
Un abonnement à JoVE est nécessaire pour voir ce contenu. Connectez-vous ou commencez votre essai gratuit.
Method Article
Un flux de travail pour l’optimisation de la formulation de nanoparticules lipidiques (LNP) à l’aide d’expériences de processus de mélange conçues et de modèles d’ensemble auto-validés (SVEM)
Dans cet article
Résumé
Ce protocole fournit une approche de l’optimisation de la formulation par rapport aux facteurs d’étude de mélange, continus et catégoriels qui minimise les choix subjectifs dans la construction de la conception expérimentale. Pour la phase d’analyse, une procédure d’ajustement de modélisation efficace et facile à utiliser est utilisée.
Résumé
Nous présentons une approche de style Quality by Design (QbD) pour optimiser les formulations de nanoparticules lipidiques (LNP), visant à offrir aux scientifiques un flux de travail accessible. La restriction inhérente à ces études, où les rapports molaires des lipides ionisables, auxiliaires et PEG doivent totaliser jusqu’à 100%, nécessite des méthodes de conception et d’analyse spécialisées pour tenir compte de cette contrainte de mélange. En nous concentrant sur les facteurs lipidiques et de processus couramment utilisés dans l’optimisation de la conception LNP, nous fournissons des étapes qui évitent bon nombre des difficultés qui surviennent traditionnellement dans la conception et l’analyse d’expériences de processus de mélange en utilisant des plans de remplissage d’espace et en utilisant le cadre statistique récemment développé de modèles d’ensemble auto-validés (SVEM). En plus de produire des formulations optimales candidates, le flux de travail construit également des résumés graphiques des modèles statistiques ajustés qui simplifient l’interprétation des résultats. Les formulations candidates nouvellement identifiées sont évaluées avec des cycles de confirmation et peuvent éventuellement être menées dans le cadre d’une étude de deuxième phase plus complète.
Introduction
Les formulations de nanoparticules lipidiques (LNP) pour les systèmes d’administration de gènes in vivo impliquent généralement quatre lipides constitutifs des catégories des lipides ionisables, auxiliaires et PEG 1,2,3. Que ces lipides soient étudiés seuls ou simultanément avec d’autres facteurs autres que le mélange, les expériences pour ces formulations nécessitent des conceptions de « mélange » parce que - étant donné une formulation candidate - l’augmentation ou la diminution du rapport de l’un quelconque des lipides entraîne nécessairement une diminution ou une augmentation correspondante de la somme des rapports des trois autres lipides.
À titre d’illustration, il est supposé que nous optimisons une formulation LNP qui utilise actuellement une recette définie qui sera traitée comme la référence. L’objectif est de maximiser la puissance du LNP tout en visant secondairement à minimiser la taille moyenne des particules. Les facteurs d’étude qui sont variés dans l’expérience sont les rapports molaires des quatre lipides constitutifs (ionisable, cholestérol, DOPE, PEG), le rapport N:P, le débit et le type de lipide ionisable. Les lipides ionisables et auxiliaires (y compris le cholestérol) peuvent varier sur une gamme plus large de rapports molaires, 10-60%, que le PEG, qui variera de 1 à 5% dans cette illustration. La recette de la formulation de référence et les fourchettes des autres facteurs et leur granularité arrondie sont spécifiées dans le dossier supplémentaire 1. Pour cet exemple, les scientifiques sont en mesure d’effectuer 23 essais (lots uniques de particules) en une seule journée et aimeraient l’utiliser comme taille d’échantillon s’il répond aux exigences minimales. Les résultats simulés de cette expérience sont fournis dans le dossier supplémentaire 2 et le dossier supplémentaire 3.
Rampado et Peer4 ont récemment publié un article de synthèse sur le sujet des expériences conçues pour l’optimisation des systèmes d’administration de médicaments à base de nanoparticules. Kauffman et coll.5 ont examiné les études d’optimisation de la LNP à l’aide de plans de criblage factoriels fractionnaires et définitifs6; Cependant, ces types de modèles ne peuvent pas s’adapter à une contrainte de mélange sans recourir à l’utilisation de « variables inutilisées »7 inefficaces et ne sont généralement pas utilisés lorsque des facteurs de mélange sont présents 7,8. Au lieu de cela, les « plans optimaux » capables d’incorporer une contrainte de mélange sont traditionnellement utilisés pour les expériences de processus de mélange9. Ces plans ciblent une fonction spécifiée par l’utilisateur des facteurs d’étude et ne sont optimaux (dans l’un des nombreux sens possibles) que si cette fonction saisit la véritable relation entre les facteurs de l’étude et les réponses. Il convient de noter qu’il existe une distinction dans le texte entre les « plans optimaux » et les « formulations optimales candidates », ces dernières désignant les meilleures formulations identifiées par un modèle statistique. Les conceptions optimales présentent trois inconvénients principaux pour les expériences de processus de mélange. Premièrement, si le scientifique ne parvient pas à anticiper une interaction des facteurs d’étude lors de la spécification du modèle cible, le modèle résultant sera biaisé et peut produire des formulations candidates de qualité inférieure. Deuxièmement, les conceptions optimales placent la plupart des passages sur la limite extérieure de l’espace factoriel. Dans les études LNP, cela peut conduire à un grand nombre de séries perdues si les particules ne se forment pas correctement à des extrêmes des paramètres lipidiques ou de processus. Troisièmement, les scientifiques préfèrent souvent avoir des essais expérimentaux à l’intérieur de l’espace factoriel pour obtenir un sens indépendant du modèle de la surface de réponse et observer le processus directement dans des régions auparavant inexplorées de l’espace factoriel.
Un autre principe de conception consiste à cibler une couverture approximativement uniforme de l’espace factoriel (contraint par le mélange) avec un plan de remplissaged’espace 10. Ces conceptions sacrifient une certaine efficacité expérimentale par rapport aux conceptions optimales9 (en supposant que l’espace factoriel entier conduit à des formulations valides) mais présentent plusieurs avantages dans un compromis qui sont utiles dans cette application. La conception de remplissage de l’espace ne fait pas d’hypothèses a priori sur la structure de la surface de réponse; Cela lui donne la souplesse nécessaire pour saisir les relations imprévues entre les facteurs de l’étude. Cela rationalise également la génération de conception, car il n’est pas nécessaire de prendre des décisions sur les termes de régression à ajouter ou à supprimer lorsque la taille d’exécution souhaitée est ajustée. Lorsque certains points de conception (recettes) conduisent à des formulations échouées, les plans de remplissage d’espace permettent de modéliser la limite de défaillance sur les facteurs de l’étude tout en soutenant les modèles statistiques pour les réponses à l’étude par rapport aux combinaisons de facteurs réussies. Enfin, la couverture intérieure de l’espace factoriel permet une exploration graphique indépendante du modèle de la surface de réponse.
Pour visualiser le sous-espace facteur de mélange d’une expérience de processus de mélange, des « tracés ternaires » triangulaires spécialisés sont utilisés. La figure 1 motive cet usage : dans le cube de points où trois ingrédients sont chacun autorisés à aller de 0 à 1, les points qui satisfont une contrainte que la somme des ingrédients est égale à 1 sont surlignés en rouge. La contrainte de mélange sur les trois ingrédients réduit l’espace factoriel possible à un triangle. Dans les applications LNP avec quatre ingrédients de mélange, nous produisons six diagrammes ternaires différents pour représenter l’espace factoriel en traçant deux lipides à la fois par rapport à un axe « Autres » qui représente la somme des autres lipides.

Figure 1 : Régions à facteurs triangulaires. Dans le diagramme de remplissage d’espace dans le cube, les petits points gris représentent des formulations qui ne sont pas cohérentes avec la contrainte de mélange. Les plus grands points rouges se trouvent sur un triangle inscrit dans le cube et représentent des formulations pour lesquelles la contrainte de mélange est satisfaite. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}
En plus des facteurs de mélange lipidique, il existe souvent un ou plusieurs facteurs de processus continus tels que le rapport N:P, la concentration tampon ou le débit. Des facteurs catégoriques peuvent être présents, tels que le type de lipide ionisable, le type de lipide auxiliaire ou le type tampon. L’objectif est de trouver une formulation (un mélange de lipides et de paramètres pour les facteurs de processus) qui maximise une certaine mesure de la puissance et / ou améliore les caractéristiques physico-chimiques telles que la minimisation de la taille des particules et de l’indice de polydispersité, la maximisation du pourcentage d’encapsulation et la minimisation des effets secondaires - tels que la perte de poids corporel - dans les études in vivo . Même en partant d’une recette de référence raisonnable, il peut y avoir un intérêt à réoptimiser en fonction d’un changement dans la charge utile génétique ou en considérant des changements dans les facteurs de processus ou les types de lipides.
Cornell7 fournit un texte définitif sur les aspects statistiques des expériences de mélange et de processus de mélange, Myers et al.9 fournissant un excellent résumé des sujets de conception et d’analyse de mélange les plus pertinents pour l’optimisation. Cependant, ces travaux peuvent surcharger les scientifiques de détails statistiques et de terminologie spécialisée. Les logiciels modernes de conception et d’analyse d’expériences fournissent une solution robuste qui prendra suffisamment en charge la plupart des problèmes d’optimisation LNP sans avoir à faire appel à la théorie pertinente. Bien que les études plus complexes ou hautement prioritaires bénéficieront toujours de la collaboration avec un statisticien et puissent utiliser des conceptions optimales plutôt que de remplir l’espace, notre objectif est d’améliorer le niveau de confort des scientifiques et d’encourager l’optimisation des formulations LNP sans faire appel à des tests inefficaces à un facteur à la fois (OFAT)11 ou simplement se contenter de la première formulation qui satisfait aux spécifications.
Dans cet article, un flux de travail est présenté qui utilise un logiciel statistique pour optimiser un problème générique de formulation LNP, en traitant les problèmes de conception et d’analyse dans l’ordre dans lequel ils seront rencontrés. En fait, la méthode fonctionnera pour les problèmes d’optimisation généraux et ne se limite pas aux LNP. En cours de route, plusieurs questions courantes qui se posent sont abordées et des recommandations sont fournies qui sont fondées sur l’expérience et les résultatsde simulation 12. Le cadre récemment développé de modèles d’ensemble auto-validés (SVEM)13 a grandement amélioré l’approche autrement fragile de l’analyse des résultats des expériences de mélange-processus, et nous utilisons cette approche pour fournir une stratégie simplifiée d’optimisation de la formulation. Bien que le flux de travail soit construit d’une manière générale qui peut être suivie à l’aide d’autres progiciels, JMP 17 Pro est unique en ce sens qu’il offre SVEM ainsi que les outils de résumé graphique que nous avons jugés nécessaires pour simplifier l’analyse autrement obscure des expériences de processus de mélange. Par conséquent, des instructions spécifiques à JMP sont également fournies dans le protocole.
SVEM utilise la même base de modèle de régression linéaire que l’approche traditionnelle, mais elle nous permet d’éviter les modifications fastidieuses qui sont nécessaires pour ajuster un « modèle complet » d’effets candidats en utilisant une approche de base de sélection directe ou de sélection pénalisée (Lasso). En outre, SVEM fournit un ajustement amélioré du « modèle réduit » qui minimise le potentiel d’incorporation du bruit (processus plus variance analytique) qui apparaît dans les données. Il fonctionne en faisant la moyenne des modèles prédits résultant de la repondération répétée de l’importance relative de chaque exécution dans le modèle 13,14,15,16,17,18. SVEM fournit un cadre pour la modélisation des expériences de processus de mélange qui est à la fois plus facile à mettre en œuvre que la régression traditionnelle en une seule injection et donne des candidats de formulation optimale de meilleure qualité12,13. Les détails mathématiques de SVEM dépassent le cadre de cet article et même un résumé superficiel au-delà de la revue de littérature pertinente détournerait l’attention de son principal avantage dans cette application: il permet une procédure simple, robuste et précise click-to-run pour les praticiens.
Le flux de travail présenté est conforme à l’approche Quality by Design (QbD)19 du développement pharmaceutique20. Le résultat de l’étude sera une compréhension de la relation fonctionnelle qui relie les attributs des matériaux et les paramètres de procédé aux attributs de qualité critiques (AQC)21. Daniel et al.22 discutent de l’utilisation d’un cadre QbD spécifiquement pour la production de plateformes d’ARN : notre flux de travail pourrait être utilisé comme un outil dans ce cadre.
Protocole
L’expérience décrite dans la section Résultats représentatifs a été réalisée conformément au Guide sur le soin et l’utilisation des animaux de laboratoire et les procédures ont été effectuées conformément aux lignes directrices établies par notre Comité de soin et d’utilisation des animaux en établissement (IACUC). Des souris Balb/C femelles âgées de 6 à 8 semaines ont été obtenues commercialement. Les animaux ont reçu de l’eau et de l’eau standard ad libitum et ont été logés dans des conditions standard avec des cycles lumière/obscurité de 12 heures, à une température de 65-75 ° F (~ 18-23 ° C) avec 40-60% d’humidité.
1. Consignation de l’objectif, des réponses et des facteurs de l’étude
REMARQUE : Dans ce protocole, JMP 17 Pro est utilisé pour concevoir et analyser l’expérience. Un logiciel équivalent peut être utilisé en suivant des étapes similaires. Pour obtenir des exemples et des instructions supplémentaires pour toutes les étapes effectuées dans la section 1, veuillez vous référer au dossier supplémentaire 1.
- Résumez le but de l’expérience dans un document horodaté.
- Énumérez les réponses primaires (AQC) qui seront mesurées au cours de l’expérience.
- Énumérez toutes les réponses secondaires (p. ex. restrictions en aval sur les propriétés physicochimiques) qui pourraient être mesurées.
- Énumérez les paramètres de processus qui peuvent être liés aux réponses, y compris ceux qui sont les plus pertinents pour l’objectif de l’étude.
- Si l’étude se déroule sur plusieurs jours, incluez un facteur de « blocage » catégorique journalier.
REMARQUE: Cela équilibre les paramètres de facteurs entre les jours pour éviter que les changements de niveau jour dans la moyenne du processus ne soient confondus avec les facteurs de l’étude. - Sélectionnez les facteurs à faire varier et ceux à maintenir constants pendant l’étude.
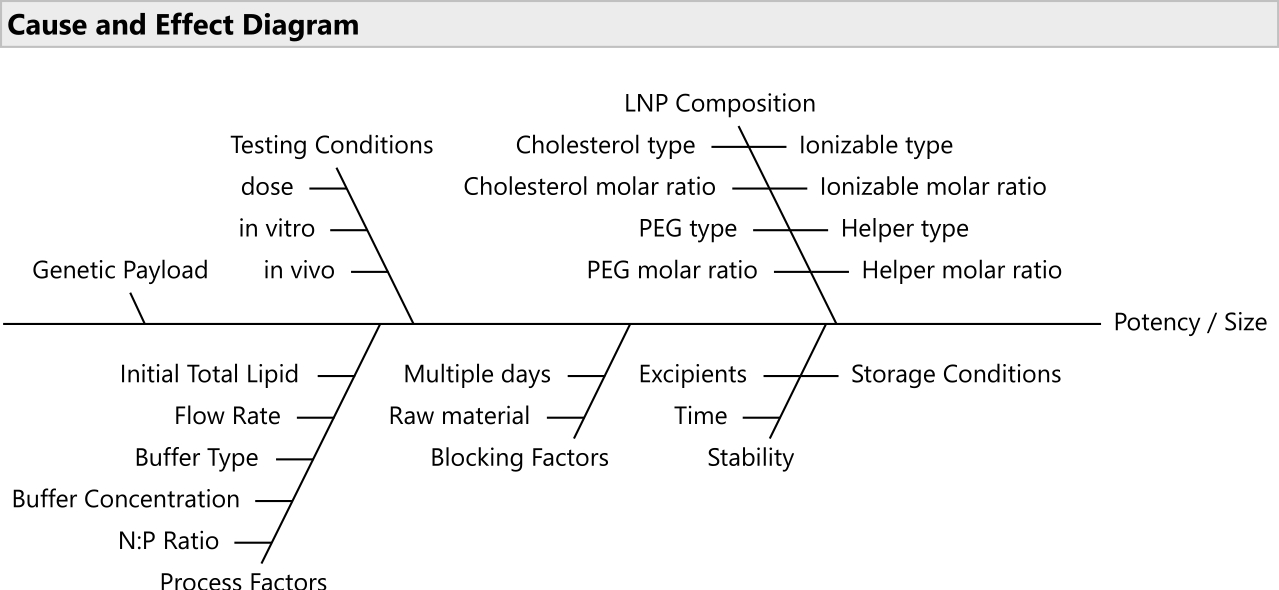
REMARQUE : Utilisez des outils de priorisation des risques tels que les analyses des effets des modes de défaillance20 pour sélectionner le sous-ensemble de facteurs le plus pertinent (figure 2). Habituellement, tous les lipides devraient être autorisés à varier; bien que dans certains cas à budget limité, il est raisonnable de verrouiller le PEG à un ratio fixe. - Établissez les plages pour les différents facteurs et la précision décimale pertinente pour chacun.
- Décider de la taille du plan d’étude (le nombre de lots uniques de particules) en utilisant les heuristiques minimale et maximale. Les essais de contrôle inclus manuellement ne sont pas pris en compte dans la taille d’exécution recommandée par l’heuristique.
Remarque : Les heuristiques suivantes supposent que les réponses sont continues. L’heuristique minimale suppose qu’il sera possible d’effectuer une étude de suivi, si nécessaire, en plus d’effectuer des cycles de confirmation pour les formulations optimales candidates. S’il n’est possible d’effectuer que des exécutions de confirmation, il est préférable de budgétiser le nombre d’exécutions obtenues à partir de l’heuristique maximale. Pour les réponses primaires binaires, demandez l’aide d’un statisticien pour déterminer le nombre approprié d’exécutions.- Heuristique minimale : Allouez trois exécutions par facteur de mélange, deux par facteur de processus continu et une par niveau de chaque facteur catégoriel.
NOTE: Pour une étude avec quatre facteurs lipidiques, deux variables de processus catégorielles continues et une variable de processus catégoriel à trois voies, cela conduit à une suggestion de (3 x 4) + (2 x 2) + 3 = 19 cycles de remplissage d’espace. Ajoutez des essais supplémentaires si certains risquent de tomber en panne en raison de problèmes de formulation ou de mesure. - Heuristique maximale : Lancez le logiciel pour construire des conceptions optimales et entrez les paramètres requis pour un second ordre (y compris les effets principaux, les interactions bidirectionnelles entre tous les effets et les effets quadratiques pour les facteurs de processus continus). Calculez la taille d’exécution minimale selon l’algorithme du logiciel. Ajouter 1 au résultat obtenu à partir du logiciel pour définir l’heuristique maximale.
Remarque : Reportez-vous au fichier supplémentaire 1 pour obtenir des instructions détaillées sur l’exécution de ces étapes. Un cas échantillon avec quatre facteurs lipidiques, deux variables de processus catégorielles continues et une variable de processus catégoriel à trois voies, conduit à une taille d’exécution recommandée de 34 (33 à partir de la recommandation logicielle + 1). Toute course au-delà de cette date serait probablement mieux utilisée pour des études de confirmation ou de suivi.
- Heuristique minimale : Allouez trois exécutions par facteur de mélange, deux par facteur de processus continu et une par niveau de chaque facteur catégoriel.

Figure 2 : Diagramme de cause à effet. Le diagramme montre les facteurs communs dans un problème d’optimisation de formulation LNP. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}
2. Création de la table de conception avec un design remplissant l’espace
- Ouvrez JMP et naviguez dans la barre de menus jusqu’à DOE > Special Purpose > Space Filling Design.
- Entrez les réponses à l’étude (voir le dossier supplémentaire 1).
- Facultatif : ajoutez des colonnes pour les réponses supplémentaires, en indiquant si chacune doit être agrandie, réduite ou ciblée en cliquant sur Ajouter une réponse.
Remarque : Ces paramètres peuvent être modifiés ultérieurement et n’affectent pas la conception. De même, des colonnes supplémentaires pour des réponses supplémentaires peuvent être ajoutées après la création de la table de conception. - Entrez les facteurs d’étude et les fourchettes correspondantes. Utilisez le bouton Mélange pour ajouter des facteurs de mélange, le bouton Continu pour ajouter des facteurs continus ou le bouton Catégoriel pour ajouter des facteurs catégoriels.
NOTE: Cet exemple d’étude utilise les facteurs et les plages illustrés à la figure 3, qui comprennent le rapport molaire ionisable (compris entre 0,1 et 0,6), le rapport molaire auxiliaire (également entre 0,1 et 0,6), le rapport molaire cholestérol (entre 0,1 et 0,6), le rapport molaire PEG (de 0,01 à 0,05) et le type de lipide ionisable (qui peut être H101, H102 ou H103). - Entrez le nombre prédéterminé d’exécutions pour la conception dans le champ Nombre d’exécutions .
- Facultatif : Augmentez la taille moyenne du cluster de 50 à 2000 via le menu triangle rouge en regard de l’en-tête Conception de remplissage d’espace et dans le sous-menu Options avancées .
REMARQUE: Il s’agit d’un paramètre pour l’algorithme de remplissage d’espace qui peut conduire à une construction de conception légèrement meilleure au prix d’un temps de calcul supplémentaire. - Générez la table de conception de remplissage d’espace pour les facteurs choisis et la taille de l’exécution. Cliquez sur Remplissage flexible rapide, puis sur Créer un tableau.
REMARQUE : les deux premières exécutions d’un exemple de conception sont illustrées à la figure 4. - Ajoutez une colonne Notes au tableau pour annoter les exécutions créées manuellement. Double-cliquez sur le premier en-tête de colonne vide pour ajouter une colonne, puis double-cliquez sur le nouvel en-tête de colonne pour modifier le nom.
- Le cas échéant, incorporez manuellement les exécutions de contrôle de référence dans la table de conception. Inclure une réplique pour l’un des repères de contrôle. Marquez le nom du banc d’essai dans la colonne Notes et codez par couleur les lignes de réplication du banc d’essai pour faciliter l’identification du graphique.
- Ajoutez une nouvelle ligne en double-cliquant sur le premier en-tête de ligne vide et entrez les paramètres du facteur de référence. Dupliquez cette ligne pour créer une réplique de l’étalon. Mettez en surbrillance les deux lignes et accédez à Lignes > Couleurs pour attribuer une couleur à des fins graphiques.
REMARQUE : La réplication fournit une estimation indépendante du modèle du processus ainsi qu’une variance analytique et fournit des informations graphiques supplémentaires.
- Ajoutez une nouvelle ligne en double-cliquant sur le premier en-tête de ligne vide et entrez les paramètres du facteur de référence. Dupliquez cette ligne pour créer une réplique de l’étalon. Mettez en surbrillance les deux lignes et accédez à Lignes > Couleurs pour attribuer une couleur à des fins graphiques.
- Si l’un des contrôles de référence dépasse la plage des facteurs de l’étude, indiquez-le dans la colonne « Notes » pour une exclusion future de l’analyse.
- Arrondir les facteurs de mélange à la granularité appropriée. Pour ce faire,
- Mettez en surbrillance les en-têtes de colonne pour les facteurs de mélange, cliquez avec le bouton droit sur l’un des en-têtes de colonne et accédez à Nouvelle colonne de formule > Transformer > arrondi..., entrez l’intervalle d’arrondi correct, puis cliquez sur OK.
- Assurez-vous qu’aucune ligne n’est sélectionnée en cliquant sur le triangle inférieur à l’intersection des en-têtes de ligne et de colonne.
- Copiez les valeurs des colonnes arrondies nouvellement créées (Ctrl + C) et collez-les (Ctrl + V) dans les colonnes de mélange d’origine. Enfin, supprimez les colonnes de valeurs arrondies temporaires.
- Après avoir arrondi les ratios lipidiques, vérifiez que leur somme est égale à 100 % en sélectionnant les en-têtes de colonne pour les facteurs de mélange, en cliquant avec le bouton droit sur l’un d’eux et en accédant à Nouvelle colonne de formule > Combiner > somme. Si la somme d’une ligne n’est pas égale à 1, ajustez manuellement l’un des facteurs de mélange, en veillant à ce que le paramètre de facteur reste dans la plage de facteurs. Supprimez la colonne somme une fois les ajustements effectués.
- Suivez la même procédure que celle utilisée pour arrondir les facteurs de mélange afin d’arrondir les facteurs de procédé à leur granularité respective.
- Formatez les colonnes lipidiques pour qu’elles s’affichent sous forme de pourcentages avec le nombre de décimales souhaité : sélectionnez les en-têtes de colonne, cliquez avec le bouton droit de la souris et choisissez Standardiser les attributs.... Dans la fenêtre suivante, définissez Format sur Pourcentage et ajustez le nombre de décimales selon vos besoins.
- Si des exécutions manuelles sont ajoutées telles que des bancs d’essai, re-randomisez l’ordre des lignes du tableau : ajoutez une nouvelle colonne avec des valeurs aléatoires (cliquez avec le bouton droit sur le dernier en-tête de colonne et sélectionnez Nouvelle colonne de formule > Aléatoire > Normale aléatoire). Triez cette colonne par ordre croissant en cliquant avec le bouton droit sur son en-tête, puis supprimez la colonne.
- Facultatif : ajoutez une colonne Run ID . Renseignez-le avec la date actuelle, le nom de l’expérience et le numéro de ligne de la table.
REMARQUE : reportez-vous à la section (Figure 5) pour un exemple. - Générer des diagrammes ternaires pour visualiser les points de conception sur les facteurs lipidiques (Figure 6). Examinez également la distribution de l’exécution sur les facteurs de processus (Figure 7) : sélectionnez Graphe > Tracé ternaire. Sélectionnez uniquement les facteurs de mélange pour X, Traçage.
- Pour examiner la distribution sur les facteurs de processus, sélectionnez Analyser > Distribution et entrez les facteurs de processus pour Y, Colonnes.
REMARQUE : Le spécialiste de la formulation doit confirmer la faisabilité de tous les essais. S’il existe des exécutions irréalisables, redémarrez la conception en tenant compte des contraintes nouvellement découvertes.

Figure 3 : Facteurs et fourchettes de l’étude. Les captures d’écran des paramètres dans le logiciel expérimental sont utiles pour reproduire la configuration de l’étude. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

Figure 4 : Sortie initiale pour une conception de remplissage d’espace. En montrant les deux premières lignes du tableau, les paramètres doivent être arrondis à la précision souhaitée tout en s’assurant que la somme des quantités de lipides est égale à 1. Le benchmark a été ajouté manuellement au tableau. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

Figure 5 : Tableau d’étude formaté. Les niveaux de facteur ont été arrondis et formatés et une colonne Run ID a été ajoutée. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

Figure 6 : Points de conception sur un tracé ternaire. Les 23 formulations sont présentées en fonction des rapports Ionizable, Helper et « Others » (Cholesterol+PEG) correspondants. Le point vert au centre représente le rapport molaire de référence 33:33:33:1 de Ionizable (H101):Cholesterol:Helper (DOPE):P EG. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

Figure 7 : Distribution des facteurs de processus non mélangés dans l’expérience. Les histogrammes montrent comment les essais expérimentaux sont espacés entre le type de lipide ionisable, le rapport N:P et le débit. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}
3. Exécution de l’expérience
- Exécutez l’expérience dans l’ordre fourni par la table de conception. Enregistrez les lectures dans les colonnes intégrées à la table expérimentale.
- Si plusieurs dosages sont effectués pour la même réponse sur un lot de formulation identique, calculer une moyenne pour ces résultats dans chaque lot. Ajoutez une colonne pour chaque mesure de test au tableau.
- Pour obtenir une moyenne, sélectionnez toutes les colonnes associées, cliquez avec le bouton droit sur l’un des en-têtes de colonne sélectionnés, puis choisissez Nouvelle colonne de formule > Combiner > moyenne. Utilisez cette colonne Moyenne pour l’analyse des réponses futures.
REMARQUE : Sans recommencer la recette, les mesures répétées des essais ne capturent que la variance des essais et ne constituent pas des répétitions indépendantes.
- Pour obtenir une moyenne, sélectionnez toutes les colonnes associées, cliquez avec le bouton droit sur l’un des en-têtes de colonne sélectionnés, puis choisissez Nouvelle colonne de formule > Combiner > moyenne. Utilisez cette colonne Moyenne pour l’analyse des réponses futures.
- Documenter toute occurrence de précipitation de formulation ou de problèmes de tolérabilité in vivo (tels qu’une perte de poids corporelle grave ou la mort) avec des indicateurs binaires (0/1) dans une nouvelle colonne pour chaque type de problème.
4. Analyse des résultats expérimentaux
- Tracez les lectures et examinez les distributions des réponses : ouvrez Graph > Graph Builder et faites glisser chaque réponse dans la zone Y pour des graphiques individuels. Répétez cette opération pour toutes les réponses.
- Examinez la distance relative entre les répétitions codées par couleur, le cas échéant. Cela permet de comprendre la variation totale (processus et analyse) au niveau de l’étalon par rapport à la variabilité due aux changements dans les paramètres factoriels dans l’ensemble de l’espace factoriel (Figure 8).
- Déterminez si la réponse brute doit être modélisée ou si une transformation doit être utilisée à la place. Pour les réponses qui sont limitées à être positives, mais qui ne sont pas limitées ci-dessus (p. ex., la puissance), ajuster à la fois une distribution normale et une distribution log-normale aux résultats expérimentaux. Si la distribution lognormale correspond mieux à un AICc inférieur (critère d’information d’Akaike corrigé), alors prenez une transformation logarithmique de cette réponse.
- Accédez à Analyser la distribution > et sélectionnez la réponse pour Y, Colonnes. Dans le rapport de distribution qui en résulte, cliquez sur le triangle rouge en regard du nom de la réponse et choisissez Ajustement continu > Ajustement normal et Ajustement continu > Ajustement Lognormal dans le menu déroulant. Dans le rapport Comparer les distributions suivant, vérifiez les valeurs AICc pour déterminer quelle distribution correspond le mieux à la réponse.
- Pour effectuer une transformation de journal, cliquez avec le bouton droit sur l’en-tête de colonne de réponse et sélectionnez Nouvelle colonne de formule > Journal > journal. Lorsqu’un modèle est créé et qu’une colonne de prédiction sur l’échelle logarithmique est enregistrée, reconvertissez la réponse à l’échelle d’origine en sélectionnant Nouvelle colonne de formule > Journal > Exp.
- Pour les réponses proportionnelles limitées entre 0 et 1, comparez l’ajustement d’une distribution normale et bêta. Si la distribution bêta a un AICc inférieur, effectuez une transformation logit. Dans le rapport Distribution de la réponse, choisissez Ajustement continu > Ajustement normal et Ajustement continu > Ajustement bêta.
- Pour la transformation logit, cliquez avec le bouton droit sur l’en-tête de colonne de réponse dans la table de données, puis sélectionnez Nouvelle colonne de formule > Spécialité > Logit. Après la création du modèle, enregistrez la colonne de prédiction. Pour revenir à l’échelle d’origine, utilisez Nouvelle colonne de formule > Spécialité > Logistique.
REMARQUE : L’analyse SVEM basée sur la régression est robuste aux écarts par rapport à la normalité dans la distribution des réponses. Cependant, ces transformations peuvent conduire à une interprétation plus facile des résultats et à un meilleur ajustement des modèles.
- Pour la transformation logit, cliquez avec le bouton droit sur l’en-tête de colonne de réponse dans la table de données, puis sélectionnez Nouvelle colonne de formule > Spécialité > Logit. Après la création du modèle, enregistrez la colonne de prédiction. Pour revenir à l’échelle d’origine, utilisez Nouvelle colonne de formule > Spécialité > Logistique.
- Représenter graphiquement les exécutions sur un tracé ternaire. Coloriez les points en fonction des réponses (ou des réponses transformées si une transformation a été appliquée) : Graphe ouvert > Tracé ternaire. Sélectionnez uniquement les facteurs de mélange pour X, Traçage. Cliquez avec le bouton droit sur l’un des graphiques résultants, sélectionnez Légende de ligne , puis sélectionnez la colonne de réponse (transformée).
REMARQUE: La coloration des points en fonction des réponses donne une perspective visuelle indépendante du modèle du comportement par rapport aux facteurs de mélange. - Supprimez le script de modèle généré par la conception de remplissage d’espace.
- Construire un modèle indépendant pour chaque réponse en fonction des facteurs de l’étude, en répétant les étapes suivantes pour chaque réponse.
REMARQUE : Dans le cas d’une réponse binaire secondaire (par exemple, échec de formulation ou mort de souris), modélisez également cette réponse. Modifiez le paramètre de distribution cible de Normal à Binomial. - Construire un modèle « complet » comprenant tous les effets candidats. Ce modèle devrait inclure les principaux effets de chaque facteur, les interactions bidirectionnelles et tridirectionnelles, les termes cubiques quadratiques et partiels dans les facteurs de procédé et les termes cubiques de Scheffé pour les facteurs de mélange23,24.
Remarque : Utilisez le même ensemble d’effets candidats pour chaque réponse. La technique de sélection des modèles SVEM affinera indépendamment les modèles pour chaque réponse, ce qui pourrait entraîner des modèles réduits uniques pour chacun. La figure 9 illustre certains de ces effets candidats. Les sous-étapes suivantes détaillent ce processus.- Sélectionnez Analyser > ajuster le modèle.
- S’assurer que les facteurs bloquants (p. ex. le jour) ne sont pas autorisés à interagir avec d’autres facteurs de l’étude. Sélectionnez les facteurs bloquants et cliquez sur Ajouter. N’incluez pas ces facteurs dans les sous-étapes suivantes.
REMARQUE : Il est important de tenir compte des facteurs bloquants dans le modèle, mais les facteurs bloquants ne devraient pas être autorisés à interagir avec d’autres facteurs de l’étude. L’objectif principal des facteurs bloquants est d’aider à contrôler la variabilité de l’expérience et d’améliorer la sensibilité de l’expérience. - Mettez en évidence tous les facteurs de l’étude. Modifiez la valeur du champ Degré sur 3 (elle est définie sur 2 par défaut). Cliquez sur Factorial to Degree.
Remarque : Cette action inclut les effets principaux ainsi que les interactions bidirectionnelles et tridirectionnelles dans le modèle. - Sélectionnez uniquement les facteurs non mélangeux dans la fenêtre de sélection. Cliquez sur Macros > Partial Cubic.
Remarque : Cette action introduit des effets quadratiques pour les facteurs de processus continus et leur interaction avec d’autres facteurs non mélangeurs dans le modèle. - Choisissez uniquement les facteurs de mélange dans la liste de sélection. Cliquez sur Macros > Scheffe Cubic. Désactivez l’option No Intercept par défaut (reportez-vous à la figure 9).
REMARQUE: L’inclusion d’une interception dans le modèle est une étape essentielle lors de l’utilisation des méthodes Lasso et est également utile dans le contexte de la sélection directe. Le paramètre traditionnel par défaut No Intercept est généralement en place parce que l’ajustement d’une interception simultanément avec tous les effets principaux du mélange, sans modifications telles que l’approche SVEM, n’est pas réalisable avec la procédure régulière de régression des moindres carrés12. - Spécifiez la colonne de réponse : mettez en surbrillance la colonne de réponse et cliquez sur Y.
- Définissez le paramètre Personnalité sur Régression généralisée. Gardez la distribution définie sur Normal.
- Enregistrez cette configuration de modèle dans la table de données pour l’utiliser avec des réponses supplémentaires en cliquant sur le menu triangle rouge à côté de Spécification du modèle et en sélectionnant Enregistrer dans la table de données.
- Appliquez la méthode de sélection directe SVEM pour ajuster le modèle réduit, sans inclusion obligatoire des effets principaux du facteur de mélange, et stockez la colonne de la formule de prédiction dans le tableau de données.
- Dans la boîte de dialogue Ajuster le modèle , cliquez sur Exécuter.
- Pour Méthode d’estimation, sélectionnez SVEM Forward Selection (Sélection directe SVEM).
- Développez les menus Contrôles avancés > Forcer les termes et décochez les cases associées aux principaux effets du mélange. Seule la case Terme d’interception doit rester cochée. La figure 10 affiche la configuration par défaut où les effets principaux sont forcés. Pour cette étape, ces cases doivent être décochées pour permettre au modèle d’inclure ou d’exclure ces effets en fonction de la procédure de sélection directe.
- Cliquez sur OK pour exécuter la procédure SVEM Forward Selection.
- Tracer les réponses réelles par les réponses prédites du modèle SVEM pour vérifier une capacité prédictive raisonnable. (figure 11). Cliquez sur le triangle rouge en regard de SVEM Forward Selection (Sélection directe SVEM ) et sélectionnez Diagnostic Plots > Plot Actual by Predicted.
- Cliquez sur le triangle rouge en regard de SVEM Forward Selection (Sélection directe SVEM ) et sélectionnez Save Columns > Save Prediction Formula (Enregistrer les colonnes Save Prediction Formula ) pour créer une colonne contenant la formule de prédiction dans la table de données.
- Facultatif : Répétez les étapes ci-dessus en utilisant SVEM Lasso comme méthode d’estimation pour déterminer si une recette optimale différente est suggérée après avoir effectué les étapes suivantes. Si c’est le cas, exécutez les deux recettes en tant que confirmations (voir la section 5) pour voir laquelle fonctionne le mieux dans la pratique12.
- Répétez les étapes de création de modèle pour chaque réponse.
- Une fois que les colonnes de prédiction de toutes les réponses sont enregistrées dans la table de données, représentez graphiquement les traces de réponse pour toutes les colonnes de réponse prédites à l’aide de la plateforme Profiler : Sélectionnez Graphique > Profileur, puis sélectionnez toutes les colonnes de prédiction créées à l’étape précédente pour Y, Formule de prédiction, puis cliquez sur OK (Figure 12).
- Identifier la ou les formulations optimales candidates.
- Définissez la « fonction de désirabilité » pour chaque réponse, en précisant si la réponse doit être maximisée, réduite ou adaptée à une cible. Définissez toutes les réponses primaires pour utiliser un poids d’importance de 1,0 et toutes les réponses secondaires pour utiliser un poids d’importance de 0,2. Dans le menu Triangle rouge de Prediction Profiler, sélectionnez Optimisation et désirabilité > Fonctions de désirabilité, puis Optimisation et désirabilité > Définir les désirabilités. Entrez les paramètres dans les fenêtres suivantes.
REMARQUE : Les poids importants sont relatifs et subjectifs, il est donc utile de vérifier la sensibilité de l’optimum combiné aux variations de ces poids dans une fourchette raisonnable (p. ex., d’une pondération égale à une pondération de 1:5). - Commandez au profileur pour trouver les paramètres de facteur optimaux qui maximisent la fonction de désirabilité (Figure 12) : dans le profileur, sélectionnez Optimisation et désirabilité > Maximiser la désirabilité.
REMARQUE : Les valeurs prédites des réponses aux candidats optimaux peuvent surestimer la valeur des réponses asymétriques à droite, comme la puissance; Cependant, les essais de confirmation fourniront des observations plus précises de ces formulations candidates. L’objectif principal est de localiser la formulation optimale (les paramètres de la recette optimale). - Notez les paramètres de facteur optimaux et notez les pondérations importantes utilisées pour chaque réponse : dans le menu Prediction Profiler , sélectionnez Paramètres de facteur > Mémoriser les paramètres.
- Définissez la « fonction de désirabilité » pour chaque réponse, en précisant si la réponse doit être maximisée, réduite ou adaptée à une cible. Définissez toutes les réponses primaires pour utiliser un poids d’importance de 1,0 et toutes les réponses secondaires pour utiliser un poids d’importance de 0,2. Dans le menu Triangle rouge de Prediction Profiler, sélectionnez Optimisation et désirabilité > Fonctions de désirabilité, puis Optimisation et désirabilité > Définir les désirabilités. Entrez les paramètres dans les fenêtres suivantes.
- Facultatif : Pour les facteurs catégoriques tels que le type de lipide ionisable, trouvez les formulations conditionnellement optimales pour chaque niveau de facteur.
- Définissez d’abord le niveau souhaité du facteur dans le profileur, puis maintenez la touche Ctrl enfoncée et cliquez avec le bouton gauche de la souris à l’intérieur du graphique de ce facteur et sélectionnez Paramètre des facteurs de verrouillage. Sélectionnez Optimisation et désirabilité > Maximiser la désirabilité pour trouver l’optimum conditionnel avec ce facteur verrouillé à son paramètre actuel.
- Déverrouillez les paramètres de facteur avant de continuer, en utilisant le même menu que celui utilisé pour verrouiller les paramètres de facteur.
- Répétez le processus d’optimisation après avoir ajusté les pondérations d’importance des réponses (en utilisant Optimisation et désirabilité > Définir les désirabilités), peut-être seulement en optimisant la ou les réponses primaires ou en définissant certaines des réponses secondaires pour avoir plus ou moins de poids d’importance, ou en définissant l’objectif des réponses secondaires sur Aucun (Figure 13).
- Enregistrez le nouveau candidat optimal (dans le menu Prediction Profiler, sélectionnez Paramètres de facteur > Mémoriser les paramètres.)
- Produire des résumés graphiques des régions optimales de l’espace factoriel : générer un tableau de données avec 50 000 lignes remplies avec des paramètres de facteurs générés aléatoirement dans l’espace factoriel autorisé, ainsi que les valeurs prédites correspondantes du modèle réduit pour chacune des réponses et la fonction de désirabilité conjointe.
- Dans le profileur, sélectionnez Table aléatoire de sortie. Définissez le nombre d’exécutions à simuler ? sur 50 000 et cliquez sur OK .
REMARQUE : Cela génère un nouveau tableau avec les valeurs prédites des réponses à chacune des 50 000 formulations. La colonne Désirabilité dépend des pondérations d’importance pour les réponses qui sont en place lorsque l’option Tableau aléatoire de sortie est sélectionnée. - Dans la table nouvellement créée, ajoutez une nouvelle colonne qui calcule le percentile de la colonne Désirabilité. Utilisez cette colonne de centile dans les tracés ternaires au lieu de la colonne de désirabilité brute. Cliquez avec le bouton droit sur l’en-tête de colonne Désirabilité et sélectionnez Nouvelle colonne de formule > Probabilité distributive > cumulée pour créer une nouvelle colonne Probabilité cumulée [Désirabilité].
- Générez les graphiques décrits dans les étapes suivantes. Modifiez à plusieurs reprises le jeu de couleurs des graphiques afin d’afficher les prédictions pour chaque réponse et pour la colonne Probabilité cumulée [Désirabilité].
- Construire des diagrammes ternaires pour les quatre facteurs lipidiques. Dans le tableau, accédez à Graphique > Tracé ternaire , sélectionnez les facteurs de mélange pour X, Traçage, puis cliquez sur OK. Cliquez avec le bouton droit dans l’un des graphiques obtenus, sélectionnez Légende de ligne, puis sélectionnez la colonne de réponse prévue. Remplacez la liste déroulante Couleurs par Jet.
REMARQUE: Ceci affiche les régions les plus performantes et les moins performantes en ce qui concerne les facteurs lipidiques. La figure 14 montre les percentiles de la désirabilité articulaire lorsqu’on considère la maximisation de la puissance (importance = 1) et la minimisation de la taille (importance = 0,2), tout en faisant la moyenne sur tous les facteurs qui ne sont pas représentés sur les axes du tracé ternaire. La figure 15 montre la taille brute prévue. Il est également raisonnable de décomposer ces graphiques conditionnellement en fonction d’autres facteurs, tels que la création d’un ensemble distinct de tracés ternaires pour chaque type de lipide ionisable avec un filtre de données locales (disponible dans le menu triangle rouge à côté de Diagramme ternaire). - De même, utilisez Graph > Graph Builder pour tracer les 50 000 points codés par couleur (représentant des formulations uniques) par rapport aux facteurs de processus sans mélange, individuellement ou conjointement, et recherchez les relations entre la ou les réponses et les facteurs. Recherchez les paramètres de facteur qui donnent la plus grande désirabilité. Explorez différentes combinaisons de facteurs dans les graphiques.
Remarque : Lorsque vous coloriez des graphiques, utilisez Probabilité cumulée [Désirabilité], mais lorsque vous tracez la désirabilité sur l’axe vertical par rapport aux facteurs de processus, utilisez la colonne Désirabilité brute. La colonne Désirabilité peut également être placée sur un axe de la visualisation 3D du graphique > du nuage de points avec deux autres facteurs de processus pour l’exploration multivariée. La figure 16 montre l’intérêt articulaire de toutes les formulations qui peuvent être formées avec chacun des trois types de lipides ionisables. Les formulations les plus souhaitables utilisent H102, H101 fournissant des alternatives potentiellement compétitives. - Enregistrez le profileur et ses paramètres mémorisés dans la table de données. Cliquez sur le triangle rouge en regard de Profiler et sélectionnez Enregistrer le script > dans la table de données....
- Dans le profileur, sélectionnez Table aléatoire de sortie. Définissez le nombre d’exécutions à simuler ? sur 50 000 et cliquez sur OK .

Figure 8 : Lectures de puissance observées à partir de l’expérience. Les points montrent les valeurs de puissance qui ont été observées à partir des 23 essais; Les essais de référence répliqués sont affichés en vert. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

Figure 9 : Boîte de dialogue du logiciel pour lancer l’analyse. Les effets candidats ont été saisis avec la réponse de puissance cible, et l’option Aucune interception n’a pas été cochée. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

Graphique 10. Boîte de dialogue supplémentaire pour spécifier les options SVEM. Par défaut, les principaux effets lipidiques sont forcés dans le modèle. Parce qu’une interception est incluse, nous vous recommandons de décocher ces cases afin de ne pas forcer les effets. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

Figure 11 : Réel par placette prévue. Cette figure représente la puissance observée par rapport à la valeur prédite pour chaque formulation par le modèle SVEM. La corrélation n’a pas besoin d’être aussi forte que dans cet exemple, mais on s’attend à voir au moins une corrélation modérée et à vérifier les valeurs aberrantes. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

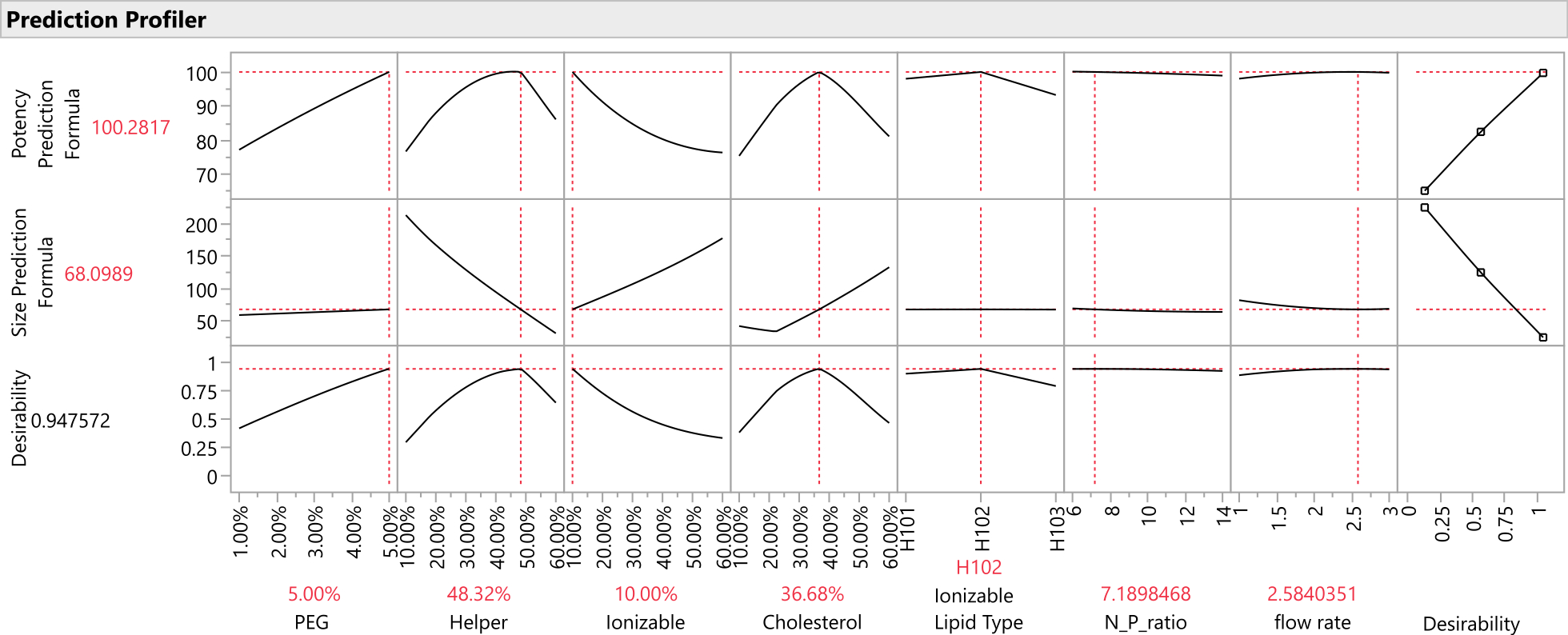
Figure 12 : Profileur de prédiction. Les deux rangées supérieures de graphiques montrent les tranches de la fonction de réponse prédite à la formulation optimale (telle qu’identifiée par l’approche SVEM). La rangée inférieure de graphiques montre la « désirabilité » pondérée de la formulation, qui est une fonction de la dernière colonne de graphiques qui montre que la puissance devrait être maximisée et la taille devrait être minimisée. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

Figure 13 : Trois formulations optimales candidates issues de la sélection SVEM-Forward. La modification de la pondération de l’importance relative des réponses peut conduire à différentes formulations optimales. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

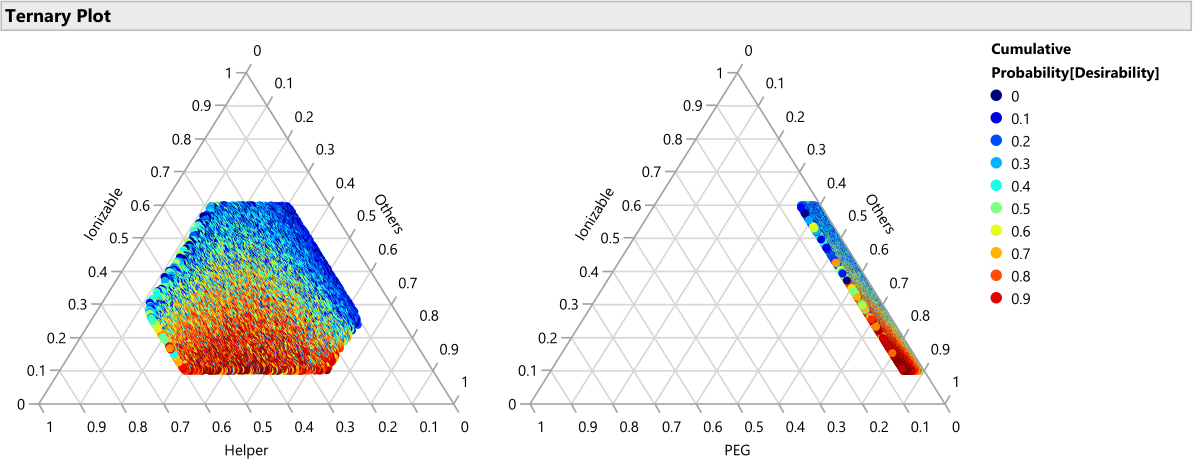
Figure 14 : Tracés ternaires pour le centile de désirabilité. Le graphique montre les 50 000 formulations codées par couleur par percentile de désirabilité, où la désirabilité est définie avec un poids d’importance de 1,0 pour maximiser la puissance et 0,2 pour minimiser la taille, ces graphiques montrent que la région optimale des formulations se compose de pourcentages plus faibles de lipides ionisables et de pourcentages plus élevés de PEG. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

Figure 15 : Tracé ternaire de la taille prévue. Le graphique montre les prédictions de taille du modèle SVEM pour chacune des 50 000 formulations. La taille est minimisée avec des pourcentages plus élevés de lipides auxiliaires et maximisée avec des pourcentages plus faibles d’aide. Étant donné que les autres facteurs varient librement entre les 50 000 formulations tracées, cela implique que cette relation se vérifie dans les gammes des autres facteurs (PEG, débit, etc.). Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}

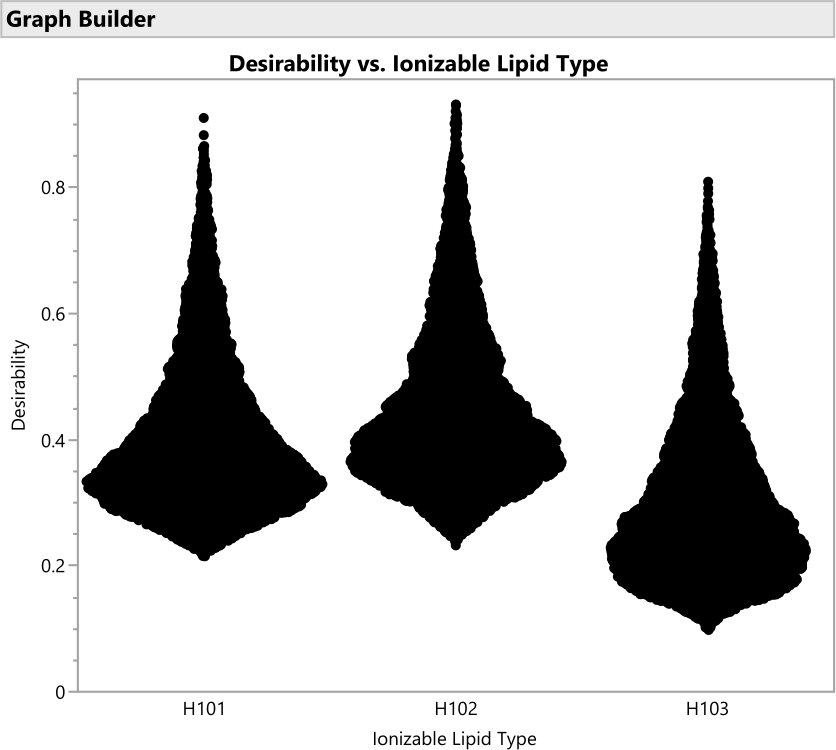
Figure 16 : Tracés de violon pour l’opportunité de formulations impliquant les trois différents types de lipides ionisables. Chacun des 50 000 points représente une formulation unique de tout l’espace factoriel autorisé. Les pics de ces distributions sont les valeurs maximales de désirabilité qui sont calculées analytiquement avec le profileur de prédiction. H102 a le plus grand pic et produit ainsi la formulation optimale. L’approche SVEM pour construire le modèle qui génère cette sortie filtre automatiquement les facteurs statistiquement non significatifs : le but de ce graphique est de considérer la signification pratique à travers les niveaux de facteurs. Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}
5. Exécution de la confirmation
- Préparez un tableau énumérant les candidats optimaux identifiés précédemment (figure 17).
NOTE: Les valeurs True Puissance et Vraie Taille de la Figure 17 sont remplies à l’aide des fonctions génératrices simulées: en pratique, elles seront obtenues en formulant puis en mesurant les performances de ces recettes.- Inclure le contrôle de référence avec l’ensemble des pistes candidates qui seront formulées et mesurées.
- Si l’une des formulations de l’expérience s’est avérée donner des résultats souhaitables, peut-être en surpassant le benchmark, sélectionnez la meilleure à ajouter au tableau candidat et testez à nouveau avec de nouvelles formulations.
REMARQUE : ajoutez manuellement les exécutions souhaitées à la table candidate ou utilisez les paramètres mémorisés de la fenêtre Profileur si ces exécutions proviennent de l’expérience précédente. Identifiez le numéro de ligne de l’exécution, accédez à Paramètres de facteur de > du Profileur de prédiction > Définissez sur Données de la ligne, puis entrez le numéro de ligne. Ensuite, choisissez Prediction Profiler > Factor Settings > Remember Settings et étiquetez de manière appropriée (par exemple, « benchmark » ou « meilleure exécution à partir de l’expérience précédente »). - Cliquez avec le bouton droit sur le tableau Paramètres mémorisés dans le profileur et sélectionnez Créer en tableau de données.
REMARQUE : en fonction de la priorité et du budget de l’étude, envisagez d’exécuter des répétitions pour chaque cycle de confirmation, en particulier si vous remplacez le benchmark. Créez et analysez chaque formulation deux fois, en utilisant le résultat moyen pour le classement. Faites attention à tous les candidats ayant une large gamme de réponses dans les deux répétitions, car cela pourrait indiquer une variance élevée du processus. - Si nécessaire en raison de contraintes budgétaires, sélectionnez parmi les candidats identifiés pour correspondre au budget expérimental ou pour éliminer les candidats redondants.
- Effectuez les exécutions de confirmation. Construisez les formulations et rassemblez les lectures.
- Vérifiez la cohérence entre les résultats de l’expérience originale et les résultats du lot de confirmation pour les repères ou autres recettes répétées. S’il y a un changement important et inattendu, réfléchissez à ce qui a pu contribuer au changement et s’il est possible que toutes les exécutions du lot de confirmation aient été affectées.
- Comparez les performances des formulations optimales candidates. Déterminez si de nouveaux candidats ont surpassé le benchmark.
- Facultatif : Ajoutez le résultat des exécutions de confirmation à la table expérimentale et relancez l’analyse de la section 4.
REMARQUE : L’étape suivante du flux de travail fournit des instructions pour construire une étude de suivi avec ces exécutions si vous le souhaitez.

Figure 17 : Tableau des dix candidats optimaux à exécuter en tant qu’essais de confirmation. La puissance réelle et la taille réelle ont été remplies à partir des fonctions génératrices de simulation (sans aucune variation supplémentaire de processus ou d’analyse). Veuillez cliquer ici pour voir une version agrandie de cette figure.
{kind=link}
6. Facultatif : Conception d’une étude de suivi à mener en même temps que les cycles de confirmation
- Évaluer la nécessité d’une étude de suivi en tenant compte des critères suivants :
- Déterminer si la formulation optimale se situe le long de l’une des limites du facteur et si une deuxième expérience est souhaitée pour élargir au moins une des plages de facteurs.
- Évaluez si l’expérience initiale a utilisé une taille d’exécution relativement petite ou des plages de facteurs relativement grandes et s’il est nécessaire de « zoomer » sur la région optimale identifiée avec des séries supplémentaires et une analyse mise à jour.
- Vérifiez si un facteur supplémentaire est introduit. Il peut s’agir d’un niveau d’un facteur catégorique tel qu’un lipide ionisable supplémentaire ou d’un facteur qui est resté constant dans l’étude initiale, par exemple, la concentration tampon.
- Si aucune des conditions ci-dessus n’est remplie, passez à l’étape 7.
- Préparez-vous à d’autres essais expérimentaux qui seront effectués en même temps que les essais de confirmation.
- Définir les limites factorielles assurant un chevauchement partiel avec la région à partir de l’étude initiale. S’il n’y a pas de chevauchement, une nouvelle étude doit être conçue.
- Développer les nouvelles séries expérimentales avec une conception de remplissage d’espace. Sélectionnez DOE > Special Purpose > Space Filling Design.
REMARQUE: Pour les utilisateurs avancés, envisagez une conception optimale D via DOE > Custom Design. - Une fois les séries de remplissage d’espace générées, incorporez manuellement deux ou trois séries de l’expérience d’origine qui se trouvent dans le nouvel espace factoriel. Distribuez ces exécutions de manière aléatoire dans la table expérimentale en suivant les étapes décrites dans la section 2 pour ajouter des lignes, puis randomisez l’ordre des lignes.
REMARQUE: Ceux-ci seront utilisés pour estimer tout changement dans les moyennes de réponse entre les blocs. - Concaténez les exécutions de confirmation et le nouveau remplissage d’espace s’exécute dans une seule table et randomisez l’ordre d’exécution. Utilisez Tables > Concaténate , puis créez et triez par une nouvelle colonne aléatoire pour randomiser l’ordre d’exécution, comme décrit dans la Section 2.
- Formulez les nouvelles recettes et recueillez les résultats.
- Concaténez les nouvelles séries expérimentales et les résultats dans la table de données d’expérience d’origine, en introduisant une colonne d’ID d’expérience pour indiquer la source de chaque résultat. Utilisez Tables > Concaténer et sélectionnez l’option Créer une colonne source.
- Vérifiez que les propriétés de colonne pour chaque facteur affichent la plage combinée pour les deux études : cliquez avec le bouton droit sur l’en-tête de colonne de chaque facteur et examinez les plages de propriétés Codage et Mélange , le cas échéant.
- Commencez l’analyse des résultats de la nouvelle expérience.
- Incluez la colonne d’ID d’expérience en tant que terme dans le modèle pour servir de facteur de blocage. Assurez-vous que ce terme n’interagit pas avec les facteurs de l’étude. Exécutez le script de boîte de dialogue Ajuster le modèle enregistré dans le tableau de la section 4, sélectionnez la colonne ID d’expérience et cliquez sur Ajouter pour l’inclure dans la liste des effets candidats.
- Exécutez cette boîte de dialogue Modèle d’ajustement sur la table de données concaténées pour analyser conjointement les résultats de la nouvelle expérience et de l’étude initiale. Respectez les instructions précédentes pour générer des formulations optimales candidates mises à jour et des résumés graphiques.
- Pour la validation, analysez indépendamment les résultats de la nouvelle expérience, en excluant les résultats de l’expérience initiale. C’est-à-dire effectuer les étapes décrites à la section 4 de la nouvelle table expérimentale.
- S’assurer que les formulations optimales identifiées par ces modèles s’alignent étroitement avec celles reconnues par l’analyse conjointe.
- Examiner les résumés graphiques pour confirmer que les analyses conjointes et individuelles des nouveaux résultats expérimentaux présentent des comportements de surface de réponse similaires (ce qui signifie qu’il existe une relation similaire entre la ou les réponses et les facteurs).
- Comparez les analyses combinées et individuelles des nouveaux résultats avec l’expérience initiale pour plus de cohérence. Utilisez des structures de graphiques similaires pour la comparaison et examinez les recettes optimales identifiées pour les différences.
7. Documenter les conclusions scientifiques finales de l’étude
- Si le contrôle de référence passe à une recette nouvellement identifiée en raison de l’étude, consigner le nouveau paramètre et spécifier les fichiers de conception et d’analyse qui enregistrent son origine.
- Tenir à jour tous les tableaux expérimentaux et les résumés d’analyse, de préférence avec des noms de fichiers estampillés, pour référence future.
Résultats
Cette approche a été validée pour les deux types de lipides largement classés : les lipides classiques de type MC3 et les lipidoïdes (par exemple, C12-200), généralement dérivés de la chimie combinatoire. Par rapport à une formulation de référence de LNP développée à l’aide d’une méthode One Factor at a Time (OFAT), les formulations candidates générées par notre flux de travail démontrent fréquemment des améliorations de puissance de 4 à 5 fois sur une échelle logarithmique, comme le montrent ...
Discussion
Un logiciel moderne pour la conception et l’analyse d’expériences de processus de mélange permet aux scientifiques d’améliorer leurs formulations de nanoparticules lipidiques dans un flux de travail structuré qui évite les expériences OFAT inefficaces. L’approche de modélisation SVEM récemment développée élimine bon nombre des modifications de régression obscures et des stratégies de réduction des modèles qui auraient pu auparavant distraire les scientifiques avec des considérations statistiques ?...
Déclarations de divulgation
La stratégie de conception expérimentale qui sous-tend ce flux de travail a été utilisée dans deux demandes de brevet dont l’un des auteurs est un inventeur. En outre, Adsurgo, LLC est un partenaire JMP certifié. Toutefois, l’élaboration et la publication de ce document ont été entreprises sans aucune forme d’incitation financière, d’encouragement ou d’autres incitations de la part de JMP.
Remerciements
Nous sommes reconnaissants à l’éditeur et aux arbitres anonymes pour les suggestions qui ont amélioré l’article.
matériels
| Name | Company | Catalog Number | Comments |
| JMP Pro 17.1 | JMP Statistical Discovery LLC |
Références
- Dolgin, E. Better lipids to power next generation of mRNA vaccines. Science. 376 (6594), 680-681 (2022).
- Hou, X., Zaks, T., Langer, R., Dong, Y. Lipid nanoparticles for mRNA delivery. Nature Reviews Materials. 6 (12), 1078-1094 (2021).
- Huang, X., et al. The landscape of mRNA nanomedicine. Nature Medicine. 28, 2273-2287 (2022).
- Rampado, R., Peer, D. Design of experiments in the optimization of nanoparticle-based drug delivery systems. Journal of Controlled Release. 358, 398-419 (2023).
- Kauffman, K. J., et al. Optimization of lipid nanoparticle formulations for mRNA delivery in vivo with fractional factorial and definitive screening designs. Nano Letters. 15, 7300-7306 (2015).
- Jones, B., Nachtsheim, C. J. A class of three-level designs for definitive screening in the presence of second-order effects. Journal of Quality Technology. 43, 1-15 (2011).
- Cornell, J. . Experiments with Mixtures: Designs, Models, and the Analysis of Mixture Data. Wiley Series in Probability and Statistics. , (2002).
- Jones, B. Proper and improper use of definitive screening designs (DSDs). JMP user Community. , (2016).
- Myers, R., Montgomery, D., Anderson-Cook, C. . Response Surface Methodology. , (2016).
- Lekivetz, R., Jones, B. Fast flexible space-filling designs for nonrectangular regions. Quality and Reliability Engineering International. 31, 829-837 (2015).
- Czitrom, V. One-factor-at-a-time versus designed experiments. The American Statistician. 53, 126-131 (1999).
- Karl, A., Wisnowski, J., Rushing, H. JMP Pro 17 remedies for practical struggles with mixture experiments. JMP Discovery Conference. , (2022).
- Lemkus, T., Gotwalt, C., Ramsey, P., Weese, M. L. Self-validated ensemble models for design of experiments. Chemometrics and Intelligent Laboratory Systems. 219, 104439 (2021).
- Gotwalt, C., Ramsey, P. Model validation strategies for designed experiments using bootstrapping techniques with applications to biopharmaceuticals. JMP Discovery Conference. , (2018).
- Xu, L., Gotwalt, C., Hong, Y., King, C. B., Meeker, W. Q. Applications of the fractional-random-weight bootstrap. The American Statistician. 74 (4), 345-358 (2020).
- Ramsey, P., Levin, W., Lemkus, T., Gotwalt, C. SVEM: A paradigm shift in design and analysis of experiments. JMP Discovery Conference Europe. , (2021).
- Ramsey, P., Gaudard, M., Levin, W. Accelerating innovation with space filling mixture designs, neural networks and SVEM. JMP Discovery Conference. , (2021).
- Lemkus, T. Self-Validated Ensemble modelling. Doctoral Dissertations. 2707. , (2022).
- Juran, J. M. . Juran on Quality by Design: The New Steps for Planning Quality into Goods and Services. , (1992).
- Yu, L. X., et al. Understanding pharmaceutical quality by design. The AAPS Journal. 16, 771 (2014).
- Simpson, J. R., Listak, C. M., Hutto, G. T. Guidelines for planning and evidence for assessing a well-designed experiment. Quality Engineering. 25, 333-355 (2013).
- Daniel, S., Kis, Z., Kontoravdi, C., Shah, N. Quality by design for enabling RNA platform production processes. Trends in Biotechnology. 40 (10), 1213-1228 (2022).
- Scheffé, H. Experiments with mixtures. Journal of the Royal Statistical Society Series B. 20, 344-360 (1958).
- Brown, L., Donev, A. N., Bissett, A. C. General blending models for data from mixture experiments. Technometrics. 57, 449-456 (2015).
- Herrera, M., Kim, J., Eygeris, Y., Jozic, A., Sahay, G. Illuminating endosomal escape of polymorphic lipid nanoparticles that boost mRNA delivery. Biomaterials Science. 9 (12), 4289-4300 (2021).
- Lemkus, T., Ramsey, P., Gotwalt, C., Weese, M. Self-validated ensemble models for design of experiments. ArXiv. , 2103.09303 (2021).
- Goos, P., Jones, B. . Optimal Design of Experiments: A Case Study Approach. , (2011).
- Rushing, H. DOE Gumbo: How hybrid and augmenting designs can lead to more effective design choices. JMP Discovery Conference. , (2020).
Réimpressions et Autorisations
Demande d’autorisation pour utiliser le texte ou les figures de cet article JoVE
Demande d’autorisationExplorer plus d’articles
This article has been published
Video Coming Soon
À PROPOS DE JoVE
Copyright © 2025 MyJoVE Corporation. Tous droits réservés.