
Zum Anzeigen dieser Inhalte ist ein JoVE-Abonnement erforderlich. Melden Sie sich an oder starten Sie Ihre kostenlose Testversion.
Method Article
Ein Workflow zur Optimierung der Formulierung von Lipid-Nanopartikeln (LNP) unter Verwendung von Experimenten mit designten Mischungsprozessen und selbstvalidierten Ensemblemodellen (SVEM)
In diesem Artikel
Zusammenfassung
Dieses Protokoll bietet einen Ansatz zur Formulierungsoptimierung über Mischungs-, kontinuierliche und kategoriale Studienfaktoren, der subjektive Entscheidungen bei der Konstruktion des Versuchsdesigns minimiert. Für die Analysephase wird ein effektives und einfach zu handhabendes Modellierungsanpassungsverfahren verwendet.
Zusammenfassung
Wir stellen einen Quality by Design (QbD)-ähnlichen Ansatz zur Optimierung von Lipid-Nanopartikel-Formulierungen (LNP) vor, der darauf abzielt, Wissenschaftlern einen zugänglichen Arbeitsablauf zu bieten. Die inhärente Beschränkung in diesen Studien, bei der die molaren Verhältnisse von ionisierbaren, Helfer- und PEG-Lipiden bis zu 100 % betragen müssen, erfordert spezielle Design- und Analysemethoden, um diese Mischungsbeschränkung zu berücksichtigen. Wir konzentrieren uns auf Lipid- und Prozessfaktoren, die üblicherweise bei der LNP-Designoptimierung verwendet werden, und bieten Schritte, die viele der Schwierigkeiten vermeiden, die traditionell bei der Planung und Analyse von Mischungsprozessexperimenten auftreten, indem wir raumfüllende Designs verwenden und den kürzlich entwickelten statistischen Rahmen der selbstvalidierten Ensemblemodelle (SVEM) verwenden. Neben der Erstellung optimaler Formulierungen erstellt der Workflow auch grafische Zusammenfassungen der angepassten statistischen Modelle, die die Interpretation der Ergebnisse vereinfachen. Die neu identifizierten Kandidatenformulierungen werden mit Bestätigungsläufen bewertet und können optional im Rahmen einer umfassenderen Zweitphasenstudie durchgeführt werden.
Einleitung
Lipid-Nanopartikel-Formulierungen (LNP) für In-vivo-Gentransfersysteme enthalten im Allgemeinen vier Bestandteile von Lipiden aus den Kategorien ionisierbare, Helfer- und PEG-Lipide 1,2,3. Unabhängig davon, ob diese Lipide allein oder gleichzeitig mit anderen Nicht-Mischungsfaktoren untersucht werden, erfordern Experimente für diese Formulierungen "Mischungs"-Designs, da - bei einer Kandidatenformulierung - das Erhöhen oder Verringern des Verhältnisses eines der Lipide notwendigerweise zu einer entsprechenden Abnahme oder Zunahme der Summe der Verhältnisse der anderen drei Lipide führt.
Zur Veranschaulichung wird angenommen, dass wir eine LNP-Formulierung optimieren, die derzeit eine festgelegte Rezeptur verwendet, die als Benchmark behandelt wird. Ziel ist es, die Wirksamkeit des LNP zu maximieren, während sekundär die durchschnittliche Partikelgröße minimiert wird. Die Untersuchungsfaktoren, die im Experiment variiert werden, sind die molaren Verhältnisse der vier konstituierenden Lipide (ionisierbar, Cholesterin, DOPE, PEG), das N:P-Verhältnis, die Flussrate und der ionisierbare Lipidtyp. Die ionisierbaren Lipide und Hilfslipide (einschließlich Cholesterin) dürfen über einen größeren Bereich des molaren Verhältnisses, 10-60 %, variieren als PEG, das in dieser Abbildung von 1-5 % variiert wird. Die Benchmark-Formulierungsrezeptur und die Bereiche der anderen Faktoren sowie deren Rundungsgranularität sind in der Ergänzungsdatei 1 angegeben. Für dieses Beispiel sind die Wissenschaftler in der Lage, 23 Durchläufe (einzigartige Chargen von Partikeln) an einem einzigen Tag durchzuführen und möchten diese als Stichprobengröße verwenden, wenn sie die Mindestanforderungen erfüllt. Simulierte Ergebnisse für dieses Experiment finden Sie in den Ergänzungsdateien 2 und 3 .
Rampado und Peer4 haben ein aktuelles Übersichtspapier zum Thema geplante Experimente zur Optimierung von Nanopartikel-basierten Drug-Delivery-Systemen veröffentlicht. Kauffman et al.5 betrachteten LNP-Optimierungsstudien unter Verwendung von fraktionsfaktoriellen und definitiven Screening-Designs6; Diese Arten von Versuchsplänen können jedoch keine Mischungsbeschränkung berücksichtigen, ohne auf die Verwendung ineffizienter "Schlupfvariablen"7 zurückzugreifen, und werden in der Regel nicht verwendet, wenn Mischungsfaktoren vorhanden sind 7,8. Stattdessen werden traditionell "optimale Designs", die in der Lage sind, eine Mischungsbeschränkung zu berücksichtigen, für Mischungsprozessexperimenteverwendet 9. Diese Designs zielen auf eine benutzerdefinierte Funktion der Studienfaktoren ab und sind nur dann optimal (in einem von mehreren möglichen Sinne), wenn diese Funktion die wahre Beziehung zwischen den Studienfaktoren und den Antworten erfasst. Beachten Sie, dass im Text zwischen "optimalen Designs" und "optimalen Formulierungskandidaten" unterschieden wird, wobei sich letztere auf die besten Formulierungen beziehen, die durch ein statistisches Modell identifiziert wurden. Optimale Designs bringen drei Hauptnachteile für Experimente mit Mischprozessen mit sich. Erstens, wenn der Wissenschaftler bei der Spezifizierung des Zielmodells keine Wechselwirkung der Studienfaktoren antizipiert, wird das resultierende Modell verzerrt und kann minderwertige Kandidatenformulierungen hervorbringen. Zweitens platzieren optimale Versuchspläne die meisten Durchläufe an der äußeren Begrenzung des Faktorraums. In LNP-Studien kann dies zu einer großen Anzahl von verlorenen Durchläufen führen, wenn sich die Partikel an keinen Extremen der Lipid- oder Prozesseinstellungen korrekt bilden. Drittens bevorzugen Wissenschaftler oft experimentelle Läufe im Inneren des Faktorraums, um ein modellunabhängiges Gefühl für die Wirkungsfläche zu gewinnen und den Prozess direkt in bisher unerforschten Regionen des Faktorraums zu beobachten.
Ein alternatives Designprinzip besteht darin, mit einem raumfüllenden Design 10 eine annähernd gleichmäßige Abdeckung des (mischungsbeschränkten) Faktorraumsanzustreben. Diese Versuchspläne opfern eine gewisse experimentelle Effizienz im Vergleich zu optimalen Versuchsplänen9 (unter der Annahme, dass der gesamte Faktorraum zu gültigen Formulierungen führt), bieten jedoch mehrere Vorteile in einem Kompromiss, die in dieser Anwendung nützlich sind. Das raumfüllende Design macht keine a priori Annahmen über die Struktur der Antwortfläche; Dies gibt ihm die Flexibilität, unvorhergesehene Beziehungen zwischen den Studienfaktoren zu erfassen. Dadurch wird auch die Entwurfserstellung optimiert, da keine Entscheidungen darüber getroffen werden müssen, welche Regressionsterme hinzugefügt oder entfernt werden sollen, wenn die gewünschte Laufgröße angepasst wird. Wenn einige Designpunkte (Rezepte) zu fehlgeschlagenen Formulierungen führen, ermöglichen raumfüllende Designs die Modellierung der Fehlergrenze über die Studienfaktoren und unterstützen gleichzeitig statistische Modelle für die Studienantworten über die erfolgreichen Faktorkombinationen. Schließlich ermöglicht die innere Abdeckung des Faktorraums eine modellunabhängige grafische Erkundung der Wirkungsfläche.
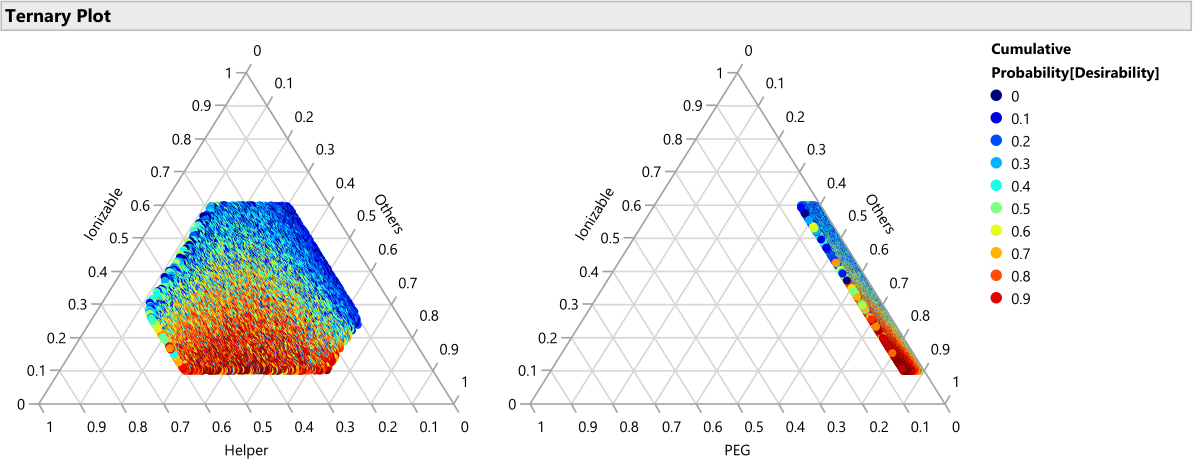
Zur Visualisierung des Mischungsfaktor-Unterraums eines Mischungsprozess-Experiments werden spezielle dreieckige "ternäre Plots" verwendet. Abbildung 1 motiviert diese Verwendung: Im Punktwürfel, in dem jeweils drei Zutaten im Bereich von 0 bis 1 liegen dürfen, werden die Punkte, die die Bedingung erfüllen, dass die Summe der Zutaten gleich 1 ist, rot hervorgehoben. Die Mischungsbeschränkung für die drei Zutaten reduziert den möglichen Faktorraum auf ein Dreieck. In LNP-Anwendungen mit vier Mischungsbestandteilen erzeugen wir sechs verschiedene ternäre Diagramme, um den Faktorraum darzustellen, indem wir zwei Lipide gleichzeitig gegen eine "Andere"-Achse auftragen, die die Summe der anderen Lipide darstellt.

Abbildung 1: Bereiche des Dreiecksfaktors. Im raumfüllenden Diagramm innerhalb des Würfels stellen die kleinen grauen Punkte Formulierungen dar, die nicht mit der Mischungsbeschränkung übereinstimmen. Die größeren roten Punkte liegen auf einem Dreieck, das in den Würfel eingeschrieben ist, und stellen Formulierungen dar, für die die Mischungsbeschränkung erfüllt ist. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}
Zusätzlich zu den Lipidmischungsfaktoren gibt es oft einen oder mehrere kontinuierliche Prozessfaktoren wie das N:P-Verhältnis, die Pufferkonzentration oder die Durchflussrate. Es können kategoriale Faktoren vorhanden sein, wie z. B. der ionisierbare Lipidtyp, der Helferlipidtyp oder der Puffertyp. Ziel ist es, in In-vivo-Studien eine Formulierung (eine Mischung aus Lipiden und Einstellungen für Prozessfaktoren) zu finden, die ein gewisses Maß an Wirksamkeit maximiert und/oder physikalisch-chemische Eigenschaften wie die Minimierung der Partikelgröße und des PDI (Polydispersitätsindex), die Maximierung der prozentualen Verkapselung und die Minimierung von Nebenwirkungen - wie z. B. Körpergewichtsverlust - verbessert. Selbst wenn man von einem vernünftigen Benchmark-Rezept ausgeht, kann es bei einer Änderung der genetischen Nutzlast oder bei der Berücksichtigung von Änderungen der Prozessfaktoren oder Lipidtypen an einer erneuten Optimierung interessiert sein.
Cornell7 bietet einen definitiven Text über die statistischen Aspekte von Mischungs- und Mischprozessexperimenten, wobei Myers et al.9 eine hervorragende Zusammenfassung der relevantesten Mischungsdesign- und Analysethemen für die Optimierung liefern. Diese Arbeiten können Wissenschaftler jedoch mit statistischen Details und Fachterminologie überfrachten. Moderne Software für die Planung und Analyse von Experimenten bietet eine robuste Lösung, die die meisten LNP-Optimierungsprobleme ausreichend unterstützt, ohne sich auf die entsprechende Theorie berufen zu müssen. Während kompliziertere Studien oder Studien mit hoher Priorität immer noch von der Zusammenarbeit mit einem Statistiker profitieren und eher optimale als platzfüllende Designs verwenden können, ist es unser Ziel, den Komfort der Wissenschaftler zu verbessern und die Optimierung von LNP-Formulierungen zu fördern, ohne an ineffiziente OFAT-Tests (One-Factor-at-a-Time)11 zu appellieren oder sich einfach mit der ersten Formulierung zufrieden zu geben, die den Spezifikationen entspricht.
In diesem Artikel wird ein Workflow vorgestellt, der statistische Software verwendet, um ein generisches LNP-Formulierungsproblem zu optimieren und Design- und Analyseprobleme in der Reihenfolge anzugehen, in der sie auftreten werden. Tatsächlich wird die Methode für allgemeine Optimierungsprobleme funktionieren und ist nicht auf LNPs beschränkt. Auf dem Weg dorthin werden mehrere häufig auftretende Fragen angesprochen und Empfehlungen gegeben, die auf Erfahrungen und Simulationsergebnissen basieren12. Das kürzlich entwickelte Framework der selbstvalidierten Ensemble-Modelle (SVEM)13 hat den ansonsten fragilen Ansatz zur Analyse von Ergebnissen aus Mix-Prozess-Experimenten erheblich verbessert, und wir verwenden diesen Ansatz, um eine vereinfachte Strategie für die Formulierungsoptimierung bereitzustellen. Während der Arbeitsablauf in einer allgemeinen Art und Weise aufgebaut ist, die mit anderen Softwarepaketen befolgt werden könnte, ist JMP 17 Pro einzigartig, da es SVEM zusammen mit den grafischen Zusammenfassungswerkzeugen bietet, die wir als notwendig erachtet haben, um die ansonsten obskure Analyse von Mischprozessexperimenten zu vereinfachen. Daher werden auch JMP-spezifische Anweisungen im Protokoll bereitgestellt.
SVEM verwendet die gleiche lineare Regressionsmodellgrundlage wie der traditionelle Ansatz, ermöglicht es uns jedoch, langwierige Modifikationen zu vermeiden, die erforderlich sind, um ein "vollständiges Modell" von Kandidateneffekten anzupassen, indem wir entweder einen Vorwärtsselektions- oder einen Penalized Selection-Basisansatz (Lasso) verwenden. Darüber hinaus bietet SVEM eine verbesserte "reduzierte Modellanpassung", die das Potenzial für die Einbeziehung von Rauschen (Prozess plus analytische Varianz), das in den Daten auftritt, minimiert. Es funktioniert, indem die prognostizierten Modelle gemittelt werden, die sich aus der wiederholten Neugewichtung der relativen Wichtigkeit der einzelnen Durchläufe im Modell 13,14,15,16,17,18 ergeben. SVEM bietet einen Rahmen für die Modellierung von Mix-Prozess-Experimenten, der sowohl einfacher zu implementieren ist als die herkömmliche Single-Shot-Regression als auch qualitativ bessere optimale Formulierungskandidaten liefert12,13. Die mathematischen Details von SVEM würden den Rahmen dieses Artikels sprengen, und selbst eine oberflächliche Zusammenfassung über die relevante Literaturrecherche hinaus würde von seinem Hauptvorteil in dieser Anwendung ablenken: Es ermöglicht ein einfaches, robustes und genaues Click-to-Run-Verfahren für Praktiker.
Der vorgestellte Workflow steht im Einklang mit dem Quality by Design (QbD)19-Ansatz für die pharmazeutische Entwicklung20. Das Ergebnis der Studie wird ein Verständnis der funktionalen Beziehung sein, die die Materialattribute und Prozessparameter mit kritischen Qualitätsmerkmalen (CQAs) verbindet21. Daniel et al.22 diskutieren die Verwendung eines QbD-Frameworks speziell für die RNA-Plattformproduktion: Unser Workflow könnte als Werkzeug innerhalb dieses Frameworks verwendet werden.
Access restricted. Please log in or start a trial to view this content.
Protokoll
Der im Abschnitt "Repräsentative Ergebnisse" beschriebene Versuch wurde in Übereinstimmung mit dem Leitfaden für die Pflege und Verwendung von Versuchstieren durchgeführt, und die Verfahren wurden nach den Richtlinien unseres Institutional Animal Care and Use Committee (IACUC) durchgeführt. 6-8 Wochen alte weibliche Balb/C-Mäuse wurden kommerziell beschafft. Die Tiere erhielten ad libitum Standardfutter und Wasser und wurden unter Standardbedingungen mit 12-stündigen Hell-Dunkel-Zyklen bei einer Temperatur von 65-75 °F (~18-23 °C) und 40-60% Luftfeuchtigkeit untergebracht.
1. Erfassung des Studienzwecks, der Antworten und der Faktoren
HINWEIS: In diesem Protokoll wird JMP 17 Pro für die Planung und Analyse des Experiments verwendet. Gleichwertige Software kann nach ähnlichen Schritten verwendet werden. Beispiele und weitere Anweisungen für alle in Abschnitt 1 ausgeführten Schritte finden Sie im Ergänzungsdossier 1.
- Fassen Sie den Zweck des Experiments in einem Dokument mit Datumsstempel zusammen.
- Listen Sie die primären Antworten (CQAs) auf, die während des Experiments gemessen werden.
- Listen Sie alle sekundären Reaktionen (z. B. nachgelagerte Einschränkungen der physikalisch-chemischen Eigenschaften) auf, die gemessen werden könnten.
- Listen Sie Prozessparameter auf, die sich auf die Antworten beziehen können, einschließlich derjenigen, die für den Zweck der Studie am relevantesten sind.
- Wenn die Studie über mehrere Tage läuft, sollten Sie einen kategorischen "Blockierungsfaktor" für den Tag einbeziehen.
HINWEIS: Dadurch werden die Faktoreinstellungen über Tage hinweg ausgeglichen, um zu verhindern, dass Verschiebungen auf Tagesebene im Prozessmittelwert mit den Studienfaktoren verwechselt werden. - Wählen Sie die Faktoren aus, die variiert werden sollen, und diejenigen, die während der Studie konstant gehalten werden sollen.
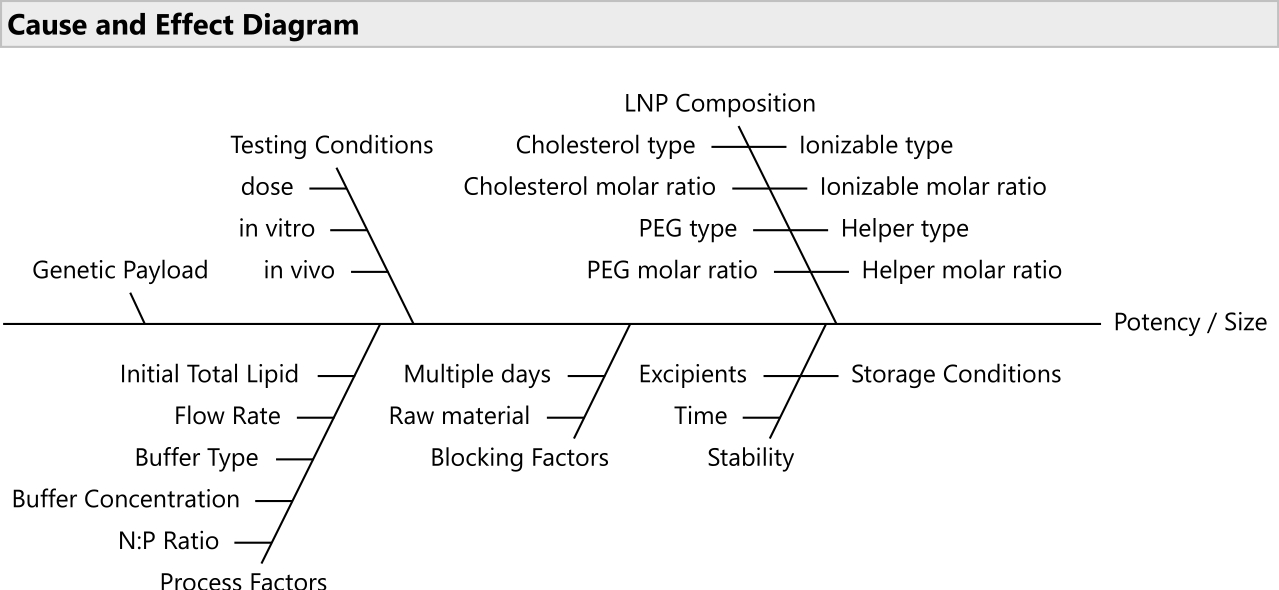
HINWEIS: Verwenden Sie Tools zur Risikopriorisierung, wie z. B. Fehlermöglichkeitseffektanalysen20 , um die relevanteste Teilmenge von Faktoren auszuwählen (Abbildung 2). Normalerweise sollten alle Lipide variieren dürfen; obwohl es in einigen Fällen mit begrenztem Budget sinnvoll ist, PEG auf ein festes Verhältnis zu sperren. - Legen Sie die Bereiche für die unterschiedlichen Faktoren und die jeweils relevante Dezimalgenauigkeit fest.
- Bestimmen Sie die Größe des Studiendesigns (die Anzahl der eindeutigen Partikelchargen) mithilfe der minimalen und maximalen Heuristik. Manuell eingeschlossene Kontrollbenchmarkläufe werden nicht auf die von den Heuristiken empfohlene Laufgröße angerechnet.
HINWEIS: Bei den folgenden Heuristiken wird davon ausgegangen, dass die Antworten kontinuierlich sind. Die minimale Heuristik geht davon aus, dass es möglich sein wird, bei Bedarf eine Folgestudie durchzuführen, zusätzlich zur Durchführung von Bestätigungsläufen für optimale Kandidatenformulierungen. Wenn es nur möglich ist, Bestätigungsläufe durchzuführen, ist es besser, die Anzahl der Durchläufe zu budgetieren, die aus der maximalen Heuristik erhalten werden. Wenden Sie sich bei binären primären Antworten an einen Statistiker, um die geeignete Anzahl von Durchläufen zu ermitteln.- Minimale Heuristik: Ordnen Sie drei Durchläufe pro Mischungsfaktor, zwei pro kontinuierlichem Prozessfaktor und einen pro Stufe jedes kategorialen Faktors zu.
HINWEIS: Für eine Studie mit vier Lipidfaktoren, zwei kontinuierlichen und einer dreiseitigen kategorialen Prozessvariablen führt dies zu einem Vorschlag von (3 x 4) + (2 x 2) + 3 = 19 raumfüllenden Durchläufen. Fügen Sie zusätzliche Durchläufe hinzu, wenn einige aufgrund von Formulierungs- oder Messproblemen wahrscheinlich fehlschlagen. - Maximale Heuristik: Starten Sie die Software zum Erstellen optimaler Entwürfe und geben Sie die erforderlichen Parameter für eine zweite Ordnung ein (einschließlich Haupteffekte, wechselseitige Wechselwirkungen zwischen allen Effekten und quadratische Effekte für kontinuierliche Prozessfaktoren). Berechnen Sie die minimale Laufgröße gemäß dem Algorithmus der Software. Addieren Sie 1 zu dem von der Software erhaltenen Ergebnis, um die maximale Heuristik zu definieren.
HINWEIS: Detaillierte Anweisungen zum Ausführen dieser Schritte finden Sie in der Zusatzdatei 1 . Ein Beispielfall mit vier Lipidfaktoren, zwei kontinuierlichen und einer dreiseitigen kategorialen Prozessvariablen, führt zu einer empfohlenen Durchlaufgröße von 34 (33 aus Softwareempfehlung + 1). Darüber hinausgehende Läufe sollten wahrscheinlich besser für Bestätigungs- oder Folgestudien verwendet werden.
- Minimale Heuristik: Ordnen Sie drei Durchläufe pro Mischungsfaktor, zwei pro kontinuierlichem Prozessfaktor und einen pro Stufe jedes kategorialen Faktors zu.

Abbildung 2: Ursache-Wirkungs-Diagramm. Das Diagramm zeigt gemeinsame Faktoren in einem LNP-Formulierungsoptimierungsproblem. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}
2. Erstellung des Designtisches mit raumfüllendem Design
- Öffnen Sie JMP und navigieren Sie in der Menüleiste zu DOE > Special Purpose > Space Filling Design.
- Geben Sie die Antworten auf die Studie ein (siehe Ergänzungsdatei 1).
- Optional: Fügen Sie Spalten für zusätzliche Antworten hinzu und geben Sie an, ob jede maximiert, minimiert oder als Ziel verwendet werden soll, indem Sie auf Antwort hinzufügen klicken.
HINWEIS: Diese Einstellungen können später geändert werden und wirken sich nicht auf das Design aus. Ebenso können nach dem Erstellen der Zeichnungstabelle zusätzliche Spalten für zusätzliche Antworten hinzugefügt werden. - Geben Sie die Untersuchungsfaktoren und die entsprechenden Bereiche ein. Verwenden Sie die Schaltfläche Mischung , um Mischungsfaktoren hinzuzufügen, die Schaltfläche Stetig , um kontinuierliche Faktoren hinzuzufügen, oder die Schaltfläche Kategorial, um kategoriale Faktoren hinzuzufügen.
HINWEIS: In dieser Beispielstudie werden die in Abbildung 3 dargestellten Faktoren und Bereiche verwendet, darunter das Verhältnis ionisierbarer Molare (zwischen 0,1 und 0,6), das Molarverhältnis von Helfern (ebenfalls zwischen 0,1 und 0,6), das Molverhältnis Cholesterin (zwischen 0,1 und 0,6), das molare PEG-Verhältnis (von 0,01 bis 0,05) und der ionisierbare Lipidtyp (der H101 sein kann, H102 oder H103). - Geben Sie die vorgegebene Anzahl von Durchläufen für den Versuchsplan in das Feld Anzahl der Durchläufe ein.
- Optional: Erhöhen Sie die durchschnittliche Clustergröße von der Standardeinstellung von 50 auf 2000 über das Menü mit dem roten Dreieck neben der Kopfzeile " Raumfüllendes Design " und im Untermenü "Erweiterte Optionen ".
HINWEIS: Dies ist eine Einstellung für den raumfüllenden Algorithmus, die zu einer etwas besseren Entwurfskonstruktion auf Kosten zusätzlicher Rechenzeit führen kann. - Generieren Sie die platzfüllende Versuchsplantabelle für die ausgewählten Faktoren und die Laufgröße. Klicken Sie auf "Schnelles flexibles Füllen" und dann auf "Tabelle erstellen".
HINWEIS: Die ersten beiden Durchläufe eines Beispielentwurfs sind in Abbildung 4 dargestellt. - Fügen Sie der Tabelle eine Notizenspalte hinzu, um manuell erstellte Ausführungen mit Anmerkungen zu versehen. Doppelklicken Sie auf die erste leere Spaltenüberschrift, um eine Spalte hinzuzufügen, und doppelklicken Sie dann auf die neue Spaltenüberschrift, um den Namen zu bearbeiten.
- Integrieren Sie ggf. manuell Benchmark-Kontrollläufe in die Entwurfstabelle. Fügen Sie ein Replikat für einen der Kontroll-Benchmarks hinzu. Markieren Sie den Benchmark-Namen in der Spalte " Notizen" und kodieren Sie die Benchmark-Replikationszeilen farblich, um die Identifizierung des Diagramms zu erleichtern.
- Fügen Sie eine neue Zeile hinzu, indem Sie auf die erste leere Zeilenüberschrift doppelklicken und die Einstellungen für den Benchmark-Faktor eingeben. Duplizieren Sie diese Zeile, um eine Replik des Benchmarks zu erstellen. Markieren Sie beide Zeilen und navigieren Sie zu Zeilen > Farben , um eine Farbe für die grafische Darstellung zuzuweisen.
HINWEIS: Das Replikat bietet eine modellunabhängige Schätzung des Prozesses sowie der analytischen Varianz und bietet zusätzliche grafische Einblicke.
- Fügen Sie eine neue Zeile hinzu, indem Sie auf die erste leere Zeilenüberschrift doppelklicken und die Einstellungen für den Benchmark-Faktor eingeben. Duplizieren Sie diese Zeile, um eine Replik des Benchmarks zu erstellen. Markieren Sie beide Zeilen und navigieren Sie zu Zeilen > Farben , um eine Farbe für die grafische Darstellung zuzuweisen.
- Wenn Benchmark-Kontrollläufe den Bereich der Studienfaktoren überschreiten, vermerken Sie dies in der Spalte "Anmerkungen" für den zukünftigen Ausschluss von der Analyse.
- Runden Sie die Mischungsfaktoren auf die entsprechende Körnung. Um dies zu tun,
- Markieren Sie die Spaltenüberschriften für die Mischungsfaktoren, klicken Sie mit der rechten Maustaste auf eine der Spaltenüberschriften, navigieren Sie zu Neue Formelspalte > Transformieren > Runden..., geben Sie das richtige Rundungsintervall ein, und klicken Sie auf OK.
- Stellen Sie sicher, dass keine Zeilen ausgewählt sind, indem Sie auf das untere Dreieck am Schnittpunkt von Zeilen- und Spaltenüberschriften klicken.
- Kopieren Sie die Werte aus den neu erstellten gerundeten Spalten (Strg + C) und fügen Sie sie (Strg + V) in die ursprünglichen Mischungsspalten ein. Löschen Sie abschließend die temporären gerundeten Wertspalten.
- Nachdem Sie die Lipidverhältnisse gerundet haben, überprüfen Sie, ob ihre Summe 100 % beträgt, indem Sie die Spaltenüberschriften für die Mischungsfaktoren auswählen, mit der rechten Maustaste auf einen klicken und zu Spalte Neue Formel > > Summe kombinieren gehen. Wenn die Summe einer Zeile nicht gleich 1 ist, passen Sie einen der Mischungsfaktoren manuell an, um sicherzustellen, dass die Faktoreinstellung innerhalb des Faktorbereichs bleibt. Löschen Sie die Summenspalte, nachdem die Anpassungen vorgenommen wurden.
- Befolgen Sie das gleiche Verfahren wie beim Runden der Mischungsfaktoren, um die Prozessfaktoren auf ihre jeweilige Granularität zu runden.
- Formatieren Sie die Lipidspalten so, dass sie als Prozentsätze mit der gewünschten Anzahl von Dezimalstellen angezeigt werden: Wählen Sie die Spaltenüberschriften aus, klicken Sie mit der rechten Maustaste, und wählen Sie Attribute standardisieren.... Legen Sie im nächsten Fenster Format auf Prozent fest, und passen Sie die Anzahl der Dezimalstellen nach Bedarf an.
- Wenn manuelle Ausführungen, wie z. B. Benchmarks, hinzugefügt werden, randomisieren Sie die Reihenfolge der Tabellenzeilen erneut: Fügen Sie eine neue Spalte mit zufälligen Werten hinzu (klicken Sie mit der rechten Maustaste auf die letzte Spaltenüberschrift, und wählen Sie Neue Formelspalte > Zufällig > Zufällig Normal). Sortieren Sie diese Spalte in aufsteigender Reihenfolge, indem Sie mit der rechten Maustaste auf die Spaltenüberschrift klicken, und löschen Sie dann die Spalte.
- Optional: Fügen Sie eine Ausführungs-ID-Spalte hinzu. Füllen Sie diese mit dem aktuellen Datum, dem Experimentnamen und der Zeilennummer aus der Tabelle aus.
HINWEIS: Siehe (Abbildung 5) für ein Beispiel. - Generieren Sie ternäre Diagramme, um die Designpunkte über den Lipidfaktoren zu visualisieren (Abbildung 6). Untersuchen Sie außerdem die Ausführungsverteilung über die Prozessfaktoren (Abbildung 7): Wählen Sie Diagramm > ternäres Diagramm aus. Wählen Sie nur die Mischungsfaktoren für X, Plotten aus.
- Um die Verteilung über die Prozessfaktoren zu untersuchen, wählen Sie > Verteilung analysieren aus, und geben Sie die Prozessfaktoren für Y, Spalten ein.
HINWEIS: Der Formulierungswissenschaftler sollte die Durchführbarkeit aller Durchläufe bestätigen. Wenn nicht durchführbare Ausführungen vorhanden sind, starten Sie den Entwurf unter Berücksichtigung der neu entdeckten Einschränkungen neu.

Abbildung 3: Untersuchungsfaktoren und -bereiche. Screenshots von Einstellungen in experimenteller Software sind nützlich, um den Studienaufbau zu reproduzieren. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 4: Initiale Ausgabe für ein raumfüllendes Design. In den ersten beiden Zeilen der Tabelle müssen die Einstellungen auf die gewünschte Genauigkeit gerundet werden, wobei gleichzeitig sichergestellt werden muss, dass die Summe der Lipidbeträge 1 ergibt. Der Benchmark wurde manuell in die Tabelle eingefügt. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 5: Formatierte Studientabelle. Die Faktorstufen wurden gerundet und formatiert, und es wurde eine Spalte mit der Ausführungs-ID hinzugefügt. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 6: Versuchsplanpunkte auf einem ternären Diagramm. Die 23 Formulierungen sind in Abhängigkeit von den entsprechenden Verhältnissen von ionisierbar, Hilfs- und "Sonstiges" (Cholesterin + PEG) dargestellt. Der grüne Punkt in der Mitte stellt das molare Benchmark-Verhältnis von 33:33:33:1 von ionisierbar (H101):Cholesterin:Helfer (DOPE):P EG dar. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 7: Verteilung der nicht-gemischten Prozessfaktoren im Experiment. Die Histogramme zeigen, wie die Versuchsläufe über den ionisierbaren Lipidtyp, das N:P-Verhältnis und die Flussrate verteilt sind. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}
3. Ausführen des Experiments
- Führen Sie das Experiment in der Reihenfolge aus, die in der Entwurfstabelle angegeben ist. Notieren Sie die Messwerte in den Spalten, die in die Versuchstabelle eingebaut sind.
- Wenn mehrere Assays für dieselbe Reaktion auf eine identische Formulierungscharge durchgeführt werden, berechnen Sie einen Durchschnitt für diese Ergebnisse innerhalb jeder Charge. Fügen Sie der Tabelle eine Spalte für jede Assay-Messung hinzu.
- Um einen Durchschnitt zu erhalten, wählen Sie alle verwandten Spalten aus, klicken Sie mit der rechten Maustaste auf eine der ausgewählten Spaltenüberschriften und wählen Sie Neue Formelspalte > > Durchschnitt kombinieren. Verwenden Sie diese Spalte "Durchschnitt " für die Analyse zukünftiger Antwortvariablen.
HINWEIS: Ohne das Rezept neu zu starten, erfassen wiederholte Assay-Messungen nur die Assay-Varianz und stellen keine unabhängigen Replikate dar.
- Um einen Durchschnitt zu erhalten, wählen Sie alle verwandten Spalten aus, klicken Sie mit der rechten Maustaste auf eine der ausgewählten Spaltenüberschriften und wählen Sie Neue Formelspalte > > Durchschnitt kombinieren. Verwenden Sie diese Spalte "Durchschnitt " für die Analyse zukünftiger Antwortvariablen.
- Dokumentieren Sie jedes Auftreten von Formulierungsfällungen oder In-vivo-Verträglichkeitsproblemen (z. B. schwerer Gewichtsverlust oder Tod) mit binären (0/1) Indikatoren in einer neuen Spalte für jeden Problemtyp.
4. Analyse der experimentellen Ergebnisse
- Stellen Sie die Messwerte dar und untersuchen Sie die Verteilungen der Antwortvariablen: Öffnen Sie Graph > Graph Builder und ziehen Sie jede Antwortvariable in den Y-Bereich für einzelne Diagramme. Wiederholen Sie diesen Vorgang für alle Antworten.
- Untersuchen Sie den relativen Abstand zwischen den farbcodierten Wiederholungsläufen, falls einer enthalten war. Dies ermöglicht das Verständnis der Gesamtstreuung (Prozess- und Analysestreuung) am Benchmark im Vergleich zur Variabilität aufgrund von Änderungen der Faktoreinstellungen über den gesamten Faktorraum (Abbildung 8).
- Bestimmen Sie, ob die unformatierte Antwortvariable modelliert werden soll oder ob stattdessen eine Transformation verwendet werden soll. Für Antwortvariablen, die darauf beschränkt sind, positiv zu sein, aber oben unbegrenzt sind (z. B. Potenz), passen Sie sowohl eine Normalverteilung als auch eine Lognormalverteilung an die experimentellen Ergebnisse an. Wenn die Lognormalverteilung besser zu einem niedrigeren AICc passt (korrigiertes Informationskriterium von Akaike), dann nehmen Sie eine logarithmische Transformation dieser Antwort vor.
- Navigieren Sie zu Analyze > Distribution , und wählen Sie die Antwort für Y, Spalten aus. Klicken Sie im daraufhin angezeigten Verteilungsbericht auf das rote Dreieck neben dem Namen der Antwort, und wählen Sie im Dropdown-Menü Kontinuierliche Anpassung > Normale anpassen und Kontinuierliche Anpassung > Lognormal anpassen aus. Überprüfen Sie im nachfolgenden Bericht " Verteilungen vergleichen" die AICc-Werte, um festzustellen, welche Verteilung besser zur Antwortvariablen passt.
- Um eine Protokolltransformation durchzuführen, klicken Sie mit der rechten Maustaste auf die Überschrift der Antwortspalte, und wählen Sie Neue Formelspalte > Protokoll > Protokoll aus. Wenn ein Modell erstellt und eine Vorhersagespalte auf der logarithmischen Skala gespeichert wird, transformieren Sie die Antwortvariable wieder in die ursprüngliche Skala, indem Sie Neue Formelspalte > Protokoll > Exp auswählen.
- Vergleichen Sie für proportionale Antwortvariablen, die zwischen 0 und 1 begrenzt sind, die Anpassung einer Normalverteilung und einer Betaverteilung. Wenn die Beta-Distribution einen niedrigeren AICc aufweist, führen Sie eine Logit-Transformation durch. Wählen Sie im Verteilungsbericht für die Antwortvariable die Option Continuous Fit > Fit Normal und Continuous Fit > Fit Beta aus.
- Klicken Sie für die Logit-Transformation mit der rechten Maustaste auf die Überschrift der Antwortspalte in der Datentabelle, und wählen Sie Neue Formelspalte > Spezial > Logit aus. Speichern Sie nach der Modellerstellung die Vorhersagespalte. Um den ursprünglichen Maßstab wiederherzustellen, verwenden Sie Neue Formelspalte > Spezialität > Logistik.
HINWEIS: Die regressionsbasierte SVEM-Analyse ist robust gegenüber Abweichungen von der Normalverteilung der Antwortvariablen. Diese Transformationen können jedoch zu einer einfacheren Interpretation der Ergebnisse und zu einer verbesserten Anpassung der Modelle führen.
- Klicken Sie für die Logit-Transformation mit der rechten Maustaste auf die Überschrift der Antwortspalte in der Datentabelle, und wählen Sie Neue Formelspalte > Spezial > Logit aus. Speichern Sie nach der Modellerstellung die Vorhersagespalte. Um den ursprünglichen Maßstab wiederherzustellen, verwenden Sie Neue Formelspalte > Spezialität > Logistik.
- Stellen Sie die Durchläufe in einem ternären Diagramm grafisch dar. Färben Sie die Punkte entsprechend den Antwortvariablen (oder den transformierten Antwortvariablen, wenn eine Transformation angewendet wurde): Öffnen Sie Diagramm > ternäres Diagramm. Wählen Sie nur die Mischungsfaktoren für X, Plotten aus. Klicken Sie mit der rechten Maustaste auf eines der resultierenden Diagramme, wählen Sie Zeilenlegende und dann die (transformierte) Antwortspalte aus.
HINWEIS: Durch das Einfärben der Punkte nach den Antwortvariablen erhalten Sie eine modellunabhängige visuelle Perspektive des Verhaltens in Bezug auf Mischungsfaktoren. - Löschen Sie das Modellskript, das vom raumfüllenden Design generiert wurde.
- Erstellen Sie ein unabhängiges Modell für jede Antwortvariable in Abhängigkeit von den Studienfaktoren, und wiederholen Sie die folgenden Schritte für jede Antwortvariable.
HINWEIS: Im Falle einer sekundären binären Antwort (z. B. Formulierungsfehler oder Mäusetod) modellieren Sie diese Antwort ebenfalls. Ändern Sie die Einstellung für die Zielverteilung von Normal in Binomial. - Konstruieren Sie ein "vollständiges" Modell, das alle möglichen Effekte enthält. Dieses Modell sollte die Haupteffekte jedes Faktors, Zwei- und Dreiwegewechselwirkungen, quadratische und partielle kubische Terme in den Prozessfaktoren und kubische Scheffé-Terme für die Mischungsfaktoren23,24 enthalten.
HINWEIS: Verwenden Sie für jede Antwort den gleichen Satz von Kandidateneffekten. Die SVEM-Modellauswahltechnik verfeinert die Modelle für jede Antwortvariable unabhängig voneinander, was möglicherweise zu eindeutigen reduzierten Modellen für jede Antwort führt. Abbildung 9 veranschaulicht einige dieser Kandidateneffekte. In den folgenden Teilschritten wird dieser Prozess detailliert beschrieben.- Wählen Sie > Modell anpassen analysieren aus.
- Stellen Sie sicher, dass blockierende Faktoren (z. B. Tag) nicht mit anderen Studienfaktoren interagieren dürfen. Wählen Sie alle blockierenden Faktoren aus und klicken Sie auf Hinzufügen. Beziehen Sie diese Faktoren in keinen der nachfolgenden Teilschritte ein.
HINWEIS: Es ist wichtig, blockierende Faktoren im Modell zu berücksichtigen, aber blockierende Faktoren sollten nicht mit anderen Studienfaktoren interagieren dürfen. Der Hauptzweck von Blockierungsfaktoren besteht darin, die Variabilität des Experiments zu kontrollieren und die Sensitivität des Experiments zu verbessern. - Heben Sie alle Studienfaktoren hervor. Ändern Sie den Wert des Feldes Grad in 3 (standardmäßig auf 2 festgelegt). Klicken Sie auf Fakultät zu Grad.
ANMERKUNG: Diese Aktion umfasst Haupteffekte sowie Zwei- und Drei-Wege-Wechselwirkungen im Modell. - Wählen Sie im Auswahlfenster nur die Nicht-Mischungsfaktoren aus. Klicken Sie auf Makros > Teilkubisch.
ANMERKUNG: Diese Aktion führt zu quadratischen Effekten für die kontinuierlichen Prozessfaktoren und deren Wechselwirkung mit anderen Nicht-Mischungsfaktoren im Modell. - Wählen Sie nur die Mischungsfaktoren aus der Auswahlliste aus. Klicken Sie auf Makros > Scheffe Cubic. Deaktivieren Sie die Standardoption "Kein Abfangen " (siehe Abbildung 9).
HINWEIS: Das Einfügen eines Achsenabschnitts in das Modell ist ein wesentlicher Schritt bei der Verwendung von Lasso-Methoden und auch im Kontext der Vorwärtsauswahl hilfreich. Die traditionelle Standardeinstellung Kein Achsenabschnitt ist in der Regel vorhanden, da das gleichzeitige Anpassen eines Schnittpunkts mit allen Haupteffekten des Gemisches ohne Modifikationen wie den SVEM-Ansatz mit dem regulären Regressionsverfahren der kleinsten Quadrate12 nicht möglich ist. - Geben Sie die Antwortspalte an: Markieren Sie die Antwortspalte und klicken Sie auf Y.
- Ändern Sie die Persönlichkeitseinstellung in Generalisierte Regression. Behalten Sie die Einstellung "Verteilung " auf " Normal" bei.
- Speichern Sie diese Modellkonfiguration in der Datentabelle, um sie mit weiteren Antworten zu verwenden, indem Sie auf das rote Dreiecksmenü neben Modellspezifikation klicken und In Datentabelle speichern auswählen.
- Wenden Sie die SVEM-Vorwärtsauswahlmethode an, um sie an das reduzierte Modell anzupassen, ohne dass die Haupteffekte des Mischungsfaktors zwingend einbezogen werden müssen, und speichern Sie die Vorhersageformelspalte in der Datentabelle.
- Klicken Sie im Dialogfeld Modell anpassen auf Ausführen.
- Wählen Sie für die Schätzmethode die Option SVEM-Vorwärtsauswahl aus.
- Erweitern Sie die Menüs "Erweiterte Steuerung" > "Begriffe erzwingen" und deaktivieren Sie die Kästchen, die mit den Haupteffekten der Mischung verknüpft sind. Nur das Kontrollkästchen Begriff abfangen sollte aktiviert bleiben. Abbildung 10 zeigt die Standardeinstellung, in der die Haupteffekte erzwungen werden. Für diesen Schritt müssen diese Kontrollkästchen deaktiviert werden, damit das Modell diese Effekte basierend auf dem Vorwärtsauswahlverfahren ein- oder ausschließen kann.
- Klicken Sie auf Los , um die SVEM-Vorwärtsauswahl auszuführen.
- Stellen Sie die tatsächlichen Antworten anhand der vorhergesagten Antworten aus dem SVEM-Modell dar, um eine angemessene Vorhersagefähigkeit zu überprüfen. (Abbildung 11). Klicken Sie auf das rote Dreieck neben SVEM-Vorwärtsauswahl , und wählen Sie Diagnosediagramme > Diagramm tatsächlich nach Vorhersage aus.
- Klicken Sie auf das rote Dreieck neben SVEM-Vorwärtsauswahl , und wählen Sie Spalten speichern > Vorhersageformel speichern aus, um eine neue Spalte mit der Vorhersageformel in der Datentabelle zu erstellen.
- Optional: Wiederholen Sie die obigen Schritte mit SVEM Lasso als Schätzmethode , um festzustellen, ob nach dem Ausführen der nachfolgenden Schritte ein anderes optimales Rezept vorgeschlagen wird. Wenn dies der Fall ist, führen Sie beide Rezepte als Bestätigungsausführungen aus (siehe Abschnitt 5), um zu sehen, welche in Praxis12 am besten funktioniert.
- Wiederholen Sie die Schritte zum Erstellen des Modells für jede Antwort.
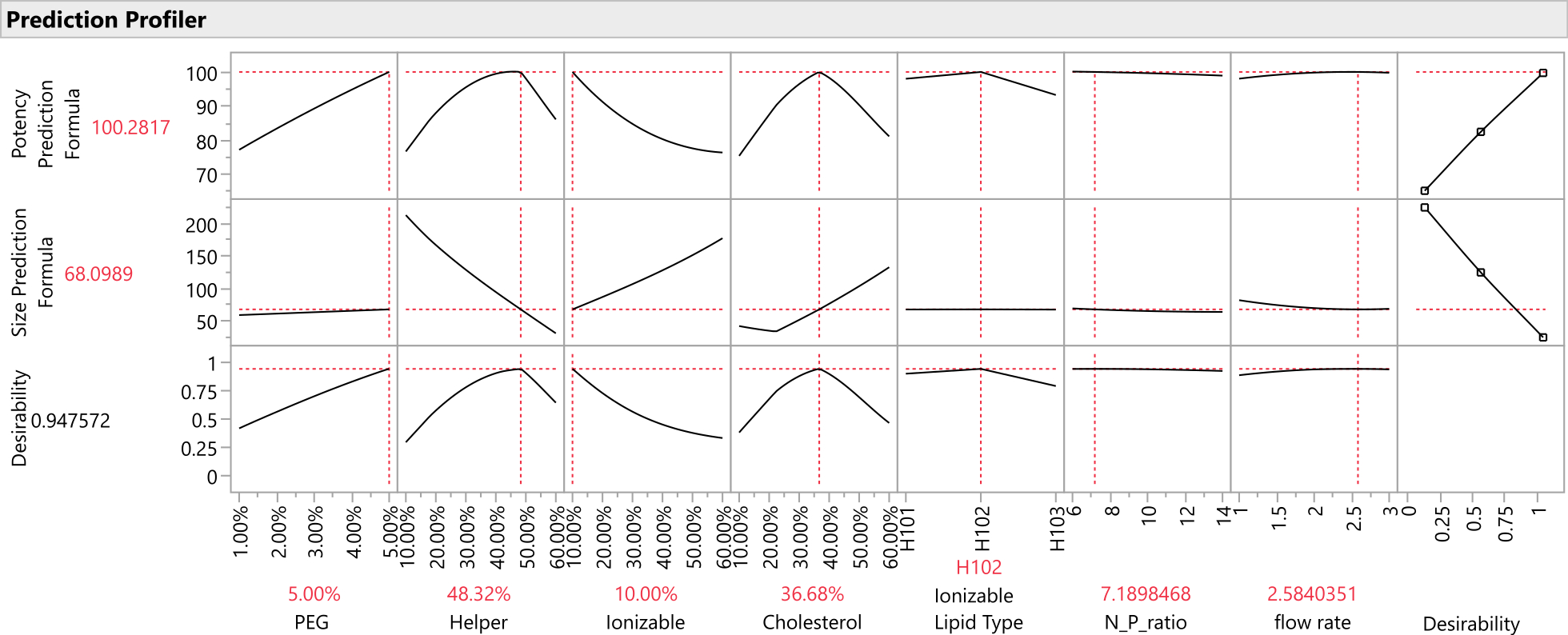
- Nachdem die Vorhersagespalten für alle Antwortvariablen in der Datentabelle gespeichert wurden, stellen Sie die Antwortverläufe für alle Spalten der vorhergesagten Antwort mithilfe der Profiler-Plattform grafisch dar: Wählen Sie Diagramm > Profiler aus, und wählen Sie alle Vorhersagespalten aus, die im vorherigen Schritt für Y, Vorhersageformel erstellt wurden, und klicken Sie auf OK (Abbildung 12).
- Identifizieren Sie geeignete optimale Formulierung(en).
- Definieren Sie die "Erwünschtheitsfunktion" für jede Antwort und geben Sie an, ob die Antwort maximiert, minimiert oder mit einem Ziel abgeglichen werden soll. Legen Sie für alle primären Antworten eine Wichtigkeitsgewichtung von 1,0 und für alle sekundären Antworten eine Wichtigkeitsgewichtung von 0,2 fest. Wählen Sie im Menü des roten Dreiecks des Vorhersageprofilers die Optionen Optimierung und Erwünschtheit > Erwünschtheitsfunktionen und dann Optimierung und Erwünschtheit > Erwünschtheitsfunktionen festlegen aus. Geben Sie die Einstellungen in den folgenden Fenstern ein.
HINWEIS: Die wichtigen Gewichte sind relativ und subjektiv, daher lohnt es sich, die Empfindlichkeit des kombinierten Optimums gegenüber Änderungen dieser Gewichte innerhalb eines angemessenen Bereichs zu überprüfen (z. B. von gleicher Gewichtung zu 1:5-Gewichtung). - Befehlen Sie dem Profiler, die optimalen Faktoreinstellungen zu finden, die die Erwünschtheitsfunktion maximieren (Abbildung 12): Wählen Sie im Profiler Optimierung und Erwünschtheit > Maximierung der Erwünschtheit aus.
HINWEIS: Die prognostizierten Werte der Antworten bei den optimalen Kandidaten können den Wert rechtsschiefer Antworten wie z. B. die Potenz überschätzen. Die Bestätigungsläufe werden jedoch genauere Beobachtungen dieser Kandidatenformulierungen liefern. Das Hauptziel besteht darin, die optimale Rezeptur (die Einstellungen der optimalen Rezeptur) zu finden. - Notieren Sie die optimalen Faktoreinstellungen, und notieren Sie sich die wichtigen Gewichtungen, die für jede Antwortvariable verwendet werden: Wählen Sie im Menü " Vorhersage-Profiler " die Option " Faktoreinstellungen" > "Einstellungen speichern" aus.
- Definieren Sie die "Erwünschtheitsfunktion" für jede Antwort und geben Sie an, ob die Antwort maximiert, minimiert oder mit einem Ziel abgeglichen werden soll. Legen Sie für alle primären Antworten eine Wichtigkeitsgewichtung von 1,0 und für alle sekundären Antworten eine Wichtigkeitsgewichtung von 0,2 fest. Wählen Sie im Menü des roten Dreiecks des Vorhersageprofilers die Optionen Optimierung und Erwünschtheit > Erwünschtheitsfunktionen und dann Optimierung und Erwünschtheit > Erwünschtheitsfunktionen festlegen aus. Geben Sie die Einstellungen in den folgenden Fenstern ein.
- Optional: Für kategoriale Faktoren, wie z. B. den ionisierbaren Lipidtyp, finden Sie die bedingt optimalen Formulierungen für jede Faktorstufe.
- Legen Sie zuerst die gewünschte Stufe des Faktors im Profiler fest, halten Sie dann die Strg-Taste gedrückt, klicken Sie mit der linken Maustaste in das Diagramm dieses Faktors und wählen Sie Einstellung der Faktoren sperren. Wählen Sie Optimierung und Erwünschtheit > Erwünschtheit maximieren aus, um das bedingte Optimum zu finden, bei dem dieser Faktor auf der aktuellen Einstellung fixiert ist.
- Entsperren Sie die Faktoreinstellungen, bevor Sie fortfahren, und verwenden Sie dasselbe Menü, in dem Sie die Faktoreinstellungen gesperrt haben.
- Wiederholen Sie den Optimierungsprozess, nachdem Sie die Wichtigkeitsgewichtungen der Antworten angepasst haben (mithilfe von Optimierung und Erwünschtheit > Festlegen von Erwünschtheiten), möglicherweise nur die primäre(n) Antwortvariable(n) optimieren oder einige der sekundären Antwortvariablen so festlegen, dass sie mehr oder weniger wichtig sind, oder das Ziel der sekundären Antworten auf Keine festlegen (Abbildung 13).
- Notieren Sie den neuen optimalen Kandidaten (wählen Sie im Menü "Vorhersage-Profiler" die Option "Faktoreinstellungen" > "Einstellungen speichern" aus.)
- Erstellen Sie grafische Zusammenfassungen der optimalen Bereiche des Faktorraums: Generieren Sie eine Datentabelle mit 50.000 Zeilen, die mit zufällig generierten Faktoreneinstellungen innerhalb des zulässigen Faktorraums gefüllt sind, zusammen mit den entsprechenden vorhergesagten Werten aus dem reduzierten Modell für jede der Antwortvariablen und die gemeinsame Erwünschtheitsfunktion.
- Wählen Sie im Profiler die Option Zufallstabelle ausgeben aus. Legen Sie Wie viele Durchläufe sollen simuliert? auf 50.000 fest, und klicken Sie auf OK .
HINWEIS: Dadurch wird eine neue Tabelle mit den vorhergesagten Werten der Antwortvariablen für jede der 50.000 Formulierungen generiert. Die Spalte " Erwünschtheit" hängt von den Wichtigkeitsgewichtungen für die Antworten ab, die vorhanden sind, wenn die Option " Ausgabe-Zufallstabelle" ausgewählt ist. - Fügen Sie in der neu erstellten Tabelle eine neue Spalte hinzu, die das Perzentil der Spalte "Erwünschtheit" berechnet. Verwenden Sie diese Perzentilspalte in den ternären Diagrammen anstelle der unformatierten Spalte "Erwünschtheit". Klicken Sie mit der rechten Maustaste auf die Spaltenüberschrift Erwünschtheit, und wählen Sie Neue Formelspalte > Verteilungs- > Kumulative Wahrscheinlichkeit aus, um eine neue Spalte Kumulative Wahrscheinlichkeit[Erwünschtheit] zu erstellen.
- Generieren Sie die in den folgenden Schritten beschriebenen Grafiken. Ändern Sie wiederholt das Farbschema der Grafiken, um die Vorhersagen für jede Antwortvariable und für die Spalte Kumulative Wahrscheinlichkeit[Erwünschtheit] anzuzeigen.
- Konstruieren Sie ternäre Diagramme für die vier Lipidfaktoren. Navigieren Sie in der Tabelle zu Diagramm > ternäres Diagramm, wählen Sie die Mischungsfaktoren für X, Diagramm aus, und klicken Sie auf OK. Klicken Sie mit der rechten Maustaste in eines der resultierenden Diagramme, wählen Sie Zeilenlegende aus, und wählen Sie dann die Spalte für die vorhergesagte Antwort aus. Ändern Sie das Dropdown-Menü "Farben" in "Jet".
HINWEIS: Hier werden die Regionen mit der besten und schlechtesten Leistung in Bezug auf die Lipidfaktoren angezeigt. Abbildung 14 zeigt die Perzentile der Gelenkerwünschtheit bei der Maximierung der Potenz (Wichtigkeit = 1) und der Minimierung der Größe (Wichtigkeit = 0,2) bei Mittelung aller Faktoren, die nicht auf den ternären Diagrammachsen angezeigt werden. Abbildung 15 zeigt die prognostizierte Rohgröße. Es ist auch sinnvoll, diese Diagramme bedingt nach anderen Faktoren aufzuschlüsseln, z. B. durch das Erstellen eines eindeutigen Satzes ternärer Diagramme für jeden ionisierbaren Lipidtyp mit einem lokalen Datenfilter (verfügbar über das rote Dreiecksmenü neben Ternärdiagramm). - Verwenden Sie Graph > Graph Builder , um die 50.000 farbcodierten Punkte (die eindeutige Formulierungen darstellen) einzeln oder gemeinsam gegen die Prozessfaktoren ohne Mischung darzustellen und nach Beziehungen zwischen den Antwortvariablen und den Faktoren zu suchen. Suchen Sie nach den Faktoreinstellungen, die die höchste Erwünschtheit ergeben. Untersuchen Sie verschiedene Kombinationen von Faktoren in den Grafiken.
HINWEIS: Verwenden Sie beim Einfärben von Diagrammen die kumulative Wahrscheinlichkeit [ Erwünschtheit], aber wenn Sie die Erwünschtheit auf der vertikalen Achse gegen Prozessfaktoren darstellen, verwenden Sie die unformatierte Spalte Erwünschtheit . Die Spalte " Erwünschtheit " kann auch auf einer Achse der 3D-Visualisierung "Diagramm > Streudiagramm " zusammen mit zwei anderen Prozessfaktoren für die multivariate Exploration platziert werden. Abbildung 16 zeigt die gemeinsame Erwünschtheit aller Formulierungen, die mit jedem der drei ionisierbaren Lipidtypen gebildet werden können. Die begehrtesten Formulierungen verwenden H102, wobei H101 einige potenziell wettbewerbsfähige Alternativen bietet. - Speichern Sie den Profiler und die gespeicherten Einstellungen wieder in der Datentabelle. Klicken Sie auf das rote Dreieck neben Profiler , und wählen Sie Skript > Datentabelle speichern... aus.
- Wählen Sie im Profiler die Option Zufallstabelle ausgeben aus. Legen Sie Wie viele Durchläufe sollen simuliert? auf 50.000 fest, und klicken Sie auf OK .

Abbildung 8: Beobachtete Potenzwerte aus dem Experiment. Die Punkte zeigen die Potenzwerte, die bei den 23 Durchläufen beobachtet wurden; Die replizierten Benchmark-Ausführungen werden grün angezeigt. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 9: Software-Dialog zum Initiieren der Analyse. Die Kandidateneffekte wurden zusammen mit der Zielpotenz eingegeben, und die Option "Kein Abfangen" wurde deaktiviert. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 10. Zusätzlicher Dialog zum Festlegen von SVEM-Optionen. Standardmäßig werden die Haupteffekte des Lipids in das Modell erzwungen. Da ein Schnittpunkt enthalten ist, empfehlen wir, diese Kontrollkästchen zu deaktivieren, um die Effekte nicht zu erzwingen. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 11: Ist-Zustand nach vorhergesagtem Diagramm. In dieser Abbildung wird die beobachtete Potenz mit dem Wert verglichen, der für jede Formulierung vom SVEM-Modell vorhergesagt wird. Die Korrelation muss nicht so stark sein wie in diesem Beispiel, aber es wird erwartet, dass zumindest eine moderate Korrelation zu sehen ist und nach Ausreißern gesucht wird. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 12: Vorhersage-Profiler. Die oberen beiden Zeilen der Diagramme zeigen die Schichten der vorhergesagten Antwortfunktion bei der optimalen Formulierung (wie durch den SVEM-Ansatz identifiziert). Die untere Reihe der Diagramme zeigt die gewichtete "Erwünschtheit" der Formulierung, die eine Funktion der letzten Spalte von Diagrammen ist, die zeigt, dass die Potenz maximiert und die Größe minimiert werden sollte. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 13: Drei optimale Formulierungskandidaten aus SVEM-Forward Selection. Eine Änderung der relativen Gewichtung der Antworten kann zu unterschiedlichen optimalen Formulierungen führen. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 14: Ternäre Diagramme für das Perzentil der Erwünschtheit. Das Diagramm zeigt die 50.000 Formulierungen, farbcodiert nach Perzentil der Erwünschtheit, wobei die Erwünschtheit mit einem Wichtigkeitsgewicht von 1,0 für die Maximierung der Potenz und 0,2 für die Minimierung der Größe festgelegt ist, diese Diagramme zeigen, dass der optimale Bereich der Formulierungen aus niedrigeren Anteilen ionisierbarer Lipide und höheren Anteilen an PEG besteht. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

Abbildung 15: Ternäres Diagramm für die vorhergesagte Größe. Das Diagramm zeigt die Größenvorhersagen aus dem SVEM-Modell für jede der 50.000 Formulierungen. Die Größe wird durch höhere Anteile an Helferlipiden minimiert und mit niedrigeren Anteilen an Helfern maximiert. Da die anderen Faktoren in den 50.000 dargestellten Formulierungen frei variieren, bedeutet dies, dass diese Beziehung über die Bereiche der anderen Faktoren (PEG, Durchflussrate usw.) hinweg gilt. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}

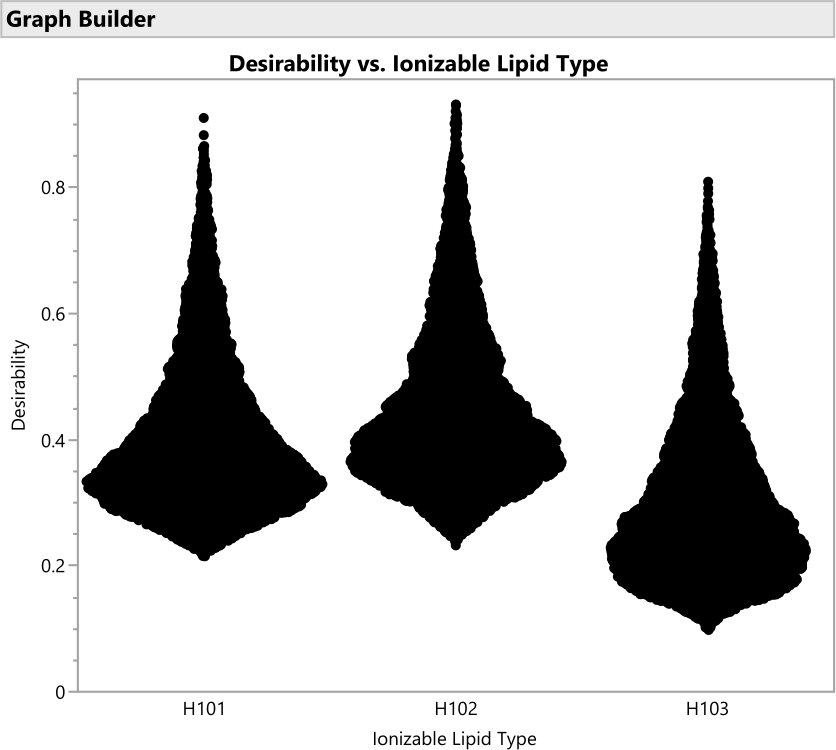
Abbildung 16: Violindiagramme für die Erwünschtheit von Formulierungen mit den drei verschiedenen ionisierbaren Lipidtypen. Jeder der 50.000 Punkte stellt eine eindeutige Formulierung aus dem gesamten zulässigen Faktorraum dar. Die Spitzen dieser Verteilungen sind die Maximalwerte der Erwünschtheit, die analytisch mit dem Vorhersageprofiler berechnet werden. H102 hat den größten Peak und ergibt somit die optimale Formulierung. Der SVEM-Ansatz zum Erstellen des Modells, das diese Ausgabe generiert, filtert statistisch nicht signifikante Faktoren automatisch heraus: Der Zweck dieses Diagramms besteht darin, die praktische Signifikanz über die Faktorstufen hinweg zu berücksichtigen. Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}
5. Quittierungsläufe
- Erstellen Sie eine Tabelle, in der die zuvor identifizierten optimalen Kandidaten aufgeführt sind (Abbildung 17).
HINWEIS: Die Werte für "Wahre Potenz " und " Wahre Größe " in Abbildung 17 werden mithilfe der simulierten Generierungsfunktionen ausgefüllt: In der Praxis werden diese durch die Formulierung und anschließende Messung der Leistung dieser Rezepte ermittelt.- Schließen Sie das Benchmark-Steuerelement in den Satz von Kandidatenläufen ein, die formuliert und gemessen werden.
- Wenn sich herausstellt, dass eine der Formulierungen aus dem Experiment die gewünschten Ergebnisse liefert, z. B. indem sie den Benchmark übertrifft, wählen Sie die besten aus, um sie der Kandidatentabelle hinzuzufügen, und testen Sie sie zusammen mit neuen Formulierungen erneut.
Hinweis: Fügen Sie der Kandidatentabelle entweder manuell die gewünschten Ausführungen hinzu, oder verwenden Sie die gespeicherten Einstellungen des Profiler-Fensters, wenn diese Ausführungen aus dem vorherigen Experiment stammen. Identifizieren Sie die Zeilennummer der Ausführung, navigieren Sie zu Prediction Profiler > Factor Settings > Set to Data in Row, und geben Sie die Zeilennummer ein. Wählen Sie dann Prediction Profiler > Factor Settings > Remember Settings aus, und beschriften Sie sie entsprechend (z. B. "Benchmark" oder "Best Run aus dem vorherigen Test"). - Klicken Sie im Profiler mit der rechten Maustaste auf die Tabelle " Gespeicherte Einstellungen ", und wählen Sie "In Datentabelle umwandeln" aus.
HINWEIS: Abhängig von der Priorität und dem Budget der Studie sollten Sie für jeden Bestätigungslauf Replikationen durchführen, insbesondere wenn der Benchmark ersetzt wird. Erstellen und analysieren Sie jede Formulierung zweimal, wobei Sie das durchschnittliche Ergebnis für das Ranking verwenden. Achten Sie auf alle Kandidaten mit einem großen Ansprechbereich über die beiden Replikate hinweg, da dies auf eine hohe Prozessvarianz hindeuten könnte. - Falls dies aufgrund von Budgetbeschränkungen erforderlich ist, können Sie aus den identifizierten Kandidaten eine Auswahl treffen, um das experimentelle Budget zu erreichen oder redundante Kandidaten zu eliminieren.
- Führen Sie die Rückmeldeläufe durch. Konstruieren Sie die Formulierungen und sammeln Sie die Messwerte.
- Überprüfen Sie die Konsistenz zwischen den Ergebnissen des ursprünglichen Experiments und den Ergebnissen des Bestätigungsbatches für Benchmarks oder andere wiederholte Rezepte. Wenn es eine große und unerwartete Verschiebung gibt, überlegen Sie, was zu der Verschiebung beigetragen haben könnte und ob es möglich ist, dass alle Ausführungen aus dem Bestätigungsbatch betroffen waren.
- Vergleichen Sie die Leistung der optimalen Rezepturen. Untersuchen Sie, ob neue Kandidaten die Benchmark übertroffen haben.
- Optional: Fügen Sie das Ergebnis der Bestätigungsläufe der Versuchstabelle hinzu, und führen Sie die Analyse in Abschnitt 4 erneut aus.
HINWEIS: Der nächste Schritt des Arbeitsablaufs enthält Anweisungen zum Erstellen einer Folgestudie zusammen mit diesen Durchläufen, falls gewünscht.

Abbildung 17: Tabelle mit zehn optimalen Kandidaten, die als Bestätigungsläufe ausgeführt werden sollen. Die wahre Potenz und die wahre Größe wurden aus den simulationsgenerierenden Funktionen ausgefüllt (ohne zusätzliche Prozess- oder analytische Variation). Bitte klicken Sie hier, um eine größere Version dieser Abbildung zu sehen.
{kind=link}
6. Optional: Entwerfen einer Folgestudie, die gleichzeitig mit den Bestätigungsläufen durchgeführt werden soll
- Beurteilen Sie die Notwendigkeit einer Folgestudie unter Berücksichtigung der folgenden Kriterien:
- Bestimmen Sie, ob die optimale Formulierung entlang einer der Faktorgrenzen liegt und ob ein zweites Experiment gewünscht wird, um mindestens einen der Faktorbereiche zu erweitern.
- Bewerten Sie, ob im ersten Experiment eine relativ kleine Durchlaufgröße oder relativ große Faktorbereiche verwendet wurden und ob die identifizierte optimale Region mit zusätzlichen Durchläufen und aktualisierten Analysen "vergrößert" werden muss.
- Prüfen Sie, ob ein zusätzlicher Faktor eingeführt wird. Dabei kann es sich um die Höhe eines kategorialen Faktors handeln, z. B. ein zusätzliches ionisierbares Lipid, oder um einen Faktor, der in der ersten Studie konstant blieb, z. B. die Pufferkonzentration.
- Wenn keine der oben genannten Bedingungen erfüllt ist, fahren Sie mit Schritt 7 fort.
- Bereiten Sie sich darauf vor, dass gleichzeitig mit den Bestätigungsläufen weitere experimentelle Durchläufe ausgeführt werden.
- Definieren Sie die Faktorgrenzen, um eine teilweise Überlappung mit der Region aus der ursprünglichen Studie zu gewährleisten. Liegt keine Überschneidung vor, muss eine neue Studie konzipiert werden.
- Entwickeln Sie die neuen Versuchsläufe mit einem raumfüllenden Design. Wählen Sie DOE > Design für spezielle Zwecke > raumfüllenden Design aus.
HINWEIS: Für fortgeschrittene Benutzer sollten Sie ein D-optimales Design über DOE > Custom Design in Betracht ziehen. - Nachdem die raumfüllenden Durchläufe generiert wurden, fügen Sie manuell zwei oder drei Durchläufe aus dem ursprünglichen Experiment hinzu, die innerhalb des neuen Faktorraums liegen. Verteilen Sie diese Durchläufe nach dem Zufallsprinzip innerhalb der experimentellen Tabelle, indem Sie die in Abschnitt 2 beschriebenen Schritte ausführen, um Zeilen hinzuzufügen und dann die Zeilenreihenfolge zu randomisieren.
HINWEIS: Diese werden verwendet, um jede Verschiebung der Antwortmittelwerte zwischen Blöcken zu schätzen. - Verketten Sie die Bestätigungsläufe und die neuen platzfüllenden Durchläufe in einer einzigen Tabelle, und randomisieren Sie die Durchlaufreihenfolge. Verwenden Sie Tabellen > Verketten , und erstellen und sortieren Sie dann nach einer neuen Zufallsspalte, um die Ausführungsreihenfolge zu randomisieren, wie in Abschnitt 2 beschrieben.
- Formulieren Sie die neuen Rezepte und sammeln Sie die Ergebnisse.
- Verketten Sie die neuen experimentellen Ausführungen und Ergebnisse mit der ursprünglichen Experimentdatentabelle, und führen Sie eine experiment-ID-Spalte ein, um die Quelle der einzelnen Ergebnisse anzugeben. Verwenden Sie Tabellen > Verketten, und wählen Sie die Option Quellspalte erstellen aus.
- Stellen Sie sicher, dass die Spalteneigenschaften für jeden Faktor den kombinierten Bereich für beide Studien anzeigen: Klicken Sie mit der rechten Maustaste auf die Spaltenüberschrift für jeden Faktor, und untersuchen Sie die Eigenschaftsbereiche Kodierung und Mischung, falls vorhanden.
- Beginnen Sie mit der Analyse der Ergebnisse des neuen Experiments.
- Fügen Sie die Spalte experiment-ID als Begriff in das Modell ein, um als Blockierungsfaktor zu dienen. Stellen Sie sicher, dass dieser Begriff nicht mit den Studienfaktoren interagiert. Führen Sie das in Abschnitt 4 in der Tabelle gespeicherte Dialogskript Modell anpassen aus, wählen Sie die Spalte experiment-ID aus und klicken Sie auf Hinzufügen , um es in die Liste der Kandidateneffekte aufzunehmen.
- Führen Sie dieses Dialogfeld Modell anpassen für die verkettete Datentabelle aus, um die Ergebnisse des neuen Experiments und der ersten Studie gemeinsam zu analysieren. Halten Sie sich an frühere Anweisungen, um aktualisierte optimale Formulierungskandidaten und grafische Zusammenfassungen zu erstellen.
- Analysieren Sie zur Validierung unabhängig voneinander die Ergebnisse des neuen Experiments, wobei die Ergebnisse des ursprünglichen Experiments ausgeschlossen werden. Das heißt, führen Sie die in Abschnitt 4 beschriebenen Schritte auf der neuen Versuchstabelle aus.
- Stellen Sie sicher, dass die optimalen Formulierungen, die von diesen Modellen identifiziert werden, eng mit denen übereinstimmen, die von der gemeinsamen Analyse erkannt werden.
- Überprüfen Sie die grafischen Zusammenfassungen, um zu bestätigen, dass sowohl die gemeinsame als auch die individuelle Analyse der neuen experimentellen Ergebnisse ein ähnliches Verhalten der Antwortoberfläche aufweisen (was bedeutet, dass eine ähnliche Beziehung zwischen den Antwortvariablen und den Faktoren besteht).
- Vergleichen Sie die kombinierten und individuellen Analysen neuer Ergebnisse mit dem ersten Experiment, um die Konsistenz zu gewährleisten. Verwenden Sie ähnliche Graphenstrukturen zum Vergleich und untersuchen Sie die identifizierten optimalen Rezepte auf Unterschiede.
7. Dokumentation der abschließenden wissenschaftlichen Schlussfolgerungen der Studie
- Sollte sich die Benchmark-Kontrolle aufgrund der Studie auf eine neu identifizierte Rezeptur ändern, protokollieren Sie die neue Einstellung und geben Sie die Design- und Analysedateien an, die ihre Herkunft aufzeichnen.
- Bewahren Sie alle Versuchstabellen und Analysezusammenfassungen auf, vorzugsweise mit Dateinamen mit Datumsstempel, um später darauf zurückgreifen zu können.
Access restricted. Please log in or start a trial to view this content.
Ergebnisse
Dieser Ansatz wurde für beide allgemein klassifizierten Lipidtypen validiert: MC3-ähnliche klassische Lipide und Lipidoide (z. B. C12-200), die im Allgemeinen aus der kombinatorischen Chemie stammen. Im Vergleich zu einer Benchmark-LNP-Formulierung, die mit einer One-Factor-at-a-Time-Methode (OFAT) entwickelt wurde, zeigen die durch unseren Workflow generierten Kandidatenformulierungen häufig Potenzverbesserungen von 4- bis 5-fach auf logarithmischer Skala, wie in den Luziferase-Messwerten der Mausleber in
Access restricted. Please log in or start a trial to view this content.
Diskussion
Moderne Software für die Planung und Analyse von Experimenten mit Mischungsprozessen ermöglicht es Wissenschaftlern, ihre Lipid-Nanopartikel-Formulierungen in einem strukturierten Arbeitsablauf zu verbessern, der ineffiziente OFAT-Experimente vermeidet. Der kürzlich entwickelte SVEM-Modellierungsansatz eliminiert viele der obskuren Regressionsmodifikationen und Modellreduktionsstrategien, die Wissenschaftler zuvor möglicherweise mit überflüssigen statistischen Überlegungen abgelenkt haben. Sobald die Ergebnisse ge...
Access restricted. Please log in or start a trial to view this content.
Offenlegungen
Die experimentelle Designstrategie, die diesem Workflow zugrunde liegt, wurde in zwei Patentanmeldungen eingesetzt, bei denen einer der Autoren Erfinder ist. Darüber hinaus ist Adsurgo, LLC ein zertifizierter JMP-Partner. Die Entwicklung und Veröffentlichung dieses Papiers erfolgte jedoch ohne jegliche Form von finanziellen Anreizen, Ermutigungen oder anderen Anreizen durch JMP.
Danksagungen
Wir danken dem Herausgeber und den anonymen Gutachtern für Vorschläge, die den Artikel verbessert haben.
Access restricted. Please log in or start a trial to view this content.
Materialien
| Name | Company | Catalog Number | Comments |
| JMP Pro 17.1 | JMP Statistical Discovery LLC |
Referenzen
- Dolgin, E. Better lipids to power next generation of mRNA vaccines. Science. 376 (6594), 680-681 (2022).
- Hou, X., Zaks, T., Langer, R., Dong, Y. Lipid nanoparticles for mRNA delivery. Nature Reviews Materials. 6 (12), 1078-1094 (2021).
- Huang, X., et al. The landscape of mRNA nanomedicine. Nature Medicine. 28, 2273-2287 (2022).
- Rampado, R., Peer, D. Design of experiments in the optimization of nanoparticle-based drug delivery systems. Journal of Controlled Release. 358, 398-419 (2023).
- Kauffman, K. J., et al. Optimization of lipid nanoparticle formulations for mRNA delivery in vivo with fractional factorial and definitive screening designs. Nano Letters. 15, 7300-7306 (2015).
- Jones, B., Nachtsheim, C. J. A class of three-level designs for definitive screening in the presence of second-order effects. Journal of Quality Technology. 43, 1-15 (2011).
- Cornell, J. Experiments with Mixtures: Designs, Models, and the Analysis of Mixture Data. Wiley Series in Probability and Statistics. , Wiley. (2002).
- Jones, B. Proper and improper use of definitive screening designs (DSDs). JMP user Community. , https://community.jmp.com/t5/JMP-Blog/Proper-and-improper-use-of-Definitive-Screening-Designs-DSDs/bc-p/546773 (2016).
- Myers, R., Montgomery, D., Anderson-Cook, C. Response Surface Methodology. , Wiley. (2016).
- Lekivetz, R., Jones, B. Fast flexible space-filling designs for nonrectangular regions. Quality and Reliability Engineering International. 31, 829-837 (2015).
- Czitrom, V. One-factor-at-a-time versus designed experiments. The American Statistician. 53, 126-131 (1999).
- Karl, A., Wisnowski, J., Rushing, H. JMP Pro 17 remedies for practical struggles with mixture experiments. JMP Discovery Conference. , (2022).
- Lemkus, T., Gotwalt, C., Ramsey, P., Weese, M. L. Self-validated ensemble models for design of experiments. Chemometrics and Intelligent Laboratory Systems. 219, 104439(2021).
- Gotwalt, C., Ramsey, P. Model validation strategies for designed experiments using bootstrapping techniques with applications to biopharmaceuticals. JMP Discovery Conference. , (2018).
- Xu, L., Gotwalt, C., Hong, Y., King, C. B., Meeker, W. Q. Applications of the fractional-random-weight bootstrap. The American Statistician. 74 (4), 345-358 (2020).
- Ramsey, P., Levin, W., Lemkus, T., Gotwalt, C. SVEM: A paradigm shift in design and analysis of experiments. JMP Discovery Conference Europe. , (2021).
- Ramsey, P., Gaudard, M., Levin, W. Accelerating innovation with space filling mixture designs, neural networks and SVEM. JMP Discovery Conference. , (2021).
- Lemkus, T. Self-Validated Ensemble modelling. Doctoral Dissertations. 2707. , https://scholars.unh.edu/dissertation/2707 (2022).
- Juran, J. M. Juran on Quality by Design: The New Steps for Planning Quality into Goods and Services. , Free Press. (1992).
- Yu, L. X., et al. Understanding pharmaceutical quality by design. The AAPS Journal. 16, 771(2014).
- Simpson, J. R., Listak, C. M., Hutto, G. T. Guidelines for planning and evidence for assessing a well-designed experiment. Quality Engineering. 25, 333-355 (2013).
- Daniel, S., Kis, Z., Kontoravdi, C., Shah, N. Quality by design for enabling RNA platform production processes. Trends in Biotechnology. 40 (10), 1213-1228 (2022).
- Scheffé, H. Experiments with mixtures. Journal of the Royal Statistical Society Series B. 20, 344-360 (1958).
- Brown, L., Donev, A. N., Bissett, A. C. General blending models for data from mixture experiments. Technometrics. 57, 449-456 (2015).
- Herrera, M., Kim, J., Eygeris, Y., Jozic, A., Sahay, G. Illuminating endosomal escape of polymorphic lipid nanoparticles that boost mRNA delivery. Biomaterials Science. 9 (12), 4289-4300 (2021).
- Lemkus, T., Ramsey, P., Gotwalt, C., Weese, M. Self-validated ensemble models for design of experiments. ArXiv. , 2103.09303(2021).
- Goos, P., Jones, B. Optimal Design of Experiments: A Case Study Approach. , John Wiley & Sons, Ltd. (2011).
- Rushing, H. DOE Gumbo: How hybrid and augmenting designs can lead to more effective design choices. JMP Discovery Conference. , (2020).
Access restricted. Please log in or start a trial to view this content.
Nachdrucke und Genehmigungen
Genehmigung beantragen, um den Text oder die Abbildungen dieses JoVE-Artikels zu verwenden
Genehmigung beantragenWeitere Artikel entdecken
This article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. Alle Rechte vorbehalten