
Method Article
Attraverso gli occhi di un cane: decodifica fMRI di video naturalistici dalla corteccia del cane
In questo articolo
Riepilogo
Gli algoritmi di apprendimento automatico sono stati addestrati per utilizzare modelli di attività cerebrale per "decodificare" gli stimoli presentati agli esseri umani. Qui, dimostriamo che la stessa tecnica può decodificare contenuti video naturalistici dal cervello di due cani domestici. Scopriamo che i decoder basati sulle azioni nei video hanno avuto successo nei cani.
Abstract
I recenti progressi che utilizzano l'apprendimento automatico e la risonanza magnetica funzionale (fMRI) per decodificare gli stimoli visivi dalla corteccia umana e non umana hanno portato a nuove intuizioni sulla natura della percezione. Tuttavia, questo approccio deve ancora essere applicato in modo sostanziale ad animali diversi dai primati, sollevando interrogativi sulla natura di tali rappresentazioni in tutto il regno animale. Qui, abbiamo utilizzato la risonanza magnetica funzionale da sveglio in due cani domestici e due esseri umani, ottenuta mentre ciascuno guardava video naturalistici appositamente creati per il cane. Abbiamo quindi addestrato una rete neurale (Ivis) a classificare il contenuto video da un totale di 90 minuti di attività cerebrale registrata da ciascuno. Abbiamo testato sia un classificatore basato su oggetti, che tenta di discriminare categorie come cane, umano e auto, sia un classificatore basato su azioni, che tenta di discriminare categorie come mangiare, annusare e parlare. Rispetto ai due soggetti umani, per i quali entrambi i tipi di classificatori hanno ottenuto risultati ben superiori al caso, solo i classificatori basati sull'azione sono riusciti a decodificare i contenuti video dei cani. Questi risultati dimostrano la prima applicazione nota dell'apprendimento automatico per decodificare video naturalistici dal cervello di un carnivoro e suggeriscono che la visione del mondo dall'occhio del cane potrebbe essere molto diversa dalla nostra.
Introduzione
Il cervello degli esseri umani, come altri primati, dimostra la parcellazione del flusso visivo in percorsi dorsali e ventrali con funzioni distinte e ben note: il "cosa" e il "dove"degli oggetti. Questa dicotomia cosa/dove è stata un'euristica utile per decenni, ma le sue basi anatomiche sono ora note per essere molto più complesse, con molti ricercatori a favore di una parcellazione basata sul riconoscimento rispetto all'azione ("cosa" vs. "come")2,3,4,5. Inoltre, mentre la nostra comprensione dell'organizzazione del sistema visivo dei primati continua ad essere raffinata e dibattuta, molto rimane sconosciuto su come il cervello di altre specie di mammiferi rappresenti le informazioni visive. In parte, questa lacuna è il risultato dell'attenzione storica su una manciata di specie nelle neuroscienze visive. Nuovi approcci all'imaging cerebrale, tuttavia, stanno aprendo la possibilità di studiare in modo non invasivo i sistemi visivi di una gamma più ampia di animali, il che potrebbe fornire nuove intuizioni sull'organizzazione del sistema nervoso dei mammiferi.
I cani (Canis lupus familiaris) rappresentano una ricca opportunità per studiare la rappresentazione degli stimoli visivi in una specie evolutivamente distante dai primati, in quanto potrebbero essere l'unico animale che può essere addestrato a partecipare in modo cooperativo alla risonanza magnetica senza la necessità di sedazione o costrizione 6,7,8. A causa della loro co-evoluzione con gli esseri umani negli ultimi 15.000 anni, anche i cani abitano i nostri ambienti e sono esposti a molti degli stimoli che gli esseri umani incontrano quotidianamente, compresi gli schermi video, che sono il modo preferito per presentare gli stimoli in uno scanner MRI. Anche così, i cani possono elaborare questi stimoli ambientali comuni in modi molto diversi dagli esseri umani, il che pone la domanda su come è organizzata la loro corteccia visiva. Le differenze di base, come la mancanza di una fovea o l'essere un dicromatico, possono avere conseguenze significative a valle non solo per la percezione visiva di livello inferiore, ma anche per la rappresentazione visiva di livello superiore. Diversi studi di fMRI nei cani hanno dimostrato l'esistenza di regioni di elaborazione del viso e degli oggetti che sembrano seguire l'architettura generale del flusso dorsale/ventrale osservata nei primati, sebbene non sia chiaro se i cani abbiano regioni di elaborazione del volto di per sé o se queste regioni siano selettive per la morfologia della testa (ad esempio, cane vs. umano)9, 10,11,12,13. Indipendentemente da ciò, si prevede che il cervello di un cane, essendo più piccolo della maggior parte dei primati, sia menomodulare, quindi potrebbe esserci una maggiore mescolanza di tipi di informazioni nei flussi o addirittura un privilegio di certi tipi di informazioni, come le azioni. È stato suggerito, ad esempio, che il movimento potrebbe essere una caratteristica più saliente nella percezione visiva canina rispetto alla consistenza o al colore15. Inoltre, poiché i cani non hanno le mani, uno dei mezzi principali attraverso i quali interagiamo con il mondo, la loro elaborazione visiva, in particolare degli oggetti, può essere molto diversa da quella dei primati. In linea con ciò, abbiamo recentemente trovato prove che l'interazione con gli oggetti da parte della bocca rispetto alla zampa ha portato a una maggiore attivazione nelle regioni selettive dell'oggetto nel cervello del cane16.
Sebbene i cani possano essere abituati agli schermi video nel loro ambiente domestico, ciò non significa che siano abituati a guardare le immagini in un ambiente sperimentale allo stesso modo di un essere umano. L'uso di stimoli più naturalistici può aiutare a risolvere alcune di queste domande. Nell'ultimo decennio, gli algoritmi di apprendimento automatico hanno ottenuto un notevole successo nella decodifica di stimoli visivi naturalistici provenienti dall'attività cerebrale umana. I primi successi si sono concentrati sull'adattamento dei classici disegni bloccati per utilizzare l'attività cerebrale sia per classificare i tipi di stimoli che un individuo stava vedendo, sia per le reti cerebrali che codificavano queste rappresentazioni 17,18,19. Man mano che venivano sviluppati algoritmi più potenti, in particolare le reti neurali, è stato possibile decodificare stimoli più complessi, inclusi i video naturalistici20,21. Questi classificatori, che sono tipicamente addestrati sulle risposte neurali a questi video, generalizzano a nuovi stimoli, consentendo loro di identificare ciò che un particolare soggetto stava osservando al momento della risposta fMRI. Ad esempio, alcuni tipi di azioni nei film possono essere decodificati con precisione dal cervello umano, come saltare e girarsi, mentre altri (ad esempio, il trascinamento) non possono22. Allo stesso modo, sebbene molti tipi di oggetti possano essere decodificati dalle risposte fMRI, le categorie generali sembrano essere più difficili. La decodifica cerebrale non è limitata agli esseri umani, fornendo un potente strumento per capire come le informazioni sono organizzate nei cervelli di altre specie. Analoghi esperimenti di fMRI con primati non umani hanno trovato rappresentazioni distinte nel lobo temporale per le dimensioni dell'animazione e della faciness/corporeità, che sono parallele a quelle degli esseri umani23.
Come primo passo verso la comprensione delle rappresentazioni dei cani degli stimoli visivi naturalistici, la risonanza magnetica funzionale da sveglio è stata utilizzata in due cani domestici altamente esperti di risonanza magnetica per misurare le risposte corticali ai video appropriati per il cane. In questo studio, i video naturalistici sono stati utilizzati a causa della loro potenziale maggiore validità ecologica per un cane e per il loro successo dimostrato con le reti neurali che mappano il contenuto video al movimento del cane24. Nel corso di tre sessioni separate, sono stati ottenuti 90 minuti di dati fMRI dalle risposte di ciascun cane a 256 video clip unici. Per confronto, la stessa procedura è stata eseguita su due volontari umani. Quindi, utilizzando una rete neurale, abbiamo addestrato e testato i classificatori per discriminare "oggetti" (ad esempio, umano, cane, auto) o "azioni" (ad esempio, parlare, mangiare, annusare) utilizzando un numero variabile di classi. Gli obiettivi di questo studio erano duplici: 1) determinare se gli stimoli video naturalistici potessero essere decodificati dalla corteccia del cane; e 2) in tal caso, fornire un primo sguardo per capire se l'organizzazione era simile a quella degli esseri umani.
Protocollo
Lo studio sui cani è stato approvato dalla Emory University IACUC (PROTO201700572) e tutti i proprietari hanno dato il consenso scritto per la partecipazione del loro cane allo studio. Le procedure dello studio sull'uomo sono state approvate dall'IRB della Emory University e tutti i partecipanti hanno fornito il consenso scritto prima della scansione (IRB00069592).
1. Partecipanti
- Selezionare i partecipanti (cani e umani) che non hanno avuto precedenti esposizioni agli stimoli presentati nello studio.
NOTA: I cani partecipanti erano due cani da compagnia locali offerti volontariamente dai loro proprietari per la partecipazione all'addestramento e alla scansione fMRI coerenti con quanto precedentemente descritto7. Bhubo era un Boxer-mix maschio di 4 anni e Daisy era una femmina di Boston terrier di 11 anni. Entrambi i cani avevano precedentemente partecipato a diversi studi fMRI (Bhubo: 8 studi, Daisy: 11 studi), alcuni dei quali prevedevano la visione di stimoli visivi proiettati su uno schermo mentre si trovavano nello scanner. Sono stati selezionati per la loro capacità dimostrata di rimanere nello scanner senza muoversi per lunghi periodi di tempo con il loro proprietario fuori dalla vista. Allo studio hanno partecipato anche due esseri umani (un maschio di 34 anni e una femmina di 25 anni). Né i cani né gli esseri umani sono stati precedentemente esposti agli stimoli mostrati in questo studio.
2. Stimoli
- Filma i video (1920 pixel x 1440 pixel, 60 fotogrammi al secondo [fps]) montati su un giunto cardanico stabilizzatore portatile.
NOTA: In questo studio, i video sono stati girati ad Atlanta, in Georgia, nel 2019.- Gira video naturalistici da una "vista a volo d'uomo", tenendo il gimbal all'incirca all'altezza del ginocchio. Progetta i video per catturare gli scenari quotidiani della vita di un cane.
NOTA: Questi includevano scene di camminare, nutrire, giocare, esseri umani che interagiscono (tra loro e con i cani), cani che interagiscono tra loro, veicoli in movimento e animali non cani (Figura 1A; Film supplementare 1). In alcune clip, i soggetti del video interagivano direttamente con la telecamera, ad esempio accarezzandola, annusandola o giocandoci, mentre in altre la telecamera veniva ignorata. Ulteriori filmati di cervi sono stati ottenuti da una trappola fotografica posizionata localmente (1920 pixel x 1080 pixel, 30 fps). - Modifica i video in 256 "scene" uniche di 7 secondi. Ogni scena raffigurava un singolo evento, come gli esseri umani che si abbracciavano, un cane che correva o un cervo che camminava. Assegna a ogni scena un numero univoco e un'etichetta in base al suo contenuto (vedi sotto).
- Gira video naturalistici da una "vista a volo d'uomo", tenendo il gimbal all'incirca all'altezza del ginocchio. Progetta i video per catturare gli scenari quotidiani della vita di un cane.
- Modifica le scene in cinque video compilation più grandi di circa 6 minuti ciascuno. Usa i video compilation piuttosto che un lungo film per presentare un'ampia varietà di stimoli in sequenza.
NOTA: Presentare un'ampia varietà di stimoli sarebbe difficile da ottenere se i video fossero catturati in una lunga "ripresa". Ciò è coerente con gli studi di decodifica fMRI nell'uomo20,22. Inoltre, la presentazione di compilation di brevi clip ha permesso di creare più facilmente un set di controllo su cui è stato possibile testare l'algoritmo addestrato (vedere la sezione 7, analisi, di seguito), in quanto era possibile tenere fuori le singole clip invece di un lungo filmato. Quattro video compilation avevano 51 scene uniche e uno ne aveva 52. Non c'erano interruzioni o schermi vuoti tra le scene. - Seleziona le scene in modo semi-casuale per assicurarti che ogni video contenga esempi di tutte le principali categorie di etichette: cani, esseri umani, veicoli, animali non umani e interazioni.
NOTA: Durante il processo di compilazione, tutte le scene sono state sottoposte a downsampling a 1920 pixel x 1080 pixel a 30 fps per corrispondere alla risoluzione del proiettore MRI.
3. Progettazione sperimentale
- Scansiona i partecipanti in uno scanner MRI 3T mentre guardi i video di compilazione proiettati su uno schermo montato sul retro del foro MRI.
- Riproduci i video senza audio.
- Per i cani, ottenere un posizionamento stabile della testa mediante un addestramento preliminare per posizionare la testa in un poggiamento su misura, modellato sulla mascella inferiore da metà muso a dietro la mandibola.
- Fissare la mentoniera a un ripiano di legno che si estende sulla bobina ma lascia spazio sufficiente per le zampe sottostanti, con il risultato che ogni cane assume una posizione di "sfinge" (Figura 1B). Non sono state utilizzate restrizioni. Per ulteriori informazioni sul protocollo di addestramento, vedere i precedenti studi sui cani fMRI da svegli7.
- Lascia che i soggetti partecipino a cinque corse per sessione, ognuna delle quali consiste in un video compilation guardato dall'inizio alla fine, presentato in ordine casuale. Per i cani, fare brevi pause tra ogni corsa. Consegna al cane ricompense in cibo durante queste pause.
- Lascia che ogni soggetto partecipi a tre sessioni nell'arco di 2 settimane. Ciò consente al soggetto di guardare ciascuno dei cinque video di compilazione unici tre volte, ottenendo un tempo di risonanza magnetica funzionale aggregato di 90 minuti per individuo.
4. Imaging
- Scansiona i partecipanti al cane seguendo un protocollo coerente con quello impiegato in precedenti studi fMRI su cani da sveglio 7,25.
- Ottenere le scansioni funzionali utilizzando una sequenza di imaging ecoplanare a scatto singolo per acquisire volumi di 22 fette sequenziali da 2,5 mm con un gap del 20% (TE = 28 ms, TR = 1.430 ms, angolo di ribaltamento = 70°, matrice 64 x 64, dimensione voxel nel piano 2,5 mm, FOV = 160 mm).
- Per i cani, orientare le fette dorsalmente al cervello con la direzione di codifica di fase da destra a sinistra, poiché i cani si siedono nella risonanza magnetica in una posizione "sfinge", con il collo in linea con il cervello. La codifica di fase da destra a sinistra evita artefatti avvolgenti dal collo alla parte anteriore della testa. Inoltre, il principale artefatto di suscettibilità nei cani da scansione proviene dal seno frontale, con conseguente distorsione del lobo frontale.
- Per l'uomo, ottenere fette assiali con codifica di fase in direzione antero-posteriore.
- Per consentire il confronto con le scansioni del cane (stesso TR/TE), utilizzare l'acquisizione di fette multibanda (CMRR, University of Minnesota) per gli esseri umani con un fattore di accelerazione multibanda di 2 (GRAPPA = 2, TE = 28 ms, TR = 1.430 ms, angolo di ribaltamento = 55°, matrice 88 x 88, voxel nel piano da 2,5 mm, quarantaquattro fette da 2,5 mm con un gap del 20%).
- Per i cani, acquisire anche un'immagine strutturale pesata in T2 dell'intero cervello per ciascun partecipante utilizzando una sequenza spin-echo turbo con voxel isotropi da 1,5 mm. Per i partecipanti umani, utilizzare una sequenza MPRAGE pesata in T1 con voxel isotropi da 1 mm.
NOTA: Nel corso di tre sessioni sono stati ottenuti circa 4.000 volumi funzionali per ciascun partecipante.
5. Etichette di stimolo
- Per addestrare un modello a classificare il contenuto presentato nei video, etichettare prima le scene. Per fare ciò, dividi le scene di 7 s che compongono ogni video compilation in clip di 1,4 s. Etichetta le clip brevi piuttosto che i singoli fotogrammi poiché ci sono elementi del video che non possono essere catturati dai fotogrammi fissi, alcuni dei quali possono essere particolarmente salienti per i cani e, quindi, utili nella decodifica, come il movimento.
NOTA: è stata scelta una lunghezza del clip di 1,4 s perché era abbastanza lunga per catturare questi elementi dinamici e corrispondeva strettamente al TR di 1,43 s, il che consente di eseguire la classificazione volume per volume. - Distribuisci in modo casuale queste clip da 1,4 s (n = 1.280) ai membri del laboratorio per etichettare manualmente ogni clip utilizzando un modulo di invio in stile casella di controllo pre-programmato.
NOTA: Sono state scelte 94 etichette per comprendere il maggior numero possibile di caratteristiche chiave dei video, inclusi soggetti (ad esempio, cane, umano, gatto), numero di soggetti (1, 2, 3+), oggetti (ad esempio, auto, bicicletta, giocattolo), azioni (ad esempio, mangiare, annusare, parlare), interazioni (ad esempio, umano-umano, uomo-cane) e ambientazione (interno, esterno), tra gli altri. Questo ha prodotto un vettore di etichetta a 94 dimensioni per ogni clip (Tabella supplementare 1). - Come controllo di coerenza, selezionare un sottoinsieme casuale per la rietichettatura da parte di un secondo membro del lab. In questo caso, le etichette sono risultate altamente coerenti tra gli individui (>95%). Per quelle etichette che non erano coerenti, consenti ai due membri del laboratorio di rivedere la clip in questione e raggiungere un consenso sull'etichetta.
- Per ogni esecuzione, utilizzare i file di registro con timestamp per determinare l'inizio dello stimolo video rispetto al primo volume di scansione.
- Per tenere conto del ritardo tra la presentazione dello stimolo e la risposta BOLD, convolgere le etichette con una doppia funzione di risposta emodinamica gamma (HRF) e interpolare al TR delle immagini funzionali (1.430 ms) utilizzando le funzioni Python numpy.convolve() e interp().
NOTA: Il risultato finale è stata una matrice di etichette convolute per il numero totale di volumi di scansione per ciascun partecipante (94 etichette x 3.932, 3.920, 3.939 e 3.925 volumi per Daisy, Bhubo, Human 1 e Human 2, rispettivamente). - Raggruppa queste etichette dove necessario per creare macroetichette per ulteriori analisi. Ad esempio, combina tutte le istanze di camminata (passeggiata con il cane, passeggiata umana, passeggiata con l'asino) per creare un'etichetta "camminata".
- Per rimuovere ulteriormente la ridondanza nel set di etichette, calcolare il fattore di inflazione della varianza (VIF) per ciascuna etichetta, escludendo le macroetichette, che sono ovviamente altamente correlate.
NOTA: VIF è una misura della multicollinearità nelle variabili predittive, calcolata facendo regredire ciascun predittore rispetto a ogni altro. VIF più alti indicano predittori più altamente correlati. Questo studio ha utilizzato una soglia VIF di 2, riducendo le 94 etichette a 52 etichette uniche, in gran parte non correlate (Tabella supplementare 1).
6. Pre-elaborazione fMRI
- La pre-elaborazione comporta la correzione del movimento, la censura e la normalizzazione utilizzando la suite AFNI (NIH) e le sue funzioni associate26,27. Utilizza una correzione del movimento del corpo rigido a due passaggi e sei parametri per allineare i volumi a un volume target rappresentativo della posizione media della testa del partecipante durante le corse.
- Eseguire la censura per rimuovere i volumi con uno spostamento superiore a 1 mm tra le scansioni, nonché quelli con intensità del segnale voxel anomala superiore allo 0,1%. Per entrambi i cani, oltre l'80% dei volumi è stato conservato dopo la censura e per gli esseri umani è stato conservato oltre il 90%.
- Per migliorare il rapporto segnale/rumore dei singoli voxel, eseguire un lieve livellamento spaziale utilizzando 3dmerge e un kernel gaussiano da 4 mm a metà larghezza massima.
- Per controllare l'effetto di caratteristiche visive di basso livello, come il movimento o la velocità, che possono differire a seconda dello stimolo, calcolare il flusso ottico tra fotogrammi consecutivi di clip video22,28. Calcola il flusso ottico utilizzando l'algoritmo Farneback in OpenCV dopo il downsampling a 10 fotogrammi al secondo29.
- Per stimare l'energia del movimento in ogni fotogramma, calcolare la somma dei quadrati del flusso ottico di ciascun pixel e prendere la radice quadrata del risultato, calcolando efficacemente il flusso ottico medio euclideo da un fotogramma al successivo 28,30. Questo genera corsi temporali di energia di movimento per ogni video compilation.
- Ricampionarli in modo che corrispondano alla risoluzione temporale dei dati fMRI, convoluti con una doppia funzione di risposta emodinamica gamma (HRF) come sopra e concatenati per allinearsi con la presentazione dello stimolo per ciascun soggetto.
- Utilizzare questo corso temporale, insieme ai parametri di movimento generati dalla correzione del movimento descritta sopra, come unici regressori a un modello lineare generale (GLM) stimato per ogni voxel con 3dDeconvolve di AFNI. Usare i residui di questo modello come input per l'algoritmo di Machine Learning descritto di seguito.
7. Analisi
- Decodificare quelle regioni del cervello che contribuiscono in modo significativo alla classificazione degli stimoli visivi, addestrando un modello per ogni singolo partecipante che può poi essere utilizzato per classificare i contenuti video in base ai dati cerebrali dei partecipanti. Utilizzare l'algoritmo di apprendimento automatico Ivis, un metodo non lineare basato su reti neurali siamesi (SNN) che ha dimostrato successo su dati biologici ad alta dimensione31.
NOTA: Le SNN contengono due sottoreti identiche che vengono utilizzate per apprendere la somiglianza degli input in modalità supervisionata o non supervisionata. Sebbene le reti neurali siano cresciute in popolarità per la decodifica cerebrale a causa della loro potenza generalmente maggiore rispetto ai metodi lineari come le macchine a vettori di supporto (SVM), abbiamo utilizzato un SNN qui a causa della sua robustezza allo squilibrio di classe e della necessità di un minor numero di esemplari. Rispetto alle macchine a vettori di supporto (SVM) e ai classificatori di foreste casuali (RF) addestrati sugli stessi dati, abbiamo riscontrato che Ivis ha più successo nella classificazione dei dati cerebrali attraverso più combinazioni di etichette, come determinato da varie metriche, tra cui il punteggio F1 medio, la precisione, il richiamo e l'accuratezza del test (vedi sotto). - Per ogni partecipante, convertire i residui dell'intero cervello in un formato appropriato per l'input nella rete neurale Ivis. Concatena e maschera le cinque corse in ciascuna delle loro tre sessioni, conservando solo i voxel cerebrali.
- Appiattisci la dimensione spaziale, ottenendo una matrice bidimensionale di voxel dal tempo.
- Concatena le etichette convolute dei video mostrati in ogni corsa, in modo che corrispondano alle esecuzioni fMRI.
- Censura sia i dati fMRI che le etichette corrispondenti in base ai volumi contrassegnati nella pre-elaborazione.
- Selezionare le etichette di destinazione da decodificare, di seguito denominate "classi", e conservare solo i volumi che contengono queste classi. Per semplicità, considerare le classi come mutuamente esclusive e non includere volumi appartenenti a più classi per la decodifica, lasciando solo esemplari puri.
- Suddividere i dati in set di training e set di test. Usa una divisione di cinque volte, selezionando casualmente il 20% delle scene da utilizzare come set di prova.
NOTA: Ciò significava che, se una determinata scena veniva selezionata per il set di test, tutte le clip e i volumi funzionali ottenuti durante questa scena venivano tenuti fuori dal set di allenamento. Se la divisione fosse stata eseguita indipendentemente dalla scena, i volumi della stessa scena sarebbero apparsi sia nel set di training che nel set di test e il classificatore avrebbe dovuto solo abbinarli a quella particolare scena per essere riuscito a classificarli. Tuttavia, per classificare correttamente i volumi trattenuti dalle nuove scene, il classificatore doveva abbinarli a una classe più generale e indipendente dalla scena. Questo è stato un test più robusto della generalizzabilità del successo del classificatore rispetto alla sospensione di singole clip. - Bilancia il set di addestramento sottocampionando il numero di volumi in ogni classe in modo che corrisponda a quello della classe più piccola utilizzando il pacchetto scikit-learn imbalanced-learn.
- Per ogni partecipante, addestrare e testare l'algoritmo Ivis su 100 iterazioni, ogni volta utilizzando una divisione test-treno univoca (parametri Ivis: k = 5, modello = "maaten", n_epochs_without_progress = 30, supervision_weight = 1). Questi valori dei parametri sono stati in gran parte selezionati sulla base delle dimensioni e della complessità del set di dati, come raccomandato dagli autori dell'algoritmo nella sua documentazione32. Il "numero di epoche senza avanzamento" e il "peso di supervisione" (0 per non supervisionato, 1 per supervisionato) sono stati sottoposti a un'ulteriore messa a punto dei parametri per ottimizzare il modello.
- Per ridurre il numero di funzionalità utilizzate per addestrare il classificatore dall'intero cervello ai voxel più informativi, utilizzare un classificatore di foreste casuali (RFC) utilizzando scikit-learn per classificare ogni voxel in base all'importanza della funzionalità.
NOTA: Sebbene la RFC non abbia funzionato al di sopra del rischio da sola, è servita allo scopo utile di filtrare i voxel non informativi, che avrebbero contribuito solo al rumore dell'algoritmo Ivis. Questo è simile all'uso dei test F per la selezione delle funzionalità prima di passare al classificatore33. Solo il 5% dei voxel più alti del set di addestramento è stato utilizzato per l'addestramento e i test. Il numero preferito di voxel è stato selezionato come 5% come soglia conservativa nel tentativo di ridurre il numero di voxel non informativi prima dell'addestramento della rete neurale. Risultati qualitativamente simili sono stati ottenuti sia per l'uomo che per i cani quando si utilizza una percentuale maggiore di voxel. Sebbene i cervelli umani siano più grandi di quelli canini, i modelli umani hanno avuto successo anche quando addestrati su un numero assoluto di voxel uguale a quelli inclusi nei modelli canini, molto più piccolo del 5% dei voxel (~250 voxel; tutti i punteggi LRAP medi >99° percentile). Per coerenza, quindi, presentiamo i risultati utilizzando il 5% dei voxel più alti per entrambe le specie. - Normalizza la media del 5% dei voxel più informativi in tutte le 100 corse, trasformali nello spazio strutturale di ciascun partecipante e poi nello spazio dell'atlante di gruppo (atlanti: umani34 e cani35) e sommalo tra i partecipanti per ogni specie. Sovrapponi l'importanza delle funzioni sugli atlanti e colorali in base al punteggio di importanza utilizzando ITK-SNAP36.
Risultati
Le metriche più comuni per valutare le prestazioni del modello nelle analisi di Machine Learning includono precisione, accuratezza, richiamo e punteggio F1. L'accuratezza è la percentuale complessiva di previsioni del modello corrette, dati i dati veri. La precisione è la percentuale di previsioni positive del modello che sono effettivamente positive (ad esempio, il tasso di veri positivi), mentre il richiamo è la percentuale di veri positivi nei dati originali che il modello è in grado di prevedere con successo. Il punteggio F1 è la media ponderata della precisione e del richiamo e funge da misura alternativa dell'accuratezza che è più robusta per lo squilibrio di classe. Tuttavia, l'Ivis differisce da altri algoritmi di apprendimento automatico comunemente usati in quanto il suo output non è binario. Dato un particolare input di voxel cerebrali, ogni elemento di output rappresenta le probabilità corrispondenti a ciascuna delle classi. Il calcolo dell'accuratezza, della precisione, del richiamo e di F1 per questi output richiedeva la loro binarizzazione in un modo "chi vince prende tutto", in cui la classe con la probabilità più alta era considerata quella prevista per quel volume. Questo approccio ha eliminato informazioni importanti sulla classificazione di queste probabilità che erano rilevanti per valutare la qualità del modello. Pertanto, mentre abbiamo ancora calcolato queste metriche tradizionali, abbiamo utilizzato il punteggio LRAP (Label Ranking Average Precision) come metrica principale per calcolare l'accuratezza del modello sul set di test. Questa metrica misura essenzialmente in che misura il classificatore ha assegnato probabilità più elevate alle etichette vere37.
A diversi livelli, il classificatore di reti neurali ha avuto successo sia per gli esseri umani che per i cani. Per gli esseri umani, l'algoritmo è stato in grado di classificare sia gli oggetti che le azioni, con modelli a tre classi per entrambi che hanno raggiunto un'accuratezza media del 70%. Il punteggio LRAP è stato utilizzato come metrica primaria per calcolare l'accuratezza del modello sul set di test; Questa metrica misura la misura in cui il classificatore ha assegnato probabilità più elevate alle etichette vere37. Per entrambi gli esseri umani, i punteggi LRAP mediani erano superiori al 99° percentile di un insieme di etichette permutate in modo casuale per tutti i modelli testati (Tabella 1; Figura 2). Per i cani, solo il modello d'azione aveva un rango percentile LRAP mediano significativamente maggiore del caso in entrambi i partecipanti (Tabella 1; p = 0,13 per gli oggetti e p < 0,001 per le azioni; punteggio LRAP medio del modello di azione a tre classi per i cani = 78° percentile). Questi risultati erano veri per tutti i soggetti individualmente, così come quando raggruppati per specie.
Dato il successo del classificatore, è stato eseguito il training e il test con classi aggiuntive per determinare i limiti del modello. Ciò includeva il calcolo delle matrici di dissimilarità per tutte le 52 potenziali classi di interesse utilizzando l'algoritmo di clustering gerarchico del pacchetto Python scipy, che raggruppava le classi in base alla somiglianza della risposta cerebrale di un individuo a ciascuna, come definito dalla correlazione a coppie. Dei modelli aggiuntivi testati, il modello con il più alto percentile mediano di LRAP in entrambi i cani aveva cinque classi: l'originale "parlare", "mangiare" e "annusare", più due nuove classi, "accarezzare" e "giocare" (Figura 2). Questo modello aveva un rango percentile LRAP mediano significativamente maggiore di quello previsto casualmente per tutti i partecipanti (Tabella 1; p < 0,001 sia per i cani che per gli esseri umani; punteggio LRAP medio del modello di azione di cinque classi per i cani = 81° percentile).
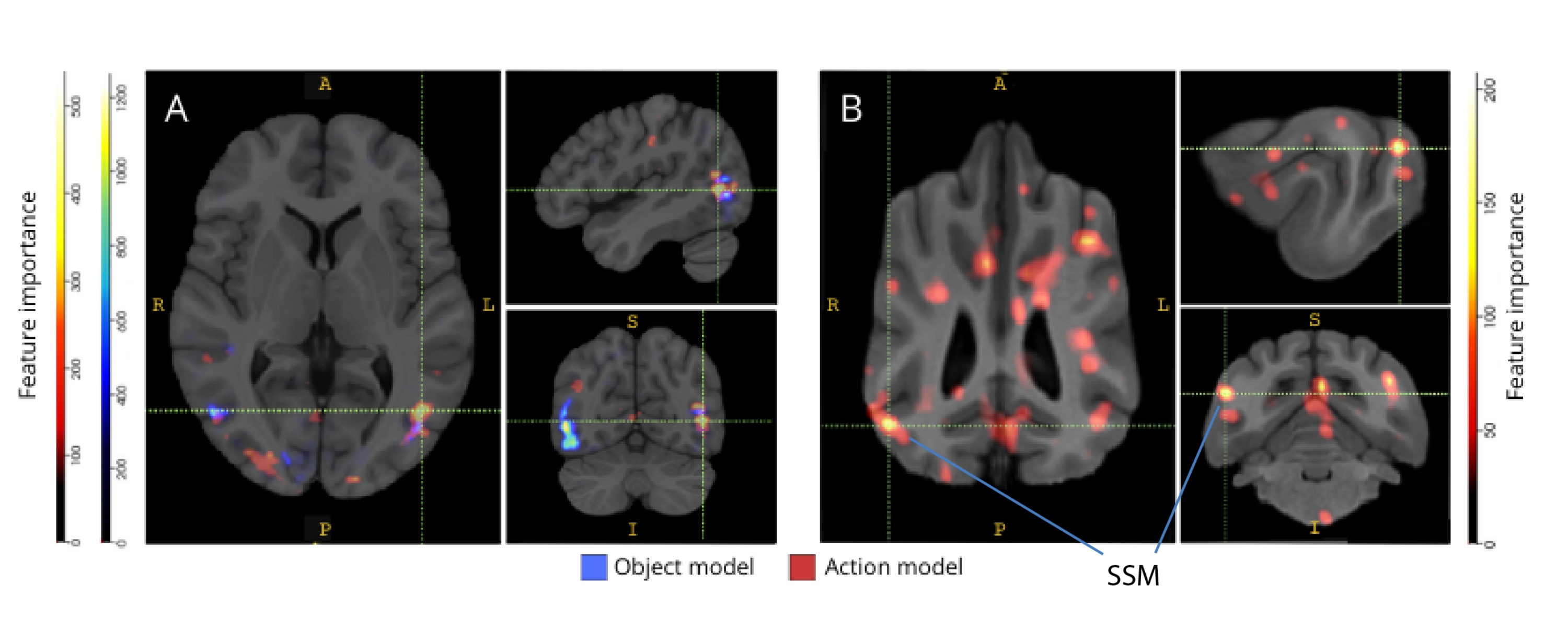
Quando sono stati rimappati nei rispettivi atlanti cerebrali, i punteggi di importanza delle caratteristiche dei voxel hanno rivelato una serie di gruppi di voxel informativi nelle cortecce occipitale, parietale e temporale sia dei cani che degli esseri umani (Figura 3). Negli esseri umani, i modelli basati sugli oggetti e sull'azione hanno rivelato un modello più focale rispetto ai cani e nelle regioni tipicamente associate al riconoscimento degli oggetti, sebbene con lievi differenze nella posizione spaziale dei voxel basati sugli oggetti e dei voxel basati sull'azione.
Abbiamo verificato che queste differenze di specie non erano il risultato del movimento correlato al compito dei cani che si muovevano più su alcuni tipi di video rispetto ad altri (ad esempio, video diversi dai cani, ad esempio, automobili). Abbiamo calcolato la norma euclidea dei sei parametri di movimento e adattato un modello lineare a effetti misti utilizzando il pacchetto R lme4, con la classe come effetto fisso e il numero di corsa come effetto casuale per ogni cane. Per ciascuno dei modelli finali, non abbiamo riscontrato alcun effetto significativo del tipo di classe sul movimento né per Daisy (F(2, 2252) = 0,83, p = 0,44 per basato su oggetti e F(4, 1235) = 1,87, p = 0,11 per basato su azione) o Bhubo (F(2, 2231) = 1,71, p = 0,18 per basato su oggetti e F(4, 1221) = 0,94, p = 0,45 per basato su azione).

Figura 1: Video naturalistici e presentazione in risonanza magnetica. (A) Esempi di fotogrammi da clip video mostrati ai partecipanti. (B) Bhubo, un Boxer-mix di 4 anni, guarda video mentre si sottopone a risonanza magnetica funzionale da sveglio. Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

Figura 2: Prestazioni del modello nei cani e nell'uomo. La distribuzione dei punteggi LRAP, presentati come classifiche percentili delle loro distribuzioni nulle, oltre 100 iterazioni di addestramento e test dell'algoritmo di apprendimento automatico Ivis per un modello basato su oggetti a tre classi, un modello basato sull'azione a tre classi e un modello basato sull'azione a cinque classi, in cui i modelli hanno tentato di classificare le risposte BOLD agli stimoli video naturalistici ottenuti tramite fMRI risvegliata nei cani e nell'uomo. I punteggi sono aggregati per specie. Un punteggio LRAP con un ranking percentile molto alto indica che è molto improbabile che il modello raggiunga quel punteggio LRAP per caso. Un modello che non si comporta meglio del caso avrebbe un punteggio LRAP mediano di ~50. Le linee tratteggiate rappresentano la classificazione percentile del punteggio LRAP mediano per ciascuna specie in tutte le 100 esecuzioni. Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}

Figura 3: Regioni importanti per la discriminazione dei modelli di azione a tre classi e a cinque classi. (A) Partecipanti umani e (B) cani. I voxel sono stati classificati in base all'importanza delle loro caratteristiche utilizzando un classificatore di foreste casuale, calcolato in media in tutte le iterazioni dei modelli. Il 5% dei voxel più alti (cioè quelli utilizzati per addestrare i modelli) sono presentati qui, aggregati per specie e trasformati in spazio di gruppo per scopi di visualizzazione (atlanti: esseri umani34 e cani35). Le etichette mostrano le regioni del cervello del cane con punteggi di importanza delle caratteristiche elevati, sulla base di quelli identificati da Johnson et al.35. Abbreviazione: SSM = il giro soprasilviano. Clicca qui per visualizzare una versione più grande di questa figura.
{kind=link}
| Tipo di modello | Precisione dell'allenamento | Accuratezza del test | Punteggio F1 | Precisione | Ricordare | Percentile mediano del punteggio LRAP | |
| Umano 1 | Oggetto (3 classi) | 0.98 | 0.69 | 0.48 | 0.52 | 0.49 | >99 |
| Azione (3 classi) | 0.98 | 0.72 | 0.51 | 0.54 | 0.54 | >99 | |
| Azione (5 classi) | 0.97 | 0.51 | 0.28 | 0.37 | 0.27 | >99 | |
| Umano 2 | Oggetto (3 classi) | 0.98 | 0.68 | 0.45 | 0.5 | 0.47 | >99 |
| Azione (3 classi) | 0.98 | 0.69 | 0.46 | 0.5 | 0.48 | >99 | |
| Azione (5 classi) | 0.97 | 0.53 | 0.3 | 0.4 | 0.27 | >99 | |
| Bhubo | Oggetto (3 classi) | 0.99 | 0.61 | 0.38 | 0.41 | 0.39 | 57 |
| Azione (3 classi) | 0.98 | 0.63 | 0.38 | 0.4 | 0.4 | 87 | |
| Azione (5 classi) | 0.99 | 0.45 | 0.16 | 0.29 | 0.13 | 88 | |
| Margherita | Oggetto (3 classi) | 1 | 0.61 | 0.38 | 0.43 | 0.39 | 43 |
| Azione (3 classi) | 0.97 | 0.62 | 0.35 | 0.38 | 0.35 | 60 | |
| Azione (5 classi) | 0.99 | 0.44 | 0.16 | 0.27 | 0.13 | 76 |
Tabella 1: Metriche aggregate dell'algoritmo di apprendimento automatico Ivis su 100 iterazioni di addestramento e test sulle risposte BOLD a stimoli video naturalistici ottenuti tramite fMRI da svegli in cani e esseri umani. I modelli a oggetti avevano tre classi target ("cane", "umano", "auto"), e i modelli d'azione avevano tre o cinque classi (tre classi: "parlare", "mangiare", "annusare"; cinque classi: "parlare", "mangiare", "annusare", "accarezzare", "giocare"). I valori significativamente maggiori della probabilità sono mostrati in grassetto.
Tabella supplementare 1: Etichette di classe. Clicca qui per scaricare questo file.
Filmato supplementare 1: Esempio di video clip. Clicca qui per scaricare questo file.
Discussione
I risultati di questo studio dimostrano che i video naturalistici inducono rappresentazioni nel cervello dei cani che sono abbastanza stabili da poter essere decodificate con la risonanza magnetica funzionale, in modo simile ai risultati ottenuti sia negli esseri umani che nelle scimmie 20,23. Mentre precedenti studi fMRI sul sistema visivo canino hanno presentato stimoli spogli, come un volto o un oggetto su uno sfondo neutro, i risultati dimostrano che i video naturalistici, con più persone e oggetti che interagiscono tra loro, inducono modelli di attivazione nella corteccia del cane che possono essere decodificati con un'affidabilità che si avvicina a quella osservata nella corteccia umana. Questo approccio apre nuove strade di indagine su come è organizzato il sistema visivo del cane.
Sebbene il campo della fMRI canina sia cresciuto rapidamente, fino ad oggi, questi esperimenti si sono basati su stimoli relativamente poveri, come immagini di persone o oggetti su sfondi neutri 10,12,13. Inoltre, mentre questi esperimenti hanno iniziato a identificare regioni cerebrali analoghe all'area fusiforme del viso dei primati (FFA), coinvolta nell'elaborazione del volto, e alla corteccia occipitale laterale (LOC), per l'elaborazione degli oggetti, rimane disaccordo sulla natura di queste rappresentazioni, ad esempio se i cani hanno aree del viso di per sé che rispondono a caratteristiche salienti simili a quelle dei primati o se hanno rappresentazioni separate per cani e umani o volti e teste. ad esempio 9,13. I cani, ovviamente, non sono primati, e non sappiamo come interpretino questi stimoli artificiali avulsi dai loro consueti contesti multisensoriali con suoni e odori. Alcune prove suggeriscono che i cani non trattano le immagini di oggetti come rappresentazioni di cose reali12. Sebbene non sia possibile creare una vera esperienza multisensoriale nello scanner, l'uso di video naturalistici può mitigare parte dell'artificialità fornendo stimoli dinamici che corrispondono più da vicino al mondo reale, almeno per un cane. Per le stesse ragioni, l'uso di stimoli naturalistici nella ricerca fMRI umana ha guadagnato popolarità, dimostrando, ad esempio, che le sequenze di eventi in un film sono rappresentate nella corteccia su più scale temporali e che i film sono efficaci nell'indurre un'attivazione emotiva affidabile38. Pertanto, mentre i video naturalistici rimangono stimoli relativamente poveri, il loro successo nelle neuroscienze umane pone la domanda se risultati simili possano essere ottenuti nei cani.
I nostri risultati mostrano che un classificatore di reti neurali è riuscito a decodificare alcuni tipi di contenuti naturalistici dal cervello dei cani. Questo successo è un'impresa impressionante data la complessità degli stimoli. È importante sottolineare che, poiché il classificatore è stato testato su clip video invisibili, il modello di decodifica ha raccolto ampie categorie identificabili tra le clip piuttosto che proprietà specifiche per le singole scene. Va notato che esistono più metriche per quantificare le prestazioni di un classificatore di machine learning (Tabella 1). Poiché i video naturalistici, per loro natura, non avranno occorrenze uguali di tutte le classi, abbiamo adottato un approccio prudente costruendo una distribuzione nulla dalla permutazione casuale delle etichette e valutando il significato a cui si fa riferimento. Quindi, abbiamo scoperto che il successo dei modelli di cani era statisticamente significativo, raggiungendo punteggi dal 75° al 90° percentile, ma solo quando i video erano codificati in base alle azioni presenti, come giocare o parlare.
I set di test, a differenza dei set di addestramento, non erano bilanciati tra le classi. Comprendendo solo il 20% dei dati, il sottocampionamento alla classe più piccola avrebbe comportato campioni di dimensioni molto piccole per ogni classe, in modo tale che qualsiasi statistica calcolata sarebbe stata inaffidabile. Per evitare la possibilità di un'accuratezza gonfiata da questo squilibrio, la distribuzione nulla dell'LRAP è stata calcolata permutando casualmente l'ordine delle classi 1.000 volte per ogni iterazione del modello. Questa distribuzione nulla fungeva da riferimento per le prestazioni probabili del modello per caso. Quindi, il vero LRAP è stato poi convertito in una classificazione percentile in questa distribuzione nulla. Un ranking percentile molto alto, ad esempio il 95%, indicherebbe che un punteggio così alto si è verificato solo il 5% delle volte in 1.000 permutazioni casuali. Si potrebbe quindi ritenere che un modello di questo tipo abbia prestazioni ben superiori al caso. Per determinare se queste classifiche percentili sono significativamente maggiori di quelle attese per caso, ovvero il 50° percentile, statisticamente, è stata calcolata la classificazione percentile LRAP mediana in tutte le 100 iterazioni per ciascun modello ed è stato eseguito un test di rango con segno Wilcoxon su un campione.
Sebbene l'obiettivo principale fosse quello di sviluppare un decodificatore di stimoli visivi naturalistici per i cani, i confronti con gli esseri umani sono inevitabili. Qui, notiamo due differenze principali: per ogni tipo di classificatore, i modelli umani hanno ottenuto risultati migliori rispetto ai modelli canini; e i modelli umani hanno ottenuto buoni risultati sia per i modelli basati su oggetti che per quelli basati sull'azione, mentre i modelli canini si sono comportati solo per quelli basati sull'azione. Le prestazioni superiori dei modelli umani potrebbero essere dovute a diversi fattori. I cervelli umani sono circa 10 volte più grandi di quelli dei cani, quindi ci sono più voxel da cui scegliere per costruire un classificatore. Per mettere i modelli sullo stesso piano, si dovrebbe usare lo stesso numero di voxel, ma questo potrebbe essere in senso assoluto o relativo. Sebbene il modello finale fosse basato sul 5% dei voxel informativi più alti in ciascun cervello (una misura relativa), risultati simili sono stati ottenuti utilizzando un numero fisso di voxel. Pertanto, sembra più probabile che le differenze di prestazioni siano correlate al modo in cui gli esseri umani e i cani percepiscono gli stimoli video. Come notato sopra, mentre i cani e gli esseri umani sono entrambi multisensoriali nella loro percezione, gli stimoli possono essere più poveri per un cane che per un essere umano. I segnali di dimensione, ad esempio, possono andare persi, con tutto ciò che sembra essere una versione giocattolo del mondo reale. Ci sono alcune prove che i cani classificano gli oggetti in base alle dimensioni e alla consistenza prima che alla forma, che è quasi l'opposto degli esseri umani39. Inoltre, l'odore, non considerato qui, è probabilmente un'importante fonte di informazioni per la discriminazione degli oggetti nei cani, in particolare nell'identificazione di conspecifici o esseri umani 40,41,42. Tuttavia, anche in assenza di dimensioni o segnali olfattivi, nell'ambiente insolito dello scanner MRI, il fatto che il classificatore funzionasse dice che c'erano ancora informazioni rilevanti per i cani che potevano essere recuperate dal loro cervello. Con solo due cani e due esseri umani, le differenze di specie potrebbero anche essere dovute a differenze individuali. I due cani, tuttavia, rappresentavano il meglio dei cani addestrati alla risonanza magnetica ed eccellevano nel rimanere fermi durante la visione dei video. Mentre una dimensione del campione più ampia consentirebbe certamente di tracciare distinzioni più affidabili tra le specie, il piccolo numero di cani che sono in grado di eseguire la risonanza magnetica funzionale da svegli e che guarderanno video per periodi abbastanza lunghi limiterà sempre la generalizzabilità a tutti i cani. Mentre è possibile che razze specializzate, come i levrieri, possano avere risposte cerebrali visive più finemente sintonizzate, crediamo che il temperamento e l'addestramento individuali siano più probabilmente i principali determinanti di ciò che è recuperabile dal cervello di un cane.
Queste differenze di specie sollevano la questione di quale aspetto dei video i cani stessero prestando attenzione. Un approccio per rispondere a questa domanda si basa su stimoli video più semplici. Quindi, utilizzando immagini isolate di, diciamo, esseri umani, cani e automobili, sia individualmente che insieme su sfondi neutri, potremmo essere in grado di decodificare le dimensioni salienti di un cane. Tuttavia, questo è metodologicamente inefficiente e impoverisce ulteriormente gli stimoli provenienti dal mondo reale. La questione dell'attenzione può essere risolta con il solo approccio della decodifica, in effetti, utilizzando le prestazioni del modello per determinare ciò di cui ci si sta occupando43. In questo senso, i risultati suggeriscono che, mentre gli esseri umani si occupavano sia degli attori che delle azioni, i cani erano più concentrati sulle azioni stesse. Ciò potrebbe essere dovuto a differenze nelle caratteristiche di movimento di basso livello, come la frequenza di movimento quando gli individui giocano rispetto a mangiare, o potrebbe essere dovuto a una rappresentazione categoriale di queste attività a un livello più alto. La distribuzione dei voxel informativi in tutta la corteccia del cane suggerisce che queste rappresentazioni non sono solo caratteristiche di basso livello che altrimenti sarebbero confinate alle regioni visive. Ulteriori studi che utilizzano una più ampia varietà di stimoli video possono illuminare il ruolo del movimento nella discriminazione di categoria da parte dei cani.
In sintesi, questo studio ha dimostrato la fattibilità del recupero di informazioni visive naturalistiche dalla corteccia del cane utilizzando la risonanza magnetica funzionale nello stesso modo in cui viene fatto per la corteccia umana. Questa dimostrazione mostra che, anche senza suoni o odori, le dimensioni salienti di scene complesse sono codificate dai cani che guardano video e che queste dimensioni possono essere recuperate dal loro cervello. In secondo luogo, in base al piccolo numero di cani che possono svolgere questo tipo di compito, le informazioni possono essere distribuite più ampiamente nella corteccia rispetto a quelle tipicamente osservate negli esseri umani e i tipi di azioni sembrano essere recuperati più facilmente rispetto all'identità degli attori o degli oggetti. Questi risultati aprono la strada a un nuovo modo di esaminare il modo in cui i cani percepiscono gli ambienti che condividono con gli esseri umani, compresi gli schermi video, e suggeriscono ricche strade per l'esplorazione futura di come loro e altri animali non primati "vedono" il mondo.
Divulgazioni
Nessuno.
Riconoscimenti
Ringraziamo Kate Revill, Raveena Chhibber e Jon King per le loro utili intuizioni nello sviluppo di questa analisi, Mark Spivak per la sua assistenza nel reclutamento e nell'addestramento dei cani per la risonanza magnetica e Phyllis Guo per il suo aiuto nella creazione e nell'etichettatura dei video. Ringraziamo anche i nostri devoti proprietari di cani, Rebecca Beasley (Daisy) e Ashwin Sakhardande (Bhubo). Gli studi sull'uomo sono stati sostenuti da una sovvenzione del National Eye Institute (Grant R01 EY029724 a D.D.D.).
Materiali
| Name | Company | Catalog Number | Comments |
| 3 T MRI Scanner | Siemens | Trio | |
| Audio recordings of scanner noise | homemade | none | |
| Camera gimbal | Hohem | iSteady PRO 3 | |
| Dog-appropriate videos | homemade | none | |
| fMRI processing software | AFNI | 20.3.01 | |
| Mock scanner components | homemade | none | Mock head coil and scanner tube |
| Neural net software | Ivis | 1.7.1 | |
| Optical flow software | OpenCV | 4.2.0.34 | |
| Projection system for scanner | homemade | none | |
| Trophy Cam HD | Bushnell | 119874 | |
| Video camera | GoPro | HERO7 | |
| Visualization software | ITK-SNAP | 3.6.0 | |
| Windows Video Editor | Microsoft | Windows 11 version |
Riferimenti
- Mishkin, M., Ungerleider, L. G., Macko, K. A. Object vision and spatial vision: Two cortical pathways. Trends in Neurosciences. 6, 414-417 (1983).
- de Haan, E. H. F., Cowey, A. On the usefulness of 'what' and 'where' pathways in vision. Trends in Cognitive Sciences. 15 (10), 460-466 (2011).
- Freud, E., Plaut, D. C., Behrmann, M. What' is happening in the dorsal visual pathway. Trends in Cognitive Sciences. 20 (10), 773-784 (2016).
- Goodale, M. A., Milner, A. D. Separate visual pathways for perception and action. Trends in Neurosciences. 15 (1), 20-25 (1992).
- Schenk, T., McIntosh, R. D. Do we have independent visual streams for perception and action? Do we have independent visual streams for perception and action. Cognitive Neuroscience. 1 (1), 52-78 (2010).
- Andics, A., Gácsi, M., Faragó, T., Kis, A., Miklós, &. #. 1. 9. 3. ;. Report voice-sensitive regions in the dog and human brain are revealed by comparative fMRI. Current Biology. 24 (5), 574-578 (2014).
- Berns, G. S., Brooks, A. M., Spivak, M. Functional MRI in awake unrestrained dogs. PLoS One. 7 (5), 38027 (2012).
- Karl, S., et al. Training pet dogs for eye-tracking and awake fMRI. Behaviour Research Methods. 52, 838-856 (2019).
- Bunford, N., et al. Comparative brain imaging reveals analogous and divergent patterns of species and face sensitivity in humans and dogs. Journal of Neuroscience. 40 (43), 8396-8408 (2020).
- Cuaya, L. V., Hernández-Pérez, R., Concha, L. Our faces in the dog's brain: Functional imaging reveals temporal cortex activation during perception of human faces. PLoS One. 11 (3), 0149431 (2016).
- Dilks, D. D., et al. Awake fMRI reveals a specialized region in dog temporal cortex for face processing. PeerJ. 2015 (8), 1115 (2015).
- Prichard, A., et al. 2D or not 2D? An fMRI study of how dogs visually process objects. Animal Cognition. 24 (5), 1143-1151 (2021).
- Thompkins, A. M., et al. Separate brain areas for processing human and dog faces as revealed by awake fMRI in dogs (Canis familiaris). Learning & Behavior. 46 (4), 561-573 (2018).
- Zhang, K., Sejnowski, T. J. A universal scaling law between gray matter and white matter of cerebral cortex. Proceedings of the National Academy of Sciences of the United States of America. 97 (10), 5621-5626 (2000).
- Bradshaw, J., Rooney, N., Serpell, J. Dog Social Behavior and Communication. The Domestic Dog: Its Evolution, Behavior and Interactions with People. , 133-160 (2017).
- Prichard, A., et al. The mouth matters most: A functional magnetic resonance imaging study of how dogs perceive inanimate objects. The Journal of Comparative Neurology. 529 (11), 2987-2994 (2021).
- Haxby, J. V., Connolly, A. C., Guntupalli, J. S. Decoding neural representational spaces using multivariate pattern analysis. Annual Review of Neuroscience. 37, 435-456 (2014).
- Kamitani, Y., Tong, F. Decoding the visual and subjective contents of the human brain. Nature Neuroscience. 8 (5), 679-685 (2005).
- Kay, K. N., Naselaris, T., Prenger, R. J., Gallant, J. L. Identifying natural images from human brain activity. Nature. 452 (7185), 352-355 (2008).
- Nishimoto, S., et al. Reconstructing visual experiences from brain activity evoked by natural movies. Current Biology. 21 (19), 1641-1646 (2011).
- vander Meer, J. N., Breakspear, M., Chang, L. J., Sonkusare, S., Cocchi, L. Movie viewing elicits rich and reliable brain state dynamics. Nature Communications. 11 (1), 5004 (2020).
- Huth, A. G., De Heer, W. A., Griffiths, T. L., Theunissen, F. E., Gallant, J. L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature. 532 (7600), 453-458 (2016).
- Kriegeskorte, N., et al. Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron. 60 (6), 1126-1141 (2008).
- Ehsani, K., Bagherinezhad, H., Redmon, J., Mottaghi, R., Farhadi, A. Who let the dogs out? Modeling dog behavior from visual data. Proceedings of the IEEE Conference on Computer Vision and Pattern. 2018, 4051-4060 (2018).
- Berns, G. S., Brooks, A., Spivak, M. Replicability and heterogeneity of awake unrestrained canine fMRI responses. PLoS One. 9 (5), 98421 (2013).
- Cox, R. W. AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research. 29 (3), 162-173 (1996).
- Prichard, A., Chhibber, R., Athanassiades, K., Spivak, M., Berns, G. S. Fast neural learning in dogs: A multimodal sensory fMRI study. Scientific Reports. 8, 14614 (2018).
- Russ, B. E., Kaneko, T., Saleem, K. S., Berman, R. A., Leopold, D. A. Distinct fMRI responses to self-induced versus stimulus motion during free viewing in the macaque. The Journal of Neuroscience. 36 (37), 9580-9589 (2016).
- Farnebäck, G., Bigun, J., Gustavsson, T. Two-Frame Motion Estimation Based on Polynomial Expansion. In Image Analysis. Scandinavian Conference on Image Analysis. Lecture Notes in Computer Science. 2749, 363-370 (2003).
- Elias, D. O., Land, B. R., Mason, A. C., Hoy, R. R. Measuring and quantifying dynamic visual signals in jumping spiders). Journal of Comparative Physiology A. 192, 799-800 (2006).
- Szubert, B., Cole, J. E., Monaco, C., Drozdov, I. Structure-preserving visualisation of high dimensional single-cell datasets. Scientific Reports. 9, 8914 (2019).
- Tian, H., Tao, P. IVIS dimensionality reduction framework for biomacromolecular simulations. Journal of Chemical Information and Modeling. 60 (10), 4569-4581 (2020).
- Hebart, M. N., Gorgen, K., Haynes, J. The decoding toolbox (TDT): A versatile software package for multivariate analyses of functional imaging data. Frontiers in Neuroinformatics. 8, 88 (2015).
- Mazziotta, J., et al. A probabilistic atlas and reference system for the human brain: International Consortium for Brain Mapping (ICBM). Philosophical Transactions of the Royal Society B: Biological Sciences. 356 (1412), 1293-1322 (2001).
- Johnson, P. J., et al. Stereotactic cortical atlas of the domestic canine brain. Scientific Reports. 10, 4781 (2020).
- Yushkevich, P. A., et al. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. NeuroImage. 31 (3), 1116-1128 (2006).
- Fürnkranz, J., Hüllermeier, E., Loza Mencía, E., Brinker, K. Multilabel classification via calibrated label ranking. Machine Learning. 73 (2), 133-153 (2008).
- Sonkusare, S., Breakspear, M., Guo, C. Naturalistic stimuli in neuroscience: Critically acclaimed. Trends in Cognitive Sciences. 23 (8), 699-714 (2019).
- vander Zee, E., Zulch, H., Mills, D. Word generalization by a dog (Canis familiaris): Is shape important. PLoS One. 7 (11), 49382 (2012).
- Bekoff, M. Observations of scent-marking and discriminating self from others by a domestic dog (Canis familiaris): Tales of displaced yellow snow. Behavioural Processes. 55 (2), 75-79 (2001).
- Berns, G. S., Brooks, A. M., Spivak, M. Scent of the familiar: An fMRI study of canine brain responses to familiar and unfamiliar human and dog odors. Behavioural Processes. 110, 37-46 (2015).
- Schoon, G. A. A., de Bruin, J. C. The ability of dogs to recognize and cross-match human odours. Forensic Science International. 69 (2), 111-118 (1994).
- Kamitani, Y., Tong, F. Decoding seen and attended motion directions from activity in the human visual cortex. Current Biology. 16 (11), 1096-1102 (2006).
Ristampe e Autorizzazioni
Richiedi autorizzazione per utilizzare il testo o le figure di questo articolo JoVE
Richiedi AutorizzazioneThis article has been published
Video Coming Soon
Personale delle biblioteche
Copyright © 2025 MyJoVE Corporation. Tutti i diritti riservati