
Accedi
È necessario avere un abbonamento a JoVE per visualizzare questo. Accedi o inizia la tua prova gratuita.
Method Article
Identificazione di Coding e classi di RNA Non codificanti espressa in suina sangue intero
In questo articolo
Riepilogo
Qui, presentiamo un protocollo ottimizzato per l'elaborazione di codifica (mRNA) e non codificanti (ncRNA) globina ridotta RNA-seq librerie da un campione di sangue intero singolo.
Abstract
L'avvento di sempre più potenti e innovative tecniche di sequenziamento di generazione successiva ha aperto nuove strade nella capacità di esaminare l'espressione genica sottostanti relazionato ai processi biologici di interesse. Queste innovazioni non solo permettono ai ricercatori di osservare l'espressione delle sequenze di mRNA che codificano per geni che funzione cellulare di effetto, ma le molecole di RNA (ncRNA) non codificanti che rimangono non tradotte, ma ancora hanno anche funzioni di regolamentazione. Anche se i ricercatori hanno la possibilità di osservare l'espressione di mRNA e di ncRNA, era consuetudine per uno studio di concentrarsi su uno o l'altro. Tuttavia, quando gli studi sono interessati nell'espressione di mRNA e di ncRNA, molte volte usano campioni separati per esaminare o codifica o non-codificazione RNAs a causa della differenza nelle preparazioni di biblioteca. Questo può portare alla necessità di più campioni che può aumentare il tempo, materiali di consumo e lo stress degli animali. Inoltre, può causare i ricercatori a decidere di preparare i campioni per sola analisi, solitamente il mRNA, limitando il numero di domande biologiche che possono essere studiate. Tuttavia, ncRNAs estendersi su più classi con ruoli regolatori che espressione di mRNA di effetto. Perché ncRNA sono importanti per i processi biologici fondamentali e disordine di questi processi in durante l'infezione, possono, pertanto, fare obiettivi attraenti per terapeutica. Questo manoscritto viene illustrato un protocollo modificato per la generazione mRNA e non codificanti RNA librerie di espressione, tra cui RNA virale, da un singolo campione di sangue intero. Ottimizzazione del presente protocollo, migliorato purezza RNA, aumentata di legatura per recupero di RNAs metilato e omesso selezione di dimensioni, per consentire la cattura di altre specie di RNA.
Introduzione
Sequenziamento di nuova generazione (NGS) è emerso come un potente strumento per lo studio dei cambiamenti che si verificano a livello genomico di organismi biologici. Preparazione del campione per i metodi di NGS può essere variata a seconda del microrganismo, tipo di tessuto, e soprattutto le domande i ricercatori sono desiderosi di indirizzo. Molti studi sono rivolti a NGS come mezzo per studiare le differenze nell'espressione genica tra gli Stati come individui sani e malati1,2,3,4. Il sequenziamento di prendere posto su una base di intero genoma e consente un ricercatore di catturare la maggior parte, se non tutte, le informazioni genomiche per un marcatore genetico particolare in un momento indicano.
I marcatori più comuni dell'espressione osservati sono il RNA messaggero (mRNA). Le procedure più usate per le librerie durante la preparazione per RNA-seq sono ottimizzate per il recupero di molecole di mRNA mediante l'utilizzo di una serie di purificazioni, frammentazioni e legature5,6. Tuttavia, la decisione su come un protocollo dev'essere eseguito si basa pesantemente sul tipo di campione e le domande circa il campione ha detto. Nella maggior parte dei casi viene estratto il RNA totale; Eppure, non tutte le molecole di RNA sono di interesse e in casi come gli studi di espressione di mRNA eccessivamente abbondanti specie di RNA, come RNA ribosomiale (rRNA) devono essere rimossi per aumentare il numero di trascrizioni rilevabili connesso con i mRNA. Il metodo più popolare e ampiamente utilizzato per rimuovere le molecole di rRNA abbondante è la riduzione delle trascrizioni di poliadenilazione RNA denominato polyA svuotamento7. Questo approccio funziona bene per l'analisi dell'espressione di mRNA come non influenza i trascritti di mRNA. Tuttavia, negli studi che sono interessati a RNA non codificante o virale, deplezione di polyA rimuove anche queste molecole.
Molti studi scelgono di concentrarsi sulla preparazione libreria sequenza di RNA per esaminare sia espressione di mRNA (codifica) o una particolare classe di grande o piccolo RNA non codificanti. Anche se ci sono altre procedure8 come la nostra che consentono la preparazione di campioni doppi, molti studi preparano librerie da campioni separati per studi separati quando disponibile. Per uno studio come il nostro, ciò richiederebbe normalmente più campioni di sangue, aumentando il tempo, materiali di consumo e lo stress degli animali. L'obiettivo del nostro studio è stato quello di essere in grado di utilizzare sangue intero da animali per identificare e quantificare le diverse classi di entrambi mRNA e RNA non codificanti espressi tra sano e patogenicità suina virus riproduttivo e respiratorio sindrome (HP-PRRSV) ha sfidato suini9,10 pur avendo solo un campione di sangue intero singolo (2,5 mL) da ogni suino. Per fare questo, abbiamo bisogno di ottimizzare l'estrazione tipica e protocolli di creazione di librerie per generare i dati appropriati per consentire analisi di mRNA e di non-codificanti RNA (ncRNA) espressione11 da un singolo campione.
Ciò ha richiamato la necessità di un protocollo che ha permesso per mRNA e analisi di RNA non codificante perché il kit standard disponibili e metodi per la creazione di estrazione del RNA e la biblioteca sono stati destinati principalmente al mRNA e utilizzano una deplezione di poly-A passaggio12. Questo passaggio avrebbe reso impossibile il recupero di RNA non codificante o trascrizioni virali dal campione. Di conseguenza, era necessario un metodo ottimizzato che ha permesso per estrazione di RNA totale senza svuotamento polyA campione. Il metodo presentato in questo manoscritto è stato ottimizzato per consentire l'uso di sangue intero come tipo di campione e di costruire librerie di sequenziamento per sia mRNA che ncRNAs di piccole e grandi dimensioni. Il metodo è stato ottimizzato per consentire l'analisi di RNA non codificanti rilevabili tutti così come mantenere il RNA virale per successive indagini13. In tutto, il nostro protocollo di preparazione libreria ottimizzata consente per l'indagine di più molecole di RNA da un campione di sangue intero singolo.
L'obiettivo generale dietro l'uso di questo metodo era quello di sviluppare un processo che ha permesso per la raccolta di non-codificanti RNA sia mRNA da un campione di sangue intero. Questo ci permette di avere mRNA, ncRNA e RNA virale per ogni animale nel nostro studio provengono da un singolo campione9. Questo, in definitiva, consente più scientifico scoperta senza costi aggiuntivi di animale e dà un quadro più completo dell'espressione di ogni singolo campione. Il metodo descritto consente per l'esame dei regolatori dell'espressione genica, nonché a consentire per il completamento degli studi correlativi confrontando entrambi mRNA e l'espressione di RNA non codificanti utilizzando un campione di sangue intero singolo. Il nostro studio ha utilizzato questo protocollo per esaminare i cambiamenti nell'espressione genica e possibili regolatori epigenetici in viralmente infettato 9 - settimana-vecchi maschi maiali commerciali.
Access restricted. Please log in or start a trial to view this content.
Protocollo
Protocolli degli animali sono state approvate dal comitato di uso e cura degli animali di National Animal Disease Center (USDA-ARS-NADC).
1. raccolta di sangue suina campioni
- Prelevare campioni di sangue in provette di RNA. Raccogliere ~2.5 mL o più, se più grandi tubi di raccolta sono disponibili.
2. lavorazione del sangue suina campioni
- Centrifugare le provette di sangue a 5.020 x g per 10 min a temperatura ambiente (15-25 ° C). Se l'elaborazione congelato campioni Incubare la provetta a temperatura ambiente per un minimo di 2 h prima della centrifugazione.
- Rimuovere il surnatante e aggiungere 8 mL di acqua RNAsi-libera al pellet. Chiudi e vortice il pellet fino a che è visibilmente sciolto. Centrifugare le provette a 5.020 x g per 10 min a temperatura ambiente per recuperare la pallina. Eliminare il surnatante tutti e preservare il pellet.
3. organico estrazione di RNA totale e piccoli RNA (miRNA Kit di isolamento)
- Iniziare estrazione del RNA totale di pipettaggio 300 µ l di tampone di lisi associazione al pellet dal punto 2.2.
- Vortice e trasferire la miscela in un nuovo etichettati 1.5 mL provetta. Aggiungere 30 µ l di omogenato additivo dal kit. Vortice del tubo e posto sul ghiaccio per 10 min.
- Rimuovere il tubo e aggiungere 300 µ l di acido-fenolo: reagente di cloroformio dal kit. Vortice del tubo per mescolare. Centrifugare a 10.000 x g per 5 min a temperatura ambiente.
- Rimuovere con cautela la fase acquosa (300-350 µ l) in una nuova provetta. Nota il volume per il passaggio successivo.
4. procedura di isolamento del RNA totale
- Basato sulla quantità di recupero acquosa (300-350 µ l) aggiungere 1,25 x volume di etanolo al 100% (~ 375 µ l) fase acquosa. Mescolare il campione con una pipetta.
- Nuove provette di raccolta set-up contenente una cartuccia di filtro per ogni campione. Pipetta ~ 675 µ l della miscela lisato/etanolo sulla cartuccia filtro.
Nota: Non aggiungere > 700 µ l di cartuccia filtrante in una sola volta. Per grandi volumi di applicare in successione. - Centrifugare brevemente (~ 15-20 s) a 10.000 x g per passare il liquido attraverso il filtro. Non girare più difficile di questo.
- Scartare il flusso attraverso e, se necessario, ripetere la centrifugazione con il rimanente composto di lisato/etanolo fino a quando è stato applicato. Mantenere lo stesso tubo di raccolta e cartuccia di filtro per il passaggio successivo.
- Aggiungere 700 µ l di soluzione di lavaggio 1 dal kit per la cartuccia del filtro e centrifugare (~ 10 s) per tirare attraverso il filtro. Scartare il flusso attraverso e mantengono lo stesso tubo di raccolta e cartuccia filtro.
- Aggiungere 500 µ l di soluzione di lavaggio 2/3. Centrifuga per disegnare il liquido attraverso la cartuccia del filtro. Scartare il flusso attraverso. Ripetere il ciclo di lavaggio.
- Inthe stesso tubo, girare la cartuccia del filtro un ulteriore 60 s per rimuovere qualsiasi residuo liquido dal filtro. Trasferire la cartuccia di filtro in una provetta di raccolta fresca.
- Aggiungere 100 µ l di acqua esente da nucleasi pre-riscaldata (95 ° C) al centro della cartuccia filtrante. Girare per circa 20-30 secondi alla velocità max centrifuga da tavolo.
Nota: RNA è contenuto nell'eluito e può ora essere ulteriormente elaborato o conservato a-20 ° C o di sotto. Arricchimento per piccoli RNA non è stata eseguita.
5. globina riduzione (basato su un protocollo ottimizzato per campioni di sangue intero porcina)14,15
Nota: Globina riduzione viene eseguita in modo che le librerie non sono sovrappopolate con legge mappatura di geni della globina, che abbasserebbe il numero di letture disponibili per eseguire il mapping ad altri geni di maggiore interesse14,15 .
- Ibridazione con globina riduzione oligos
- Denaturare il RNA (campione di 6 µ g RNA in massimo 7 µ l di volume) Dispensazione campione estratto in una provetta di reazione di nucleasi-free sottili di 0,2 mL e inserendo in un termociclatore a 70 ° C per 2 min. È chiave per tubi di ghiaccio immediatamente dopo il primo passo di denaturare per una qualità ottimale del RNA. È necessario nessun trattamento di dnasi.
- Mentre cool tubi preparare un 400 µ l di 10 x mix oligo di globina riduzione: 100 µ l di due HBA oligos (5'-GATCTCCGAGGCTCCAGCTTAACGGT-3' e 5'-TCAACGATCAGGAGGTCAGGGTGCAA-3') a 30 µM, due HBB oligos (5'-AGGGGAACTTAGTGGTACTTGTGGGC-3', e 5'-GGTTCAGAGGAAAAAGGGCTCCTCCT-3') a 120 µM per reazione, ottenendo una concentrazione finale di 7,5 µM HBA oligos e 30 µM HBB oligos. Preparare il tampone di ibridazione x oligo 10: 100 mM Tris-HCL, pH 7,6; 200 mM KCl.
- Preparare la miscela di ibridazione: 6 µ g di campione di RNA (massimo 7 µ l), 2 µ l della 400 µ l di miscela di globina riduzione oligo (concentrazione finale di 2 X), 1 µ l di tampone di ibridazione x oligo 10: 10x (concentrazione finale 1 x). Aggiungere acqua priva di nucleasi ad un volume finale di 10 µ l.
- Impostare il termociclatore a 70 ° C per 5 min raffreddare immediatamente a 4 ° C e procedere alla digestione RNasi H.
- Digestione di RNasi H
- Diluire 10 x RNasi H (10 U / µ l) a 1 x RNasi H con RNAsi H 1x.
Nota: La RNasi buffer arriva a 10x e dovrà essere diluito con 1x RNasi H tampone a 1x prima dell'uso. - Preparare la miscela di reazione di RNasi H combinando: 2 µ l di 10 x buffer RNasi, 1 µ l di inibitore di RNAsi a 2 µ l di 1x RNasi H e 5 µ l di acqua priva di nucleasi a un volume totale di 10 µ l.
- Mescolare accuratamente i campioni di ibridazione della globina riduzione con 10 µ l della miscela di reazione di RNasi H e digest a 37 ° C per 10 min raffreddare a 4 ° C.
- Interrompere la digestione tramite l'aggiunta di 1,0 µ l di EDTA 0.5 M per ogni campione e procedere immediatamente alla sottofase.
- Diluire 10 x RNasi H (10 U / µ l) a 1 x RNasi H con RNAsi H 1x.
- La RNasi H-trattati RNA pulitura totale.
- Purificare la RNasi H trattati RNA usando un kit di pulitura di purificazione di eluizione basati su silice-membrana secondo le istruzioni del produttore. Premix buffer: per il buffer di lavaggio per capi delicati, Aggiungi 44 mL di etanolo al 100%.
- Non trasferire il campione ad un nuovo tubo. Aggiungere 80 µ l di acqua RNAsi-libera e 350 µ l di tampone di lisi. Aggiungere 250 µ l di etanolo al 100% diluito RNA e mescolare bene di pipettaggio.
Nota: Non centrifugare. Passare immediatamente al punto 5.3.3. - Una cartuccia di filtro di eluizione inserita in un tubo di raccolta da 2 mL per raccogliere il flusso attraverso il trasferimento del 700 µ l di campione. Centrifuga per 15 s a ≥ 8.000 x g. Scartare il flusso continuo.
- Ripetere questa operazione inserendo la cartuccia di filtro di eluizione in un nuovo tubo di raccolta da 2 mL. Aggiungere 500 µ l di buffer di lavaggio per capi delicati per la cartuccia del filtro e centrifugare per 15 s a ≥ 8.000 x g per lavare la membrana di cartuccia del filtro. Scartare il flusso continuo. Riutilizzare il tubo di raccolta al punto 5.3.5.
- Ora usando la stessa provetta, aggiungere un altro 500 µ l di etanolo di 80% per la cartuccia del filtro. Questa volta Centrifugare la provetta per 2 min a ≥ 8.000 x g. Raccogliere la colonna di spin di eluizione per il passo successivo e scartare il tubo di flusso continuo sia la collezione.
- Inserire la cartuccia di filtro di eluizione dall'ultimo passaggio in un nuovo tubo di raccolta da 2 mL. Lasciare il coperchio aperto sulla cartuccia filtro e centrifugare a massima velocità per 5 min asciugare la membrana di colonna di spin e prevenire etanolo riporto. Gettare la provetta di raccolta e flusso continuo.
Nota: Per evitare danni angolo i coperchi per puntare in una direzione opposta a quella del rotore. - Togliere la cartuccia del filtro secchi e inserire un nuovo tubo di raccolta di 1,5 mL. 14 µ l di acqua RNAsi-libera per filtrare membrana cartuccia avendo cura di aggiungere l'acqua RNAsi-libera direttamente al centro. Centrifuga per 60 s a tutta velocità per eluire il RNA.
- Valutare la qualità dei campioni di RNA della globina-ridotto (passaggio 6). Procedere alla preparazione di campioni di mRNA (passaggio 7) e piccoli RNA libreria preparazione (fase 8)16,17.
Nota: RNA della globina-ridotto campioni ora possa essere conservato a-20 ° C, tuttavia si raccomanda di conservare a-80 ° C per la conservazione a lungo termine.
6. valutazione del RNA
- Quantificare la concentrazione di RNA usando uno spettrofotometro. Esaminare il rapporto di lunghezza d'onda di 260 e 280 nm. Rapporti di ~ 2 o superiore sono considerati puri per RNA e valori inferiori indicano qualche contaminazione. Lo strumento utilizza questo rapporto per determinare la concentrazione di RNA come ng / µ l.
- Valutare la qualità di RNA utilizzando 1 µ l (100 ng) di campione in un chip di appropriato. Prodotto finale dovrebbe essere un RIN di ~ 2 o superiore e un picco a ~ 280 nt per singolo mRNA leggere librerie; piccoli RNA librerie picchi a 143 corrispondono a Mirna.
7. preparazione del campione RNA totale per il mRNA e lunga ncRNA librerie in panne. 16
- Nota: Portare il tampone di eluizione e rRNA perle di rimozione a temperatura ambiente. Pre-Etichettare provette PCR sottili 0,2 ml (piastra può anche essere utilizzata). Passaggi di protocollo basati su istruzioni16 del produttore.
- Iniziare con 4 µ l di RNA della globina-ridotto. Aggiungere 6 µ l di acqua priva di nucleasi, 5 µ l di tampone di associazione di rRNA e 5 µ l di miscela di rimozione di rRNA per tubo (1st tubo). Pipetta per mescolare e ri-cap. Posto nel termociclatore con coperchio riscaldato 100 ° C per 5 min a 68° c. Togliere e lasciare a temperatura ambiente per 60 s.
- Risospendere perline rimozione rRNA Vortex; aggiungere 35 µ l di perline al nuovo tubo PCR (2nd) e pipettare campione dai tubi 1st su perline in 2 tubi dind . Incubare 2nd PCR provetta a temperatura ambiente per 3 min. Posizionare sul supporto magnetico per 7 min.
Nota: Mescolare accuratamente ogni campione di pipettaggio per svuotamento ottimale di rRNA. Innalzamento/abbassamento tubo nello stand può aiutare a velocizzare il processo di separazione. - Trasferimento il surnatante dalla provetta PCR 2nd a corrispondenti 3rd PCR tubo e posto a magnetico stand per un minimo di 60 s. Ripetere il trasferimento in una nuova provetta PCR solo se le perline non vengono spostate ai lati del tubo.
- Perline di purificazione del campione mix Vortex; aggiungere 99 µ l in ciascuna provetta PCR 3rd . Lasciar per riposare a temperatura ambiente per 15 minuti posto su supporto magnetico per 5 min, mosse di perline di garantire ai lati. Pipetta per scartare il surnatante.
- Tenere 3rd tubo impostata su supporto magnetico. Aggiungere 200 µ l di etanolo al 70%, mentre facendo attenzione a non si accalcano le perline. Lasciar per riposare per almeno 30 s e pipetta per scartare il surnatante. Ripetere il passaggio.
- Lasciare il campione ad asciugare a temperatura ambiente per 15 min su supporto magnetico. Centrifugare il tampone di eluizione kit per 5 s a 600 x g. Rimuovere il tubo e 11 µ l di tampone di eluizione mescolando accuratamente. Incubare per 2 min in panchina poi almeno 5 min sul supporto magnetico a temperatura ambiente.
- Trasferire 8,5 µ l di supernatante dai 3rd per un nuovo (4th) provetta PCR. Aggiungere 8,5 µ l di Elute/Prime/frammento alto mix dal kit. Mescolare bene. Cap e luogo in un termociclatore con pre-riscaldata lid per 8 min a 94 ° C, tenere a 4 ° C. Rimuovere e centrifugare.
- Sintesi del cDNA del primo filo
- Consentire primo filo sintesi mix da kit a temperatura ambiente e centrifugare a 600 × g per 5 s. trasferire 50 µ l di trascrittasi inversa nel primo mix sintesi strand. Trascrittasi inversa può essere aggiunto a filo prima sintesi con un rapporto di 1:9.
- Capo primo mix di sintesi nel 4 ° provetta con il campione/8 µ l della combinata della trascrittasi inversa. Tappo e centrifugare 600 x g per 5 s. posto in termociclatore con coperchio pre-riscaldato a 100 ° C. Correre per: 10 min a 25 ° C, 15 min a 42 ° C, per 15 min a 70 ° C, poi il resto a 4 ° C. Volume finale è ~ 25 µ l per pozzetto. Immediatamente passare alla fase successiva.
- Sintesi del cDNA del filo secondo
- Portare fine riparazione reagente (ERR) e seconda Strand Mix (SSM) a temperatura ambiente e centrifugare a 600 x g per 5 s. Mix ERR con tampone di risospensione alle 01:50 diluizione. 4th dalla provetta e aggiungere 5 µ l di ERR diluito e 20 µ l di SSM a ciascuna; Pipetta per mescolare bene. Volume finale ~ 50 µ l ds cDNA.
- Tappo e incubare in termociclatore per 1 ora a 16 ° C. Quando il ciclo è completo, rimuovere i tappi e permettono di venire a temperatura sulla parte superiore del banco.
- passaggio di pulizia cDNA DS
- Iniziare mescolando le perline paramagnetico solido fase reversibile immobilizzazione (SPRI) Vortex. Trasferire il campione nella provetta 4th(ds cDNA) 90 µ l delle perline e mescolare. Volume finale è 140 µ l. Consenti tubi a riposare a temperatura ambiente per 15 min. Incubare su supporto magnetico per ~ 5 min. Rimuovere ~ 135 µ l del surnatante da ogni pozzetto. Ci dovrebbe lasciato in ciascun pozzetto 5 µ l.
- Lasciare il tubo sul supporto magnetico e lavare con l'aggiunta di 200 µ l di etanolo di 80%. Lasciar per riposare per 30 s e poi rimuovere e gettare il surnatante. Ripetere il ciclo di lavaggio. Lasciare tubi sul supporto magnetico per 15 minuti per far asciugare.
- Centrifugare il tampone di risospensione a 600 x g per 5 s dopo il suo arrivo a temperatura ambiente. Togliere i tubi dal cavalletto. Trasferire 17.5 µ l di tampone di risospensione nella provetta e mescolare. Lasciate che i tubi Incubare sulla parte superiore del banco per 2 min poi mossa a supporto magnetico per 5 min.
- Pipettare 15 µ l del supernatante contenente i campioni di cDNA di ds in nuove provette di set di (5th) 0,2 mL con pareti sottili. Passare alla fase successiva prontamente o sigillare e conservare a-15 ° C a-25 ° C per non più di 7 giorni.
- Adenilato 3' estremità.
- Pipettare 2,5 µ l di tampone di risospensione di temperatura nella provetta del campione poi aggiungere 12,5 µ l di mix A-Tailing scongelati. Miscelare completamente pipettando.
Nota: Nessun controllo di A-tailing utilizzato. - Tappo e incubare in un termociclatore con coperchio pre-riscaldato 100 ° C. Eseguire a 37 ° C per 30 min, poi a 70 ° C per 5 min con coperchio riscaldato. Consentire il termociclatore riposare a 4 ° C.
- Pipettare 2,5 µ l di tampone di risospensione di temperatura nella provetta del campione poi aggiungere 12,5 µ l di mix A-Tailing scongelati. Miscelare completamente pipettando.
- Legare gli adattatori indice
- Portare i tubi di RNA adattatore e il mix di interrompere legatura Buffer a temperatura ambiente. Per ciascuno, centrifugare a 600 x g per 5 s. mix di legatura di lasciare nel congelatore fino a che pronto per l'uso. Dovrebbe essere noto campione pool di disposizione per l'indicizzazione.
- Aggiungere 2,5 µ l di tampone di risospensione e 2,5 µ l di miscela di legatura per ogni provetta. Ora pipettare in 2,5 µ l della scheda di RNA corretta in ogni provetta. Selezione di adattatore deve essere eseguita da istruzioni del produttore per il kit scelto.
- Richiudere il tappo e mescolare per centrifugazione per 1 minuto a 280 x g. Incubare in un termociclatore per 10 min a 30 ° C. Aggiungere 5 µ l di tampone di legatura Stop al campione per fermare la reazione e mescolare bene.
- Begin pulitura mescolando perline paramagnetici SPRI Vortex 60 µ l di trasferire 42 s. di perline in ogni provetta. Mix thoroughlythen Incubare per 15 minuti sulla parte superiore del banco.
- Spostare tubi supporto magnetico e lasciare fino a quando il liquido diventa chiara (~ 5 min). Una volta chiaro rimuovere e scartare 79,5 µ l del surnatante. Lasciare tubi su supporto magnetico e lavare con l'aggiunta di 200 µ l di etanolo di 80%. Lasciar per riposare per almeno 30 s quindi rimuovere e gettare il surnatante. Ripetere il ciclo di lavaggio. Lasciare il supporto magnetico per ulteriori ~ 15 min consentire per l'essiccazione. Non perturbino perline durante fasi di lavaggio.
- Aggiungere 52,5 µ l di tampone di risospensione nella provetta e mescolare fino a quando le perle sono completamente ri-sospensione. Incubare per 2 min sulla parte superiore del banco. Provetta con il campione mossa torna a supporto magnetico fino a liquido è chiaro (~ 5 min).
- Lasciare sul cavalletto e delicatamente Pipettare 50 µ l del surnatante a nuovo (6th) tubi. Aggiungere 50 µ l di perline SPRI agitati con vortex. Lasciare per incubare su banco per 15 min.
- Spostare a supporto magnetico e lasciare che la piastra di rimanere fino a quando il liquido diventa chiara (~ 5 min). Surnatante di scartare 95 µ l of lasciando 5 µ l in ogni provetta.
- Lasciare tubi su supporto magnetico e lavare con l'aggiunta di 200 µ l di etanolo di 80%. Consentire il tubo a sedere per 30 s quindi rimuovere ed eliminare il surnatante. Ripetere il lavaggio. Lasciate che i tubi a secco su supporto magnetico per 15 min.
- Aggiungere in 22,5 µ l di tampone di risospensione e mescolare fino a quando non vengono sospesi, perline. Incubare su banco per 2 min, poi passare al supporto magnetico fino a quando il liquido diventa chiaro (~ 5 min). Pipettare 20 µ l di campione in nuove provette per PCR (7th).
- Portare i reattivi necessari a temperatura ambiente. Trasferire 5 µ l di miscela di primer PCR e 25 µ l di mix master PCR da kit a campione (7th PCR tubo) contenente campioni indicizzati. Mescolare il campione e tappo tubo.
- Inserire le provette nel termociclatore con coperchio pre-riscaldato. Eseguire il programma: 98 ° C per 30 s, quindi 15 cicli di 98 ° C per 10 s, 60 ° C per 30 s, 72 ° C per 30 s, 72 ° C per 5 min, Hold a 4 ° C.
- Ripulire i campioni aggiungendo 50 µ l di perline SPRI sufficientemente misti per il tubo di campionamento e pipettare per combinare. Consentire la reazione Incubare sulla parte superiore del banco per 15 min.
- Spostare il tubo in un supporto magnetico e incubare fino a quando il liquido diventa chiara (~ 5 min). Surnatante di scartare 95 µ l of lasciando 5 µ l in ogni provetta.
- Lasciare il tubo su supporto magnetico e lavare con l'aggiunta di 200 µ l di etanolo di 80%. Lasciar per riposare per almeno 30 s e quindi di rimuovere e scartare il surnatante. Ripetere questo passaggio di lavaggio. Lasciare il supporto magnetico per 15 minuti per far asciugare.
- Aggiungere in 32,5 µ l di tampone di risospensione e mescolare fino a quando le sfere sono completamente ri-sospensione. Incubare su banco per 2 min, poi passare al supporto magnetico fino a quando il liquido diventa chiaro (~ 5 min). Pipettare 30 µ l di campione da ciascuna provetta in un nuovo tubo PCR.
- Valutare la qualità e quantità del DNA ripetendo i punti 6.1 e 6.2 con il chip appropriato. Passare al pool di step (passo 9).
8. piccoli RNA libreria preparazione per la sncRNA. 17
Nota: La procedura protocollo basata su istruzioni17 del produttore.
- Iniziare la preparazione di biblioteca del RNA piccolo con ~ 220 ng - ~1.1 µ g / µ l di RNA della globina ridotta campioni (4 µ l).
- Legatura di adattatore
- Legare l'adattatore 3' mescolando accuratamente 1 µ l di adattatore, 2 µ l di acqua priva di nucleasi e 4 µ l di campione di RNA della globina-ridotto. Incubare a 70 ° C per 2 min e poi collocare immediatamente sul ghiaccio.
- Aggiungere 10 µ l di tampone di legatura: 2x e 3 µ l di miscela di enzima di legatura, miscelare e incubare 16 ° C per 18 h.
Nota: Aumento tempo di incubazione del campione per 18 ore a una temperatura di 16 ° C è consigliabile per gli studi interessati in metilati specie di RNA, come piwi RNAs. Il tempo di incubazione più lungo consente una maggiore efficienza di legatura grazie alla classe di modifiche durante la fase di legatura di adattatore 3'. - Aggiungere 1 µ l di primer di trascrizione inversa in 4,5 µ l di acqua priva di nucleasi alla miscela di legatura per evitare la formazione di adattatore-dimero dell'eccesso 3' adattatore.
- Incubare in un termociclatore preriscaldato programmato per 5 min a 75 ° C, 15 min a 37 ° C, 15 min a 25 ° C e tenere a 4° C.
- Denaturare 1 µ l di pre-diluito 5'-adattatore per campione in un termociclatore a 70 ° C per 2 min e poi collocare immediatamente sul ghiaccio.
- Aggiungere 1 µ l di denaturato 5'-adattatore, 1 µ l di 10 x 5' buffer di legatura e 2,5 µ l di 5' enzima di legatura. Mescolare e incubare a 25 ° C per 1 h.
- amplificazione e sintesi del cDNA
- Mescolare accuratamente di pipettaggio 30 µ l di RNA 5 ′ / 3 ′-adattatore-legati, 8 µ l di tampone di primo-filo, 1 µ l di inibitore di RNAsi e 1 µ l della trascrittasi inversa. Incubare la miscela a 50 ° C per 60 minuti procedere immediatamente all'amplificazione di PCR o calore inattivare la reazione a 70 ° C per 15 min e conservare a-20 ° C.
- PCR amplificano il 40 µ l di reazione Transcriptase aggiungendo 50 µ l di master mix di PCR, 2,5 µ l di primer di RNA PCR, aggiungere 2,5 µ l di designato RNA PCR Primer indice a campione e l'acqua priva di nucleasi per un volume totale di 100 µ l. Miscelare pipettando. Eseguire PCR nel termociclatore usando le seguenti condizioni in bicicletta: denaturazione iniziale a 94 ° C per 30 s; 11 cicli di 94 ° C per 15 s, ricottura a 62 ° C per 30 s e l'estensione a 70 ° C per 15 s; seguito da un'estensione finale a 70 ° C per 5 min; campioni possono essere tenuti a 4 ° C nel ciclatore.
- Nota: Gli indici vengono aggiunti a scopo di esempio pool.
- Pulizia del campione
- Dal kit di pulizia del DNA aggiungere 500 µ l di tampone di associazione (5 M Gu-HCl, 30% isopropanolo) ai 100 µ l di campione amplificato di PCR per consentire l'efficiente associazione alla membrana spin-colonna.
Nota: Se il buffer di associazione dispone di indicatore di pH incluso verifica che il colore della miscela è giallo. - Pipetta miscela 600 µ l di campione e buffer di associazione in una cartuccia di filtro all'interno di un tubo di raccolta da 2 mL, spin per 30-60 s a 17.900 x g in una centrifuga da tavolo. Gettare il flusso continuo.
- Lavare la cartuccia filtrante nella provetta di raccolta stessa con 0,75 mL di tampone di lavaggio kit in dotazione (10 mM Tris-HCl pH 7.5, 80% etanolo) spinning per 30-60 s a 17.900 x g in una centrifuga da tavolo ed eliminando il flusso-attraverso. Girare la cartuccia di filtro a secco per un supplemento di 60 s.
- Posizionare la cartuccia di filtro in una provetta pulita 1,5 mL. Aggiungere 30 µ l di tampone di eluizione (10 mM Tris-HCl pH 8,5), lasciare la colonna riposare per 60 s e poi spin per 60 s a 17.900 x g in una centrifuga da tavolo.
- Dal kit di pulizia del DNA aggiungere 500 µ l di tampone di associazione (5 M Gu-HCl, 30% isopropanolo) ai 100 µ l di campione amplificato di PCR per consentire l'efficiente associazione alla membrana spin-colonna.
- Valutare la qualità del campione ripetendo i punti 6.1 e 6.2 con il chip di DNA appropriato. Spostare al pool di step (passo 9).
9. campione pool per il sequenziamento
- Piscina con codice a barre e QC'ed campioni di impostazione ed etichettatura nuovi tubi (o un piatto PCR ben 96) per contenere campioni di mRNA o ncRNA. Trasferire 13 µ l di ogni libreria di 10nM con codice a barre corrispondenti provette (o pozzetti nella piastra di nuovo) per le istruzioni16,17 del produttore. Inviare campioni riuniti per il sequenziamento, essere certi di scegliere lunghezze leggi simili se i campioni devono essere eseguiti sullo stesso chip.
Access restricted. Please log in or start a trial to view this content.
Risultati
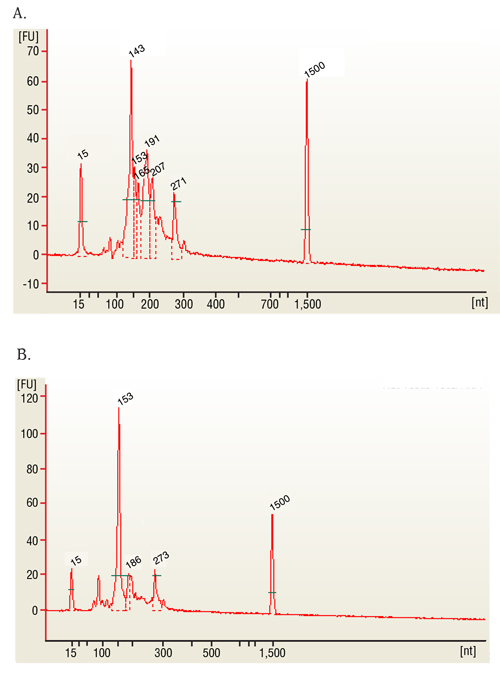
I campioni rappresentativi nel nostro studio sono la globina e campioni di sangue intero di ribo-vuotati. Il risultato rappresentativo del protocollo è costituito da un esempio di libreria impoverito della globina con un numero di integrità di RNA (RIN) sopra 7 (Figura 1a) e rapporti di concentrazione di 260/280 nm pari o superiore a 2 (Figura 1b e c 1). Convalida dei risultati del campione è ...
Access restricted. Please log in or start a trial to view this content.
Discussione
Il primo passo fondamentale nel protocollo che rendeva ottimizzato inclusa la procedura di svuotamento della globina aggiunto, che ha permesso di ottenere letture di qualità da campioni di sangue intero. Una delle più grandi limitazioni sull'utilizzo di sangue intero in studi di sequenziamento sono il numero elevato di letture nel campione che mappa alle molecole della globina e ridurre le letture che potrebbero mappe ad altre molecole di interesse18. Pertanto, nell'ottimizzare il protocollo per...
Access restricted. Please log in or start a trial to view this content.
Divulgazioni
Gli autori non hanno nulla a rivelare.
Menzione di marchi o prodotti commerciali in questo articolo è solo scopo di fornire informazioni specifiche e non implica raccomandazione o approvazione da parte del dipartimento di agricoltura degli Stati Uniti. USDA è un fornitore di pari opportunità e il datore di lavoro.
Riconoscimenti
Quest'opera è stata sostenuta principalmente dalla da USDA catino AFRI 2013-67015-21236 e in parte da USDA catino AFRI 2015-67015-23216. Questo studio è stato sostenuto in parte da un appuntamento al agricole ricerca servizio ricerca partecipazione programma amministrato dall'Istituto Oak Ridge per scienza e formazione (ORISE) attraverso un accordo tra agenzie tra il dipartimento dell'energia ( DOE) e il dipartimento dell'agricoltura statunitense. ORISE è gestito da Oak Ridge Associated Università DOE contratto no. DE-AC05-06OR2310.
Vorremmo ringraziare il Dr. Kay Faaberg per i cloni infettivi HP-PRRSV, Dr. Susan Brockmeier per il suo aiuto con gli animali coinvolti nell'esperimento e Sue Ohlendorf per assistenza di segreteria in preparazione del manoscritto.
Access restricted. Please log in or start a trial to view this content.
Materiali
| Name | Company | Catalog Number | Comments |
| PAXgene Tubes | PreAnalytix | 762165 | |
| Molecular Biology Grade Water | ThermoFisher | 10977-015 | |
| mirVana miRNA Isolation Kit | ThermoFisher | AM1560 | |
| Rneasy MinElute Clean Up Kit | QIAGEN | 74204 | |
| 100% Ethanol | Decon Labs, Inc. | 2716 | |
| 0.2 mL thin-walled tubes | ThermoFisher | 98010540 | |
| 1.5 mL RNase/DNase - free tubes | Any supplier | ||
| Veriti 96-well Thermocycler | ThermoFisher | 4375786R | |
| Globin Reduction Oligo (α 1) | Any supplier | Sequence GAT CTC CGA GGC TCC AGC TTA ACG GT | |
| Globin Reduction Oligo (α 2) | Any supplier | Sequence TCA ACG ATC AGG AGG TCA GGG TGC AA | |
| Globin Reduction Oligo (β 1) | Any supplier | Sequence AGG GGA ACT TAG TGG TAC TTG TGG GT | |
| Globin Reduction Oligo (β 2) | Any supplier | Sequence GGT TCA GAG GAA AAA GGG CTC CTC CT | |
| 10X Oligo Hybridization Buffer | |||
| -Tris-HCl, pH 7.6 | Fisher Scientific | BP1757-100 | |
| -KCl | Millipore Sigma | 60142-100ML-F | |
| 10X RNase H Buffer | |||
| -Tris-HCl, pH 7.6 | Fisher Scientific | BP1757-100 | |
| -DTT | ThermoFisher | Y00147 | |
| -MgCl2 | Promega | A351B | |
| -Molecular Biology Grade Water | ThermoFisher | 10977-015 | |
| RNase H | ThermoFisher | AM2292 | |
| SUPERase-IN | ThermoFisher | AM2694 | Rnase inhibitor |
| EDTA | Millipore Sigma | E7889 | |
| Microcentrifuge | Any supplier | ||
| 2100 Electrophoresis BioAnalyzer Instrument | Agilent Technologies | G2938C | |
| Agilent RNA 6000 Nano Kit | Agilent Technologies | 5067-1511 | |
| Agilent High Sensitivity DNA Kit | Agilent Technologies | 5067-4626 | |
| TruSeq Stranded Total RNA Library Prep Kit with Ribo-Zero | Illumina | RS-122-2201 | mRNA kit; Human/Mouse/Rat Set A (48 samples, 12 indexes) |
| TruSeq Stranded Total RNA Sample Preparation Guide | Illumina | Available on-line | |
| RNAClean XP Beads | BeckmanCoulter | A63987 | |
| AMPure XP Beads | BeckmanCoulter | A63880 | |
| MicroAmp Optical 8-tube Strip | ThermoFisher | N8010580 | 0.2 ml thin-walled tubes |
| MicroAmp Optical 8-tube Strip Cap | ThermoFisher | N801-0535 | |
| RNase/DNase - free reagent reservoirs | Any supplier | ||
| SuperScript II Reverse Transcriptase | ThermoFisher | 18064-014 | |
| MicroAmp Optical 96 well plates | ThermoFisher | N8010560 | These were used in place of .3mL plates as needed |
| MicroAmp Optical adhesive film | ThermoFisher | 4311971 | |
| NEBNext Multiplex Small RNA Library Prep Set for Illumina® (Set 1) | New England Biolabs | E73005 | small RNA kit |
| NEBNext Multiplex Small RNA Library Prep Set for Illumina® (Set 2) | New England Biolabs | E75805 | small RNA kit |
| QIAQuick PCR Purification Kit | QIAGEN | 28104 | |
| 96S Super Magnet Plate | ALPAQUA | A001322 |
Riferimenti
- Finotello, F., Di Camillo, B. Measuring differential gene expression with RNA-seq: challenges and strategies for data analysis. Briefings in Functional Genomics. 14 (2), 130-142 (2015).
- Coble, D. J., et al. RNA-seq analysis of broiler liver transcriptome reveals novel responses to high ambient temperature. BMC Genomics. 15, 1084(2014).
- Koltes, J. E., et al. Identification of a putative quantitative trait nucleotide in guanylate binding protein 5 for host response to PRRS virus infection. BMC Genomics. 16, 412(2015).
- Miller, L. C., et al. Comparative analysis of signature genes in PRRSV-infected porcine monocyte-derived cells to different stimuli. PLoS One. 12 (7), 0181256(2017).
- Head, S. R., et al. Library construction for next-generation sequencing: overviews and challenges. Biotechniques. 56 (2), 61-64 (2014).
- Wang, Z., Gerstein, M., Snyder, M. RNA-Seq: a revolutionary tool for transcriptomics. Nature reviews. Genetics. 10 (1), 57-63 (2009).
- Dominic, O. N., Heike, G., Martin, S. Ribosomal RNA Depletion for Efficient Use of RNA-Seq Capacity. Current Protocols in Molecular Biology. 103 (1), 11-14 (2013).
- Pollet, S. FR-AgEncode: a French pilot project to enrich the annotation of livestock genomes- RNA Extraction Protocol. , Available from: ftp://ftp.faang.ebi.ac.uk/ftp/protocols/assays/INRA_SOP_RNA_extraction_20160504.pdf (2015).
- Fleming, D. S., Miller, L. C. Identification of small non-coding RNA classes expressed in swine whole blood during HP-PRRSV infection. Virology. 517, 56-61 (2018).
- Fleming, D. S., Miller, L. C. Small non-coding RNA expression status in animals faced with highly pathogenic porcine reproductive and respiratory syndrome virus (HP-PRRSV). Proceedings of the World Congress on Genetics Applied to Livestock Production. (11), Species - Porcine 2 (2018).
- Bivens Nathan, J., Zhou, M. RNA-Seq Library Construction Methods for Transcriptome Analysis. Current Protocols in Plant Biology. 1 (1), 197-215 (2016).
- Cui, P., et al. A comparison between ribo-minus RNA-sequencing and polyA-selected RNA-sequencing. Genomics. 96 (5), 259-265 (2010).
- Guo, Y., et al. RNAseq by Total RNA Library Identifies Additional RNAs Compared to Poly(A) RNA Library. BioMed Research International. 2015, 9(2015).
- Choi, I., et al. Increasing gene discovery and coverage using RNA-seq of globin RNA reduced porcine blood samples. BMC Genomics. 15, 954(2014).
- Wu, K., Miyada, G., Martin, J., Finkelstein, D. Globin reduction protocol: A method for processing whole blood RNA samples for improved array results. , Available from: http://media.affymetrix.com:80/support/technical/technotes/blood2_technote.pdf (2007).
- TruSeq® Stranded Total RNA Sample Preparation Guide. Illumina. , (2018).
- New England Biolabs Inc. Protocol for use with NEBNext Multiplex Small RNA Library Prep Kit for Illumina (Index Primers 1-48) (E7560). , Available from: https://www.neb.com/~/media/Catalog/All-Protocols/758F75A29CDE4D03954E1EF75E78EA3D/Content/manualE7560_Figure_1.jpg (2018).
- Shin, H., et al. Variation in RNA-Seq transcriptome profiles of peripheral whole blood from healthy individuals with and without globin depletion. PLoS One. 9 (3), 91041(2014).
- Costa, V., Angelini, C., De Feis, I., Ciccodicola, A. Uncovering the complexity of transcriptomes with RNA-Seq. Journal of Biomedicine and Biotechnology. 2010, 853916(2010).
- Martens-Uzunova, E. S., Olvedy, M., Jenster, G. Beyond microRNA--novel RNAs derived from small non-coding RNA and their implication in cancer. Cancer Letters. 340 (2), 201-211 (2013).
{kind=link}
Access restricted. Please log in or start a trial to view this content.
Ristampe e Autorizzazioni
Richiedi autorizzazione per utilizzare il testo o le figure di questo articolo JoVE
Richiedi AutorizzazioneThis article has been published
Video Coming Soon
ISSN 2689-3649
Personale delle biblioteche
Copyright © 2025 MyJoVE Corporation. Tutti i diritti riservati
Utilizziamo i cookies per migliorare la tua esperienza sul nostro sito web.
Continuando a utilizzare il nostro sito web o cliccando “Continua”, accetti l'utilizzo dei cookies.