
Method Article
A través de los ojos de un perro: decodificación de resonancia magnética funcional de videos naturalistas de la corteza del perro
En este artículo
Resumen
Los algoritmos de aprendizaje automático han sido entrenados para utilizar patrones de actividad cerebral para "decodificar" los estímulos que se presentan a los humanos. Aquí, demostramos que la misma técnica puede decodificar contenido de video naturalista del cerebro de dos perros domésticos. Encontramos que los decodificadores basados en las acciones de los videos tuvieron éxito en los perros.
Resumen
Los avances recientes que utilizan el aprendizaje automático y las imágenes de resonancia magnética funcional (fMRI) para decodificar estímulos visuales de la corteza humana y no humana han dado lugar a nuevos conocimientos sobre la naturaleza de la percepción. Sin embargo, este enfoque aún no se ha aplicado sustancialmente a otros animales que no sean primates, lo que plantea preguntas sobre la naturaleza de tales representaciones en todo el reino animal. Aquí, utilizamos resonancia magnética funcional despierta en dos perros domésticos y dos humanos, obtenida mientras cada uno miraba videos naturalistas especialmente creados para perros. A continuación, entrenamos una red neuronal (Ivis) para clasificar el contenido de vídeo a partir de un total de 90 minutos de actividad cerebral grabada de cada uno. Probamos un clasificador basado en objetos, que intenta discriminar categorías como perro, humano y coche, y un clasificador basado en acciones, que intenta discriminar categorías como comer, olfatear y hablar. En comparación con los dos sujetos humanos, para quienes ambos tipos de clasificadores funcionaron muy por encima del azar, solo los clasificadores basados en acciones tuvieron éxito en la decodificación del contenido de video de los perros. Estos resultados demuestran la primera aplicación conocida del aprendizaje automático para decodificar videos naturalistas del cerebro de un carnívoro y sugieren que la visión del mundo desde el punto de vista de un perro puede ser bastante diferente a la nuestra.
Introducción
Los cerebros de los humanos, al igual que otros primates, demuestran la parcelación de la corriente visual en vías dorsales y ventrales con funciones distintas y bien conocidas: el "qué" y el "dónde"de los objetos. Esta dicotomía qué/dónde ha sido una heurística útil durante décadas, pero ahora se sabe que su base anatómica es mucho más compleja, y muchos investigadores están a favor de una parcelación basada en el reconocimiento frente a la acción ("qué" frente a "cómo")2,3,4,5. Además, aunque nuestra comprensión de la organización del sistema visual de los primates sigue siendo refinada y debatida, aún se desconoce mucho sobre cómo los cerebros de otras especies de mamíferos representan la información visual. En parte, esta laguna es el resultado del enfoque histórico en un puñado de especies en la neurociencia visual. Sin embargo, los nuevos enfoques de las imágenes cerebrales están abriendo la posibilidad de estudiar de forma no invasiva los sistemas visuales de una gama más amplia de animales, lo que puede arrojar nuevos conocimientos sobre la organización del sistema nervioso de los mamíferos.
Los perros (Canis lupus familiaris) presentan una rica oportunidad para estudiar la representación de los estímulos visuales en una especie evolutivamente distante de los primates, ya que pueden ser el único animal que puede ser entrenado para participar cooperativamente en la resonancia magnética sin necesidad de sedación o restricciones 6,7,8. Debido a su coevolución con los humanos durante los últimos 15.000 años, los perros también habitan nuestros entornos y están expuestos a muchos de los estímulos que los humanos encuentran a diario, incluidas las pantallas de video, que son la forma preferida de presentar los estímulos en un escáner de resonancia magnética. Aun así, los perros pueden procesar estos estímulos ambientales comunes de maneras bastante diferentes a las de los humanos, lo que plantea la pregunta de cómo está organizada su corteza visual. Las diferencias básicas, como la falta de fóvea o el hecho de ser un dicromático, pueden tener consecuencias posteriores significativas no solo para la percepción visual de nivel inferior, sino también para la representación visual de nivel superior. Varios estudios de resonancia magnética funcional en perros han demostrado la existencia de regiones de procesamiento facial y de objetos que parecen seguir la arquitectura general de la corriente dorsal/ventral observada en los primates, aunque no está claro si los perros tienen regiones de procesamiento facial per se o si estas regiones son selectivas para la morfología de la cabeza (por ejemplo, perro vs. humano)9. 10,11,12,13. En cualquier caso, se predice que el cerebro de un perro, al ser más pequeño que el de la mayoría de los primates, sería menosmodular, por lo que puede haber una mayor mezcla de tipos de información en los flujos o incluso privilegiar ciertos tipos de información, como las acciones. Se ha sugerido, por ejemplo, que el movimiento podría ser una característica más sobresaliente en la percepción visual canina que la textura o el color15. Además, como los perros no tienen manos, uno de los principales medios a través de los cuales interactuamos con el mundo, su procesamiento visual, particularmente de los objetos, puede ser bastante diferente al de los primates. En línea con esto, recientemente encontramos evidencia de que la interacción con los objetos por la boca frente a la pata resultó en una mayor activación en las regiones selectivas de objetos en el cerebro del perro16.
Aunque los perros pueden estar acostumbrados a las pantallas de video en su entorno familiar, eso no significa que estén acostumbrados a mirar imágenes en un entorno experimental de la misma manera que lo haría un humano. El uso de estímulos más naturalistas puede ayudar a resolver algunas de estas cuestiones. En la última década, los algoritmos de aprendizaje automático han logrado un éxito considerable en la decodificación de estímulos visuales naturalistas de la actividad cerebral humana. Los primeros éxitos se centraron en la adaptación de diseños clásicos y bloqueados para utilizar la actividad cerebral tanto para clasificar los tipos de estímulos que un individuo estaba viendo, como las redes cerebrales que codificaban estas representaciones 17,18,19. A medida que se desarrollaron algoritmos más potentes, especialmente redes neuronales, se pudieron decodificar estímulos más complejos, incluidos los videos naturalistas20,21. Estos clasificadores, que generalmente se entrenan en las respuestas neuronales a estos videos, se generalizan a estímulos nuevos, lo que les permite identificar lo que un sujeto en particular estaba observando en el momento de la respuesta de fMRI. Por ejemplo, ciertos tipos de acciones en las películas se pueden decodificar con precisión desde el cerebro humano, como saltar y girar, mientras que otros (por ejemplo, arrastrar) nopueden. De manera similar, aunque muchos tipos de objetos se pueden decodificar a partir de las respuestas de fMRI, las categorías generales parecen ser más difíciles. La decodificación del cerebro no se limita a los humanos, ya que proporciona una poderosa herramienta para comprender cómo se organiza la información en los cerebros de otras especies. Experimentos análogos de resonancia magnética funcional con primates no humanos han encontrado representaciones distintas en el lóbulo temporal para las dimensiones de animacidad y faciness/corporeidad, que es paralela a la de los humanos23.
Como primer paso hacia la comprensión de las representaciones de los perros de los estímulos visuales naturalistas, se utilizó la resonancia magnética funcional despierta en dos perros domésticos muy hábiles en resonancia magnética para medir las respuestas corticales a los videos apropiados para perros. En este estudio, se utilizaron videos naturalistas debido a su validez ecológica potencialmente mayor para un perro y debido a su éxito demostrado con redes neuronales que mapean el contenido de video con el movimiento del perro24. Durante tres sesiones separadas, se obtuvieron 90 minutos de datos de resonancia magnética funcional de las respuestas de cada perro a 256 clips de video únicos. A modo de comparación, se realizó el mismo procedimiento en dos voluntarios humanos. Luego, usando una red neuronal, entrenamos y probamos clasificadores para discriminar "objetos" (por ejemplo, humano, perro, automóvil) o "acciones" (por ejemplo, hablar, comer, olfatear) utilizando un número variable de clases. Los objetivos de este estudio eran dos: 1) determinar si los estímulos de video naturalistas podían decodificarse a partir de la corteza del perro; y 2) si es así, proporcione un primer vistazo a si la organización era similar a la de los humanos.
Protocolo
El estudio con perros fue aprobado por la IACUC de la Universidad de Emory (PROTO201700572), y todos los propietarios dieron su consentimiento por escrito para la participación de su perro en el estudio. Los procedimientos de estudio en humanos fueron aprobados por el IRB de la Universidad de Emory, y todos los participantes dieron su consentimiento por escrito antes de la exploración (IRB00069592).
1. Participantes
- Seleccionar a los participantes (perros y humanos) sin exposición previa a los estímulos presentados en el estudio.
NOTA: Los perros participantes fueron dos perros domésticos locales ofrecidos voluntariamente por sus dueños para participar en el entrenamiento y escaneo de fMRI consistente con lo descrito anteriormente7. Bhubo era un macho de 4 años, y Daisy era una hembra de 11 años. Ambos perros habían participado previamente en varios estudios de resonancia magnética funcional (Bhubo: 8 estudios, Daisy: 11 estudios), algunos de los cuales implicaron ver estímulos visuales proyectados en una pantalla mientras estaban en el escáner. Fueron seleccionados debido a su capacidad demostrada para permanecer en el escáner sin moverse durante largos períodos de tiempo con su propietario fuera de la vista. Dos humanos (un hombre de 34 años y una mujer de 25 años) también participaron en el estudio. Ni los perros ni los humanos habían tenido una exposición previa a los estímulos mostrados en este estudio.
2. Estímulos
- Filme los videos (1920 píxeles x 1440 píxeles, 60 cuadros por segundo [fps]) montados en un cardán estabilizador de mano.
NOTA: En este estudio, los videos se filmaron en Atlanta, Georgia, en 2019.- Filme videos naturalistas desde una "vista de perro", sosteniendo el cardán aproximadamente a la altura de la rodilla. Diseña los videos para capturar escenarios cotidianos en la vida de un perro.
NOTA: Estas incluían escenas de caminar, alimentarse, jugar, humanos interactuando (entre sí y con perros), perros interactuando entre sí, vehículos en movimiento y animales que no eran perros (Figura 1A; Película complementaria 1). En algunos clips, los sujetos del video interactuaron directamente con la cámara, por ejemplo, acariciándola, olfateándola o jugando con ella, mientras que en otros, se ignoró la cámara. Se obtuvieron imágenes adicionales de ciervos de una cámara trampa colocada localmente (1920 píxeles x 1080 píxeles, 30 fps). - Edita los videos en 256 "escenas" únicas de 7 s. Cada escena representaba un solo evento, como humanos abrazándose, un perro corriendo o un ciervo caminando. Asigne a cada escena un número y una etiqueta únicos de acuerdo con su contenido (ver más abajo).
- Filme videos naturalistas desde una "vista de perro", sosteniendo el cardán aproximadamente a la altura de la rodilla. Diseña los videos para capturar escenarios cotidianos en la vida de un perro.
- Edite las escenas en cinco videos recopilatorios más grandes de aproximadamente 6 minutos cada uno. Utilice videos recopilatorios en lugar de una película larga para presentar una amplia variedad de estímulos en secuencia.
NOTA: Presentar una amplia variedad de estímulos sería difícil de lograr si los videos se capturaran en una sola "toma" larga. Esto es consistente con los estudios de decodificación de fMRI en humanos20,22. Además, la presentación de compilaciones de clips cortos facilitó la creación de un conjunto de retención en el que se pudo probar el algoritmo entrenado (véase la sección 7, análisis, a continuación), ya que fue posible sostener los clips individuales en lugar de una película larga. Cuatro videos recopilatorios tenían 51 escenas únicas y uno tenía 52. No hubo pausas ni pantallas en blanco entre las escenas. - Seleccione las escenas de forma semialeatoria para asegurarse de que cada vídeo contenga ejemplares de todas las categorías principales de la etiqueta: perros, humanos, vehículos, animales no humanos e interacciones.
NOTA: Durante el proceso de compilación, todas las escenas se redujeron a 1920 píxeles x 1080 píxeles a 30 fps para que coincidieran con la resolución del proyector de resonancia magnética.
3. Diseño experimental
- Escanee a los participantes en un escáner de resonancia magnética 3T mientras mira los videos de compilación proyectados en una pantalla montada en la parte posterior del orificio de resonancia magnética.
- Reproduce los videos sin sonido.
- En el caso de los perros, se debe lograr una posición estable de la cabeza mediante un entrenamiento previo para colocar la cabeza en un mentonero hecho a medida, moldeado a la mandíbula inferior desde la mitad del hocico hasta detrás de la mandíbula.
- Fije la mentonera a un estante de madera que se extienda por la bobina pero que permita suficiente espacio para las patas debajo, lo que hace que cada perro asuma una posición de "esfinge" (Figura 1B). No se utilizaron restricciones. Para obtener más información sobre el protocolo de adiestramiento, consulte los estudios previos de resonancia magnética funcional con perros despiertos7.
- Permita que los sujetos participen en cinco carreras por sesión, cada una de las cuales consiste en un video recopilatorio visto de principio a fin, presentado en un orden aleatorio. En el caso de los perros, tome descansos cortos entre cada carrera. Entregue recompensas de comida durante estos descansos al perro.
- Permita que cada sujeto participe en tres sesiones a lo largo de 2 semanas. Esto permite al sujeto ver cada uno de los cinco videos recopilatorios únicos tres veces, lo que produce un tiempo agregado de resonancia magnética funcional de 90 minutos por individuo.
4. Imágenes
- Escanear a los perros participantes siguiendo un protocolo consistente con el empleado en estudios previos de resonancia magnética funcional con perros despiertos 7,25.
- Obtenga los escaneos funcionales utilizando una secuencia de imágenes ecoplanas de una sola toma para adquirir volúmenes de 22 cortes secuenciales de 2,5 mm con un espacio del 20% (TE = 28 ms, TR = 1.430 ms, ángulo de giro = 70°, matriz de 64 x 64, tamaño de vóxel en el plano de 2,5 mm, FOV = 160 mm).
- En el caso de los perros, oriente las rodajas dorsalmente al cerebro con la dirección de codificación de fase de derecha a izquierda, mientras los perros se sientan en la resonancia magnética en una posición de "esfinge", con el cuello alineado con el cerebro. La codificación de fase de derecha a izquierda evita artefactos envolventes desde el cuello hasta la parte delantera de la cabeza. Además, el principal artefacto de susceptibilidad en los perros de escaneo proviene del seno frontal, lo que resulta en una distorsión del lóbulo frontal.
- En el caso de los humanos, se obtienen cortes axiales con codificación de fase en la dirección antero-posterior.
- Para permitir la comparación con los escaneos de perros (mismo TR/TE), utilice la adquisición de cortes multibanda (CMRR, Universidad de Minnesota) para los humanos con un factor de aceleración multibanda de 2 (GRAPPA = 2, TE = 28 ms, TR = 1.430 ms, ángulo de volteo = 55°, matriz de 88 x 88, vóxeles en el plano de 2,5 mm, cuarenta y cuatro cortes de 2,5 mm con un espacio del 20%).
- En el caso de los perros, también adquieran una imagen estructural ponderada en T2 de todo el cerebro de cada participante utilizando una secuencia turbo de espín-eco con vóxeles isótropos de 1,5 mm. Para los participantes humanos, utilice una secuencia MPRAGE ponderada en T1 con vóxeles isótropos de 1 mm.
NOTA: En el transcurso de tres sesiones, se obtuvieron aproximadamente 4.000 volúmenes funcionales para cada participante.
5. Etiquetas de estímulo
- Con el fin de entrenar un modelo para clasificar el contenido presentado en los vídeos, etiquete primero las escenas. Para ello, divide las 7 escenas s que componen cada vídeo recopilatorio en clips de 1,4 s. Etiquete clips cortos en lugar de fotogramas individuales, ya que hay elementos de vídeo que no pueden ser capturados por fotogramas fijos, algunos de los cuales pueden ser especialmente destacados para los perros y, por lo tanto, útiles para la decodificación, como el movimiento.
NOTA: Se eligió una longitud de clip de 1,4 s porque era lo suficientemente larga para capturar estos elementos dinámicos y coincidía estrechamente con el TR de 1,43 s, lo que permite realizar la clasificación volumen por volumen. - Distribuya aleatoriamente estos clips de 1,4 s (n = 1.280) a los miembros del laboratorio para etiquetar manualmente cada clip mediante un formulario de envío de estilo de casilla de verificación preprogramado.
NOTA: Se eligieron 94 etiquetas para abarcar tantas características clave de los videos como fuera posible, incluidos los sujetos (por ejemplo, perro, humano, gato), el número de sujetos (1, 2, 3+), los objetos (por ejemplo, automóvil, bicicleta, juguete), las acciones (por ejemplo, comer, olfatear, hablar), las interacciones (por ejemplo, humano-humano, humano-perro) y el entorno (interior, exterior), entre otros. Esto produjo un vector de etiqueta de 94 dimensiones para cada clip (Tabla Suplementaria 1). - Como comprobación de coherencia, seleccione un subconjunto aleatorio para que un segundo miembro del laboratorio vuelva a etiquetarlo. En este caso, se encontró que las etiquetas eran muy consistentes entre los individuos (>95%). Para aquellas etiquetas que no eran consistentes, permita que los dos miembros del laboratorio vuelvan a ver el clip en cuestión y lleguen a un consenso sobre la etiqueta.
- Para cada ejecución, utilice archivos de registro con marca de tiempo para determinar el inicio del estímulo de vídeo en relación con el volumen de la primera exploración.
- Para tener en cuenta el retraso entre la presentación del estímulo y la respuesta BOLD, convoluye las etiquetas con una función de respuesta hemodinámica gamma doble (HRF) e interpole al TR de las imágenes funcionales (1.430 ms) utilizando las funciones de Python numpy.convolve() e interp().
NOTA: El resultado final fue una matriz de etiquetas convolucionadas por el número total de volúmenes de escaneo para cada participante (94 etiquetas x 3.932, 3.920, 3.939 y 3.925 volúmenes para Daisy, Bhubo, Human 1 y Human 2, respectivamente). - Agrupe estas etiquetas donde sea necesario para crear macroetiquetas para su posterior análisis. Por ejemplo, combine todas las instancias de caminar (caminar con perros, caminar con humanos, caminar con burros) para crear una etiqueta de "caminar".
- Para eliminar aún más la redundancia en el conjunto de etiquetas, calcule el factor de inflación de la varianza (VIF) para cada etiqueta, excluyendo las macroetiquetas, que obviamente están altamente correlacionadas.
NOTA: VIF es una medida de multicolinealidad en variables predictoras, calculada mediante la regresión de cada predictor frente a todos los demás. Los VIF más altos indican predictores más altamente correlacionados. Este estudio empleó un umbral VIF de 2, reduciendo las 94 etiquetas a 52 etiquetas únicas, en gran parte no correlacionadas (Tabla suplementaria 1).
6. Preprocesamiento de fMRI
- El preprocesamiento implica la corrección de movimiento, la censura y la normalización utilizando la suite AFNI (NIH) y sus funciones asociadas26,27. Utilice una corrección de movimiento de cuerpo rígido de dos pasos y seis parámetros para alinear los volúmenes con un volumen objetivo que sea representativo de la posición media de la cabeza del participante a lo largo de las carreras.
- Realice la censura para eliminar volúmenes con un desplazamiento de más de 1 mm entre escaneos, así como aquellos con intensidades de señal de vóxeles atípicas superiores al 0,1%. Para ambos perros, más del 80% de los volúmenes se conservaron después de la censura, y para los humanos, se conservaron más del 90%.
- Para mejorar la relación señal-ruido de vóxeles individuales, realice un suavizado espacial leve utilizando 3dmerge y un kernel gaussiano de 4 mm a la mitad del máximo de ancho completo.
- Para controlar el efecto de las características visuales de bajo nivel, como el movimiento o la velocidad, que pueden diferir según el estímulo, calcule el flujo óptico entre fotogramas consecutivos de clips de vídeo22,28. Calcule el flujo óptico utilizando el algoritmo de Farneback en OpenCV después de reducir el muestreo a 10 fotogramas por segundo29.
- Para estimar la energía de movimiento en cada fotograma, calcule la suma de los cuadrados del flujo óptico de cada píxel y tome la raíz cuadrada del resultado, calculando efectivamente el flujo óptico promedio euclidiano de un fotograma a lossiguientes 28,30. Esto genera cursos de tiempo de energía de movimiento para cada video recopilatorio.
- Vuelva a muestrearlos para que coincidan con la resolución temporal de los datos de fMRI, convolucionados con una función de respuesta hemodinámica (HRF) gamma doble como se indicó anteriormente y concatenados para alinearse con la presentación del estímulo para cada sujeto.
- Utilice este curso de tiempo, junto con los parámetros de movimiento generados a partir de la corrección de movimiento descrita anteriormente, como los únicos regresores a un modelo lineal general (GLM) estimado para cada vóxel con 3dDeconvolve de AFNI. Utilice los valores residuales de este modelo como entradas para el algoritmo de aprendizaje automático que se describe a continuación.
7. Análisis
- Decodificar aquellas regiones del cerebro que contribuyen significativamente a la clasificación de los estímulos visuales, entrenando un modelo para cada participante individual que luego se puede usar para clasificar el contenido de video en función de los datos cerebrales de los participantes. Utilice el algoritmo de aprendizaje automático Ibis, un método no lineal basado en redes neuronales siamesas (SNN) que ha demostrado tener éxito en datos biológicos de alta dimensión31.
NOTA: Las SNN contienen dos subredes idénticas que se utilizan para aprender la similitud de las entradas en modo supervisado o no supervisado. Aunque las redes neuronales han crecido en popularidad para la decodificación del cerebro debido a su mayor potencia sobre los métodos lineales como las máquinas de vectores de soporte (SVM), usamos una SNN aquí debido a su robustez para el desequilibrio de clases y la necesidad de menos ejemplares. En comparación con las máquinas de vectores de soporte (SVM) y los clasificadores de bosque aleatorio (RF) entrenados con los mismos datos, descubrimos que Ivis tiene más éxito en la clasificación de datos cerebrales en múltiples combinaciones de etiquetas, según lo determinado por varias métricas, incluida la puntuación F1 media, la precisión, el recuerdo y la exactitud de las pruebas (ver más abajo). - Para cada participante, convierta los residuos de todo el cerebro a un formato apropiado para la entrada en la red neuronal de Ivis. Concatenar y enmascarar las cinco ejecuciones en cada una de sus tres sesiones, conservando solo los vóxeles cerebrales.
- Aplanar la dimensión espacial, lo que da como resultado una matriz bidimensional de vóxeles por tiempo.
- Concatene las etiquetas convolucionadas de los vídeos que se muestran en cada ejecución, correspondientes así a las ejecuciones de fMRI.
- Censurar tanto los datos de fMRI como las etiquetas correspondientes de acuerdo con los volúmenes marcados en el preprocesamiento.
- Seleccione las etiquetas de destino que se van a descodificar (en lo sucesivo denominadas "clases") y conserve solo los volúmenes que contengan estas clases. Para simplificar, trate las clases como mutuamente excluyentes y no incluya volúmenes que pertenezcan a varias clases para la descodificación, dejando solo ejemplos puros.
- Divida los datos en conjuntos de entrenamiento y prueba. Utilice una división quíntuple, seleccionando aleatoriamente el 20% de las escenas para que actúen como conjunto de prueba.
NOTA: Esto significaba que, si se seleccionaba una escena determinada para el conjunto de prueba, todos los clips y volúmenes funcionales obtenidos durante esta escena se mantenían fuera del conjunto de entrenamiento. Si la división se hubiera realizado independientemente de la escena, los volúmenes de la misma escena habrían aparecido tanto en el conjunto de entrenamiento como en el conjunto de prueba, y el clasificador solo habría tenido que hacerlos coincidir con esa escena en particular para tener éxito en la clasificación. Sin embargo, para clasificar correctamente los volúmenes retenidos de nuevas escenas, el clasificador tenía que hacerlos coincidir con una clase más general e independiente de la escena. Esta fue una prueba más sólida de la generalizabilidad del éxito del clasificador en comparación con la retención de clips individuales. - Equilibre el conjunto de entrenamiento submuestreando el número de volúmenes de cada clase para que coincida con el de la clase más pequeña mediante el paquete scikit-learn imbalanced-learn.
- Para cada participante, entrene y pruebe el algoritmo de Ivis en 100 iteraciones, cada vez utilizando una división única de tren de prueba (parámetros de Ivis: k = 5, model = "maaten", n_epochs_without_progress = 30, supervision_weight = 1). Estos valores de parámetros se seleccionaron en gran medida sobre la base del tamaño y la complejidad del conjunto de datos, según lo recomendado por los autores del algoritmo en su documentación32. El "número de épocas sin progreso" y el "peso de la supervisión" (0 para no supervisado, 1 para supervisado) se sometieron a un ajuste de parámetros adicional para optimizar el modelo.
- Para reducir el número de características que se usan para entrenar el clasificador desde todo el cerebro hasta solo los vóxeles más informativos, use un clasificador de bosque aleatorio (RFC) usando scikit-learn para clasificar cada vóxel de acuerdo con la importancia de su característica.
NOTA: Aunque el RFC no funcionó por sí solo, sirvió para el propósito útil de filtrar vóxeles no informativos, lo que habría contribuido solo con ruido al algoritmo Ivis. Esto es similar al uso de pruebas F para la selección de características antes de pasar al clasificador33. Solo el 5% superior de vóxeles del conjunto de entrenamiento se usó en el entrenamiento y las pruebas. El número preferido de vóxeles se seleccionó como 5% como umbral conservador en un esfuerzo por reducir el número de vóxeles no informativos antes de entrenar la red neuronal. También se obtuvieron resultados cualitativamente similares tanto para humanos como para perros cuando se utilizó una mayor proporción de vóxeles. Aunque los cerebros humanos son más grandes que los cerebros de los perros, los modelos humanos también tuvieron éxito cuando se entrenaron con un número absoluto de vóxeles igual a los incluidos en los modelos de perros, mucho menor que el 5% de los vóxeles (~ 250 vóxeles; todos los puntajes promedio de LRAP >percentil 99). Por lo tanto, para mantener la coherencia, presentamos los resultados utilizando el 5% superior de vóxeles para ambas especies. - Normalice el 5% promedio de vóxeles más informativos en las 100 carreras, transfórmelo al espacio estructural de cada participante y luego al espacio de atlas grupal (atlas: humanos34 yperros 35), y súmelo entre los participantes para cada especie. Superponga la importancia de las características en los atlas y coloréelos según la puntuación de importancia utilizando ITK-SNAP36.
Resultados
Las métricas más comunes para evaluar el rendimiento del modelo en los análisis de aprendizaje automático incluyen la precisión, la exactitud, la recuperación y la puntuación F1. La precisión es el porcentaje general de predicciones del modelo que son correctas, dados los datos verdaderos. La precisión es el porcentaje de las predicciones positivas del modelo que son realmente positivas (es decir, la tasa de verdaderos positivos), mientras que la recuperación es el porcentaje de verdaderos positivos en los datos originales que el modelo puede predecir con éxito. La puntuación F1 es el promedio ponderado de la precisión y la recuperación, y actúa como una medida alternativa de precisión que es más robusta para el desequilibrio de clase. Sin embargo, el Ivis difiere de otros algoritmos de aprendizaje automático comúnmente utilizados en que su salida no es binaria. Dada una entrada particular de vóxeles cerebrales, cada elemento de salida representa las probabilidades correspondientes a cada una de las clases. El cálculo de la exactitud, la precisión, el recuerdo y la F1 de estos resultados requirió binarizarlos de una manera en la que "el ganador se lo lleva todo", donde la clase con la probabilidad más alta se consideró la predicha para ese volumen. Este enfoque eliminó información importante sobre la clasificación de estas probabilidades que era relevante para evaluar la calidad del modelo. Por lo tanto, aunque seguimos calculando estas métricas tradicionales, utilizamos la puntuación de la precisión media de la clasificación de etiquetas (LRAP) como métrica principal para calcular la precisión del modelo en el conjunto de pruebas. Esta métrica mide esencialmente hasta qué punto el clasificador asignó mayores probabilidades a las etiquetas verdaderas37.
En diferentes grados, el clasificador de redes neuronales fue exitoso tanto para humanos como para perros. En el caso de los humanos, el algoritmo fue capaz de clasificar tanto objetos como acciones, con modelos de tres clases para ambos que lograron una precisión media del 70%. La puntuación LRAP se utilizó como métrica principal para calcular la precisión del modelo en el conjunto de pruebas; Esta métrica mide el grado en que el clasificador asignó mayores probabilidades a las etiquetas verdaderas37. Para ambos humanos, la mediana de las puntuaciones de LRAP fue mayor que el percentil 99 de un conjunto de etiquetas permutadas aleatoriamente para todos los modelos evaluados (Tabla 1; Figura 2). En el caso de los perros, solo el modelo de acción tuvo una mediana de rango percentil LRAP significativamente mayor que el azar en ambos participantes (Tabla 1; p = 0,13 para los objetos y p < 0,001 para las acciones; puntuación media del modelo de acción de tres clases LRAP para perros = percentil 78). Estos resultados fueron válidos para todos los sujetos individualmente, así como cuando se agruparon por especies.
Dado el éxito del clasificador, entrenamos y probamos con clases adicionales para determinar los límites del modelo. Esto incluyó el cálculo de matrices de disimilitud para las 52 clases potenciales de interés utilizando el algoritmo de agrupamiento jerárquico del paquete de Python, que agrupó las clases en función de la similitud de la respuesta cerebral de un individuo a cada una, según lo definido por la correlación por pares. De los modelos adicionales probados, el modelo con la clasificación percentil LRAP mediana más alta en ambos perros tenía cinco clases: el original "hablar", "comer" y "olfatear", además de dos nuevas clases, "acariciar" y "jugar" (Figura 2). Este modelo tuvo una mediana de rango percentil LRAP significativamente mayor que la predicha por casualidad para todos los participantes (Tabla 1; p < 0,001 tanto para perros como para humanos; Puntuación media del modelo de acción de cinco clases LRAP para perros = percentil 81).
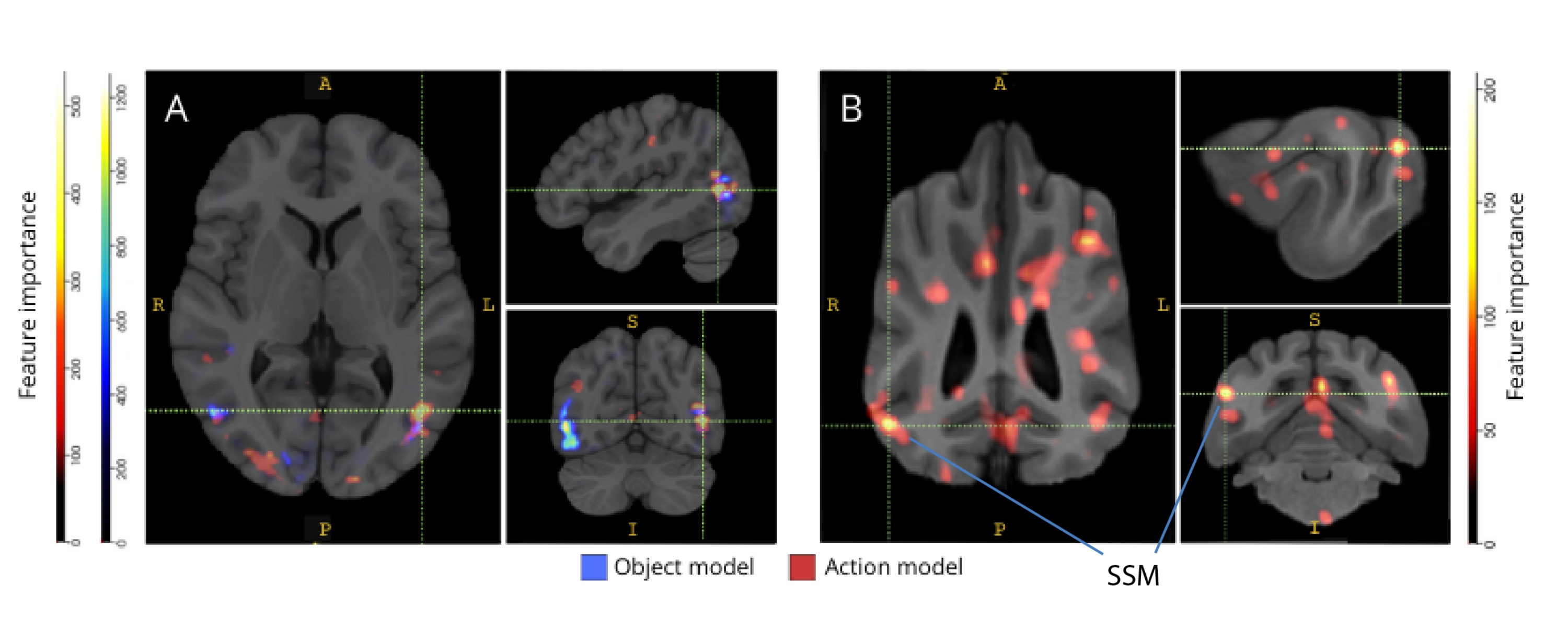
Cuando se mapearon hacia atrás en sus respectivos atlas cerebrales, las puntuaciones de importancia de las características de los vóxeles revelaron una serie de grupos de vóxeles informativos en las cortezas occipital, parietal y temporal tanto de perros como de humanos (Figura 3). En los humanos, los modelos basados en objetos y en acción revelaron un patrón más focal que en los perros y en las regiones típicamente asociadas con el reconocimiento de objetos, aunque con ligeras diferencias en la ubicación espacial de los vóxeles basados en objetos y los vóxeles basados en acción.
Verificamos que estas diferencias de especies no eran el resultado del movimiento correlacionado con la tarea de los perros, moviéndose más a algunos tipos de videos que a otros (por ejemplo, videos que no sean perros, por ejemplo, automóviles). Calculamos la norma euclidiana de los seis parámetros de movimiento y ajustamos un modelo lineal de efectos mixtos utilizando el paquete R lme4, con la clase como un efecto fijo y el número de carrera como un efecto aleatorio para cada perro. Para cada uno de los modelos finales, no encontramos ningún efecto significativo del tipo de clase sobre el movimiento para Daisy (F(2, 2252) = 0.83, p = 0.44 para el basado en objetos y F(4, 1235) = 1.87, p = 0.11 para el basado en acción) o Bhubo (F(2, 2231) = 1.71, p = 0.18 para el basado en objetos y F(4, 1221) = 0.94, p = 0.45 para el basado en acción).

Figura 1: Videos naturalistas y presentación en resonancia magnética. (A) Ejemplos de fotogramas de clips de video mostrados a los participantes. (B) Bhubo, un niño de 4 años, viendo videos mientras se somete a una resonancia magnética funcional despierto. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 2: Modelar el rendimiento en perros y humanos. La distribución de las puntuaciones LRAP, presentadas como clasificaciones de percentiles de sus distribuciones nulas, más de 100 iteraciones de entrenamiento y prueba del algoritmo de aprendizaje automático Ivis para un modelo basado en objetos de tres clases, un modelo basado en acciones de tres clases y un modelo basado en acciones de cinco clases, donde los modelos intentaron clasificar las respuestas BOLD a estímulos de video naturalistas obtenidos a través de resonancia magnética funcional despierta en perros y humanos. Las puntuaciones se agregan por especie. Una puntuación LRAP con una clasificación de percentil muy alta indica que sería muy poco probable que el modelo alcanzara esa puntuación LRAP por casualidad. Un modelo que no tenga un rendimiento mejor que el azar tendría una clasificación percentil mediana de la puntuación LRAP de ~50. Las líneas discontinuas representan la mediana de la clasificación percentil de la puntuación LRAP para cada especie en las 100 carreras. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}

Figura 3: Regiones importantes para la discriminación de los modelos de acción de tres clases de objetos y cinco clases de acción. (A) Participantes humanos y (B) perros. Los vóxeles se clasificaron según su importancia de características utilizando un clasificador de bosque aleatorio, promediado en todas las iteraciones de los modelos. Aquí se presenta el 5% superior de los vóxeles (es decir, los que se utilizan para entrenar modelos), agregados por especie y transformados en espacio de grupo con fines de visualización (atlas: humanos34 y perros35). Las etiquetas muestran regiones del cerebro del perro con puntuaciones de importancia de características altas, basadas en las identificadas por Johnson et al.35. Abreviatura: SSM = el giro suprasilvio. Haga clic aquí para ver una versión más grande de esta figura.
{kind=link}
| Tipo de modelo | Precisión del entrenamiento | Precisión de la prueba | Puntuación F1 | Precisión | Recordar | Percentil medio de la puntuación LRAP | |
| Humano 1 | Objeto (clase 3) | 0.98 | 0.69 | 0.48 | 0.52 | 0.49 | >99 |
| Acción (3 clases) | 0.98 | 0.72 | 0.51 | 0.54 | 0.54 | >99 | |
| Acción (5 clases) | 0.97 | 0.51 | 0.28 | 0.37 | 0.27 | >99 | |
| Humano 2 | Objeto (clase 3) | 0.98 | 0.68 | 0.45 | 0.5 | 0.47 | >99 |
| Acción (3 clases) | 0.98 | 0.69 | 0.46 | 0.5 | 0.48 | >99 | |
| Acción (5 clases) | 0.97 | 0.53 | 0.3 | 0.4 | 0.27 | >99 | |
| Bhubo | Objeto (clase 3) | 0.99 | 0.61 | 0.38 | 0.41 | 0.39 | 57 |
| Acción (3 clases) | 0.98 | 0.63 | 0.38 | 0.4 | 0.4 | 87 | |
| Acción (5 clases) | 0.99 | 0.45 | 0.16 | 0.29 | 0.13 | 88 | |
| Margarita | Objeto (clase 3) | 1 | 0.61 | 0.38 | 0.43 | 0.39 | 43 |
| Acción (3 clases) | 0.97 | 0.62 | 0.35 | 0.38 | 0.35 | 60 | |
| Acción (5 clases) | 0.99 | 0.44 | 0.16 | 0.27 | 0.13 | 76 |
Tabla 1: Métricas agregadas del algoritmo de aprendizaje automático Ivis a lo largo de 100 iteraciones de entrenamiento y pruebas sobre las respuestas BOLD a estímulos de video naturalistas obtenidos a través de fMRI despierto en perros y humanos. Los modelos de objetos tenían tres clases de objetivos ("perro", "humano", "coche"), y los modelos de acción tenían tres o cinco clases (tres clases: "hablar", "comer", "olfatear"; cinco clases: "hablar", "comer", "olfatear", "acariciar", "jugar"). Los valores significativamente mayores que el azar se muestran en negrita.
Tabla complementaria 1: Etiquetas de clase. Haga clic aquí para descargar este archivo.
Vídeo complementario 1: Clip de vídeo de muestra. Haga clic aquí para descargar este archivo.
Discusión
Los resultados de este estudio demuestran que los videos naturalistas inducen representaciones en el cerebro de los perros que son lo suficientemente estables durante múltiples sesiones de imágenes como para que puedan ser decodificados con fMRI, similar a los resultados obtenidos tanto en humanos como en monos20,23. Mientras que los estudios anteriores de resonancia magnética funcional del sistema visual canino han presentado estímulos reducidos, como una cara u objeto sobre un fondo neutro, los resultados aquí demuestran que los videos naturalistas, con múltiples personas y objetos interactuando entre sí, inducen patrones de activación en la corteza del perro que se pueden decodificar con una confiabilidad que se acerca a la observada en la corteza humana. Este enfoque abre nuevas vías de investigación sobre cómo se organiza el sistema visual del perro.
A pesar de que el campo de la resonancia magnética funcional canina ha crecido rápidamente, hasta la fecha, estos experimentos se han basado en estímulos relativamente pobres, como imágenes de personas u objetos sobre fondos neutros 10,12,13. Además, si bien estos experimentos han comenzado a identificar regiones cerebrales análogas al área de la cara fusiforme (FFA) de los primates, involucrada en el procesamiento de la cara, y la corteza occipital lateral (LOC), para el procesamiento de objetos, sigue habiendo desacuerdo sobre la naturaleza de estas representaciones, como si los perros tienen áreas de la cara per se que responden a características sobresalientes similares a las de los primates o si tienen representaciones separadas para perros y humanos o caras y cabezas. Por ejemplo, 9,13. Los perros, por supuesto, no son primates, y no sabemos cómo interpretan estos estímulos artificiales divorciados de sus contextos multisensoriales habituales con sonidos y olores. Algunas evidencias sugieren que los perros no tratan las imágenes de objetos como representaciones de cosas reales12. Aunque no es posible crear una verdadera experiencia multisensorial en el escáner, el uso de videos naturalistas puede mitigar parte de la artificialidad al proporcionar estímulos dinámicos que se acercan más al mundo real, al menos para un perro. Por las mismas razones, el uso de estímulos naturalistas en la investigación de la resonancia magnética funcional humana ha ganado popularidad, demostrando, por ejemplo, que las secuencias de eventos en una película están representadas en la corteza a través de múltiples escalas de tiempo y que las películas son efectivas para induciruna activación emocional confiable. Como tal, si bien los videos naturalistas siguen siendo estímulos relativamente pobres, su éxito en la neurociencia humana plantea la pregunta de si se pueden obtener resultados similares en perros.
Nuestros resultados muestran que un clasificador de redes neuronales tuvo éxito en decodificar algunos tipos de contenido naturalista de cerebros de perros. Este éxito es una hazaña impresionante dada la complejidad de los estímulos. Es importante destacar que, dado que el clasificador se probó en clips de vídeo no vistos, el modelo de decodificación seleccionó categorías amplias que eran identificables en los clips en lugar de las propiedades específicas de las escenas individuales. Debemos tener en cuenta que existen múltiples métricas para cuantificar el rendimiento de un clasificador de aprendizaje automático (Tabla 1). Como los videos naturalistas, por su naturaleza, no tendrán ocurrencias iguales de todas las clases, adoptamos un enfoque prudente al construir una distribución nula a partir de la permutación aleatoria de etiquetas y evaluar la importancia a la que se hace referencia. Luego, encontramos que el éxito de los modelos de perros fue estadísticamente significativo, logrando puntajes de percentil 75-90, pero solo cuando los videos se codificaron en función de las acciones presentes, como jugar o hablar.
Los conjuntos de prueba, a diferencia de los conjuntos de entrenamiento, no estaban equilibrados en todas las clases. Al comprender solo el 20% de los datos, el submuestreo al tamaño de clase más pequeño habría dado como resultado tamaños de muestra muy pequeños para cada clase, de modo que cualquier estadística calculada habría sido poco confiable. Para evitar la posibilidad de una precisión inflada por este desequilibrio, la distribución nula del LRAP se calculó permutando aleatoriamente el orden de las clases 1.000 veces para cada iteración del modelo. Esta distribución nula actuó como referencia para determinar el rendimiento del modelo por casualidad. A continuación, el LRAP verdadero se convirtió en una clasificación de percentiles en esta distribución nula. Una clasificación de percentil muy alta, por ejemplo, 95%, indicaría que una puntuación tan alta surgió solo el 5% de las veces en 1.000 permutaciones aleatorias. Por lo tanto, podría considerarse que un modelo de este tipo tiene un rendimiento muy superior al azar. Para determinar si estas clasificaciones de percentiles son significativamente mayores que las esperadas por el azar, es decir, el percentil 50, estadísticamente, se calculó la mediana de la clasificación de percentiles LRAP en las 100 iteraciones de cada modelo y se realizó una prueba de rango con signo de Wilcoxon de una muestra.
Aunque el objetivo principal era desarrollar un decodificador de estímulos visuales naturalistas para perros, las comparaciones con los humanos son inevitables. Aquí, observamos dos diferencias principales: para cada tipo de clasificador, los modelos humanos se desempeñaron mejor que los modelos de perros; Y los modelos humanos tuvieron un buen desempeño tanto para los modelos basados en objetos como para los modelos basados en acción, mientras que los modelos de perros solo funcionaron para los modelos basados en acción. El rendimiento superior de los modelos humanos podría deberse a varios factores. Los cerebros humanos son aproximadamente 10 veces más grandes que los cerebros de los perros, por lo que hay más vóxeles a partir de los cuales elegir construir un clasificador. Para poner los modelos en pie de igualdad, se debe usar el mismo número de vóxeles, pero esto puede ser en un sentido absoluto o relativo. Aunque el modelo final se basó en el 5% superior de vóxeles informativos en cada cerebro (una medida relativa), se obtuvieron resultados similares utilizando un número fijo de vóxeles. Por lo tanto, parece más probable que las diferencias de rendimiento estén relacionadas con la forma en que los humanos y los perros perciben los estímulos de video. Como se señaló anteriormente, mientras que los perros y los humanos son multisensoriales en su percepción, los estímulos pueden ser más pobres para un perro que para un humano. Las señales de tamaño, por ejemplo, pueden perderse, y todo parece ser una versión de juguete del mundo real. Existe cierta evidencia de que los perros categorizan los objetos en función del tamaño y la textura antes que la forma, lo cual es casi opuestoa los humanos. Además, el olfato, no considerado aquí, es probablemente una fuente importante de información para la discriminación de objetos en perros, particularmente en la identificación de congéneres o humanos 40,41,42. Sin embargo, incluso en ausencia de señales de tamaño o olor, en el entorno inusual del escáner de resonancia magnética, el hecho de que el clasificador funcionara dice que todavía había información relevante para los perros que podía recuperarse de sus cerebros. Con solo dos perros y dos humanos, las diferencias entre especies también podrían deberse a diferencias individuales. Los dos perros, sin embargo, representaron lo mejor de los perros entrenados por resonancia magnética y se destacaron por mantenerse quietos mientras miraban videos. Si bien un tamaño de muestra más grande ciertamente permitiría establecer distinciones más confiables entre especies, el pequeño número de perros que son capaces de hacer resonancia magnética funcional despiertos y que verán videos durante períodos lo suficientemente largos siempre limitará la generalización a todos los perros. Si bien es posible que las razas especializadas, como los lebreles, tengan respuestas cerebrales visuales más finas, creemos que es más probable que el temperamento y el entrenamiento individuales sean los principales determinantes de lo que se puede recuperar del cerebro de un perro.
Estas diferencias entre especies plantean la cuestión de a qué aspecto de los videos estaban prestando atención los perros. Un enfoque para responder a esta pregunta se basa en estímulos de video más simples. Luego, mediante el uso de imágenes aisladas de, por ejemplo, humanos, perros y automóviles, tanto individualmente como juntos sobre fondos neutros, podríamos ser capaces de aplicar ingeniería inversa a las dimensiones sobresalientes de un perro. Sin embargo, esto es metodológicamente ineficiente y empobrece aún más los estímulos del mundo real. La cuestión de la atención puede resolverse sólo mediante el enfoque de decodificación, en efecto, utilizando el modelo de rendimiento para determinar a qué se está prestando atención43. En esta línea, los resultados sugieren que, mientras los humanos atendían tanto a los actores como a las acciones, los perros estaban más centrados en las acciones en sí. Esto puede deberse a diferencias en las características de movimiento de bajo nivel, como la frecuencia de movimiento cuando los individuos juegan en lugar de comer, o puede deberse a una representación categórica de estas actividades a un nivel superior. La distribución de vóxeles informativos a lo largo de la corteza del perro sugiere que estas representaciones no son solo características de bajo nivel que de otro modo estarían confinadas a regiones visuales. Un estudio adicional utilizando una variedad más amplia de estímulos de video puede iluminar el papel del movimiento en la discriminación de categorías por parte de los perros.
En resumen, este estudio ha demostrado la viabilidad de recuperar información visual naturalista de la corteza del perro utilizando fMRI de la misma manera que se hace para la corteza humana. Esta demostración muestra que, incluso sin sonido ni olores, las dimensiones sobresalientes de escenas complejas son codificadas por los perros que ven videos y que estas dimensiones se pueden recuperar de sus cerebros. En segundo lugar, debido al pequeño número de perros que pueden realizar este tipo de tareas, la información puede estar más ampliamente distribuida en la corteza que en los humanos, y los tipos de acciones parecen ser más fáciles de recuperar que la identidad de los actores u objetos. Estos resultados abren una nueva forma de examinar cómo los perros perciben los entornos que comparten con los humanos, incluidas las pantallas de video, y sugieren vías ricas para la exploración futura de cómo ellos y otros animales no primates "ven" el mundo.
Divulgaciones
Ninguno.
Agradecimientos
Agradecemos a Kate Revill, Raveena Chhibber y Jon King por sus útiles ideas en el desarrollo de este análisis, a Mark Spivak por su ayuda en el reclutamiento y entrenamiento de perros para la resonancia magnética y a Phyllis Guo por su ayuda en la creación y el etiquetado de videos. También agradecemos a nuestros dedicados dueños de perros, Rebecca Beasley (Daisy) y Ashwin Sakhardande (Bhubo). Los estudios en humanos fueron apoyados por una subvención del Instituto Nacional del Ojo (Subvención R01 EY029724 al D.D.D.).
Materiales
| Name | Company | Catalog Number | Comments |
| 3 T MRI Scanner | Siemens | Trio | |
| Audio recordings of scanner noise | homemade | none | |
| Camera gimbal | Hohem | iSteady PRO 3 | |
| Dog-appropriate videos | homemade | none | |
| fMRI processing software | AFNI | 20.3.01 | |
| Mock scanner components | homemade | none | Mock head coil and scanner tube |
| Neural net software | Ivis | 1.7.1 | |
| Optical flow software | OpenCV | 4.2.0.34 | |
| Projection system for scanner | homemade | none | |
| Trophy Cam HD | Bushnell | 119874 | |
| Video camera | GoPro | HERO7 | |
| Visualization software | ITK-SNAP | 3.6.0 | |
| Windows Video Editor | Microsoft | Windows 11 version |
Referencias
- Mishkin, M., Ungerleider, L. G., Macko, K. A. Object vision and spatial vision: Two cortical pathways. Trends in Neurosciences. 6, 414-417 (1983).
- de Haan, E. H. F., Cowey, A. On the usefulness of 'what' and 'where' pathways in vision. Trends in Cognitive Sciences. 15 (10), 460-466 (2011).
- Freud, E., Plaut, D. C., Behrmann, M. What' is happening in the dorsal visual pathway. Trends in Cognitive Sciences. 20 (10), 773-784 (2016).
- Goodale, M. A., Milner, A. D. Separate visual pathways for perception and action. Trends in Neurosciences. 15 (1), 20-25 (1992).
- Schenk, T., McIntosh, R. D. Do we have independent visual streams for perception and action? Do we have independent visual streams for perception and action. Cognitive Neuroscience. 1 (1), 52-78 (2010).
- Andics, A., Gácsi, M., Faragó, T., Kis, A., Miklós, &. #. 1. 9. 3. ;. Report voice-sensitive regions in the dog and human brain are revealed by comparative fMRI. Current Biology. 24 (5), 574-578 (2014).
- Berns, G. S., Brooks, A. M., Spivak, M. Functional MRI in awake unrestrained dogs. PLoS One. 7 (5), 38027 (2012).
- Karl, S., et al. Training pet dogs for eye-tracking and awake fMRI. Behaviour Research Methods. 52, 838-856 (2019).
- Bunford, N., et al. Comparative brain imaging reveals analogous and divergent patterns of species and face sensitivity in humans and dogs. Journal of Neuroscience. 40 (43), 8396-8408 (2020).
- Cuaya, L. V., Hernández-Pérez, R., Concha, L. Our faces in the dog's brain: Functional imaging reveals temporal cortex activation during perception of human faces. PLoS One. 11 (3), 0149431 (2016).
- Dilks, D. D., et al. Awake fMRI reveals a specialized region in dog temporal cortex for face processing. PeerJ. 2015 (8), 1115 (2015).
- Prichard, A., et al. 2D or not 2D? An fMRI study of how dogs visually process objects. Animal Cognition. 24 (5), 1143-1151 (2021).
- Thompkins, A. M., et al. Separate brain areas for processing human and dog faces as revealed by awake fMRI in dogs (Canis familiaris). Learning & Behavior. 46 (4), 561-573 (2018).
- Zhang, K., Sejnowski, T. J. A universal scaling law between gray matter and white matter of cerebral cortex. Proceedings of the National Academy of Sciences of the United States of America. 97 (10), 5621-5626 (2000).
- Bradshaw, J., Rooney, N., Serpell, J. Dog Social Behavior and Communication. The Domestic Dog: Its Evolution, Behavior and Interactions with People. , 133-160 (2017).
- Prichard, A., et al. The mouth matters most: A functional magnetic resonance imaging study of how dogs perceive inanimate objects. The Journal of Comparative Neurology. 529 (11), 2987-2994 (2021).
- Haxby, J. V., Connolly, A. C., Guntupalli, J. S. Decoding neural representational spaces using multivariate pattern analysis. Annual Review of Neuroscience. 37, 435-456 (2014).
- Kamitani, Y., Tong, F. Decoding the visual and subjective contents of the human brain. Nature Neuroscience. 8 (5), 679-685 (2005).
- Kay, K. N., Naselaris, T., Prenger, R. J., Gallant, J. L. Identifying natural images from human brain activity. Nature. 452 (7185), 352-355 (2008).
- Nishimoto, S., et al. Reconstructing visual experiences from brain activity evoked by natural movies. Current Biology. 21 (19), 1641-1646 (2011).
- vander Meer, J. N., Breakspear, M., Chang, L. J., Sonkusare, S., Cocchi, L. Movie viewing elicits rich and reliable brain state dynamics. Nature Communications. 11 (1), 5004 (2020).
- Huth, A. G., De Heer, W. A., Griffiths, T. L., Theunissen, F. E., Gallant, J. L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature. 532 (7600), 453-458 (2016).
- Kriegeskorte, N., et al. Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron. 60 (6), 1126-1141 (2008).
- Ehsani, K., Bagherinezhad, H., Redmon, J., Mottaghi, R., Farhadi, A. Who let the dogs out? Modeling dog behavior from visual data. Proceedings of the IEEE Conference on Computer Vision and Pattern. 2018, 4051-4060 (2018).
- Berns, G. S., Brooks, A., Spivak, M. Replicability and heterogeneity of awake unrestrained canine fMRI responses. PLoS One. 9 (5), 98421 (2013).
- Cox, R. W. AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research. 29 (3), 162-173 (1996).
- Prichard, A., Chhibber, R., Athanassiades, K., Spivak, M., Berns, G. S. Fast neural learning in dogs: A multimodal sensory fMRI study. Scientific Reports. 8, 14614 (2018).
- Russ, B. E., Kaneko, T., Saleem, K. S., Berman, R. A., Leopold, D. A. Distinct fMRI responses to self-induced versus stimulus motion during free viewing in the macaque. The Journal of Neuroscience. 36 (37), 9580-9589 (2016).
- Farnebäck, G., Bigun, J., Gustavsson, T. Two-Frame Motion Estimation Based on Polynomial Expansion. In Image Analysis. Scandinavian Conference on Image Analysis. Lecture Notes in Computer Science. 2749, 363-370 (2003).
- Elias, D. O., Land, B. R., Mason, A. C., Hoy, R. R. Measuring and quantifying dynamic visual signals in jumping spiders). Journal of Comparative Physiology A. 192, 799-800 (2006).
- Szubert, B., Cole, J. E., Monaco, C., Drozdov, I. Structure-preserving visualisation of high dimensional single-cell datasets. Scientific Reports. 9, 8914 (2019).
- Tian, H., Tao, P. IVIS dimensionality reduction framework for biomacromolecular simulations. Journal of Chemical Information and Modeling. 60 (10), 4569-4581 (2020).
- Hebart, M. N., Gorgen, K., Haynes, J. The decoding toolbox (TDT): A versatile software package for multivariate analyses of functional imaging data. Frontiers in Neuroinformatics. 8, 88 (2015).
- Mazziotta, J., et al. A probabilistic atlas and reference system for the human brain: International Consortium for Brain Mapping (ICBM). Philosophical Transactions of the Royal Society B: Biological Sciences. 356 (1412), 1293-1322 (2001).
- Johnson, P. J., et al. Stereotactic cortical atlas of the domestic canine brain. Scientific Reports. 10, 4781 (2020).
- Yushkevich, P. A., et al. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. NeuroImage. 31 (3), 1116-1128 (2006).
- Fürnkranz, J., Hüllermeier, E., Loza Mencía, E., Brinker, K. Multilabel classification via calibrated label ranking. Machine Learning. 73 (2), 133-153 (2008).
- Sonkusare, S., Breakspear, M., Guo, C. Naturalistic stimuli in neuroscience: Critically acclaimed. Trends in Cognitive Sciences. 23 (8), 699-714 (2019).
- vander Zee, E., Zulch, H., Mills, D. Word generalization by a dog (Canis familiaris): Is shape important. PLoS One. 7 (11), 49382 (2012).
- Bekoff, M. Observations of scent-marking and discriminating self from others by a domestic dog (Canis familiaris): Tales of displaced yellow snow. Behavioural Processes. 55 (2), 75-79 (2001).
- Berns, G. S., Brooks, A. M., Spivak, M. Scent of the familiar: An fMRI study of canine brain responses to familiar and unfamiliar human and dog odors. Behavioural Processes. 110, 37-46 (2015).
- Schoon, G. A. A., de Bruin, J. C. The ability of dogs to recognize and cross-match human odours. Forensic Science International. 69 (2), 111-118 (1994).
- Kamitani, Y., Tong, F. Decoding seen and attended motion directions from activity in the human visual cortex. Current Biology. 16 (11), 1096-1102 (2006).
Reimpresiones y Permisos
Solicitar permiso para reutilizar el texto o las figuras de este JoVE artículos
Solicitar permisoThis article has been published
Video Coming Soon
ACERCA DE JoVE
Copyright © 2025 MyJoVE Corporation. Todos los derechos reservados