
Method Article
Глазами собаки: фМРТ-декодирование натуралистических видео из коры головного мозга собаки
В этой статье
Резюме
Алгоритмы машинного обучения были обучены использовать паттерны мозговой активности для «расшифровки» стимулов, представляемых людям. В этой статье мы демонстрируем, что тот же метод может декодировать натуралистический видеоконтент из мозга двух домашних собак. Мы обнаружили, что декодеры, основанные на действиях в видеороликах, были успешными у собак.
Аннотация
Недавние достижения в области машинного обучения и функциональной магнитно-резонансной томографии (фМРТ) для расшифровки визуальных стимулов из человеческой и нечеловеческой коры головного мозга привели к новому пониманию природы восприятия. Тем не менее, этот подход еще не был применен к животным, отличным от приматов, что поднимает вопросы о природе таких представлений в животном мире. Здесь мы использовали фМРТ в сознании двух домашних собак и двух людей, полученную во время просмотра специально созданных натуралистических видео для собак. Затем мы обучили нейронную сеть (Ivis) классифицировать видеоконтент на основе 90 минут записанной активности мозга с каждой из них. Мы протестировали как объектно-ориентированный классификатор, пытаясь различить такие категории, как собака, человек и автомобиль, так и классификатор, основанный на действиях, пытаясь различить такие категории, как еда, обнюхание и разговор. По сравнению с двумя людьми, для которых оба типа классификаторов показали себя намного лучше, чем случайно, только классификаторы, основанные на действиях, были успешны в расшифровке видеоконтента от собак. Эти результаты демонстрируют первое известное применение машинного обучения для декодирования натуралистических видео из мозга плотоядного животного и предполагают, что взгляд на мир с точки зрения собаки может сильно отличаться от нашего.
Введение
Мозг человека, как и у других приматов, демонстрирует парцелляцию зрительного потока на дорсальные и вентральные пути с четкими и хорошо известными функциями — «что» и «где» объектов. Эта дихотомия «что/где» была полезной эвристикой на протяжении десятилетий, но теперь известно, что ее анатомическая основа гораздо более сложна, и многие исследователи предпочитают парцелляцию, основанную на распознавании, а не на действии («что» против «как»)2,3,4,5. Кроме того, в то время как наше понимание организации зрительной системы приматов продолжает уточняться и обсуждаться, многое остается неизвестным о том, как мозг других видов млекопитающих представляет визуальную информацию. Отчасти этот пробел является результатом исторического внимания к горстке видов в визуальной нейробиологии. Новые подходы к визуализации мозга, однако, открывают возможность неинвазивного изучения зрительных систем более широкого круга животных, что может дать новое понимание организации нервной системы млекопитающих.
Собаки (Canis lupus familiaris) предоставляют прекрасную возможность для изучения репрезентации визуальных стимулов у видов, эволюционно далеких от приматов, поскольку они могут быть единственными животными, которых можно обучить совместному участию в МРТ-сканировании без необходимости введения седативных препаратов или ограничений 6,7,8. Благодаря своей совместной эволюции с человеком за последние 15 000 лет, собаки также населяют нашу окружающую среду и подвергаются воздействию многих стимулов, с которыми люди сталкиваются ежедневно, включая видеоэкраны, которые являются предпочтительным способом представления стимулов в МРТ-сканере. Тем не менее, собаки могут обрабатывать эти обычные стимулы окружающей среды способами, совершенно отличными от человеческих, что вызывает вопрос о том, как организована их зрительная кора. Основные различия, такие как отсутствие ямки или наличие дихромата, могут иметь значительные последствия не только для зрительного восприятия более низкого уровня, но и для визуальной репрезентации более высокого уровня. Несколько исследований фМРТ на собаках продемонстрировали существование областей обработки как лица, так и объекта, которые, по-видимому, следуют общей архитектуре дорсального/вентрального потока, наблюдаемой у приматов, хотя остается неясным, есть ли у собак области обработки лица как таковые, или эти области являются селективными по морфологии головы (например, собака против человека)9. 10,11,12,13. Как бы то ни было, мозг собаки, будучи меньше, чем у большинства приматов, должен быть менее модульным, поэтому в потоках может наблюдаться большее смешивание типов информации или даже привилегированное использование определенных типов информации, таких как действия. Например, было высказано предположение, что движение может быть более заметной чертой в зрительном восприятии собак, чем текстура или цвет. Кроме того, поскольку у собак нет рук, одного из основных средств, с помощью которых мы взаимодействуем с миром, их визуальная обработка, особенно объектов, может сильно отличаться от таковой у приматов. В соответствии с этим, мы недавно обнаружили доказательства того, что взаимодействие с объектами ртом, а не лапой, приводит к большей активации в объектно-селективныхобластях мозга собаки.
Хотя собаки могут привыкнуть к видеоэкранам в своей домашней обстановке, это не означает, что они привыкли смотреть на изображения в экспериментальных условиях так же, как это сделал бы человек. Использование более натуралистичных стимулов может помочь решить некоторые из этих вопросов. В последнее десятилетие алгоритмы машинного обучения достигли значительных успехов в расшифровке натуралистических визуальных стимулов из активности мозга человека. Ранние успехи были сосредоточены на адаптации классических, блокированных конструкций для использования активности мозга как для классификации типов стимулов, которые видит человек, так и для классификации мозговых сетей, которые кодируют этипредставления. По мере разработки более мощных алгоритмов, особенно нейронных сетей, можно было расшифровывать более сложные стимулы, в том числе натуралистические видео20,21. Эти классификаторы, которые обычно обучаются на нейронных реакциях на эти видео, обобщаются до новых стимулов, что позволяет им идентифицировать, что конкретный субъект наблюдал во время ответа на фМРТ. Например, некоторые виды действий в кино могут быть точно расшифрованы из человеческого мозга, такие как прыжки и повороты, в то время как другие (например, перетаскивание) не могутбыть расшифрованы. Аналогичным образом, хотя многие типы объектов могут быть расшифрованы по ответам фМРТ, общие категории представляются более сложными. Декодирование мозга не ограничивается людьми, предоставляя мощный инструмент для понимания того, как информация организована в мозге других видов. Аналогичные эксперименты с фМРТ с нечеловекообразными приматами обнаружили различные представления в височной доле для измерений одушевленности и лица/телесности, что соответствует таковому у человека23.
В качестве первого шага к пониманию представлений собак о натуралистических визуальных стимулах, фМРТ в сознании была использована у двух домашних собак, обладающих высоким уровнем МРТ, для измерения реакций коры головного мозга на видео, подходящие для собак. В этом исследовании использовались натуралистические видеоролики из-за их потенциально большей экологической значимости для собаки и из-за их продемонстрированного успеха с нейронными сетями, которые сопоставляют видеоконтент с движениями собаки. В течение трех отдельных сеансов было получено 90 минут данных фМРТ из ответов каждой собаки на 256 уникальных видеоклипов. Для сравнения, такая же процедура была проведена на двух добровольцах. Затем, используя нейронную сеть, мы обучили и протестировали классификаторы, чтобы различать либо «объекты» (например, человек, собака, автомобиль), либо «действия» (например, разговор, еда, обнюхивание) с использованием различного количества классов. Цели этого исследования были двояки: 1) определить, можно ли декодировать натуралистические видеостимулы из коры головного мозга собаки; и 2) если да, то сначала расскажите о том, была ли организация похожа на человеческую.
протокол
Исследование собак было одобрено IACUC Университета Эмори (PROTO201700572), и все владельцы дали письменное согласие на участие своей собаки в исследовании. Процедуры исследования на людях были одобрены IRB Университета Эмори, и все участники предоставили письменное согласие перед сканированием (IRB00069592).
1. Участники
- Выберите участников (собак и людей), которые ранее не сталкивались со стимулами, представленными в исследовании.
ПРИМЕЧАНИЕ: Собаками-участницами были две местные домашние собаки, добровольно предоставленные их владельцами для участия в обучении и сканировании фМРТ в соответствии с описанным ранее7. Бхубо был 4-летним кобелем помеси боксера, а Дейзи была 11-летней сукой помеси бостон-терьера. Обе собаки ранее участвовали в нескольких исследованиях фМРТ (Бхубо: 8 исследований, Дейзи: 11 исследований), некоторые из которых включали наблюдение за визуальными стимулами, проецируемыми на экран, находясь в сканере. Они были выбраны из-за продемонстрированной ими способности оставаться в сканере, не двигаясь в течение длительного периода времени, когда их владелец находится вне поля зрения. В исследовании также приняли участие два человека (мужчина, 34 года, и одна женщина, 25 лет). Ни собаки, ни люди ранее не сталкивались со стимулами, показанными в этом исследовании.
2. Стимулы
- Снимайте видео (1920 x 1440 пикселей, 60 кадров в секунду [fps]), установленные на ручном стабилизаторе.
ПРИМЕЧАНИЕ: В этом исследовании видео были сняты в Атланте, штат Джорджия, в 2019 году.- Снимайте натуралистические видео с «собачьего взгляда», держа стабилизатор примерно на уровне колена. Создавайте видеоролики так, чтобы запечатлеть повседневные сценарии из жизни собаки.
ПРИМЕЧАНИЕ: Они включали сцены ходьбы, кормления, игр, взаимодействия людей (друг с другом и с собаками), собак, взаимодействующих друг с другом, движущихся транспортных средств и животных, не являющихся собаками (Рисунок 1A; Дополнительный фильм 1). В некоторых клипах объекты на видео напрямую взаимодействовали с камерой, например, гладили, нюхали или играли с ней, в то время как в других камера игнорировалась. Дополнительные кадры с оленями были получены с локально размещенной фотоловушки (1920 пикселей x 1080 пикселей, 30 кадров в секунду). - Редактируйте видео в 256 уникальных «сцен» по 7 секунд. Каждая сцена изображала одно и то же событие, например, обнимающиеся люди, бегущую собаку или выгуливающегося оленя. Присвойте каждой сцене уникальный номер и метку в соответствии с ее содержанием (см. ниже).
- Снимайте натуралистические видео с «собачьего взгляда», держа стабилизатор примерно на уровне колена. Создавайте видеоролики так, чтобы запечатлеть повседневные сценарии из жизни собаки.
- Смонтируйте сцены в пять больших видеороликов-компиляций продолжительностью примерно 6 минут каждый. Используйте видеоподборки, а не один длинный фильм, чтобы последовательно представить широкий спектр стимулов.
ПРИМЕЧАНИЕ: Было бы трудно представить широкий спектр стимулов, если бы видео были сняты одним длинным «дублем». Это согласуется с исследованиями по расшифровке фМРТ у людей20,22. Кроме того, представление компиляций коротких клипов позволило упростить создание набора для удержания, на котором можно было протестировать обученный алгоритм (см. раздел 7, анализы, ниже), так как можно было удерживать отдельные клипы вместо одного длинного фильма. Четыре видео-компиляции содержали 51 уникальную сцену, а одно — 52. Между сценами не было перерывов или пустых экранов. - Выберите сцены полуслучайным образом, чтобы убедиться, что каждое видео содержит образцы из всех основных категорий лейбла — собаки, люди, транспортные средства, животные и взаимодействия.
ПРИМЕЧАНИЕ: В процессе компиляции дискретизация всех сцен была уменьшена до 1920 x 1080 пикселей со скоростью 30 кадров в секунду, чтобы соответствовать разрешению МРТ-проектора.
3. Экспериментальный дизайн
- Сканируйте участников с помощью 3Т-МРТ-сканера, просматривая видеоподборки, проецируемые на экран, установленный в задней части отверстия МРТ.
- Воспроизводите видео без звука.
- Для собак обеспечьте стабильное положение головы путем предварительного обучения, чтобы поместить голову в специально изготовленный подбородок, отлитый от нижней челюсти от середины морды до задней челюсти.
- Прикрепите подбородок к деревянной полке, которая охватывает катушку, но оставляет достаточно места для лап под ней, в результате чего каждая собака принимает положение «сфинкса» (Рисунок 1B). Никакие ограничения не использовались. Для получения дополнительной информации о протоколе дрессировки см. предыдущие исследования собак с фМРТ в бодрствующем состоянии7.
- Пусть испытуемые участвуют в пяти прогонах за сеанс, каждый из которых состоит из одного видео-компиляции, просмотренного от начала до конца, представленного в случайном порядке. Для собак делайте короткие перерывы между каждой пробежкой. Доставляйте собаке еду во время этих перерывов.
- Пусть каждый испытуемый примет участие в трех занятиях в течение 2 недель. Это позволяет испытуемому посмотреть каждое из пяти уникальных видео компиляции три раза, в результате чего совокупное время фМРТ составляет 90 минут на каждого человека.
4. Визуализация
- Сканируйте собак, участвующих в исследовании, в соответствии с протоколом, который использовался в предыдущих исследованиях фМРТ на собакахв сознании 7,25.
- Получение функциональных сканов с использованием однокадровой эхопланарной последовательности визуализации для получения объемов 22 последовательных срезов 2,5 мм с интервалом 20% (TE = 28 мс, TR = 1 430 мс, угол поворота = 70°, матрица 64 x 64, размер вокселя в плоскости 2,5 мм, поле зрения = 160 мм).
- У собак срезы ориентируются дорсально по отношению к мозгу с фазокодирующим направлением справа налево, поскольку собаки сидят на МРТ в позе «сфинкса», шея которого находится на одной линии с мозгом. Фазовое кодирование справа налево позволяет избежать огибающих артефактов от шеи до передней части головы. Кроме того, основной артефакт восприимчивости у сканирующих собак исходит из лобной пазухи, что приводит к деформации лобной доли.
- Для человека получают аксиальные срезы с фазовым кодированием в передне-заднем направлении.
- Для сравнения с сканированием собак (тот же TR/TE) используйте многополосный сбор срезов (CMRR, Университет Миннесоты) для людей с многополосным коэффициентом ускорения 2 (GRAPPA = 2, TE = 28 мс, TR = 1,430 мс, угол поворота = 55°, матрица 88 x 88, воксели 2,5 мм в плоскости, сорок четыре среза 2,5 мм с зазором 20%).
- Для собак также необходимо получить Т2-взвешенное структурное изображение всего мозга для каждого участника с помощью последовательности турбо-спин-эхо с изотропными вокселями 1,5 мм. Для участников из числа людей используйте Т1-взвешенную последовательность MPRAGE с изотропными вокселями 1 мм.
ПРИМЕЧАНИЕ: В ходе трех сессий было получено около 4 000 функциональных томов для каждого участника.
5. Метки стимулов
- Чтобы научить модель классифицировать контент, представленный в видео, сначала пометьте сцены. Для этого разделите сцены продолжительностью 7 секунд, из которых состоит каждое видео компиляции, на клипы продолжительностью 1,4 секунды. Маркируйте короткие клипы, а не отдельные кадры, так как существуют элементы видео, которые не могут быть запечатлены неподвижными кадрами, некоторые из них могут быть особенно заметными для собак и, следовательно, полезными при расшифровке, например, движение.
ПРИМЕЧАНИЕ: Длина клипа 1,4 с была выбрана, потому что этого было достаточно для захвата этих динамических элементов и близко соответствовало TR 1,43 с, что позволяет выполнять классификацию по объему. - Случайным образом распределите эти клипы продолжительностью 1,4 с (n = 1,280) среди участников лаборатории, чтобы вручную пометить каждый клип с помощью предварительно запрограммированной формы подачи в стиле флажка.
ПРИМЕЧАНИЕ: Было выбрано 94 метки, чтобы охватить как можно больше ключевых характеристик видео, включая темы (например, собака, человек, кошка), количество объектов (1, 2, 3+), объекты (например, автомобиль, велосипед, игрушка), действия (например, еда, обнюхивание, разговор), взаимодействия (например, человек-человек, человек-собака) и обстановка (в помещении, на улице), среди прочего. В результате для каждого клипа был получен 94-мерный вектор этикетки (Дополнительная таблица 1). - В качестве проверки согласованности выберите случайное подмножество для повторной маркировки вторым сотрудником лаборатории. Здесь было обнаружено, что метки очень последовательны у разных людей (>95%). Для тех меток, которые не были согласованы, позвольте двум членам лаборатории пересмотреть рассматриваемый клип и прийти к консенсусу по метке.
- Для каждого запуска используйте файлы журнала с отметками времени, чтобы определить начало видеостимула относительно первого объема сканирования.
- Чтобы учесть задержку между предъявлением стимула и реакцией BOLD, свёрните метки с помощью функции двойного гамма-гемодинамического отклика (HRF) и интерполируйте до TR функциональных изображений (1430 мс) с помощью функций Python numpy.convolve() и interp().
ПРИМЕЧАНИЕ: Конечным результатом стала матрица свертнутых меток по общему количеству томов сканирования для каждого участника (94 метки x 3 932, 3 920, 3 939 и 3 925 томов для Daisy, Bhubo, Human 1 и Human 2 соответственно). - Сгруппируйте эти метки там, где это необходимо, чтобы создать макрометки для дальнейшего анализа. Например, объедините все случаи выгула (выгул собаки, выгул человека, выгул осла), чтобы создать метку "прогулка".
- Чтобы еще больше устранить избыточность в наборе меток, рассчитайте коэффициент инфляции дисперсии (VIF) для каждой метки, исключая макрометки, которые, очевидно, сильно коррелированы.
ПРИМЕЧАНИЕ: VIF — это мера мультиколлинеарности в предикторных переменных, вычисляемая путем регрессии каждого предиктора относительно каждого другого. Более высокие VIF указывают на более высоко коррелированные предикторы. В этом исследовании использовался порог VIF, равный 2, сократив 94 метки до 52 уникальных, в значительной степени некоррелированных меток (дополнительная таблица 1).
6. Предварительная обработка фМРТ
- Предварительная обработка включает в себя коррекцию движения, цензуру и нормализацию с использованием пакета AFNI (NIH) и связанных с ним функций26,27. Используйте двухпроходную коррекцию движения твердого тела с шестью параметрами, чтобы выровнять объемы по целевому объему, который представляет среднее положение головы участника во время пробежек.
- Выполняйте цензурирование для удаления объемов с смещением более 1 мм между сканированиями, а также с интенсивностью сигнала вокселя более 0,1%. Для обеих собак более 80% объемов было сохранено после цензуры, а для человека — более 90%.
- Чтобы улучшить отношение сигнал/шум отдельных вокселей, выполните мягкое пространственное сглаживание с помощью 3dmerge и ядра Гаусса диаметром 4 мм на полной ширине полумаксимума.
- Чтобы контролировать влияние низкоуровневых визуальных особенностей, таких как движение или скорость, которые могут отличаться в зависимости от стимула, рассчитайте оптический поток между последовательными кадрами видеоклипов22,28. Рассчитать оптический поток с помощью алгоритма Фарнебека в OpenCV после даунсемплинга до 10 кадров в секунду29.
- Чтобы оценить энергию движения в каждом кадре, вычислите сумму квадратов оптического потока каждого пикселя и возьмите квадратный корень из полученного результата, эффективно вычислив евклидово среднее оптическое течение от одного кадра к следующему28,30. Это генерирует временные потоки энергии движения для каждого видео компиляции.
- Повторите их выборку, чтобы они соответствовали временному разрешению данных фМРТ, свернутые с функцией двойного гамма-гемодинамического ответа (ЧСС), как указано выше, и объединенные для согласования с предъявлением стимула для каждого субъекта.
- Используйте этот временной ход вместе с параметрами движения, сгенерированными в результате коррекции движения, описанной выше, в качестве единственных регрессоров для общей линейной модели (GLM), оцененных для каждого воксела с помощью 3dDeconvolve от AFNI. Используйте остатки этой модели в качестве входных данных для алгоритма машинного обучения, описанного ниже.
7. Анализы
- Декодируйте те области мозга, которые вносят значительный вклад в классификацию визуальных стимулов, обучая модели для каждого отдельного участника, которая затем может быть использована для классификации видеоконтента на основе данных о мозге участников. Используйте алгоритм машинного обучения Ivis, нелинейный метод, основанный на сиамских нейронных сетях (SNN), который показал успех на многомерных биологических данных31.
ПРИМЕЧАНИЕ: SNN содержат две идентичные подсети, которые используются для изучения сходства входных данных в контролируемом или неконтролируемом режимах. Несмотря на то, что популярность нейронных сетей для декодирования мозга возросла из-за их в целом большей мощности над линейными методами, такими как машины опорных векторов (SVM), мы использовали здесь SNN из-за ее устойчивости к дисбалансу классов и необходимости меньшего количества образцов. По сравнению с методами опорных векторов (SVM) и классификаторами случайного леса (RF), обученными на одних и тех же данных, мы обнаружили, что Ivis более успешно классифицирует данные мозга по нескольким комбинациям меток, что определяется различными метриками, включая средний балл F1, точность, полноту и точность тестов (см. ниже). - Для каждого участника преобразуйте остатки всего мозга в формат, подходящий для ввода в нейронную сеть Ivis. Объединяйте и маскируйте пять прогонов в каждом из трех сеансов, сохраняя только воксели мозга.
- Сгладьте пространственную размерность, в результате чего получится двумерная матрица вокселей по времени.
- Объедините свернутые метки видео, отображаемых в каждом прогоне, таким образом, в соответствии с прогонами фМРТ.
- Цензурируйте как данные фМРТ, так и соответствующие метки в соответствии с объемами, помеченными в предварительной обработке.
- Выберите целевые метки для декодирования (далее именуемые «классами») и сохраните только те тома, которые содержат эти классы. Для простоты относитесь к классам как к взаимоисключающим и не включайте в декодирование тома, принадлежащие нескольким классам, оставляя только чистые экземпляры.
- Разделите данные на обучающие и тестовые наборы. Используйте пятикратное разделение, случайным образом выбирая 20% сцен в качестве тестового набора.
ПРИМЕЧАНИЕ: Это означало, что если данная сцена была выбрана для тестового набора, то все клипы и функциональные объемы, полученные во время этой сцены, были исключены из обучающего набора. Если бы разбиение выполнялось независимо от сцены, объемы из одной и той же сцены появились бы как в обучающем, так и в тестовом наборе, и классификатору нужно было бы только сопоставить их с этой конкретной сценой, чтобы успешно классифицировать их. Однако, чтобы правильно классифицировать отложенные объемы из новых сцен, классификатор должен был сопоставить их с более общим, независимым от сцен классом. Это был более надежный тест на обобщаемость успеха классификатора по сравнению с удержанием отдельных клипов. - Сбалансируйте обучающий набор, уменьшив количество томов в каждом классе до уровня наименьшего класса с помощью пакета scikit-learndbalanced imbalanced.
- Для каждого участника обучить и протестировать алгоритм Ivis на 100 итерациях, каждый раз используя уникальное разделение тестового поезда (параметры Ivis: k = 5, model = "maaten", n_epochs_without_progress = 30, supervision_weight = 1). Эти значения параметров были в значительной степени выбраны на основе размера и сложности набора данных, как рекомендовано авторами алгоритма в его документации32. Дополнительные параметры "Количество эпох без прогресса" и "Вес супервизии" (0 для неконтролируемых, 1 для контролируемых) подверглись дополнительной настройке параметров для оптимизации модели.
- Чтобы сократить количество признаков, используемых для обучения классификатора всего мозга, до наиболее информативных вокселей, используйте классификатор случайного леса (RFC) с использованием scikit-learn для ранжирования каждого вокселя в соответствии с его важностью.
ПРИМЕЧАНИЕ: Несмотря на то, что RFC сам по себе не был более случайным, он служил полезной цели отсеивания неинформативных вокселей, которые внесли бы только шум в алгоритм Ivis. Это аналогично использованию F-тестов для выбора признаков перед переходом к классификатору33. В обучении и тестировании использовались только первые 5% вокселей из обучающей выборки. Предпочтительное количество вокселей было выбрано в качестве 5% в качестве консервативного порога с целью уменьшения количества неинформативных вокселей перед обучением нейронной сети. Качественно аналогичные результаты были получены и для человека, и для собак при использовании большей доли вокселей. Хотя человеческий мозг больше, чем мозг собаки, человеческие модели также были успешны при обучении на абсолютном числе вокселей, равном тому, которое включено в модели собак, намного меньше, чем 5% вокселей (~250 вокселей; все средние баллы LRAP >99-й процентиль). Поэтому для согласованности мы представляем результаты, используя верхние 5% вокселей для обоих видов. - Нормализуйте средние 5% наиболее информативных вокселей по всем 100 прогонам, преобразуйте в структурное пространство каждого участника, а затем в пространство атласа группы (атласы: люди34 и собаки35) и суммируйте их по участникам для каждого вида. Наложите важные элементы на атласы и раскрасьте их в соответствии с оценкой важности с помощью ITK-SNAP36.
Результаты
К наиболее распространенным метрикам для оценки производительности модели в анализе машинного обучения относятся точность, полнота и оценка F1. Точность — это общий процент правильных прогнозов модели с учетом истинных данных. Точность — это процент положительных прогнозов модели, которые на самом деле являются положительными (т. е. истинно положительный процент), в то время как полнота — это процент истинно положительных результатов в исходных данных, которые модель может успешно предсказать. Оценка F1 — это средневзвешенное значение точности и полноты, которое действует как альтернативная мера точности, более устойчивая к классовому дисбалансу. Тем не менее, Ivis отличается от других широко используемых алгоритмов машинного обучения тем, что его выходные данные не являются двоичными. При наличии определенного ввода вокселей мозга каждый выходной элемент представляет вероятности, соответствующие каждому из классов. Вычисление точности, прецизионности, полноты и F1 для этих выходов требовало бинаризации их по принципу «победитель получает все», где класс с наибольшей вероятностью считался предсказанным для этого объема. Такой подход исключил важную информацию о ранжировании этих вероятностей, которая имела отношение к оценке качества модели. Таким образом, хотя мы по-прежнему вычисляли эти традиционные метрики, мы использовали оценку средней точности ранжирования меток (LRAP) в качестве основной метрики для вычисления точности модели на тестовом наборе. Эта метрика по существу измеряет, в какой степени классификатор присвоил более высокие вероятности истинным меткам37.
В разной степени нейросетевой классификатор оказался успешным как для человека, так и для собак. Для людей алгоритм смог классифицировать как объекты, так и действия, при этом трехклассовые модели для обоих достигли средней точности 70%. Оценка LRAP использовалась в качестве основного показателя для вычисления точности модели на тестовом наборе; Этот показатель измеряет степень, в которой классификатор присвоил более высокие вероятности истинным меткам37. Для обоих людей медианные баллы LRAP были выше 99-го процентиля случайно переставленного набора меток для всех протестированных моделей (Таблица 1; Рисунок 2). Для собак только модель действия имела медианный процентильный ранг LRAP, значительно превышающий случайность у обоих участников (Таблица 1; p = 0,13 для объектов и p < 0,001 для действий; средний показатель LRAP по модели действия трех классов для собак = 78-й процентиль). Эти результаты были справедливы для всех испытуемых в отдельности, а также при группировке по видам.
Учитывая успешность классификатора, мы обучили и протестировали с помощью дополнительных классов, чтобы определить пределы модели. Это включало в себя вычисление матриц несходства для всех 52 потенциальных классов, представляющих интерес, с использованием алгоритма иерархической кластеризации пакета Python scipy, который кластеризовал классы на основе сходства реакции мозга индивидуума на каждый из них, определяемой парной корреляцией. Из дополнительных протестированных моделей модель с самым высоким медианным процентилем LRAP у обеих собак имела пять классов: исходные «говорящие», «еда» и «обнюхивающие», а также два новых класса: «ласкающая» и «играющая» (рис. 2). Эта модель имела медианный ранг процентиля LRAP значительно выше, чем тот, который был предсказан случайно для всех участников (Таблица 1; p < 0,001 как для собак, так и для человека; среднее значение модели действия пяти классов LRAP для собак = 81-й процентиль).
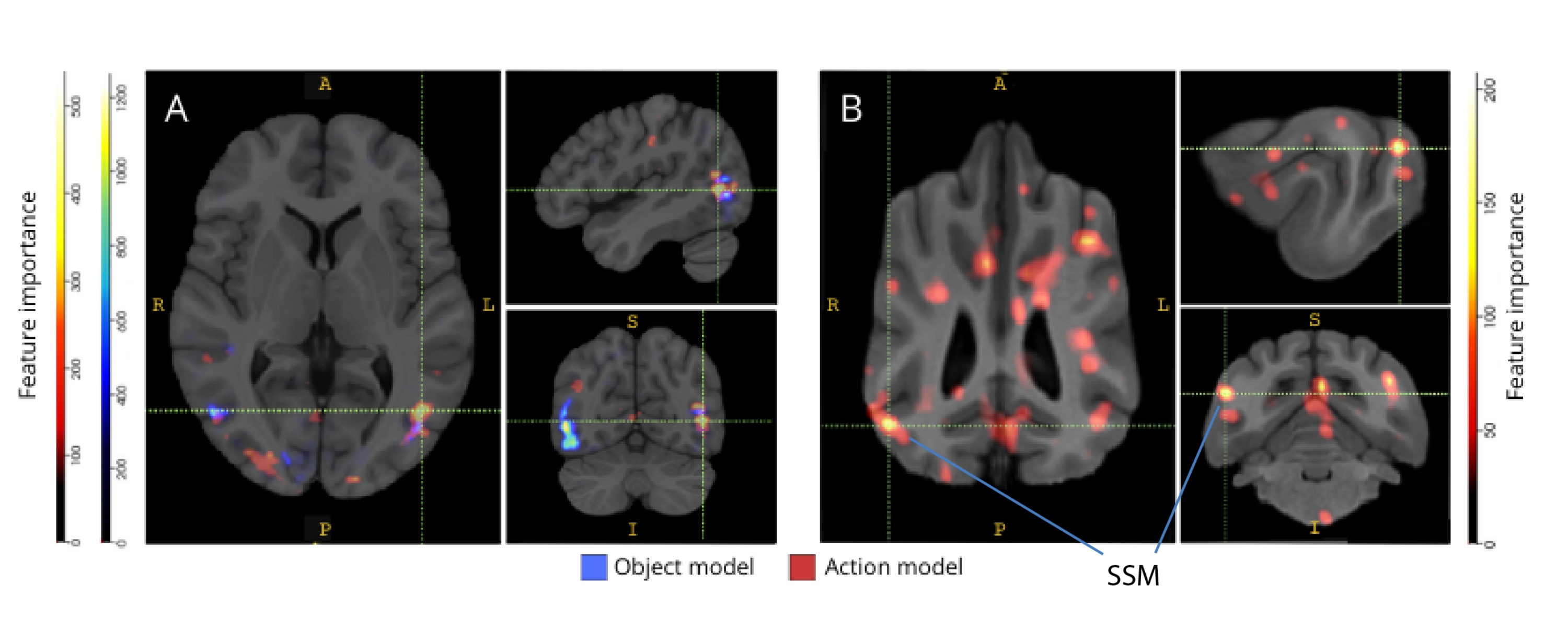
При обратном отображении на соответствующие атласы мозга оценки важности функций вокселей выявили ряд кластеров информативных вокселей в затылочной, теменной и височной коре как собак, так и людей (рис. 3). У людей объектно-ориентированные и основанные на действии модели выявили более фокальную закономерность, чем у собак и в областях, обычно связанных с распознаванием объектов, хотя и с небольшими различиями в пространственном расположении объектно-ориентированных вокселей и вокселей, основанных на действиях.
Мы проверили, что эти видовые различия не являются результатом коррелированных с задачами движений собак, которые больше реагируют на одни типы видео, чем на другие (например, на видео, отличные от собачьих, скажем, на автомобилях). Мы рассчитали евклидову норму шести параметров движения и подогнали линейную модель смешанных эффектов с использованием пакета R lme4, где класс является фиксированным эффектом и число прогона как случайный эффект для каждой собаки. Для каждой из итоговых моделей мы не обнаружили значимого влияния типа класса на движение ни для Daisy (F(2, 2252) = 0,83, p = 0,44 для объектно-ориентированных и F(4, 1235) = 1,87, p = 0,11 для основанных на действии), ни для Bhubo (F(2, 2231) = 1,71, p = 0,18 для объектных и F(4, 1221) = 0,94, p = 0,45 для основанных на действии).

Рисунок 1: Натуралистические видео и презентация в МРТ. (A) Примеры кадров из видеоклипов, показанных участникам. (Б) Бхубо, 4-летний боксер-микс, смотрит видео во время прохождения фМРТ в сознании. Пожалуйста, нажмите здесь, чтобы просмотреть увеличенную версию этой цифры.
{kind=link}

Рисунок 2: Производительность модели у собак и людей. Распределение баллов LRAP, представленное в виде процентильных ранжировок их нулевых распределений, более 100 итераций обучения и тестирования алгоритма машинного обучения Ivis для трехклассовой объектно-ориентированной модели, трехклассовой модели, основанной на действии, и пятиклассовой модели, где модели пытались классифицировать СМЕЛЫЕ ответы на натуралистические видеостимулы, полученные с помощью МРТ в сознании у собак и людей. Баллы агрегируются по видам. Оценка LRAP с очень высоким процентильным рейтингом указывает на то, что модель вряд ли случайно достигнет этого балла LRAP. Модель, работающая не лучше, чем случайность, будет иметь медианный процентиль баллов LRAP, равный ~50. Пунктирными линиями обозначен средний процентиль баллов LRAP для каждого вида на всех 100 прогонах. Пожалуйста, нажмите здесь, чтобы просмотреть увеличенную версию этой цифры.
{kind=link}

Рисунок 3: Области, важные для различения трехклассовых объектных и пятиклассовых моделей действий. (А) Человек и (Б) собака. Воксели были ранжированы в соответствии с их важностью признаков с помощью случайного классификатора леса, усредненного по всем итерациям моделей. Здесь представлены первые 5% вокселей (т.е. те, которые используются для обучения моделей), агрегированные по видам и преобразованные в групповое пространство для целей визуализации (атласы: люди34 и собаки35). Метки показывают области мозга собак с высокими показателями важности признаков, основанными на показателях, выявленных Johnson et al.35. Сокращение: SSM = надсильвийская извилина. Пожалуйста, нажмите здесь, чтобы просмотреть увеличенную версию этой цифры.
{kind=link}
| Тип модели | Точность обучения | Точность испытаний | Счет Формулы-1 | Точность | Вспоминать | Медиана процентиля оценки LRAP | |
| Человек 1 | Объект (3 класс) | 0.98 | 0.69 | 0.48 | 0.52 | 0.49 | >99 |
| Экшн (3 класс) | 0.98 | 0.72 | 0.51 | 0.54 | 0.54 | >99 | |
| Экшен (5 класс) | 0.97 | 0.51 | 0.28 | 0.37 | 0.27 | >99 | |
| Человек 2 | Объект (3 класс) | 0.98 | 0.68 | 0.45 | 0.5 | 0.47 | >99 |
| Экшн (3 класс) | 0.98 | 0.69 | 0.46 | 0.5 | 0.48 | >99 | |
| Экшен (5 класс) | 0.97 | 0.53 | 0.3 | 0.4 | 0.27 | >99 | |
| Бхубо | Объект (3 класс) | 0.99 | 0.61 | 0.38 | 0.41 | 0.39 | 57 |
| Экшн (3 класс) | 0.98 | 0.63 | 0.38 | 0.4 | 0.4 | 87 | |
| Экшен (5 класс) | 0.99 | 0.45 | 0.16 | 0.29 | 0.13 | 88 | |
| Маргаритка | Объект (3 класс) | 1 | 0.61 | 0.38 | 0.43 | 0.39 | 43 |
| Экшн (3 класс) | 0.97 | 0.62 | 0.35 | 0.38 | 0.35 | 60 | |
| Экшен (5 класс) | 0.99 | 0.44 | 0.16 | 0.27 | 0.13 | 76 |
Таблица 1: Агрегированные метрики алгоритма машинного обучения Ivis за 100 итераций обучения и тестирования СМЕЛЫХ реакций на натуралистические видеостимулы, полученные с помощью фМРТ в сознании у собак и людей. Объектные модели имели три целевых класса («собака», «человек», «автомобиль»), а модели действий имели три или пять классов (три класса: «говорящий», «едущий», «нюхающий»; пять классов: «говорящий», «принимающий», «нюхающий», «гладящий», «играющий»). Значения, значительно превышающие случайность, выделены жирным шрифтом.
Дополнительная таблица 1: Этикетки классов. Пожалуйста, нажмите здесь, чтобы загрузить этот файл.
Дополнительный фильм 1: Образец видеоклипа. Пожалуйста, нажмите здесь, чтобы загрузить этот файл.
Обсуждение
Результаты этого исследования демонстрируют, что натуралистические видео вызывают представления в мозге собак, которые достаточно стабильны в течение нескольких сеансов визуализации, чтобы их можно было декодировать с помощью фМРТ, аналогичной результатам, полученным как у людей, так и у обезьян. В то время как предыдущие исследования зрительной системы собак с помощью фМРТ представляли урезанные стимулы, такие как лицо или объект на нейтральном фоне, результаты здесь демонстрируют, что натуралистические видео, в которых множество людей и объектов взаимодействуют друг с другом, вызывают паттерны активации в коре головного мозга собаки, которые могут быть декодированы с достоверностью, близкой к той, которая наблюдается в коре головного мозга человека. Такой подход открывает новые возможности для изучения того, как организована зрительная система собаки.
Несмотря на то, что область фМРТ собак быстро развивалась, на сегодняшний день эти эксперименты опирались на относительно бедные стимулы, такие как изображения людей или объектов на нейтральном фоне 10,12,13. Кроме того, несмотря на то, что эти эксперименты начали идентифицировать области мозга, аналогичные веретенообразной области лица (FFA) приматов, участвующей в обработке лица, и латеральной затылочной коре (LOC) для обработки объектов, остаются разногласия по поводу природы этих представлений, например, есть ли у собак области лица как таковые, реагирующие на схожие характерные черты, как у приматов, или у них есть отдельные представления для собак и людей или лица и головы. Например 9,13. Собаки, конечно, не являются приматами, и мы не знаем, как они интерпретируют эти искусственные стимулы, оторванные от их обычного мультисенсорного контекста со звуками и запахами. Некоторые данные свидетельствуют о том, что собаки не относятся к изображениям объектов как к репрезентациям реальных вещей12. Несмотря на то, что в сканере невозможно создать настоящий мультисенсорный опыт, использование натуралистических видео может смягчить некоторую искусственность, предоставляя динамические стимулы, которые более точно соответствуют реальному миру, по крайней мере, для собаки. По тем же причинам использование натуралистических стимулов в исследованиях фМРТ человека приобрело популярность, демонстрируя, например, что последовательности событий в фильме представлены в коре головного мозга в нескольких временных масштабах и что фильмы эффективны для индуцирования надежной активации эмоций. Таким образом, в то время как натуралистические видео остаются относительно бедными стимулами, их успех в неврологии человека вызывает вопрос о том, можно ли получить подобные результаты у собак.
Наши результаты показывают, что классификатор нейронной сети успешно расшифровал некоторые типы натуралистического контента из мозга собак. Этот успех является впечатляющим достижением, учитывая сложность стимулов. Важно отметить, что, поскольку классификатор был протестирован на невидимых видеоклипах, модель декодирования выбрала широкие категории, которые можно было идентифицировать по клипам, а не свойства, специфичные для отдельных сцен. Следует отметить, что существует несколько метрик для количественной оценки производительности классификатора машинного обучения (таблица 1). Поскольку натуралистические видео по своей природе не будут иметь одинаковых вхождений всех классов, мы выбрали разумный подход, построив нулевое распределение из случайной перестановки меток и оценив значимость, на которую ссылается это. Затем мы обнаружили, что успех моделей собак был статистически значимым, достигнув 75-90-го процентилей, но только тогда, когда видео были закодированы на основе присутствующих действий, таких как игра или разговор.
Тестовые наборы, в отличие от обучающих, не были сбалансированы между классами. Составляя только 20% данных, недостаточная выборка до наименьшего размера класса привела бы к очень малому размеру выборки для каждого класса, так что любая рассчитанная статистика была бы ненадежной. Чтобы избежать возможности завышения точности из-за этого дисбаланса, нулевое распределение LRAP было вычислено путем случайной перестановки порядка классов 1000 раз для каждой итерации модели. Это нулевое распределение выступало в качестве ориентира для определения того, насколько хорошо модель может работать случайно. Затем истинный LRAP был преобразован в ранжирование процентиля в этом нулевом распределении. Очень высокий процентильный рейтинг, например, 95%, указывает на то, что такой высокий показатель возникал только в 5% случаев в 1000 случайных перестановок. Таким образом, можно считать, что такая модель работает намного выше случайности. Чтобы определить, являются ли эти процентильные рейтинги значительно выше, чем ожидалось случайно, то есть 50-й процентиль, статистически был рассчитан медианный ранжирование процентиля LRAP по всем 100 итерациям для каждой модели, и был проведен тест на ранг Вилкоксона с одной выборкой.
Несмотря на то, что основной целью была разработка декодера натуралистических визуальных стимулов для собак, сравнения с людьми неизбежны. Здесь мы отметим два основных различия: для каждого типа классификатора человеческие модели показали лучшие результаты, чем модели собак; Человеческие модели хорошо справлялись как с объектными, так и с активными моделями, в то время как модели с собаками работали только с моделями, основанными на действиях. Превосходная производительность человеческих моделей может быть обусловлена несколькими факторами. Человеческий мозг примерно в 10 раз больше, чем мозг собаки, поэтому существует больше вокселей, из которых можно выбрать для построения классификатора. Чтобы поставить модели в равное положение, следует использовать одинаковое количество вокселей, но это может быть как в абсолютном, так и в относительном смысле. Хотя окончательная модель была основана на верхних 5% информативных вокселей в каждом мозге (относительная мера), аналогичные результаты были получены при использовании фиксированного числа вокселей. Таким образом, кажется более вероятным, что различия в производительности связаны с тем, как люди и собаки воспринимают видеостимулы. Как отмечалось выше, в то время как собаки и люди обладают мультисенсорным восприятием, стимулы могут быть более бедными для собаки, чем для человека. Например, подсказки по размеру могут быть потеряны, и все выглядит как игрушечная версия реального мира. Есть некоторые свидетельства того, что собаки классифицируют объекты на основе размера и текстуры, а не формы, что почти противоположночеловеку. Кроме того, запах, который здесь не рассматривается, вероятно, является важным источником информации для распознавания объектов у собак, особенно при идентификации сородичей или людей 40,41,42. Тем не менее, даже при отсутствии сигналов размера или запаха, в необычной обстановке МРТ-сканера, тот факт, что классификатор вообще работал, говорит о том, что у собак все еще была актуальная для собак информация, которую можно было извлечь из их мозга. Поскольку у нас всего две собаки и два человека, видовые различия также могут быть обусловлены индивидуальными различиями. Тем не менее, эти две собаки представляли собой лучших из обученных МРТ собак и преуспели в удержании неподвижности во время просмотра видео. В то время как больший размер выборки, безусловно, позволил бы провести более надежные различия между видами, небольшое количество собак, способных проводить фМРТ в бодрствующем состоянии и которые будут смотреть видео в течение достаточно долгого времени, всегда ограничивает возможность обобщения на всех собак. Хотя возможно, что специализированные породы, такие как борзые, могут иметь более тонко настроенные зрительные реакции мозга, мы считаем, что индивидуальный темперамент и дрессировка, скорее всего, являются основными детерминантами того, что можно извлечь из мозга собаки.
Эти видовые различия поднимают вопрос о том, на какой аспект видео обращали внимание собаки. Один из подходов к ответу на этот вопрос основан на более простых видеостимулах. Затем, используя отдельные изображения, скажем, людей, собак и автомобилей, как по отдельности, так и вместе на нейтральном фоне, мы могли бы реконструировать характерные размеры собаки. Однако это методологически неэффективно и еще больше обедняет стимулы из реального мира. Вопрос о внимании может быть решен только с помощью подхода к декодированию, по сути, с использованием характеристик модели для определения того, на что обращают внимание43. Таким образом, полученные результаты свидетельствуют о том, что в то время как люди обращали внимание как на актеров, так и на действия, собаки были более сосредоточены на самих действиях. Это может быть связано с различиями в низкоуровневых характеристиках движения, таких как частота движений во время игры и приема пищи, или может быть связано с категориальным представлением этих действий на более высоком уровне. Распределение информативных вокселей по всей коре головного мозга собаки позволяет предположить, что эти представления не являются просто низкоуровневыми особенностями, которые в противном случае были бы ограничены зрительными областями. Дальнейшие исследования с использованием более широкого спектра видеостимулов могут пролить свет на роль движения в категории дискриминации собак.
Таким образом, это исследование продемонстрировало возможность восстановления натуралистической визуальной информации из коры головного мозга собаки с помощью фМРТ таким же образом, как это делается для коры головного мозга человека. Эта демонстрация показывает, что даже без звука или запаха характерные размеры сложных сцен кодируются собаками, смотрящими видео, и что эти измерения могут быть восстановлены из их мозга. Во-вторых, основываясь на небольшом количестве собак, которые могут выполнять задачи такого типа, информация может быть более широко распространена в коре головного мозга, чем это обычно наблюдается у людей, и типы действий, по-видимому, легче восстановить, чем личность акторов или объектов. Эти результаты открывают новый способ изучения того, как собаки воспринимают окружающую среду, которую они делят с людьми, включая видеоэкраны, и предлагают широкие возможности для будущих исследований того, как они и другие животные, не являющиеся приматами, «видят» мир.
Раскрытие информации
Никакой.
Благодарности
Мы благодарим Кейт Ревилл, Равину Чиббер и Джона Кинга за их полезные идеи при разработке этого анализа, Марка Спивака за его помощь в наборе и обучении собак для МРТ, а также Филлис Гуо за ее помощь в создании видео и маркировке. Мы также благодарим наших преданных владельцев собак, Ребекку Бисли (Дейзи) и Ашвина Сахарданде (Бхубо). Исследования на людях были поддержаны грантом Национального института глаза (Grant R01 EY029724 to D.D.D.).
Материалы
| Name | Company | Catalog Number | Comments |
| 3 T MRI Scanner | Siemens | Trio | |
| Audio recordings of scanner noise | homemade | none | |
| Camera gimbal | Hohem | iSteady PRO 3 | |
| Dog-appropriate videos | homemade | none | |
| fMRI processing software | AFNI | 20.3.01 | |
| Mock scanner components | homemade | none | Mock head coil and scanner tube |
| Neural net software | Ivis | 1.7.1 | |
| Optical flow software | OpenCV | 4.2.0.34 | |
| Projection system for scanner | homemade | none | |
| Trophy Cam HD | Bushnell | 119874 | |
| Video camera | GoPro | HERO7 | |
| Visualization software | ITK-SNAP | 3.6.0 | |
| Windows Video Editor | Microsoft | Windows 11 version |
Ссылки
- Mishkin, M., Ungerleider, L. G., Macko, K. A. Object vision and spatial vision: Two cortical pathways. Trends in Neurosciences. 6, 414-417 (1983).
- de Haan, E. H. F., Cowey, A. On the usefulness of 'what' and 'where' pathways in vision. Trends in Cognitive Sciences. 15 (10), 460-466 (2011).
- Freud, E., Plaut, D. C., Behrmann, M. What' is happening in the dorsal visual pathway. Trends in Cognitive Sciences. 20 (10), 773-784 (2016).
- Goodale, M. A., Milner, A. D. Separate visual pathways for perception and action. Trends in Neurosciences. 15 (1), 20-25 (1992).
- Schenk, T., McIntosh, R. D. Do we have independent visual streams for perception and action? Do we have independent visual streams for perception and action. Cognitive Neuroscience. 1 (1), 52-78 (2010).
- Andics, A., Gácsi, M., Faragó, T., Kis, A., Miklós, &. #. 1. 9. 3. ;. Report voice-sensitive regions in the dog and human brain are revealed by comparative fMRI. Current Biology. 24 (5), 574-578 (2014).
- Berns, G. S., Brooks, A. M., Spivak, M. Functional MRI in awake unrestrained dogs. PLoS One. 7 (5), 38027 (2012).
- Karl, S., et al. Training pet dogs for eye-tracking and awake fMRI. Behaviour Research Methods. 52, 838-856 (2019).
- Bunford, N., et al. Comparative brain imaging reveals analogous and divergent patterns of species and face sensitivity in humans and dogs. Journal of Neuroscience. 40 (43), 8396-8408 (2020).
- Cuaya, L. V., Hernández-Pérez, R., Concha, L. Our faces in the dog's brain: Functional imaging reveals temporal cortex activation during perception of human faces. PLoS One. 11 (3), 0149431 (2016).
- Dilks, D. D., et al. Awake fMRI reveals a specialized region in dog temporal cortex for face processing. PeerJ. 2015 (8), 1115 (2015).
- Prichard, A., et al. 2D or not 2D? An fMRI study of how dogs visually process objects. Animal Cognition. 24 (5), 1143-1151 (2021).
- Thompkins, A. M., et al. Separate brain areas for processing human and dog faces as revealed by awake fMRI in dogs (Canis familiaris). Learning & Behavior. 46 (4), 561-573 (2018).
- Zhang, K., Sejnowski, T. J. A universal scaling law between gray matter and white matter of cerebral cortex. Proceedings of the National Academy of Sciences of the United States of America. 97 (10), 5621-5626 (2000).
- Bradshaw, J., Rooney, N., Serpell, J. Dog Social Behavior and Communication. The Domestic Dog: Its Evolution, Behavior and Interactions with People. , 133-160 (2017).
- Prichard, A., et al. The mouth matters most: A functional magnetic resonance imaging study of how dogs perceive inanimate objects. The Journal of Comparative Neurology. 529 (11), 2987-2994 (2021).
- Haxby, J. V., Connolly, A. C., Guntupalli, J. S. Decoding neural representational spaces using multivariate pattern analysis. Annual Review of Neuroscience. 37, 435-456 (2014).
- Kamitani, Y., Tong, F. Decoding the visual and subjective contents of the human brain. Nature Neuroscience. 8 (5), 679-685 (2005).
- Kay, K. N., Naselaris, T., Prenger, R. J., Gallant, J. L. Identifying natural images from human brain activity. Nature. 452 (7185), 352-355 (2008).
- Nishimoto, S., et al. Reconstructing visual experiences from brain activity evoked by natural movies. Current Biology. 21 (19), 1641-1646 (2011).
- vander Meer, J. N., Breakspear, M., Chang, L. J., Sonkusare, S., Cocchi, L. Movie viewing elicits rich and reliable brain state dynamics. Nature Communications. 11 (1), 5004 (2020).
- Huth, A. G., De Heer, W. A., Griffiths, T. L., Theunissen, F. E., Gallant, J. L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature. 532 (7600), 453-458 (2016).
- Kriegeskorte, N., et al. Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron. 60 (6), 1126-1141 (2008).
- Ehsani, K., Bagherinezhad, H., Redmon, J., Mottaghi, R., Farhadi, A. Who let the dogs out? Modeling dog behavior from visual data. Proceedings of the IEEE Conference on Computer Vision and Pattern. 2018, 4051-4060 (2018).
- Berns, G. S., Brooks, A., Spivak, M. Replicability and heterogeneity of awake unrestrained canine fMRI responses. PLoS One. 9 (5), 98421 (2013).
- Cox, R. W. AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research. 29 (3), 162-173 (1996).
- Prichard, A., Chhibber, R., Athanassiades, K., Spivak, M., Berns, G. S. Fast neural learning in dogs: A multimodal sensory fMRI study. Scientific Reports. 8, 14614 (2018).
- Russ, B. E., Kaneko, T., Saleem, K. S., Berman, R. A., Leopold, D. A. Distinct fMRI responses to self-induced versus stimulus motion during free viewing in the macaque. The Journal of Neuroscience. 36 (37), 9580-9589 (2016).
- Farnebäck, G., Bigun, J., Gustavsson, T. Two-Frame Motion Estimation Based on Polynomial Expansion. In Image Analysis. Scandinavian Conference on Image Analysis. Lecture Notes in Computer Science. 2749, 363-370 (2003).
- Elias, D. O., Land, B. R., Mason, A. C., Hoy, R. R. Measuring and quantifying dynamic visual signals in jumping spiders). Journal of Comparative Physiology A. 192, 799-800 (2006).
- Szubert, B., Cole, J. E., Monaco, C., Drozdov, I. Structure-preserving visualisation of high dimensional single-cell datasets. Scientific Reports. 9, 8914 (2019).
- Tian, H., Tao, P. IVIS dimensionality reduction framework for biomacromolecular simulations. Journal of Chemical Information and Modeling. 60 (10), 4569-4581 (2020).
- Hebart, M. N., Gorgen, K., Haynes, J. The decoding toolbox (TDT): A versatile software package for multivariate analyses of functional imaging data. Frontiers in Neuroinformatics. 8, 88 (2015).
- Mazziotta, J., et al. A probabilistic atlas and reference system for the human brain: International Consortium for Brain Mapping (ICBM). Philosophical Transactions of the Royal Society B: Biological Sciences. 356 (1412), 1293-1322 (2001).
- Johnson, P. J., et al. Stereotactic cortical atlas of the domestic canine brain. Scientific Reports. 10, 4781 (2020).
- Yushkevich, P. A., et al. User-guided 3D active contour segmentation of anatomical structures: Significantly improved efficiency and reliability. NeuroImage. 31 (3), 1116-1128 (2006).
- Fürnkranz, J., Hüllermeier, E., Loza Mencía, E., Brinker, K. Multilabel classification via calibrated label ranking. Machine Learning. 73 (2), 133-153 (2008).
- Sonkusare, S., Breakspear, M., Guo, C. Naturalistic stimuli in neuroscience: Critically acclaimed. Trends in Cognitive Sciences. 23 (8), 699-714 (2019).
- vander Zee, E., Zulch, H., Mills, D. Word generalization by a dog (Canis familiaris): Is shape important. PLoS One. 7 (11), 49382 (2012).
- Bekoff, M. Observations of scent-marking and discriminating self from others by a domestic dog (Canis familiaris): Tales of displaced yellow snow. Behavioural Processes. 55 (2), 75-79 (2001).
- Berns, G. S., Brooks, A. M., Spivak, M. Scent of the familiar: An fMRI study of canine brain responses to familiar and unfamiliar human and dog odors. Behavioural Processes. 110, 37-46 (2015).
- Schoon, G. A. A., de Bruin, J. C. The ability of dogs to recognize and cross-match human odours. Forensic Science International. 69 (2), 111-118 (1994).
- Kamitani, Y., Tong, F. Decoding seen and attended motion directions from activity in the human visual cortex. Current Biology. 16 (11), 1096-1102 (2006).
Перепечатки и разрешения
Запросить разрешение на использование текста или рисунков этого JoVE статьи
Запросить разрешениеСмотреть дополнительные статьи
This article has been published
Video Coming Soon
Авторские права © 2025 MyJoVE Corporation. Все права защищены