
È necessario avere un abbonamento a JoVE per visualizzare questo. Accedi o inizia la tua prova gratuita.
Method Article
Un flusso di lavoro per l'ottimizzazione della formulazione di nanoparticelle lipidiche (LNP) utilizzando esperimenti di processo di miscela progettati e modelli di ensemble autoconvalidati (SVEM)
In questo articolo
Riepilogo
Questo protocollo fornisce un approccio all'ottimizzazione della formulazione rispetto a fattori di studio di miscela, continui e categoriali che riduce al minimo le scelte soggettive nella costruzione del progetto sperimentale. Per la fase di analisi, viene impiegata una procedura di adattamento di modellazione efficace e facile da usare.
Abstract
Presentiamo un approccio in stile Quality by Design (QbD) per l'ottimizzazione delle formulazioni di nanoparticelle lipidiche (LNP), con l'obiettivo di offrire agli scienziati un flusso di lavoro accessibile. La restrizione intrinseca in questi studi, in cui i rapporti molari dei lipidi ionizzabili, helper e PEG devono sommarsi fino al 100%, richiede metodi di progettazione e analisi specializzati per soddisfare questo vincolo di miscela. Concentrandoci sui fattori lipidici e di processo comunemente utilizzati nell'ottimizzazione della progettazione LNP, forniamo passaggi che evitano molte delle difficoltà che tradizionalmente sorgono nella progettazione e nell'analisi di esperimenti di processo di miscelazione impiegando progetti di riempimento dello spazio e utilizzando il quadro statistico recentemente sviluppato di modelli di ensemble autoconvalidati (SVEM). Oltre a produrre formulazioni ottimali candidate, il flusso di lavoro crea anche riepiloghi grafici dei modelli statistici adattati che semplificano l'interpretazione dei risultati. Le formulazioni candidate appena identificate vengono valutate con cicli di conferma e facoltativamente possono essere condotte nel contesto di uno studio di seconda fase più completo.
Introduzione
Le formulazioni di nanoparticelle lipidiche (LNP) per sistemi di rilascio genico in vivo coinvolgono generalmente quattro lipidi costituenti delle categorie di lipidi ionizzabili, helper e PEG 1,2,3. Sia che questi lipidi vengano studiati da soli o contemporaneamente ad altri fattori non miscelati, gli esperimenti per queste formulazioni richiedono disegni di "miscela" perché - data una formulazione candidata - aumentare o diminuire il rapporto di uno qualsiasi dei lipidi porta necessariamente ad una corrispondente diminuzione o aumento della somma dei rapporti degli altri tre lipidi.
Per esempio, si suppone che stiamo ottimizzando una formulazione LNP che attualmente utilizza una ricetta impostata che verrà trattata come punto di riferimento. L'obiettivo è massimizzare la potenza del LNP mentre secondariamente mira a ridurre al minimo la dimensione media delle particelle. I fattori di studio che variano nell'esperimento sono i rapporti molari dei quattro lipidi costituenti (ionizzabili, colesterolo, DOPE, PEG), il rapporto N/P, la portata e il tipo di lipide ionizzabile. I lipidi ionizzabili e helper (compreso il colesterolo) possono variare su un intervallo più ampio di rapporto molare, 10-60%, rispetto al PEG, che sarà variato dall'1-5% in questa illustrazione. La ricetta di formulazione di riferimento e gli intervalli degli altri fattori e la loro granularità di arrotondamento sono specificati nella scheda supplementare 1. Per questo esempio, gli scienziati sono in grado di eseguire 23 esecuzioni (lotti unici di particelle) in un solo giorno e vorrebbero usarlo come dimensione del campione se soddisfa i requisiti minimi. I risultati simulati per questo esperimento sono disponibili nel file supplementare 2 e nel file supplementare 3.
Rampado e Peer4 hanno pubblicato un recente documento di revisione sul tema degli esperimenti progettati per l'ottimizzazione dei sistemi di somministrazione di farmaci basati su nanoparticelle. Kauffman et al.5 hanno considerato studi di ottimizzazione LNP utilizzando disegni di screening fattoriale frazionario e definitivo6; Tuttavia, questi tipi di disegni e modelli non possono soddisfare un vincolo di miscela senza ricorrere all'uso di "variabili di allentamento" inefficienti7 e non sono tipicamente utilizzati quando sono presenti fattori di miscela 7,8. Invece, i "progetti ottimali" in grado di incorporare un vincolo di miscela sono tradizionalmente utilizzati per esperimenti di processo di miscela9. Questi disegni mirano a una funzione specificata dall'utente dei fattori di studio e sono ottimali (in uno dei numerosi sensi possibili) solo se questa funzione cattura la vera relazione tra i fattori di studio e le risposte. Si noti che vi è una distinzione nel testo tra "progetti ottimali" e "candidati formulativi ottimali", con quest'ultimo che si riferisce alle migliori formulazioni identificate da un modello statistico. I progetti ottimali presentano tre svantaggi principali per gli esperimenti di processo di miscela. In primo luogo, se lo scienziato non riesce ad anticipare un'interazione dei fattori di studio quando specifica il modello target, allora il modello risultante sarà distorto e può produrre formulazioni candidate inferiori. In secondo luogo, i progetti ottimali posizionano la maggior parte delle corse sul confine esterno dello spazio fattoriale. Negli studi LNP, questo può portare a un gran numero di corse perse se le particelle non si formano correttamente a qualsiasi estremo delle impostazioni lipidiche o di processo. In terzo luogo, gli scienziati spesso preferiscono avere corse sperimentali all'interno dello spazio fattoriale per ottenere un senso indipendente dal modello della superficie di risposta e per osservare il processo direttamente in regioni precedentemente inesplorate dello spazio fattoriale.
Un principio di progettazione alternativo consiste nell'mirare a una copertura uniforme approssimativa dello spazio dei fattori (vincolato dalla miscela) con un design che riempie lo spazio10. Questi progetti sacrificano una certa efficienza sperimentale rispetto ai progetti ottimali9 (supponendo che l'intero spazio fattoriale porti a formulazioni valide) ma presentano diversi vantaggi in un compromesso che sono utili in questa applicazione. Il design di riempimento dello spazio non fa alcuna ipotesi a priori sulla struttura della superficie di risposta; Ciò gli conferisce la flessibilità di catturare relazioni impreviste tra i fattori di studio. Ciò semplifica anche la generazione del progetto perché non richiede di prendere decisioni su quali termini di regressione aggiungere o rimuovere quando viene regolata la dimensione di esecuzione desiderata. Quando alcuni punti di progettazione (ricette) portano a formulazioni fallite, i progetti di riempimento dello spazio consentono di modellare il limite del fallimento sui fattori di studio, supportando anche modelli statistici per le risposte allo studio rispetto alle combinazioni di fattori di successo. Infine, la copertura interna dello spazio fattoriale consente un'esplorazione grafica indipendente dal modello della superficie di risposta.
Per visualizzare il sottospazio del fattore di miscela di un esperimento di processo di miscelazione, vengono utilizzati "grafici ternari" triangolari specializzati. La figura 1 motiva questo utilizzo: nel cubo di punti in cui tre ingredienti possono essere compresi tra 0 e 1, i punti che soddisfano un vincolo secondo cui la somma degli ingredienti è uguale a 1 sono evidenziati in rosso. Il vincolo della miscela sui tre ingredienti riduce lo spazio dei fattori fattibili a un triangolo. Nelle applicazioni LNP con quattro ingredienti di miscela, produciamo sei diversi grafici ternari per rappresentare lo spazio fattoriale tracciando due lipidi alla volta contro un asse "Altri" che rappresenta la somma degli altri lipidi.

Figura 1: Regioni a fattore triangolare. Nel grafico di riempimento dello spazio all'interno del cubo, i piccoli punti grigi rappresentano formulazioni incoerenti con il vincolo della miscela. I punti rossi più grandi giacciono su un triangolo inscritto all'interno del cubo e rappresentano formulazioni per le quali il vincolo della miscela è soddisfatto. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}
Oltre ai fattori di miscela lipidica, ci sono spesso uno o più fattori di processo continui come il rapporto N: P, la concentrazione del tampone o la portata. Possono essere presenti fattori categoriali, come il tipo di lipide ionizzabile, il tipo di lipidi helper o il tipo di tampone. L'obiettivo è trovare una formulazione (una miscela di lipidi e impostazioni per i fattori di processo) che massimizzi una certa misura di potenza e / o migliori le caratteristiche fisico-chimiche come minimizzare la dimensione delle particelle e il PDI (indice di polidispersione), massimizzare l'incapsulamento percentuale e minimizzare gli effetti collaterali - come la perdita di peso corporeo - negli studi in vivo . Anche quando si parte da una ricetta di riferimento ragionevole, potrebbe esserci interesse a ri-ottimizzare dato un cambiamento nel carico utile genetico o quando si considerano cambiamenti nei fattori di processo o nei tipi lipidici.
Cornell7 fornisce un testo definitivo sugli aspetti statistici degli esperimenti di miscela e processo di miscelazione, con Myers et al.9 che fornisce un eccellente riassunto degli argomenti di progettazione e analisi delle miscele più rilevanti per l'ottimizzazione. Tuttavia, questi lavori possono sovraccaricare gli scienziati con dettagli statistici e con terminologia specializzata. Il software moderno per la progettazione e l'analisi degli esperimenti fornisce una soluzione robusta che supporterà sufficientemente la maggior parte dei problemi di ottimizzazione LNP senza dover ricorrere alla teoria pertinente. Mentre gli studi più complicati o ad alta priorità trarranno comunque beneficio dalla collaborazione con uno statistico e potrebbero impiegare progetti ottimali piuttosto che ingombranti, il nostro obiettivo è migliorare il livello di comfort degli scienziati e incoraggiare l'ottimizzazione delle formulazioni LNP senza fare appello a test inefficienti a un fattore alla volta (OFAT)11 o semplicemente accontentarsi della prima formulazione che soddisfa le specifiche.
In questo articolo viene presentato un flusso di lavoro che utilizza software statistico per ottimizzare un problema di formulazione LNP generico, affrontando i problemi di progettazione e analisi nell'ordine in cui verranno riscontrati. In effetti, il metodo funzionerà per problemi di ottimizzazione generali e non è limitato agli LNP. Lungo il percorso, vengono affrontate diverse domande comuni che sorgono e vengono fornite raccomandazioni basate sull'esperienza e sui risultati della simulazione12. Il framework recentemente sviluppato di modelli di ensemble autoconvalidati (SVEM)13 ha notevolmente migliorato l'approccio altrimenti fragile all'analisi dei risultati degli esperimenti sui processi di miscelazione e utilizziamo questo approccio per fornire una strategia semplificata per l'ottimizzazione della formulazione. Mentre il flusso di lavoro è costruito in modo generale che potrebbe essere seguito utilizzando altri pacchetti software, JMP 17 Pro è unico nell'offrire SVEM insieme agli strumenti di riepilogo grafico che abbiamo trovato necessari per semplificare l'analisi altrimenti arcana degli esperimenti di processo di miscela. Di conseguenza, nel protocollo vengono fornite anche istruzioni specifiche per JMP.
SVEM utilizza la stessa base del modello di regressione lineare dell'approccio tradizionale, ma ci consente di evitare noiose modifiche necessarie per adattarsi a un "modello completo" di effetti candidati utilizzando un approccio di base di selezione in avanti o di selezione penalizzata (Lazo). Inoltre, SVEM fornisce un "modello ridotto" migliorato che riduce al minimo il potenziale di incorporare il rumore (processo più varianza analitica) che appare nei dati. Funziona calcolando la media dei modelli previsti risultanti dalla riponderazione ripetuta dell'importanza relativa di ciascuna esecuzione nel modello 13,14,15,16,17,18. SVEM fornisce un framework per la modellazione di esperimenti di processo di miscela che è sia più facile da implementare rispetto alla tradizionale regressione a colpo singolo e produce candidati di formulazione ottimale di migliore qualità12,13. I dettagli matematici di SVEM vanno oltre lo scopo di questo documento e anche un sommario sommario oltre la revisione della letteratura pertinente distrarrebbe dal suo principale vantaggio in questa applicazione: consente una procedura click-to-run semplice, robusta e accurata per i professionisti.
Il flusso di lavoro presentato è coerente con l'approccio Quality by Design (QbD)19 allo sviluppo farmaceutico20. Il risultato dello studio sarà la comprensione della relazione funzionale che collega gli attributi dei materiali e i parametri di processo agli attributi critici di qualità (CQA)21. Daniel et al.22 discutono l'utilizzo di un framework QbD specifico per la produzione di piattaforme RNA: il nostro flusso di lavoro potrebbe essere utilizzato come strumento all'interno di questo framework.
Access restricted. Please log in or start a trial to view this content.
Protocollo
L'esperimento descritto nella sezione Risultati rappresentativi è stato condotto in conformità con la Guida per la cura e l'uso degli animali da laboratorio e le procedure sono state eseguite seguendo le linee guida stabilite dal nostro Comitato istituzionale per la cura e l'uso degli animali (IACUC). Sono stati ottenuti commercialmente topi femmina Balb/C di 6-8 settimane. Gli animali hanno ricevuto ad libitum chow e acqua standard e sono stati alloggiati in condizioni standard con cicli luce / buio di 12 ore, a una temperatura di 65-75 ° F (~ 18-23 ° C) con 40-60% di umidità.
1. Registrazione dello scopo, delle risposte e dei fattori dello studio
NOTA: in questo protocollo, JMP 17 Pro viene utilizzato per la progettazione e l'analisi dell'esperimento. È possibile utilizzare software equivalenti seguendo passaggi simili. Per esempi e ulteriori istruzioni per tutti i passaggi eseguiti nella Sezione 1, fare riferimento al File supplementare 1.
- Riassumere lo scopo dell'esperimento in un documento contrassegnato dalla data.
- Elencare le risposte primarie (CQA) che verranno misurate durante l'esperimento.
- Elencare eventuali risposte secondarie (ad esempio, restrizioni a valle sulle proprietà fisico-chimiche) che potrebbero essere misurate.
- Elencare i parametri di processo che possono essere correlati alle risposte, compresi quelli più rilevanti per lo scopo dello studio.
- Se lo studio durerà più giorni, includere un fattore di "blocco" categorico del giorno.
NOTA: Questo bilancia le impostazioni dei fattori tra i giorni per evitare che i cambiamenti a livello di giorno nella media del processo vengano confusi con i fattori di studio. - Selezionare i fattori da variare e quelli da mantenere costanti durante lo studio.
NOTA: utilizzare strumenti di prioritizzazione dei rischi come le analisi degli effetti in modalità guasto20 per selezionare il sottoinsieme di fattori più rilevante (Figura 2). Di solito, tutti i lipidi dovrebbero essere lasciati variare; anche se in alcuni casi con budget limitato, è ragionevole bloccare il PEG a un rapporto fisso. - Stabilire gli intervalli per i fattori variabili e la precisione decimale pertinente per ciascuno.
- Decidere la dimensione del progetto dello studio (il numero di lotti unici di particelle) utilizzando l'euristica minima e massima. Le esecuzioni del benchmark di controllo incluse manualmente non vengono conteggiate ai fini della dimensione di esecuzione consigliata dall'euristica.
Nota : la seguente euristica presuppone che le risposte siano continue. L'euristica minima presuppone che sarà possibile eseguire uno studio di follow-up, se necessario, oltre a eseguire cicli di conferma per le formulazioni ottimali candidate. Se sarà possibile eseguire solo esecuzioni di conferma, è meglio preventivare il numero di esecuzioni ottenute dall'euristica massima. Per le risposte primarie binarie, chiedere aiuto a uno statistico per determinare il numero appropriato di esecuzioni.- Euristica minima: Allocare tre cicli per fattore di miscela, due per fattore di processo continuo e uno per livello di ciascun fattore categoriale.
NOTA: Per uno studio con quattro fattori lipidici, due continui e una variabile di processo categorico a tre vie, questo porta a suggerire di (3 x 4) + (2 x 2) + 3 = 19 esecuzioni di riempimento dello spazio. Aggiungere ulteriori esecuzioni se è probabile che alcune falliscano a causa di problemi di formulazione o misurazione. - Euristica massima: Avviare il software per la creazione di progetti ottimali e inserire i parametri richiesti per un secondo ordine (inclusi effetti principali, interazioni bidirezionali tra tutti gli effetti ed effetti quadratici per fattori di processo continui). Calcola la dimensione minima di esecuzione secondo l'algoritmo del software. Aggiungere 1 al risultato ottenuto dal software per definire l'euristica massima.
Nota : fare riferimento al file supplementare 1 per istruzioni dettagliate sull'esecuzione di questi passaggi. Un caso campione con quattro fattori lipidici, due continui e una variabile di processo categorica a tre vie, porta a una dimensione di esecuzione consigliata di 34 (33 dalla raccomandazione software + 1). Qualsiasi corsa oltre questo sarebbe probabilmente meglio utilizzata per studi di conferma o follow-up.
- Euristica minima: Allocare tre cicli per fattore di miscela, due per fattore di processo continuo e uno per livello di ciascun fattore categoriale.

Figura 2: Diagramma di causa ed effetto. Il diagramma mostra i fattori comuni in un problema di ottimizzazione della formulazione LNP. Fare clic qui per visualizzare una versione ingrandita di questa figura.
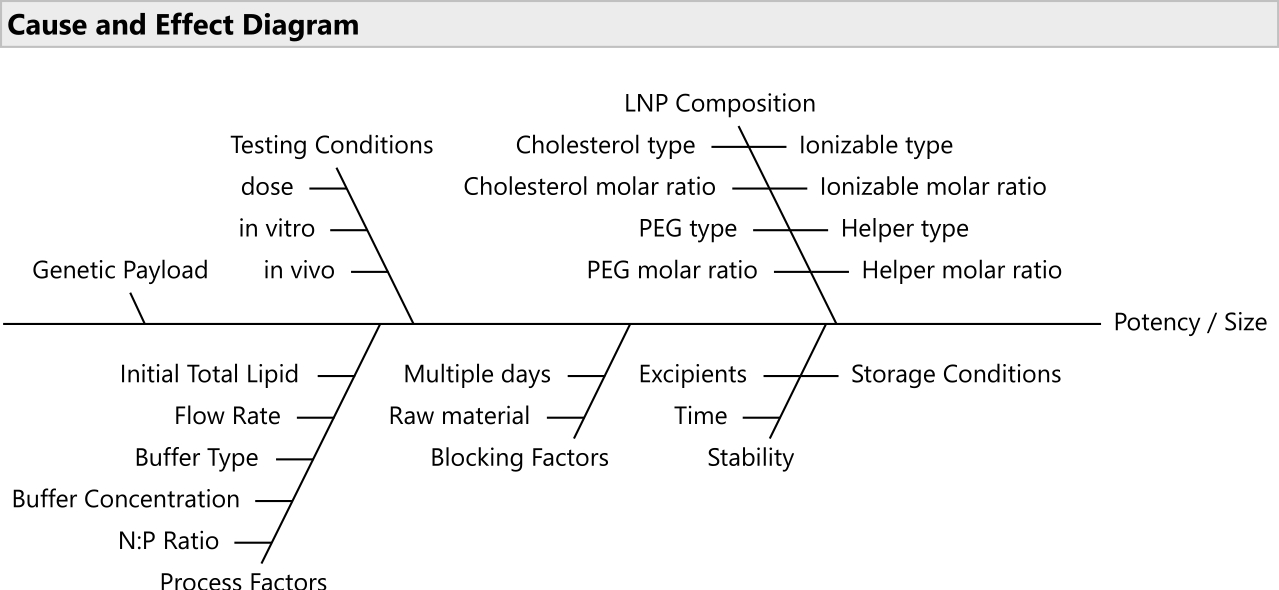{kind=link}
2. Creazione del tavolo di design con un design che riempie lo spazio
- Aprite JMP e navigate nella barra dei menu fino a DOE > Special Purpose > Space Filling Design.
- Inserire le risposte dello studio (vedere il file supplementare 1).
- Facoltativo: aggiungere colonne per ulteriori risposte, indicando se ciascuna deve essere ingrandita, ridotta a icona o destinata facendo clic su Aggiungi risposta.
NOTA: queste impostazioni possono essere modificate in seguito e non influiscono sulla progettazione. Analogamente, è possibile aggiungere colonne aggiuntive per ulteriori risposte dopo aver creato la tabella dati. - Inserisci i fattori di studio e gli intervalli corrispondenti. Utilizzare il pulsante Miscela per aggiungere fattori di miscela, il pulsante Continuo per aggiungere fattori continui o il pulsante Categorico per aggiungere fattori categorici.
NOTA: Questo esempio di studio utilizza i fattori e gli intervalli illustrati nella Figura 3, che includono il rapporto molare ionizzabile (compreso tra 0,1 e 0,6), il rapporto molare Helper (anche tra 0,1 e 0,6), il rapporto molare colesterolo (tra 0,1 e 0,6), il rapporto molare PEG (da 0,01 a 0,05) e il tipo lipidico ionizzabile (che può essere H101, H102 o H103). - Immettere il numero predeterminato di esecuzioni per il progetto nel campo Numero di esecuzioni .
- Facoltativo: aumentare la dimensione media del cluster dal valore predefinito di 50 a 2000 tramite il menu triangolo rosso accanto all'intestazione Progettazione riempimento spazio e nel sottomenu Opzioni avanzate .
NOTA: questa è un'impostazione per l'algoritmo di riempimento dello spazio che può portare a una costruzione di progettazione leggermente migliore al costo di un tempo computazionale aggiuntivo. - Generare la tabella di progettazione che riempie lo spazio per i fattori scelti e le dimensioni dell'esecuzione. Fare clic su Riempimento rapido e flessibile, quindi fare clic su Crea tabella.
Nota : le prime due esecuzioni da un progetto di esempio sono illustrate nella Figura 4. - Aggiungere una colonna Note alla tabella per annotare eventuali esecuzioni create manualmente. Fare doppio clic sulla prima intestazione di colonna vuota per aggiungere una colonna, quindi fare doppio clic sulla nuova intestazione di colonna per modificare il nome.
- Se applicabile, incorporare manualmente le esecuzioni di controllo del benchmark nella tabella di progettazione. Includi una replica per uno dei benchmark di controllo. Contrassegna il nome del benchmark nella colonna Note e codifica a colori le righe di replica del benchmark per una facile identificazione del grafico.
- Aggiungi una nuova riga facendo doppio clic sulla prima intestazione di riga vuota e inserisci le impostazioni del fattore di benchmark. Duplicare questa riga per creare una replica del benchmark. Evidenziate entrambe le righe e passate a Righe > Colori per assegnare un colore ai fini della creazione grafica.
NOTA: la replica fornisce una stima indipendente dal modello del processo più la varianza analitica e fornirà ulteriori informazioni grafiche.
- Aggiungi una nuova riga facendo doppio clic sulla prima intestazione di riga vuota e inserisci le impostazioni del fattore di benchmark. Duplicare questa riga per creare una replica del benchmark. Evidenziate entrambe le righe e passate a Righe > Colori per assegnare un colore ai fini della creazione grafica.
- Se le prove di controllo del benchmark superano l'intervallo dei fattori di studio, indicarlo nella colonna "Note" per la futura esclusione dall'analisi.
- Arrotondare i fattori di miscela alla granularità appropriata. Per fare ciò,
- Evidenziare le intestazioni di colonna per i fattori di miscela, fare clic con il pulsante destro del mouse su una delle intestazioni di colonna e passare a Nuova colonna formula > Trasforma > arrotondamento..., immettere l'intervallo di arrotondamento corretto e fare clic su OK.
- Assicuratevi che non sia selezionata alcuna riga facendo clic sul triangolo inferiore all'intersezione delle intestazioni di riga e colonna.
- Copiare i valori dalle colonne arrotondate appena create (Ctrl + C) e incollare (Ctrl + V) nelle colonne della miscela originale. Infine, eliminare le colonne dei valori arrotondati temporanei.
- Dopo aver arrotondato i rapporti lipidici, verificare che la loro somma sia uguale a 100% selezionando le intestazioni di colonna per i fattori di miscela, facendo clic con il pulsante destro del mouse su uno e passando a Nuova colonna Formula > Combina > somma. Se la somma di una riga non è uguale a 1, regolare manualmente uno dei fattori di miscela, assicurandosi che l'impostazione dei fattori rimanga all'interno dell'intervallo di fattori. Eliminare la colonna di somma dopo aver apportato le modifiche.
- Seguire la stessa procedura utilizzata per arrotondare i fattori di miscela per arrotondare i fattori di processo alla rispettiva granularità.
- Formattare le colonne lipidiche da visualizzare come percentuali con il numero desiderato di decimali: selezionare le intestazioni di colonna, fare clic con il pulsante destro del mouse e scegliere Standardizza attributi.... Nella finestra successiva, impostare Formato su Percentuale e regolare il numero di decimali in base alle esigenze.
- Se vengono aggiunte esecuzioni manuali, ad esempio benchmark, selezionare nuovamente l'ordine delle righe della tabella: aggiungere una nuova colonna con valori casuali (fare clic con il pulsante destro del mouse sull'ultima intestazione di colonna e selezionare Nuova colonna formula > Casuale > Normale casuale). Ordinare la colonna in ordine crescente facendo clic con il pulsante destro del mouse sull'intestazione della colonna e quindi eliminare la colonna.
- Facoltativo: aggiungere una colonna Run ID . Compila questo con la data corrente, il nome dell'esperimento e il numero di riga della tabella.
NOTA: vedere (Figura 5) per un esempio. - Generare grafici ternari per visualizzare i punti di progettazione sui fattori lipidici (Figura 6). Inoltre, esaminare la distribuzione della corsa sui fattori di processo (Figura 7): selezionare Grafico > Grafico ternario. Selezionate solo i fattori di miscela per X, Plottaggio.
- Per esaminare la distribuzione sui fattori processo, selezionare Analizza > distribuzione e immettere i fattori processo per Y, Colonne.
NOTA: Lo scienziato della formulazione deve confermare la fattibilità di tutte le esecuzioni. Se esistono esecuzioni non fattibili, riavviare la progettazione tenendo conto dei vincoli appena individuati.

Figura 3: Fattori e intervalli di studio. Le schermate delle impostazioni all'interno del software sperimentale sono utili per riprodurre l'impostazione dello studio. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 4: Output iniziale per un progetto che riempie spazio. Mostrando le prime due righe della tabella, le impostazioni devono essere arrotondate alla precisione desiderata, assicurandosi anche che la somma dei lipidi sia pari a 1. Il benchmark è stato aggiunto alla tabella manualmente. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 5: Tabella di studio formattata. I livelli dei fattori sono stati arrotondati e formattati ed è stata aggiunta una colonna Run ID. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 6: Punti di progettazione su un grafico ternario. Le 23 formulazioni sono mostrate in funzione dei corrispondenti rapporti Ionizzabile, Helper e "Altri" (Colesterolo+PEG). Il punto verde al centro rappresenta il benchmark 33:33:33:1 rapporto molare di Ionizable (H101):Colesterolo:Helper (DOPE):P EG. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 7: Distribuzione dei fattori di processo non miscelati nell'esperimento. Gli istogrammi mostrano come le corse sperimentali sono distanziate tra tipo lipidico ionizzabile, rapporto N-P e portata. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}
3. Esecuzione dell'esperimento
- Eseguire l'esperimento nell'ordine fornito dalla tabella dati. Registrare le letture nelle colonne incorporate nella tabella sperimentale.
- Se vengono eseguiti più test per la stessa risposta su un lotto di formulazione identico, calcolare una media per questi risultati all'interno di ciascun lotto. Aggiungere una colonna per ogni misurazione del test alla tabella.
- Per ottenere una media, selezionare tutte le colonne correlate, fare clic con il pulsante destro del mouse su una delle intestazioni di colonna selezionate e scegliere Nuova colonna formula > Combina > Media. Utilizzare questa colonna Media per l'analisi delle risposte future.
NOTA: senza ricominciare la ricetta, le misurazioni ripetute del saggio catturano solo la varianza del saggio e non costituiscono repliche indipendenti.
- Per ottenere una media, selezionare tutte le colonne correlate, fare clic con il pulsante destro del mouse su una delle intestazioni di colonna selezionate e scegliere Nuova colonna formula > Combina > Media. Utilizzare questa colonna Media per l'analisi delle risposte future.
- Documentare qualsiasi occorrenza di precipitazioni della formulazione o problemi di tollerabilità in vivo (come grave perdita di peso corporeo o morte) con indicatori binari (0/1) in una nuova colonna per ogni tipo di problema.
4. Analisi dei risultati sperimentali
- Tracciare le letture ed esaminare le distribuzioni delle risposte: aprire Graph > Graph Builder e trascinare ogni risposta nell'area Y per i singoli grafici. Ripeti questa operazione per tutte le risposte.
- Esaminare la distanza relativa tra le esecuzioni di replica codificate a colori, se ne è stata inclusa una. Ciò consente di comprendere la variazione totale (di processo e analitica) al benchmark rispetto alla variabilità dovuta a cambiamenti nelle impostazioni fattoriali nell'intero spazio fattoriale (Figura 8).
- Determinare se la risposta non elaborata deve essere modellata o se deve essere utilizzata una trasformazione. Per le risposte che sono limitate ad essere positive ma sono illimitate sopra (ad esempio, potenza), adattare sia una distribuzione normale che una distribuzione lognormale ai risultati sperimentali. Se la distribuzione lognormale si adatta meglio con un AICc inferiore (corretto il criterio informativo di Akaike), allora prendi una trasformazione logaritmica di quella risposta.
- Passare ad Analizza distribuzione > e selezionare la risposta per Y, Colonne. Nel report di distribuzione risultante, fare clic sul triangolo rosso accanto al nome della risposta e scegliere Adattamento continuo > Adatta normale e Adattamento continuo > Adatta normale dal menu a discesa. Nel successivo rapporto Confronta distribuzioni, controllare i valori AICc per accertare quale distribuzione si adatta meglio alla risposta.
- Per eseguire una trasformazione del log, fare clic con il pulsante destro del mouse sull'intestazione della colonna di risposta e scegliere Nuova colonna Formula > Registro > registro. Quando viene creato un modello e viene salvata una colonna di stima sulla scala logaritmica, trasformare nuovamente la risposta nella scala originale selezionando Nuova colonna formula > Registro > Exp.
- Per le risposte proporzionali limitate tra 0 e 1, confrontare l'adattamento di una distribuzione normale e beta. Se la distribuzione beta ha un AICc inferiore, eseguire una trasformazione logit. Nel rapporto Distribuzione della risposta, scegliere Adattamento continuo > Adattamento normale e Adattamento continuo > Adattamento beta.
- Per la trasformazione logit, fare clic con il pulsante destro del mouse sull'intestazione della colonna di risposta nella tabella dati e scegliere Nuova colonna formula > Specialità > Logit. Post creazione del modello, salvare la colonna di previsione. Per ripristinare la scala originale, utilizzare Nuova colonna Formula > Specialità > Logistica.
NOTA: l'analisi SVEM basata sulla regressione è robusta per le deviazioni dalla normalità nella distribuzione della risposta. Tuttavia, queste trasformazioni possono portare a una più facile interpretazione dei risultati e a una migliore adattamento dei modelli.
- Per la trasformazione logit, fare clic con il pulsante destro del mouse sull'intestazione della colonna di risposta nella tabella dati e scegliere Nuova colonna formula > Specialità > Logit. Post creazione del modello, salvare la colonna di previsione. Per ripristinare la scala originale, utilizzare Nuova colonna Formula > Specialità > Logistica.
- Rappresentare graficamente le corse su un grafico ternario. Colorare i punti in base alle risposte (o alle risposte trasformate se è stata applicata una trasformazione): aprite Grafico > Grafico ternario. Selezionate solo i fattori di miscela per X, Plottaggio. Fare clic con il pulsante destro del mouse su uno dei grafici risultanti, selezionare Legenda riga e quindi selezionare la colonna di risposta (trasformata).
NOTA: colorare i punti in base alle risposte offre una prospettiva visiva indipendente dal modello del comportamento in relazione ai fattori di miscela. - Eliminate lo script Modello generato dal progetto di riempimento dello spazio.
- Costruire un modello indipendente per ogni risposta in funzione dei fattori di studio, ripetendo i seguenti passaggi per ogni risposta.
NOTA: Nel caso di una risposta binaria secondaria (ad esempio, fallimento della formulazione o morte del topo), modellare anche questa risposta. Modificare l'impostazione della distribuzione di destinazione da Normale a Binomiale. - Costruisci un modello "completo" che comprenda tutti gli effetti candidati. Questo modello dovrebbe includere gli effetti principali di ciascun fattore, le interazioni a due e tre vie, i termini cubici quadratici e parziali nei fattori di processo e i termini cubici di Scheffé per i fattori di miscela23,24.
NOTA: utilizzare lo stesso set di effetti candidati per ogni risposta. La tecnica di selezione del modello SVEM perfezionerà in modo indipendente i modelli per ogni risposta, risultando potenzialmente in modelli ridotti unici per ciascuno. La Figura 9 illustra alcuni di questi effetti candidati. I seguenti passaggi secondari descrivono dettagliatamente questo processo.- Selezionare Analizza > Adatta modello.
- Assicurarsi che i fattori di blocco (ad esempio, Day) non siano autorizzati a interagire con altri fattori di studio. Selezionare eventuali fattori di blocco e fare clic su Aggiungi. Non includere questi fattori in nessuno dei passaggi secondari successivi.
NOTA: i fattori di blocco sono importanti da tenere in considerazione nel modello, ma i fattori di blocco non dovrebbero interagire con altri fattori di studio. Lo scopo principale dei fattori di blocco è quello di aiutare a controllare la variabilità dell'esperimento e migliorare la sensibilità dell'esperimento. - Evidenzia tutti i fattori di studio. Modificare il valore del campo Grado impostandolo su 3 (per impostazione predefinita è impostato su 2). Clicca su fattoriale al grado.
NOTA: questa azione include gli effetti principali e le interazioni a due e tre vie nel modello. - Selezionate solo i fattori non di miscela nella finestra di selezione. Fare clic su Macro > Cubico parziale.
NOTA: questa azione introduce effetti quadratici per i fattori di processo continui e la loro interazione con altri fattori non di miscela nel modello. - Scegliere solo i fattori di miscela dall'elenco di selezione. Fare clic su Macro > Scheffe Cubic. Disattivare l'opzione predefinita Nessuna intercettazione (fare riferimento alla Figura 9).
NOTA: l'inclusione di un'intercetta nel modello è un passaggio essenziale quando si utilizzano i metodi Lasso ed è utile anche nel contesto della selezione diretta. L'impostazione predefinita tradizionale No Intercept è di solito in atto perché adattare un'intercetta simultaneamente a tutti gli effetti principali della miscela, senza modifiche come l'approccio SVEM, non è fattibile con la normale procedura di regressione dei minimi quadrati12. - Specificare la colonna di risposta: evidenziare la colonna di risposta e fare clic su Y.
- Modificare l'impostazione Personalità in Regressione generalizzata. Mantieni la distribuzione impostata su Normale.
- Salvate questa configurazione del modello nella tabella dati per utilizzarla con risposte aggiuntive facendo clic sul menu triangolo rosso accanto a Specifica modello (Model Specification ) e selezionando Salva nella tabella dati.
- Applicare il metodo di selezione diretta SVEM per adattarlo al modello ridotto, senza includere obbligatoriamente gli effetti principali del fattore di miscela, e memorizzare la colonna della formula di previsione nella tabella dati.
- Nella finestra di dialogo Adatta modello , fate clic su Esegui.
- Per il metodo di stima, selezionare SVEM Forward Selection.
- Espandi i menu Controlli avanzati > Forza termini e deseleziona le caselle associate agli effetti principali della miscela. Solo la casella del termine Intercetta deve rimanere selezionata. Nella Figura 10 viene illustrata la configurazione predefinita in cui vengono forzati gli effetti principali. Per questo passaggio, queste caselle devono essere deselezionate per consentire al modello di includere o escludere questi effetti in base alla procedura di selezione in avanti.
- Fare clic su Vai per eseguire la procedura di selezione diretta SVEM.
- Tracciare le risposte effettive in base alle risposte previste dal modello SVEM per verificare una ragionevole capacità predittiva. (Figura 11). Fare clic sul triangolo rosso accanto a Selezione diretta SVEM e selezionare Grafici diagnostici > Traccia effettivo per previsto.
- Fare clic sul triangolo rosso accanto a Selezione diretta SVEM e selezionare Salva colonne > Salva formula di previsione per creare una nuova colonna contenente la formula di stima nella tabella dati.
- Facoltativo: ripetere i passaggi precedenti utilizzando SVEM Lasso come metodo di stima per determinare se viene suggerita una ricetta ottimale diversa dopo aver eseguito i passaggi successivi. In tal caso, eseguire entrambe le ricette come prove di conferma (discusse nella Sezione 5) per vedere quale funziona meglio nella pratica12.
- Ripetere i passaggi di creazione del modello per ogni risposta.
- Una volta salvate le colonne di stima per tutte le risposte nella tabella dati, rappresentare graficamente le tracce di risposta per tutte le colonne di risposta previste utilizzando la piattaforma Profiler: Selezionare Grafico > Profiler, selezionare tutte le colonne di stima create nel passaggio precedente per Y, Formula di stima, e fare clic su OK (Figura 12).
- Identificare le formulazioni ottimali del candidato.
- Definire la "funzione di desiderabilità" per ogni risposta, specificando se la risposta deve essere massimizzata, ridotta a icona o abbinata a una destinazione. Impostare tutte le risposte primarie in modo che utilizzino un peso di importanza pari a 1,0 e qualsiasi risposta secondaria utilizzi un peso di importanza pari a 0,2. Dal menu triangolo rosso di Prediction Profiler, selezionare Ottimizzazione e desiderabilità > Funzioni di desiderabilità, quindi Ottimizzazione e Desiderabilità > Imposta desiderabilità. Immettere le impostazioni nelle finestre successive.
NOTA: I pesi importanti sono relativi e soggettivi, quindi vale la pena verificare la sensibilità dell'optimum combinato alle variazioni di questi pesi entro un intervallo ragionevole (ad esempio, da una ponderazione uguale alla ponderazione 1:5). - Comanda al profiler di trovare le impostazioni dei fattori ottimali che massimizzano la funzione di desiderabilità (Figura 12): dal profiler, selezionare Ottimizzazione e desiderabilità > Massimizza desiderabilità.
NOTA: I valori previsti delle risposte ai candidati ottimali possono sovrastimare il valore delle risposte inclinate a destra come la potenza; Tuttavia, le prove di conferma forniranno osservazioni più accurate di queste formulazioni candidate. L'obiettivo principale è individuare la formulazione ottimale (le impostazioni della ricetta ottimale). - Registrare le impostazioni dei fattori ottimali e annotare le ponderazioni importanti utilizzate per ogni risposta: dal menu Profilo di previsione , selezionare Impostazioni fattore > Memorizza impostazioni.
- Definire la "funzione di desiderabilità" per ogni risposta, specificando se la risposta deve essere massimizzata, ridotta a icona o abbinata a una destinazione. Impostare tutte le risposte primarie in modo che utilizzino un peso di importanza pari a 1,0 e qualsiasi risposta secondaria utilizzi un peso di importanza pari a 0,2. Dal menu triangolo rosso di Prediction Profiler, selezionare Ottimizzazione e desiderabilità > Funzioni di desiderabilità, quindi Ottimizzazione e Desiderabilità > Imposta desiderabilità. Immettere le impostazioni nelle finestre successive.
- Facoltativo: per fattori categoriali come il tipo lipidico ionizzabile, trovare le formulazioni condizionatamente ottimali per ciascun livello di fattori.
- Per prima cosa imposta il livello desiderato del fattore nel profiler, quindi tieni premuto il tasto Ctrl e fai clic con il pulsante sinistro del mouse all'interno del grafico di quel fattore e seleziona Blocca fattori impostazione. Selezionare Ottimizzazione e desiderabilità > Massimizza desiderabilità per trovare l'optimum condizionale con questo fattore bloccato all'impostazione corrente.
- Sblocca le impostazioni del fattore prima di procedere, utilizzando lo stesso menu utilizzato per bloccare le impostazioni del fattore.
- Ripetere il processo di ottimizzazione dopo aver regolato i pesi di importanza delle risposte (utilizzando Ottimizzazione e Desiderabilità > Imposta desiderabilità), magari ottimizzando solo le risposte primarie o impostando alcune delle risposte secondarie in modo che abbiano più o meno importanza o impostando l'obiettivo delle risposte secondarie su Nessuno (Figura 13).
- Registrare il nuovo candidato ottimale (dal menu Profilo prrevisione, selezionare Impostazioni fattore > Memorizza impostazioni).
- Produrre riepiloghi grafici delle regioni ottimali dello spazio fattoriale: generare una tabella di dati con 50.000 righe popolate con impostazioni di fattori generate casualmente all'interno dello spazio fattoriale consentito, insieme ai corrispondenti valori previsti dal modello ridotto per ciascuna delle risposte e la funzione di desiderabilità congiunta.
- Nel profiler, selezionare Output tabella casuale. Impostare Quante esecuzioni simulare? su 50.000 e fare clic su OK .
NOTA: in questo modo viene generata una nuova tabella con i valori previsti delle risposte in ciascuna delle 50.000 formulazioni. La colonna Desiderabilità dipende dai pesi di importanza per le risposte presenti quando è selezionata l'opzione Tabella casuale di output . - Nella tabella appena creata aggiungere una nuova colonna che calcola il percentile della colonna Desiderabilità. Utilizzare questa colonna percentile nei grafici ternari anziché la colonna Desiderabilità non elaborata. Fare clic con il pulsante destro del mouse sull'intestazione della colonna Desiderabilità e scegliere Nuova colonna Formula > Probabilità distributiva > cumulativa per creare una nuova colonna Probabilità cumulativa [Desiderabilità].
- Generare gli elementi grafici descritti nei passaggi seguenti. Modificare ripetutamente la combinazione di colori della grafica per visualizzare le previsioni per ogni risposta e per la colonna Probabilità cumulativa[Desiderabilità].
- Costruire grafici ternari per i quattro fattori lipidici. Nella tabella passare a Grafico > Grafico ternario, selezionare i fattori di combinazione per X, Plottazione e fare clic su OK. Fare clic con il pulsante destro del mouse in uno dei grafici risultanti, selezionare Legenda riga e quindi selezionare la colonna di risposta prevista. Modificare l'elenco a discesa Colori in Jet.
NOTA: visualizza le regioni con le prestazioni migliori e peggiori rispetto ai fattori lipidici. La Figura 14 mostra i percentili della desiderabilità congiunta quando si considera la massimizzazione della potenza (importanza = 1) e la minimizzazione della dimensione (importanza = 0,2), facendo la media su tutti i fattori che non sono mostrati sugli assi del grafico ternario. La Figura 15 mostra le dimensioni non elaborate previste. È anche ragionevole suddividere questi grafici in modo condizionale su altri fattori, come la creazione di un insieme distinto di grafici ternari per ciascun tipo di lipide ionizzabile con un filtro dati locale (disponibile dal menu triangolo rosso accanto a Grafico ternario). - Allo stesso modo, utilizzare Graph > Graph Builder per tracciare i 50.000 punti codificati a colori (che rappresentano formulazioni uniche) rispetto ai fattori di processo non miscelati, singolarmente o congiuntamente, e cercare relazioni tra le risposte e i fattori. Cerca le impostazioni dei fattori che producono la massima desiderabilità. Esplora diverse combinazioni di fattori nella grafica.
NOTA: quando colorate i grafici, usate Probabilità cumulativa [Desiderabilità], ma quando tracciate la desiderabilità sull'asse verticale rispetto ai fattori processo, utilizzate la colonna Desiderabilità non elaborata. La colonna Desiderabilità può anche essere posizionata su un asse della visualizzazione 3D grafico > grafico a dispersione insieme ad altri due fattori di processo per l'esplorazione multivariata. La figura 16 mostra la desiderabilità congiunta di tutte le formulazioni che possono essere formate con ciascuno dei tre tipi di lipidi ionizzabili. Le formulazioni più desiderabili utilizzano H102, con H101 che fornisce alcune alternative potenzialmente competitive. - Salvare il profiler e le relative impostazioni memorizzate nella tabella dati. Fare clic sul triangolo rosso accanto a Profiler e selezionare Salva script > nella tabella dati....
- Nel profiler, selezionare Output tabella casuale. Impostare Quante esecuzioni simulare? su 50.000 e fare clic su OK .

Figura 8: Letture di potenza osservate dall'esperimento. I punti mostrano i valori di potenza che sono stati osservati dalle 23 esecuzioni; Le esecuzioni del benchmark replicate sono visualizzate in verde. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 9: Finestra di dialogo software per l'avvio dell'analisi. Gli effetti candidati sono stati inseriti insieme alla risposta di potenza target e l'opzione Nessuna intercetta è stata deselezionata. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 10. Finestra di dialogo aggiuntiva per specificare le opzioni SVEM. Per impostazione predefinita, gli effetti principali dei lipidi sono forzati nel modello. Poiché è inclusa un'intercettazione, si consiglia di deselezionare queste caselle per non forzare gli effetti. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 11: Effettivo per trama prevista. Questa figura traccia la potenza osservata rispetto al valore previsto per ogni formulazione dal modello SVEM. La correlazione non deve essere così forte come in questo esempio, ma l'aspettativa è di vedere almeno una correlazione moderata e di verificare la presenza di valori anomali. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 12: Profiler di previsione. Le prime due righe di grafici mostrano le sezioni della funzione di risposta prevista alla formulazione ottimale (come identificato dall'approccio SVEM). La riga inferiore dei grafici mostra la "desiderabilità" ponderata della formulazione, che è una funzione dell'ultima colonna di grafici che mostra che la potenza dovrebbe essere massimizzata e la dimensione dovrebbe essere ridotta al minimo. Fare clic qui per visualizzare una versione ingrandita di questa figura.
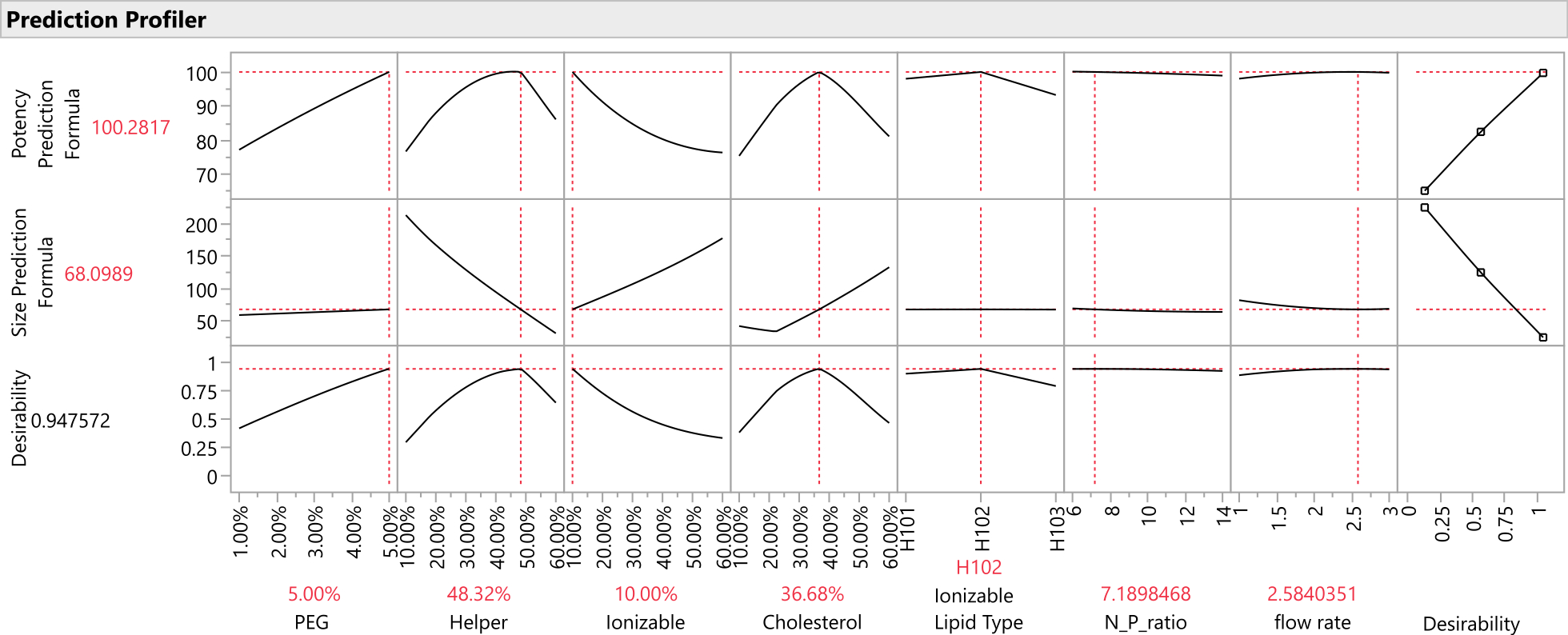{kind=link}

Figura 13: Tre candidati formulatori ottimali di SVEM-Forward Selection. Modificare la ponderazione dell'importanza relativa delle risposte può portare a diverse formulazioni ottimali. Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 14: Grafici ternari per il percentile di desiderabilità. Il grafico mostra le 50.000 formulazioni codificate a colori per percentile di desiderabilità, dove la desiderabilità è impostata con importanza peso di 1,0 per massimizzare la potenza e 0,2 per minimizzare le dimensioni, questi grafici mostrano che la regione ottimale delle formulazioni è costituita da percentuali più basse di lipidi ionizzabili e percentuali più elevate di PEG. Fare clic qui per visualizzare una versione ingrandita di questa figura.
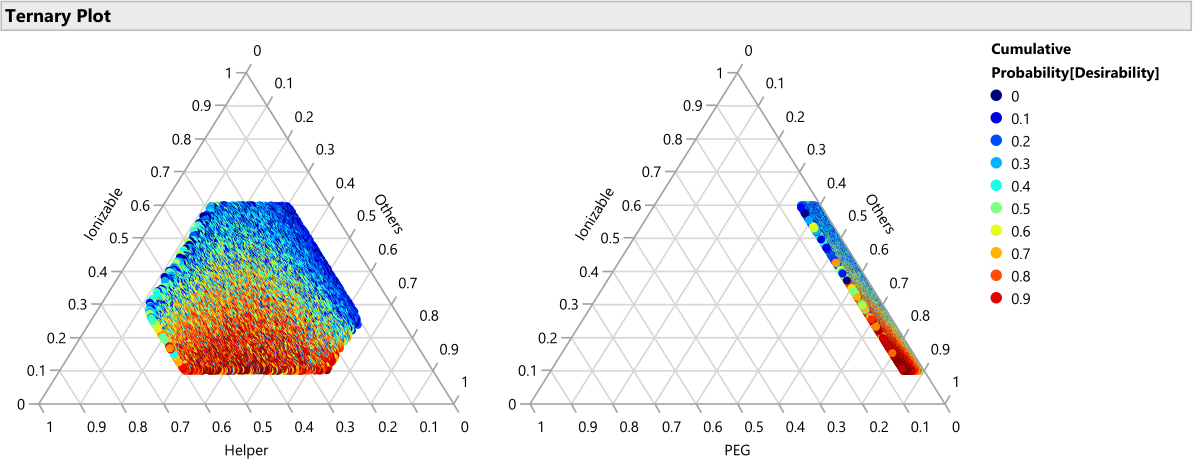{kind=link}

Figura 15: Grafico ternario per la dimensione prevista. Il grafico mostra le previsioni delle dimensioni del modello SVEM per ciascuna delle 50.000 formulazioni. La dimensione è ridotta al minimo con percentuali più elevate di lipidi helper e massimizzata con percentuali più basse di aiutante. Poiché gli altri fattori variano liberamente tra le 50.000 formulazioni tracciate, ciò implica che questa relazione vale per tutti gli intervalli degli altri fattori (PEG, portata, ecc.). Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}

Figura 16: Diagrammi di violino per la desiderabilità di formulazioni che coinvolgono i tre diversi tipi di lipidi ionizzabili. Ciascuno dei 50.000 punti rappresenta una formulazione unica da tutto lo spazio fattoriale consentito. I picchi di queste distribuzioni sono i valori massimi di desiderabilità che vengono calcolati analiticamente con il profiler di previsione. H102 ha il picco più grande e quindi produce la formulazione ottimale. L'approccio SVEM alla costruzione del modello che genera questo output filtra automaticamente i fattori statisticamente insignificanti: lo scopo di questo grafico è considerare la significatività pratica tra i livelli fattoriali. Fare clic qui per visualizzare una versione ingrandita di questa figura.
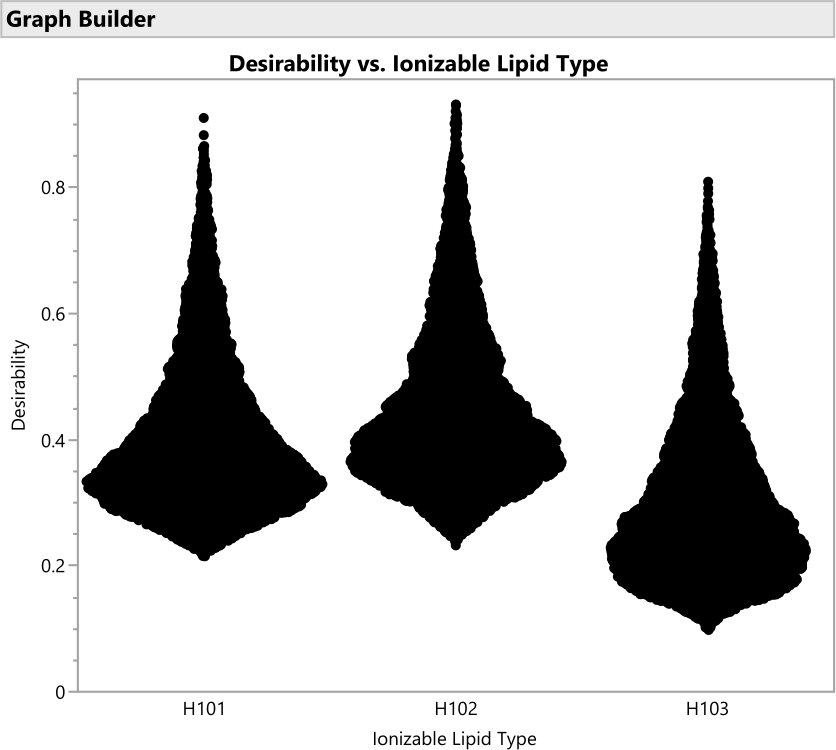{kind=link}
5. Cicli di conferma
- Preparare una tabella che elenca i candidati ottimali identificati in precedenza (Figura 17).
NOTA: I valori True Potency e True Size in Figura 17 sono compilati utilizzando le funzioni generatrici simulate: in pratica, queste saranno ottenute formulando e quindi misurando le prestazioni di queste ricette.- Includere il controllo del benchmark con l'insieme di corse candidate che verranno formulate e misurate.
- Se una qualsiasi delle formulazioni dell'esperimento è risultata produrre risultati desiderabili, magari sovraperformando il benchmark, selezionare il meglio da aggiungere alla tabella dei candidati e ripetere il test insieme alle nuove formulazioni.
NOTA: aggiungere manualmente le esecuzioni desiderate alla tabella dei candidati oppure utilizzare le impostazioni memorizzate della finestra del profiler se queste esecuzioni provengono dall'esperimento precedente. Identificare il numero di riga dell'esecuzione, passare a Impostazioni fattore > Profiler di previsione > Imposta su Dati nella riga e immettere il numero di riga. Quindi, scegli Impostazioni di Prediction Profiler > Factor > Memorizza impostazioni ed etichetta in modo appropriato (ad esempio, "benchmark" o "esecuzione ottimale dell'esperimento precedente"). - Fare clic con il pulsante destro del mouse sulla tabella Impostazioni memorizzate nel profiler e selezionare Crea in tabella dati.
NOTA: a seconda della priorità e del budget dello studio, prendere in considerazione l'esecuzione di repliche per ogni esecuzione di conferma, soprattutto se si sostituisce il benchmark. Crea e analizza ogni formulazione due volte, utilizzando il risultato medio per la classificazione. Prestare attenzione a tutti i candidati con un ampio intervallo di risposta tra le due repliche in quanto ciò potrebbe indicare un'elevata varianza del processo. - Se necessario a causa di vincoli di budget, selezionare tra i candidati identificati per adeguarsi al budget sperimentale o per eliminare i candidati ridondanti.
- Eseguire le corse di conferma. Costruisci le formulazioni e raccogli le letture.
- Verificare la coerenza tra i risultati dell'esperimento originale e i risultati del batch di conferma per i benchmark o altre ricette ripetute. Se si verifica uno spostamento di grandi dimensioni e imprevisto, considerare ciò che potrebbe aver contribuito allo spostamento e se è possibile che tutte le esecuzioni dal batch di conferma siano state interessate.
- Confronta le prestazioni delle formulazioni ottimali del candidato. Scopri se alcuni nuovi candidati hanno sovraperformato il benchmark.
- Facoltativo: aggiungere il risultato delle serie di conferma alla tabella sperimentale ed eseguire nuovamente l'analisi nella Sezione 4.
NOTA: il passaggio successivo del flusso di lavoro fornisce istruzioni per la creazione di uno studio di follow-up insieme a queste esecuzioni, se lo si desidera.

Figura 17: Tabella dei dieci candidati ottimali da eseguire come prove di conferma. La vera potenza e la vera dimensione sono state compilate dalle funzioni di generazione della simulazione (senza alcun processo aggiunto o variazione analitica). Fare clic qui per visualizzare una versione ingrandita di questa figura.
{kind=link}
6. Facoltativo: progettazione di uno studio di follow-up da eseguire in concomitanza con le esecuzioni di conferma
- Valutare la necessità di uno studio di follow-up considerando i seguenti criteri:
- Determinare se la formulazione ottimale si trova lungo uno dei limiti dei fattori e se si desidera un secondo esperimento per espandere almeno uno degli intervalli di fattori.
- Valutare se l'esperimento iniziale ha utilizzato una dimensione di esecuzione relativamente piccola o intervalli di fattori relativamente grandi e se è necessario "ingrandire" la regione ottimale identificata con esecuzioni aggiuntive e analisi aggiornate.
- Controlla se viene introdotto un fattore aggiuntivo. Questo potrebbe essere un livello di un fattore categoriale come un lipide ionizzabile aggiuntivo o un fattore che è rimasto costante nello studio iniziale, ad esempio la concentrazione tampone.
- Se nessuna delle condizioni precedenti è soddisfatta, procedere al passaggio 7.
- Preparare ulteriori esecuzioni sperimentali da eseguire in concomitanza con le esecuzioni di conferma.
- Definire i limiti fattoriali garantendo una parziale sovrapposizione con la regione dallo studio iniziale. Se non esistono sovrapposizioni, deve essere progettato un nuovo studio.
- Sviluppa le nuove piste sperimentali con un design che riempie lo spazio. Seleziona DOE > Special Purpose > Space Filling Design.
NOTA: per gli utenti avanzati, prendere in considerazione un design D-optimal tramite DOE > Custom Design. - Dopo aver generato le esecuzioni di riempimento dello spazio, incorporare manualmente due o tre esecuzioni dell'esperimento originale che si trovano all'interno del nuovo spazio fattoriale. Distribuire queste esecuzioni in modo casuale all'interno della tabella sperimentale utilizzando i passaggi descritti nella Sezione 2 per aggiungere righe e quindi randomizzare l'ordine delle righe.
NOTA: Questi verranno utilizzati per stimare qualsiasi spostamento nei mezzi di risposta tra i blocchi. - Concatenare le esecuzioni di conferma e le nuove esecuzioni di riempimento dello spazio in un'unica tabella e randomizzare l'ordine di esecuzione. Utilizzare Tabelle > Concatenare e quindi creare e ordinare in base a una nuova colonna casuale per randomizzare l'ordine di esecuzione, come descritto nella Sezione 2.
- Formulare le nuove ricette e raccogliere i risultati.
- Concatenare le nuove esecuzioni sperimentali e i risultati alla tabella dei dati dell'esperimento originale, introducendo una colonna ID esperimento per indicare l'origine di ciascun risultato. Utilizzare Tabelle > Concatena e selezionare l'opzione Crea colonna di origine.
- Verificare che le proprietà della colonna per ciascun fattore visualizzino l'intervallo combinato per entrambi gli studi: fare clic con il pulsante destro del mouse sull'intestazione della colonna per ciascun fattore ed esaminare gli intervalli di proprietà Codifica e Miscela , se presenti.
- Inizia l'analisi dei risultati del nuovo esperimento.
- Includere la colonna ID esperimento come termine nel modello da utilizzare come fattore di blocco. Assicurarsi che questo termine non interagisca con i fattori di studio. Eseguite lo script della finestra di dialogo Adatta modello salvato nella tabella nella Sezione 4, selezionate la colonna ID esperimento e fate clic su Aggiungi per includerla nell'elenco degli effetti candidati.
- Eseguire questa finestra di dialogo Adatta modello sulla tabella dati concatenata per analizzare congiuntamente i risultati del nuovo esperimento e dello studio iniziale. Attenersi alle istruzioni precedenti per generare candidati di formulazione ottimali aggiornati e riepiloghi grafici.
- Per la convalida, analizzare in modo indipendente i risultati del nuovo esperimento, escludendo i risultati dell'esperimento iniziale. In altre parole, eseguire i passaggi descritti nella Sezione 4 nella nuova tabella sperimentale.
- Garantire che le formulazioni ottimali identificate da questi modelli siano strettamente allineate con quelle riconosciute dall'analisi congiunta.
- Rivedere i riassunti grafici per confermare che sia le analisi congiunte che quelle individuali dei nuovi risultati sperimentali mostrano comportamenti simili della superficie di risposta (il che significa che esiste una relazione simile tra le risposte e i fattori).
- Confronta le analisi combinate e individuali dei nuovi risultati con l'esperimento iniziale per coerenza. Utilizzare strutture grafiche simili per il confronto ed esaminare le ricette ottimali identificate per le differenze.
7. Documentare le conclusioni scientifiche finali dello studio
- Se il controllo del benchmark cambia in una nuova ricetta identificata a causa dello studio, registrare la nuova impostazione e specificare i file di progettazione e analisi che ne registrano l'origine.
- Mantenere tutte le tabelle sperimentali e i riepiloghi di analisi, preferibilmente con nomi di file contrassegnati da data, per riferimento futuro.
Access restricted. Please log in or start a trial to view this content.
Risultati
Questo approccio è stato convalidato in entrambi i tipi lipidici ampiamente classificati: lipidi classici simili a MC3 e lipidoidi (ad esempio, C12-200), generalmente derivati dalla chimica combinatoria. Rispetto a una formulazione LNP di riferimento sviluppata utilizzando un metodo One Factor at a Time (OFAT), le formulazioni candidate generate attraverso il nostro flusso di lavoro dimostrano spesso miglioramenti di potenza da 4 a 5 volte su scala logaritmica, come mostrato nelle letture della luciferasi epatica di top...
Access restricted. Please log in or start a trial to view this content.
Discussione
Il moderno software per la progettazione e l'analisi di esperimenti di processo di miscela consente agli scienziati di migliorare le loro formulazioni di nanoparticelle lipidiche in un flusso di lavoro strutturato che evita una sperimentazione OFAT inefficiente. L'approccio di modellazione SVEM recentemente sviluppato elimina molte delle modifiche di regressione arcana e delle strategie di riduzione del modello che potrebbero aver precedentemente distratto gli scienziati con considerazioni statistiche estranee. Una volta...
Access restricted. Please log in or start a trial to view this content.
Divulgazioni
La strategia di progettazione sperimentale alla base di questo flusso di lavoro è stata impiegata in due domande di brevetto in cui uno degli autori è un inventore. Inoltre, Adsurgo, LLC è un partner JMP certificato. Tuttavia, lo sviluppo e la pubblicazione di questo documento sono stati intrapresi senza alcuna forma di incentivo finanziario, incoraggiamento o altri incentivi da parte di JMP.
Riconoscimenti
Siamo grati all'editore e ai referee anonimi per i suggerimenti che hanno migliorato l'articolo.
Access restricted. Please log in or start a trial to view this content.
Materiali
| Name | Company | Catalog Number | Comments |
| JMP Pro 17.1 | JMP Statistical Discovery LLC |
Riferimenti
- Dolgin, E. Better lipids to power next generation of mRNA vaccines. Science. 376 (6594), 680-681 (2022).
- Hou, X., Zaks, T., Langer, R., Dong, Y. Lipid nanoparticles for mRNA delivery. Nature Reviews Materials. 6 (12), 1078-1094 (2021).
- Huang, X., et al. The landscape of mRNA nanomedicine. Nature Medicine. 28, 2273-2287 (2022).
- Rampado, R., Peer, D. Design of experiments in the optimization of nanoparticle-based drug delivery systems. Journal of Controlled Release. 358, 398-419 (2023).
- Kauffman, K. J., et al. Optimization of lipid nanoparticle formulations for mRNA delivery in vivo with fractional factorial and definitive screening designs. Nano Letters. 15, 7300-7306 (2015).
- Jones, B., Nachtsheim, C. J. A class of three-level designs for definitive screening in the presence of second-order effects. Journal of Quality Technology. 43, 1-15 (2011).
- Cornell, J. Experiments with Mixtures: Designs, Models, and the Analysis of Mixture Data. Wiley Series in Probability and Statistics. , Wiley. (2002).
- Jones, B. Proper and improper use of definitive screening designs (DSDs). JMP user Community. , https://community.jmp.com/t5/JMP-Blog/Proper-and-improper-use-of-Definitive-Screening-Designs-DSDs/bc-p/546773 (2016).
- Myers, R., Montgomery, D., Anderson-Cook, C. Response Surface Methodology. , Wiley. (2016).
- Lekivetz, R., Jones, B. Fast flexible space-filling designs for nonrectangular regions. Quality and Reliability Engineering International. 31, 829-837 (2015).
- Czitrom, V. One-factor-at-a-time versus designed experiments. The American Statistician. 53, 126-131 (1999).
- Karl, A., Wisnowski, J., Rushing, H. JMP Pro 17 remedies for practical struggles with mixture experiments. JMP Discovery Conference. , (2022).
- Lemkus, T., Gotwalt, C., Ramsey, P., Weese, M. L. Self-validated ensemble models for design of experiments. Chemometrics and Intelligent Laboratory Systems. 219, 104439(2021).
- Gotwalt, C., Ramsey, P. Model validation strategies for designed experiments using bootstrapping techniques with applications to biopharmaceuticals. JMP Discovery Conference. , (2018).
- Xu, L., Gotwalt, C., Hong, Y., King, C. B., Meeker, W. Q. Applications of the fractional-random-weight bootstrap. The American Statistician. 74 (4), 345-358 (2020).
- Ramsey, P., Levin, W., Lemkus, T., Gotwalt, C. SVEM: A paradigm shift in design and analysis of experiments. JMP Discovery Conference Europe. , (2021).
- Ramsey, P., Gaudard, M., Levin, W. Accelerating innovation with space filling mixture designs, neural networks and SVEM. JMP Discovery Conference. , (2021).
- Lemkus, T. Self-Validated Ensemble modelling. Doctoral Dissertations. 2707. , https://scholars.unh.edu/dissertation/2707 (2022).
- Juran, J. M. Juran on Quality by Design: The New Steps for Planning Quality into Goods and Services. , Free Press. (1992).
- Yu, L. X., et al. Understanding pharmaceutical quality by design. The AAPS Journal. 16, 771(2014).
- Simpson, J. R., Listak, C. M., Hutto, G. T. Guidelines for planning and evidence for assessing a well-designed experiment. Quality Engineering. 25, 333-355 (2013).
- Daniel, S., Kis, Z., Kontoravdi, C., Shah, N. Quality by design for enabling RNA platform production processes. Trends in Biotechnology. 40 (10), 1213-1228 (2022).
- Scheffé, H. Experiments with mixtures. Journal of the Royal Statistical Society Series B. 20, 344-360 (1958).
- Brown, L., Donev, A. N., Bissett, A. C. General blending models for data from mixture experiments. Technometrics. 57, 449-456 (2015).
- Herrera, M., Kim, J., Eygeris, Y., Jozic, A., Sahay, G. Illuminating endosomal escape of polymorphic lipid nanoparticles that boost mRNA delivery. Biomaterials Science. 9 (12), 4289-4300 (2021).
- Lemkus, T., Ramsey, P., Gotwalt, C., Weese, M. Self-validated ensemble models for design of experiments. ArXiv. , 2103.09303(2021).
- Goos, P., Jones, B. Optimal Design of Experiments: A Case Study Approach. , John Wiley & Sons, Ltd. (2011).
- Rushing, H. DOE Gumbo: How hybrid and augmenting designs can lead to more effective design choices. JMP Discovery Conference. , (2020).
Access restricted. Please log in or start a trial to view this content.
Ristampe e Autorizzazioni
Richiedi autorizzazione per utilizzare il testo o le figure di questo articolo JoVE
Richiedi AutorizzazioneEsplora altri articoli
This article has been published
Video Coming Soon
Personale delle biblioteche
Copyright © 2025 MyJoVE Corporation. Tutti i diritti riservati