
Se requiere una suscripción a JoVE para ver este contenido. Inicie sesión o comience su prueba gratuita.
Method Article
Identificación de la codificación y las clases de ARN no codificante expresado en cerdos sangre entera
En este artículo
Resumen
Aquí, presentamos un protocolo optimizado para el proceso de codificación (mRNA) y no codificantes (ncRNA) globina reducida RNA-seq bibliotecas de una muestra de sangre entera sola.
Resumen
La llegada del innovador y cada vez más potentes técnicas de secuenciación siguiente de generación ha abierto nuevos caminos en la capacidad de examinar la expresión de genes subyacentes relacionadas con procesos biológicos de interés. Estas innovaciones no sólo permiten a los investigadores observar la expresión de las secuencias de ARNm que codifican para los genes función celular efecto, pero también las no codificantes (ncRNA) las moléculas de ARN que permanecen sin traducir, pero todavía tienen funciones reguladoras. Aunque los investigadores tienen la capacidad de observar la expresión de mRNA y ncRNA, ha sido habitual para un estudio que se centran en uno o el otro. Sin embargo, cuando los estudios están interesados en la expresión de mRNA y ncRNA, muchas veces utilizan las muestras separadas para examinar la codificación o no-codificación RNAs debido a la diferencia en la preparación de la biblioteca. Esto puede conducir a la necesidad de más muestras que puede aumentar el tiempo, consumibles y el estrés animal. Además, puede causar los investigadores deciden preparar muestras para análisis sólo uno, generalmente el mRNA, limitar el número de cuestiones biológicas que pueden ser investigadas. Sin embargo, ncRNAs abarcan múltiples clases con funciones reguladoras expresión de mRNA de efecto. Porque ncRNA son importantes para los procesos biológicos fundamentales y desorden de estos procesos en durante la infección, por lo tanto, pueden, hacer objetivos atractivos para la terapéutica. Este manuscrito muestra un protocolo modificado para la generación de mRNA y no codificante del RNA expresión bibliotecas, incluyendo el ARN viral, de una sola muestra de sangre entera. Optimización del presente Protocolo, mejora la pureza del RNA mayor ligadura para recuperación de RNAs metilados y omite la selección del tamaño, para permitir la captura de las especies de RNA más.
Introducción
Secuencia de la generación siguiente (NGS) ha surgido como una poderosa herramienta para la investigación de los cambios que ocurren a nivel genómico de organismos biológicos. Preparación de muestras para métodos NGS puede variar dependiendo del organismo, tipo de tejido, y lo más importante las preguntas de los investigadores están deseosos de dirección. Muchos estudios han recurrido a NGS como medio de estudiar las diferencias en la expresión génica entre Estados como individuos sanos y enfermos1,2,3,4. La secuencia coloque sobre una base de todo el genoma y permite a un investigador capturar la mayoría, si no todos, de la información genómica para un determinado marcador genético a la vez el punto.
Los marcadores más comunes de expresión observados son el Mensajero RNAs (mRNAs). Los procedimientos más utilizados para preparar las bibliotecas para RNA-seq se optimizan para la recuperación de las moléculas de mRNA mediante el uso de una serie de purificaciones, fragmentaciones y trompas5,6. Sin embargo, la decisión sobre cómo un protocolo debe realizarse depende en gran medida el tipo de muestra y las preguntas sobre dicha muestra. En la mayoría de los casos se extrajo ARN total; sin embargo, no todas las moléculas de ARN son de interés y en casos como los estudios de expresión de mRNA excesivamente abundantes especies de RNA, como el ARN ribosómico (ARNr) necesitan ser removidas para aumentar el número de transcripciones perceptibles asociados con los mRNAs. El método más popular y ampliamente utilizado para eliminar las abundantes moléculas de rRNA es la reducción de las transcripciones de cofia RNA conocido como polyA agotamiento7. Este enfoque funciona bien para el análisis de la expresión de mRNA como no afecta a los transcritos de ARNm. Sin embargo, en estudios que están interesados en RNAs no codificantes o virales, agotamiento de polyA también elimina estas moléculas.
Muchos estudios deciden centrarse en la preparación de biblioteca de secuencia de RNA para examinar cualquier expresión del mRNA (codificación) o una clase determinada de ARN no codificante de pequeño o grande. Aunque hay otros procedimientos8 como la nuestra que permiten la preparación de la muestra doble, muchos estudios preparan bibliotecas de muestras independientes para estudios por separado cuando esté disponible. Para un estudio como el nuestro, esto requeriría normalmente múltiples muestras de sangre, aumentando el tiempo, consumibles y el estrés animal. El objetivo de nuestro estudio era ser capaz de usar sangre de animales para identificar y cuantificar las diferentes clases de ambos mRNA y RNA no codificante expresó entre disgenésico sano y altamente patógena y virus del síndrome respiratorio (HP-PRRS) desafió a cerdos9,10 a pesar de tener sólo una muestra de sangre entera sola (2,5 mL) de cada cerdo. Para ello, necesitábamos optimizar la extracción típica y protocolos de creación de biblioteca para generar los datos adecuados para permitir análisis de mRNA y no codificante del RNA (ncRNA) expresión11 de una sola muestra.
Esto impulsó la necesidad de un protocolo que permitió mRNA y análisis de ARN no codificante porque los kits estándar disponibles y métodos para la extracción de RNA y biblioteca de la creación fueron pensados principalmente para mRNA y utilizan un agotamiento poly-A paso12. Este paso habría hecho imposible recuperar ARN no codificante o transcripciones virales de la muestra. Por lo tanto, era necesario un método optimizado que permite para la extracción de RNA total sin agotamiento de polyA la muestra. El método presentado en este manuscrito se ha optimizado para permitir el uso de sangre entera como un tipo de muestra y construir bibliotecas de la secuencia de mRNA y ncRNAs de tamaños pequeños y grandes. El método ha sido optimizado para permitir el análisis de todos detectables no-codificación RNAs como retener RNAs virales para posterior investigación13. En todos, nuestro protocolo de preparación de biblioteca optimizada permite la investigación de múltiples moléculas de RNA de una muestra de sangre entera solo.
El objetivo detrás del uso de este método fue desarrollar un proceso que permitió la colección no codificante del RNA tanto de ARNm de una muestra de sangre entera. Esto nos permite tener ncRNA y mRNA y RNA viral para cada animal en nuestro estudio de una sola muestra9. Esto, en última instancia, permite el descubrimiento científico más sin costes adicionales de animales y da una imagen más completa de la expresión de cada muestra individual. El método descrito permite la examinación de los reguladores de expresión génica así como permitiendo estudios correlativos comparando ambos de mRNA y la expresión de RNA no codificante con una muestra de sangre entera sola. Nuestro estudio utiliza este protocolo para examinar los cambios en la expresión génica y posibles reguladores epigenéticos en viralmente infectaron cerdos comerciales masculinos 9 - semanas de edad.
Access restricted. Please log in or start a trial to view this content.
Protocolo
Protocolos animales fueron aprobados por la Comisión de uso y de cuidado de animales del Centro Nacional de enfermedad Animal (USDA-ARS-NADC).
1. colección de sangre porcina muestras
- Obtener muestras de sangre en tubos de RNA. Recoger ~2.5 mL o más si se dispone de tubos más grandes.
2. procesamiento de sangre porcina muestras
- Centrifugar los tubos de sangre a 5.020 x g por 10 min a temperatura ambiente (15-25 ° C). Si muestras procesamiento congelado incuban el tubo a temperatura ambiente durante un mínimo de 2 h antes de centrifugar.
- Eliminar el sobrenadante y añadir 8 mL de agua libre de ARNasa a la pelotilla. Cerrar y agitar la pastilla hasta que se disuelve visiblemente. Centrifugar muestra tubos a 5.020 x g durante 10 min a temperatura ambiente para recuperar el pellet. Deseche el sobrenadante todos y preservar la pelotilla.
3. orgánica extracción de ARN Total y pequeño arn (miRNA Kit de aislamiento)
- Comienzan extracción de RNA total por pipeteo 300 μL de tampón de Unión lysis a la pelotilla del paso 2.2.
- Vórtice y la transferencia de la mezcla a un nuevo etiquetado tubo de centrífuga de 1.5 mL. Añadir 30 μl de homogenado añadido del kit. Mezclar el tubo y lugar en el hielo durante 10 minutos.
- Retire el tubo y añadir 300 μL de fenol ácido: reactivo de cloroformo del kit. Vórtice del tubo para mezclar. Centrifugar a 10.000 x g durante 5 min a temperatura ambiente.
- Retire con cuidado la fase acuosa (300-350 μL) a un tubo nuevo. Tenga en cuenta el volumen para el siguiente paso.
4 procedimiento de aislamiento de RNA total
- Basado en la cantidad de recuperación acuosa (300-350 μL) añadir volumen 1,25 x 100% (~ 375 μL) de etanol en fase acuosa. Mezclar la muestra con una pipeta.
- Configuración nuevos tubos de recogida que contiene un cartucho de filtro para cada muestra. Pipeta ~ 675 μl de la mezcla de lisado y etanol en el cartucho del filtro.
Nota: No añadir > 700 μl a cartucho a la vez. Para volúmenes mayores se aplican en la sucesión. - Centrifugar brevemente (~ 15-20 s) a 10.000 x g paso de líquido a través del filtro. No girar mucho más que esto.
- Deseche el flujo a través y, si es necesario, repetir la centrifugación con la mezcla restante de lisado y etanol hasta que todo ha sido aplicado. Conservar el mismo tubo de filtro cartucho y colección para el siguiente paso.
- Agregar 700 μl de solución de lavado 1 desde el kit al cartucho de filtro y centrifugar brevemente (~ 10 s) para tirar a través del filtro. Deseche el flujo a través y retener el mismo tubo filtro de cartucho y colección.
- Añadir 500 μl de solución de lavado 2/3. Centrífuga para extraer el líquido a través del cartucho de filtro. Deseche el flujo a través. Repita el paso de lavado.
- InThe del mismo tubo, gire el cartucho del filtro un adicional 60 s para eliminar cualquier líquido residual del filtro. Transfiera el cartucho del filtro a un tubo de colección fresca.
- Añada 100 μl de agua libre de nucleasa de precalentado (95 ° C) al centro del cartucho del filtro. Vuelta de aproximadamente 20-30 s a la velocidad máxima de la centrífuga de mesa.
Nota: RNA está contenida en el efluente y puede ahora ser más tratado o almacenado a-20 ° C o por debajo de. Enriquecimiento de pequeños RNAs no se realizó.
5. globina (basada en un protocolo optimizado para las muestras de sangre completa porcina) reducción de14,15
Nota: Globina reducción se realiza para que las bibliotecas no están sobrepobladas con Lee mapeo de genes de la globina, que reduciría el número de lecturas disponibles para asignar a otros genes de mayor interés14,15 .
- Hibridación con globina reducción oligos
- Desnaturalizar el RNA (6 μg RNA muestra en máximo volumen μl 7) pipetear la muestra extraída en un tubo de pared delgada libre de nucleasa reacción de 0.2 mL y colocando en un termociclador a 70 ° C por 2 min. Es clave para tubos de hielo inmediatamente después del primer paso de desnaturalizar para óptima calidad de RNA. Se necesita ningún tratamiento de DNasa.
- Mientras que enfriar tubos preparar 400 μL de 10 x mezcla de globina reducción oligo: 100 μl de dos HBA oligos (5'-GATCTCCGAGGCTCCAGCTTAACGGT-3' y 5'-TCAACGATCAGGAGGTCAGGGTGCAA-3') en 30 μm, dos oligos HBB (5'-AGGGGAACTTAGTGGTACTTGTGGGC-3', y 5'-GGTTCAGAGGAAAAAGGGCTCCTCCT-3') en 120 μm por reacción, dando una concentración final de oligos HBA de 7,5 μm y 30 μm HBB oligos. Preparar el tampón de hibridación de x oligo 10: 100 mM Tris-HCL, pH 7.6; 200 mM de KCl.
- Preparar la mezcla de hibridación: 6 μg de muestra de RNA (volumen máximo de μl 7), 2 μl de 400 μL de 10 x mezcla de oligo reducción de globina (último concentración 2 X), 1 μl de tampón de hibridación de x oligo 10 (concentración final 1 x). Añadir agua libre de nucleasas hasta un volumen final de 10 μl.
- Sistema termociclador a 70 ° C por 5 min enfriar inmediatamente a 4 ° C y proceder a la digestión Rnasa H.
- Digestión Rnasa H
- Diluir 10 x Rnasa H (10 U / μL) a 1 x Rnasa H con 1 x buffer de la Rnasa H.
Nota: La RNasa Tampón viene en 10 x y tendrá que ser diluido con 1 x Rnasa H tampón 1 x antes de usar. - Preparar la mezcla de reacción Rnasa H combinando: 2 μl de 10 x tampón, 1 μl de inhibidor de Rnasa de 2 μl de 1 x Rnasa H y 5 μl de agua libre de nucleasa para un volumen total 10 μl de Rnasa.
- Homogeneizar las muestras de la hibridación de reducción de la globina con 10 μl de la mezcla de reacción Rnasa H y digerir a 37 ° C durante 10 minutos enfriar a 4 ° C.
- Detener la digestión por la adición de 1,0 μL de EDTA de 0,5 M a cada muestra y proceder de inmediato a la etapa de limpieza.
- Diluir 10 x Rnasa H (10 U / μL) a 1 x Rnasa H con 1 x buffer de la Rnasa H.
- Rnasa H tratados Total RNA limpieza.
- Purificar la Rnasa H tratamiento RNA usando un kit de limpieza de membrana-basados en sílice elución purificación según las instrucciones del fabricante. Premezcla de buffers: Añadir el tampón de lavado suave, 44 mL de etanol al 100%.
- No transferir la muestra a un tubo nuevo. Añadir 80 μl de agua libre de ARNasa y 350 μl de tampón de lisis. Añadir 250 μl de etanol al 100% a la RNA diluido y mezclar bien mediante pipeteo.
Nota: No centrifugue. Proceder de inmediato a paso 5.3.3. - Ahora traslado el 700 μl de muestra a un cartucho de filtro de elución en un tubo de recogida de 2 mL para recoger el flujo a través. Centrifugar durante 15 s ≥ x 8.000 g. Deseche el flujo a través.
- Repetir este proceso al colocar el cartucho de filtro de elución en un nuevo tubo de recogida de 2 mL. Añadir 500 μl del buffer de lavado suave para el cartucho del filtro y centrifugar durante 15 s ≥ x 8.000 g para lavar la membrana del filtro del cartucho. Deseche el flujo a través. Reutilizar el tubo de la colección en paso 5.3.5.
- Ahora utilizando el mismo tubo de muestra, añadir otro 500 μl de etanol al 80% para el cartucho del filtro. Este tiempo centrifugar el tubo durante 2 min a ≥ x 8.000 g. Recoge la columna de elución de la vuelta para el siguiente paso y deseche el tubo el flujo y colección.
- Ponga el cartucho de filtro de elución del último paso en un nuevo tubo de recogida de 2 mL. Deje la tapa abra el cartucho del filtro y centrifugar a máxima velocidad durante 5 minutos secar la membrana de la columna de giro y evitar etanol transportan. Deseche el tubo de flujo y colección.
Nota: Para evitar daño de ángulo de las tapas para que apunte en una dirección opuesta a la del rotor. - Tome el cartucho del filtro seco y coloque en un tubo de colección nuevo de 1,5 mL. Añadir 14 μl de agua libre de ARNasa a filtro de membrana de cartucho, asegúrese de añadir el agua libre de ARNasa directamente al centro. Centrifugar durante 60 s a toda velocidad a fin de eluir el RNA.
- Evaluar la calidad de muestras de RNA reducida de globina (paso 6). Proceder a la preparación de la muestra del mRNA (paso 7) y pequeños RNA biblioteca preparación (paso 8)16,17.
Nota: Las muestras de RNA reducida de globina pueden ahora almacenarse a-20 ° C, sin embargo la conservación a-80 ° C se recomienda para preservación a largo plazo.
6. evaluación del ARN
- Cuantificar la concentración de RNA usando un espectrofotómetro. Examinar la relación de la longitud de onda de 260 y 280 nm. Relaciones de 2 o más se consideran puros para el ARN y valores más bajos indican cierta contaminación. El instrumento utiliza esta relación para determinar la concentración de RNA como ng/μl.
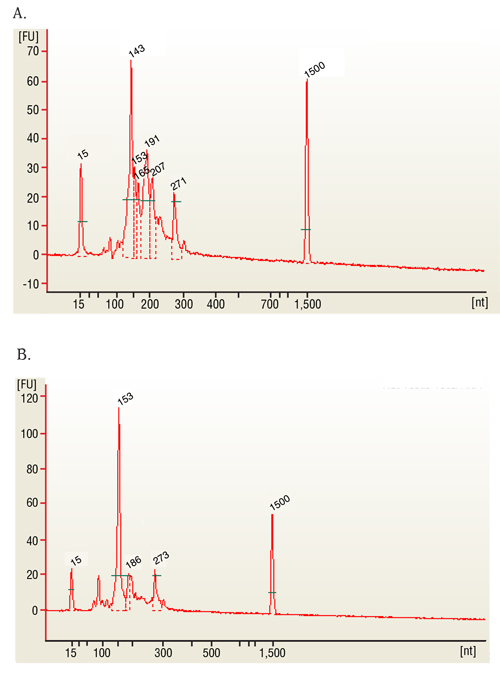
- Evaluar la calidad del RNA usando 1 μl (100 ng) de la muestra en un chip adecuado. Producto final debe ser un RIN de 2 o superior y un pico a ~ 280 nt para mRNA solo leer bibliotecas; picos de las bibliotecas de pequeños RNA en 143 corresponden a miRNAs.
7. preparación de muestras de RNA Total para el mRNA y las bibliotecas ncRNA largo trenzado. 16
- Nota: Llevar tampón de elución y rRNA granos de extracción a temperatura ambiente. La etiqueta de 0.2 ml pared delgada PCR tubos (placas también se pueden utilizar). Pasos de protocolo basados en de las instrucciones del fabricante16.
- Comience con 4 μL de ARN reducida de globina. Añadir 5 μl de mezcla de extracción rRNA por tubo (1st ), 6 μl de agua libre de nucleasas y 5 μl de tampón de unión de rRNA. Pipeta para mezclar y tapar. Colocar en termociclador con 100 ° C tapa calentada durante 5 minutos a 68° C. retirar y dejar a temperatura ambiente durante 60 s.
- Suspender cuentas de retiro de rRNA en el vórtex; Añadir 35 μl de granos a nuevo tubo PCR (2nd) y pipetear una muestra de los tubos 1st en granos en los 2 tubos dend . Incubar el tubo PCR de 2nd a temperatura ambiente durante 3 minutos. Coloque en el soporte magnético para 7 minutos.
Nota: Homogeneizar cada muestra mediante pipeteo óptimo agotamiento de rRNA. Cómo subir y bajar el tubo en el soporte puede ayudar a acelerar el proceso de separación. - Transferencia el sobrenadante del tubo PCR de 2nd de juego 3 tubo PCR derd y lugar a la magnética reposar un mínimo de 60 s. repetir la transferencia a un nuevo tubo PCR sólo si los granos no se mueven a los lados del tubo.
- Granos de purificación de las muestras mezcla por vortex; Añada 99 μL en cada tubo PCR 3rd . Permiten sentarse a temperatura ambiente durante 15 min lugar en soporte magnético para 5 minutos Asegúrese de movimientos de cuentas a los lados. Pipeta para descartar el sobrenadante.
- Mantener 3 tubo derd en soporte magnético. Añadir 200 μL de etanol al 70% mientras que teniendo cuidado de no empujar los granos. Dejar para reposar al menos 30 s y pipeta para descartar el sobrenadante. Repita el paso.
- Permita que la muestra y secar a temperatura ambiente durante 15 min en el soporte magnético. Centrifugue el tampón de elución kit para 5 s a 600 x g. Retire el tubo y agregar 11 μl de tampón de elución mezclar bien. Incúbelos durante 2 minutos en el Banco y luego al menos 5 min en el soporte magnético a temperatura ambiente.
- Transferir 8,5 μl de sobrenadante de la 3rd a un nuevo (4th) tubo PCR. Añadir 8,5 μl de mezcla fragmento de Elute de primer alto del kit. Mezclar bien. Tapa y coloque en un termociclador con precalentado tapa durante 8 min a 94 ° C, mantener a 4 ° C. Retire y centrifugar brevemente.
- Sintetizar la primera hebra ADNc
- Permite el primer filamento síntesis mezcla del kit a temperatura ambiente y centrifugar a 600 × g durante 5 s. transferir 50 μl de transcriptasa reversa en la primera mezcla de síntesis de strand. Transcriptasa inversa pueden agregarse a la primera cadena de síntesis en una proporción de 1:9.
- Pipeta 8 μl de la transcriptasa inversa combinada/filamento primero mezcla de síntesis en el 4 º tubo con la muestra. La tapa y centrifugar 600 x g durante 5 s. lugar en termociclador con tapa precalentada a 100 ° C. Por: 10 min a 25 ° C, 15 min a 42 ° C, 15 min a 70 ° C, luego reposar a 4 ° C. Volumen final es de ~ 25 μl por pocillo. Pasar inmediatamente al siguiente paso.
- Sintetizar la segunda cadena cDNA
- Reactivo de reparación final (ERR) y segundo filamento de la mezcla (SSM) a temperatura ambiente y centrifugar a 600 x g por 5 s. mezcla de ERR con buffer de resuspensión en 1:50 dilución. Quitar el tapón 4th tubo y añadir 5 μl de ERR diluido y 20 μl de SSM a cada uno; Pipeta para mezclar bien. Volumen final 50 μl ds cDNA.
- Tapa e incubar en termociclador durante 1 hora a 16 ° C. Cuando se completa el ciclo, quitar los tapones y permita que se ponga a temperatura ambiente en la parte superior del Banco.
- paso de limpieza de ADNc de DS
- Comenzar mezclando los granos paramagnético sólido fase Reversible inmovilización (SPRI) en el vórtex. Transferencia de 90 μl de los granos a la muestra en el tubo 4 deth(ds cDNA) y mezclar. Volumen final es 140 μl. permitir tubos reposar a temperatura ambiente 15 minutos incuban en soporte magnético ~ 5 minutos. Quitar el ~ 135 μl de sobrenadante de cada pozo. Allí debe 5 μL en cada pocillo.
- Dejar el tubo en el soporte magnético y lavado mediante la adición de 200 μL de etanol al 80%. Dejar para reposar de 30 s y luego quitar y desechar sobrenadante. Repita el paso de lavado. Dejar los tubos en el soporte magnético durante 15 minutos permitir que se seque.
- Centrifugue el buffer de resuspensión a 600 x g , 5 s después de llegar a la temperatura ambiente. Retire los tubos de soporte. Transferencia de 17.5 μl de buffer de resuspensión en el tubo y mezclar. Dejar tubos incubar en la mesa por 2 min luego traslado a soporte magnético durante 5 minutos.
- Pipetear 15 μl del sobrenadante que contiene las muestras de cDNA ds a nuevos tubos de (5th) 0.2 mL pared delgada. Pasar al paso siguiente sin demora o sellar y almacenar a-15 ° C a-25 ° C durante no más de 7 días.
- Extremos 3' adenilato.
- Pipetear 2,5 μl de buffer de resuspensión de temperatura en el tubo de muestra y añadir 12.5 μl de mezcla de relave A descongelado. Mezcla homogénea mediante pipeteo.
Nota: No A tizón control utilizado. - Tapa e incubar en un termociclador con 100 ° C tapa precalentada. Correr a 37 ° C durante 30 min, luego a 70 ° C por 5 min con la tapa caliente. Permitir que el termociclador a 4 ° c.
- Pipetear 2,5 μl de buffer de resuspensión de temperatura en el tubo de muestra y añadir 12.5 μl de mezcla de relave A descongelado. Mezcla homogénea mediante pipeteo.
- Ligan adaptadores de índice
- Llevar los tubos adaptador de ARN y la mezcla deje de ligadura Buffer a temperatura ambiente. Para cada uno, centrifugar a 600 x g durante 5 s. mezcla de ligadura de dejar en el congelador hasta que esté listo para su uso. Muestra puesta en común acuerdo para la indización debe conocerse.
- Añadir 2,5 μl de buffer de resuspensión y 2,5 μl de mezcla de ligadura a cada tubo de muestras. Ahora pipetear en 2,5 μl del adaptador adecuado de RNA en cada tubo de muestras. Selección del adaptador debe realizarse por las instrucciones del fabricante para el kit elegido.
- Volver a tapar y mezclar por centrifugación durante 1 min a x 280 g. Incubar en un termociclador durante 10 minutos a 30 ° C. Añadir 5 μl de tampón de ligadura de detener a la muestra para detener la reacción y mezclar bien.
- Empezar limpiar mezclando granos paramagnéticos de SPRI en el vórtex para 60 μL de transferencia 42 s. de granos a cada tubo. Mezcla thoroughlythen incubar durante 15 min en la parte superior del Banco.
- Hacia los tubos de soporte magnético y dejar hasta que se convierte líquido claro (~ 5 min). Una vez claro, retire y deseche 79,5 μl del sobrenadante. Dejar los tubos en el soporte magnético y lavado mediante la adición de 200 μL de etanol al 80%. Dejar para reposar al menos 30 s y luego quitar y desechar sobrenadante. Repita el paso de lavado. Deja en soporte magnético adicional ~ 15 minutos permitir el secado. No rompen los granos durante pasos de lavado.
- Añadir 52.5 μl de buffer de resuspensión en el tubo de muestra y mezclar hasta que los granos estén completamente suspendidos de nuevo. Incúbelos durante 2 minutos en la parte superior del Banco. Tubo de la muestra del movimiento a soporte magnético hasta que el líquido es claro (~ 5 min).
- Dejar en el stand y cuidadosamente pipetee 50 μl de sobrenadante a nuevo (6th) tubos. Añada 50 μl de granos de la SPRI de agitarse. Dejar para incubar en la mesa durante 15 minutos.
- Trasladar a soporte magnético y dejar reposar la placa hasta que se convierte líquido claro (~ 5 min). Sobrenadante de descarte 95 μl of dejando 5 μL en cada tubo.
- Dejar los tubos en soporte magnético y lavado mediante la adición de 200 μL de etanol al 80%. Permitir que tubo por 30 s, luego retire y deseche el sobrenadante. Repetir el lavado. Deje que se seque en soporte magnético para el minuto 15 tubos.
- Añadir en 22,5 μl de buffer de resuspensión y mezclar hasta que los granos se suspenden. Incubar en Banco por 2 min y luego pasar a soporte magnético hasta vueltas líquidos claro (~ 5 min). Pipetear 20 μl de muestra en tubos PCR nuevo (7mayo).
- Componentes del kit necesarios de llevar a temperatura ambiente. Transferencia de 5 μl de la mezcla de la cartilla PCR y 25 μl de la mezcla principal de PCR kit de muestra (7th PCR tubo) que contiene las muestras indexadas. Mezclar el tubo de muestra y la tapa.
- Colocar tubos en el termociclador con tapa previamente calentada. Ejecutar programa: 98 ° C por 30 s, después de 15 ciclos de 98 ° C durante 10 s, 60 ° C durante 30 s, 72 ° C por 30 s, 72 ° C por 5 min mantener a 4 ° C.
- Limpiar las muestras añadiendo 50 μl de granos suficientemente mezclados de la SPRI muestra tubo y pipeta para combinar. Permite la reacción a incubar en la mesa durante 15 minutos.
- Mover el tubo a un soporte magnético e incubar hasta que se convierte líquido claro (~ 5 min). Sobrenadante de descarte 95 μl of dejando 5 μL en cada tubo.
- Dejar el tubo en el soporte magnético y lavado mediante la adición de 200 μL de etanol al 80%. Dejar para reposar al menos 30 s y luego quite y descarte el sobrenadante. Repita este paso de lavado. Deja en soporte magnético durante 15 minutos permitir que se seque.
- Añadir en 32,5 μl de buffer de resuspensión y mezclar hasta que los granos están completamente suspendidos de nuevo. Incubar en Banco por 2 min y luego pasar a soporte magnético hasta vueltas líquidos claro (~ 5 min). Tomar con pipeta 30 μl de la muestra de cada tubo en un nuevo tubo PCR.
- Evaluar calidad y cantidad de ADN repitiendo los pasos 6.1 y 6.2 con el chip correspondiente. Pasar a la puesta en común (paso 9).
8. pequeños ARN biblioteca de preparación para el sncRNAs. 17
Nota: Protocolo a unos pasos partiendo de las instrucciones del fabricante17.
- Inicio preparación de biblioteca de RNA pequeño con ~ 220 ng - ~1.1 μg / μl de ARN reducida de globina muestras (4 μL).
- Ligadura de adaptador
- Ligar el adaptador 3' mezclando bien 1 μl de adaptador, 2 μl de agua libre de nucleasas y 4 μL de la muestra de RNA reducida de globina. Incubar a 70 ° C por 2 min y luego colocar inmediatamente en hielo.
- Añadir 10 μl de 2 x de buffer de la ligadura, y 3 μl de mezcla de enzima de la ligadura, mezclar e incubar a 16 ° C por 18 h.
Nota: Tiempo de incubación muestra aumento a 18 horas a una temperatura menor de 16 ° C se recomienda para estudios interesados en especies de RNA desnaturalizadas, como Pío RNAs. El tiempo de incubación más largo permite una mayor eficacia de la ligadura debido a la clase de modificaciones durante la fase de ligadura adaptador 3'. - Añadir 1 μl de la cartilla de transcripción inversa en 4.5 μl de agua libre de nucleasa a la mezcla de la ligadura para evitar la formación de adaptador-dimer de exceso 3' adaptador.
- Incubar en un termociclador precalentado programado durante 5 minutos a 75 ° C, 15 min a 37 ° C, 15 min a 25 ° C y mantener a 4° C.
- Desnaturalizar 1 μl de previamente diluido 5' adaptador por muestra en un termociclador a 70 ° C por 2 min y luego colocar inmediatamente en hielo.
- Añadir 1 μl de desnaturalizada 5'-adaptador, 1 μl de tampón de ligadura de 10 x 5' y 2.5 μl de enzima de la ligadura de 5'. Mezclar e incubar a 25 ° C durante 1 hora.
- amplificación y síntesis de cDNA
- Homogeneizar por pipeteo 30 μl de RNA 5′/3′-adaptador-ligarse, 8 μl de tampón de primera línea, 1 μl de inhibidor de la Rnasa y 1 μl de transcriptasa reversa. Incubar la mezcla a 50 ° C por 60 minutos proceder inmediatamente a la amplificación de PCR o calor inactivar la reacción a 70 ° C durante 15 minutos y almacenar a-20 ° C.
- PCR amplificación 40 μl de reacción de transcriptasa inversa mediante la adición de 50 μl de la mezcla principal de PCR, 2.5 μl de cebador de RNA PCR, añadir 2,5 μl de designado RNA PCR Primer índice a la muestra y agua libre de nucleasas hasta un volumen total de 100 μl. mezclar mediante pipeteo. PCR se ejecutan en el termociclador con las siguientes condiciones de ciclo: desnaturalización inicial a 94 ° C por 30 s; 11 ciclos de 94 ° C durante 15 s, recocido a 62 ° C por 30 s y la extensión a 70 ° C por 15 s; seguido de una extensión final a 70 ° C por 5 min; las muestras pueden guardarse a 4 ° C en el cycler.
- Nota: Los índices se añaden para propósito de la agrupación de la muestra.
- Muestra de limpiar
- Kit de limpieza de ADN de añadir 500 μl de tampón de unión (5 M Gu-HCl, 30% isopropanol) a 100 μl de muestra amplificada PCR para permitir eficiente Unión a la membrana de la columna de vuelta.
Nota: Si el tampón de Unión tiene indicador de pH incluye verificar que el color de la mezcla es de color amarillo. - Mezcla de 600 μl de pipeta de muestra y tampón de Unión en un cartucho de filtro dentro de un tubo de recogida de 2 mL, vuelta para 30-60 s a 17.900 x g en una centrífuga de mesa. Descartar a través de flujo.
- Lavar el cartucho del filtro en el mismo tubo de obtención con 0,75 mL de tampón de lavado suministrado (pH de 10 mM Tris-HCl 7.5, etanol al 80%) de 30-60 s a 17.900 x g en una centrífuga de mesa de giro y desechando el flujo-a través de. Girar el cartucho del filtro seco para un adicional 60 s.
- Coloque el cartucho de filtro en un tubo limpio de 1.5 mL de la colección. Añadir 30 μl de tampón de elución (10 mM Tris-HCl pH 8.5), deje que la columna repose durante 60 s y luego vuelta por 60 s en 17.900 x g en una centrífuga de mesa.
- Kit de limpieza de ADN de añadir 500 μl de tampón de unión (5 M Gu-HCl, 30% isopropanol) a 100 μl de muestra amplificada PCR para permitir eficiente Unión a la membrana de la columna de vuelta.
- Evaluar calidad de la muestra repitiendo los pasos 6.1 y 6.2 con el chip de DNA adecuado. Mueva a la agrupación de paso (paso 9).
9. puesta en común para la secuencia de la muestra
- Piscina con código de barras y QC'ed muestras y etiquetado nuevos tubos (o una placa PCR bien 96) para contener muestras de mRNA o ncRNA. Transferencia 13 μl de cada biblioteca de 10nM de código de barras tubos correspondientes (o pozos en la nueva placa) por instrucciones16,17 del fabricante. Presentar muestras agrupadas para la secuencia, asegúrese de elegir longitudes similares de lectura si las muestras están para ejecutarse en el mismo chip.
Access restricted. Please log in or start a trial to view this content.
Resultados
Las muestras representativas en nuestro estudio son la globina y muestras de sangre entera ribo-agotado. El resultado representativo del protocolo consiste en una muestra de biblioteca empobrecido de la globina con un número de la integridad del RNA (RIN) por encima de 7 (figura 1a) y cocientes de concentración 260/280 nm en o por encima de 2 (figura 1b y 1 c). Validación de los resultados de ...
Access restricted. Please log in or start a trial to view this content.
Discusión
El primer paso crítico en el protocolo que ha optimizado incluye los pasos de agotamiento de la globina añadido, que permite obtener lecturas de calidad de muestras de sangre entera. Una de las más grandes limitaciones sobre el uso de sangre entera en los estudios de secuenciación son los altos números de Lee en la muestra que se asignan a las moléculas de globina y reducirá la lee que puede asignar a otras moléculas de interés18. Por lo tanto, optimizar el protocolo para nuestro tipo de ...
Access restricted. Please log in or start a trial to view this content.
Divulgaciones
Los autores no tienen nada que revelar.
Mención de nombres comerciales o productos comerciales en este artículo es únicamente con el propósito de proporcionar información específica y no implica recomendación o aprobación por el Departamento de agricultura de Estados Unidos. USDA es un proveedor de igualdad de oportunidades y el empleador.
Agradecimientos
Este trabajo fue apoyado principalmente por el por el USDA NIFA AFRI 2013-67015-21236 y en parte por el USDA NIFA AFRI 2015-67015-23216. Este estudio fue apoyado en parte por una cita a la agrícola servicio investigación participación programa de investigación administrado por el Instituto Oak Ridge para la ciencia y educación (ORISE) a través de un acuerdo interagencial entre el Departamento de energía ( DOE) y el Departamento de agricultura de Estados Unidos. ORISE es administrada por Oak Ridge Associated universidades bajo contrato DOE no. DE-AC05-06OR2310.
Nos gustaría dar las gracias a Dr. Kay Faaberg para los clones infecciosos HP-PRRS, el Dr. Susan Brockmeier por su ayuda con los animales involucrados en el experimento y Sue Ohlendorf para asistencia secretarial en la preparación del manuscrito.
Access restricted. Please log in or start a trial to view this content.
Materiales
| Name | Company | Catalog Number | Comments |
| PAXgene Tubes | PreAnalytix | 762165 | |
| Molecular Biology Grade Water | ThermoFisher | 10977-015 | |
| mirVana miRNA Isolation Kit | ThermoFisher | AM1560 | |
| Rneasy MinElute Clean Up Kit | QIAGEN | 74204 | |
| 100% Ethanol | Decon Labs, Inc. | 2716 | |
| 0.2 mL thin-walled tubes | ThermoFisher | 98010540 | |
| 1.5 mL RNase/DNase - free tubes | Any supplier | ||
| Veriti 96-well Thermocycler | ThermoFisher | 4375786R | |
| Globin Reduction Oligo (α 1) | Any supplier | Sequence GAT CTC CGA GGC TCC AGC TTA ACG GT | |
| Globin Reduction Oligo (α 2) | Any supplier | Sequence TCA ACG ATC AGG AGG TCA GGG TGC AA | |
| Globin Reduction Oligo (β 1) | Any supplier | Sequence AGG GGA ACT TAG TGG TAC TTG TGG GT | |
| Globin Reduction Oligo (β 2) | Any supplier | Sequence GGT TCA GAG GAA AAA GGG CTC CTC CT | |
| 10X Oligo Hybridization Buffer | |||
| -Tris-HCl, pH 7.6 | Fisher Scientific | BP1757-100 | |
| -KCl | Millipore Sigma | 60142-100ML-F | |
| 10X RNase H Buffer | |||
| -Tris-HCl, pH 7.6 | Fisher Scientific | BP1757-100 | |
| -DTT | ThermoFisher | Y00147 | |
| -MgCl2 | Promega | A351B | |
| -Molecular Biology Grade Water | ThermoFisher | 10977-015 | |
| RNase H | ThermoFisher | AM2292 | |
| SUPERase-IN | ThermoFisher | AM2694 | Rnase inhibitor |
| EDTA | Millipore Sigma | E7889 | |
| Microcentrifuge | Any supplier | ||
| 2100 Electrophoresis BioAnalyzer Instrument | Agilent Technologies | G2938C | |
| Agilent RNA 6000 Nano Kit | Agilent Technologies | 5067-1511 | |
| Agilent High Sensitivity DNA Kit | Agilent Technologies | 5067-4626 | |
| TruSeq Stranded Total RNA Library Prep Kit with Ribo-Zero | Illumina | RS-122-2201 | mRNA kit; Human/Mouse/Rat Set A (48 samples, 12 indexes) |
| TruSeq Stranded Total RNA Sample Preparation Guide | Illumina | Available on-line | |
| RNAClean XP Beads | BeckmanCoulter | A63987 | |
| AMPure XP Beads | BeckmanCoulter | A63880 | |
| MicroAmp Optical 8-tube Strip | ThermoFisher | N8010580 | 0.2 ml thin-walled tubes |
| MicroAmp Optical 8-tube Strip Cap | ThermoFisher | N801-0535 | |
| RNase/DNase - free reagent reservoirs | Any supplier | ||
| SuperScript II Reverse Transcriptase | ThermoFisher | 18064-014 | |
| MicroAmp Optical 96 well plates | ThermoFisher | N8010560 | These were used in place of .3mL plates as needed |
| MicroAmp Optical adhesive film | ThermoFisher | 4311971 | |
| NEBNext Multiplex Small RNA Library Prep Set for Illumina® (Set 1) | New England Biolabs | E73005 | small RNA kit |
| NEBNext Multiplex Small RNA Library Prep Set for Illumina® (Set 2) | New England Biolabs | E75805 | small RNA kit |
| QIAQuick PCR Purification Kit | QIAGEN | 28104 | |
| 96S Super Magnet Plate | ALPAQUA | A001322 |
Referencias
- Finotello, F., Di Camillo, B. Measuring differential gene expression with RNA-seq: challenges and strategies for data analysis. Briefings in Functional Genomics. 14 (2), 130-142 (2015).
- Coble, D. J., et al. RNA-seq analysis of broiler liver transcriptome reveals novel responses to high ambient temperature. BMC Genomics. 15, 1084(2014).
- Koltes, J. E., et al. Identification of a putative quantitative trait nucleotide in guanylate binding protein 5 for host response to PRRS virus infection. BMC Genomics. 16, 412(2015).
- Miller, L. C., et al. Comparative analysis of signature genes in PRRSV-infected porcine monocyte-derived cells to different stimuli. PLoS One. 12 (7), 0181256(2017).
- Head, S. R., et al. Library construction for next-generation sequencing: overviews and challenges. Biotechniques. 56 (2), 61-64 (2014).
- Wang, Z., Gerstein, M., Snyder, M. RNA-Seq: a revolutionary tool for transcriptomics. Nature reviews. Genetics. 10 (1), 57-63 (2009).
- Dominic, O. N., Heike, G., Martin, S. Ribosomal RNA Depletion for Efficient Use of RNA-Seq Capacity. Current Protocols in Molecular Biology. 103 (1), 11-14 (2013).
- Pollet, S. FR-AgEncode: a French pilot project to enrich the annotation of livestock genomes- RNA Extraction Protocol. , Available from: ftp://ftp.faang.ebi.ac.uk/ftp/protocols/assays/INRA_SOP_RNA_extraction_20160504.pdf (2015).
- Fleming, D. S., Miller, L. C. Identification of small non-coding RNA classes expressed in swine whole blood during HP-PRRSV infection. Virology. 517, 56-61 (2018).
- Fleming, D. S., Miller, L. C. Small non-coding RNA expression status in animals faced with highly pathogenic porcine reproductive and respiratory syndrome virus (HP-PRRSV). Proceedings of the World Congress on Genetics Applied to Livestock Production. (11), Species - Porcine 2 (2018).
- Bivens Nathan, J., Zhou, M. RNA-Seq Library Construction Methods for Transcriptome Analysis. Current Protocols in Plant Biology. 1 (1), 197-215 (2016).
- Cui, P., et al. A comparison between ribo-minus RNA-sequencing and polyA-selected RNA-sequencing. Genomics. 96 (5), 259-265 (2010).
- Guo, Y., et al. RNAseq by Total RNA Library Identifies Additional RNAs Compared to Poly(A) RNA Library. BioMed Research International. 2015, 9(2015).
- Choi, I., et al. Increasing gene discovery and coverage using RNA-seq of globin RNA reduced porcine blood samples. BMC Genomics. 15, 954(2014).
- Wu, K., Miyada, G., Martin, J., Finkelstein, D. Globin reduction protocol: A method for processing whole blood RNA samples for improved array results. , Available from: http://media.affymetrix.com:80/support/technical/technotes/blood2_technote.pdf (2007).
- TruSeq® Stranded Total RNA Sample Preparation Guide. Illumina. , (2018).
- New England Biolabs Inc. Protocol for use with NEBNext Multiplex Small RNA Library Prep Kit for Illumina (Index Primers 1-48) (E7560). , Available from: https://www.neb.com/~/media/Catalog/All-Protocols/758F75A29CDE4D03954E1EF75E78EA3D/Content/manualE7560_Figure_1.jpg (2018).
- Shin, H., et al. Variation in RNA-Seq transcriptome profiles of peripheral whole blood from healthy individuals with and without globin depletion. PLoS One. 9 (3), 91041(2014).
- Costa, V., Angelini, C., De Feis, I., Ciccodicola, A. Uncovering the complexity of transcriptomes with RNA-Seq. Journal of Biomedicine and Biotechnology. 2010, 853916(2010).
- Martens-Uzunova, E. S., Olvedy, M., Jenster, G. Beyond microRNA--novel RNAs derived from small non-coding RNA and their implication in cancer. Cancer Letters. 340 (2), 201-211 (2013).
{kind=link}
Access restricted. Please log in or start a trial to view this content.
Reimpresiones y Permisos
Solicitar permiso para reutilizar el texto o las figuras de este JoVE artículos
Solicitar permisoThis article has been published
Video Coming Soon
ACERCA DE JoVE
Copyright © 2025 MyJoVE Corporation. Todos los derechos reservados