Richtig-Positiv-Rate), während die Erinnerung der Prozentsatz der richtig positiven Ergebnisse in den ursprünglichen Daten ist, die das Modell erfolgreich vorhersagen kann. Der F1-Score ist der gewichtete Durchschnitt von Präzision und Abruf und fungiert als alternatives Maß für die Genauigkeit, das robuster gegenüber Klassenungleichgewichten ist. Der Ivis unterscheidet sich jedoch von anderen häufig verwendeten Algorithmen des maschinellen Lernens dadurch, dass seine Ausgabe nicht binär ist. Bei einer bestimmten Eingabe von Gehirnvoxeln stellt jedes Ausgabeelement die Wahrscheinlichkeiten dar, die jeder der Klassen entsprechen. Die Berechnung von Genauigkeit, Präzision, Abruf und F1 für diese Ausgaben erforderte eine Binarisierung nach dem Motto "Der Gewinner bekommt alles", wobei die Klasse mit der höchsten Wahrscheinlichkeit als die für dieses Volumen vorhergesagte Klasse betrachtet wurde. Bei diesem Ansatz wurden wichtige Informationen über die Rangfolge dieser Wahrscheinlichkeiten eliminiert, die für die Beurteilung der Qualität des Modells relevant waren. Während wir also weiterhin diese traditionellen Metriken berechnet haben, haben wir den LRAP-Wert (Label Ranking Average Precision) als primäre Metrik verwendet, um die Genauigkeit des Modells im Testsatz zu berechnen. Diese Metrik misst im Wesentlichen, inwieweit der Klassifikator den True-Labels höhere Wahrscheinlichkeiten zuordnete37.
In unterschiedlichem Maße war der Klassifikator des neuronalen Netzes sowohl für Menschen als auch für Hunde erfolgreich. Für den Menschen war der Algorithmus in der Lage, sowohl Objekte als auch Aktionen zu klassifizieren, wobei Drei-Klassen-Modelle für beide eine mittlere Genauigkeit von 70 % erreichten. Der LRAP-Score wurde als primäre Metrik verwendet, um die Genauigkeit des Modells im Testsatz zu berechnen. Diese Metrik misst das Ausmaß, in dem der Klassifikator den True-Labels höhere Wahrscheinlichkeiten zugewiesenhat 37. Bei beiden Menschen waren die medianen LRAP-Scores für alle getesteten Modelle größer als das 99. Perzentil eines zufällig permutierten Satzes von Labels (Tabelle 1; Abbildung 2). Bei Hunden hatte nur das Aktionsmodell bei beiden Teilnehmern einen medianen LRAP-Perzentilrang, der signifikant größer war als der Zufall (Tabelle 1; p = 0,13 für Objekte und p < 0,001 für Aktionen; mittlerer LRAP-Score des Drei-Klassen-Aktionsmodells für Hunde = 78. Perzentil). Diese Ergebnisse galten sowohl für alle Probanden einzeln als auch für die Gruppierung nach Arten.
Angesichts des Erfolgs des Klassifizierers haben wir mit zusätzlichen Klassen trainiert und getestet, um die Grenzen des Modells zu bestimmen. Dazu gehörte die Berechnung von Unähnlichkeitsmatrizen für die gesamten 52 potenziellen Klassen von Interesse unter Verwendung des hierarchischen Clustering-Algorithmus des Python-Pakets scipy, der Klassen basierend auf der Ähnlichkeit der Gehirnreaktion eines Individuums auf jede einzelne gruppierte, wie sie durch paarweise Korrelation definiert ist. Von den zusätzlich getesteten Modellen hatte das Modell mit dem höchsten medianen LRAP-Perzentil-Ranking bei beiden Hunden fünf Klassen: die ursprünglichen Klassen "Sprechen", "Fressen" und "Schnüffeln" sowie zwei neue Klassen, "Streicheln" und "Spielen" (Abbildung 2). Dieses Modell hatte einen medianen LRAP-Perzentilrang, der signifikant höher war als der zufällig für alle Teilnehmer vorhergesagte (Tabelle 1; p < 0,001 sowohl für Hunde als auch für Menschen; Mittlerer LRAP-Score des Fünf-Klassen-Aktionsmodells für Hunde = 81. Perzentil).
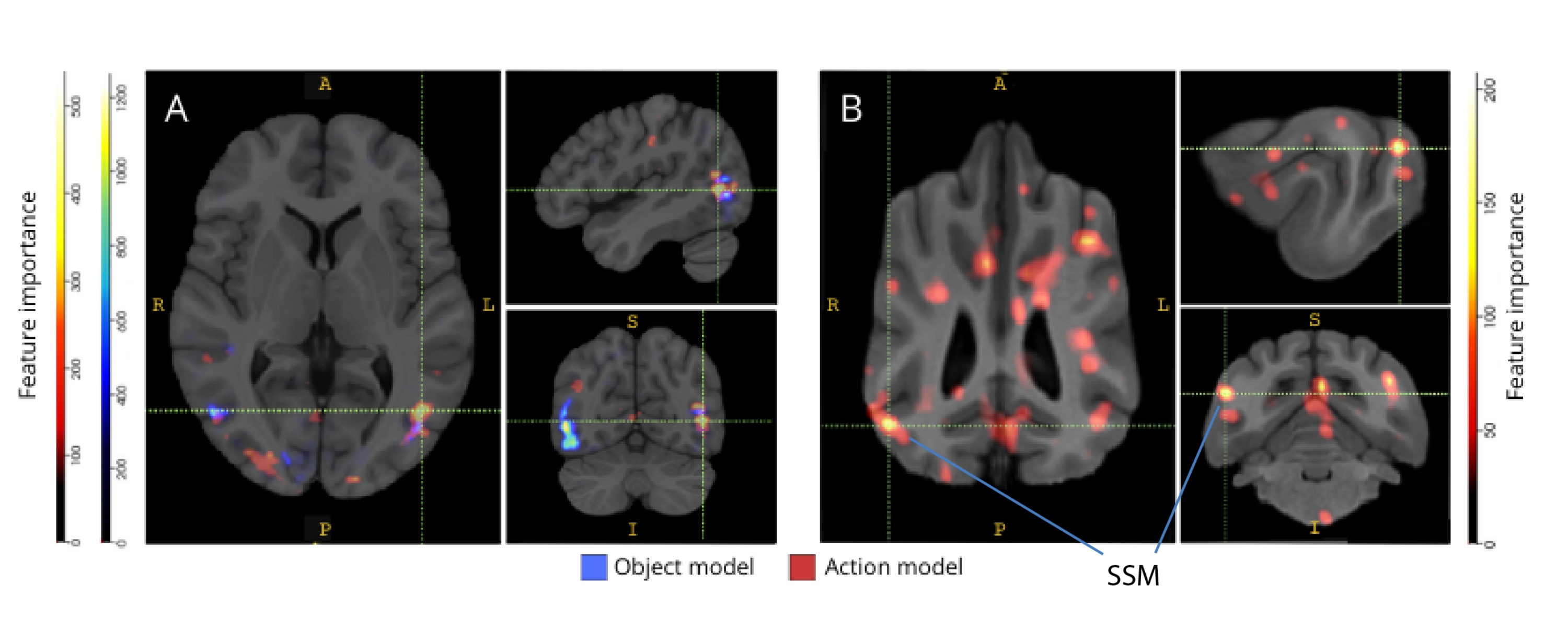
Bei der Rückkartierung auf ihre jeweiligen Hirnatlanten zeigten die Merkmalsbedeutungswerte der Voxel eine Reihe von Clustern informativer Voxel im okzipitalen, parietalen und temporalen Kortex sowohl von Hunden als auch von Menschen (Abbildung 3). Beim Menschen zeigten die objektbasierten und handlungsbasierten Modelle ein fokussiveres Muster als bei Hunden und in Regionen, die typischerweise mit Objekterkennung assoziiert sind, wenn auch mit leichten Unterschieden in der räumlichen Lokalisierung von objektbasierten Voxeln und handlungsbasierten Voxeln.
Wir überprüften, dass diese Artenunterschiede nicht das Ergebnis der aufgabenkorrelierten Bewegung der Hunde waren, die sich zu bestimmten Arten von Videos mehr bewegten als zu anderen (z. B. Videos mit anderen als Hunden, z. B. Autos). Wir berechneten die euklidische Norm der sechs Bewegungsparameter und passten ein lineares Mixed-Effects-Modell mit dem R-Paket lme4 an, mit Klasse als festem Effekt und Laufnummer als Zufallseffekt für jeden Hund. Für jedes der endgültigen Modelle fanden wir keinen signifikanten Effekt des Klassentyps auf die Bewegung für Daisy (F(2, 2252) = 0,83, p = 0,44 für objektbasiert und F(4, 1235) = 1,87, p = 0,11 für aktionsbasiert) oder Bhubo (F(2, 2231) = 1,71, p = 0,18 für objektbasiert und F(4, 1221) = 0,94, p = 0,45 für aktionsbasiert).

Abbildung 1: Naturalistische Videos und Präsentation in MRT-Fassung. (A) Beispielbilder aus Videoclips, die den Teilnehmern gezeigt wurden. (B) Bhubo, ein 4-jähriger Boxer-Mix, der Videos anschaut, während er sich einer fMRT im Wachzustand unterzieht. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}

Abbildung 2: Modellleistung bei Hunden und Menschen. Die Verteilung der LRAP-Scores, dargestellt als Perzentil-Rankings ihrer Nullverteilungen, über 100 Iterationen des Trainings und Testens des Ivis-Algorithmus für maschinelles Lernen für ein objektbasiertes Modell mit drei Klassen, ein aktionsbasiertes Modell mit drei Klassen und ein aktionsbasiertes Modell mit fünf Klassen, wobei Modelle versuchten, BOLD-Reaktionen auf naturalistische Videostimuli zu klassifizieren, die über Wach-fMRT bei Hunden und Menschen. Die Bewertungen werden nach Arten aggregiert. Ein LRAP-Score mit einem sehr hohen Perzentil-Ranking deutet darauf hin, dass es sehr unwahrscheinlich ist, dass das Modell diesen LRAP-Score zufällig erreicht. Ein Modell, das nicht besser als der Zufall abschneidet, hätte einen Median des LRAP-Score-Perzentil-Rankings von ~50. Gestrichelte Linien stellen die mediane LRAP-Score-Perzentil-Rangfolge für jede Art über alle 100 Läufe dar. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}

Abbildung 3: Regionen, die für die Unterscheidung von Drei-Klassen-Objekt- und Fünf-Klassen-Handlungsmodellen wichtig sind. (A) Menschliche und (B) Hunde-Teilnehmer. Die Voxel wurden nach ihrer Merkmalsbedeutung mit einem Random-Forest-Klassifikator eingestuft, der über alle Iterationen der Modelle gemittelt wurde. Die oberen 5% der Voxel (d.h. diejenigen, die zum Trainieren von Modellen verwendet werden) werden hier dargestellt, nach Arten aggregiert und zu Visualisierungszwecken in den Gruppenraum transformiert (Atlanten: Mensch34 und Hund35). Die Beschriftungen zeigen Gehirnregionen von Hunden mit hohen Werten für die Merkmalsbedeutung, basierend auf den von Johnson et al.35 identifizierten. Abkürzung: SSM = der suprasylvische Gyrus. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
{kind=link}
| Modelltyp | Genauigkeit des Trainings | Genauigkeit des Tests | F1-Punktzahl | Präzision | Rückruf | Median-Perzentil des LRAP-Scores | |
| Mensch 1 | Objekt (3 Klassen) | 0.98 | 0.69 | 0.48 | 0.52 | 0.49 | >99 |
| Aktion (3 Klassen) | 0.98 | 0.72 | 0.51 | 0.54 | 0.54 | >99 | |
| Aktion (5 Klassen) | 0.97 | 0.51 | 0.28 | 0.37 | 0.27 | >99 | |
| Mensch 2 | Objekt (3 Klassen) | 0.98 | 0.68 | 0.45 | 0.5 | 0.47 | >99 |
| Aktion (3 Klassen) | 0.98 | 0.69 | 0.46 | 0.5 | 0.48 | >99 | |
| Aktion (5 Klassen) | 0.97 | 0.53 | 0.3 | 0.4 | 0.27 | >99 | |
| Bhubo | Objekt (3 Klassen) | 0.99 | 0.61 | 0.38 | 0.41 | 0.39 | 57 |
| Aktion (3 Klassen) | 0.98 | 0.63 | 0.38 | 0.4 | 0.4 | 87 | |
| Aktion (5 Klassen) | 0.99 | 0.45 | 0.16 | 0.29 | 0.13 | 88 | |
| Gänseblümchen | Objekt (3 Klassen) | 1 | 0.61 | 0.38 | 0.43 | 0.39 | 43 |
| Aktion (3 Klassen) | 0.97 | 0.62 | 0.35 | 0.38 | 0.35 | 60 | |
| Aktion (5 Klassen) | 0.99 | 0.44 | 0.16 | 0.27 | 0.13 | 76 |
Tabelle 1: Aggregierte Metriken des Ivis-Algorithmus für maschinelles Lernen über 100 Iterationen von Training und Tests von BOLD-Reaktionen auf naturalistische Videoreize, die über Wach-fMRT bei Hunden und Menschen erhalten wurden. Die Objektmodelle hatten drei Zielklassen ("Hund", "Mensch", "Auto"), und die Aktionsmodelle hatten entweder drei oder fünf Klassen (drei Klassen: "sprechen", "essen", "schnüffeln"; fünf Klassen: "sprechen", "essen", "schnüffeln", "streicheln", "spielen"). Werte, die deutlich größer als der Zufall sind, werden fett dargestellt.
Ergänzende Tabelle 1: Klassenbezeichnungen. Bitte klicken Sie hier, um diese Datei herunterzuladen.
Ergänzender Film 1: Beispiel-Videoclip. Bitte klicken Sie hier, um diese Datei herunterzuladen.
Diskussion
Die Ergebnisse dieser Studie zeigen, dass naturalistische Videos Repräsentationen im Gehirn von Hunden induzieren, die über mehrere Bildgebungssitzungen hinweg stabil genug sind, dass sie mit fMRT entschlüsselt werden können - ähnlich den Ergebnissen, die sowohl bei Menschen als auch bei Affen erzielt wurden20,23. Während frühere fMRT-Studien des visuellen Systems von Hunden abgespeckte Reize wie ein Gesicht oder ein Objekt vor einem neutralen Hintergrund präsentiert haben, zeigen die Ergebnisse hier, dass naturalistische Videos, in denen mehrere Menschen und Objekte miteinander interagieren, Aktivierungsmuster im Hundekortex induzieren, die mit einer Zuverlässigkeit entschlüsselt werden können, die der des menschlichen Kortex nahe kommt. Dieser Ansatz eröffnet neue Wege der Untersuchung, wie das visuelle System des Hundes organisiert ist.
Obwohl das Gebiet der fMRT bei Hunden schnell gewachsen ist, stützten sich diese Experimente bisher auf relativ dürftige Reize, wie z. B. Bilder von Menschen oder Objekten vor neutralen Hintergründen 10,12,13. Obwohl diese Experimente begonnen haben, Gehirnregionen zu identifizieren, die analog zur fusiformen Gesichtszone (FFA) von Primaten sind, die an der Gesichtsverarbeitung beteiligt ist, und dem lateralen okzipitalen Kortex (LOC) für die Objektverarbeitung, gibt es nach wie vor Uneinigkeit über die Art dieser Repräsentationen, wie z.B. ob Hunde per se Gesichtsbereiche haben, die auf ähnliche hervorstechende Merkmale wie Primaten reagieren, oder ob sie getrennte Repräsentationen für Hunde und Menschen oder Gesichter und Köpfe haben. Zum Beispiel 9,13. Hunde sind natürlich keine Primaten, und wir wissen nicht, wie sie diese künstlichen Reize interpretieren, losgelöst von ihren üblichen multisensorischen Kontexten mit Geräuschen und Gerüchen. Einige Hinweise deuten darauf hin, dass Hunde Bilder von Objekten nicht als Darstellungen realer Dinge behandeln12. Obwohl es nicht möglich ist, ein echtes multisensorisches Erlebnis im Scanner zu schaffen, kann die Verwendung naturalistischer Videos einen Teil der Künstlichkeit abschwächen, indem dynamische Reize bereitgestellt werden, die der realen Welt besser entsprechen, zumindest für einen Hund. Aus den gleichen Gründen hat die Verwendung naturalistischer Reize in der menschlichen fMRT-Forschung an Popularität gewonnen, was beispielsweise zeigt, dass Ereignissequenzen in einem Film im Kortex über mehrere Zeitskalen hinweg dargestellt werden und dass Filme eine zuverlässige Emotionsaktivierung wirksam induzierenkönnen 38. Obwohl naturalistische Videos nach wie vor relativ arme Reize sind, wirft ihr Erfolg in den menschlichen Neurowissenschaften die Frage auf, ob ähnliche Ergebnisse bei Hunden erzielt werden können.
Unsere Ergebnisse zeigen, dass ein Klassifikator für neuronale Netze erfolgreich darin war, einige Arten von naturalistischen Inhalten aus Hundegehirnen zu entschlüsseln. Dieser Erfolg ist angesichts der Komplexität der Reize eine beeindruckende Leistung. Da der Klassifikator an ungesehenen Videoclips getestet wurde, erkannte das Decodierungsmodell breite Kategorien, die über Clips hinweg identifizierbar waren, und nicht Eigenschaften, die für einzelne Szenen spezifisch waren. Wir sollten beachten, dass es mehrere Metriken gibt, um die Leistung eines Klassifikators für maschinelles Lernen zu quantifizieren (Tabelle 1). Da naturalistische Videos von Natur aus nicht alle Klassen gleich häufig vorkommen, haben wir einen vorsichtigen Ansatz gewählt, indem wir eine Nullverteilung aus der zufälligen Permutation von Labels konstruiert und die damit verbundene Signifikanz bewertet haben. Dann stellten wir fest, dass der Erfolg der Hundemodelle statistisch signifikant war und Werte von 75 bis 90 Perzentilen erreichte, aber nur, wenn die Videos auf der Grundlage der vorhandenen Aktionen wie Spielen oder Sprechen codiert wurden.
Die Testsätze waren im Gegensatz zu den Trainingssätzen nicht klassenübergreifend ausgewogen. Da nur 20 % der Daten erfasst wurden, hätte die Unterstichprobenziehung auf die kleinste Klassengröße zu sehr kleinen Stichprobengrößen für jede Klasse geführt, so dass die berechneten Statistiken unzuverlässig gewesen wären. Um die Möglichkeit einer überhöhten Genauigkeit durch dieses Ungleichgewicht zu vermeiden, wurde die Nullverteilung des LRAP berechnet, indem die Reihenfolge der Klassen für jede Modelliteration 1.000 Mal zufällig permutiert wurde. Diese NULL-Verteilung diente als Referenz dafür, wie gut das Modell wahrscheinlich zufällig funktionierte. Anschließend wurde der wahre LRAP in eine Perzentilrangfolge in dieser NULL-Verteilung konvertiert. Ein sehr hohes Perzentil-Ranking, z. B. 95 %, würde bedeuten, dass ein so hoher Wert nur in 5 % der Fälle in 1.000 zufälligen Permutationen auftrat. Ein solches Modell könnte daher als weit über dem Zufall liegend angesehen werden. Um festzustellen, ob diese Perzentil-Rankings signifikant höher sind als die zufällig erwartete, d. h. das 50. Perzentil, wurde statistisch gesehen die mediane LRAP-Perzentil-Rangfolge über alle 100 Iterationen für jedes Modell berechnet und ein Wilcoxon-Rangtest mit Vorzeichen bei einer Stichprobe durchgeführt.
Obwohl das primäre Ziel darin bestand, einen Decoder für naturalistische visuelle Reize für Hunde zu entwickeln, sind Vergleiche mit dem Menschen unvermeidlich. Hier stellen wir zwei Hauptunterschiede fest: Für jede Art von Klassifikator schnitten die menschlichen Modelle besser ab als die Hundemodelle; Und die menschlichen Modelle schnitten sowohl bei objekt- als auch bei aktionsbasierten Modellen gut ab, während die Hundemodelle nur bei aktionsbasierten Modellen abschnitten. Die überlegene Leistung der menschlichen Modelle könnte auf mehrere Faktoren zurückzuführen sein. Menschliche Gehirne sind etwa 10-mal größer als Hundegehirne, so dass es mehr Voxel gibt, aus denen man wählen kann, um einen Klassifikator zu erstellen. Um die Modelle auf eine gleiche Stufe zu stellen, sollte man die gleiche Anzahl von Voxeln verwenden, aber dies kann entweder im absoluten oder relativen Sinne sein. Obwohl das endgültige Modell auf den oberen 5% der informativen Voxel in jedem Gehirn basierte (ein relatives Maß), wurden ähnliche Ergebnisse mit einer festen Anzahl von Voxeln erzielt. Daher scheint es wahrscheinlicher, dass Leistungsunterschiede damit zusammenhängen, wie Menschen und Hunde Videoreize wahrnehmen. Wie oben erwähnt, sind Hunde und Menschen zwar beide multisensorisch in ihrer Wahrnehmung, aber die Reize können für einen Hund ärmer sein als für einen Menschen. Größenhinweise können zum Beispiel verloren gehen, da alles wie eine Spielzeugversion der realen Welt aussieht. Es gibt Hinweise darauf, dass Hunde Objekte nach Größe und Textur kategorisieren, bevor sie Form haben, was fast das Gegenteil von Menschen ist39. Darüber hinaus ist der Geruch, der hier nicht berücksichtigt wird, wahrscheinlich eine wichtige Informationsquelle für die Objektunterscheidung bei Hunden, insbesondere bei der Identifizierung von Artgenossen oder Menschen 40,41,42. Aber selbst ohne Größen- oder Geruchshinweise in der ungewöhnlichen Umgebung des MRT-Scanners sagt die Tatsache, dass der Klassifikator überhaupt funktionierte, dass es immer noch Informationen gab, die für die Hunde relevant waren und aus ihrem Gehirn wiederhergestellt werden konnten. Bei nur zwei Hunden und zwei Menschen könnten die Artenunterschiede auch auf individuelle Unterschiede zurückzuführen sein. Die beiden Hunde stellten jedoch die besten der MRT-trainierten Hunde dar und zeichneten sich dadurch aus, dass sie beim Anschauen von Videos still hielten. Während eine größere Stichprobengröße sicherlich zuverlässigere Unterscheidungen zwischen den Spezies ermöglichen würde, wird die geringe Anzahl von Hunden, die in der Lage sind, Wach-fMRT durchzuführen und Videos lange genug ansehen, die Verallgemeinerbarkeit immer auf alle Hunde beschränken. Es ist zwar möglich, dass spezialisierte Rassen wie Windhunde fein abgestimmte visuelle Gehirnreaktionen haben, aber wir glauben, dass das individuelle Temperament und die Ausbildung eher die Hauptdeterminanten dafür sind, was aus dem Gehirn eines Hundes wiederhergestellt werden kann.
Diese Artenunterschiede werfen die Frage auf, auf welchen Aspekt der Videos die Hunde geachtet haben. Ein Ansatz zur Beantwortung dieser Frage setzt auf einfachere Video-Stimuli. Indem wir dann isolierte Bilder von Menschen, Hunden und Autos verwenden, sowohl einzeln als auch zusammen vor neutralen Hintergründen, könnten wir in der Lage sein, die hervorstechenden Dimensionen auf einen Hund zurückzuentwickeln. Dies ist jedoch sowohl methodisch ineffizient als auch verarmt die Reize aus der realen Welt weiter. Die Frage der Aufmerksamkeit kann allein durch den Dekodierungsansatz gelöst werden, d. h. durch die Verwendung der Modellleistung, um zu bestimmen, worauf geachtet wird43. In diesem Sinne deuten die Ergebnisse darauf hin, dass die Menschen sich zwar sowohl um die Akteure als auch um die Handlungen kümmerten, während sich die Hunde mehr auf die Handlungen selbst konzentrierten. Dies kann auf Unterschiede in Bewegungsmerkmalen auf niedriger Ebene zurückzuführen sein, wie z. B. die Bewegungshäufigkeit, wenn Individuen spielen und nicht essen, oder es könnte auf eine kategorische Darstellung dieser Aktivitäten auf einer höheren Ebene zurückzuführen sein. Die Verteilung der informativen Voxel in der Hirnrinde des Hundes deutet darauf hin, dass es sich bei diesen Repräsentationen nicht nur um Low-Level-Merkmale handelt, die sonst auf visuelle Regionen beschränkt wären. Weitere Studien mit einer größeren Vielfalt an Videoreizen könnten die Rolle der Bewegung bei der Kategoriediskriminierung durch Hunde beleuchten.
Zusammenfassend lässt sich sagen, dass diese Studie die Machbarkeit der Wiederherstellung naturalistischer visueller Informationen aus der Hirnrinde von Hunden mit Hilfe von fMRT auf die gleiche Weise gezeigt hat, wie dies bei der menschlichen Großhirnrinde der Fall ist. Diese Demonstration zeigt, dass auch ohne Geräusche oder Gerüche hervorstechende Dimensionen komplexer Szenen von Hunden beim Anschauen von Videos kodiert werden und dass diese Dimensionen aus ihrem Gehirn wiederhergestellt werden können. Zweitens können aufgrund der geringen Anzahl von Hunden, die diese Art von Aufgabe ausführen können, die Informationen im Kortex weiter verbreitet sein, als dies normalerweise beim Menschen der Fall ist, und die Arten von Handlungen scheinen leichter wiederhergestellt zu werden als die Identität der Akteure oder Objekte. Diese Ergebnisse eröffnen eine neue Art der Untersuchung, wie Hunde die Umwelt wahrnehmen, die sie mit Menschen teilen, einschließlich Videobildschirmen, und schlagen reichhaltige Wege für die zukünftige Erforschung der Art und Weise vor, wie sie und andere Nicht-Primatentiere die Welt "sehen".
Offenlegungen
Nichts.
Danksagungen
Wir danken Kate Revill, Raveena Chhibber und Jon King für ihre hilfreichen Einblicke in die Entwicklung dieser Analyse, Mark Spivak für seine Unterstützung bei der Rekrutierung und Ausbildung von Hunden für die MRT und Phyllis Guo für ihre Hilfe bei der Videoerstellung und -kennzeichnung. Wir danken auch unseren engagierten Hundebesitzern Rebecca Beasley (Daisy) und Ashwin Sakhardande (Bhubo). Die Humanstudien wurden durch ein Stipendium des National Eye Institute (Grant R01 EY029724 an D.D.D.) unterstützt.
Materialien
| Name | Company | Catalog Number | Comments |
| 3 T MRI Scanner | Siemens | Trio | |
| Audio recordings of scanner noise | homemade | none | |
| Camera gimbal | Hohem | iSteady PRO 3 | |
| Dog-appropriate videos | homemade | none | |
| fMRI processing software | AFNI | 20.3.01 | |
| Mock scanner components | homemade | none | Mock head coil and scanner tube |
| Neural net software | Ivis | 1.7.1 | |
| Optical flow software | OpenCV | 4.2.0.34 | |
| Projection system for scanner | homemade | none | |
| Trophy Cam HD | Bushnell | 119874 | |
| Video camera | GoPro | HERO7 | |
| Visualization software | ITK-SNAP | 3.6.0 | |
| Windows Video Editor | Microsoft | Windows 11 version |
Referenzen
- Mishkin, M., Ungerleider, L. G., Macko, K. A. Object vision and spatial vision: Two cortical pathways. Trends in Neurosciences. 6, 414-417 (1983).
- de Haan, E. H. F., Cowey, A. On the usefulness of 'what' and 'where' pathways in vision. Trends in Cognitive Sciences. 15 (10), 460-466 (2011).
- Freud, E., Plaut, D. C., Behrmann, M. What' is happening in the dorsal visual pathway. Trends in Cognitive Sciences. 20 (10), 773-784 (2016).
- Goodale, M. A., Milner, A. D. Separate visual pathways for perception and action. Trends in Neurosciences. 15 (1), 20-25 (1992).
- Schenk, T., McIntosh, R. D. Do we have independent visual streams for perception and action? Do we have independent visual streams for perception and action. Cognitive Neuroscience. 1 (1), 52-78 (2010).
- Andics, A., Gácsi, M., Faragó, T., Kis, A., Miklós, &. #. 1. 9. 3. ;. Report voice-sensitive regions in the dog and human brain are revealed by comparative fMRI. Current Biology. 24 (5), 574-578 (2014).
- Berns, G. S., Brooks, A. M., Spivak, M. Functional MRI in awake unrestrained dogs. PLoS One. 7 (5), 38027 (2012).
- Karl, S., et al. Training pet dogs for eye-tracking and awake fMRI. Behaviour Research Methods. 52, 838-856 (2019).
- Bunford, N., et al. Comparative brain imaging reveals analogous and divergent patterns of species and face sensitivity in humans and dogs. Journal of Neuroscience. 40 (43), 8396-8408 (2020).
- Cuaya, L. V., Hernández-Pérez, R., Concha, L. Our faces in the dog's brain: Functional imaging reveals temporal cortex activation during perception of human faces. PLoS One. 11 (3), 0149431 (2016).
- Dilks, D. D., et al. Awake fMRI reveals a specialized region in dog temporal cortex for face processing. PeerJ. 2015 (8), 1115 (2015).
- Prichard, A., et al. 2D or not 2D? An fMRI study of how dogs visually process objects. Animal Cognition. 24 (5), 1143-1151 (2021).
- Thompkins, A. M., et al. Separate brain areas for processing human and dog faces as revealed by awake fMRI in dogs (Canis familiaris). Learning & Behavior. 46 (4), 561-573 (2018).
- Zhang, K., Sejnowski, T. J. A universal scaling law between gray matter and white matter of cerebral cortex. Proceedings of the National Academy of Sciences of the United States of America. 97 (10), 5621-5626 (2000).
- Bradshaw, J., Rooney, N., Serpell, J. Dog Social Behavior and Communication. The Domestic Dog: Its Evolution, Behavior and Interactions with People. , 133-160 (2017).
- Prichard, A., et al. The mouth matters most: A functional magnetic resonance imaging study of how dogs perceive inanimate objects. The Journal of Comparative Neurology. 529 (11), 2987-2994 (2021).
- Haxby, J. V., Connolly, A. C., Guntupalli, J. S. Decoding neural representational spaces using multivariate pattern analysis. Annual Review of Neuroscience. 37, 435-456 (2014).
- Kamitani, Y., Tong, F. Decoding the visual and subjective contents of the human brain. Nature Neuroscience. 8 (5), 679-685 (2005).
- Kay, K. N., Naselaris, T., Prenger, R. J., Gallant, J. L. Identifying natural images from human brain activity. Nature. 452 (7185), 352-355 (2008).
- Nishimoto, S., et al. Reconstructing visual experiences from brain activity evoked by natural movies. Current Biology. 21 (19), 1641-1646 (2011).
- vander Meer, J. N., Breakspear, M., Chang, L. J., Sonkusare, S., Cocchi, L. Movie viewing elicits rich and reliable brain state dynamics. Nature Communications. 11 (1), 5004 (2020).
- Huth, A. G., De Heer, W. A., Griffiths, T. L., Theunissen, F. E., Gallant, J. L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature. 532 (7600), 453-458 (2016).
- Kriegeskorte, N., et al. Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron. 60 (6), 1126-1141 (2008).
- Ehsani, K., Bagherinezhad, H., Redmon, J., Mottaghi, R., Farhadi, A. Who let the dogs out? Modeling dog behavior from visual data. Proceedings of the IEEE Conference on Computer Vision and Pattern. 2018, 4051-4060 (2018).
- Berns, G. S., Brooks, A., Spivak, M. Replicability and heterogeneity of awake unrestrained canine fMRI responses. PLoS One. 9 (5), 98421 (2013).
- Cox, R. W. AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research. 29 (3), 162-173 (1996).
- Prichard, A., Chhibber, R., Athanassiades, K., Spivak, M., Berns, G. S. Fast neural learning in dogs: A multimodal sensory fMRI study. Scientific Reports. 8, 14614 (2018).
- Russ, B. E., Kaneko, T., Saleem, K. S., Berman, R. A., Leopold, D. A. Distinct fMRI responses to self-induced versus stimulus motion during free viewing in the macaque. The Journal of Neuroscience. 36 (37), 9580-9589 (2016).
- Farnebäck, G., Bigun, J., Gustavsson, T. Two-Frame Motion Estimation Based on Polynomial Expansion. In Image Analysis. Scandinavian Conference on Image Analysis. Lecture Notes in Computer Science. 2749, 363-370 (2003).
- Elias, D. O., Land, B. R., Mason, A. C., Hoy, R. R. Measuring and quantifying dynamic visual signals in jumping spiders). Journal of Comparative Physiology A. 192, 799-800 (2006).
- Szubert, B., Cole, J. E., Monaco, C., Drozdov, I. Structure-preserving visualisation of high dimensional single-cell datasets. Scientific Reports. 9, 8914 (2019).
- Tian, H., Tao, P. IVIS dimensionality reduction framework for biomacromolecular simulations. Journal of Chemical Information and Modeling. 60 (10), 4569-4581 (2020).
- Hebart, M. N., Gorgen, K., Haynes, J. The decoding toolbox (TDT): A versatile software package for multivariate analyses of functional imaging data. Frontiers in Neuroinformatics. 8, 88 (2015).
- Mazziotta, J., et al. A probabilistic atlas and reference system for the human brain: International Consortium for Brain Mapping (ICBM). Philosophical Transactions of the Royal Society B: Biological Sciences. 356 (1412), 1293-1322 (2001).
- Johnson, P. J., et al. Stereotactic cortical atlas of the domestic canine brain. Scientific Reports. 10, 4781 (2020).
- Yushkevich, P. A., et al. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. NeuroImage. 31 (3), 1116-1128 (2006).
- Fürnkranz, J., Hüllermeier, E., Loza Mencía, E., Brinker, K. Multilabel classification via calibrated label ranking. Machine Learning. 73 (2), 133-153 (2008).
- Sonkusare, S., Breakspear, M., Guo, C. Naturalistic stimuli in neuroscience: Critically acclaimed. Trends in Cognitive Sciences. 23 (8), 699-714 (2019).
- vander Zee, E., Zulch, H., Mills, D. Word generalization by a dog (Canis familiaris): Is shape important. PLoS One. 7 (11), 49382 (2012).
- Bekoff, M. Observations of scent-marking and discriminating self from others by a domestic dog (Canis familiaris): Tales of displaced yellow snow. Behavioural Processes. 55 (2), 75-79 (2001).
- Berns, G. S., Brooks, A. M., Spivak, M. Scent of the familiar: An fMRI study of canine brain responses to familiar and unfamiliar human and dog odors. Behavioural Processes. 110, 37-46 (2015).
- Schoon, G. A. A., de Bruin, J. C. The ability of dogs to recognize and cross-match human odours. Forensic Science International. 69 (2), 111-118 (1994).
- Kamitani, Y., Tong, F. Decoding seen and attended motion directions from activity in the human visual cortex. Current Biology. 16 (11), 1096-1102 (2006).
Nachdrucke und Genehmigungen
Genehmigung beantragen, um den Text oder die Abbildungen dieses JoVE-Artikels zu verwenden
Genehmigung beantragenThis article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. Alle Rechte vorbehalten